MySQL--explain执行计划详解
什么是执行计划?
SQL的执行计划,通俗来说就是SQL的执行情况,一条SQL语句扫描哪些表,那个子查询先执行,是否用到了索引等等,只有当我们知道了这些情况之后才知道,才可以更好的去优化SQL,而这个过程MySQL帮助我们生成好了,这就是执行计划。
执行计划的作用?
- 可以看到表的读取顺序。
- 可以直观看到索引的使用情况。
- 可以看到每张表中的数据查询情况,有多少条数据被扫描获取。
- 可以看到查询表数据的类型。
一句话概括,可以帮我们写出优雅、高性能的SQL。
准备数据:
#创建user表
CREATE TABLE `user` (`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键id',`user_name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '用户姓名',`user_code` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '用户工号',`age` tinyint DEFAULT NULL COMMENT '用户年龄',`address` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '用户地址',`hobby` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '用户爱好',PRIMARY KEY (`id`) USING BTREE,KEY `index_name` (`user_name`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户表';#准备数据
INSERT INTO `user`(id, user_name, user_code, age, address, hobby)VALUES(1, '张三', 'TC-00000001', 25, '湖北', '篮球');
INSERT INTO `user`(id, user_name, user_code, age, address, hobby)VALUES(2, '李四', 'TC-00000001', 26, '湖南', '足球');
INSERT INTO `user`(id, user_name, user_code, age, address, hobby)VALUES(3, '王五', 'TC-00000001', 23, '广东', '电影');#创建索引
create index index_name on user(user_name);
查看user表中的所有索引:
show index from user;
结果:

查看执行计划的语法:
- explain + SQL查询语句。
- desc + SQL查询语句,估计有部分同学不知道desc 这个关键字还可以查看执行计划。
使用explain 查看SQL执行计划:
#
explain select * from user where user_name='张三';;
执行计划:

使用desc 查看SQL执行计划:
#
desc select * from user where user_name='张三';;
执行计划:

根据对比可以看出explain、desc 都可以看SQL的执行计划。
执行计划各个指标的说明:
- id:SQL的执行顺序,id越大优先级越高,越先被执行。
- select_type:每个select子句的类型。
SIMPLE,简单的查询,不包含子查询或者union查询。
PRIMARY,最外层查询,查询中包含任何复杂的子查询,则最外层查询被标记为PRIMARY。
DERIVED,衍生的,在from列表中包含子查询,其类型会别标记为DERIVED。 - table:表名。
- type:访问类型,需要重点关注,直接体现了SQL语句的性能,常见的类型 system->const->eq_ref->ref->range->index->all,性能依次从好到差。
const、system:主键索引或唯一索引的所有列与常量比较时,表里最多有一个匹配行,读取一次。
eq_ref:命中主键索引或者唯一索引,查询结果最多返回一条数据。
ref:使用普通索引或者唯一索引的部分前缀,索引和某个值对比的时候,会查询到多行结果。
range:只检索给定范围的行。
index:只遍历索引树。
all:全表扫描,MySQL会遍历全表找到匹配的数据行,性能最差。 - piossible_keys:可能用到的索引。
- key:实际查询用到的索引。
- key_len:索引中使用的字节数,可以通过该列计算查询中使用的索引的长度。
- rows:表示MySQL根据表情况及索引使用情况,估算找到目标数据需要扫描的行数,这个值越小越好。
- filtered:表示经过条件过滤后剩余记录所占百分比,这个数据越大越好。
- Extra:Extra有以下几个常用的值。
Using index,查询的列被索引覆盖(覆盖索引),并且where筛选条件是索引的前导列,是查询性能高的表现。
Using where,查询的列没有被索引覆盖,where筛选条件不是索引的前导列。
Using where Using index,查询的列没有被索引覆盖,但是where筛选条件是所有列之一但不是索引前导列。
NULL,查询的列没有被索引覆盖,但是where查询条件使用了索引前导列。
Using index condition,查询条件虽然用到了索引列,但是有部分条件无法使用索引列,先会使用索引列的条件搜索一遍,在使用其他条件搜索。
Using temporay,MySQL需要建立一张临时表来处理数据,常出现在分组或排序查询中,这种情况是需要优化的。
Using filesort,文件排序,MySQL会对查询结果进行外部排序,而无法使用索引排序,这种情况也是要优化的。
key_len说明:
key_len:表示索引使用的字节数,通过这个值可以算出索引使用了哪些列,不同类型的数据在MySQL中占用的字节数如下,供参考。
字符串类型:
- char(n):n字节。
- varchar(n):如果使用utf-8编码,占用字节数为3n+2,2是用存储字符串长度。
- varchar(n):如果使用utf8mb4编码,占用字节数为4n+2,2是用存储字符串长度。
数值类型:
- tinyint:1字节。
- smallint:2字节。
- int:4字节。
- bigint:8字节。
时间类型:
- date:3字节。
- timestamp:4字节。
- datetime:8字节。
如果字段允许为空,则额外需要一个字节去记录是否为空。
如有不正确的地方请各位指出纠正。
相关文章:
MySQL--explain执行计划详解
什么是执行计划? SQL的执行计划,通俗来说就是SQL的执行情况,一条SQL语句扫描哪些表,那个子查询先执行,是否用到了索引等等,只有当我们知道了这些情况之后才知道,才可以更好的去优化SQL…...
)
【NERF】入门学习整理(一)
【NERF】入门学习整理 1. 【NERF】入门学习整理1.1 基础含义输入输出2.位置编码含义3.代码中实际网路结构4.Volume Render部分(64个采样点处理)5.Volume Render部分(64个采样点处理)【NERF】及其变种(二) 1. 【NERF】入门学习整理 1.1 基础含义输入输出 深度学习模型中…...

基于ZYNQ PS-SPI的Flash驱动开发
本文使用PS-SPI实现Flash读写,PS-SPI的基础资料参考Xilinx UG1085的文档说明,其基础使用方法是,配置SPI模式,控制TXFIFO/RXFIFO,ZYNQ的IP自动完成发送TXFIFO数据,接收数据到RXFIFO,FIFO深度为12…...

Linux Shell:local关键字
Linux Shell:local关键字 在 Bash 中,local 是一个用于声明局部变量的关键字。当在函数内部使用 local 声明变量时,该变量只能在函数内部使用,并且不会对函数外部的同名变量产生影响。这样可以确保在函数内部定义的变量不会意外地…...

如何开发python毕业设计
开发Python毕业设计需要以下步骤: 选择项目主题: 选择一个与你的兴趣和专业相关的主题。确保主题具有一定的挑战性,但又不至于过于复杂,以确保你能够在规定时间内完成项目。 制定项目计划: 制定一个清晰的项目计划&…...
D*算法超详解 (D星算法 / Dynamic A*算法/ Dstar算法)(死循环解决--跟其他资料不一样奥)
所需先验知识(没有先验知识可能会有大碍,了解的话会对D*的理解有帮助):A*算法/ Dijkstra算法 何为D*算法 Dijkstra算法是无启发的寻找图中两节点的最短连接路径的算法,A*算法则是在Dijkstra算法的基础上加入了启发函数…...
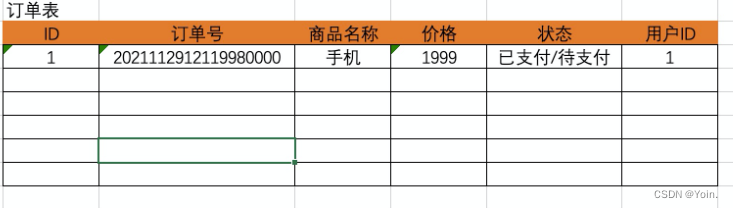
django学习记录07——订单案例(复选框+ajax请求)
1.订单的数据表 1.1 数据表结构 1.2 数据表的创建 models.py class Order(models.Model):"""订单号"""oid models.CharField(max_length64, verbose_name"订单号")title models.CharField(max_length64, verbose_name"名称&…...

Qt 定时器事件
文章目录 1 定时器事件1.1 界面布局1.2 关联信号槽1.3 重写timerEvent1.4 实现槽函数 启动定时器 2 定时器类 项目完整的源代码 QT中使用定时器,有两种方式: 定时器类:QTimer定时器事件:QEvent::Timer,对应的子类是QTi…...

LLM 推理优化探微 (2) :Transformer 模型 KV 缓存技术详解
编者按:随着 LLM 赋能越来越多需要实时决策和响应的应用场景,以及用户体验不佳、成本过高、资源受限等问题的出现,大模型高效推理已成为一个重要的研究课题。为此,Baihai IDP 推出 Pierre Lienhart 的系列文章,从多个维…...
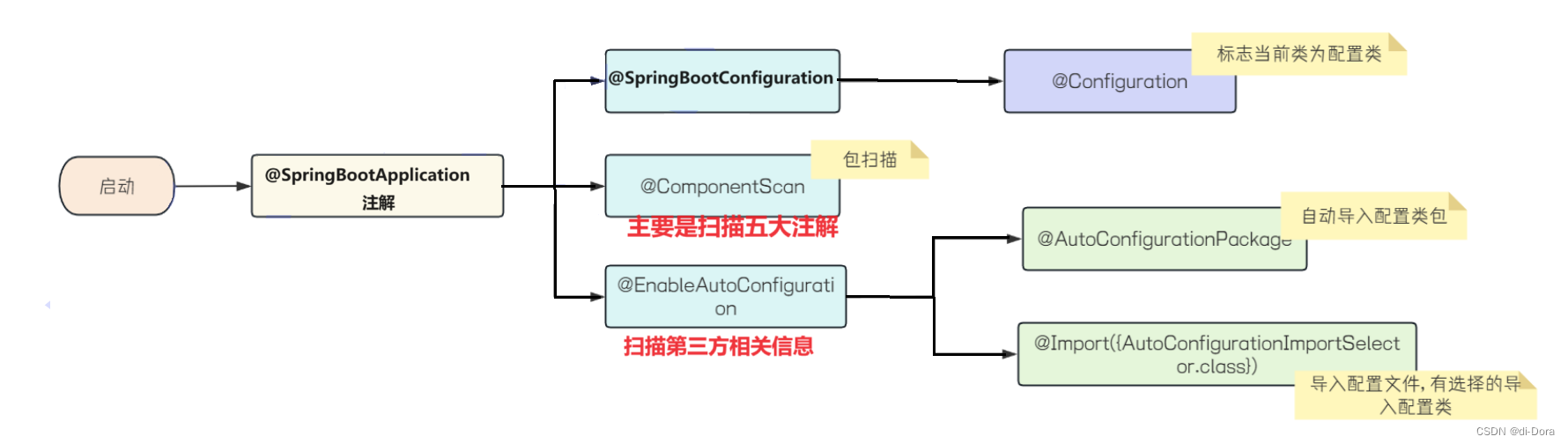
JavaEE进阶(15)Spring原理:Bean的作用域、Bean的生命周期、Spring Boot自动配置(加载Bean、SpringBoot原理分析)
接上次博客:JavaEE进阶(14)Linux基本使用和程序部署(博客系统部署)-CSDN博客 目录 关于Bean的作用域 概念 Bean的作用域 Bean的生命周期 源码阅读 Spring Boot自动配置 Spring 加载Bean 问题描述 原因分析 …...
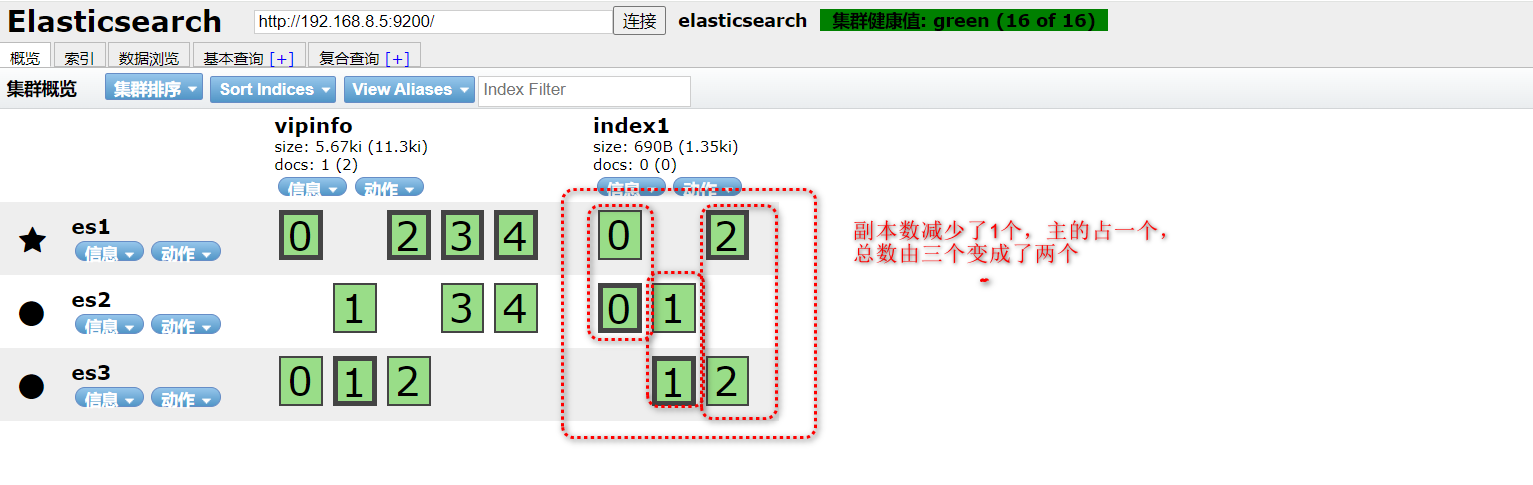
ELK-介绍及Elasticsearch集群搭建
ELK是三个开源软件的缩写,分别为Elasticsearch、Logstash、kibana它们都是开源软件。后来新增了一个FileBeat,它是一个轻量及的日志收集处理工具,因为Logstash由java程序开发,比较消耗内存资源,后来将Logstash使用go语…...

保障数据安全,提升性能:探秘Redis AOF持久化机制在在线购物网站的应用
AOF(Append-Only File)日志介绍 Redis使用AOF持久化来保证数据的可靠性。AOF日志是一个追加写文件,记录了所有对Redis数据进行修改的命令。 AOF的常规用途 通常,人们将Redis的AOF用于将后端数据库中的数据存储在内存中…...

魔众智能AI系统v2.1.0版本支持主流大模型(讯飞星火、文心一言、通义千问、腾讯混元、Azure、MiniMax、Gemini)
支持主流大模型(讯飞星火、文心一言、通义千问、腾讯混元、Azure、MiniMax、Gemini) [新功能] 系统全局消息提示 UI 全新优化 [新功能] JS 库增加【ijs】类型字符串,支持默认可执行代码 [新功能] 分类快捷操作工具类 CategoryUtil [新功能…...

抖音视频评论区用户采集工具使用教程
抖音视频评论区用户采集工具是一款用于收集抖音视频评论区用户信息的工具。通过该工具,用户可以提取抖音视频评论区的用户昵称、评论内容、点赞数等信息,并进行数据分析和统计。该工具可以帮助用户了解抖音视频评论区的用户特点和评论趋势,提…...

c 不同类型指针的转换
int 指针与unsigned char类型指针互转 #include <stdio.h> #include <stdlib.h>int main(void){int a(0x1<<24)|(0x2<<16)|(0x3<<8)|0x4; //0x1020304printf("16进制:%x\n",a);u_int8_t *p(u_int8_t *)&a; //int指针转为unsig…...
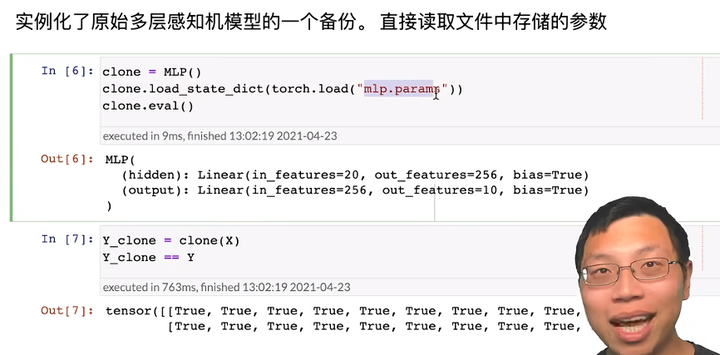
16 PyTorch 神经网络基础【李沐动手学深度学习v2】
1. 模型构造 在构造自定义块之前,我们先回顾一下多层感知机的代码。 下面的代码生成一个网络,其中包含一个具有256个单元和ReLU激活函数的全连接隐藏层, 然后是一个具有10个隐藏单元且不带激活函数的全连接输出层。 层和块 构造单层神经网咯…...
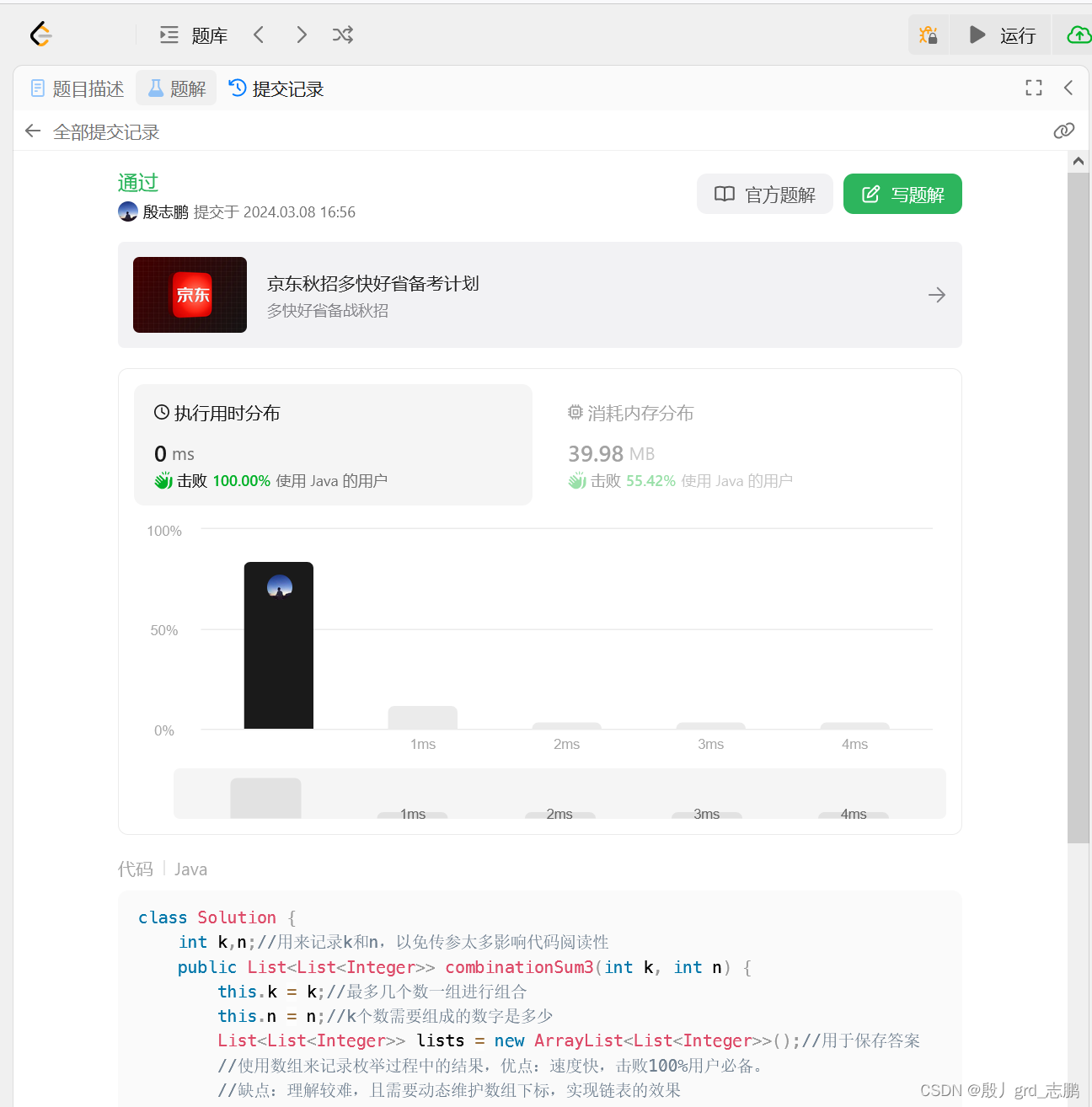
java数据结构与算法刷题-----LeetCode216. 组合总和 III
java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 文章目录 解题思路 此题是77题的扩展题,仅仅加了一个条件而已&…...

vscode remote ssh 连接 ubuntu/linux报错解决方法
1、问题: WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY! Someone could be eavesdropping on you right now (man-in-the-middle attack)! It is also possible that a host key has just been changed. The fin…...

Normalizer(归一化)和MinMaxScaler(最小-最大标准化)的区别详解
1.Normalizer(归一化)(更加推荐使用) 优点:将每个样本向量的欧几里德长度缩放为1,适用于计算样本之间的相似性。 缺点:只对每个样本的特征进行缩放,不保留原始数据的分布形状。 公式…...

覆盖element-ui的el-menu样式记录:背景图片、菜单图标、菜单高亮与鼠标悬浮高亮、调整子菜单等样式
页面中修改el-menu 设置background-color"transparent",menu菜单下的背景图片则能正常显示了 <el-menuclass"el-menu-demo"mode"horizontal"background-color"transparent"><el-menu-item index"1">…...

SKILL语言实战指南:数字IC设计中的自动化利器
1. SKILL语言:数字IC设计的瑞士军刀 第一次接触SKILL语言是在十年前的一个芯片设计项目里,当时需要手动修改上千个标准单元的布局参数。我的mentor看我对着电脑屏幕发呆,随手扔过来几行SKILL脚本:"试试这个,比你点…...
)
3 《3D Gaussian Splatting: From Theory to Real-Time Implementation》第三级:压缩、轻量化与存储优化 (一)
目录 第一部分:原理详解 1.1 Scaffold-GS原理:神经高斯与锚点的空间层次结构 1.1.1 神经高斯与锚点的空间层次结构 1.1.2 局部感知神经解码与视锥剔除机制 1.1.3 锚点层级扩展与多尺度场景覆盖 1.2 可微分量化:Laplacian-based Rate Proxy与熵约束优化 1.2.1 Laplaci…...
)
EVA-01部署教程:Qwen2.5-VL-7B模型微调+领域适配(NERV战术语料)
EVA-01部署教程:Qwen2.5-VL-7B模型微调领域适配(NERV战术语料) 1. 引言:欢迎来到NERV指挥中心 想象一下,你面前有一个能看懂图片、理解复杂场景、还能用“战术术语”和你对话的AI助手。它不仅能告诉你图片里有什么&a…...

算法训练营第三天|209.长度最小的子数组
题目链接:https://leetcode.cn/problems/minimum-size-subarray-sum/视频讲解:https://www.bilibili.com/video/BV1tZ4y1q7XE题目描述:测试用例:算法描述:使用的是滑动窗口(双指针)算法 代码分析…...

**图优化实战:基于Python与NetworkX的高效路径规划与结构优化**在现代软件系统设计中,**图数据结构**已成
图优化实战:基于Python与NetworkX的高效路径规划与结构优化 在现代软件系统设计中,图数据结构已成为解决复杂问题的核心工具之一。无论是社交网络分析、推荐系统建模,还是智能交通调度、任务依赖管理,图优化都扮演着关键角色。本文…...

Go语言怎么做前缀和_Go语言前缀和算法教程【进阶】
Go中一维前缀和需用make([]int, n1)创建,prefix[0]0,递推prefix[i]prefix[i-1]nums[i-1],使区间[l,r]和为prefix[r1]-prefix[l];二维同理,prefixi表示前i行j列和,递推公式为“上左?左上当前”,…...

Batch Normalization在VAE中的花式用法:从防梯度消失到解决posterior collapse的完整指南
Batch Normalization在VAE中的创新实践:突破后验坍塌的工程指南 当变分自编码器遇上Batch Normalization,会擦出怎样的火花?这个看似简单的技术组合,正在重塑生成模型的训练范式。想象一下,当你精心设计的VAE模型在训练…...

Agent 系列之 ReWOO:从蓝图规划到高效求解的架构革新
1. ReWOO框架的革新性设计 第一次听说ReWOO这个框架时,我正被一个复杂的NLP项目折磨得焦头烂额。当时使用的ReAct框架在处理多步骤推理任务时,不仅响应速度慢,Token消耗更是高得惊人。直到尝试了ReWOO,才发现原来大模型推理还能这…...

hph的构造详解 内部结构图
HPH身为核心液压组件,其具备的精密构造对设备运行效率与寿命有着直接的影响。从外壳所选用的材质,到内部流道的精心设计,其间的每个细节都蕴含着关键因素,都值得我们进行深入的拆解分析。 壳体材质怎么选 HPH壳体一般选用高强度球…...

3分钟魔法:让Navicat Premium试用期无限续杯的神奇脚本
3分钟魔法:让Navicat Premium试用期无限续杯的神奇脚本 【免费下载链接】navicat-premium-reset-trial Reset macOS Navicat Premium 15/16/17 app remaining trial days 项目地址: https://gitcode.com/gh_mirrors/na/navicat-premium-reset-trial 你是否曾…...