Python基础快速入门
Python基础快速入门
前置知识
Python
Python是一种广泛使用的高级编程语言,以其易于学习和使用的语法而闻名。以下是Python的一些主要特点:
-
高级语言:Python是一种高级语言,这意味着它提供了较高层次的抽象,使编程更容易理解和实现。它管理了许多底层细节,如内存管理。
-
解释型语言:与编译型语言不同,Python代码在运行时被解释器逐行解释和执行。这使得快速开发和测试成为可能,因为不需要编译过程。
-
动态类型:Python是动态类型的,这意味着变量在赋值时自动确定其数据类型,而无需显式声明。
-
可读性:Python的设计哲学强调代码的可读性。它的语法简洁,结构清晰,使得Python代码更容易阅读和维护。
-
广泛的标准库:Python拥有一个庞大的标准库,提供了许多用于处理文件、网络通信、文本处理和许多其他任务的模块。
-
跨平台兼容性:Python代码可以在多种操作系统上运行,包括Windows、macOS和Linux,通常无需修改代码。
-
多范式编程:Python支持多种编程范式,包括面向对象编程、命令式编程、函数式编程和过程式编程。
-
广泛的应用:Python在许多领域都有应用,包括Web开发、数据科学、人工智能、科学计算、自动化脚本等。
-
强大的社区支持:Python有一个非常活跃的社区,提供大量的文档、库、框架和工具。
Python常用于学习编程的基础,同时也是许多专业开发者和数据科学家的首选工具。由于其多功能性和易用性,Python已成为当今最受欢迎和广泛使用的编程语言之一。
Python解释器
Python解释器是一个软件,用于执行Python代码。它是Python语言的核心,负责读取、解析、执行编写的Python代码,并将其转换为计算机可以理解的低级机器语言。以下是对Python解释器的详细解释:
-
解释执行:Python解释器是一种“解释型”语言执行环境。这意味着它会逐行读取源代码,解释这些代码,然后执行。这与“编译型”语言不同,编译型语言需要在执行前将整个源代码转换成机器代码。
-
交互式解释器:Python提供了一个交互式解释器,通常称为Python shell。在这个环境中,你可以输入Python代码,并立即看到代码执行的结果。这对于学习、实验和快速测试代码片段非常有用。
-
脚本执行:除了交互式执行外,Python解释器还可以执行存储在文件中的Python脚本。这些脚本文件通常以
.py为扩展名。 -
字节码编译:虽然Python通常被认为是解释型语言,但实际上,在执行之前,它会将源代码编译成称为字节码的中间形式。这个字节码然后由Python虚拟机(PVM)执行。这个过程提高了执行效率,但不像完全编译的语言那样快。
-
动态类型:Python解释器在运行时动态地推断变量的类型,而不是在编译时。这为编程提供了灵活性,但也意味着类型错误可能只在实际执行相关代码时才会被发现。
-
内存管理:Python解释器管理所有内存分配和垃圾回收。这意味着程序员不需要担心内存管理的细节,尽管这可能会导致额外的性能开销。
-
内置函数和类型:Python解释器提供了一组内置的函数和数据类型,使得常见任务(如数学运算、字符串处理等)更加容易。
-
标准库:除了基本功能外,Python解释器还附带了一个广泛的标准库,提供了额外的模块和功能,用于各种任务,如文件I/O、网络编程、多线程等。
-
扩展性:Python解释器可以使用C或C++(以及其他语言)编写的扩展来扩展。这允许执行速度更快的代码,或者是利用那些已经用其他语言编写好的库。
-
多种实现:虽然最广泛使用的是官方的CPython解释器,但还有其他实现,如PyPy(一个以速度为主要目标的实现)、Jython(可以运行在Java平台上的Python实现)和IronPython(集成在.NET平台上的实现)。
Python解释器因其灵活性和易用性而广受欢迎,它是Python编程语言能够在多种领域成功应用的关键因素之一。
代码编辑器
代码编辑器是一种专门用于编写和编辑计算机程序代码的软件。它为编程提供了一个便捷、高效的环境,通常包括多种功能来简化和加速软件开发过程。以下是代码编辑器的一些详细特点和功能:
-
语法高亮:大多数代码编辑器提供语法高亮功能,可以根据编程语言的语法规则给不同的代码元素(如变量、函数、关键字)上不同的颜色。这提高了代码的可读性,帮助程序员快速识别代码结构和潜在错误。
-
代码自动完成:这个功能能够在编程时自动完成代码结构或建议变量名、函数名等,从而加速编程过程并减少打字错误。
-
错误检查和调试:许多现代的代码编辑器内置了错误检测和调试工具,能够实时显示语法错误或逻辑错误,甚至提供调试功能,如设置断点、检查变量值等。
-
代码折叠和大纲视图:代码折叠允许临时隐藏部分代码,简化视图,便于专注于当前工作的代码段。大纲视图则提供了代码结构的概览,方便快速导航到不同部分。
-
多语言支持:大多数代码编辑器支持多种编程语言,提供不同语言的语法高亮、自动完成和错误检测等功能。
-
版本控制集成:许多编辑器集成了Git等版本控制系统,方便开发者进行代码版本管理和协作。
-
可定制和扩展:用户通常可以根据自己的需要定制编辑器的外观(如主题、字体大小)和行为(如快捷键设置)。此外,通过安装插件或扩展,可以增加额外的功能,如代码格式化、数据库管理等。
-
文件和项目管理:代码编辑器通常提供文件浏览器和项目管理工具,帮助开发者组织和管理项目文件。
-
集成开发环境(IDE):某些代码编辑器是集成开发环境的一部分,提供了更全面的开发工具,包括编译器、调试器和图形界面设计等。
-
跨平台兼容性:许多代码编辑器可以在不同的操作系统上运行,如Windows、macOS和Linux。
代码编辑器是程序员日常工作的基础工具,它们的高级功能和定制选项可以显著提高编程效率和舒适度。从简单的文本编辑器到功能丰富的IDE,它们在软件开发的每个阶段都发挥着关键作用。
IDE集成开发环境
集成开发环境(IDE,Integrated Development Environment)是一种提供全面软件开发功能的应用程序。它通常集成了编写、调试、测试和部署软件所需的各种工具。IDE的主要目的是提高开发者的生产力,通过提供一体化的开发工具集来简化编程过程。以下是IDE的一些主要特点和功能:
-
代码编辑器:IDE包含一个高级的代码编辑器,提供语法高亮、自动代码完成、智能缩进等功能,以提高代码的可读性和编写效率。
-
编译器或解释器:大多数IDE包含一个编译器或解释器,可以将源代码转换为可执行程序。这些编译器通常是针对特定编程语言的,例如Java、C++或Python。
-
调试工具:IDE提供了调试工具,使开发者能够逐步执行代码,检查和修改变量值,设置断点等,从而帮助发现和修复程序中的错误。
-
图形用户界面(GUI)构建器:许多IDE提供了图形界面构建器,允许开发者通过拖放组件来设计用户界面,而无需手动编写所有界面代码。
-
代码库管理:IDE通常与版本控制系统(如Git)集成,提供代码提交、分支管理、合并冲突解决等功能,方便团队协作和代码版本管理。
-
构建自动化工具:IDE提供了构建自动化工具,可以自动完成编译、链接、打包等步骤,简化了从源代码到可执行程序的转换过程。
-
测试工具:集成的测试工具可以帮助开发者编写和执行代码的单元测试、集成测试等,确保软件的质量和稳定性。
-
文档和帮助:IDE通常包含详细的文档、API参考和编程指南,帮助开发者理解和使用不同的编程语言和库。
-
插件和扩展:许多IDE支持插件或扩展,允许开发者根据需要添加新的功能或集成第三方工具和服务。
-
多语言和多平台支持:现代IDE通常支持多种编程语言,并能在多个操作系统上运行,如Windows、macOS和Linux。
IDE的核心优势在于它提供了一个集成的工作环境,将所有必要的开发工具组合在一起。这不仅减少了开发者在不同工具之间切换的时间,而且还通过提供智能提示、代码自动完成和可视化调试等功能来增强开发体验。无论是针对个人开发者还是大型开发团队,IDE都是提高开发效率、简化复杂软件项目开发流程的关键工具。
虚拟环境venv
在Python中,虚拟环境是一个独立的目录树,可以在其中安装Python包,而不会影响全局Python环境(即系统级别的Python安装)。这个功能由 venv 模块提供,它是Python 3.3及更高版本的标准库的一部分。以下是虚拟环境(venv)的详细解释:
创建原因
- 隔离依赖:不同的项目可能需要不同版本的库。虚拟环境使得每个项目都可以有自己独立的库,而不会相互冲突。
- 权限问题:在没有管理员权限的系统上安装全局库可能会遇到问题。使用虚拟环境,用户可以在自己的空间内安装包。
- 干净的环境:为新项目创建一个干净的环境,不会带有不必要的库。
组件和结构
- bin/Scripts:这个目录包含了虚拟环境的可执行文件,例如Python解释器和pip工具。它还包括一个激活脚本,用于将虚拟环境的可执行文件路径添加到系统的PATH变量中。
- lib/Lib:这里存放虚拟环境独有的Python库。
- include:包含编译Python包所需的C语言头文件。
- pyvenv.cfg:这是一个配置文件,其中包含了虚拟环境的设置信息,例如它指向的Python解释器。
使用流程
- 创建:使用
python -m venv /path/to/new/virtual/environment创建新的虚拟环境。 - 激活:
- Windows:
\path\to\env\Scripts\activate.bat - Unix 或 MacOS:
source /path/to/env/bin/activate
- Windows:
- 使用:激活后,你可以使用
pip安装包,这些包将只安装在虚拟环境中。 - 退出:输入
deactivate命令可以退出虚拟环境,回到全局Python环境。
最佳实践
- 版本控制:将
requirements.txt加入版本控制,而不是整个venv文件夹。 - 项目隔离:为每个项目创建单独的虚拟环境。
- 自动化:使用自动化脚本来创建和管理虚拟环境,确保环境的一致性。
虚拟环境在Python开发中非常有用,特别是在处理多个项目或与他人协作时。它们帮助确保项目的可移植性,因为依赖关系可以通过简单的 requirements.txt 文件来管理和复制。

这张图显示的是一个典型的Python虚拟环境(venv)的文件夹结构。在这个结构中,可以看到以下几个元素:
-
venv:这是虚拟环境的顶层文件夹,通常以
venv命名,表明这是一个虚拟环境目录。 -
Lib:这个子文件夹包含了虚拟环境安装的所有Python库。当你在虚拟环境中使用
pip install安装包时,这些包都会被放在这里,与系统全局Python环境隔离开。 -
Scripts:在Windows系统中,这个子文件夹包含了一些脚本文件,用于激活虚拟环境、运行Python解释器以及启动其他与Python相关的工具。在Unix或Mac系统中,这个文件夹被命名为
bin。 -
.gitignore:这是一个Git版本控制系统的配置文件,用于指定哪些文件或文件夹应该被Git忽略,不加入到版本控制中。通常,虚拟环境文件夹
venv会被添加到.gitignore中,因为每个开发者通常会在本地创建和管理自己的虚拟环境。 -
pyvenv.cfg:这是虚拟环境的配置文件,包含了虚拟环境的相关设置,比如使用的Python解释器的路径等。
这张图展示的是虚拟环境的基本结构,该环境通常用于隔离项目依赖,确保开发环境的一致性。虚拟环境是Python开发的最佳实践之一,能够避免不同项目之间的包冲突和版本问题。
基础语法
在Python中,print 函数是用来输出信息到控制台的内置函数。下面是 print 函数的基本语法和一些注意事项:
基本语法:
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)
*objects:表示可以打印多个对象,这些对象将按给定的顺序转换为字符串形式并输出。对象之间默认用空格分隔。sep:是分隔符参数,用于指定对象之间的分隔符,默认是空格。end:是结束参数,指定打印完所有对象后紧跟的字符串,默认是换行符\n。file:是输出流参数,指定print函数的输出目标,默认是标准输出流sys.stdout,也可以指定为文件对象以将输出重定向到文件。flush:是刷新参数,表示是否强制刷新输出流,默认为False。如果为True,则会确保所有输出都直接写入到目标文件,而不会停留在任何缓冲区中。
注意事项:
-
对象转换:
print函数会将传递给它的对象转换为字符串表示。如果对象是一个字符串,它将直接被输出;如果不是,Python会尝试调用对象的__str__()或__repr__()方法来获取可打印的字符串表示。 -
默认换行:默认情况下,每次调用
print后都会在末尾添加一个换行符,使得连续的print调用输出在不同的行。如果不希望在输出后加换行符,可以将end参数设置为空字符串或其他字符串。 -
编码问题:在打印某些特殊字符或在不同的操作系统环境下时,可能会遇到编码问题。确保控制台或文件的编码设置可以正确处理字符串的编码。
-
性能考虑:频繁的
print操作可能会影响程序性能,特别是在循环中或将输出重定向到文件时。在性能敏感的应用程序中,可能需要考虑限制输出或使用其他日志机制。 -
线程安全:在多线程环境中,多个线程可能会尝试同时打印,这可能会导致输出混乱。在这种情况下,可能需要使用锁来同步访问到
print函数。 -
文件输出:使用
file参数将输出重定向到文件时,确保文件以正确的模式(通常是文本模式't'或二进制模式'b')打开。如果文件对象的写操作不是原子的,也应考虑线程安全问题。 -
缓冲区刷新:在某些情况下(比如,写入到文件时),输出可能会被缓存。如果需要立即看到输出,可以设置
flush=True。 -
错误处理:如果
print操作可能引发异常(如在写入文件时),确保合理处理这些异常。
示例:
print("Hello, World!") # 打印字符串
print(100) # 打印一个整数
print(3.14) # 打印一个浮点数
print("A", "B", "C", sep='-', end='.') # 打印 "A-B-C."
print("Next line", file=sys.stderr) # 将输出重定向到标准错误
with open('output.txt', 'w') as f:print("Hello, File!", file=f) # 将输出写入到文件
使用print函数时,最好是清楚知道自己想要输出什么,并且根据需要调整sep、end、file和flush参数。
字符串拼接
在Python中,字符串拼接是将多个字符串连接成一个单一字符串的过程。这个操作在处理文本时非常常见和有用。下面是Python中进行字符串拼接的几种常见方法:
使用加号 +
这是最直接的拼接方法,简单地将两个字符串用加号 + 连接起来。
str1 = "Hello"
str2 = "World"
result = str1 + " " + str2 # 结果是 "Hello World"
使用字符串格式化
字符串格式化提供了更为灵活的方式来拼接字符串,尤其是当涉及到将非字符串值插入到字符串中时。
- 传统的
%格式化:
name = "Alice"
greeting = "Hello, %s" % name # 结果是 "Hello, Alice"
str.format()方法:
name = "Alice"
greeting = "Hello, {}".format(name) # 结果是 "Hello, Alice"
- 格式化字符串字面量(也称为 f-strings,Python 3.6+):
name = "Alice"
greeting = f"Hello, {name}" # 结果是 "Hello, Alice"
使用 join() 方法
当你有一个字符串列表或元组,并且想要通过某个分隔符将它们拼接起来时,join() 方法非常有用。
words = ["Hello", "World"]
result = " ".join(words) # 结果是 "Hello World"
使用字符串的 += 操作
虽然这不是拼接大量字符串的高效方式,但它可以用于逐个构建最终字符串。
result = ""
for word in ["Hello", "World"]:result += word + " "
result = result.strip() # 移除尾部空格,结果是 "Hello World"
注意事项
- 性能:使用加号
+进行大量的字符串拼接可能在性能上不是最佳选择,尤其是在循环中,因为字符串是不可变的,这意味着每次拼接操作都会创建一个新的字符串。相比之下,join()方法通常会更高效,因为它只在最终的字符串创建时,才会把所有的元素组合在一起。 - 类型问题:在拼接字符串时,必须确保所有对象都是字符串类型。如果试图拼接非字符串类型,Python会抛出一个
TypeError。在这种情况下,需要使用str()将对象转换为字符串。 - 可读性:在选择拼接方法时,应考虑到代码的可读性。例如,f-strings不仅简洁,而且易于阅读和维护。
字符串拼接是Python编程中常用的一个特性,理解不同方法及其适用场景对编写清晰、有效的代码至关重要。
单双引号转义
在Python中,单引号(')和双引号(")被用于定义字符串。当你需要在字符串中包含这些引号时,就需要使用转义字符(\)来避免语法错误。转义字符告诉Python解释器,紧随其后的字符应该被视为字符串的一部分,而不是字符串的结束或其他特殊意义。以下是单双引号转义的详细解释:
单引号转义
如果你的字符串是由单引号界定的,那么在字符串中包含一个单引号时需要使用反斜杠来转义:
sentence = 'It\'s a beautiful day.'
print(sentence) # 输出: It's a beautiful day.
在这个例子中,\' 允许单引号在由单引号包围的字符串中被包含。
双引号转义
同样地,如果你的字符串是由双引号界定的,那么在字符串中包含一个双引号时需要用反斜杠来转义:
sentence = "He said, \"Hello, World!\""
print(sentence) # 输出: He said, "Hello, World!"
这里,\" 允许双引号在由双引号包围的字符串中被包含。
不需要转义的情况
当你在双引号字符串中包含单引号时,或者在单引号字符串中包含双引号时,不需要转义:
sentence1 = "It's a beautiful day."
sentence2 = 'He said, "Hello, World!"'
print(sentence1) # 输出: It's a beautiful day.
print(sentence2) # 输出: He said, "Hello, World!"
这样做可以避免使用转义字符,使得字符串更容易阅读。
转义其他特殊字符
除了单双引号,还有其他特殊字符可以用转义字符来表示:
\n表示换行符\t表示制表符(Tab)\\表示字面量的反斜线\r表示回车符\b表示退格符\f表示换页符\u后跟Unicode码表示Unicode字符
原始字符串
Python也支持所谓的原始字符串,通过在字符串前加 r 来创建。原始字符串不会处理转义字符,而是将反斜杠视为普通字符:
path = r'C:\Users\Name\Folder'
print(path) # 输出: C:\Users\Name\Folder
在原始字符串中,即使是反斜杠也不需要转义。
注意事项
- 在原始字符串中,最后一个字符不能是单独的反斜杠,因为它会转义字符串结束的引号。
- 在处理路径或正则表达式时,原始字符串尤其有用,因为它们经常包含许多反斜杠。
- 如果在字符串中错误地使用了转义字符,可能会导致不易察觉的逻辑错误。
正确使用单双引号转义对于确保字符串的正确定义和预期行为是非常重要的。在编写涉及文本处理的Python代码时,这是一个基本而重要的技能。
换行
在Python中,换行是一个控制字符,用于标记字符串中文本行的结束和下一行的开始。默认情况下,在Python的字符串中使用\n表示换行。
使用换行符
当你在Python的字符串中包含\n时,无论是在单引号、双引号还是三引号定义的字符串中,它都会被解释为换行符。例如:
print("这是第一行\n这是第二行")
上面的代码会输出:
这是第一行
这是第二行
这里,\n使得"这是第一行"和"这是第二行"被打印在不同的行上。
打印时的换行
Python的print函数默认在字符串的末尾添加一个换行符,这意味着每次调用print函数,之后的输出将从新的一行开始:
print("第一行")
print("第二行")
这将输出:
第一行
第二行
控制换行
你可以通过修改print函数的end参数来控制换行行为。如果你不希望在字符串末尾添加换行符,可以这样做:
print("同一行的开始", end="")
print(", 同一行的结束")
这将输出:
同一行的开始, 同一行的结束
多行字符串
在Python中,使用三引号('''或""")可以创建多行字符串,这时候字符串中的换行会按照字面上的位置被保留:
multi_line_string = """第一行
第二行
第三行"""
print(multi_line_string)
上面的代码会按照你在三引号字符串中输入的格式来输出文本:
第一行
第二行
第三行
跨平台换行符
当处理跨平台文件操作时,换行符可能会引起问题,因为不同的操作系统使用不同的换行符标准。Unix/Linux使用\n,而Windows使用\r\n。Python的文件操作通常会抽象这些差异,但有时你可能需要手动处理它们,尤其是在读取或写入二进制文件时。
注意事项
- 在正则表达式中,
\n用来匹配换行符。 - 在处理文件时,建议总是以文本模式打开文件(默认情况),这样Python会自动地转换换行符。
- 当使用原始字符串(如
r"raw\nstring")时,字符串内的\n不会被当作换行符解释,而是作为普通字符的反斜线和字母n。
正确使用和理解换行符在处理文本文件、打印输出以及字符串操作时非常重要。
三引号跨行字符串
在Python中,三引号(triple quotes)— 可以是三个单引号 (''') 或三个双引号 (""") — 用于创建多行字符串。使用三引号定义的字符串可以在不使用转义序列(如 \n 表示换行)的情况下直接跨越多行。以下是三引号字符串的详细解释:
基本使用
三引号字符串可以跨越多行,包含所有的行间文字,包括换行符、空格和缩进。例如:
multi_line_string = """第一行
第二行
第三行"""
print(multi_line_string)
输出将是:
第一行
第二行
第三行
在这个例子中,字符串包含两个换行符,每个换行符分隔字符串中的文本行。
保持格式
三引号字符串保留了文本的格式,包括空格和缩进,这在编写格式化文本或长字符串时非常有用。例如:
poem = '''《静夜思》
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。'''
print(poem)
这将完整地保持原有的格式,包括每行前的缩进和换行。
作为文档字符串(docstrings)
在Python中,三引号字符串通常被用作模块、函数、类和方法的文档字符串(docstrings)。文档字符串是一种特殊的注释,用于说明代码的功能。例如:
def my_function():"""这是一个函数的文档字符串(docstring)。这里可以解释函数的作用、参数和返回值。"""pass
通过调用 help(my_function) 可以访问这个文档字符串。
用于字符串的操作
三引号字符串可以像常规字符串一样操作,包括连接、复制和使用字符串方法。例如:
html_content = """<html>
<head>
<title>我的网页</title>
</head>
<body>
<p>欢迎来到我的网页。</p>
</body>
</html>"""# 字符串可以使用标准的字符串方法
print(html_content.upper())
注意事项
- 虽然三引号字符串对于保持文本格式很有用,但在字符串的开头和结尾处的缩进会被包含在字符串中。如果你不想在字符串中包含这些缩进,需要小心地处理这些空白。
- 在使用三引号字符串作为文档字符串时,通常遵循PEP 257的约定,即在字符串的开始和结束部分不添加空白行。
总的来说,Python中的三引号字符串提供了一种方便的方式来处理多行和格式化文本,同时也是编写文档字符串的标准方式。
变量
在Python中,变量是用于存储数据值的标识符。变量在编程中非常重要,因为它们允许程序处理动态数据,同时也增强了代码的可读性和可维护性。以下是Python中变量使用方法的详细解释以及一些注意事项:
使用方法
-
声明和初始化:在Python中,你不需要显式声明变量的类型。当你赋值时,变量就被声明了。
x = 5 # x 是一个整数 name = "Alice" # name 是一个字符串 -
变量命名:
- 变量名可以包含字母、数字和下划线。
- 变量名必须以字母或下划线开头。
- 变量名是区分大小写的(例如,
myVar和myvar是两个不同的变量)。
-
动态类型:Python是动态类型语言,这意味着同一个变量可以重新赋值为不同类型的数据。
x = 4 # x 是一个整数 x = "Sally" # 现在 x 是一个字符串 -
多变量赋值:Python允许你在一行中为多个变量赋值。
a, b, c = 5, 3.2, "Hello" -
链式赋值:用相同的值初始化多个变量。
a = b = c = 5
注意事项
-
变量命名规范:
- 使用有意义的变量名,以提高代码的可读性。
- 遵守 PEP 8 的命名约定,例如使用小写字母和下划线分隔单词(
my_variable)。
-
不要覆盖内置函数:避免使用Python内置函数或关键字作为变量名(如
list,str)。 -
全局变量和局部变量:
- 在函数外定义的变量是全局变量,可在整个程序中访问。
- 在函数内定义的变量是局部变量,只能在函数内访问。
- 使用
global关键字可以在函数内修改全局变量。
-
不声明类型:不需要(也不能)声明变量的数据类型,Python会在运行时自动推断。
-
内存管理:Python自动管理变量的内存分配和回收。
-
常量:Python没有内置的常量类型,但约定以全部大写字母命名来表示常量(如
PI = 3.14)。 -
命名冲突:当局部变量与全局变量同名时,局部变量会在其作用域内覆盖全局变量。
-
删除变量:使用
del语句来删除变量,这会从内存中移除变量。
示例
def my_function():global xx = "fantastic"my_function()
print("Python is " + x) # Python is fantastic
在实际编程过程中,正确和高效地使用变量对于编写可读和可维护的代码至关重要。遵循良好的命名约定和代码风格,以及理解变量作用域和生命周期,是每个Python程序员必须掌握的基础。
命名规则
在Python中,变量命名是遵循一定规则和约定的。正确地命名变量不仅有助于避免语法错误,还可以使你的代码更易于阅读和维护。以下是Python中变量命名的主要规则和最佳实践:
基本规则
-
字符类型:变量名可以包含字母、数字和下划线(
_)。 -
开头字符:变量名必须以字母或下划线开头。它不能以数字开头。
-
区分大小写:Python中的变量名是区分大小写的。例如,
myvariable、myVariable和MyVariable会被视为不同的变量。 -
避免关键字:不能使用Python的保留关键字作为变量名。这些关键字有特殊的语法意义,例如:
if、for、while、class、def、return等。 -
长度限制:理论上,变量名长度没有限制,但遵循清晰简洁的原则总是好的。
命名约定
-
小写字母:一般情况下,变量名应全部使用小写字母。
-
下划线分隔:如果变量名由多个单词组成,应使用下划线来分隔这些单词,例如:
my_variable。 -
避免使用单个字符:尽管单个字符(如
x、y、z)可以用作变量名,但除非在数学计算中使用,否则应避免使用,因为这样的命名缺乏描述性。 -
描述性命名:变量名应具有描述性,即一看到变量名就能大致了解其用途。例如,使用
student_name而不是sn。 -
特殊情况:
- 类名:通常使用首字母大写的驼峰命名法,例如:
MyClass。 - 私有变量:以单下划线开头的变量名(如
_private)在Python中通常表示非公开的部分,不应该被外部访问。 - 特殊变量:以双下划线开头和结尾的变量(如
__init__)是Python中特殊的方法或属性。
- 类名:通常使用首字母大写的驼峰命名法,例如:
实例
# 合法命名
my_name = "John"
counter = 0
_temperature = 32.5
MAX_SIZE = 100
class MyClass: pass# 非法命名
2name = "Jane" # 不能以数字开头
my-name = "Doe" # 不能包含连字符
global = "value" # 不能使用关键字
遵循这些命名规则和约定不仅可以帮助你避免语法问题,还能使你的代码更易于阅读和理解,这对于任何规模的项目都是非常重要的。
数学运算
在Python中,基本的数学运算包括加法、减法、乘法、除法等,和其他编程语言类似。以下是Python中常见数学运算的详细解释以及一些注意事项。
常见数学运算符
-
加法(
+):加法运算符用于两个数相加。result = 5 + 3 # 结果是 8 -
减法(
-):减法运算符用于从一个数中减去另一个数。result = 5 - 3 # 结果是 2 -
乘法(
*):乘法运算符用于两个数相乘。result = 5 * 3 # 结果是 15 -
除法(
/):除法运算符用于一个数除以另一个数。在Python 3中,它总是返回一个浮点数。result = 5 / 2 # 结果是 2.5 -
整除(
//):整除运算符用于获取除法的整数部分。result = 5 // 2 # 结果是 2 -
取余(
%):取余运算符用于返回除法的余数。result = 5 % 2 # 结果是 1 -
幂运算(
**):幂运算符用于返回一个数的指数次幂。result = 5 ** 2 # 结果是 25
注意事项
-
除法中的类型:在Python 3中,普通除法(
/)总是返回浮点数,即使两个操作数都是整数。如果你需要整数结果(忽略小数部分),应使用整除(//)。 -
操作数类型:当操作数是不同类型时(如一个是整数,另一个是浮点数),Python会自动将它们转换为相同类型(通常是更通用的类型,如浮点数),然后进行运算。
-
零除错误:除以零(在任何运算中)会导致
ZeroDivisionError。在进行除法运算时,应确保分母不为零。 -
复合赋值运算符:Python支持复合赋值运算符,如
+=,-=,*=,/=,//=,%=,**=,用于在原变量的基础上进行操作并重新赋值。 -
数学函数:对于更高级的数学运算(如求平方根、三角函数等),可以使用Python的内置
math模块。 -
精度问题:在处理浮点数时,要注意精度问题。由于计算机对浮点数的表示限制,某些浮点运算可能会有轻微的精度误差。
示例
import math# 基本数学运算
a = 10
b = 3
print(a + b) # 加法
print(a - b) # 减法
print(a * b) # 乘法
print(a / b) # 除法
print(a // b) # 整除
print(a % b) # 取余
print(a ** b) # 幂运算# 使用math模块
print(math.sqrt(16)) # 平方根
print(math.sin(math.pi / 2)) # 正弦函数
在进行数学运算时,理解操作数的类型和可能的转换、运算符的行为以及潜在的错误情况(如零除)是非常重要的。这将有助于避
免常见的错误,并编写出更可靠和精确的代码。
导入math库并使用
在Python中,导入math库并使用它提供的函数和常量非常简单。math库是Python的标准库之一,提供了许多对浮点数进行数学运算的函数。以下是如何导入math库以及如何使用它的一些常见功能:
导入math库
要使用math库中的任何函数或常量,首先需要导入它:
import math
这条语句导入了整个math模块,使得你可以访问它的所有功能。
使用math库中的函数和常量
一旦导入了math模块,你就可以使用.运算符来调用其内部的函数和常量了。以下是一些示例:
- 计算平方根:
sqrt_result = math.sqrt(25) # 计算25的平方根
print(sqrt_result) # 输出: 5.0
- 三角函数:
sin_result = math.sin(math.pi / 2) # 计算pi/2的正弦值
print(sin_result) # 输出: 1.0
- 对数函数:
log_result = math.log(100, 10) # 计算以10为底的100的对数
print(log_result) # 输出: 2.0
- 常量:
print(math.pi) # π的值
print(math.e) # 自然对数的底数
- 舍入函数:
print(math.ceil(4.7)) # 向上取整,输出: 5
print(math.floor(4.7)) # 向下取整,输出: 4
注意事项
math模块的函数通常只接受浮点数或整数类型的参数。- 如果需要对复数进行操作,应该使用
cmath模块。 math模块中的某些函数可能在特定的输入值上不可用(如负数的平方根),在这种情况下会抛出ValueError或OverflowError。- 使用
math模块的函数比Python的内置函数(如使用**进行幂运算)有更高的性能和精度。
通过导入和使用math模块,你可以让Python程序轻松处理各种复杂的数学运算。
注释
在Python中,注释是用来解释代码的文本,它们不会被Python解释器执行。注释可以帮助别人理解你的代码,或者提醒自己代码的某些细节。在Python中,有两种类型的注释:单行注释和多行注释。
单行注释
- 使用井号
#开始单行注释。#后面的任何文本都会被Python解释器忽略。 - 通常用于简短说明代码的某个部分或禁用某行代码。
# 这是一个单行注释
print("Hello, World!") # 这也是一个注释
多行注释
- Python没有专门的多行注释符号,但可以使用三引号(
'''或""")来创建多行字符串,并将其作为多行注释使用。 - 这些多行字符串不赋值给任何变量时,Python会忽略它们。
'''
这是一个多行注释
包含了多行文本
'''
print("Hello, World!")"""
另一个多行注释的示例
"""
注意事项
-
清晰性:注释应该清晰且易于理解,尽量避免含糊不清或误导的语言。
-
及时更新:确保随着代码的更改,注释也得到相应的更新。过时的注释可能比没有注释更加误导人。
-
不要过度注释:避免对显而易见的代码进行注释。过多的注释可能会干扰代码的可读性。
-
代码清晰原则:良好的代码应该尽可能清晰自解释,只在必要时添加注释。
-
避免注释掉旧代码:避免将旧代码注释掉以保留。使用版本控制系统(如Git)来跟踪代码的历史变更。
-
遵守团队规范:如果你在团队环境中工作,应遵守团队关于注释的规范和约定。
-
文档字符串:对于函数和类,应使用文档字符串(docstrings)而不是普通注释,这样可以通过工具生成文档,并通过
help()函数查看。
示例:函数的文档字符串
def add(a, b):"""这个函数返回两个数的和。参数:a (int): 第一个数b (int): 第二个数返回:int: 两数之和"""return a + b
在编写Python代码时,合理使用注释是一个非常好的习惯。它不仅能帮助别人理解你的代码,也是自我记录和理解的有用工具。
数据类型
Python中的数据类型分为多种,每种类型都有其特定的使用方法和注意事项。以下是一些主要数据类型的详细解释和它们的使用方法:
1. 数字类型(Integers, Floats, Complex Numbers)
-
整数(Integers)
- 使用:直接赋值。
- 注意:整数的大小只受限于机器的内存。
x = 100 -
浮点数(Floats)
- 使用:包含小数点的数字。
- 注意:浮点数有精度限制,可能导致舍入错误。
y = 3.14 -
复数(Complex Numbers)
- 使用:
j或J表示虚部。 - 注意:主要用于科学计算。
z = 1 + 2j - 使用:
2. 序列类型(Strings, Lists, Tuples)
-
字符串(Strings)
- 使用:用单引号或双引号包围的字符序列。
- 注意:字符串是不可变的。
str = "Hello, World!"
在Python中,字符串是非常常用且功能强大的数据类型,用于存储和表示文本信息。以下是Python中字符串的使用方法及其注意事项的详细解释:
字符串的创建
- 可以通过将文本放入单引号(
')或双引号(")中来创建字符串。string1 = 'Hello' string2 = "World"
- 对于跨多行的字符串,可以使用三引号(
'''或""")。multi_line_string = """这是一个 多行 字符串"""字符串的基本操作
- 连接:使用加号(
+)连接字符串。greeting = string1 + " " + string2 # "Hello World"
- 重复:使用星号(
*)重复字符串。repeated = "Hi! " * 3 # "Hi! Hi! Hi! "
- 索引:使用方括号访问特定位置的字符。
char = string1[1] # 'e'
- 切片:使用方括号获取子字符串。
sub_string = string2[1:4] # "orl"字符串的内置方法
Python的字符串对象有许多内置方法,可用于执行常见的文本操作。例如:
str.lower():将字符串转换为小写。str.upper():将字符串转换为大写。str.strip():去除字符串两端的空白字符。str.find(sub):返回子字符串的索引。str.replace(old, new):替换字符串中的内容。格式化字符串
%操作符:旧式的字符串格式化方法。name = "Alice" "Hello, %s" % name
str.format()方法:较新的字符串格式化方法。"Hello, {}".format(name)
- 格式化字符串字面值(F-strings):Python 3.6+ 引入的一种更简洁的格式化方式。
f"Hello, {name}"注意事项
- 不可变性:字符串在Python中是不可变的,这意味着一旦创建,就不能更改字符串中的单个字符。
- 转义字符:特殊字符(如换行符
\n和制表符\t)可以通过反斜杠进行转义。- 原始字符串:通过在字符串前加
r来创建原始字符串,其中的转义字符不会被处理。raw_string = r"Raw\nString"
- 字符串和字节:在Python 3中,字符串(Unicode)和字节(
bytes)是不同的类型。需要注意编码和解码。- 性能:对于大量的字符串拼接操作,建议使用
.join()方法而不是+操作符,以获得更好的性能。字符串是Python中用于文本处理的关键数据类型,掌握其基本用法对于编写有效的Python代码至关重要。
-
列表(Lists)
- 使用:用方括号表示,元素可变。
- 注意:列表可以包含不同类型的元素。
my_list = [1, "Hello", 3.14] -
元组(Tuples)
- 使用:用圆括号表示,元素不可变。
- 注意:元组一旦创建,不能更改其内容。
my_tuple = (1, "Hello", 3.14)
3. 映射类型(Dictionaries)
-
字典(Dictionaries)
- 使用:键值对的集合,用大括号表示。
- 注意:键必须是不可变类型,且唯一。
my_dict = {"name": "Alice", "age": 25}
4. 集合类型(Sets, Frozen Sets)
-
集合(Sets)
- 使用:无序且不重复的元素集,用大括号表示。
- 注意:集合本身是可变的,但其元素必须是不可变的。
my_set = {1, 2, 3} -
冻结集合(Frozen Sets)
- 使用:不可变版本的集合。
- 注意:一旦创建,不能更改。
my_frozenset = frozenset([1, 2, 3])
5. 布尔类型(Booleans)
-
布尔(Booleans)
- 使用:
True或False。 - 注意:常用于条件判断。
is_valid = True - 使用:
6. 二进制类型(Bytes, Byte Arrays)
-
字节(Bytes)
- 使用:不可变的字节序列,用于处理二进制数据。
- 注意:以
b或B前缀表示。
my_bytes = b"Hello" -
字节数组(Byte Arrays)
- 使用:可变的字节序列。
- 注意:适用于需要改变字节内容的场景。
my_byte_array = bytearray(my_bytes)
注意事项
- 动态类型:Python是动态类型的,所以不需要显式声明变量的数据类型。
- 强类型:Python是强类型语言,这意味着不能隐式地将一个数据类型转换为另一个类型(例如,不能将字符串和整数相加)。
- 可变与不可变:理解哪些数据类型是可变的(如列表、字典、集合、字节数组)和不可变的(如字符串、元组、冻结集合)是重要的。
- 精度和性能:在处理大量数据
或要求高性能的程序时,选择合适的数据类型非常关键。例如,处理数值数据时浮点数和整数的选择将影响精度和性能。
- 内存管理:大型数据结构(如大型列表或字典)可能会占用大量内存。
理解这些数据类型的使用方法和注意事项对于编写有效且高效的Python代码至关重要。
NoneType
在Python中,None 是一个特殊的常量,用来表示空值或“无”。它是 NoneType 数据类型的唯一值。None 在很多场景中都非常有用,特别是在需要表示某些东西不存在或未定义时。以下是 NoneType 的详细解释、使用方法及注意事项。
使用方法
-
表示未定义或空值:
None可以用来表示变量已被声明但尚未赋予具体值。result = None -
作为函数默认返回值:
如果一个函数没有明确的返回语句,它会默认返回None。def func():passprint(func()) # 输出: None -
作为可选参数的默认值:
在函数定义中,None常用作默认参数值。def greet(name=None):if name is None:return "Hello!"else:return f"Hello, {name}!"print(greet()) # 输出: Hello! -
对象属性的初始值:
在类的实例化过程中,None可以用作对象属性的初始值。class MyClass:def __init__(self):self.my_attribute = None
注意事项
-
与其他“空”值的区别:
None不同于False、0或空的容器(如[]或'')。在布尔上下文中,虽然None被视为False,但它们是不同的。 -
检查 None 值:
检查变量是否为None时,应使用is而不是==。if my_var is None:# Do something -
None是单例:
在Python中,None是一个单例对象。这意味着任何赋值为None的变量都指向相同的内存地址。 -
函数中使用
None作为默认参数:
如果函数参数默认为可变对象(如列表或字典),则应使用None作为默认值,然后在函数内部检查它。def append_to(element, to=None):if to is None:to = []to.append(element)return to -
避免滥用
None:
过度依赖None可能会使代码难以理解和维护。在可能的情况下,考虑使用更具体的默认值或异常处理。 -
类型注解中的
None:
在使用类型注解时,如果函数可以返回None,应该使用Optional。例如def func() -> Optional[int]:表示函数可能返回int类型,也可能返回None。
None 是Python编程中一个基本而重要的概念。正确理解和使用 None 对于编写清晰、可靠且易于维护的代码至关重要。
len()
在Python中,len() 函数是一个内置函数,用于返回对象的长度或元素数量。它可以用于多种不同类型的对象,如字符串、列表、元组、字典、集合等。以下是关于 len() 函数的详细解释和使用方法,以及使用时的一些注意事项。
使用方法
-
字符串(Strings):返回字符串中字符的数量。
my_string = "Hello" print(len(my_string)) # 输出: 5 -
列表(Lists):返回列表中元素的数量。
my_list = [1, 2, 3, 4, 5] print(len(my_list)) # 输出: 5 -
元组(Tuples):返回元组中元素的数量。
my_tuple = (1, 2, 3) print(len(my_tuple)) # 输出: 3 -
字典(Dictionaries):返回字典中键值对的数量。
my_dict = {'a': 1, 'b': 2, 'c': 3} print(len(my_dict)) # 输出: 3 -
集合(Sets):返回集合中元素的数量。
my_set = {1, 2, 3, 4} print(len(my_set)) # 输出: 4
注意事项
-
对象必须是可迭代的:
len()函数适用于任何定义了长度的可迭代对象。如果尝试对非迭代对象(如整数)使用len(),将引发TypeError。 -
空对象:对于空字符串、空列表、空元组等,
len()将返回0。 -
字典和集合:对于字典,
len()返回的是键值对的数量,而不是键或值的数量;对于集合,len()返回的是集合中不重复元素的数量。 -
自定义对象:如果你定义了自己的类,并希望能使用
len()函数,你需要在类中定义__len__()方法。 -
性能:
len()函数通常非常快,因为它直接返回已经存储的长度值,而不是实际计算元素数量。
示例:自定义对象使用 len()
class MyClass:def __init__(self):self.items = [1, 2, 3]def __len__(self):return len(self.items)my_obj = MyClass()
print(len(my_obj)) # 输出: 3
在这个示例中,MyClass 类定义了 __len__() 方法,该方法返回 items 属性的长度。因此,可以使用 len() 函数来获取 MyClass 实例的长度。
总的来说,len() 函数是Python中一个非常实用的工具,适用于获取多种数据结构的长度。理解其使用方法和限制对编写有效的Python代码很重要。
Type()
在Python中,type() 函数是一个内置函数,用于返回一个对象的类型。这个函数非常有用,特别是在进行类型检查或者需要根据对象类型执行不同操作时。以下是 type() 函数的使用方法及其注意事项的详细解释:
使用方法
-
基本使用:
使用type()函数可以得到任何Python对象的类型。x = 5 print(type(x)) # 输出: <class 'int'>y = "Hello" print(type(y)) # 输出: <class 'str'> -
用于比较类型:
type()的返回值可以用于与其他类型对象进行比较。if type(x) is int:print("x 是一个整数") -
用于分支处理:
可以用type()检查变量类型,然后根据类型执行不同的操作。if type(y) is str:print("y 是一个字符串")
注意事项
-
不推荐用于类型检查:
虽然可以用type()进行类型检查,但在许多情况下,更推荐使用isinstance()函数。isinstance()考虑了继承,因此对于子类的实例也会返回True,更加灵活。if isinstance(x, int):print("x 是一个整数") -
返回的是类型对象:
type()返回的是类型对象,而不是简单的字符串。例如,<class 'int'>而不仅仅是'int'。 -
用于自定义类:
在自定义类的实例上使用type()会返回该类。class MyClass:passmy_instance = MyClass() print(type(my_instance)) # 输出: <class '__main__.MyClass'> -
元类:
type()还可以作为元类来使用,用于动态创建新的类。这是一个高级用法,通常只在需要动态生成类时使用。 -
可读性和维护性:
过度依赖type()进行类型检查可能会使代码难以阅读和维护。在设计代码时,应尽量使用Python的多态性和鸭子类型特性,以提高代码的灵活性和可维护性。
type() 函数是探索和理解Python对象及其类型系统的有力工具。正确使用它可以帮助你更好地理解代码的行为和结构。然而,也应该注意其正确用法和潜在的限制。
交互模式
Python交互模式,也称为Python解释器或Python shell,是一种可以直接运行Python命令的环境。在这个模式下,你可以逐行输入Python代码,并立即看到执行结果。这对于学习Python、测试代码片段或进行临时数据分析非常有用。以下是Python交互模式的使用方法及其注意事项的详细解释:
使用方法
-
启动Python交互模式:
- 在命令行或终端中输入
python或python3(取决于你的安装和环境变量)并按回车。
- 在命令行或终端中输入
-
执行命令:
- 在提示符(通常是
>>>)后输入Python代码或表达式,然后按回车执行。 - 你可以执行所有有效的Python代码,包括变量赋值、函数调用、导入模块等。
- 在提示符(通常是
-
多行语句:
- 对于跨多行的语句(如定义函数、for循环、with语句等),交互模式会提供一个次级提示符(通常是
...)以继续输入。 - 输入完成后,按回车即可执行整个多行语句。
- 对于跨多行的语句(如定义函数、for循环、with语句等),交互模式会提供一个次级提示符(通常是
-
退出交互模式:
- 输入
exit()或按Ctrl+D(在某些系统上是Ctrl+Z然后回车)退出交互模式。
- 输入
注意事项
-
命令历史:
- 在交互模式下,你可以使用上下箭头键浏览之前执行过的命令。
-
不适合大型程序:
- 对于较大的编程项目,使用交互模式可能不太实用。此时应考虑使用文本编辑器或IDE编写Python脚本文件。
-
临时性质:
- 在交互模式中输入的命令和创建的变量在退出时会丢失。如果你需要保存代码,应该将其写入文件。
-
测试和调试:
- 交互模式非常适合测试小段代码和调试,可以快速尝试不同的命令和函数。
-
输出显示:
- 交互模式会自动显示表达式的结果。例如,如果你输入
2 + 2,它会立即显示结果4。
- 交互模式会自动显示表达式的结果。例如,如果你输入
-
粘贴多行代码:
- 当粘贴多行代码时,可能需要特别注意缩进和空行。不正确的缩进可能导致语法错误。
-
使用辅助工具:
- 除了标准的Python交互模式,还有增强的交互环境,如IPython和Jupyter Notebook,提供了更多高级功能。
Python交互模式是探索Python语言、快速测试代码和执行临时任务的有力工具。了解其使用方法和限制有助于更高效地利用这个强大的特性。
在pycharm中使用交互模式
PyCharm是由JetBrains开发的一款流行的Python IDE(集成开发环境),它提供了一个功能丰富的环境来编写Python代码。PyCharm也支持交互模式,即可以在IDE内部使用Python控制台来执行Python代码片段。以下是在PyCharm中使用交互模式的详细步骤和注意事项:
如何使用交互模式
-
打开Python控制台:
- 在PyCharm中,你可以通过点击右下角的"Python Console"按钮来打开一个交互式Python控制台。
- 另外,你也可以通过主菜单选择 “View” -> “Tool Windows” -> “Python Console” 来打开它。
-
输入和执行代码:
- 在打开的Python控制台中,你会看到一个交互式提示符(通常是
>>>)。 - 在此处,你可以输入Python代码,按回车后代码将立即执行。
- 你可以执行任意有效的Python代码,包括变量赋值、函数定义、模块导入等。
- 在打开的Python控制台中,你会看到一个交互式提示符(通常是
-
使用控制台功能:
- 在PyCharm的Python控制台中,你可以利用IDE提供的一些附加功能,如智能代码补全、代码检查和快速文档查看。
-
多行代码:
- 对于跨多行的代码(如循环或函数定义),PyCharm控制台允许你在按回车键后继续输入,而不是立即执行代码。
注意事项
-
项目环境:
- PyCharm控制台使用的是当前PyCharm项目的Python解释器环境。确保你的项目设置正确,以使用合适的Python版本和库。
-
保存代码:
- 与Python交互模式不同,PyCharm的控制台不会在会话结束时自动保存代码。如果你需要保存所写的代码,应手动复制到文件中。
-
性能考虑:
- 对于复杂的项目或大量数据处理,IDE控制台可能会比直接运行Python脚本慢一些,因为IDE本身也占用系统资源。
-
图形界面应用:
- 如果你在控制台中运行涉及图形用户界面(GUI)的代码,如使用matplotlib绘图,确保所有GUI事件循环都能正常运行。
-
重启控制台:
- 如果需要清空当前控制台并重新开始,可以点击控制台窗口中的重启按钮。
使用PyCharm中的Python控制台可以有效地进行代码的快速测试和调试,同时利用IDE提供的强大功能,如代码补全和即时错误检查。这使得交互模式在PyCharm中变得更加高效和强大。
input()
在Python中,input() 函数用于获取用户的文本输入。当 input() 函数执行时,程序会暂停,等待用户输入文本并按回车键。输入的文本以字符串形式返回。以下是 input() 函数的使用方法及注意事项的详细解释:
使用方法
-
基本用法:
input()函数可以在括号内包含一个字符串作为提示语,该提示语将在用户输入前显示。
name = input("请输入你的名字: ") print("你好, " + name) -
与变量结合:
- 通常将
input()的返回值赋值给一个变量,用于后续操作。
age = input("请输入你的年龄: ") print("你的年龄是: " + age) - 通常将
-
转换输入类型:
input()返回的是字符串(str)类型。如果需要数值类型,必须显式转换。
age = int(input("请输入你的年龄: ")) print("明年你将是 " + str(age + 1) + " 岁")
注意事项
-
返回类型始终为字符串:
- 无论用户输入什么,
input()总是返回一个字符串。如果期望的是其他类型(如整数或浮点数),需要使用相应的函数(如int()或float())进行转换。
- 无论用户输入什么,
-
安全性和验证:
- 用户的输入可能是不可预测的。如果程序对输入做进一步处理,应考虑进行适当的验证和错误处理,以避免程序因意外输入而崩溃。
- 对于输入数字等情况,考虑使用
try-except语句捕获可能的转换错误。
-
阻塞程序执行:
input()函数将阻塞程序的执行,直到用户输入文本并按回车键。这意味着程序在用户没有响应时将不会继续向下执行。
-
命令行交互:
input()函数主要用于简单的命令行交互。对于更复杂的用户界面,可能需要考虑其他方法,如使用图形界面。
-
Python 2.x版本的差异:
- 在Python 2.x中,有两个不同的输入函数:
input()和raw_input()。在Python 2.x中,input()会尝试解析输入的内容,而raw_input()则总是返回字符串。在Python 3.x中,input()的行为与Python 2.x中的raw_input()相同。
- 在Python 2.x中,有两个不同的输入函数:
-
控制台输入:
- 当使用IDE运行脚本时,应确保IDE支持控制台输入。
input() 函数是Python中获取用户输入的简单而直接的方法。它在小型脚本和基础学习实践中非常有用,但在构建复杂的应用程序时,可能需要更高级的用户输入处理方法。
数据类型转换
在Python中,数据类型转换是将一个数据类型的值转换为另一个数据类型的过程。Python提供了内置的函数来帮助进行常见的数据类型转换。以下是Python中数据类型转换的使用方法及其注意事项的详细解释:
使用方法
-
整数转换(
int()):- 将其他数据类型转换为整数。
- 浮点数转换为整数会去掉小数部分。
- 字符串转换为整数必须包含有效的整数值。
int(3.14) # 结果: 3 int("123") # 结果: 123 -
浮点数转换(
float()):- 将其他数据类型转换为浮点数。
- 整数或含数字的字符串可以转换为浮点数。
float(5) # 结果: 5.0 float("2.56") # 结果: 2.56 -
字符串转换(
str()):- 将其他数据类型转换为字符串。
- 几乎所有类型都可以通过此方法转换为其字符串表示。
str(10) # 结果: "10" str(3.14) # 结果: "3.14" -
布尔转换(
bool()):- 将其他数据类型转换为布尔值。
- 常见的“假”值包括
None、0、空字符串和空容器(如空列表)。
bool(0) # 结果: False bool("Hello") # 结果: True
注意事项
-
有效性和合理性:
- 在转换数据类型时,确保数据是有效的和合理的。例如,尝试将非数字字符串转换为数字将引发
ValueError。
- 在转换数据类型时,确保数据是有效的和合理的。例如,尝试将非数字字符串转换为数字将引发
-
精度损失:
- 在将浮点数转换为整数时,小数部分将被舍去,可能导致精度损失。
-
隐式类型转换:
- 在某些操作中,Python会自动进行类型转换,例如算术运算时将整数转换为浮点数。然而,显式转换通常更清晰可控。
-
转换布尔值:
- 任何非零数值或非空对象都会转换为
True。0、None和空容器(如[]、{})会转换为False。
- 任何非零数值或非空对象都会转换为
-
字符串格式:
- 在将数字转换为字符串时,结果将是数字的直接文本表示,而不是格式化的输出。对于格式化输出,可以使用字符串格式化技术。
-
异常处理:
- 当转换可能导致错误时(如将不正确格式的字符串转换为数字),应使用异常处理(
try-except块)来优雅地处理错误情况。
- 当转换可能导致错误时(如将不正确格式的字符串转换为数字),应使用异常处理(
数据类型转换是Python编程中常见的任务,理解如何正确地进行转换及其潜在陷阱对于编写健壮且有效的代码至关重要。
条件语句
Python中的条件语句允许基于一定条件来控制程序的执行流程。以下是Python中条件语句的使用方法及其注意事项的详细解释:
使用方法
-
if语句:- 最基本的条件语句,如果条件为真,则执行缩进的代码块。
if condition:# 条件为真时执行的代码 -
else语句:- 与
if配合使用,当if的条件不为真时执行。
if condition:# 条件为真时执行的代码 else:# 条件不为真时执行的代码 - 与
-
elif语句:- “else if” 的缩写,用于检查多个条件。如果前面的
if或elif条件不为真,会继续检查elif的条件。
if condition1:# 条件1为真时执行的代码 elif condition2:# 条件1不为真且条件2为真时执行的代码 else:# 前面的条件都不为真时执行的代码 - “else if” 的缩写,用于检查多个条件。如果前面的
注意事项
-
条件表达式:
- 条件表达式需要计算为布尔值
True或False。可以是比较操作(如==,!=,>,<等),逻辑操作(如and,or,not),或任何返回布尔值的表达式。
- 条件表达式需要计算为布尔值
-
缩进:
- Python严格要求代码缩进来定义代码块。确保
if,elif,else下的代码块正确缩进。
- Python严格要求代码缩进来定义代码块。确保
-
冒号:
if,elif,else语句末尾需要使用冒号(:)。
-
单行
if语句:- 对于简单的条件,可以使用单行
if语句。
if condition: do_something() - 对于简单的条件,可以使用单行
-
elif和else是可选的:- 不是每个
if都需要elif或else。可以根据需要选择使用。
- 不是每个
-
条件判断的复杂性:
- 避免过于复杂的条件判断。过长或过复杂的条件语句可能难以阅读和维护。考虑分解复杂条件或使用函数。
-
布尔“真值”:
- 在Python中,除了
False,None,0,空字符串"",空列表[],空字典{},空集合set()被视为False,其他值都被视为True。
- 在Python中,除了
-
避免使用
==来比较单例值:- 使用
is来比较单例值,例如None。即使用if x is None:而不是if x == None:。
- 使用
Python中的条件语句是控制程序逻辑和流程的基本工具。正确地使用这些结构可以帮助你编写出既清晰又有效的代码。
嵌套/多条件判断
在Python中,嵌套条件判断或多条件判断是一种常见的结构,用于根据多个条件确定程序的执行路径。正确使用这种结构可以使你的代码更加灵活和强大,但也可能导致代码难以阅读和维护。以下是Python中嵌套和多条件判断的使用方法及注意事项的详细解释:
使用方法
-
嵌套条件判断:
- 嵌套条件判断是在一个条件语句(如
if)内部使用另一个条件语句。
if condition1:if condition2:# 当condition1和condition2都为True时执行else:# 当condition1为True但condition2不为True时执行 - 嵌套条件判断是在一个条件语句(如
-
多条件判断:
- 多条件判断是使用逻辑运算符(如
and,or)连接多个条件表达式。
if condition1 and condition2:# 当condition1和condition2都为True时执行 elif condition1 or condition2:# 当condition1或condition2至少一个为True时执行 - 多条件判断是使用逻辑运算符(如
注意事项
-
保持简洁:
- 尽量保持条件语句的简洁。避免过于复杂或深度嵌套的条件判断,因为这会使代码难以阅读和维护。
-
明确逻辑:
- 每个条件应该清楚且易于理解。避免在单个条件中包含过多的逻辑。
-
括号的使用:
- 在多条件判断中,合理使用括号来明确不同条件的优先级,特别是在混合使用
and和or时。
- 在多条件判断中,合理使用括号来明确不同条件的优先级,特别是在混合使用
-
避免重复代码:
- 尽量减少重复代码。如果在多个条件分支中执行相同的代码,考虑将其移出条件语句。
-
逻辑运算符的短路行为:
- Python中的
and和or操作符具有短路行为:and在遇到第一个False时停止计算;or在遇到第一个True时停止计算。理解这一点对编写有效的条件语句很重要。
- Python中的
-
使用
elif而非嵌套if:- 当有多个互斥的条件时,使用
elif比嵌套if更清晰。
- 当有多个互斥的条件时,使用
-
避免过度使用
else:- 在某些情况下,可以省略
else语句,尤其是当你在if或elif分支中结束函数时。
- 在某些情况下,可以省略
-
测试复杂条件:
- 对于复杂的嵌套或多条件语句,编写测试用例以确保它们按预期工作。
通过合理运用嵌套和多条件判断,你可以处理更复杂的逻辑情况。然而,始终需要注意保持代码的清晰和可维护性。
逻辑运算
在Python中,逻辑运算常用于组合多个条件判断。主要的逻辑运算符包括and、or和not。以下是逻辑运算的使用方法及其注意事项的详细解释:
使用方法
-
and运算符:and用于确保所有给定的条件都为真。只有当所有条件都为真时,整个表达式才为真。
if condition1 and condition2:# 当condition1和condition2都为True时执行 -
or运算符:or用于确保至少一个给定的条件为真。如果任一条件为真,则整个表达式为真。
if condition1 or condition2:# 当condition1或condition2至少一个为True时执行 -
not运算符:not用于反转条件的布尔值。如果条件为真,则not使其为假;如果条件为假,则not使其为真。
if not condition1:# 当condition1为False时执行
注意事项
-
逻辑与优先级:
not的优先级高于and和or。使用括号来明确复杂表达式中的运算符优先级。
if not condition1 and condition2:# 实际为 if (not condition1) and condition2: -
短路评估:
- Python采用短路逻辑来评估逻辑表达式。例如,如果
and表达式的第一个条件为False,则整个表达式立即判断为False,不再评估后面的条件。同样,如果or表达式的第一个条件为True,则整个表达式立即判断为True。
- Python采用短路逻辑来评估逻辑表达式。例如,如果
-
布尔上下文:
- Python中许多对象和表达式都可以在布尔上下文中使用,其中
None、任何数值型的零(0、0.0等)、空序列(''、[]、{})都被视为False。
- Python中许多对象和表达式都可以在布尔上下文中使用,其中
-
代码可读性:
- 尽管Python允许复杂的逻辑表达式,但应注意保持代码的可读性。对于非常复杂的逻辑,考虑将其分解为多个条件语句。
-
比较与逻辑运算结合:
- 可以将比较运算(如
==、!=、<、>)与逻辑运算结合起来创建复杂的条件。
if 0 < x < 10 and y != 0:# 当x在0到10之间且y不为0时执行 - 可以将比较运算(如
-
逻辑运算符与位运算符的区别:
- 不要将逻辑运算符(
and,or,not)与位运算符(&,|,~)混淆。后者用于位级操作,适用于整数。
- 不要将逻辑运算符(
逻辑运算是控制程序流程的强大工具,能够处理复杂的条件。正确使用逻辑运算符可以提高代码的灵活性和表现力,同时需要注意保持代码的清晰和易读性。
列表
Python中的列表是一种灵活的数据类型,用于存储序列化的数据集合。列表是可变的,意味着它们的内容可以在创建后被修改。以下是Python列表的使用方法及注意事项的详细解释:
使用方法
-
创建列表:
- 列表可以通过括在方括号内的一系列逗号分隔的值来创建。
my_list = [1, 2, 3, "Hello", 3.14] -
访问列表元素:
- 列表元素可以通过索引访问,索引从0开始。
first_element = my_list[0] # 获取第一个元素 -
修改列表元素:
- 由于列表是可变的,你可以更改其元素。
my_list[1] = "Python" -
添加元素:
- 使用
append()方法在列表末尾添加元素。 - 使用
insert()方法在指定位置添加元素。
my_list.append("new item") my_list.insert(2, "another item") - 使用
-
删除元素:
- 使用
remove()方法删除具有指定值的元素。 - 使用
pop()方法删除指定索引处的元素。 - 使用
del关键字删除元素或整个列表。
my_list.remove("Hello") my_list.pop(1) del my_list[2] - 使用
-
列表切片:
- 使用切片来访问列表的子集。
sub_list = my_list[1:3] # 获取索引1到2的元素 -
列表遍历:
- 使用
for循环遍历列表。
for element in my_list:print(element) - 使用
-
列表推导式:
- 使用列表推导式快速生成列表。
squares = [x**2 for x in range(10)]
注意事项
-
列表是可变的:
- 列表可以修改,这意味着添加、删除或更改元素会改变原始列表。
-
列表可以包含不同类型的元素:
- 列表可以存储任意类型的数据,包括其他列表。
-
索引越界:
- 访问不存在的索引将导致
IndexError。
- 访问不存在的索引将导致
-
切片操作:
- 切片操作返回列表的新副本。原始列表不受影响。
-
列表的复制:
- 仅使用
=赋值列表将不会创建其副本。要复制列表,请使用copy()方法或切片操作。
- 仅使用
-
列表和字符串的区别:
- 字符串虽然与列表类似,但是不可变的。字符串的每个元素都是一个字符。
-
性能考虑:
- 列表的某些操作(如在列表前端添加/删除元素)可能不是很高效。在需要频繁进行这类操作时,考虑使用其他数据类型,如
deque。
- 列表的某些操作(如在列表前端添加/删除元素)可能不是很高效。在需要频繁进行这类操作时,考虑使用其他数据类型,如
-
修改列表时遍历:
- 在遍历列表的同时修改它可能会导致意外的结果或错误。一种常见的做法是创建列表的副本进行遍历。
Python列表是一个多功能且强大的数据结构,适用于多种不同的编程任务。正确理解和使用列表及其方法对于编写有效且高效的Python代码非常重要。
字典
在Python中,字典是一种可变的容器模型,可以存储任意类型对象。字典的每个元素都是一个键值对。以下是Python中字典的使用方法及其注意事项的详细解释:
使用方法
-
创建字典:
- 使用花括号
{}或dict()函数创建字典。键值对以键: 值的形式表示。
my_dict = {'name': 'Alice', 'age': 25} another_dict = dict(name='Bob', age=30) - 使用花括号
-
访问字典元素:
- 使用键来访问字典中的值。
name = my_dict['name'] -
添加或修改元素:
- 直接使用键来添加或修改字典中的元素。
my_dict['email'] = 'alice@example.com' my_dict['age'] = 26 -
删除元素:
- 使用
del语句或字典的pop()方法删除元素。
del my_dict['name'] age = my_dict.pop('age') - 使用
-
检查键是否存在:
- 使用
in关键字来检查键是否存在于字典中。
if 'name' in my_dict:print('Name is present in the dictionary') - 使用
-
遍历字典:
- 使用
for循环遍历字典的键或值。
for key in my_dict:print(key, my_dict[key]) - 使用
-
字典推导式:
- 使用字典推导式快速生成字典。
squares = {x: x*x for x in range(6)} -
获取所有键或值:
- 使用
keys()或values()方法获取字典中所有的键或值。
keys = my_dict.keys() values = my_dict.values() - 使用
注意事项
-
键的唯一性:
- 字典中的键必须是唯一的。如果对同一个键赋值两次,后一个值会覆盖前一个值。
-
键的不可变性:
- 字典的键必须是不可变类型,如字符串、数字或元组。
-
访问不存在的键:
- 尝试访问不存在的键会引发
KeyError。可以使用get()方法访问键,如果键不存在,则返回None或指定的默认值。
email = my_dict.get('email', 'Not found') - 尝试访问不存在的键会引发
-
修改字典大小时的迭代:
- 在迭代字典的同时修改其大小(添加或删除元素)可能会引发错误。如果需要这样做,请先创建一个副本。
-
字典的排序:
- 默认情况下,字典的元素没有特定的顺序。如果需要有序的字典,可以使用
collections.OrderedDict。
- 默认情况下,字典的元素没有特定的顺序。如果需要有序的字典,可以使用
-
使用
update()合并字典:- 用
update()方法可以将一个字典的键值对合并到另一个字典中。
- 用
-
性能优势:
- 字典在查找、添加和删除键值对时非常高效,其性能优于列表。
Python字典是一种非常灵活和高效的数据结构,适用于需要键值对映射的场景。正确地使用字典可以提高数据组织和处理的效率。
元组
Python中的元组(Tuple)是一种不可变的序列类型,常用于存储不应改变的数据序列。元组与列表相似,但一旦创建,它们的内容就不能修改。以下是Python中元组的使用方法及注意事项的详细解释:
使用方法
-
创建元组:
- 使用圆括号
()创建元组,元素间用逗号分隔。
my_tuple = (1, 2, 3, "Hello") - 使用圆括号
-
无括号元组:
- 创建元组时括号是可选的,除非元组为空或必须表明元组的存在。
another_tuple = 4, 5, 6 empty_tuple = () single_element_tuple = (5,) # 单元素元组需加逗号 -
访问元组元素:
- 通过索引访问元组中的元素。
element = my_tuple[2] # 访问第三个元素 -
切片操作:
- 使用切片来访问元组的一部分。
sub_tuple = my_tuple[1:3] -
遍历元组:
- 使用
for循环遍历元组。
for item in my_tuple:print(item) - 使用
-
元组拆包:
- 将元组的元素分配给变量。
a, b, c, d = my_tuple -
不可变性:
- 元组一旦创建,就不能修改其内容(不可添加、删除或更改元素)。
-
嵌套元组:
- 元组可以包含其他元组作为元素。
nested_tuple = (1, (2, 3), (4, 5, 6))
注意事项
-
元素不可变:
- 元组的不可变性意味着一旦定义,你不能更改、添加或删除元组的元素。这种不可变性使得元组在某些情况下比列表更合适。
-
单元素元组:
- 创建只包含一个元素的元组时,必须在元素后添加逗号,否则它不会被识别为元组。
-
元组与列表的选择:
- 通常,如果你的数据不会改变,使用元组更安全;如果数据需要动态更改,使用列表。
-
元组的有效性:
- 元组可以用作字典的键,因为它们是不可变的,而列表则不能。
-
性能:
- 元组在某些情况下比列表更快,因为它们的不可变性允许Python进行优化。
-
不可变性的深入理解:
- 虽然元组本身是不可变的,但如果元组包含可变对象(如列表),这些对象可以被更改。
-
内存效率:
- 由于元组的不可变性,它们通常比列表更内存效率。
Python元组是一种简单且强大的数据类型,适合用于保护数据不被修改的场景。正确使用元组可以使你的程序更安全、更清晰、更高效。
字典和元组结合
在Python中,字典和元组可以以多种方式结合使用,利用各自的特点来解决特定的编程问题。以下是字典和元组结合使用的一些常见场景及其详细解释:
1. 使用元组作为字典的键
由于元组是不可变的,它们可以作为字典的键使用。这在需要用多个值作为键来索引数据时非常有用。
# 元组作为字典键
coordinates_dict = {(35.6895, 139.6917): "Tokyo",(40.7128, -74.0060): "New York",(34.0522, -118.2437): "Los Angeles"}
# 访问字典
location = coordinates_dict[(35.6895, 139.6917)]
2. 字典项作为元组
字典的项可以通过items()方法转换为包含键值对的元组。这在需要迭代或处理字典的键和值时非常有用。
# 字典项作为元组
my_dict = {"a": 1, "b": 2, "c": 3}
for key, value in my_dict.items():print(key, value)
3. 使用元组列表来创建字典
可以使用元组的列表来创建字典,每个元组包含两个元素:键和值。
# 元组列表创建字典
tuple_list = [("a", 1), ("b", 2), ("c", 3)]
my_dict = dict(tuple_list)
4. 将字典键、值或项转换为元组
可以将字典的键、值或整个项转换为元组,以便进行各种操作。
# 将字典键转换为元组
keys_tuple = tuple(my_dict.keys())# 将字典值转换为元组
values_tuple = tuple(my_dict.values())# 将字典项转换为元组
items_tuple = tuple(my_dict.items())
注意事项
-
元组键的不可变性:
- 当使用元组作为字典键时,请确保元组中的所有元素都是不可变的。
-
性能考虑:
- 将字典项转换为元组可能不是特别高效,特别是在处理大型字典时。只有在需要这种类型转换时才这样做。
-
字典的有序性:
- 从Python 3.7开始,字典保持插入顺序。但是,将字典的项转换为元组时,应该注意元素的顺序。
-
元组列表创建字典:
- 使用元组列表创建字典时,如果列表中存在重复的键,后出现的键值对将覆盖先出现的。
-
数据结构选择:
- 根据你的具体需求选择使用元组还是列表作为字典键或值。元组用于不可更改的数据,而列表用于可能需要更改的数据。
通过将字典和元组结合使用,你可以创建更复杂的数据结构,以满足特定的编程需求。正确地利用这些数据结构的特性可以使你的代码更加高效和灵活。
for循环
Python中的for循环是一种常用的迭代结构,用于遍历序列(如列表、元组、字符串)或其他可迭代对象。以下是Python中for循环的使用方法及注意事项的详细解释:
使用方法
-
遍历序列:
- 使用
for循环来遍历列表、元组、字符串等序列。
for element in [1, 2, 3, 4, 5]:print(element) - 使用
-
遍历字典:
- 可以遍历字典的键、值或键值对。
my_dict = {"a": 1, "b": 2, "c": 3} for key in my_dict:print(key, my_dict[key])在Python中,遍历字典是一种常见的操作。由于字典是键值对的集合,你可以遍历键、值或键值对。以下是Python中使用
for循环遍历字典的方法及其注意事项的详细解释:使用方法
- 遍历字典的键:
- 默认情况下,遍历字典会遍历其键。
my_dict = {"a": 1, "b": 2, "c": 3} for key in my_dict:print(key) # 输出: a, b, c- 遍历字典的值:
- 使用
values()方法遍历字典的值。
for value in my_dict.values():print(value) # 输出: 1, 2, 3- 遍历字典的键值对:
- 使用
items()方法同时遍历键和值。
for key, value in my_dict.items():print(key, value) # 输出: a 1, b 2, c 3注意事项
- 修改字典大小:
- 在遍历字典的过程中不应修改其大小(添加或删除键值对)。这样做可能导致运行时错误。
- 字典视图对象:
keys(),values(), 和items()方法返回的是字典的视图对象,而不是列表。这些视图对象提供了字典项的动态视图,反映了字典的当前状态。
- 字典的无序性:
- 字典是无序的。遍历字典的顺序可能与添加键值对的顺序不同。从Python 3.7开始,字典保持了插入顺序,但依赖于这一特性的代码可能在早期Python版本中不正确。
- 并发修改:
- 如果在遍历字典的同时需要修改字典,考虑先制作字典的副本或创建一个新字典。
- 遍历效率:
- 对于大型字典,遍历操作可能会消耗较多资源。如果只需访问特定几个元素,直接访问会更高效。
- 使用迭代器:
- 使用
iter()函数可以创建一个迭代器,这对于大型字典或复杂的迭代逻辑可能更有效。
- 键和值的数据类型:
- 当遍历字典时,记住键和值可以是任何数据类型。遍历时的逻辑应考虑到数据类型的多样性。
遍历字典是访问和操作字典数据的基本方式。正确使用这些遍历技术可以帮助你编写出更有效和易于维护的代码。
-
使用
range()函数:range()函数生成一个数字序列,常用于for循环中。
for i in range(5): # 默认从0开始,到5结束,不包括5print(i) -
列表推导式:
- 使用
for循环在单行内创建列表。
squares = [x*x for x in range(10)] - 使用
-
嵌套循环:
- 在一个
for循环内部使用另一个for循环。
for i in range(3):for j in range(3):print(i, j) - 在一个
注意事项
-
循环控制语句:
break:退出当前循环。continue:跳过当前循环的剩余部分,直接开始下一次迭代。pass:不做任何操作,常用于占位。
-
修改列表时的迭代:
- 在迭代列表的同时修改列表可能会导致意外的行为。考虑先复制列表或创建新列表。
-
迭代器和可迭代对象:
- 确保你在
for循环中使用的对象是可迭代的。不是所有对象都可以迭代。
- 确保你在
-
避免过度嵌套:
- 尽量避免使用过多嵌套的
for循环,因为这会使代码难以阅读和维护。
- 尽量避免使用过多嵌套的
-
循环变量泄露:
- 在Python 3中,循环变量(如上述例子中的
i和j)在循环结束后仍然可访问。在某些情况下,这可能会导致意外的行为。
- 在Python 3中,循环变量(如上述例子中的
-
性能考虑:
- 对于大型数据集,考虑循环的效率。在可能的情况下,使用内置函数(如
map()或列表推导式)可以提高性能。
- 对于大型数据集,考虑循环的效率。在可能的情况下,使用内置函数(如
Python中的for循环是处理序列和可迭代对象的有效工具。合理使用for循环可以提高代码的清晰性和效率。
range()
在Python中,range() 函数是一种内置函数,用于生成一个不可变的数值序列。这个函数在使用for循环进行迭代时非常有用。以下是Python中range()函数的使用方法及注意事项的详细解释:
使用方法
-
基本用法:
range(n)生成从0到n-1的整数序列。
for i in range(5):print(i) # 输出 0, 1, 2, 3, 4 -
指定起始值:
range(start, stop)生成从start到stop-1的整数序列。
for i in range(1, 5):print(i) # 输出 1, 2, 3, 4 -
带有步长:
range(start, stop, step)生成一个从start开始,以step为步长,到stop-1结束的序列。
for i in range(0, 10, 2):print(i) # 输出 0, 2, 4, 6, 8 -
逆序生成:
- 使用负数作为步长可以生成一个逆序的序列。
for i in range(5, 0, -1):print(i) # 输出 5, 4, 3, 2, 1
注意事项
-
range的结束值是不包含的:- 在
range(start, stop, step)中,序列将不包括结束值stop。
- 在
-
range生成的是“range对象”,而不是实际的列表:range()函数返回的是一个迭代器,而不是一个实际的列表。要获取列表,需要将其转换为列表。
list_range = list(range(5)) # [0, 1, 2, 3, 4] -
步长不能为零:
- 如果
step为0,则会引发ValueError,因为不能生成此类序列。
- 如果
-
只能用于整数:
range()只适用于整数。对于浮点数,需要使用不同的方法。
-
有效的负步长:
- 如果使用负步长,确保
start大于stop,否则结果序列将是空的。
- 如果使用负步长,确保
-
性能考虑:
- 由于
range对象在迭代前不会生成所有元素,使用range比使用等效的列表更内存高效。
- 由于
-
适用于
for循环:range通常与for循环一起使用,但也可以与其他迭代工具和结构一起使用。
Python中的range()函数是处理数字序列的有效工具。它在循环和其他迭代场景中特别有用,并且由于其特性,对于大型范围的数字处理非常高效。
While循环
在Python中,while 循环用于在满足某个条件的情况下重复执行一段代码。它是编程中常用的控制流工具之一。以下是Python中while循环的使用方法及注意事项的详细解释:
使用方法
-
基本结构:
while循环会一直执行其内部的代码块,直到条件表达式不再为真。
count = 0 while count < 5:print(count)count += 1 -
使用
break退出循环:- 使用
break语句可以提前退出while循环,即使循环条件仍然为真。
while True:response = input("输入 'exit' 来退出循环: ")if response == 'exit':break - 使用
-
使用
continue跳过迭代:continue语句用于跳过当前迭代的剩余部分,并继续下一次迭代。
count = 0 while count < 5:count += 1if count == 3:continueprint(count) -
while循环中的else:while循环可以有一个可选的else块。如果循环正常结束(没有通过break退出),则会执行else块。
count = 0 while count < 5:print(count)count += 1 else:print("循环正常结束")
注意事项
-
防止无限循环:
- 确保循环的条件最终会变为假,以防止无限循环。
-
循环条件的更新:
- 在
while循环中,确保更新影响循环条件的变量,否则可能导致无限循环。
- 在
-
慎用
while True:- 使用
while True创建无限循环时,务必确保循环内部有一个可靠的退出条件(如break语句)。
- 使用
-
性能考虑:
- 对于大量或复杂的数据,考虑
while循环的性能影响,尤其是在涉及到网络操作或文件I/O时。
- 对于大量或复杂的数据,考虑
-
调试无限循环:
- 如果不小心写出了无限循环,可以使用IDE的中断功能或者在终端中使用
Ctrl+C来停止程序。
- 如果不小心写出了无限循环,可以使用IDE的中断功能或者在终端中使用
-
循环变量的初始化:
- 在循环开始前,确保已经正确初始化了循环变量。
-
循环和异常处理:
- 在
while循环中使用异常处理(try-except)时要特别小心,确保异常不会意外导致无限循环。
- 在
while 循环是Python中实现重复执行任务的强大工具。正确使用它们可以使你的代码逻辑清晰且高效,但务必注意避免常见的陷阱,特别是无限循环的问题。
格式化字符串
在Python中,字符串格式化是一种常见的操作,用于创建具有特定格式的字符串。字符串格式化常用于组合字符串和非字符串类型的数据,以及在输出中设置特定的格式。以下是Python中几种主要字符串格式化方法的使用及注意事项的详细解释:
1. 百分号(%)格式化
百分号格式化是一种较老的字符串格式化方法,使用 % 符号。
示例:
name = "Alice"
age = 25
height = 1.75# 基本格式化
formatted_string = "Hello, %s. You are %d." % (name, age)
print(formatted_string) # 输出: Hello, Alice. You are 25.# 浮点数格式化
formatted_height = "Height: %.2f meters." % height
print(formatted_height) # 输出: Height: 1.75 meters.
注意事项:
- 使用
%s(字符串)、%d(整数)和%f(浮点数)等格式化符号。 - 字符串中的
%字符必须被转义为%%。 - 较新的Python代码可能更偏向于使用
str.format()或F-strings。
2. str.format() 方法
str.format() 方法提供了一种更灵活的方式来格式化字符串。
示例:
# 使用位置参数
formatted_string = "Hello, {}. You are {}.".format(name, age)
print(formatted_string) # 输出: Hello, Alice. You are 25.# 使用关键字参数
formatted_string = "Hello, {n}. You are {a}.".format(n=name, a=age)
print(formatted_string) # 输出: Hello, Alice. You are 25.# 指定小数点精度
formatted_height = "Height: {:.2f} meters.".format(height)
print(formatted_height) # 输出: Height: 1.75 meters.
注意事项:
{}用作占位符。- 可以使用位置或关键字参数。
- 可以在占位符内部进行更复杂的格式化。
3. 格式化字符串字面量(F-strings)
F-strings是Python 3.6中引入的,提供了一种简洁的格式化字符串方法。
示例:
# 基本用法
formatted_string = f"Hello, {name}. You are {age}."
print(formatted_string) # 输出: Hello, Alice. You are 25.# 包含表达式
formatted_age = f"Next year, you will be {age + 1}."
print(formatted_age) # 输出: Next year, you will be 26.# 指定格式
formatted_height = f"Height: {height:.2f} meters."
print(formatted_height) # 输出: Height: 1.75 meters.
注意事项:
- 以
f或F为前缀。 - 可以直接在字符串中嵌入表达式。
- 要求Python 3.6或更高版本。
在使用这些字符串格式化方法时,请考虑到代码的可读性、维护性以及执行环境。每种方法都有其适用场景,合理选择可以使代码更加简洁和高效。
F字符串
在Python中,格式化字符串字面量,通常称为“f字符串”,是一种表达字符串的方式,它允许你在字符串内部嵌入表达式。从Python 3.6开始引入,f字符串是进行字符串格式化的一种快速而简洁的方法。
使用方法
-
基本用法:
- 在字符串前加上字母
f或F,然后在花括号{}中直接嵌入变量或表达式。
name = "Alice" age = 25 greeting = f"Hello, {name}. You are {age}." print(greeting) # 输出: Hello, Alice. You are 25. - 在字符串前加上字母
-
表达式嵌入:
- 可以在花括号中直接嵌入有效的Python表达式。
a = 5 b = 10 result = f"Five plus ten is {a + b}." print(result) # 输出: Five plus ten is 15. -
调用函数:
- 在花括号内调用函数。
name = "ALICE" formatted = f"Name in lowercase is {name.lower()}." print(formatted) # 输出: Name in lowercase is alice. -
格式规范:
- 在花括号内使用冒号(
:)后跟格式规范,如设置小数点精度。
pi = 3.1415926 formatted = f"Pi rounded to two decimal places is {pi:.2f}." print(formatted) # 输出: Pi rounded to two decimal places is 3.14. - 在花括号内使用冒号(
注意事项
-
Python版本:
- f字符串是在Python 3.6及更高版本中引入的。确保你的环境中的Python版本支持f字符串。
-
避免复杂表达式:
- 尽管可以在f字符串中嵌入复杂表达式,但为了保持代码的可读性,最好避免过于复杂的嵌入表达式。
-
转义花括号:
- 如果你需要在f字符串中包含字面的花括号,需要对其进行转义,即使用两个花括号
{{或}}。
formatted = f"{{Hello}} {name}!" print(formatted) # 输出: {Hello} Alice! - 如果你需要在f字符串中包含字面的花括号,需要对其进行转义,即使用两个花括号
-
安全性:
- 当使用f字符串处理用户输入或外部数据时,要注意安全性,避免执行恶意代码。
-
性能:
- 相对于传统的字符串格式化方法(如
%格式化或str.format()),f字符串在性能上通常更优,因为它们在运行时被解析和格式化。
- 相对于传统的字符串格式化方法(如
f字符串是Python中一种非常高效和易用的字符串格式化方法,适用于多种不同的格式化需求。正确使用f字符串可以使你的代码更简洁、更易读。
函数
Python中的函数是组织好的、可重用的、用来执行相关操作的代码块。函数是提高代码可读性和避免代码重复的重要方式。以下是Python函数的使用方法及注意事项的详细解释:
使用方法
-
定义函数:
- 使用
def关键字来定义一个函数,后跟函数名和括号内的参数。
def greet(name):return f"Hello, {name}!" - 使用
-
调用函数:
- 通过函数名和括号内的参数值来调用函数。
message = greet("Alice") print(message) # 输出: Hello, Alice! -
参数和返回值:
- 函数可以有参数和返回值。参数是传递给函数的值,返回值是函数执行后返回的值。
def add(a, b):return a + b sum = add(5, 3) -
默认参数:
- 函数参数可以有默认值。
def greet(name, greeting="Hello"):return f"{greeting}, {name}!" -
关键字参数:
- 在调用函数时可以使用关键字参数,这样参数的顺序可以不同于定义时的顺序。
message = greet(greeting="Hi", name="Bob") -
可变参数:
- 使用星号
*定义可变数量的参数。
def add(*numbers):return sum(numbers) total = add(1, 2, 3, 4) - 使用星号
-
关键字可变参数:
- 使用双星号
**定义可接受任意数量的关键字参数的函数。
def config(**settings):for key, value in settings.items():print(f"{key}: {value}") - 使用双星号
注意事项
-
函数命名规范:
- 遵循Python中的命名规范,通常使用小写字母和下划线。
-
文档字符串:
- 为函数编写文档字符串(docstring),说明函数的目的和参数。
-
避免副作用:
- 尽可能使函数纯粹:一个函数应完成一项单一的任务,避免在函数中修改全局变量或执行其他有副作用的操作。
-
参数的传递:
- 在Python中,可变类型作为参数传递到函数时,会按引用传递;不可变类型则按值传递。
-
函数的复用性:
- 设计函数时考虑其复用性,避免过度特定化。
-
递归深度:
- 如果使用递归,注意Python对递归深度有限制,过深的递归可能导致
RecursionError。
- 如果使用递归,注意Python对递归深度有限制,过深的递归可能导致
-
参数类型检查:
- Python是动态类型语言,但可以通过类型注解或在函数内部进行参数类型检查,增加代码的可读性和安全性。
合理使用函数是编写高效、可读且可维护Python代码的关键。理解函数的正确使用方法和最佳实践可以帮助你更好地组织和优化代码结构。
导入模块
在Python中,模块是包含一组函数和变量的文件,用于组织代码和提高代码重用性。导入模块是Python编程中常见的操作。以下是Python中导入模块的几种常用方法及其详细解释:
基本导入
- 整体导入:
- 使用
import关键字导入整个模块。这是最基本的导入方式。
import math result = math.sqrt(16) # 使用模块名作为前缀来调用函数 - 使用
导入特定内容
-
导入特定函数:
- 使用
from ... import ...从模块中导入特定的函数或类。
from math import sqrt result = sqrt(16) # 直接调用函数,无需前缀 - 使用
-
导入多个函数:
- 可以从同一个模块中导入多个函数。
from math import sqrt, cos
使用别名
-
为模块指定别名:
- 使用
as关键字给模块指定一个别名。
import math as m result = m.sqrt(16) # 使用别名调用函数 - 使用
-
为函数指定别名:
- 同样可以为导入的特定函数或类指定别名。
from math import sqrt as square_root result = square_root(16)
导入模块所有内容
- 导入模块中的所有项:
- 使用
from ... import *导入模块中的所有内容。这种方法不建议使用,因为它可能导致命名冲突。
from math import * result = sqrt(16) # 可能引起命名冲突 - 使用
注意事项
- 命名冲突:避免使用
from module import *,因为它可能导致命名冲突。最好是只导入所需的特定功能。 - 模块路径:确保Python解释器能找到你要导入的模块。对于自定义模块,它们需要在Python的模块搜索路径中。
- 性能:不必要地导入大量模块会增加程序启动时间,尤其是一些大型库。
- 可读性:使用
import module(并通过module.function调用函数)可以提高代码可读性。 - 虚拟环境:在不同项目中使用虚拟环境,以便为每个项目维护不同的模块版本。
正确地导入和使用模块是编写高效、结构化和可维护Python代码的关键。
导入第三方库的模块
在Python中,使用第三方库是扩展程序功能的常见做法。这些库通常不包含在Python标准库中,需要单独安装。以下是如何使用第三方库的模块的详细步骤和注意事项:
安装第三方库
-
使用pip:
- Python的包管理工具pip是安装第三方库的标准方式。在命令行中使用pip安装库。
pip install library_name例如,要安装著名的科学计算库NumPy,使用:
pip install numpy -
虚拟环境:
- 在使用第三方库时,建议创建一个虚拟环境。这有助于管理依赖关系,确保项目设置不会影响全局Python安装。
python -m venv myenv source myenv/bin/activate # 在Unix或macOS上 myenv\Scripts\activate # 在Windows上
导入第三方库的模块
-
导入模块:
- 一旦安装了第三方库,你就可以在Python脚本中像使用标准库一样导入其模块。
import numpy array = numpy.array([1, 2, 3]) -
导入特定功能:
- 也可以从库中导入特定的函数、类或变量。
from numpy import array my_array = array([1, 2, 3]) -
使用模块别名:
- 有时为了方便,可以给导入的模块指定一个别名。
import numpy as np my_array = np.array([1, 2, 3])
注意事项
-
了解库的文档:
- 在使用任何第三方库之前,阅读其官方文档是非常重要的。这有助于了解如何正确安装和使用该库。
-
兼容性问题:
- 检查第三方库是否与你的Python版本兼容。
-
安全性考虑:
- 只从可靠的源安装库。一些不安全的库可能包含恶意代码。
-
管理依赖:
- 对于较大的项目,使用
requirements.txt文件或其他依赖管理工具来跟踪项目依赖。
- 对于较大的项目,使用
-
虚拟环境:
- 在虚拟环境中安装和使用第三方库,以避免版本冲突并保持你的全局环境干净。
-
性能考虑:
- 第三方库可能会增加程序的运行时开销。在性能敏感的应用中,这一点尤其重要。
通过使用第三方库,你可以显著扩展Python的功能,利用社区的力量解决各种复杂的问题。正确地安装、导入和使用这些库将帮助你提高开发效率。
面向对象编程
Python是一种支持面向对象编程(OOP)的语言。面向对象编程是一种编程范式,它使用“对象”来设计软件。在OOP中,对象是具有属性(数据)和方法(操作数据的函数)的数据结构。以下是Python中面向对象编程的关键概念及其详细解释:
1. 类(Class)
- 定义:
- 类是创建对象的蓝图。它定义了对象的属性和方法。
- 示例:
class Dog:def __init__(self, name):self.name = name # 属性def speak(self): # 方法return "Woof!"
2. 对象(Object)
- 定义:
- 对象是类的实例。对象中定义了类的所有特征。
- 示例:
my_dog = Dog("Buddy") print(my_dog.name) # 访问属性 print(my_dog.speak()) # 调用方法
3. 继承(Inheritance)
- 定义:
- 继承是一种机制,子类可以继承父类的属性和方法,而无需重新定义。
- 示例:
class Bulldog(Dog): # 继承Dog类def run(self, speed):return f"My speed is {speed}."
4. 封装(Encapsulation)
- 定义:
- 封装是将数据(属性)和操作数据的代码(方法)捆绑在一起的过程。
- 示例:
class Car:def __init__(self, speed):self.__speed = speed # 私有属性def drive(self):return f"Driving at {self.__speed} speed."
5. 多态(Polymorphism)
- 定义:
- 多态是指同一操作作用于不同的对象时可以有不同的解释。
- 示例:
for dog in [Dog("Tommy"), Bulldog("Max")]:print(dog.speak()) # 不同的对象调用相同的方法
注意事项
- 命名约定:
- 类名通常遵循大写字母开头的约定(如
CamelCase)。
- 类名通常遵循大写字母开头的约定(如
- 私有成员:
- 在Python中,通过在属性或方法名前加双下划线
__来表示私有(不希望在类之外直接访问)。
- 在Python中,通过在属性或方法名前加双下划线
- 特殊方法:
- 例如
__init__()(构造函数),__str__()等。
- 例如
- 类和实例变量:
- 类变量是对于类的所有实例共享的。实例变量是每个对象实例特有的。
- 资源管理:
- 使用特殊方法,如
__enter__()和__exit__()进行资源管理(通常与with语句一起使用)。
- 使用特殊方法,如
面向对象编程是Python中非常强大的功能之一,正确使用可以使代码更加模块化,易于理解和维护。
面向对象编程的优点
Python中的面向对象编程(OOP)是一种编程范式,它使用“对象”来设计软件。对象是具有属性(数据)和方法(操作数据的函数)的数据结构。以下是Python中面向对象编程的主要优点及相关实例的详细解释:
优点
-
模块化和代码组织:
- OOP允许将程序划分为多个独立的单元或对象,每个对象负责自己的功能。这种模块化使得程序易于理解、开发和维护。
-
代码重用和可维护性:
- 通过继承,可以创建新的类(子类)来继承现有类(父类)的属性和方法,减少代码重复。
-
封装:
- 封装隐藏了对象的内部细节,只暴露必要的接口。这保护了对象的内部状态并防止外部代码的干扰。
-
抽象化:
- OOP允许开发者专注于接口而不是内部实现,通过抽象化简化复杂性。
-
多态性:
- 多态性允许将子类对象视为其父类类型,但实现可以不同,增加了程序的灵活性。
实例
假设我们正在编写一个程序来管理一个动物园中的动物。我们可以使用OOP的方法来构建程序。
-
定义基类:
- 创建一个基类
Animal,包含所有动物共有的属性和方法。
class Animal:def __init__(self, name):self.name = namedef speak(self):pass # 由子类实现 - 创建一个基类
-
继承和多态:
- 创建特定动物的子类,如
Dog和Cat,它们继承自Animal类。
class Dog(Animal):def speak(self):return "Woof!"class Cat(Animal):def speak(self):return "Meow!" - 创建特定动物的子类,如
-
封装和抽象化:
speak方法在Animal类中被定义(抽象化),但其具体实现在子类中(封装)。- 外部代码不需要知道每种动物是如何“说话”的,只知道它们可以“说话”。
-
使用多态性:
- 可以对所有动物类型统一调用
speak方法,而无需了解具体的动物类型。
animals = [Dog("Buddy"), Cat("Whiskers")]for animal in animals:print(f"{animal.name}: {animal.speak()}") - 可以对所有动物类型统一调用
注意事项
- 设计合理的类结构:避免过度使用继承,尤其是多重继承,因为它可能会使代码结构变得复杂且难以维护。
- 封装数据:避免直接暴露对象的内部状态,而是使用公共的接口(方法)来访问或修改它们。
- 合理运用多态:多态性提供了接口的一致性,但也需要小心确保各个子类的行为是一致和预期的。
面向对象编程提供了一个清晰、灵活且强大的方法来组织和管理代码。在Python中正确地使用面向对象的特性,可以帮助你构建更加模块化和可维护的应用程序。
创建类
在Python中,类是面向对象编程的基础,用于创建新的对象实例。类定义了一组属性(变量)和方法(函数),这些属性和方法共同构成了对象的状态和行为。以下是Python中创建类的使用方法及注意事项的详细解释:
创建类的使用方法
-
定义类:
- 使用
class关键字来定义一个类。类名通常采用驼峰命名法。
class MyClass:pass - 使用
-
构造函数:
__init__方法是一个特殊的方法,当创建新实例时会自动调用。它用于初始化对象的属性。
class MyClass:def __init__(self, value):self.attribute = value -
实例方法:
- 在类中定义的函数称为实例方法,它们的第一个参数通常是
self,指代对象本身。
class MyClass:def __init__(self, value):self.attribute = valuedef method(self):return self.attribute * 2 - 在类中定义的函数称为实例方法,它们的第一个参数通常是
-
创建实例:
- 创建类的实例就像调用一个函数一样,传递给构造函数的参数。
my_instance = MyClass(5) -
类变量和实例变量:
- 类变量是类的所有实例共享的变量,而实例变量是每个实例特有的。
class MyClass:class_variable = "This is a class variable"def __init__(self, value):self.instance_variable = value
注意事项
-
命名约定:
- 类名应该采用大写字母开头的驼峰命名法。
-
正确使用
self:- 实例方法的第一个参数应该是
self,它表示类的实例。
- 实例方法的第一个参数应该是
-
封装性:
- 避免直接访问实例变量,而是使用getter和setter方法。
-
不要忘记
self:- 在定义实例方法时,不要忘记将
self作为第一个参数。
- 在定义实例方法时,不要忘记将
-
继承:
- 考虑类之间的关系,是否需要使用继承来共享和重用代码。
-
文档字符串:
- 为类和方法提供文档字符串,说明其用途。
-
特殊方法:
- 利用特殊方法(如
__str__、__repr__等)来定义或修改类的默认行为。
- 利用特殊方法(如
-
私有成员:
- 使用双下划线(
__)前缀来定义私有变量和方法。
- 使用双下划线(
通过定义和使用类,Python允许你创建复杂的数据结构,提高代码的可读性和可维护性。正确理解和应用这些原则和最佳实践对于编写高质量的Python代码非常重要。
类继承
在Python中,类继承允许一个类(称为子类)继承另一个类(称为父类或基类)的属性和方法。这是面向对象编程的一个核心特征,用于增强代码的重用性和可维护性。
使用方法
-
创建基类:
- 定义一个普通的Python类,它将作为其他类的基类。
class Animal:def __init__(self, name):self.name = namedef speak(self):raise NotImplementedError("Subclass must implement this method") -
创建子类:
- 子类继承基类。通过在类定义中将基类作为参数传递来实现继承。
class Dog(Animal):def speak(self):return f"{self.name} says Woof!" -
使用继承的类:
- 创建子类的实例,并使用其方法。
my_dog = Dog("Buddy") print(my_dog.speak()) # 输出: Buddy says Woof! -
调用基类的方法:
- 使用
super()函数调用父类的方法。
class Cat(Animal):def speak(self):return super().speak() + f" and {self.name} says Meow!" - 使用
-
检查实例的类型:
- 使用
isinstance()检查某个实例是否是一个类的实例。
pet = Dog("Max") print(isinstance(pet, Animal)) # 输出: True - 使用
注意事项
-
正确使用构造函数:
- 如果子类有自己的
__init__方法,需要显式调用父类的__init__方法,或者父类的__init__不会被自动调用。
- 如果子类有自己的
-
方法重写:
- 子类可以重写继承自父类的方法。确保重写的方法符合父类的设计和使用意图。
-
单一职责原则:
- 每个类都应该专注于一个任务或功能。避免创建“上帝对象”。
-
深度继承链:
- 避免过深的继承链。深层次的继承结构可能会使代码变得复杂,难以维护和理解。
-
多重继承:
- 谨慎使用多重继承,因为它可能导致复杂的方法解析顺序和某些意外的行为。
-
isinstance vs issubclass:
- 使用
isinstance()检查对象的类型,使用issubclass()检查类的继承关系。
- 使用
-
抽象基类:
- 考虑使用抽象基类(ABCs)来强制子类实现特定的方法或属性。
通过使用类继承,您可以创建一个清晰的层次结构和代码重用,从而使您的程序更加模块化和高效。
子类调用父类的构造方法并添加自己独有的属性
在Python中,子类调用父类的构造方法通常是为了继承和初始化父类中定义的属性。同时,子类还可以添加自己独有的属性。以下是详细解释及示例:
调用父类的构造方法
在Python中,子类可以通过super()函数调用父类的构造方法。super()返回一个代表父类的临时对象,通过这个对象可以调用父类的方法。这在子类的构造函数中特别有用,因为它允许你先初始化父类的部分,然后添加或修改子类特有的部分。
示例
假设有一个基类Person,代表所有人的通用属性,如姓名和年龄。然后有一个子类Employee,继承自Person,但增加了职位和工资等属性。
# 父类
class Person:def __init__(self, name, age):self.name = nameself.age = age# 子类
class Employee(Person):def __init__(self, name, age, position, salary):super().__init__(name, age) # 调用父类的构造方法self.position = position # 添加子类特有的属性self.salary = salary # 添加子类特有的属性# 创建Person类的实例
person = Person(name="Alice", age=30)# 打印Person实例的属性
print(f"Name: {person.name}, Age: {person.age}")# 创建Employee类的实例
employee = Employee(name="Bob", age=35, position="Manager", salary=50000)# 打印Employee实例的属性
print(f"Name: {employee.name}, Age: {employee.age}, Position: {employee.position}, Salary: {employee.salary}")在这个例子中,Employee类通过调用super().__init__(name, age)继承了Person类的属性(name和age),同时添加了position和salary两个属性。
注意事项
-
正确使用
super():- 使用
super()时不需要传递self参数。
- 使用
-
保持父类不变性:
- 当重用父类的方法时,确保不违反父类的设计和行为。
-
父类初始化:
- 在子类中,首先调用父类的构造方法是个好习惯。这确保父类的初始化逻辑在子类属性添加或修改之前执行。
-
参数传递:
- 在调用父类的构造方法时,确保传递正确的参数。
-
多重继承:
- 如果使用多重继承,
super()的行为可能会变得复杂。确保理解Python中的方法解析顺序(MRO)。
- 如果使用多重继承,
-
重写父类方法:
- 如果子类重写了父类的某些方法,请确保在需要时调用父类的方法。
通过使用继承和super()函数,子类可以有效地重用和扩展父类的功能,同时保持代码的整洁和可维护性。
基于您提供的要求,我们可以设计一个人力系统,其中包含两个子类:
FullTimeEmployee和PartTimeEmployee,它们都继承自一个共同的基类,例如Employee。基类Employee将包含所有员工共有的属性和方法,而两个子类将具有特定于全职或兼职员工的属性和方法。下面是基于您的描述实现这个人力系统的代码示例:
基类
Employeeclass Employee:def __init__(self, name, id):self.name = nameself.id = iddef print_info(self):print(f"Name: {self.name}, ID: {self.id}")def calculate_monthly_pay(self):raise NotImplementedError("This method should be implemented by subclasses.")子类
FullTimeEmployeeclass FullTimeEmployee(Employee):def __init__(self, name, id, monthly_salary):super().__init__(name, id)self.monthly_salary = monthly_salarydef calculate_monthly_pay(self):return self.monthly_salary子类
PartTimeEmployeeclass PartTimeEmployee(Employee):def __init__(self, name, id, daily_salary, work_days):super().__init__(name, id)self.daily_salary = daily_salaryself.work_days = work_daysdef calculate_monthly_pay(self):return self.daily_salary * self.work_days实例化并使用类
# 实例化全职员工 full_time_employee = FullTimeEmployee(name="Alice", id="1001", monthly_salary=3000) full_time_employee.print_info() print(f"Monthly Pay: {full_time_employee.calculate_monthly_pay()}")# 实例化兼职员工 part_time_employee = PartTimeEmployee(name="Bob", id="2001", daily_salary=100, work_days=20) part_time_employee.print_info() print(f"Monthly Pay: {part_time_employee.calculate_monthly_pay()}")注意事项:
正确使用继承:
FullTimeEmployee和PartTimeEmployee都继承自Employee,复用了共同的代码。方法重写:
calculate_monthly_pay方法在两个子类中被重写,以提供不同的实现。异常处理:在基类中的
calculate_monthly_pay方法使用了NotImplementedError。这是一种良好的做法,用于指示子类必须重写此方法。初始化父类:子类的构造方法中使用
super().__init__(name, id)来确保父类正确初始化。封装:类属性被封装在类的内部,对外提供了方法来访问或修改它们(例如
print_info和calculate_monthly_pay方法)。
相对路径和绝对路径
在Python中,处理文件时经常需要指定文件的路径。路径可以是绝对路径或相对路径。以下是如何使用这两种路径类型对文件进行操作的详细解释:
绝对路径
绝对路径是从文件系统的根目录到目标文件或目录的完整路径。它不依赖于当前工作目录的位置。
示例:
# 假设在Windows系统上
file_path = "C:\\Users\\Username\\Documents\\example.txt"# 或在Unix/Linux系统上
file_path = "/home/username/documents/example.txt"with open(file_path, "r") as file:content = file.read()
相对路径
相对路径是相对于当前工作目录的路径。它不是从根目录开始的,而是从当前工作目录开始。
示例:
假设当前工作目录是/home/username/projects,且要操作的文件位于/home/username/projects/documents/example.txt。
file_path = "documents/example.txt"with open(file_path, "r") as file:content = file.read()
在这个示例中,"documents/example.txt"是相对于/home/username/projects的相对路径。
注意事项
-
工作目录:
- 当使用相对路径时,它是相对于当前工作目录。你可以使用
os.getcwd()查看当前工作目录,使用os.chdir(path)更改工作目录。
- 当使用相对路径时,它是相对于当前工作目录。你可以使用
-
路径分隔符:
- 在Windows系统中,路径分隔符是反斜杠
\,而在Unix/Linux系统中是斜杠/。为了使代码更具可移植性,建议使用os.path.join()来构建路径。
- 在Windows系统中,路径分隔符是反斜杠
-
使用
os.path模块:os.path模块提供了很多用于路径操作的函数,如os.path.abspath()可以将相对路径转换为绝对路径。
-
跨平台兼容性:
- 为了使代码在不同的操作系统上都能正确运行,应尽量避免硬编码路径分隔符。使用
os.path.join()可以在不同系统上生成正确的路径。
- 为了使代码在不同的操作系统上都能正确运行,应尽量避免硬编码路径分隔符。使用
-
安全性:
- 当处理外部来源的路径时,要考虑到安全性,避免路径遍历等安全漏洞。
通过正确使用相对路径和绝对路径,你可以灵活地在Python程序中读取和写入不同位置的文件。
文件操作
在Python中,文件操作是进行数据读写的基本技能之一。Python为文件操作提供了内置函数和方法,使得读取和写入文件变得简单直观。以下是Python中文件操作的详细解释:
打开文件
使用内置的open()函数来打开文件。这个函数返回一个文件对象,是后续所有读写操作的关键。
file = open("example.txt", "r") # "r" 表示读取模式
文件模式
open()函数的第二个参数是文件模式:
"r": 只读模式。"w": 写入模式,如果文件存在则覆盖,不存在则创建。"a": 追加模式,如果文件存在,追加在文件末尾,不存在则创建。"r+": 读写模式。"b": 二进制模式,例如"rb"或"wb"。
读取文件
一旦文件被打开,你可以使用文件对象的方法来读取内容:
read(size): 读取指定数量的数据。readline(): 读取一行。readlines(): 读取所有行,返回一个列表。
content = file.read() # 读取整个文件
file.close() # 关闭文件
写入文件
在写入模式下,可以使用文件对象的write()方法写入数据:
file = open("example.txt", "w")
file.write("Hello, world!")
file.close()
使用with语句
为了确保文件正确关闭,可以使用with语句,这样文件会在with块结束时自动关闭:
with open("example.txt", "r") as file:content = file.read()
# 文件在这里已经关闭
注意事项
-
文件路径:
- 当指定文件名时,如果不是绝对路径,则相对于当前工作目录。
-
关闭文件:
- 总是确保打开的文件被关闭,以释放系统资源。使用
with语句可以自动管理这一点。
- 总是确保打开的文件被关闭,以释放系统资源。使用
-
文件模式的选择:
- 根据需求选择合适的文件模式,特别注意
"w"模式,因为它会覆盖现有文件。
- 根据需求选择合适的文件模式,特别注意
-
处理异常:
- 在文件操作过程中可能会发生IO错误,例如文件不存在等。可以使用
try...except块来处理这些异常。
- 在文件操作过程中可能会发生IO错误,例如文件不存在等。可以使用
-
读写权限:
- 当尝试读取或写入文件时,确保有适当的文件系统权限。
-
编码问题:
- 在处理非文本文件或文本文件的特殊编码时,需要注意编码和解码的问题。
文件操作是大多数程序中的常见任务,正确使用Python的文件操作接口可以帮助你高效地处理文件数据。
主函数
在Python中,虽然没有像C或Java那样的显式“主函数”概念,但通常使用一个被称为主函数的代码块来作为程序的入口点。这是通过检查特殊变量__name__来实现的。当Python文件被直接运行时,__name__变量被设置为"__main__";而当文件作为模块被其他文件导入时,__name__则被设置为模块的名字。
使用方法
-
定义主函数:
- 主函数通常被定义为一个名为
main()的普通函数。
def main():# 你的程序代码print("Hello, World!") - 主函数通常被定义为一个名为
-
检查
__name__:- 在文件的末尾,检查
__name__变量是否等于"__main__"。如果是,就调用main()函数。
if __name__ == "__main__":main() - 在文件的末尾,检查
注意事项
-
代码的组织性:
- 使用主函数可以使代码更加有组织。它允许你将程序的执行逻辑与模块的定义分离,提高代码的可读性和可维护性。
-
可重用性和可测试性:
- 当文件被作为模块导入时,主函数中的代码不会被执行。这有助于你在其他地方重用代码,并且可以更方便地对函数进行单元测试。
-
避免全局代码:
- 将程序的主要功能放在主函数中,而不是直接放在全局作用域中。全局作用域中的代码在导入时将被执行,这可能导致意想不到的副作用。
-
程序的入口点:
- 主函数提供了明确的程序入口点,这在理解和调试代码时非常有帮助,尤其是在较大的项目中。
通过使用这种模式,你可以在Python中有效地模拟主函数的行为,使你的程序更加清晰和结构化,同时提高代码的重用性和可测试性。
异常类型
Python中有多种内置的异常类型,用于处理不同的错误和异常情况。以下是一些常见的异常类型,以及它们的简要说明和使用实例:
1. SyntaxError
- 说明:当Python解释器遇到语法错误时抛出。
- 实例:
这将引发print("Hello World" # 缺少闭合括号SyntaxError,因为缺少右括号。
2. NameError
- 说明:尝试访问未声明的变量时抛出。
- 实例:
这将引发print(undeclared_variable)NameError,因为undeclared_variable没有定义。
3. TypeError
- 说明:当操作或函数应用于不适当类型的对象时抛出。
- 实例:
这将引发"2" + 2 # 尝试将字符串和整数相加TypeError,因为Python不能将字符串和整数相加。
4. IndexError
- 说明:在使用序列中不存在的索引时抛出。
- 实例:
这将引发my_list = [1, 2, 3] print(my_list[3]) # 索引超出列表长度IndexError,因为索引3超出了列表的范围。
5. KeyError
- 说明:在字典中访问不存在的键时抛出。
- 实例:
这将引发my_dict = {"name": "Alice"} print(my_dict["age"]) # "age"键不存在KeyError,因为字典中没有键"age"。
6. ValueError
- 说明:当函数接收到具有正确类型但不适当的值时抛出。
- 实例:
这将引发int("xyz") # 尝试将非数字字符串转换为整数ValueError,因为字符串"xyz"不能转换为整数。
7. ZeroDivisionError
- 说明:在除法或模运算的除数为零时抛出。
- 实例:
这将引发1 / 0 # 除以零ZeroDivisionError,因为除以零是不允许的。
8. FileNotFoundError
- 说明:尝试访问不存在的文件或目录时抛出。
- 实例:
这将引发with open("nonexistent_file.txt") as file:content = file.read()FileNotFoundError,因为文件nonexistent_file.txt不存在。
注意事项
- 合适的异常处理:应根据具体的错误情况选择合适的异常类型进行处理。
- 避免过度使用异常捕获:不要使用空的或过于宽泛的
except语句,这可能会掩盖其他错误。 - 异常传播:在不确定如何处理异常时,可以让它传播给上层调用者,直至找到合适的处理方式。
通过理解和正确使用这些异常类型,你可以使你的Python程序更加健壮和易于调试。
捕捉异常
在Python中,捕捉异常是通过try和except语句块来实现的。这个机制允许你处理可能发生的错误,而不是让整个程序因为一个未处理的异常而崩溃。以下是如何在Python中捕捉异常的详细解释,包括具体实例:
捕捉异常的基本用法
- 使用
try和except:- 将可能引发异常的代码放在
try块中。 - 将异常处理代码放在
except块中。 - 可以指定要捕获的异常类型。
- 将可能引发异常的代码放在
示例:
try:# 可能引发异常的代码result = 10 / 0
except ZeroDivisionError:# 处理特定类型的异常print("You can't divide by zero!")
在这个例子中,尝试除以零会引发ZeroDivisionError。这个异常在except块中被捕获,程序打印出错误消息而不是崩溃。
捕捉多种异常
你可以在一个except块中指定多个异常类型,来捕捉不同类型的异常。
示例:
try:# 代码number = int("not_a_number")
except (ValueError, TypeError):# 处理ValueError或TypeError异常print("Invalid input!")
使用except而不指定异常类型
如果except没有指定异常类型,它会捕获所有类型的异常。这种做法应该小心使用,以避免隐藏程序中的其他错误。
示例:
try:# 代码undefined_var
except:# 捕获所有类型的异常print("An error occurred!")
访问异常对象
使用as关键字,你可以访问与异常相关联的对象,并从中获取更多信息。
示例:
try:# 代码1 / 0
except ZeroDivisionError as e:# 访问异常对象print(f"Error occurred: {e}")
注意事项
-
不要过度使用广泛的异常捕获:捕获所有异常(
except:)可能会隐藏其他错误,让调试变得困难。 -
针对性的异常处理:最好是捕获特定的异常类型,这样你可以对不同的错误情况作出更精确的反应。
-
清理资源:可以使用
finally块来确保即使在异常发生时也执行必要的清理工作,如关闭文件。 -
异常的传播:如果当前
except块不处理捕获到的异常,异常将会被传播到上层的try块。
通过理解如何在Python中捕捉和处理异常,你可以编写更健壮、更易于维护的代码,并提供更好的错误处理逻辑。
异常处理
在Python中,异常处理是一种重要的错误处理机制,允许程序在遇到错误时优雅地恢复和响应。异常处理使用try、except、else和finally语句来捕获和处理错误。
使用方法
-
基本异常处理:
- 使用
try和except块来捕获并处理异常。
try:# 可能引发异常的代码result = 10 / 0 except ZeroDivisionError:# 异常处理代码print("Divided by zero!") - 使用
-
捕获多个异常:
- 可以使用一个
except块来捕获多种类型的异常。
try:# 代码 except (TypeError, ValueError) as e:print(f"An error occurred: {e}") - 可以使用一个
-
完整的异常处理块:
else块:如果没有异常发生,将执行else块中的代码。finally块:无论是否发生异常,都将执行finally块中的代码。
try:# 代码 except ZeroDivisionError:# 异常处理 else:# 没有异常时执行 finally:# 总是执行 -
触发异常:
- 使用
raise语句主动抛出异常。
if some_condition:raise ValueError("A value error happened.") - 使用
注意事项
-
捕获具体异常:
- 建议捕获具体的异常,而不是使用一个通用的
except块。这有助于更准确地处理错误并提供更有用的错误信息。
- 建议捕获具体的异常,而不是使用一个通用的
-
避免过度使用
try-except:- 不要滥用
try-except块来掩盖代码中的问题。合理使用异常处理来应对真正不可预测的错误情况。
- 不要滥用
-
使用
else和finally:else块在没有异常发生时执行,适合放置一些只有在try块成功执行后才需要运行的代码。finally块适合用于清理操作,如关闭文件或释放资源,无论是否发生异常都需要执行。
-
异常传播:
- 在
except块中,如果重新抛出异常或不捕获异常,则异常会向上层调用者传播。
- 在
-
记录异常信息:
- 在处理异常时,记录详细的异常信息对于调试和日志记录非常重要。
-
自定义异常:
- 可以通过继承
Exception类来定义自己的异常类型,以满足特定应用的需求。
- 可以通过继承
通过正确使用异常处理,你的Python程序可以更加健壮和易于维护,同时也提供了更好的用户体验和调试便利性。
测试
在Python中进行测试和找出bug是确保代码质量和功能正确性的重要步骤。Python提供了多种测试工具和技术,从简单的打印语句到专门的测试框架。以下是一些常用的测试方法及其详细解释:
1. 手动测试
手动测试是最基本的测试方法,通常包括打印输出和手动运行代码。
- 使用print语句:在代码中的关键位置添加
print()语句来输出变量的值或程序的状态,帮助理解代码的行为。 - 交互式测试:使用Python交互式解释器或Jupyter Notebook来逐段运行代码,观察每部分的输出。
2. 断言
断言(assertions)用于在代码中设置检查点,确保特定条件为真。如果条件不满足,程序将抛出AssertionError。
def add_positive_numbers(x, y):assert x > 0 and y > 0, "Both numbers must be positive"return x + yadd_positive_numbers(1, -1) # 将抛出AssertionError
3. 单元测试
单元测试是自动化测试的一种形式,用于测试代码的最小单元(如函数或方法)。
- 使用unittest框架:Python标准库中的
unittest模块提供了一个测试框架。你可以创建一个测试用例的子类,并在其中定义测试方法。import unittestclass TestAddition(unittest.TestCase):def test_add_positive_numbers(self):self.assertEqual(add_positive_numbers(1, 2), 3)def test_add_negative_numbers(self):with self.assertRaises(AssertionError):add_positive_numbers(-1, 2)if __name__ == '__main__':unittest.main()
4. 集成测试
集成测试是指测试代码中不同模块之间的交互。这通常涉及多个组件的联合测试,以确保它们协同工作。
5. 使用第三方测试框架
可以使用第三方测试框架,如pytest,它提供了更灵活的语法和强大的功能。
注意事项
- 代码覆盖率:使用代码覆盖率工具(如
coverage.py)来检查测试覆盖了多少代码。 - 持续集成:考虑使用持续集成工具(如Jenkins, Travis CI, GitHub Actions)来自动运行测试。
- 测试驱动开发(TDD):考虑采用测试驱动开发的方法,即先写测试,然后编写满足测试的代码。
- 模拟和测试隔离:对于依赖外部资源(如数据库或网络服务)的代码,考虑使用模拟(mocking)来隔离和测试。
- 测试不同类型的输入:确保测试各种边界条件和异常情况。
- 定期维护测试代码:随着程序的发展,确保定期更新和维护测试代码。
通过结合以上方法,可以有效地在Python中进行测试,提高代码的质量和稳定性。
单元测试unittest使用
在Python中,unittest是一个内置的测试框架,它支持自动化测试、共享测试代码的设置(setup)和拆除(teardown)代码,以及测试用例集的聚合。以下是如何使用unittest进行测试的详细解释,包括一个具体的实例:
使用unittest进行测试
-
编写测试用例:
- 测试用例是继承自
unittest.TestCase的类。 - 每个测试方法都应该以
test开头,这样它们才会被测试运行器识别为测试。
- 测试用例是继承自
-
设置和拆除:
- 可以在测试类中定义
setUp和tearDown方法。setUp方法在每个测试方法之前运行,tearDown方法在每个测试方法之后运行。
- 可以在测试类中定义
-
断言:
- 使用
assert方法来检查预期结果,例如assertEqual、assertTrue、assertFalse等。
- 使用
-
运行测试:
- 通过调用
unittest.main()来运行测试。这个函数将搜索测试用例,并自动运行它们。
- 通过调用
实例
假设有一个简单的函数add,可以将两个数字相加。我们将编写一些测试来验证这个函数。
# 被测试的函数
def add(x, y):return x + y# 测试用例
import unittestclass TestAddFunction(unittest.TestCase):def setUp(self):# 在每个测试方法之前执行print("Setting up")def tearDown(self):# 在每个测试方法之后执行print("Tearing down")def test_add_positive_numbers(self):self.assertEqual(add(1, 2), 3)def test_add_negative_numbers(self):self.assertEqual(add(-1, -1), -2)def test_add_zero(self):self.assertEqual(add(0, 0), 0)if __name__ == '__main__':unittest.main()
在这个实例中,TestAddFunction类包含了三个测试方法,分别测试了不同情况下的加法运算。setUp和tearDown方法可以用来设置测试环境或清理资源,尽管在这个例子中它们只是打印信息。
运行这个脚本时,unittest框架会自动识别并执行所有以test开头的方法。
注意事项
-
独立的测试:
- 每个测试方法应该是独立的,不依赖于其他测试的结果。
-
小而集中的测试:
- 每个测试应专注于特定的功能点,避免编写大而复杂的测试。
-
使用断言:
- 合理使用各种断言方法来确保代码的行为符合预期。
-
异常测试:
- 如果函数预期会抛出异常,可以使用
assertRaises方法来测试。
- 如果函数预期会抛出异常,可以使用
-
测试覆盖率:
- 考虑使用覆盖率工具来确保代码的重要部分都被测试覆盖。
使用unittest框架,你可以为Python代码编写稳健的自动化测试,提高代码质量和可维护性。
unittest查找测试用例规则
在Python中,unittest框架通过一套特定的规则来查找测试用例。这些规则确定了哪些类和方法被认为是测试用例,以及如何组织测试代码,以便unittest能够自动找到并执行它们。以下是unittest查找测试用例的具体方式及其详细解释:
1. 测试文件命名
unittest默认查找以test开头的文件名。例如,test_example.py会被认为是一个包含测试用例的文件。
2. 测试类和方法命名
- 在这些测试文件中,
unittest寻找继承自unittest.TestCase的类。 - 在这些类中,任何以
test开头的方法都被视为一个测试用例。 - 例如,一个名为
TestExample的类中的test_function方法会被认为是一个测试用例。
3. 使用测试发现(Test Discovery)
- 当在命令行中使用
python -m unittest discover时,unittest会在当前目录及其子目录中搜索测试文件。 - 可以通过
-s选项来指定开始搜索的目录,通过-p来指定匹配的文件模式。例如,python -m unittest discover -s tests -p "*_test.py"会在tests目录中搜索所有以_test.py结尾的文件。
4. 手动加载测试用例
- 也可以手动创建一个测试套件(Test Suite),在其中显式添加测试用例或测试类。然后,使用
unittest.TextTestRunner来运行这个套件。
注意事项
-
测试文件位置:
- 确保测试文件位于
unittest搜索的目录中。通常,将测试文件放在项目的根目录或专门的测试目录中。
- 确保测试文件位于
-
测试类的继承:
- 只有继承自
unittest.TestCase的类中的方法才会被认为是测试用例。
- 只有继承自
-
测试方法的独立性:
- 每个测试方法应该是独立的,这样它们可以单独运行,而不会互相影响。
-
setUp和tearDown方法:
- 可以在测试类中使用
setUp和tearDown方法来进行每个测试前后的准备和清理工作。
- 可以在测试类中使用
通过遵循这些规则和最佳实践,unittest能够有效地识别和执行项目中的测试用例。
unittest.TestCase类的常见测试方法
unittest.TestCase 是Python标准库unittest框架的核心组件之一,提供了一系列用于编写测试用例的方法。以下是一些常见的TestCase类方法及其用法:
1. setUp和tearDown
setUp方法:在每个测试方法运行之前调用,用于测试准备。tearDown方法:在每个测试方法运行之后调用,用于清理代码。
示例:
class MyTests(unittest.TestCase):def setUp(self):# 测试前的准备工作self.list = [1, 2, 3]def tearDown(self):# 测试后的清理工作del self.list
2. 断言方法
assertEqual(a, b):检查a和b是否相等。assertTrue(x):检查x是否为True。assertFalse(x):检查x是否为False。assertRaises(Error, func, *args, **kwargs):检查func(*args, **kwargs)是否抛出Error。
示例:
class MyTests(unittest.TestCase):def test_equal(self):self.assertEqual(1 + 1, 2)def test_true(self):self.assertTrue(1 + 1 == 2)def test_false(self):self.assertFalse(1 + 1 == 3)def test_raises(self):with self.assertRaises(ZeroDivisionError):_ = 1 / 0
3. 其他常用断言
assertIn(a, b):检查a是否在b中。assertIsNone(x):检查x是否为None。assertIsInstance(a, b):检查对象a是否是类b的实例。
示例:
class MyTests(unittest.TestCase):def test_in(self):self.assertIn(1, [1, 2, 3])def test_is_none(self):self.assertIsNone(None)def test_instance(self):self.assertIsInstance("hello", str)
注意事项
- 独立性:每个测试应该是独立的。不要让测试间的结果相互影响。
- 小型测试:尽可能使测试小而集中。每个测试应只测试一个功能。
- 可读性:测试代码也是代码,保持其清晰和可维护性是很重要的。
- 命名规则:测试方法的名称应该描述它测试的功能,并以
test开头。 - 测试覆盖率:尽量提高代码的测试覆盖率,测试各种边界条件和异常情况。
通过使用unittest.TestCase类的这些方法和最佳实践,你可以编写出可靠和高效的自动化测试用例。
高阶函数
高阶函数在Python中是一种非常有用的功能,它指的是能够接受函数作为参数,或者返回一个函数作为结果的函数。这种类型的函数使得Python编程更加灵活和表达力强。
使用方法
-
作为参数的函数:
- 高阶函数可以接受一个或多个函数作为输入。这些函数作为参数传递,通常用于对数据进行操作。
- 示例:
map()函数接受一个函数和一个列表,然后将该函数应用于列表中的每个元素。def square(x):return x * xnumbers = [1, 2, 3, 4] squared = map(square, numbers) print(list(squared)) # 输出: [1, 4, 9, 16]
-
返回函数的函数:
- 高阶函数还可以返回另一个函数,允许动态地创建和返回函数。
- 示例:闭包用于创建特定的函数实例。
def power(exponent):def inner(base):return base ** exponentreturn innersquare = power(2) print(square(3)) # 输出: 9
注意事项
-
可读性:
- 在使用高阶函数时,应考虑到代码的可读性。过度使用或在复杂场景中使用高阶函数可能会使代码难以理解。
-
性能考虑:
- 在某些情况下,高阶函数(如
map和filter)可能不如列表推导式或循环快。在关注性能的情况下,需要考虑是否有更合适的选择。
- 在某些情况下,高阶函数(如
-
函数作为一等公民:
- 在Python中,函数是一等公民,这意味着可以像使用其他对象一样使用函数。这是高阶函数工作的基础。
-
状态封装:
- 高阶函数返回的函数可以封装状态(闭包),这是一种强大的功能,但也需要小心状态管理,避免不必要的副作用。
-
测试和调试:
- 测试和调试涉及高阶函数的代码可能比普通函数更复杂,因为函数的动态性质可能会隐藏错误。
-
函数接口明确:
- 当编写接受函数作为参数的高阶函数时,应明确该函数的接口(参数和返回值)。这有助于其他开发者理解和正确使用你的高阶函数。
通过合理地使用高阶函数,你可以使Python代码更加灵活、更具表达力。同时,它们在处理像函数式编程这样的范式时非常有用。
匿名函数
在Python中,匿名函数通常指的是通过lambda关键字定义的函数。lambda函数是一种简洁的定义函数的方式,通常用于需要小型、一次性或内联函数的场合。
使用方法
-
基本语法:
lambda函数的基本语法是:lambda arguments: expression。- 这里的
expression是一个表达式,它在函数被调用时计算并返回其结果。
-
示例:
- 下面是一个
lambda函数的简单例子,它接受两个参数并返回它们的和:add = lambda x, y: x + y print(add(2, 3)) # 输出: 5
- 下面是一个
-
与高阶函数结合使用:
lambda函数通常与高阶函数(如map、filter和sorted)结合使用。- 示例:使用
lambda函数来提取列表中每个元素的第二个元素:pairs = [(1, 'one'), (2, 'two'), (3, 'three')] pairs.sort(key=lambda pair: pair[1]) print(pairs) # 输出: [(3, 'three'), (1, 'one'), (2, 'two')]
注意事项
-
简洁性:
lambda函数应该简短且简单。如果函数变得复杂,最好使用标准的函数定义。
-
限制:
lambda函数限制为单个表达式。这意味着不能有多个独立的语句或注释。
-
可读性:
- 在某些情况下,使用
lambda函数可能会降低代码的可读性。请在使代码更简洁和保持良好可读性之间取得平衡。
- 在某些情况下,使用
-
不使用循环或条件语句:
lambda函数不允许使用循环或多个条件语句。在需要这些结构的场合,请使用常规函数。
-
无名称:
lambda函数是匿名的,这意味着它们没有名字。如果需要对函数进行调试或测试,可能会不便。
-
作用域:
- 与常规函数一样,
lambda函数也有自己的作用域,并遵循相同的作用域规则。
- 与常规函数一样,
self.list = [1, 2, 3]
def tearDown(self):# 测试后的清理工作del self.list
### 2. 断言方法- **`assertEqual(a, b)`**:检查`a`和`b`是否相等。
- **`assertTrue(x)`**:检查`x`是否为True。
- **`assertFalse(x)`**:检查`x`是否为False。
- **`assertRaises(Error, func, *args, **kwargs)`**:检查`func(*args, **kwargs)`是否抛出`Error`。#### 示例:
```python
class MyTests(unittest.TestCase):def test_equal(self):self.assertEqual(1 + 1, 2)def test_true(self):self.assertTrue(1 + 1 == 2)def test_false(self):self.assertFalse(1 + 1 == 3)def test_raises(self):with self.assertRaises(ZeroDivisionError):_ = 1 / 0
3. 其他常用断言
assertIn(a, b):检查a是否在b中。assertIsNone(x):检查x是否为None。assertIsInstance(a, b):检查对象a是否是类b的实例。
示例:
class MyTests(unittest.TestCase):def test_in(self):self.assertIn(1, [1, 2, 3])def test_is_none(self):self.assertIsNone(None)def test_instance(self):self.assertIsInstance("hello", str)
注意事项
- 独立性:每个测试应该是独立的。不要让测试间的结果相互影响。
- 小型测试:尽可能使测试小而集中。每个测试应只测试一个功能。
- 可读性:测试代码也是代码,保持其清晰和可维护性是很重要的。
- 命名规则:测试方法的名称应该描述它测试的功能,并以
test开头。 - 测试覆盖率:尽量提高代码的测试覆盖率,测试各种边界条件和异常情况。
通过使用unittest.TestCase类的这些方法和最佳实践,你可以编写出可靠和高效的自动化测试用例。
高阶函数
高阶函数在Python中是一种非常有用的功能,它指的是能够接受函数作为参数,或者返回一个函数作为结果的函数。这种类型的函数使得Python编程更加灵活和表达力强。
使用方法
-
作为参数的函数:
- 高阶函数可以接受一个或多个函数作为输入。这些函数作为参数传递,通常用于对数据进行操作。
- 示例:
map()函数接受一个函数和一个列表,然后将该函数应用于列表中的每个元素。def square(x):return x * xnumbers = [1, 2, 3, 4] squared = map(square, numbers) print(list(squared)) # 输出: [1, 4, 9, 16]
-
返回函数的函数:
- 高阶函数还可以返回另一个函数,允许动态地创建和返回函数。
- 示例:闭包用于创建特定的函数实例。
def power(exponent):def inner(base):return base ** exponentreturn innersquare = power(2) print(square(3)) # 输出: 9
注意事项
-
可读性:
- 在使用高阶函数时,应考虑到代码的可读性。过度使用或在复杂场景中使用高阶函数可能会使代码难以理解。
-
性能考虑:
- 在某些情况下,高阶函数(如
map和filter)可能不如列表推导式或循环快。在关注性能的情况下,需要考虑是否有更合适的选择。
- 在某些情况下,高阶函数(如
-
函数作为一等公民:
- 在Python中,函数是一等公民,这意味着可以像使用其他对象一样使用函数。这是高阶函数工作的基础。
-
状态封装:
- 高阶函数返回的函数可以封装状态(闭包),这是一种强大的功能,但也需要小心状态管理,避免不必要的副作用。
-
测试和调试:
- 测试和调试涉及高阶函数的代码可能比普通函数更复杂,因为函数的动态性质可能会隐藏错误。
-
函数接口明确:
- 当编写接受函数作为参数的高阶函数时,应明确该函数的接口(参数和返回值)。这有助于其他开发者理解和正确使用你的高阶函数。
通过合理地使用高阶函数,你可以使Python代码更加灵活、更具表达力。同时,它们在处理像函数式编程这样的范式时非常有用。
匿名函数
在Python中,匿名函数通常指的是通过lambda关键字定义的函数。lambda函数是一种简洁的定义函数的方式,通常用于需要小型、一次性或内联函数的场合。
使用方法
-
基本语法:
lambda函数的基本语法是:lambda arguments: expression。- 这里的
expression是一个表达式,它在函数被调用时计算并返回其结果。
-
示例:
- 下面是一个
lambda函数的简单例子,它接受两个参数并返回它们的和:add = lambda x, y: x + y print(add(2, 3)) # 输出: 5
- 下面是一个
-
与高阶函数结合使用:
lambda函数通常与高阶函数(如map、filter和sorted)结合使用。- 示例:使用
lambda函数来提取列表中每个元素的第二个元素:pairs = [(1, 'one'), (2, 'two'), (3, 'three')] pairs.sort(key=lambda pair: pair[1]) print(pairs) # 输出: [(3, 'three'), (1, 'one'), (2, 'two')]
注意事项
-
简洁性:
lambda函数应该简短且简单。如果函数变得复杂,最好使用标准的函数定义。
-
限制:
lambda函数限制为单个表达式。这意味着不能有多个独立的语句或注释。
-
可读性:
- 在某些情况下,使用
lambda函数可能会降低代码的可读性。请在使代码更简洁和保持良好可读性之间取得平衡。
- 在某些情况下,使用
-
不使用循环或条件语句:
lambda函数不允许使用循环或多个条件语句。在需要这些结构的场合,请使用常规函数。
-
无名称:
lambda函数是匿名的,这意味着它们没有名字。如果需要对函数进行调试或测试,可能会不便。
-
作用域:
- 与常规函数一样,
lambda函数也有自己的作用域,并遵循相同的作用域规则。
- 与常规函数一样,
lambda函数在Python中提供了一种快速定义小型函数的方式,尤其是在需要临时函数时。它们在函数式编程风格中尤其有用,但应注意在合适的场景中使用,避免过度复杂化。
相关文章:
Python基础快速入门
Python基础快速入门 前置知识 Python Python是一种广泛使用的高级编程语言,以其易于学习和使用的语法而闻名。以下是Python的一些主要特点: 高级语言:Python是一种高级语言,这意味着它提供了较高层次的抽象,使编程更…...
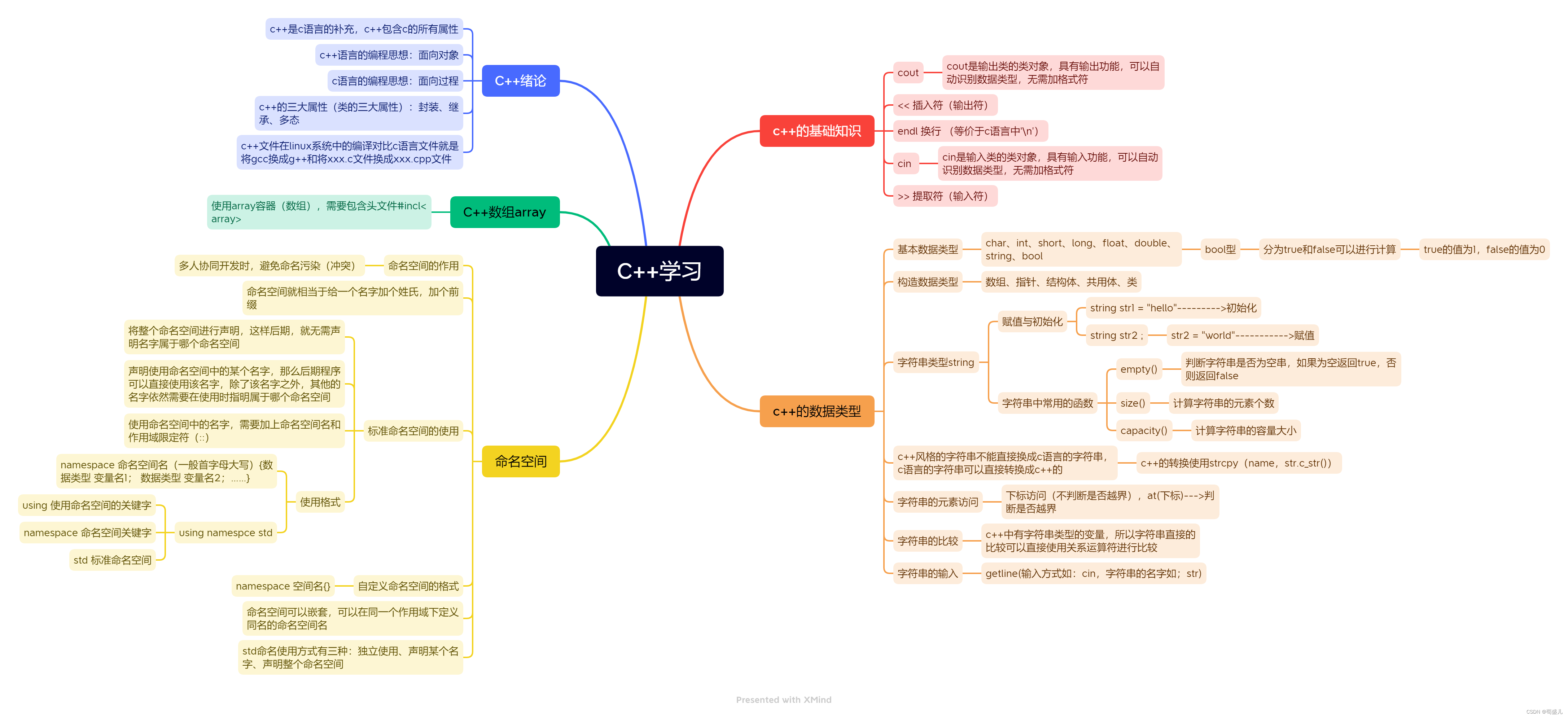
C++的学习
代码练习 输入一个字符串,统计其中大写字母、小写字母、数字、空格以及其他字符的个数 #include <iostream>using namespace std;int main() {cout << "请输入一个字符串" << endl;string str;getline(cin,str);int capital 0;int l…...

工地安全反光衣穿戴监测报警摄像机
工地安全反光衣穿戴监测报警摄像机是为了提高工地施工人员的安全意识和监管效率而设计的。这种设备结合了反光衣、监测系统和报警摄像机的功能,可以有效减少工地事故的发生。 首先,工地安全反光衣是一种具有高度可见度的服装,能够使穿戴者在夜…...
UNIAPP微信小程序中使用Base64编解码原理分析和算法实现
为何要加上UNIAPP及微信小程序,可能是想让检索的翻围更广把。😇 Base64的JS原生编解码在uni的JS引擎中并不能直接使用,因此需要手写一个原生的Base64编解码器。正好项目中遇到此问题,需要通过URLLink进行小程序跳转并携带Base64参…...

人工智能|机器学习——K-means系列聚类算法k-means/ k-modes/ k-prototypes/ ......(划分聚类)
1.k-means聚类 1.1.算法简介 K-Means算法又称K均值算法,属于聚类(clustering)算法的一种,是应用最广泛的聚类算法之一。所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,…...
注意力、自注意力和多头注意力的区别
本文作者: slience_me 注意力、自注意力和多头注意力的区别 理解注意力(Attention)、自注意力(Self-Attention)和多头注意力(Multi-Head Attention)之间的区别非常重要,因为它们是自…...

FTP,SFTP,FTPS,SSL,TSL简介,区别,联系,使用场景说明
文章目录 简介FTPFTPSSFTP加密场景选择FTPS还是SFTPFTP、SFTP、FTPS区别、联系和具体使用场景如何使用FTP、SFTP和FTPSSSLTLSSSL和TLS区别和联系,以及使用场景SSL和TLS技术上的区别一些问题隐式的TLS(FTPS/SSL)或者显式的TLS(FTPS…...

路由算法与路由协议
路由选择协议的核心是路由算法,即需要何种算法来获得路由表中的各个项目。 路由算法的目的很简单:给定一组路由器以及连接路由器的链路,路由算法要找到一条从源路由器到目标路由器的最佳路径。通常,最佳路径是指具有最低费用的路…...
dubbo接口自动化用例性能优化
前言 去年换了一个新部门,看了下当前的自动化用例的情况,发现存在三类性能问题: 本地调试运行时等待时间较长,就算是一个简单的case,执行时间都需要1分钟以上单用例执行时间比较长,部分用例执行时间超过2…...

.net core框架
ASP.NET Core 入门 跨平台开源框架 B/S 类与方法 Console 部分称为“类”。 类“拥有”方法;或者可以说方法存在于类中。 WriteLine() 部分称为“方法”。 想要使用方法就要知道方法在哪里 —————————— 执行流 一次执行一段 ASP.NET Core 是什么东西…...
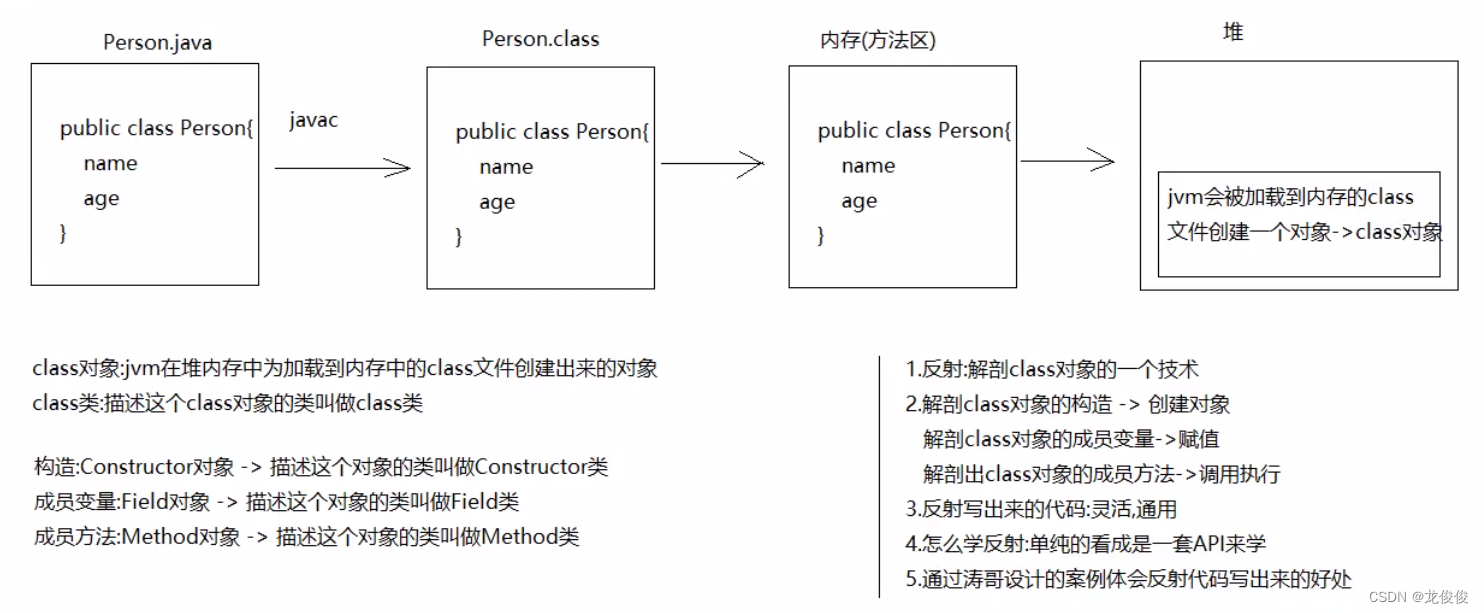
学习大数据,所需要Java基础(9)
文章目录 网络编程实现简答客户端和服务器端的交互编写客户端编写服务端 文件上传文件上传客户端以及服务器端实现文件上传服务器端实现(多线程)文件上传服务器端(连接池版本)关闭资源工具类 BS架构服务器案例案例分析BS结构服务器…...
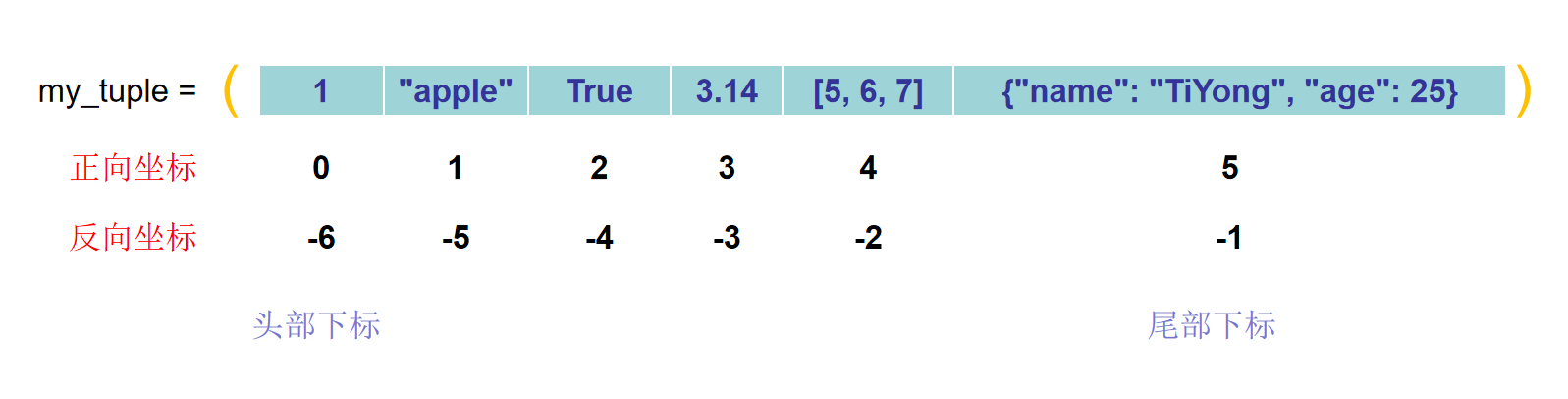
Python元组(Tuple)深度解析!
目录 1. 什么是元组? 2. 创建元组 3.访问元组 4.元组的运算 5.修改元组不可行 6.元组的应用场景 前面的博客里,我们详细介绍了列表(List)这一种数据类型,现在我们来讲讲与列表相似的一种数据类型,元组…...

排序 Comparable接口、Comparator接口
String类的Comparable接口 1、String类实现了Comparable<String>接口,并提供了compareTo方法的实现,因此,字符串对象(即String类型的实例)可以直接调用compareTo()方法来比较它们。2、String类的compareTo()方法…...
得帆助力大族激光主数据平台建设,用数据为企业生产力赋能
本期客户 大族激光科技产业集团股份有限公司(以下简称“大族激光”)是一家从事工业激光加工设备与自动化等配套设备及其关键器件的研发、生产、销售,激光、机器人及自动化技术在智能制造领域的系统解决方案的优质提供商,是国内激光…...

实名认证电子签署:防范合同纠纷,提升交易信任
当今社会,随着数字化和信息化的发展,电子合同已经成为商务活动中常见的签署方式。而在签署电子合同时进行实名认证,是为了确保合同的真实性、合法性和安全性。本文将从法律、技术和实际应用等方面详细解释为什么签署电子合同需要进行实名认证…...

c++ primer中文版第五版作业第十八章
仓库地址 文章目录 18.118.218.318.418.518.618.718.818.918.1018.1118.1218.1318.1418.1518.16位置一using声明 位置二using声明 位置一using指示 位置二using指示 18.1718.1818.1918.2018.2118.2218.2318.2418.2518.2618.2618.2818.2918.30 18.1 此时r是一个range_error类型…...

vue触发真实的点击 事件 跟用户行为一致
<template><div><button ref"myButton" click"handleClick">按钮</button></div> </template><script> export default {methods: {handleClick() {const button this.$refs.myButton;// 创建一个鼠标点击事件…...

Java进程CPU高负载排查
Java进程CPU高负载排查步骤_java进程cpu使用率高排查_YouluBank的博客-CSDN博客 【问题定位】使用arthas定位CPU高的问题_arthas cpu高_秋装什么的博客-CSDN博客 CPU飙升可能原因 CPU 上下文切换过多。 对于 CPU 来说,同一时刻下每个 CPU 核心只能运行-个线程&…...

Linux编程4.1 网络编程-前导
1、内容概述 网络的基本概念TCP/IP协议概述OSI和TCP/IP模型掌握TCP协议网络基础编程掌握UDP协议网络基础檹网络高级编程 2、计算机联网的目的 使用远程资源共享信息、程序和数据分布处理 3、基本概念 单服务与多客户端的进程间通信C/S client server 由于,跨计…...

【微信小程序】传参存储
目录 一、本地数据存储 wx.setStorage wx.setStorageSync 1.1、异步缓存 存取数据 1.2、同步缓存 存取数据 二、使用url跳转路径携带参数 2.1、 wx.redirectTo({}) 2.2、 wx.navigateTo({}) 2.3、 wx.switchTab({}) 2.4 、wx.reLaunch({}) 2.5、组件跳转 三、…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

Claude Code 之父:2026 年我一行代码都没写,编程已被 AI 解决
2026 年,你还在一行一行敲代码吗?Claude Code 的创造者、Anthropic 核心人物 Boris Cherny,在公开访谈里抛出一句让整个行业震动的话:2026 年到现在,我没有写过一行代码。所有开发工作,100% 交给 AI 代理完…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...

FeHelper前端助手:30+开发工具集,让你的浏览器变身效率神器
FeHelper前端助手:30开发工具集,让你的浏览器变身效率神器 【免费下载链接】FeHelper 😍FeHelper--Web前端助手(Awesome!Chrome & Firefox & MS-Edge Extension, All in one Toolbox!) 项目地址:…...

Ubuntu经常安装软件
1、垃圾清理工具stacer sudo apt updatesudo apt install stacer apt cleanapt autocleanapt autoremove 2、类似与everything的工具Fsearcch 1sudo add-apt-repository ppa:christian-boxdoerfer/fsearch-stable 2sudo apt update 3sudo apt install fsearch (注…...

Arduino ADC自检:用RC电路诊断模数转换器故障
1. 项目概述:当你的体重秤开始“说谎”你有没有遇到过这样的情况:站上家里的电子体重秤,屏幕上跳出来的数字让你瞬间怀疑人生?要么是轻得离谱,要么是重得吓人,更诡异的是,它可能只在两个固定的、…...

Python-for-Android 完整指南:5分钟将Python应用打包为Android APK
Python-for-Android 完整指南:5分钟将Python应用打包为Android APK 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android࿰…...

ImageGlass:一个支持90+图像格式的轻量级Windows图片查看器
ImageGlass:一个支持90图像格式的轻量级Windows图片查看器 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 还在为Windows自带的图片查看器功能单一而烦恼吗&…...

使用curl命令调试Taotoken API接口的常见问题排查
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令调试Taotoken API接口的常见问题排查 基础教程类,面向所有需要通过HTTP直接与API交互的开发者,…...