【Pytorch】新手入门:基于sklearn实现鸢尾花数据集的加载
【Pytorch】新手入门:基于sklearn实现鸢尾花数据集的加载

🌈 个人主页:高斯小哥
🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望得到您的订阅和支持~
💡 创作高质量博文(平均质量分92+),分享更多关于深度学习、PyTorch、Python领域的优质内容!(希望得到您的关注~)
🌵文章目录🌵
- 🌸一、鸢尾花数据集简介
- 📚二、基于Python加载鸢尾花数据集
- 🎨三、探索鸢尾花数据集
- 🔍四、使用鸢尾花数据集进行模型训练
- 🛠️五、优化模型性能
- 🛠️六、使用鸢尾花数据集进行模型选择
- 📚七、总结与进一步学习
🌸一、鸢尾花数据集简介
鸢(yuān)尾花数据集(Iris dataset)是机器学习和统计学中常用的一个经典数据集,主要用于分类任务。它包含了三类不同的鸢尾花(Setosa、Versicolour和Virginica)的四个特征,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度。这些特征都是连续型数值变量,使得它非常适合用于演示和测试分类算法。
这个数据集非常受欢迎,因为它的简单性和易理解性。同时,由于其特征的多样性和类别之间的可区分性,它成为了很多机器学习初学者和研究者的首选数据集。
📚二、基于Python加载鸢尾花数据集
在Python中,我们可以使用sklearn库中的datasets模块来轻松加载鸢尾花数据集。sklearn是一个强大的机器学习库,提供了大量的数据集和工具,方便我们进行机器学习和数据分析。
下面是一个简单的示例代码,演示如何加载鸢尾花数据集:
from sklearn import datasets# 加载鸢尾花数据集
iris = datasets.load_iris()# 打印数据集描述
# print(iris.DESCR) # 可选# 获取特征数据
X = iris.data# 获取目标标签
y = iris.target# 打印特征数据的前5行
print("特征数据前5行:\n", X[:5])# 打印目标标签的前5个
print("目标标签前5个:\n", y[:5])# 获取特征名称
feature_names = iris.feature_names
print("特征名称:\n", feature_names)# 获取目标标签的名称
target_names = iris.target_names
print("目标标签名称:\n", target_names)
输出:
特征数据前5行:[[5.1 3.5 1.4 0.2][4.9 3. 1.4 0.2][4.7 3.2 1.3 0.2][4.6 3.1 1.5 0.2][5. 3.6 1.4 0.2]]
目标标签前5个:[0 0 0 0 0]
特征名称:['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
目标标签名称:['setosa' 'versicolor' 'virginica']
在这个例子中,我们首先导入了sklearn.datasets模块,然后调用load_iris()函数加载鸢尾花数据集。加载后的数据集存储在iris对象中,我们可以通过这个对象访问数据集的各个部分。
通过iris.data,我们可以获取特征数据,它是一个形状为(150, 4)的NumPy数组,其中每一行代表一个样本,每一列代表一个特征。
通过iris.target,我们可以获取目标标签,它是一个长度为150的一维数组,其中每个元素表示对应样本的类别标签(0、1或2)。
此外,iris.DESCR包含了数据集的详细描述,iris.feature_names包含了特征名称,iris.target_names包含了目标标签的名称。
🎨三、探索鸢尾花数据集
在加载了鸢尾花数据集之后,我们可以进行一些基本的探索性分析,以了解数据的分布和特性。
例如,我们可以使用matplotlib库来绘制特征之间的散点图,观察不同类别之间的分布关系:
# 导入必要的库
import matplotlib.pyplot as plt # 导入matplotlib库,用于绘图
import seaborn as sns # 导入seaborn库,基于matplotlib的图形可视化Python库
import pandas as pd # 导入pandas库,用于数据处理和分析
from sklearn import datasets # 从sklearn库中导入datasets模块,用于加载数据集# 加载鸢尾花数据集
iris = datasets.load_iris() # 使用datasets模块的load_iris函数加载鸢尾花数据集# 将特征和标签转换为DataFrame
df_iris = pd.DataFrame(iris.data, columns=iris.feature_names) # 将特征数据转换为pandas的DataFrame,并设置列名为鸢尾花的特征名称
df_iris['target'] = pd.Series(iris.target) # 将标签数据转换为pandas的Series,并添加到DataFrame中作为新列'target'# 将标签转换为类别名称,以便在图中显示
df_iris['target'] = df_iris['target'].map({0: iris.target_names[0], 1: iris.target_names[1], 2: iris.target_names[2]})
# 使用map函数将标签(整数)映射为实际的类别名称(字符串),使得在图中显示时更加直观# 绘制特征之间的散点图
sns.pairplot(df_iris, hue="target", palette="husl", vars=iris.feature_names, diag_kind="kde")
# 使用seaborn的pairplot函数绘制特征之间的散点图
# hue参数指定根据哪一列对数据进行着色,这里根据'target'列(即类别)
# palette参数指定着色方案,这里使用"husl"方案
# vars参数指定要绘制的特征列,这里使用iris数据集中的所有特征名称
# diag_kind参数指定对角线子图的类型,这里使用"kde"表示核密度估计图plt.show() # 显示绘制的图形
以上代码使用Python中的matplotlib和seaborn库来可视化鸢尾花数据集的特征和标签。鸢尾花数据集是一个经典的小型数据集,常用于分类算法的入门和测试。它包含了三类鸢尾花(Setosa、Versicolour、Virginica)的四个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)的测量值以及对应的类别标签。
首先,代码通过datasets.load_iris()函数加载了鸢尾花数据集,并将特征和标签转换为pandas DataFrame格式,以便后续的数据处理和可视化。然后,代码将标签(整数形式)转换为实际的类别名称,使得在图中显示时更加直观。
接下来,代码使用seaborn的pairplot函数绘制了特征之间的散点图,并根据类别标签对点进行着色。通过对角线子图展示的是每个特征的核密度估计图,这有助于了解每个特征的分布情况。
最后,通过调用plt.show()函数,代码显示了绘制的图形:

🔍四、使用鸢尾花数据集进行模型训练
加载和探索了鸢尾花数据集之后,我们可以开始使用它来进行模型的训练和测试。以下是一个简单的例子,展示如何使用鸢尾花数据集训练一个支持向量机(SVM)分类器:
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn import datasets# 加载鸢尾花数据集
iris = datasets.load_iris()# 打印数据集描述
# print(iris.DESCR) # 可选# 获取特征数据
X = iris.data# 获取目标标签
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建SVM分类器
clf = svm.SVC(kernel='linear') # 线性核函数# 训练模型
clf.fit(X_train, y_train)# 预测测试集
y_pred = clf.predict(X_test)# 打印分类报告
print(classification_report(y_test, y_pred, target_names=iris.target_names))
输出:
precision recall f1-score supportsetosa 1.00 1.00 1.00 19versicolor 1.00 1.00 1.00 13virginica 1.00 1.00 1.00 13accuracy 1.00 45macro avg 1.00 1.00 1.00 45
weighted avg 1.00 1.00 1.00 45
在这个例子中,我们首先使用train_test_split函数将数据集划分为训练集和测试集。然后,我们创建了一个SVM分类器,并使用训练集对其进行训练。接着,我们使用训练好的模型对测试集进行预测,并最后打印出分类报告以评估模型的性能。
分类报告中的精确度、召回率、F1值等指标,能够为我们提供关于模型在不同类别上的表现信息。这些指标有助于我们了解模型的优点和可能存在的问题,从而指导我们进行模型的优化。
🛠️五、优化模型性能
当我们得到初始的分类结果后,通常需要对模型进行优化以提高其性能。优化模型性能的方法有很多,包括但不限于调整模型参数、使用不同的模型、进行特征选择或特征工程等。
例如,在上面的SVM例子中,我们可以尝试改变SVM的核函数,如使用径向基函数(RBF)核而不是线性核,来查看是否能获得更好的性能。我们还可以尝试调整正则化参数C,以控制模型对误差的容忍度。
此外,我们还可以考虑对数据进行标准化或归一化,以使特征之间的尺度更加一致,从而可能提高模型的性能。
🛠️六、使用鸢尾花数据集进行模型选择
在机器学习中,我们经常需要在不同的模型之间进行选择,以找到最适合我们数据的模型。鸢尾花数据集为我们提供了一个很好的平台来进行模型选择和比较。
我们可以使用交叉验证等技术来评估不同模型在鸢尾花数据集上的性能,并选择性能最好的模型。例如,我们可以比较SVM、决策树、随机森林、K近邻等模型在鸢尾花数据集上的表现,并选择最适合的模型。
📚七、总结与进一步学习
通过本博客的学习,我们了解了鸢尾花数据集的基本信息和加载方法,学习了如何探索和使用鸢尾花数据集进行模型训练和评估,以及如何进行模型优化和选择。
鸢尾花数据集虽然简单,但它包含了许多机器学习的基础概念和方法。通过实践这些方法和概念,我们可以逐渐积累机器学习的知识和经验,为进一步学习更复杂的模型和算法打下基础。
希望本博客对你有所帮助,祝你学习愉快,收获满满!#鸢尾花数据集 #Python机器学习 #SVM分类器 #模型优化与选择
相关文章:
【Pytorch】新手入门:基于sklearn实现鸢尾花数据集的加载
【Pytorch】新手入门:基于sklearn实现鸢尾花数据集的加载 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望…...
maven项目引入私有jar,并打包到java.jar中
私有jar存放位置 maven依赖 <dependency><groupId>com.hikvision.ga</groupId><artifactId>artemis-http-client</artifactId><version>1.1.10</version><scope>system</scope><systemPath>${project.basedir}/s…...

Django中的Cookie和Session
文章目录 cookie是什么Django中如何使用cookieCookie使用示例session是什么Django中如何使用会话sessionSession使用示例小结 HTTP协议本身是”无状态”的,在一次请求和下一次请求之间没有任何状态保持,服务器无法识别来自同一用户的连续请求。有了cooki…...
)
Git-安装与使用(快速上手图文教程)
Git-安装与使用(快速上手图文教程) - 知乎 克隆: 首先你进去你要存放代码的位置,比如将代码存放到D盘,然后在D盘中右键,点击Git Bash Here,就是说本地仓库要在D盘建立。然后出现git 命令行界面…...
VBA_NZ系列工具NZ02:VBA读取PDF使用说明
我的教程一共九套及VBA汉英手册一部,分为初级、中级、高级三大部分。是对VBA的系统讲解,从简单的入门,到数据库,到字典,到高级的网抓及类的应用。大家在学习的过程中可能会存在困惑,这么多知识点该如何组织…...
所在的位置)
如何在paddlehub库中找到paddlehub.Module()所在的位置
要在PaddleHub库中找到paddlehub.Module()的位置,您可以通过以下步骤在PaddleHub库的源代码中进行查找: 1.确定PaddleHub库的安装位置:首先,确定您安装PaddleHub库的位置。通常,PaddleHub库会被安装在Python的site-pa…...

创建旅游景点图数据库Neo4J技术验证
文章目录 创建旅游景点图数据库Neo4J技术验证写在前面基础数据建库python3源代码KG效果KG入库效率优化方案PostGreSQL建库 创建旅游景点图数据库Neo4J技术验证 写在前面 本章主要实践内容: (1)neo4j知识图谱库建库。使用导航poi中的公园、景…...

Docker一键部署WordPress
使用Docker安装WordPress相对传统安装方式更加便捷高效,因为它可以快速创建一个包含所有必要组件(Web服务器、PHP和MySQL数据库)的独立容器环境。下面是一个简化的步骤说明如何使用Docker和Docker Compose安装WordPress: 一 安装…...
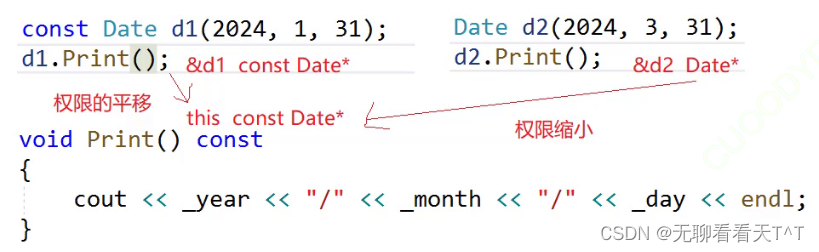
C++的类与对象(五):赋值运算符重载与日期类的实现
目录 比较两个日期对象 运算符重载 赋值运算符重载 连续赋值 日期类的实现 Date.h文件 Date.cpp文件 Test.cpp文件 const成员 取地址及const取地址操作符重载 比较两个日期对象 问题描述:内置类型可直接用运算符比较,自定义类型的对象是多个…...

【uni-app小程序开发】实现一个背景色渐变的滑动条slider
先直接附上背景色渐变的滑动条slider uni-module插件地址:https://ext.dcloud.net.cn/plugin?id16841 最近做的一个用uni-appvue2开发的微信小程序项目中要实现一个滑动进度控制条,如下图所示: 1. 滑动条需要渐变背景色 2. 滑块的背景色需…...

Claude3横空出世:颠覆GPT-4,Anthropic与亚马逊云科技共启AI新时代
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…...

【AI视野·今日NLP 自然语言处理论文速览 第八十三期】Wed, 6 Mar 2024
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 6 Mar 2024 Totally 74 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers MAGID: An Automated Pipeline for Generating Synthetic Multi-modal Datasets Authors Hossein Aboutalebi, …...
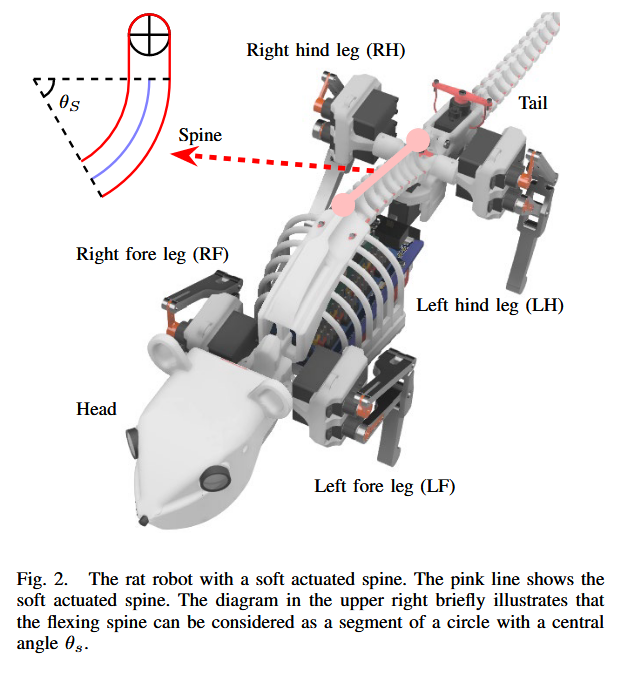
【AI视野·今日Robot 机器人论文速览 第八十二期】Tue, 5 Mar 2024
AI视野今日CS.Robotics 机器人学论文速览 Tue, 5 Mar 2024 Totally 63 papers 👉上期速览✈更多精彩请移步主页 Interesting: 📚双臂机器人拧瓶盖, (from 伯克利) website: https://toruowo.github.io/bimanual-twist 📚水下抓取器, (from …...

流量分析-webshell管理工具
文章目录 CSCS的工作原理CS流量特征 菜刀phpJSPASP 蚁剑冰蝎哥斯拉 对于常见的webshell管理工具有中国菜刀,蚁剑,冰蝎,哥斯拉。同时还有渗透工具cobaltstrike(CS)。 CS CobaltStrike有控制端,被控端,服务端。(相当于黑…...

备考2025年AMC8数学竞赛:吃透2000-2024年600道AMC8真题就够
我们继续来随机看五道AMC8的真题和解析,根据实践经验,对于想了解或者加AMC8美国数学竞赛的孩子来说,吃透AMC8历年真题是备考最科学、最有效的方法之一。 即使不参加AMC8竞赛,吃透了历年真题600道和背后的知识体系,那么…...
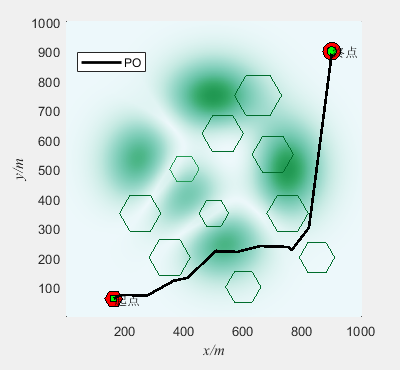
基于鹦鹉优化算法(Parrot optimizer,PO)的无人机三维路径规划(提供MATLAB代码)
一、无人机路径规划模型介绍 无人机三维路径规划是指在三维空间中为无人机规划一条合理的飞行路径,使其能够安全、高效地完成任务。路径规划是无人机自主飞行的关键技术之一,它可以通过算法和模型来确定无人机的航迹,以避开障碍物、优化飞行…...

linux Shell 命令行-02-var 变量
拓展阅读 linux Shell 命令行-00-intro 入门介绍 linux Shell 命令行-02-var 变量 linux Shell 命令行-03-array 数组 linux Shell 命令行-04-operator 操作符 linux Shell 命令行-05-test 验证是否符合条件 linux Shell 命令行-06-flow control 流程控制 linux Shell 命…...

C#MQTT编程10--MQTT项目应用--工业数据上云
1、文章回顾 这个系列文章已经完成了9个内容,由浅入深地分析了MQTT协议的报文结构,并且通过一个有效的案例让伙伴们完全理解理论并应用到实际项目中,这节继续上马一个项目应用,作为本系列的结束,奉献给伙伴们&#x…...

exceljs解析和生成excel文件
安装 npm install exceljs解析excel 通过 Workbook 的 readFile 方法可以拿到workbook对象, workbook对象包含的概念有 worksheet(工作表) --> row(行) --> cell(单元格).于是可以通过依次遍历 worksheet, row, cell来拿到单元格的数据直接通过 worksheet.getSheetValue…...
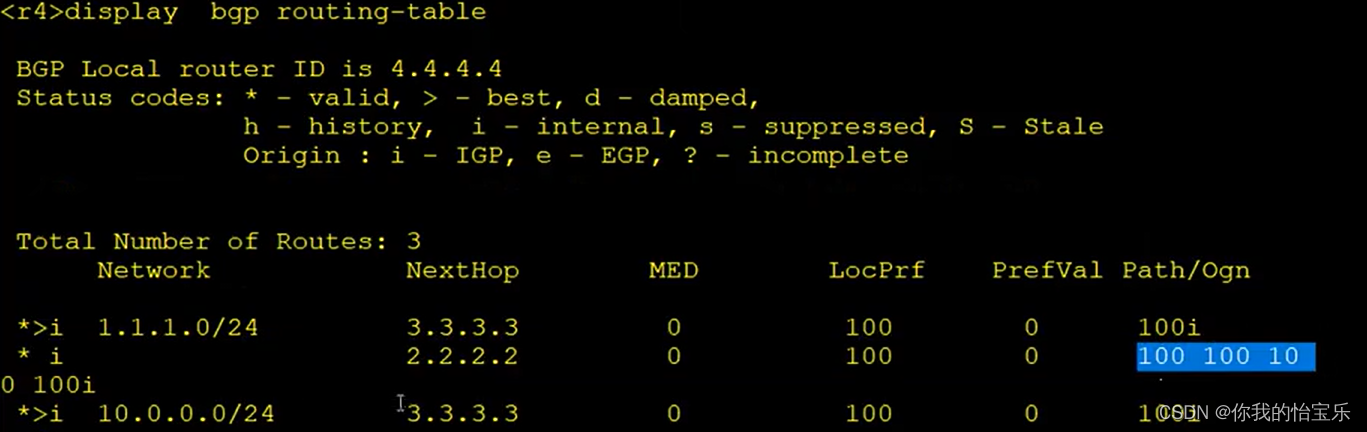
HCIP —— BGP 路径属性 (上)
目录 BGP 路径属性 1.优选Preferred-Value属性值最大的路由 2.优选Local-preference 属性数值大的路由 3.本地始发的BGP路由优先于其他对等体处学习到的路由。 4..优选AS_PATH属性值最短的路由 BGP 路径属性 BGP的路由选路是存在优选规则的,下图为华为官网提供…...
)
LiuJuan Z-Image详细步骤:自定义权重注入全流程(含键名清洗脚本)
LiuJuan Z-Image详细步骤:自定义权重注入全流程(含键名清洗脚本) 1. 引言:为什么需要自定义权重注入? 如果你用过一些开源的图片生成模型,可能会发现一个头疼的问题:好不容易找到一个别人训练…...

深入拆解Java线程:生命周期流转与核心方法底层原理
线程是Java并发编程的核心执行单元,理解其生命周期与状态转换机制,以及interrupt()、wait()、notify()、join()等核心方法的底层原理,是编写高效、稳定并发程序的基础。一、Java线程的生命周期与状态转换Java线程的状态由java.lang.Thread.St…...

Kro实战:如何创建第一个ResourceGraphDefinition实例
Kro实战:如何创建第一个ResourceGraphDefinition实例 【免费下载链接】kro kro | Kube Resource Orchestrator 项目地址: https://gitcode.com/gh_mirrors/kr/kro Kro(Kube Resource Orchestrator)是一款强大的Kubernetes资源编排工具…...

Fish Speech-1.5多语种TTS部署案例:国际学校双语教学音频批量生成实践
Fish Speech-1.5多语种TTS部署案例:国际学校双语教学音频批量生成实践 想象一下,一所国际学校的老师,每天需要为不同年级、不同语言背景的学生准备中英文对照的教学音频。传统方法要么是老师自己录制,耗时耗力且难以保证发音标准…...

PDF与OFD电子发票解析技术实战:从格式转换到精准识别
1. 电子发票解析的现状与挑战 财务数字化转型浪潮下,电子发票已成为企业日常经营的重要凭证。但实际业务中,财务人员常被PDF和OFD两种格式的电子发票处理搞得焦头烂额。我见过不少企业财务部,光是手工录入发票信息就要配备3-5人的专职团队&am…...

5大方法实现Alienware灯光、风扇与电源的深度个性化控制
5大方法实现Alienware灯光、风扇与电源的深度个性化控制 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools Alienware设备用户常面临原厂软件功能受限、个…...

如何快速掌握League-Toolkit:英雄联盟智能助手的完整使用指南
如何快速掌握League-Toolkit:英雄联盟智能助手的完整使用指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League-Toolkit是一个…...

抖音无水印批量下载神器:douyin-downloader深度技术解析与实战指南
抖音无水印批量下载神器:douyin-downloader深度技术解析与实战指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fa…...

YOLOv12开发利器:IntelliJ IDEA/PyCharm深度学习项目配置详解
YOLOv12开发利器:IntelliJ IDEA/PyCharm深度学习项目配置详解 你是不是还在用记事本或者简单的编辑器写YOLOv12的代码?每次改几行代码,就要切到终端去运行,调试起来更是麻烦,打印日志看得眼花缭乱。其实,有…...

MTools安全加固方案:输入过滤、输出脱敏、模型沙箱运行机制详解
MTools安全加固方案:输入过滤、输出脱敏、模型沙箱运行机制详解 1. 项目背景与安全需求 在人工智能技术快速发展的今天,文本处理工具已经成为日常工作和学习中不可或缺的助手。MTools作为一个多功能文本工具箱,集成了文本总结、关键词提取、…...