h2database源码解析-查询优化器原理
目录
- 一、成本计算规则
- 二、单表查询
- 三、多表关联查询
一、成本计算规则
h2的查询优化器基于成本的,因此在执行查询前,会基于成本计算使用哪个索引,如果涉及多表关联,还会计算不同表关联顺序的成本,最终基于最小成本得出执行计划。
单表查询时,遍历表的各个索引,索引遍历的顺序是先主键索引,然后二级索引。h2先假设使用该索引,然后基于该索引计算成本,索引不同,成本的计算规则也不同。
单主键索引的成本计算规则是最简单的,规则为:10*(总记录数+1000) 。但是如果是二级索引或者是主键有多个字段,那计算规则就比较复杂了。在Index.getCostRangeIndex()里面具体描述了成本计算规则,只要是基于索引计算成本(元数据表除外),那么都会调用下面这个方法,该方法的返回值乘以10,就是基于该索引进行查询所需成本:
//masks:数组中的元素与表的字段一一对应,比如数组第一个元素对应表的第一个字段,依以此类推,数组中的元素值表示该字段在查询语句中的比较类型,比如等值比较,元素值为1,比如大于等于,元素值为2,如果该字段在多个查询条件里面出现,比如既有大于等于也有等于操作,那么元素值为3(计算方式是1|2)//rowCount:表示表里面行记录总数//filters:每个TableFilter代表一个表//filter:如果多表关联查询,该参数表示正在处理filters[filter]//sortOrder:是否有order by子句//allColumnsSet:记录了本次查询涉及到的所有表的所有字段//isScanIndex:当前是否是表扫描,主键索引属于表扫描索引,二级索引不属于protected final long getCostRangeIndex(int[] masks, long rowCount, TableFilter[] filters, int filter,SortOrder sortOrder, boolean isScanIndex, AllColumnsForPlan allColumnsSet) {//成本是按行数+此偏移量计算的,以避免在表中不包含记录时使用错误索引rowCount += Constants.COST_ROW_OFFSET;int totalSelectivity = 0;long rowsCost = rowCount;if (masks != null) {int i = 0, len = columns.length;boolean tryAdditional = false;//从该索引的第一个字段开始遍历while (i < len) {Column column = columns[i++];//按顺序获取索引的每个字段int index = column.getColumnId();//获取字段在表里面的顺序int mask = masks[index];//获取该字段在查询语句里面的比较类型if ((mask & IndexCondition.EQUALITY) == IndexCondition.EQUALITY) {//使用到了索引中的一个字段,并且是等值操作if (i > 0 && i == uniqueColumnColumn) {//该索引是唯一索引,且遍历完索引的所有字段后发现查询语句中对该索引字段都是使用了等值操作//可见使用唯一索引的成本非常低rowsCost = 3;break;}//下面计算公式依赖于该字段的区分度(getSelectivity),区分度可以根据表优化或者重建重新计算totalSelectivity = 100 - ((100 - totalSelectivity) *(100 - column.getSelectivity()) / 100);long distinctRows = rowCount * totalSelectivity / 100;if (distinctRows <= 0) {distinctRows = 1;}rowsCost = 2 + Math.max(rowCount / distinctRows, 1);} else if ((mask & IndexCondition.RANGE) == IndexCondition.RANGE) {//当前字段是范围比较操作,比如betweenrowsCost = 2 + rowsCost / 4;tryAdditional = true;//tryAdditional表示不是等值操作break;} else if ((mask & IndexCondition.START) == IndexCondition.START) {//大于等于操作rowsCost = 2 + rowsCost / 3;tryAdditional = true;break;} else if ((mask & IndexCondition.END) == IndexCondition.END) {//小于等于操作rowsCost = rowsCost / 3;tryAdditional = true;break;} else {if (mask == 0) {// Adjust counter of used columns (i)i--;}break;}}//在上面遍历索引字段的过程中,一旦发现非等值比较或者该字段不再查询语句里面,便结束字段遍历if (tryAdditional) {//如果为true,表示查询语句里面有非等值比较查询while (i < len && masks[columns[i].getColumnId()] != 0) {//如果索引中某个字段使用了非等值操作,那么后续的字段不能像等值操作一样通过该索引高效过滤数据,但是依然可以使用索引过滤数据,因此下面使用rowsCost--i++;rowsCost--;}}// 增加额外未使用列的索引成本// len表示当前索引中字段的个数rowsCost += len - i;}//如果ORDER BY子句与此索引的排序相一致,那么它的成本将响应降低long sortingCost = 0;if (sortOrder != null) {sortingCost = 100 + rowCount / 10;}//下面的if分支判断为true时表示当前SQL语句有order by子句,且不是使用主键索引查询if (sortOrder != null && !isScanIndex) {//sortOrderMatches表示order by子句的排序规则是否与索引匹配boolean sortOrderMatches = true;int coveringCount = 0;//sortTypes表示order by子句里面各个字段的排序规则,下文有详细介绍int[] sortTypes = sortOrder.getSortTypesWithNullOrdering();TableFilter tableFilter = filters == null ? null : filters[filter];//从order by子句的第一个字段开始遍历for (int i = 0, len = sortTypes.length; i < len; i++) {if (i >= indexColumns.length) {//这里表示当前排序的字段多于索引中的字段,在这种情况下,我们依然可以使用该索引,只是相对于包含更多排序字段的索引,coveringCount值小而已,进而影响其成本break;}//获得对应的数据库表字段Column col = sortOrder.getColumn(i, tableFilter);//如果col为null,表示该排序字段不是当前表的字段if (col == null) {sortOrderMatches = false;break;}IndexColumn indexCol = indexColumns[i];//当前正在遍历order by子句的第i个字段,将该字段与索引中的第i个字段比较,如果字段一致,那么意味着可以使用索引排序,否则不能使用if (!col.equals(indexCol.column)) {sortOrderMatches = false;break;}int sortType = sortTypes[i];//如果order by子句的第i个字段与索引的第i个字段相同,那么比较排序规则,如果也一致,那么可以使用索引排序,否则不能使用if (sortType != indexCol.sortType) {sortOrderMatches = false;break;}//如果排序字段与索引字段相同,而且排序规则也一致,增大coveringCount,coveringCount越大,成本越小coveringCount++;}if (sortOrderMatches) {//coveringCount确保当我们有两个或多个覆盖索引时,我们选择覆盖更多的索引sortingCost = 100 - coveringCount;}}//如果当前的SQL语句,使用主键查询和使用某个二级索引查询的成本相同,而且二级索引可以满足查询需要,那么使用索引查询即可//如果needsToReadFromScanIndex=true,表示查询除了使用二级索引外还需要回表查询boolean needsToReadFromScanIndex;if (!isScanIndex && allColumnsSet != null) {needsToReadFromScanIndex = false;//获取SQL语句中使用到该表的所有字段ArrayList<Column> foundCols = allColumnsSet.get(getTable());if (foundCols != null) {//获取main index column,在h2里面main index比较复杂,//不过可以简单理解为,如果当前主键索引只有一个字段,那么getMainIndexColumn()返回的就是该字段在表中的字段位置,//如果有多个字段或者没有索引,那么该方法返回的是一个常量SearchRow.ROWID_INDEXint main = table.getMainIndexColumn();//遍历SQL语句里面涉及到该表的所有字段,如果这些字段在当前索引中都有,那么表示可以使用该索引查询,不用回表loop: for (Column c : foundCols) {int id = c.getColumnId();//下面判断了id == SearchRow.ROWID_INDEX,因为二级索引里面默认有主键列if (id == SearchRow.ROWID_INDEX || id == main) {continue;}//columns表示当前索引中涉及到表字段for (Column c2 : columns) {if (c == c2) {continue loop;}}//SQL中有一个字段不在索引里面,那么除了使用二级索引查询外,还需要回表查询needsToReadFromScanIndex = true;break;}}} else {needsToReadFromScanIndex = true;}long rc;//下面是计算最终的成本if (isScanIndex) {//如果当前是使用主键查询rc = rowsCost + sortingCost + 20;} else if (needsToReadFromScanIndex) {//如果需要回表查询,那么还要计算上使用主键查询的成本rc = rowsCost + rowsCost + sortingCost + 20;} else {//下面的计算公式使用了索引列的个数,这是因为当我们选择覆盖索引时,//我们选择列数最少的覆盖索引(索引中的列数越多,成本越高),因为较小的索引占用的数据空间更小。rc = rowsCost + sortingCost + columns.length;}return rc;}
order by子句里面可以指定字段的排序规则,是ASC还是DESC,对于可以为NULL的字段,还有两种排序规则,分别是无论升序还是降序NULL值始终在最前以及无论升序还是降序NULL值始终在最后的排序规则,在h2中使用常量ASCENDING(0)、DESCENDING(1)、NULLS_FIRST(2)、NULLS_LAST(4)表示上述四种排序规则,不过后面两种不能在SQL语句中指定,h2会基于系统默认值设定,默认情况下,升序是NULL值始终在前,降序是NULL值始终在最后。所以默认情况下,对于order by id ,name desc子句,上面代码里面数组变量sortTypes[0]=ASCENDING | NULLS_FIRST=2,sortTypes[1]=DESCENDING | NULLS_LAST=5。
在h2中,全表扫描、回表查询指的都是使用主键查询。h2的表都是使用主键维护的表。
getCostRangeIndex()方法是计算执行计划成本的最核心方法,它的返回值表示的就是当前表使用该索引查询的成本。通过本方法,对表查询时就可以判断出使用哪个索引查询成本最低。上面的方法代码量并不多,但是涉及的内容比较多,通过上面的方法可以看到什么样的索引是“好”索引。下面总结一下“好”索引的特点:
- 索引能覆盖SQL语句中的所有字段,这种索引也叫作覆盖索引;
- 索引遵循最左前缀原则,因此尽量不要由对索引中间字段或者开头字段进行范围查询,这会导致后面的字段无法使用索引;
- 排序的字段及顺序对索引的使用也有影响;
- 索引是唯一索引,而且查询语句对该索引都是等值查询,这种索引成本最低。
不过,h2的优化器还有有局限性的,比如计算成本时,没有考虑该表或者索引是否已经在缓存中了。
下面分几种场景介绍h2如何使用getCostRangeIndex()方法确定执行计划。
二、单表查询
单表查询是最简单的,首先使用主键索引计算成本,然后遍历各个二级索引计算成本,从这里面选择成本最小的索引,之后便使用该表进行查询。
三、多表关联查询
当关联表的个数小于等于7个时,h2会计算出这些表的所有排列,对每个排列从第一个表开始遍历,根据查询条件,通过getCostRangeIndex()方法确定每个表使用哪个索引的成本最低,并得到最低成本,然后使用如下伪代码计算出该排列的总成本:
//item.cost是对每个表进行查询的最小成本,double cost = 1;//遍历每个表,tables表示一个排列//tables[i].cost表示表的最小成本for (int i = 0; i < tables.length; i++) {cost += cost * tables[i].cost;}
这样便可以从这些排列里面找到成本最低的排列。之后h2使用该排列中表的顺序依次操作每个表。
不过h2也有一个提前终止条件,可以提前终止对排列的遍历,代码如下:
private boolean canStop(int x) {return (x & 127) == 0// don't calculate for simple queries (no rows or so)&& cost >= 0// 100 microseconds * cost&& System.nanoTime() - startNs > cost * 100_000L;}
入参x是一个计数器,表示已经遍历了多少个排列了,每遍历一个排列,x会增加1,x从0开始计数。当canStop()返回true时,那么后续的排列便不再遍历。这会导致最优的排列可能没有遍历到。
h2提供了Permutations类用于生成下一个排列,该算法是由Alan Tucker实现的。
如果关联表的个数大于7个,h2是无法遍历所有排列的。h2使用随机+贪心算法来搜索较好的排列。与暴力搜索不同,随机+贪心不一定能找到最好的排列顺序,但是至少可以找到次优的排列。
相关文章:

h2database源码解析-查询优化器原理
目录一、成本计算规则二、单表查询三、多表关联查询一、成本计算规则 h2的查询优化器基于成本的,因此在执行查询前,会基于成本计算使用哪个索引,如果涉及多表关联,还会计算不同表关联顺序的成本,最终基于最小成本得出…...

2月11日,30秒知全网,精选7个热点
///国产邮轮首制船将于今年5月底出坞,年底交付 浦东新区近期将发布相关政策支持包括外高桥造船在内的船舶产业发展 ///首批个人养老金理财产品名单发布:3家机构7只产品 中国理财网发布的信息显示,首批个人养老金理财产品名单发布࿰…...

vue组件的构成 <template> <script> <style>节点的使用 <
1.vue组件组成结构 每个.vue组件都由3部分构成,分别是: template ->组件的模板结构script ->组件的JavaScript行为style ->组件的样式 其中,每个组件中必须包含template模板结构,而script行为和style样式是可选的组成部分。 2.组…...
windows + vscode + rust
1 安装VSCODE略2 安装rust插件1、说明:第4步本人是一个一个点击状态。上图禁用按钮在没装之前是显示“安装”按钮,应该点击“安装”也可以。2、还需要安装C插件,搜索C即可,装微软的3 创建rust工程由于初次使用,不知道目…...

二十九、异常处理
目录 ①前言: ②常见的运行时异常 ③常见的编译时异常 ④异常的处理机制 ⑤自定义异常 ①前言: 1.什么是异常? 异常是程序在“编译”或者“执行”的过程中可能出现的问题,注意:语法错误不算在异常体系中。 比如: 数据索引越界异常&…...
RTOS之二环境搭建初识RTOS
参考:https://blog.csdn.net/kouxi1/article/details/123650688视频:https://www.bilibili.com/video/BV1b14y1c783/RTOS本质就是切换线程栈,栈换了环境就换了,一个重要的结构tcb(linux叫PCB或thread_info)…...

【Java】 JAVA Notes
JAVA语言帮助笔记Java的安装与JDKJava命名规范JAVA的数据类型自动类型转换强制类型转换JAVA的运算符取余运算结果的符号逻辑运算的短路运算三元运算符运算符优先级JAVA的流程控制分支结构JAVA类Scanner类Math 类random方法获取随机数Java的安装与JDK JDK安装网站:h…...
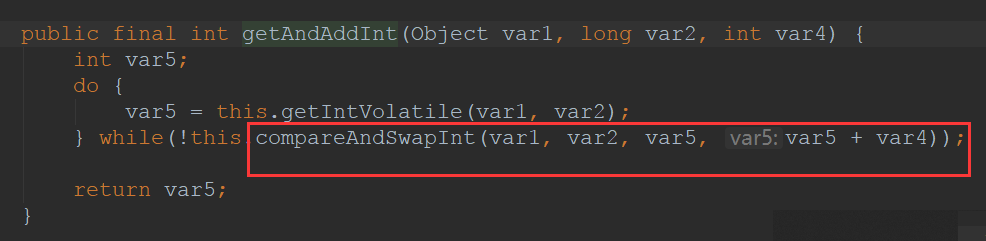
Java笔记-volatile和AtomicInteger
目录1. volatile1.1.什么是volatile1.2.JMM-Java内存模型2 验证volatile的特性2.1 可见性2.2.验证volatile不保证原子性2.3 volatile实现禁止指令重排序3.使用AtomicInteger解决volatile的不能实现原子性的问题3.2 AtomicInteger的方法说明:3.3 CAS3.4 应用1. volat…...

[标准库]STM32F103R8T6 高级定时器--PWM输出和带死区互补PWM输出
前言 STM32F103系列的MCU,相比普通的51单片机,在输出硬件PWM这个功能上要强不少,两者实现的方式都类似,都是通过一个定时器来启用硬件PWM输出,不过在输出PWM通道的数量上,32F103要强上不少。仅通过一个高级…...

Camtasia2023最新版电脑视频录屏记录编辑软件
在Mac或Wind上有各种可用的视频记录和编辑软件,其中Camtasia被称为视频记录器和视频编辑器。录屏软件Camtasia2023到底有什么特色功能?本文将帮助您选择理想的选择来开始视频捕获,创建和编辑。Camtasia2023是Mac/win平台上一款使用非常简单的…...

管理用户安全性
每个数据库用户帐户都包括以下项:唯一的用户名验证方法 默认表空间临时表空间用户概要文件初始使用者组帐户状态验证用户口令验证、外部验证、全局验证管理员验证操作系统安全性:• DBA 必须具有创建或删除文件的操作系统权限。• 普通数据库用户不应具有…...

分享113个JS菜单导航,总有一款适合您
分享113个JS菜单导航,总有一款适合您 113个JS菜单导航下载链接:https://pan.baidu.com/s/1d4nnh-UAxNnSp9kfMBmPAw?pwdcw23 提取码:cw23 Python采集代码下载链接:https://wwgn.lanzoul.com/iKGwb0kye3wj base_url "http…...
RuoYi-Cloud 部署
RuoYi-Cloud部署 1. 下载 点击右侧链接可以进入gitee的源码下载地址: 偌依微服务源码gitee下载地址 2. 数据库部署 依据如下步骤创建系统所需数据环境,脚本执行没有先后次序要求: 在Mysql 中创建 ry-cloud 主数据库,并执行 …...

DockerFile文件详解
一、DockerFile文件说明1、概述 Dockerfile是用来构建Docker镜像的文本文件,文本内容包含了一条条构建镜像所需的指令、参数和说明。可以在Docker文件中使用RUN,CMD,FROM,EXPOSE,ENV等指令。即:Dockerfile仅…...
Java程序运行机制
Java语言既具有编译型语言的特征,又具有解释型语言的特征,Java程序要经过先编译后解释两个阶段。高级语言的运行机制📍编译型语言使用专门的编译器,针对特定的平台(移植性差),将高级语言的源代码…...
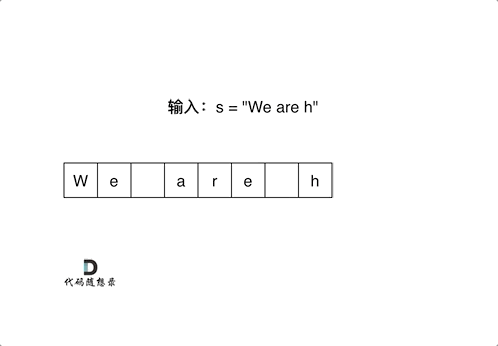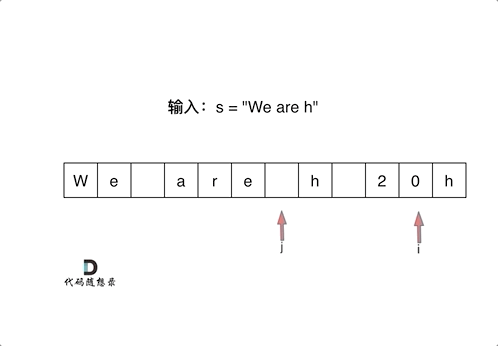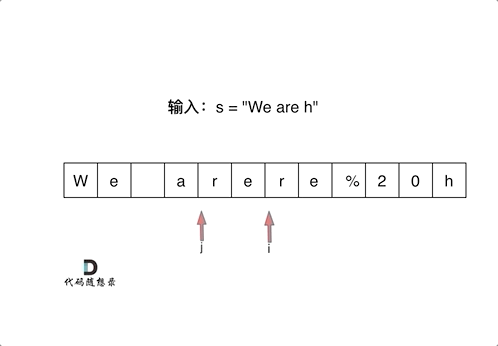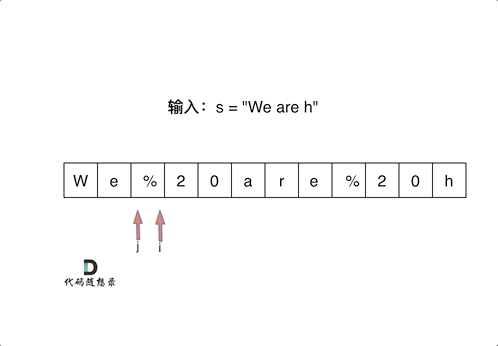
LeetCode刷题------字符串
目录 LeetCode:344.反转字符串 LeetCode:541. 反转字符串II LeetCode:剑指Offer 05.替换空格 LeetCode:151.翻转字符串里的单词 LeetCode:剑指Offer58-II.左旋转字符串 LeetCode:28. 实现 strStr() …...

区块链技术与应用2——BTC-数据结构
文章目录比特币中的数据结构1. 区块链(block chain)2. 默克尔树(Merkle tree)3.哈希指针的问题比特币中的数据结构 1. 区块链(block chain) 哈希指针: (1)保存数值的位置…...

BiseNet v1论文及其代码详解
来源:投稿 作者:蓬蓬奇 编辑:学姐 BiSeNet v1说明: 文章链接:https://arxiv.org/abs/1808.00897 官方开源代码:https://github.com/CoinCheung/BiSeNet (本文未使用) 文章标题&am…...

(超详细)Navicat的安装和激活,亲测有效
步骤一:准备安装包 下载Navicat,我用的v15最好一致(私信可以发你安装包和注册码)步骤二:关闭杀毒软件,然后需要断掉网络(一定断网) 步骤三:一路next安装,安装…...

JDY-31蓝牙模块使用指南
前言 本来是想买个hc-05,这种非常常用的模块,但是在优信电子买的时候,说有个可以替代的,没注意看,买回来折腾半天。 这个模块是从机模块,蓝牙模块分为主机从机和主从一体的,主机与从机的区别就…...

如何利用Marketing-for-Engineers营销自动化工具:节省90%时间的终极指南
如何利用Marketing-for-Engineers营销自动化工具:节省90%时间的终极指南 【免费下载链接】Marketing-for-Engineers A curated collection of marketing articles & tools to grow your product. 项目地址: https://gitcode.com/gh_mirrors/ma/Marketing-for…...

从零构建开发者效率工具:CLI脚手架与自动化工作流实践
1. 项目概述与核心价值最近在开源社区里,一个名为smouj/smouj的项目引起了我的注意。乍一看这个标题,可能会让人有些摸不着头脑,它不像常见的vue/vue或tensorflow/tensorflow那样直白地揭示了其技术栈。但恰恰是这种看似“神秘”的命名&#…...
)
ElevenLabs Starter计划实战指南(新手必看的4步激活+2次配额翻倍技巧)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs Starter计划的核心定位与适用边界 ElevenLabs Starter 计划是面向开发者、内容创作者及小型团队推出的免费语音合成入门方案,旨在以零门槛方式提供高质量、低延迟的文本转语音&…...

Neo-Launcher数据库架构:数据存储和管理的深度解析
Neo-Launcher数据库架构:数据存储和管理的深度解析 【免费下载链接】Neo-Launcher Neo-Launcher 项目地址: https://gitcode.com/gh_mirrors/ne/Neo-Launcher Neo-Launcher是一款由Neo Collective开发的开源启动器应用,其高效的数据存储和管理系统…...

基于本地LLM与多智能体架构的DD游戏引擎实现与优化
1. 项目概述:一个本地化、多智能体驱动的龙与地下城游戏引擎最近在折腾一个挺有意思的项目,叫 TD-LLM-DND。简单来说,这是一个让你能在自己电脑上,用本地运行的大语言模型(LLM)来跑一场“龙与地下城”&…...

2016年FPGA市场格局:巨头并购、技术演进与工程师实战指南
1. 2016年FPGA市场格局:一场没有悬念的卫冕战聊起2016年的FPGA市场,就像看一场结局早已注定的体育比赛。赛灵思(Xilinx)毫无悬念地再次登顶年度营收榜首,这已经是它连续十几年稳坐头把交椅了。根本不需要什么复杂的财务…...

Windows和Office激活难题?KMS智能激活脚本让你轻松告别烦恼
Windows和Office激活难题?KMS智能激活脚本让你轻松告别烦恼 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾经因为Windows系统突然弹出激活提示而中断工作?是否遇…...

IP2366至为芯支持C口双向快充的140W多串锂电池充放电SOC芯片
英集芯IP2366是一款应用于移动电源、电动工具、智能家居、储能电源等方案的多串锂电池充电SOC芯片。支持高达140W的双向同步升降压充放电,充电电流可达5A。支持2至6节锂电池/磷酸铁锂电池串联,集成PD3.1、QC3.0等多种快充协议。内置14bit ADC,…...

党建知识竞赛系统推荐:满足各级党组织需求的智能化工具
🚩 党建知识竞赛系统推荐:满足各级党组织需求的智能化工具创新党员教育形式 提升学习实效 推动智慧党建🎯 一、核心价值与功能需求在新时代加强党的建设背景下,如何创新党员教育形式、提升学习实效,是各级党组织面临…...

从ARIMA差分到MIM网络:一个老派时间序列技巧如何革新了深度学习预测
从差分思想到记忆网络:传统时间序列技巧如何重塑深度学习架构 在气象预报的雷达回波图中,降水云团的形态每秒钟都在剧烈变化;城市交通流量监测数据里,早晚高峰的波动与平峰期形成鲜明对比;股票市场的价格曲线更是以难以…...