爱奇艺 CTR 场景下的 GPU 推理性能优化
01
背景介绍
GPU 目前大量应用在了爱奇艺深度学习平台上。GPU 拥有成百上千个处理核心,能够并行的执行大量指令,非常适合用来做深度学习相关的计算。在 CV(计算机视觉),NLP(自然语言处理)的模型上,已经广泛的使用了 GPU,相比 CPU 通常能够更快、更经济的完成模型的训练和推理。
CTR (Click Trough Rate) 模型广泛使用在推荐、广告、搜索等场景中,用来估算用户点击某个广告、视频的概率。在 CTR 模型的训练场景中已经大量使用了 GPU,在提升训练速度的同时和降低了所需的服务器成本。
但在推理场景下,当我们直接把训练好的模型通过 Tensorflow-serving 部署在 GPU 之后,发现推理效果并不理想。表现在:
推理延迟高,CTR 类模型通常是面向终端用户的,对于推理延迟非常敏感。
GPU 利用率低,计算能力未能全部发挥出来。
02
原因分析
分析工具
Tensorflow Board,tensorflow 官方提供的工具,能够可视化的查看计算流图中各个阶段的耗时,并汇总算子的总耗时。
Nsight 是 NVIDIA 面向 CUDA 开发者提供的开发工具套件,能够对 CUDA 程序进行相对底层的跟踪、调试和性能分析。
分析结论
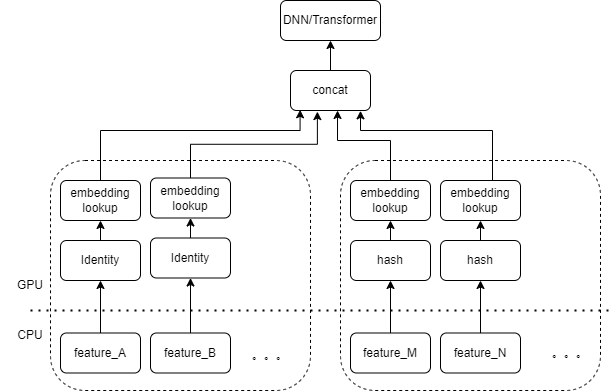
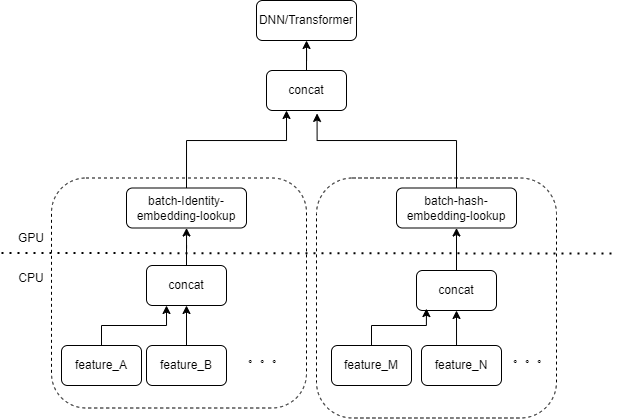
典型的 CTR 模型输入,包含大量的稀疏类特征(如设备 ID、最近浏览视频 ID 等)。Tensorflow 的 FeatureColumn 会对这些特征进行处理,首先进行 identity/hash 操作,得到 embedding table 的 index。再经 embedding lookup 和求均值等操作后,得到对应的 embedding tensor。多个特征对应的 embedding tensor 拼接后得到一个新的 tensor,再进入后续的 DNN/Transformer 等结构。
因此每个稀疏特征在模型的输入层,都会启动若干个算子。每个算子会对应着一次或者几次 GPU 计算,即 cuda kernel。每个 cuda kernel 包括两个阶段,launch cuda kernel(启动 kernel 所必需的 overhead) 和 kernel 执行(在 cuda 核心上真正执行矩阵计算)。稀疏特征 identity/hash/embedding lookup 对应的算子计算量较小,launch kernel 的耗时往往超过 kernel 执行的时间。一般来说 CTR 模型包含了几十到几百个稀疏特征,理论上就会有数百次 launch kernel,是当前主要的性能瓶颈。
在使用 GPU 训练 CTR 模型时,没有遇到这个问题。因为训练本身是一个离线任务,不关注延迟,所以训练时候的 batch size 都可以很大。虽然仍会进行多次 launch kernel,只要执行 kernel 时候计算的样本数量足够多,lauch kernel 的开销平均到每个样本上的时间就很小了。而对于在线推理的场景,如果要求 Tensorflow Serving 收到足够的推理请求并合并批次后再进行计算,那么推理延迟就会很高。
03
优化方案
我们的目标是在基本不改变训练代码,不改变服务框架的前提下,进行性能优化。我们很自然的想到两个方法,减少启动的 kernel 数量,提高 kernel 启动的速度。
算子融合
基本操作就是将多个连续的操作或算子合并成一个单一的算子,一方面可以减少 cuda kernel 启动的次数,另一方面可以把计算过程中一些中间结果存在寄存器或者共享内存,只在算子的最后把计算结果写入全局的 cuda 内存。
主要有两种方法
基于深度学习编译器的自动融合
针对业务的手动算子融合
自动融合
我们尝试了多种深度学习编译器,如 TVM/TensorRT/XLA,实测可以实现 DNN 部分少量算子的融合,如连续的 MatrixMat/ADD/Relu。由于 TVM/TensorRT 需要导出 onnx 等中间格式,需要修改原有模型的上线流程。所以我们通过 tf.ConfigProto() 开启 tensorflow 内置的 XLA 来进行融合。
但自动融合对稀疏特征相关的算子并没有很好的融合效果。
手动算子融合
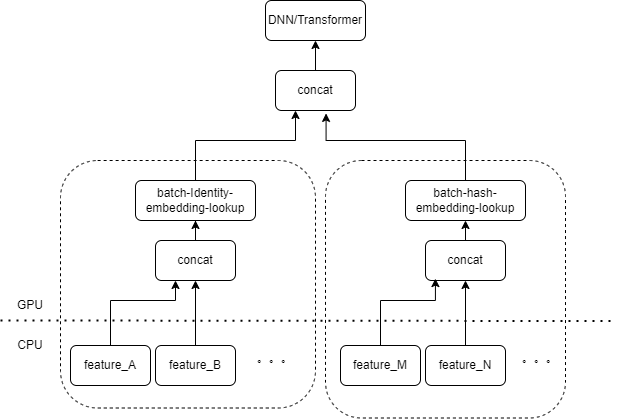
我们很自然的想到,如果有多个特征在输入层被相同类型的 FeatureColumn 组合所处理,那么我们可以实现一个算子,把多个特征的输入拼接成数组作为算子的输入。算子的输出是一个张量,这个张量的 shape 和原本多个特征分别计算后再拼接得到的张量 shape 一致。
以原有的 IdentityCategoricalColumn + EmbeddingColumn 组合为例,我们实现了 BatchIdentiyEmbeddingLookup 算子,达到相同的计算逻辑。
为了方便算法同学使用,我们封装了一个新的 FusedFeatureLayer,来代替原生的 FeatureLayer;除了包含融合算子,还实现了以下逻辑:
融合的逻辑在推理时候生效,训练时候走原来的逻辑。
需要对特征进行排序,保证相同类型的特征可以排在一起。
由于每个特征的输入均为变长,在这里我们额外生成了一个索引数组,来标记输入数组的每个元素属于哪个特征。
对于业务来说,只需要替换原来的 FeatureLayer 即可达到融合的效果。
实测原本数百次的 launch kernel,经过手动融合后缩减到了 10 次以内。大大减少了启动 kernel 的开销。
MultiStream 提高 launch 效率
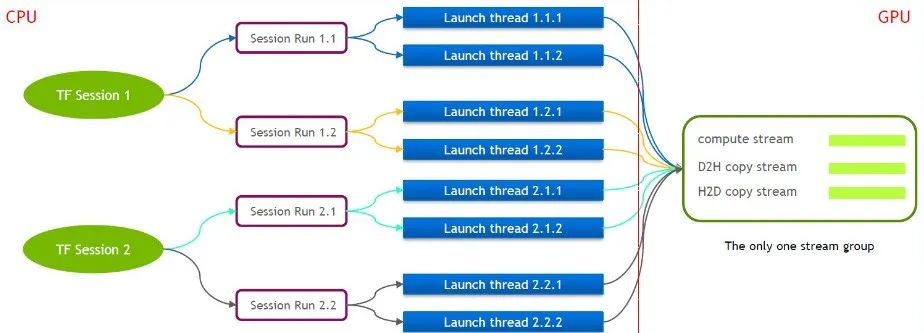
TensorFlow 本身是一个单流模型,只包含一个 Cuda Stream Group(由 Compute Stream、H2D Stream,D2H Stream 和 D2D Stream 组成)多个 kernel 只能在同一个 Compute Stream 上串行执行效率较低。即使通过多个 tensorflow 的 session 来 launch cuda kernel,在 GPU 侧仍然需要排队。
为此 NVIDIA 的技术团队维护了一个自己的 Tensorflow 分支,支持多个 Stream Group 同时执行。以此来提高 launch cuda kernel 的效率。我们将此特性移植到了我们的 Tensorflow Serving 里。
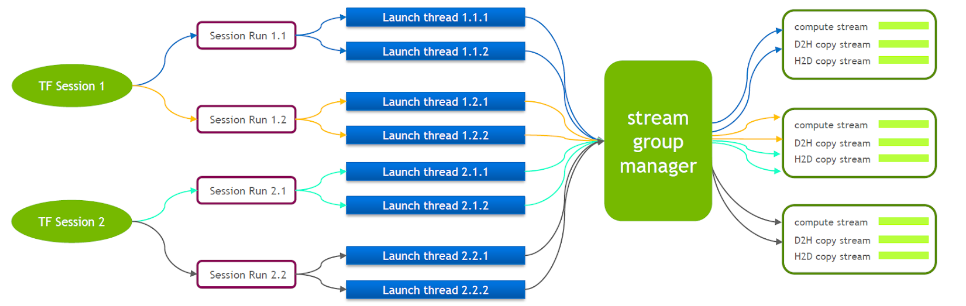
在 Tensorflow Serving 运行时候,需要开启 Nvidia MPS,减少多个 CUDA Context 间的相互干扰。
小数据拷贝优化
在前边优化基础上,我们针对小数据拷贝进一步做了优化。当 Tensorflow Serving 从请求中反序列化出中各个特征的值后,会多次调用 cudamemcpy,将数据从 host 拷贝到 device。调用次数取决于特征数量。
大部分 CTR 类业务,实测当 batchsize 较小时和,先将数据在 host 侧拼接,再一次性的调用 cudamemcpy 效率会更高一些。
合并批次
GPU 场景下需要开启批次合并。默认情况下 Tensorflow Serving 是不对请求进行合并的。为了更好的利用 GPU 的并行计算能力,让一次前向计算时候可以包含更多的样本。我们在运行时候打开了 Tensorflow Serving 的 enable_batching 选项,来对多个请求进行批次合并。同时需要提供一个 batch config 文件,重点配置以下参数,以下是我们总结的一些经验。
max_batch_size:一个批次允许的最大请求数量,可以稍微大一点。
batch_timeout_micros:合并一个批次等待的最长时间,即使该批次的数量未达到max_batch_size,也会立即进行计算(单位是微秒),理论上延迟要求越高,这儿设置的越小,最好设置在 5 毫秒以下。
num_batch_threads:最大推理并发线程,在开启了 MPS 之后,设置成 1 到 4 都可以,再多延迟会高。
在这里需要注意的是,CTR 类模型大部分输入的稀疏特征都为变长特征。如果客户端没有专门做约定,可能出现多个请求中在某个特征上的长度不一致。Tensorflow Serving 有一个默认的 padding 逻辑,给较短的请求在对应的特征上补 0。而对于变长特征使用 -1 来表示空,默认的补 0 会事实上改变原有的请求的含义。
比如用户 A 最近的观看视频 id 为 [3,5],用户 B 最近的观看视频 id 为 [7,9,10]。如果默认补齐,请求变成 [[3,5,0], [7,9,10]],在后续的处理中,模型会认为 A 最近观看了 id 为 3,5,0 的 3 个视频。
因此我们修改了 Tensorflow Serving 响应的补齐逻辑,遇到这种情况会补齐为 [[3,5,-1], [7,9,10]]。第一行的含义仍然是观看了视频 3,5。
04
最终效果
经过各种上述各种优化,在延迟和吞吐量满足了我们的需求,并落地在推荐个性化 Push、瀑布流业务上。业务效果如下:
吞吐量相比原生Tensorflow GPU 容器提升 6 倍以上
延迟和 CPU 基本一致,满足业务需求
支持相同的 QPS 时候,成本降低 40% 以上

也许你还想看
爱奇艺数据湖实战 - Hive数仓平滑入湖
稀疏大模型在爱奇艺广告排序场景中的实践
爱奇艺图片格式演进
相关文章:
爱奇艺 CTR 场景下的 GPU 推理性能优化
01 背景介绍 GPU 目前大量应用在了爱奇艺深度学习平台上。GPU 拥有成百上千个处理核心,能够并行的执行大量指令,非常适合用来做深度学习相关的计算。在 CV(计算机视觉),NLP(自然语言处理)的模型…...
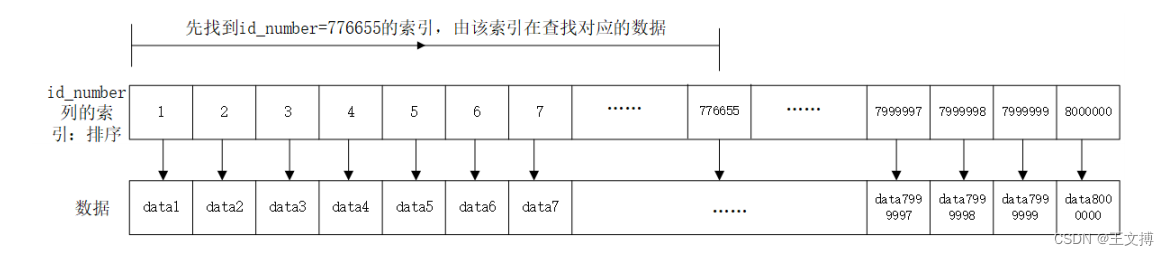
详解MySql索引
目录 一 、概念 二、使用场景 三、索引使用 四、索引存在问题 五、命中索引问题 六、索引执行原理 一 、概念 索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。暂时可以理解成C语言的指针,文章后面详解 二、使用场景 数据量较大,且…...

struct 和 union 的区别?
struct和union的分对应点总结 存储方式: struct:struct中的每个成员都拥有独立的内存空间。一个struct变量的总长度是其所有成员的长度之和,且通常会根据编译器的内存对齐规则进行适当调整。union:union中的所有成员共享同一段内…...
Linux - 安装 Jenkins(详细教程)
目录 前言一、简介二、安装前准备三、下载与安装四、配置镜像地址五、启动与关闭六、常用插件的安装 前言 虽然说网上有很多关于 Jenkins 安装的教程,但是大部分都不够详细,或者是需要搭配 docker 或者 k8s 等进行安装,对于新手小白而已&…...

【JAVA】JAVA方法的学习和创造
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法|MySQL| 💫个人格言:“没有罗马,那就自己创造罗马~” 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不…...
Rust写一个wasm入门并在rspack和vite项目中使用(一)
rust打包wasm文档 文档地址 安装cargo-generate cargo install cargo-generate 安装过程中有问题的话手动安装cargo-generate下载地址 根据自己的系统下载压缩包,然后解压到用户/.cargo/bind目录下,将解压后的文件放到该目录下即可。 创建wasm项目 …...

HTTP和HTTPS的区别,HTTPS加密原理是?
HTTP和HTTPS都是网络传输协议,主要用于浏览器和服务器之间的数据传输,但它们在数据传输的安全性、加密方式、端口等方面有所不同。 数据传输的安全性:HTTP是明文传输,数据不加密,容易被黑客窃听、篡改或者伪造&#x…...

基于Spring Boot+Vue的校园二手交易平台
目录 一、 绪论1.1 开发背景1.2 系统开发平台1.3 系统开发环境 二、需求分析2.1 问题分析2.2 系统可行性分析2.2.1 技术可行性2.2.2 操作可行性 2.3 系统需求分析2.3.1 学生功能需求2.3.2 管理员功能需求2.3.3游客功能需求 三、系统设计3.1 功能结构图3.2 E-R模型3.3 数据库设计…...

什么是软件开发?软件开发阶段划分是什么?并以LabVIEW为例进行说明
软件开发是一种创建、设计、编码、测试和维护应用程序、框架或其他软件组件的过程。它涉及从理解需求到设计、实现、测试、部署和最终维护的全过程。软件开发可以用来创建新的软件应用、系统软件、游戏、或开发网络应用等。 软件开发过程通常可以分为以下几个阶段:…...

PTAL1-006 连续因子
c语言中的小小白-CSDN博客c语言中的小小白关注算法,c,c语言,贪心算法,链表,mysql,动态规划,后端,线性回归,数据结构,排序算法领域.https://blog.csdn.net/bhbcdxb123?spm1001.2014.3001.5343 给大家分享一句我很喜欢我话: 知不足而奋进,望远山而前行&am…...
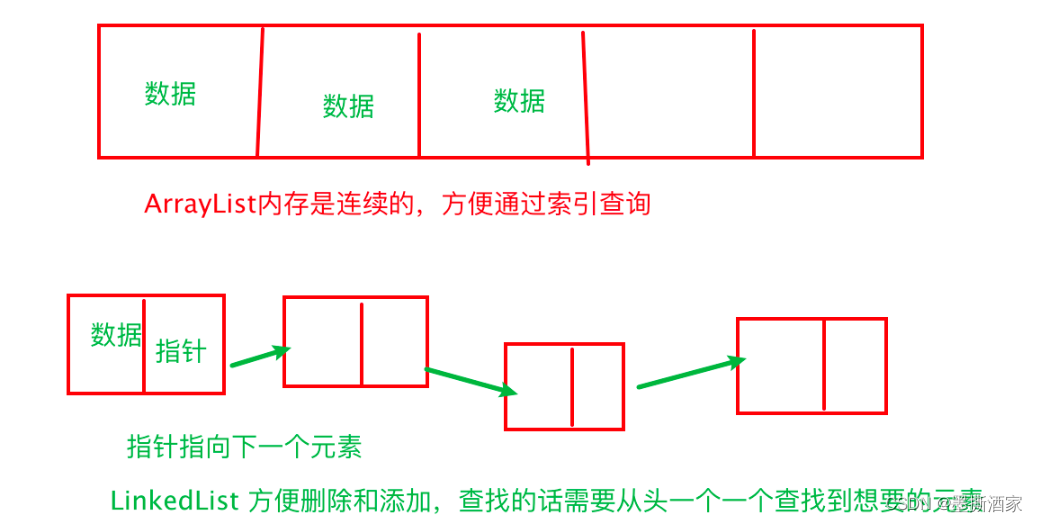
【Java】容器|Set、List、Map及常用API
目录 一、概述 二、List 1、List的常用API 2、ArrayList 3、List遍历 三、Set 1、Set的常用方法: 2、HashSet 3、遍历集合: 四、Map 1、Map常用API 2、HashMap 3、遍历Map 五、迭代器 一、概述 在Java中所有的容器都属于Collection接口下的内容 1…...
Navicat 面试题及答案整理,最新面试题
Navicat 在数据库管理中的主要用途有哪些? Navicat 是一款数据库管理工具,其主要用途包括: 1、多数据库支持: Navicat 支持多种数据库连接,包括 MySQL、Oracle、PostgreSQL、SQLite、SQL Server 等,方便用…...

android studio 连接mumu模拟器调试
1、打开mumu模拟器 2、在Android Studio 中 控制台 cd 到 sdk 目录下 platform-tools 文件夹,有一个adb.exe 可运行程序 一般指令: adb connect 127.0.0.1:7555 但是这个执行在window环境下可能会报错 解决方法是在 adb 之前加 ".\", 问题…...

四连通与八连通的区别 -- 图例讲解
概念 四连通区域:指从某个点出发,只能通过上、下、左、右四个方向的运动到达区域内的其他点,且不能跨越区域的边界。 八连通区域:除了上、下、左、右四个方向,还可以沿对角线方向(左上、右上、左下、右下…...
关于分布式微服务数据源加密配置以及取巧方案(含自定义加密配置)
文章目录 前言Spring Cloud 第一代1、创建config server项目并加入加解密key2、启动项目,进行数据加密3、实际项目中的测试server Spring Cloud Alibaba低版本架构不支持,取巧实现无加密配置,联调环境问题加密数据源配置原理探究自定义加密解…...
快速了解JavaScript
1.1 javaScript 历史 创始人 布兰登 艾奇 生于1961年 在1995设计LiveScript后改名为JavaScript 1.2 javaScript 是什么类型的语言 JavaScript是一种在客户端运行的脚本语言(不需要编译,由js引擎逐行解释执行) 1.3 JavaScript可以做什么 …...
【安全类书籍-3】XSS跨站脚剖析与防御
目录 内容简介 作用 下载地址 内容简介 这本书涵盖以下几点: XSS攻击原理:解释XSS是如何利用Web应用未能有效过滤用户输入的缺陷,将恶意脚本注入到网页中,当其他用户访问时被执行,实现攻击者的目的,例如窃取用户会话凭证、实施钓鱼攻击等。 XSS分类:分为存储型XSS(…...

http postman
地址 : https://oaqas.lingyiitech.com:9800/auth-api/openapi/dingtalk-oa/topapi/message/corpconversation/asyncsend_v2?token40216bf0ceea8e56b778d537b20f5d23 https://oaqas.lingyiitech.com:9800/auth-api/openapi/dingtalk-oa/topapi/message/corpconve…...

[数据集][目标检测]螺丝螺母检测数据集VOC+YOLO格式2100张13类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2100 标注数量(xml文件个数):2100 标注数量(txt文件个数):2100 标注…...

华为鲲鹏ARM处理器920、916系列
鲲鹏处理器-鲲鹏社区 (hikunpeng.com) 产品规格 鲲鹏920系列 型号: 7260(64核)、5250(48核)、5220(32核)、3210(24核)7260核数64核 主频2.6GHz 内存通道8TDP功耗180W 组…...
)
微信小程序uView实战:u-picker三级联动避坑指南(附完整代码)
uView框架下u-picker三级联动的深度实践与性能优化 在微信小程序开发中,地区选择器几乎是每个涉及用户地址功能的必备组件。uView作为一款优秀的小程序UI框架,其u-picker组件提供了强大的多级联动功能,但在实际开发中,不少开发者会…...
)
深度学习特征分解、SVD 与 PCA —— 矩阵的“质因数分解“(六)
1. 定位导航 本篇是第2章线性代数的终篇,覆盖三个最有力的矩阵分析工具:特征分解、奇异值分解(SVD)、主成分分析(PCA)。此外还包括三个辅助工具:Moore-Penrose 伪逆、迹运算、行列式。 这些工具贯穿深度学习的方方面面——PCA 用于数据预处理和降维,SVD 用于模型压缩…...

哔哩下载姬:三步搞定B站视频永久收藏的智能工具
哔哩下载姬:三步搞定B站视频永久收藏的智能工具 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等)…...

突破性数字音乐解放方案:QMCDecode实战指南与3大智能转换场景解密
突破性数字音乐解放方案:QMCDecode实战指南与3大智能转换场景解密 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&#…...

【Java微服务Istio配置黄金法则】:20年架构师亲授5大避坑指南与生产级配置模板
第一章:Java微服务Istio配置的核心认知与演进脉络Istio 作为云原生服务网格的事实标准,其配置体系并非孤立存在,而是深度耦合于 Java 微服务的生命周期、通信契约与可观测性需求。早期 Spring Cloud Netflix 生态依赖客户端库(如 …...

Ostrakon-VL-8B实战:模拟互联网产品A/B测试中的视觉效果分析
Ostrakon-VL-8B实战:模拟互联网产品A/B测试中的视觉效果分析 每次产品迭代,设计团队和产品经理之间总少不了一场“拉锯战”。新版本的设计稿出来了,A方案简洁现代,B方案信息突出,到底哪个更能吸引用户点击?…...

忍者像素绘卷效果展示:云端画布背景+金橙配色+浮雕UI真实渲染效果
忍者像素绘卷效果展示:云端画布背景金橙配色浮雕UI真实渲染效果 1. 视觉风格惊艳呈现 忍者像素绘卷带来了全新的视觉体验,将传统像素艺术与现代设计理念完美融合。这款基于Z-Image-Turbo深度优化的图像生成工具,创造了一个明亮通透的创作环…...

别再搞混了!海康相机Bayer、Mono、YUV格式详解与选型避坑指南
工业相机图像格式全解析:从Bayer到YUV的实战选型策略 第一次接触工业相机参数表时,看到BayerRG8、Mono12 Packed、YUV422这些术语是不是感觉像在读天书?去年我在自动化检测项目上就曾因为选错图像格式,导致整套视觉算法推倒重来。…...

xgboost 训练一个 限制各个因素相关性的模型
XGB/LGB调参秘籍,解锁新高度! 在机器学习特别是风控模型的应用中,XGBoost和LightGBM因其出色的性能而备受青睐。然而,要充分发挥这些模型的潜力,合理的参数调校至关重要。今天,我们就来深入探讨XGBoost/Lig…...

探索XPopup:一款强大的Android弹窗库,让UI交互更灵动
探索XPopup:一款强大的Android弹窗库,让UI交互更灵动 【免费下载链接】XPopup 🔥XPopup2.0版本重磅来袭,2倍以上性能提升,带来可观的动画性能优化和交互细节的提升!!!功能强大&#…...