超越标签的探索:K-means与DBSCAN在数据分析中的新视角
最近在苦恼为我的数据决定分组问题,在查找资料时,恰好看到机器学习中的无监督学习的聚类分析,正好适用于我的问题,但是我之前学机器学习时。正好没有学习无监督部分,因为我认为绝大多数问题都是有标签的监督学习,正是大意了,这不巧了正好遇上了,那就赶紧学习一下吧。
最近正在苦恼为我的数据决定分组问题,在查找资料时,恰好看到机器学习中的无监督学习的聚类分析,正好适用于我的问题,但是我之前学机器学习时。正好没有学习无监督部分,因为我认为绝大多数问题都是有标签的监督学习,真是大意了,这不巧了正好遇上了,那就赶紧学习一下吧。

说到无监督学习,还真是强大,无监督学习的优点是可以处理没有标签的数据,发现数据的潜在规律和特征,适用于探索性的数据分析。就好像不需要老师教,就可以自己根据数据之间的关系对数据进行分组。

因为我的问题比较适合K-means和DBSCAN解决,这篇文章我主要介绍这两种算法。
DBSCAN聚类分析是一种基于密度的聚类算法,它可以发现任意形状的簇,并且能够识别出噪声点。与之相比,K-means聚类算法是一种基于距离的聚类算法,它将数据划分为K个球形的簇,但是对噪声点和非球形的簇不太适合。下面我将用Python代码和图片来展示这两种算法的原理和效果。
首先,我们导入一些必要的库,如numpy, matplotlib, sklearn等,并生成一些随机的数据点,其中有四个簇和一些噪声点。
import os
os.environ["OMP_NUM_THREADS"] = "1"
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans, DBSCAN# 生成随机数据
X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.6, random_state=0)
# 添加一些噪声点
X = np.r_[X, np.random.randn(10, 2) + [2, 2]]
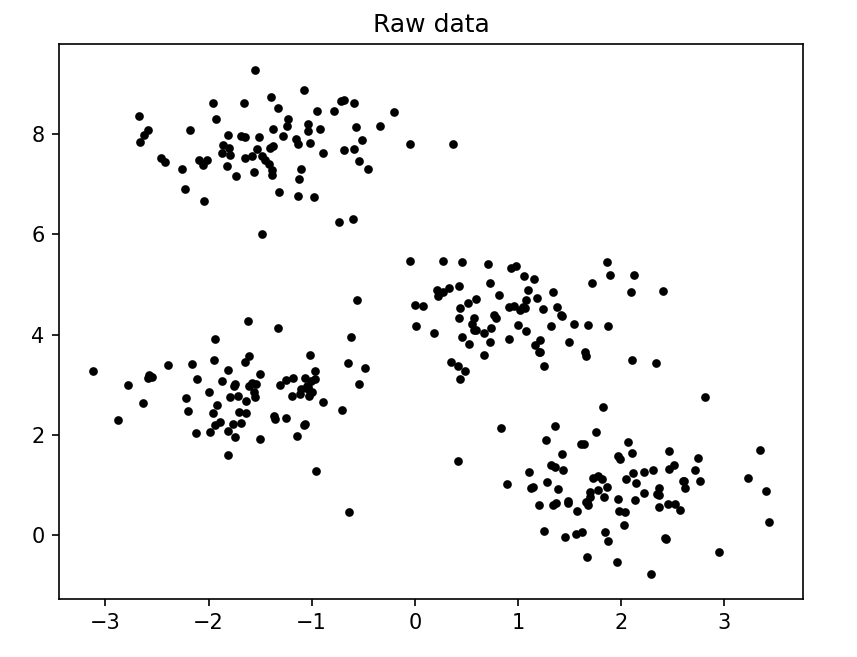
plt.scatter(X[:, 0], X[:, 1], s=10, c='k')
plt.title('Raw data')
plt.show()
通过肉眼看到原始数据,还是比较聚集的,但是处于边界的这些点属于哪一个组(簇)呢,还是得通过聚类算法来确定。
k-means聚类分析
接下来,我们用K-means算法来对数据进行聚类,设置K=4,即我们想要得到四个簇。我们可以用sklearn库中的KMeans类来实现,它有以下几个重要的参数:
- n_clusters: 聚类的个数,即K值
- init: 初始质心的选择方法,可以是’random’或’k-means++',后者是一种优化的方法,可以加速收敛,但是是选择优化方法啦。🤭
- n_init: 随机初始化的次数,算法会选择其中最好的一次作为最终结果
- max_iter: 最大迭代次数,当迭代达到这个次数时,算法会停止,即使没有收敛
- tol: 容忍度,当质心的移动小于这个值时,算法会认为已经收敛,停止迭代
我们可以用fit函数来训练模型,用predict函数来对数据进行预测,用inertia_属性来获取误差平方和,用cluster_centers_属性来获取质心的坐标。代码如下:
# K-means聚类
kmeans = KMeans(n_clusters=4, init='k-means++', n_init=10, max_iter=300, tol=1e-4, random_state=0)
y_pred = kmeans.fit_predict(X)
sse = kmeans.inertia_
centers = kmeans.cluster_centers_
print('K-means SSE:', sse)
plt.scatter(X[:, 0], X[:, 1], s=10, c=y_pred)
plt.scatter(centers[:, 0], centers[:, 1], s=100, c='r', marker='*')
plt.title('K-means clustering')
plt.show()
k-means的均方差和为232.678,这个结果表示聚类效果还不错。

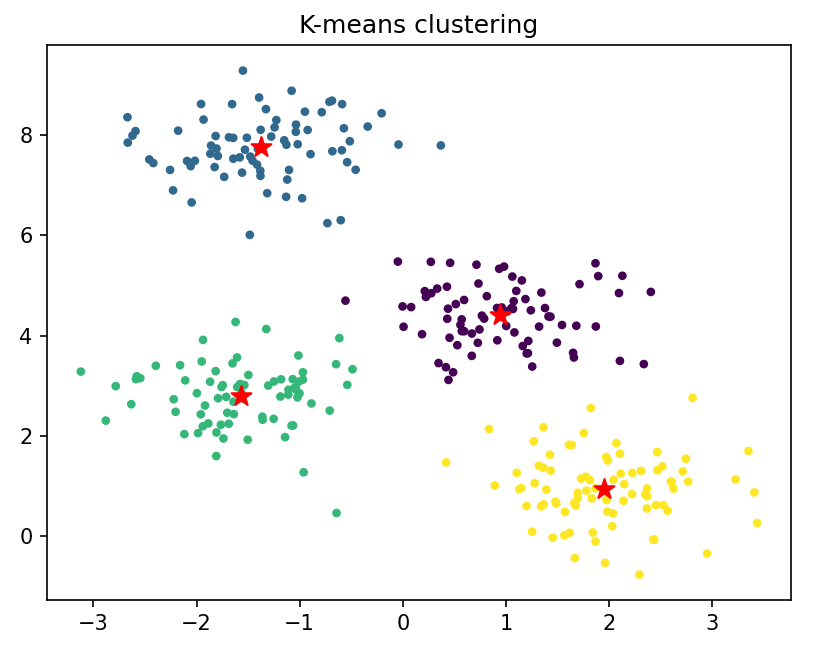
从-means聚类图中可以看出,K-means算法可以大致将数据分为四个簇,但是对于一些噪声点和边界点,它的划分效果不太理想,因为它只考虑了距离,而没有考虑密度。另外,K-means算法需要事先指定K值,如果K值不合适,可能会导致聚类效果很差。
DBSCAN聚类分析
下面,使用DBSCAN算法来对数据进行聚类,它不需要指定簇的个数,而是根据数据的密度来划分簇。我们可以用sklearn库中的DBSCAN类来实现,它有以下几个重要的参数:
- eps: 邻域半径,即判断一个点是否为核心点的距离阈值;
- min_samples: 邻域内的最小样本数,即判断一个点是否为核心点的密度阈值;
- metric: 距离度量方式,可以是’euclidean’,‘manhattan’,'cosine’等;
- algorithm: 邻域查询的算法,可以是’auto’,‘ball_tree’,‘kd_tree’,'brute’等,不同的算法有不同的时间和空间复杂度
然后可以用fit方法来训练模型,用fit_predict方法来对数据进行预测,用labels_属性来获取每个点的簇标签,用core_sample_indices_属性来获取核心点的索引。代码如下:
# DBSCAN聚类
dbscan = DBSCAN(eps=0.5, min_samples=5, metric='euclidean', algorithm='auto')
y_pred = dbscan.fit_predict(X)
labels = dbscan.labels_
core_indices = dbscan.core_sample_indices_
n_clusters = len(set(labels)) - (1 if -1 in labels else 0) # 去掉噪声点的簇个数
print('DBSCAN clusters:', n_clusters)
plt.scatter(X[:, 0], X[:, 1], s=10, c=y_pred)
plt.scatter(X[core_indices, 0], X[core_indices, 1], s=100, c='r', marker='*')
plt.title('DBSCAN clustering')
plt.show()
k-DBSCAN聚类分析总共是聚类了4个簇。


从图中可以看出,DBSCAN算法可以更好地将数据分为四个簇,并且能够识别出噪声点(黑色的点),因为它考虑了距离和密度,而且不需要事先指定簇的个数。另外,DBSCAN算法可以处理任意形状的簇,而不局限于球形的簇。
总结
总结一下,K-means和DBSCAN是两种常用的聚类算法,它们各有优缺点,适用于不同的场景。
K-means算法简单易懂,运行速度快,但是需要指定簇的个数,对噪声点和非球形的簇不太适合。DBSCAN算法不需要指定簇的个数,可以发现任意形状的簇,并且能够识别出噪声点,但是运行速度慢一些,对于不同密度的簇可能效果不好。
在实际应用中,还是需要根据数据的特点和需求来选择合适的聚类算法,不过如果愿意耐心多次对比参数,训练聚类分析算法,还是推荐DBSCAN算法。

相关文章:
超越标签的探索:K-means与DBSCAN在数据分析中的新视角
最近在苦恼为我的数据决定分组问题,在查找资料时,恰好看到机器学习中的无监督学习的聚类分析,正好适用于我的问题,但是我之前学机器学习时。正好没有学习无监督部分,因为我认为绝大多数问题都是有标签的监督学习&#…...
linux板子vscode gdb 远程调试
板子:hi3556v200 交叉编译工具:arm-himix200-linux 主机:win10虚拟机的ubuntu16.4 gdb:gdb-8.2.tar.gz 1.在ubuntu交叉编译gdb(Remote g packet reply is too long解决) 建议修改gdb8.2/gdb目录下面的remote.c解决…...

nginx代理服务器配置
nginx代理服务器配置 需要配置环境需求 1、一台1.1.1.1服务器,一台2.2.2.2服务器 前端包路径在1.1.1.1 /etc/dist 下 后端服务在2.2.2.2 上 暴露端口为9999 2、需求 现在需要访问 1.1.1.1:80访问到2.2.2.2 上面的9999后端服务 3、配置nginx ①:在…...
基于Matlab的视频人面检测识别,Matalb实现
博主简介: 专注、专一于Matlab图像处理学习、交流,matlab图像代码代做/项目合作可以联系(QQ:3249726188) 个人主页:Matlab_ImagePro-CSDN博客 原则:代码均由本人编写完成,非中介,提供…...
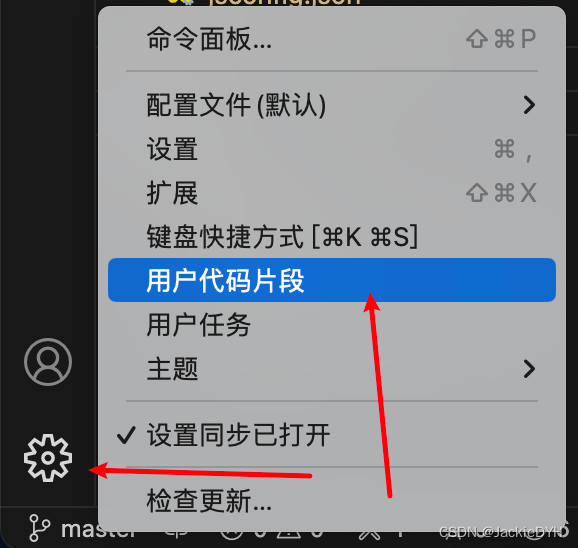
VSCode创建用户代码片段-案例demo
示例 - 在线生成代码片段 Vue3代码片段 {"vue3": {scope": "javascript,typescript,html,vue","prefix": "vue3","body": ["<template>","$1","</template>",""…...

河南大学-数字图像处理-图像变换
计算机与信息工程学院实验报告 序号:20 姓名:__杨馥瑞___ 学号:_2212080042_ 专业:__数据科学与大数据技术 年级:___2022级_____ 课程:数字图像处理 主讲教师:张延锋 辅导教师&#x…...

华为OD七日集训第3期 - 按算法分类,由易到难,循序渐进,玩转OD
目录 一、适合人群二、本期训练时间三、如何参加四、七日集训第 3 期五、精心挑选21道高频100分经典题目,作为入门。第1天、逻辑分析第2天、字符串处理第3天、矩阵第4天、深度优先搜索dfs算法第5天、回溯法第6天、二分查找第7天、图、正则表达式 大家好,…...

Android中的进程间通讯
一、简介 进程间通讯(InterProcess Communication) 指在不同进程之间传播或交换信息,Android是基于Linux 系统的,在Linux 中进程间是不能直接通讯的,IPC就是为了解决这一问题 每个操作系统都有相应的IPC机制&#x…...

day03vue学习
day03 一、今日目标 1.生命周期 生命周期介绍生命周期的四个阶段生命周期钩子声明周期案例 2.综合案例-小黑记账清单 列表渲染添加/删除饼图渲染 3.工程化开发入门 工程化开发和脚手架项目运行流程组件化组件注册 4.综合案例-小兔仙首页 拆分模块-局部注册结构样式完善…...

32. 最长有效括号
给你一个只包含 ( 和 ) 的字符串,找出最长有效(格式正确且连续)括号 子串 的长度。 示例 1: 输入:s "(()" 输出:2 解释:最长有效括号子串是 "()"示例 2: 输…...

如何在 docker 容器内部运行 docker命令
场景: 有些场景在容器内部需要调用 docker 命令。为此,本文梳理2种可以在容器内部执行docker命令的方法。 方法1:基于 docker.sock /var/run/docker.sock是默认的Unix socket(套接字),socket是同一机器中进程间通讯的一种方式。…...
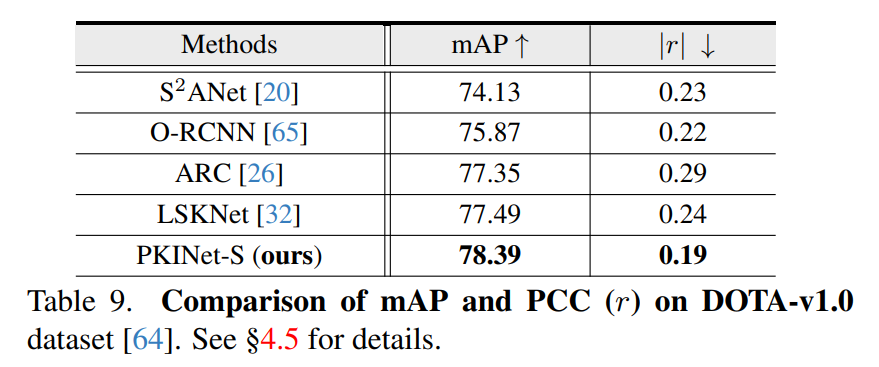
Poly Kernel Inception Network在遥感检测中的应用
摘要 https://export.arxiv.org/pdf/2403.06258 遥感图像(RSI)中的目标检测经常面临一些日益严重的挑战,包括目标尺度的巨大变化和多样的上下文环境。先前的方法试图通过扩大骨干网络的空间感受野来解决这些挑战,要么通过大核卷积…...

tiktok 与 赵长鹏 遭遇了什么
对于美丽国来说,比特币是国家资产,赵长鹏动了国家资产的奶酪,当然要被消灭;新闻媒体是国家资产,TIKTOK作为新兴媒体也动了国家资产的奶酪,当然也在消灭之列;高端芯片、波音飞机也是国家资产&…...
)
Lua中文语言编程源码-第七节,更改lstrlib.c 标准字符串操作与模式匹配库函数, 使Lua加载中文库关键词(标准字符串操作与模式匹配库相关)
源码已经更新在CSDN的码库里: git clone https://gitcode.com/funsion/CLua.git在src文件夹下的lstrlib.c 标准字符串操作与模式匹配库函数,表明这个C源文件实现了Lua的标准字符串操作与模式匹配库,即提供了与字符串操作相关的API和功能实现…...
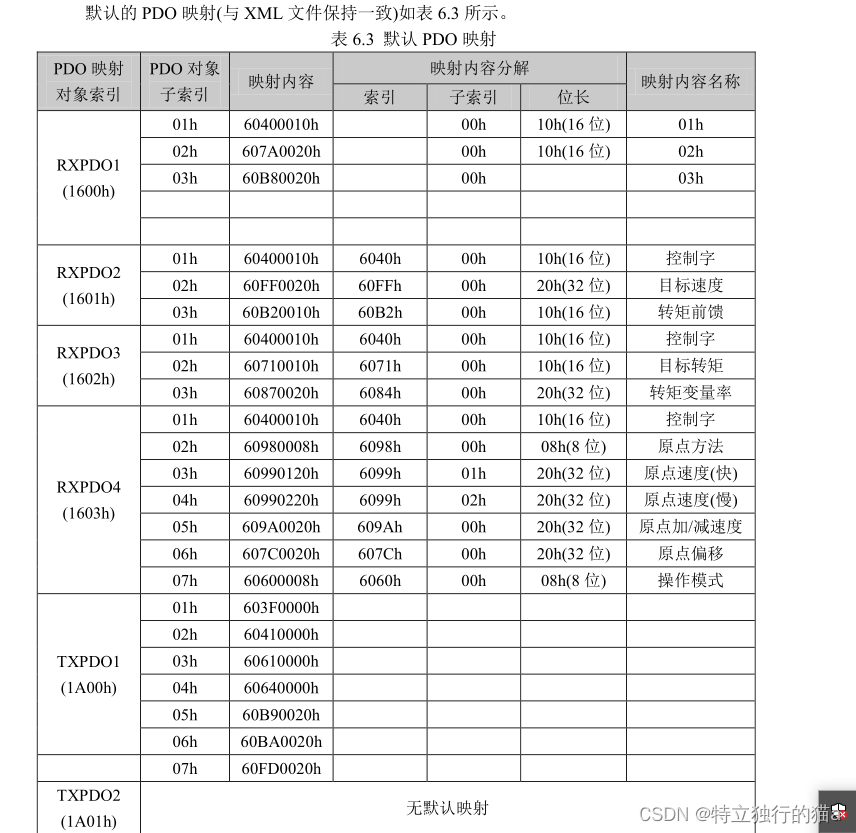
EtherCAT开源主站 IGH 介绍及主站伺服控制过程
目录 前言 IGH EtherCAT主站介绍 主要特点和功能 使用场景 SOEM 主站介绍 SOEM 的特点和功能 SOEM 的使用场景 IGH 主站 和 SOEM对比 1. 功能和复杂性 2. 资源消耗和移植性 3. 使用场景 EtherCAT 通信原理 EtherCAT主站控制伺服过程 位置规划模式 原点复归模式…...

自然语言:python实现自然语言处理中计算文件中的英语字母的熵
下面是一个示例代码,实现了计算文件中英语字母的熵的功能。 import mathdef calculate_entropy(text):# 统计字母的出现次数letter_count {}total_count 0for char in text:if char.isalpha():char char.lower()letter_count[char] letter_count.get(char, 0) …...

分类预测 | Matlab实现BiTCN双向时间卷积神经网络数据分类预测/故障识别
分类预测 | Matlab实现BiTCN双向时间卷积神经网络数据分类预测/故障识别 目录 分类预测 | Matlab实现BiTCN双向时间卷积神经网络数据分类预测/故障识别分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matlab实现BiTCN双向时间卷积神经网络数据分类预测/故障识别。 2.自…...

基于SpringBoot的后勤管理系统【附源码】
后勤管理系统开发说明 开发语言:Java 框架:ssm JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7(一定要5.7版本) 数据库工具:Navicat11 开发软件:eclipse/myecli…...
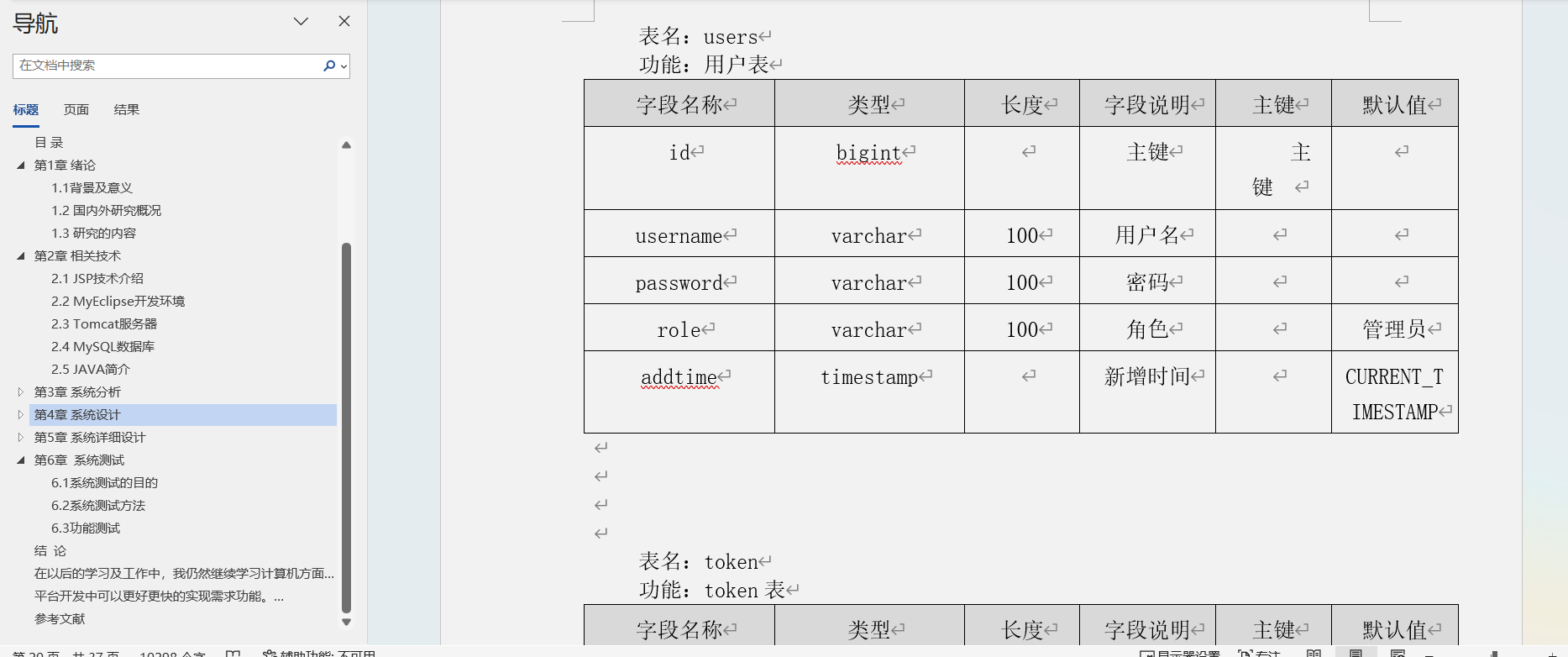
智能仓储系统|基于JSP技术+ Mysql+Java+ Tomcat的智能仓储系统设计与实现(可运行源码+数据库+设计文档)
推荐阅读100套最新项目 最新ssmjava项目文档视频演示可运行源码分享 最新jspjava项目文档视频演示可运行源码分享 最新Spring Boot项目文档视频演示可运行源码分享 2024年56套包含java,ssm,springboot的平台设计与实现项目系统开发资源(可…...
Layui实现删除及修改后停留在当前页
1、功能概述? 我们在使用layui框架的table显示数据的时候,会经常的使用分页技术,这个我们期望能够期望修改数据能停留在当前页,或者删除数据的时候也能够停留在当前页,这样的用户体验会更好一些,但往往事与…...

RWKV7-1.5B-g1a一文详解:轻量中文对话与文案续写实战
RWKV7-1.5B-g1a一文详解:轻量中文对话与文案续写实战 1. 模型简介 rwkv7-1.5B-g1a 是一款基于RWKV-7架构的多语言文本生成模型,特别适合中文场景下的轻量级应用。这个1.5B参数的模型在保持较小体积的同时,能够出色完成基础问答、文案续写、简…...

告别手动更新!GAMIT/GLOBK数据处理中tables表文件的自动化管理与避坑指南
告别手动更新!GAMIT/GLOBK数据处理中tables表文件的自动化管理与避坑指南 在GNSS数据处理领域,GAMIT/GLOBK作为科研和工程项目的核心工具链,其精度和可靠性高度依赖于各类表文件的及时更新。然而,许多中高级用户在实际操作中常陷…...
的注册表锁定机制与长期试用方案)
深度技术解析:IDM激活脚本(IAS)的注册表锁定机制与长期试用方案
深度技术解析:IDM激活脚本(IAS)的注册表锁定机制与长期试用方案 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script Internet Dow…...
告别Transformer?手把手复现SegNeXt语义分割模型(附PyTorch代码)
从零实现SegNeXt:用纯卷积架构挑战Transformer的语义分割霸主地位 在计算机视觉领域,语义分割技术正经历着一场静默的革命。当大多数研究者将目光聚焦于Transformer架构时,SegNeXt却用纯粹的卷积神经网络(CNN)设计刷新…...

NSC_BUILDER:Switch游戏文件管理的全能解决方案
NSC_BUILDER:Switch游戏文件管理的全能解决方案 【免费下载链接】NSC_BUILDER Nintendo Switch Cleaner and Builder. A batchfile, python and html script based in hacbuild and Nuts python libraries. Designed initially to erase titlerights encryption fro…...

LaTeX排版踩坑记:用了soul包高亮,为什么一加\cite就报错?
LaTeX排版进阶:soul包高亮冲突的底层原理与系统化解决方案 当你正在用LaTeX优雅地排版论文,突然在引用文献时遭遇神秘的报错——这种体验就像穿着正装踩到香蕉皮。soul包作为文本装饰的瑞士军刀,其高亮和删除线功能深受喜爱,但一旦…...
)
仅剩最后23套田间网关固件兼容包!Python农业物联网部署必备的8个设备驱动补丁(含Raspberry Pi 5专用版)
第一章:田间网关固件兼容包的农业物联网部署意义 在农业物联网(Agri-IoT)规模化落地过程中,田间网关作为边缘侧核心枢纽,承担着多源异构传感器数据汇聚、协议转换、本地决策与上云协同等关键职能。然而,我国…...

Meixiong Niannian与SpringBoot微服务架构
Meixiong Niannian与SpringBoot微服务架构 1. 引言 在当今快速发展的AI应用领域,如何将强大的画图引擎无缝集成到企业级系统中是一个关键挑战。Meixiong Niannian作为一款高性能的AI画图引擎,能够生成高质量的图像内容,而SpringBoot微服务架…...
风格化研究:模拟Typora等工具的极简文档配图)
ABYSSAL VISION(Flux.1-Dev)风格化研究:模拟Typora等工具的极简文档配图
ABYSSAL VISION(Flux.1-Dev)风格化研究:模拟Typora等工具的极简文档配图 不知道你有没有过这样的体验:写技术文档或者博客的时候,文字部分洋洋洒洒,逻辑清晰,但一到需要配图说明的地方就卡壳了…...

别再乱改文件夹权限了!深入理解IIS应用程序池标识与ASP.NET临时目录的权限管理
深入解析IIS应用程序池权限管理:从临时目录到生产环境的最佳实践 当你在IIS中部署ASP.NET应用时,是否遇到过这样的错误:"当前标识(IIS APPPOOL\DefaultAppPool)没有对Temporary ASP.NET Files的写访问权限"?这个看似简单…...