RediSearch比Es搜索还快的搜索引擎
1、介绍
RediSearch是一个Redis模块,为Redis提供查询、二次索引和全文搜索。要使用RediSearch,首先要在Redis数据上声明索引。然后可以使用重新搜索查询语言来查询该数据。RedSearch使用压缩的反向索引进行快速索引,占用内存少。RedSearch索引通过提供精确的短语匹配、模糊搜索和数字过滤等功能增强了

2、实现特性
- 基于文档的多个字段全文索引
- 高性能增量索引
- 文档排序(由用户在索引时手动提供)
- 在子查询之间使用 AND 或 NOT 操作符的复杂布尔查询
- 可选的查询子句
- 基于前缀的搜索
- 支持字段权重设置
- 自动完成建议(带有模糊前缀建议)
- 精确的短语搜索
- 在许多语言中基于词干分析的查询扩展
- 支持用于查询扩展和评分的自定义函数
- 将搜索限制到特定的文档字段
- 数字过滤器和范围
- 使用 Redis 自己的地理命令进行地理过滤
- Unicode 支持(需要 UTF-8 字符集)
- 检索完整的文档内容或只是ID 的检索
- 支持文档删除和更新与索引垃圾收集
- 支持部分更新和条件文档更新
3、对比 Elasticsearch
如下图所示,RediSearch 构建索引的时间为 221 秒,而 Elasticsearch 为 349 秒,快了 58%。

4、索引构建测试
我们模拟了一个多租户电子商务应用程序,其中每个租户代表一个产品类别并维护自己的索引。对于此基准测试,我们构建了 50K 个索引(或产品),每个索引最多存储 500 个文档(或项目),总共 2500 万个文档。RediSearch 仅用了 201 秒就构建了索引,平均每秒运行 125K 个索引。然而,Elasticsearch 在 921 个索引后崩溃了,显然它不是为应对这种负载而设计的。

5、查询性能测试
一旦数据集被索引,我们就使用在专用负载生成器服务器上运行的 32 个客户端启动两个单词的搜索查询。如下图所示,RediSearch 吞吐量达到了 12.5K 操作/秒,而 Elasticsearch 为 3.1K 操作/秒,速度提高了 4 倍。此外,RediSearch 延迟稍好一些,平均为 8 毫秒,而 Elasticsearch 为 10 毫秒。
6、安装
安装目前分为源码和docker安装两种方式,具体可以看笔者的RediSearch编译安装(一) 这里就不做过多的阐述了。
7. 命令行操作
1、创建
1.1 创建索引
创建索引不妨想象成创建表结构,表一般基本属性有表名、字段和字段类别等,所以我们可以考虑将索引名代表表名,字段代表字段,属性即表示属性。
xxx.xxx.xxx.xxx:0>ft.create "student" schema "name" text weight 5.0 "sex" text "desc" text "class" tag
"OK"
student 表示索引名,name、sex、desc表示字段,text表示类型(这样表示只是为了便于理解)
“weight”为权重,默认值为 1.0
type student
"none"
我们创建的索引redis是不认识的,这证明使用的是插件。
1.2 创建文档
创建文档上下文的过程不妨想想成向表中插入数据,这里请注意字段名可以使用双引号但切记一定要用英文,这里之所以着重提出是因为有些编译器中文双引号和英文双引号用肉眼实在难以辨认否则会出现
“Fields must be specified in FIELD VALUE pairs”(其实是将“ 当作内容处理了以至于缺少了字段)
ft.add student 001 1.0 language "chinese" fields name "张三" sex "男" desc "这是一个学生" class "一班"
"OK"
其中001为文档ID,"1.0"为评分缺少此值会报"Could not parse document score"异常
language 指明使用的语言默认是英文编码 如果没有此标记存储是没有问题的但不可以通过中文字符查询
1.3 查询
1.3.1 基本查询
1.3.1.1 全量查询
xxx.xxx.xxx.xxx:0>FT.SEARCH student * SORTBY sex desc RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"2) "张三"3) "sex"4) "男"5) "desc"6) "这是一个学生"4) "002"
5) 1) "name"2) "张三"3) "sex"4) "男"5) "desc"6) "这是一个学生"1.3.1.2 匹配查询
xxx.xxx.xxx.xxx:0>ft.search student "张三" limit 0 10 RETURN 3 name sex desc
1) "2"
2) "001"
3) 1) "name"2) "张三"3) "sex"4) "男"5) "desc"6) "这是一个学生"4) "002"
5) 1) "name"2) "张三"3) "sex"4) "男"5) "desc"6) "这是一个学生"
limit 与mysql相识主要用于分页,此处是全量匹配,如果没有设置language “chinese” 此处查询为0,
1.3.2 模糊匹配
1.3.2.1 后置匹配
ft.search student "李*" SORTBY sex desc RETURN 3 name sex desc
1) "1"
2) "003"
3) 1) "name"2) "李四"3) "sex"4) "男"5) "desc"6) "这是一个学生"
1.3.2.2 模糊搜索
xxx.xxx.xxx.xxx:0>FT.SEARCH beers "%%张店%%"
1) "1"
2) "beer:1"
3) 1) "name"2) "集团本部已发布【文明就餐公约】,2号楼办公人员午餐的就餐时间是11:45~13:00,现经行政服务部进行抽查,发现我们部门有员工违规就餐现象。请大家务必遵守,相互转告,对于外地回到集团办公的同事,亦请遵守,谢谢!"3) "org"4) "山东省淄博市张店区"5) "school"6) "山东理工大学"
别高兴太早全量模糊匹配是由很大限制的,他基于Levenshtein距离(LD)进行模糊匹配。术语的模糊匹配是通过在术语周围加“%”来实现的,模糊匹配的最大LD为3,
确切的说这只是一种相识度查询,并非一般意义上的模糊搜索,
但是: 如果仔细观察会发现通过精确匹配时不仅能够将完整value值查询出来而且还查询出其他处于文档某个位置的key请看官方提供的一个例子:
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txt “Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]”
FT.CREATE idx SCHEMA txt TEXT
FT.ADD idx docCn 1.0 LANGUAGE chinese FIELDS txt "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"
FT.SEARCH idx "数据" LANGUAGE chinese HIGHLIGHT SUMMARIZE
# Outputs:
# <b>数据</b>?... <b>数据</b>进行写操作。由于完全实现了发布... <b>数据</b>冗余很有帮助。[8...
之所以会出现这样的效果是因为redisearch对文本进行了分词,其使用的工具是friso相比es的ik还是弱一些前者主要是对中文分词,体积小可移植性强。
从而我们可以结合后后置匹配算法
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "数*" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"2) "Redis支持主从同步。<b>数据</b>可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对<b>数据</b>进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和<b>数据</b>冗余很有帮助。[8]"或者结合Levenshtein算法这样基本上能够满足业务查询需求
xxx.xxx.xxx.xxx:0>FT.SEARCH idx "%%单的树%%" LANGUAGE chinese HIGHLIGHT
1) "1"
2) "docCn"
3) 1) "txt"2) "Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层<b>树</b>复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步<b>树</b>时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。[8]"
1.3.2.3 字段查询
通过字段查询也可以实现模糊搜索,直接给例子,后面跟着官网上给的sql 和 redisearch的对照表
ft.search student *
1) "2"
2) "doudou"
3) 1) "name"2) "豆豆"3) "jtzz"4) "“检索”是很多产品中"5) "phone"6) "18563717107"4) "ttao"
5) 1) "name"2) "姚元涛"3) "jtzz"4) "一个生病的人只"5) "phone"6) "18563717107"ft.search student '@phone:185* @name:豆豆'
1) "1"
2) "doudou"
3) 1) "name"2) "豆豆"3) "jtzz"4) "“检索”是很多产品中"5) "phone"6) "18563717107"| sql | redisearch |
|---|---|
| WHERE x=‘foo’ AND y=‘bar’ | @x:foo @y:bar |
| WHERE x=‘foo’ AND y!=‘bar’ | @x:foo -@y:bar |
| WHERE x=‘foo’ OR y=‘bar’ | (@x:foo) |
| WHERE x IN (‘foo’, ‘bar’,‘hello world’) | @x:(foo |
| WHERE y=‘foo’ AND x NOT IN (‘foo’,‘bar’) | @y:foo (-@x:foo) (-@x:bar) |
| WHERE x NOT IN (‘foo’,‘bar’) | -@x:(foo |
| WHERE num BETWEEN 10 AND 20 | @num:[10 20] |
| WHERE num >= 10 | @num:[10 +inf] |
| WHERE num > 10 | @num:[(10 +inf] |
| WHERE num < 10 | @num:[-inf (10] |
| WHERE num <= 10 | @num:[-inf 10] |
| WHERE num < 10 OR num > 20 | @num:[-inf (10] |
| WHERE name LIKE ‘john%’ | @name:john* |
1.4 删除
1.3.1 删除文档
xxx.xxx.xxx.xxx:0>ft.del student 002
"1"
1.3.3 删除索引
xxx.xxx.xxx.xxx:0>ft.drop student
"OK"
1.5 查看
1.5.1 查看所有索引
xxx.xxx.xxx.xxx:0>FT._LIST
1) "student1"
2) "ttao"
3) "idx"
4) "student"
5) "myidx"
6) "123"
7) "myIndex"
8) "testung"
9) "student2"
1.5.2 查看索引文档中的数据
1.5.2.1 获取单条数据
xxx.xxx.xxx.xxx:0>ft.get student 001
1) "name"
2) "张三"
3) "sex"
4) "男"
5) "desc"
6) "这是一个学生"
7) "class"
8) "一班"
1.5.2.2 获取多条数据
xxx.xxx.xxx.xxx:0>ft.mget student 001 002
1) 1) "name"2) "张三"3) "sex"4) "男"5) "desc"6) "这是一个学生"7) "class"8) "一班"2) 1) "name"2) "张三"3) "sex"4) "男"5) "desc"6) "这是一个学生"7) "class"8) "一班"1.6 索引别名操作
1.6.1 添加别名
123.232.112.84:0>FT.ALIASADD xs student
"OK"
给索引student起个xs的别名,一个索引可以起多个别名
1.6.2 修改别名
1.6.3 删除别名
123.232.112.84:0>FT.ALIASDEL xs
"OK"
相关文章:
RediSearch比Es搜索还快的搜索引擎
1、介绍 RediSearch是一个Redis模块,为Redis提供查询、二次索引和全文搜索。要使用RediSearch,首先要在Redis数据上声明索引。然后可以使用重新搜索查询语言来查询该数据。RedSearch使用压缩的反向索引进行快速索引,占用内存少。RedSearch索…...

mybatis-plus 的saveBatch性能分析
Mybatis-Plus 的批量保存saveBatch 性能分析 目录 Mybatis-Plus 的批量保存saveBatch 性能分析背景批量保存的使用方案循环插入使用PreparedStatement 预编译优点:缺点: Mybatis-Plus 的saveBatchMybatis-Plus实现真正的批量插入自定义sql注入器定义通用…...

python异常:pythonIOError异常python打开文件异常
1.python读取不存在的文件时,抛出异常 通过 open()方法以读“r”的方式打开一个 abc.txt 的文件(该文件不存在),执行 open()打开一个不存在的文件时会抛 IOError 异常,通过 Python 所提供的 try...except...语句来接收…...

电话机器人语音识别用哪家更好精准度更高。
语音识别系统的选择取决于你的具体需求,包括但不限于识别精度、速度、易用性、价格等因素。以下是一些在语音识别领域表现较好的公司和产品: 科大讯飞:科大讯飞是中国最大的语音识别技术提供商之一,其语音识别技术被广泛应用于各…...
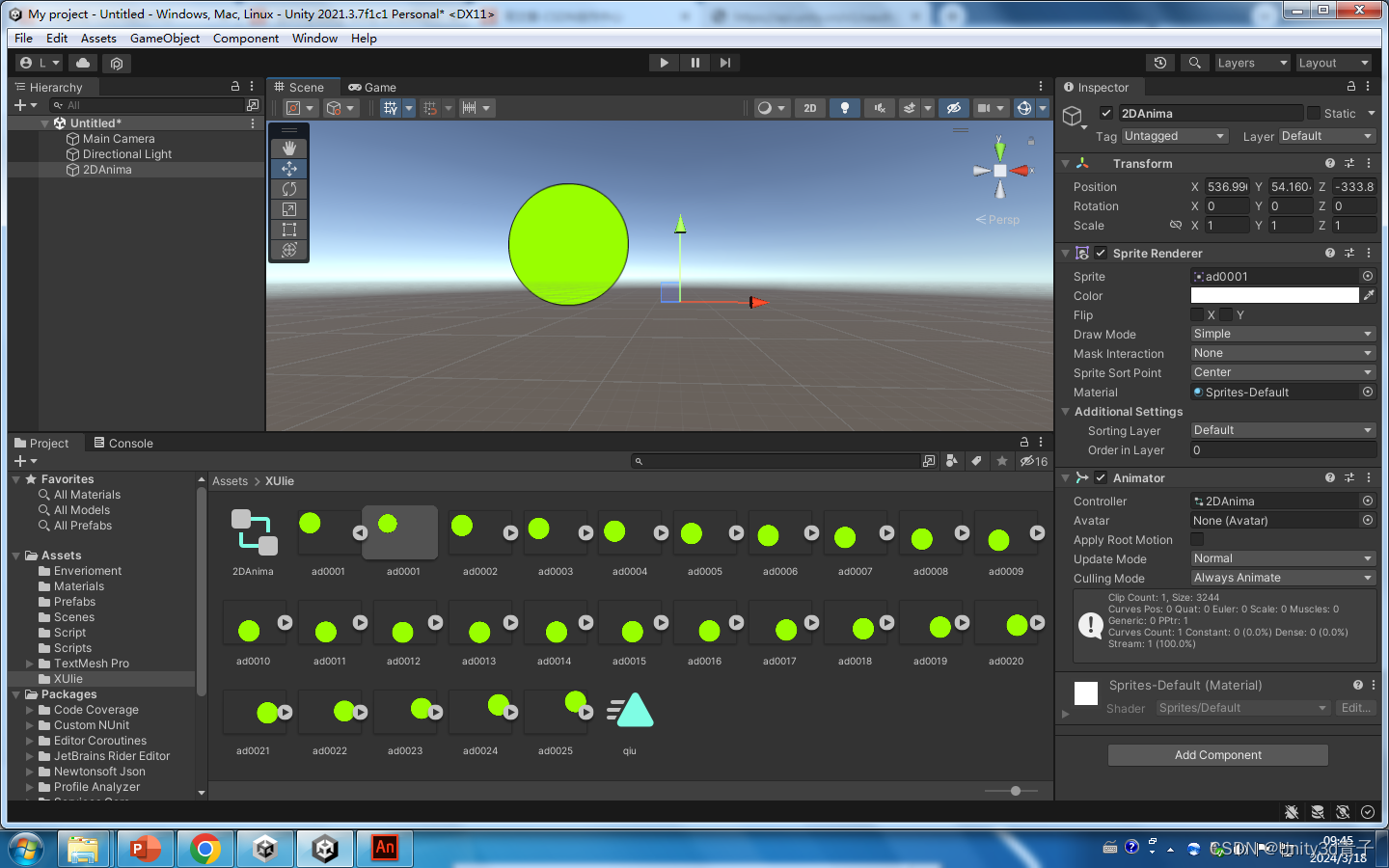
【Unity动画】Unity如何导入序列帧动画(GIF)
Unity 不支持GIF动画的直接播放,我们需要使用序列帧的方式 01准备好序列帧 02全部拖到Unity 仓库文件夹中 03全选修改成精灵模式Sprite 2D ,根据需要修改尺寸,点击Apply 04 创建一个空物体 拖动序列上去 然后全选所有序列帧,拖到这个空物体…...

uniapp APP 上传文件
/*** 上传文件*/uploadPhoneFile:function(callback,params {}) {let fileType [.pdf,.doc,.xlsx,.docx,.xls]// #ifdef APP-PLUSplus.io.chooseFile({title: 选择文件, filetypes: [doc, docx], // 允许的文件类型 multiple: false, // 是否允许多选 },(e)>{const tem…...
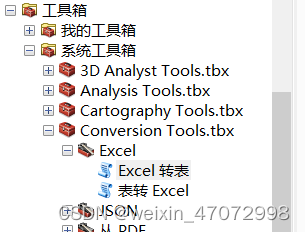
arcgis数据导出到excel
将arcgis属性数据导出到excel: 1) 工具箱\系统工具箱\Conversion Tools.tbx\Excel\Excel 转表 2)用excel打开导出的图层文件中后缀为.dbf的数据(方便快捷,但是中文易乱码)...

吴恩达深度学习环境本地化构建wsl+docker+tensorflow+cuda
Tensorflow2 on wsl using cuda 动机环境选择安装步骤1. WSL安装2. docker安装2.1 配置Docker Desktop2.2 WSL上的docker使用2.3 Docker Destop的登陆2.4 测试一下 3. 在WSL上安装CUDA3.1 Software list needed3.2 [CUDA Support for WSL 2](https://docs.nvidia.com/cuda/wsl-…...

R语言:microeco:一个用于微生物群落生态学数据挖掘的R包:第七:trans_network class
# 网络是研究微生物生态共现模式的常用方法。在这一部分中,我们描述了trans_network类的所有核心内容。 # 网络构建方法可分为基于关联的和非基于关联的两种。有几种方法可以用来计算相关性和显著性。 #我们首先介绍了基于关联的网络。trans_network中的cal_cor参数…...

ubuntu下在vscode中配置matplotlibcpp
ubuntu下在vscode中配置matplotlibcpp 系统:ubuntu IDE:vscode 库:matplotlib-cpp matplotlibcpp.h文件可以此网址下载:https://github.com/lava/matplotlib-cpp 下载的压缩包中有该头文件,以及若干实例程序。 参考…...

Vue面试题,背就完事了
1.vue的生命周期有哪些及每个生命周期做了什么? Vue.js 的生命周期可以分为以下几个核心阶段,每个阶段都伴随着特定的钩子函数(生命周期钩子)来执行相应的操作: 创建阶段: beforeCreate:实例被创建后、数…...
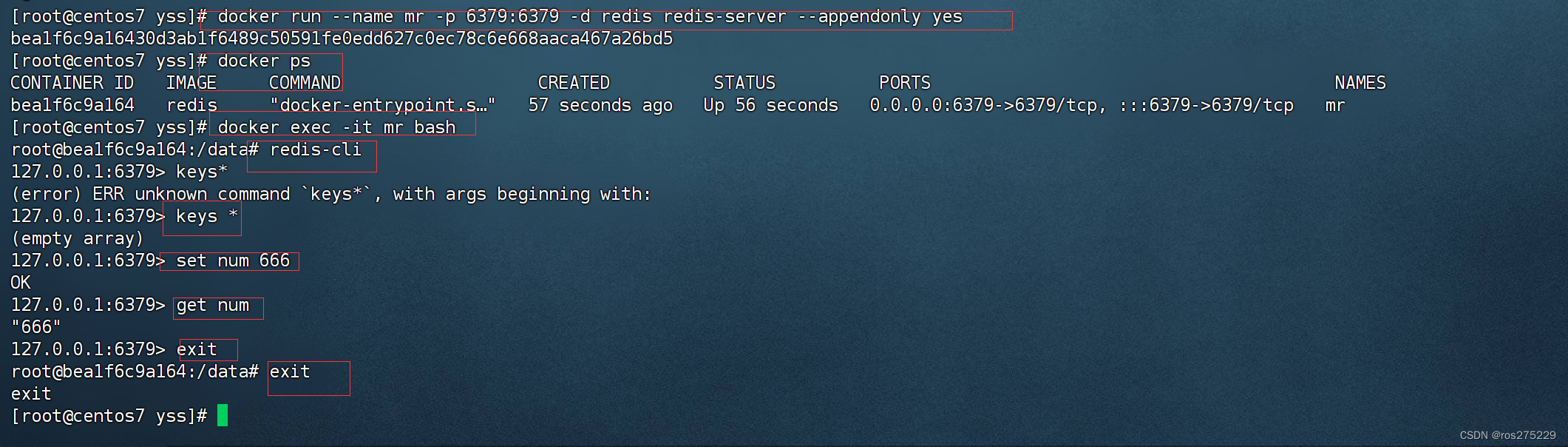
centos创建并运行一个redis容器 并支持数据持久化
步骤 : 创建redis容器命令 docker run --name mr -p 6379:6379 -d redis redis-server --appendonly yes 进入容器 : docker exec -it mr bash 链接redis : redis-cli 查看数据 : keys * 存入一个数据 : set num 666 获取数据 : get num 退出客户端 : exit 再退…...
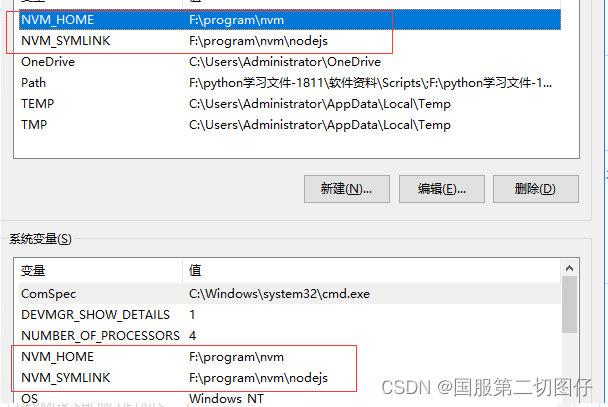
nvm安装和使用保姆级教程(详细)
一、 nvm是什么 : nvm全英文也叫node.js version management,是一个nodejs的版本管理工具。nvm和npm都是node.js版本管理工具,为了解决node.js各种版本存在不兼容现象可以通过它可以安装和切换不同版本的node.js。 二、卸载之前安装的node: …...
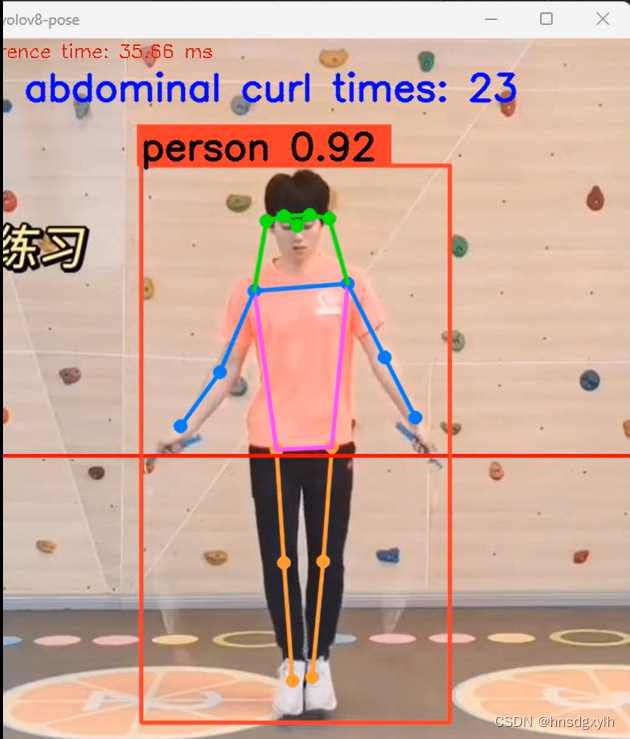
跳绳计数,YOLOV8POSE
跳绳计数,YOLOV8POSE 通过计算腰部跟最初位置的上下波动,计算跳绳的次数...

阿里云ecs服务器配置反向代理上传图片
本文所有软件地址: 链接:https://pan.baidu.com/s/12OSFilS-HNsHeXTOM47iaA 提取码:dqph 为什么要使用阿里云服务器? 项目想让别人通过外网进行访问就需要部署到我们的服务器当中 1.国内知名的服务器介绍 国内比较知名的一些…...

免费阅读篇 | 芒果YOLOv8改进110:注意力机制GAM:用于保留信息以增强渠道空间互动
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可 该专栏完整目录链接: 芒果YOLOv8深度改进教程 该篇博客为免费阅读内容,直接改进即可🚀🚀…...
返回值及含义)
GetLastError()返回值及含义
https://www.cnblogs.com/ericsun/archive/2012/08/10/2631808.html 〖0〗-操作成功完成。 〖1〗-功能错误。 〖2〗-系统找不到指定的文件。 〖3〗-系统找不到指定的路径。 〖4〗-系统无法打开文件。 〖5〗-拒绝访问。 〖6〗-句柄无效。 〖7〗-存储控制块被损坏。 〖8〗-存储空…...

k8s admin 用户生成token
k8s 版本 1.28 创建一个admin的命名空间 admin-namespce.yaml kind: Namespace apiVersion: v1 metadata: name: admin labels: name: admin 部署进k8s kubectl apply -f admin-namespce.yaml 查看k8s namespace 的列表 kubectl get namespace查看当前生效的…...
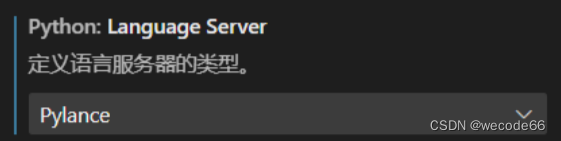
【vscode】vscode重命名变量后多了很多空白行
这种情况,一般出现在重新安装 vscode 后出现。 原因大概率是语言服务器没设置好或设置对。 以 Python 为例,到设置里搜索 "python.languageServer",将 Python 的语言服务器设置为 Pylance 即可。...
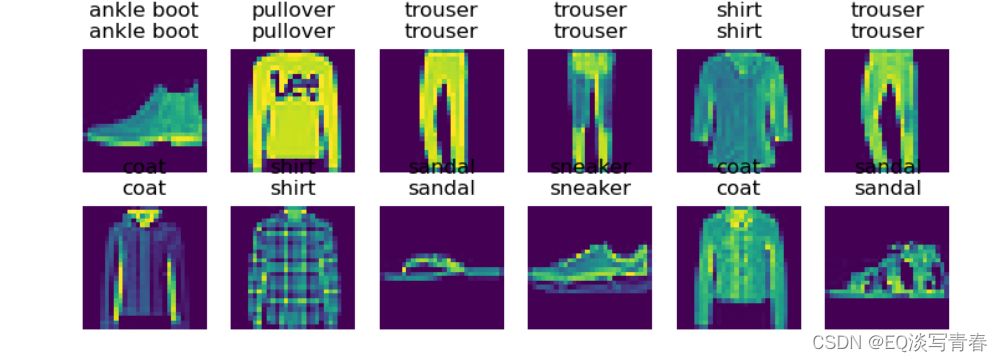
深度学习实战模拟——softmax回归(图像识别并分类)
目录 1、数据集: 2、完整代码 1、数据集: 1.1 Fashion-MNIST是一个服装分类数据集,由10个类别的图像组成,分别为t-shirt(T恤)、trouser(裤子)、pullover(套衫…...

【限时解密】Claude 3.5 Sonnet专属编程模式:仅开放给前500家企业的上下文感知补全协议
更多请点击: https://kaifayun.com 第一章:Claude 3.5 Sonnet编程辅助的核心能力边界与适用场景 Claude 3.5 Sonnet 在编程辅助领域展现出显著的推理深度与上下文理解能力,但其本质仍是基于大规模语言模型的生成式系统,不具备实时…...

认知殖民的几何级放大器:论概率拟合AI范式的内生危机、利益锁定与公理驱动的范式跃迁
认知殖民的几何级放大器:论概率拟合AI范式的内生危机、利益锁定与公理驱动的范式跃迁 摘要 当前,以大语言模型为核心的生成式人工智能掀起全球技术热潮,“涌现特性”“通用人工智能”等概念持续主导行业舆论与研发风向。然而剥离技术表象与…...

LimboAI在Godot 4中实现可维护游戏AI的工程化方案
1. 这不是又一个“AI行为树”教程——LimboAI在Godot 4里真正解决的是什么问题? 你有没有在Godot 4里写过这样的AI逻辑:一个巡逻的守卫,发现玩家后追击,进入攻击距离就挥剑,被击中后后退、喊话、短暂硬直,…...

DeepSeek / Qwen 大模型在昇腾上的推理优化实战
前言 把DeepSeek-V3和Qwen2.5-72B部署到昇腾910B集群上。客户说"GPU上跑得好好的,换昇腾应该也行吧"。结果第一天就被砸懵——同样的模型、同样的batch,昇腾上吞吐只有GPU的60%。不是算力不够,是我根本没搞清楚CANN的优化逻辑和CUD…...

Taotoken的计费透明与账单追溯功能让我的每一分钱都花得明白
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的计费透明与账单追溯功能让我的每一分钱都花得明白 作为独立开发者或小型技术团队的负责人,管理项目成本是日…...

如何快速配置大麦抢票自动化工具:5个步骤实现高效网络诊断与抓包分析
如何快速配置大麦抢票自动化工具:5个步骤实现高效网络诊断与抓包分析 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 你是否曾因大麦网抢…...
)
人机协作新范式:高效论文写作全流程AI论文平台推荐(2026 最新)
2026年AI论文平台持续升级,论文写作全流程可拆解为文献调研→选题/开题→大纲/初稿→文献综述→降重/去AI味→润色/格式→查重/投稿七大环节,以下工具按环节精准匹配,兼顾中文适配、降重能力、去AI痕迹、学术合规四大核心需求,覆盖…...

贝叶斯压缩技术优化空间回归模型计算效率
1. 空间回归模型与贝叶斯压缩概述空间回归模型是分析地理空间数据的核心工具,它通过空间位置信息建模变量间的非平稳关系。传统方法如高斯过程回归虽然灵活,但在处理大规模数据时面临O(N)的计算复杂度瓶颈。贝叶斯数据压缩技术通过随机线性变换实现维度约…...
:新建一个flutter项目)
【Flutter3.8x】flutter从入门到实战基础教程(一):新建一个flutter项目
初始化项目步骤 vscode中安装flutter插件ctrlshiftp弹出命令框点击flutter:new project系统会自动生成一个项目,其中会让选择一个文件夹存放源码,自行选择就行 启动安卓模拟器把文件定位在main.dart上,然后再点击这里如果启动失败,…...

深度解析Python SECS/GEM协议实现:secsgem库的现代架构设计
深度解析Python SECS/GEM协议实现:secsgem库的现代架构设计 【免费下载链接】secsgem Simple Python SECS/GEM implementation 项目地址: https://gitcode.com/gh_mirrors/se/secsgem 在半导体制造行业,设备与主机系统之间的标准化通信是自动化生…...