【PyTorch】进阶学习:BCEWithLogitsLoss在多标签分类任务中的正确使用---logits与标签形状指南
【PyTorch】进阶学习:BCEWithLogitsLoss在多标签分类任务中的正确使用—logits与标签形状指南

🌈 个人主页:高斯小哥
🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望得到您的订阅和支持~
💡 创作高质量博文(平均质量分92+),分享更多关于深度学习、PyTorch、Python领域的优质内容!(希望得到您的关注~)
🌵文章目录🌵
- 🔥一、PyTorch进阶学习:BCEWithLogitsLoss初探
- 🧠二、深入理解logits与标签的形状
- 🚀三、优化器与训练过程
- 📈四、评估模型性能
- 🎨五、优化BCEWithLogitsLoss的使用
- 🔍六、调试与错误排查
- 📚七、总结与进一步学习
🔥一、PyTorch进阶学习:BCEWithLogitsLoss初探
在深度学习的旅程中,我们经常会遇到各种各样的损失函数。对于多标签分类任务,BCEWithLogitsLoss是一个常用的损失函数。在PyTorch中,BCEWithLogitsLoss结合了Sigmoid层和二元交叉熵损失(Binary Cross Entropy Loss),使得在训练过程中能够直接接收未经过Sigmoid激活的logits作为输入,从而提高计算效率。
首先,我们需要了解BCEWithLogitsLoss的基本原理。它主要用于处理二分类问题,但在多标签分类任务中,通过扩展每个标签为一个独立的二分类问题,也可以得到应用。
接下来,我们通过代码示例来演示如何在PyTorch中使用BCEWithLogitsLoss。
import torch
import torch.nn as nn
import torch.optim as optim# 假设有一个batch的样本,每个样本有3个标签
num_samples = 10
num_labels = 3# 随机生成logits,形状为[batch_size, num_labels]
logits = torch.randn(num_samples, num_labels)# 随机生成标签,形状也为[batch_size, num_labels],每个标签为0或1
labels = torch.randint(0, 2, (num_samples, num_labels))# 实例化BCEWithLogitsLoss
criterion = nn.BCEWithLogitsLoss()# 计算损失
loss = criterion(logits, labels)# 打印损失值
print(f"Loss: {loss.item()}")
在上面的代码中,我们创建了一个随机的logits张量和标签张量,并使用BCEWithLogitsLoss来计算损失。注意,logits和标签的形状都是[batch_size, num_labels],这是多标签分类任务中常见的形状。
🧠二、深入理解logits与标签的形状
在多标签分类任务中,每个样本可能同时属于多个类别。 因此,我们的模型需要为每个类别输出一个预测值(即logits),并且我们需要为每个类别提供一个标签。这就是为什么logits和标签的形状都是[batch_size, num_labels]的原因。
logits表示模型对每个类别的原始预测分数,而标签则表示每个样本真实所属的类别。在计算损失时,BCEWithLogitsLoss会对logits应用Sigmoid函数,并将其与标签进行比较,从而得到每个类别的损失,并最终将这些损失求和得到总损失。
🚀三、优化器与训练过程
在训练过程中,我们除了需要定义损失函数外,还需要一个优化器来更新模型的参数。以下是一个简单的训练循环示例:
# 定义模型
model = nn.Linear(input_dim, num_labels)# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)# 假设我们有一些输入数据X
X = torch.randn(num_samples, input_dim)# 训练循环
for epoch in range(num_epochs):# 前向传播logits = model(X)# 计算损失loss = criterion(logits, labels)# 反向传播optimizer.zero_grad()loss.backward()# 更新参数optimizer.step()# 打印损失值print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}")
在这个示例中,我们定义了一个简单的线性模型,并使用Adam优化器进行参数更新。在每个epoch中,我们执行前向传播、计算损失、反向传播和参数更新。
📈四、评估模型性能
在训练过程中,我们通常会在验证集上评估模型的性能。对于多标签分类任务,我们可能会使用准确率、精确率、召回率或F1分数等指标来评估模型。这些指标可以帮助我们更全面地了解模型的表现。
在PyTorch中,我们可以使用sklearn.metrics模块来计算这些指标。以下是一个简单的示例:
from sklearn.metrics import classification_report# 假设我们有模型在验证集上的预测结果preds和真实标签val_labels
preds = model(val_X) # val_X是验证集上的输入数据
preds = (preds > 0.5).float() # 应用阈值得到最终的预测标签# 计算分类报告
report = classification_report(val_labels.view(-1).long(), preds.view(-1).long(), target_names=label_names)
print(report)
🎨五、优化BCEWithLogitsLoss的使用
虽然BCEWithLogitsLoss是一个强大的损失函数,但在实际使用中,我们可能需要进行一些调整以优化其性能。
首先,需要注意的是,BCEWithLogitsLoss在计算损失时已经内部集成了Sigmoid函数,因此在模型输出后不需要再手动应用Sigmoid。这有助于减少计算量并提高数值稳定性。
其次,对于不平衡的数据集,我们可能需要调整损失函数的权重。BCEWithLogitsLoss允许我们为每个类别指定不同的权重,以便更好地处理类别不平衡的问题。通过为少数类别分配更高的权重,我们可以使模型更加关注这些类别,并尝试提高它们的预测性能。
最后,我们还可以尝试调整损失函数的超参数,如权重衰减(weight decay)或正则化项,以进一步控制模型的复杂度并防止过拟合。
🔍六、调试与错误排查
在使用BCEWithLogitsLoss时,我们可能会遇到一些错误或异常。以下是一些常见的问题及其解决方案:
-
形状不匹配:确保logits和标签的形状完全匹配。它们都应该具有相同的batch_size和num_labels。
-
数据类型问题:logits和标签的数据类型应该是
torch.float。如果标签是整数类型,你需要将其转换为浮点数。 -
数值稳定性:在某些情况下,logits的值可能非常大或非常小,这可能导致数值不稳定。你可以尝试对logits进行裁剪(clipping)或使用其他技术来提高数值稳定性。
-
梯度爆炸或消失:如果损失函数变得非常大或非常小,这可能会导致梯度爆炸或消失。你可以尝试调整学习率或使用其他优化技术来解决这个问题。
当遇到错误时,请仔细阅读错误信息并检查你的代码。使用打印语句(print statements)来检查logits和标签的形状和值,这有助于你定位问题所在。
📚七、总结与进一步学习
通过本博客的学习,我们深入了解了如何在PyTorch中使用BCEWithLogitsLoss来处理多标签分类任务。我们讨论了logits和标签的形状要求,并j展示了如何在训练循环中使用这个损失函数。此外,我们还探讨了优化损失函数使用的一些策略以及常见的调试和错误排查技巧。
为了进一步深入学习,你可以查阅PyTorch的官方文档以获取更多关于BCEWithLogitsLoss的详细信息。你还可以尝试将其应用于其他多标签分类任务,并探索不同的模型架构和优化策略。
希望本博客对你有所帮助,并激发你对深度学习和PyTorch的进一步探索的兴趣!😊
相关文章:
【PyTorch】进阶学习:BCEWithLogitsLoss在多标签分类任务中的正确使用---logits与标签形状指南
【PyTorch】进阶学习:BCEWithLogitsLoss在多标签分类任务中的正确使用—logits与标签形状指南 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTo…...

ocr关键信心提取数据集
doc/doc_ch/dataset/kie_datasets.md PaddlePaddle/PaddleOCR - Gitee.com https://huggingface.co/datasets/howard-hou/OCR-VQA OCR-VQA Dataset | Papers With Code...
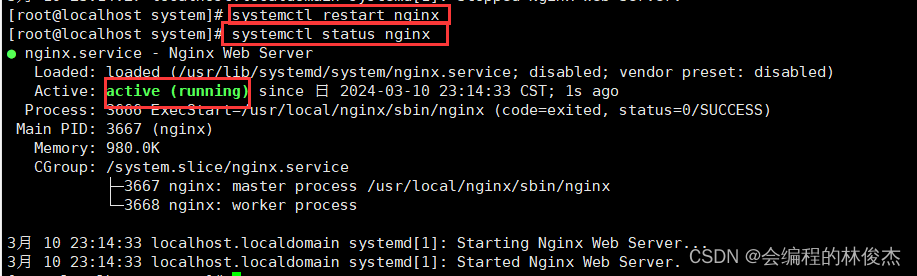
Linux中,配置systemctl操作Nginx
最近在通过Linux系统学一些技术,但是在启动Nginx时,总是需要执行其安装路径下的脚本文件,要么我们需要先进入其安装路径,要么我们每次执行命令直接拼上Nginx的完整目录,如启动时命令为/usr/local/nginx/sbin/nginx。 可…...
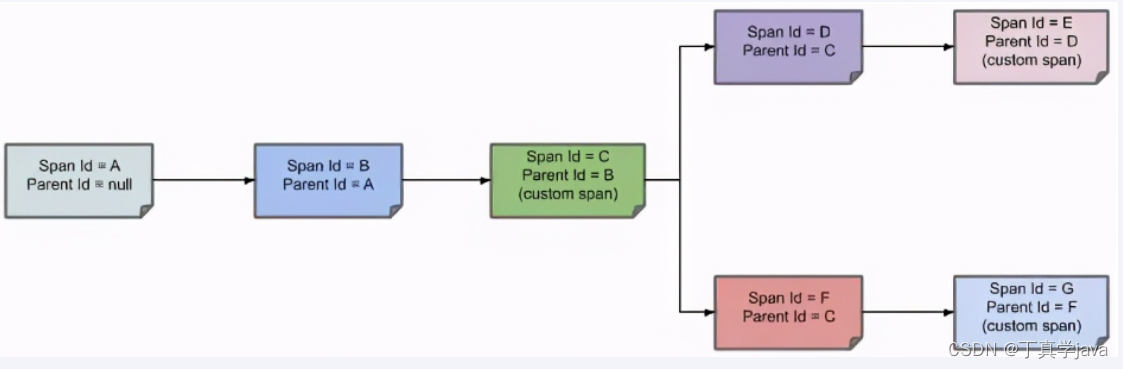
Sleuth(Micrometer)+ZipKin分布式链路追踪
Sleuth(Micrometer)ZipKin分布式链路追踪 Micrometer springboot3之前还可以用sleuth,springboot3之后就被Micrometer所替代 官网https://github.com/spring-cloud/spring-cloud-sleuth 为什么会出现这个技术? 在微服务框架中,一个由客户…...

fanout模式
生产者: public class Provider {public static void main(String[] args) throws IOException {Connection connection RabbitMQUtils.getConnection();Channel channel connection.createChannel();//通道声明指定的交换机 参数1:交换机名称 参数2&…...

Docker基础—CentOS中卸载Docker
要卸载已经安装好的 Docker,可以按照以下步骤进行: 1 停止正在运行的 Docker 服务 sudo systemctl stop docker 2 卸载 Docker 软件包 sudo yum remove docker-ce 3 删除 Docker 数据和配置文件(可选) sudo rm -rf /var/lib…...

深入解读 Elasticsearch 磁盘水位设置
本文将带你通过查看 Elasticsearch 源码来了解磁盘使用阈值在达到每个阶段的处理情况。 跳转文章末尾获取答案 环境 本文使用 Macos 系统测试,512M 的磁盘,目前剩余空间还有 60G 左右,所以按照 Elasticsearch 的设定,ES 中分片应…...
M1电脑 Xcode15升级遇到的问题
遇到四个问题 一、模拟器下载经常报错。 二、Xcode15报错: SDK does not contain libarclite 三、报错coreAudioTypes not found 四、xcode模拟器运行一次下次必定死机 一、模拟器下载经常报错。 可以https://developer.apple.com/download/all/?qios 下载最新的模拟器&…...
)
软考 系统架构设计师之回归及知识点回顾(3)
接前一篇文章:软考 系统架构设计师之回归及知识点回顾(2) 继续回顾一下之前已经介绍和讲解过的系统架构设计师中的知识点: 7. 净室软件工程 净室(Cleaning Room)软件工程是一种应用数学与统计学理论&…...

探索stable diffusion的奇妙世界--01
目录 1. 理解prompt提示词: 2. Prompt中的技术参数: 3. Prompt中的Negative提示词: 4. Prompt中的特殊元素: 5. Prompt在stable diffusion中的应用: 6. 作品展示: 在AI艺术领域,stable di…...

C语言数组的维数该如何理解?
一、问题 什么叫做维,维是不是数组中数的个数呢? 二、解答 维数是数组元素的下标个数。使⽤数组的时候,如果只有⼀个下标,则称为⼀维数组,⼀维数组⼀般表示⼀种线性数据的组合。⼆维数组则是有两个下标,可…...
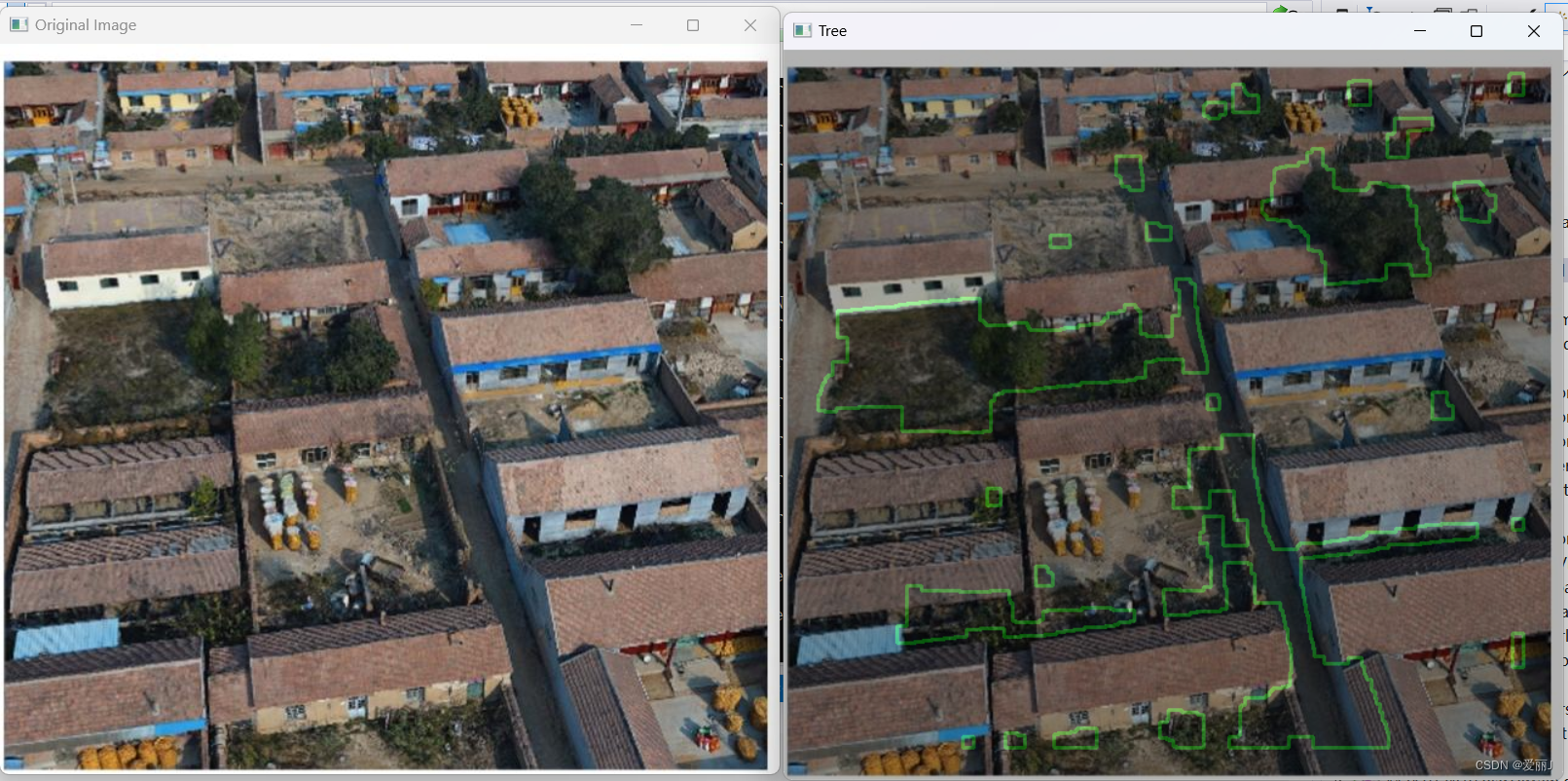
opencv解析系列 - 基于DOM提取大面积植被(如森林)
Note:简单提取,不考虑后处理(填充空洞、平滑边界等) #include <iostream> #include "opencv2/imgproc.hpp" #include "opencv2/highgui.hpp" #include <opencv2/opencv.hpp> using namespace cv…...

【Leetcode】299. 猜数字游戏
文章目录 题目思路代码结果 题目 题目链接 你在和朋友一起玩 猜数字(Bulls and Cows)游戏,该游戏规则如下: 写出一个秘密数字,并请朋友猜这个数字是多少。朋友每猜测一次,你就会给他一个包含下述信息的提…...

JWT身份验证
在实际项目中一般会使用jwt鉴权方式。 JWT知识点 jwt,全称json web token ,JSON Web令牌是一种开放的行业标准RFC 7519方法,用于在两方安全地表示声明。具体网上有许多文章介绍,这里做简单的使用。 1.数据结构 JSON Web Token…...

IOS面试题object-c 71-80
71. 简单介绍下NSURLConnection类及 sendSynchronousRequest:returningResponse:error:与– initWithRequest:delegate:两个方法的区别?NSURLConnection 主要用于网络访问,其中 sendSynchronousRequest:returningResponse:error:是同步访问数据,即当前…...

计算机mfc140.dll文件缺失的修复方法分析,一键修复mfc140.dll
电脑显示mfc140.dll文件缺失信息时,不必担心,这通常是个容易解决的小问题。接下来让我们详细探究并解决mfc140.dll文件缺失的状况。以下将详述相应的解决方案,从而帮助您轻松克服这一技术难题。通过几个简单步骤,即可恢复正常使用…...

web前端框架
目前比较火热的几门框架: React React是由Facebook(脸书)开发和创建的开源框架。React 用于开发丰富的用户界面,特别是当您需要构建单页应用程序时。它是最强大的前端框架。 弊端: 您不具备 JavaScript 的实践知识,则建议不要使用 React。同样&#x…...
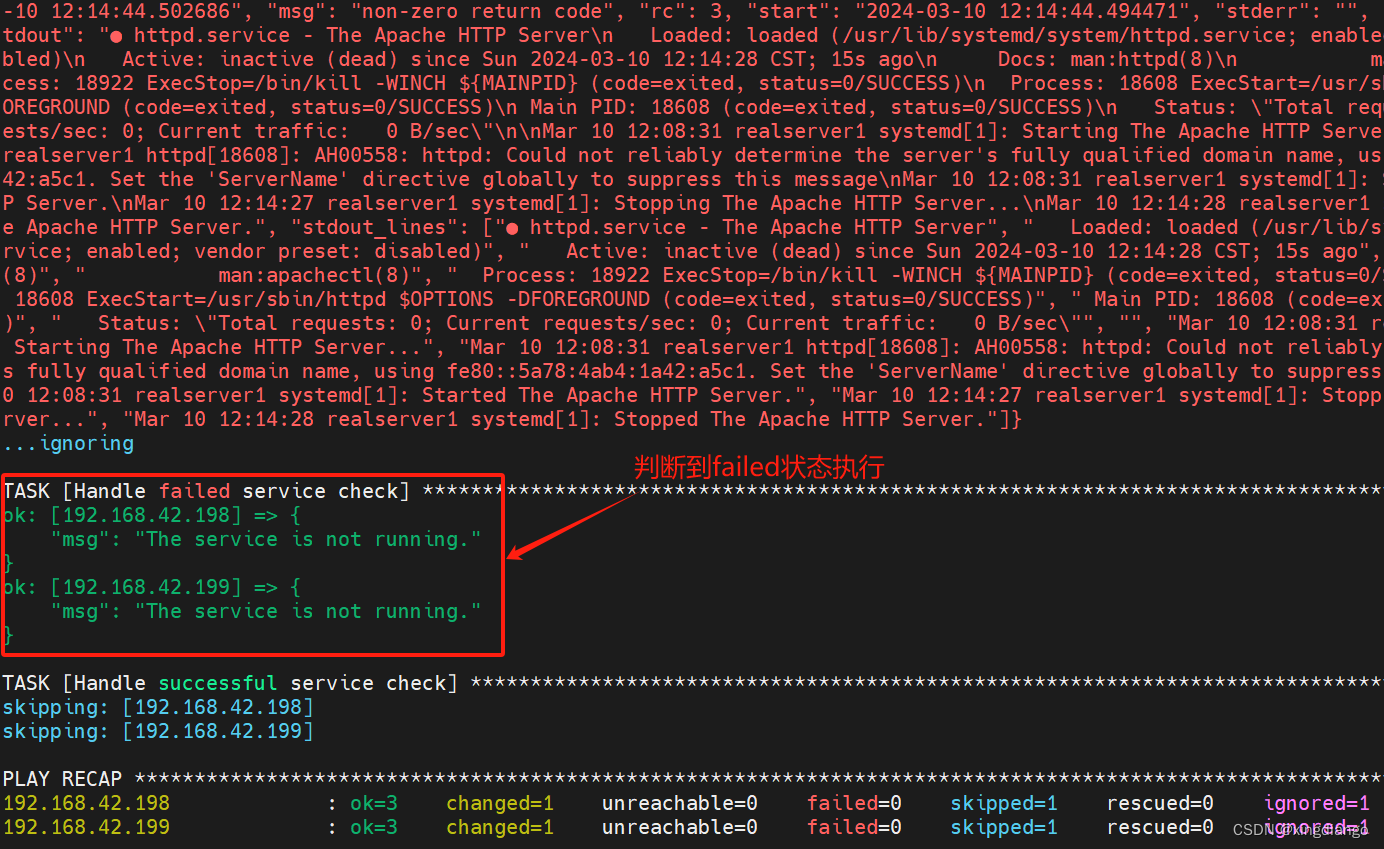
关于playbook中when条件过滤报The conditional check ‘result|failed‘ failed的问题
问题现象 在使用plabook中的when做过滤脚本如下: --- - hosts: realserversremote_user: roottasks:- name: Check if httpd service is runningcommand: systemctl status httpdregister: resultignore_errors: True- name: Handle failed service checkdebug:ms…...

【设计模式专题之抽象工厂模式】3. 家具工厂
题目描述 小明家新开了两个工厂用来生产家具,一个生产现代风格的沙发和椅子,一个生产古典风格的沙发和椅子,现在工厂收到了一笔订单,请你帮他设计一个系统,描述订单需要生产家具的信息。 输入描述 输入的第一行是一…...

架构:Apache Kafka Connect实现sqlserver数据实时同步
实现Apache Kafka Connect与SQL Server之间的实时数据同步,您可以使用Kafka Connect的JDBC Source Connector。以下是一个基本的步骤: 1. 安装Kafka Connect:确保您已经安装了Apache Kafka 和 Kafka Connect。您可以从Apache Kafka的官方网站…...

【ABAP】-TSV_TNEW_PAGE_ALLOC_FAILED:从ADRV冗余数据膨胀到BP维护性能危机的深度剖析与根治
1. 问题现象与业务影响 那天下午三点,采购部门的Lisa正在维护一个关键供应商的BP主数据。突然,她的SAP界面卡住了,紧接着弹出一个红色错误框:"TSV_TNEW_PAGE_ALLOC_FAILED - 内存分配失败"。这个看似简单的错误背后&…...
)
解决tomcat8-maven-plugin插件运行报错的完整指南(含常见错误排查)
解决tomcat8-maven-plugin插件运行报错的完整指南 最近在项目中使用tomcat8-maven-plugin插件时,遇到了不少令人头疼的问题。特别是那个经典的类加载器冲突错误,让不少开发者都踩过坑。本文将系统梳理这些常见问题,提供经过验证的解决方案&am…...

Windows多显示器DPI缩放终极控制指南:告别显示不一致的烦恼
Windows多显示器DPI缩放终极控制指南:告别显示不一致的烦恼 【免费下载链接】SetDPI 项目地址: https://gitcode.com/gh_mirrors/se/SetDPI 还在为Windows多显示器DPI缩放不一致而烦恼吗?SetDPI是一款免费、高效的C命令行工具,让你通…...

3个高级技巧:用ComfyUI Manager彻底改变你的AI绘画工作流
3个高级技巧:用ComfyUI Manager彻底改变你的AI绘画工作流 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various cu…...

如何通过3个关键步骤将HDRI全景图转换为立方体贴图:从概念到实践
如何通过3个关键步骤将HDRI全景图转换为立方体贴图:从概念到实践 【免费下载链接】HDRI-to-CubeMap Image converter from spherical map to cubemap 项目地址: https://gitcode.com/gh_mirrors/hd/HDRI-to-CubeMap HDRI-to-CubeMap是一个基于浏览器的专业工…...

Java Swing文件分类系统开发全记录
个人文件分类管理系统设计与开发实录从零开始打造一个Java Swing桌面应用的全过程记录前言 作为一名Java学习者,在完成基础知识的学习后,我一直想动手做一个完整的小项目来巩固所学。刚好借Java课程设计要求完成一个项目的契机,经过反复思考&…...

终极Walkway.js进阶教程:掌握复杂交互动画与响应式设计的完整指南
终极Walkway.js进阶教程:掌握复杂交互动画与响应式设计的完整指南 【免费下载链接】walkway An easy way to animate SVG elements. 项目地址: https://gitcode.com/gh_mirrors/wa/walkway Walkway.js是一款轻量级的SVG动画库,让开发者能够轻松为…...

三步轻松唤醒Flash记忆:CefFlashBrowser完整使用指南
三步轻松唤醒Flash记忆:CefFlashBrowser完整使用指南 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 你是否还记得那些经典的Flash游戏?是否还在为无法重温儿时的F…...

如何在Blender中轻松导入导出3MF格式:3D打印工作流完整指南
如何在Blender中轻松导入导出3MF格式:3D打印工作流完整指南 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 你是否曾经在Blender中创建了精美的3D模型&#x…...
)
ElasticSearch系列二(索引操作、文档操作、查询、深度分页、排序、DSL、检索原理)
文章目录索引操作创建索引查看索引删除索引更新索引获取索引的统计信息文档创建、修改、删除创建文档修改文档删除文档批量操作_bulk文档查询简单KV对查询ES高级查询(Query DSL)批量查询_mget和_msearch查询所有match_all分页(from、to&#…...