搭建 es 集群
一、VMware准备机器
首先准备三台机器
这里我直接使用 VMware 构建三个虚拟机 都是基于 CentOS7
然后创建新用户
部署 es 需要单独创建一个用户,我这里在构建虚拟机的时候直接创建好了
然后将安装包上传
可以使用 rz 命令上传,也可以使用工具上传
工具包地址:链接:https://pan.baidu.com/s/1sGJW4jErofM3aj2CeU1ncg?pwd=eo6a
提取码:eo6a
上传后进行解压
三台机器都需要
tar zxvf elasticsearch-7.17.3-linux-x86_64.tar.gz 解压完成

二、配置 jdk
es7 以上内置了 jdk 环境,

但是需要配置一下:
# linux 进入用户主目录,比如/home/heyue/es/目录下,设置用户级别的环境变量
vim .bash_profile
#设置ES_JAVA_HOME和ES_HOME的路径
export ES_JAVA_HOME=/home/heyue/es/elasticsearch-7.17.3/jdk
export ES_HOME=/home/heyue/es/elasticsearch-7.17.3
export PATH=$PATH:/home/heyue/es/elasticsearch-7.17.3/jdk/bin
#执行以下命令使配置生效
source .bash_profile三、先单机启动
这里可以先启动三台单机的 es
然后配置 ElasticSearch
配置 elasticsearch.yaml 文件
vim elasticsearch.yml#开启远程访问
network.host: 0.0.0.0
#单节点模式 初学者建议设置为此模式
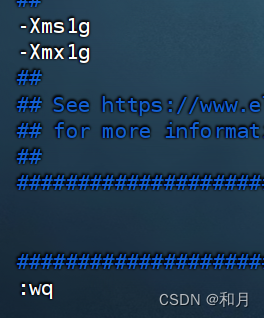
discovery.type: single-node修改 JVM 内存 我这里内存比较小,可以根据自己服务器情况进行设置
修改config/jvm.options配置文件,调整jvm堆内存大小
启动 es
bin/elasticsearch # -d 后台启动
bin/elasticsearch -d启动成功后通过浏览器访问
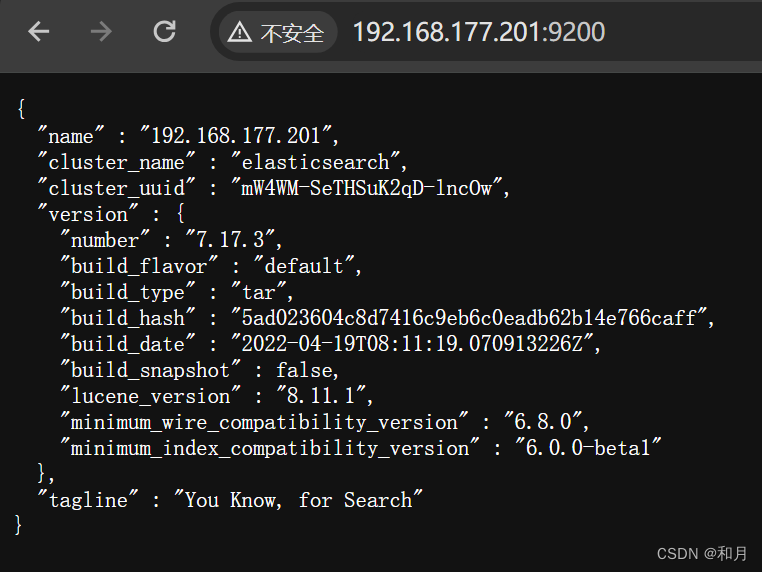
如果访问不通,可以看下防火墙端口是否开放:
添加防火墙规则:
打开端口,例如打开端口 9200(HTTP):
sudo firewall-cmd --zone=public --add-port=9200/tcp --permanent重新加载防火墙规则以应用更改:
sudo firewall-cmd --reload查看已打开的端口:
sudo firewall-cmd --list-ports然后可以看到 我这里三台 单机 es 已经启动成功

四、安装 kibana
然后随便找一台机器安装 kibana
同样的上传压缩包,解压
修改配置文件
vim config/kibana.yml修改一下几个地方
端口:
![]()
网卡监听:
![]()
es URL:
![]()
中文:
![]()
然后启动 kibana
nohup bin/kibana &
可以看到启动成功
这里注意,别忘了 开放端口 5601

五、集群配置
域名映射
可以先进行域名映射,便于后面维护
执行命令:
vim /etc/hosts注意:这里如果其实文件只读,可以对文件增加写入权限,也可以使用 root 进行修改
添加以下配置:
192.168.177.201 es-node1
192.168.177.201 es-node2
192.168.177.201 es-node3
三台机器同样的操作
然后修改 elasticsearch.yml 配置
首先把刚刚单机配置注释
![]()
其他配置:
# 指定集群名称3个节点必须一致
cluster.name: es-cluster
#指定节点名称,每个节点名字唯一
node.name: node-1
#是否有资格为master节点,默认为true
node.master: true
#是否为data节点,默认为true
node.data: true
# 绑定ip,开启远程访问,可以配置0.0.0.0
network.host: 0.0.0.0
#指定web端口
#http.port: 9200
#指定tcp端口
#transport.tcp.port: 9300
#用于节点发现
discovery.seed_hosts: ["es-node1", "es-node2", "es-node3"]
#7.0新引入的配置项,初始仲裁,仅在整个集群首次启动时才需要初始仲裁。
#该选项配置为node.name的值,指定可以初始化集群节点的名称
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#解决跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"配置好之后,先 kill 掉刚刚启动的进程,三台机器同样的操作

!!!注意修改完成之后,一定一定要记得切换用户,不要使用 root!不要使用 root!不要使用 root!不要使用 root!不要使用 root!不要使用 root!
然后由于刚刚进行单机启动了,所以还需要删除 data 文件夹
# 注意:如果运行过单节点模式,需要删除data目录, 否则会导致无法加入集群
rm -rf data
# 启动ES服务 bin/elasticsearch -d
重新启动:
bin/elasticsearch -d报错以及解决方案
发现报错可以按照以下方案解决:
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错

然后进行配置:
注意需要先切换到 root
#切换到root用户
vim /etc/security/limits.conf末尾添加如下配置:* soft nofile 65536* hard nofile 65536* soft nproc 4096* hard nproc 4096[2]: max number of threads [1024] for user [es] is too low, increase to at least [4096]
无法创建本地线程问题,用户最大可创建线程数太小
vim /etc/security/limits.d/20-nproc.conf改为如下配置:
* soft nproc 4096[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
最大虚拟内存太小,调大系统的虚拟内存
vim /etc/sysctl.conf
追加以下内容:
vm.max_map_count=262144
保存退出之后执行如下命令:
sysctl -p[4]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
缺少默认配置,至少需要配置discovery.seed_hosts/discovery.seed_providers/cluster.initial_master_nodes中的一个参数.
- discovery.seed_hosts: 集群主机列表
- discovery.seed_providers: 基于配置文件配置集群主机列表
- cluster.initial_master_nodes: 启动时初始化的参与选主的node,生产环境必填
vim config/elasticsearch.yml
#添加配置
discovery.seed_hosts: ["127.0.0.1"]
cluster.initial_master_nodes: ["node-1"]#或者指定配置单节点(集群单节点)
discovery.type: single-node[5]

注意:es默认不能用root用户启动,生产环境建议为elasticsearch创建用户。
#为elaticsearch创建用户并赋予相应权限
adduser es
passwd es
chown -R es:es elasticsearch-7.17.3配置完成后,注意,一定一定 要记得切换用户,es 不支持 root 启动
如果已经使用 root 启动报错了,需要先执行以下命令进行替换
回到 es 文件夹,执行以下命令,里面的 heyue 换成自己的用户名
chown -R heyue:heyue elasticsearch-7.17.3如果出现以下信息,那么恭喜,集群搭建成功

六、更新 kibana 配置
然后还需要修改一下 kibana 配置,配置为集群
vim config/kibana.ymlelasticsearch.hosts: ["http://192.168.65.174:9200","http://192.168.65.192:9200","http://192.168.65.204:9200"]
七、安装 Cerebro 客户端
先上传,然后解压
unzip cerebro-0.9.4.zip
解压完成后直接启动
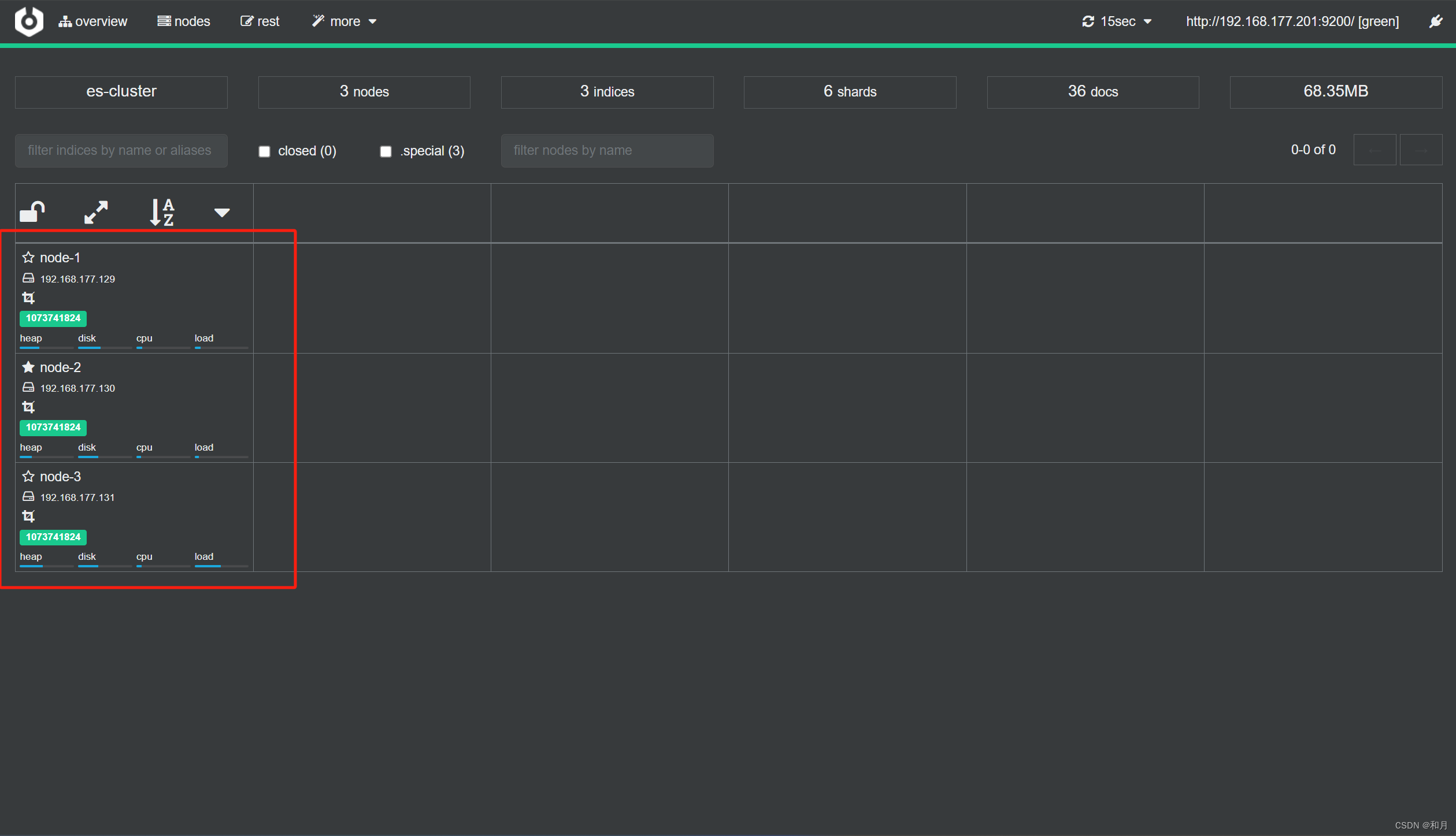
nohup bin/cerebro > cerebro.log &然后页面上输入 es 地址链接

到这里,看到这个页面,恭喜 es 集群已经完成搭建完成
 这里是基于原生安装包的方式进行搭建,基于 docker 搭建也是一样的,使用docker 启动三个单机,然后修改里面的配置文件即可
这里是基于原生安装包的方式进行搭建,基于 docker 搭建也是一样的,使用docker 启动三个单机,然后修改里面的配置文件即可
未来的自己一定会感谢今天努力的自己,加油,我们一起进步!!!
相关文章:
搭建 es 集群
一、VMware准备机器 首先准备三台机器 这里我直接使用 VMware 构建三个虚拟机 都是基于 CentOS7 然后创建新用户 部署 es 需要单独创建一个用户,我这里在构建虚拟机的时候直接创建好了 然后将安装包上传 可以使用 rz 命令上传,也可以使用工具上传 工…...

Android弹出通知
发现把Android通知渠道的重要性设置为最高时,当发送通知时,通知能直接弹出来显示,以前一直搞不明白为什么别的app的通知可以弹出来,我的不行,搞了半天原来是这个属性在作怪,示例如下: class Ma…...

如何用 UDP 实现可靠传输?并以LabVIEW为例进行说明
UDP(用户数据报协议)本身是一个无连接的、不可靠的传输协议,它不提供数据包的到达确认、排序保证或重传机制。因此,如果要在UDP上实现可靠传输,就需要在应用层引入额外的机制。以下是一些常见的方法: 确认和…...

【任职资格】某大型商业金融银行任职资格体系搭建项目纪实
【客户背景】某大型商业金融银行位于南方某省,成立于上个世纪九十年代,是一家具有独立法人资格的股份制商业银行,经过多年发展,下辖20多家分行,近200多个营业网点,并于21世纪初成功上市,规模不断…...

如何利用IP地址分析风险和保障网络安全
随着网络攻击的不断增加和演变,保障网络安全已经成为了企业和组织不可忽视的重要任务。在这样的背景下,利用IP地址分析风险和建立IP风险画像标签成为了一种有效的手段。本文将深入探讨IP风险画像标签的作用以及如何利用它来保障网络安全。 IP风险画像查…...

轧钢自动化中的智能仪器:监控、控制和优化新视角
摘要:轧钢自动化是现在及未来的发展趋势,而自动化的轧钢发展,更是离不开形形色色的智能仪器,本文来看看那些应用于轧钢生产中的测量仪。 关键词:智能仪器,在线测量仪,测径仪,测宽仪,测厚仪,测长仪,工业数据分析采集软件…...

第十四届蓝桥杯省赛C++B组题解
考点 暴力枚举,搜索,数学,二分,前缀和,简单DP,优先队列,链表,LCA,树上差分 A 日期统计 暴力枚举: #include<bits/stdc.h> using namespace std; int …...

语音控制模块_雷龙发展
一 硬件原理 1,串口 uart串口控制模式,即异步传送收发器,通过其完成语音控制。 发送uart将来自cpu等控制设备的并行数据转换为串行形式,并将其串行发送到接收uart,接收uart然后将串行数据转换为接收数据接收设备的并行…...
idea 开发serlvet班级通讯录管理系统idea开发mysql数据库web结构计算机java编程layUI框架开发
一、源码特点 idea开发 java servlet 班级通讯录管理系统是一套完善的web设计系统mysql数据库 系统采用serlvetdaobean mvc 模式开发,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 servlet 班…...

Python高级语法
Python高级语 1 列表推导式1.1 什么是列表推导式1.2 列表推导式的使用 2 字典推导式2.1 什么是字典推导式2.2 字典推导式的使用 3 元组推导式4 集合推导式5 三元表达式5.1 什么是三元表达式5.2 三元表达式的使用 1 列表推导式 1.1 什么是列表推导式 列表推导式的英文…...
HTML5语义化元素
在HTML5之前,网站的分布层级有哪些呢? nav,header,main,footer 这样做有一个弊端 我们往往过多的使用div,通过ID或class来区分元素 对于浏览器来说这些元素不够语义化 对于我来说搜索引擎来说,不…...

Android 性能优化——APP启动优化
一、APP启动流程 首先在《Android系统和APP启动流程》中我们介绍了 APP 的启动流程,但都是 FW 层的流程,这里我们主要分析一下在 APP 中的启动流程。要了解 APP 层的启动流程,首先要了解 APP 启动的分类。 1、启动分类 冷启动 应用从头开始…...
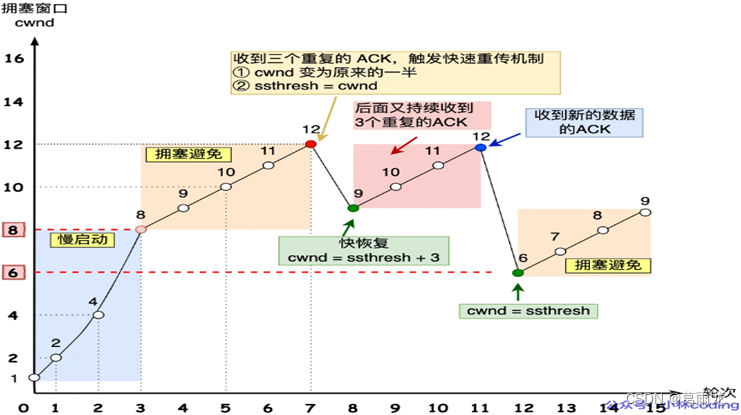
计算机网络:TCP篇
计网tcp部分面试总结 tcp报文格式: 序列号:通过SYN传给接收端,当SYN为1,表示请求建立连接,且设置序列号初值,后面没法送一次数据,就累加数据大小,保证包有序。 确认应答号&#x…...

【NLP11-迁移学习】
1、了解迁移学习中的有关概念 1.1、预训练模型(pretrained model) 一般情况下预训练模型都是大型模型,具备复杂的网络结构,众多的参数量,以及在足够大的数据集下进行训练而产生的模型。在NLP领域,预训练模型往往是语…...

Android11 FallbackHome启动和关闭流程分析
Android 7.0引入了新特性:Direct Boot Mode,设备启动后进入的一个新模式,直到用户解锁(unlock)设备此阶段结束。在这个模式下,系统调用 resolveHomeActivity 找到的是FallbackHome ,而不是我们的…...

elasticsearch-java api 8 升级
es client api 升级 背景 公司项目从sring-boot2 升级到了spring-boot3 ,es的服务端也跟着升级到了es8 ,而es的客户端7和服务端8 是不兼容的, 客户端es 7使用的是: elasticsearch-rest-high-level-client es 8 升级到…...

HCIA_IP路由基础问题?
目录 1. 什么是路由?2. 什么是路由器?3. 什么是路由信息?4. 路由器信息和路由表的区别?5. 路由表的生成方式?6.直连路由生效条件是什么?7.Inloopback0是什么接口?8.最优路由选择的原则ÿ…...

(黑马出品_高级篇_01)SpringCloud+RabbitMQ+Docker+Redis+搜索+分布式
(黑马出品_高级篇_01)SpringCloudRabbitMQDockerRedis搜索分布式 微服务技术——保护 今日目标1.初识Sentinel1.1.雪崩问题及解决方案1.2.服务保护技术对比1.3.Sentinel介绍和安装1.3.1.初识Sentinel1.3.2.安装Sentinel 1.…...
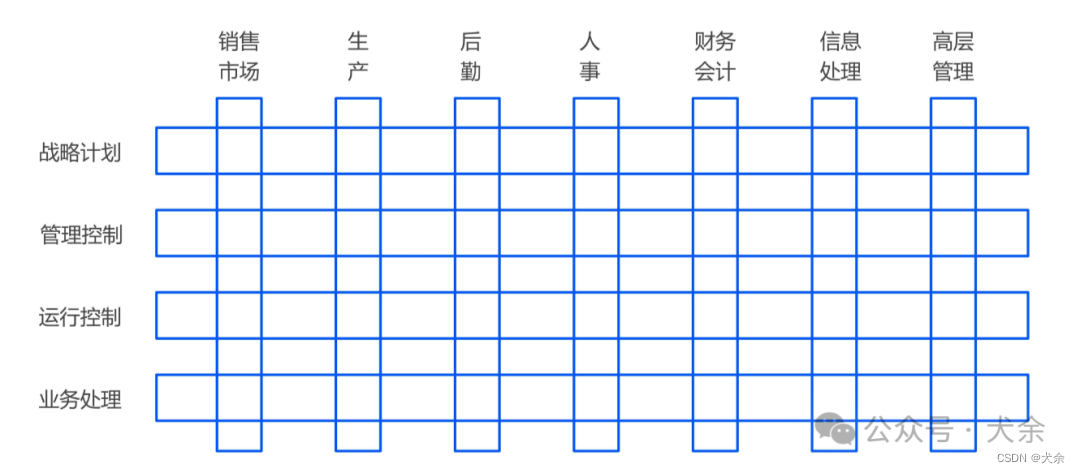
高架学习笔记之信息系统分类概览
目录 零、前言 一、业务处理系统(TPS) 概念 功能 特点 二、管理信息系统(MIS) 概念 功能 组成 三、决策支持系统(DSS) 概念 功能 特点 组成 1. 数据仓库 2. 数据挖掘工具 3. 决策模型 4. 可视化界面 四、专家系统(ES) 概念 特点 组成 求解过程 专家系统…...

2023新版mapinfo美化电子地图 新版2013Arcgis shp电子地图 下载
2023新版MapInfo和电子地图美化,以及2013版ArcGIS的SHP电子地图设计,是地理信息系统(GIS)领域中的两个重要话题。下面将分别对这两个主题进行描述。 样图: 链接:https://pan.baidu.com/s/1WB4AGsycyBGagVq5…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...