Spark Catalyst
Spark Catalyst
- 逻辑计划
- 逻辑计划解析
- 逻辑计划优化
- Catalyst 规则优化过程
- 物理计划
- Spark Plan
- JoinSelection
- 生成 Physical Plan
- EnsureRequirements
Spark SQL 端到端的优化流程:
- Catalyst 优化器 : 包含逻辑优化/物理优化
- Tungsten :
Spark SQL的优化过程 :

逻辑计划
val userFile: String = _
val usersDf = spark.read.parquet(userFile)val txFile: String = _
val txDf = spark.read.parquet(txFile)val users = usersDf.select("name", "age", "userId").filter($"age" < 30).filter($"gender".isin("M"))val result = txDF.select("price", "volume", "userId").join(users, Seq("userId"), "inner").groupBy(col("name"), col("age")).agg(sum(col("price") * col("volume")).alias("sum")result.write.parquet("_")
计算逻辑 :
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EkAXwKmc-1678098435847)(../../png/Catalyst/image-20230213212938895.png)]](https://img-blog.csdnimg.cn/8acd1864ebf84ca6a21dc306551e54f0.png)
Catalyst 逻辑优化阶段:
- 逻辑计划解析 : 把 Unresolved Logical Plan 换为 Analyzed Logical Plan
- 逻辑计划优化 : 基于启发式规则(Heuristics Based Rules) ,把 Analyzed Logical Plan 转为 Optimized Logical Plan
Catalyst 逻辑优化阶段
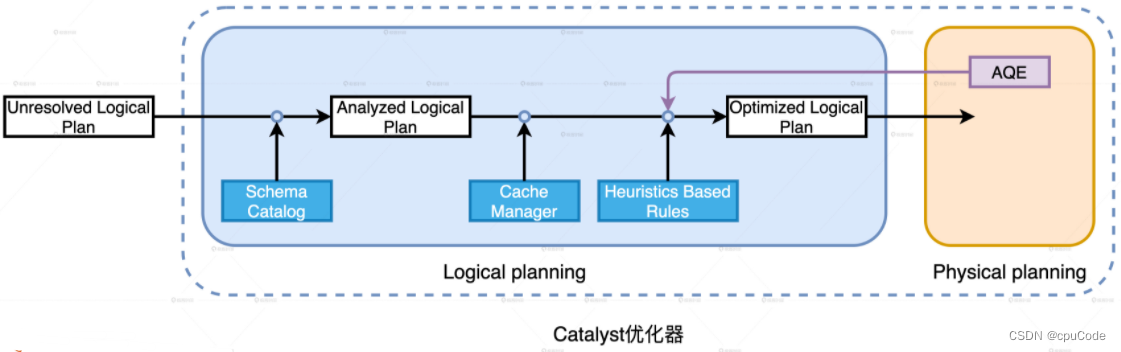
Unresolved Logical Plan :

逻辑计划解析
逻辑计划解析 : 结合 DataFrame 的 Schema ,确认计划中的表名、字段名、字段类型和实际数据是否一致。确认后,就生成 Analyzed Logical Plan
Analyzed Logical Plan :

逻辑计划优化
同种计算逻辑的多种实现方式 :
- 按照不同的顺序对算子做排列组合
- 最好顺序:能省则省、能拖则拖的开发原则,选择所有实现方式中最优
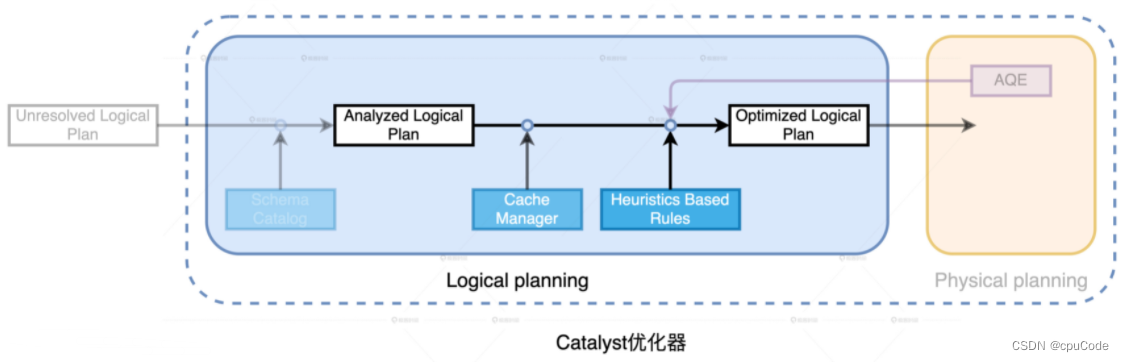
Catalyst 优化规则范畴 :
- 谓词下推(Predicate Pushdown):把谓词 (过滤条件
age < 30) 推到离数据源最近 - 列剪裁(Column Pruning): 只扫描与查询相关的字段
- 常量替换 (Constant Folding): 如 :
age <12 + 18优化成age < 30
Cache Manager 优化 :
- Cache Manager :维护与缓存相关信息。即:维护 Mapping 映射字典,Key :逻辑计划,Value :对应的 Cache 元信息
- 当 Catalyst 进行逻辑计划优化时,先在 Cache Manager 查找,当该逻辑计划分支在 Cache Manager 时,就进行替换该计划
Optimized Logical Plan :

Catalyst 规则优化过程
逻辑计划(Logical Plan),物理计划(Physical Plan)都继承 QueryPlan
QueryPlan 父类: TreeNode
- TreeNode :语法树中对节点的抽象
- TreeNode 有个字段 children ,类型是 Seq[TreeNode]
- 利用 TreeNode 类型,能构建出树结构
TreeNode 定义了很多高阶函数,如:transformDown
- transformDown 的形参: 各种优化规则,返回类型是 TreeNode
- transformDown 是递归函数,先优化当前节点,再依次优化 children 中的子节点,直到整棵树的叶子节点
transformDown 类似转换过程:
//Expression的转换
import org.apache.spark.sql.catalyst.expressions._val myExpr: Expression = Multiply(Subtract(Literal(6), Literal(4)), Subtract(Literal(1), Literal(9)))val transformed: Expression = myExpr transformDown {// 二元操作符,转成加法操作case BinaryOperator(l, r) => Add(l, r)// 大于 5 ,转成 1case IntegerLiteral(i) if i > 5 => Literal(1)// 小于 5 ,转成转成 0case IntegerLiteral(i) if i < 5 => Literal(0)
}
转换过程意图:
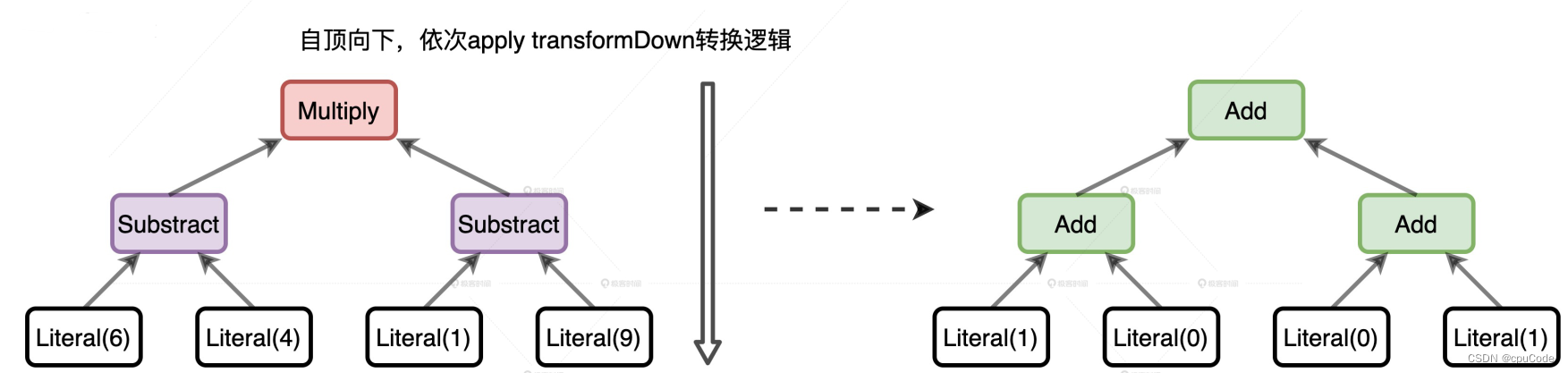
物理计划
物理计划阶段(Physical Planning) :
- 优化 Spark Plan :根据优化策略 (Strategies),把逻辑计划的关系操作符映射成物理操作符
- 生成 Physical Plan :根据 Preparation Rules,对 Spark Plan 进行完善
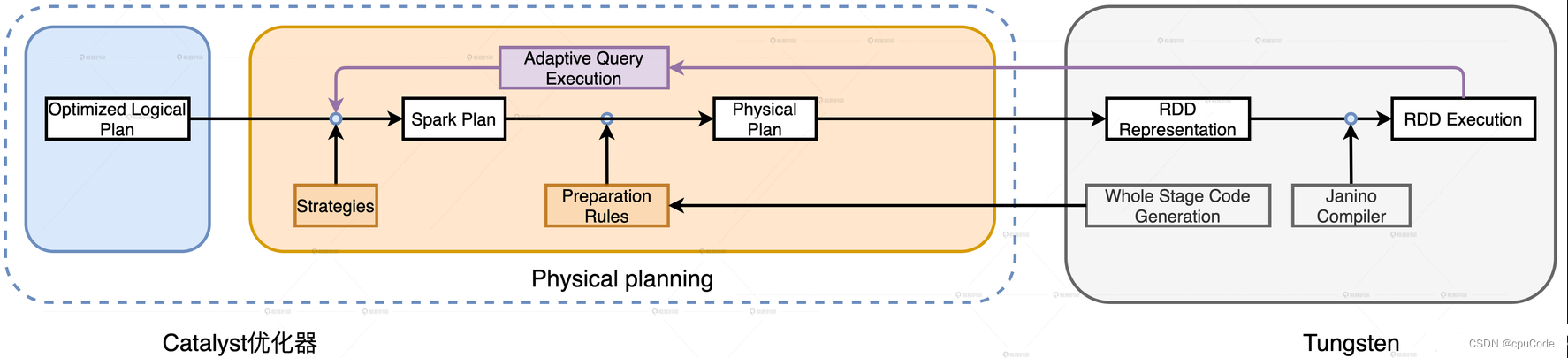
Spark Plan
Spark Plan 优化策略 :
- 基于模式匹配的偏函数(Partial Functions),把逻辑计划中的操作符平行映射为 Spark Plan 中的物理算子
| 类型 | 优化策略 | 含义&作用 |
|---|---|---|
| 通用 | BasicOperators | 逻辑到物理的基本映射:如Project/Filter/Sort |
| JoinSelection | 静态 Joln 策略选择 | |
| InMemoryScans | 缓存策略,对应逻辑优化阶段的 Cache Manager | |
| Aggregation | 聚合策路 | |
| Window | 窗口计算策酪 | |
| SpecialLimits | 与 Limit 相关的优化策路 | |
| PythonEvals | Python UDF 优化策路 | |
| SparkScripts | Transformation 脚本优化策略 | |
| Streaming | StatefulAggregationStrategy | 有状态的聚合策略 |
| StreamingDeduplicationStrategy | 流处理中的去重策路 | |
| StreamingGlobalLimitStrategy | 流处理中的 Limit 处理策略 | |
| StreamingJoinStrategy | 流处理中的 Join 策略 | |
| StreamingRelationStrategy | 数据源读取策酪 | |
| FlatMapGroupsWithStateStrategy | 流处理中的 FlatMap 优化 |
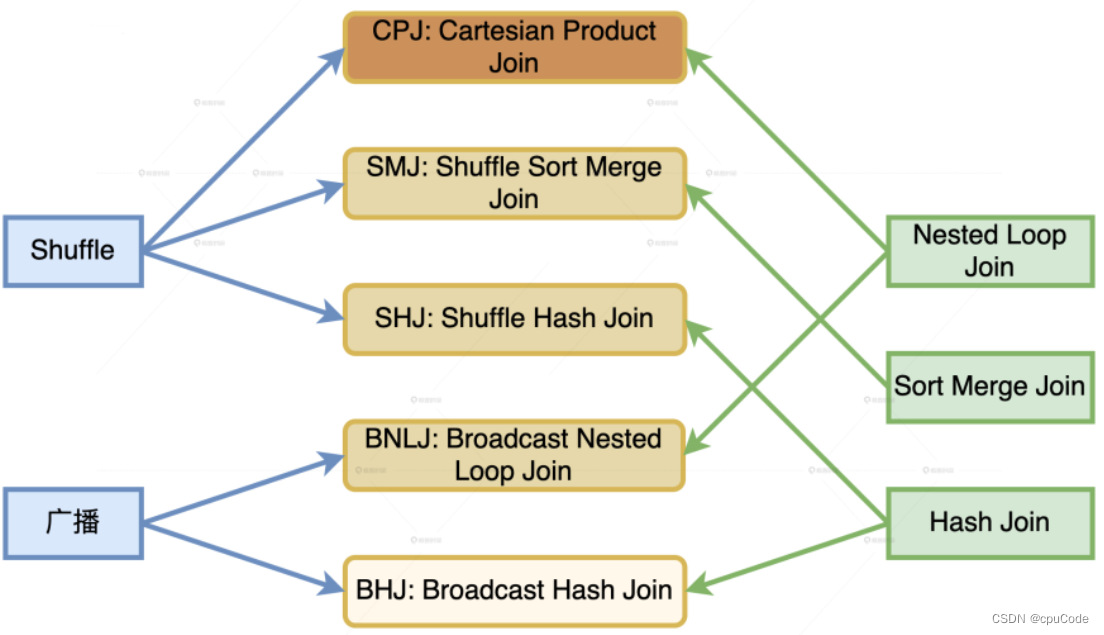
JoinSelection
Catalyst 运行时的 Join 策略:
| Join 策略 | 执行效率排序 | 含义 |
|---|---|---|
| Broadcast Hash Join (BHJ) | 最优 | 小表构建哈希表,把小表广播进行关联 |
| Shuffle Sort Merge Join (SMJ) | 次优 | 先 Shuffle , 再排序进行关联 |
| Shuffle Hash Join (SHJ) | 次优 | 先 Shuffle , 再构建哈希表进行关联 |
| Broadcast Nested Loop Join (BNLJ) | 最差 | 将小表广播进行关联 |
| Shuffle Cartesian Product Join (CPJ) | 最差 | 先 Shuffle 进行关联 |
数据分发与 Join 实现机制的组合 :
Join 策略的先决条件 :
- 条件型 : 判决 5 大 Join 策略的先决条件
- 指令型:开发者提供的 Join Hints
5 种 Join 策略的先决条件:
| 选择顺序 | Join 策略 | Join 类型 | 表大小 | ||
|---|---|---|---|---|---|
| 等值 Join | Inner Join | 不能 Full Outer Join | 能广播 | ||
| 1 | BHJ | √ | √ | √ | |
| 2 | SMJ | √ | |||
| 3 | SHJ | √ | |||
| 4 | BNLJ | √ | |||
| 5 | CPJ | √ |
指令型信息: Join Hints,允许个人选择 Join 策略
- 选择 SHJ :
val result = txDF.select("price", "volume", "userId").join(users.hint("shuffle_hash"), Seq("userId"), "inner").groupBy(col("name"), col("age")).agg(sum(col("price") * col("volume")).alias("revenue"))
Spark Plan :Join 策略是 SMJ
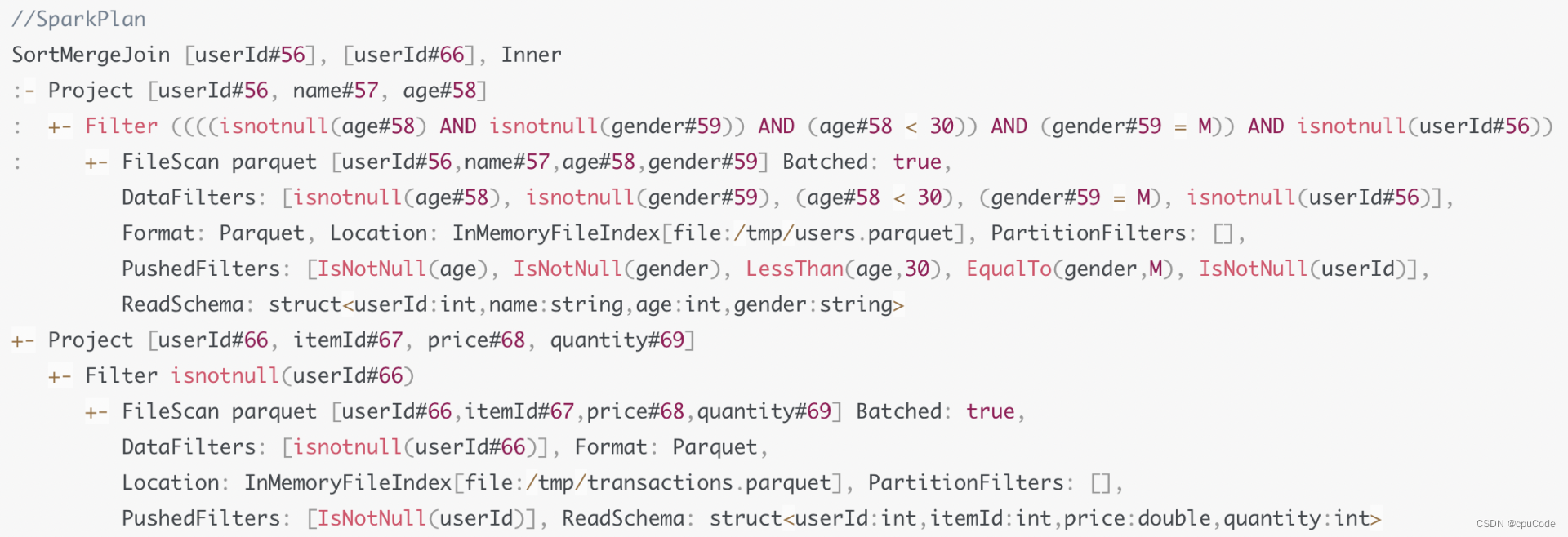
生成 Physical Plan
从 Spark Plan 到 Physical Plan 的转换,需要 Preparation Rules 规则
Preparation Rules :
| Preparation Rules | 含义 | 作用 |
|---|---|---|
| EnsureRequirements | 确保每个操作符的输入要求,必要时添加 Shuffle/Sort | 为 Physical Plan 补充必要的操作,保证 Spark Plan 计划的每个步骤能够顺利执行 |
| CollapseCodegenStages | Tungsten 优化机制:全阶段代码生成(Whole Stage Code Generation) | 在同个 Stage 内部,尽可能地把所有操作和计算捏合成一个函数,提升计算效率 |
| ReuseExchange | 内存或磁盘中的存储复用 | 同样的执行计划能共享广播变量或 Shuffle 的中间结果,避免重复的 Shuffle 操作 |
| ReuseSubquery | 子查询复用 | 复用同样的查询结果,避免重复计算 |
| PlanSubquery | 生成子查询 | 对子查询应用 Preparation Rules |
| ExtractPythonUDFs | 提取 Python 的 UDF 函数 | 把 Python UDF 分发到单独的 Python 进程 |
EnsureRequirements
EnsureRequirements (满足前提条件) : 对执行计划中的每个操作符节点,都有 4 个属性用来描述数据输入/ 输出的分布状态
| 操作符属性 | 含义 |
|---|---|
| outputPartitioning | 输出数据的分区规则 |
| outputOrdering | 输出数据的排序规则 |
| requireChildDistribution | 要求输入数据满足某种分区规则 |
| requireChildOrdering | 要求输入数据满足某种排序规则 |
Project 不满足 SortMergeJoin 的 Requirements:
- outputPartitioning 属性 :Unknow,未 Shuffle
- outputOrdering 属性: None ,未排序
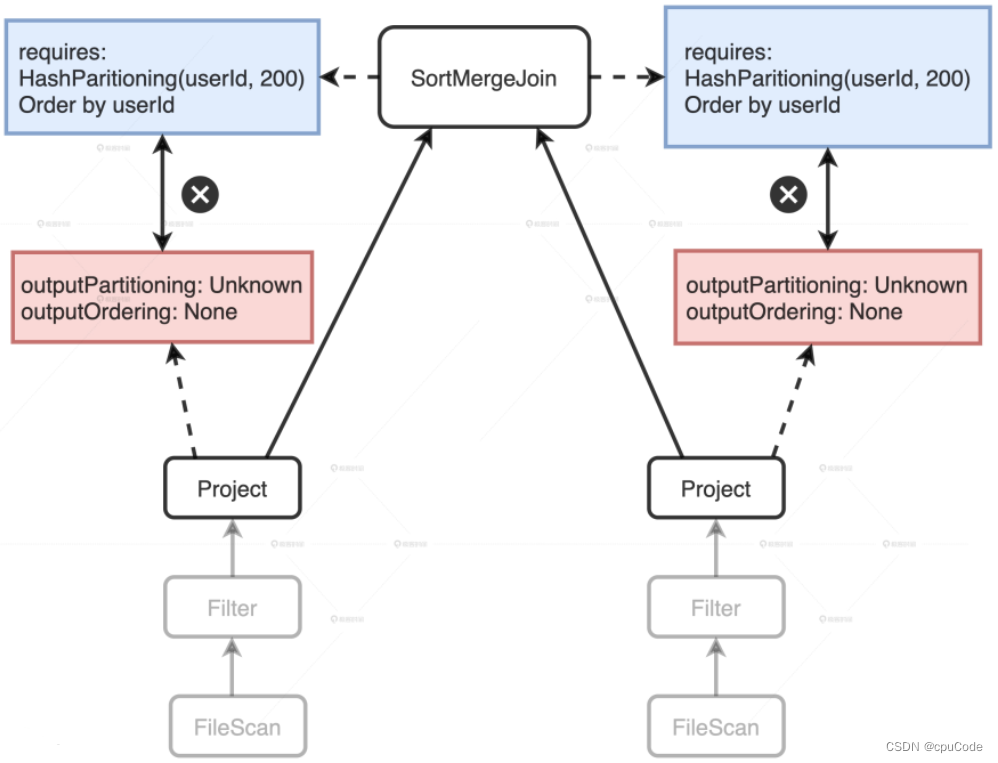
EnsureRequirements 规则添加 Exchange/Sort :
- Exchange : Shuffle 操作,满足 SortMergeJoin 对数据分布的要求
- Sort :排序,满足 SortMergeJoin 对数据有序的要求
- 调用 Physical Plan 的 doExecute 方法,把结构化查询的计算结果,转换成
RDD[InternalRow] - InternalRow :Tungsten 设计的定制化二进制数据结构
- 调用 RDD[InternalRow] 上的 Action 算子,Spark 就触发 Physical Plan 执行
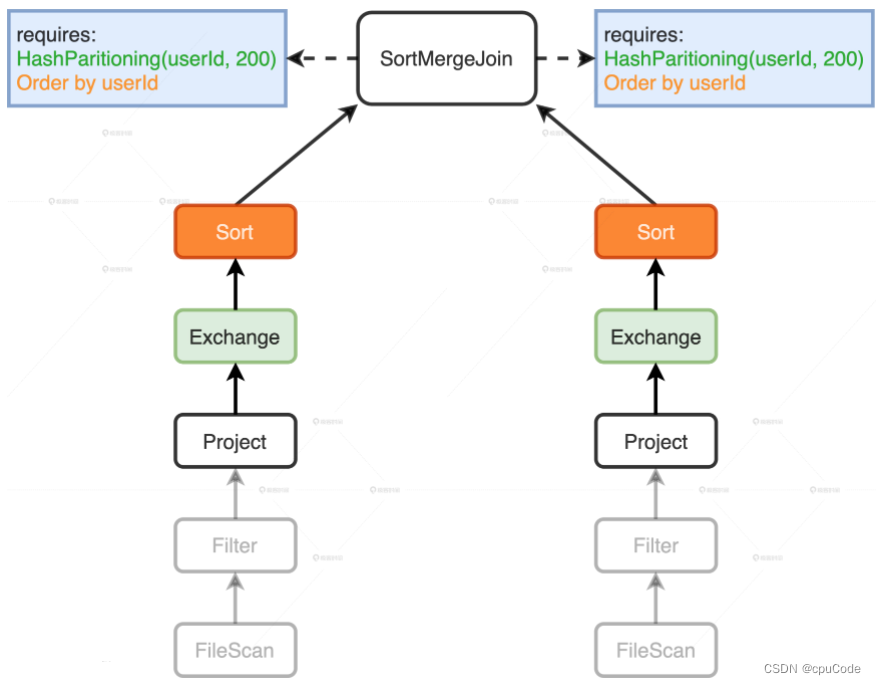
Physical Plan :
- EnsureRequirements 在两个分支上添加 Exchange/Sort
*(数字):*: WSCG,数字 : Stage 编号- 数字相同会 WSCG 合成

相关文章:
Spark Catalyst
Spark Catalyst逻辑计划逻辑计划解析逻辑计划优化Catalyst 规则优化过程物理计划Spark PlanJoinSelection生成 Physical PlanEnsureRequirementsSpark SQL 端到端的优化流程: Catalyst 优化器 : 包含逻辑优化/物理优化Tungsten : Spark SQL的优化过程 : 逻辑计划 …...

element 远程搜索下拉加载
created() { this.getList(); this.getGroupList(); }, directives: { /** 下拉框懒加载 */ “el-select-loadmore”: { bind(el, binding) { const SELECTWRAP_DOM el.querySelector( “.el-select-dropdown .el-select-dropdown__wrap” ); SELECTWRAP_DOM.addEventListener…...

空间复杂度与顺序表的具体实现操作(1)
最近更新的少,主要是因为参加了ACM竞赛空间复杂度空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度 。空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量…...

【springmvc】Rest ful风格
RESTful 1、RESTful简介 REST:Representational State Transfer,表现层资源状态转移。 a>资源 资源是一种看待服务器的方式,即,将服务器看作是由很多离散的资源组成。每个资源是服务器上一个可命名的抽象概念。因为资源是一…...
)
华为OD机试真题Python实现【用户调度】真题+解题思路+代码(20222023)
用户调度 题目 在通信系统中有一个常见的问题是对用户进行不同策略的调度,会得到不同系统消耗的性能。 假设由N个待串行用户,每个用户可以使用A/B/C三种不同的调度策略。 不同的策略会消耗不同的系统资源,请你根据如下规则进行用户调度,并返回总的消耗资源数。 规则是: …...

JavaSE学习笔记总结day19
今日内容 二、线程安全的集合 三、死锁 四、线程通信 五、生产者消费者 六、线程池 零、 复习昨日 创建线程的几种方式 1) 继承 2) 实现Runnable 3) callable接口 Future接口 4) 线程池 启动线程的方法 start() 线程的几种状态 什么是线程不安全 setName getName Thread.curr…...
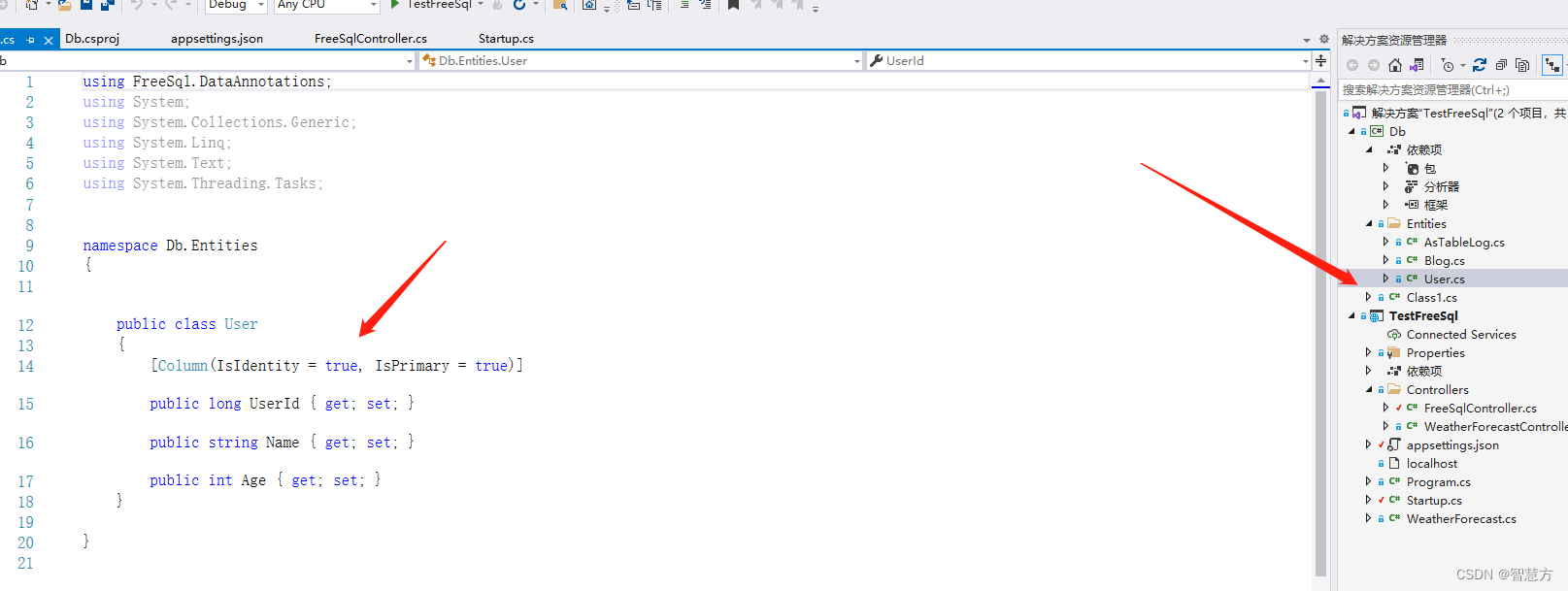
FreeSql使用
目的: 1.方库分表 2.主从分离 3.分布式事务 过程: 官网:指南 | FreeSql 官方文档 1.Startup.cs 添加配置(本地数据库MySql) ConfigureServices: Func<IServiceProvider, IFreeSql> fsql r >{IFreeSql …...

Hadoop集群搭建,基于3.3.4hadoop和centos8【图文教程-从零开始搭建Hadoop集群】,常见问题解决
Hadoop集群搭建,基于3.3.4hadoop和centos8【小白图文教程-从零开始搭建Hadoop集群】,常见问题解决Hadoop集群搭建,基于3.3.4hadoop1.虚拟机的创建1.1 第一台虚拟机的创建1.2 第一台虚拟机的安装1.3 第一台虚拟机的网络配置1.3.1 主机名和IP映…...
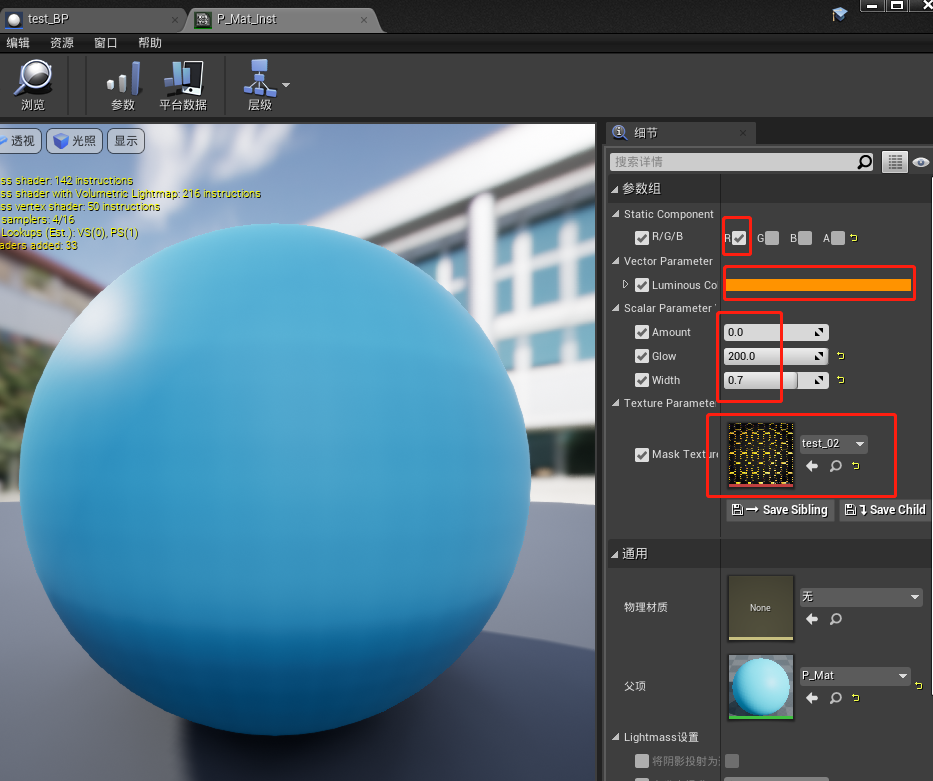
UE4 材质学习 (焚烧材质)
效果步骤随便从网上下载一张图片(地址:链接/链接),导入UE中新建一个材质函数这里命名为“E_Function”双击打开该材质函数,由于需要输出变发光和变透明两种效果,因此这里需要两个输出节点:分别命…...

【c++】STL常用算法2—常用查找算法
文章目录常用查找算法findfind_ifadjacent_findbinary_searchcountcount_if常用查找算法 算法简介: find//查找元素 find_if//按条件查找元素 adjacent_find//查找相邻重复元素 binary_search//二分查找法 count//统计元素个数 count_if//按条件统计元素个数find …...
史上最全最详细的Java架构师成长路径图,程序员必备
从新手码农到高级架构师,要经过几步?要多努力,才能成为为人倚重的技术专家?本文将为你带来一张程序员发展路径图,但你需要知道的是,天下没有普适的道理,具体问题还需具体分析,实践才…...

第五章 事务管理
1.事务概念 *什么是事务:事务是数据库操作最基本单元,逻辑上是一组操作,要么都成功,要么都失败 *事务的特性(ACID):原子性、隔离性、一致性、持久性 2.搭建事务操作环境 *模拟场景ÿ…...
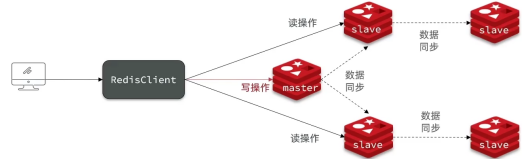
Redis:主从同步
Redis:主从同步一. 概述二. 原理(1) 全量同步(2) 增量同步(3) 优化Redis主从集群三. 总结一. 概述 引入: Redis主从集群采用一个Master负责写,多个Slave负责读的方式(读多写少),那么如何让读取数据时多个从…...
Unity Animator.Play(stateName, layer, normalizedTime) 播放动画函数用法
原理 接口: public void Play(string stateName, int layer -1, float normalizedTime float.NegativeInfinity);参数含义stateName动画状态机的某个状态名字layer第几层的动画状态机,-1 表示播放第一个状态或者第一个哈希到的状态normalizedTime从s…...

python学习——【第三弹】
前言 上一篇文章 python学习——【第二弹】中学习了python中的运算符内容,这篇文章接着学习python中的流程控制语句。 流程控制指的是代码运行逻辑、分支走向、循环控制,是真正体现我们程序执行顺序的操作。流程控制一般分为顺序执行、条件判断和循环控…...

科技云报道:AI大模型背后,竟是惊人的碳排放
科技云报道原创。 自从ChatGPT这样的大型语言模型在全球引起轰动以来,很少有人注意到,训练和运行大型语言模型正在产生惊人的碳排放量。 虽然OpenAI和谷歌都没有说过他们各自产品的计算成本是多少,但据第三方研究人员分析,ChatG…...

如何根据实际需求选择合适的三维实景建模方式?
随着实景三维中国建设的推进,对三维实景建模的数字化需求大幅增加。由于三维实景建模具有采集速度快、计算精度高等建模优势,引起了各个行业的高度关注。三维实景建模是一种应用数码相机或者激光扫描仪对现有场景进行多角度环视拍摄,然后利用…...
CENTO OS上的网络安全工具(十八)ClickHouse及编程环境部署
这篇其实去年就写好了,孰知就在12月31日那一天打进决赛圈,一躺,二过年,三休假,四加班,居然到了三个月以后,才有机会将它发出来…… 一年也就四个季度不是,实在是光阴荏苒,…...
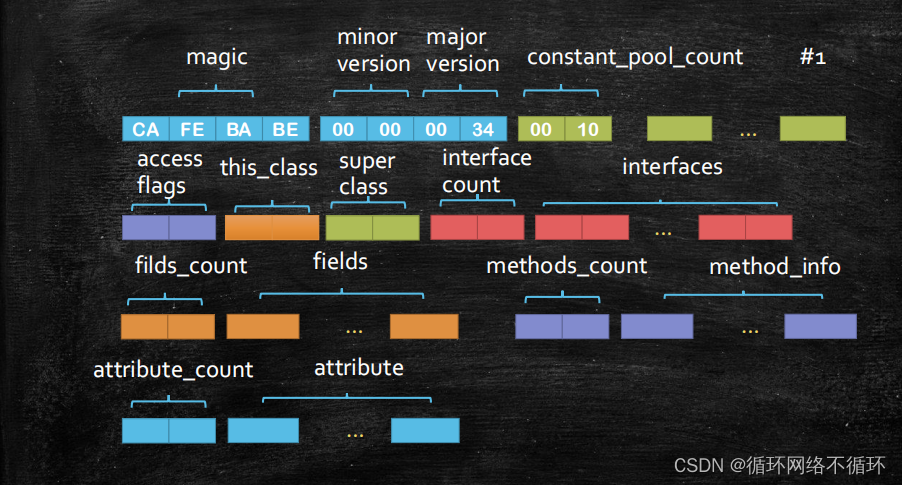
Java中class文件的格式
常见的class文件格式如下图所示,下面我将对一下格式一一作出解释。 一、magic 该部分主要是对语言类型的规范,只有magic这个部分是CAFEBABE时才能被检测为Java语言,否则则不是。 二、minor version和major version minor version主要表示了…...

C++排序算法
排序算法复习 冒泡排序 链接:https://www.runoob.com/w3cnote/bubble-sort.html 每次循环对比【相邻】两个元素,将最大的元素放到数组最后 void bubbleSort(int* arr, int n){//每次确认一个元素的最终位置,循环n-1次即可确认全部元素的最…...

Origin 9 绘图避坑指南:7个高频问题解决,让你的科研图表一次成型
Origin 9 科研绘图实战:7个高频问题深度解析与优化方案 科研绘图是数据可视化的重要环节,而Origin 9作为经典的科学绘图软件,其功能强大但操作细节繁多。许多用户在初次接触或日常使用中常会遇到各种棘手问题,导致绘图效率低下、图…...

AI与地缘政治双重冲击下,内存市场产能大迁移与供应链危机
1. 风暴之眼:当AI狂潮撞上地缘断供如果你最近想给电脑加条内存或者换个固态硬盘,大概率会被价格吓一跳。这不仅仅是简单的“涨价”,而是整个存储市场的底层逻辑正在被两股巨力彻底重塑。一边是AI数据中心对高性能内存近乎贪婪的吞噬ÿ…...

USGv6新规驱动IPv6单栈部署:从协议原理到实战测试的全面指南
1. 从USGv6新版规范看IPv6单栈部署的必然性与实战准备最近,行业里关于IPv6单栈网络(IPv6-Only)的讨论又热了起来。这阵风潮的源头,是美国国家标准与技术研究院(NIST)近期更新了其“美国政府IPv6配置文件”&…...

从车窗升降到自动驾驶:用5个真实故事看懂汽车总线LIN、CAN、CAN-FD、FlexRay和以太网的进化史
从车窗升降到自动驾驶:用5个真实故事看懂汽车总线技术的进化史 清晨七点,当上班族按下车钥匙解锁按钮时,车门锁、后视镜展开、仪表盘亮起的动作几乎同步完成——这背后是汽车电子系统数十年的进化缩影。从最初控制车窗升降的简单信号传输&…...

Tokscale:AI编程助手Token成本监控与优化实战指南
1. 项目概述:为什么你需要一个AI助手“电费”监控器 如果你和我一样,每天的工作流里塞满了各种AI编程助手——从OpenCode、Claude Code到Cursor、Copilot CLI,甚至还在尝试各种新冒出来的工具,那你肯定有过这样的瞬间:…...
)
079、多轴运动控制:插补器设计(圆弧插补)
079 多轴运动控制:插补器设计(圆弧插补) 从一次现场调试说起 去年在深圳某激光切割设备厂,客户反馈切割圆孔时总在四个象限点出现“鼓包”。我带着示波器去现场,抓出XY轴的位置误差曲线,发现每次经过0、90、180、270这些特殊角度时,速度曲线都会出现一个明显的尖峰。当…...

用 LangChain 克隆一个 ChatGPT:LLMChain + Memory 实战
0 前言 ChatGPT 之所以好用,核心在于: 个性化的系统提示词多轮对话记忆 本文基于 LangChain,用不到 30 行代码复刻这两个能力,构建一个可自定义人格的对话 AI。 1 技术栈组件说明LLMChainLangChain 的核心链,将 LLM、P…...

实在Agent实测:解决采购合同审核流程冗长与原材料交付周期拉长的架构之道
大家好,我是企业架构师老王。站在2026年5月这个时间节点回看,全球供应链的复杂程度已远超三年前的预判。近期我在为几家制造型企业做数字化诊断时发现,一个幽灵般的困境正在吞噬企业的利润:采购合同审核流程冗长,直接导…...

3步搞定安卓应用Windows安装:告别臃肿模拟器的终极解决方案
3步搞定安卓应用Windows安装:告别臃肿模拟器的终极解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了那些占用大量系统资源、启动缓慢的…...

别再只用流水灯了!用Arduino和74HC595驱动数码管/点阵屏的完整教程
从流水灯到智能显示:74HC595驱动数码管与点阵屏的实战指南 在创客社区里,74HC595移位寄存器几乎成了"流水灯"的代名词——无数入门教程用它来演示如何用少量IO口控制多颗LED。但当你真正需要构建一个电子钟、温湿度显示器或简易信息板时&#…...