k8s HPA 自动伸缩机制 (配置,资源限制,)
目录
一、概念
核心概念
工作原理
HPA 的配置关键参数
关键组件
使用场景
注意事项
如何确保程序稳定和服务连续
二、metrics-server
部署 metrics-server
准备 metrics-server 镜像:
使用 Helm 安装 metrics-server:
配置 metrics-server:
安装 metrics-server:
验证 metrics-server 部署:
三、部署 HPA
上传镜像文件:
创建 Deployment 和 Service 资源:
应用资源定义:
四、配置和使用 HPA
创建 HPA 控制器
监控 HPA 状态
压力测试
查看 Pod 状态
五、资源限制
资源限制的重要性
cgroup 的作用
Pod 资源限制
示例配置解释
命名空间资源限制
ResourceQuota
计算资源配额:
配置对象数量配额限制:
LimitRange
一、概念
HPA(Horizontal Pod Autoscaler)是Kubernetes中实现自动扩缩容Pod副本数量的机制。它允许集群中的工作负载(如Deployments、ReplicaSets和StatefulSets)根据实际的负载情况自动调整Pod的数量,以此来优化资源的使用和提高服务的响应能力。
核心概念
-
水平扩展(Horizontal Scaling):增加Pod的数量来分摊负载,与垂直扩展(增加单个Pod的资源)相对。
-
Pod副本(Pod Replicas):运行应用程序的容器实例,通常是在Deployment或ReplicaSet等控制器下管理的。
-
指标(Metrics):用于触发HPA扩缩容的度量值,如CPU使用率、内存使用量、自定义的应用程序指标等。
工作原理
-
指标收集:HPA监控Pod的资源使用情况,如CPU和内存利用率。这些指标可以通过Kubernetes的Metrics API获取,或者使用自定义的指标提供者(如Prometheus)。
-
计算扩缩容:HPA根据当前的资源使用情况和预设的目标值(如CPU的目标利用率)计算出所需的Pod副本数量。如果当前的资源使用超过了目标值,HPA会增加Pod副本数量;如果资源使用低于目标值,HPA会减少Pod副本数量。
-
执行扩缩容:HPA通过更新相关的Deployment或ReplicaSet来改变Pod副本的数量。增加副本时,Kubernetes会创建新的Pod;减少副本时,会删除多余的Pod。
HPA 的配置关键参数
-
ScaleTargetRef:指定 HPA 将要作用的资源对象,如 Deployment、Replica Set 或 RC 的名称。
-
MinReplicas:最小副本数,即使在负载很低时也不会低于这个数量。
-
MaxReplicas:最大副本数,即使在负载很高时也不会超过这个数量。
-
Metrics:定义用于触发伸缩的度量标准和目标值。例如,可以设置 CPU 的利用率目标,当实际利用率超过这个目标值时,HPA 会增加副本数量;当利用率低于目标值时,HPA 会减少副本数量。
关键组件
-
HPA控制器(HPA Controller):
-
这是HPA的核心组件,负责周期性地检查Pod的资源使用情况,并根据这些信息计算出所需的Pod副本数量。
-
它使用Metrics Server或其他监控工具来获取资源使用数据。
-
Metrics Server:
-
Metrics Server是Kubernetes集群中的一个组件,用于聚合资源使用数据,并通过Metrics API提供这些数据。
-
它提供了CPU和内存使用率等资源指标,这些指标是HPA进行扩缩容决策的基础。
-
自定义指标适配器(Custom Metrics Adapter):
-
当需要使用自定义指标(如来自Prometheus的指标)时,自定义指标适配器允许HPA使用这些外部指标。
-
它通过Custom Metrics API将外部指标转换为Kubernetes可以理解的格式。
-
Deployment/ReplicaSet:
-
HPA通常与Deployment或ReplicaSet一起使用,这些是定义了Pod副本数量和更新策略的高级抽象。
-
当HPA决定调整副本数量时,它会通过修改Deployment或ReplicaSet的规格来实现。
-
Pods:
-
Pod是Kubernetes中的基本工作单元,HPA的目标就是根据指标自动调整Pod的数量。
-
每个Pod可以有一个或多个容器,HPA关注的是整个Pod的资源使用情况。
-
API服务器(API Server):
-
Kubernetes API服务器是集群的通信中心,所有资源的创建、更新和删除都通过它进行。
-
HPA控制器通过API服务器与集群中的其他组件交互,如更新Deployment或ReplicaSet的副本数量。
-
Kubelet:
-
Kubelet是运行在每个节点上的守护进程,负责维护Pod的生命周期,包括启动、停止容器。
-
当HPA触发扩容时,Kubelet会在节点上启动新的Pod实例。
-
监控和日志系统:
-
虽然不是HPA的直接组件,但监控和日志系统对于理解和调试HPA的行为至关重要。
-
它们提供了关于Pod状态、资源使用和扩缩容事件的详细信息。
-
这些组件共同工作,使得HPA能够根据实际的负载情况自动调整Pod的数量,从而实现应用程序的弹性伸缩。
使用场景
-
应对流量波动:在Web服务中,流量可能在一天中的不同时间有很大波动。HPA可以根据流量自动调整Pod数量,以保持服务的响应性。
-
负载均衡:当新的Pod加入集群时,负载均衡器(如Kubernetes Service)会自动将流量路由到新的Pod,实现负载均衡。
-
资源优化:通过自动调整Pod数量,HPA有助于避免资源浪费,并确保资源得到最佳利用。
注意事项
-
周期性检测:HPA 根据
kube-controller-manager服务的启动参数horizontal-pod-autoscaler-sync-period来定义检测周期,默认为 30 秒。这意味着 HPA 控制器会每 30 秒检查一次 Pod 的 CPU 使用率,以决定是否需要调整副本数量。 -
Kubernetes 资源对象:HPA 是 Kubernetes 中的一种资源对象,与 Replication Controller(RC)、Deployment 或 Replica Set 等资源对象类似。HPA 通过监控这些控制器管理的 Pod 负载变化情况,来动态调整副本数量。例如,如果一个 Deployment 管理了多个 Pod,HPA 将会监控这些 Pod 的平均 CPU 使用率,并根据这个指标来增加或减少 Pod 的数量。
-
metrics-server 部署:为了使 HPA 能够获取到 Pod 的度量数据,
metrics-server必须部署在 Kubernetes 集群中。metrics-server通过 resource metrics API 提供集群资源的使用情况,包括 CPU 和内存的使用情况。这样,HPA 就可以利用这些数据来做出伸缩决策。
如何确保程序稳定和服务连续
-
快速扩容:
-
当 CPU 负载超过 HPA 设置的目标百分比时,HPA 会迅速增加 Pod 的副本数,以快速分摊负载并减轻单个 Pod 的压力。
-
快速扩容有助于避免性能瓶颈和响应时间的显著增加,这对于保持用户体验和服务质量至关重要。
-
缓慢缩容:
-
当 CPU 负载下降到目标百分比以下时,HPA 不会立即减少 Pod 的副本数。这是因为:
-
稳定性: 快速缩容可能会导致服务不稳定,尤其是在业务高峰期。如果缩容过于积极,剩余的 Pod 可能无法处理突然增加的负载,从而导致服务中断。
-
避免震荡: 避免因网络波动或其他临时负载变化导致的不必要缩放。缓慢缩容有助于减少因缩放操作本身引起的性能震荡。
-
预热: 新创建的 Pod 需要时间来“预热”,即加载应用资源、建立网络连接等。缓慢缩容可以确保在移除 Pod 之前,它们已经为服务做好了准备。
-
-
缩放策略:
-
HPA 缩放策略包括两个主要参数:
scaleDownDelayAfterAdd和scaleDownUnneededTime。 -
scaleDownDelayAfterAdd控制在添加新 Pod 后,HPA 等待多长时间才开始考虑缩放操作。 -
scaleDownUnneededTime控制在 Pod 被认为是“不需要”的之前,HPA 等待多长时间。这个时间过后,如果 Pod 仍然没有达到 CPU 使用率目标,HPA 将开始缩放过程。
通过这种设计,Kubernetes HPA 旨在平衡快速响应和资源稳定性之间的关系,确保在面对不断变化的负载时,应用程序能够持续稳定地运行。这种平衡有助于避免因缩放操作导致的服务中断和性能问题。
二、metrics-server
metrics-server 是 Kubernetes 集群中的一个关键组件,它的作用是聚合和提供集群资源的使用情况。这些信息对于 Kubernetes 集群的各种内部组件和外部工具来说非常重要,它们依赖这些数据来进行决策和操作。以下是 metrics-server 的一些关键功能和用途:
-
资源使用情况聚合:
-
metrics-server 收集集群中每个节点的资源使用数据,包括 CPU 和内存的使用情况。
-
它还提供了 Pod 级别的资源使用信息。
-
支持 Kubernetes 核心功能:
-
Horizontal Pod Autoscaler (HPA): HPA 依赖 metrics-server 提供的数据来自动调整 Pod 副本的数量,以保持应用程序的稳定运行。
-
kubectl:
kubectl top命令使用 metrics-server 的数据来显示集群中节点和 Pod 的资源使用情况。 -
Scheduler: Kubernetes 的调度器使用节点的资源使用情况来做出调度决策,决定在哪里运行新的 Pod。
-
安全性:
-
metrics-server 可以配置为使用安全的 kubelet API,这意味着它可以在不暴露节点上 kubelet 的端口的情况下收集资源使用数据。
-
部署和维护:
-
metrics-server 通常作为 Kubernetes 集群的一部分进行部署,它可以使用 Helm chart 或者直接从容器镜像部署。
-
它需要在集群中的每个节点上运行,以便收集所有节点的资源使用情况。
-
配置选项:
-
可以通过配置文件或 Helm chart 的 values 文件来调整 metrics-server 的行为,例如设置日志级别、指定 kubelet 的地址和端口、配置资源请求和限制等。
部署 metrics-server
metrics-server:是kubernetes集群资源使用情况的聚合器,收集数据给kubernetes集群内使用,如kubectl、hpa、scheduler等。
准备 metrics-server 镜像:
-
将 metrics-server 的镜像包
metrics-server.tar上传到所有 Node 节点的/opt目录。 -
使用
docker load -i metrics-server.tar命令加载镜像到本地 Docker 环境。
cd /opt/
docker load -i metrics-server.tar
使用 Helm 安装 metrics-server:
- 创建一个目录
/opt/metrics用于存放 metrics-server 的配置文件。
mkdir /opt/metrics
cd /opt/metrics
- 移除旧的 Helm 仓库(如果已添加):
helm repo remove stable
- 添加新的 Helm 仓库,可以选择使用官方源或镜像源:
helm repo add stable https://charts.helm.sh/stable
# 或
helm repo add stable http://mirror.azure.cn/kubernetes/charts
- 更新 Helm 仓库:
helm repo update
- 从 Helm 仓库拉取 metrics-server chart:
helm pull stable/metrics-server
配置 metrics-server:
- 编辑
metrics-server.yaml文件,配置 metrics-server 的参数,例如指定镜像仓库和标签,以及设置日志参数等。
vim metrics-server.yaml
args:
- --logtostderr
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
image:repository: k8s.gcr.io/metrics-server-amd64tag: v0.3.2
安装 metrics-server:
- 使用
helm install命令安装 metrics-server 到kube-system命名空间,并应用自定义的配置文件:
helm install metrics-server stable/metrics-server -n kube-system -f metrics-server.yaml
验证 metrics-server 部署:
- 使用
kubectl get pods -n kube-system | grep metrics-server命令查看 metrics-server Pod 是否成功部署。
helm install metrics-server stable/metrics-server -n kube-system -f metrics-server.yaml
- 等待一段时间后,可以使用
kubectl top node命令查看节点资源使用情况。
kubectl top node
- 使用
kubectl top pods --all-namespaces命令查看所有命名空间中的 Pod 资源使用情况。
kubectl top pods --all-namespaces
通过这些步骤,可以确保 metrics-server 成功部署在 Kubernetes 集群中,并且可以提供集群资源使用情况的聚合信息,这对于 Kubernetes 集群的运维和自动扩缩容策略的实施非常关键。
三、部署 HPA
部署一个用于测试水平 Pod 自动扩缩容(HPA)的示例应用程序
上传镜像文件:
-
将
hpa-example.tar镜像文件上传到所有节点的/opt目录。 -
hpa-example.tar 是谷歌基于 PHP 语言开发的用于测试 HPA 的镜像,其中包含了一些可以运行 CPU 密集计算任务的代码。
-
使用
docker load -i hpa-example.tar命令加载镜像到本地 Docker 环境。
cd /opt
docker load -i hpa-example.tar
- 确认镜像已正确加载,使用
docker images | grep hpa-example命令查看镜像列表。
docker images | grep hpa-example
创建 Deployment 和 Service 资源:
- 创建一个名为
hpa-pod.yaml的文件,定义一个 Deployment 和一个 Service 资源。
vim hpa-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:run: php-apachename: php-apache
spec:replicas: 1selector:matchLabels:run: php-apachetemplate:metadata:labels:run: php-apachespec:containers:- image: gcr.io/google_containers/hpa-examplename: php-apacheimagePullPolicy: IfNotPresentports:- containerPort: 80resources:requests:cpu: 200m
---
apiVersion: v1
kind: Service
metadata:name: php-apache
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:run: php-apache
-
在 Deployment 中,指定
hpa-example镜像,并设置 CPU 请求资源为200m(200 毫核)。 -
创建 Service 以暴露 Deployment 中的 Pod,使其可以通过网络访问。
应用资源定义:
-
使用
kubectl apply -f hpa-pod.yaml命令应用资源定义,创建 Deployment 和 Service。 -
使用
kubectl get pods命令查看 Pod 状态,确认 Pod 已成功创建并处于运行状态。
kubectl apply -f hpa-pod.yamlkubectl get pods
通过这些步骤,可以在 Kubernetes 集群中部署一个应用程序,并使用 HPA 根据实际负载自动调整 Pod 副本数,从而实现应用程序的自动扩缩容。
四、配置和使用 HPA
在 Kubernetes 集群中使用 kubectl autoscale 命令创建一个水平 Pod 自动扩缩容(HPA)控制器,并对其进行了压力测试
创建 HPA 控制器
- 使用
kubectl autoscale命令创建 HPA 控制器,设置 CPU 负载阈值为请求资源的 50%,并指定最小和最大 Pod 数量限制:
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
监控 HPA 状态
- 使用
kubectl get hpa命令查看 HPA 的状态,包括当前的 CPU 负载百分比、最小和最大 Pod 数量以及当前的 Pod 副本数。
//需要等一会儿,才能获取到指标信息 TARGETS
kubectl get hpakubectl top pods
压力测试
- 创建一个临时的测试客户端容器,使用
kubectl run命令启动一个busybox容器,并在其中运行一个无限循环的wget命令,以模拟对php-apache服务的持续访问:
kubectl run -it load-generator --image=busybox /bin/sh
#增加负载
while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
- 观察 HPA 控制器的响应,可以看到随着 CPU 负载的增加,Pod 的副本数从 1 个增加到最大限制的 10 个。
#打开一个新的窗口,查看负载节点数目
kubectl get hpa -w
#如果 cpu 性能较好导致负载节点上升不到 10 个,可再创建一个测试客户端同时测试:
kubectl run -i --tty load-generator1 --image=busybox /bin/sh
# 加负载
while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
查看 Pod 状态
- 使用
kubectl get pods命令查看集群中的 Pod 状态,确认已经根据负载增加了新的 Pod 实例。
kubectl get pods
- 通过这个过程,验证了 HPA 控制器能够根据实际的 CPU 负载情况自动调整 Pod 的数量,以保持服务的稳定性和响应性。当 CPU 负载超过设定的阈值时,HPA 控制器会增加 Pod 的副本数以分摊负载;当负载降低时,它会减少 Pod 的数量以节省资源。这种自动扩缩容机制对于处理不同负载情况下的应用程序非常有用,它有助于提高资源利用率和用户体验。
五、资源限制
资源限制的重要性
-
防止资源饥饿: 通过为 Pod 设置资源请求(
requests)和限制(limits),可以防止单个应用程序消耗过多资源,导致其他应用程序因资源不足而受到影响。 -
优先级和抢占: 资源限制还与 Pod 的调度和优先级相关。Kubernetes 可以根据 Pod 的资源请求和限制来决定哪些 Pod 应该在资源紧张时被调度或抢占。
-
成本管理: 通过合理配置资源限制,可以避免在云环境中过度使用资源,从而有助于控制成本。
cgroup 的作用
-
控制组: cgroup(Control Groups)是 Linux 内核的一个特性,它允许对系统资源进行分组管理和限制。
-
资源隔离: cgroup 通过为每个组设置资源配额和限制,实现了对 CPU、内存、I/O 等资源的隔离和控制。
Pod 资源限制
-
requests: 指定 Pod 运行所需的最小资源量。Kubernetes 调度器会考虑这些请求来决定在哪个节点上调度 Pod。如果节点无法满足 Pod 的资源请求,Pod 将不会被调度到该节点。 -
limits: 指定 Pod 可以使用的最大资源量。如果 Pod 尝试使用超过其限制的资源,系统将通过 cgroup 强制限制资源使用,可能会导致 Pod 被杀死或重启。
示例配置解释
在提供的示例中,定义了一个包含资源限制的 Pod 配置:
spec:containers:- image: xxxximagePullPolicy: IfNotPresentname: authports:- containerPort: 8080protocol: TCPresources:limits:cpu: "2" # 限制 CPU 使用量为 2 个单位(可以是核心数或毫核)memory: 1Gi # 限制内存使用量为 1Gi(Gibibytes)requests:cpu: 250m # 请求 CPU 使用量为 250 毫核memory: 250Mi # 请求内存使用量为 250Mi(Mebibytes)
在这个配置中,auth 容器请求了 250 毫核的 CPU 和 250Mi 的内存,同时设置了 2 个单位的 CPU 和 1Gi 内存的限制。这意味着 Kubernetes 会确保 auth 容器至少有 250 毫核的 CPU 和 250Mi 的内存可用,但如果资源充足,它可以使用更多,但不会超过 2 个单位的 CPU 和 1Gi 的内存。
通过这种方式,可以为 Kubernetes 集群中的 Pod 设置合理的资源请求和限制,以确保应用程序的性能和稳定性,同时优化资源的使用。
命名空间资源限制
在 Kubernetes 中使用 ResourceQuota 和 LimitRange 资源类型来对命名空间级别的资源使用进行限制和管理
ResourceQuota
ResourceQuota 允许管理员限制命名空间中可以使用的计算资源和配置对象的数量。这有助于防止意外的资源过度使用,确保集群资源的公平分配。
计算资源配额:
apiVersion: v1
kind: ResourceQuota #使用 ResourceQuota 资源类型
metadata:name: compute-resourcesnamespace: spark-cluster #指定命令空间
spec:hard:pods: "20" #设置 Pod 数量最大值requests.cpu: "2"requests.memory: 1Gilimits.cpu: "4"limits.memory: 2Gi
-
在提供的第一个示例中,
ResourceQuota被命名为compute-resources,它限制了spark-cluster命名空间中的资源使用: -
pods:最多允许 20 个 Pod。 -
requests.cpu和requests.memory:所有 Pod 总和的 CPU 和内存请求量上限。 -
limits.cpu和limits.memory:单个 Pod 能够使用的 CPU 和内存量上限。
配置对象数量配额限制:
apiVersion: v1
kind: ResourceQuota
metadata:name: object-countsnamespace: spark-cluster
spec:hard:configmaps: "10"persistentvolumeclaims: "4" #设置 pvc 数量最大值replicationcontrollers: "20" #设置 rc 数量最大值secrets: "10"services: "10"services.loadbalancers: "2"
-
第二个示例中的
ResourceQuota被命名为object-counts,它限制了spark-cluster命名空间中的配置对象数量: -
configmaps、persistentvolumeclaims、replicationcontrollers、secrets、services:这些项限制了各种类型配置对象的数量。 -
services.loadbalancers:特别限制了使用负载均衡器类型的服务数量。
LimitRange
-
如果Pod没有设置requests和limits,则会使用当前命名空间的最大资源;如果命名空间也没设置,则会使用集群的最大资源。K8S 会根据 limits 限制 Pod 使用资源,当内存超过 limits 时 cgruops 会触发 OOM。
-
LimitRange允许管理员设置命名空间中 Pod 或容器的资源请求和限制的默认值。这有助于确保即使 Pod 没有明确设置requests和limits,也不会超出命名空间或集群级别的资源限制。
apiVersion: v1
kind: LimitRange #使用 LimitRange 资源类型
metadata:name: mem-limit-rangenamespace: test #可以给指定的 namespace 增加一个资源限制
spec:limits:- default: #default 即 limit 的值memory: 512Micpu: 500mdefaultRequest: #defaultRequest 即 request 的值memory: 256Micpu: 100mtype: Container #类型支持 Container、Pod、PVC
-
LimitRange示例中,mem-limit-range为test命名空间中的所有容器设置了默认的内存和 CPU 限制: -
default:设置了默认的资源限制值。 -
defaultRequest:设置了默认的资源请求值。 -
type:指定了这些限制适用于的类型,可以是Container、Pod或PersistentVolumeClaim (PVC)。
通过这些资源限制,Kubernetes 管理员可以精细地控制集群资源的使用,避免资源浪费,并确保集群的稳定性和效率。这些限制对于多租户环境或需要严格资源管理的场景尤为重要。
相关文章:
)
k8s HPA 自动伸缩机制 (配置,资源限制,)
目录 一、概念 核心概念 工作原理 HPA 的配置关键参数 关键组件 使用场景 注意事项 如何确保程序稳定和服务连续 二、metrics-server 部署 metrics-server 准备 metrics-server 镜像: 使用 Helm 安装 metrics-server: 配置 metrics-server: 安装 metrics-server: …...

vulhub中GIT-SHELL 沙盒绕过漏洞复现(CVE-2017-8386)
GIT-SHELL 沙盒绕过(CVE-2017-8386)导致任意文件读取、可能的任意命令执行漏洞。 测试环境 为了不和docker母机的ssh端口冲突,将容器的ssh端口设置成3322。本目录下我生成了一个id_rsa,这是ssh的私钥,连接的时候请指…...

SpringBoot+vue3打造企业级一体化SaaS系统
SpringBootvue3打造企业级一体化SaaS系统 简介: 全面提升前后端技术水平,独立完成全栈项目开发能力,快速进击全栈工程师,最终在面试中脱颖而出。整合后端主流技术(Spring Boot、物理数据库隔离、加载动态权限、多…...
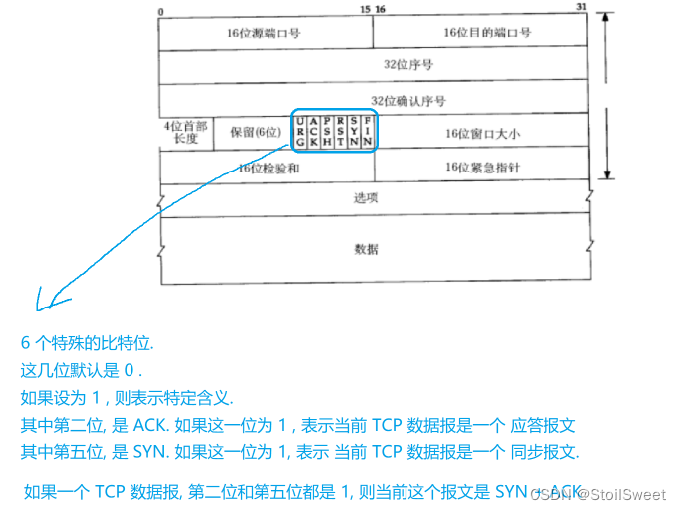
探讨TCP的可靠性以及三次握手的奥秘
🌟 欢迎来到 我的博客! 🌈 💡 探索未知, 分享知识 !💫 本文目录 1. TCP的可靠性机制1.2可靠性的基础上,尽可能得提高效率 2. TCP三次握手过程3. 为何不是四次握手? 在互联网的复杂世界中,TCP&am…...

openai常见的两个错误:BadRequestError和OpenAIError
错误1:openai.OpenAIError: The api_key client option must be set either by passing api_key..... 在通过openai创建客户端必须要设置api key,如果你事先已经在本机的环境中设置未起效可以手动设置,注意手动设置时不要用下面的形式 import openai f…...

2核4g服务器够用吗?
2核4G服务器够用吗?够用。阿腾云以2核4G5M服务器搭建网站为例,5M带宽下载速度峰值可达640KB/秒,阿腾云以搭建网站为例,假设优化后平均大小为60KB,则5M带宽可支撑10个用户同时在1秒内打开网站,并发数为10&am…...
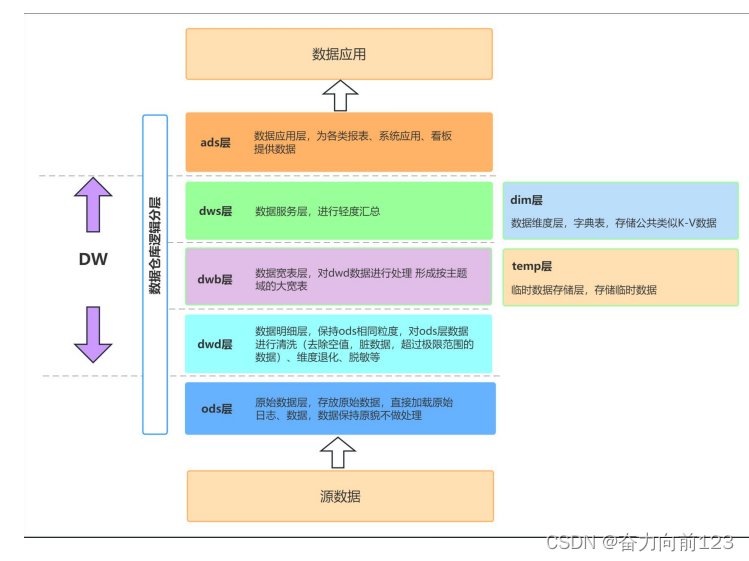
数据仓库数据分层详解
数据仓库中的数据分层是一种重要的数据组织方式,其目的是为了在管理数据时能够对数据有一个更加清晰的掌控。以下是数据仓库中的数据分层详解: 原始数据层(Raw Data Layer):这是数仓中最底层的层级,用于存…...
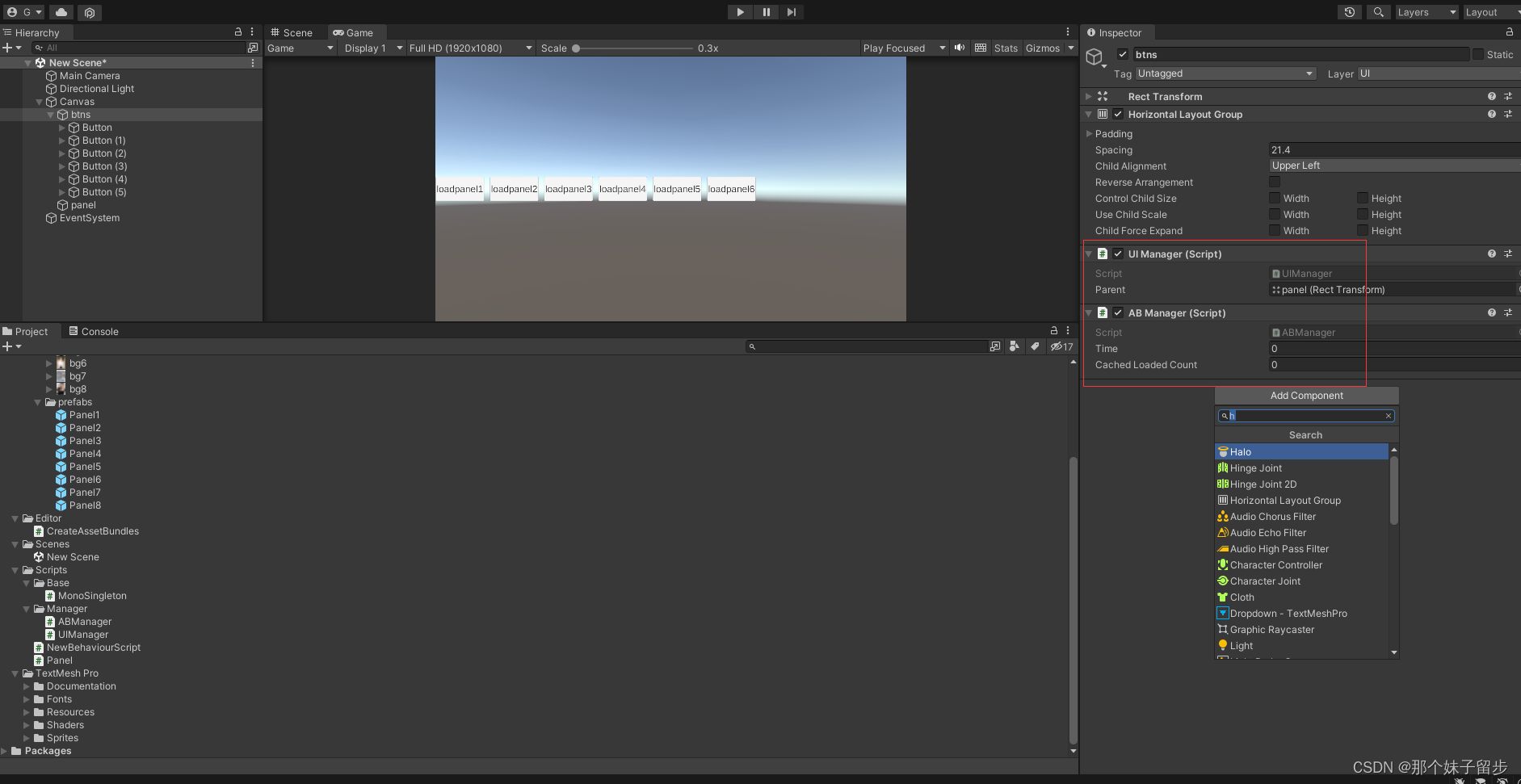
unity内存优化之AB包篇(微信小游戏)
1.搭建资源服务器使用(HFS软件(https://www.pianshen.com/article/54621708008/)) using System.Collections; using System.Collections.Generic; using UnityEngine;using System;public class Singleton<T> where T : class, new() {private static readonly Lazy<…...
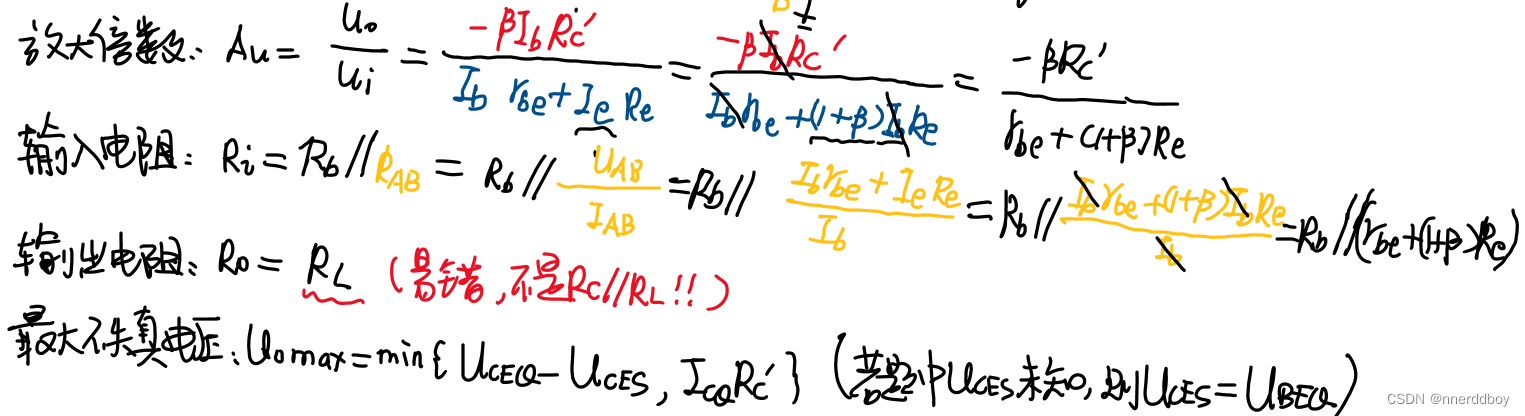
白话模电:3.三极管(考研面试与笔试常考问题)
一、三极管的简单判断 1.判断三极 1)给了图 左边是b,有箭头是e,剩下是c 2)给了电位 b:中间值,e:较近值(离中间值),c:较远值(离中间值) 2.判断流向 bc同向(共同流向“|”或共同流离“|”),e与bc反向 3.判断材料 4.判断类型 5.判断能否构…...

LeetCode 395. 至少有K个重复字符的最长子串
解题思路 一道滑动窗口题型,不过滑动窗口的长度是不同种类元素的个数。 这里需要定义两个变量 cnt,overk。overk表示的是满足大于k的字符数, cnt表示的是该窗口中不同元素的个数且cnt>1&&cnt<26。 相关代码 class Solution {public int longestSub…...
C#重新认识笔记_ FixUpdate + Update
C#重新认识笔记_ FixUpdate Update Update: 刷新频率不一致,非物理对象的移动,简单的刷新可用, FixedUpdate: 刷新频率一致,按照固定频率刷新,一般调用FixedUpdate之后,会立即进入必要的物理计算中,因此,任何影响刚…...
Django 解决新建表删除后无法重新创建等问题
Django 解决新建表删除后无法重新创建等问题 问题发生描述处理办法首先删除了app对应目录migrations下除 __init__.py以外的所有文件:然后,删除migrations中关于你的app的同步数据数据库记录最后,重新执行迁移插入 问题发生描述 Django创建的表…...
Qt教程 — 3.3 深入了解Qt 控件:Input Widgets部件(2)
目录 1 Input Widgets简介 2 如何使用Input Widgets部件 2.1 QSpinBox组件-窗口背景不透明调节器 2.2 DoubleSpinBox 组件-来调节程序窗口的整体大小 2.3 QTimeEdit、QDateEdit、QDateTimeEdit组件-编辑日期和时间的小部件 Input Widgets部件部件较多,将分为三…...

数据分析-Pandas的直接用Matplotlib绘图
数据分析-Pandas的直接用Matplotlib绘图 数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律? 数据表…...
Jmeter---分布式
分布式:多台机协作,以集群的方式完成测试任务,可以提高测试效率。 分布式架构:控制机(分发任务)与多台执行机(执行任务) 环境搭建: 不同的测试机上安装 Jmeter 配置基…...

安卓基础面试题
自定义view Android自定义View-CSDN博客 view和viewgroup View和ViewGroup的区别- view的事件分发 事件分发详解---历史最容易理解 组件化 Android-组件化开发 什么是ANR Android ANR详解-CSDN博客 Android性能优化 Android 优化-CSDN博客 Aroute 原理 Arouter框架原理…...
如何在 Linux ubuntu 系统上搭建 Java web 程序的运行环境
如何在 Linux ubuntu 系统上搭建 Java web 程序的运行环境 基于包管理器进行安装 Linux 会把一些软件包放到对应的服务器上,通过包管理器这样的程序,来把这些软件包给下载安装 ubuntu系统上的包管理器是 apt centos系统上的包管理器 yum 注:…...
Redis实现分布式锁源码分析
为什么使用分布式锁 单机环境并发时,使用synchronized或lock接口可以保证线程安全,但它们是jvm层面的锁,分布式环境并发时,100个并发的线程可能来自10个服务节点,那就是跨jvm了。 简单分布式锁实现 SETNX 格式&…...

SCI 图像处理期刊
引用 一区 1. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 顶刊:是 出版商:IEEE 2. IEEE Transactions on Multimedia 顶刊:是 出版商:IEEE 3. Information Fusion 顶刊:是 出版商:ELSEVIER 4.IEEE TRANSACTIONS ON IMAGE PROCESSING 顶刊:是 出版商:I…...
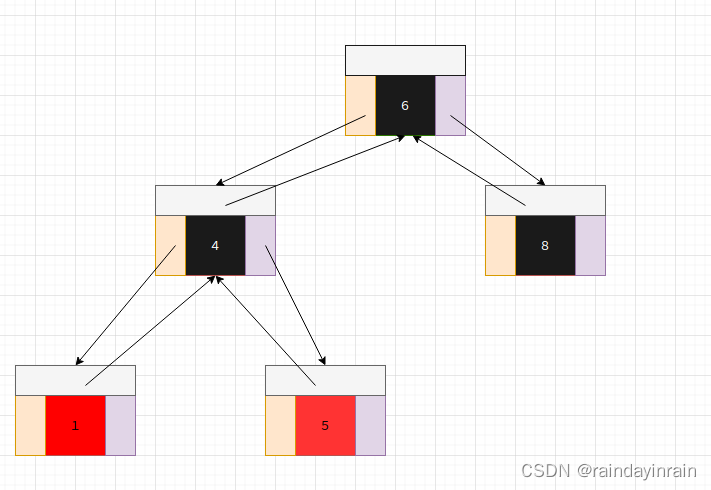
数据结构-红黑树
1.容器 容器用于容纳元素集合,并对元素集合进行管理和维护. 传统意义上的管理和维护就是:增,删,改,查. 我们分析每种类型容器时,主要分析其增,删,改ÿ…...

UE5 BaseEditorSettings.ini加载原理与配置生效机制
1. 为什么你改了BaseEditorSettings.ini却没生效?——从UE5编辑器启动流程讲起很多人在UE5项目里折腾半天,把BaseEditorSettings.ini文件翻来覆去改了十几遍,重启编辑器后发现:缩放比例还是不对、网格间距没变、甚至“启用实时预览…...

解决Claude Code访问不稳定与Token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定与Token不足的痛点 许多开发者将Claude Code作为日常编程的得力助手,用于代码生成、问题调试…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法
1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法500块钱一个询盘,你敢信?做1688运营培训这么多年,这个数字我都觉得离谱。前阵子遇到一个老板,一上来就开始吐槽1688,说1688就是个垃圾平…...

不止于绘图:用GMT 6.4的`grdtrack`和`project`命令玩转地形剖面分析与可视化
不止于绘图:用GMT 6.4的grdtrack和project命令玩转地形剖面分析与可视化 当我们谈论地理空间分析时,很多人首先想到的是绘制精美的地图。但GMT(Generic Mapping Tools)的真正魅力在于它强大的地理计算能力。本文将带你超越基础绘图…...

AutoPentest:面向红队的渗透测试决策引擎架构解析
1. 这不是又一个“自动化扫描器”,而是一套能替你做决策的渗透测试工作流引擎AutoPentest这个名字,第一眼容易让人联想到Nmap加个for循环、或者Burp Suite里点几下Intruder——但实际用过的人很快会意识到:它根本不在同一个维度上。我第一次在…...

完整指南:如何在5分钟内快速上手BioAge生物年龄计算工具包
完整指南:如何在5分钟内快速上手BioAge生物年龄计算工具包 【免费下载链接】BioAge Biological Age Calculations Using Several Biomarker Algorithms 项目地址: https://gitcode.com/gh_mirrors/bi/BioAge BioAge生物年龄计算工具包是一款基于R语言开发的强…...

SMUDebugTool:AMD Ryzen处理器深度调试与性能调优完全指南
SMUDebugTool:AMD Ryzen处理器深度调试与性能调优完全指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...

当B站字幕不再只是弹幕:你的个人学习宝库解锁指南
当B站字幕不再只是弹幕:你的个人学习宝库解锁指南 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还记得那个深夜吗?你正在B站追着某个技术…...

密码学入门:区块链中的密码学原理
密码学入门:区块链中的密码学原理 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊密码学这个重要话题。作为一个Web3探索者,密码学是区块链的基础。今天就来分享一下区块链中常用的密码学原理。 为什么密码学很重要&a…...