【Pytorch】进阶学习:深入解析 sklearn.metrics 中的 classification_report 函数---分类性能评估的利器
【Pytorch】进阶学习:深入解析 sklearn.metrics 中的 classification_report 函数—分类性能评估的利器

🌈 个人主页:高斯小哥
🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望得到您的订阅和支持~
💡 创作高质量博文(平均质量分92+),分享更多关于深度学习、PyTorch、Python领域的优质内容!(希望得到您的关注~)
🌵文章目录🌵
- 📊一、分类性能评估的重要性
- 🔍二、深入了解classification_report函数
- 🚀三、使用classification_report评估模型性能
- 🔎四、解读classification_report的内容
- 🎯五、优化模型性能
- 📈六、使用classification_report进行模型选择
- 💡七、总结与进一步学习
📊一、分类性能评估的重要性
在机器学习中,分类任务是非常常见的一类问题。当我们训练一个分类模型后,如何评估模型的性能是一个至关重要的问题。sklearn.metrics中的classification_report函数就是评估分类模型性能的一个利器。通过这个函数,我们可以得到模型的准确率、精确率、召回率以及F1分数等指标,从而全面评估模型的性能。
🔍二、深入了解classification_report函数
classification_report函数是sklearn.metrics模块中的一个函数,它接收真实标签和预测标签作为输入,并返回一个文本报告,展示了主要分类指标的详细信息。
下面是classification_report函数的基本用法:
from sklearn.metrics import classification_reporty_true = [0, 1, 2, 2, 0] # 真实标签
y_pred = [0, 0, 2, 2, 0] # 预测标签report = classification_report(y_true, y_pred)
print(report)
输出内容将包括每个类别的精确度、召回率、F1分数以及支持数(即该类别的样本数):
precision recall f1-score support0 0.67 1.00 0.80 21 0.00 0.00 0.00 12 1.00 1.00 1.00 2accuracy 0.80 5macro avg 0.56 0.67 0.60 5
weighted avg 0.67 0.80 0.72 5
🚀三、使用classification_report评估模型性能
在机器学习的实践中,我们通常会在验证集或测试集上评估模型的性能。下面是一个使用classification_report评估模型性能的示例:
首先,我们定义并训练一个支持向量机分类器model,并且我们有一个测试集X_test和对应的真实标签y_test。
# 导入sklearn.datasets模块中的load_iris函数,用于加载鸢尾花数据集
from sklearn.datasets import load_iris# 导入sklearn.metrics模块中的classification_report函数,用于生成分类报告
from sklearn.metrics import classification_report# 导入sklearn.model_selection模块中的train_test_split函数,用于划分数据集为训练集和测试集
from sklearn.model_selection import train_test_split# 导入sklearn.svm模块中的SVC类,用于创建支持向量机分类器
from sklearn.svm import SVC# 使用load_iris函数加载鸢尾花数据集
iris = load_iris()# 获取数据集中的特征数据,存储在变量X中
X = iris.data# 获取数据集中的目标标签,存储在变量y中
y = iris.target# 使用train_test_split函数划分数据集,其中80%的数据作为训练集,20%的数据作为测试集
# random_state参数用于设置随机数生成器的种子,确保每次划分的结果一致
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建一个SVC分类器对象,使用线性核函数,C值为1,并设置随机数生成器的种子为42
model = SVC(kernel='linear', C=1, random_state=42)# 使用fit方法对模型进行训练,传入训练集的特征数据和目标标签
model.fit(X_train, y_train)# 使用训练好的模型对测试集进行预测,返回预测的目标标签
y_pred = model.predict(X_test)# 使用classification_report函数生成分类报告,传入测试集的真实目标标签和预测的目标标签
# target_names参数传入鸢尾花的种类名称,用于在报告中显示具体的类别名称
report = classification_report(y_test, y_pred, target_names=iris.target_names)# 打印分类报告,展示每个类别的精确度、召回率、F1分数等信息
print(report)
这段代码首先加载了鸢尾花数据集,并划分了训练集和测试集。然后,我们使用线性支持向量机(SVC)训练了一个分类模型,并在测试集上进行了预测。最后,我们使用classification_report函数打印出了模型的评估报告:
precision recall f1-score supportsetosa 1.00 1.00 1.00 10versicolor 1.00 1.00 1.00 9virginica 1.00 1.00 1.00 11accuracy 1.00 30macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
🔎四、解读classification_report的内容
classification_report的输出内容包含了丰富的信息,下面我们来解读一下这些内容:
- precision:精确率,表示预测为正例的样本中真正为正例的比例。精确率越高,说明模型预测为正例的样本中,真正为正例的样本越多。
- recall:召回率,表示真正为正例的样本中被预测为正例的比例。召回率越高,说明模型找出了越多的真正正例。
- f1-score:F1分数,是精确率和召回率的调和平均数。F1分数越高,说明模型在精确率和召回率之间取得了更好的平衡。
- support:支持数,即该类别的样本数。
此外,classification_report还会输出每个类别的上述指标以及它们的平均值。这些指标可以帮助我们全面评估模型的性能,并根据需要调整模型参数或尝试其他模型。
🎯五、优化模型性能
当我们得到classification_report的评估结果后,如果发现模型的性能不佳,我们可以尝试一些方法来优化模型性能:
- 调整模型参数:根据评估结果,我们可以调整模型的参数,如改变学习率、增加迭代次数、调整正则化项等,以提高模型的性能。
- 特征工程:通过特征选择、特征提取或特征变换等方法,改善输入特征的质量,从而提高模型的性能。
- 尝试其他模型:如果当前模型的性能无法满足需求,我们可以尝试其他类型的模型,如决策树、随机森林、神经网络等,看是否能够获得更好的性能。
📈六、使用classification_report进行模型选择
当我们有多个候选模型时,可以使用classification_report来辅助我们进行模型选择。通过比较不同模型在测试集上的评估报告,我们可以选择性能最优的模型。
下面是一个简单的示例,展示了如何使用classification_report来比较两个模型的性能:
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练第一个模型:支持向量机
model1 = SVC(kernel='linear', C=1, random_state=42)
model1.fit(X_train, y_train)
y_pred1 = model1.predict(X_test)
report1 = classification_report(y_test, y_pred1, target_names=iris.target_names)
print("Model 1 (SVC) Report:\n", report1)# 训练第二个模型:K近邻
model2 = KNeighborsClassifier(n_neighbors=3)
model2.fit(X_train, y_train)
y_pred2 = model2.predict(X_test)
report2 = classification_report(y_test, y_pred2, target_names=iris.target_names)
print("Model 2 (KNN) Report:\n", report2)在上面的代码中,我们训练了两个不同的模型:支持向量机(SVC)和K近邻(KNN),并分别打印了它们的classification_report。通过比较两个报告的指标,我们可以选择性能更好的模型。
💡七、总结与进一步学习
classification_report是评估分类模型性能的一个强大工具,它提供了丰富的指标来帮助我们全面评估模型的性能。通过解读报告中的精确率、召回率、F1分数等指标,我们可以了解模型在不同类别上的表现,并根据需要进行优化。
要进一步提高模型性能,除了调整模型参数和进行特征工程外,还可以尝试集成学习、深度学习等更高级的方法。此外,了解不同评估指标的含义和优缺点也是非常重要的,这有助于我们更准确地评估模型的性能。
希望本博客能够帮助你深入理解classification_report函数,并学会如何使用它来评估和优化分类模型的性能。如果你对机器学习领域的其他话题感兴趣,欢迎继续探索和学习!
相关文章:
【Pytorch】进阶学习:深入解析 sklearn.metrics 中的 classification_report 函数---分类性能评估的利器
【Pytorch】进阶学习:深入解析 sklearn.metrics 中的 classification_report 函数—分类性能评估的利器 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合…...
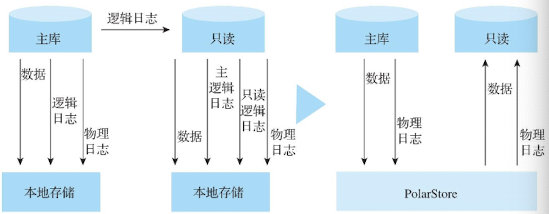
探索云原生数据库技术:构建高效可靠的云原生应用
数据库是应用开发中非常重要的组成部分,可以进行数据的存储和管理。随着企业业务向数字化、在线化和智能化的演进过程中,面对指数级递增的海量存储需求和挑战以及业务带来的更多的热点事件、突发流量的挑战,传统的数据库已经很难满足和响应快…...
Jmeter+Ant+Git/SVN+Jenkins实现持续集成接口测试,一文精通(一)
前言 Jmeter,Postman一些基本大家相比都懂。那么真实在项目中去使用,又是如何使用的呢?本文将一文详解jmeter接口测试 一、接口测试分类 二、目前接口架构设计 三、市面上的接口测试工具 四、Jmeter简介,安装,环境…...

CSAPP Malloc lab
CSAPP Malloc Lab 目标 实现一个简单的动态存储分配器。 评分标准 空间利用率应当减少internal 和 external fragmentation. memory utilization memory utilization payload / heap size fragmentation internal fragmentation external fragmentation throughput T 越接…...

(黑马出品_06)SpringCloud+RabbitMQ+Docker+Redis+搜索+分布式
(黑马出品_06)SpringCloudRabbitMQDockerRedis搜索分布式 微服务技术ES搜索和数据分析 今日目标1. 查询文档1.1.DSL查询分类1.2.全文检索查询1.2.1.使用场景1.2.2.基本语法1.2.3.示例 1.3.精准查询1.3.1.term查询1.3.2.ran…...
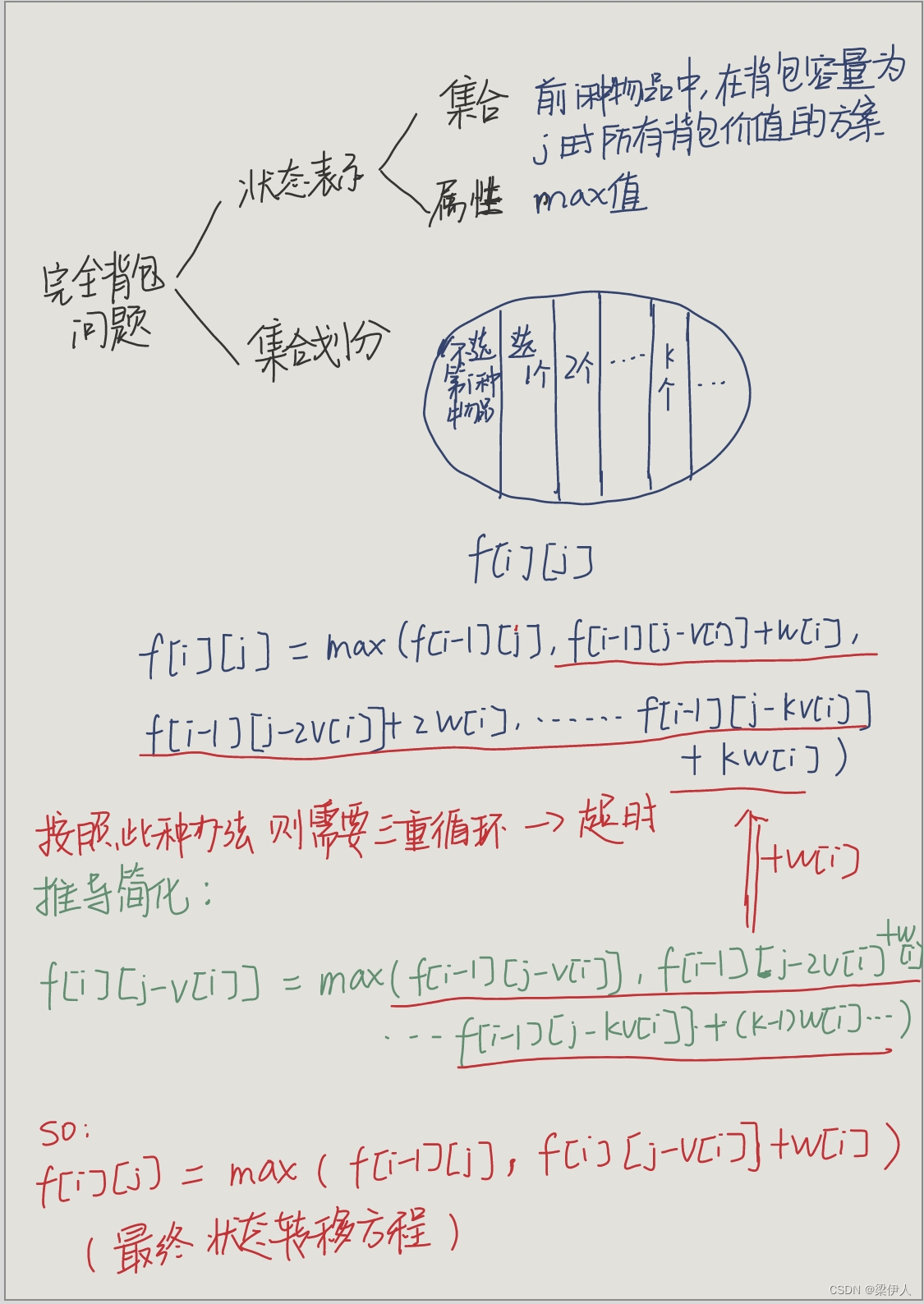
算法学习之动态规划DP——背包问题
一、01背包问题 (一)题目 有 N 件物品和一个容量是 V的背包。每件物品只能使用一次。 第i件物品的体积是 vi,价值是 wi。 求解将哪些物品装入背包,可使这些物品的总体积不超过背包容量,且总价值最大。 输出最大价值…...
LeetCode刷题日志-17.电话号码的字母组合
纯暴力解法,digits有多长,就循环多少次进行字母组合 class Solution {public List<String> letterCombinations(String digits) {List<String> reslut new ArrayList<>();if(digits.equals(""))return reslut;Map<Inte…...

选修-单片机作业第1/2次
第一次作业 第二次作业 1、51 系列单片机片内由哪几个部分组成?各个部件的最主要功能是什么? 51系列单片机的内部主要由以下几个部分组成,每个部件的主要功能如下: 1. **中央处理器(CPU)**:这是…...

微信小程序开发系列(十七)·事件传参·mark-自定义数据
目录 步骤一:按钮的创建 步骤二:按钮属性配置 步骤三:添加点击事件 步骤四:参数传递 步骤五:打印数据 步骤六:获取数据 步骤七:父进程验证 总结:data-*自定义数据和mark-自定…...
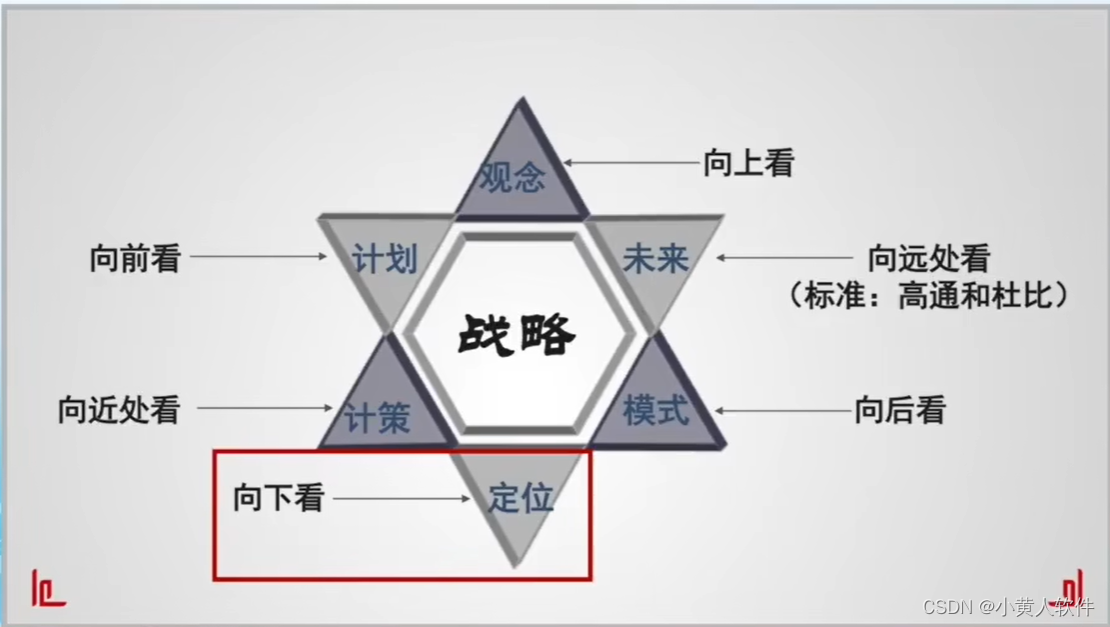
企业战略管理 找准定位 方向 使命 边界 要干什么事 要做多大的生意 资源配置投入
AI突破千行百业,也难打破护城河 作为每个企业或个人的立命生存之本,有的企业在某个领域长期努力筑起了高高的护城河。 战略是什么?用处,具体内容 企业战略是指企业为了实现长期目标,制定的总体规划和长远发展方向。…...
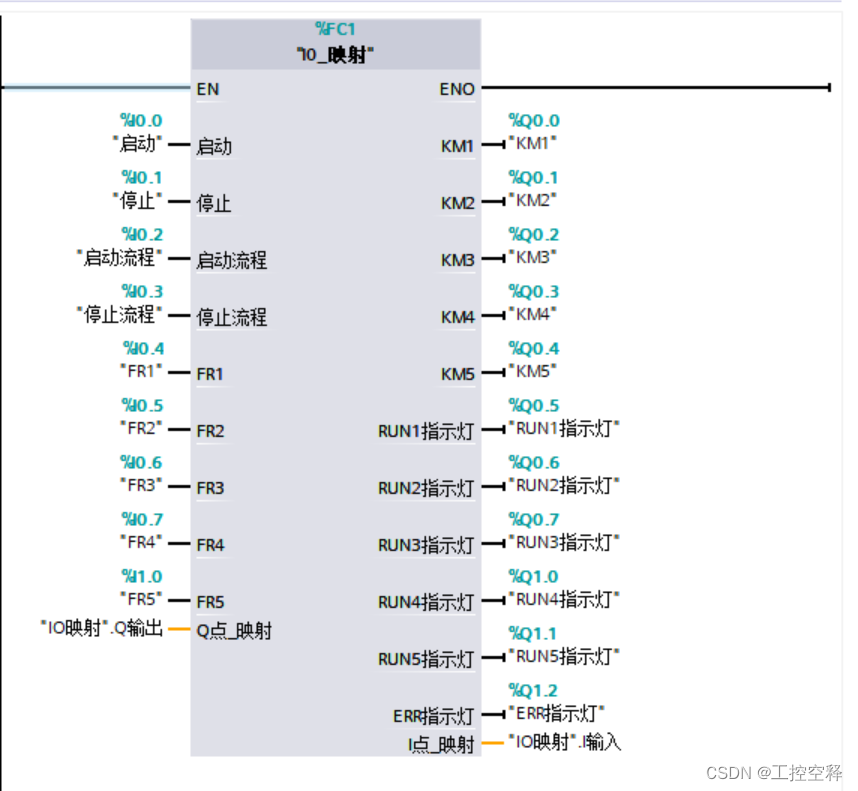
记录西门子:IO隔离SCL编程
在PLC变量中创建IO输入输出 在PLC类型中创建输入和输出,并将PLC变量的输入输出名称复制过来 创建一个FC块或者FB块 创建一个DB块 MAIN主程序中:...
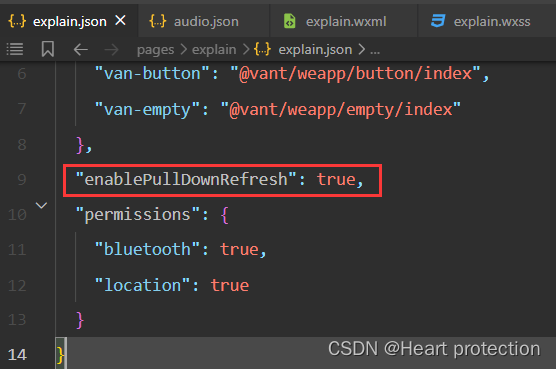
微信小程序如何实现下拉刷新
1.首先在你需要实现下拉刷新页面的json文件中写入"enablePullDownRefresh": true。 2.在js文件的onPullDownRefresh() 事件中实现下拉刷新。 实现代码 onPullDownRefresh() {console.log(开始下拉刷新)wx.showNavigationBarLoading()//在标题栏中显示加载图标this.d…...
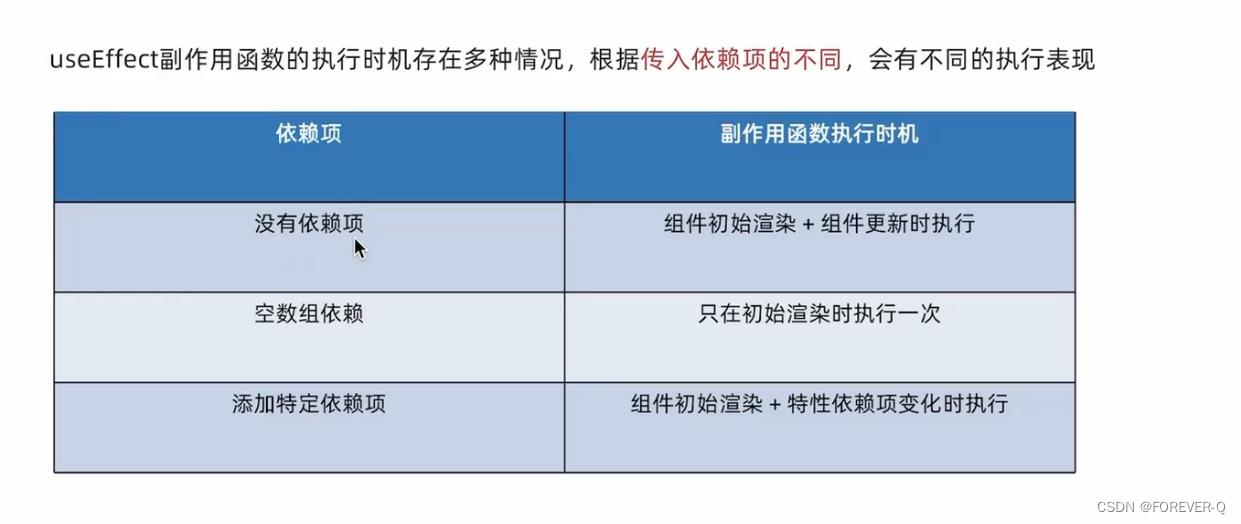
React-useEffect
1.概念 说明:用于在React组件中创建不是由事件引起而是由渲染本身引起的操作,比如发送 A列AX请求,更改DOM等。 2.案例 // useEffect用于组件不是由事件引起的而是由渲染本身引起的操作,如ajax,更改Dom等。 import { useEffect,…...

web蓝桥杯真题:展开你的扇子
代码: /*TODO:请补充 CSS 代码*/#box:hover #item7 {transform: rotate(10deg); } #box:hover #item6 {transform: rotate(-10deg); } #box:hover #item8 {transform: rotate(20deg); } #box:hover #item5 {transform: rotate(-20deg); } #box:hover #i…...

阿里P9大佬分享:如何让代码更加灵活
面试官: 你好,今天我们要讨论的是命令模式。首先,你能解释一下什么是命令模式吗? 求职者: 当然可以。命令模式是一种行为设计模式,它将一个请求封装成一个对象,从而让你使用不同的请求、队列或者日志请求来参数化其他…...

SpringBoot中加载配置文件的优先级
在Spring Boot中,加载配置文件的优先级按照以下顺序进行,后续的配置会覆盖之前的配置: 默认属性:这些属性在Spring Boot本身中定义,并且通常是不可变的。它们作为后备值。 应用程序属性:这些属性在应用程序…...

Mysql命令行客户端
命令行客户端 操作数据库操作数据表 操作数据库 mysql> create database mike charsetutf8; Query OK, 1 row affected (0.01 sec) mysql> show databases; -------------------- | Database | -------------------- | information_schema | | mike …...

开源的python 游戏开发库介绍
本文将为您详细讲解开源的 Python 游戏开发库,以及它们的特点、区别和应用场景。Python 社区提供了多种游戏开发库,这些库可以帮助您在 Python 应用程序中实现游戏逻辑、图形渲染、声音处理等功能。 1. Pygame 特点 - 基于 Python 的游戏开发库。…...

批量提取PDF指定区域内容到 Excel 以及根据PDF里面第一页的标题来批量重命名-附思路和代码实现
首先说明下,PDF需要是电子版本的,不能是图片或者无法选中的那种。 需求1:假如我有一批数量比较多的同样格式的PDF电子文档,需要把特定多个区域的数字或者文字提取出来 需求2:我有一批PDF文档,但是文件的名…...
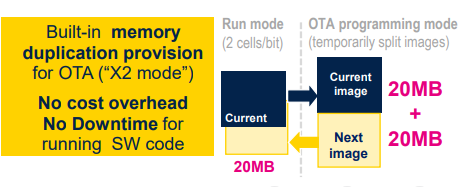
PCM会重塑汽车OTA格局吗(1)
目录 1.汽车OTA概述 2.ST如何考虑OTA? 2.1 Stellar四大亮点 2.2 PCM技术视角下的OTA 3.小结 1.汽车OTA概述 随着智能网联汽车的飞速发展,汽车OTA也越来越盛行; 目前来讲OTA分为FOTA和SOTA(Software-over-the-air)两种,区别…...

3天掌握微信机器人开发:Wechaty Puppet WeChat终极指南
3天掌握微信机器人开发:Wechaty Puppet WeChat终极指南 【免费下载链接】puppet-wechat Wechaty Puppet Provider for WeChat 项目地址: https://gitcode.com/gh_mirrors/pu/puppet-wechat Wechaty Puppet WeChat是一个强大的开源微信机器人框架,…...

如何快速上手AssetStudio:Unity资源提取终极指南
如何快速上手AssetStudio:Unity资源提取终极指南 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and additional impro…...

LFM2.5-1.2B-Thinking-GGUF算力适配:Jetson Orin Nano边缘部署教程
LFM2.5-1.2B-Thinking-GGUF算力适配:Jetson Orin Nano边缘部署教程 1. 模型与平台介绍 LFM2.5-1.2B-Thinking-GGUF是Liquid AI推出的轻量级文本生成模型,专为低算力环境优化设计。该模型采用GGUF格式,结合llama.cpp运行时,能够在…...

终极指南:如何用BiliTools构建你的个人B站资源图书馆 [特殊字符]
终极指南:如何用BiliTools构建你的个人B站资源图书馆 🎬 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/Bil…...

CentOs7网络配置实战:从动态IP到静态IP的完美切换
1. 为什么需要静态IP?动态IP的烦恼我懂 刚装完CentOS7的朋友肯定遇到过这个糟心事:昨天还能正常连接的服务器,今天重启后就死活连不上了。一查IP地址,好家伙,又自动换了!这种动态分配IP的方式(D…...
:网络开发过程与逻辑网络设计)
网络工程师-网络规划与设计(一):网络开发过程与逻辑网络设计
一、引言1.1 核心概念定义网络规划与设计是将业务需求转化为可落地网络技术方案的系统工程,覆盖从需求调研到运维优化的全生命周期,是网络可靠性、可扩展性、安全性的核心保障。在软考网络工程师考试中,本章节属于网络系统设计与管理模块&…...

同花顺_策略解码_五彩K线实战指南
1. 五彩K线入门:从代码看市场语言 第一次打开同花顺的五彩K线功能时,我盯着屏幕上突然变得花花绿绿的走势图愣了半天。这些红红绿绿的标记背后,其实藏着程序员用代码翻译的市场密码。就像交通信号灯用颜色指挥车辆通行,五彩K线用颜…...

uni-app中H5页面通过web-view跳转小程序的完整解决方案
1. 为什么H5页面跳转小程序会报错? 最近在做一个uni-app项目时,遇到了一个典型问题:在H5页面中通过web-view跳转小程序时,控制台报错"wx.miniProgram is undefined"或者"navigateTo is undefined"。这个问题困…...

【笔试真题】- 携程-2026.04.12
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围在线刷题 bishipass.com 携程-2026.04.12 题目一:双仓配货 1️⃣:固定构造 4 和 2n-4 即可。 2️⃣:关键结论是所有不小于 4 的偶数都是合数。 难度:Low 题目二:灯带调色窗口 1️⃣…...

别再死记硬背了!用D触发器设计任意进制计数器的通用思路与Verilog实现
从状态机到Verilog:用D触发器构建任意进制计数器的通用方法论 在数字电路设计中,计数器就像乐高积木中的基础模块——看似简单却能构建出复杂系统。传统教学中,我们常被要求死记硬背特定进制(如12进制)的计数器设计&am…...