Elasticsearch:调整近似 kNN 搜索
在我之前的文章 “Elasticsearch:调整搜索速度”,我详细地描述了如何调整正常的 BM25 的搜索速度。在今天的文章里,我们来进一步探讨如何提高近似 kNN 的搜索速度。希望对广大的向量搜索开发者有一些启示。
Elasticsearch 支持近似 k 最近邻搜索,以有效查找与查询向量最接近的 k 个向量。 由于近似 kNN 搜索的工作方式与其他查询不同,因此对其性能有特殊的考虑。其中许多建议有助于提高搜索速度。 使用近似 kNN,索引算法在底层运行搜索以创建向量索引结构。 因此,这些相同的建议也有助于提高索引速度。
减少向量内存占用
默认的 element_type是 float。 但这可以通过 quantization 在索引时间时自动进行标量量化。具体的介绍可以详细阅读文章 “Elasticsearch:dense vector 数据类型及标量量化”。 量化会将所需的内存减少 4 倍,但也会降低向量的精度并增加该字段的磁盘使用量(最多增加 25%)。 磁盘使用量增加是 Elasticsearch 存储量化向量和未量化向量的结果。 例如,当量化 40GB 浮点向量时,将为量化向量存储额外的 10GB 数据。 总磁盘使用量为50GB,但快速搜索的内存使用量将减少到10GB。
对于 dim 大于或等于 384 的浮点向量,强烈建议使用量化索引。
降低向量维数
kNN 搜索的速度与向量维数成线性关系,因为每个相似度计算都会考虑两个向量中的每个元素。 只要有可能,最好使用维度较低的向量。 一些嵌入模型有不同的维度大小,有更低和更高维度的选项。 你还可以尝试使用 PCA 等降维技术。 在尝试不同的方法时,衡量对相关性的影响非常重要,以确保搜索质量仍然可以接受。
从 _source 中排除向量字段
Elasticsearch 将在索引时传递的原始 JSON 文档存储在 _source 字段中。 默认情况下,搜索结果中的每个命中都包含完整文档 _source。 当文档包含 dense_vector 字段时,_source 可能非常大且加载成本昂贵。 这可能会显着降低 kNN 搜索的速度。
你可以通过 excludes 映射参数禁用在 _source 中存储 dense_vector 字段。 这可以防止在搜索期间加载和返回大向量,并且还可以减少索引大小。 _source 中省略的向量仍然可以在 kNN 搜索中使用,因为它依赖于单独的数据结构来执行搜索。 在使用 excludes 参数之前,请确保查看从 _source 中省略字段的缺点。
另一种选择是使用 synthetic_source(如果所有索引字段都支持)。
确保数据节点有足够的内存
Elasticsearch 使用 HNSW 算法进行近似 kNN 搜索。 HNSW 是一种基于图的算法,只有当大多数向量数据保存在内存中时才能有效地工作。 你应该确保数据节点至少有足够的 RAM 来保存向量数据和索引结构。 要检查向量数据的大小,你可以使用分析索引磁盘使用情况 API。 作为一个宽松的经验法则,并假设默认的 HNSW 选项,使用的字节将为 num_vectors * 4 * (num_dimensions + 12)。 当使用字节 element_type 时,所需的空间将更接近 num_vectors * (num_dimensions + 12)。 请注意,所需的 RAM 用于文件系统缓存,它与 Java 堆分开。
数据节点还应该为其他需要 RAM 的方式留下缓冲区。 例如,你的索引可能还包括文本字段和数字,这也受益于使用文件系统缓存。 建议使用你的特定数据集运行基准测试,以确保有足够的内存来提供良好的搜索性能。 你可以在这里和这里找到我们用于夜间基准测试的一些数据集和配置示例。
预热文件系统缓存
如果运行 Elasticsearch 的机器重新启动,文件系统缓存将为空,因此操作系统需要一些时间才能将索引的热区域加载到内存中,以便搜索操作快速。 你可以使用 index.store.preload 设置显式告诉操作系统哪些文件应根据文件扩展名立即加载到内存中。
警告:如果文件系统缓存不够大,无法容纳所有数据,则在太多索引或太多文件上急切地将数据加载到文件系统缓存中将使搜索速度变慢。 谨慎使用。
以下文件扩展名用于近似 kNN 搜索:
- 向量值的 vec 和 veq
- HNSW 图的 vex
- 用于元数据的 vem、vemf 和 vemq
减少索引段的数量
Elasticsearch 分片由段(segment)组成,段是索引中的内部存储元素。 对于近似 kNN 搜索,Elasticsearch 将每个段的向量值存储为单独的 HNSW 图,因此 kNN 搜索必须检查每个段。 最近的 kNN 搜索并行化使得跨多个片段的搜索速度大大加快,但如果片段较少,kNN 搜索的速度仍然可以提高数倍。 默认情况下,Elasticsearch 通过后台合并过程定期将较小的段合并为较大的段。 如果这还不够,你可以采取明确的步骤来减少索引段的数量。
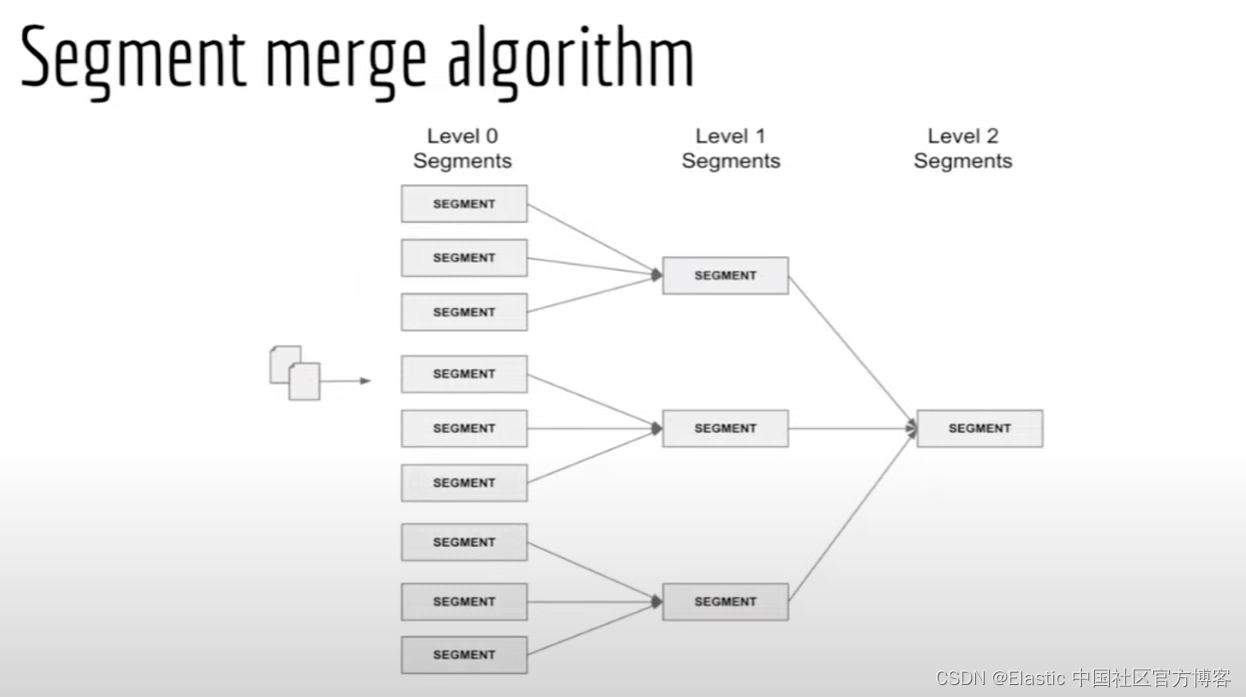
Lucene 合并,同时索引所有维基百科(英文)
强制合并到一个段
Force merge 操作强制进行索引合并。 如果强制合并到一个段,kNN 搜索只需要检查一个包含所有内容的 HNSW 图。 强制合并 dense_vector 字段是一项昂贵的操作,可能需要大量时间才能完成。
警告:我们建议仅强制合并只读索引(意味着索引不再接收写入)。 当文档被更新或删除时,旧版本不会立即删除,而是软删除并标记为 “墓碑”。 这些软删除文档会在定期段合并期间自动清除。 但强制合并可能会导致生成非常大(> 5GB)的段,这些段不符合常规合并的条件。 因此,软删除文档的数量会迅速增长,从而导致更高的磁盘使用率和更差的搜索性能。 如果你定期强制合并接收写入的索引,这也会使快照更加昂贵,因为新文档无法增量备份。
在批量索引期间创建大段
常见的模式是首先执行初始批量上传,然后使索引可用于搜索。 你可以调整索引设置以鼓励 Elasticsearch 创建更大的初始段,而不是强制合并:
- 确保批量上传期间没有搜索,并通过将其设置为 -1 来禁用 index.refresh_interval。 这可以防止刷新操作并避免创建额外的段。
- 为 Elasticsearch 提供一个较大的索引缓冲区,以便它可以在刷新之前接受更多文档。 默认情况下,indices.memory.index_buffer_size 设置为堆大小的 10%。 对于像 32GB 这样的大堆大小,这通常就足够了。 为了允许使用完整的索引缓冲区,你还应该增加限制 index.translog.flush_threshold_size。
避免在搜索过程中建立大量索引
积极地索引文档可能会对近似 kNN 搜索性能产生负面影响,因为索引线程会窃取搜索的计算资源。 当同时索引和搜索时,Elasticsearch 也会频繁刷新,这会创建几个小段。 这也会损害搜索性能,因为当分段较多时,近似 kNN 搜索速度会变慢。
如果可能,最好在近似 kNN 搜索期间避免大量索引。 如果你需要重新索引所有数据,可能是因为向量嵌入模型发生了变化,那么最好将新文档重新索引到单独的索引中,而不是就地更新它们。 这有助于避免上述速度减慢,并防止由于频繁的文档更新而导致昂贵的合并操作。
在 Linux 上使用适度的预读值来避免页面缓存抖动
搜索可能会导致大量随机读取 I/O。 当底层块设备具有较高的预读值时,可能会执行大量不必要的读取 I/O,特别是当使用内存映射访问文件时(请参阅存储类型)。
大多数 Linux 发行版对单个普通设备使用 128KiB 的合理预读值,但是,当使用软件 raid、LVM 或 dm-crypt 时,生成的块设备(支持 Elasticsearch path.data)最终可能会具有非常大的预读值(在 几个 MiB 的范围)。 这通常会导致严重的页面(文件系统)缓存抖动,从而对搜索(或更新)性能产生不利影响。
你可以使用 lsblk -o NAME,RA,MOUNTPOINT,TYPE,SIZE 检查当前值(以 KiB 为单位)。 有关如何更改此值的信息,请参阅发行版的文档(例如,使用 udev 规则在重新启动后保持不变,或通过 blockdev --setra 作为瞬态设置)。 我们建议预读值为 128KiB。
在 Linux 上使用适度的预读值 (readahead) 来避免页面缓存抖动
搜索可能会导致大量随机读取 I/O。 当底层块设备具有较高的预读值时,可能会执行大量不必要的读取 I/O,特别是当使用内存映射访问文件时(请参阅存储类型)。
大多数 Linux 发行版对单个普通设备使用 128KiB 的合理预读值,但是,当使用软件 raid、LVM 或 dm-crypt 时,生成的块设备(支持 Elasticsearch path.data)最终可能会具有非常大的预读值(在 几个 MiB 的范围)。 这通常会导致严重的页面(文件系统)缓存抖动,从而对搜索(或更新)性能产生不利影响。
你可以使用 lsblk -o NAME,RA,MOUNTPOINT,TYPE,SIZE 检查当前值(以 KiB 为单位)。 有关如何更改此值的信息,请参阅发行版的文档(例如,使用 udev 规则在重新启动后保持不变,或通过 blockdev --setra 作为瞬态设置)。 我们建议预读值为 128KiB。
警告:blockdev 期望值以 512 字节扇区为单位,而 lsblk 报告值以 KiB 为单位。 例如,要将 /dev/nvme0n1 的预读临时设置为 128KiB,请指定 blockdev --setra 256 /dev/nvme0n1。
相关文章:
Elasticsearch:调整近似 kNN 搜索
在我之前的文章 “Elasticsearch:调整搜索速度”,我详细地描述了如何调整正常的 BM25 的搜索速度。在今天的文章里,我们来进一步探讨如何提高近似 kNN 的搜索速度。希望对广大的向量搜索开发者有一些启示。 Elasticsearch 支持近似 k 最近邻…...

UE5数字孪生系列笔记(二)
智慧城市数字孪生系统 制作流云动画效果 首先添加一个图像在需要添加流云效果的位置 添加动画效果让其旋转 这个动画效果是程序开始就要进行的,所以要在EventConstruct中就可以启动这个动画效果 添加一个一样的图像在这里,效果是从此处进行放大消散 添…...
基于vue实现bilibili网页
学校要求的实验设计,基于vue实现bilibili网页版,可实现以下功能 (1)基本的悬浮动画和页面渲染 (2)可实现登录和未登录的页面变化 (3)在登录页面的,实现密码判断,或者短信验证方式的倒数功能 (4)实现轮播图 (5)实现预览视频(GIF) (6)页面下拉到一定高度出现top栏以及右下角的返回…...
计算机二级(Python)真题讲解每日一题:《十字叉》
描述 …...
基于正点原子潘多拉STM32L496开发板的简易示波器
一、前言 由于需要对ADC采样性能的评估,重点在于对原波形的拟合性能。 考虑到数据的直观性,本来计划采集后使用串口导出,并用图形做数据拟合,但是这样做的效率低下,不符合实时观察的需要,于是将开发板的屏幕…...

【Docker】apisix 容器化部署
APISIX环境标准软件基于Bitnami apisix 构建。当前版本为3.8.0 你可以通过轻云UC部署工具直接安装部署,也可以手动按如下文档操作,该项目已经全面开源,可以从如下环境获取 配置文件地址: https://gitee.com/qingplus/qingcloud-platform qi…...

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的障碍物检测系统(深度学习代码+UI界面+训练数据集)
摘要:开发障碍物检测系统对于道路安全性具有关键作用。本篇博客详细介绍了如何运用深度学习构建一个障碍物检测系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5,展示了不同模型间的性能…...

从零开始学HCIA之SDN04
1、VXLAN数据封装 (1)Original L2 Frame,原始以太网报文,业务应用的以太网帧。 (2)VXLAN Header,VXLAN协议新定义的VXLAN头,长度为8字节。VXLAN ID(VNI)为2…...

GET 和 POST 有什么区别?
1.从缓存的角度,GET 请求会被浏览器主动缓存下来,留下历史记录,而 POST 默认不会。 2.从编码的角度,GET 只能进行 URL 编码,只能接收 ASCII 字符,而 POST 没有限制。 3.从参数的角度,GET 一般放…...
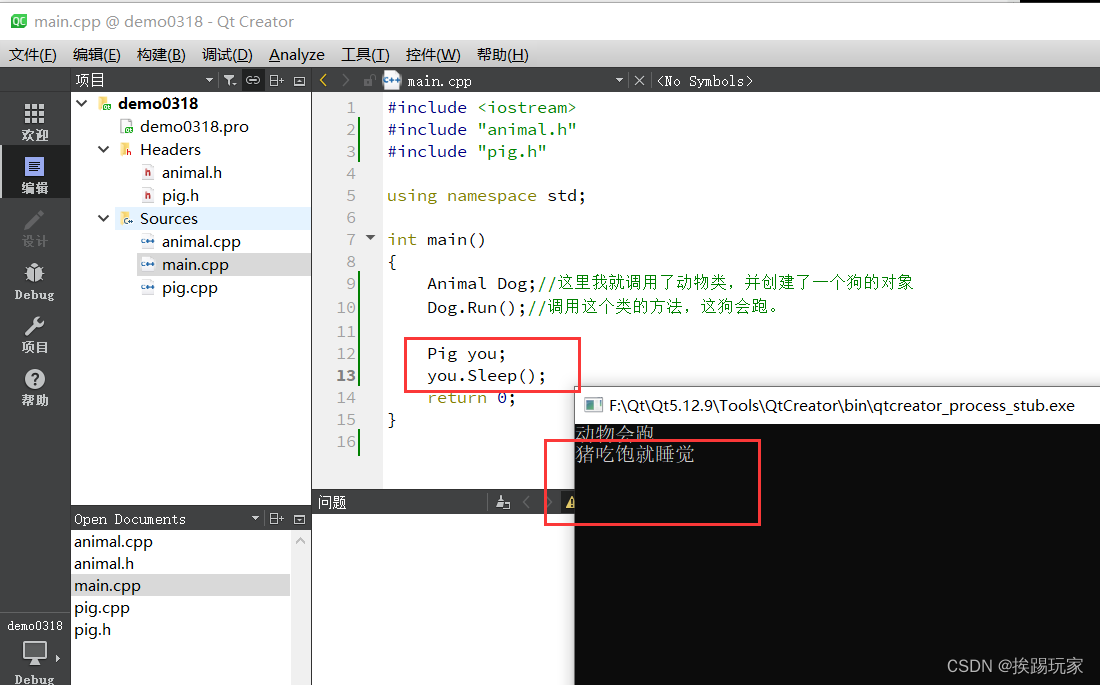
Qt学习--继承(并以分文件实现)
基类 & 派生类 一个类可以派生自多个类,这意味着,它可以从多个基类继承数据和函数。定义一个派生类,我们使用一个类派生列表来指定基类。类派生列表以一个或多个基类命名。 总结:简单来说,父类有的,子…...

软考75-上午题-【面向对象技术3-设计模式】-设计模式的要素
一、题型概括 上午、下午题(试题五、试题六,二选一) 每一个设计模式都有一个对应的类图。 二、23种设计模式 创建型设计模式:5 结构型设计模式:7 行为设计模式:11 考试考1-2种。 三、设计模式的要素 3…...
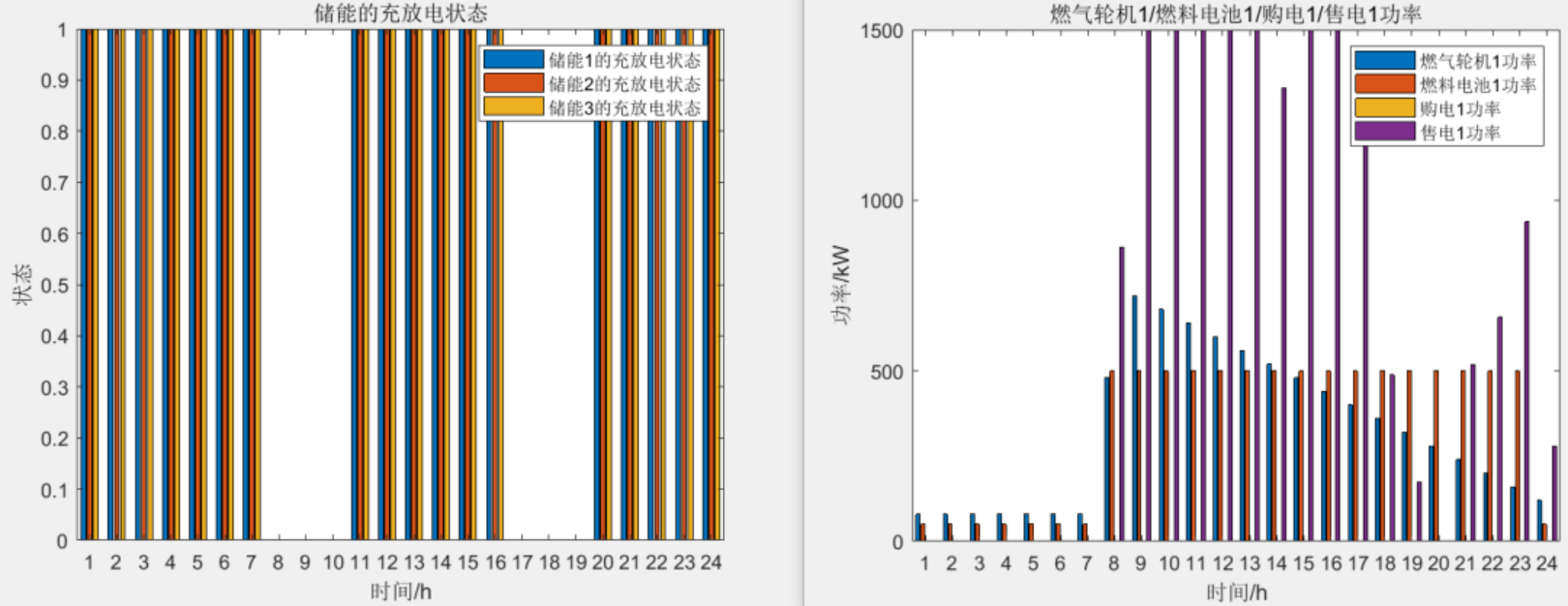
Matlab|面向低碳经济运行目标的多微网能量互联优化调度
目录 主要内容 优化流程 部分程序 结果一览 下载链接 主要内容 该程序为多微网协同优化调度模型,系统在保障综合效益的基础上,调度时优先协调微网与微网之间的能量流动,将与大电网的互联交互作为备用,降低微网与大电…...
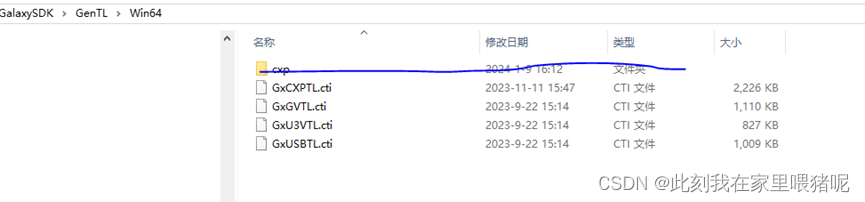
3.Gen<I>Cam文件配置
Gen<I>Cam踩坑指南 我使用的是大恒usb相机,第一步到其官网下载大恒软件安装包,安装完成后图标如图所示,之后连接相机,打开软件,相机显示一切正常。之后查看软件的安装目录如图,发现有GenICam和GenTL两个文件&am…...
用法详细介绍)
【兆易创新GD32H759I-EVAL开发板】 TLI(TFT LCD Interface)用法详细介绍
大纲 1. 引言 2. TLI外设特点 3. TLI硬件架构 4. TLI寄存器功能 5. TLI的配置和使用步骤 6. TLI图层概念 7. 图像处理和显示优化 8. 基于GD32H759I-EVAL开发板的TLI应用示例 1. 引言 在当今的嵌入式系统设计中,图形用户界面(GUI)的应…...
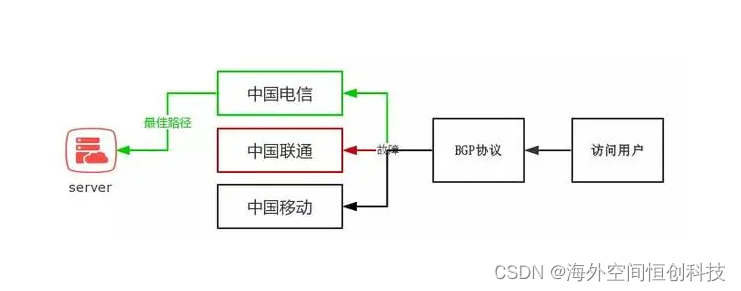
恒创科技:什么是BGP线路服务器?BGP机房的优点是什么?
在当今的互联网架构中,BGP(边界网关协议)线路服务器和BGP机房扮演着至关重要的角色。BGP作为一种用于在自治系统(AS)之间交换路由信息的路径向量协议,它确保了互联网上的数据能够高效、准确地从一个地方传输到另一个地方。那么,究竟什么是BGP…...
苍穹外卖-day04:项目实战-套餐管理(新增套餐,分页查询套餐,删除套餐,修改套餐,起售停售套餐)业务类似于菜品模块
苍穹外卖-day04 课程内容 新增套餐套餐分页查询删除套餐修改套餐起售停售套餐 要求: 根据产品原型进行需求分析,分析出业务规则设计接口梳理表之间的关系(分类表、菜品表、套餐表、口味表、套餐菜品关系表)根据接口设计进行代…...

深入探索C与C++的混合编程
实现混合编程的技术细节 混合使用C和C可能由多种原因驱动。一方面,现有的大量优秀C语言库为特定任务提供了高效的解决方案,将这些库直接应用于C项目中可以节省大量的开发时间和成本。另一方面,C的高级特性如类、模板和异常处理等,…...

数组中的flat方法如何实现
数组的成员有时还是数组,Array.prototype.flat()用于将嵌套的数组“拉平”,变成一维的数组。该方法返回一个新数组,对原数据没有影响。 [1, 2, [3, 4]].flat() // [1, 2, 3, 4]那flat怎么来实现呢? 1、使用while循环 实现的代码…...

计算机考研|北航北理北邮怎么选?
北航985,北理985,北邮211 虽然北邮事211,但是北邮的计算机实力一点也不弱,学科评级,计算机是A 北航计算机评级也是A,北理的计算机评级是A- 所以,这三所学校在实力上来说,真的大差…...
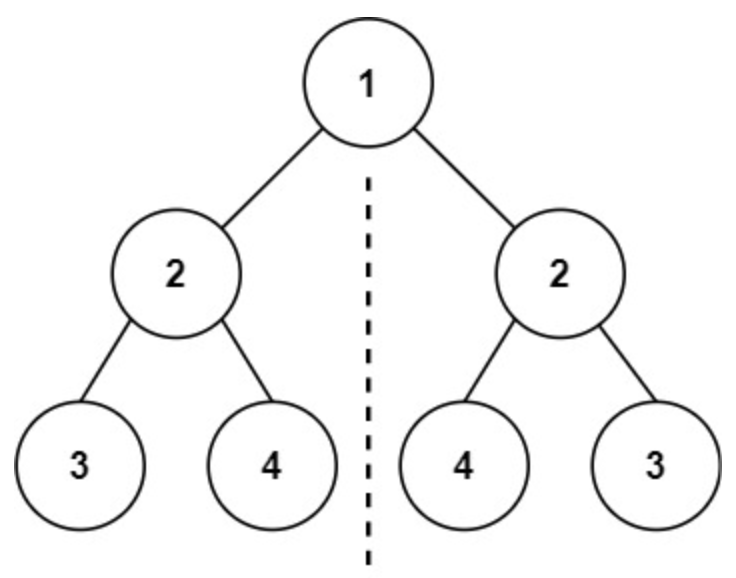
面试算法-52-对称二叉树
题目 给你一个二叉树的根节点 root , 检查它是否轴对称。 示例 1: 输入:root [1,2,2,3,4,4,3] 输出:true 解 class Solution {public boolean isSymmetric(TreeNode root) {return dfs(root, root);}public boolean dfs(Tr…...
)
自动驾驶、机器人导航都在用:实战调参卡尔曼滤波的Q和R(Python/OpenCV示例)
自动驾驶与机器人导航中的卡尔曼滤波实战:Q和R参数调优指南卡尔曼滤波在状态估计领域就像一位不知疲倦的裁判,不断在系统预测和传感器测量之间寻找平衡点。而Q(过程噪声协方差)和R(测量噪声协方差)这两个关…...

MySQL报错注入实战:从错误信息读取到文件写入
1. 这不是“SQL注入教程”,而是一次真实渗透测试中的边界突破实践很多人看到“基于报错的SQL注入”第一反应是:老掉牙的技术,现在还有用?我去年在给一家本地政务系统做授权渗透时,就遇到了一个看似完全无感的登录接口—…...

服务器被入侵后如何应急响应:安全运维实战指南
1. 这不是演习:当告警邮件凌晨三点弹出来时,你手边该有什么 “服务器CPU持续100%、SSH登录异常增多、/tmp目录下出现陌生可执行文件”——这类告警我见过太多次。不是在靶场演练,不是在CTF赛题里,而是真实发生在某次金融客户核心A…...

ML/MM混合方法在药物结合自由能计算中的基准评估与实战指南
1. 项目概述与核心挑战在计算机辅助药物设计的核心战场上,预测一个候选药物分子(配体)与靶点蛋白结合的紧密程度——即结合自由能,是决定项目成败的关键。这个数值直接关联到药物的效力和选择性,传统上需要通过耗时耗力…...

如何用OneMore插件让OneNote成为你的高效笔记神器
如何用OneMore插件让OneNote成为你的高效笔记神器 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore 你是否曾经在使用OneNote时感到功能不够用?想要更强大的…...

Vaultwarden同步失败排查指南:日志诊断与5分钟修复
1. 这不是Bitwarden客户端的问题,而是你本地运行的Vaultwarden服务“断联”了很多人看到手机App里点“同步”没反应、网页端新建密码点保存后刷新就消失、或者浏览器插件提示“无法连接到服务器”,第一反应是重装客户端、清缓存、换网络——结果折腾半天…...

基尔代尔 才是天才吗
是的,如果“天才”指的是那种从无到有、定义整个行业基本框架的开创者,那么加里基尔代尔(Gary Kildall)无疑是真正的天才。如果说蒂姆帕特森是一位顶级的“实现者”,那基尔代尔就是站在更高维度上的“奠基人”。他与帕…...

两个世界的同一种崩溃:从窗口黑屏到宇宙热寂的同构联想
一、两个世界的同一种崩溃 一段着色器代码中 cell.xy 的缩放因子从 9 被修改为 99。着色器随即呈现完全黑屏——既无报错信息,也无渲染异常,只有纯粹、彻底、连噪点都不存在的黑色。在屏幕的某个抽象维度上,发生了一件与理论物理学家在黑板上…...
)
保姆级教程:用Arbe或大陆4D毫米波雷达点云数据,手把手实现Freespace检测(附Python伪代码)
毫米波雷达点云实战:从数据到可行驶区域的完整工程指南在自动驾驶感知系统中,可行驶区域检测(Freespace)直接决定了车辆路径规划的可行空间边界。相比激光雷达和摄像头方案,4D毫米波雷达凭借全天候工作能力、成本优势和…...

计算机视觉模型公平性优化:如何规避帕累托低效陷阱
1. 项目概述:当公平遇上效率,一个被忽视的视觉模型“隐形税”最近在复现和评估几个主流的公平性算法时,我遇到了一个令人困惑的现象:在多个公开的人脸识别和医疗影像分类数据集上,那些旨在提升模型对特定群体ÿ…...