爬虫入门到精通_框架篇16(Scrapy框架基本使用)_名人名言的抓取
1 目标站点分析
抓取网站:http://quotes.toscrape.com/
主要显示了一些名人名言,以及作者、标签等等信息:
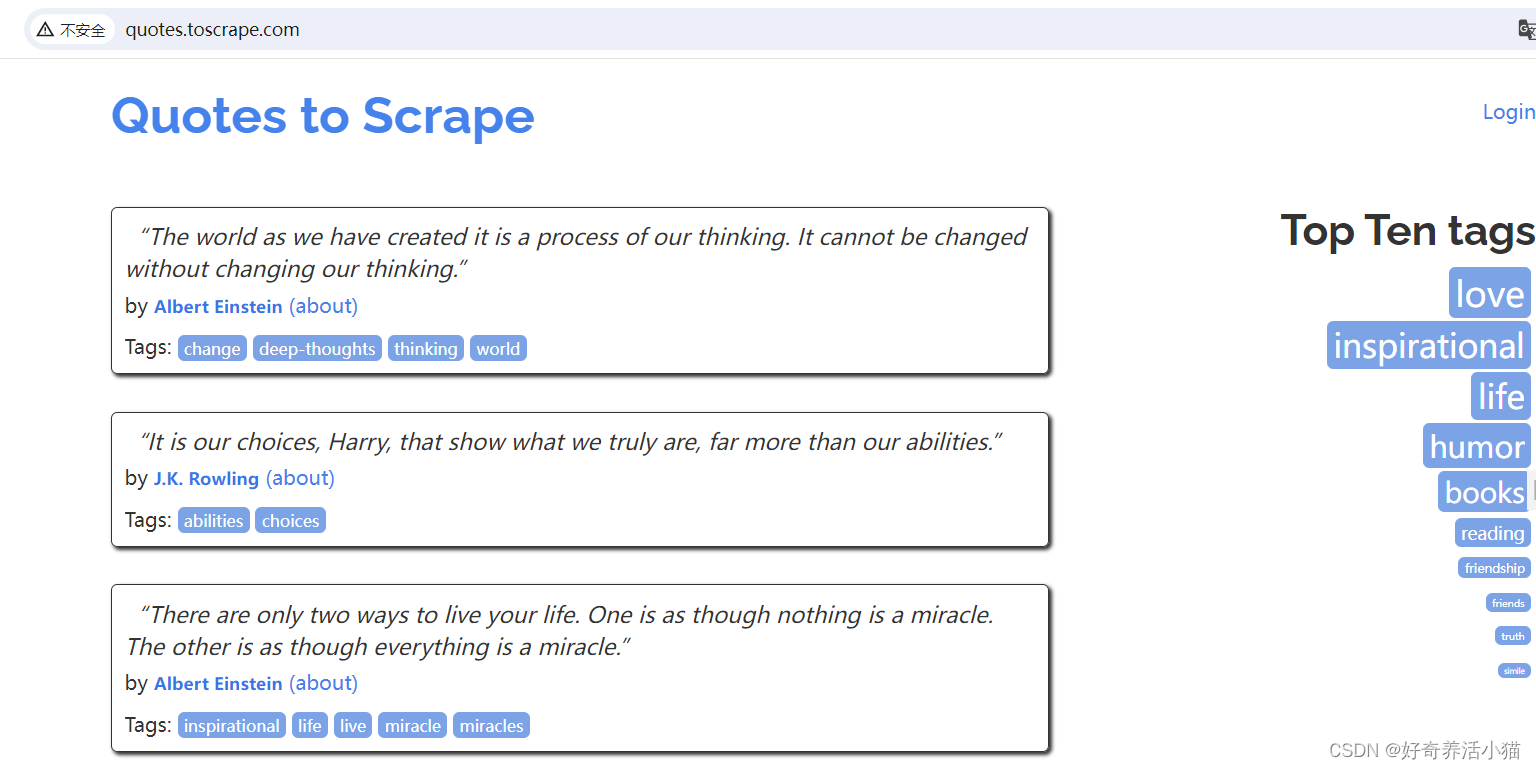
点击next,page变为2:
2 流程框架
- 抓取第一页:请求第一页的URL并得到源代码,进行下一步分析。
- 获取内容和下一页链接:分析源代码,提取首页内容,获取下一页链接等待进一步爬取。
- 翻页爬取:请求下一页信息,分析内容并请求再下一页链接。
- 保存爬取内容:将爬取结果保存为特定格式如文本,数据库。
3 代码实战
新建一个项目
scrapy startproject quotetutorial
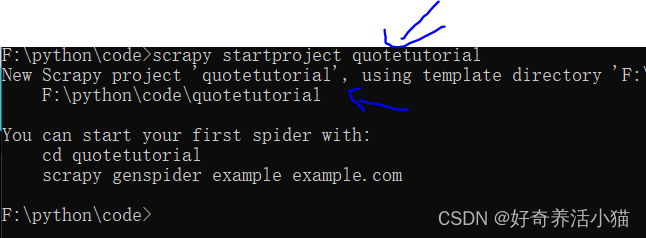
创建一个spider(名为quotes):

使用pycharm来打开已经在本地生成的项目:

scrapy.cfg:配置文件
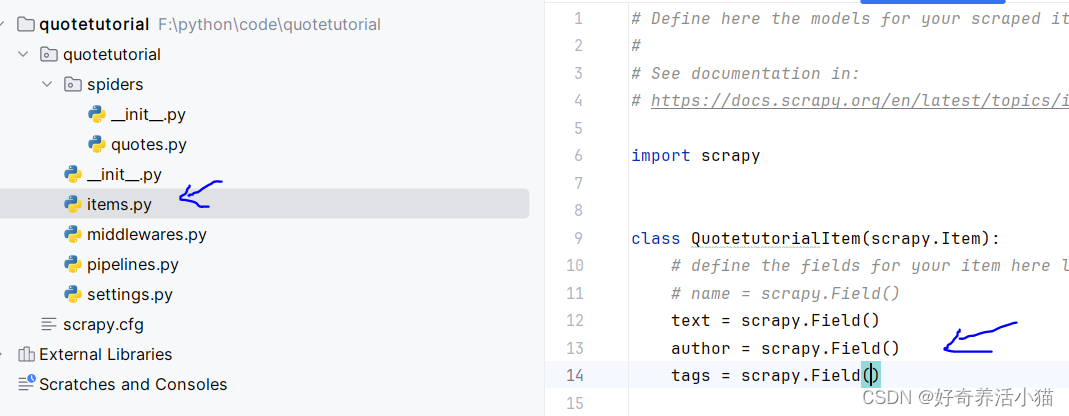
items.py:保存数据的数据结构
middlewares.py:爬取过程中定义的一些中间件,可以用来处理Request,Response以及Exceptions等操作,也可以用来修改Request, Response等相关的配置
pipelines.py:项目管道,可以用来输出一些items
settings.py:定义了许多配置信息
quotes.py:主要的运行代码
执行这个爬虫程序:
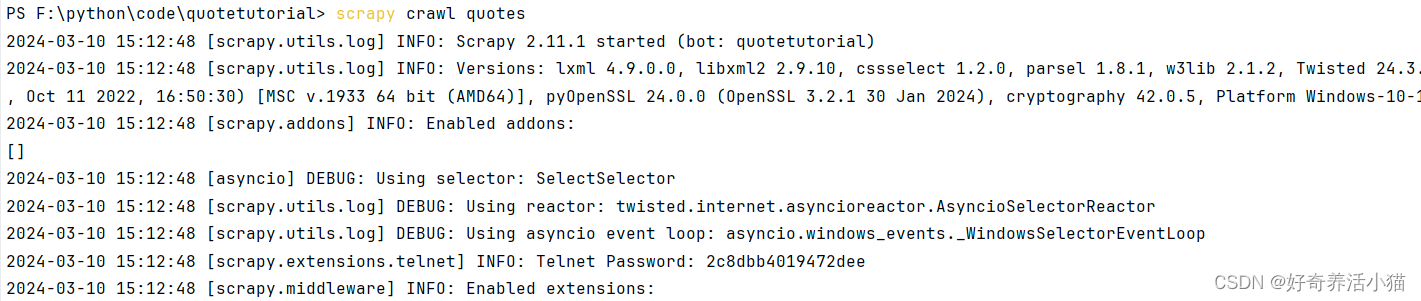
可以看到控制台中打印出了许多调试信息,可以看出,它和普通的爬虫不太一样,Scrapy提供了很多额外的输出。
抓取第一页

1.更改QuotesSpider这个类,通过css选中quote这个区块,
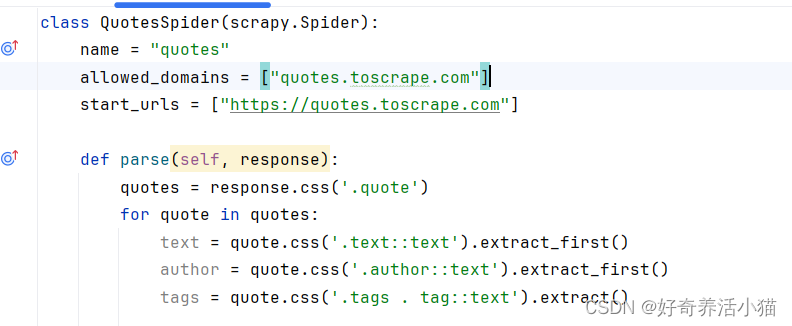
def parse(self, response):quotes = response.css('.quote')for quote in quotes:text = quote.css('.text::text').extract_first()author = quote.css('.author::text').extract_first()tags = quote.css('.tags . tag::text').extract()
这样的解析方法和pyquery非常相似:
.text :指的是标签的class.
::text :是Scrapy特有的语法结构,表示输出标签里面的文本内容.
extract_first() :方法表示获取第一个内容.
extract :会把所有结果都找出来(类似于find和findall).
说明:Scrapy还为我们提供了一个非常强大的工具–shell,在命令行中输入“scrapy shell quotes.toscrape.com”,可以进入命令行交互模式:
例如,直接输入response,回车后会直接执行这条语句。:
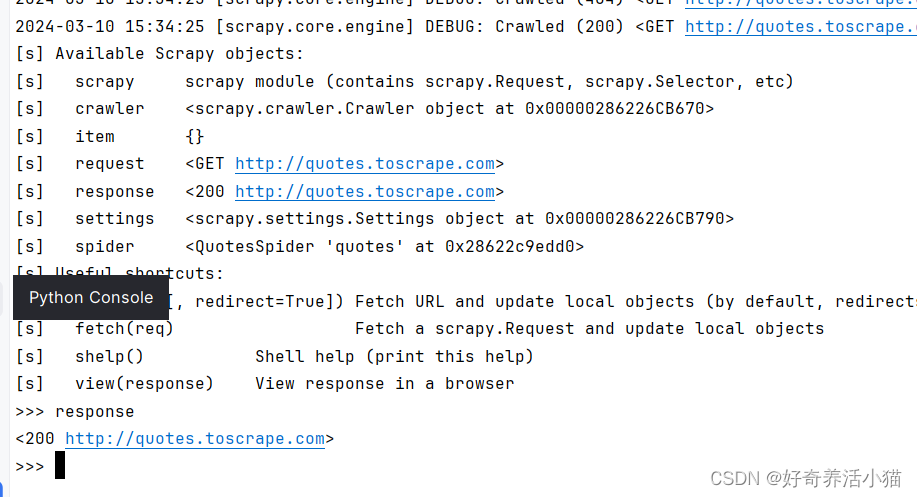
试试刚才写的方法的效果:先查看“response.css(’.quote’)”的输出:

这是一个list类型的数据,里面的内容是Selector选择器,查看第一个结果:此时若直接输入quotes会报错。
先执行quotes = response.css(‘.quote’),然后quotes[0]。

.text和.text::text的区别:data数据的输出和不输出

2.借助Scrapy提供的“items.py”定义统一的数据结构,指定一些字段之类的,将爬取到的结果作为一个个整体存下来。根据提示更改文件如下:
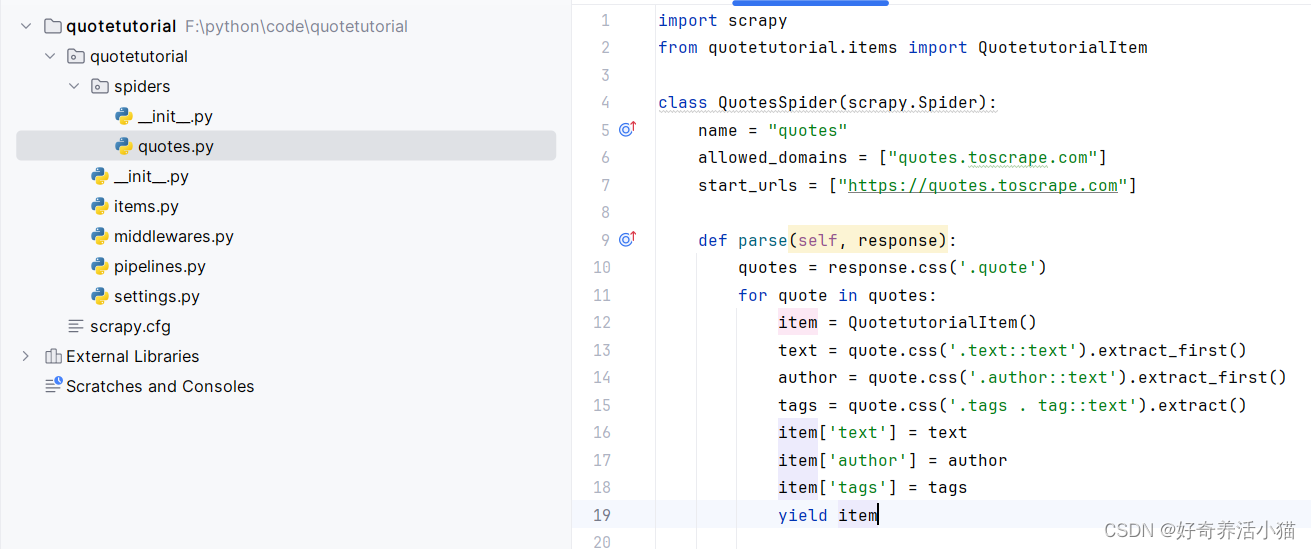
3. 要在parse方法中调用我们刚才定义的items,将提取出的网页信息存储到item,然后调用yield方法将item生成出来。
获取内容和下一页链接
import scrapy
from quotetutorial.items import QuotetutorialItemclass QuotesSpider(scrapy.Spider):name = "quotes"allowed_domains = ["quotes.toscrape.com"]start_urls = ["https://quotes.toscrape.com"]def parse(self, response):quotes = response.css('.quote')for quote in quotes:item = QuotetutorialItem()text = quote.css('.text::text').extract_first()author = quote.css('.author::text').extract_first()tags = quote.css('.tags .tag::text').extract()item['text'] = textitem['author'] = authoritem['tags'] = tagsyield itemnext = response.css('.pager .next a::attr(href)').extract_first()url = response.urljoin(next)yield scrapy.Request(url=url, callback=self.parse)
最后调用Request,第一个参数就是要请求的url,第二个参数“callback”是回调函数的意思,也就是请求之后得到的response由谁来处理,这里我们还是调用parse,因为parse方法就是用来处理索引页的,这就相当于完成了一个递归的调用,可以一直不断地调用parse方法获取下一页的链接并对访问得到的信息进行处理。
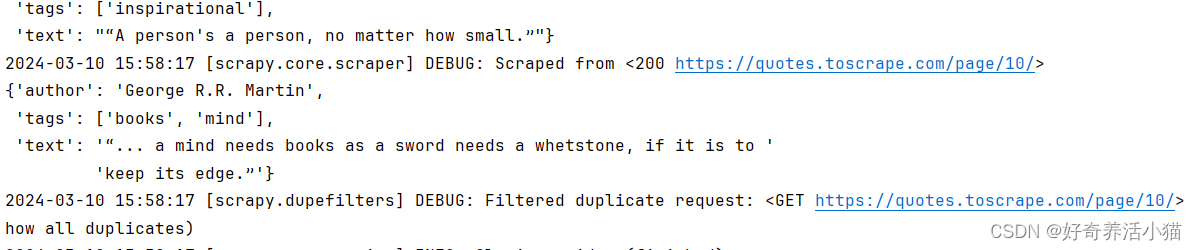
再次重新运行程序,可以看到输出了10页的内容,这是因为该网站只有10页内容:
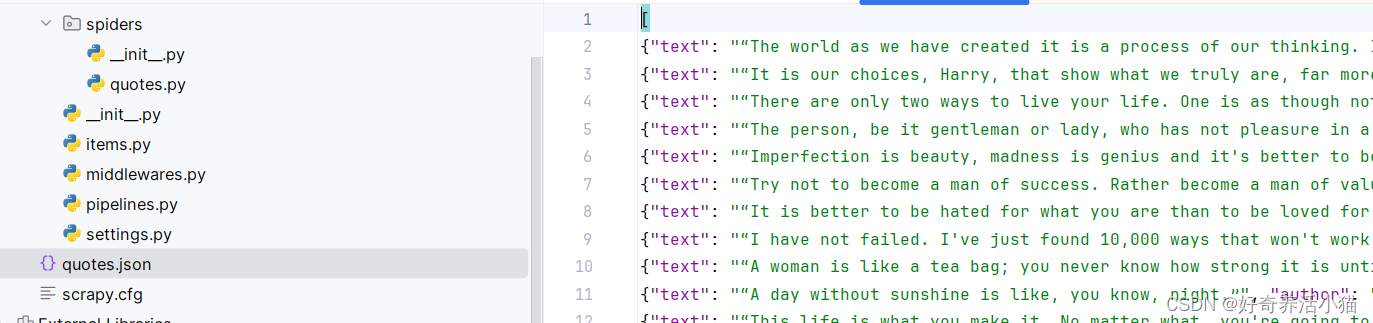
保存爬取到的信息
在原来的命令后面增加“-o 文件名称.json”,爬取完成后就会生成一个“quotes.json”文件,把获取到的信息保存成了标准的json格式。
scrapy crawl quotes -o quotes.json
Scrapy还提供了其它存储格式,比如“jl”格式,在命令行输入如下命令就可以得到jl格式文件。相比于json格式,它没有了最前面和最后面的的大括号,每条数据独占一行:
scrapy crawl quotes -o quotes.jl
或者保存成csv格式:
scrapy crawl quotes -o quotes.csv
它还支持xml、pickle和marshal等格式。
Scrapy还提供了一种远程ftp的保存方式,可以将爬取结果通过ftp的形式进行保存,例如:
scrapy crawl quotes -o ftp://user:pass@ftp.example.com/path/quotes.csv
数据处理
在将爬取到的内容进行保存之前,还需要对item进行相应的处理,因为在解析完之后,有一些item可能不是我们想要的,或者我们想把item保存到数据库里面,就需要借助Scrapy的Pipeline工具。
更改pipelines.py文件:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
import pymongoclass TextPipeline:def __init__(self):self.limit = 50def process_item(self, item, spider):if item['text']:if len(item['text']) > self.limit:item['text'] = item['text'][0:self.limit].rstrip() + '...'return itemelse:return DropItem('Missing Text')class MongoPipeline(object):def __init__(self, mongo_uri, mongo_db):self.mongo_uri = mongo_uriself.mongo_db = mongo_db@classmethoddef from_crawler(cls, crawler):return cls(mongo_uri=crawler.settings.get('MONGO_URI'),mongo_db=crawler.settings.get('MONGO_DB'))def open_spider(self, spider):self.client = pymongo.MongoClient(self.mongo_uri)self.db = self.client[self.mongo_db]def process_item(self, item, spider):name = item.__class__.__name__self.db['quotes'].insert(dict(item))return itemdef close_spider(self, spider):self.client.close()
更改setting:
MONGO_URI = 'localhost'
MONGO_DB = 'quotestutorial'
pipeline似乎没生效,要想让pipeline生效,需要在settings里面指定pipeline。
后面的序号300和400这样,代表pipeline运行的优先级顺序,序号越小表示优先级越高,会优先进行调用。
MONGO_URI = 'localhost'
MONGO_DB = 'quotestutorial'ITEM_PIPELINES = {'quotetutorial.pipelines.TextPipeline': 300,'quotetutorial.pipelines.MongoPipeline': 400,
}
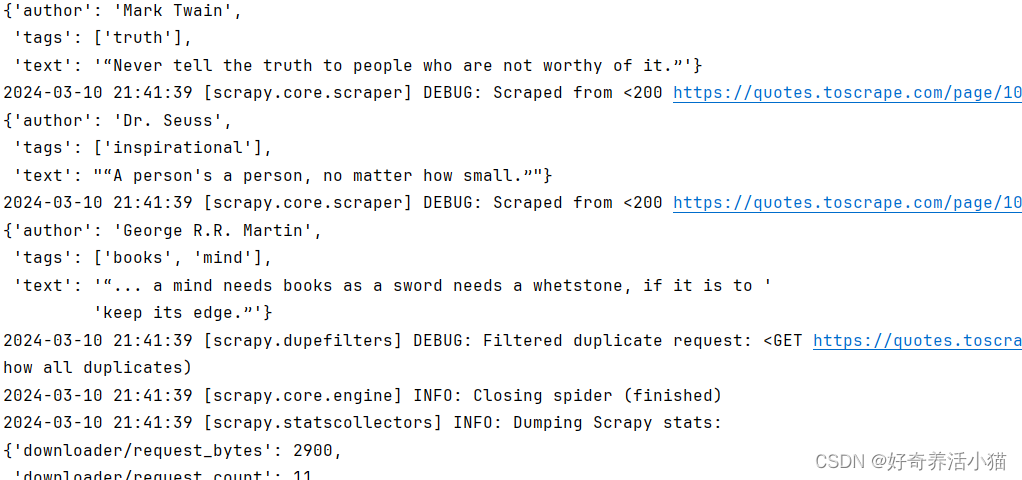
将程序写好后我们可以再次运行,(命令行输入“scrapy crawl quotes”),可以看到输出的text过长的话,后面就被省略号代替了,同时数据也被存入了MongoDB数据库。
相关文章:
爬虫入门到精通_框架篇16(Scrapy框架基本使用)_名人名言的抓取
1 目标站点分析 抓取网站:http://quotes.toscrape.com/ 主要显示了一些名人名言,以及作者、标签等等信息: 点击next,page变为2: 2 流程框架 抓取第一页:请求第一页的URL并得到源代码,进行下…...
)
mac inter 芯片遇到程序无法打开(无法验证开发者)
mac inter 芯片遇到程序无法打开(无法验证开发者) 解决方案 终端运行命令: sudo xattr -r -d com.apple.quarantine 文件路径(直接把文件拖入到终端,可以自动找到文件路径)即可令其获得权限 补充知识: 通过gpt可以…...

科技成果鉴定测试如何进行?第三方检测机构进行鉴定测试的好处
科技成果鉴定测试,作为科技领域中一项重要的质量检验手段,具有广泛的应用范围。旨在为科技成果的研发者和使用者提供客观、科学、权威的鉴定结果,从而评估科技成果的技术水平和市场竞争力。 科技成果鉴定测试是对科技成果进行系统、全面的…...
八、词嵌入语言模型(Word Embedding)
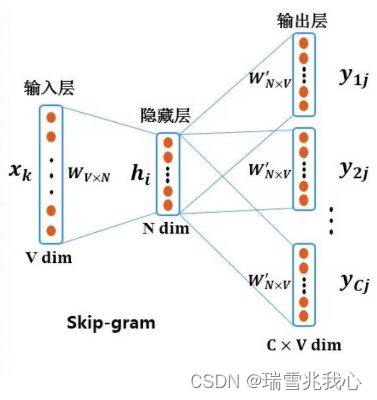
词嵌入(Word Embedding, WE),任务是把不可计算、非结构化的词转换为可以计算、结构化的向量,从而便于进行数学处理。 一个更官方一点的定义是:词嵌入是是指把一个维数为所有词的数量的高维空间(one-hot形式…...

重学SpringBoot3-WebMvcConfigurer接口
摘要: 本文详细介绍了SpringBoot 3中的WebMvcConfigurer接口,旨在帮助读者深入理解其原理和实现,从而能够更好地使用SpringBoot进行Web开发。阅读本文需要大约30分钟。 关键词:SpringBoot, WebMvcConfigurer, SpringMVC, Web开发…...
《深入理解springCloud与微服务》笔记
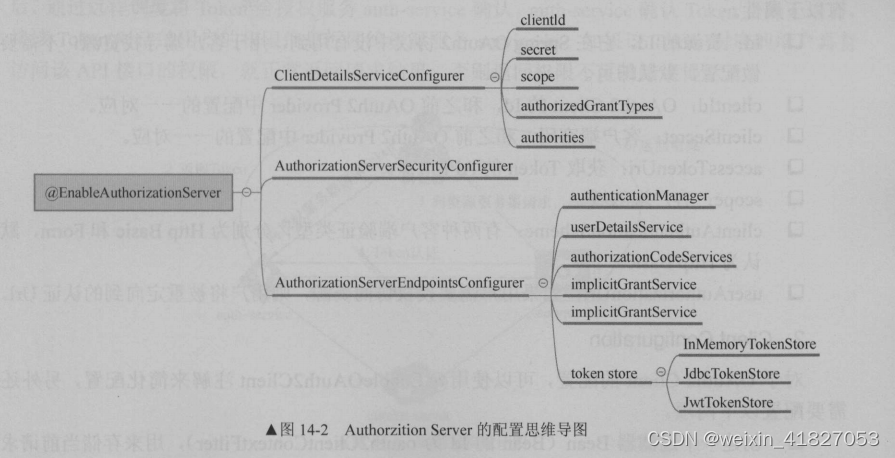
第一章 微服务介绍 1.3 微服务的不足 1.3.2 分布式事务 CAP 理论,即同时满足“一致性”“可用性”和“分区容错”是 件不可能的事。 Consistency :指数据的强一致性。如果写入某个数据成功,之后读取,读到的都是新写入的数据&a…...

Vivado原语模板
1.原语的概念 原语是一种元件! FPGA原语是芯片制造商已经定义好的基本电路元件,是一系列组成逻辑电路的基本单元,FPGA开发者编写逻辑代码时可以调用原语进行底层构建。 2.原语的分类 原语可分为预定义原语和用户自定义原语。预定义原语为如and/or等门级原语不需要例化,可以…...
【linux本地安装tinycudann包教程】
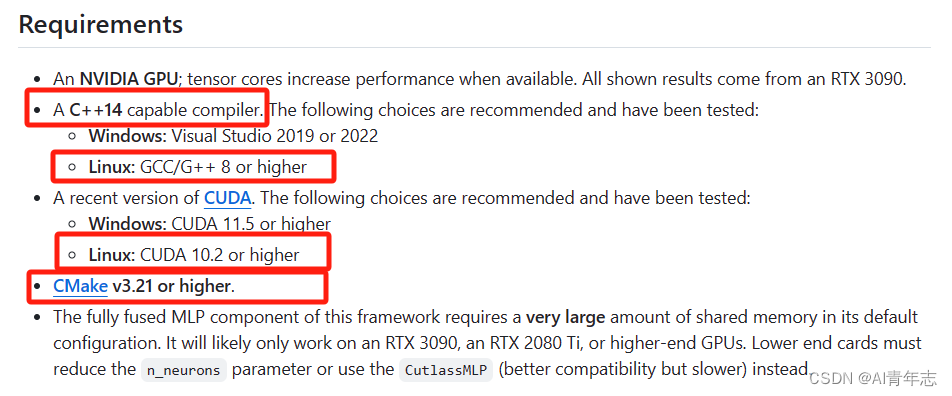
【linux本地安装tinycudann包教程】 tiny-cuda-nn官网链接 如果你是windows 10系统的,想要安装tiny-cuda-nn可以参考我的文章——windows 10安装tiny-cuda-n包 根据官网要求:C++要求对应14,其实这样就已经告诉我们linux系统中的gcc版本不能高于9,同时下面又告诉我们gcc版…...
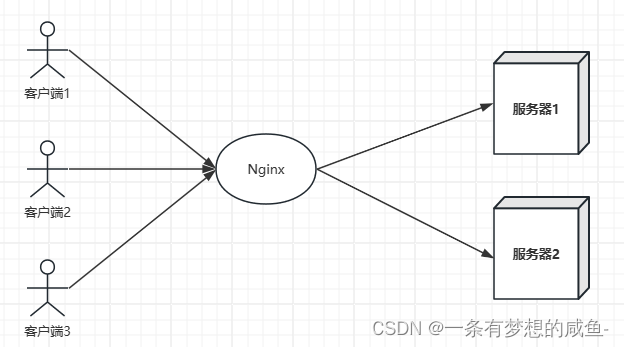
使用Nginx进行负载均衡
什么是负载均衡 Nginx是一个高性能的开源反向代理服务器,也可以用作负载均衡器。通过Nginx的负载均衡功能,可以将流量分发到多台后端服务器上,实现负载均衡,提高系统的性能、可用性和稳定性。 如下图所示: Nginx负…...

什么护眼台灯效果好?热门护眼台灯全方位测评推荐
台灯可以说是佳佳必备,尤其是家中有正在上学的孩子的更是需要一款好的台灯,不管是看书、写字都离不开台灯。不过很多家长在挑选台灯时往往仅关注到光线亮度是否充足,而忽略掉光线均匀度、舒适度等等方面的问题。所以选择一款优质的护眼台灯是…...

云上三问,迈向智能时代的关键
在今天的中国,第一热词是什么?面对这个问题,“新质生产力”当仁不让,而智能化技术毫无疑问是“新质生产力”最重要的来源之一。 在这样的大势下,大型政企是向新技术要“新质生产力”的时代先锋。云服务,则是…...

【网络安全】手机不幸被远程监控,该如何破解,如何预防?
手机如果不幸被远程监控了,用三招就可以轻松破解,再用三招可以防范于未然。 三招可破解可解除手机被远程监控 1、恢复出厂设置 这一招是手机解决软件故障和系统故障的终极大招。只要点了恢复出厂设置,你手机里后装的各种APP全部将灰飞烟灭…...

每日OJ题_哈希表④_力扣219. 存在重复元素 II
目录 力扣219. 存在重复元素 II 解析代码 力扣219. 存在重复元素 II 219. 存在重复元素 II 难度 简单 给你一个整数数组 nums 和一个整数 k ,判断数组中是否存在两个 不同的索引 i 和 j ,满足 nums[i] nums[j] 且 abs(i - j) < k 。如果存在&am…...

42.坑王驾到第八期:uniCloud报错
uniCloud 报错 今天调用云函数来调试小程序的时候突然暴了一个奇葩错误,require(…).main is not a function。翻官方文档后发现,原来是这样:**如果你写的是云对象,入口文件应为 index.obj.js,如果你写的是云函数入口…...

Linux常用操作命令
Linux常用操作命令 1.文件管理catfile 2.文档编辑3.文件传输4.磁盘管理5.磁盘维护6.网络通讯7.系统管理8.系统设置9.备份压缩10.设备管理 Linux 英文解释为 Linux is not Unix。 Linux内核最初只是由芬兰人李纳斯托瓦兹(Linus Torvalds)在赫尔辛基大学上…...
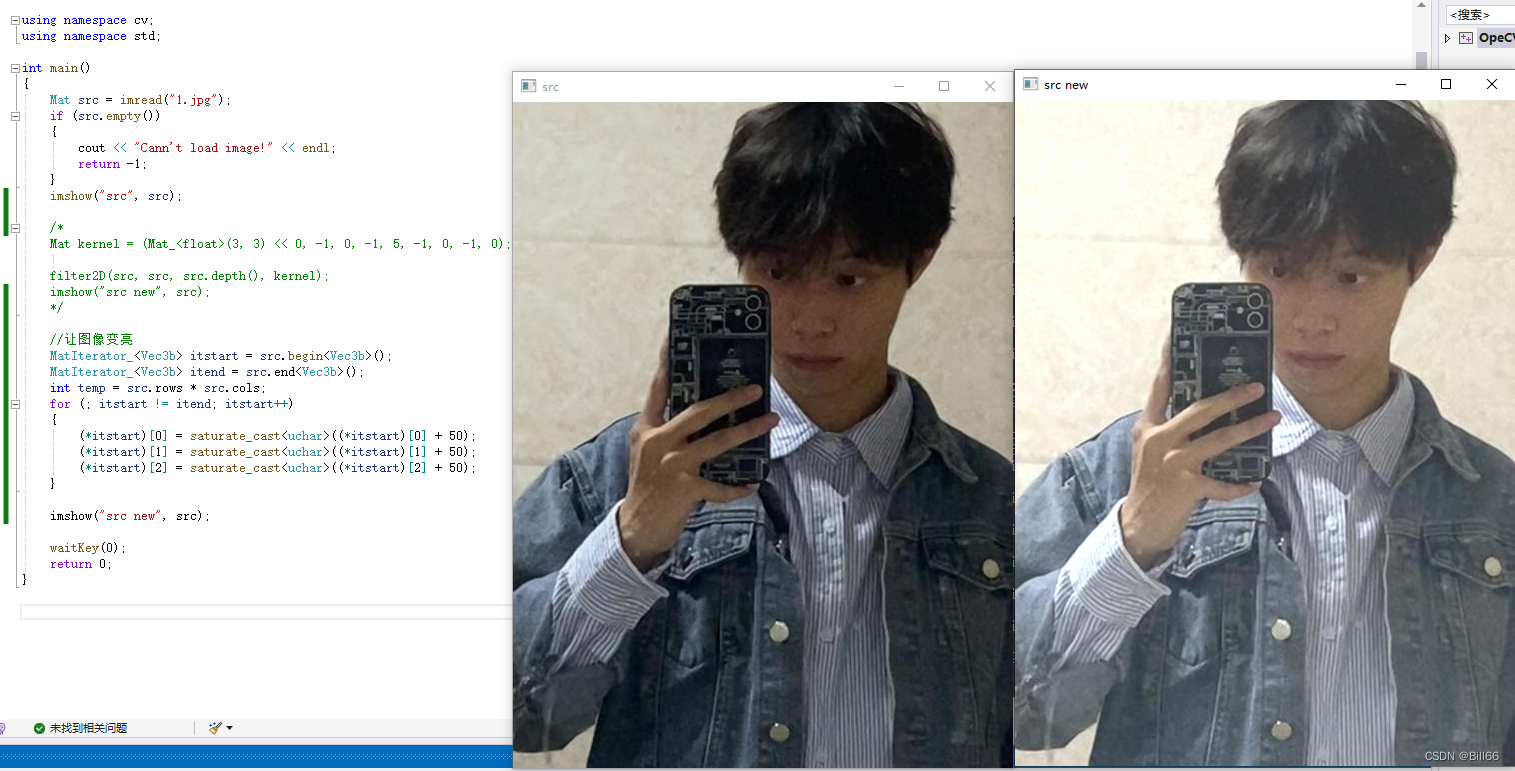
OpenCV的常用数据类型
OpenCV涉及的常用数据类型除包含C的基本数据类型,如:char、uchar,int、unsigned int,short 、long、float、double等数据类型外, 还包含Vec,Point、Scalar、Size、Rect、RotatedRect、Mat等类。C中的基本数据类型不需再做说明下面重点介绍一下…...
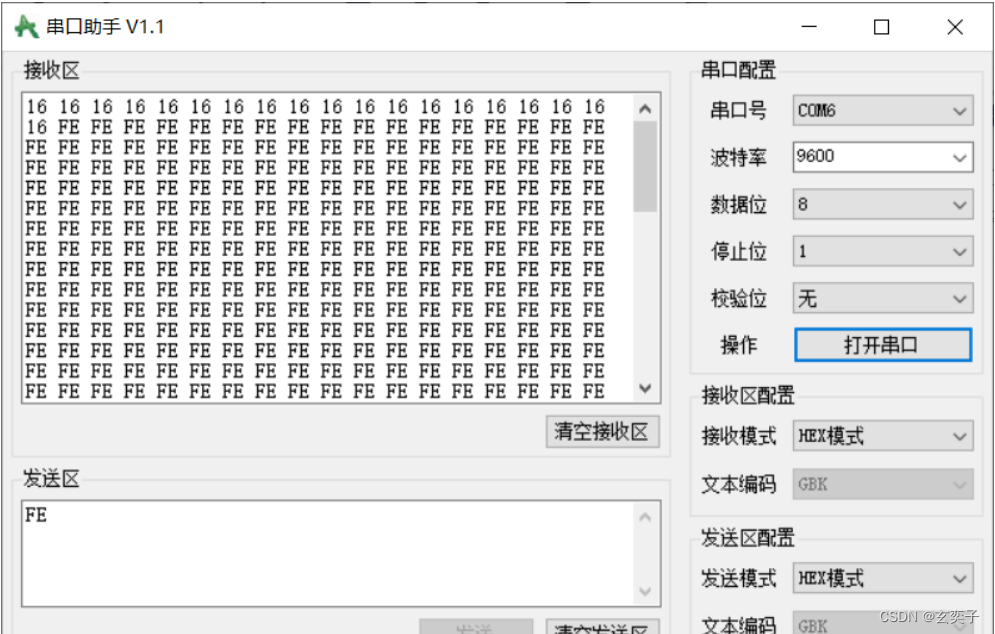
STM32串口通信—串口的接收和发送详解
目录 前言: STM32串口通信基础知识: 1,STM32里的串口通信 2,串口的发送和接收 串口发送: 串口接收: 串口在STM32中的配置: 1. RCC开启USART、串口TX/RX所对应的GPIO口 2. 初始化GPIO口 …...

《汇编语言》第3版 (王爽) 第14章
第14章 端口 检测点14.1 (1).编程,读取CMOS RAM的2号单元的内容。 mov al,2 ;向al写入2 out 70,al ;将2送入端口70h in al,71 ;从端口71h读取2号单元的内容在CMOS RAM中用6个字节存放当前时间(以BCD码形式存放)&…...
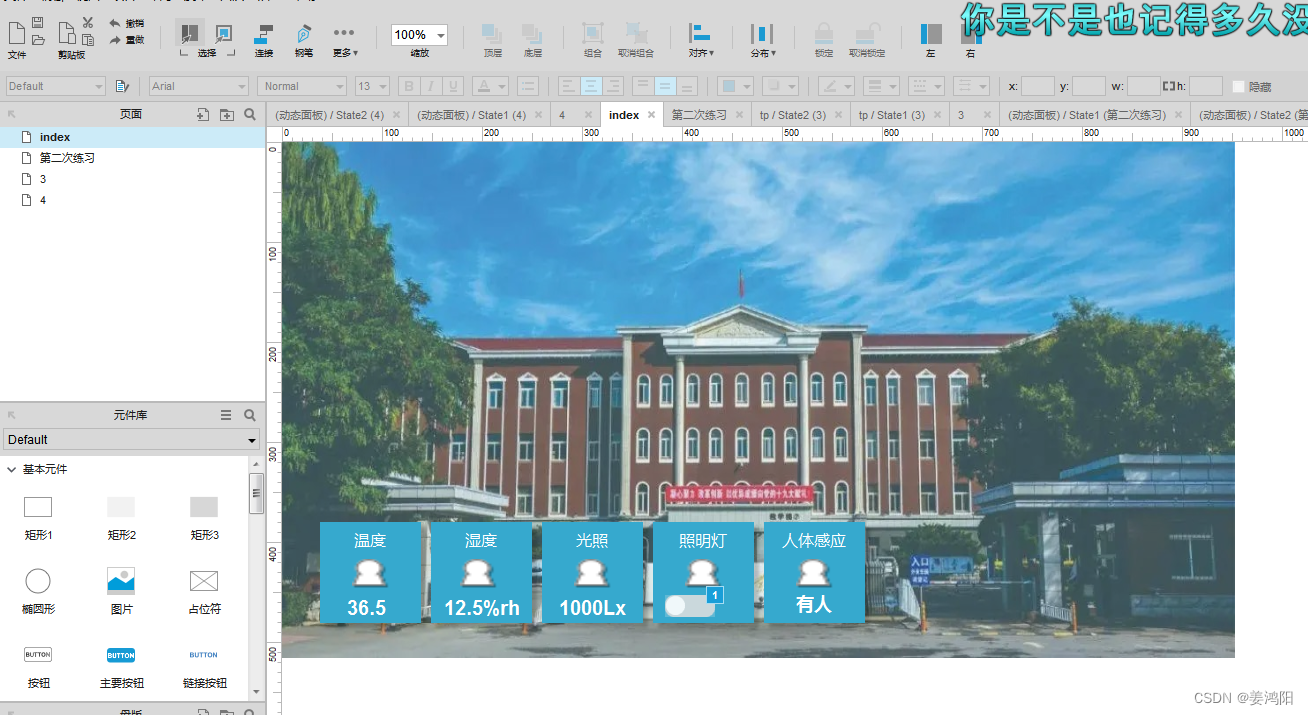
Axure原型设计项目效果 全国职业院校技能大赛物联网应用开发赛项项目原型设计题目
目录 前言 一、2022年任务书3效果图 二、2022年任务书5效果图 三、2022年国赛正式赛卷 四、2023年国赛第一套样题 五、2023年国赛第二套样题 六、2023年国赛第三套样题 七、2023年国赛第四套样题 八、2023年国赛第七套样题 九、2023年国赛正式赛题(第八套…...
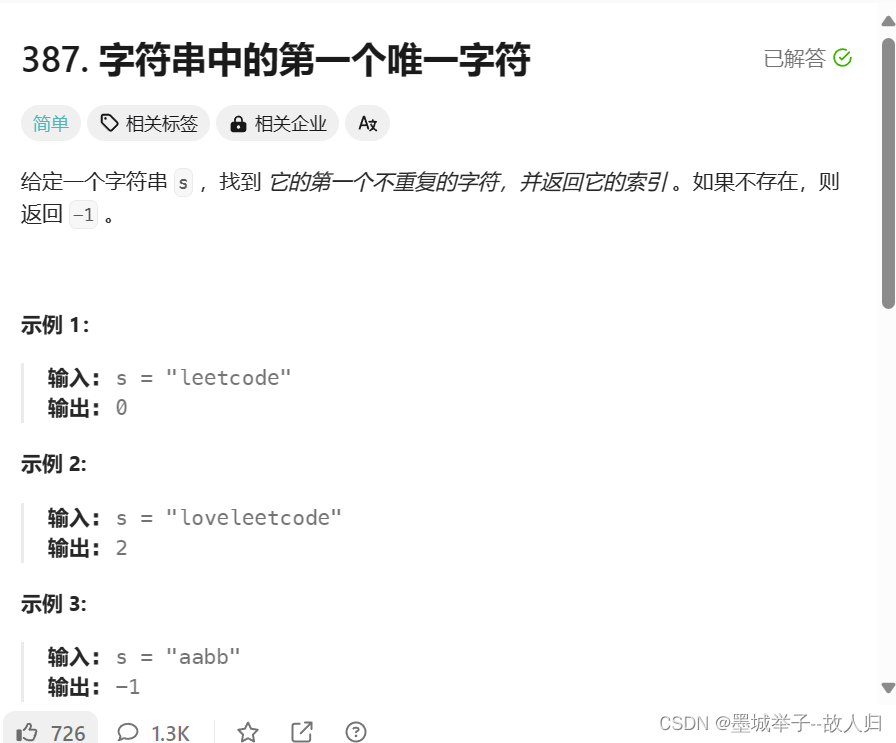
力扣串题:字符串中的第一个唯一字母
映射做法:将字母转为数字之类的转化必须在运算中实现如-a int firstUniqChar(char * s){int a[26] {0};int len strlen(s);int i;for (i 0; i < len; i)a[s[i] - a];for (i 0; i < len; i) {if (a[s[i] - a] 1)return i;}return -1; }...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...

机器学习与深度学习在社交媒体心理健康检测中的权衡与选择
1. 项目概述:当AI遇见心灵,社交媒体心理健康检测的技术十字路口在社交媒体成为我们数字生活延伸的今天,海量的文本数据无意中记录着用户的情感波动与心理状态。作为一名长期混迹于数据科学和自然语言处理(NLP)一线的从…...

Arduino ADC自检:用RC电路诊断模数转换器故障
1. 项目概述:当你的体重秤开始“说谎”你有没有遇到过这样的情况:站上家里的电子体重秤,屏幕上跳出来的数字让你瞬间怀疑人生?要么是轻得离谱,要么是重得吓人,更诡异的是,它可能只在两个固定的、…...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...

别让依赖毁了你的实验:记一次Vision Mamba复现中causal_conv1d与mamba-ssm的版本“打架”事件
Vision Mamba复现实战:破解依赖冲突的工程化解决方案在深度学习项目的复现过程中,依赖管理往往是最容易被忽视却又最常导致问题的环节。最近在复现Vision Mamba模型时,我遭遇了一场典型的Python依赖"战争"——causal_conv1d与mamba…...
)
告别Appium!用Python+UIAutomator2搞定Android自动化测试(附完整环境搭建与实战代码)
PythonUIAutomator2:Android自动化测试的高效实践指南 在移动应用测试领域,效率与稳定性始终是工程师们追求的核心目标。传统方案如Appium虽然功能全面,但在执行速度和资源消耗方面往往难以满足高频测试需求。本文将带您探索基于Python和UIA…...
)
别再只用JSON了!用Protobuf给Go微服务接口性能提升10倍(附完整代码)
别再只用JSON了!用Protobuf给Go微服务接口性能提升10倍(附完整代码) 在微服务架构中,接口性能往往是决定系统吞吐量的关键因素。许多开发者习惯性地使用JSON作为数据交换格式,却不知道这可能在无形中成为性能瓶颈。本…...

June主题定制教程:从模板修改到样式定制的完整解决方案
June主题定制教程:从模板修改到样式定制的完整解决方案 【免费下载链接】june June is a forum (Deprecated) 项目地址: https://gitcode.com/gh_mirrors/ju/june June是一款开源论坛项目,通过本教程你将学习如何轻松定制June论坛的主题外观&…...

城通网盘解析工具:3分钟获取直连地址的完整高效解决方案
城通网盘解析工具:3分钟获取直连地址的完整高效解决方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 城通网盘解析工具 ctfileGet 是一款专为破解城通网盘下载限制而设计的开源工具&…...

Burp Suite Galaxy插件实战:上下文感知解密中枢搭建指南
1. 为什么Galaxy插件不是“又一个加解密工具”,而是Burp生态里真正能落地的解密中枢 你有没有遇到过这样的场景:在Burp Suite里抓到一串密文,比如 eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9... ,第一反应是复制进JWT.io——结果发现…...