【Datawhale组队学习:Sora原理与技术实战】训练一个 sora 模型的准备工作,video caption 和算力评估
训练 Sora 模型
在 Sora 的技术报告中,Sora 使用视频压缩网络将各种大小的视频压缩为潜在空间中的时空 patches sequence,然后使用 Diffusion Transformer 进行去噪,最后解码生成视频。

Open-Sora 在下图中总结了 Sora 可能使用的训练流程。

训练链路:

数据准备
开源数据集:
VideoInstruct-100K:
VideoInstruct100K 是使用人工辅助和半自动注释技术生成的高质量视频对话数据集。数据集中的问题答案与以下内容相关:
- 视频摘要
- 基于描述的问题答案(探索空间、时间、关系和推理概念)
- 创意/生成性问题解答
链接:https://modelscope.cn/datasets/AI-ModelScope/VideoInstruct-100K
panda-70m:
Panda-70M 是一个包含 70M 高质量视频字幕对的大规模数据集。该存储库分为三个部分:
- 数据集数据加载包括列出 Panda-70M 数据的 csv 文件以及下载数据集的代码。
- 分割包括将长视频分割成多个语义一致的短片的代码。
- 字幕包括在 Panda-70M 上训练的拟议视频字幕模型。
链接:https://modelscope.cn/datasets/AI-ModelScope/panda-70m
Youku-mPLUG:
Youku-mPLUG 预训练数据集挖掘自优酷站内海量的优质短视频内容
- 包含千万级别约 36TB 的视频、文本数据。
- 其中视频均为覆盖 10 ~ 120 秒的 UGC 短视频内容,文本为视频对应的描述标题,长度 5 ~ 30 不等。
- 该数据集抽取时品类均衡,内容共包含 45 个大类。
链接:https://modelscope.cn/datasets/modelscope/Youku-AliceMind
MSR-VTT:
MSR-VTT(Microsoft Research Video to Text)是一个开放域视频字幕的大规模数据集。
- 由 20 个类别的 10,000 个视频片段组成,每个视频片段由 Amazon Mechanical Turks 标注了 20 个英文句子。
- 所有标题中约有 29,000 个独特单词。
- 标准分割使用 6,513 个 split 用于训练,497 个 split 用于验证,2,990 个 split 用于测试。
链接:https://modelscope.cn/datasets/AI-ModelScope/msr-vtt
Shot2Story:
视频文本基准和用于多镜头视频理解的可扩展代码。包含 20k 视频的详细长摘要和 80k 视频镜头的镜头字幕。
链接:https://modelscope.cn/datasets/AI-ModelScope/Shot2Story
InternVid:
InternVid 是一个以视频为中心的大规模多模态数据集,可以学习强大且可转移的视频文本表示,以实现多模态理解和生成。 InternVid 数据集包含超过 700 万个视频,持续近 76 万小时,产生 2.34 亿个视频剪辑,并附有总共 4.1B 个单词的详细描述。
链接:https://modelscope.cn/datasets/AI-ModelScope/InternVid
webvid-10M:
大型文本视频数据集,包含从素材网站抓取的1000 万个视频文本对。
链接:https://modelscope.cn/datasets/AI-ModelScope/webvid-10M
数据预处理
目前主流 LLM 框架缺乏针对 video 数据 统一便捷的管理和处理能力,且多模态数据处理标准方案缺失
- Huggingface-Datasets 官方认为 video 比 image 更棘手,暂未支持
- 相关 video 库对该场景过于庞杂或简单
- FFmpeg:150w 行+源码,大量底层细节
- pytorchvideo:主要支持加载和少量单 video 模态的tensor transform(翻转、扰动、采样等)
- SORA 官方仅模糊提及使用了 DALLE3 来生成 caption,细粒度的"caption --> spacetime patch"建模比较关键
- 从 SORA 模型效果看,数据需要有变化的时长、分辨率和宽高比
Data-Juicer扩展了对多模态数据的支持,已实现上百个专用的视频、图像、音频、文本等多模态数据处理算子及工具,帮助用户分析、清洗及生成大规模高质量数据。
- 支持视频数据的高性能 IO 和处理
- 支持并行化数据加载:lazy load with pyAV and ffmpeg;多模态数据路径签名
- 并行化算子处理:支持单机多核;GPU 调用;Ray 多机分布式
- [WIP] 分布式调度优化;分布式存储优化
- 基础算子(细粒度模态间匹配及生成)
- 基础算子(视频时空维度)

- 基础算子(细粒度模态间匹配及生成)

- 进阶算子(视频内容)

- DJ-SORA 数据菜谱及数据集

- DJ-SORA 数据验证及模型训练

开源链接:https://github.com/alibaba/data-juicer/docs/DJ_SORA_ZH.md
模型选型和训练
视频 VQVAE
VideoGPT 使用 VQ-VAE,通过采用 3D 卷积和轴向自注意力来学习原始视频的下采样离散潜在表示。然后使用一个简单的类似 GPT 的架构,使用时空位置编码对离散潜在变量进行自回归建模。用于 BAIR Robot 数据集上的视频生成,并从 UCF-101 和 Tumbler GIF 生成高保真自然图像数据集(TGIF)。
https://github.com/wilson1yan/VideoGPT/
Diffusion Transformer
普遍认为 Diffusion Transformer 模型是 Sora 的技术基础,通过结合 diffusion model 和 transformer,从而达到可以 scale up model 来提升图像生成质量的效果。我们总结了三个目前开源的 Diffusion Transformer 研究如下,并总结了最佳实践,可以在魔搭社区的免费算力上运行和测试。
UViT:All are Worth Words: A ViT Backbone for Diffusion Models
论文链接:https://arxiv.org/abs/2209.12152
代码库链接:https://github.com/baofff/U-ViT
模型链接:https://modelscope.cn/models/thu-ml/imagenet256_uvit_huge
DiT:Scalable Diffusion Models with Transformers
论文链接:https://arxiv.org/abs/2212.09748
代码库链接:https://github.com/facebookresearch/DiT
模型链接:https://modelscope.cn/models/AI-ModelScope/DiT-XL-2-256x256/summary
SiT:Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers (SiT)
论文链接:https://arxiv.org/pdf/2401.08740.pdf
代码库链接:https://github.com/willisma/SiT
模型链接:https://modelscope.cn/models/AI-ModelScope/SiT-XL-2-256
总结
U-ViT是一种简单且通用的基于 ViT 的扩散概率模型的主干网络,U-ViT 把所有输入,包括图片、时间、条件都当作 token 输入,并且引入了long skip connection。U-ViT 在无条件生成、类别条件生成以及文到图生成上均取得了可比或者优于 CNN 的结果。为未来扩散模型中骨干网络研究提供见解,并有利于大规模跨模态数据集的生成建模。
DiT同样的提出了使用 ViT 代替 U-Net 的思想,不同的是 DiT 中没有引入 long skip connection 也依然取得了杰出的效果。推测原因可能有:
- DiT 出色的Adaptive layer norm以及零初始化的设计能够有效提升生成质量;
- DiT 在建模特征空间表现良好,但在建模像素空间表现欠缺,可能在用扩散概率模型建模像素空间分布时 long skip connection 是至关重要的;
- 即使在建模特征空间上,DiT 没有 long skip connection 也能取得很好的效果,但 long skip connection 在加速收敛方面也起着关键的作用。
而近期推出的可扩展插值变压器 (SiT),是建立在 DiT 基础上的生成模型系列。 **插值框架,**相比标准的 diffusion 模型允许以更灵活的方式连接两个 distributions,使得对影响生成的各种设计选择的模块化研究成为可能。SiT 在 ImageNet 256x256 基准上模型大小和效果超过了 DiT 和 UViT,SiT 实现了 2.06 的 FID-50K 分数。
Video-caption
OpenAI 训练了一个具备高度描述性的视频标题生成(Video Captioning)模型,使用这个模型为所有的视频训练数据生成了高质量文本标题,再将视频和高质量标题作为视频文本对进行训练。通过这样的高质量的训练数据,保障了文本(prompt)和视频数据之间高度的 align。通过近期的讨论和资料,我们推测 Video Captioning 模型是由多模态大语言模型 VLM(如**GPT4V 模型)**微调出来的。开发者也可以通过视频抽帧+开源 VLM 生成描述+LLM 总结描述的方式,生成较好的视频描述。下面是一些开源的多模态模型:
零一万物 VL 模型(Yi-VL-34B)
代码库链接:https://github.com/01-ai/Yi/tree/main/VL
模型链接:https://modelscope.cn/models/01ai/Yi-VL-34B/
通义千问 VL 模型(Qwen-VL-Chat)
论文链接:https://arxiv.org/abs/2308.12966
代码库链接:https://github.com/QwenLM/Qwen-VL
模型链接:https://modelscope.cn/models/qwen/Qwen-VL-Chat
浦语·灵笔 2-视觉问答-7B(internlm-xcomposer2-vl-7b)
代码库链接:https://github.com/InternLM/InternLM-XComposer
模型链接:https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm-xcomposer2-vl-7b/summary
CogVLM 模型:
技术报告:https://zhipu-ai.feishu.cn/wiki/LXQIwqo1OiIVTykMh9Lc3w1Fn7g
代码库链接:https://github.com/THUDM/CogVLM
模型链接:https://modelscope.cn/models/ZhipuAI/CogVLM/summary
MiniCPM-V 模型:
论文链接:https://arxiv.org/abs/2308.12038
代码库链接:https://github.com/OpenBMB/OmniLMM/
模型链接:https://modelscope.cn/models/OpenBMB/MiniCPM-V/summary
Video-LLaVA 模型:
论文链接:https://arxiv.org/abs/2311.10122
代码库链接:https://github.com/PKU-YuanGroup/Video-LLaVA
模型链接:https://modelscope.cn/models/PKU-YuanLab/Video-LLaVA-7B/summary
总结对比
从模型参数量来看,零一万物,CogVLM 的模型是百亿参数,但是仅支持英文,通义,灵笔等模型可以较好的支持中文,Video-LLaVA 可以支持直接对视频的理解,可以根据需求来选择具体的多模态大语言模型。
参考资料
sora-tutorial/docs/chapter3/chapter3_1/chapter3_1.md at main · datawhalechina/sora-tutorial (github.com)
学习视频:【AI+X组队学习】Sora原理与技术实战:训练一个sora模型的准备工作,video caption和算力评估_哔哩哔哩_bilibili
Open-Sora:https://hpc-ai.com/blog/open-so
相关文章:
【Datawhale组队学习:Sora原理与技术实战】训练一个 sora 模型的准备工作,video caption 和算力评估
训练 Sora 模型 在 Sora 的技术报告中,Sora 使用视频压缩网络将各种大小的视频压缩为潜在空间中的时空 patches sequence,然后使用 Diffusion Transformer 进行去噪,最后解码生成视频。 Open-Sora 在下图中总结了 Sora 可能使用的训练流程。…...
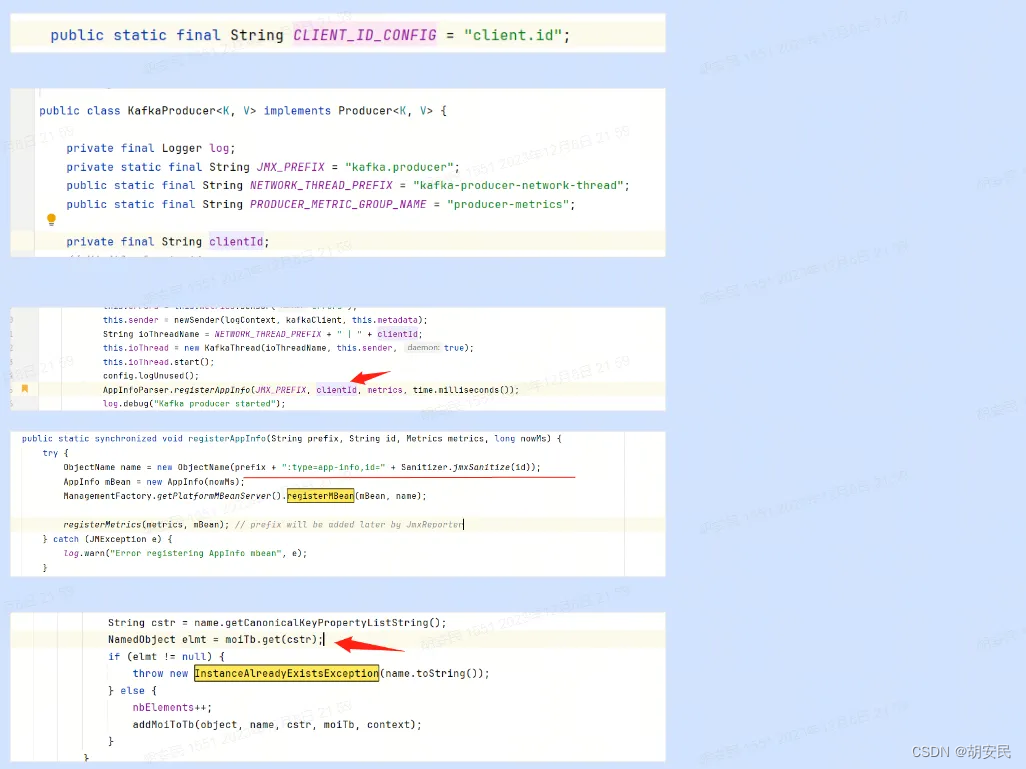
Kafka-生产者报错javax.management.InstanceAlreadyExistsException
生产者发送消息到 kafka 中,然后控制台报错 然后根据日志查看 kafka 的源码发现了问题原因 说的是MBean已经注册了,然后报异常了,这样就会导致生产者的kafka注册失败, 原因是项目上生产者没有配置clientId,默认都是空导致的, 多个生产者(项目)注册到kafka集群中的 id 都相同。 …...

Java常见问题:编辑tomcat运行环境、部署若伊系统
文章目录 引言I Eclipse1.1 编辑tomcat运行环境II JDK2.1 驱动程序无法通过使用安全套接字层(SSL)加密与 SQL Server 建立安全连接2.2 restriction on required library2.3 The type javax.servlet.http.HttpServletRequest cannot be resolved.的解决方法III npm3.1 npm报错:…...
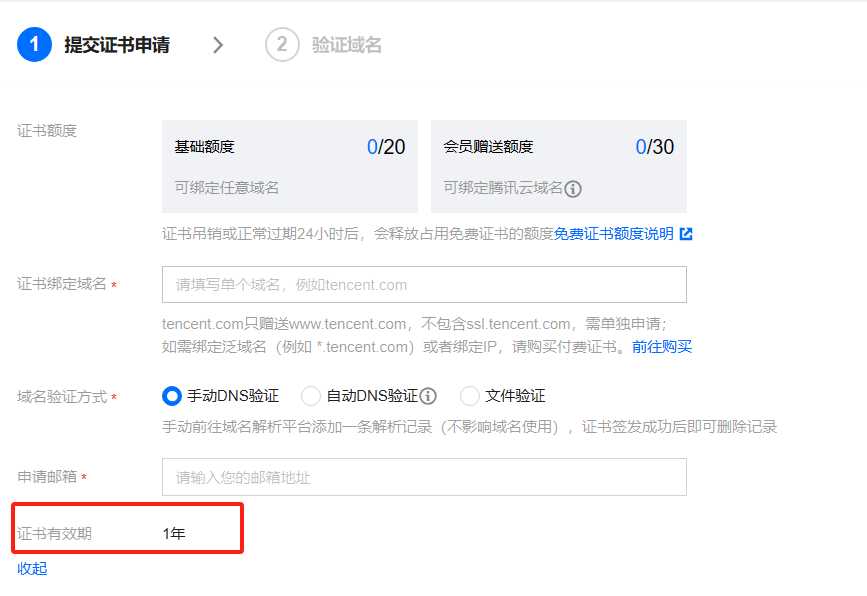
阿里云免费证书改为3个月,应对方法很简单
情商高点的说法是 Google 积极推进90天免费证书,各服务商积极响应。 情商低点的话,就是钱的问题。 现在基本各大服务商都在2024年停止签发1年期的免费SSL证书产品,有效期都缩短至3个月。 目前腾讯云倒还是一年期。 如果是一年期的话&#x…...

安装Pytorch——CPU版本
安装Pytorch——CPU版本 1. 打开pytorch官网2. 选择pip安装pytorch-cpu3.复制安装命令4. 在cmd命令窗口,进入你的虚拟环境4.1 创建虚拟环境4.2 进行安装 5. 安装成功6. 进行测试——如下面步骤,如图6.1 输入 python6.2 输入 import torch6.2 输入 print …...

MySQL中出现‘max_allowed_packet‘ variable.如何解决
默认情况下,MySQL的max_allowed_packet参数可能设置得相对较小,这对于大多数常规操作来说足够了。但是,当你尝试执行包含大量数据的操作(如大批量插入或大型查询)时,可能会超过这个限制,从而导致…...
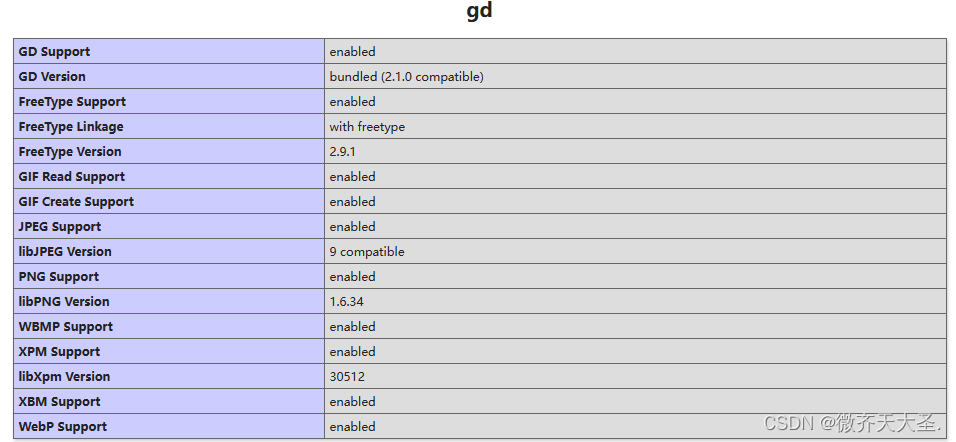
PHP 生成图片
1.先确认是否有GD库 echo phpinfo(); // 创建一个真彩色图像 $image imagecreatetruecolor(120, 50);// 分配颜色 $bgColor imagecolorallocate($image, 255, 255, 255); // 白色背景 $textColor imagecolorallocate($image, 230, 230, 230); // 黑色文字// 填充背景 image…...

【Spring Boot 3】【JSON】读取JSON文件
【Spring Boot 3】【JSON】读取JSON文件 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花…...

网络学习:邻居发现协议NDP
目录 前言: 一、报文内容 二、地址解析----NS/NA 目标的被请求组播IP地址 邻居不可达性检测: 重复地址检测 路由器发现 地址自动配置 默认路由器优先级和路由信息发现 重定向 前言: 邻居发现协议NDP(Neighbor Discovery…...

Spring事务传播行为总结
事务传播行为介绍 Spring中的7个事务传播行为: 事务行为说明特点PROPAGATION_REQUIRED支持当前事务,假设当前没有事务。就新建一个事务父事务与子事务要么都成功,要么都失败PROPAGATION_SUPPORTS支持当前事务,假设当前没有事务࿰…...

AWTK slider_circle 控件发布
slider_circle 控件。 主要特色: 支持正向和反向支持设置滑块的半径支持背景线宽和颜色支持前景线宽和颜色支持设置是否显示值的文本支持设置起始角度和结束角度支持设置格式化值的格式字符串支持使用图片填充背景和前景 界面效果: 注意: …...

BitMap 和 HyperLogLog
目录 BitMap 常用命令 应用场景 日活统计 用户签到 HyperLogLog 什么是基数? 常用命令 应用场景 BitMap 问: "有10亿个不重复的无序的正数,如果快速排序?" 这看上去很简单,就是一个排序而已,但是大部分排序算…...

德人合科技 | 公司办公终端、电脑文件资料 \ 数据透明加密防泄密管理软件系统
天锐绿盾是一款全面的企业级数据安全解决方案,它专注于为企业办公终端、电脑文件资料提供数据透明加密防泄密管理。 首页 德人合科技——www.drhchina.com 这款软件系统的主要功能特点包括: 1. **透明加密技术**: 天锐绿盾采用了透明加密技…...

0基础 三个月掌握C语言(11)
字符函数和字符串函数 为了方便操作字符和字符串 C语言标准库中提供了一系列库函数 接下来我们学习一下这些函数 字符分类函数 C语言提供了一系列用于字符分类的函数,这些函数定义在ctype.h头文件中。这些函数通常用于检查字符是否属于特定的类别,例如…...
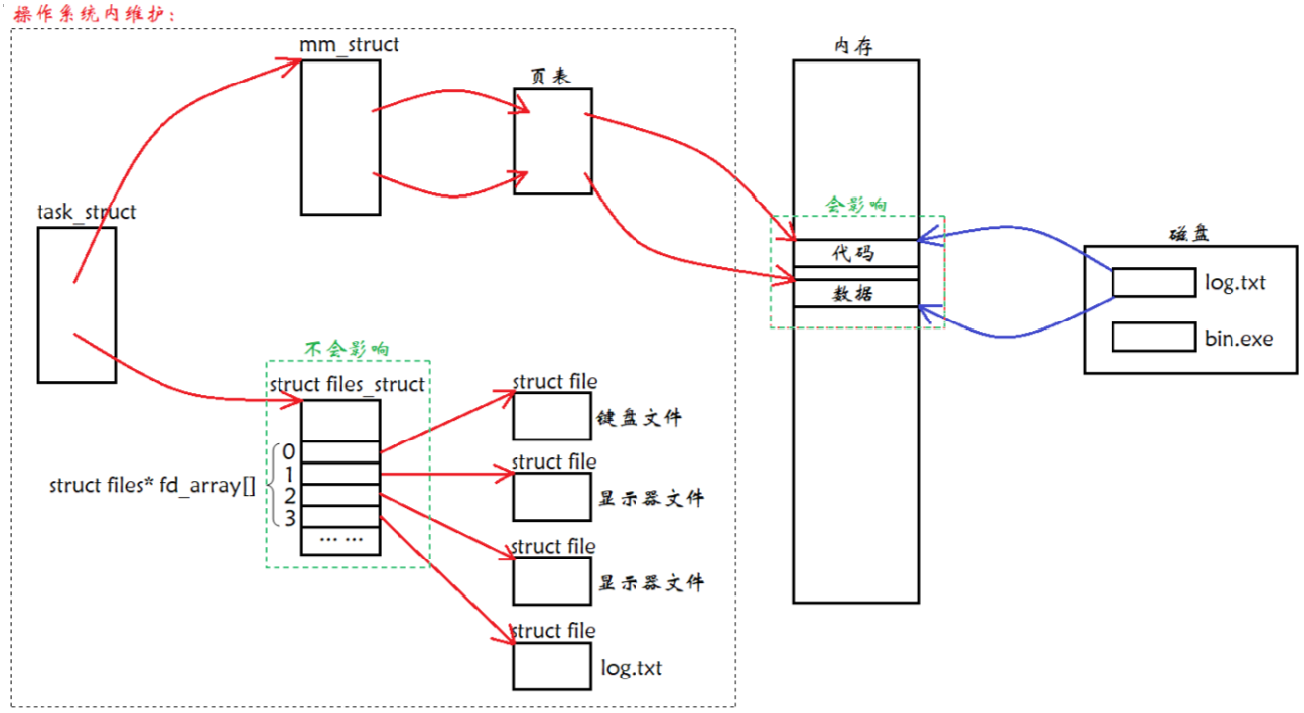
【Linux】基础 IO(文件描述符)-- 详解
一、前言 1、文件的宏观理解 文件在哪呢? 从广义上理解,键盘、显示器、网卡、声卡、显卡、磁盘等几乎所有的外设都可以称之为文件,因为 “Linux 下,一切皆文件”。 从狭义上的理解,文件在磁盘(硬件&#…...

如何降低云计算成本?
降低云计算成本的方法有很多,以下是一些关键的策略和建议: 优化资源使用: 自动缩放:根据工作负载的需求自动调整计算资源的大小。对于不需要大量扩展的低优先级工作负载,可以设置性能限制,并在适当的情况下…...

C# 打开文件对话框(OpenFileDialog)
OpenFileDialog:可以打开指定后缀名的文件,既能单个打开文件也能批量打开文件 /// <summary>/// 批量打开文档/// 引用:System.Window.Fomrs.OpenFileDialog/// </summary>public void OpenFile(){OpenFileDialog dialog new Op…...

《LeetCode热题100》笔记题解思路技巧优化_Part_3
《LeetCode热题100》笔记&题解&思路&技巧&优化_Part_3 😍😍😍 相知🙌🙌🙌 相识😢😢😢 开始刷题链表🟢1. 相交链表🟢2. 反转链表&…...
Rocket MQ 从入门到实践
为什么要使用消息队列,解决什么问题?(消峰、解藕、异步) 消峰填谷 客户端》 网关 〉 消息队列》秒杀服务 异步解耦 消息队列中的重要概念理解。(主题、消费组、队列,游标?) 主题&…...

Vue中的Vnode虚拟Dom一文详解
VNode 是什么? VNode 是 Virtual Node 的缩写,它是 Vue.js 中用来描述真实 DOM 节点的对象。在 Vue 中,每个组件都会被渲染成一个 VNode 树,然后由虚拟 DOM 算法(Virtual DOM Algorithm)将其转化为真实的 …...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...

Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间
Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦…...

想深耕网络安全行业,这些必备条件缺一不可
网络空间的攻防对抗日益激烈,网络安全已成为企业生存和国家安全的命脉,它负责构筑数字世界的坚固防线,保护核心资产与用户隐私免受侵害。 想要成为一名优秀的网络安全专家,除了敏锐的安全意识和高度的责任感,更需要锤…...

观察Token消耗明细,Taotoken用量看板如何帮助控制预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Token消耗明细,Taotoken用量看板如何帮助控制预算 对于个人开发者或项目管理者而言,在使用大模型API时…...

Lovable电商网站搭建,为什么92%的初创团队在第3周就遭遇性能雪崩?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署。其核心基于 Vue 3(Composition API&a…...

每日一书㉗ | 刻意练习:为什么有些人努力一辈子还是平庸?
“本文来自「乐想屋」公众号,系列更新[每日一书],每次5分钟,帮你把书读薄,把知识用活”先问你一个问题。你身边有没有这样的人:入行时间比你短,但能力已经甩你好几条街。他们好像没有特别刻苦,但…...

抖音批量下载工具:免费获取无水印视频的终极解决方案
抖音批量下载工具:免费获取无水印视频的终极解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

抖音下载器深度解析:零基础轻松批量下载无水印视频
抖音下载器深度解析:零基础轻松批量下载无水印视频 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...

Windows安卓应用安装终极指南:APK Installer让你的电脑变身安卓平台
Windows安卓应用安装终极指南:APK Installer让你的电脑变身安卓平台 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为无法在Windows电脑上直接安装安卓…...
)
【仅限首批200家认证用户】DeepSeek v3.2.1重复检测私有化部署补丁包(含GPU内存泄漏热修复+增量扫描加速模块)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力…...