3.12练习题解
1.台阶问题:

这道题目一看其实很容易想到可以用dp的板子去做,并且只需要用一维dp即可,其中dp的下标表示到达当前阶梯总共有多少种方法,由于结果有可能会很大所以一定要记得边记录边模,代码实现如下:
#include<bits/stdc++.h>
using namespace std;
const int mod = 100003;
int n,k;
int dp[100010];
int main(){ios::sync_with_stdio(false);cin.tie(nullptr);cout.tie(nullptr);cin>>n>>k;dp[0]=dp[1]=1;for(int i=2;i<=n;i++){for(int j=1;j<=k;j++){if(i>=j){dp[i]=(dp[i]+dp[i-j]) % mod;} }}cout<<dp[n]%mod;return 0;
}2.递增三元组:

这一道题目的意思是比较好理解的,我们需要考虑的是,由于给的N的极限值是1e5,所以暴力的方式时间复杂度n的三方肯定会爆,于是我们就要考虑如何对时间复杂度进行优化。
我们可以这样进行考虑,由于数组b是中间数组,我们不妨先对三个数组进行排序,然后我们对b进行枚举,对于每一次枚举,我们在a数组中找到所有小于当前枚举对应的b数组下标元素的个数,然后再找到c数组中所有大于当前b数组下标所对应的元素个数,再把当前符合条件的总个数加到ans上面即可。
再继续思考我们对于每次枚举,然后在a,c数组中查找符合要求的,都可以通过二分进行查找从而降低时间复杂度。所以代码如下:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;typedef long long LL;
const int N = 1e5+10;
int num[3][N];int main() {int n;scanf("%d", &n);for(int i = 0; i < 3; ++i) for(int j = 1; j <= n; ++j) scanf("%d", &num[i][j]);for(int i = 0; i < 3; ++i)sort(num[i]+1, num[i]+n+1);LL ans = 0;//枚举B,寻找A满足的个数以及C满足的个数相乘for(int i = 1; i <= n; ++i) {int key = num[1][i];//A中二分查找第一个不小于key的数的下标int pos1 = lower_bound(num[0]+1, num[0]+n+1, key)-num[0]-1;//C中二分查找第一个大于key的数的下标int pos2 = upper_bound(num[2]+1, num[2]+n+1, key)-num[2];if(pos1 >= 1 && pos2 <= n) {ans += (LL)pos1*(n-pos2+1);}}cout<<ans<<endl;return 0;
}
这段代码有需要解释的地方:
num[0]+1:这是指向num数组的第一个元素的下一个位置的指针。换句话说,它指向num数组中的第二个元素。num[0]+n+1:这是指向num数组的最后一个元素的下一个位置的指针。换句话说,它指向num数组之后的第一个位置。lower_bound(num[0]+1, num[0]+n+1, key):这是在num数组的第二个元素和最后一个元素之间(不包括最后一个元素)查找第一个不小于key的元素的迭代器。lower_bound(...)-num[0]-1:这将返回的迭代器与num数组的第一个元素的指针相减,然后减去1。这样,我们得到的是找到的元素在num数组中的索引。
所以,pos1存储的是key在num数组中的位置,如果key不在num数组中,则pos1将是key应该插入的位置,以保持num数组的有序性。
简而言之,这段代码在num数组中查找key的位置,并返回其索引。如果key不在数组中,则返回应该插入key的位置。
在C++中,指针的算术运算实际上是对指针所指向的内存地址进行算术运算。当两个指针指向同一个数组或同一个对象的成员时,它们之间的差值表示两个元素之间的偏移量,这个偏移量是以元素为单位,而不是以字节为单位。
对于数组num,num[0]是一个指向数组第一个元素的指针。当我们执行lower_bound函数时,得到的是一个迭代器,它指向数组中第一个不小于key的元素。这个迭代器也是一个指针,指向数组中的某个元素。
当从lower_bound返回的迭代器中减去num[0]时,得到的是两个指针之间的偏移量,这个偏移量表示从数组的第一个元素到找到的元素之间有多少个元素。因为lower_bound返回的迭代器指向的是数组中的元素,而不是元素之间的空隙,所以这个偏移量实际上就是找到的元素在数组中的下标(从0开始计数)。
最后,减去1,是因为我们希望得到的是下标而不是偏移量。在C++中,数组的下标是从0开始的,而指针的偏移量是从1开始的(即,指向第一个元素的指针偏移量为0,指向第二个元素的指针偏移量为1,依此类推)。因此,减去1将偏移量转换为正确的下标。
所以,lower_bound(...)-num[0]-1的结果就是找到的元素在数组中的下标。
第二种方法:双指针优化:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;typedef long long LL;
const int N = 1e5+10;
int num[3][N];int main() {int n;scanf("%d", &n);for(int i = 0; i < 3; ++i) for(int j = 1; j <= n; ++j) scanf("%d", &num[i][j]);for(int i = 0; i < 3; ++i)sort(num[i]+1, num[i]+n+1);LL ans = 0;//枚举B,寻找A满足的个数以及C满足的个数相乘int a = 1, c = 1;for(int i = 1; i <= n; ++i) {int key = num[1][i];while(a<=n && num[0][a] < key) a++;while(c<=n && num[2][c] <= key) c++;ans += (LL)(a-1)*(n-c+1);}cout<<ans<<endl;return 0;
}其实也就是将二分中的部分更改了一下。
之前的双指针算法时间复杂度的瓶颈为:排序O(nlog2n)
考虑是否可以不排序在O(n)的时间内解决此问题呢?
既然要排序实现快速的查找A中小于B[i]的数的个数,可以将数组A中所有元素出现的次数存入一个哈希表中,因为数组中元素的范围只有n5, 可以开一个大的数组cnta 作为哈希表。
在枚举B中元素时,我们需要快速查找找小于B[i]的所有元素的总数,只需要在枚举之前先将求出表中各数的前缀和即可。
查找C与查找A同理可得。
代码如下:
//前缀和
#include <iostream>
#include <cstdio>using namespace std;typedef long long LL;
const int N = 1e5+10;
int A[N], B[N], C[N];
int cnta[N], cntc[N], sa[N], sc[N];int main() {int n;scanf("%d", &n);//获取数i在A中有cntc[i]个,并对cnt求前缀和safor(int i = 1; i <= n; ++i) {scanf("%d", &A[i]);cnta[++A[i]]++;}sa[0] = cnta[0];for(int i = 1; i < N; ++i) sa[i] = sa[i-1]+cnta[i];//B只读取即可for(int i = 1; i <= n; ++i) scanf("%d", &B[i]), B[i]++;//获取数i在C中有cntc[i]个,并对cnt求前缀和scfor(int i = 1; i <= n; ++i) {scanf("%d", &C[i]);cntc[++C[i]]++;}sc[0] = cntc[0];for(int i = 1; i < N; ++i) sc[i] = sc[i-1]+cntc[i]; //遍历B求解LL ans = 0;for(int i = 1; i <= n; ++i) {int b = B[i];ans += (LL)sa[b-1] * (sc[N-1] - sc[b]);}cout<<ans<<endl;return 0;
}感谢您的观看。
相关文章:
3.12练习题解
1.台阶问题: 这道题目一看其实很容易想到可以用dp的板子去做,并且只需要用一维dp即可,其中dp的下标表示到达当前阶梯总共有多少种方法,由于结果有可能会很大所以一定要记得边记录边模,代码实现如下: #incl…...

Java中实现双向链表
一、目标 最近项目中实现双向链表,同时转为满二叉树。 二、代码 用java实现双向链表的代码如下: class TreeNode {int val;TreeNode left;TreeNode right;TreeNode(int x) { val x; } }public class FullBinaryTree {public TreeNode createTree(int[…...

【DevOps实战之k8s】使用Prometheus和Grafana监控K8S集群
【DevOps实战之k8s】使用Prometheus和Grafana监控K8S集群 目录 【DevOps实战之k8s】使用Prometheus和Grafana监控K8S集群系统架构Kubernetes集群指标抓取指标可视化警告PromQL示例按命名空间统计集群中的Pod数按命名空间重启Pod未就绪的PodCPU过度使用Memory过度使用健康的集群…...

【读论文】【精读】3D Gaussian Splatting for Real-Time Radiance Field Rendering
文章目录 1. What:2. Why:3. How:3.1 Real-time rendering3.2 Adaptive Control of Gaussians3.3 Differentiable 3D Gaussian splatting 4. Self-thoughts 1. What: What kind of thing is this article going to do (from the a…...
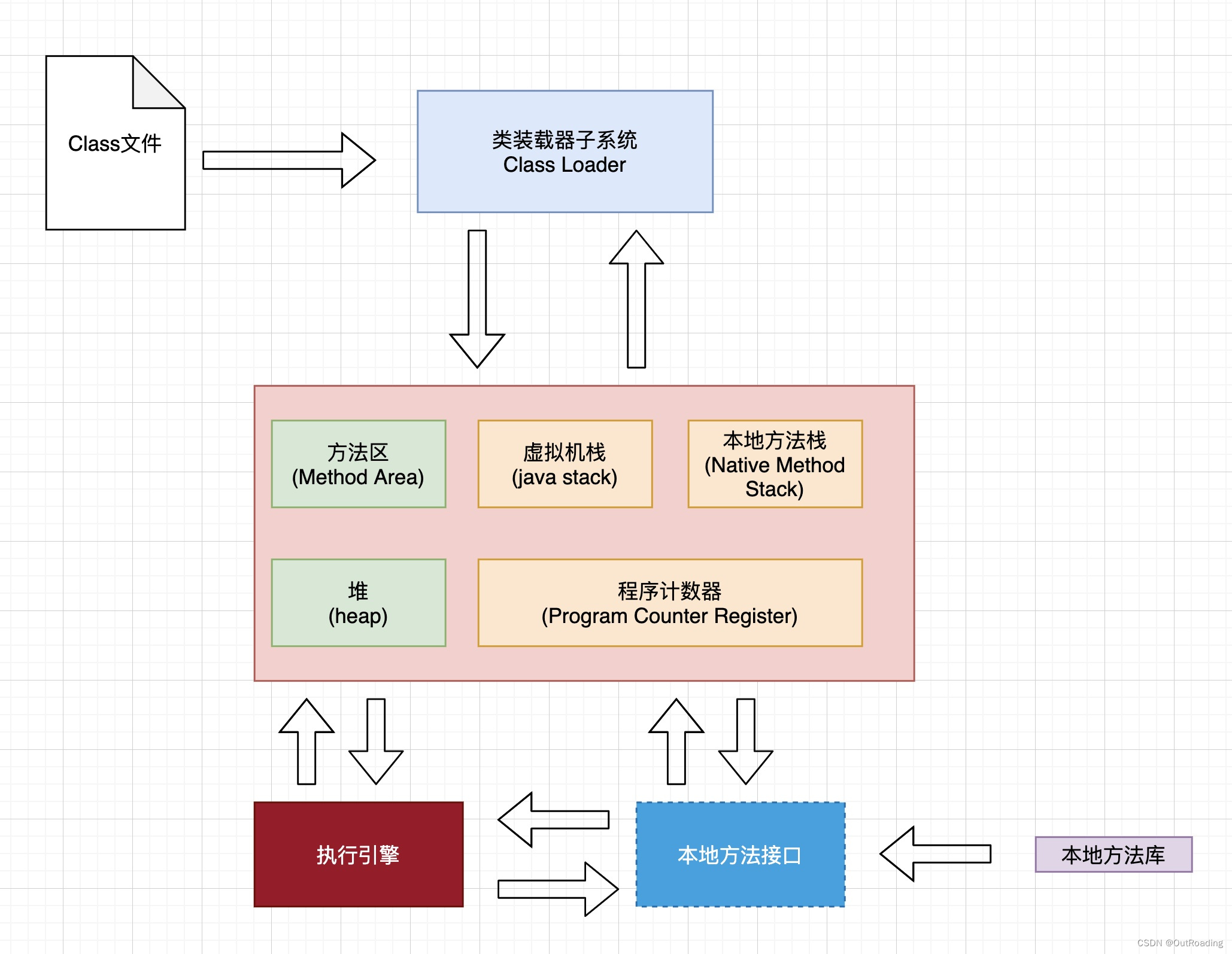
JVM理解学习
参考视频 JVM架构总览图 程序计数器 程序计数器,物理上用寄存器实现。 作用: 记住下一条JVM指令的执行地址 特点: 1 是线程私有的,随着线程的创建而创建,随着线程的消息而消息 2 是一小块内存 3 唯一不会内存溢出的地方…...

使用 Ruby 或 Python 在文件中查找
对于经常使用爬虫的我来说,在大多数文本编辑器都会有“在文件中查找”功能,主要是方便快捷的查找自己说需要的内容,那我有咩有可能用Ruby 或 Python实现类似的查找功能?这些功能又能怎么实现? 问题背景 许多流行的文本…...

python实现冒泡排序
冒泡排序是一种简单的排序算法,它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。 以下是用Python实现冒泡排序的代…...
)
大数据开发(HBase面试真题-卷二)
大数据开发(HBase面试真题) 1、HBase读写数据流程?2、HBase的读写缓存?3、在删除HBase中的一个数据的时候,它什么时候真正的进行删除呢?4、HBase的一个region由哪些东西组成?5、HBase的rowkey为…...
基于springboot+vue的线上教育系统(源码+论文)
目录 前言 一、功能设计 二、功能实现 三、库表设计 四、论文 前言 现在大家的生活方式正在被计算机的发展慢慢改变着,学习方式也逐渐由书本走向荧幕,我认为这并不是不能避免的,但说实话,现在的生活方式与以往相比有太大的改变,人们的娱乐方式不仅仅…...

01-shell的自学课-基础变量学习
一、echo变量的一个坑 声明【临时变量】,然后打印出来;(拓展:env是linux的全局变量) [rootgong ~]# xinjizhiwashell [rootgong ~]# echo $xinjizhiwa shell [rootgong ~]# echo $xinjizhiwa-haha shell-haha [rootgo…...

鸿蒙Harmony应用开发—ArkTS声明式开发(基础手势:Span)
作为Text组件的子组件,用于显示行内文本的组件。 说明: 该组件从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 该组件从API Version 10开始支持继承父组件Text的属性,即如果子组件未设置…...

前端框架的演进之路:从静态网页到现代交互体验的探索
前端框架的发展史 随着互联网的快速发展,前端技术也在不断进步,前端框架作为前端开发的重要工具,经历了从简单到复杂、从单一到多元的演变过程。本文将回顾前端框架的发展史,探讨其变迁背后的原因和趋势。 一、静态网页时代 在…...

在Linux/Ubuntu/Debian中设置字体
下载字体。 下载你喜欢的字体,双击并安装。 之后更新字体缓存: fc-cache -f -v安装 GNOME 调整。 GNOME Tweaks 是一个工具,允许你自定义 GNOME 桌面环境的各个方面,包括字体。 如果你还没有安装 GNOME Tweaks: …...

Python 常用内置函数,及实例演示
Python的内置函数非常强大,可以帮助你完成各种任务。以下是20个非常有用的Python内置函数及其使用实例: 1. abs() 返回数字的绝对值。 print(abs(-5)) # 输出:52. all() 如果迭代器的所有元素都为真(或迭代器为空)…...

C++标准输入输出和名字空间
C标准输入输出和名字空间 标准输入输出 在C中,标准输入输出(I/O)是通过标准库中的iostream库来实现的,它提供了一套流(stream)抽象来进行数据的输入和输出操作。这套流抽象包括输入流用于读取数据&#x…...

hive逗号分割行列转换
select * from ( select back_receipt_nos,order_no,reject_no from ods_oneplus.ods_us_wms_reject_order_match_all_d where order_no 10150501385980001 ) t1 lateral view explode(split(t1.back_receipt_nos, ,)) t as back_receipt_no where 1 1;...
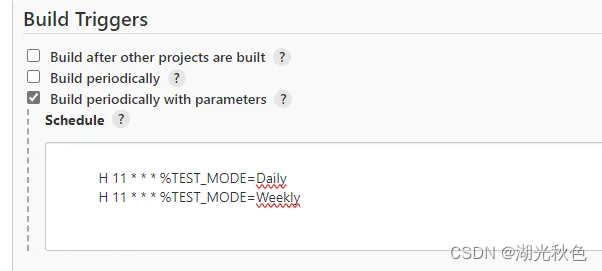
Jenkins插件Parameterized Scheduler用法
Jenkins定时触发构建的同时设定参数。可以根据不同的定时构建器设置不同参数或环境变量的值。可以设置多个参数。并结合when控制stage流程的执行。结合when和triggeredBy区分定时构建的stage和手动执行的stage。 目录 什么是Parameterized Scheduler?如何配置实现呢…...

西门子S7.NET通信库【读】操作详解
在使用西门子PLC进行工业自动化控制的过程中,经常需要与PLC进行数据交换。S7.NET是一款广泛应用于.NET平台的西门子PLC通信库,它为开发者提供了一系列的API函数,以便在C#、VB.NET等.NET语言中轻松实现与西门子PLC的数据交互。本文将详细介绍如…...

Qt/C++音视频开发69-保存监控pcm音频数据到mp4文件/监控录像/录像存储和回放/264/265/aac/pcm等
一、前言 用ffmpeg做音视频保存到mp4文件,都会遇到一个问题,尤其是在视频监控行业,就是监控摄像头设置的音频是PCM/G711A/G711U,解码后对应的格式是pcm_s16be/pcm_alaw/pcm_mulaw,将这个原始的音频流保存到mp4文件是会…...

闲聊Swift的枚举关联值
闲聊Swift的枚举关联值 枚举,字面上理解,就是把东西一件件列出来。 在许多计算机语言中,枚举都是一种重要的数据结构。使用枚举可以使代码更简洁,语义性更强,更加健壮。 Swift语言也不例外。但和其他语言相比…...

Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 [特殊字符]
Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 🚀 【免费下载链接】spring-cloud-aws The New Home for Spring Cloud AWS 项目地址: https://gitcode.com/gh_mirrors/sp/spring-cloud-aws Spring Cloud AWS 是一个强大的开源框架&…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

2605.VGGT-Omega 论文解读: 3D重建的Scaling Law, Register Attention效率革命 | Oxford+Meta CVPR26 Oral
VGGT-Omega: Scaling Feed-Forward 3D Reconstruction Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schonberger, et al. Visual Geometry Group, Oxford Meta AI | CVPR 2026 Oral | arXiv 2605.15195 Paper | Project Page 一句话总结 VGGT-Om…...

电容损坏深度诊断,从外观到 ESR精准区分容衰与漏电
在 PCB 故障中,电容损坏占比超 40%,是当之无愧的 “头号杀手”。很多工程师仅靠 “鼓包漏液” 判断电容好坏,殊不知80% 的电容损坏是隐性的—— 外观平整但容值衰减、ESR 升高、轻微漏电,导致供电不稳、系统重启、噪声增大&#x…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...

Unity塔防底层架构:ScriptableObject驱动的数据契约设计
1. 这不是“又一个塔防模板”,而是塔防开发的底层操作系统我第一次在Asset Store点开Tower Defense Toolkit 4(TDTK-4)的预览图时,下意识划走了——界面太“干净”了,没有炫酷的粒子特效演示,没有满屏飞舞的…...

对比不同模型在创意生成任务中的效果与token消耗差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比不同模型在创意生成任务中的效果与token消耗差异 在为一场创意大赛准备素材时,我们面临一个常见的选择:…...