采用 Amazon DocumentDB 和 Amazon Bedrock 上的 Claude 3 构建游戏行业产品推荐

前言
大语言模型(LLM)自面世以来即展示了其创新能力,但 LLM 面临着幻觉等挑战。如何通过整合外部数据库的知识,检索增强生成(RAG)已成为通用和可行的解决方案。这提高了模型的准确性和可信度,特别是对于知识密集型任务,并允许持续的知识更新和特定领域信息的集成。在 RAG 过程中,通常向量数据库会是其非常重要的组件,主要体现在数据存储、高效查询等方面,它可以为 RAG 提供丰富的数据来源和输入方式,并支持高效的计算和处理,从而促进生成式 AI 的发展和应用。Amazon DocumentDB(兼容 MongoDB)现已支持向量数据库以毫秒级的响应时间存储、索引和搜索数百万个向量。向量是非结构化数据的数字表示,例如文本,由机器学习(ML)模型创建,有助于捕捉底层数据的语义含义。Amazon DocumentDB 的向量搜索可以存储来自 Amazon Bedrock、Amazon SageMaker,以及其他第三方或专有模型等的向量。
借助 Amazon DocumentDB 的向量搜索功能(Vector Search),可以轻松地为机器学习(包括生成式 AI 应用程序)设置、操作和扩展向量数据库。在一个云原生文档数据库引擎里, 实现向量和业务标量数据的统一管理,不再需要花费大量时间熟悉和管理独立的专用向量数据库引擎,以及跨数据引擎同步数据。向量搜索功能与 LLM 相结合,能够根据含义搜索数据库,从而解锁各种用例,包括语义搜索、产品推荐、个性化和聊天机器人。
Amazon DocumentDB 的向量搜索将 JSON 文档数据库的灵活性、丰富的查询功能、全文检索与向量搜索的能力相结合。使用现有 Amazon DocumentDB 灵活的文档结构数据,结合向量数据存储、索引(最多可支持索引 2000 维,目前支持 IVFFlat 和 HNSW 索引)和搜索, 来构建机器学习和生成 AI 用例,如语义搜索体验、产品推荐、个性化、聊天机器人、欺诈检测和异常检测。Amazon DocumentDB 的向量搜索在所有可用 Amazon DocumentDB 的区域,基于 DocumentDB 5.0 实例的集群上可用。
Amazon DocumentDB 支持全文检索,可以针对文本索引字段中搜索部分或全部关键字,对大型字符串数据执行特定术语或短语的文本搜索,使用权重为索引字段分配不同的级别,并根据相关性对搜索结果进行排序。可以用于帮助客户构建知识库系统。和向量查询结合,可以实现 RAG 双路召回的功能。Amazon DocumentDB 结合向量和文本搜索可实现混合搜索,使用双路召回的方式对用户的查询进行检索,分别对查询语句和文档进行向量化和相似度计算以及基于分词的全文检索,两个查询并行执行。而针对返回的结果,再根据特定的逻辑进行合并和排序(比如加权平均、排序融合等),双壁合一得到一个最终的检索结果集合。使用混合搜索来实现双路召回的优势是,它可以克服向量检索和关键词检索各自的局限性, 获得更精准和更多样化的检索结果。
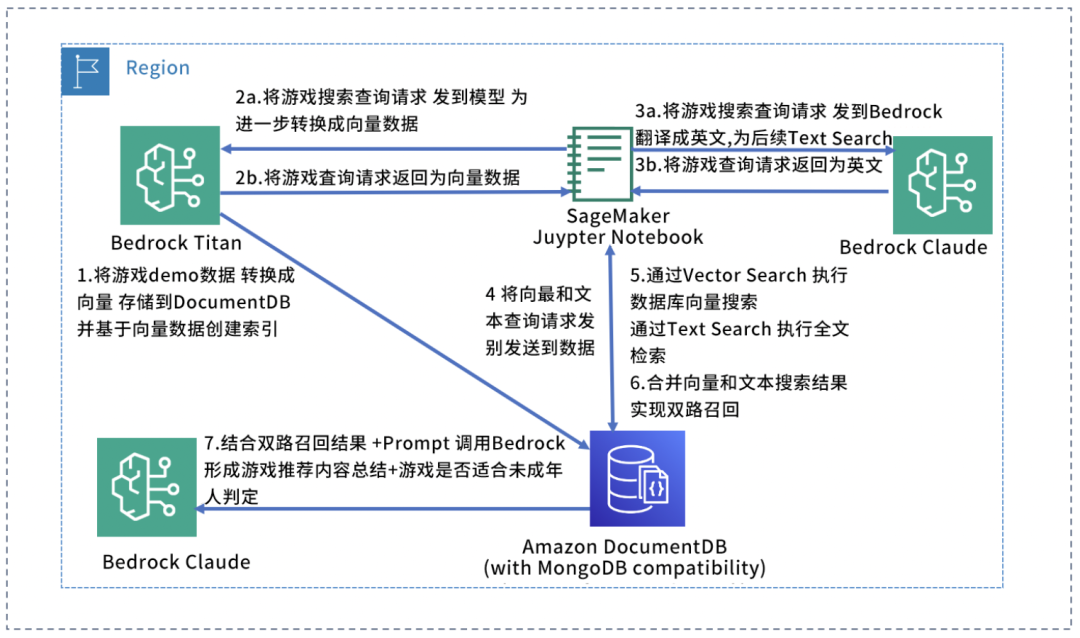
本文将展示如何采用 Amazon DocumentDB 和 Amazon Bedrock 构建游戏行业产品推荐,文中的 Demo 已经接入了目前最新发布的 Bedrock Claude 3 Sonnet 模型。Anthropic 目前的评估表明,Claude 3 模型系列在数学应用题解决(MATH)和多语言数学(MGSM)基准(目前用于大语言模型的关键基准)方面优于同类模型。另外我们使用了 Amazon Bedrock Titan 模型来生成向量,并使用 DocumentDB 将 Titan 生成的向量存储在 Amazon DocumentDB 数据库中,利用 DocumentDB Vector Search 的相似性向量搜索和 DocumentDB Text Search 全文检索功能实现 RAG 双路召回,并将 RAG 双路召回合并结果,返回给 Amazon Bedrock Claude 3 Sonnet,进行内容总结归并。
架构
环境部署
通过 Cloudformation 部署所需的资源
(区域请选择 us-east-1)
为了简化示例环境的入门体验,我们创建了 Amazon CloudFormation 基础模板来设置示例环境所需的资源。这些模板旨在部署一致的网络基础设施和客户端体验的软件包和组件,方便示例的开展。
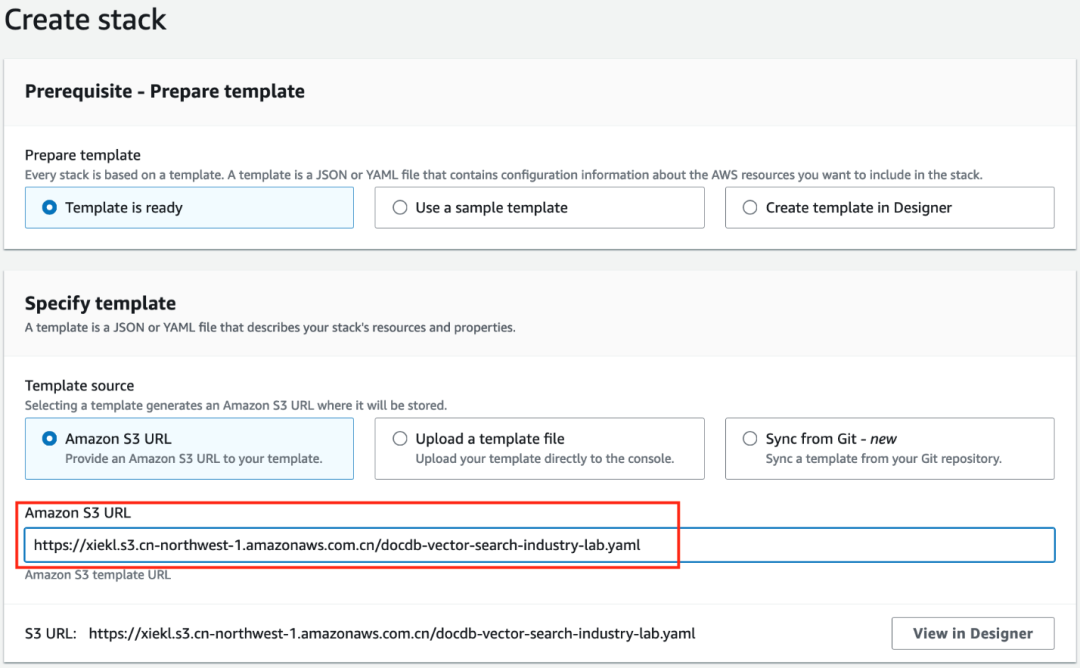
在亚马逊云科技控制台上点击 CloudFormation 页面,点击 Launch Stack(create stack)按钮来初始化您的环境。
请选择 Template source: Amazon S3 URL
请选择 Amazon S3 URL: https://xiekl.s3.cn-northwest-1.amazonaws.com.cn/docdb-vector-search-indutry-lab.yaml
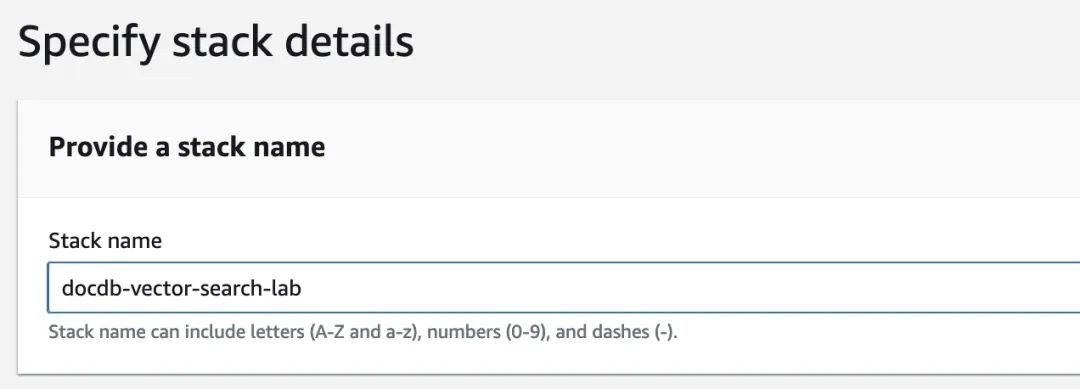
在名为“Stack Name”的字段中,填入值为 docdb-vector-search-lab
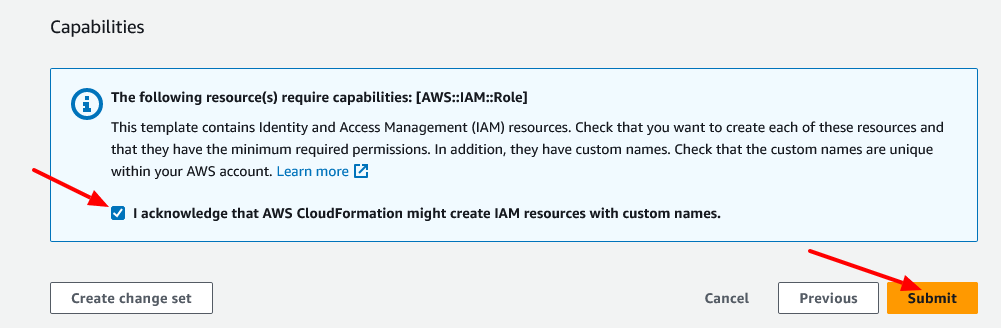
点击“下一步” ,在下一页接受默认设置,点击“下一步”。在最后一页,滚动到底部,选中确认创建 IAM 资源的复选框,然后点击“创建堆栈”
该 Stack 会创建:
一个新的 VPC、相关的子网、路由等
一个 docDB 数据库集群
一个 SageMaker Notebook 实例
支持的角色
完成这些配置大约需要十几分钟时间。您可以在主堆栈的堆栈详情页面监控状态
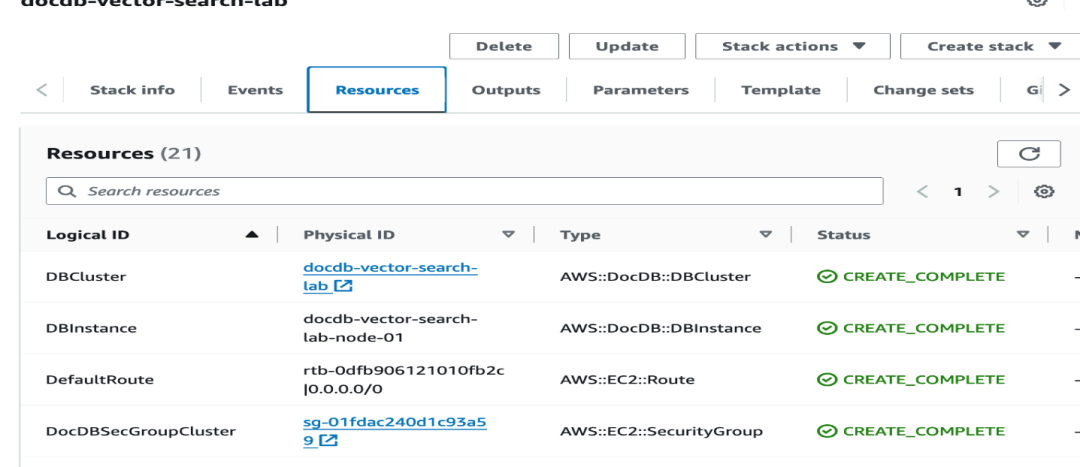
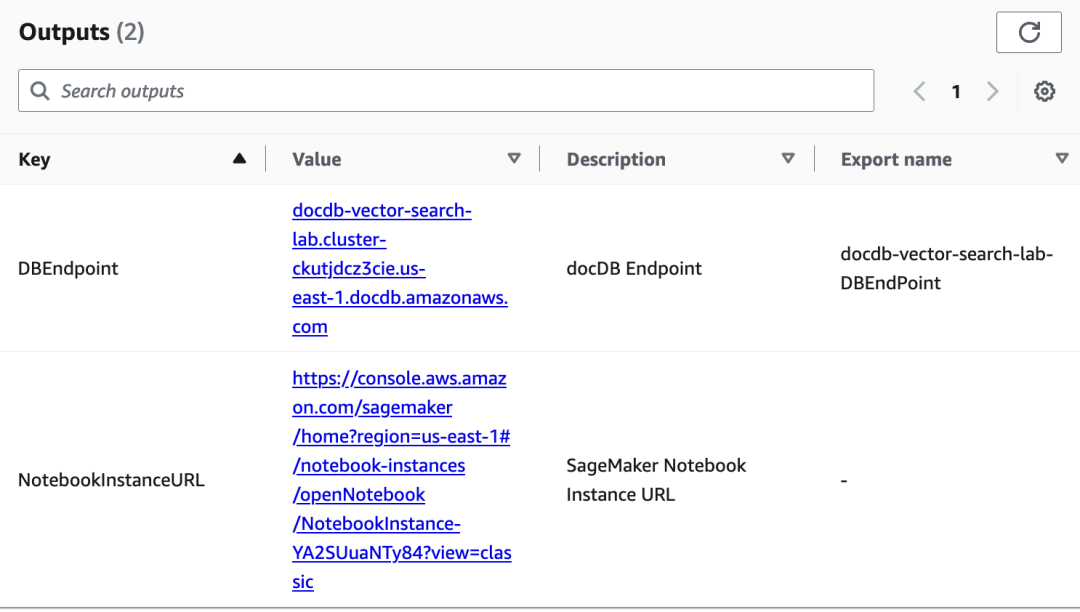
一旦状态变为 CREATE_COMPLETE,点击 Outputs 选项卡,记下 DBEndpint 和 NotebookInstanceURL 以备后用
赋予所访问的 Amazon Bedrock
大语言模型权限
访问 Amazon Bedrock Model Access 页面:https://us-east-1.console.aws.amazon.com/bedrock/home?region=us-east-1#modelaccess,选择 Manage Model Access
选中 Titan Embedding G1- Text 和 Claude 模型左侧的 checkbox,然后 save changes。
看到两个模型的 Access Status 为:Access granted

使用 Juypter Notebook
本示例采用了 Jupyter Notebook 来与 Bedrock 和 DocumentDB 数据库进行交互。Jupyter Notebook 是一个开源 Web 应用程序,您可以用它来创建和共享包含实时代码、计算、可视化和叙述文本的文档。
打开 Jupyter Notebook
1. 转到 Amazon SageMaker 控制台,列出正在运行的 notebook 实例。您应该看到一个正在运行的实例,单击打开 Jupyter 的链接
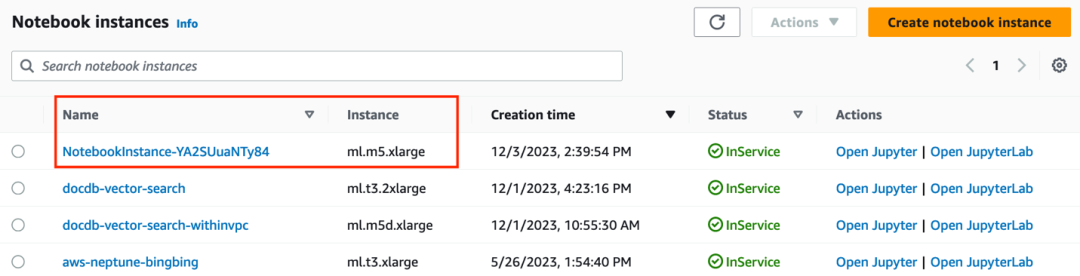
2. 点击 Open Jupyter,点击 Two-way-recall 目录
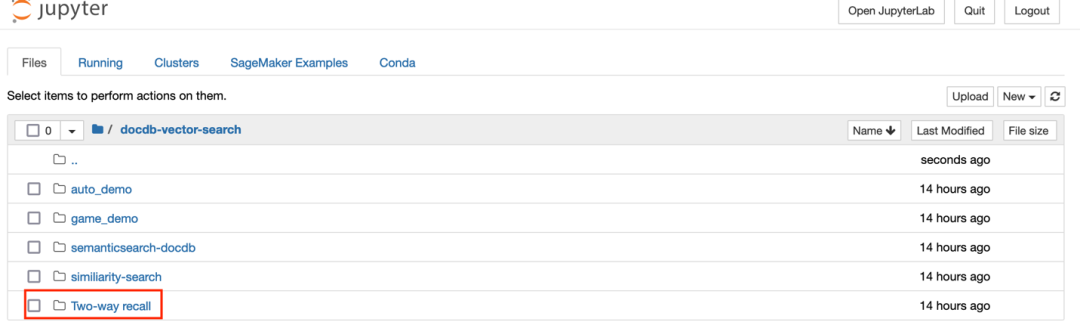
3. 点击 genai-docdb-similiarity-search-gaming.ipynb 文件以加载 Notebook 内容
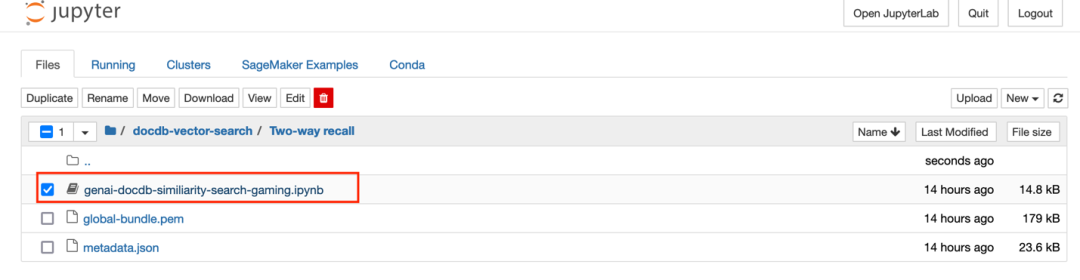
4. 在下拉菜单中选择 conda_python3 内核,然后点击 “设置内核” 。您可以在右上角查看所选的内核,如果您想更改现有的内核:
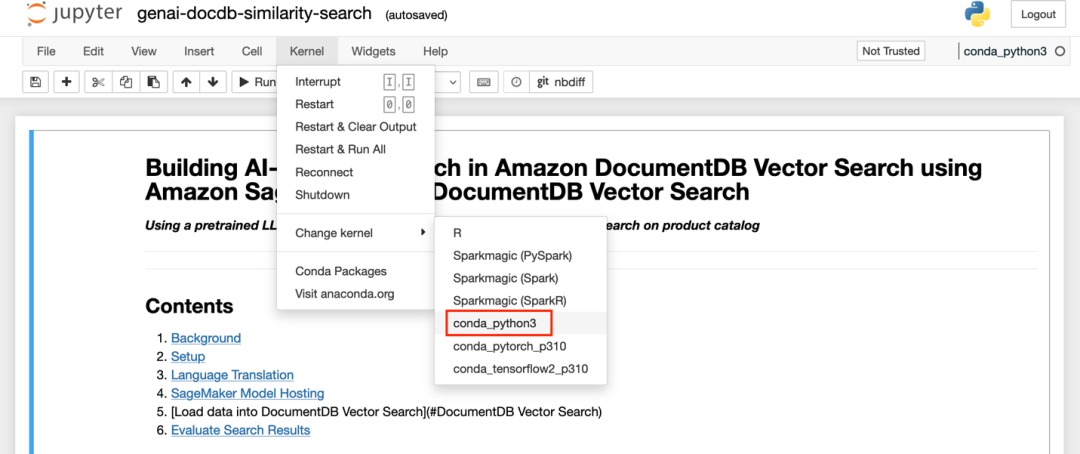
在 Notebook 中执行相似度查询
现在我们来构建游戏推荐方案:用户输入大致的游戏描述,系统能进行游戏推荐。
查找相似游戏的一个核心组件是把用户描述对应的固定长度的句子或者词进行向量化,也就是抽取“特征向量”。通常情况下这些向量是离线生成并存储起来的,以便后续查找时实现快速检索。本示例中使用了 Amazon Bedrock Titan 模型来生成向量数据。
为了实现对文本相似项目的高效搜索,我们使用 Amazon Bedrock Titan 模型生成固定长度的句子 Embedding,即“特征向量”,并使用 Amazon DocumentDB (MongoDB compatibility) 的 Vector Search 实现最近邻搜索扩展。DocumentDB Vector search 允许您存储和搜索向量空间中的点,并为这些点找到“最近邻”。使用案例包括产品推荐(基于搜索输入,匹配到最相近的产品)、图像识别和欺诈检测。
为了后续的全文检索,基于游戏英文描述做 Text Index,目前 DocumentDB 仅支持基于英文词根进行全文检索, 所以基于游戏英文描述创建索引。
本示例构建步骤为:
1)初始设置,准备环境调用 Amazon Bedrock Titan 模型;
2)将游戏 example dataset 生成特征向量;
3)把这些特征向量存储在 Amazon DocumentDB 向量数据类型中,创建向量索引。 基于游戏英文描述,创建文本索引;
4)探索一些示例查询,通过执行 DocumentDB 向量和文本搜索,实现 RAG 双路召回,合并双路召回结果,并结合 Bedrock Claude LLM 形成可视化结果。
具体步骤
安装示例所需的 python 库
!pip install -U pymongo tqdm boto3 requests scikit-image游戏 demo 数据
example: [
{“url”: “游戏图片url”,
“name”: “游戏名称”,
“descriptions”: [“游戏类别:免费开玩;英雄射击;多人;第一人称射击;射击”,
“游戏介绍: xxxxxx”,
“成人内容描述: 无暴力血腥。”],
“descriptions_en”:[“Game genres: Free to Play;Battle Royale;Multiplayer;Shoote”,
“Game Introduction: xxxxxx”,
“MATURE CONTENT DESCRIPTION: No violence or gore.”],
“recommendation”: “内存: 8 GB RAM,DirectX 版本: 11,网络: 宽带互联网连接,存储空间: 需要 35 GB 可用空间”}
]
import urllib.request
import os
import json
import boto3
from multiprocessing import cpu_count
from tqdm.contrib.concurrent import process_map
filename = 'metadata.json'with open(filename) as json_file:results = json.load(json_file)
if not os.path.exists(filename):print ("metadata.json file not exits")
results[0]
print(results[0])Bedrock 模型环境准备
安装 langchain:
# for bedrock model call
%pip install langchain==0.0.305 --force-reinstall创建 Bedrock Client:
#for bedrock model call
import json
import os
import sysimport boto3bedrock_client = boto3.client("bedrock-runtime", region_name="us-east-1")准备 Bedrock Titan 模型调用,为后续生成 Embedding 数据:
# for bedrock model call
from langchain.embeddings import BedrockEmbeddingsbedrock_embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v1", client=bedrock_client)准备 Bedrock LLM Claude3 模型调用,并计算 LLM 执行时间:
# calculate your LLM(Claude3) execution time
import timedef timer_llm_claude3(prompt, if_print=1):start_time = time.time()body = json.dumps({"max_tokens": 4096,"messages": [{"role": "user", "content": prompt}],"anthropic_version": "bedrock-2023-05-31"})response = bedrock_client.invoke_model(body=body, modelId="anthropic.claude-3-sonnet-20240229-v1:0")response_body = json.loads(response.get("body").read())end_time = time.time()elapsed_time = end_time - start_timeif if_print == 1:print("----------------------------------------- OutPut -----------------------------------------")print("Elapsed time: ", elapsed_time, "seconds")return response_body.get("content")[0]['text']Bedrock Titan 模型调用,生成 Embedding 数据:
# for Bedrock Embedding model calldef generate_embeddings(data):r = bedrock_embeddings.embed_query(data)return r在这一步中,我们将获取产品描述以及生成的向量,并将这些向量存储到 DocumentDB 中,通过调用函数 generate_embeddings,调用 Amazon Bedrock Titan 生成 Embedding 数据。
建立与 DocumentDB 的数据库连接:
# Set up a connection to your Amazon DocumentDB (MongoDB compatibility) cluster and creating the database
import pymongoclient = pymongo.MongoClient(
"docdb-vector-search-*******.com:27017",
username="masteruser",
password="******",
retryWrites=False,
tls='true',
tlsCAFile='global-bundle.pem')
db = client.similarity
collection = db.games修改 docDB Cluster Endpoint为CloudFormation output docDB endpoint
修改 password=” Password1″
生成向量数据,并将向量数据存储到 docDB,创建 docDB 向量索引(IvFflat 算法;相似度:欧距;维度:1536):
import pymongo
import boto3
import json
for x in results:description1 = ' '.join(x.get('descriptions', []))vector = generate_embeddings(description1)record = { "name": x.get('name'),"descriptions": description1,"descriptions_en": ' '.join(x.get('descriptions_en', [])),"recommendation":x.get('recommendation'),"url": x.get('url'),"descriptions_embeddings": vector}rec_id1 = collection.insert_one(record)
collection.create_index ([("descriptions_embeddings","vector")], vectorOptions={
"lists": 1,
"similarity": "euclidean",
"dimensions": 1536})基于游戏英文描述字段,创建文本索引:
#DocumentDB Text Search
collection.create_index({"descriptions_en": "text"})执行 DocumentDB 向量和文本搜索,生成 RAG 双路召回,合并召回结果(游戏推荐结果),同时会形成 Prompt 调用 Bedrock Claude 模型来完成推荐内容总结归并,并判断游戏是否适合未成年人:
from skimage import io
import matplotlib.pyplot as plt
import requests
from langchain.prompts import PromptTemplatemulti_var_prompt = PromptTemplate(input_variables=["instructions"], template="""
Human:
你是一个优秀的游戏推荐员,需要你进行游戏的总结推荐<Objective>
- 带上游戏名称和游戏类别
- 附上游戏介绍,需要进行优化总结
- 指出玩该游戏需要的主机配置
- 判断是否适合未成年人玩
</Objective><instructions>
{instructions}
</instructions>
你的目标是根据<Objective>里的目标,列出<instructions>里的游戏名称,游戏类别,游戏介绍,用户的主机配置并判断该游戏是否适合未成年人,不需要有其他无关的文字内容Assistant:""")def similarity_search(search_text):en_response= timer_llm_claude3("你是一位翻译人员,将以下翻译成英文,不要多余的话术,只要翻译即可,翻译后的内容需要去掉game这个单词:"+search_text)print(en_response)data = {"inputs": search_text}res1 = generate_embeddings(data['inputs'])向量搜索,返回相似度最接近的两个产品:
#Vector Search (向量搜索 返回相似度最接近的两个产品)query = {"vectorSearch" : {"vector" : res1, "path": "descriptions_embeddings", "similarity": "euclidean", "k": 2}}projection = {"_id":0,"name":1,"recommendation":1,"url":1,"descriptions":1,"descriptions_en":1,"descriptions_embeddings": 1}r = collection.aggregate([{'$search': query},{"$project": projection}])基于游戏英文描述进行文本搜索,按返回 Score 进行排序:
#Text Search (基于游戏英文描述进行文本搜索, 按返回Score进行排序)tsr = collection.find({"$text": {"$search": en_response}}, {"score": {"$meta": "textScore"}}).sort({"score": {"$meta": "textScore"}})urls = []plt.rcParams["figure.figsize"] = [7.50, 3.50]plt.rcParams["figure.autolayout"] = True合并 RAG 双路召回结果:
# merge two-way recall result (合并RAG双路召回结果)merged_list = []for doc in tsr:merged_list.append(doc)for doc in r:merged_list.append(doc)unique_set = set() result = []for item in merged_list:dict_str = str(item['name'])print(dict_str)if dict_str not in unique_set and len(result)<2:unique_set.add(dict_str)result.append(item) for x in result:# print(x)# Pass in values to the input variablesprompt = multi_var_prompt.format(instructions="游戏名称:"+x["name"] + ".\n游戏描述:" +x["descriptions"] +".\n主机配置建议:"+ x["recommendation"])response= timer_llm_claude3(prompt)print(response)url = x["url"].split('?')[0]urldata = requests.get(url).contenta = io.imread(url)plt.imshow(a)plt.axis('off')plt.show()现在我们调用上面的函数进行一些搜索。比如输入多人射击游戏:
similarity_search(“多人射击游戏”)
以下是根据上述向量和文本搜索,生成 RAG 双路召回,合并双路召回结果,结合 LLM 形成的游戏推荐内容:
——————OutPut ——————
Elapsed time: 4.0840065479278564 seconds
游戏名称:虚拟射击游戏 1
游戏类别:免费开玩、英雄射击、多人、第一人称射击、射击
游戏介绍:虚拟射击游戏 1 是一款免费的大逃杀英雄射击游戏,玩家可控制各种拥有独特技能的传奇角色,体验战术小队玩法和创新游戏元素,在边境之地与其他玩家展开激烈对决。游戏提供丰富的角色选择、深度的战术玩法和革新元素,带来全新的大逃杀竞技体验。
主机配置:
– 内存:8 GB RAM
– DirectX 版本:11
– 网络:宽带互联网连接
– 存储空间:需要 35GB 可用空间
适合年龄:由于游戏没有暴力血腥内容,适合未成年人玩。

——————OutPut ——————
Elapsed time:3.8321468830108643
游戏名称:虚拟射击游戏 2
游戏类别:第一人称射击;射击;多人;竞技;动作;电竞
优化总结:
虚拟射击游戏 2 是一款优秀的竞技类第一人称射击游戏,提供了逼真的渲染效果、先进的网络系统、强大的社区创意工坊工具等。游戏包含全球及区域排行榜、升级后的地图、动态烟雾弹等新元素,为玩家带来革命性的游戏体验。此外,游戏还拥有全新设计的声画效果,令画面声音更加震撼。
主机配置:
内存:8 GB RAM
显卡:1 GB 或以上
DirectX 版本:11
存储空间:需要 85 GB 可用空间
不适合未成年人:
虚拟射击游戏 2 包含强烈的暴力和血腥内容,因此不太适合未成年人游玩。

总结
将 Amazon DocumentDB 和 Amazon Bedrock 无缝集成,在同一个 Amazon DocumentDB 云原生文档数据库引擎中,将向量和业务标量数据统一存储,将向量搜索和文本搜索无缝集成,能够快速构建 RAG 双路召回,为优化基于 LLM 产品目录相似性搜索体验提供了高效的解决方案。企业可以提高相似性搜索、个性化推荐和欺诈检测的准确性和速度,由此进一步提高用户满意度和提供更加个性化的体验。
本篇作者

刘冰冰
亚马逊云科技数据库解决方案架构师,负责基于亚马逊云科技的数据库解决方案的咨询与架构设计,同时致力于大数据方面的研究和推广。在加入亚马逊云科技之前曾在 Oracle 工作多年,在数据库云规划、设计运维调优、DR 解决方案、大数据和数仓以及企业应用等方面有丰富的经验。

周宇翔
亚马逊云科技解决方案架构师,负责基于亚马逊云科技的云计算方案架构的咨询和设计,在 Edge,Serverless 等方向具有丰富的实践经验。目前专注于游戏行业。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!

相关文章:
采用 Amazon DocumentDB 和 Amazon Bedrock 上的 Claude 3 构建游戏行业产品推荐
前言 大语言模型(LLM)自面世以来即展示了其创新能力,但 LLM 面临着幻觉等挑战。如何通过整合外部数据库的知识,检索增强生成(RAG)已成为通用和可行的解决方案。这提高了模型的准确性和可信度,特…...
论文阅读:Diffusion Model-Based Image Editing: A Survey
Diffusion Model-Based Image Editing: A Survey 论文链接 GitHub仓库 摘要 这篇文章是一篇基于扩散模型(Diffusion Model)的图片编辑(image editing)方法综述。作者从多个方面对当前的方法进行分类和分析,包括学习…...

数据结构:顺序表的奥秘
🎉个人名片: 🐼作者简介:一名乐于分享在学习道路上收获的大二在校生🐻❄个人主页🎉:GOTXX 🐼个人WeChat:ILXOXVJE🐼本文由GOTXX原创,首发CSDN&a…...

conda 设置国内源 windows+linux
默认的conda源连接不好,时好时坏,而且速度很慢,可以使用国内的源 如果没有安装conda,可以参考: miniconda安装:链接 anaconda安装winlinux:链接 windows使用命令提示符,linux使用…...
)
SQL中的不加锁查询 with(nolock)
WITH(NOLOCK) 是一种 SQL Server 中的表提示(table hint),可以用来告诉数据库引擎在查询数据时不要加锁,以避免因为锁等待导致查询性能下降。 当多个事务同时访问同一张表时,数据库引擎会对表进行锁定,以确…...

代码讲解:如何把3D数据转换成旋转的视频?
目录 3D数据集下载 读取binvox文件 使用matplotlib创建图 动画效果 完整代码 3D数据集下载 这里以shapenet数据集为例,可以访问外网的可以去直接申请下载;我也准备了一个备份在百度网盘的数据集,可以参考: ShapeNet简介和下…...
LVS集群 ----------------(直接路由 )DR模式部署 (二)
一、LVS集群的三种工作模式 lvs-nat:修改请求报文的目标IP,多目标IP的DNAT lvs-dr:操纵封装新的MAC地址(直接路由) lvs-tun:隧道模式 lvs-dr 是 LVS集群的 默认工作模式 NAT通过网络地址转换实现的虚拟服务器&…...

微软亚太区AI智能应用创新业务负责人许豪,将出席“ISIG-AIGC技术与应用发展峰会”
3月16日,第四届「ISIG中国产业智能大会」将在上海中庚聚龙酒店拉开序幕。本届大会由苏州市金融科技协会指导,企智未来科技(AIGC开放社区、RPA中国、LowCode低码时代)主办。大会旨在聚合每一位产业成员的力量,深入探索A…...

vim寄存器和宏
目录 1.寄存器1.1.寄存器相关命令 2.宏2.1.宏的录制和回放2.1.1.避免宏回放回到开头重做2.1.2.先搜索 2.2.宏的编辑2.2.1.特殊字符 3.递归的宏4.跨文件运行宏 1.寄存器 寄存器说明注释a-z手动复制数据"寄存器"无名寄存器""p等效为p0-9最后10次删除操作的历…...

使用数据库实现增删改查
#include<myhead.h>//定义添加数据函数int do_add(sqlite3 *ppDb) {//1.准备sql语句,输入要添加的信息int add_numb; //工号char add_name[20]; //姓名char add_sex[10]; //性别double add_score; //工资printf("请输入要添加的工号:")…...
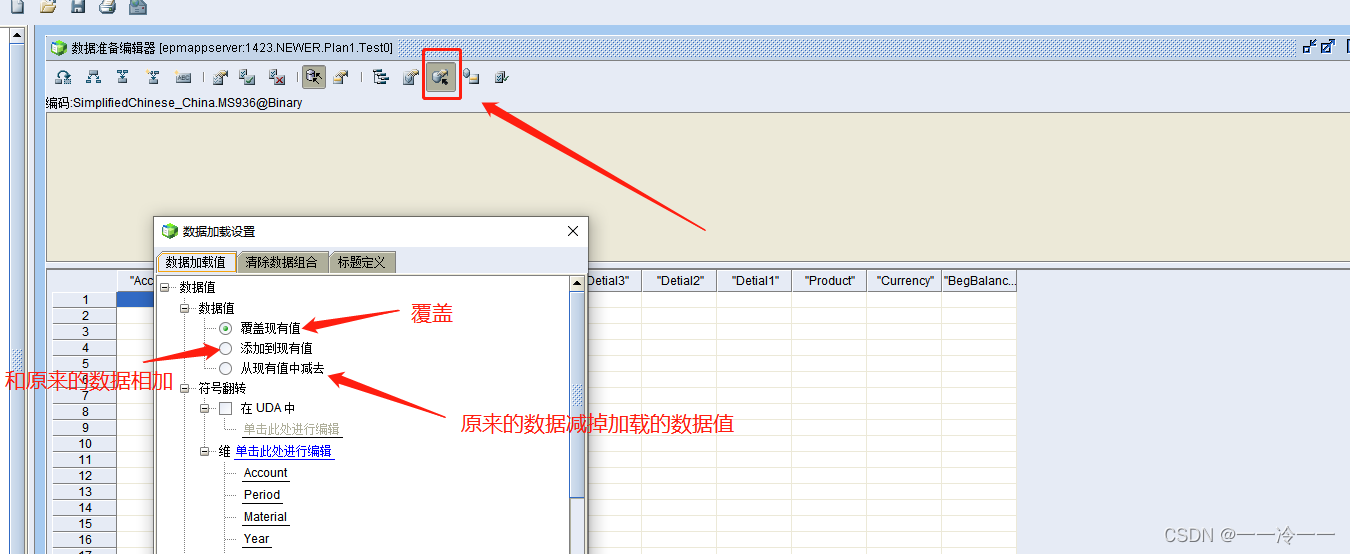
Oracle Essbase 多维库导入文件数据步骤操作
第一步: 先确定导入数据的维度数量(清楚自己需要导入什么数据和范围) 第二步: 设置加载的规则 1.创建规则 2.编辑规则-》打开数据文件 通过数据文件来确定加载规则的加载格式 先查看数据文件格式: 将数据文件导入&…...

【自然语言处理】BitNet b1.58:1bit LLM时代
论文地址:https://arxiv.org/pdf/2402.17764.pdf 相关博客 【自然语言处理】【大模型】BitNet:用1-bit Transformer训练LLM 【自然语言处理】BitNet b1.58:1bit LLM时代 【自然语言处理】【长文本处理】RMT:能处理长度超过一百万t…...
【Axure高保真原型】可视化动点素材
今天和粉丝们免费分享可视化动点素材的原型模板,该模板使用简单,复制粘贴,预览时即可实现动点效果,本案例提供红黄蓝绿4中颜色的动点,如果需要其他颜色,可以自行编辑svg里面的代码 【原型效果】 【模板下载…...

分布式数据库 GaiaDB-X 金融应用实践
1 银行新一代核心系统建设背景及架构 在银行的 IT 建设历程中,尤其是中大行,大多都基于大型机和小型机来构建核心系统。随着银行业务的快速发展,这样的系统对业务的支持越来越举步维艰,主要体现在以下四个方面: 首先是…...

机器学习中的经典算法总结
经典算法 有监督算法逻辑回归支持向量机SVM决策树朴素贝叶斯K近邻(KNN) 无监督算法K-meansPCA主成分分析预留模版 有监督算法 逻辑回归 简介 逻辑回归是机器学习中一种经典的分类算法,通常用于二分类任务,基本思想是构建一个线性…...
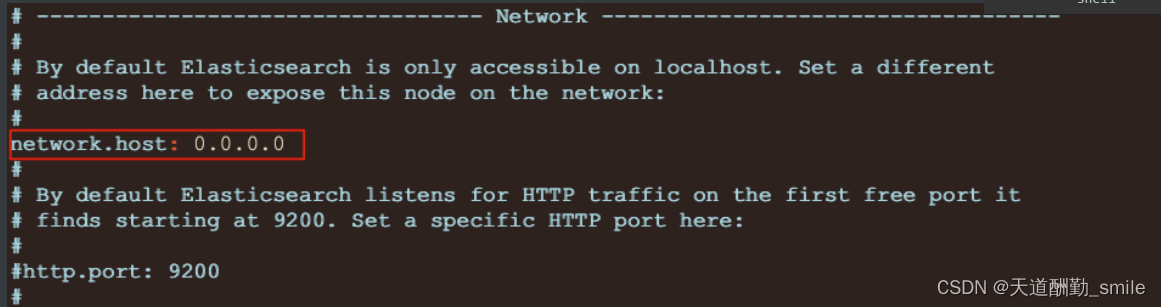
ElasticSearch 学习(docker,传统方式安装、安装遇到的问题解决,)
目录 简介 什么是ElasticSearch 安装 传统方式安装 开启远程访问 Docker方式安装 Kibana 简介 安装 传统方式安装 Docker方式安装 compose方式安装 简介 什么是ElasticSearch ElasticSearch 简称 ES ,是基于Apache Lucene构建的开源搜索引擎,…...
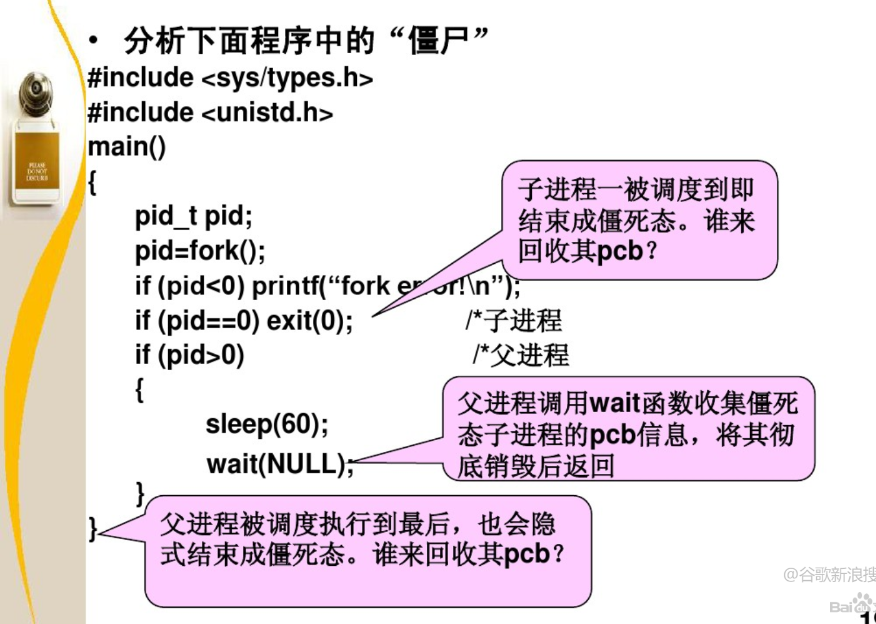
[百度二面]操作系统进程、锁相关面试题
2.22 什么是死锁 在多道程序环境下,多个进程可以竞争有限数量的资源。当一个进程申请资源时,如果这时没有可用资源,那么这个进程进入等待状态。有时,如果所申请的资源被其他等待进程占有,那么该等待进程有可能再也无法…...

IP劫持的危害及应对策略
随着互联网的发展,网络安全问题日益凸显,其中IP劫持作为一种常见的网络攻击手段,对个人和企业的信息安全造成了严重的威胁。IP数据云将分析IP劫持的危害,并提出相应的应对策略。 IP地址查询:IP数据云 - 免费IP地址查询…...

Mac安装oh-my-zsh
目录 命令下载 卸载命令 注意 命令下载 curl -L https://raw.github.com/robbyrussell/oh-my-zsh/master/tools/install.sh | sh 卸载命令 uninstall_oh_my_zsh 注意 终端init的时候并不会执行~/.bash_profile、~/.bashrc等脚本了, 这是因为其默认启动执行脚本…...

【Web开发】深度学习HTML(超详细,一篇就够了)
💓 博客主页:从零开始的-CodeNinja之路 ⏩ 收录文章:【Web开发】深度学习html(超详细,一篇就够了) 🎉欢迎大家点赞👍评论📝收藏⭐文章 目录 HTML1. HTML基础1.1 什么是HTML1.2 认识HTML标签1.3 HTML文件基本…...

Redis RDB和AOF深入比较
Redis RDB 和 AOF 深入比较 Redis 的持久化机制是其作为内存数据库能够保证数据安全的关键。RDB 和 AOF 是两种核心方案,它们在原理、性能、数据安全性等方面有着本质区别。本文将深入剖析这两种机制,并给出生产环境的选型建议。 一、核心原理对比 1.1 RDB(Redis Database…...

如何在绝地求生中配置罗技鼠标宏实现精准压枪:3分钟快速上手指南
如何在绝地求生中配置罗技鼠标宏实现精准压枪:3分钟快速上手指南 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 你是否在《绝地求生…...

2025年开源大模型趋势入门必看:Qwen2.5+弹性GPU部署实战指南
2025年开源大模型趋势入门必看:Qwen2.5弹性GPU部署实战指南 1. 为什么选择Qwen2.5-7B-Instruct 如果你正在寻找一个既强大又实用的AI模型,Qwen2.5-7B-Instruct绝对值得关注。这个模型在中等体量模型中表现出色,不仅能力全面,而且…...

3步实现飞书文档本地转换:Cloud Document Converter全场景解决方案
3步实现飞书文档本地转换:Cloud Document Converter全场景解决方案 【免费下载链接】cloud-document-converter Convert Lark Doc to Markdown 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-document-converter 想象一下,当你需要将飞书文…...

Gazebo中高效加载DEM高程图的实用技巧与常见问题解决
1. 为什么你的Gazebo DEM高程图加载总是失败? 第一次在Gazebo里加载DEM高程图时,我盯着空荡荡的仿真界面整整发呆了半小时——明明按照教程操作,为什么就是显示不出来?后来才发现,DEM加载是个典型的"看着简单&…...

ACSL-6310-06TE,多通道双向15MBd高速数字逻辑门光耦合器
简介今天我要向大家介绍的是 Broadcom 的光耦合器——ACSL-6310-06TE。它是一款三通道、双向(2/1配置)高速数字逻辑门光耦合器。该器件采用专有的GaAsP LED背发射设计,内部集成具有高增益和高带宽的两级放大器,输出端为肖特基钳位…...

实测飞算JavaAI vs Copilot:效率提升不是一点点,完整项目生成才是关键差距
实测飞算JavaAI vs Copilot:效率提升不是一点点,完整项目生成才是关键差距## 开篇:一个Java开发者的日常困境干了三年Java,你大概已经习惯了这样的节奏:早上产品经理丢过来一个需求——"做个用户权限管理模块&…...

Xv6 Lab3: Optimizing Page Tables for Direct User-Kernel Memory Access
1. Xv6页表机制概述 Xv6采用三级页表结构实现虚拟地址到物理地址的转换。每个进程拥有独立的用户页表,而内核则使用全局的内核页表。这种设计带来一个关键限制:当内核需要访问用户空间数据时(如系统调用参数),必须通过…...

三步构建你的专属知识星球离线图书馆
三步构建你的专属知识星球离线图书馆 【免费下载链接】zsxq-spider 爬取知识星球内容,并制作 PDF 电子书。 项目地址: https://gitcode.com/gh_mirrors/zs/zsxq-spider 你是否曾经在知识星球上发现一篇深度好文,想要反复研读却只能在手机上翻看&a…...

飞书文档转Markdown的终极解决方案:feishu2md完整指南
飞书文档转Markdown的终极解决方案:feishu2md完整指南 【免费下载链接】feishu2md 一键命令下载飞书文档为 Markdown(寻找维护者) 项目地址: https://gitcode.com/gh_mirrors/fe/feishu2md 在数字化协作时代,飞书已成为众多…...