AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.03.10-2024.03.15
论文目录~
- 1.3D-VLA: A 3D Vision-Language-Action Generative World Model
- 2.PosSAM: Panoptic Open-vocabulary Segment Anything
- 3.Anomaly Detection by Adapting a pre-trained Vision Language Model
- 4.Introducing Routing Functions to Vision-Language Parameter-Efficient Fine-Tuning with Low-Rank Bottlenecks
- 5.AVIBench: Towards Evaluating the Robustness of Large Vision-Language Model on Adversarial Visual-Instructions
- 6.Annotation Free Semantic Segmentation with Vision Foundation Models
- 7.Select and Distill: Selective Dual-Teacher Knowledge Transfer for Continual Learning on Vision-Language Models
- 8.Anatomical Structure-Guided Medical Vision-Language Pre-training
- 9.PoIFusion: Multi-Modal 3D Object Detection via Fusion at Points of Interest
- 10.Are Vision Language Models Texture or Shape Biased and Can We Steer Them?
- 11.The First to Know: How Token Distributions Reveal Hidden Knowledge in Large Vision-Language Models?
- 12.VisionGPT: Vision-Language Understanding Agent Using Generalized Multimodal Framework
- 13.DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation
- 14.AIGCs Confuse AI Too: Investigating and Explaining Synthetic Image-induced Hallucinations in Large Vision-Language Models
- 15.An Empirical Study of Parameter Efficient Fine-tuning on Vision-Language Pre-train Model
- 16.Language-Driven Visual Consensus for Zero-Shot Semantic Segmentation
- 17.TaskCLIP: Extend Large Vision-Language Model for Task Oriented Object Detection
- 18.Beyond Text: Frozen Large Language Models in Visual Signal Comprehension
- 19.MoPE-CLIP: Structured Pruning for Efficient Vision-Language Models with Module-wise Pruning Error Metric
- 20.Synth 2 ^2 2: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
- 21.Unleashing Network Potentials for Semantic Scene Completion
- 22.MoAI: Mixture of All Intelligence for Large Language and Vision Models
- 23.In-context learning enables multimodal large language models to classify cancer pathology images
- 24.KEBench: A Benchmark on Knowledge Editing for Large Vision-Language Models
- 25.Towards Zero-shot Human-Object Interaction Detection via Vision-Language Integration
- 26.SELMA: Learning and Merging Skill-Specific Text-to-Image Experts with Auto-Generated Data
- 27.The Power of Noise: Toward a Unified Multi-modal Knowledge Graph Representation Framework
- 28.3D Semantic Segmentation-Driven Representations for 3D Object Detection
- 29.FontCLIP: A Semantic Typography Visual-Language Model for Multilingual Font Applications
- 30.Multi-modal Semantic Understanding with Contrastive Cross-modal Feature Alignment
1.3D-VLA: A 3D Vision-Language-Action Generative World Model
标题:3D-VLA:三维视觉-语言-动作生成世界模型
author:Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, Chuang Gan
publish:Project page: https://vis-www.cs.umass.edu/3dvla/
date Time:2024-03-14
paper pdf:http://arxiv.org/pdf/2403.09631v1
摘要:
最近的视觉-语言-动作(VLA)模型依赖于二维输入,缺乏与更广阔的三维物理世界的整合。此外,它们通过学习从感知到行动的直接映射来进行行动预测,忽视了世界的巨大动态以及行动与动态之间的关系。与此相反,人类拥有世界模型,可以描绘对未来场景的想象,并据此规划行动。为此,我们提出了3D-VLA,引入了一系列新的体现基础模型,通过生成世界模型将三维感知、推理和行动无缝连接起来。具体来说,3D-VLA 建立在基于三维的大型语言模型(LLM)之上,并引入了一组交互标记来与具身环境互动。此外,为了给模型注入生成能力,我们训练了一系列具身扩散模型,并将它们与 LLM 对齐,以预测目标图像和点云。为了训练我们的 3D-VLA 模型,我们从现有的机器人数据集中提取了大量与 3D 相关的信息,从而策划了一个大规模的 3D 体感指令数据集。我们在保留的数据集上进行的实验证明,3D-VLA 显著提高了体现环境中的推理、多模态生成和规划能力,展示了其在现实世界应用中的潜力。
2.PosSAM: Panoptic Open-vocabulary Segment Anything
标题:PosSAM: 全景开放词汇分割任意物体
author:Vibashan VS, Shubhankar Borse, Hyojin Park, Debasmit Das, Vishal Patel, Munawar Hayat, Fatih Porikli
date Time:2024-03-14
paper pdf:http://arxiv.org/pdf/2403.09620v1
摘要:
在本文中,我们介绍了一种开放式词汇全视角分割模型,它在端到端框架中有效地统一了任意分割模型(SAM)和视觉语言 CLIP 模型的优势。虽然 SAM 擅长生成空间感知遮罩,但它的解码器在识别物体类别信息方面存在不足,往往会在没有额外指导的情况下进行过度分割。现有的方法通过使用多阶段技术和单独的模型来生成类别感知提示(如边界框或分割掩码),从而解决了这一局限性。我们提出的方法 PosSAM 是一种端到端模型,它利用 SAM 丰富的空间特征生成实例感知掩码,并利用 CLIP 的语义区分特征进行有效的实例分类。具体来说,我们解决了 SAM 的局限性,并提出了一种新颖的本地判别池(LDP)模块,该模块利用与类别无关的 SAM 和类别感知的 CLIP 特征来实现无偏见的开放词汇分类。此外,我们还引入了掩码感知选择性集合(MASE)算法,该算法可自适应地提高生成掩码的质量,并在每幅图像的推理过程中提高开放词汇分类的性能。我们进行了广泛的实验,证明我们的方法在多个数据集上具有很强的泛化特性,与 SOTA 开放词汇全景分割方法相比,我们的方法取得了最先进的性能,并有大幅提高。在COCO到ADE20K和ADE20K到COCO的设置中,PosSAM的性能都大大优于以前的先进方法,分别为2.4 PQ和4.6 PQ。项目网站:https://vibashan.github.io/possam-web/.
3.Anomaly Detection by Adapting a pre-trained Vision Language Model
标题:通过调整预先训练的视觉语言模型进行异常检测
author:Yuxuan Cai, Xinwei He, Dingkang Liang, Ao Tong, Xiang Bai
date Time:2024-03-14
paper pdf:http://arxiv.org/pdf/2403.09493v1
摘要:
最近,大型视觉和语言模型在适应许多下游任务时取得了成功。在本文中,我们提出了一个名为 CLIP-ADA 的统一框架,用于通过调整预训练的 CLIP 模型进行异常检测。为此,我们做了两项重要改进:1) 为了在多类别工业图像中实现统一的异常检测,我们引入了可学习提示,并建议通过自监督学习将其与异常模式关联起来。2) 为了充分利用 CLIP 的表示能力,我们引入了异常区域细化策略,以提高定位质量。在测试过程中,通过直接计算可学习提示的表示与图像之间的相似度来定位异常。综合实验证明了我们框架的优越性,例如,我们在 MVTec-AD 和 VisA 上的异常检测和定位分别达到了 97.5/55.6 和 89.3/33.1 的一流水平。此外,我们提出的方法还在训练数据较少的情况下取得了令人鼓舞的性能,而这一点更具挑战性。
4.Introducing Routing Functions to Vision-Language Parameter-Efficient Fine-Tuning with Low-Rank Bottlenecks
标题:在视觉语言参数高效微调中引入路由函数,解决低库瓶颈问题
author:Tingyu Qu, Tinne Tuytelaars, Marie-Francine Moens
date Time:2024-03-14
paper pdf:http://arxiv.org/pdf/2403.09377v1
摘要:
主流的参数高效微调(PEFT)方法,如 LoRA 或 Adapter,可将模型的隐藏状态投射到较低的维度,使预先训练好的模型能够通过这一低阶瓶颈适应新数据。然而,涉及多种模态的 PEFT 任务,如视觉语言(VL)任务,不仅需要适应新数据,还需要学习不同模态之间的关系。针对 VL PEFT 任务,我们提出了一系列称为路由函数的操作,以增强低等级瓶颈中的 VL 对齐。路由函数采用线性运算,不引入新的可训练参数。我们对其行为进行了深入分析。在各种 VL PEFT 设置中,路由函数显著提高了原始 PEFT 方法的性能,在 VQAv2( RoBERTa large \text{RoBERTa}_{\text{large}} RoBERTalarge+ViT-L/16)上提高了 20% 以上,在 COCO Captioning(GPT2-medium+ViT-L/16)上提高了 30%。此外,在对 CLIP-BART 等预先训练的多模态模型进行微调时,我们还观察到在一系列 VL PEFT 任务中取得了较小但一致的改进。
5.AVIBench: Towards Evaluating the Robustness of Large Vision-Language Model on Adversarial Visual-Instructions
标题:AVIBench:在对抗性视觉指令上评估大型视觉语言模型的鲁棒性
author:Hao Zhang, Wenqi Shao, Hong Liu, Yongqiang Ma, Ping Luo, Yu Qiao, Kaipeng Zhang
date Time:2024-03-14
paper pdf:http://arxiv.org/pdf/2403.09346v1
摘要:
大型视觉语言模型(LVLM)在很好地响应用户的视觉指令方面取得了重大进展。然而,这些包含图像和文本的指令很容易受到有意和无意的攻击。尽管 LVLM 对此类威胁的鲁棒性至关重要,但目前在这一领域的研究仍然有限。为了弥补这一差距,我们引入了 AVIBench,这是一个旨在分析 LVLMs 在面对各种对抗性视觉指令(AVIs)时的鲁棒性的框架,包括四种基于图像的 AVIs、十种基于文本的 AVIs 和九种内容偏差 AVIs(如性别、暴力、文化和种族偏差等)。我们生成的 260K AVI 包含五类多模态能力(九项任务)和内容偏差。然后,我们对 14 个开源 LVLM 进行了综合评估,以评估它们的性能。AVIBench 也是从业人员评估 LVLM 对 AVI 的鲁棒性的便捷工具。我们的发现和广泛的实验结果揭示了 LVLM 的漏洞,并强调即使是 GeminiProVision 和 GPT-4V 等先进的闭源 LVLM 也存在固有偏差。这强调了增强 LVLM 的稳健性、安全性和公平性的重要性。源代码和基准将公开发布。
6.Annotation Free Semantic Segmentation with Vision Foundation Models
标题:利用视觉基础模型进行无注释语义分割
author:Soroush Seifi, Daniel Olmeda Reino, Fabien Despinoy, Rahaf Aljundi
date Time:2024-03-14
paper pdf:http://arxiv.org/pdf/2403.09307v1
摘要:
语义分割是最具挑战性的视觉任务之一,通常需要大量的训练数据和昂贵的像素级注释。随着基础模型,尤其是视觉语言模型的成功,最近的研究试图在不需要大规模训练或额外图像/像素级注释的情况下实现零镜头语义分割。在这项工作中,我们在自监督预训练视觉编码器的基础上建立了一个轻量级模块,将补丁特征与预训练文本编码器进行对齐。重要的是,我们利用现有的基础模型为任何语义分割数据集生成免费注释,并免费训练我们的对齐模块。我们使用 CLIP 检测对象,使用 SAM 生成高质量的对象掩码。我们的方法可以为任何预先训练好的视觉编码器提供基于语言的语义,而且只需最少的训练。我们的模块是轻量级的,使用基础模型作为唯一的监督来源,并在没有注释的情况下从少量训练数据中显示出令人印象深刻的泛化能力。
7.Select and Distill: Selective Dual-Teacher Knowledge Transfer for Continual Learning on Vision-Language Models
标题:选择与提炼:选择性双师知识传授,实现视觉语言模型的持续学习
author:Yu-Chu Yu, Chi-Pin Huang, Jr-Jen Chen, Kai-Po Chang, Yung-Hsuan Lai, Fu-En Yang, Yu-Chiang Frank Wang
date Time:2024-03-14
paper pdf:http://arxiv.org/pdf/2403.09296v1
摘要:
大规模视觉语言模型(VLM)在未见域数据上显示出强大的零点泛化能力。然而,当将预先训练好的视觉语言模型适应一系列下游任务时,它们很容易遗忘先前学习的知识,从而降低其零点分类能力。为了解决这个问题,我们提出了一种独特的选择性双教师知识转移框架,利用最新微调的 VLM 和原始预训练的 VLM 作为双教师,分别保留先前学习的知识和零点分类能力。由于只能访问未标注的参考数据集,我们提出的框架通过测量双教师 VLM 的特征差异来执行选择性知识提炼机制。因此,我们的选择性双教师知识蒸馏可以减轻对先前所学知识的灾难性遗忘,同时保留预训练 VLM 的零点能力。通过在基准数据集上进行大量实验,我们发现我们提出的框架在防止灾难性遗忘和零点退化方面优于最先进的持续学习方法。
8.Anatomical Structure-Guided Medical Vision-Language Pre-training
标题:解剖结构引导的医学视觉语言预训练
author:Qingqiu Li, Xiaohan Yan, Jilan Xu, Runtian Yuan, Yuejie Zhang, Rui Feng, Quanli Shen, Xiaobo Zhang, Shujun Wang
date Time:2024-03-14
paper pdf:http://arxiv.org/pdf/2403.09294v1
摘要:
通过视觉语言预训练学习医学视觉表征已取得显著进展。尽管取得了可喜的成绩,但它仍然面临着挑战,即局部配准缺乏可解释性和临床相关性,以及图像报告对的内部和外部表征学习不足。为了解决这些问题,我们提出了解剖结构引导(ASG)框架。具体来说,我们将原始报告解析为<解剖区域、发现、存在>三元组,并充分利用每个元素作为监督来加强表征学习。对于解剖区域,我们与放射科医生合作设计了一种自动解剖区域-句子配准范例,将其视为探索细粒度局部配准的最小语义单位。对于发现和存在,我们将它们视为图像标签,应用图像标签识别解码器将图像特征与每个样本中各自的标签关联起来,并构建用于对比学习的软标签,以改进不同图像-报告对的语义关联。我们在两个下游任务(包括五个公共基准)上对所提出的 ASG 框架进行了评估。实验结果表明,我们的方法优于最先进的方法。
9.PoIFusion: Multi-Modal 3D Object Detection via Fusion at Points of Interest
标题:PoIFusion:通过兴趣点融合进行多模态 3D 物体检测
author:Jiajun Deng, Sha Zhang, Feras Dayoub, Wanli Ouyang, Yanyong Zhang, Ian Reid
publish:NIL
date Time:2024-03-14
paper pdf:http://arxiv.org/pdf/2403.09212v1
摘要:
在这项工作中,我们提出了一个简单而有效的多模态三维物体检测框架–PoIFusion,用于将 RGB 图像和激光雷达点云的信息融合到兴趣点(缩写为 PoI)。在技术上,我们的 PoIFusion 遵循基于查询的物体检测范例,将物体查询表述为动态三维方框。PoIs由每个查询框随机生成,作为表示三维物体的关键点,并在多模态融合中扮演基本单元的角色。具体来说,我们将 PoIs 投射到每种模态的视图中,以采样相应的特征,并通过动态融合块在每个 PoI 上整合多模态特征。此外,我们还将来自同一查询框的 PoI 的特征汇总在一起,以更新查询特征。我们的方法避免了视图变换造成的信息丢失,并消除了计算密集型的全局关注,使多模态三维物体检测器更加适用。我们在 nuScenes 数据集上进行了大量实验,以评估我们的方法。值得注意的是,我们的PoIFusion实现了74.9%的NDS和73.4%的mAP,创造了多模态三维物体检测基准的最新记录。代码将通过 \url{https://djiajunustc.github.io/projects/poifusion} 提供。
10.Are Vision Language Models Texture or Shape Biased and Can We Steer Them?
标题:视觉语言模型是否存在纹理或形状偏差,我们能否引导它们?
author:Paul Gavrikov, Jovita Lukasik, Steffen Jung, Robert Geirhos, Bianca Lamm, Muhammad Jehanzeb Mirza, Margret Keuper, Janis Keuper
date Time:2024-03-14
paper pdf:http://arxiv.org/pdf/2403.09193v1
摘要:
视觉语言模型(VLM)在短短几年内极大地改变了计算机视觉模型的面貌,开启了一系列令人兴奋的新应用,包括零镜头图像分类、图像字幕和视觉问题解答。与纯粹的视觉模型不同,它们提供了一种通过语言提示访问视觉内容的直观方式。此类模型的广泛适用性促使我们思考它们是否也与人类视觉相一致–具体来说,它们在多大程度上通过多模态融合采用了人类引起的视觉偏差,或者它们是否只是继承了纯视觉模型的偏差。一个重要的视觉偏差是纹理与形状偏差,或者说局部信息比全局信息更重要。在本文中,我们研究了各种流行的 VLM 中的这种偏差。有趣的是,我们发现 VLM 通常比其视觉编码器更具形状偏差,这表明在多模态模型中,视觉偏差在一定程度上受到文本的调节。如果文字确实会影响视觉偏差,这就表明我们可能不仅能通过视觉输入,还能通过语言来引导视觉偏差:我们通过大量实验证实了这一假设。例如,仅通过提示,我们就能将形状偏差从最低的 49% 引导到最高的 72%。就目前而言,人类对形状的强烈偏好(96%)仍然是所有测试过的 VLM 无法达到的。
11.The First to Know: How Token Distributions Reveal Hidden Knowledge in Large Vision-Language Models?
标题:第一个知道:代词分布如何揭示大型视觉语言模型中的隐藏知识?
author:Qinyu Zhao, Ming Xu, Kartik Gupta, Akshay Asthana, Liang Zheng, Stephen Gould
publish:Under review. Project page:
https://github.com/Qinyu-Allen-Zhao/LVLM-LP
date Time:2024-03-14
paper pdf:http://arxiv.org/pdf/2403.09037v1
摘要:
大型视觉语言模型(LVLM)旨在解释和响应人类指令,但偶尔也会因指令不当而产生幻觉或有害内容。本研究利用线性探测来揭示 LVLM 输出层的隐藏知识。我们证明,第一个令牌的对数分布包含足够的信息来决定是否响应指令,包括识别无法回答的视觉问题、防御多模式越狱攻击和识别欺骗性问题。在生成回复的过程中,这些隐藏知识会在后续令牌的对数中逐渐丢失。因此,我们在生成第一个标记时说明了一种简单的解码策略,从而有效地改进了生成的内容。在实验中,我们发现了一些有趣的见解:首先,CLIP 模型已经包含了解决这些任务的强烈信号,这表明现有数据集可能存在偏差。其次,我们观察到在另外三个任务中利用第一对数分布提高了性能,包括数学解题中的不确定性、减轻幻觉和图像分类。最后,在相同的训练数据下,对 LVLMs 进行简单的微调可以提高模型的性能,但在这些任务上仍然不如线性探测。
12.VisionGPT: Vision-Language Understanding Agent Using Generalized Multimodal Framework
标题:VisionGPT:使用通用多模态框架的视觉语言理解代理
author:Chris Kelly, Luhui Hu, Bang Yang, Yu Tian, Deshun Yang, Cindy Yang, Zaoshan Huang, Zihao Li, Jiayin Hu, Yuexian Zou
publish:17 pages, 5 figures, and 1 table. arXiv admin note: substantial text
overlap with arXiv:2311.10125
date Time:2024-03-14
paper pdf:http://arxiv.org/pdf/2403.09027v1
摘要:
随着大型语言模型(LLM)和视觉基础模型的出现,如何将这些开源或 API 可用模型的智能和能力结合起来,实现开放世界的视觉感知仍是一个未决问题。在本文中,我们介绍了 VisionGPT,以巩固和自动整合最先进的基础模型,从而促进视觉语言理解和面向视觉的人工智能的发展。VisionGPT 建立在一个通用的多模态框架之上,该框架有三个主要特点:(1) 以 LLM(如 LLaMA-2)为支点,将用户请求分解为详细的行动建议,以调用合适的基础模型;(2) 自动整合基础模型的多源输出,并为用户生成全面的响应;(3) 可适应广泛的应用,如文本条件下的图像理解/生成/编辑和视觉问题解答。本文概述了 VisionGPT 的架构和功能,展示了它通过提高效率、通用性、通用化和性能来彻底改变计算机视觉领域的潜力。我们的代码和模型将公开发布。关键词VisionGPT、开放世界视觉感知、视觉语言理解、大型语言模型和基础模型
13.DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation
标题:DialogGen:用于多轮文本到图像生成的多模式互动对话系统
author:Minbin Huang, Yanxin Long, Xinchi Deng, Ruihang Chu, Jiangfeng Xiong, Xiaodan Liang, Hong Cheng, Qinglin Lu, Wei Liu
publish:Project page: https://hunyuan-dialoggen.github.io/
date Time:2024-03-13
paper pdf:http://arxiv.org/pdf/2403.08857v1
摘要:
近年来,文本到图像(T2I)生成模型取得了长足的进步。然而,对于普通用户来说,与这些模型进行有效互动具有挑战性,因为需要专业的提示工程知识,而且无法进行多轮图像生成,阻碍了动态和迭代的创建过程。最近的一些尝试试图将多模态大语言模型(MLLM)与 T2I 模型相结合,将用户的自然语言指令变为现实。因此,多模态大语言模型的输出模态得到了扩展,而 T2I 模型的多轮生成质量也因多模态大语言模型强大的多模态理解能力而得到了提高。然而,随着输出模态数量的增加和对话的深入,许多此类作品在识别正确的输出模态和生成相应的连贯图像方面面临挑战。因此,我们提出了 DialogGen,这是一个有效的管道,用于对现成的 MLLM 和 T2I 模型进行对齐,以建立多模态交互对话系统(MIDS),实现多轮文本到图像的生成。它由绘图提示对齐、仔细的训练数据整理和错误纠正组成。此外,随着 MIDS 领域的蓬勃发展,迫切需要全面的基准来公平地评估 MIDS 的输出模态正确性和多模态输出一致性。为了解决这个问题,我们推出了多模态对话基准(DialogBen),这是一个全面的双语基准,旨在评估 MLLM 生成支持图像编辑的准确、连贯的多模态内容的能力。它包含两个评估指标,用于衡量模型切换模式的能力和输出图像的一致性。我们在 DialogBen 上进行的大量实验和用户研究表明,与其他最新模型相比,DialogGen 非常有效。
14.AIGCs Confuse AI Too: Investigating and Explaining Synthetic Image-induced Hallucinations in Large Vision-Language Models
标题:AIGC 也让人工智能感到困惑:在大型视觉语言模型中调查和解释合成图像引起的幻觉
author:Yifei Gao, Jiaqi Wang, Zhiyu Lin, Jitao Sang
date Time:2024-03-13
paper pdf:http://arxiv.org/pdf/2403.08542v1
摘要:
人工智能生成的内容(AIGC)正朝着更高质量的方向发展。与人工智能生成内容之间日益增长的互动给数据驱动的人工智能界带来了新的挑战:虽然人工智能生成的内容在各种人工智能模型中发挥了至关重要的作用,但它们所带来的潜在隐患尚未得到彻底研究。除了面向人类的伪造检测之外,人工智能生成的内容也给原本设计用于处理自然数据的人工智能模型带来了潜在问题。在本研究中,我们强调了人工智能合成图像会加剧大型视觉语言模型(LVLM)的幻觉现象。值得注意的是,我们的研究结果揭示了一个一致的AIGC (textbf{幻觉偏差}:合成图像诱发的物体幻觉具有数量更多和位置分布更均匀的特点,即使与自然图像相比,这些合成图像也没有表现出不真实或额外的相关视觉特征。此外,我们对 Q-former 和线性投影仪的研究表明,合成图像在视觉投影后可能会出现象征性偏差,从而放大幻觉偏差。
15.An Empirical Study of Parameter Efficient Fine-tuning on Vision-Language Pre-train Model
标题:视觉语言预训练模型参数有效微调的实证研究
author:Yuxin Tian, Mouxing Yang, Yunfan Li, Dayiheng Liu, Xingzhang Ren, Xi Peng, Jiancheng Lv
publish:Accepted by ICME2024
date Time:2024-03-13
paper pdf:http://arxiv.org/pdf/2403.08433v1
摘要:
最近的研究应用了参数高效微调技术(PEFT),以有效缩小预训练和下游训练之间的性能差距。各种 PEFT 有两个重要因素,即可访问数据大小和可微调参数大小。对 PEFT 的一个自然预期是,各种 PEFT 的性能与数据大小和可微调参数大小呈正相关。然而,根据对五个 PEFT 在两个下游视觉语言(VL)任务上的评估,我们发现只有当下游数据和任务与预训练不一致时,这种直觉才会成立。在下游微调与预训练一致的情况下,数据大小不再影响性能,而可微调参数大小的影响却不是单调的。我们认为这一观察结果可以指导各种 PEFT 的训练策略选择。
16.Language-Driven Visual Consensus for Zero-Shot Semantic Segmentation
标题:零镜头语义分割的语言驱动视觉共识
author:Zicheng Zhang, Tong Zhang, Yi Zhu, Jianzhuang Liu, Xiaodan Liang, QiXiang Ye, Wei Ke
date Time:2024-03-13
paper pdf:http://arxiv.org/pdf/2403.08426v1
摘要:
以 CLIP 为代表的预训练视觉语言模型,通过转换解码器将视觉特征与类嵌入对齐,生成语义掩码,从而推进零镜头语义分割。尽管效果显著,但这一范例中的主流方法也遇到了挑战,包括对已见类别的过度拟合和掩码中的小碎片。为了缓解这些问题,我们提出了一种语言驱动的视觉共识(LDVC)方法,以改善语义和视觉信息的一致性。具体来说,我们利用类嵌入作为锚点,因为它们具有离散性和抽象性,从而将视觉特征导向类嵌入。此外,为了避免视觉部分因其冗余性而产生的对齐噪音,我们将路由注意引入自我注意,以寻求视觉共识,从而增强同一对象内的语义一致性。通过视觉语言提示策略,我们的方法大大提高了分割模型对未见类别的泛化能力。实验结果证明了我们方法的有效性,与最先进的方法相比,我们在 PASCAL VOC 2012 和 COCO-Stuff 164k 未见类别的 mIoU 分别提高了 4.5 和 3.6。
17.TaskCLIP: Extend Large Vision-Language Model for Task Oriented Object Detection
标题:TaskCLIP:扩展大型视觉语言模型,实现面向任务的目标检测
author:Hanning Chen, Wenjun Huang, Yang Ni, Sanggeon Yun, Fei Wen, Hugo Latapie, Mohsen Imani
date Time:2024-03-12
paper pdf:http://arxiv.org/pdf/2403.08108v1
摘要:
面向任务的物体检测旨在找到适合完成特定任务的物体。作为一项具有挑战性的任务,它需要同时进行视觉数据处理和模糊语义推理。最近的解决方案主要是一体化模型。然而,物体检测骨干都是在没有文本监督的情况下预先训练的。因此,为了满足任务要求,这些复杂的模型需要在高度不平衡和稀缺的数据集上进行大量学习,结果导致性能受限、训练费力、通用性差。相比之下,我们提出的 TaskCLIP 是一种更自然的两阶段设计,由一般对象检测和任务引导对象选择组成。特别是对于后者,我们采用了最近取得成功的大型视觉语言模型(VLM)作为我们的支柱,它为图像和文本提供了丰富的语义知识和统一的嵌入空间。然而,由于对象图像的嵌入与其视觉属性(主要是形容词短语)之间的不对齐,VLM 的天真应用会导致质量不达标。为此,我们在预先训练的 VLMs 之后设计了一个基于变换器的对齐器,以重新校准这两种嵌入。最后,我们采用可训练的评分函数对 VLM 匹配结果进行后处理,以便选择对象。实验结果表明,我们的 TaskCLIP 比最先进的基于 DETR 的模型 TOIST 性能高出 3.5%,而且只需要一台英伟达 RTX 4090 就能完成训练和推理。
18.Beyond Text: Frozen Large Language Models in Visual Signal Comprehension
标题:超越文本:视觉信号理解中的冷冻大型语言模型
author:Lei Zhu, Fangyun Wei, Yanye Lu
publish:Accepted by CVPR 2024
date Time:2024-03-12
paper pdf:http://arxiv.org/pdf/2403.07874v1
摘要:
在这项工作中,我们研究了大型语言模型(LLM)直接理解视觉信号的潜力,而无需在多模态数据集上进行微调。我们方法的基本概念是将图像视为语言实体,并将其转换为从 LLM 词汇表中提取的一组离散词。为了实现这一目标,我们提出了 “视觉语言标记器”(Vision-to-Language Tokenizer),缩写为 V2T Tokenizer,它通过编码器-解码器、LLM 词汇表和 CLIP 模型的综合帮助,将图像转换为 “外语”。有了这种创新的图像编码技术,LLM 不仅能进行视觉理解,还能以自动回归的方式对图像进行去噪和还原,而且无需进行任何微调。我们进行了严格的实验来验证我们的方法,包括图像识别、图像字幕和视觉问题解答等理解任务,以及内绘、外绘、去毛刺和移位恢复等图像去噪任务。代码和模型见 https://github.com/zh460045050/V2L-Tokenizer。
19.MoPE-CLIP: Structured Pruning for Efficient Vision-Language Models with Module-wise Pruning Error Metric
标题:MoPE-CLIP:利用模块化剪枝误差度量对高效视觉语言模型进行结构化剪枝
author:Haokun Lin, Haoli Bai, Zhili Liu, Lu Hou, Muyi Sun, Linqi Song, Ying Wei, Zhenan Sun
publish:18 pages, 8 figures, Published in CVPR2024
date Time:2024-03-12
paper pdf:http://arxiv.org/pdf/2403.07839v1
摘要:
视觉语言预训练模型在各种下游任务中取得了令人印象深刻的性能。然而,这些模型体积庞大,妨碍了它们在计算资源有限的平台上的使用。我们发现,直接使用较小的预训练模型,并对 CLIP 模型进行基于幅度的剪枝处理,会导致灵活性和性能下降。最近在 VLP 压缩方面所做的努力要么是采用单模式压缩指标,导致性能有限,要么是使用可学习的掩码进行代价高昂的掩码搜索过程。在本文中,我们首先提出了 “模块剪枝误差”(MoPE)指标,通过跨模态任务的性能下降来准确评估 CLIP 模块的重要性。利用 MoPE 指标,我们引入了适用于预训练和特定任务微调压缩阶段的统一剪枝框架。在预训练方面,MoPE-CLIP 有效地利用了教师模型的知识,在保持强大的零点能力的同时显著降低了预训练成本。在微调方面,从广度到深度的连续剪枝产生了极具竞争力的特定任务模型。两个阶段的广泛实验证明了 MoPE 指标的有效性,MoPE-CLIP 优于之前最先进的 VLP 压缩方法。
20.Synth 2 ^2 2: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
标题:Synth 2 ^2 2:利用合成字幕和图像嵌入提升视觉语言模型
author:Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
publish:9 pages, 6 figures
date Time:2024-03-12
paper pdf:http://arxiv.org/pdf/2403.07750v1
摘要:
创建高质量的人工标注图像标题数据集是开发视觉语言模型(VLM)的一大瓶颈。我们提出了一种新方法,利用大型语言模型(LLM)和图像生成模型的优势来创建合成图像-文本对,从而实现高效和有效的 VLM 训练。我们的方法采用预训练文本到图像模型的方法,从 LLM 生成的标题开始合成图像嵌入。然后使用这些合成对来训练 VLM。广泛的实验证明,使用合成数据训练的 VLM 在图像字幕方面表现出了相当的性能,而所需的数据量仅为仅使用人类标注数据训练的模型的一小部分。特别是,通过使用合成数据集进行增强,我们的性能比基线高出 17%。此外,我们还证明,在图像嵌入空间进行合成比在像素空间进行合成要快 25%。这项研究为生成大规模、可定制的图像数据集引入了一种前景广阔的技术,从而提高了 VLM 性能,并在各个领域获得了更广泛的应用,同时提高了数据效率和资源利用率。
21.Unleashing Network Potentials for Semantic Scene Completion
标题:释放网络潜能,实现语义场景补全
author:Fengyun Wang, Qianru Sun, Dong Zhang, Jinhui Tang
publish:accepted by CVPR2024
date Time:2024-03-12
paper pdf:http://arxiv.org/pdf/2403.07560v2
摘要:
语义场景补全(SSC)旨在通过单视角 RGB-D 图像预测完整的三维体素占位和语义,最近的 SSC 方法通常采用多模态输入。然而,我们的研究发现了两个局限性:从单一模态学习特征效果不佳,以及对有限数据集的过度拟合。为了解决这些问题,本文从优化梯度更新的全新视角出发,提出了一种新颖的 SSC 框架–对抗模态调制网络(AMMNet)。所提出的 AMMNet 引入了两个核心模块:跨模态调制(cross-modal modulation),可实现模态间梯度流的相互依存;以及利用动态梯度竞争的定制对抗训练方案。具体来说,跨模态调制能自适应地重新校准特征,以更好地激发每种单一模态的表征潜能。对抗训练采用了梯度演化的最小博弈,并提供定制指导,从几何完整性和语义正确性两方面加强生成器对视觉保真度的感知。广泛的实验结果表明,AMMNet 的性能大大优于最先进的 SSC 方法,为提高 SSC 方法的有效性和通用性提供了一个很有前景的方向。
22.MoAI: Mixture of All Intelligence for Large Language and Vision Models
标题:MoAI:大型语言和视觉模型的混合智能
author:Byung-Kwan Lee, Beomchan Park, Chae Won Kim, Yong Man Ro
publish:Code available: https://github.com/ByungKwanLee/MoAI
date Time:2024-03-12
paper pdf:http://arxiv.org/pdf/2403.07508v1
摘要:
大型语言模型(LLMs)和指令调整的兴起导致了当前指令调整大型语言和视觉模型(LLVMs)的发展趋势。这一趋势涉及针对特定目标精心策划大量指令调整数据集,或扩大 LLVM 以管理大量视觉语言(VL)数据。然而,在分割、检测、场景图生成(SGG)和光学字符识别(OCR)等视觉感知任务中,现有的 LLVM 忽略了专业计算机视觉(CV)模型提供的详细而全面的真实世界场景理解。相反,现有的 LLVM 主要依赖于其 LLM 骨干的大容量和新兴能力。因此,我们提出了一种新的 LLVM–混合智能(MoAI),它利用从外部分割、检测、SGG 和 OCR 模型输出中获得的辅助视觉信息。MoAI 通过两个新引入的模块运行:MoAI 压缩器和 MoAI 混频器。在口头表达外部 CV 模型的输出后,MoAI-Compressor 对其进行排列和压缩,以便有效地将相关的辅助视觉信息用于 VL 任务。然后,MoAI-Mixer 利用 “专家混合”(Mixture of Experts)的概念,将三种智能(1)视觉特征、(2)来自外部 CV 模型的辅助特征和(3)语言特征融合在一起。通过这种融合,MoAI 在众多零拍摄 VL 任务中的表现明显优于开源和闭源 LLVM,尤其是与真实世界场景理解相关的任务,如物体存在、位置、关系和 OCR,而无需扩大模型大小或策划额外的视觉指令调整数据集。
23.In-context learning enables multimodal large language models to classify cancer pathology images
标题:通过上下文学习,多模态大语言模型可对癌症病理图像进行分类
author:Dyke Ferber, Georg Wölflein, Isabella C. Wiest, Marta Ligero, Srividhya Sainath, Narmin Ghaffari Laleh, Omar S. M. El Nahhas, Gustav Müller-Franzes, Dirk Jäger, Daniel Truhn, Jakob Nikolas Kather
publish:40 pages, 5 figures
date Time:2024-03-12
paper pdf:http://arxiv.org/pdf/2403.07407v1
摘要:
医学图像分类需要标注特定任务的数据集,这些数据集用于从头开始训练深度学习网络,或对基础模型进行微调。然而,这一过程对计算和技术要求很高。在语言处理领域,上下文学习提供了另一种选择,即模型从提示中学习,绕过了参数更新的需要。然而,在医学图像分析中,上下文学习仍未得到充分探索。在此,我们系统地评估了具有视觉功能的生成预训练变换器 4 模型(GPT-4V)在癌症图像处理中的应用,该模型在三个重要的癌症组织病理学任务中采用了上下文学习:它们是:结直肠癌组织亚型分类、结肠息肉亚型分类和淋巴结切片中的乳腺肿瘤检测。我们的研究结果表明,上下文学习足以媲美甚至超越针对特定任务训练的专门神经网络,同时只需要极少量的样本。总之,这项研究证明,在非特定领域数据上训练的大型视觉语言模型可以开箱即用,解决组织病理学中的医学图像处理任务。这使没有技术背景的医学专家也能使用通用人工智能模型,尤其是在注释数据稀缺的领域。
24.KEBench: A Benchmark on Knowledge Editing for Large Vision-Language Models
标题:KEBench:大型视觉语言模型的知识编辑基准
author:Han Huang, Haitian Zhong, Qiang Liu, Shu Wu, Liang Wang, Tieniu Tan
publish:13 pages
date Time:2024-03-12
paper pdf:http://arxiv.org/pdf/2403.07350v1
摘要:
目前,有关大型视觉语言模型(LVLM)知识编辑的研究还很少。编辑 LVLMs 面临的挑战是有效整合各种模式(图像和文本),同时确保修改的连贯性和上下文相关性。现有的一个基准有三个指标(可靠性、位置性和通用性)来衡量 LVLM 的知识编辑。然而,该基准在用于评估的生成图像质量方面存在不足,无法评估模型是否有效利用了与相关内容有关的编辑知识。我们采用不同的数据收集方法构建了一个新的基准– KEBench \textbf{KEBench} KEBench,并扩展了新的指标(可移植性)以进行综合评估。利用多模态知识图谱,我们的图像数据对实体表现出明显的指向性。这种指向性可进一步用于提取与实体相关的知识并形成编辑数据。我们在五个 LVLM 上进行了不同编辑方法的实验,并深入分析了这些方法对模型的影响。结果揭示了这些方法的优势和不足,希望能为今后的研究提供潜在的途径。
25.Towards Zero-shot Human-Object Interaction Detection via Vision-Language Integration
标题:通过视觉语言集成实现零镜头人-物互动检测
author:Weiying Xue, Qi Liu, Qiwei Xiong, Yuxiao Wang, Zhenao Wei, Xiaofen Xing, Xiangmin Xu
date Time:2024-03-12
paper pdf:http://arxiv.org/pdf/2403.07246v1
摘要:
人-物交互(HOI)检测旨在定位图像中的人-物对,并识别其交互类别。大多数现有方法主要侧重于监督学习,这依赖于大量的人工 HOI 注释。在本文中,我们提出了一个新颖的框架,称为 “知识集成到 HOI(KI2HOI)”,它有效地集成了视觉语言模型的知识,以改进零镜头 HOI 检测。具体来说,我们基于视觉语义设计了动词特征学习模块,通过使用动词提取解码器将相应的动词查询转换为特定于交互的类别表示。我们开发了一种有效的加法自注意机制,以生成更全面的视觉表征。此外,创新的交互表征解码器通过交叉注意机制整合了空间和视觉特征信息,从而有效地提取了信息区域。为了应对低数据下的零镜头学习,我们利用 CLIP 文本编码器中的先验知识来初始化线性分类器,以增强交互理解能力。在主流的 HICO-DET 和 V-COCO 数据集上进行的大量实验表明,我们的模型在各种零镜头和全监督设置中都优于之前的方法。
26.SELMA: Learning and Merging Skill-Specific Text-to-Image Experts with Auto-Generated Data
标题:SELMA:利用自动生成的数据学习和合并特定技能文本到图像专家
author:Jialu Li, Jaemin Cho, Yi-Lin Sung, Jaehong Yoon, Mohit Bansal
publish:First two authors contributed equally; Project website:
https://selma-t2i.github.io/
date Time:2024-03-11
paper pdf:http://arxiv.org/pdf/2403.06952v1
摘要:
最近的文本到图像(T2I)生成模型在根据文本描述生成图像方面表现出了令人印象深刻的能力。然而,这些 T2I 生成模型往往无法生成与文本输入细节精确匹配的图像,例如不正确的空间关系或丢失的对象。在本文中,我们介绍了 SELMA:特定技能专家学习与自动生成数据的合并,这是一种新颖的范式,通过在自动生成的多技能图像-文本数据集上微调模型,以及特定技能专家学习与合并,来提高 T2I 模型的忠实度。首先,SELMA 利用 LLM 的语境学习功能生成多个可教授不同技能的文本提示数据集,然后根据提示生成带有 T2I 模型的图像。接下来,SELMA 通过学习多个单一技能 LoRA(低级适应)专家,然后进行专家合并,使 T2I 模型适应新技能。我们的独立专家微调专门针对不同技能建立多个模型,而专家合并则有助于建立一个联合多技能 T2I 模型,该模型可以根据不同的文本提示生成忠实的图像,同时缓解来自不同数据集的知识冲突。我们通过实证证明,在多个基准(TIFA +2.1%,DSG +6.9%)、人类偏好度量(PickScore、ImageReward 和 HPS)以及人类评估方面,SELMA 显著提高了最先进的 T2I 扩散模型的语义对齐度和文本忠实度。此外,通过 SELMA 自动收集的图像-文本对进行的微调与使用地面实况数据进行的微调表现相当。最后,我们表明,使用较弱 T2I 模型的图像进行微调有助于提高较强 T2I 模型的生成质量,这表明 T2I 模型的弱到强泛化效果很好。
27.The Power of Noise: Toward a Unified Multi-modal Knowledge Graph Representation Framework
标题:噪音的力量:建立统一的多模式知识图谱表示框架
author:Zhuo Chen, Yin Fang, Yichi Zhang, Lingbing Guo, Jiaoyan Chen, Huajun Chen, Wen Zhang
publish:Ongoing work; 10 pages, 6 Tables, 2 Figures; Repo is available at
https://github.com/zjukg/SNAG
date Time:2024-03-11
paper pdf:http://arxiv.org/pdf/2403.06832v1
摘要:
多模态预培训的发展凸显了强大的多模态知识图谱(MMKG)表征学习框架的必要性。该框架对于将结构化知识大规模集成到多模态大型语言模型(LLM)中至关重要,其目的是缓解知识误解和多模态幻觉等问题。在这项工作中,为了评估模型在多模态知识图谱中准确嵌入实体的能力,我们将重点放在两项广泛研究的任务上:多模态知识图谱补全(MKGC)和多模态实体对齐(MMEA)。在此基础上,我们提出了一种新颖的 SNAG 方法,该方法利用基于变压器的架构,配备了模态级噪声屏蔽功能,可将多模态实体特征稳健地集成到知识图谱中。通过为 MKGC 和 MMEA 纳入特定的训练目标,我们的方法在总共十个数据集(三个用于 MKGC,七个用于 MEMA)中实现了 SOTA 性能,证明了其鲁棒性和通用性。此外,SNAG 不仅可以作为一个独立的模型,还可以增强其他现有方法,提供稳定的性能改进。我们的代码和数据可在以下网址获取:https://github.com/zjukg/SNAG。
28.3D Semantic Segmentation-Driven Representations for 3D Object Detection
标题:三维物体检测的三维语义分割驱动表示法
author:Hayeon O, Kunsoo Huh
publish:17 pages, 4 figures
date Time:2024-03-11
paper pdf:http://arxiv.org/pdf/2403.06501v1
摘要:
在自动驾驶中,与二维检测相比,三维检测能为路径规划和运动估计等下游任务提供更精确的信息。因此,三维检测研究的需求应运而生。然而,尽管使用了单视角和多视角图像以及从摄像头获取的深度图,但由于缺乏几何信息,检测精度与其他基于模态的检测器相比相对较低。所提出的多模态三维物体检测结合了从图像中获取的语义特征和从点云中获取的几何特征,但在定义统一表示法以融合不同领域的数据以及它们之间的同步方面存在困难。在本文中,我们提出了 SeSame:以点为单位的语义特征作为一种新的表现形式,以确保现有的基于激光雷达的三维检测有足够的语义信息。实验表明,我们的方法在不同难度的汽车和 KITTI 物体检测基准性能改进方面均优于之前的最先进方法。我们的代码可在以下网址获取:https://github.com/HAMA-DL-dev/SeSame
29.FontCLIP: A Semantic Typography Visual-Language Model for Multilingual Font Applications
标题:FontCLIP:多语言字体应用的语义排版视觉语言模型
author:Yuki Tatsukawa, I-Chao Shen, Anran Qi, Yuki Koyama, Takeo Igarashi, Ariel Shamir
publish:11 pages. Eurographics 2024.
https://yukistavailable.github.io/fontclip.github.io/
date Time:2024-03-11
paper pdf:http://arxiv.org/pdf/2403.06453v1
摘要:
为各种设计任务获取所需的字体可能具有挑战性,需要专业的排版知识。虽然以前的字体检索或生成工作已经缓解了其中的一些困难,但它们往往缺乏对训练数据域之外的多种语言和语义属性的支持。为了解决这个问题,我们提出了 FontCLIP:一个将大型视觉语言模型的语义理解与排版知识联系起来的模型。我们通过一种新颖的微调方法,将特定于排版的知识整合到预先训练好的 CLIP 模型的综合视觉语言知识中。我们建议使用一种复合描述性提示语,该提示语囊括了从字体属性数据集中自适应采样的属性,重点关注罗马字母字符。FontCLIP 的语义排版潜空间展示了两种前所未有的泛化能力。首先,FontCLIP 可以泛化到包括中文、日文和韩文(CJK)在内的不同语言,从而捕捉不同语言字体的排版特征,尽管它只是使用罗马字母字体进行了微调。其次,FontCLIP 可以识别训练数据中未显示的语义属性。FontCLIP 的双模态和泛化能力可实现多语言和跨语言字体检索和字形优化,从而减轻获取所需字体的负担。
30.Multi-modal Semantic Understanding with Contrastive Cross-modal Feature Alignment
标题:利用对比性跨模态特征对齐实现多模态语义理解
author:Ming Zhang, Ke Chang, Yunfang Wu
publish:10 pages, 4 figures, accepted by LREC-COLING 2024(main conference,
long paper)
date Time:2024-03-11
paper pdf:http://arxiv.org/pdf/2403.06355v1
摘要:
多模态语义理解需要整合不同模态的信息,以提取用户在文字背后的真实意图。以往的研究大多采用双编码器结构分别对图像和文本进行编码,但无法学习跨模态特征对齐,因此难以实现跨模态深度信息交互。本文提出了一种新颖的基于CLIP引导的对比学习架构来进行多模态特征对齐,将不同模态的特征投射到统一的深度空间中。在多模态讽刺语检测(MMSD)和多模态情感分析(MMSA)任务中,实验结果表明,我们提出的模型明显优于几种基线模型,与采用不同聚合方法的模型和甚至富含知识的模型相比,我们的特征对齐策略带来了明显的性能提升。更重要的是,我们的模型实现简单,无需使用特定任务的外部知识,因此可以轻松迁移到其他多模态任务中。我们的源代码见 https://github.com/ChangKe123/CLFA。
相关文章:
:2024.03.10-2024.03.15)
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.03.10-2024.03.15
论文目录~ 1.3D-VLA: A 3D Vision-Language-Action Generative World Model2.PosSAM: Panoptic Open-vocabulary Segment Anything3.Anomaly Detection by Adapting a pre-trained Vision Language Model4.Introducing Routing Functions to Vision-Language Parameter-Efficie…...
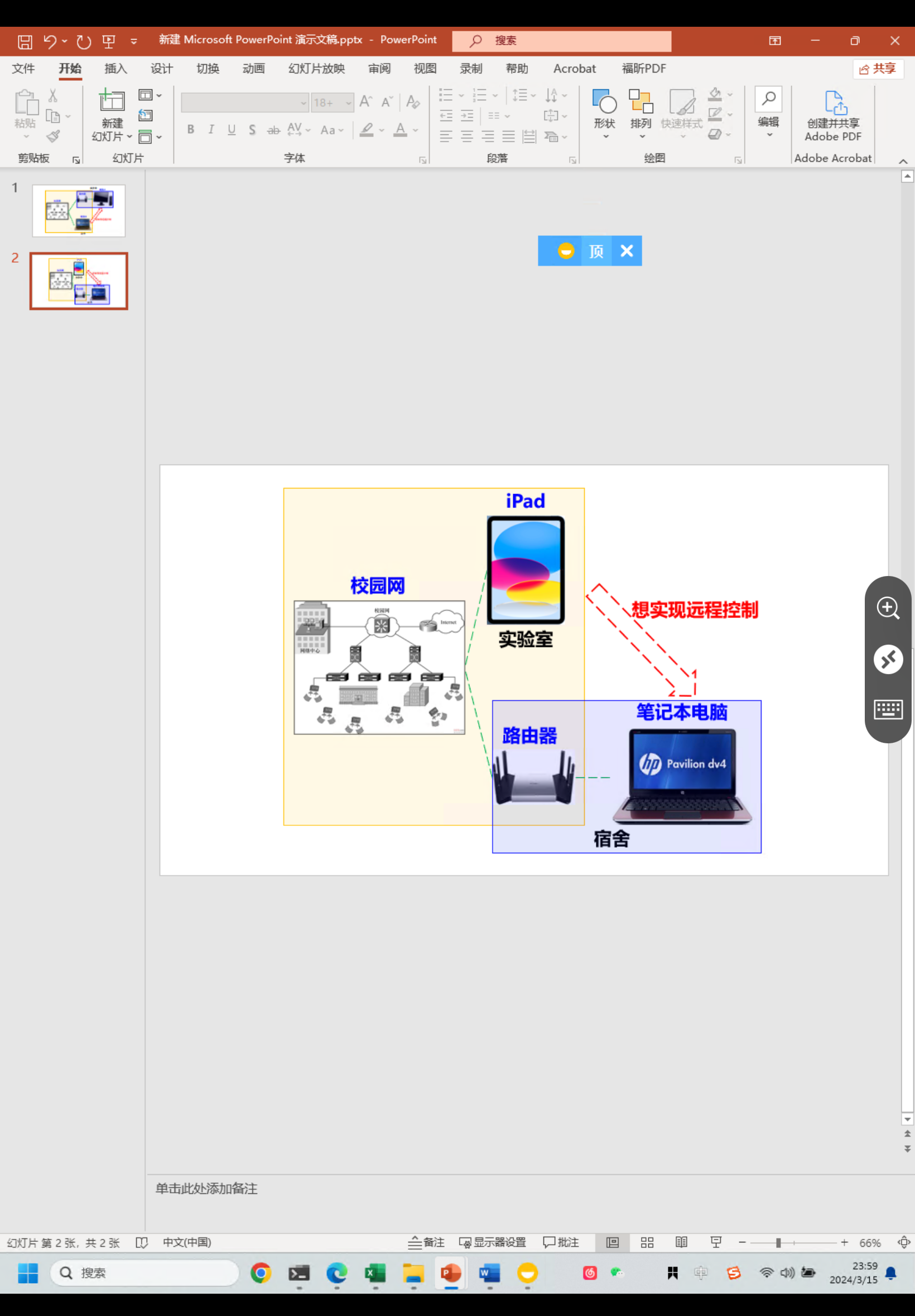
路由器端口转发远程桌面控制:一电脑连接不同局域网的另一电脑
一、引言 路由器端口转发:指在路由器上设置一定的规则,将外部的数据包转发到内部指定的设备或应用程序。这通常需要对路由器进行一些配置,以允许外部网络访问内部网络中的特定服务和设备。端口转发功能可以实现多种应用场景,例如远…...
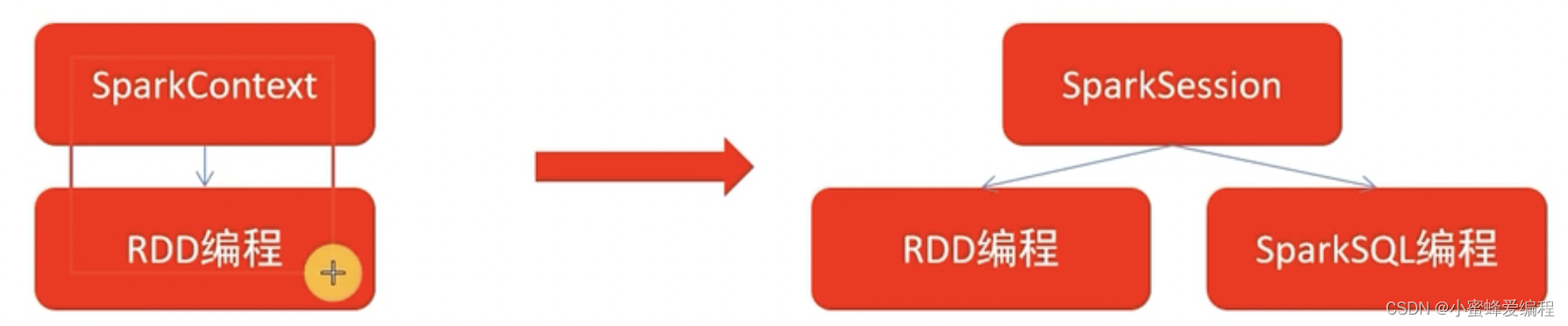
sparksession对象简介
什么是sparksession对象 spark2.0之后,sparksession对象是spark编码的统一入口对象,通常我们在rdd编程时,需要SparkContext对象作为RDD编程入口,但sparksession对象既可以作为RDD编程对象入口,在sparkcore编程中可以通…...
2、Java虚拟机之类的生命周期-连接(验证、准备、解析)
一、类的生命周期 连接阶段之验证 连接阶段的第一个环节是验证,验证的主要目的是检测Java字节码文件是否遵守了<Java虚拟机规范>中的约束。这个阶段一般是不需要程序员进行处理。 主要包含如下四个部分,具体详见<<Java虚拟机规范>>: 1、文件格…...

IPD集成产品开发:塑造企业未来竞争力的关键
随着市场竞争的日益激烈,企业对产品开发的要求也越来越高。如何在快速变化的市场环境中,既保证产品的批量生产效率,又满足客户的个性化需求,成为了企业面临的重要挑战。IPD(集成产品开发)模式,作…...
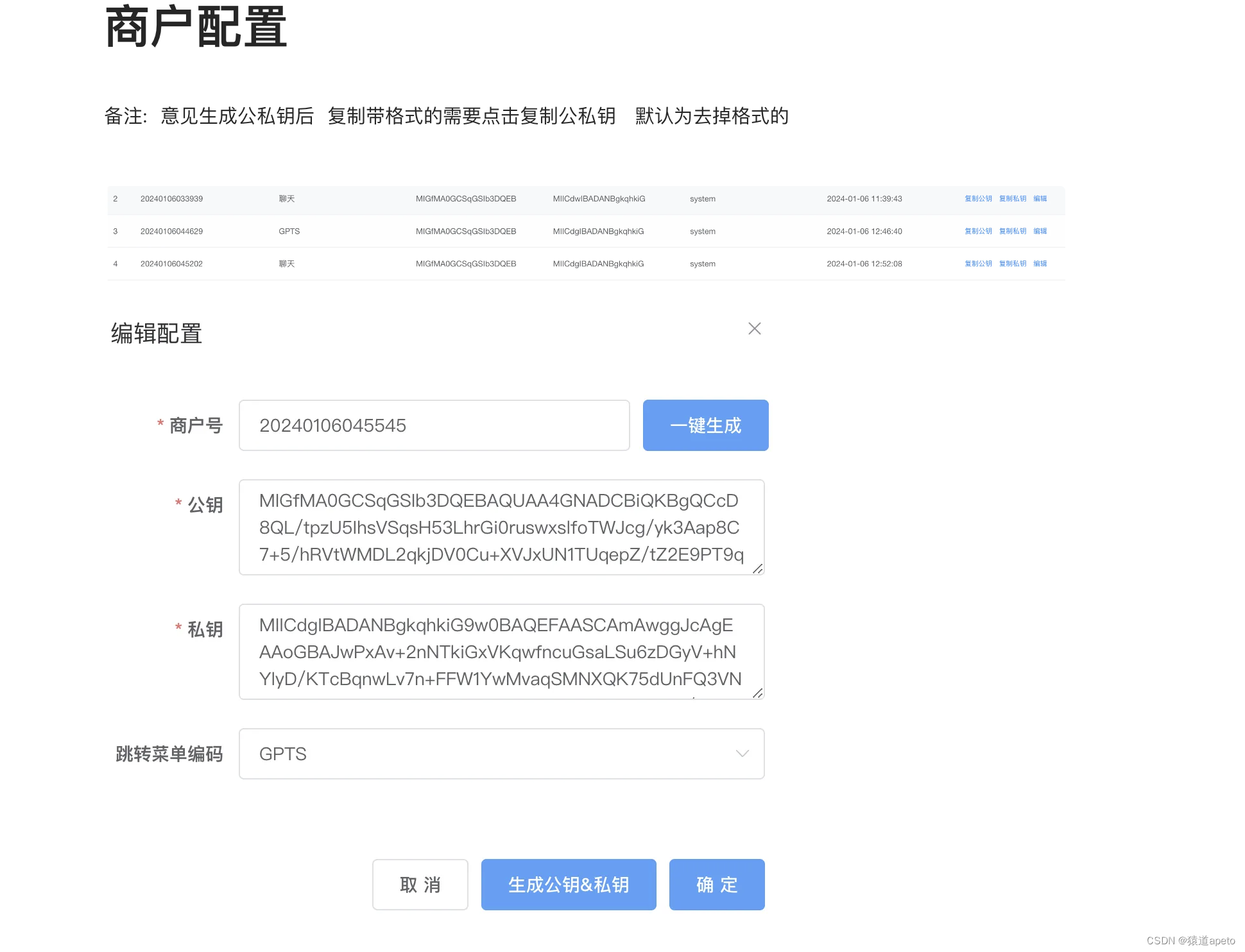
一个可商用私有化部署的基于JAVA的chat-gpt网站
目录 介绍一、核心功能1、智能对话2、AI绘画3、知识库4、一键思维导图5、应用广场6、GPTS 二、后台管理功能1、网站自定义2、多账号登录支持3、商品及会员系统4、模型配置5、兑换码生成6、三方商户用户打通 结语 介绍 java语言的私有化部署的商用网站还是比较少的 这里给大家介…...

nmcli --help(nmcli -h)nmcli文档、nmcli手册
文章目录 nmcli --helpOPTION解释OBJECT解释1. g[eneral]:查看NetworkManager的状态2. n[etworking]:启用或禁用网络3. r[adio]:查看无线电状态(例如,Wi-Fi)4. c[onnection]:列出所有的网络连接…...
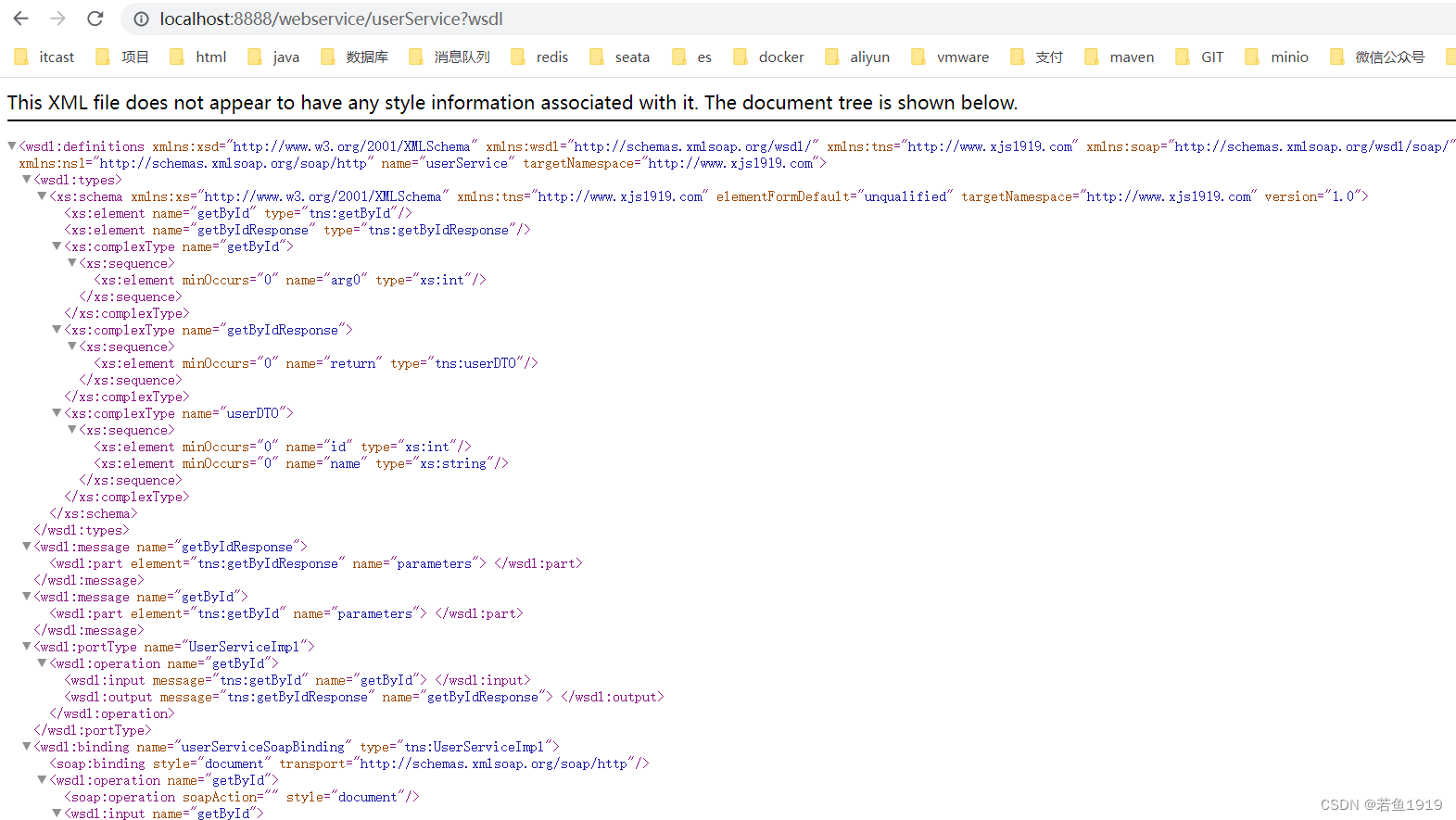
SpringBoot集成WebService
1)添加依赖 <dependency><groupId>org.apache.cxf</groupId><artifactId>cxf-spring-boot-starter-jaxws</artifactId><version>3.3.4</version><exclusions><exclusion><groupId>javax.validation<…...
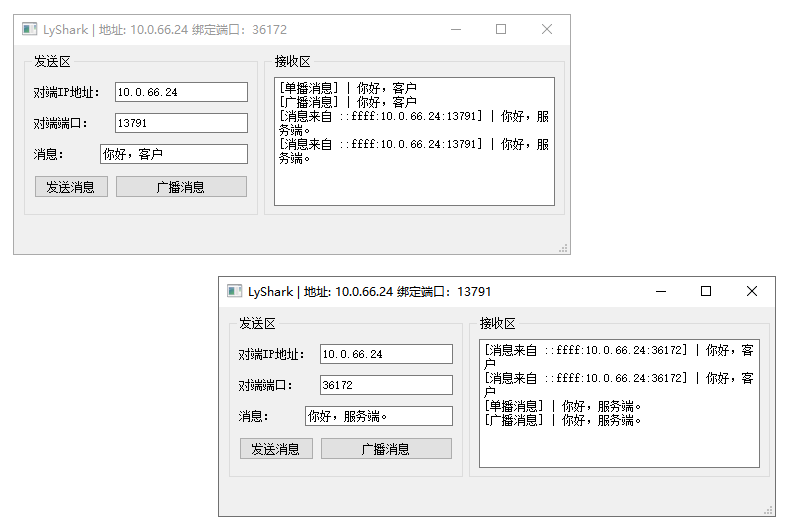
C++ Qt开发:QUdpSocket网络通信组件
Qt 是一个跨平台C图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍如何运用QUdpSocket组件实现基于UDP的网络通信…...

微信小程序小白易入门基础教程1
微信小程序 基本结构 页面配置 页面配置 app.json 中的部分配置,也支持对单个页面进行配置,可以在页面对应的 .json 文件来对本页面的表现进行配置。 页面中配置项在当前页面会覆盖 app.json 中相同的配置项(样式相关的配置项属于 app.js…...

D. Tandem Repeats? - 思维 + 双指针
题面 分析 s s s的范围很小,可以 O ( n 2 ) O(n^2) O(n2),在规定复杂度以内来完成枚举所有子串判断是否有满足条件的最大的子串,可以在第一层循环枚举子串长度 d d d,第二层循环枚举左右端点,通过双指针维护区间。对长…...

第十三届蓝桥杯省赛CC++ 研究生组
蓝桥杯2022年第十三届省赛真题-裁纸刀 蓝桥杯2022年第十三届省赛真题-灭鼠先锋 蓝桥杯2022年第十三届省赛真题-质因数个数 求个数,则只需要计数即可。求啥算啥,尽量不要搞多余操作 蓝桥杯2022年第十三届省赛真题-选数异或 蓝桥杯2022年第十三届省赛真题…...

Oracle中的commit与rollback
SQL语言分为五大类: DDL(数据定义语言:DataDefinitionLanguage) - Create、Alter、Drop 这些语句自动提交,无需用Commit提交。 DQL(数据查询语言:DataQueryLanguage) - Select 查询语句不存在是否提交问题。 DML(数据操纵语言:DataManipulationLangua…...

鸿蒙Harmony应用开发—ArkTS声明式开发(画布组件:OffscreenCanvasRenderingContext2D)
使用OffscreenCanvasRenderingContext2D在Canvas上进行离屏绘制,绘制对象可以是矩形、文本、图片等。离屏绘制是指将需要绘制的内容先绘制在缓存区,然后将其转换成图片,一次性绘制到canvas上,加快了绘制速度。 说明: 从…...

Redis如何实现主从复制?主从复制的作用是什么?Redis集群是如何工作的?它有哪些优点和缺点?
Redis如何实现主从复制?主从复制的作用是什么? Redis的主从复制是一种数据复制机制,其中一个Redis实例作为主节点(master),而其他Redis实例作为从节点(slave)。主从复制的实现过程如…...
numpy对象和random模块)
【Numpy】(2)numpy对象和random模块
numpy.array对象 numpy.array 对象是 NumPy 库的核心,它提供了一种高效的方式来存储和操作同质数据类型的多维数组。每个 numpy.array 对象都有一系列的属性,这些属性提供了关于数组的重要信息。理解这些属性对于有效地使用 NumPy 和进行数据分析是非常…...

[QJS xmake] 非常简单地在Windows下编译QuickJS!
文章目录 前言准备C编译器xmake编译包 工程准备修改版本号第一遍编译第二遍编译效果 前言 quickjs是个很厉害的东西啊,我一直想编译一下的,奈何一直没成功。现在找了点时间成功编译了,写篇文章记录一下。当前版本:2024-1-13 应该…...
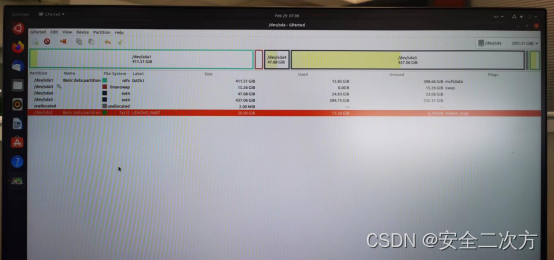
Ubuntu双系统/home分区扩容
一、Windows系统中利用磁盘管理分出空闲区域,如果多就多分一些 二、插入安装Ubuntu的U盘启动盘,lenovo电脑F12(其他电脑可选择其他类似方式)选择U盘启动项,然后选择ubuntu,出现安装界面,再选择t…...
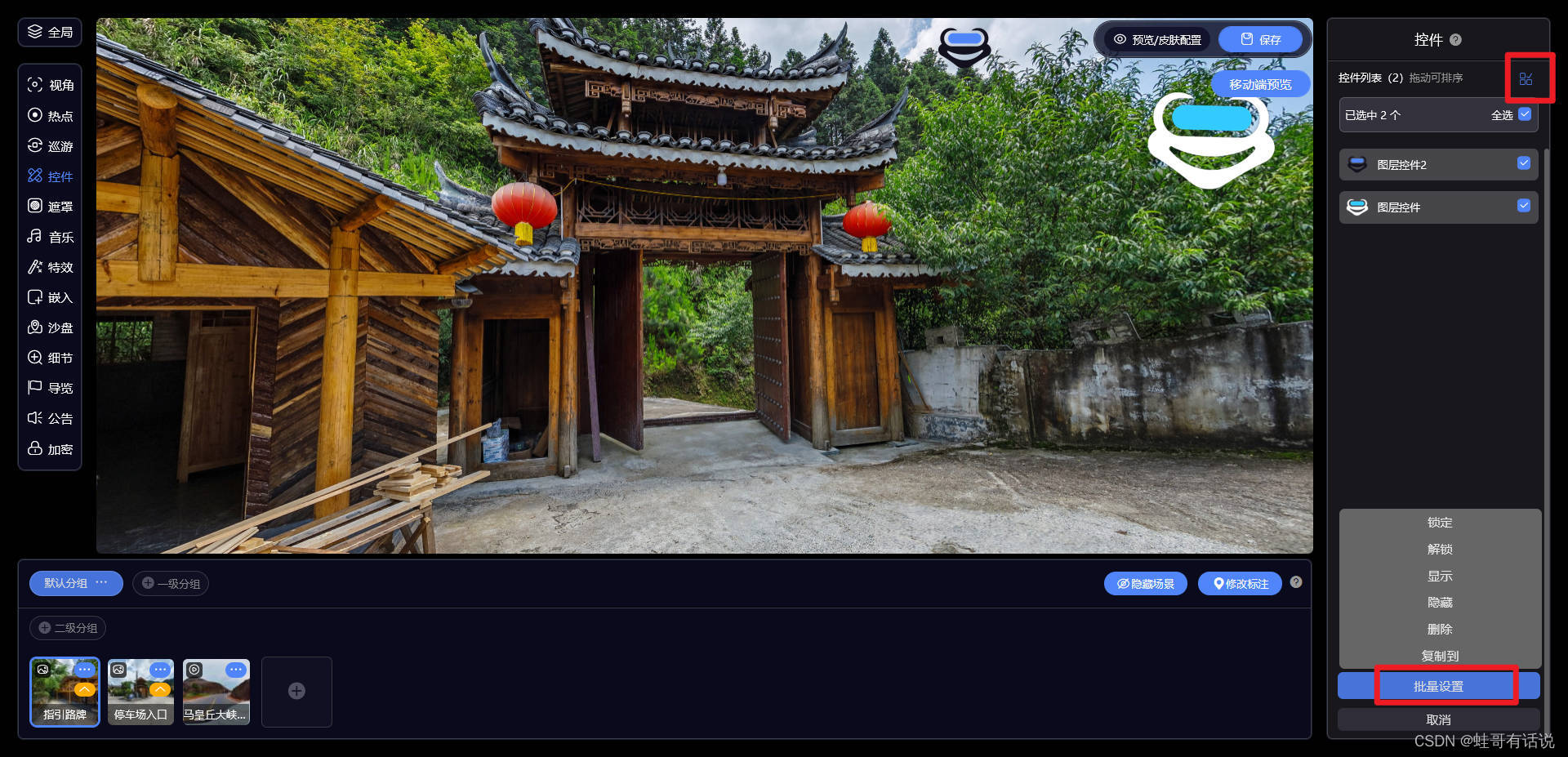
0基础学习VR全景平台篇第145篇:图层控件功能
大家好,欢迎观看蛙色VR官方——后台使用系列课程!这期,我们将为大家介绍如何使用图层控件功能。 一.如何使用图层控件功能? 进入作品编辑页面,点击左边的控件后就可以在右边进行相应设置。 二.图层控件有哪些功能&am…...

一文看懂套利的那些事儿
我们经常在投资中都有提到套利策略,经常听到某某套利,或者借用什么套利工具,股票可以套利,基金期货期权也可以套利,套利到底是什么?套利到底是如何运用的? 今天我们一文解读套利市场!…...

TypeScript + Cloudflare 全家桶部署项目全流程
我的项目技术栈是 TypeScript Cloudflare 全家桶(Workers, KV, DB, Pages)。基于现在的架构,我整理了一份**“从本地到边缘”的部署清单**。这套流程主要依赖 Wrangler CLI(Cloudflare 的官方命令行工具)来完成。 以下…...

深入Linux内核:RDMA Verbs API的object/method/attr三层模型设计与实现解析
深入Linux内核:RDMA Verbs API的object/method/attr三层模型设计与实现解析 在当今高性能计算和分布式存储领域,远程直接内存访问(RDMA)技术因其极低的延迟和高吞吐量而备受青睐。作为RDMA技术的核心接口,Verbs API的设计哲学直接影响着整个生…...

android手机禁止微信后台运行
右击app-----------view all permission------就是用这个:stop running in background --------如果不设置的话,那么即使关闭了,还是会在后台运行的。关掉了:...

Zotero Duplicates Merger:5分钟实现文献库高效整理的终极指南
Zotero Duplicates Merger:5分钟实现文献库高效整理的终极指南 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 还在为学术文献库中…...

《为什么90%的数字孪生都是假的?》——没有空间数据的“孪生”,只是一个会动的PPT
《为什么90%的数字孪生都是假的?》——没有空间数据的“孪生”,只是一个会动的PPT你看到的绝大多数“数字孪生系统”,其实只有三样东西:一个3D模型一堆跳动的数据一个看起来很炫的界面但它们有一个共同点:👉…...

[Python3高阶编程] - 阅读 Gunicorn 源代码前的准备工作
1. Gunicorn 官方代码仓库 Gunicorn 的官方 Git 仓库托管在 GitHub 上: GitHub 地址: https://github.com/benoitc/gunicorn 克隆代码: # 克隆主仓库 git clone https://github.com/benoitc/gunicorn.git# 或者使用 SSH git clone gitgithub.com:benoitc/gunico…...

技术员一键重装工具
链接:https://pan.quark.cn/s/22cfbc52af20...

Oracle EBS 6+2 段式 COA 架构 拆到最细、可直接落地 EBS 的版本,每一段的作用、限定词、长度、编码规则、为什么这么设计全部讲清楚
把 62 段式 COA 架构 拆到最细、可直接落地 EBS 的版本,每一段的作用、限定词、长度、编码规则、为什么这么设计全部讲清楚,你可以直接拿去做方案文档。一、62 段式架构总定义6 段 法定核算 管理核算的核心骨架(必须固定)2 段 …...

s10_团队协议设计:为什么多智能体协作不能只靠发消息
团队协议设计:为什么多智能体协作不能只靠发消息 很多人第一次做多智能体协作时,直觉都是:只要能让队友之间互相发消息,团队就算搭起来了。 这个想法不算错,但只对了一半。 s09 确实已经把“常驻队友 文件邮箱 线…...
)
电路分析不求人:手把手教你用戴维南定理搞定复杂电路(附Multisim仿真验证)
电路分析实战:用戴维南定理拆解复杂电路的全流程指南 当你面对一个布满电阻、电源和交叉连线的复杂电路图时,是否感到无从下手?戴维南定理就像一把瑞士军刀,能将这些看似棘手的电路简化为一个电压源和一个电阻的串联组合。但理论归…...