ElasticSearch简介及常见用法
简介
Elasticsearch 是 Elastic Stack 核心的分布式搜索和分析引擎。 Logstash 和 Beats 有助于收集、聚合和丰富您的数据并将其存储在 Elasticsearch 中。 Kibana 使您能够以交互方式探索、可视化和分享对数据的见解,并管理和监控堆栈。 Elasticsearch 可以快速索引、搜索和分析海量数据。
Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
官方文档(推荐):官方文档链接
官方中文:官方中文文档链接
社区中文:xiaoleilu.com、codingdict.com
一、基本概念
1、Index(索引)
动词:相当于 MySQL 中的 insert;
名词:相当于 MySQL 中的 Database。
2、Type(类型)
在 Index(索引)中,可以定义一个或多个类型。类似于 MySQL 中的 Table,同种类型的数据放在一起。
3、Document(文档)
保存在某个索引(Index)下,某种类型(Type)的一个数据(Document),文档是 JSON 格式的,Document 就像是 MySQL 中的某个 Table 里面的内容。
二、Docker 安装 Es
1、下载镜像文件
docker pull elasticsearch:8.12 :存储和检索数据
docker pull kibana:8.12 :可视化检索数据
2、创建实例
1.ElasticSearch
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml
chmod -R 777 /mydata/elasticsearch/ #保证权限
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \ #设置初始内存和占用最大内存
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:8.12
2.Kibana
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://xxx:9200 -p 5601:5601 \
-d kibana:8.12
#xxx为自己的虚拟机地址
三、初步检索
1、_cat
GET /_cat/nodes:查看所有节点
GET /_cat/health:查看 es 健康状况
GET /_cat/master:查看主节点
GET /_cat/indices:查看所有索引 show databases
2、索引一个文档(保存)
在 customer 索引下的 external 类型下保存 1 号数据为:
POST customer/external/1
{
"name": "John Doe"
}
#PUT 和 POST 都可以,
#POST 新增。如果不指定 id,会自动生成 id。指定 id 就会修改这个数据,并新增版本号
#PUT 可以新增可以修改。PUT 必须指定 id;由于 PUT 需要指定 id,我们一般都用来做修改
#操作,不指定 id 会报错。
3、查询文档
GET customer/external/1
结果:
{ "_index": "customer", //在哪个索引"_type": "external", //在哪个类型"_id": "1", //记录 id"_version": 2, //版本号"_seq_no": 1, //并发控制字段,每次更新就会+1,用来做乐观锁"_primary_term": 1, //同上,主分片重新分配,如重启,就会变化"found": true, "_source": { //真正的内容"name": "John Doe"}
}
4、更新文档
POST customer/external/1/_update
{ "doc":{ "name": "John Doew"}
}
或者
POST customer/external/1
{ "name": "John Doe2"
}
或者
PUT customer/external/1
{ "name": "John Doe"
}
不同:POST 操作会对比源文档数据,如果相同不会有什么操作,文档 version 不增加PUT 操作总会将数据重新保存并增加 version 版本;带_update 对比元数据如果一样就不进行任何操作。
看场景:
对于大并发更新,不带 _update;
对于大并发查询偶尔更新,带 _update;对比更新,重新计算分配规则。
5、删除文档&索引
DELETE customer/external/1
DELETE customer
6、bulk 批量 API
POST customer/external/_bulk
{"index":{"_id":"1"}}
{"name": "John Doe" }
{"index":{"_id":"2"}}
{"name": "Jane Doe" }
#语法格式:
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
四、进阶索引
1、SearchAPI
ES 支持两种基本方式检索 :
- 一个是通过使用 REST request URI 发送搜索参数(uri+检索参数)
- 另一个是通过使用 REST request body 来发送它们(uri+请求体)
检索信息
- 请求参数方式检索
GET bank/_search?q=*&sort=account_number:asc
#响应结果解释:
took - Elasticsearch 执行搜索的时间(毫秒)
time_out - 告诉我们搜索是否超时
_shards - 告诉我们多少个分片被搜索了,以及统计了成功/失败的搜索分片
hits - 搜索结果
hits.total - 搜索结果
hits.hits - 实际的搜索结果数组(默认为前 10 的文档)
sort - 结果的排序 key(键)(没有则按 score 排序)
score 和 max_score –相关性得分和最高得分(全文检索用)
- uri+请求体进行检索
GET bank/_search
{ "query": { "match_all": {}},"sort": [{ "account_number": { "order": "desc"}}]
}
2、Query DSL
(1) 基本语法格式
Elasticsearch 提供了一个可以执行查询的 Json 风格的 DSL(domain-specific language 领域特定语言)。这个被称为 Query DSL。该查询语言非常全面,并且刚开始的时候感觉有点复杂,真正学好它的方法是从一些基础的示例开始的。
- 一个查询语句 的典型结构:
{QUERY_NAME: {ARGUMENT: VALUE, ARGUMENT: VALUE,... }
}
- 如果是针对某个字段,那么它的结构如下:
{QUERY_NAME: {FIELD_NAME: {ARGUMENT: VALUE, ARGUMENT: VALUE,... }}
}
比如:
GET bank/_search
{ "query": { "match_all": {}},"from": 0, "size": 5, "sort": [{ "account_number": { "order": "desc"}}]
}
其中:
- query 定义如何查询,
- match_all 查询类型【代表查询所有的所有】,es 中可以在 query 中组合非常多的查询类型完成复杂查询
- 除了 query 参数之外,我们也可以传递其它的参数以改变查询结果。如 sort,size
- from+size 限定,完成分页功能
- sort 排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准
其他常用的语法比如:
match【匹配查询】
match_phrase【短语匹配】
multi_match【多字段匹配】
bool【复合查询】
filter【结果过滤】
term【全文检索字段用 match,其他非 text 字段匹配用 term。】
aggregations【执行聚合】(最简单的聚合方法大致等于 SQL GROUPBY 和 SQL 聚合函数)
具体使用方法见官网:ElasticSearch官方文档链接
3、分词
一个 tokenizer(分词器)接收一个字符流,将之分割为独立的 tokens(词元,通常是独立的单词),然后输出 tokens 流。例如,whitespace tokenizer 遇到空白字符时分割文本。它会将文本 “Quick brown fox!” 分割为 [Quick, brown, fox!]。该tokenizer(分词器)还负责记录各个 term(词条)的顺序或 position 位置(用于 phrase 短语和 word proximity 词近邻查询),以及 term(词条)所代表的原始 word(单词)的 start
(起始)和 end(结束)的 character offsets(字符偏移量)(用于高亮显示搜索的内容)。Elasticsearch 提供了很多内置的分词器,可以用来构建 custom analyzers(自定义分词器)。
(1)安装 ik 分词器
进入 es 容器内部 plugins 目录
docker exec -it 容器 id /bin/bash
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-anal
ysis-ik-7.4.2.zip
unzip 下载的文件
rm –rf *.zip
mv elasticsearch/ ik
以确认是否安装好了分词器
cd ../bin
elasticsearch plugin list:即可列出系统的分词器
(2)测试分词器
使用默认,请观察结果
POST _analyze
{ "text": "我是中国人"
}
使用分词器,请观察结果
POST _analyze
{ "analyzer": "ik_smart", "text": "我是中国人"
}
具体使用技巧参考以下链接:ik分词器github链接
五、Elasticsearch-Rest-Client
1)、9300:TCP
spring-data-elasticsearch:transport-api.jar:
- springboot 版本不同, transport-api.jar 不同,不能适配 es 版本
- 7.x 已经不建议使用,8 以后就要废弃
2)、9200:HTTP
- JestClient:非官方,更新慢
- RestTemplate:模拟发 HTTP 请求,ES 很多操作需要自己封装,麻烦
- HttpClient:同上
- Elasticsearch-Rest-Client:官方 RestClient,封装了 ES 操作,API 层次分明,上手简单
最终选择 Elasticsearch-Rest-Client(elasticsearch-rest-high-level-client)
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html
1、SpringBoot 整合
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>8.12</version>
</dependency>
2、配置
@Bean
RestHighLevelClient client() {
RestClientBuilder builder = RestClient.builder(new HttpHost("自己的虚拟机地址", 9200, "http"));return new RestHighLevelClient(builder);
}
3、使用
参照官方文档:
@Test
void test1() throws IOException {Product product = new Product();product.setSpuName("华为");product.setId(10L);IndexRequest request = new IndexRequest("product").id("20").source("spuName","华为","id",20L);try {IndexResponse response = client.index(request, RequestOptions.DEFAULT);System.out.println(request.toString());IndexResponse response2 = client.index(request, RequestOptions.DEFAULT);} catch (ElasticsearchException e) {if (e.status() == RestStatus.CONFLICT) {}}
}
相关文章:

ElasticSearch简介及常见用法
简介 Elasticsearch 是 Elastic Stack 核心的分布式搜索和分析引擎。 Logstash 和 Beats 有助于收集、聚合和丰富您的数据并将其存储在 Elasticsearch 中。 Kibana 使您能够以交互方式探索、可视化和分享对数据的见解,并管理和监控堆栈。 Elasticsearch 可以快速索…...

js iframe获取documen中的对象为空问题
原因其实是iframe加载是需要时间的,它还没加载完我就在js中直接获取对象了,所以获取为空 var idocument.getElementById("iframe"); i.onloadfunction(){console.log(i.contentDocument)console.log(i.contentWindow.document.getElementById…...

vue3子父组件之间的调用
子组件: capacityIndex.vue 父组件: index.vue A.子组件获取父组件属性 1.在父组件中引用子组件 import capacityIndex from "./capacityIndex"; <capacityIndex :tankInfo"tankInfo" :deviceNameInfo"deviceNameInfo…...
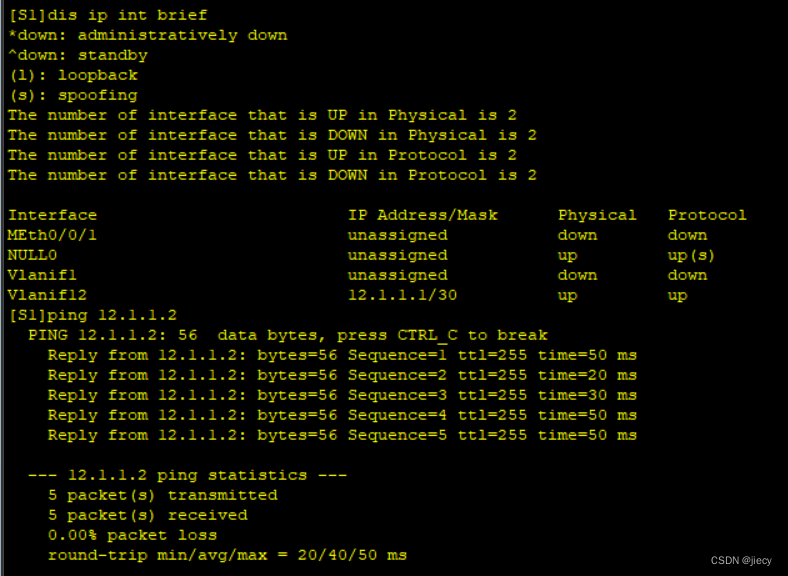
用 二层口 实现三层口 IP 通信的一个实现方法
我们一般用 undo portswitch 来将二层口转为三层口,但如果设备不支持的话,那么。。。 一、拓朴图: 二、实现方法: 起一个 vlan x,配置 vlanif地址,然后二层口划分到 vlan x 下,对端做同样的配置…...
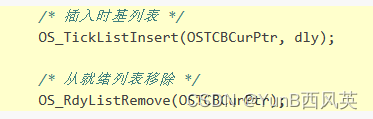
(学习日记)2024.03.12:UCOSIII第十四节:时基列表
写在前面: 由于时间的不足与学习的碎片化,写博客变得有些奢侈。 但是对于记录学习(忘了以后能快速复习)的渴望一天天变得强烈。 既然如此 不如以天为单位,以时间为顺序,仅仅将博客当做一个知识学习的目录&a…...

四.流程控制(顺序,分支,循环,嵌套)
c刚刚转过来的记得写在public static void main(String[] args)的花括号里 一.顺序结构 二.分支结构 if ,switch 1.if (条件判断) 2.if else 3.if else if else if ... else(它是一个一个否定来一个个执行判断的 4.s…...
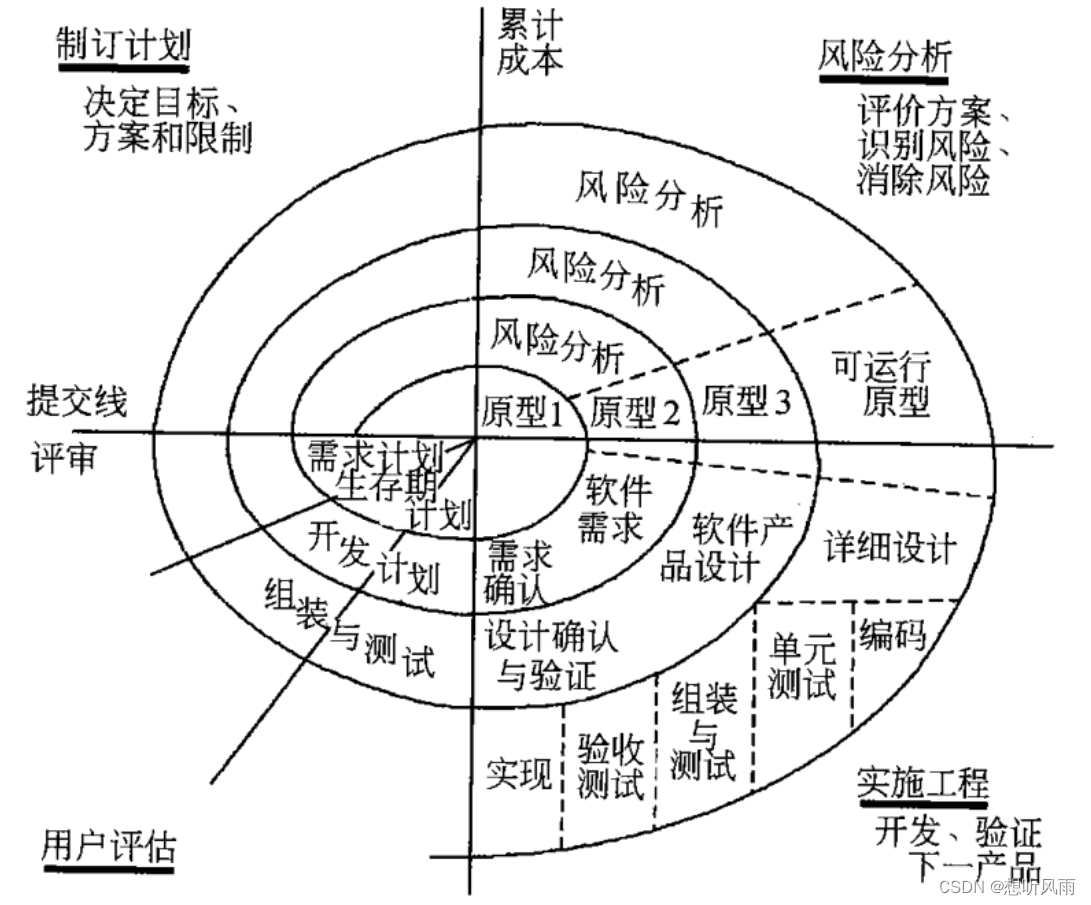
了解常用开发模型 -- 瀑布模型、螺旋模型、增量与迭代、敏捷开发
目录 瀑布模型 开发流程 开发特征 优缺点 适用场景 螺旋模型 开发流程 开发特征 优缺点 适用场景 增量与迭代开发 什么是增量开发?什么是迭代开发? 敏捷开发 什么是敏捷开发四原则(敏捷宣言)? 什么是 s…...

使用 Vue CLI 创建一个 Vue2 项目
全局安装 Vue CLI 参考官网 Vue CLI,安装命令如下 npm install -g vue/cli 目前 Vue CLI 的最新版本为 v5.0.8 创建 Vue2 项目 在希望创建项目的目录下打开命令行,键入命令 vue create my-project 其中 my-project 更改为自己需要的项目名 随后&a…...
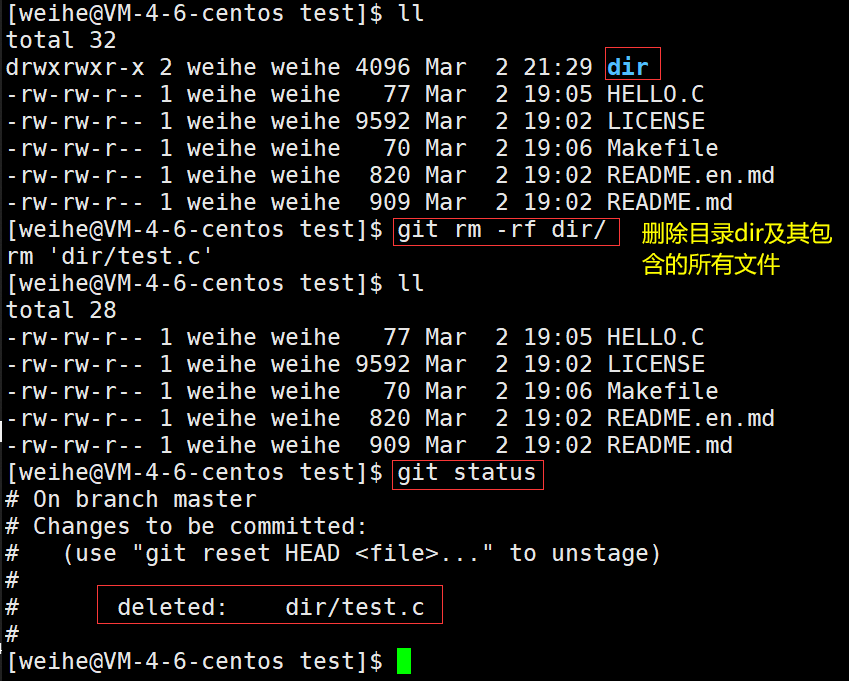
Linux工具 - 耀眼的git
~~~~ 前言耀眼的GitGit是什么(本质)Git出现的背景(本着开源的精神)在命令行中使用Git(Come on 来使用Git吧).git文件说明新建仓库git clone 克隆云端仓库到本地git addgit commit -mgit pushgit pullgit st…...

Spring Security的开发
文章目录 1,介绍2, 核心流程3, 核心原理3.1 过滤器链机制3.2 主体3.3 认证3.4 授权3.5 流程图4, 核心对象4.1 UserDetailsService 接口4.2 PasswordEncoder 接口4.3 hasAuthority方法4.4 hasAnyAuthority方法4.5 hasRole方法4.5 hasAnyRole方法5, 核心注解5.1 @PreAuthorize5.1…...
C语言 实用调试技巧
我们的博客已经更新到了数据结构,但是当我在深耕数据结构时我发现我在C语言是遗漏了一个重要的东西,那就是C语言的使用调试技巧。这篇博客对数据结构非常重要,请大家耐心观看。 1. 什么是bug? 第一次被发现的导致计算机错误的飞蛾…...

GPT的实现细节
关于GPT的代码细节,这里梳理了一下: 数据集构造 原始数据集schema: inputwho is your favorite basketball player? outputOf course Kobe Bryant!那么在构造训练集时,根据chunk size构造多个输入: input_1who is …...

docker安装Milvus
docker安装Milvus 拉去CPU版本的milvus镜像 $ sudo docker pull milvusdb/milvus:0.10.0-cpu-d061620-5f3c00 docker pull milvusdb/milvus:0.10.0-cpu-d061620-5f3c00 mkdir -p milvus/conf cd milvus/conf ls wget https://raw.githubusercontent.com/milvus-io/milvus/v0.1…...

HTML静态网页成品作业(HTML+CSS)——世博园介绍(2个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有2个页面。 二、作品演示 三、代…...

微信小程序订阅消息授权弹窗事件
微信小程序消息订阅授权弹窗事件 ,每次授权完成之后,只可以推送一条模板消息。 目录 1、HTML代码 2、JS代码 1、HTML代码 <button bindtap"openPopup" class"openPopup">订阅消息</button> 2、JS代码 // 是否设置过授…...
谷歌的后量子密码学威胁模型
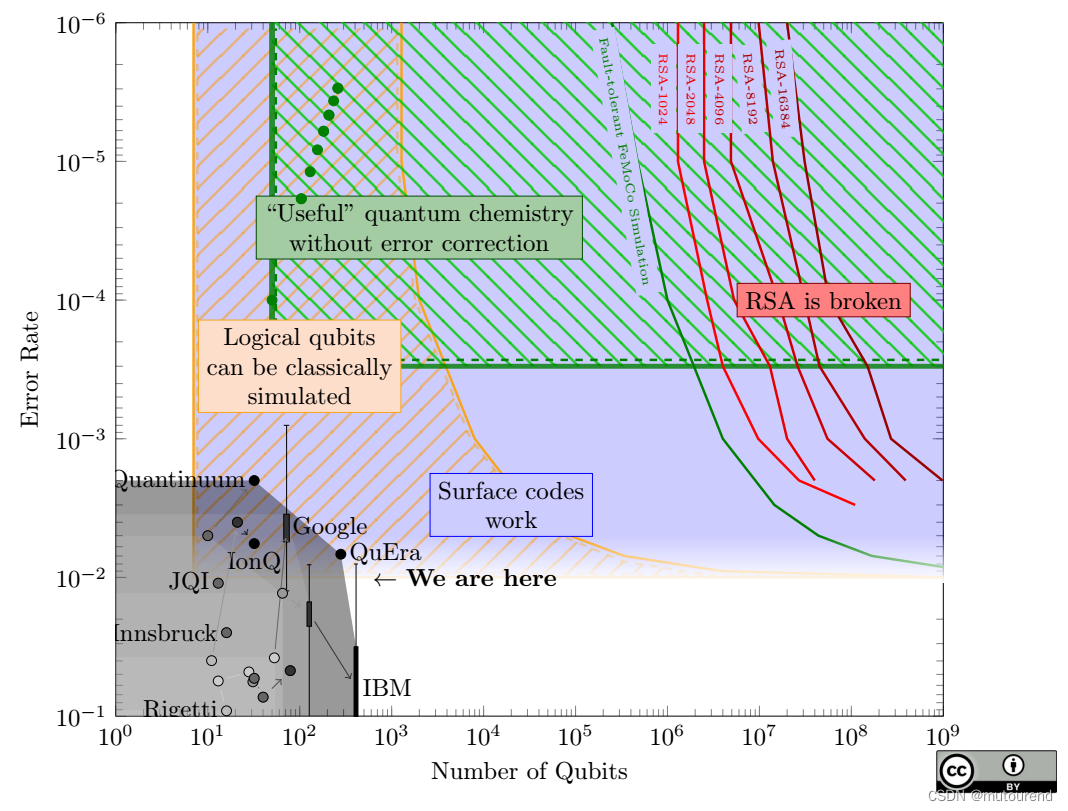
1. 引言 若现在不使用量子安全算法来加密数据,能够存储当前通信的攻击者最快十年内就能对其解密。这种先存储后解密的攻击是当前采用后量子密码学 (post-quantum cryptography,PQC) 背后的主要动机,但其他未来的量子计算威胁也需要一个深思熟…...

机器人在果园内行巡检仿真
文章目录 创建工作空间仿真果园场景搭建小车模型搭建将机器人放在仿真世界中创建工作空间 mkdir -p ~/catkin_ws/src cd ~/catkin_ws仿真果园场景搭建 cd ~/catkin_ws/src git clone https://gitcode.com/clearpathrobotics/cpr_gazebo.git小车模型搭建 DiffBot是一种具有两个…...
:十大排序算法(归并排序)c语言版)
蓝桥杯算法基础(14):十大排序算法(归并排序)c语言版
归并排序 基于分而治之的思想,拿两个已经有序的序列重新组合成一个新的有序序列. 这是一个简单的合并函数,需要两个序列都有序 //默认a和b数组都是有序的 //temp为一个数组的首地址 void mergeSort(int a[],int,alen,int b[],int blen,int* temp){int …...
力扣刷题(DAY09-DAY11)
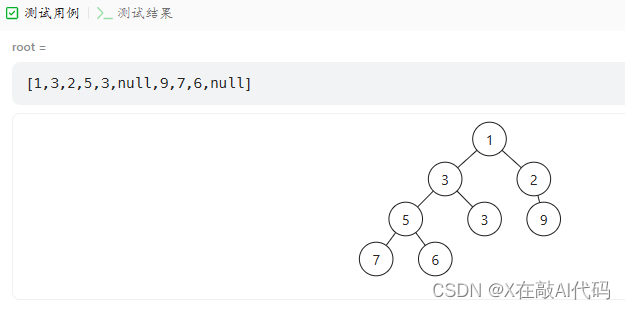
Day09 0958. 二叉树的完全性检验 知识点:完全二叉树:在一棵完全二叉树中,除了最后一层外,所有层都被完全填满,并且最后一层中的所有节点都尽可能靠左。最后一层(第 h 层)中可以包含 1 到 个节点…...

IPC之管道
什么是管道? 管道的本质是操作系统在内核中创建出的一块缓冲区,也就是内存 管道的应用 $ ps aux | grep xxx ps aux 的标准输出写到管道,grep 从管道这块内存中读取数据来作为它的一个标准输入,而且 ps 和 grep 之间是兄弟关系&a…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...

鸿蒙HarmonyOS 5军旗小游戏实现指南
1. 项目概述 本军旗小游戏基于鸿蒙HarmonyOS 5开发,采用DevEco Studio实现,包含完整的游戏逻辑和UI界面。 2. 项目结构 /src/main/java/com/example/militarychess/├── MainAbilitySlice.java // 主界面├── GameView.java // 游戏核…...

【实施指南】Android客户端HTTPS双向认证实施指南
🔐 一、所需准备材料 证书文件(6类核心文件) 类型 格式 作用 Android端要求 CA根证书 .crt/.pem 验证服务器/客户端证书合法性 需预置到Android信任库 服务器证书 .crt 服务器身份证明 客户端需持有以验证服务器 客户端证书 .crt 客户端身份…...

Selenium 查找页面元素的方式
Selenium 查找页面元素的方式 Selenium 提供了多种方法来查找网页中的元素,以下是主要的定位方式: 基本定位方式 通过ID定位 driver.find_element(By.ID, "element_id")通过Name定位 driver.find_element(By.NAME, "element_name"…...
新版NANO下载烧录过程
一、序言 搭建 Jetson 系列产品烧录系统的环境需要在电脑主机上安装 Ubuntu 系统。此处使用 18.04 LTS。 二、环境搭建 1、安装库 $ sudo apt-get install qemu-user-static$ sudo apt-get install python 搭建环境的过程需要这个应用库来将某些 NVIDIA 软件组件安装到 Je…...