Elastic Stack--09--ElasticsearchRestTemplate
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- spring-data-elasticsearch
- 提供的API
- QueryBuilders
- ElasticsearchRestTemplate 方法
- ElasticsearchRestTemplate ---操作索引
- ElasticsearchRestTemplate ---文档操作
- 1.新增文档
- index()
- save()
- 2.删除文档
- 3.修改文档
- ElasticsearchRestTemplate --- 文档查询
- query 原理分析:
- NativeSearchQuery---查询条件类
- 1.只查询一个id的 (idsQuery)
- 2.模糊搜索( matchQuery )
- operator
- multiMatchQuery
- 短语搜索--- matchPhraseQuery
- 搜索所有数据---matchAllQuery
- 3.词组搜索--精确查询指定字段(termQuery)
- termsQuery
- mathcQuery与termQuery区别:
- QueryBuilders.termQuery ------精确查询指定字段
- QueryBuilders.matchQuery ------ 按分词器进行模糊查询
- 4.范围搜索(rangeQuery)
- 5.复合条件搜索 (boolQuery)
- 6.过滤 ( boolQueryBuilder.filter)
- 7.分页和排序搜索
- 8.高亮搜索
- 9. 嵌套查询(nestedQuery)
spring-data-elasticsearch
- spring-data-elasticsearch是比较好用的一个elasticsearch客户端,本文介绍如何使用它来操作ES。本文使用spring-boot-starter-data-elasticsearch,它内部会引入spring-data-elasticsearch。
提供的API
Spring Data ElasticSearch有下边这几种方法操作ElasticSearch:
- ElasticsearchRepository(传统的方法,可以使用)
- ElasticsearchRestTemplate(推荐使用。基于RestHighLevelClient)
- ElasticsearchTemplate(ES7中废弃,不建议使用。基于TransportClient)
- RestHighLevelClient(推荐度低于ElasticsearchRestTemplate,因为API不够高级)
- TransportClient(ES7中废弃,不建议使用)
QueryBuilders
QueryBuilders是ES中的查询条件构造器
-
QueryBuilders.boolQuery #子方法must可多条件联查
-
QueryBuilders.termQuery #精确查询指定字段
-
QueryBuilders.matchQuery #按分词器进行模糊查询
-
QueryBuilders.rangeQuery #按指定字段进行区间范围查询
ElasticsearchRestTemplate 方法
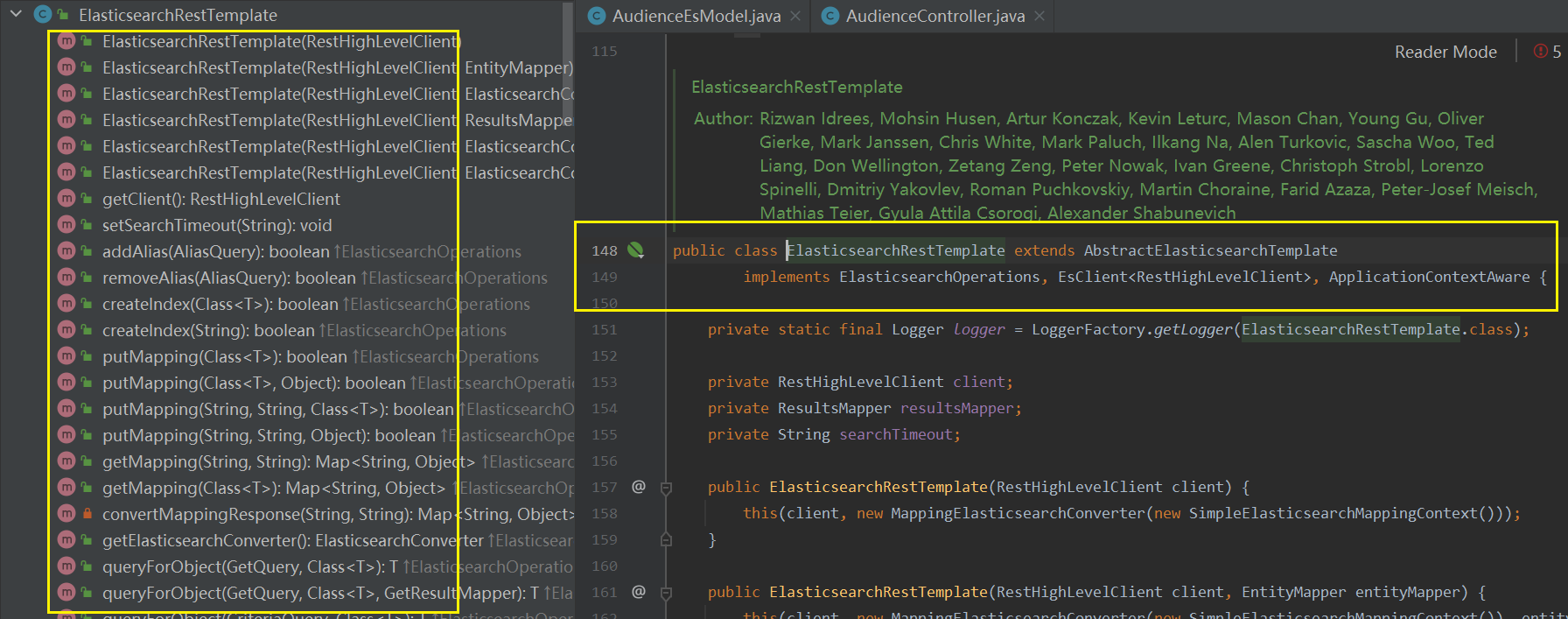
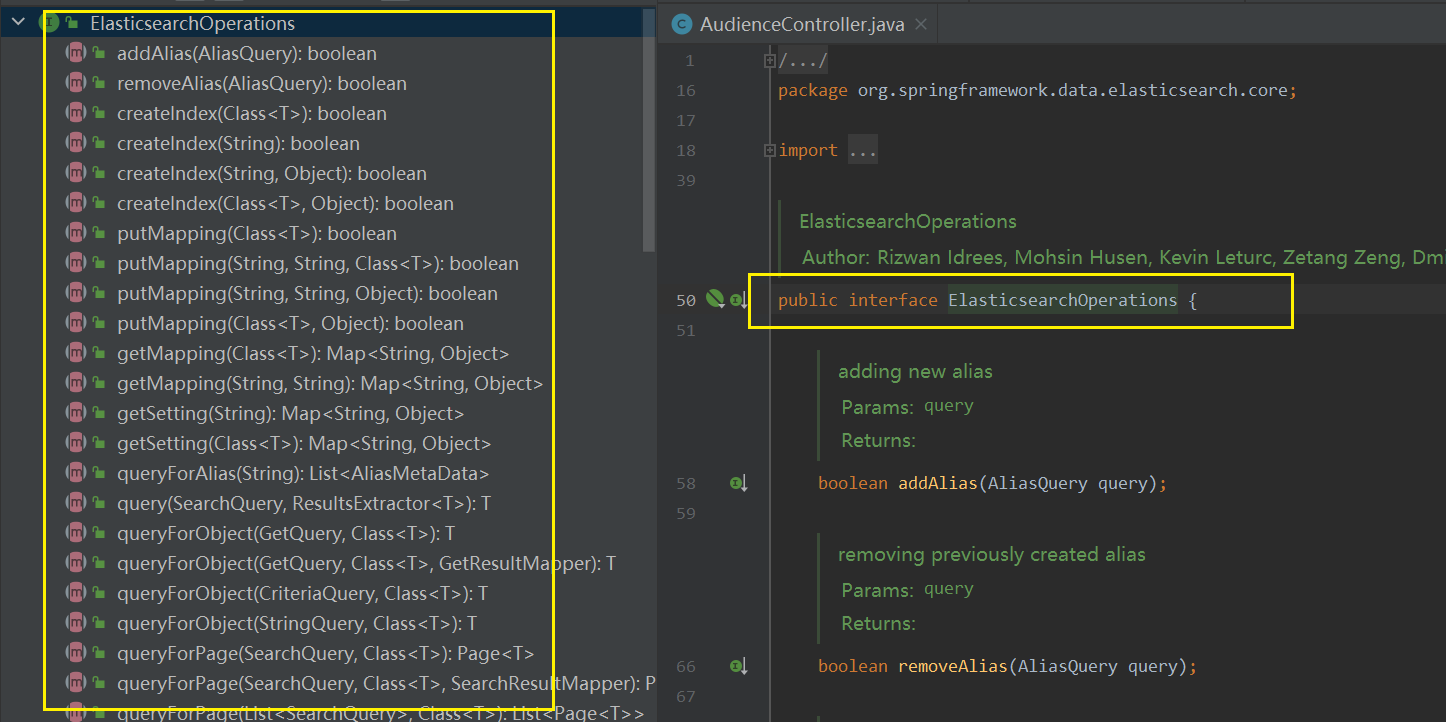
ElasticsearchRestTemplate —操作索引
/*** 测试boot整合es*/
@SpringBootTest(classes = {SpringbootEsApplication.class})
@RunWith(SpringRunner.class)
public class testES {@Autowiredprivate ElasticsearchRestTemplate restTemplate;/*** 创建索引,并设置映射。* 需要通过两次访问实现,1、创建索引;2、设置映射。*/@Testpublic void testInitIndex(){// 创建索引,根据类型上的Document注解创建boolean isCreated = restTemplate.createIndex(Item.class);// 设置映射,根据属性上的Field注解设置 0201boolean isMapped = restTemplate.putMapping(Item.class);System.out.println("创建索引是否成功:" + isCreated);System.out.println("设置映射是否成功:" + isMapped);}/*** 删除索引*/@Testpublic void deleteIndex(){// 扫描Item类型上的Document注解,删除对应的索引。boolean isDeleted = restTemplate.deleteIndex(Item.class);System.out.println("删除Item对应索引是否成功:" + isDeleted);// 直接删除对应名称的索引。isDeleted = restTemplate.deleteIndex("test_index3");System.out.println("删除default_index索引是否成功:" + isDeleted);}}ElasticsearchRestTemplate —文档操作
1.新增文档
- 如果索引和类型不存在,也可以执行进行新增,新增后自动创建索引和类型。但是 field 通过动态 mapping进行映射,elaticsearch 根据值类型进行判断每个属性类型,默认每个属性都是 standard 分词器,ik分词器是不生效的。所以一定要先通过代码进行初始化或直接在 elasticsearch 中通过命令创建所有 field 的 mapping
- 如果对象的 id 属性没有赋值,让 ES 自动生成主键,存储时 id 属性没有值,_id 存储 document 的主键值。 如果对象的 id 属性明确设置值,存储时 id 属性为设置的值,ES 中 document 对象的 _id 也是设置的值
index()
index逻辑,相当于使用PUT请求,实现数据的新增
/*** 新增数据到ES*/@Testpublic void testInsert(){Item item = new Item();item.setId("19216811");item.setTitle("沃什.伊戈.史莱姆");item.setSellPoint("关于我成为史莱姆却因为铺垫太长遭人骂这档事");item.setPrice(996666L);item.setNum(233);//方式 1:这个是构建器放入的方式IndexQuery indexQuery = new IndexQueryBuilder() // 创建一个IndexQuery的构建器.withObject(item) // 设置要新增的Java对象.build(); // 构建IndexQuery类型的对象。//方式 2: 这个是直接放入的方式
// IndexQuery query = new IndexQuery();
// query.setObject(item);// index逻辑,相当于使用PUT请求,实现数据的新增。String result = restTemplate.index(indexQuery);System.out.println(result);}批量新增,使用的是bulkIndex() 操作
/*** 批量新增* bulk操作*/@Testpublic void testBatchInsert(){List<IndexQuery> queries = new ArrayList<IndexQuery>();Item item = new Item();item.setId("20210224");item.setTitle("IPHONE 12 手机");item.setSellPoint("很贵");item.setPrice(499900L);item.setNum(999);queries.add(new IndexQueryBuilder().withObject(item).build());item = new Item();item.setId("20210225");item.setTitle("华为P40照相手机");item.setSellPoint("可以拍月亮");item.setPrice(599900L);item.setNum(999);queries.add(new IndexQueryBuilder().withObject(item).build());item = new Item();item.setId("20210226");item.setTitle("红米k30");item.setSellPoint("大品牌值得信赖");item.setPrice(699900L);item.setNum(999);queries.add(new IndexQueryBuilder().withObject(item).build());// 批量新增,使用的是bulk操作。restTemplate.bulkIndex(queries);}save()
/*** 新增单个文档*/@Testvoid insert(){Student student = new Student();student.setAge(23);student.setData("123");student.setDesc("华为手机");student.setId("1");student.setName("张三");Student save = elasticsearchRestTemplate.save(student);System.out.println(save);}/*** 批量新增*/@Testvoid batchInsert(){List<Student> list = new ArrayList<>();list.add(new Student("2","李四","苹果手机","1",22));list.add(new Student("3","王五","oppo手机","2",24));list.add(new Student("4","赵六","voio手机","3",25));list.add(new Student("5","田七","小米手机","4",26));Iterable<Student> result = elasticsearchRestTemplate.save(list);System.out.println(result);}
2.删除文档
- 根据主键删除 delete(String indexName,String typeName,String id);通过字符串指定索引,类型 和 id 值delete(Class,String id)第一个参数传递实体类类类型,建议使用此方法,减少索引名 和类型名由于手动编写出现错误的概率。 返回值为 delete 方法第二个参数值(删除文档的主键值)
/*** 删除文档*/@Testpublic void testDelete(){// 根据主键删除, 常用String result = restTemplate.delete(Item.class, "192168111");System.out.println(result);// 根据查询结果,删除查到的数据。 应用较少。DeleteQuery query = new DeleteQuery();query.setIndex("hrt-item");query.setType("item");query.setQuery(QueryBuilders.matchQuery("title", "沃什.伊戈.史莱姆1"));restTemplate.delete(query, Item.class);} /*** 根据查询条件删除*/@Testvoid delete() {QueryStringQueryBuilder queryBuilder = QueryBuilders.queryStringQuery("张三");Query query = new NativeSearchQuery(queryBuilder);ByQueryResponse QueryDelete = elasticsearchRestTemplate.delete(query, Student.class);System.out.println(QueryDelete);}
3.修改文档
- 修改操作就是新增代码,只要保证主键 id 已经存在,新增就是修改。
- 如果使用部分更新,则需要通过 update 方法实现。具体如下
全量替换
/*** 批量修改*/@Testvoid update(){Student student = new Student();student.setId("1");student.setAge(23);student.setData("99");student.setDesc("华为手机AND苹果手机");student.setName("张三");Student save = elasticsearchRestTemplate.save(student);System.out.println(save);}
部分修改
/*** 部分修改*/@Testvoid update2(){// ctx._source 固定写法String script = "ctx._source.age = 27;ctx._source.desc = 'oppo手机and苹果电脑'";UpdateQuery build = UpdateQuery.builder("3").withScript(script).build();IndexCoordinates indexCoordinates = IndexCoordinates.of("student_index");UpdateResponse update = elasticsearchRestTemplate.update(build, indexCoordinates);System.out.println(update.getResult());}
/*** 修改文档* 如果是全量替换,可以使用index方法实现,只要主键在索引中存在,就是全量替换。<=>新增or批量新增操作* 如果是部分修改,则可以使用update实现。*/@Testpublic void testUpdate() throws Exception{UpdateRequest request = new UpdateRequest();request.doc(XContentFactory.jsonBuilder().startObject().field("name", "测试update更新数据,商品名称").endObject());UpdateQuery updateQuery =new UpdateQueryBuilder().withUpdateRequest(request).withClass(Item.class).withId("20210224").build();restTemplate.update(updateQuery);}ElasticsearchRestTemplate — 文档查询
query 原理分析:

SearchQuery query = new NativeSearchQuery(QueryBuilders.matchQuery("title", "华为mate40"));List<Item> itemList = restTemplate.queryForList(query, Item.class);-
SearchQuery - 是Spring Data Elasticsearch中定义的一个搜索接口
-
NativeSearchQuery - 是SearchQuery接口的实现类 ,构造的时候,需要提供一个QueryBuilder类型的对象
-
QueryBuilder是Elasticsearch的java客户端中定义的搜索条件类型。
-
QueryBuilders - 是QueryBuilder类型的工具类,可以快速实现QueryBuilder类型对象的创建工具类中,提供了大量的静态方法,方法命名和DSL搜索中的条件关键字相关。

NativeSearchQuery—查询条件类
new NativeSearchQuery(, , ,)
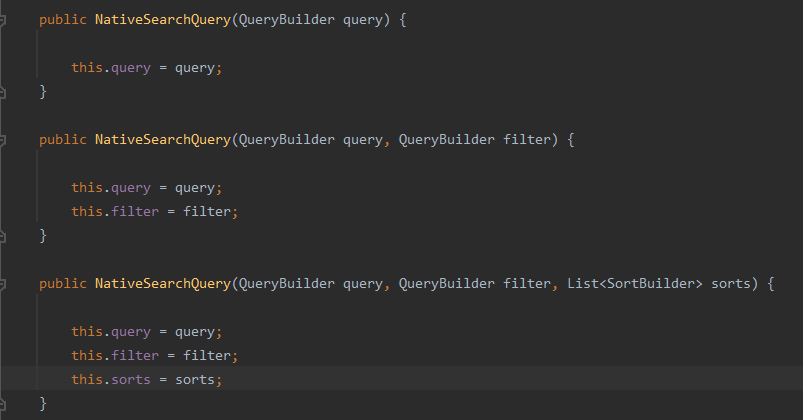
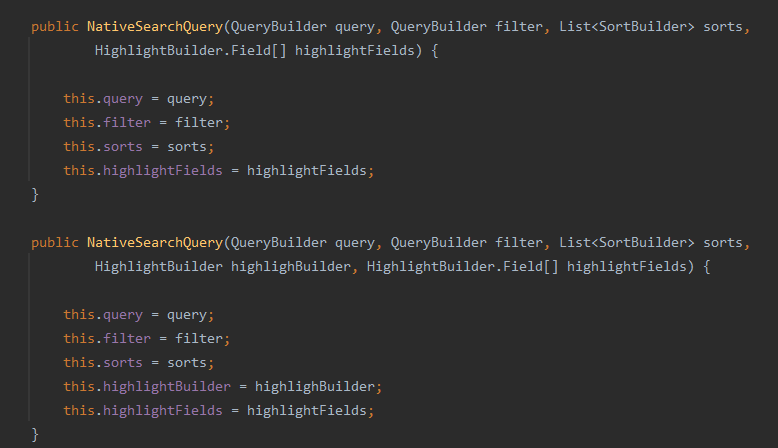
- 原生的查询条件类,用来和ES的一些原生查询方法进行搭配,实现一些比较复杂的查询,最终进行构建.build
可作为ElasticsearchTemplate. queryForPage的参数使用
//构建Search对象NativeSearchQuery query = new NativeSearchQueryBuilder()//条件.withQuery(QueryBuilders.matchQuery("title", "华为mate40"))//排序.withSort(SortBuilders.fieldSort("id").order(SortOrder.ASC))//高亮.withHighlightFields(name, ms)//分页.withPageable(PageRequest.of(pageNum - 1, pageSize))//构建.build();//queryForPage 参数一: NativeSearchQuery 封装的查询数据对象// 参数二: es对应索引实体类// 参数三: 调用高亮工具类AggregatedPage<Goods> aggregatedPage = elasticsearchTemplate.queryForPage(query , Goods.class,new Hig());1.只查询一个id的 (idsQuery)
只查询一个id的
@Autowiredprivate ElasticsearchRestTemplate restTemplate; /** 只查询一个id的* QueryBuilders.idsQuery(String...type).ids(Collection<String> ids)*/@Testpublic void testIdsQuery() {QueryBuilder query = QueryBuilders.idsQuery().ids("1");List<Item> itemList = restTemplate.queryForList(query, Item.class);}2.模糊搜索( matchQuery )
- matchQuery(“key”, Obj) 单个匹配, field不支持通配符, 前缀具高级特性
- multiMatchQuery(“text”, “field1”, “field2”…); 匹配多个字段, field有通配符忒行
- matchAllQuery(); 匹配所有文件
- matchAllQuery() 搜索所有数据
去所有 field 中搜索指定条件。
- 在kibana的dev tools中修改之前批量新增的一个数据, 目的是当我们搜索华为Mate40 时, 不仅能够搜索到
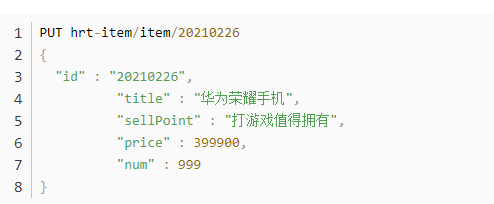
/*** 条件搜索*/@Testpublic void testMatch(){SearchQuery query = new NativeSearchQuery(QueryBuilders.matchQuery("title", "华为mate40"));List<Item> itemList = restTemplate.queryForList(query, Item.class);}operator
如果想使用一个字段匹配多个值,并且这多个值是and关系,如下 要求查询的数据中必须包含北京‘和’天津
- QueryBuilders.matchQuery(“address”,“北京 天津”).operator(Operator.AND)
如果想使用一个字段匹配多个值,并且这多个值是or关系,如下 要求查询的数据中必须包含北京‘或’天津
- QueryBuilders.matchQuery(“address”,“北京 天津”).operator(Operator.OR)
multiMatchQuery
QueryBuilders.multiMatchQuery() 会分词 一个值对应多个字段 where username = ‘zs’ or password = ‘zs’
/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* multimatch query* 创建一个匹配查询的布尔型提供字段名称和文本。* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/protected static QueryBuilder multiMatchQuery() {//现住址和家乡在【山西省太原市7429街道】的人return QueryBuilders.multiMatchQuery("zs", // Text you are looking for"username ", "password " // Fields you query on);}短语搜索— matchPhraseQuery
QueryBuilders.matchPhraseQuery() 不会分词,当成一个整体去匹配,相当于 %like%
短语搜索是对条件不分词,但是文档中属性根据配置实体类时指定的分词类型进行分词。
- 如果属性使用 ik 分词器,从分词后的索引数据中进行匹配。
/*** 短语搜索* 只要被分词后锁短语含有, 则都会被搜索到*/@Testpublic void testMatchPhrase(){SearchQuery query = new NativeSearchQuery(QueryBuilders.matchPhraseQuery("title", "华为mate40"));List<Item> itemList = restTemplate.queryForList(query, Item.class);}搜索所有数据—matchAllQuery
/*** 搜索所有数据*/@Testpublic void testMatchAll(){SearchQuery query = new NativeSearchQuery(QueryBuilders.matchAllQuery());List<Item> itemList = restTemplate.queryForList(query, Item.class);}3.词组搜索–精确查询指定字段(termQuery)
/*** 词组搜索* 只有没有被切分的词组才能搜到结果, 例如: 华为荣耀已被切分, 则搜索不到; 而荣耀 不会被切分因此能够搜索到结果* 区别于短语搜索*/@Testpublic void testTerm(){SearchQuery query = new NativeSearchQuery(QueryBuilders.termQuery("title", "mate40"));List<Item> itemList = restTemplate.queryForList(query, Item.class);}termsQuery
一个查询相匹配的多个value
/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* terms query* 一个查询相匹配的多个value* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/protected static QueryBuilder termsQuery() {return QueryBuilders.termsQuery("name", // field"葫芦580娃", "葫芦3812娃") // values.minimumMatch(1); // 设置最小数量的匹配提供了条件。默认为1。}protected static QueryBuilder termsQuery1() {List<Long> channelIdList =new ArrayList<>();return QueryBuilders.termsQuery("channel.channelId", channelIdList);}mathcQuery与termQuery区别:
- matchQuery:会将搜索词分词,再与目标查询字段进行匹配,若分词中的任意一个词与目标字段匹配上,则可查询到。
- termQuery:不会对搜索词进行分词处理,而是作为一个整体与目标字段进行匹配,若完全匹配,则可查询到
QueryBuilders.termQuery ------精确查询指定字段
QueryBuilders.matchQuery ------ 按分词器进行模糊查询
4.范围搜索(rangeQuery)
/*** 范围搜索 range* gte <==> 小于等于 ; gt <==> 小于 * lte <==> 大于等于 ; lt <==> 大于*/@Testpublic void testRange(){SearchQuery query = new NativeSearchQuery(QueryBuilders.rangeQuery("price").gte(500000L).lte(400000L));List<Item> itemList = restTemplate.queryForList(query, Item.class);}5.复合条件搜索 (boolQuery)
- must(QueryBuilders) : AND
- mustNot(QueryBuilders): NOT
- should : OR
- filter : 过滤
/*** 复合条件搜索*/@Testpublic void testBool(){// 创建一个Bool搜索条件。 相当于定义 bool:{ must:[], should:[], must_not:[] }BoolQueryBuilder builder = QueryBuilders.boolQuery();List<QueryBuilder> mustList = builder.must();//词组所搜+范围搜索mustList.add(QueryBuilders.matchQuery("title", "华为"));mustList.add(QueryBuilders.rangeQuery("price").gte(300000L));// builder.mustNot();// builder.should();SearchQuery query = new NativeSearchQuery(builder);List<Item> itemList = restTemplate.queryForList(query, Item.class);} /*** 多条件查询*/@Testvoid querysSearch(){BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();List<QueryBuilder> listQuery = new ArrayList<>();listQuery.add(QueryBuilders.matchQuery("name","张三"));listQuery.add(QueryBuilders.matchQuery("age","23"));boolQueryBuilder.must().addAll(listQuery);// 逻辑 与
// boolQueryBuilder.should().addAll(listQuery);// 逻辑 或NativeSearchQuery nativeSearchQuery = new NativeSearchQuery(boolQueryBuilder );SearchHits<Student> search = elasticsearchRestTemplate.search(nativeSearchQuery, Student.class);List<SearchHit<Student>> searchHits = search.getSearchHits();}
查询address 必须包含’汽车’ 或者’水果’的,查询id必须不能包含’2’和’0’的。此时需要构造两个条件,
- 类似mysql中的 where (address like %汽车% oraddress like %水果% ) and (id != 1 or id != 2)
@Testpublic void testBoolQuery() throws IOException {SearchRequest searchRequest = new SearchRequest(indexName);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();boolQuery.must(QueryBuilders.matchQuery("address","水果 汽车").operator(Operator.OR));boolQuery.mustNot(QueryBuilders.termsQuery("id","0","2"));searchSourceBuilder.query(boolQuery);searchRequest.source(searchSourceBuilder);SearchResponse search = client.search(searchRequest, ElasticSearchConfig.COMMON_OPTIONS);for (SearchHit documentFields : search.getHits().getHits()) {System.out.println(documentFields.getScore() + ":::" +documentFields.getSourceAsString());}}
/*** ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* boolean query and 条件组合查询* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/protected static QueryBuilder booleanQuery() {return QueryBuilders.boolQuery().must(QueryBuilders.termQuery("name", "葫芦3033娃")).must(QueryBuilders.termQuery("home", "山西省太原市7967街道")).mustNot(QueryBuilders.termQuery("isRealMen", false)).should(QueryBuilders.termQuery("now_home", "山西省太原市"));}6.过滤 ( boolQueryBuilder.filter)
- must:返回的文档必须满足must子句的条件,并且参与计算分值
- filter:返回的文档必须满足filter子句的条件。但是跟Must不一样的是,不会计算分值, 并且可以使用缓存
从上面的描述来看,你应该已经知道,如果只看查询的结果,must和filter是一样的。区别是场景不一样。如果结果需要算分就使用must,否则可以考虑使用filter。
filter查询就是用于精确过滤文档,它只关注文档是否符合条件,将匹配的文档包含在结果中。他们都不进行打分、排序或相关性计算,只担心是否匹配
- 品牌和类目的过滤
//2、根据类目ID进行过滤
if (null != param.getCategoryId()) {boolQueryBuilder.filter(QueryBuilders.termQuery("categoryId", param.getCategoryId()));
}//3、根据品牌ID进行过滤
if (null != param.getBrandId() && param.getBrandId().size() > 0) {boolQueryBuilder.filter(QueryBuilders.termsQuery("brandId", param.getBrandId()));
}
- 是否有库存
if (null != param.getHasStock()) {boolQueryBuilder.filter(QueryBuilders.termQuery("hasStock", param.getHasStock() == 1));
}
7.分页和排序搜索
如果实体类中主键只有@Id 注解,String id 对应 ES 中是 text 类型,text 类型是不允许被排序,
- 所以如果必须按照主键进行排序时需要在实体类中设置主键类型@Id @Field(type = FieldType.Keyword)
private String id;
/*** 分页和排序* 所有的Spring Data子工程中的分页和排序逻辑使用的都是相似的方式。* 根据PageRequest和Sort实现分页或排序。*/@Testpublic void testPageable(){SearchQuery query = new NativeSearchQuery(QueryBuilders.matchAllQuery());// 设置分页query.setPageable(PageRequest.of(0, 2));// 设置排序query.addSort(Sort.by(Sort.Direction.DESC, "price"));// 设置分页的同时设置排序// query.setPageable(PageRequest.of(0, 2, Sort.by(Sort.Direction.DESC, "price")))List<Item> itemList = restTemplate.queryForList(query, Item.class);}//构建Search对象NativeSearchQuery query = new NativeSearchQueryBuilder()//条件.withQuery(QueryBuilders.matchQuery("title", "华为mate40"))//排序.withSort(SortBuilders.fieldSort("id").order(SortOrder.ASC))//高亮.withHighlightFields(name, ms)//分页.withPageable(PageRequest.of(pageNum - 1, pageSize))//构建.build();//queryForPage 参数一: NativeSearchQuery 封装的查询数据对象// 参数二: es对应索引实体类// 参数三: 调用高亮工具类AggregatedPage<Goods> aggregatedPage = elasticsearchTemplate.queryForPage(query , Goods.class,new Hig());
8.高亮搜索
/*** 高亮*/@Testpublic void testHighlight(){HighlightBuilder.Field field = new HighlightBuilder.Field("title");field.preTags("<em>");field.postTags("</em>");NativeSearchQuery query =new NativeSearchQueryBuilder()// 排序.withSort(SortBuilders.fieldSort("price").order(SortOrder.ASC))// 分页.withPageable(PageRequest.of(0, 2))// 搜索条件.withQuery(QueryBuilders.matchQuery("title", "华为"))// 设置高亮字段.withHighlightFields(field).build();AggregatedPage<? extends Item> pageResult =restTemplate.queryForPage(query, Item.class, new SearchResultMapper() {// 处理搜索结果,搜索的完整结果,也就是那个集合。// response - 就是搜索的结果,相当于在Kibana中执行搜索的结果内容。// clazz - 就是返回结果的具体类型// pageable - 分页处理,就是queryForPage方法参数query中的pageable对象。public <T> AggregatedPage<T> mapResults(SearchResponse response,Class<T> clazz,Pageable pageable) {// 获取搜索的结果数据SearchHit[] hits = response.getHits().getHits();List<T> resultList = new ArrayList<T>();for(SearchHit hit : hits){// 搜索的source源Map<String, Object> map = hit.getSourceAsMap();Item item = new Item();item.setId(map.get("id").toString());item.setSellPoint(map.get("sellPoint").toString());item.setPrice(Long.parseLong(map.get("price").toString()));item.setNum(Integer.parseInt(map.get("num").toString()));// 高亮数据处理。key - 字段名, value - 是高亮数据结果Map<String, HighlightField> highlightFieldMap = hit.getHighlightFields();HighlightField highlightField = highlightFieldMap.get("title");if (highlightField == null){ // 没有高亮的titleitem.setTitle(map.get("title").toString());}else{ // 有高亮的titleitem.setTitle(highlightField.getFragments()[0].toString());}resultList.add((T)item);}// 返回处理后的结果return new AggregatedPageImpl<T>(resultList, pageable, response.getHits().getTotalHits());}// 不提供实现,这个是处理每个搜索结果的方法public <T> T mapSearchHit(SearchHit searchHit, Class<T> type) {return null;}});for(Item item : pageResult.getContent()){System.out.println(item);}}9. 嵌套查询(nestedQuery)

/*** TODO NotSolved* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~* nested query* 嵌套查询* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/protected static QueryBuilder nestedQuery() {return QueryBuilders.nestedQuery("location", // PathQueryBuilders.boolQuery() // Your query.must(QueryBuilders.matchQuery("location.lat", 0.962590433140581)).must(QueryBuilders.rangeQuery("location.lon").lt(0.00000000000000000003))).scoreMode("total"); // max, total, avg or none相关文章:
Elastic Stack--09--ElasticsearchRestTemplate
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 spring-data-elasticsearch提供的APIQueryBuildersElasticsearchRestTemplate 方法ElasticsearchRestTemplate ---操作索引 ElasticsearchRestTemplate ---文档操作…...

论坛管理系统|基于Spring Boot+ Mysql+Java+B/S架构的论坛管理系统设计与实现(可运行源码+数据库+设计文档+部署说明+视频演示)
推荐阅读100套最新项目 最新ssmjava项目文档视频演示可运行源码分享 最新jspjava项目文档视频演示可运行源码分享 最新Spring Boot项目文档视频演示可运行源码分享 目录 目录 前台功能效果图 管理员功能登录前台功能效果图 用户功能模块 系统功能设计 数据库E-R图设计 l…...

2022 Task 2 Max Sum of 2 integers sharing first and last digits
Task 2 There is an array A consisting of N integers. What’s the maximum sum of two integers from A that share their first and last digits? For example, 1007 and 167 share their first(1) and last(7) digits, whereas 2002 and 55 do not. Write a function: …...

【分布式websocket】聊天系统消息加密如何做
前言 先介绍一下对称加密算法,在介绍一下加密流程,然后是介绍一下查询加密消息的策略。然后结合现有技术架构然后去选型。 决定采用客户端解密。简而言之就是采用对称服务端加密。然后将加密内容存储到消息表的content字段。然后客户拉取content字段 然…...
网络建设与运维培训介绍和能力介绍
1.开过的发票 3.培训获奖的证书 4合同签署 5.实训设备...

3 种方法限制 K8s Pod 磁盘容量使用
容器在运行期间会产生临时文件、日志。如果没有任何配额机制,则某些容器可能很快将磁盘写满,影响宿主机内核和所有应用。 容器的临时存储,例如 emptyDir,位于目录/var/lib/kubelet/pods 下: /var/lib/kubelet/pods/ …...
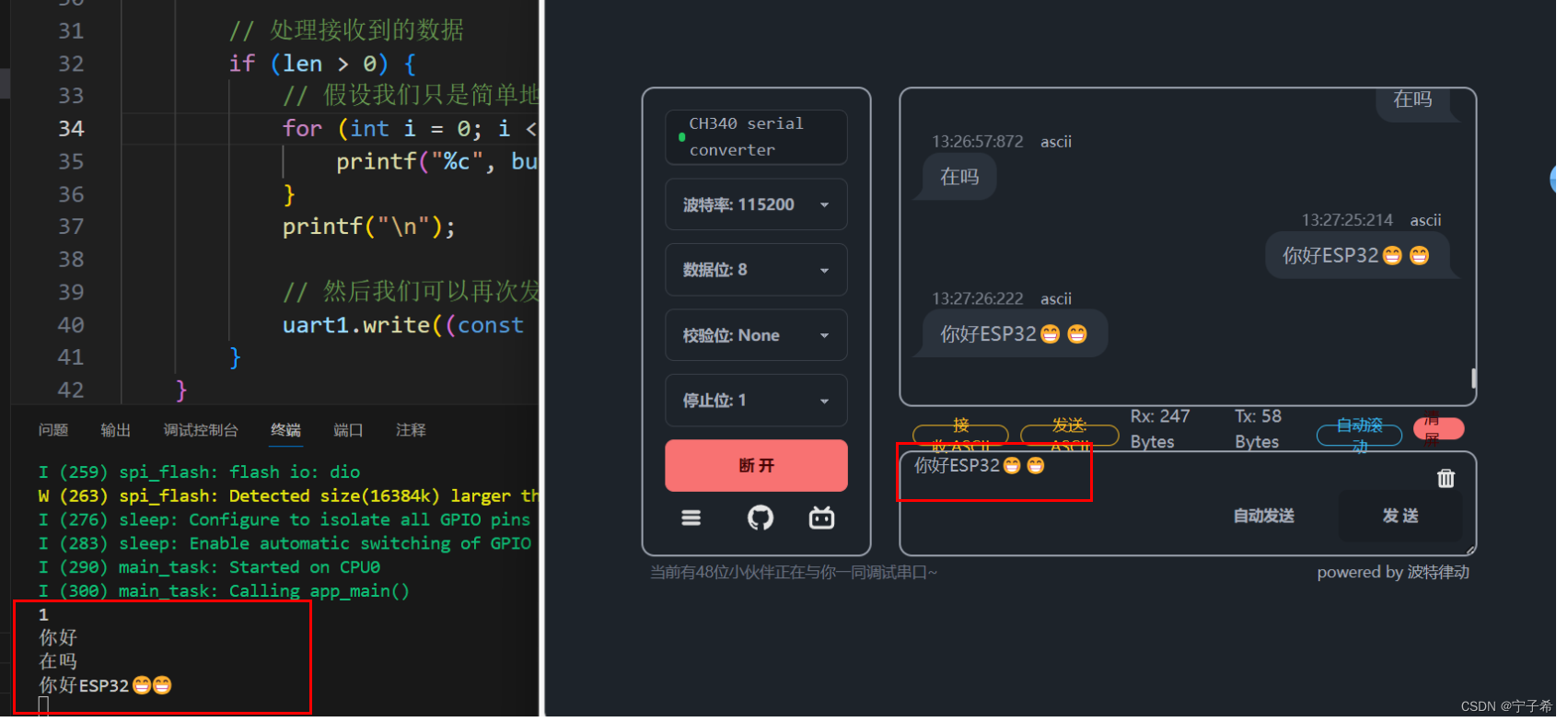
05-ESP32-S3-IDF USART
ESP32-S3 IDF USART详解 USART简介 USART是一种串行通信协议,广泛应用于微控制器和计算机之间的通信。USART支持异步和同步模式,因此它可以在没有时钟信号的情况下(异步模式)或有时钟信号的情况下(同步模式ÿ…...

安塔利斯升级php8
1、includes/classes/class.Database.php 255行 multi_query方法加返回类型 :bool query方法加返回类型:: mysqli_result|bool 2、includes/classes/class.Session.php on line 91 Optional parameter $planetID declared before required parameter $dpath is…...

Clickhouse MergeTree 原理(一)
作者:俊达 MergeTree是Clickhouse里最核心的存储引擎。Clickhouse里有一系列以MergeTree为基础的引擎(见下图),理解了基础MergeTree,就能理解整个系列的MergeTree引擎的核心原理。 本文对MergeTree的基本原理进行介绍…...

【C语言】字符串函数上
👑个人主页:啊Q闻 🎇收录专栏:《C语言》 🎉道阻且长,行则将至 前言 这篇博客是字符串函数上篇,主要是关于长度不受限制的字符串函数(strlen,strcpy,strcat,strcm…...

Java集合基础知识总结(绝对经典)
List接口继承了Collection接口,定义一个允许重复项的有序集合。该接口不但能够对列表的一部分进行处理,还添加了面向位置的操作。 实际上有两种list:一种是基本的ArrayList,其优点在于随机访问元素,另一种是更强大的L…...

Linux:导出环境变量命令export
相关阅读 Linuxhttps://blog.csdn.net/weixin_45791458/category_12234591.html?spm1001.2014.3001.5482 Linux中的内建命令export命令用于创建一个环境变量,或将一个普通变量导出为环境变量,并且在这个过程中,可以给该环境变量赋值。 下面…...
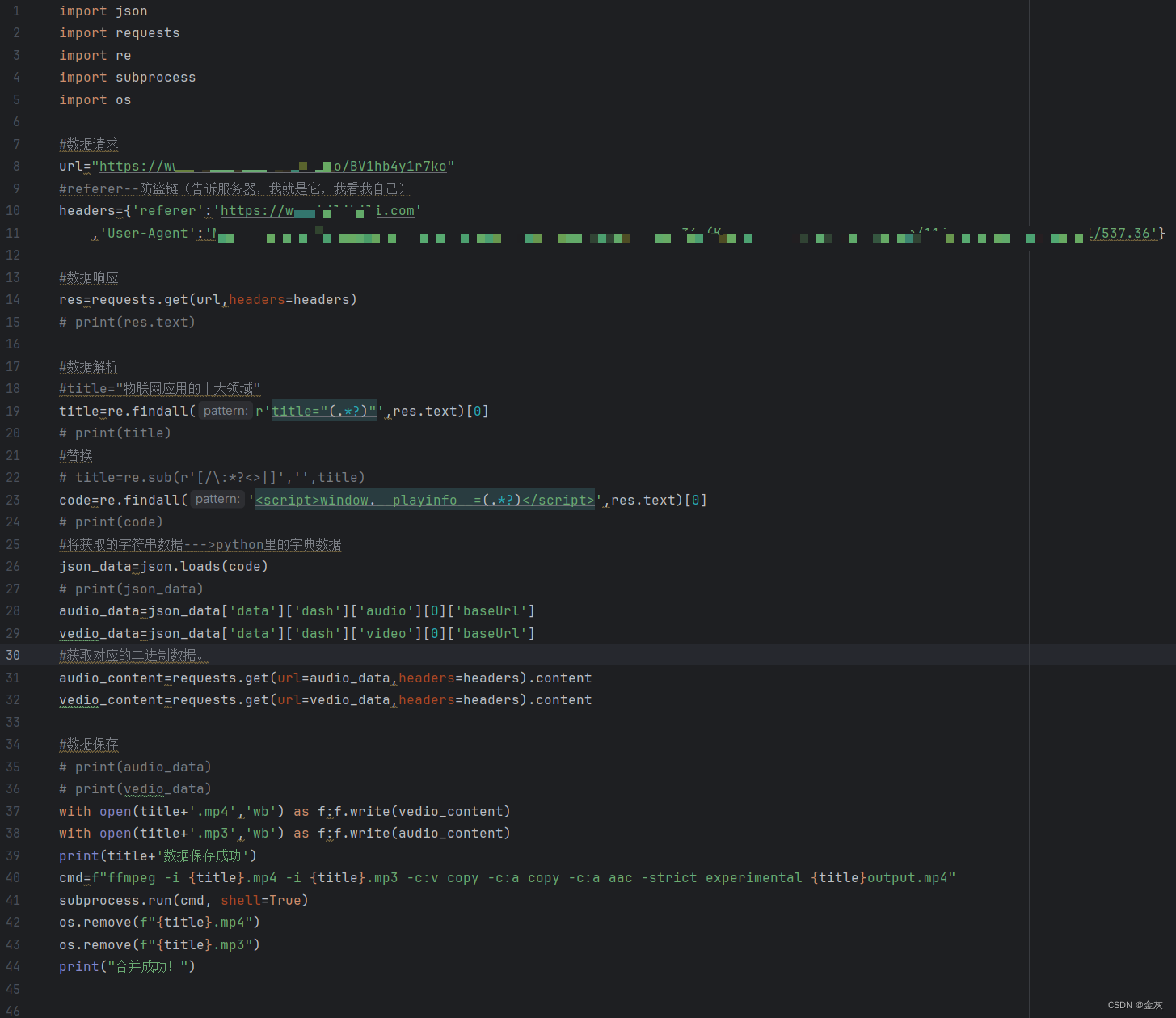
案例--某站视频爬取
众所周知,某站的视频是: 由视频和音频分开的。 所以我们进行获取,需要分别获得它的音频和视频数据,然后进行音视频合并。 这么多年了,某站还是老样子,只要加个防盗链就能绕过。(防止403…...

清华把大模型用于城市规划,回龙观和大红门地区成研究对象
引言:参与式城市规划的新篇章 随着城市化的不断推进,传统的城市规划方法面临着越来越多的挑战。这些方法往往需要大量的时间和人力,且严重依赖于经验丰富的城市规划师。为了应对这些挑战,参与式城市规划应运而生,它强…...

Vue+SpringBoot打造创意工坊双创管理系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 管理员端2.2 Web 端2.3 移动端 三、系统展示四、核心代码4.1 查询项目4.2 移动端新增团队4.3 查询讲座4.4 讲座收藏4.5 小程序登录 五、免责说明 一、摘要 1.1 项目介绍 基于JAVAVueSpringBootMySQL的创意工坊双创管理…...
Web框架开发-Django简介
一、MVC和MTV模型 MVC 所谓MVC就是把web应用分为模型(M),控制器(C)和视图(V)三层,他们之间以一种插件式的,松耦合的方式连接在一起,模型负责业务对象与数据库…...
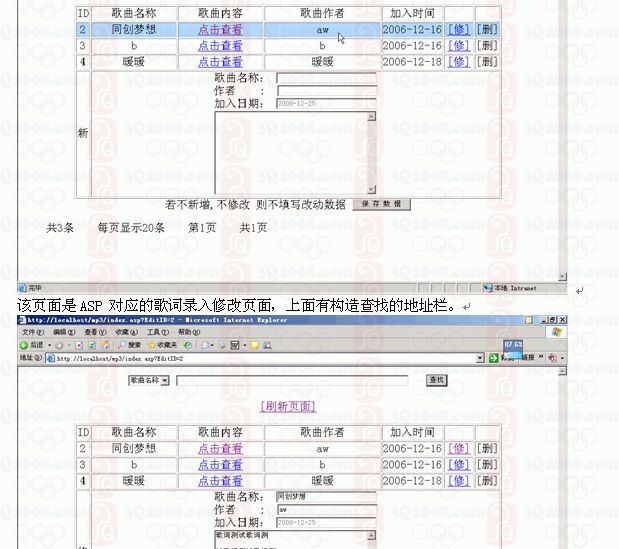
VB播放器(动态服务器获取歌词)-183-(代码+说明)
转载地址: http://www.3q2008.com/soft/search.asp?keyword183 VBASP vb动态从服务器读取歌词 VB asp交互 程序, 模式不一样, 与普通的MP3播放器不一样, 这个是可以实现歌词从服务器上查询功能的. 看好了在咨询 我可以給您演示 目 录 前 言 1 1 . 简述 2 1.1 开发…...
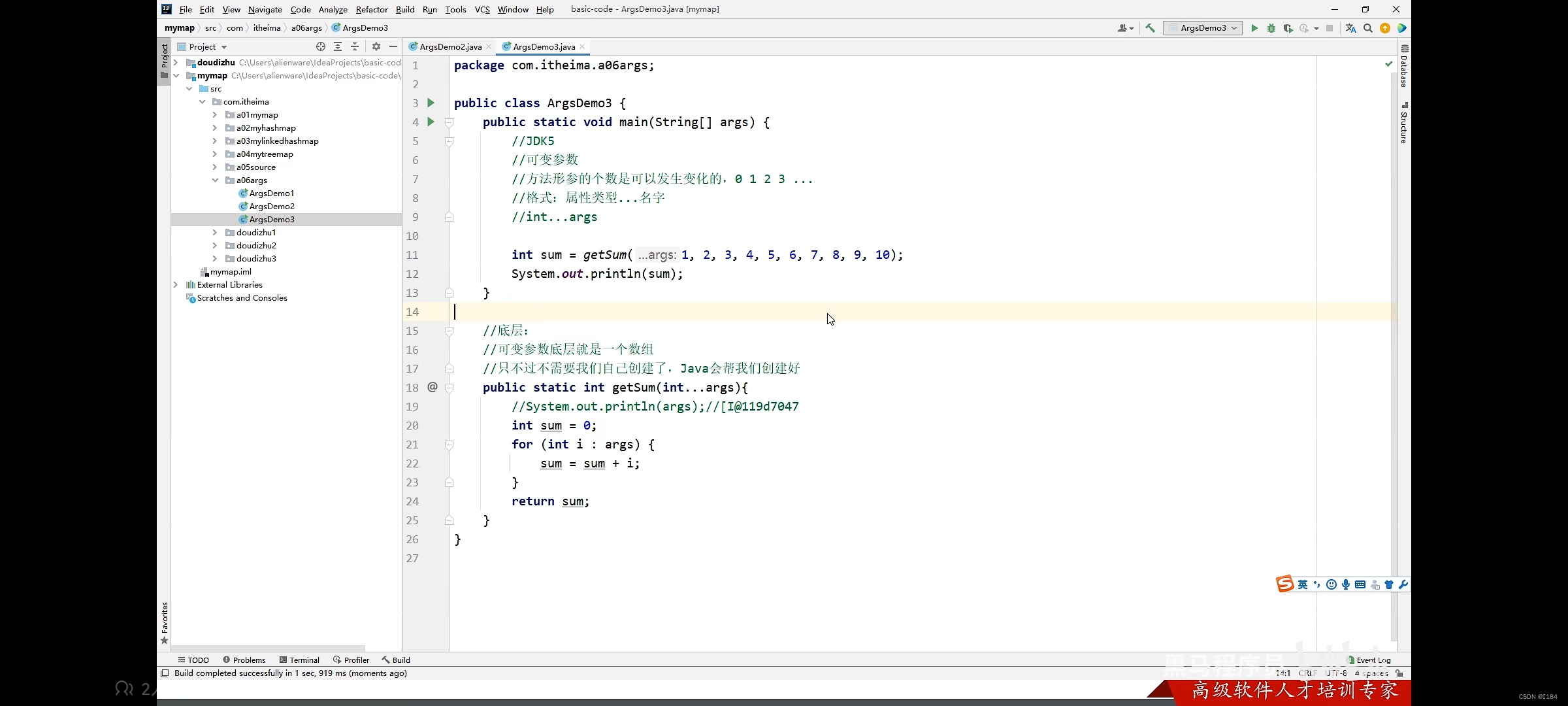
java-可变参数
可变参数是什么? 可变参数就是指传入的参数个数是可变的,不是固定的 为什么要可变参数? 当我们要传入大量的形参时,我们就可以用到可变参数了 定义格式 数据类型...变量名; 例如int ...a; 可变参数的细节: &…...
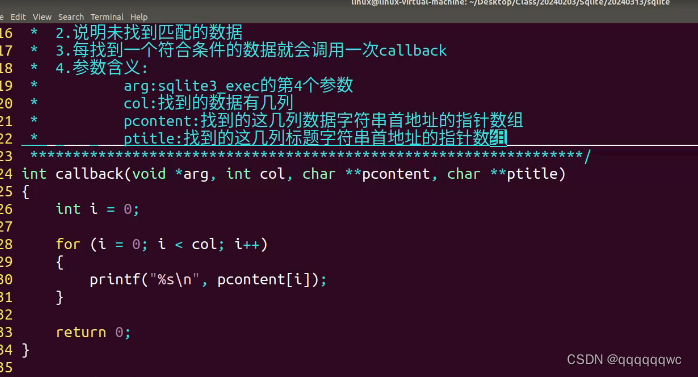
嵌入式学习day37 数据结构
1.sqlite3_open int sqlite3_open( const char *filename, /* Database filename (UTF-8) */ sqlite3 **ppDb /* OUT: SQLite db handle */ ); 功能: 打开数据库文件(创建一个数据库连接) 参数: filename:数据库文…...

嵌入式学习39-程序创建数据库及查找
1.sqlite3_open int sqlite3_open( const char *filename, /* Database filename (UTF-8) */ sqlite3 **ppDb /* OUT: SQLite db handle */ ); 功能: 打开 数据库文件(创建一个数据库连接) 参数: filename: …...
)
别再手动点菜单了!用这招让Cadence Virtuoso Schematic效率翻倍(附Net高亮快捷键配置)
电路设计效率革命:Cadence Virtuoso Schematic高阶快捷键配置指南 在集成电路设计的浩瀚宇宙中,Cadence Virtuoso如同设计师手中的光刻机,每一次精准操作都直接影响最终芯片的性能与可靠性。然而,当面对数百个晶体管组成的复杂模…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

PentestGPT实战部署指南:AI驱动的渗透测试工作流落地
1. 这不是另一个“AI安全”的概念玩具,而是一套能真正跑起来的渗透测试辅助工作流“PentestGPT”这个名字刚在GitHub上出现时,我第一反应是点开又关掉——过去三年里,我见过太多打着“AI渗透”旗号的项目:有的只是把ChatGPT API封…...

电容损坏深度诊断,从外观到 ESR精准区分容衰与漏电
在 PCB 故障中,电容损坏占比超 40%,是当之无愧的 “头号杀手”。很多工程师仅靠 “鼓包漏液” 判断电容好坏,殊不知80% 的电容损坏是隐性的—— 外观平整但容值衰减、ESR 升高、轻微漏电,导致供电不稳、系统重启、噪声增大&#x…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...

别再只比参数了!从插件生态到中文优化,聊聊ChatGPT和文心一言的“隐形”差异
超越参数之争:ChatGPT与文心一言的生态与本土化实战解析 当技术评测文章还在反复比较模型参数量与发布时间时,真正影响日常工作效率的往往是那些未被量化的"软实力"。本文将从插件生态构建与中文场景优化两个维度,带您重新认识这两…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...

Log4Shell漏洞深度解析:Spring Boot日志注入原理与四层修复方案
1. 这个漏洞不是“远程执行代码”那么简单——它是一次对Java生态信任链的系统性击穿Log4j CVE-2021-44228,业内常简称为“Log4Shell”,2021年12月爆发时,我正在给一家金融客户的Spring Boot微服务集群做灰度发布前的安全加固。凌晨三点收到告…...

通过TaotokenCLI工具一键配置开发环境接入参数
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置开发环境接入参数 对于需要接入多个大模型服务的开发者而言,手动配置每个项目的API密钥、…...