BS4网络提取selenium.chrome.WebDriver类的方法及属性
BS4网络提取selenium.chrome.WebDriver类的方法及属性
chrome.webdriver: selenium.webdriver.chrome.webdriver — Selenium 4.18.1 documentation
class selenium.webdriver.chrome.webdriver.WebDriver 是 Selenium 中用于操作 Chrome 浏览器的 WebDriver 类。WebDriver 类是 Selenium 提供的一个关键类,用于驱动浏览器执行各种操作,比如打开网页、查找元素、模拟用户操作等。
通过使用 selenium.webdriver.chrome.webdriver.WebDriver 类,结合其他 Selenium 提供的方法和类,可以实现自动化测试、网页数据抓取等功能。Chrome WebDriver 是针对 Chrome 浏览器的驱动程序,可以与 Chrome 浏览器无缝集成,实现对浏览器的控制和操作。
import requests
from bs4 import BeautifulSoupurl = "https://www.selenium.dev/selenium/docs/api/py/webdriver_chrome/selenium.webdriver.chrome.webdriver.html#module-selenium.webdriver.chrome.webdriver"response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')# with open("selenium.webdriver.chrome.webdriver.WebDriver.html", 'r', encoding='utf-8') as f:
# html_doc = f.read()
# soup = BeautifulSoup(html_doc, 'html.parser')methods = soup.find_all('dl', class_='method')
attributes = soup.find_all('dl', class_='attribute')for method in methods:dt = method.find('dt', id=True)if dt:print(f"Method ID: {dt['id']}")# print(f"Method Info: {dt.text}")for attribute in attributes:dt = attribute.find('dt', id=True)if dt:print(f"Attribute ID: {dt['id']}")# print(f"Attribute Info: {dt.text}")
# select() 方法时,通过 CSS 选择器来查找特定的元素
# 通过类名查找元素: elements = soup.select('div.content')
# 通过 ID 查找元素: element = soup.select('div#header')
# 通过标签名查找元素: elements = soup.select('a')
# 通过组合选择器查找元素: listitems = soup.select('ul.menu li')查找class为menu的ul元素下的所有li子元素# 当使用 BeautifulSoup 的 find_all() 方法进行查找时,可以结合多种条件和技巧来定位和提取需要的元素。
# 以下是归纳的一些常见的 find_all() 查找方式:
# 按标签名查找:soup.find_all('tag_name')
# 按类名查找:soup.find_all(class_='class_name')
# 按 id 查找:soup.find_all(id='element_id')
# 按属性查找:soup.find_all(attrs={'attribute': 'value'})
# 结合多个条件查找:soup.find_all('tag', class_='class_name', attrs={'attribute': 'value'})
# 按文本内容查找:soup.find_all(text='desired_text')
# 结合正则表达式的文本内容查找:soup.find_all(text=re.compile(r'regex_pattern'))
# 按子节点查找:parent_element.find_all('child_tag')
# 按序号查找:soup.find_all('tag_name')[index]
# 查找特定属性存在的元素:soup.select('[attribute]')
# 结合列表推导式进行查找:[tag for tag in soup.find_all() if condition]# 当使用 BeautifulSoup 的 find 方法查找标签元素时,可以根据不同的需求使用不同的方式来定位目标标签。
# 下面是一些常用的方式和示例:
# find_all(name, attrs, recursive, text, limit, **kwargs):在当前标签内查找所有符合条件的元素,并返回一个列表。
# 通过标签名称查找:tag = soup.find('a') # 查找第一个<a>标签
# 通过指定标签属性查找:tag = soup.find('a', {'class': 'example'}) # 查找第一个class为'example'的<a>标签
# 通过 CSS 类名查找:tag = soup.find(class_='example') # 查找第一个class为'example'的标签
# 通过 ID 查找:tag = soup.find(id='example') # 查找id为'example'的标签
# 通过正则表达式查找:tag = soup.find(text=re.compile('example')) # 查找文本内容包含'example'的标签
# 结合多个属性查找:tag = soup.find('a', {'class': 'example', 'id': 'link'}) # 查找第一个同时具有class为'example'和id为'link'的<a>标签
# 多个条件逻辑组合查找:tag = soup.find('a', class_='example', id='link') # 查找第一个同时具有class为'example'和id为'link'的<a>标签
# 使用 CSS 选择器语法查找:tag = soup.select_one('a.example#link') # 使用CSS选择器语法查找class为'example'且id为'link'的<a>标签
# 查找特定位置的标签:tag = soup.find_all('a')[2] # 获取第三个<a>标签(索引从0开始)
# 查找父节点中的特定子节点:
# parent_tag = soup.find('div', id='x')
# child_tag = parent_tag.find('a') # 在id为'parent'的<div>标签中查找第一个<a>标签
# 查找包含特定文本的标签:
# tag = soup.find(text='Example text') # 查找第一个包含文本 'Example text' 的标签返回结果:
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.add_cookie
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.add_credential
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.add_virtual_authenticator
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.back
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.bidi_connection
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.close
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.create_web_element
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.delete_all_cookies
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.delete_cookie
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.delete_downloadable_files
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.delete_network_conditions
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.download_file
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.execute
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.execute_async_script
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.execute_cdp_cmd
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.execute_script
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.file_detector_context
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.find_element
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.find_elements
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.forward
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.fullscreen_window
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_cookie
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_cookies
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_credentials
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_downloadable_files
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_issue_message
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_log
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_network_conditions
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_pinned_scripts
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_screenshot_as_base64
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_screenshot_as_file
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_screenshot_as_png
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_sinks
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_window_position
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_window_rect
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.get_window_size
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.implicitly_wait
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.launch_app
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.maximize_window
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.minimize_window
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.pin_script
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.print_page
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.quit
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.refresh
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.remove_all_credentials
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.remove_credential
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.remove_virtual_authenticator
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.save_screenshot
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.set_network_conditions
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.set_page_load_timeout
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.set_permissions
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.set_script_timeout
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.set_sink_to_use
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.set_user_verified
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.set_window_position
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.set_window_rect
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.set_window_size
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.start_client
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.start_desktop_mirroring
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.start_session
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.start_tab_mirroring
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.stop_casting
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.stop_client
Method ID: selenium.webdriver.chrome.webdriver.WebDriver.unpin
Attribute ID: selenium.webdriver.chrome.webdriver.WebDriver.capabilities
Attribute ID: selenium.webdriver.chrome.webdriver.WebDriver.current_url
Attribute ID: selenium.webdriver.chrome.webdriver.WebDriver.current_window_handle
Attribute ID: selenium.webdriver.chrome.webdriver.WebDriver.file_detector
Attribute ID: selenium.webdriver.chrome.webdriver.WebDriver.log_types
Attribute ID: selenium.webdriver.chrome.webdriver.WebDriver.mobile
Attribute ID: selenium.webdriver.chrome.webdriver.WebDriver.name
Attribute ID: selenium.webdriver.chrome.webdriver.WebDriver.orientation
Attribute ID: selenium.webdriver.chrome.webdriver.WebDriver.page_source
Attribute ID: selenium.webdriver.chrome.webdriver.WebDriver.switch_to
Attribute ID: selenium.webdriver.chrome.webdriver.WebDriver.timeouts
Attribute ID: selenium.webdriver.chrome.webdriver.WebDriver.title
Attribute ID: selenium.webdriver.chrome.webdriver.WebDriver.virtual_authenticator_id
Attribute ID: selenium.webdriver.chrome.webdriver.WebDriver.window_handles
[Finished in 107.7s]
-------------------------------
基础知识:
# 当使用 BeautifulSoup 的 find_all() 方法进行查找时,可以结合多种条件和技巧来定位和提取需要的元素。
# 以下是归纳的一些常见的 find_all() 查找方式:
# 按标签名查找:soup.find_all('tag_name')
# 按类名查找:soup.find_all(class_='class_name')
# 按 id 查找:soup.find_all(id='element_id')
# 按属性查找:soup.find_all(attrs={'attribute': 'value'})
# 结合多个条件查找:soup.find_all('tag', class_='class_name', attrs={'attribute': 'value'})
# 按文本内容查找:soup.find_all(text='desired_text')
# 结合正则表达式的文本内容查找:soup.find_all(text=re.compile(r'regex_pattern'))
# 按子节点查找:parent_element.find_all('child_tag')
# 按序号查找:soup.find_all('tag_name')[index]
# 查找特定属性存在的元素:soup.select('[attribute]')
# 结合列表推导式进行查找:[tag for tag in soup.find_all() if condition]
# find(name, attrs, recursive, text, **kwargs):在当前标签内查找第一个符合条件的元素,并返回其 Tag 对象。
# find_all(name, attrs, recursive, text, limit, **kwargs):在当前标签内查找所有符合条件的元素,并返回一个列表。
# find_parent(name, attrs, recursive, text, **kwargs):查找当前标签的父元素并返回其 Tag 对象。
# find_next_sibling(name, attrs, recursive, text, **kwargs):查找当前标签的下一个同级元素并返回其 Tag 对象。
# tag.name:用于获取元素的标签名。
# tag.text 或 tag.get_text():用于获取元素的文本内容。
# tag['attribute'] 或 tag.get('attribute'):用于获取元素的属性值。
# tag.contents:用于获取元素的子节点列表。
# tag.parent 或 tag.parents:用于获取元素的父节点或祖先节点。
# tag.next_sibling 或 tag.previous_sibling:用于获取元素的下一个兄弟节点或上一个兄弟节点。
# tag.next_element 或 tag.previous_element:用于获取元素的下一个节点或上一个节点,可以是标签、字符串或注释。
# tag.has_attr('attribute'):用于判断元素是否包含某个属性。
# tag.find_previous(name=None, attrs={}, text=None, **kwargs) 和 tag.find_all_previous(name=None, attrs={}, text=None, limit=None, **kwargs):用于查找元素前面的满足条件的元素,参数与 find() 和 find_all() 方法类似。
# tag.select_one(selector):用于按照 CSS 选择器语法查找元素,并返回第一个匹配的元素。
# tag.select(selector):用于按照 CSS 选择器语法查找元素,并返回所有匹配的元素。
select() 方法是 BeautifulSoup 中用于按照 CSS 选择器语法查找元素,并返回所有匹配的元素的功能。通过使用CSS选择器语法,可以更方便地定位和选择需要的元素。
下面是 select() 方法及其参数的详细介绍:
语法 select(selector)
参数说明
selector:字符串类型,表示 CSS 选择器语法的表达式,用于指定要查找的元素。
CSS 选择器语法示例
标签选择器:tagname,如 p 表示选择所有 <p> 标签。soup.select('p')
类选择器:.classname,如 .content 表示选择所有 class 属性为 content 的元素。soup.select('.content')
ID 选择器:#idname,如 #footer 表示选择 id 属性为 footer 的元素。soup.select('#header')
层级选择器:ancestor descendant,如 div p 表示选择所有 <p> 标签,其父元素为 <div>。soup.select('div p')
子元素选择器:parent > child,如 div.content > p 表示选择所有 <p> 标签,其父元素为 <div>,且 class 属性为 content。soup.select('div.content > p')
后代元素选择器:ancestor descendant,如 div .content 表示选择所有具有 content 类名的元素,且其祖先元素为 <div>。soup.select('div .content')
相关文章:

BS4网络提取selenium.chrome.WebDriver类的方法及属性
BS4网络提取selenium.chrome.WebDriver类的方法及属性 chrome.webdriver: selenium.webdriver.chrome.webdriver — Selenium 4.18.1 documentation class selenium.webdriver.chrome.webdriver.WebDriver 是 Selenium 中用于操作 Chrome 浏览器的 WebDriver 类。WebDriver 类…...

Prompt Engineering(提示工程)
Prompt 工程简介 在近年来,大模型(Large Model)如GPT、BERT等在自然语言处理领域取得了巨大的成功。这些模型通过海量数据的训练,具备了强大的语言理解和生成能力。然而,要想充分发挥这些大模型的潜力,仅仅…...

移远通信亮相AWE 2024,以科技力量推动智能家居产业加速发展
科技的飞速发展,为我们的生活带来了诸多便利,从传统的家电产品到智能化的家居设备,我们的居家生活正朝着更智能、更便捷的方向变革。 3月14日,中国家电及消费电子博览会(Appliance&electronics World Expo…...

Java中上传数据的安全性探讨与实践
✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨ 🎈🎈作者主页: 喔的嘛呀🎈🎈 目录 引言 一. 文件上传的风险 二. 使用合适的框架和库 1. Spr…...

Leetcode 17. 电话号码的字母组合
心路历程: 之前看过这道题的解法但是忘了。一开始想多重循环遍历,发现不知道写几个for循环,于是想到递归;发现递归需要记录选择的路径而不是返回节点值,想到了回溯。 回溯的解题模板:维护两个变量…...

蓝桥杯单片机快速开发笔记——独立键盘
一、原理分析 二、思维导图 三、示例框架 #include "reg52.h" sbit S7 P3^0; sbit S6 P3^1; sbit S5 P3^2; sbit S4 P3^3; void ScanKeys(){if(S7 0){Delay(500);if(S7 0){while(S7 0);}}if(S6 0){Delay(500);if(S6 0){while(S6 0)…...
Swift 面试题及答案整理,最新面试题
Swift 中如何实现单例模式? 在Swift中,单例模式的实现通常采用静态属性和私有初始化方法来确保一个类仅有一个实例。具体做法是:定义一个静态属性来存储这个单例实例,然后将类的初始化方法设为私有,以阻止外部通过构造…...

微信小程序上传图片c# asp.net mvc端接收案例
在微信小程序上传图片到服务器,并在ASP.NET MVC后端接收这个图片,可以通过以下步骤实现: 1. 微信小程序端 首先,在微信小程序前端,使用 wx.chooseImage API 选择图片,然后使用 wx.uploadFile API 将图片上…...

57、服务攻防——应用协议RsyncSSHRDP漏洞批扫口令猜解
文章目录 口令猜解——Hydra-FTP&RDP&SSH配置不当——未授权访问—Rsync文件备份协议漏洞——应用软件-FTP&Proftpd搭建 口令猜解——Hydra-FTP&RDP&SSH FTP:文本传输协议,端口21;RDP:windows上远程终端协议…...

java:Druid工具类解析sql获取表名
java:Druid工具类解析sql获取表名 1 前言 alibaba的druid连接池除了sql执行的功能外,还有sql语法解析的工具提供,参考依赖如下: <dependency><groupId>com.alibaba</groupId><artifactId>druid</ar…...

MySQL--深入理解MVCC机制原理
什么是MVCC? MVCC全称 Multi-Version Concurrency Control,即多版本并发控制,维持一个数据的多个版本,主要是为了提升数据库的并发访问性能,用更高性能的方式去处理数据库读写冲突问题,实现无锁并发。 什…...

数据挖掘简介与应用领域概述
数据挖掘,作为信息技术领域中的重要分支之一,旨在从大量数据中发现潜在的模式、关联和趋势,以提取有用的信息和知识。在信息爆炸时代,大量数据的积累成为了常态,数据挖掘技术的出现填补了人们处理这些数据的空白&#…...
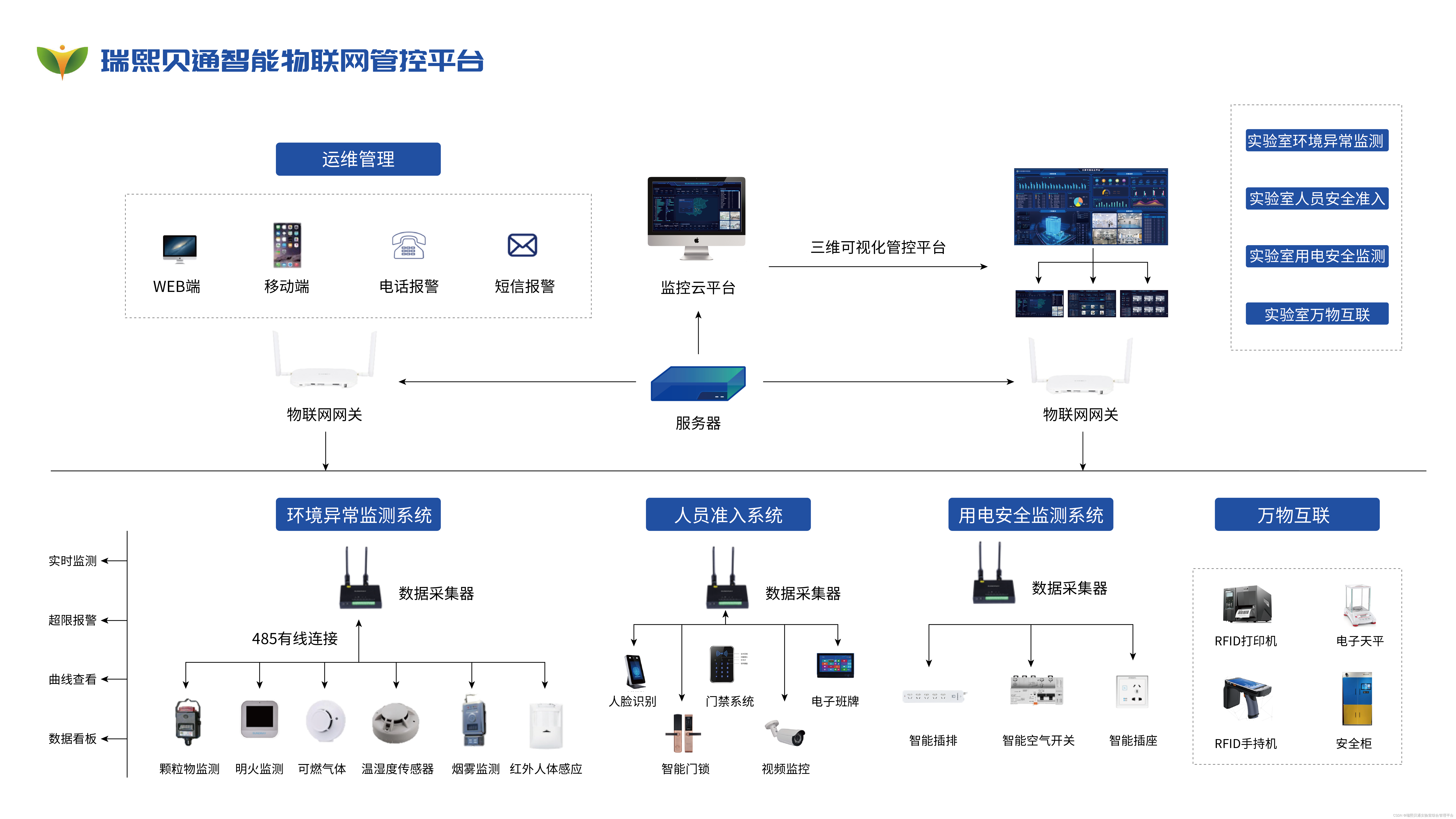
瑞熙贝通打造智慧校园实验室安全综合管理平台
一、建设思路 瑞熙贝通实验室安全综合管理平台是基于以实验室安全,用现代化管理思想与人工智能、大数据、互联网技术、物联网技术、云计算技术、人体感应技术、语音技术、生物识别技术、手机APP、自动化仪器分析技术有机结合,通过建立以实验室为中心的管…...

openstack调整虚拟机CPU 内存 磁盘 --来自gpt
在OpenStack中调整虚拟机(即实例)的CPU、内存(RAM)和磁盘大小通常涉及到以下几个步骤:首先,确定你要修改的实例名称或ID;其次,根据需要调整的资源类型,使用相应的命令进行…...
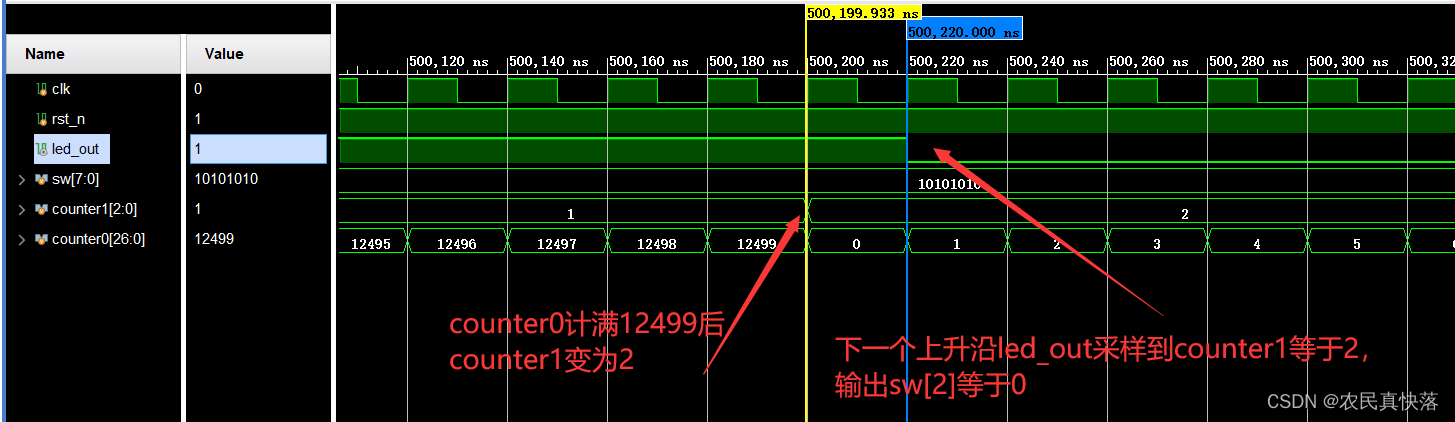
【IC设计】Verilog线性序列机点灯案例(三)(小梅哥课程)
声明:案例和代码来自小梅哥课程,本人仅对知识点做做笔记,如有学习需要请支持官方正版。 文章目录 该系列目录设计目标设计思路RTL及Testbench代码RTL代码Testbench代码 仿真结果上板视频 该系列目录 Verilog线性序列机点灯案例(一)ÿ…...

【打工日常】使用Docker部署团队协作文档工具
一、ShowDoc介绍 ShowDoc是一个适合IT团队共同协作API文档、技术文档的工具。通过showdoc,可以方便地使用markdown语法来书写出API文档、数据字典文档、技术文档、在线excel文档等等。 响应式网页设计:可将项目文档分享到电脑或移动设备查看。同时也可…...
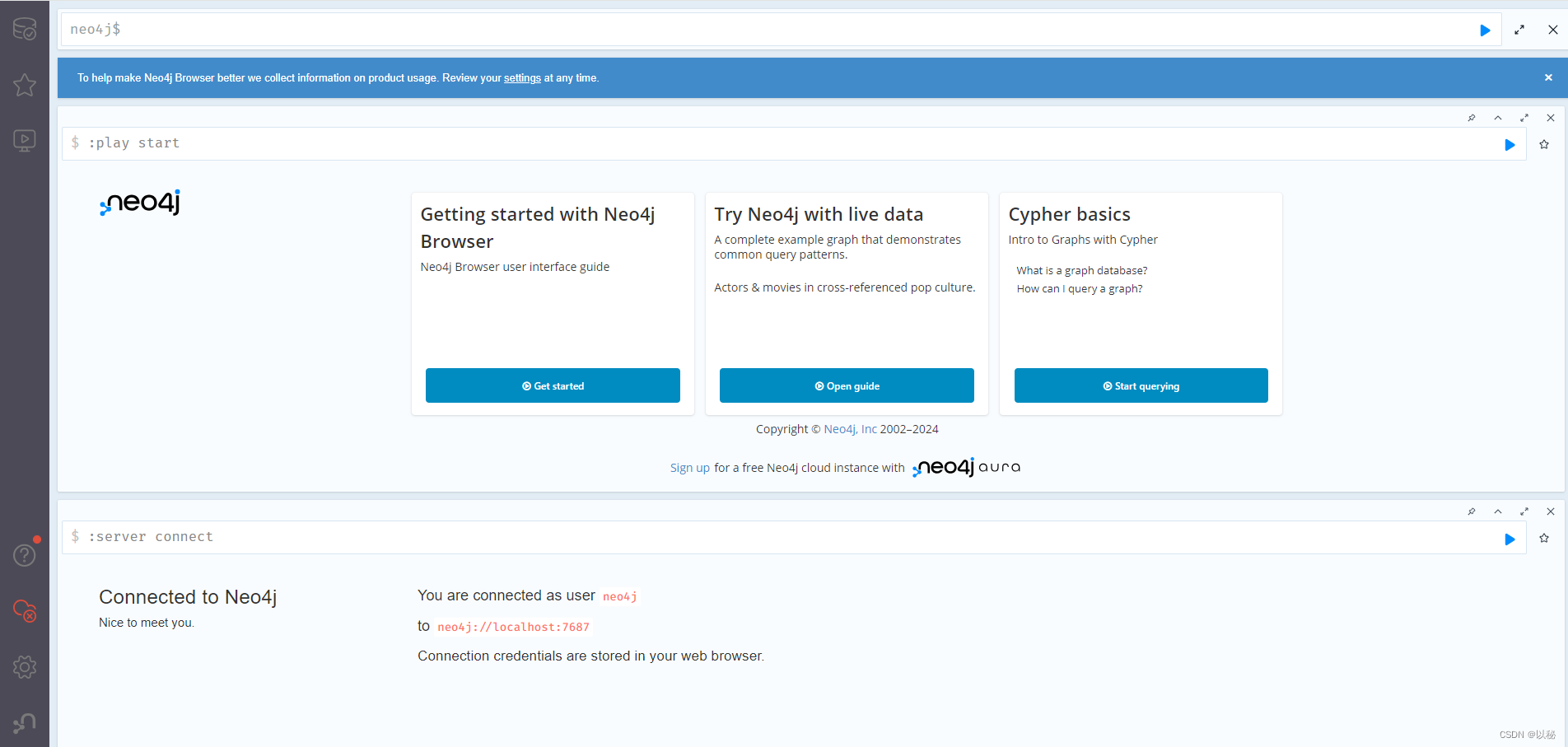
(一)Neo4j下载安装以及初次使用
(一)下载 官网地址:Neo4j Graph Database & AnamConnect data as its stored with Neo4j. Perform powerful, complex queries at scale and speed with our graph data platform.https://neo4j.com/ (二)安装并配…...

QT for Mcu的学习建议
QT for MCU(微控制器单元)是一个相对较新的领域,它允许在资源受限的微控制器上运行Qt框架,从而为嵌入式设备带来丰富的用户界面和跨平台的开发体验。以下是一些建议,可以帮助你开始学习Qt for MCU: 理解Qt…...
【C语言初阶(五)】数组
❣博主主页: 33的博客❣ ▶文章专栏分类: C语言从入门到精通◀ 🚚我的代码仓库: 33的代码仓库🚚 目录 1. 前言2.一维数组的概念3.一维数组的创建和初始化3.1数组的创建3.2数组的初始化3.3数组的类型 4.一维数组的使用4.1数组下标4.2数组元素打印4.4数组元…...

词令微信小程序怎么添加到我的小程序?
微信小程序怎么添加到我的小程序? 1、找到并打开要添加的小程序; 2、打开小程序后,点击右上角的「…」 3、点击后底部弹窗更多选项,请找到并点击「添加到我的小程序」; 4、添加成功后,就可以在首页下拉我的…...

Kerberos身份认证原理与实战排错指南
1. 为什么今天还要花时间搞懂 Kerberos?——一个被低估的“老协议”正在悄悄支撑着你的日常你每天登录公司内网查邮件、访问财务系统提交报销、用 Jenkins 构建代码、甚至在 Windows 域环境中打开一台同事的共享文件夹……这些看似顺滑的操作背后,大概率…...

如何快速批量下载高质量歌词:ZonyLrcToolsX跨平台终极解决方案
如何快速批量下载高质量歌词:ZonyLrcToolsX跨平台终极解决方案 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX 还在为本地音乐库缺少歌词而烦恼吗࿱…...

AI IDE 革命:程序员正在被重新定义
很多开发者第一次使用 Cursor 的 CtrlK 或 Composer(高级多文件编辑模式)时,都会有一种强烈的、甚至让人有些脊背发凉的冲击感。 因为: 它已经不再是那个我们熟悉的、只能在原地等待光标落下的: “代码自动补全插件&am…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...

对比按量计费与Token Plan套餐的实际成本差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按量计费与Token Plan套餐的实际成本差异 在构建和运营基于大模型的应用时,成本控制是一个核心的工程考量。Taotok…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...

Unity中实现深度遮挡:LingBot-Depth实战接入与优化
1. 这不是“加个插件就完事”的AR效果——为什么LingBot-Depth在Unity里值得专门写一篇实战教程你肯定见过那种AR应用:虚拟椅子摆在真实地板上,但当你绕到椅子后面,它依然完整显示,完全无视身后那堵真实的墙;或者一只3…...

如何高效实现Windows自动化鼠标点击:AutoClicker完整实战指南
如何高效实现Windows自动化鼠标点击:AutoClicker完整实战指南 【免费下载链接】AutoClicker AutoClicker is a useful simple tool for automating mouse clicks. 项目地址: https://gitcode.com/gh_mirrors/au/AutoClicker AutoClicker是一款专业的Windows桌…...
)
仅限首批200位架构师获取:DeepSeek-DDD联合建模工作坊实录(含领域事件风暴原始会议录像+决策日志)
更多请点击: https://kaifayun.com 第一章:DeepSeek领域驱动设计的范式演进与本质洞察 DeepSeek作为面向大规模智能体协同与复杂业务语义建模的新一代AI原生架构,其领域驱动设计(DDD)实践已突破传统分层单体范式&…...

初创公司如何通过Taotoken快速为产品原型注入多种AI能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何通过Taotoken快速为产品原型注入多种AI能力 对于初创公司而言,资源有限、时间紧迫是常态。产品原型的快速…...