yield代码解释
目录
我们的post请求爬取百度翻译的代码
详细解释
解释一
解释二
再说一下callback
总结
发现了很多人对存在有yield的代码都不理解,那就来详细的解释一下
我们的post请求爬取百度翻译的代码
import scrapy
import jsonclass TestpostSpider(scrapy.Spider):name = "testpost"allowed_domains = ["fanyi.baidu.com"]# post请求如果没有参数,那抹这个请求将没有任何的意义# 所以 start_urls 也是没有用# 而且 parse 方法也没有用了# 所以直接注释掉# TODO# start_urls = ["https://fanyi.baidu.com/sug"]## def parse(self, response):# print("==========================")# post请求就使用这个方法def start_requests(self):url = 'https://fanyi.baidu.com/sug'data = {'kw': 'final'}yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second)def parse_second(self, response):content = response.textobj = json.loads(content)print(obj)
这段代码是一个使用Scrapy框架实现的爬虫程序。代码中定义了一个名为TestpostSpider的Spider类,继承自Scrapy的Spider类。Spider类用于定义爬取和解析网页的逻辑。
该爬虫程序的目标网站是百度翻译接口(fanyi.baidu.com)。在start_requests方法中,定义了一个POST请求,请求的URL是'https://fanyi.baidu.com/sug'。请求的数据data是一个字典,包含了一个参数kw和对应的值'final'。通过scrapy.FormRequest方法发送POST请求,并指定回调函数为parse_second。
在parse_second方法中,处理了响应,将响应内容转换为JSON格式,并打印出来。
整个爬虫程序的作用是向百度翻译接口发送一个POST请求,请求参数为'final',并将返回的响应内容解析为JSON格式并打印出来。
详细解释
-
import scrapy和import json:导入Scrapy框架和JSON库。 -
class TestpostSpider(scrapy.Spider)::定义一个名为TestpostSpider的Spider类,该类继承自Scrapy的Spider类。 -
name = "testpost":指定爬虫的名称为"testpost"。 -
allowed_domains = ["fanyi.baidu.com"]:设置允许爬取的域名为"fanyi.baidu.com"。 -
def start_requests(self)::定义一个方法用于生成初始请求。-
url = 'https://fanyi.baidu.com/sug':设置目标URL为百度翻译的sug API。 -
data = {'kw': 'final'}:构造POST请求的表单数据,其中'kw'参数的值为'final'。 -
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second):使用scrapy.FormRequest生成POST请求,并指定回调函数为parse_second。yield关键字用于生成请求对象,使得Scrapy能够异步处理请求。
-
-
def parse_second(self, response)::定义一个回调函数,用于处理POST请求的响应。-
content = response.text:获取响应的文本内容。 -
obj = json.loads(content):将响应内容解析为JSON格式。注意,json.loads()方法中不需要指定encoding参数,因为Scrapy已经以Unicode格式解码了响应内容。 -
print(obj):打印解析后的JSON数据。
-
解释一
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second) 这句代码是在start_requests方法中使用yield关键字创建了一个scrapy.FormRequest对象,并将其返回。scrapy.FormRequest表示一个POST请求,可以指定请求的URL、表单数据和回调函数。
url=url:指定请求的URL为url变量的值,即'https://fanyi.baidu.com/sug'。formdata=data:指定请求的表单数据为data变量的值,即{'kw': 'final'}。callback=self.parse_second:指定请求完成后的回调函数为parse_second方法。当请求完成后,Scrapy会将响应传递给parse_second方法进行处理。
通过使用yield关键字返回scrapy.FormRequest对象,该对象将被Scrapy的引擎接收并执行。这样,Scrapy将会发送POST请求到指定的URL,并在获取到响应后调用parse_second方法进行处理。
解释二
这句代码使用了scrapy.FormRequest来生成一个POST请求。
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second)
-
url=url:指定请求的目标URL,即要发送POST请求的地址,这里是百度翻译的suggest API。 -
formdata=data:设置POST请求的表单数据,这是一个字典,其中键值对表示表单中的字段和相应的值。在这个例子中,'kw': 'final'是表单中的一个字段和值。 -
callback=self.parse_second:指定了请求成功后的回调函数,即在收到响应后要执行的函数。在这里,回调函数是parse_second,该函数会处理服务器返回的响应。 -
yield:这是关键的异步操作部分。通过使用yield,Scrapy能够以异步的方式处理请求,而不会阻塞程序的执行。这使得程序能够同时发送多个请求并处理它们的响应,提高了效率。
总体来说,这一行代码的作用是生成一个POST请求,发送到指定的URL,携带特定的表单数据,并在成功获取响应后调用parse_second函数进行处理。使用yield确保了异步操作,使得爬虫能够高效地处理多个请求。
再说一下callback
例子
import scrapyclass ExampleSpider(scrapy.Spider):name = "example"start_urls = ["http://quotes.toscrape.com/page/1/", "http://quotes.toscrape.com/page/2/"]def parse(self, response):for quote in response.css('div.quote'):text = quote.css('span.text::text').get()author = quote.css('span small::text').get()yield {'text': text,'author': author,}# 跟踪翻页链接next_page = response.css('li.next a::attr(href)').get()if next_page:yield scrapy.Request(url=next_page, callback=self.parse)
callback=self.parse 的部分指定了在新请求完成后应该调用的回调函数,也就是处理新响应的方法。在这个例子中,回调函数是 parse 方法。
在 Scrapy 中,parse 是默认的回调函数名称,用于处理初始请求的响应。当新请求被生成并完成后,Scrapy 将调用指定的回调函数来处理新的响应。这种设计使得爬虫能够以递归的方式处理多个页面,特别是在需要翻页时。
在翻页的情况下,通过 yield scrapy.Request(url=next_page, callback=self.parse) 生成了一个新的请求对象,这个请求对象将发送到下一页的 URL。当这个请求完成后,它的响应会由 parse 方法处理,从而实现了对多个页面的异步爬取。
你也可以定义其他的回调函数来处理不同的请求或响应,这取决于你的爬虫需求。例如,你可以为处理详情页的响应定义一个独立的回调函数,然后在生成请求时指定相应的回调函数。
总结
yield 在 Python 中有两个主要的用途:作为生成器(generator)的一部分和在异步编程中用于生成异步操作的结果。在 Scrapy 中,yield 主要用于异步爬取的场景,其中最常见的用法是生成请求对象和处理响应。
在 Scrapy 中,yield 通常用于:
-
生成请求对象: 使用
yield生成包含新请求的请求对象,使得 Scrapy 能够异步地发送和处理多个请求。这在处理翻页、跟踪链接等情况下非常常见。例如:yield scrapy.Request(url="http://example.com/page1", callback=self.parse_page) -
处理响应: 使用
yield生成爬取到的数据,允许 Scrapy 异步地处理和保存数据。这通常发生在回调函数中。例如:yield { 'title': response.css('h1::text').get(), 'content': response.css('div.article::text').get(), } -
异步操作:
yield在异步编程中用于生成异步操作的结果,允许程序在等待异步操作完成的同时执行其他任务。
总的来说,yield 在 Scrapy 中的使用是为了利用异步特性,允许爬虫同时执行多个任务而不阻塞,提高了爬虫的效率。它被用于生成请求、处理响应、以及在异步编程中生成异步操作的结果。
相关文章:

yield代码解释
目录 我们的post请求爬取百度翻译的代码 详细解释 解释一 解释二 再说一下callback 总结 发现了很多人对存在有yield的代码都不理解,那就来详细的解释一下 我们的post请求爬取百度翻译的代码 import scrapy import jsonclass TestpostSpider(scrapy.Spider):…...
C#四部曲(知识补充)
Unity跨平台原理 .Net相关 只要编写的时候遵循.NET的这些规则,就能在.NET平台下通用 各种源码→根据.NET规范编写→(虚拟机)生成CIL中间码(保存在程序集中)→转成操作系统原代码 跨语言← 跨平台↓ Unity跨平台原理(Mono) c#脚本→MonoC#编…...

Vue中的数据交互有几种方式
1. 单向数据流: Vue中的数据流是单向的,从父组件传递到子组件。父组件可以通过props将数据传递给子组件,子组件通过props接收并使用这些数据。这种方式适用于父子组件之间的简单通信。 2. 事件: 子组件可以通过触发自定义事件来…...

2.MySQL中的数据类型
整数类型: tinyint(m): 1个字节 范围(-128~127) 常用:性别 0和1表示性别;状态 0和1表示 int(m): 4个字节 范围(-2147483648~2147483647) 常用:数值 数值类型中的长度m是值显示长度,只有字段指定zerofill时有用 例如…...

身份证查询真伪-三要素查验-ios身份证实名认证接口调用
身份证实名认证接口联网核验是实名认证的关键一步,通过翔云OCR识别出的身份证信息,联网上传全国人口数据库,通过比对查找,确认人口数据库是否有身份证号和姓名匹配的信息,如果有那就确认身份证是真的,如果没…...

@EnableWebMvc介绍和使用详细demo
EnableWebMvc是什么 EnableWebMvc 是 Spring MVC 中的一个注解,它用于启用 Spring MVC 框架的基本功能,以便你可以使用 Spring MVC 提供的特性来处理 Web 请求。 通常情况下,在基于 Spring Boot 的应用中,并不需要显式地使用 Ena…...
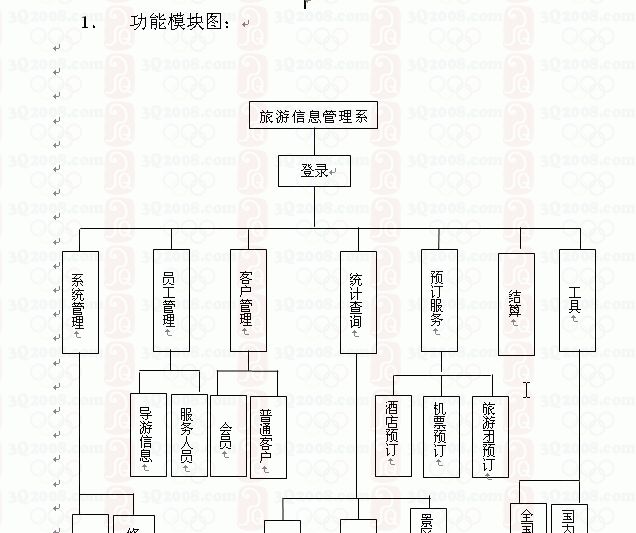
VC-旅游系统-213-(代码+说明)
转载地址: http://www.3q2008.com/soft/search.asp?keyword旅游系统 旅游信息管理系统开题报告 一、研究目的 旅游信息管理系统能帮助旅行社在游客的市场开拓、游客的信息管理、客户服务等方面进行综合处理。使旅行社能够准确的掌握客户的市场动态,充分了解对客户…...

重学SpringBoot3-ErrorMvcAutoConfiguration类
更多SpringBoot3内容请关注我的专栏:《SpringBoot3》 期待您的点赞👍收藏⭐评论✍ 重学SpringBoot3-ErrorMvcAutoConfiguration类 ErrorMvcAutoConfiguration类的作用工作原理定制 ErrorMvcAutoConfiguration示例代码1. 添加自定义错误页面2.自定义错误控…...

剑指offer面试题34 丑数
考察点 空间换时间提效知识点 题目 分析 这里面其实用到了一点点的数学知识,丑数的定义是只包含2,3,5因子的数。现在要求第1500个丑数,最简单的办法就是从数字1开始遍历,依次判断每个数字是不是丑数,如果…...
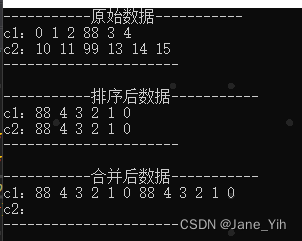
C++ std::list的merge()使用与分析
看到《C标准库第2版》对list::merge()的相关介绍,令我有点迷糊,特意敲代码验了一下不同情况的调用结果。 《C标准库第2版》对list::merge()的相关介绍 list::merge()定义 merge()的作用就是将两个list合并在一起,函数有2个版本:…...

Quartz的分布式功能化设计
Quartz的分布式功能化设计 文章目录 Quartz的分布式功能化设计主体功能实现依赖API例子JOBJob记录表设计java具体代码DateDOOperatorDOSysQuartzJobDOPageDTOQuartzJobDTOQuartzJobPageDTOQuartzJobStatusEnumQuartzJobControllerIQuartzJobServiceQuartzJobServiceImplQuartzJ…...
Caffeine缓存
本地缓存基于本地环境的内存,访问速度非常快,对于一些变更频率低、实时性要求低的数据,可以放在本地缓存中,提升访问速度 使用本地缓存能够减少和Redis类的远程缓存间的数据交互,减少网络 I/O 开销,降低这…...

AI辅助研发正在成为造福人类的新生科技力量
目录 1.AI用于药物研发 (1)药物靶点预测: (2)药物分子设计: (3)药物筛选: (4)药效和安全性预测: (5)…...

程序分享--排序算法--归并排序
关注我,持续分享逻辑思维&管理思维; 可提供大厂面试辅导、及定制化求职/在职/管理/架构辅导; 有意找工作的同学,请参考博主的原创:《面试官心得--面试前应该如何准备》,《面试官心得--面试时如何进行自…...

pg数据库和mysql区别
区别一 PostgreSQL (通常称为 PG) 和 MySQL 都是广泛使用的关系型数据库管理系统 (RDBMS)。虽然它们都是用于存储和管理数据的关系数据库,但它们在一些方面有很大的区别,如下所述: 数据类型:PostgreSQL 支持更多的数据类型&#…...
Jetpack Compose 动画正式开始学习
1. 简单值动画 //将一个Color简单值 从一个值 变化到另一个 另一个简单值 就用 animateColorAsStateval backgroundColor by animateColorAsState(if (tabPage TabPage.Home) Purple100 else Green300) 动画其实就是 一个状态不停发生改变导致 组件不断重组产生的过程 2.…...

iOS 17.4报错: libopencore-amrnb.a[arm64]
iOS 17.4报错: libopencore-amrnb.a[arm64] iOS 17.4 模拟器运行报错解决方案 iOS 17.4 模拟器运行报错 Building for ‘iOS-simulator’, but linking in object file (/XXX/lib/libopencore-amrnb.a[arm64]2) built for ‘iOS’ 解决方案 在Podfile里添加如下设…...
鼓楼夜市管理wpf+sqlserver
鼓楼夜市管理系统wpfsqlserver 下载地址:鼓楼夜市管理系统wpfsqlserver 说明文档 运行前附加数据库.mdf(或sql生成数据库) 主要技术: 基于C#wpf架构和sql server数据库 功能模块: 登录注册 鼓楼夜市管理系统主界面所有店铺信…...
【五、接口自动化测试】5分钟掌握python + requests接口测试
你好啊!我是山茶,一个持续探索AI 测试的程序员! 在做接口测试时,在python中内置了HTTP库 urllib,可以用于发送http请求。基于urllib二次封装的三方库Requests,相较于urllib更佳简介易用。所以,…...

双边市场的基本理论
双边市场由两个不同类型的用户组成,通过一个中介机构或平台进行交易,其中一边用户的决策会影响另一边用户的结果。这种影响被称为间接网络外部性,它导致了平台在吸引和平衡两边用户时面临的挑战。 平台定价在双边市场中成为核心问题…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

如何快速批量下载高质量歌词:ZonyLrcToolsX跨平台终极解决方案
如何快速批量下载高质量歌词:ZonyLrcToolsX跨平台终极解决方案 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX 还在为本地音乐库缺少歌词而烦恼吗࿱…...

长期使用Token Plan套餐在项目开发中的成本观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在项目开发中的成本观察 在AI驱动的项目开发中,成本控制与预算管理是团队负责人必须面对的现实…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参
Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参 【免费下载链接】gz-sim Open source robotics simulator. The latest version of Gazebo. 项目地址: https://gitcode.com/gh_mirrors/gz/gz-sim Gazebo Sim是一款功能强大的开源机器人模拟器ÿ…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...
 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例)
招行+工行:ReAct(Reasoning + Acting) 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例
下面我把 ReAct(Reasoning Acting) 讲清楚,并结合 ** 金融场景(含自进化智能体)** 给出可直接用的案例与话术,适合分享 / 汇报。一、ReAct 是什么(一句话)ReAct 推理(T…...