Elasticsearch:使用 Logstash 构建从 Kafka 到 Elasticsearch 的管道 - Nodejs
在我之前的文章 “Elastic:使用 Kafka 部署 Elastic Stack”,我构建了从 Beats => Kafka => Logstash => Elasticsearch 的管道。在今天的文章中,我将描述从 Nodejs => Kafka => Logstash => Elasticsearch 这样的一个数据流。在之前的文章 “Elastic:Data pipeline:使用 Kafka => Logstash => Elasticsearch” 中,我也展示了使用 Python 的方法。我的配置如下:

在上面的架构中,有几个重要的组件:
- Kafka Server:这就是数据首先发布的地方。
- Producer:扮演将数据发布到 Kafka topic 的角色。 在现实世界中,你可以具有任何可以为 kafka 主题生成数据的实体。 在我们的示例中,我们将生成伪造的用户注册数据。
- Elasticsearch:这将充当将用户注册数据存储到其自身的数据库,并提供搜索及分析。
- Logstash:Logstash 将扮演中间人的角色,在这里我们将从 Kafka topic 中读取数据,然后将其插入到 Elasticsearch 中。
- Kibana:Kibana 将扮演图形用户界面的角色,它将以可读或图形格式显示数据。
为了演示的方便,你可以在地址下载演示文件 GitHub - liu-xiao-guo/data-pipeline8。我的文件目录是这样的:
$ pwd
/Users/liuxg/data/data-pipeline8
$ tree -L 3
.
├── README.md
├── docker-elk
│ ├── docker-compose.yml
│ └── logstash_pipeline
│ └── kafka-elastic.conf
├── docker-kafka
│ └── kafka-docker-compose.yml
└── kafka_producer.js$ pwd
/Users/liuxg/data/data-pipeline8/docker-elk
$ ls -al
total 16
drwxr-xr-x 5 liuxg staff 160 May 14 2021 .
drwxr-xr-x 8 liuxg staff 256 Mar 5 07:36 ..
-rw-r--r-- 1 liuxg staff 29 May 7 2021 .env
-rw-r--r-- 1 liuxg staff 1064 May 13 2021 docker-compose.yml
drwxr-xr-x 3 liuxg staff 96 May 13 2021 logstash_pipeline
$ vi .env
$ cat .env
ELASTIC_STACK_VERSION=8.6.2上面的其它文件将在我下面的章节中介绍。如果你自己想通过手动的方式部署 Kafka 请参阅我的另外一篇文章 “使用 Kafka 部署 Elastic Stack”。
安装
Kafka,Zookeeper 及 Kafka Manager
我将使用 docker-compose 来进行安装。一旦安装好,我们可以看到:
- Kafka 在 PORT 9092 侦听
- Zookeeper 在 PORT 2181 侦听
- Kafka Manager 侦听 PORT 9000 侦听
kafka-docker-compose.yml
version: "3"
services:zookeeper:image: zookeeperrestart: alwayscontainer_name: zookeeperhostname: zookeeperports:- 2181:2181environment:ZOO_MY_ID: 1kafka:image: wurstmeister/kafkacontainer_name: kafkaports:- 9092:9092environment:KAFKA_ADVERTISED_HOST_NAME: 192.168.0.3 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181kafka_manager:image: hlebalbau/kafka-manager:stablecontainer_name: kakfa-managerrestart: alwaysports:- "9000:9000"environment:ZK_HOSTS: "zookeeper:2181"APPLICATION_SECRET: "random-secret"command: -Dpidfile.path=/dev/null我们可以使用如下的命令来进行启动(在 Docker 运行的前提下):
docker-compose -f kafka-docker-compose.yml up
一旦运行起来后,我们可以使用如下的命令来进行查看:
docker ps$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a4acc0730467 zookeeper "/docker-entrypoint.…" About a minute ago Up About a minute 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 8080/tcp zookeeper
02ec8e8a1e30 hlebalbau/kafka-manager:stable "/kafka-manager/bin/…" About a minute ago Up About a minute 0.0.0.0:9000->9000/tcp kakfa-manager
a85c32c0c08e wurstmeister/kafka "start-kafka.sh" About a minute ago Up About a minute 0.0.0.0:9092->9092/tcp kafka我们发现 Kafka Manager 运行于 9000 端口。我们打开本地电脑的 9000 端口:


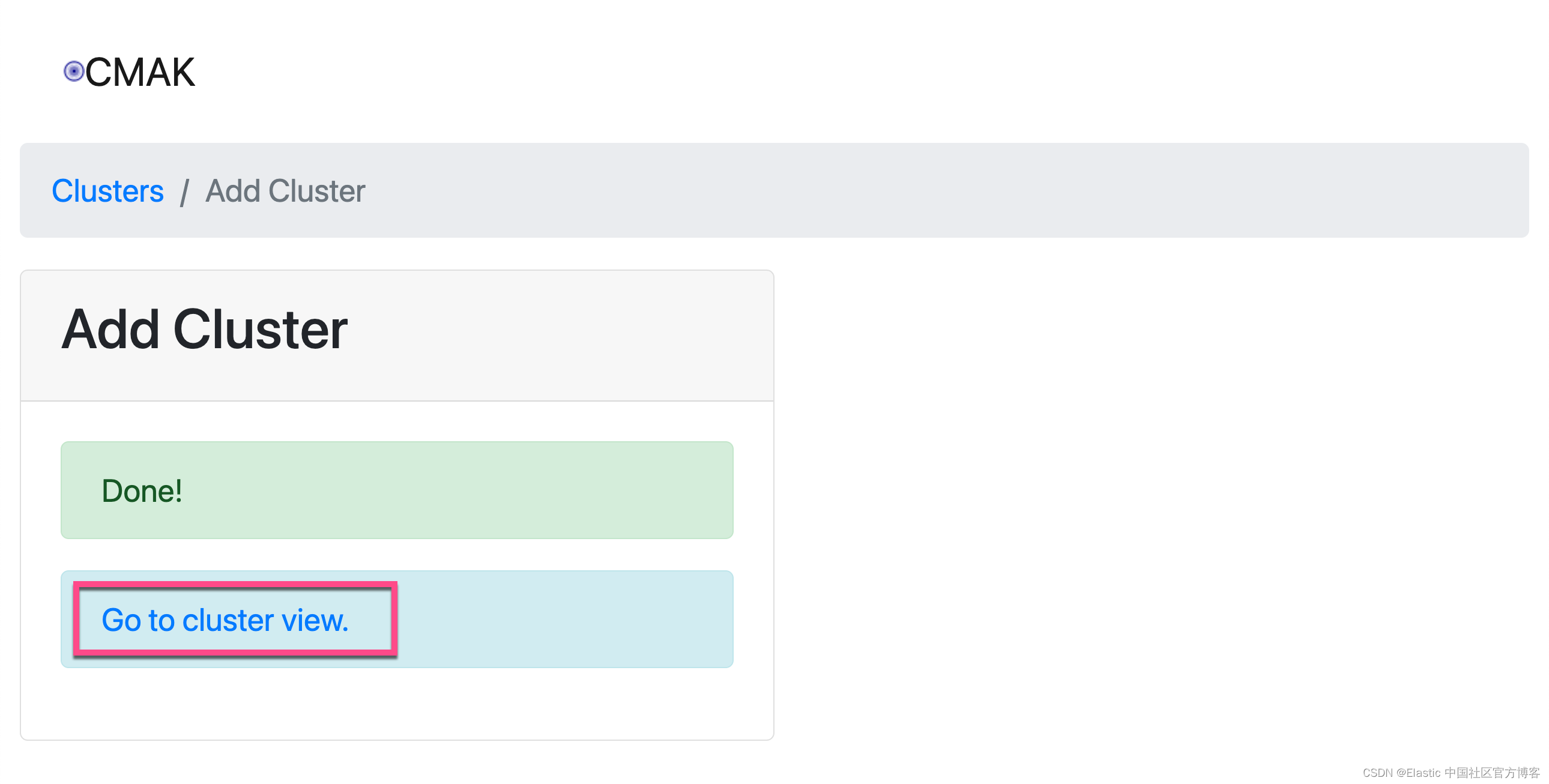 在上面它显示了一个默认的 topic,虽然不是我们想要的。
在上面它显示了一个默认的 topic,虽然不是我们想要的。



这样,我们就把 Kafka 上的 kafka_logstash topic 创建好了。
我们可以登录 kafka 容器来验证我们已经创建的 topic。我们使用如下的命令来找到 kafka 容器的名称:
docker ps -s$ docker ps -s
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES SIZE
de7453250529 hlebalbau/kafka-manager:stable "/kafka-manager/bin/…" 9 minutes ago Up 9 minutes 0.0.0.0:9000->9000/tcp kakfa-manager 117kB (virtual 427MB)
65eba68350f1 zookeeper "/docker-entrypoint.…" 9 minutes ago Up 9 minutes 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 8080/tcp zookeeper 33kB (virtual 288MB)
3394868b23e9 wurstmeister/kafka "start-kafka.sh" 9 minutes ago Up 9 minutes 0.0.0.0:9092->9092/tcp kafka 210kB (virtual 457MB)上面显示 kafka 的容器名称为 wurstmeister/kafka。我们使用如下的命令来进行登录:
docker exec -it wurstmeister/kafka /bin/bash然后我们在容器里 打入如下的命令:
$ docker exec -it kafka /bin/bash
root@3394868b23e9:/# kafka-topics.sh --list -zookeeper zookeeper:2181
__consumer_offsets
kafka_logstash上面的命令显示已经存在的被创建的 kafka_logstash topic。我们可以使用如下的命令来向这个被创建的 topic 来发送数据:
kafka-console-consumer.sh --bootstrap-server 192.168.0.3:9092 --topic kafka_logstash --from-beginningroot@3394868b23e9:/# kafka-console-consumer.sh --bootstrap-server 192.168.0.3:9092 --topic kafka_logstash --from-beginningElastic Stack 安装
我们接下来安装 Elastic Stack。同样地,我使用 docker-compose 来部署 Elasticsearch, Logstash 及 Kibana。你们可以参考我之前的文章 “Logstash:在 Docker 中部署 Logstash”。为了能够把数据传入到 Elasticsearch 中,我们需要在 Logstash 中配置一个叫做 kafka-elastic.conf 的配置文件:
kafka-elastic.conf
input {kafka {bootstrap_servers => "192.168.0.3:9092"topics => ["kafka_logstash"]}
}output {elasticsearch {hosts => ["elasticsearch:9200"]index => "kafka_logstash"workers => 1}
}请注意:在上面的 192.168.0.3 为我自己电脑的本地 IP 地址。为了说明问题的方便,我们没有对来自 kafka 里的 registered_user 这个 topic 做任何的数据处理,而直接发送到 Elasticsearch 中。
我们的 docker-compose.yml 配置文件如下:
docker-compose.yml
version: "3.9"
services:elasticsearch:image: elasticsearch:${ELASTIC_STACK_VERSION}container_name: elasticsearchenvironment:- discovery.type=single-node- ES_JAVA_OPTS=-Xms1g -Xmx1g- xpack.security.enabled=falsevolumes:- type: volumesource: es_datatarget: /usr/share/elasticsearch/dataports:- target: 9200published: 9200networks:- elastickibana:image: kibana:${ELASTIC_STACK_VERSION}container_name: kibanaports:- target: 5601published: 5601depends_on:- elasticsearchnetworks:- elastic logstash:image: logstash:${ELASTIC_STACK_VERSION}container_name: logstashports:- 5200:5200volumes: - type: bindsource: ./logstash_pipeline/target: /usr/share/logstash/pipelineread_only: truenetworks:- elastic volumes:es_data:driver: localnetworks:elastic:name: elasticdriver: bridge为方便起见,在我的安装中,我没有配置安全。如果你需要为 Elasticsearch 设置安全的话,请参考我之前的文章 “Elasticsearch:使用 Docker compose 来一键部署 Elastic Stack 8.x”。
我们使用如下的命令来启动 Elastic Stack。在 docker-compose.yml 所在的目录中打入如下的命令:
$ pwd
/Users/liuxg/data/data-pipeline8/docker-elk
$ ls
docker-compose.yml logstash_pipeline
$ docker-compose up
等所有的 Elastic Stack 运行起来后,我们再次通过如下的命令来进行查看:
docker ps$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3db5e4e6e23e kibana:8.6.2 "/bin/tini -- /usr/l…" About a minute ago Up About a minute 0.0.0.0:5601->5601/tcp kibana
210b673dd89a logstash:8.6.2 "/usr/local/bin/dock…" About a minute ago Up About a minute 5044/tcp, 9600/tcp, 0.0.0.0:5200->5200/tcp logstash
05c434edd823 elasticsearch:8.6.2 "/bin/tini -- /usr/l…" About a minute ago Up About a minute 0.0.0.0:9200->9200/tcp, 9300/tcp elasticsearch
de7453250529 hlebalbau/kafka-manager:stable "/kafka-manager/bin/…" 51 minutes ago Up 51 minutes 0.0.0.0:9000->9000/tcp kakfa-manager
65eba68350f1 zookeeper "/docker-entrypoint.…" 51 minutes ago Up 51 minutes 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 8080/tcp zookeeper
3394868b23e9 wurstmeister/kafka "start-kafka.sh" 51 minutes ago Up 51 minutes 0.0.0.0:9092->9092/tcp kafka我们可以看到 Elasticsearch 运用于 9000 端口,Kibana 运行于 5601 端口,而 Logstash 运行 5000 端口。 我们可以访问 Kibana 的端口地址 5601:

运行 Nodejs 应用导入模拟数据
我们接下来建立一个 Nodejs 的应用来模拟一些数据。首先,我们需要安装如下的包:
npm install kafkajs uuid randomstring random-mobile
我们在根目录下打入如下的命令:
npm init -y$ npm init -y
Wrote to /Users/liuxg/data/data-pipeline8/package.json:{"dependencies": {"kafkajs": "^2.2.4"},"name": "data-pipeline8","description": "This is a sample code showing how to realize the following data pipeline:","version": "1.0.0","main": "kafka_producer.js","devDependencies": {},"scripts": {"test": "echo \"Error: no test specified\" && exit 1"},"repository": {"type": "git","url": "git+https://github.com/liu-xiao-guo/data-pipeline8.git"},"keywords": [],"author": "","license": "ISC","bugs": {"url": "https://github.com/liu-xiao-guo/data-pipeline8/issues"},"homepage": "https://github.com/liu-xiao-guo/data-pipeline8#readme"
}
上述命令生成一个叫做 package.json 的文件。在以后安装的 packages,它也会自动添加到这个文件中。默认的设置显然不是我们想要的。我们需要对它做一些修改。
kafka_producer.js
// import { Kafka, logLevel } from "kafkajs";
const { Kafka } = require('kafkajs');
const logLevel = require("kafkajs");// import { v4 as uuidv4 } from "uuid";
const { v4: uuidv4 } = require('uuid');console.log(uuidv4());const kafka = new Kafka({clientId: "random-producer",brokers: ["localhost:9092"],connectionTimeout: 3000,
});var randomstring = require("randomstring");
var randomMobile = require("random-mobile");
const producer = kafka.producer({});
const topic = "kafka_logstash";const produce = async () => {await producer.connect();let i = 0;setInterval(async () => {var event = {};try {event = {globalId: uuidv4(),event: "USER-CREATED",data: {id: uuidv4(),firstName: randomstring.generate(8),lastName: randomstring.generate(6),country: "China",email: randomstring.generate(10) + "@gmail.com",phoneNumber: randomMobile(),city: "Hyderabad",createdAt: new Date(),},};await producer.send({topic,acks: 1,messages: [{value: JSON.stringify(event),},],});// if the message is written successfully, log it and increment `i`console.log("writes: ", event);i++;} catch (err) {console.error("could not write message " + err);}}, 5000);
};produce().catch(console.log)我们运行上面的 Nodejs 代码:
npm start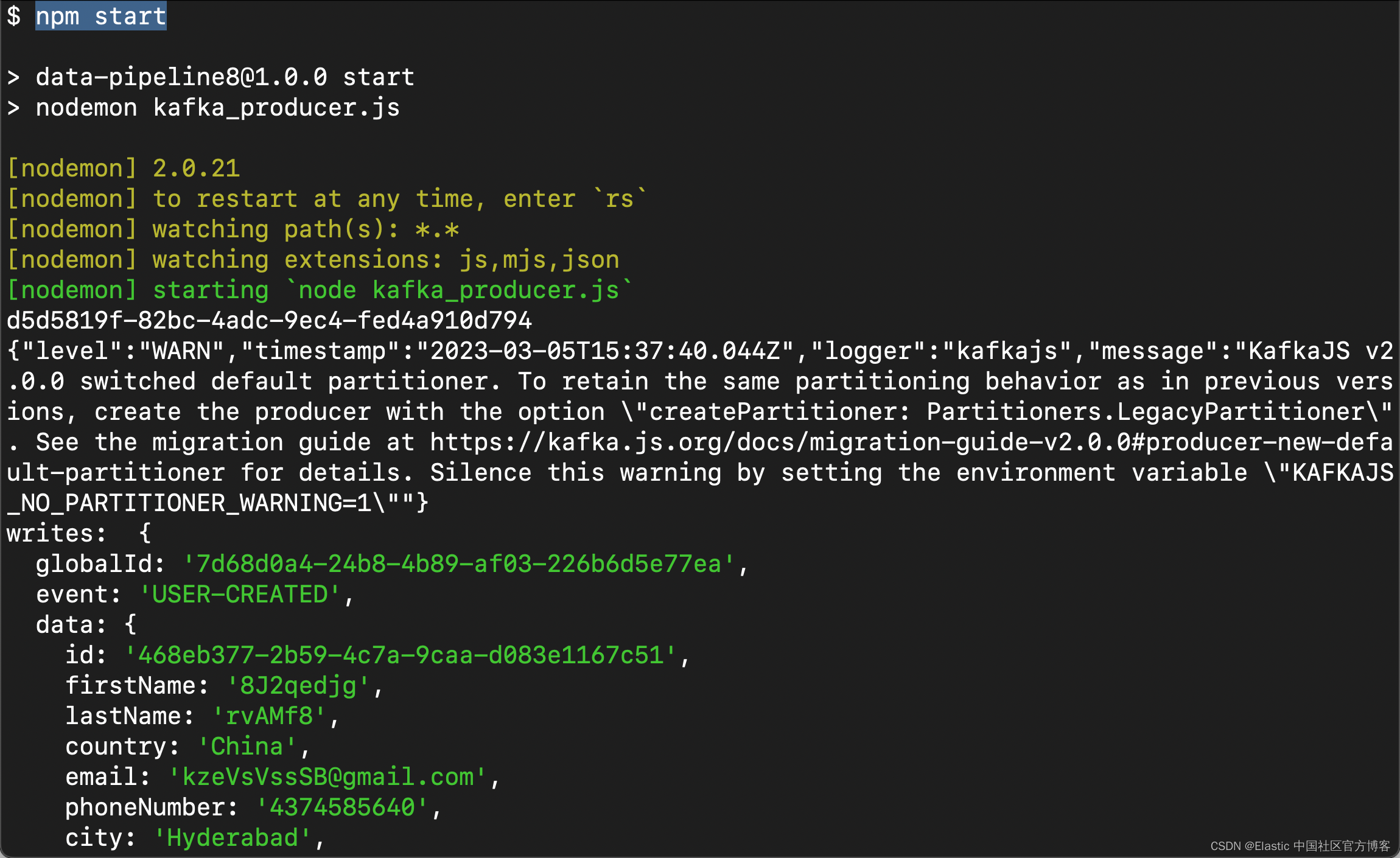
我们接下来在 Kibana 中来查看索引 kafka_logstash:
GET kafka_logstash/_count{"count": 103,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0}
}我们可以看到文档的数值在不断地增加。我们可以查看文档:
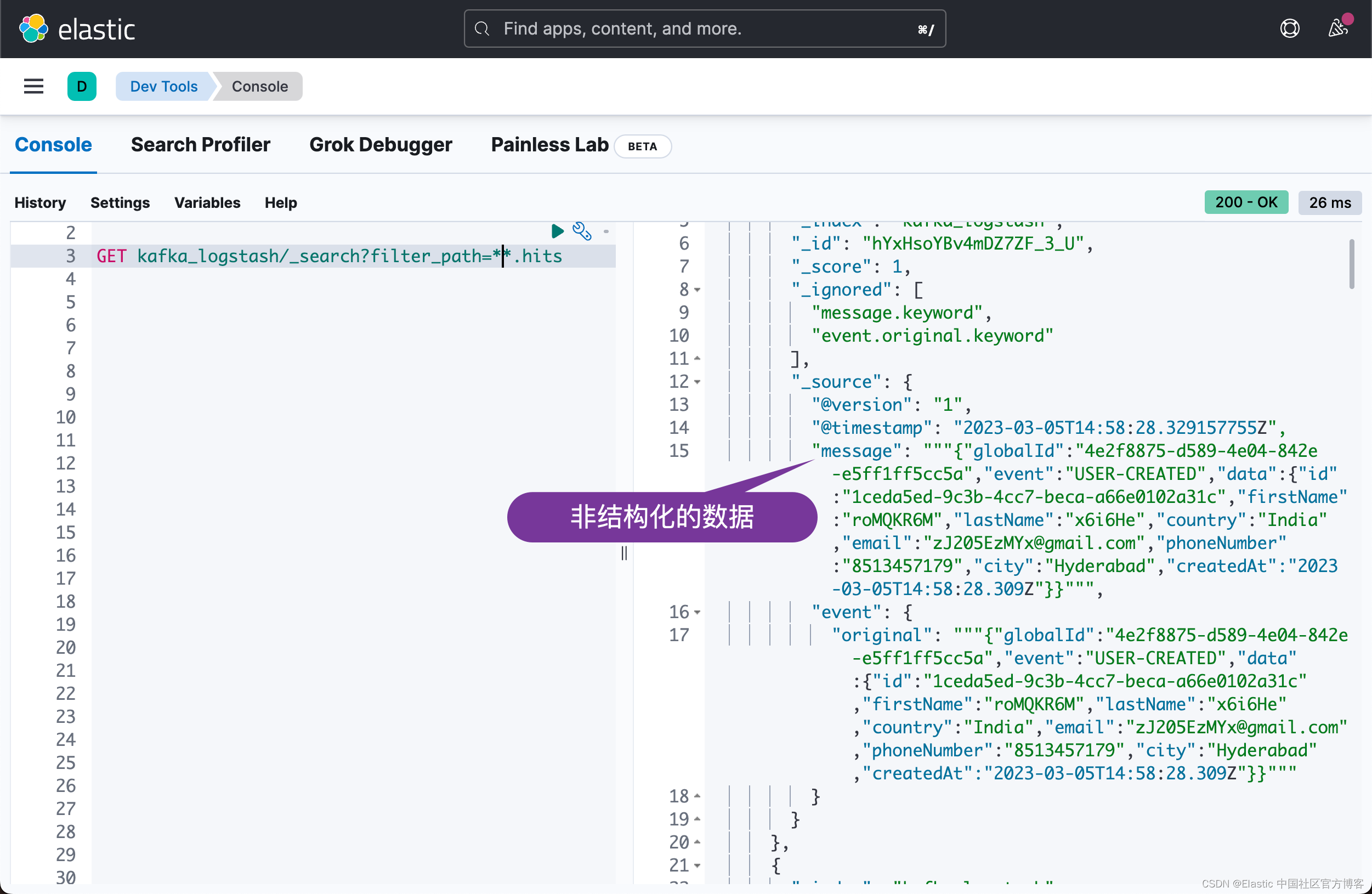
很显然我们收到了数据。从上面的结果中,我们可以看出来是一些非结构化的数据。我们可以针对 Logstash 的 pipeline 进行修改:
kafka-elastic.conf
input {kafka {bootstrap_servers => "192.168.0.3:9092"topics => ["kafka_logstash"]}
}filter {json {source => "message"}mutate {add_field => {"id" => "%{[data][id]}"}add_field => {"firstName" => "%{[data][firstName]}"}add_field => {"lastName" => "%{[data][lastName]}"}add_field => {"city" => "%{[data][city]}"}add_field => {"country" => "%{[data][country]}"}add_field => {"email" => "%{[data][email]}"}add_field => {"phoneNumber" => "%{[data][phoneNumber]}"}add_field => {"createdAt" => "%{[data][createdAt]}"}remove_field => ["data", "@version", "@timestamp", "message", "event", "globalId"]}
}output {elasticsearch {hosts => ["elasticsearch:9200"]index => "kafka_logstash"workers => 1}
}我们在 Kibana 中删除 kafka_logstash:
DELETE kafka_logstash我们停止运行 Nodejs 应用。我们把运行 Elastic Stack 的 docker-compose 关掉,并再次重新启动它:
docker-compose down
docker-compose up
我们再次运行 Nodejs 应用:

我们再次到 Kibana 中进行查看:
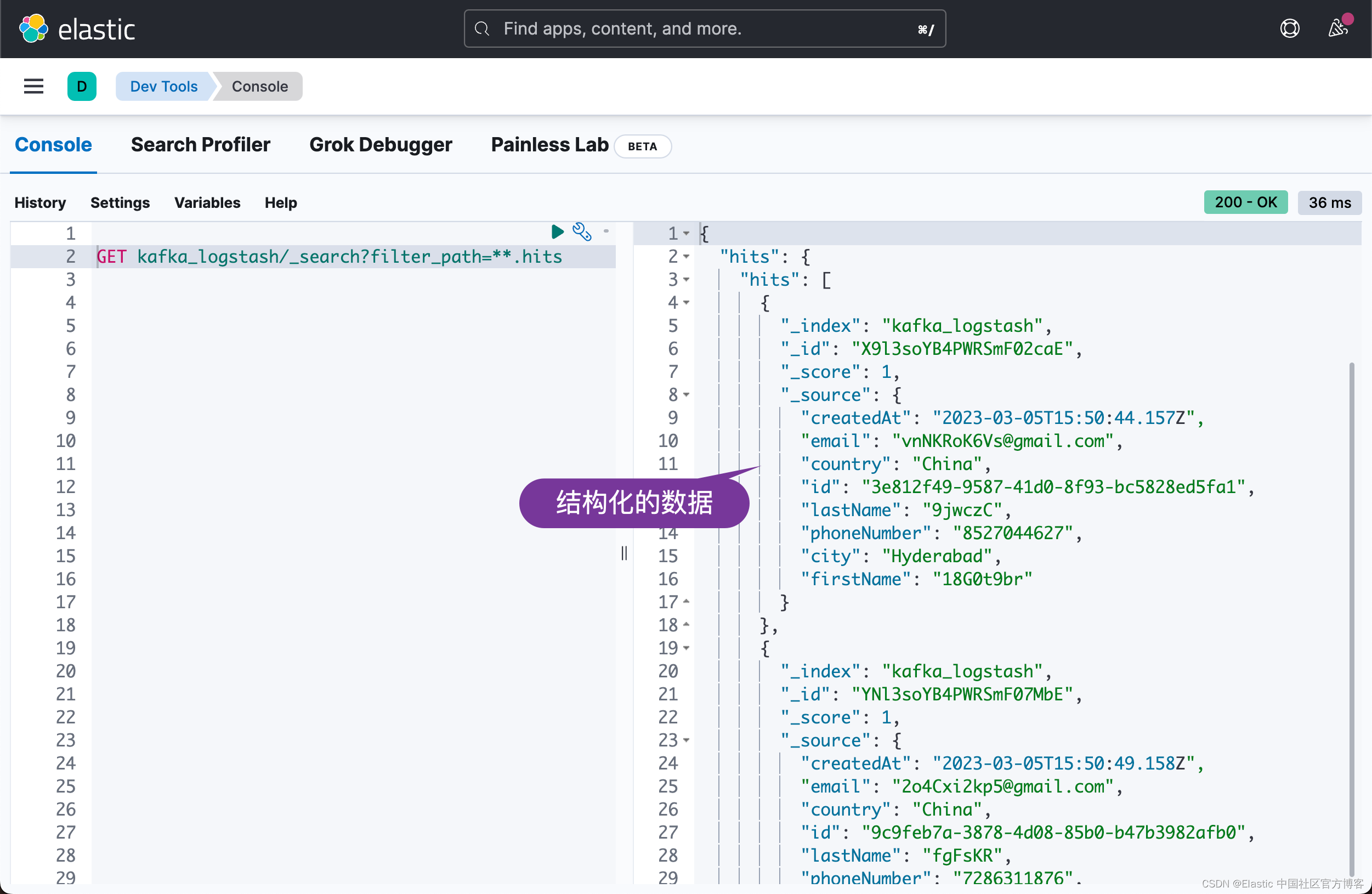
很显然,这次,我们看到结构化的输出文件。
相关文章:
Elasticsearch:使用 Logstash 构建从 Kafka 到 Elasticsearch 的管道 - Nodejs
在我之前的文章 “Elastic:使用 Kafka 部署 Elastic Stack”,我构建了从 Beats > Kafka > Logstash > Elasticsearch 的管道。在今天的文章中,我将描述从 Nodejs > Kafka > Logstash > Elasticsearch 这样的一个数据流。在…...

记录一次es的性能调优
文章目录es性能调优启用g1垃圾回收器es性能调优 成都的es集群经常出现告警,查看日志发现 [gc][11534155] overhead, spent [38.3s] collecting in the last [38.6s]这是 JVM 垃圾回收过程中的一条日志,表示在最近 38.6 秒内,JVM 进行了一次…...
内核性能评估测试及具体修改操作步骤记录
步骤记录前言一、查看环境配置二、LRU缓存空间调整三、进程扫描时间间隔四、与其他内核对比的工作负载测试(另一个内核的编译)总结前言 记录的相关操作有:查看服务器硬件环境、LRU缓存大小修改、内核命名、内核编译以及进程执行周期的设置。…...

S7-200smart远程无线模拟量信号采集案例
本参考方案使用西门子PLCS7-200SMART 结合无线通讯终端DTD434MC和DTD433F实现 PLC对远端设备模拟量的远程无线输入输出查询控制。所使用到的设备:西门子S7-200smartPLC无线数据终端DTD434MC无线模拟量信号测控终端DTD433F所使用的协议:ModbusRTU协议方案…...

Blender Python材质处理入门
本文介绍在 Blender 中如何使用 Python API 获取材质及其属性。 推荐:用 NSDT场景设计器 快速搭建3D场景。 1、如何获取材质 方法1、 获取当前激活的材质 激活材质是当前在材质槽中选择的材料。 如果你选择一个面,则活动材料将更改为分配给选定面的材质…...
ChatGPT后劲很大,问题也是
ChatGPT亮相即封神,最初的访客是程序员、工程师、AI从业者、投资人,最后是无数懵懂又好奇的普通人:ChatGPT是什么?自己会被ChatGPT取代吗?看待ChatGPT的立场也是两个极端: 快乐,是因为ChatGPT太…...

世界那么大,你哪都别去了,来我带你了解CSS3 (二)
文章目录❤️🔥CSS文档流❤️🔥CSS浮动❤️🔥CSS定位❤️🔥CSS媒体查询❤️🔥CSS文档流 文档流是文档中可显示对象在排列时所占用的位置/空间。 例如:块元素自上而下摆放,内…...

2023年再不会Redis,就要被淘汰了
目录专栏导读一、同样是缓存,用map不行吗?二、Redis为什么是单线程的?三、Redis真的是单线程的吗?四、Redis优缺点1、优点2、缺点五、Redis常见业务场景六、Redis常见数据类型1、String2、List3、Hash4、Set5、Zset6、BitMap7、Bi…...

Java SPI机制了解与应用
1. 了解SPI机制 我们在平时学习和工作中总是会听到Java SPI机制,特别是使用第三方框架的时候,那么什么是SP机制呢?SPI 全称 Service Provider Interface,是 Java 提供的一套用来被第三方实现或者扩展的接口,它可以用来…...

vue实现输入框中输完后光标自动跳到下一个输入框中
前言 最近接到这么一个需求,做一个安全码的输入框,限制为6位数,但是每一个写入的值都是一个输入框,共计6个输入框,当前输入框写入值后,光标自动跳到下一个输入框中,删除当前输入框写入的值后再自…...

如何构建 C 语言编译环境?
C语言是一种通用的编程语言,它是由Dennis Ritchie于20世纪70年代初在贝尔实验室开发的。C语言的设计目标是提供一种结构化、高效、可移植的编程语言,以支持系统编程和应用程序开发。C语言广泛用于开发操作系统、网络设备、游戏、嵌入式系统、桌面应用程序…...
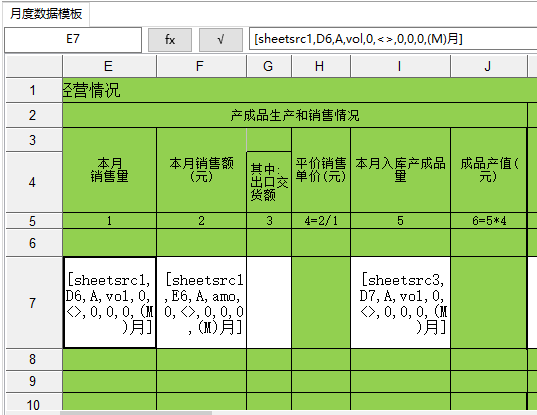
电子台账:模板制作之一——列过滤(水平过滤)
1 简介列过滤即水平过滤。一般情况下,企业数据源文件中有很多数据列,其中大部分数据列中的数据对电子台账来说是没有用的。列过滤就是确定企业数据文件的哪几列有用,以及有用的列分别对应到台账(模板)的哪一列。列过滤…...

【java】Java连接mysql数据库及mysql驱动jar包下载和使用
文章目录JDBCJDBC本质:JDBC作用:跟数据库建立连接发送 SQL 语句返回处理结果操作流程和具体的连接步骤如下:操作步骤:需要导入驱动jar包 mysql-connector-java-8.0.22.jar注册驱动获取数据库连接对象 Connection定义sql获取执行sq…...

Mysql八股文
Mysql八股文 数据库的三范式是什么 第一范式:列不可再分第二范式:行可以唯一区分,主键约束第三范式:表的非主属性不能依赖与 其他表的非主属性 外键约束且三大范式是一级一级依赖的,第二范式建立在第一范式上&#x…...

解析Android ANR问题
一、ANR介绍 ANR 由消息处理机制保证,Android 在系统层实现了一套精密的机制来发现 ANR,核心原理是消息调度和超时处理。ANR 机制主体实现在系统层,所有与 ANR 相关的消息,都会经过系统进程system_server调度,具体是ActivityManagerService服务,然后派发到应用进程完成对…...

ESP32设备驱动-MicroSD Card驱动
MicroSD Card驱动 1、SDCard介绍 SD卡是Secure Digital Card卡的简称,直译成汉语就是“安全数字卡”,是由日本松下公司、东芝公司和美国SANDISK公司共同开发研制的全新的存储卡产品。SD存储卡是一个完全开放的标准(系统),多用于MP3、数码摄像机、数码相机、电子图书、AV器…...

XC7K160T-1FBG484I、XC7A100T-2CSG324I FPGA可编程门阵列 PDF规格书
1、XC7K160T-1FBG484I说明:Kintex-7 FPGA有-3、-2、-1、-1L和-2L速度等级,其中-3具有最高的性能。-2L器件被筛选为较低的最大静态功率,并且可以在较低的核心电压下运行,以获得比-2器件更低的动态功率。-2L工业(I)温度器件仅在VCCI…...
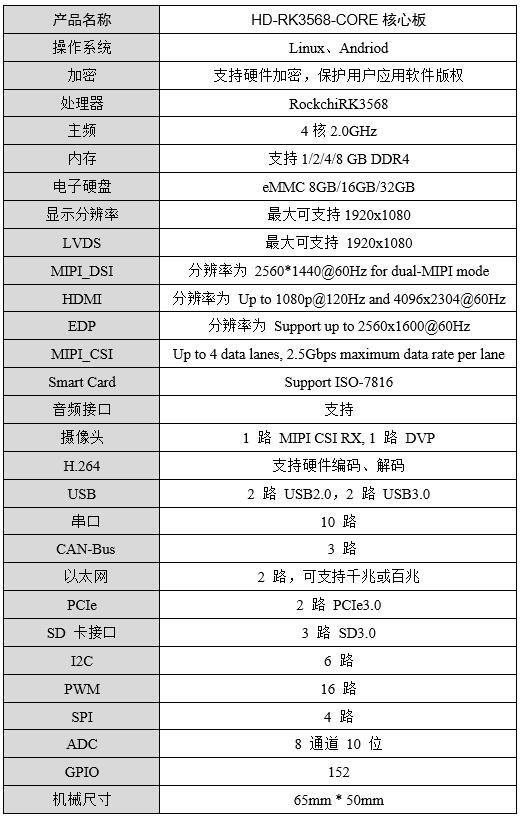
基于HD-RK3568-IO评估板的读写速度测试报告
1. 测试对象HD-RK3568-IOT 底板基于HD-RK3568-CORE工业级核心板设计(双网口、双CAN、5路串口),接口丰富,适用于工业现场应用需求,亦方便用户评估核心板及CPU的性能。适用于工业自动化控制、人机界面、中小型医疗分析器…...

jconsole远程linux下的tomcat
修改Tomcat的配置 进去 Tomcat 安装目录下的 bin 目录,编辑 catalina.sh vi catalina.sh定位到 ----- Execute The Requested Command ----------------------------------------- vi 编辑模式下,点击 Esc,输入 / ,然后粘贴 -…...
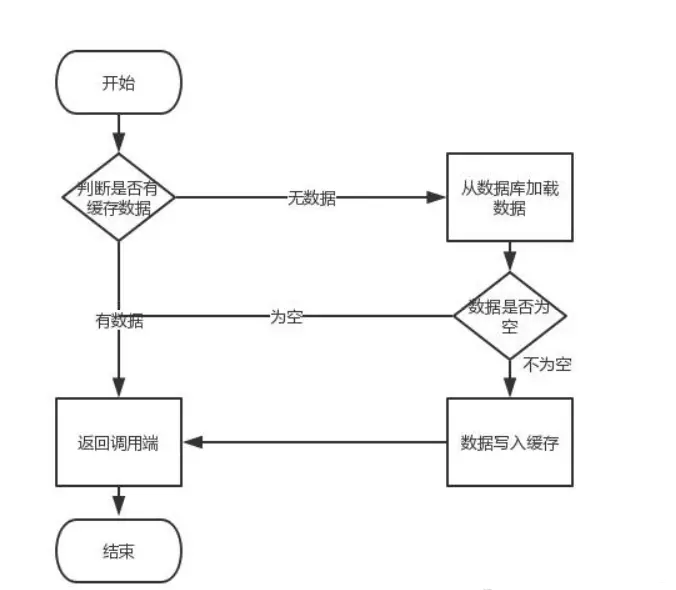
Redis和MySQL如何保持数据一致性?
在高并发的场景下,大量的请求直接访问MySQL很容易造成性能问题。所以,我们都会用Redis来做数据的缓存,削减对数据库的请求。但是,MySQL和Redis是两种不同的数据库,如何保证不同数据库之间数据的一致性就非常关键了。1.…...

SpringBoot项目快速集成Taotoken多模型API的完整教程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 SpringBoot项目快速集成Taotoken多模型API的完整教程 对于使用SpringBoot框架的Java开发者而言,接入不同的大模型服务通…...

Coding爆发打破「AI泡沫论」,MiniMax能否卡位下一个Google?
【Coding爆发打破「AI泡沫论」】 Coding的爆发,彻底断绝了「AI泡沫论」,这已成为共识。阿里财报显示MaaS ARR超过80亿元,年底还有望再涨三倍以上,意味着只有投入没有回报的周期已过去,能开始盈利,大小玩家都…...

EB Garamond 12:免费复古字体完整指南,如何优雅应用于网页和印刷设计
EB Garamond 12:免费复古字体完整指南,如何优雅应用于网页和印刷设计 【免费下载链接】EBGaramond12 项目地址: https://gitcode.com/gh_mirrors/eb/EBGaramond12 EB Garamond 12是一款基于16世纪经典设计的开源复古字体,为设计师和开…...
的模板化部署)
统信UOS系统管理员必看:一招搞定用户配置文件(.config/autostart)的模板化部署
统信UOS系统配置模板化实战:从屏保设置到全局用户环境部署 在大型企业或教育机构的桌面环境管理中,统信UOS作为国产操作系统的代表,其标准化部署能力直接影响运维效率。当我们在模板用户中精心配置了各项参数——从屏幕保护时间到电源管理策略…...

UE5保姆级教程:用Electra Player插件在场景里放视频,从导入MP4到带声音播放
UE5实战指南:Electra Player插件实现场景视频播放全流程解析 在虚幻引擎5的沉浸式场景中,视频播放功能已成为增强环境叙事的关键技术。无论是商场里的动态广告屏、科幻场景中的全息投影,还是角色手持设备的交互界面,流畅的视频播放…...

3分钟搞定容器镜像加速:public-image-mirror 终极实战指南
3分钟搞定容器镜像加速:public-image-mirror 终极实战指南 【免费下载链接】public-image-mirror 很多镜像都在国外。比如 gcr 。国内下载很慢,需要加速。致力于提供连接全世界的稳定可靠安全的容器镜像服务。 项目地址: https://gitcode.com/GitHub_T…...

多模态大模型应用开发利器:xBrain工具箱核心解析与实战
1. 项目概述:一个面向多模态大模型的开源工具箱 最近在折腾大模型应用开发,特别是涉及到图像、文本、音频等多模态任务时,常常感到工具链的割裂。文本生成有成熟的框架,视觉任务又有另一套生态,想把它们高效地整合到一…...

如何用G-Helper轻松实现华硕笔记本CPU降压:实用调优指南
如何用G-Helper轻松实现华硕笔记本CPU降压:实用调优指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, …...

基于Tauri与语义网络的本地优先知识管理工具Engram技术解析
1. 项目概述:从“记忆宫殿”到数字思维引擎最近在折腾一个叫Engram的开源项目,它来自 GitHub 上的 spectra-g。初看这个名字,你可能会联想到“记忆痕迹”或者“思维印记”,没错,它的核心目标就是成为你个人数字思维的“…...

C语言入门指南:从核心概念到实战项目,掌握指针与内存管理
1. 项目概述:一份写给新手的C语言全景地图“长文预警,比较全面的C语言入门笔记!”——这个标题背后,是一位老码农(比如我)在某个深夜,面对无数初学者在C语言入门路上反复踩坑、四处寻找零散资料…...