[ROS 系列学习教程] rosbag Python API
ROS 系列学习教程(总目录)
本文目录
- 1. 构造函数与关闭文件
- 2. 属性值
- 3. 写bag文件内容
- 4. 读bag文件内容
- 5. 将bag文件缓存写入磁盘
- 6. 重建 bag 文件索引
- 7. 获取bag文件的压缩信息
- 8. 获取bag文件的消息数量
- 9. 获取bag文件记录的起止时间
- 10. 获取话题信息与消息类型
rosbag 的 Python API 主要位于 rosbag 包的 Bag 类中,通过 import rosbag 导入。
Bag 类中的常用接口如下:
1. 构造函数与关闭文件
class Bag(f: Any,mode: str = 'r',compression: str = Compression.NONE,chunk_threshold: int = 768 * 1024,allow_unindexed: bool = False,options: Any | None = None,skip_index: bool = False
)class Compression:NONE = 'none'BZ2 = 'bz2'LZ4 = 'lz4'close(self)
其中,
-
f:bag文件 -
mode:文件操作模式(r, w, a) -
compression:文件压缩模式,见如上Compression,默认Compression.NONE -
chunk_threshold:Bag 文件中每个块的最大字节数,默认768 * 1024 -
allow_unindexed:是否允许打开未建立索引的bag文件。说明:在实际使用中,如果你只是想查看或播放bag文件中的所有消息,而不需要基于时间戳进行精确查询,那么你可以将allow_unindexed设置为True。但是,如果你打算对bag文件进行基于时间的查询或其他高级操作,最好先使用rosbag index命令建立索引,并确保在打开bag文件时allow_unindexed为False(或者简单地省略该参数,因为它默认为 False)。 -
options:字典格式,用于统一设置Bag的参数,目前只支持compression和chunk_threshold,源码处理如下:-
if options is not None:if type(options) is not dict:raise ValueError('options must be of type dict') if 'compression' in options:compression = options['compression']if 'chunk_threshold' in options:chunk_threshold = options['chunk_threshold']
-
-
skip_index:打开bag文件时是否跳过文件的索引,这可以节省一些内存和加载时间,特别是在处理非常大的bag文件时。然而,这也意味着将无法使用基于索引的高级查询功能,比如按时间戳搜索特定的消息。
2. 属性值
# 只能获取
options # 同上options
filename # bag文件名
version # rosbag的版本号
mode # 文件操作模式(r, w, a)
size # Bag文件的大小(bytes)# 可设置可获取
compression # 文件压缩模式
chunk_threshold # Bag 文件中每个块的最大字节数
3. 写bag文件内容
write(self, topic, msg, t=None, raw=False, connection_header=None)
其中,
topic:写入的topic名称msg:写入的msgt:时间戳,默认None以当前时间为时间戳raw:是否已原始数据格式写入,通常不推荐这样做。connection_header:连接头信息,通常不需要手动设置。通常用于内部处理,不是常规用法的一部分。
代码示例:
import rosbag
import rospkg
from std_msgs.msg import Int32, Stringrospack = rospkg.RosPack()
package_path = rospack.get_path('rosbag_learning')
bags_path = package_path + "/bags"bag = rosbag.Bag(bags_path+'/pytest.bag', 'w')try:s = String()s.string = 'hello'i = Int32()i.int = 42bag.write('/chatter', s)bag.write('/number', i)finally:bag.close()
4. 读bag文件内容
read_messages(self, topics=None, start_time=None, end_time=None, connection_filter=None, raw=False, return_connection_header=False)
其中,
topics:指定读取的topic,可以是一个topic列表,如果不指定,默认读取全部topic(可选)start_time:通过时间戳过滤消息(消息的最早时间戳,rospy.Time对象)(可选)end_time:通过时间戳过滤消息(消息的最晚时间戳,rospy.Time对象)(可选)connection_filter:一个函数,用于过滤连接。它应该接受一个连接对象并返回一个布尔值,以决定是否保留该连接的消息。如果为 None,则不过滤连接。raw:一个布尔值,指定是否以原始字节形式返回消息。如果为 True,则返回原始字节数据;如果为 False(默认值),则返回解析后的 ROS 消息对象。return_connection_header: 一个布尔值,如果为 True,则返回的每条消息都会是一个元组,其中第二个元素是连接头信息。如果为 False(默认值),则只返回消息本身。- 返回值:以(topic, message, timestamp)格式返回
代码示例:
import rosbag
import rospkgrospack = rospkg.RosPack()
package_path = rospack.get_path('rosbag_learning')
bags_path = package_path + "/bags"bag = rosbag.Bag(bags_path+'/pytest.bag')for topic, msg, t in bag.read_messages(topics=['/chatter', '/number']):print(f"Received message on topic {topic} at time {t}: {msg}")bag.close()
结果如下:

5. 将bag文件缓存写入磁盘
flush(self)
当你使用 write() 写入数据到 bag 文件时,数据可能不会立即被写入磁盘,而是会先被缓存起来以提高性能。调用 flush() 方法可以强制将这些缓存的数据写入到磁盘中,以确保所有挂起的数据都被写入到 bag 文件中。
它没有参数,并且执行后没有返回值。
在以下情况下,可能需要调用 flush() 方法:
-
确保数据持久化:当你想要确保所有已经写入 rosbag.Bag 对象的数据都已经持久化到磁盘上时,可以调用
flush()。这在你准备关闭 bag 文件或程序即将退出时特别有用,以确保不会有数据丢失。 -
实时备份:如果你正在实时记录数据到 bag 文件,并且想要定期备份这些数据,你可以在备份之前调用
flush(),以确保备份时所有需要的数据都已经写入到 bag 文件中。
代码示例:
import rospy
import rosbag
import rospkg
from std_msgs.msg import String, Int32rospy.init_node('bag_writer') rospack = rospkg.RosPack()
package_path = rospack.get_path('rosbag_learning')
bags_path = package_path + "/bags"# 创建一个bag文件用于写入
with rosbag.Bag(bags_path + '/flush.bag', 'w') as bag:# 写入一条消息msg = String(data='Hello, ROSbag!')bag.write('/chatter', msg, rospy.Time.now())# 在写入更多消息之前调用flush()bag.flush()# 这里可以继续写入更多消息msg = Int32(data=25)bag.write('/number', msg, rospy.Time.now())# 在退出with块之前,flush()会被自动调用(如果需要的话)
查看bag文件信息如下:

6. 重建 bag 文件索引
reindex(self)
当使用 rosbag 记录或播放数据时,rosbag 会维护一个内部索引,以便能够高效地检索和访问数据。然而,有时索引可能会损坏或变得不一致,这时就需要使用 reindex 方法来重新构建索引。
reindex(self) 方法没有参数,它会对当前打开的 bag 文件执行索引重建操作。重建索引可能需要一些时间,具体取决于 bag 文件的大小和内容。
以下是可能需要使用 reindex 方法的一些场景:
-
索引损坏:如果你怀疑 bag 文件的索引已经损坏或不一致,导致无法正常访问数据,你可以尝试使用
reindex方法来修复它。 -
添加新数据:如果你在 bag 文件关闭后向其中添加了新数据,但没有重新构建索引,那么这些新数据将不会被包含在旧的索引中。在这种情况下,你需要调用
reindex方法来更新索引,以便能够访问这些新数据。 -
优化性能:有时,即使索引没有损坏,重新构建索引也可能有助于提高访问数据的性能。特别是当 bag 文件非常大或包含大量数据时,重建索引可以帮助优化数据结构,提高检索速度。
代码示例:
import rosbag
import rospkgrospack = rospkg.RosPack()
package_path = rospack.get_path('rosbag_learning')
bags_path = package_path + "/bags"with rosbag.Bag(bags_path+'/pytest.bag', 'r') as bag:try:for topic, msg, t in bag.read_messages():print(f"Received message on topic {topic} at time {t}: {msg}")except Exception as e:print(f"An error occurred while reading the bag file: {e}")print("Reindexing the bag file...")bag.reindex() # 尝试重新索引 bag 文件print("Reindexing completed.")# 现在可以正常使用 bag 文件中的数据了
7. 获取bag文件的压缩信息
get_compression_info(self)
这个方法返回一个tuple(str, int, int),其中包含了关于 bag 文件压缩的详细信息,每一位表示如下:
tuple[0]:压缩格式,例如none(表示没有压缩)或bz2(表示使用了 bzip2 压缩)。tuple[1]:未压缩的数据大小(以字节为单位)tuple[2]:压缩后的数据大小(以字节为单位)
代码示例:
import rosbag
import rospkg rospack = rospkg.RosPack()
package_path = rospack.get_path('rosbag_learning')
bags_path = package_path + "/bags"# 打开一个存在的 bag 文件
with rosbag.Bag(bags_path+'/pytest.bag', 'r') as bag:# 获取压缩信息compression_info = bag.get_compression_info()# 打印压缩信息if compression_info:print("Compression Type:", compression_info[0])print("UnCompressed Size:", compression_info[1])print("compressed Size:", compression_info[2])else:print("The bag file is not compressed.")
8. 获取bag文件的消息数量
get_message_count(self, topic_filters=None)
这个方法允许你指定一个或多个话题过滤器(topic_filters),以便只计算特定话题的消息数。该参数接收一个字符串或字符串列表,用于指定要计算消息数的话题。如果未提供或设置为 None,则计算 bag 文件中所有话题的消息数。
代码示例:
import rosbag
import rospkg rospack = rospkg.RosPack()
package_path = rospack.get_path('rosbag_learning')
bags_path = package_path + "/bags"# 打开一个存在的 bag 文件
with rosbag.Bag(bags_path+'/pytest.bag', 'r') as bag:# 定义我们想要计算消息数的话题过滤器列表topic_filters = ['/chatter', '/number']# 获取指定话题的消息数量message_counts = bag.get_message_count(topic_filters=topic_filters)# 打印话题的消息数量print(f"Message Count: {message_counts}")
9. 获取bag文件记录的起止时间
get_start_time(self)
get_end_time(self)
get_start_time 函数的返回类型是 float,表示以秒为单位的时间戳,其中的小数部分,表示秒的分数。
代码示例:
import rosbag
import rospkg
from datetime import datetimerospack = rospkg.RosPack()
package_path = rospack.get_path('rosbag_learning')
bags_path = package_path + "/bags"# 打开一个存在的 bag 文件
with rosbag.Bag(bags_path+'/pytest.bag', 'r') as bag:# 获取 bag 文件的开始结束时间start_time = bag.get_start_time()end_time = bag.get_end_time()# 将时间转换为更易读的字符串格式start_time_str = datetime.fromtimestamp(start_time)end_time_str = datetime.fromtimestamp(end_time)# 打印开始结束时间print(f"Bag file start time: {start_time_str}")print(f"Bag file end time: {end_time_str}")
运行结果如下:

10. 获取话题信息与消息类型
get_type_and_topic_info(self, topic_filters=None)
其中,topic_filters 用于过滤指定的话题,如果没有提供,则分析所有话题。
函数返回值类型如下:
TypesAndTopicsTuple(dict(str, str), dict(str, TopicTuple(str, int, int, float)))
其中各值说明如下:
TypesAndTopicsTuple(msg_types{key:type name, val: md5hash}, topics{key: topic name, value: TopicTuple(msg_type: msg type (Ex. "std_msgs/String"),message_count: the number of messages of the particular type,connections: the number of connections,frequency: the data frequency)})
其中,
msg_types:是一个字典,key为msg类型,value为msgMD5值。topics:是一个字典,key为topic名称,value是一个元组,其中:msg_type:该topic的消息类型message_count:该topic的消息数量connections:该topic的连接数量frequency:该topic的数据频率
代码示例:
import rosbag
import rospkg
from datetime import datetimerospack = rospkg.RosPack()
package_path = rospack.get_path('rosbag_learning')
bags_path = package_path + "/bags"# 打开一个存在的 bag 文件
with rosbag.Bag(bags_path+'/pytest.bag', 'r') as bag:topic_filters = ['/chatter', '/number']msg_types, topics = bag.get_type_and_topic_info(topic_filters)print("Message Types:")for type_name, md5_hash in msg_types.items():print(f" {type_name}: {md5_hash}")print("Topics:")for type_name, topic_info in topics.items():print(" Topic: {}, Type: {}, MessageCount: {}, Connections: {}, Frequency: {}".format(type_name, topic_info.msg_type, topic_info.message_count, topic_info.connections,topic_info.frequency))
运行结果:

相关文章:
[ROS 系列学习教程] rosbag Python API
ROS 系列学习教程(总目录) 本文目录 1. 构造函数与关闭文件2. 属性值3. 写bag文件内容4. 读bag文件内容5. 将bag文件缓存写入磁盘6. 重建 bag 文件索引7. 获取bag文件的压缩信息8. 获取bag文件的消息数量9. 获取bag文件记录的起止时间10. 获取话题信息与消息类型 rosbag 的 Pyt…...

TCL管理Vivado工程
文章目录 TCL管理Vivado工程1. 项目目录2. 导出脚本文件3. 修改TCL脚本3.1 project.tcl3.2 bd.tcl 4. 工程恢复 TCL管理Vivado工程 工程结构 1. 项目目录 config: 配置文件、coe文件等。doc: 文档fpga: 最后恢复的fpga工程目录ip: ip文件mcs: bit流文件等,方便直接使用src: .…...
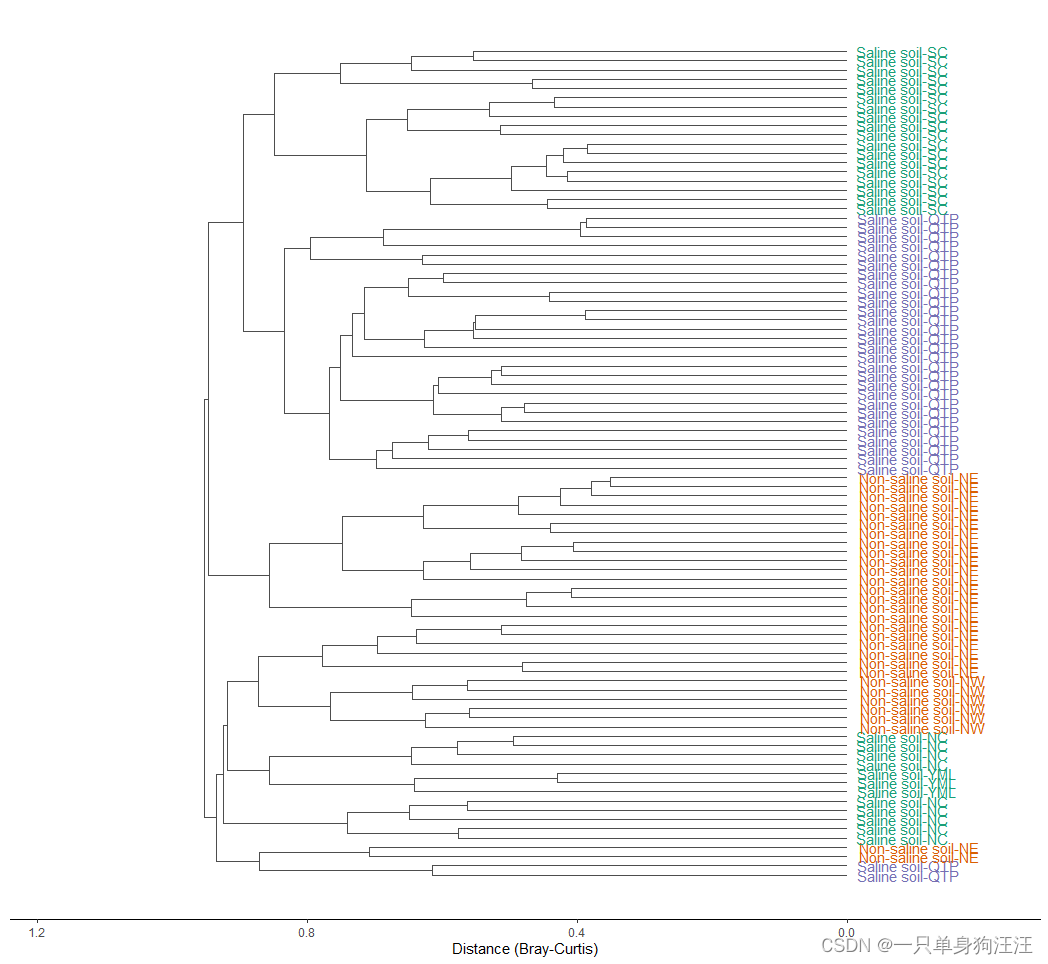
R语言:microeco:一个用于微生物群落生态学数据挖掘的R包,第四:trans_beta class
trans_beta class:利用trans_beta类可以变换和绘制beta分集的距离矩阵。该类中涉及到beta多样性的分析主要包括排序、群距、聚类和方差分析。我们首先使用PCoA显示排序。 > dataset$cal_betadiv() The result is stored in object$beta_diversity ... > t1 &…...
)
Excel文件导入导出,SpringBoot整合EasyExcel批量导入导出,采用的JDBC+EasyExcel(附带整个Demo)
目录 0.为什么mybatis的foreach比JDBC的addBatch慢 1.引入依赖 2.Controller层 3.Service层 4.Utils工具类 5.自定义监听器 6.实体类 7Mapper层 不用Mybatis的原因就是因为在大量数据插入的时候jdbc性能比mybatis好1. 首先分批读取Excel中的数据 这一点EasyExcel有自己…...
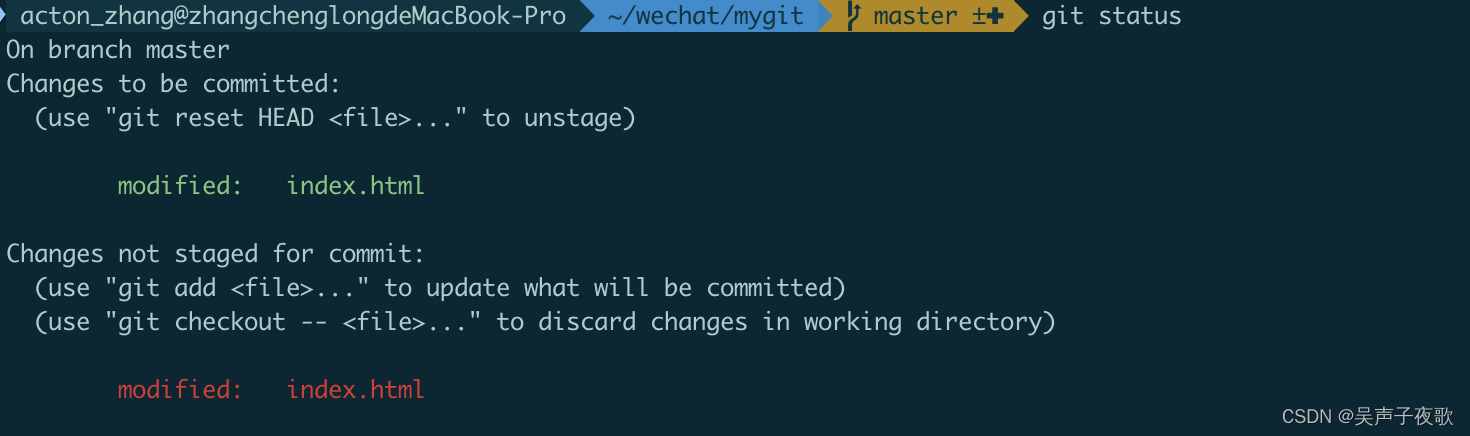
Git——本地使用详解
目录 Git1、开始版本控制1.1、初始化Repository1.2、使目录脱离Git控制 2、把文件交给Git管控2.1、创建文件后交给Git2.2、git add之后再次修改文件2.3、git add "--all"与"."参数区别2.4、把暂存区的内容提交到存储库里存档 3、工作区、暂存区与存储库3.1…...

深度学习pytorch——Tensor维度变换(持续更新)
view()打平函数 需要注意的是打平之后的tensor是需要有物理意义的,根据需要进行打平,并且打平后总体的大小是不发生改变的。 并且一定要谨记打平会导致维度的丢失,造成数据污染,如果想要恢复到原来的数据形式,是需要…...

Selenium-webdriver_manager判断是否已经下载过驱动(复用缓存驱动)
1,谷歌浏览器默认位置 2,ChromeDriverManager 下载的驱动位置 其中admin为机器的用户名 def installDriver(self):"""判断是否需要下载driver""""""找到本机谷歌浏览器版本""""""C:\P…...
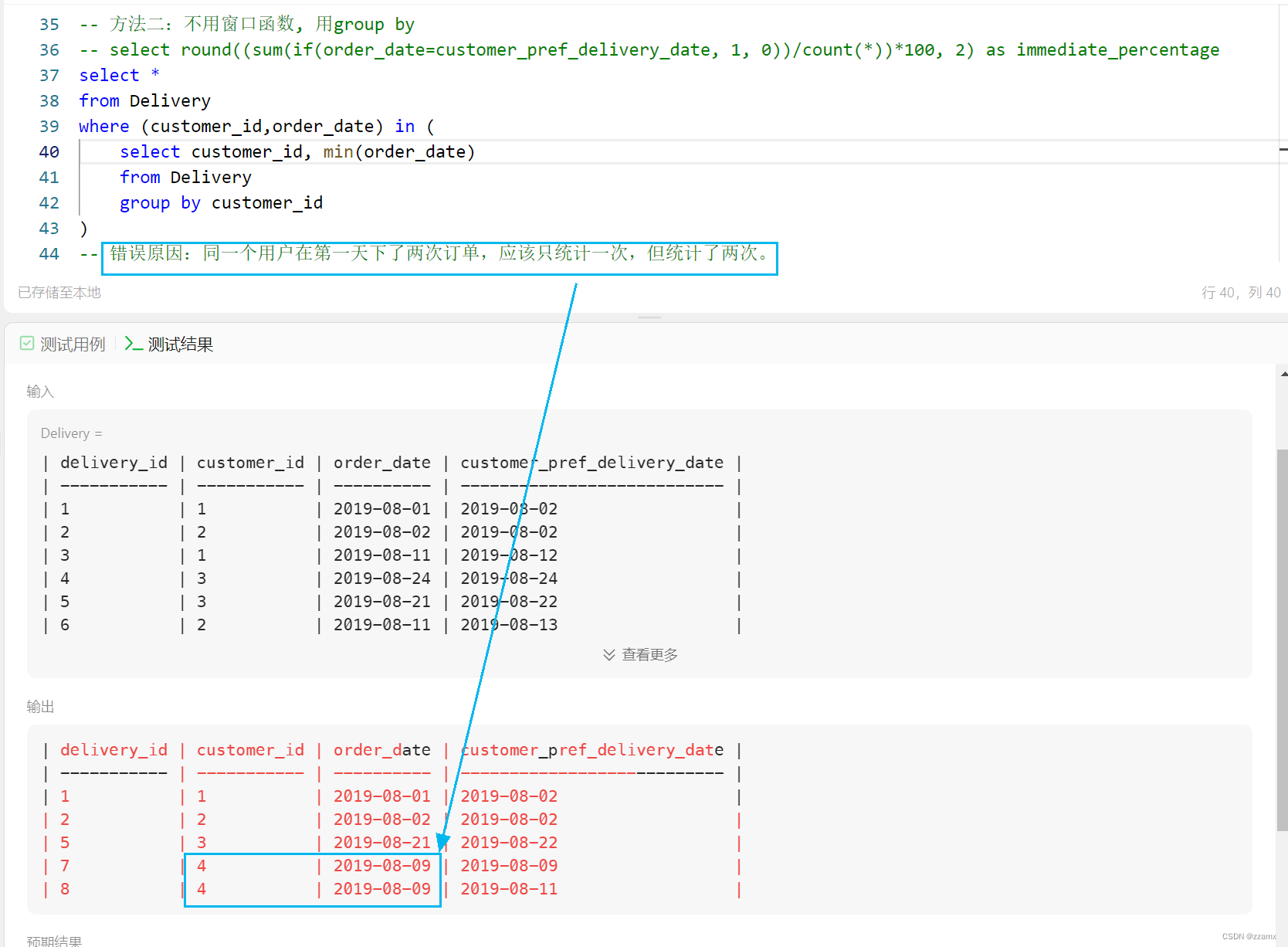
【SQL】1174. 即时食物配送 II (窗口函数row_number; group by写法;对比;定位错因)
前述 推荐学习: 通俗易懂的学会:SQL窗口函数 题目描述 leetcode题目:1174. 即时食物配送 II 写法一:窗口函数 分组排序(以customer_id 分组,按照order_date 排序),窗口函数应用。…...

mvcc介绍
前提:在介绍mvcc之前,先简单介绍一下mysql事务的相关问题,mvcc归根结底是用来解决事务并发问题的,当然这个解决不是全部解决,只是解决了其中的一部分问题! mysql事务 一、事务的基本要素(ACID&a…...

强化PaaS平台应用安全:关键策略与措施
PaaS(平台即服务,Platform-as-a-Service)是一种云计算服务模式,可以为客户提供一个完整的云平台(硬件、软件和基础架构)以用于快捷开发、运行和管理项目,从而降低了企业云计算应用的高成本和复杂…...

K8s 集群高可用master节点ETCD挂掉如何恢复?
写在前面 很常见的集群运维场景,整理分享博文内容为 K8s 集群高可用 master 节点故障如何恢复的过程理解不足小伙伴帮忙指正 不必太纠结于当下,也不必太忧虑未来,当你经历过一些事情的时候,眼前的风景已经和从前不一样了。——村上…...

【Godot 4.2】常见几何图形、网格、刻度线点求取函数及原理总结
概述 本篇为ShapePoints静态函数库的补充和辅助文档。ShapePoints函数库是一个用于生成常见几何图形顶点数据(PackedVector2Array)的静态函数库。生成的数据可用于_draw和Line2D、Polygon2D等进行绘制和显示。因为不断地持续扩展,ShapePoint…...
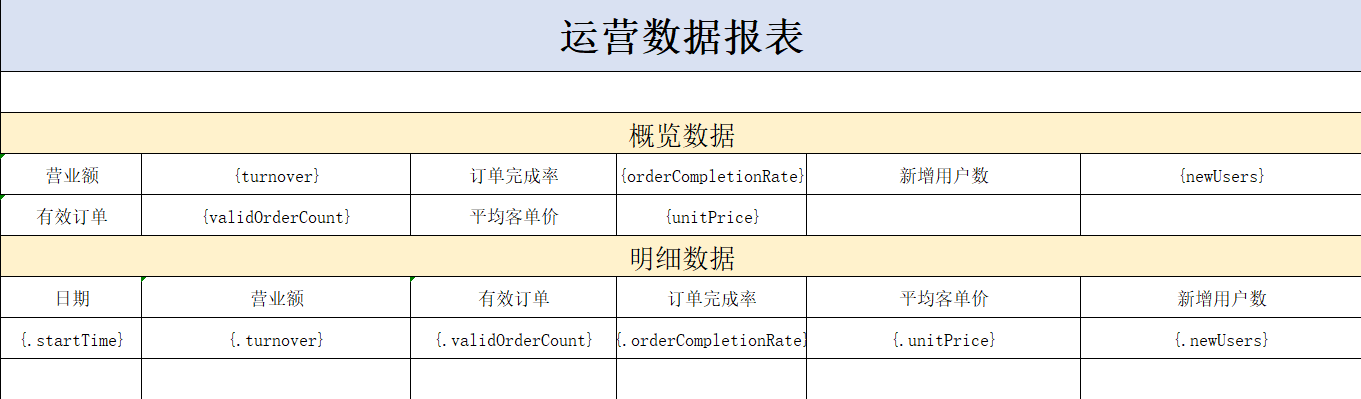
如何利用POI导出报表
一、报表格式 二、依赖坐标 <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>3.16</version> </dependency> <dependency><groupId>org.apache.poi</groupId><art…...

自动部署SSL证书到阿里云腾讯云CDN
项目地址:https://github.com/yxzlwz/ssl_update 项目简介 目前,自动申请和管理免费SSL证书的项目有很多,如个人正在使用的 acme.sh。然而在申请后,如果我们的需求不仅限于服务器本地的使用,证书的部署也是一件麻烦事…...

【系统性】 循序渐进学C++
循序渐进学C 第一阶段:基础 一、环境配置 1.1.第一个程序(基本格式) #include <iosteam> using namespace std;int main(){cout<<"hello world"<<endl;system("pause"); } 模板 #include &…...

rust - 一个日志缓存记录的通用实现
本文给出了一个通用的设计模式,通过建造者模式实例化记录对象,可自定义格式化器将实例化后的记录对象写入到指定的缓存对象中。 定义记录对象 use chrono::prelude::*; use std::{cell::RefCell, ffi::OsStr, fmt, io, io::Write, path::Path, rc::Rc,…...
(黑马))
elasticsearch(RestHighLevelClient API操作)(黑马)
操作全是换汤不换药,创建一个request,然后使用client发送就可以了 一、增加索引库数据 Testvoid testAddDocument() throws IOException {//从数据库查出数据Writer writer writerService.getById(199);//将查出来的数据处理成json字符串String json …...

用尾插的思想实现移除链表中的元素
目录 一、介绍尾插 1.链表为空 2.链表不为空 二、题目介绍 三、思路 四、代码 五、代码解析 1. 2. 3. 4. 5. 6. 六、注意点 1. 2. 一、介绍尾插 整体思路为 1.链表为空 void SLPushBack(SLTNode** pphead, SLTDataType x) {SLTNode* newnode BuyLTNode(x); …...

【Kubernetes】k8s删除master节点后重新加入集群
目录 前言一、思路二、实战1.安装etcdctl指令2.重置旧节点的k8s3.旧节点的的 etcd 从 etcd 集群删除4.在 master03 上,创建存放证书目录5.把其他控制节点的证书拷贝到 master01 上6.把 master03 加入到集群7.验证 master03 是否加入到 k8s 集群,检查业务…...
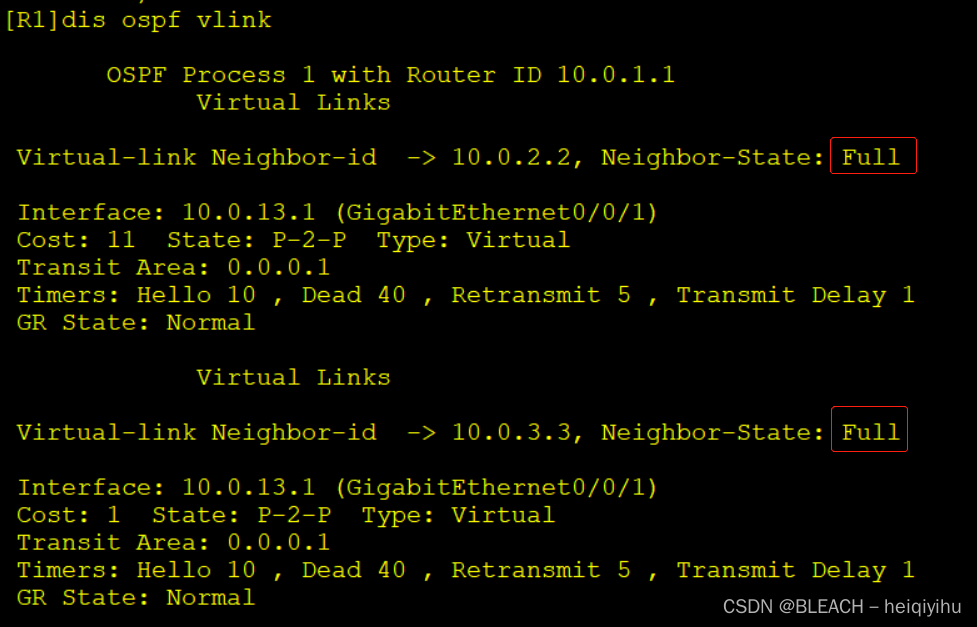
HCIP—OSPF虚链路实验
OSPF虚链路—Vlink 作用:专门解决OSPF不规则区域所诞生的技术,是一种虚拟的,逻辑的链路。实现非骨干区域和骨干区域在逻辑上直接连接。注意虚链路条件:只能穿越一个区域,通常对虚链路进行认证功能的配置。虚链路认证也…...

机器学习在宇宙中微子快味转换检测中的实践:从逻辑回归到天体物理模拟集成
1. 项目概述:当机器学习遇见宇宙深处的“幽灵粒子” 在宇宙最狂暴的舞台——核心坍缩超新星(CCSN)和双中子星并合(NSM)事件的中心,上演着一场肉眼无法观测的微观物理盛宴。这里的主角是中微子,这…...

工业级SCADA革命:FUXA零代码可视化平台如何重塑工业监控决策
工业级SCADA革命:FUXA零代码可视化平台如何重塑工业监控决策 【免费下载链接】FUXA Web-based Process Visualization (SCADA/HMI/Dashboard) software 项目地址: https://gitcode.com/gh_mirrors/fu/FUXA 在工业4.0和数字化转型浪潮中,传统SCADA…...

混合物理-ML辐射方案:攻克气候模型中次网格云效应的新范式
1. 项目概述与核心挑战在气候模拟这个庞大的数字沙盘中,地球系统模型(ESM)是我们理解未来气候演变的核心工具。然而,这个沙盘有一个长期存在的“颗粒度”难题:受限于计算资源,模型的水平分辨率通常在100到2…...

Linux 软链接和硬链接详解:ln 命令背后的 inode 原理
Linux 软链接和硬链接详解:ln 命令背后的 inode 原理 1. 前言 Linux 中经常会看到链接文件,例如: /bin -> /usr/bin python -> python3 current -> /opt/app/releases/v2Linux 链接主要有两种: 软链接:symbol…...

别再乱调了!深度解析URP相机Culling Mask与Occlusion Culling,让你的游戏性能提升一个档次
别再乱调了!深度解析URP相机Culling Mask与Occlusion Culling,让你的游戏性能提升一个档次在Unity游戏开发中,性能优化是一个永恒的话题。尤其是使用URP(Universal Render Pipeline)进行开发时,相机的合理配…...

安卓逆向实战:用frida-dexdump精准提取加固App运行时Dex
1. 这不是“脱壳”,是逆向工程里最该被正名的基础动作很多人一听到“砸壳”就想到黑产、盗版、破解,甚至有些团队内部文档里都刻意回避这个词,改用“Dex文件提取”“运行时内存Dump”这类听起来更“体面”的说法。但实话讲,在安卓…...

中文分词与词频统计全流程实战 | 全网独家复现,Python零基础落地篇 引入jieba分词优化+多策略词频统计,助力文本挖掘、舆情分析、学术研究高效落地
目录 一、核心前言(明确价值,避开踩坑) 1.1 实战意义 1.2 技术选型说明 1.3 前置准备(零基础必看) 二、核心原理(极简理解,无需深入) 2.1 中文分词原理 2.2 词频统计原理 三、全流程代码实现(零基础可复制,全程注释) 3.1 工程化目录结构(必看,避免路径错…...

5分钟实现Rhino到Blender转换:3dm文件导入完整教程
5分钟实现Rhino到Blender转换:3dm文件导入完整教程 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 你是否为Rhino模型无法在Blender中完美呈现而烦恼?im…...

LED闪灯电路板学习 过程
原理图和pcb是开源的,照着抄就行了,难点主要在于焊接,,焊接我分为三步,第一步一定要点锡,呈现45度角,大约3秒到5秒,第二步就是要夹稳零件往一边靠,第三步就是要顺水的焊锡焊另外一边,最重要就是第二步,熬过去就简单了,打了5个板子花了三天时间从零成功,重…...

Pico手柄+XRI 2.5交互系统实战:射线点击与抓取避坑指南
1. 这不是“拖拽组件就能跑通”的Demo,而是真正在Pico设备上能稳定抓取杯子、推开箱子、精准点击UI的交互系统Unity XR Interaction Toolkit(简称XRI)这两年在XR开发圈里热度很高,但很多人一上手就卡在“手柄动了,但啥…...