【python】六个常见爬虫案例【附源码】
大家好,我是博主英杰,整理了几个常见的爬虫案例,分享给大家,适合小白学习
一、爬取豆瓣电影排行榜Top250存储到Excel文件
近年来,Python在数据爬取和处理方面的应用越来越广泛。本文将介绍一个基于Python的爬虫程序,用于抓取豆瓣电影Top250的相关信息,并将其保存为Excel文件。
获取网页数据的函数,包括以下步骤:
1. 循环10次,依次爬取不同页面的信息;
2. 使用`urllib`获取html页面;
3. 使用`BeautifulSoup`解析页面;
4. 遍历每个div标签,即每一部电影;
5. 对每个电影信息进行匹配,使用正则表达式提取需要的信息并保存到一个列表中;
6. 将每个电影信息的列表保存到总列表中。
效果展示:
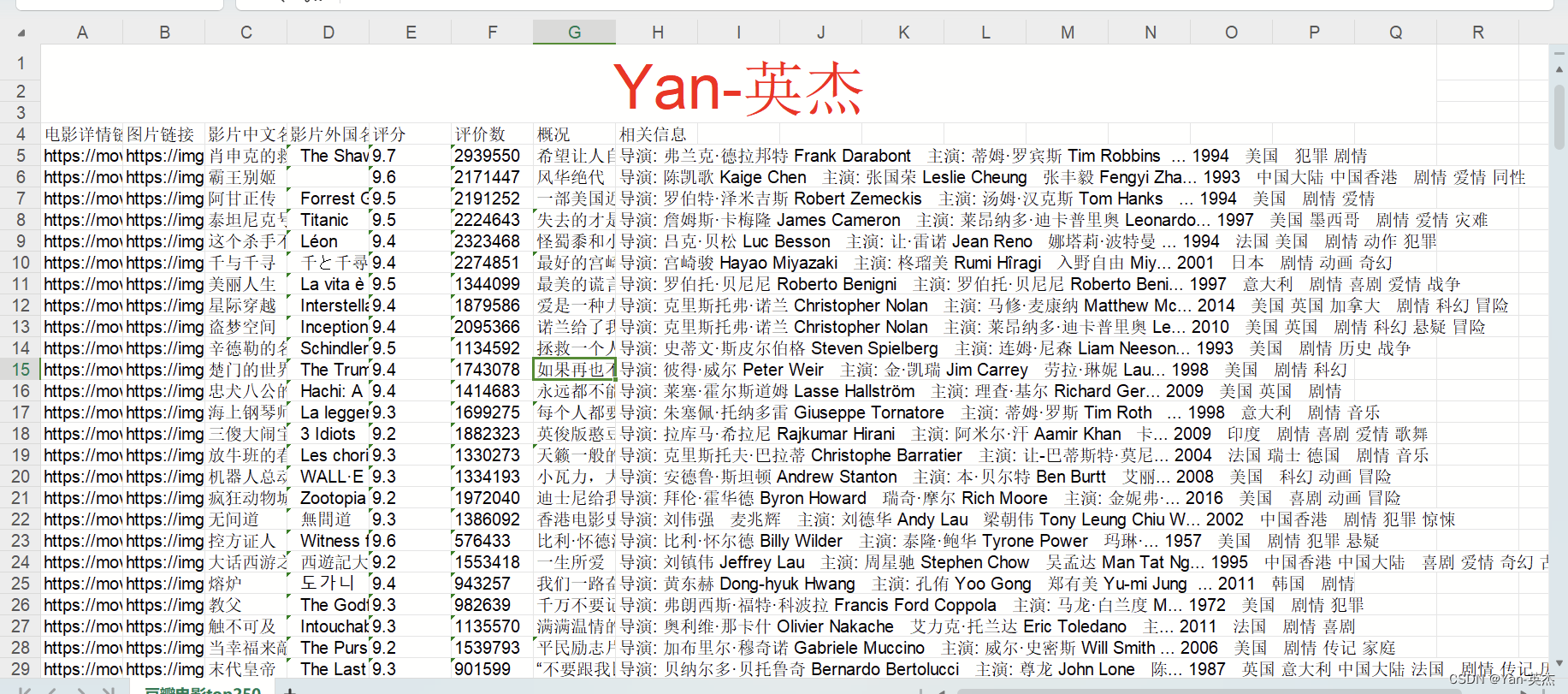
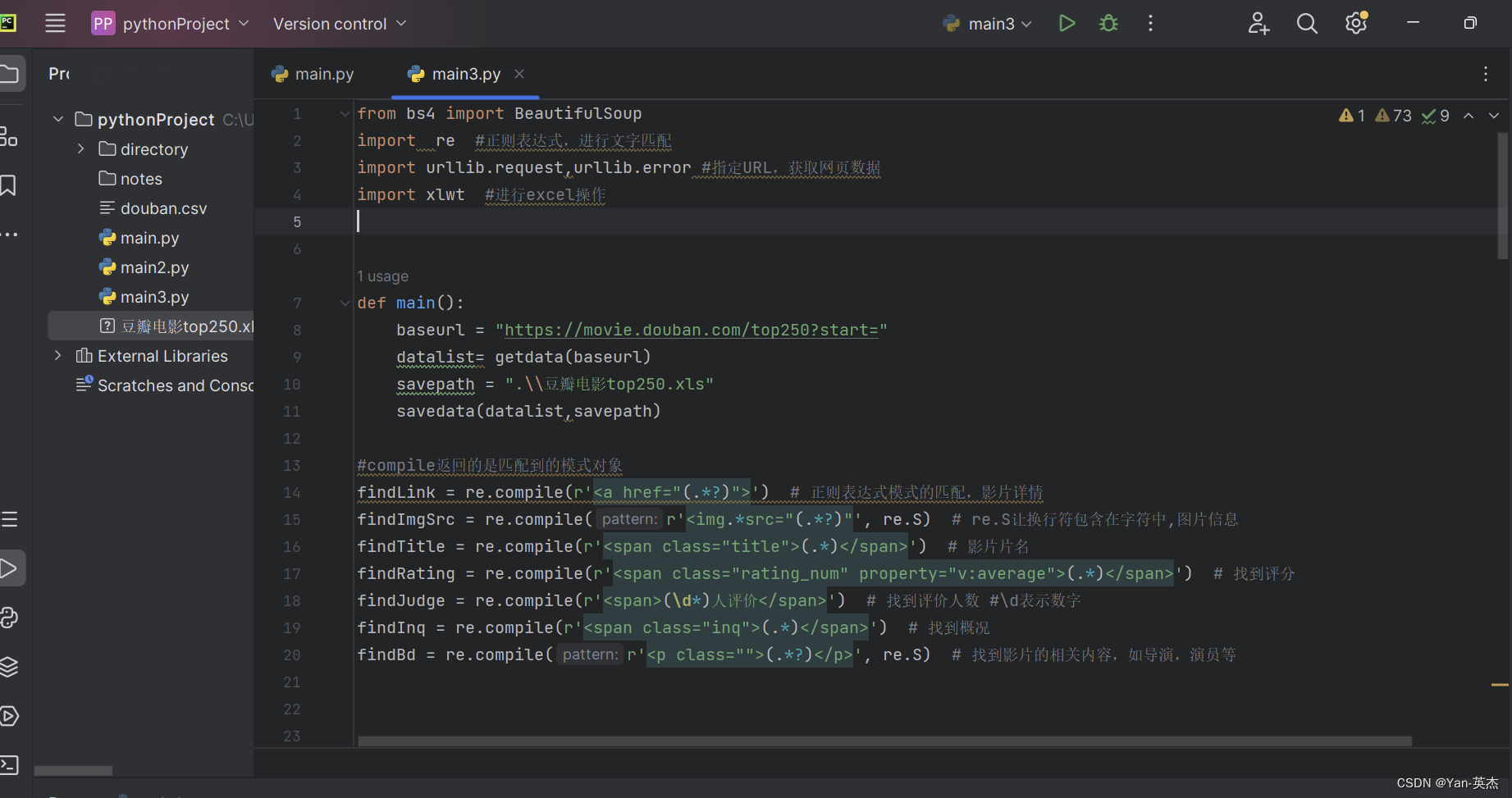
源代码:
from bs4 import BeautifulSoup
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #指定URL,获取网页数据
import xlwt #进行excel操作def main():baseurl = "https://movie.douban.com/top250?start="datalist= getdata(baseurl)savepath = ".\\豆瓣电影top250.xls"savedata(datalist,savepath)#compile返回的是匹配到的模式对象
findLink = re.compile(r'<a href="(.*?)">') # 正则表达式模式的匹配,影片详情
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # re.S让换行符包含在字符中,图片信息
findTitle = re.compile(r'<span class="title">(.*)</span>') # 影片片名
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') # 找到评分
findJudge = re.compile(r'<span>(\d*)人评价</span>') # 找到评价人数 #\d表示数字
findInq = re.compile(r'<span class="inq">(.*)</span>') # 找到概况
findBd = re.compile(r'<p class="">(.*?)</p>', re.S) # 找到影片的相关内容,如导演,演员等##获取网页数据
def getdata(baseurl):datalist=[]for i in range(0,10):url = baseurl+str(i*25) ##豆瓣页面上一共有十页信息,一页爬取完成后继续下一页html = geturl(url)soup = BeautifulSoup(html,"html.parser") #构建了一个BeautifulSoup类型的对象soup,是解析html的for item in soup.find_all("div",class_='item'): ##find_all返回的是一个列表data=[] #保存HTML中一部电影的所有信息item = str(item) ##需要先转换为字符串findall才能进行搜索link = re.findall(findLink,item)[0] ##findall返回的是列表,索引只将值赋值data.append(link)imgSrc = re.findall(findImgSrc, item)[0]data.append(imgSrc)titles=re.findall(findTitle,item) ##有的影片只有一个中文名,有的有中文和英文if(len(titles)==2):onetitle = titles[0]data.append(onetitle)twotitle = titles[1].replace("/","")#去掉无关的符号data.append(twotitle)else:data.append(titles)data.append(" ") ##将下一个值空出来rating = re.findall(findRating, item)[0] # 添加评分data.append(rating)judgeNum = re.findall(findJudge, item)[0] # 添加评价人数data.append(judgeNum)inq = re.findall(findInq, item) # 添加概述if len(inq) != 0:inq = inq[0].replace("。", "")data.append(inq)else:data.append(" ")bd = re.findall(findBd, item)[0]bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd)bd = re.sub('/', " ", bd)data.append(bd.strip()) # 去掉前后的空格datalist.append(data)return datalist##保存数据
def savedata(datalist,savepath):workbook = xlwt.Workbook(encoding="utf-8",style_compression=0) ##style_compression=0不压缩worksheet = workbook.add_sheet("豆瓣电影top250",cell_overwrite_ok=True) #cell_overwrite_ok=True再次写入数据覆盖column = ("电影详情链接", "图片链接", "影片中文名", "影片外国名", "评分", "评价数", "概况", "相关信息") ##execl项目栏for i in range(0,8):worksheet.write(0,i,column[i]) #将column[i]的内容保存在第0行,第i列for i in range(0,250):data = datalist[i]for j in range(0,8):worksheet.write(i+1,j,data[j])workbook.save(savepath)##爬取网页
def geturl(url):head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"}req = urllib.request.Request(url,headers=head)try: ##异常检测response = urllib.request.urlopen(req)html = response.read().decode("utf-8")except urllib.error.URLError as e:if hasattr(e,"code"): ##如果错误中有这个属性的话print(e.code)if hasattr(e,"reason"):print(e.reason)return htmlif __name__ == '__main__':main()print("爬取成功!!!")二、爬取百度热搜排行榜Top50+可视化
2.1 代码思路:
-
导入所需的库:
import requests
from bs4 import BeautifulSoup
import openpyxl
requests库用于发送HTTP请求获取网页内容。
BeautifulSoup库用于解析HTML页面的内容。
openpyxl库用于创建和操作Excel文件。
2.发起HTTP请求获取百度热搜页面内容:
url = 'https://top.baidu.com/board?tab=realtime'
response = requests.get(url)
html = response.content这里使用了
requests.get()方法发送GET请求,并将响应的内容赋值给变量html。
3.使用BeautifulSoup解析页面内容:
soup = BeautifulSoup(html, 'html.parser')
创建一个
BeautifulSoup对象,并传入要解析的HTML内容和解析器类型。
4.提取热搜数据:
hot_searches = []
for item in soup.find_all('div', {'class': 'c-single-text-ellipsis'}):hot_searches.append(item.text)这段代码通过调用
soup.find_all()方法找到所有<div>标签,并且指定class属性为'c-single-text-ellipsis'的元素。然后,将每个元素的文本内容添加到
hot_searches列表中。
5.保存热搜数据到Excel:
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = 'Baidu Hot Searches'使用
openpyxl.Workbook()创建一个新的工作簿对象。调用
active属性获取当前活动的工作表对象,并将其赋值给变量sheet。使用
title属性给工作表命名为'Baidu Hot Searches'。
6.设置标题:
sheet.cell(row=1, column=1, value='百度热搜排行榜—博主:Yan-英杰')使用
cell()方法选择要操作的单元格,其中row和column参数分别表示行和列的索引。将标题字符串
'百度热搜排行榜—博主:Yan-英杰'写入选定的单元格。
7.写入热搜数据:
for i in range(len(hot_searches)):sheet.cell(row=i+2, column=1, value=hot_searches[i])使用
range()函数生成一个包含索引的范围,循环遍历hot_searches列表。对于每个索引
i,使用cell()方法将对应的热搜词写入Excel文件中。
8.保存Excel文件:
workbook.save('百度热搜.xlsx')使用
save()方法将工作簿保存到指定的文件名'百度热搜.xlsx'。
9.输出提示信息:
print('热搜数据已保存到 百度热搜.xlsx')在控制台输出保存成功的提示信息。
效果展示:
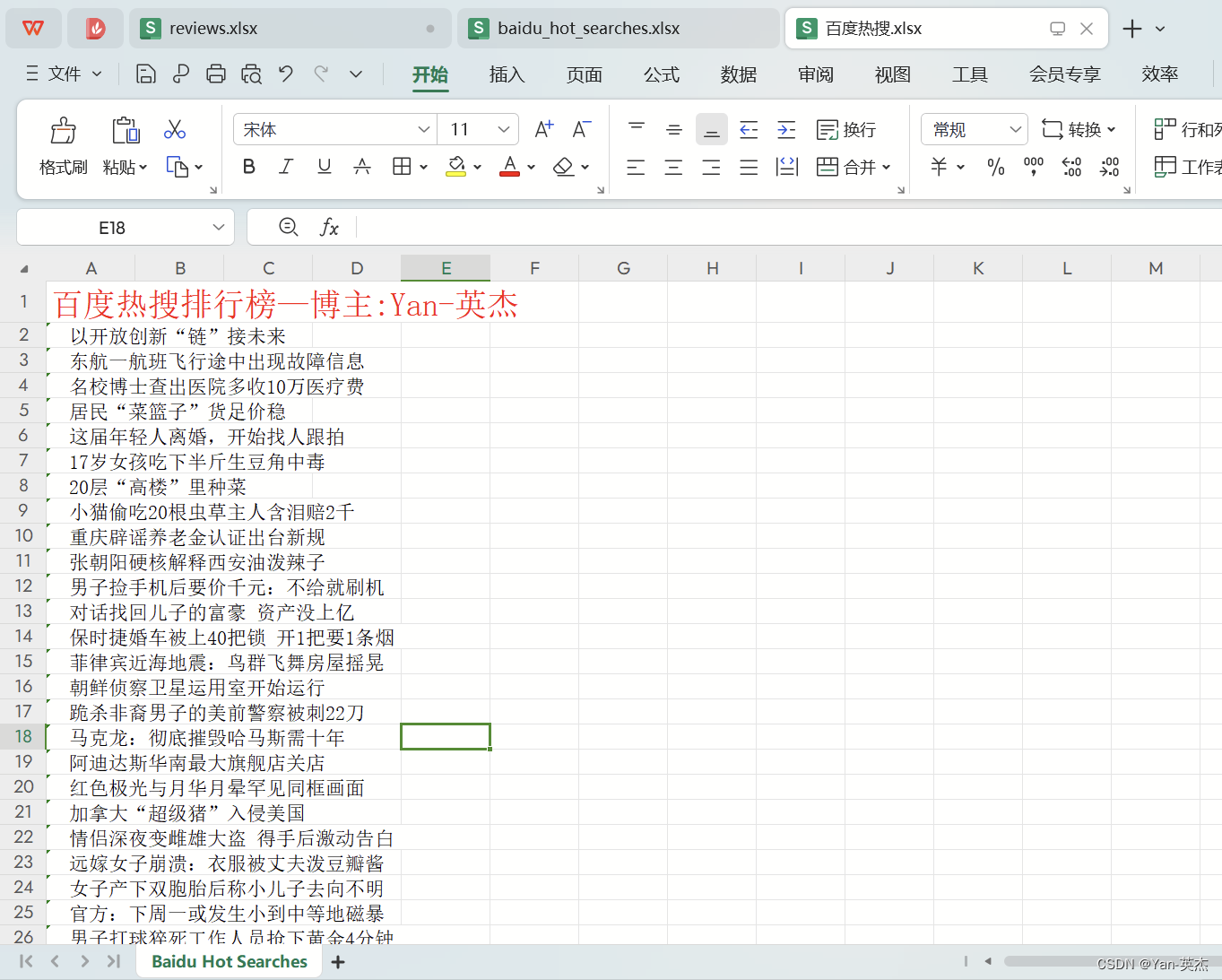
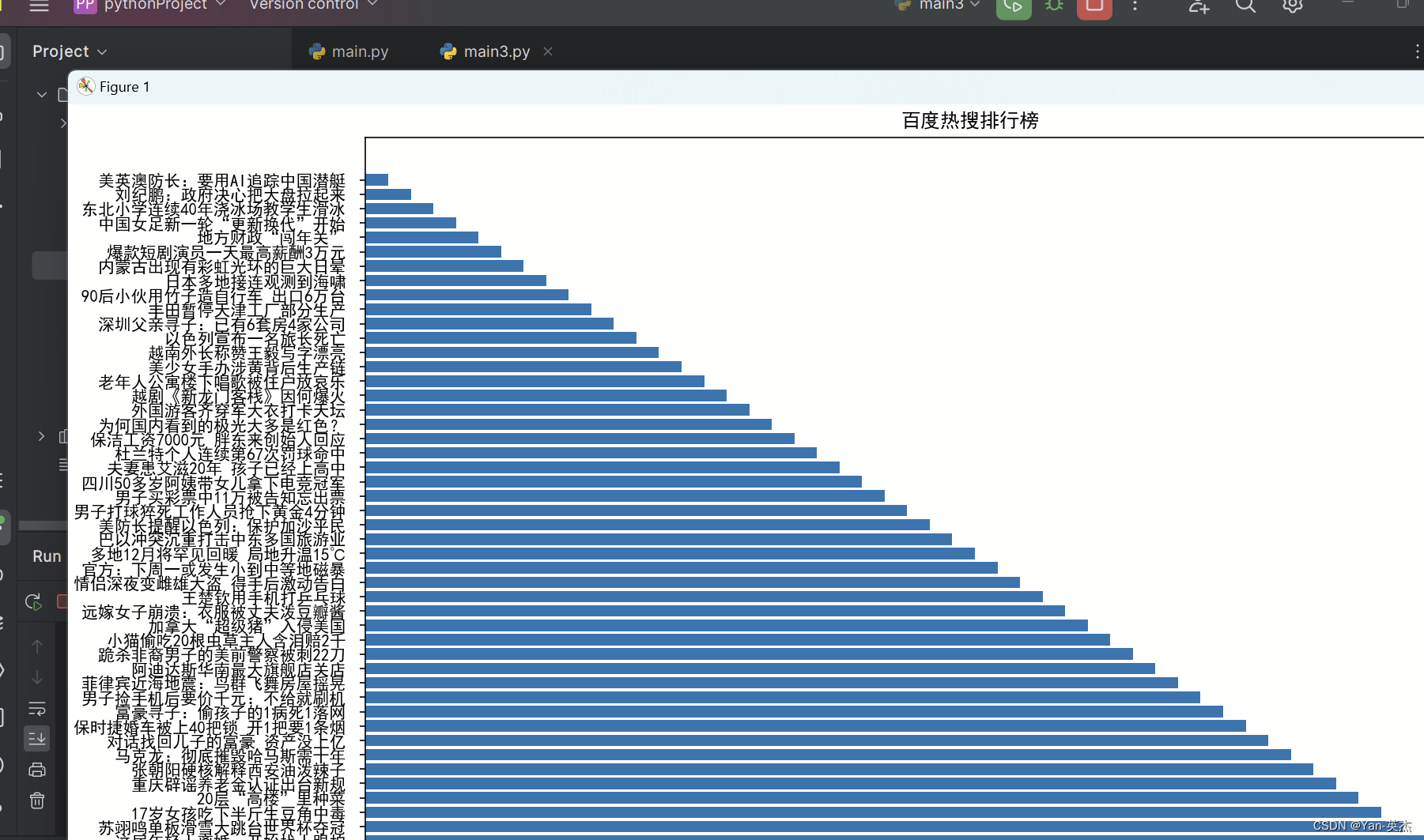
源代码:
import requests
from bs4 import BeautifulSoup
import openpyxl# 发起HTTP请求获取百度热搜页面内容
url = 'https://top.baidu.com/board?tab=realtime'
response = requests.get(url)
html = response.content# 使用BeautifulSoup解析页面内容
soup = BeautifulSoup(html, 'html.parser')# 提取热搜数据
hot_searches = []
for item in soup.find_all('div', {'class': 'c-single-text-ellipsis'}):hot_searches.append(item.text)# 保存热搜数据到Excel
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = 'Baidu Hot Searches'# 设置标题
sheet.cell(row=1, column=1, value='百度热搜排行榜—博主:Yan-英杰')# 写入热搜数据
for i in range(len(hot_searches)):sheet.cell(row=i+2, column=1, value=hot_searches[i])workbook.save('百度热搜.xlsx')
print('热搜数据已保存到 百度热搜.xlsx')可视化代码:
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt# 发起HTTP请求获取百度热搜页面内容
url = 'https://top.baidu.com/board?tab=realtime'
response = requests.get(url)
html = response.content# 使用BeautifulSoup解析页面内容
soup = BeautifulSoup(html, 'html.parser')# 提取热搜数据
hot_searches = []
for item in soup.find_all('div', {'class': 'c-single-text-ellipsis'}):hot_searches.append(item.text)# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 绘制条形图
plt.figure(figsize=(15, 10))
x = range(len(hot_searches))
y = list(reversed(range(1, len(hot_searches)+1)))
plt.barh(x, y, tick_label=hot_searches, height=0.8) # 调整条形图的高度# 添加标题和标签
plt.title('百度热搜排行榜')
plt.xlabel('排名')
plt.ylabel('关键词')# 调整坐标轴刻度
plt.xticks(range(1, len(hot_searches)+1))# 调整条形图之间的间隔
plt.subplots_adjust(hspace=0.8, wspace=0.5)# 显示图形
plt.tight_layout()
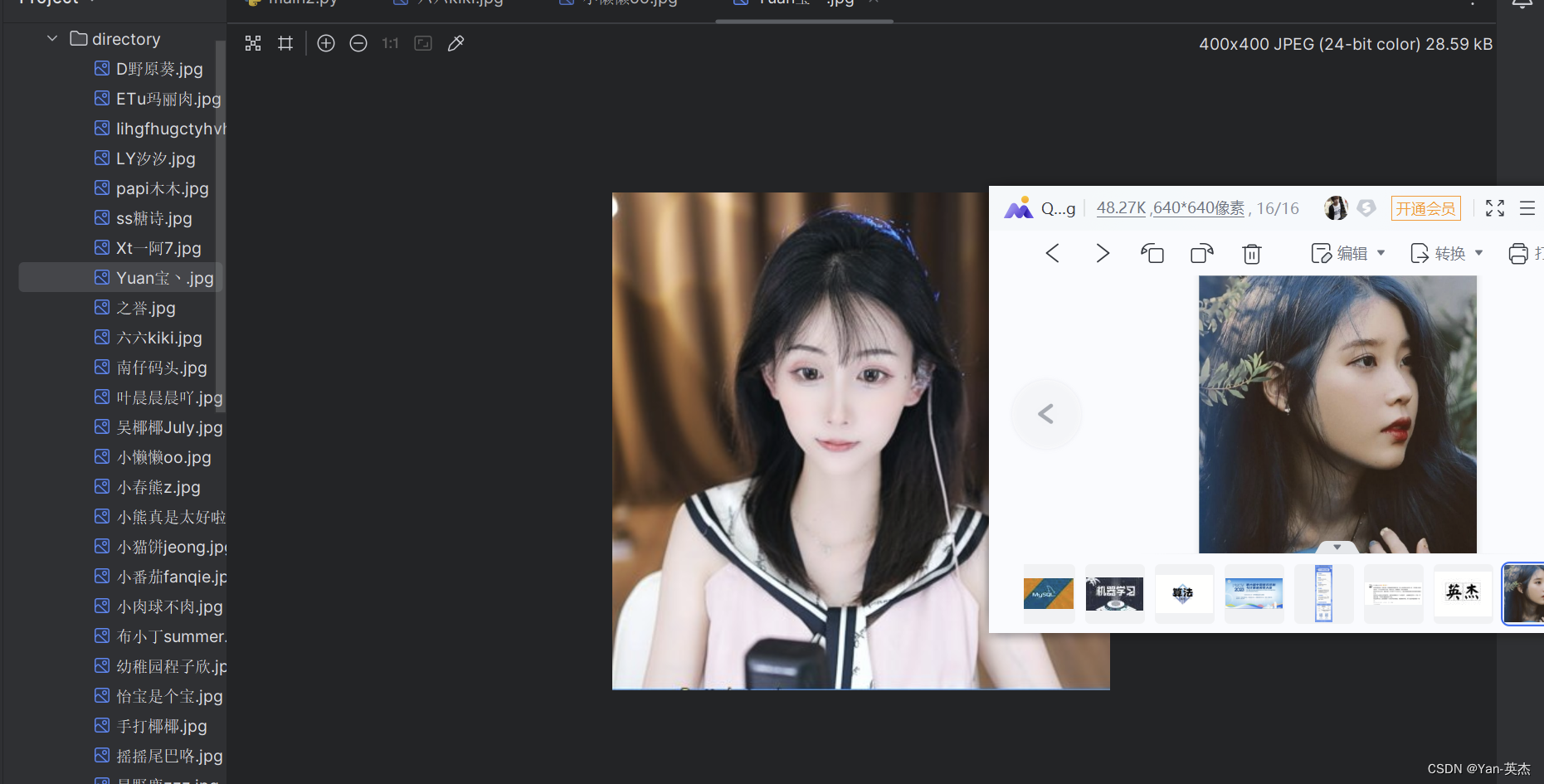
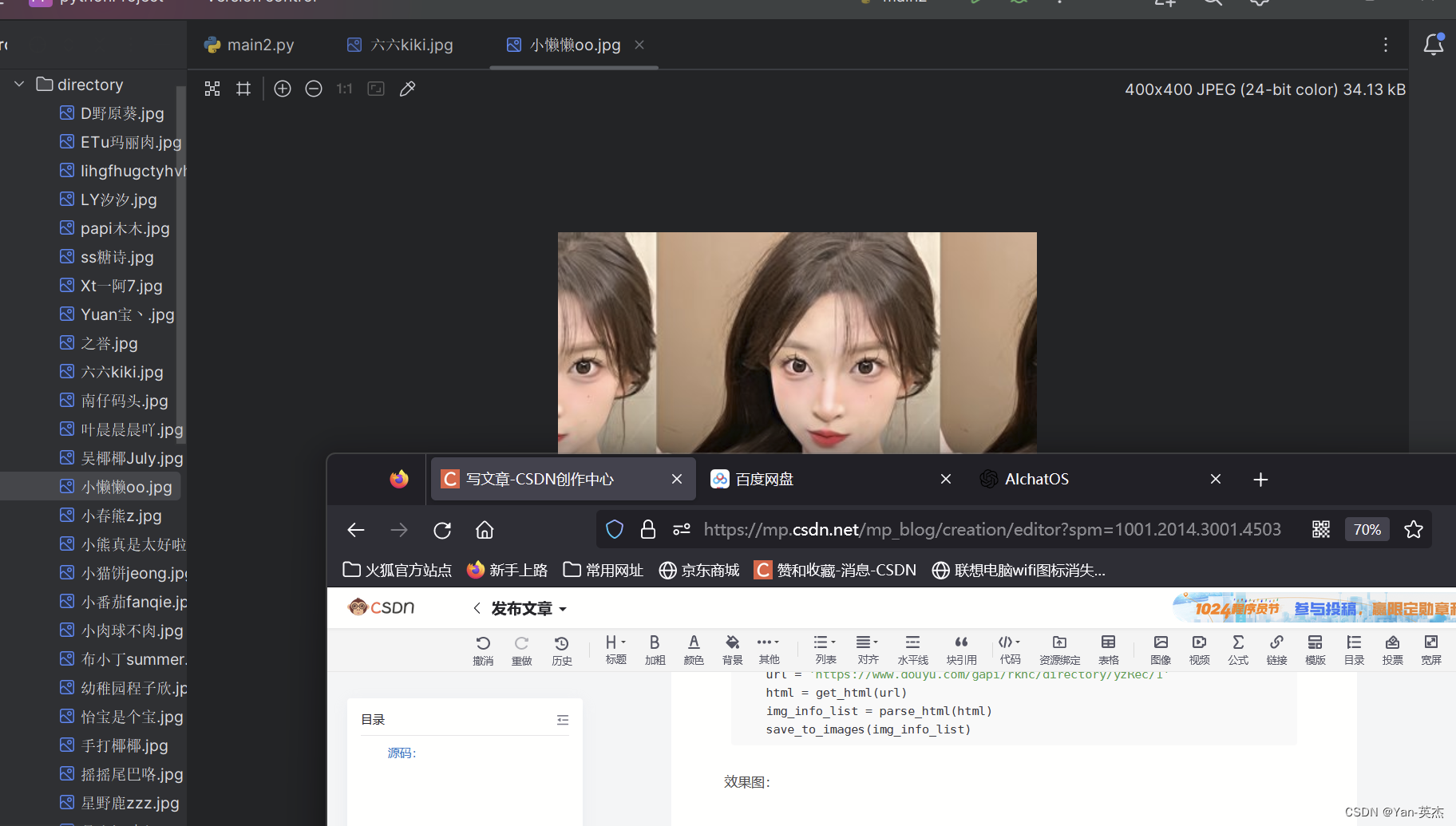
plt.show()三、爬取斗鱼直播照片保存到本地目录
效果展示:
源代码:
#导入了必要的模块requests和os
import requests
import os# 定义了一个函数get_html(url),
# 用于发送GET请求获取指定URL的响应数据。函数中设置了请求头部信息,
# 以模拟浏览器的请求。函数返回响应数据的JSON格式内容
def get_html(url):header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}response = requests.get(url=url, headers=header)# print(response.json())html = response.json()return html# 定义了一个函数parse_html(html),
# 用于解析响应数据中的图片信息。通过分析响应数据的结构,
# 提取出每个图片的URL和标题,并将其存储在一个字典中,然后将所有字典组成的列表返回
def parse_html(html):rl_list = html['data']['rl']# print(rl_list)img_info_list = []for rl in rl_list:img_info = {}img_info['img_url'] = rl['rs1']img_info['title'] = rl['nn']# print(img_url)# exit()img_info_list.append(img_info)# print(img_info_list)return img_info_list# 定义了一个函数save_to_images(img_info_list),用于保存图片到本地。
# 首先创建一个目录"directory",如果目录不存在的话。然后遍历图片信息列表,
# 依次下载每个图片并保存到目录中,图片的文件名为标题加上".jpg"后缀。
def save_to_images(img_info_list):dir_path = 'directory'if not os.path.exists(dir_path):os.makedirs(dir_path)for img_info in img_info_list:img_path = os.path.join(dir_path, img_info['title'] + '.jpg')res = requests.get(img_info['img_url'])res_img = res.contentwith open(img_path, 'wb') as f:f.write(res_img)# exit()#在主程序中,设置了要爬取的URL,并调用前面定义的函数来执行爬取、解析和保存操作。
if __name__ == '__main__':url = 'https://www.douyu.com/gapi/rknc/directory/yzRec/1'html = get_html(url)img_info_list = parse_html(html)save_to_images(img_info_list)四、爬取酷狗音乐Top500排行榜
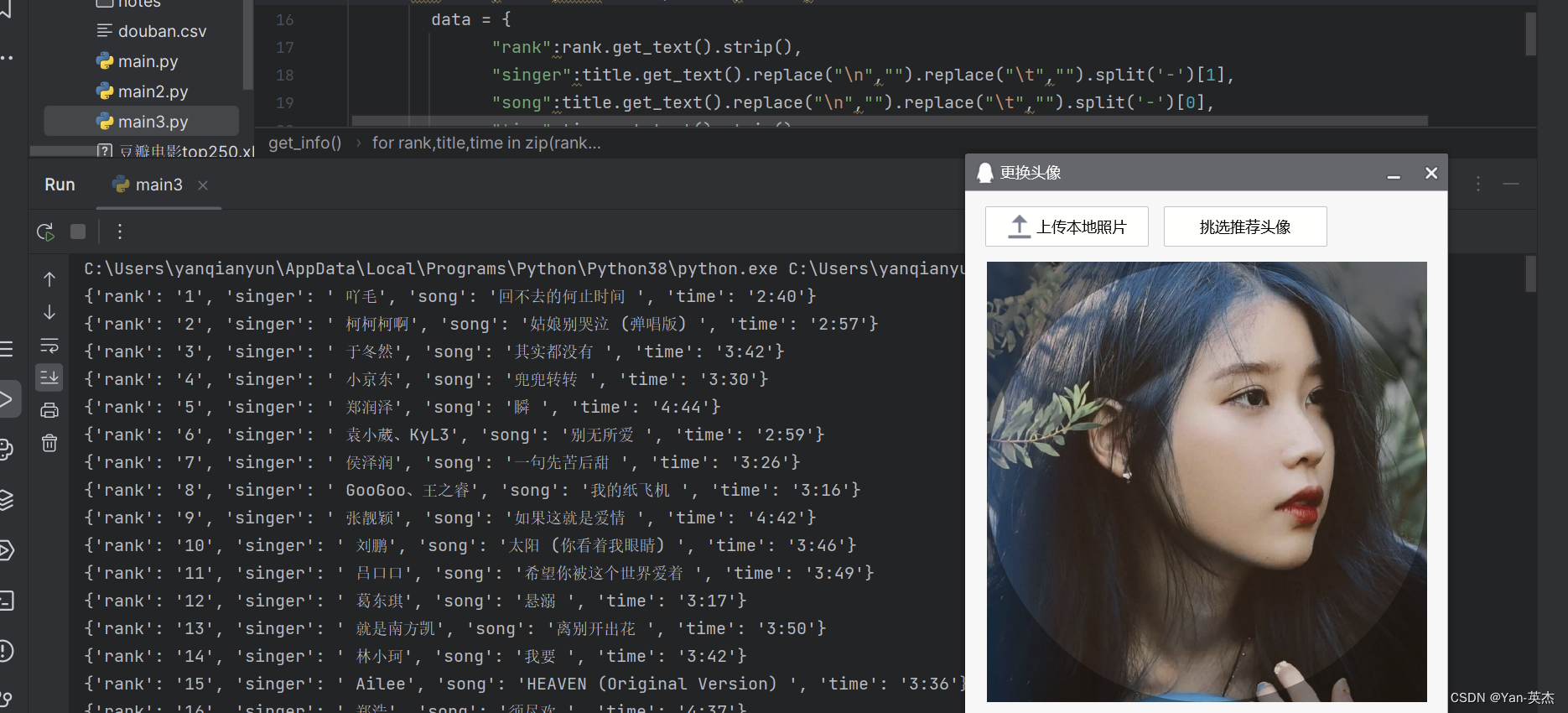
从酷狗音乐排行榜中提取歌曲的排名、歌名、歌手和时长等信息
代码思路:
效果展示:
源码:
import requests # 发送网络请求,获取 HTML 等信息
from bs4 import BeautifulSoup # 解析 HTML 信息,提取需要的信息
import time # 控制爬虫速度,防止过快被封IPheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"# 添加浏览器头部信息,模拟请求
}def get_info(url):# 参数 url :要爬取的网页地址web_data = requests.get(url, headers=headers) # 发送网络请求,获取 HTML 等信息soup = BeautifulSoup(web_data.text, 'lxml') # 解析 HTML 信息,提取需要的信息# 通过 CSS 选择器定位到需要的信息ranks = soup.select('span.pc_temp_num')titles = soup.select('div.pc_temp_songlist > ul > li > a')times = soup.select('span.pc_temp_tips_r > span')# for 循环遍历每个信息,并将其存储到字典中for rank, title, time in zip(ranks, titles, times):data = {"rank": rank.get_text().strip(), # 歌曲排名"singer": title.get_text().replace("\n", "").replace("\t", "").split('-')[1], # 歌手名"song": title.get_text().replace("\n", "").replace("\t", "").split('-')[0], # 歌曲名"time": time.get_text().strip() # 歌曲时长}print(data) # 打印获取到的信息if __name__ == '__main__':urls = ["https://www.kugou.com/yy/rank/home/{}-8888.html".format(str(i)) for i in range(1, 24)]# 构造要爬取的页面地址列表for url in urls:get_info(url) # 调用函数,获取页面信息time.sleep(1) # 控制爬虫速度,防止过快被封IP五、爬取链家二手房数据做数据分析
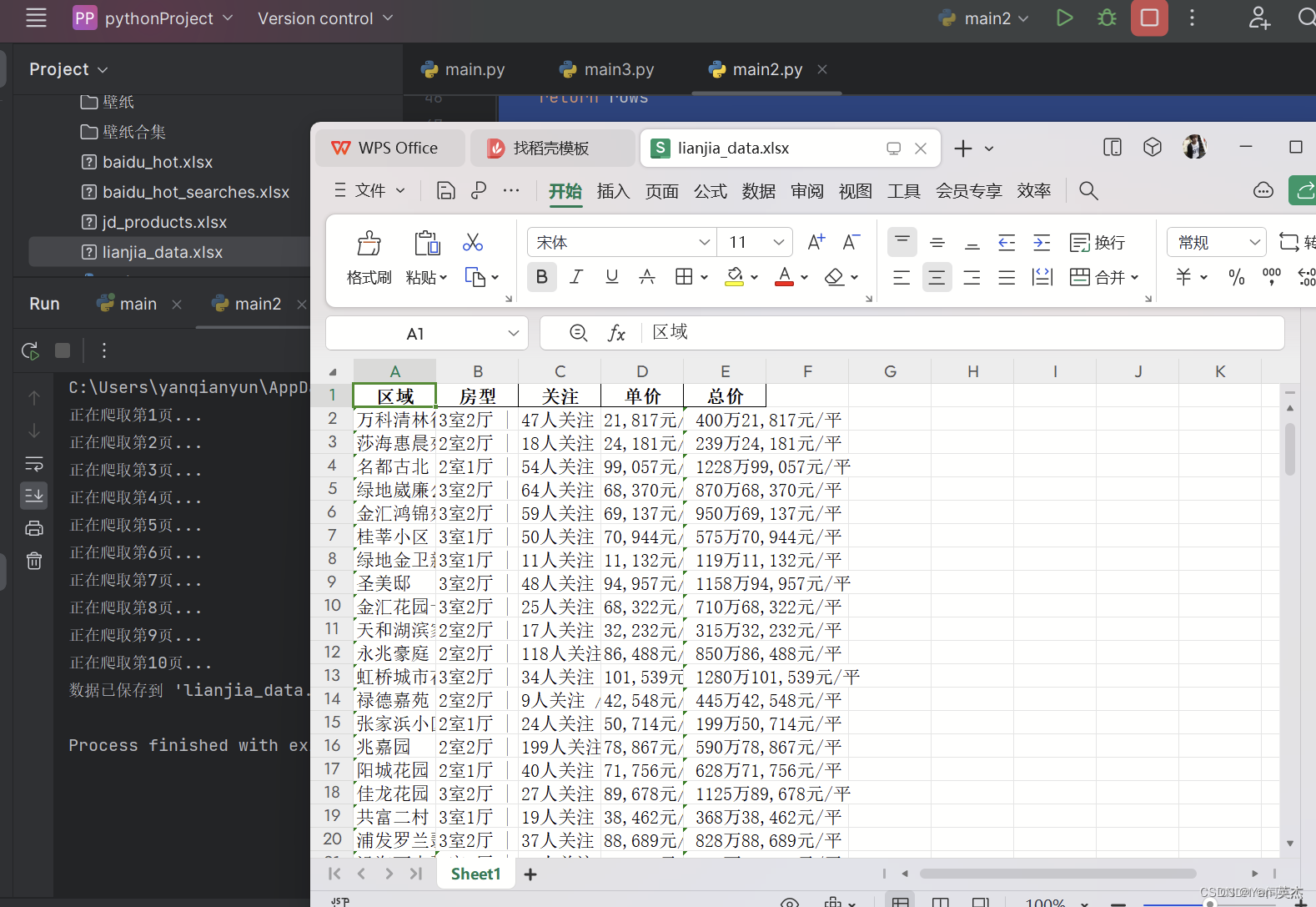
在数据分析和挖掘领域中,网络爬虫是一种常见的工具,用于从网页上收集数据。介绍如何使用 Python 编写简单的网络爬虫程序,从链家网上海二手房页面获取房屋信息,并将数据保存到 Excel 文件中。
效果图:
代码思路:
首先,我们定义了一个函数 fetch_data(page_number),用于获取指定页面的房屋信息数据。这个函数会构建对应页数的 URL,并发送 GET 请求获取页面内容。然后,使用 BeautifulSoup 解析页面内容,并提取每个房屋信息的相关数据,如区域、房型、关注人数、单价和总价。最终将提取的数据以字典形式存储在列表中,并返回该列表。
接下来,我们定义了主函数 main(),该函数控制整个爬取和保存数据的流程。在主函数中,我们循环爬取前 10 页的数据,调用 fetch_data(page_number) 函数获取每一页的数据,并将数据追加到列表中。然后,将所有爬取的数据存储在 DataFrame 中,并使用 df.to_excel('lianjia_data.xlsx', index=False) 将数据保存到 Excel 文件中。
最后,在程序的入口处,通过 if __name__ == "__main__": 来执行主函数 main()。
源代码:
import requestsfrom bs4 import BeautifulSoupimport pandas as pd# 收集单页数据 xpanx.comdef fetch_data(page_number):url = f"https://sh.lianjia.com/ershoufang/pg{page_number}/"response = requests.get(url)if response.status_code != 200:print("请求失败")return []soup = BeautifulSoup(response.text, 'html.parser')rows = []for house_info in soup.find_all("li", {"class": "clear LOGVIEWDATA LOGCLICKDATA"}):row = {}# 使用您提供的类名来获取数据 xpanx.comrow['区域'] = house_info.find("div", {"class": "positionInfo"}).get_text() if house_info.find("div", {"class": "positionInfo"}) else Nonerow['房型'] = house_info.find("div", {"class": "houseInfo"}).get_text() if house_info.find("div", {"class": "houseInfo"}) else Nonerow['关注'] = house_info.find("div", {"class": "followInfo"}).get_text() if house_info.find("div", {"class": "followInfo"}) else Nonerow['单价'] = house_info.find("div", {"class": "unitPrice"}).get_text() if house_info.find("div", {"class": "unitPrice"}) else Nonerow['总价'] = house_info.find("div", {"class": "priceInfo"}).get_text() if house_info.find("div", {"class": "priceInfo"}) else Nonerows.append(row)return rows# 主函数def main():all_data = []for i in range(1, 11): # 爬取前10页数据作为示例print(f"正在爬取第{i}页...")all_data += fetch_data(i)# 保存数据到Excel xpanx.comdf = pd.DataFrame(all_data)df.to_excel('lianjia_data.xlsx', index=False)print("数据已保存到 'lianjia_data.xlsx'")if __name__ == "__main__":main()六、爬取豆瓣电影排行榜TOP250存储到CSV文件中
代码思路:
首先,我们导入了需要用到的三个Python模块:requests、lxml和csv。
然后,我们定义了豆瓣电影TOP250页面的URL地址,并使用getSource(url)函数获取网页源码。
接着,我们定义了一个getEveryItem(source)函数,它使用XPath表达式从HTML源码中提取出每部电影的标题、URL、评分和引言,并将这些信息存储到一个字典中,最后将所有电影的字典存储到一个列表中并返回。
然后,我们定义了一个writeData(movieList)函数,它使用csv库的DictWriter类创建一个CSV写入对象,然后将电影信息列表逐行写入CSV文件。
最后,在if __name__ == '__main__'语句块中,我们定义了一个空的电影信息列表movieList,然后循环遍历前10页豆瓣电影TOP250页面,分别抓取每一页的网页源码,并使用getEveryItem()函数解析出电影信息并存储到movieList中,最后使用writeData()函数将电影信息写入CSV文件。
效果图:
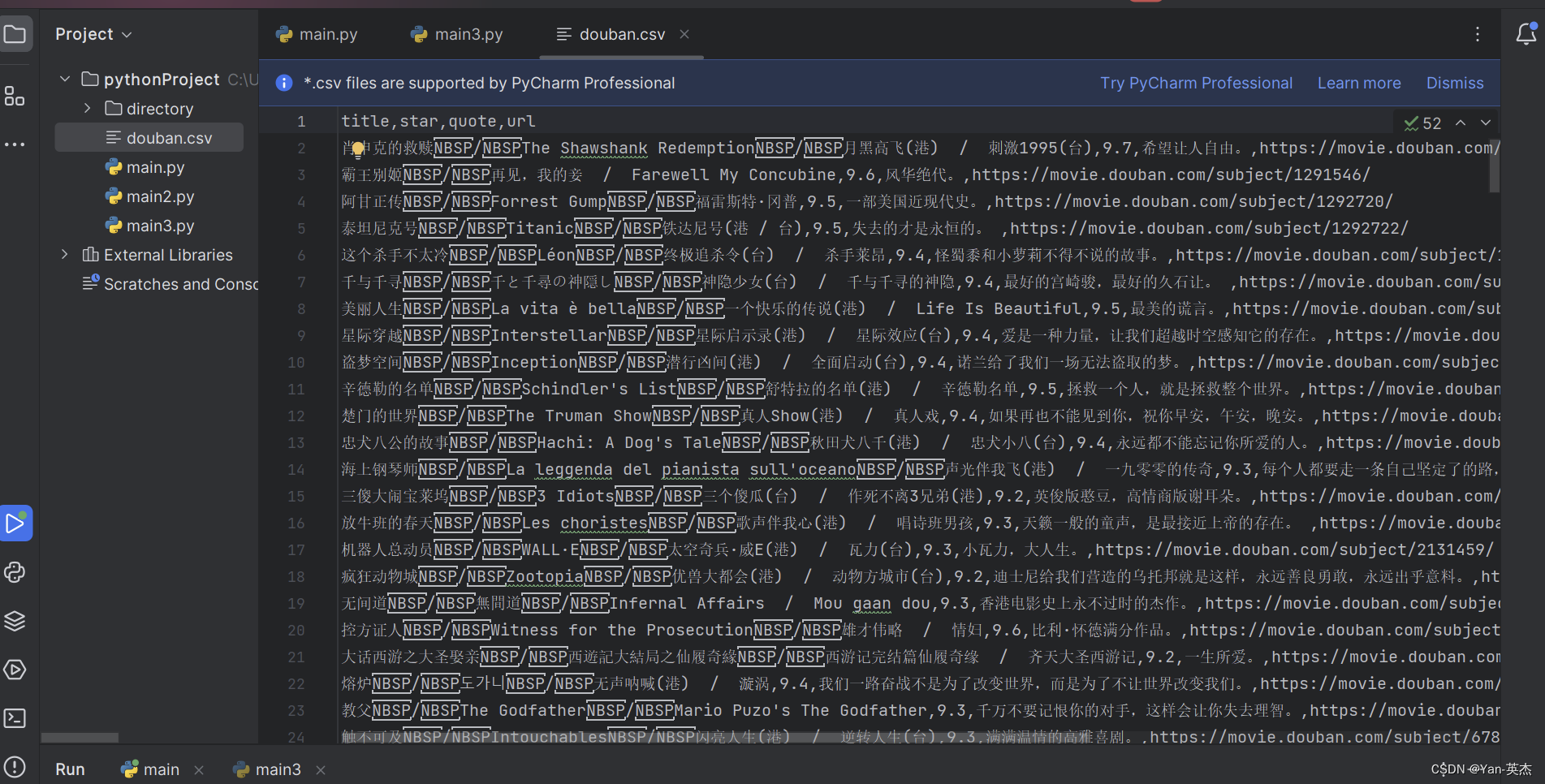
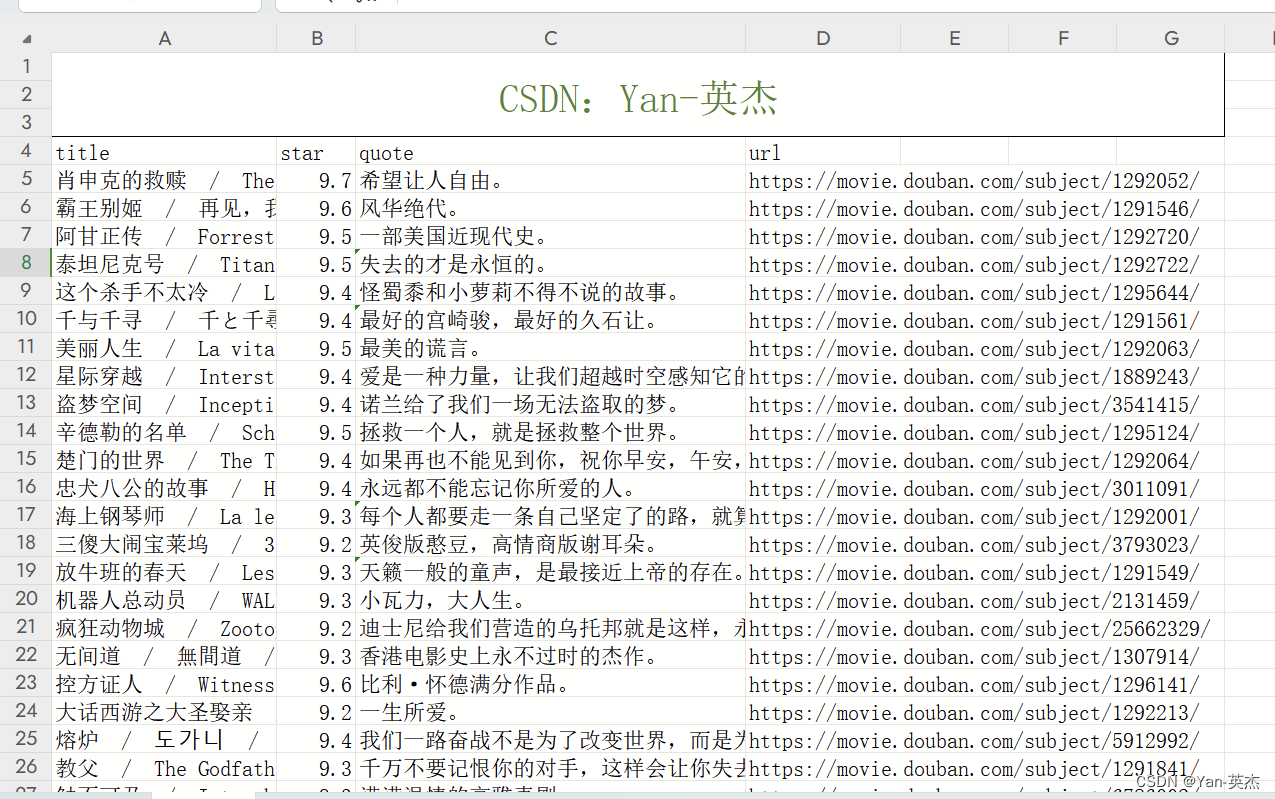
源代码:
私信博主进入交流群,一起学习探讨,如果对CSDN周边以及有偿返现活动感兴趣:
可添加博主:Yan--yingjie
如果想免费获取图书,也可添加博主微信,每周免费送数十本#代码首先导入了需要使用的模块:requests、lxml和csv。
import requests
from lxml import etree
import csv#
doubanUrl = 'https://movie.douban.com/top250?start={}&filter='# 然后定义了豆瓣电影TOP250页面的URL地址,并实现了一个函数getSource(url)来获取网页的源码。该函数发送HTTP请求,添加了请求头信息以防止被网站识别为爬虫,并通过requests.get()方法获取网页源码。
def getSource(url):# 反爬 填写headers请求头headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'}response = requests.get(url, headers=headers)# 防止出现乱码response.encoding = 'utf-8'# print(response.text)return response.text# 定义了一个函数getEveryItem(source)来解析每个电影的信息。首先,使用lxml库的etree模块将源码转换为HTML元素对象。然后,使用XPath表达式定位到包含电影信息的每个HTML元素。通过对每个元素进行XPath查询,提取出电影的标题、副标题、URL、评分和引言等信息。最后,将这些信息存储在一个字典中,并将所有电影的字典存储在一个列表中。
def getEveryItem(source):html_element = etree.HTML(source)movieItemList = html_element.xpath('//div[@class="info"]')# 定义一个空的列表movieList = []for eachMoive in movieItemList:# 创建一个字典 像列表中存储数据[{电影一},{电影二}......]movieDict = {}title = eachMoive.xpath('div[@class="hd"]/a/span[@class="title"]/text()') # 标题otherTitle = eachMoive.xpath('div[@class="hd"]/a/span[@class="other"]/text()') # 副标题link = eachMoive.xpath('div[@class="hd"]/a/@href')[0] # urlstar = eachMoive.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')[0] # 评分quote = eachMoive.xpath('div[@class="bd"]/p[@class="quote"]/span/text()') # 引言(名句)if quote:quote = quote[0]else:quote = ''# 保存数据movieDict['title'] = ''.join(title + otherTitle)movieDict['url'] = linkmovieDict['star'] = starmovieDict['quote'] = quotemovieList.append(movieDict)print(movieList)return movieList# 保存数据
def writeData(movieList):with open('douban.csv', 'w', encoding='utf-8', newline='') as f:writer = csv.DictWriter(f, fieldnames=['title', 'star', 'quote', 'url'])writer.writeheader() # 写入表头for each in movieList:writer.writerow(each)if __name__ == '__main__':movieList = []# 一共有10页for i in range(10):pageLink = doubanUrl.format(i * 25)source = getSource(pageLink)movieList += getEveryItem(source)writeData(movieList)
相关文章:
【python】六个常见爬虫案例【附源码】
大家好,我是博主英杰,整理了几个常见的爬虫案例,分享给大家,适合小白学习 一、爬取豆瓣电影排行榜Top250存储到Excel文件 近年来,Python在数据爬取和处理方面的应用越来越广泛。本文将介绍一个基于Python的爬虫程序&a…...
Java零基础-多维数组
哈喽,各位小伙伴们,你们好呀,我是喵手。 今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一个人虽可以走的更快,但一群人可以走的更远。 我是一名后…...
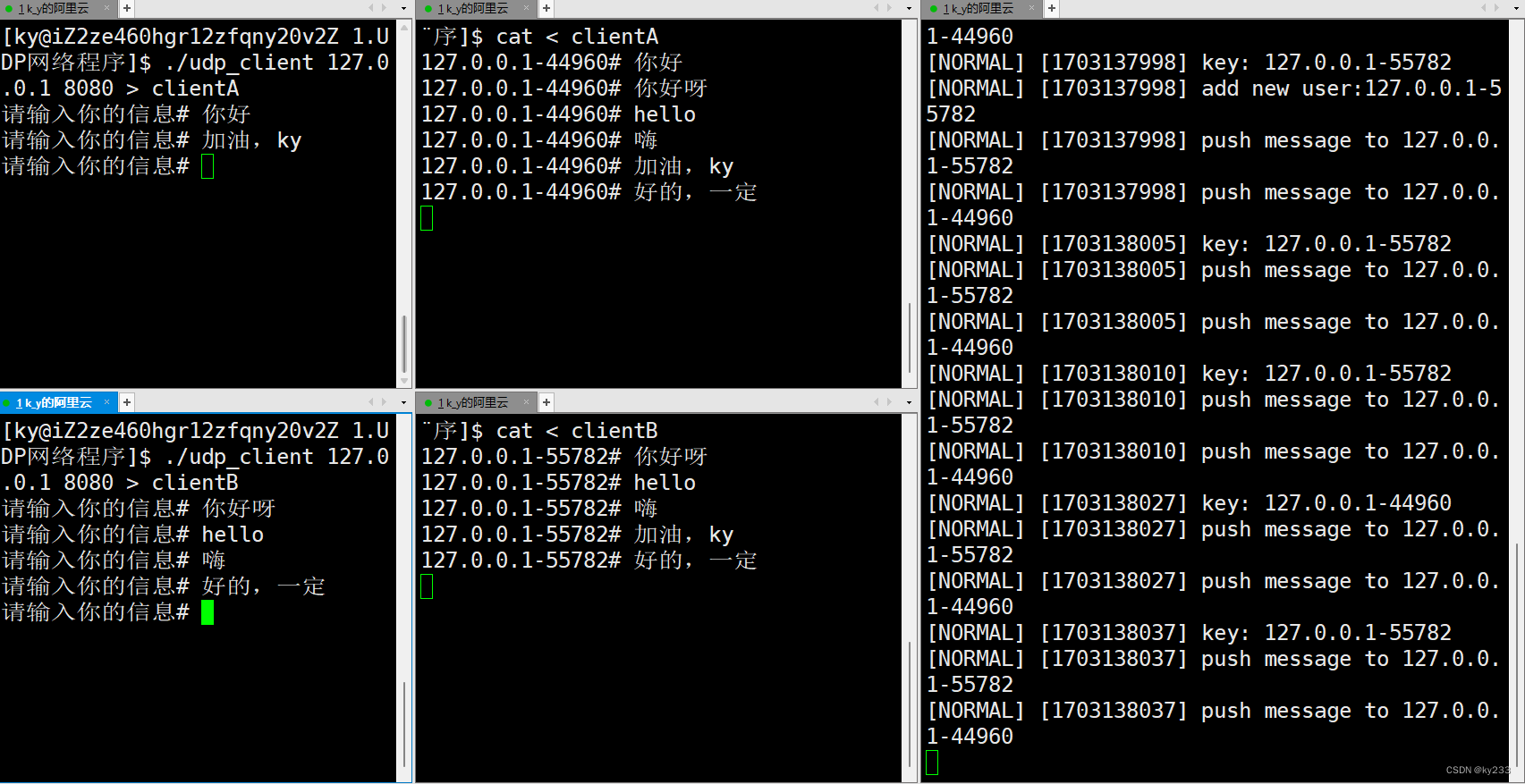
Linux网络套接字之UDP网络程序
(。・∀・)ノ゙嗨!你好这里是ky233的主页:这里是ky233的主页,欢迎光临~https://blog.csdn.net/ky233?typeblog 点个关注不迷路⌯▾⌯ 实现一个简单的对话发消息的功能! 目录…...
Apache POI 解析和处理Excel
摘要:由于开发需要批量导入Excel中的数据,使用了Apache POI库,记录下使用过程 1. 背景 Java 中操作 Excel 文件的库常用的有Apache POI 和阿里巴巴的 EasyExcel 。Apache POI 是一个功能比较全面的 Java 库,适合处理复杂的 Offi…...

SQL 注入攻击 - insert注入
环境准备:构建完善的安全渗透测试环境:推荐工具、资源和下载链接_渗透测试靶机下载-CSDN博客 一、注入原理 描述:insert注入是指通过前端注册的信息被后台通过insert操作插入到数据库中。如果后台没有做相应的处理,就可能导致insert注入漏洞。原因:后台未对用户输入进行充…...

第一个 Angular 项目 - 添加路由
第一个 Angular 项目 - 添加路由 前置项目是 第一个 Angular 项目 - 添加服务,之前的切换页面使用的是 ngIf 对渲染的组件进行判断,从而完成渲染。这一步的打算是添加路由,同时添加 edit recipe 的功能(同样通过路由实现) 用到的内容为&…...

如何简洁高效的搭建一个SpringCloud2023的maven工程
前言 依赖管理有gradle和maven,在这里选择比较常用和方便的Maven作为工程项目和依赖管理工具来搭建SpringCloud实战工程。主要用到的maven管理方式是多模块和bom依赖管理。 什么是maven的多模块依赖管理 Maven 多模块项目相对于单模块项目而言,依赖是…...

uniapp直接连接wifi(含有ios和安卓的注意事项)
前言 小程序中直接连接wifi-----微信小程序 代码 启动 //启动wifistartWifi() {return new Promise((resolve, reject) > {uni.startWifi({success: (res) > {console.log(启动wifi 成功, res)resolve(true)},fail: (err) > {console.error(启动wifi 失败, err)uni.s…...

一. Ubuntu入门
目录 一. Ubuntu系统安装 1. 安装虚拟机软件VMware 2. 安装Ubuntu操作系统 二. Ubuntu系统入门 1. Shell操作 1.1 Shell 简介 1.2 Shell基本操作 1.3 常用Shell命令 (1) 目录信息查看命令ls (2) 目录切换命令cd (3) 当前路径显示命令pwd (4) 系统信息查看命令uname…...

rk3568 Android12 增加支持 ntfs 格式
rk3568 Android12 增加支持 ntfs 格式 Windows平台上可移动硬盘支持 NTFS,FAT32,exFAT三种格式。Fat32文件格式是一种通用格式,任何USB存储设备都会预装该文件系统,可以在任何操作系统平台上使用。最主要的缺陷是只支持最大单文件大小容量为4GB,因此日常使用没有问题,只有…...

【MapReduce】02.Hadoop序列化
实现bean对象序列化步骤 自定义bean对象实现序列化接口。 1)必须实现Writable接口 2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造 public FlowBean(){super(); } 3)重写序列化方法 Override public …...

【Claude 3】一文谈谈Anthropic(Claude) 亚马逊云科技(Bedrock)的因缘际会
文章目录 前言1. Anthropic的诞生2. Anthropic的“代表作”——Claude 3的“三驾马车”3. 亚马逊云科技介绍4. 强大的全托管服务平台——Amazon Bedrock5. 亚马逊云科技(AWS)和Anthropic的联系6. Claude 3模型与Bedrock托管平台的关系7. Clude 3限时体验入口分享【⚠️截止3月1…...

c#开发100问?
什么是C#?C#是由谁开发的?C#与Java之间有哪些相似之处?C#与C有哪些不同之处?C#的主要特性是什么?请解释C#中的类和对象。C#中的命名空间是什么?什么是C#中的属性和字段?请解释C#中的继承和多态性…...

回归预测 | Matlab实现BiTCN-BiGRU-Attention双向时间卷积双向门控循环单元融合注意力机制多变量回归预测
回归预测 | Matlab实现BiTCN-BiGRU-Attention双向时间卷积双向门控循环单元融合注意力机制多变量回归预测 目录 回归预测 | Matlab实现BiTCN-BiGRU-Attention双向时间卷积双向门控循环单元融合注意力机制多变量回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.M…...
SpringCloud微服务-RabbitMQ快速入门
文章目录 RabbitMQ快速入门1、什么是MQ?2、RabbitMQ概述3、RabbitMQ的结构和概念4、常见消息模型5、HelloWorld RabbitMQ快速入门 1、什么是MQ? MQ (MessageQueue),中文是消息队列,字面来看就是存放消息的…...

OpenCV学习笔记(五)——图片的缩放、旋转、平移、裁剪以及翻转操作
目录 图像的缩放 图像的平移 图像的旋转 图像的裁剪 图像的翻转 图像的缩放 OpenCV中使用cv2.resize()函数进行缩放,格式为: resize_imagecv2.resize(image,(new_w,new_h),插值选项) 其中image代表的是需要缩放的对象,(new_w,new_h)表…...
c++ 串口通信库
根据资料整理的串口通信库,封装成为了动态库,使用者只需要调用接口即可 使用实例如下: //接受数据 void CSerialPortCommonLibDemoDlg::OnReceive() { char * str NULL; str new char[256]; _port.readAllData(str); CString s…...

数据结构之单链表及其实现!
目录 编辑 1. 顺序表的问题及思考 2.链表的概念结构和分类 2.1 概念及结构 2.2 分类 3. 单链表的实现 3.1 新节点的创建 3.2 打印单链表 3.3 头插 3.4 头删 3.5 尾插 3.6 尾删 3.7 查找元素X 3.8 在pos位置修改 3.9 在任意位置之前插入 3.10 在任意位置删除…...
Ubuntu 22.04修改静态ip
1. 备份原网络配置文件 # 配置文件名称因机器设置有异 cd /etc/netplan cp 01-network-config.yaml 01-network-config.yaml.bak# 文件内容如下 network:version: 2renderer: NetworkManager2. 修改配置文件 使用 ipconfig 命令查看网络信息,ip addr 命令也可 我这…...
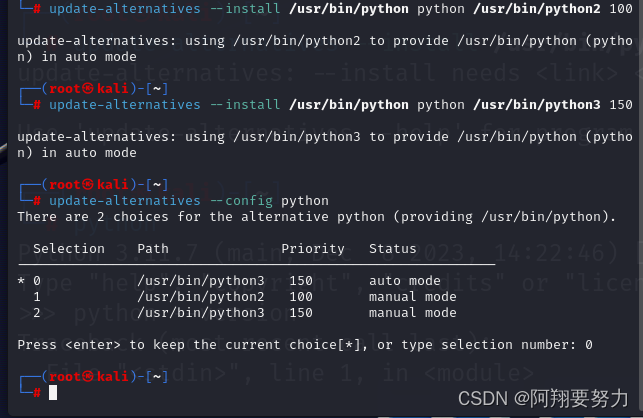
kali当中不同的python版本切换(超简单)
kali当中本身就是自带两个python版本的 配置 update-alternatives --install /usr/bin/python python /usr/bin/python2 100 update-alternatives --install /usr/bin/python python /usr/bin/python3 150 切换版本 update-alternatives --config python 0 1 2编号选择一个即可…...

基于Docker的Grafana+Loki+Promtail日志监控与Prometheus主机监控实战指南
1. 为什么需要Docker化的监控系统? 现代应用架构越来越复杂,微服务、容器化部署已经成为标配。记得我第一次接手一个分布式系统时,面对几十个服务实例的日志排查问题,用传统的grep命令就像大海捞针。直到发现了GrafanaLokiPromtai…...

3步构建智能网络管控:OpenWrt访问控制插件实战指南
3步构建智能网络管控:OpenWrt访问控制插件实战指南 【免费下载链接】luci-access-control OpenWrt internet access scheduler 项目地址: https://gitcode.com/gh_mirrors/lu/luci-access-control 在现代家庭和企业网络中,设备管理已成为网络管理…...

2025网盘直链下载神器LinkSwift:八大平台全速下载完全指南
2025网盘直链下载神器LinkSwift:八大平台全速下载完全指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / …...

UDOP-large多场景教程:英文发票/论文/表格/表单/说明书/合同六类Prompt模板库
UDOP-large多场景教程:英文发票/论文/表格/表单/说明书/合同六类Prompt模板库 1. 快速上手UDOP-large文档理解模型 Microsoft UDOP-large是微软研究院开发的通用文档处理模型,基于T5-large架构的视觉多模态模型。这个模型特别擅长处理各种英文文档&…...

Marimo 高危预认证 RCE 漏洞已遭活跃利用
聚焦源代码安全,网罗国内外最新资讯!编译:代码卫士开源响应式 Python 笔记本平台 Marimo 中存在一个严重漏洞CVE-2026-39987(CVSS评分9.3),攻击者无需认证即可实现远程代码执行 (RCE),影响 Mari…...

RealSense D435数据后处理指南:从rosbag到图片/视频的三种实用方法对比
RealSense D435数据后处理实战:三种rosbag转图片/视频方案深度评测 当你手握RealSense D435采集的rosbag数据时,是否曾为如何高效提取关键帧而头疼?作为计算机视觉和机器人领域的常用传感器,D435采集的RGB-D数据往往需要经过后处理…...

AI工程师的进化
引言:AI时代对工程师能力的重构传统工程师技能模型与AI时代的对比超级能力(Superpowers)的定义:技术深度、跨界融合、人机协作核心能力维度进化技术栈的量子跃迁从单一编程语言到全栈AI化:MLOps、AutoML工具的掌握低代…...

解放华硕笔记本性能:GHelper轻量级控制工具完全指南
解放华硕笔记本性能:GHelper轻量级控制工具完全指南 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar…...

Lingbot-Depth-Pretrain-ViTL-14模型推理优化:降低显存占用的实战技巧
Lingbot-Depth-Pretrain-ViTL-14模型推理优化:降低显存占用的实战技巧 你是不是也遇到过这种情况?好不容易找到一个效果不错的深度估计模型,比如Lingbot-Depth-Pretrain-ViTL-14,兴致勃勃地准备在自己的项目里用起来,结…...

Polaris移动端体验:Android和iOS客户端的完美同步
Polaris移动端体验:Android和iOS客户端的完美同步 【免费下载链接】polaris Polaris is a music streaming application, designed to let you enjoy your music collection from any computer or mobile device. 项目地址: https://gitcode.com/gh_mirrors/pola/…...