【Week Y2】使用自己的数据集训练YOLO-v5s
Y2-使用自己的数据集训练YOLO-v5s
- 零、遇到的问题汇总
- (1)遇到git的`import error`
- (2)`Error:Dataset not found`
- (3)`Error:删除中文后,训练图片路径不存在`
- 一、.xml文件里保存的是什么
- 二、准备好自己的数据
- 三、创建split_train_val.py 文件,运行并生成 train.txt、test.txt、val.txt
- (1)在yolov5-master工程内,新建一个.py文件,并命名为`split_train_val.py`:
- (2)将以下代码写入该文件,设置自己的`.xml`和`.txt`文件路径:
- (3)然后执行该文件,就得到下面的结果:
- (4)创建`voc_label.py`,填充图片路径
- 四、创建 `fruit.yaml `文件
- 五、开始用自己的数据集训练模型
- (1) 输入训练指令
- (2)查看训练结果
本文使用水果数据集、CPU进行训练,包含200张图像,水果类别分为4类,
Banana、Snake fruit、Dragon fruit和Pineapple。
本文先列出执行过程中遇到的问题以及解决办法,再将执行步骤一一说明,给出的代码是我修改过后的最终的代码。
需要注意的是:!!!文件路径不要包含中文!!!
零、遇到的问题汇总
(1)遇到git的import error
参考【这里】解决:

找到提示报错的路径d:\jupyter notebook\365-DL\.venv\Lib\site-packages\git\cmd.py,然后在该文件中添加一行:
os.environ['GIT_PYTHON_REFRESH'] = 'quiet'
(2)Error:Dataset not found

路径中含有中文,删除中文。
(3)Error:删除中文后,训练图片路径不存在

将split_train_val.py和voc_label.py生成的所有文件删除,重新生成。【注意检查路径】
如下所示:
【注意abs_path的路径,本文的图像路径为D:\jupyter notebook\365-DL\YOLO\Y2\yolov5-master\Y2-fruit_data\images\*.png,而abs_path=D:\jupyter notebook\365-DL\YOLO\Y2\yolov5-master】

一、.xml文件里保存的是什么
在annotations/文件夹里,打开任意一个.xml文件,这里打开fruit0.xml,文件内容如下:
注意每个标签组内的信息,后续voc_label.py文件会提取这些信息。
<annotation><folder>images</folder><filename>fruit0.png</filename><size><width>400</width><height>300</height><depth>3</depth></size><segmented>0</segmented><object><name>pineapple</name><pose>Unspecified</pose><truncated>0</truncated><occluded>0</occluded><difficult>0</difficult><bndbox><xmin>38</xmin><ymin>82</ymin><xmax>271</xmax><ymax>227</ymax></bndbox></object><object><name>snake fruit</name><pose>Unspecified</pose><truncated>0</truncated><occluded>0</occluded><difficult>0</difficult><bndbox><xmin>244</xmin><ymin>174</ymin><xmax>280</xmax><ymax>207</ymax></bndbox></object><object><name>dragon fruit</name><pose>Unspecified</pose><truncated>0</truncated><occluded>0</occluded><difficult>0</difficult><bndbox><xmin>254</xmin><ymin>228</ymin><xmax>351</xmax><ymax>300</ymax></bndbox></object>
</annotation>
二、准备好自己的数据
本次使用水果数据集,数据集包含200张图片,每张图片包含4种不同类别的水果:Banana、Snake fruit、Dragon fruit和Pineapple。

三、创建split_train_val.py 文件,运行并生成 train.txt、test.txt、val.txt
执行split_train_val.py前的文件结构:
(1)在yolov5-master工程内,新建一个.py文件,并命名为split_train_val.py:

(2)将以下代码写入该文件,设置自己的.xml和.txt文件路径:
# 导入必要的库
# 导入必要的库
import os
import random
import argparse# 创建一个参数解析器
parser = argparse.ArgumentParser()# 添加命令行参数,用于指定XML文件的路径,默认为“Annotations”文件夹
parser.add_argument('--xml_path', default='D:/jupyter notebook/365-DL/YOLO/Y2/yolov5-master/Y2-fruit_data/annotations/', type=str, help='input xml label path')# 添加命令行参数,用于指定txt标签文件的路径,默认为“ImageSets/Main”文件夹
parser.add_argument('--txt_path', default='D:/jupyter notebook/365-DL/YOLO/Y2/yolov5-master/Y2-fruit_data/ImageSets/Main', type=str, help='output txt label path')# 解析命令行参数
opt = parser.parse_args()# 定义训练验证和测试集的划分比例
trainval_percent = 1.0 # 使用全部数据
train_percent = 0.9 # 训练集占验证集的90%# 设置xml文件的路径,并根据命令行参数指定
xmlfilepath = opt.xml_path
print("xmlfilepath: ", xmlfilepath)# 设置txt文件的路径,并根据命令行参数指定
txtfilepath = opt.txt_path# 获取xml文件夹中的所有xml文件列表
total_xml = os.listdir(xmlfilepath)# 如果输出txt标签文件的文件夹不存在,创建它
if not os.path.exists(txtfilepath):os.makedirs(txtfilepath)# 获取xml文件的总数
num = len(total_xml)# 创建一个包含所有xml文件索引的列表
list_index = range(num)# 计算训练验证集的数量
tv = int(num*trainval_percent)# 计算训练集的数量
tr = int(num*train_percent)# 从所有xml文件索引中随机选择出训练验证集的索引
trainval = random.sample(list_index, tv)# 从训练验证集的索引中随机选择出训练集的索引
train = random.sample(list_index, tr)# 打开要写入的训练验证集、测试集、训练集、验证集的txt文件
file_trainval = open(txtfilepath + '/trainval.txt', 'w')
file_test = open(txtfilepath + '/test.txt', 'w')
file_train = open(txtfilepath + '/train.txt', 'w')
file_val = open(txtfilepath + '/val.txt', 'w')# 遍历所有xml文件的索引
for i in list_index:name = total_xml[i][:-4] + '\n' # 获取所有文件的名称(去掉后缀.xml),并添加换行符# 如果该索引在训练验证集中, 写入训练验证集txt文件,否则写入测试集txt文件if i in trainval: file_trainval.write(name) # if i in train: # 如果该索引在训练集中, 写入训练集txt文件,否则写入验证集txt文件file_train.write(name)else:file_val.write(name)else:file_test.write(name)# 关闭所有打开的文件
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
(3)然后执行该文件,就得到下面的结果:
打开任意一个文件,查看内容:【此处打开val.txt,文件内保存的是个文件名】
(4)创建voc_label.py,填充图片路径
voc_label.py代码如下:
# 导入必要的库
import xml.etree.ElementTree as ET
import os
from os import getcwd
# 定义数据集的名称
sets = ['train', 'val', 'test']
# 根据所用数据集,填写类别名称,本文使用水果数据集,包含4类,分别如下:
classes = ["banana", "snake fruit", "dragon fruit", "pineapple"]
# 获取当前工作目录的绝对路径
abs_path = os.getcwd() # abs_path: D:\jupyter notebook\365-DL\YOLO\Y2\yolov5-master
print("abs_path: ", abs_path)
# 定义一个函数,将边界框的坐标绝对值转换为相对于图像大小的比例
def convert(size, box):dw = 1./(size[0]) # 计算图像宽度的倒数dh = 1./(size[1]) # 计算图像高度的倒数x = (box[0] + box[1])/ 2.0 - 1 # 计算中心点的x坐标y = (box[2] + box[3])/ 2.0 - 1 # 计算中心点的y坐标w = box[1] - box[0] # 计算边界框的宽度h = box[3] - box[2] # 计算边界框的高度x = x * dw # 缩放x坐标w = w * dw # 缩放宽度y = y * dh # 缩放y坐标h = h * dh # 缩放高度return x,y,w,h# 定义一个函数,将标注文件从xml格式转为YOLO格式
dir = "D:/jupyter notebook/365-DL/YOLO/Y2/yolov5-master/Y2-fruit_data/"
def convert_annotations(image_id):# 打开xml标注文件in_file = open(dir + "annotations/%s.xml" % (image_id), encoding='UTF-8') # 打开要写入的YOLO格式标签文件out_file = open(dir + "labels/%s.txt" % (image_id), 'w')# 解析xml文件tree = ET.parse(in_file)root = tree.getroot()# 获取图像文件名filename = root.find('filename').text# 获取图像文件格式filenameFormat = filename.split(".")[1]# 获取图像尺寸信息size = root.find('size')# 获取图像的宽、高w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):# 获取对象的难度标志difficult = obj.find('difficult').text# 获取对象的类别名称cls = obj.find('name').textif cls not in classes or int(difficult)==1:continue# 获取类别索引cls_id = classes.index(cls)# 获取对象的边界框信息,包括:左上角x坐标、左上角y坐标、右下角x坐标、右下角y坐标xmlbox = obj.find('bndbox')b = ( float(xmlbox.find('xmin').text),float(xmlbox.find('xmax').text),float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text) )b1,b2,b3,b4 = b# 标注越界修正if b2 > w:b2 = wif b4 > h:b4 = hb = (b1,b2,b3,b4)# 调用convert()函数,将边界框坐标转换为YOLO格式bb = convert((w,h), b)out_file.write(str(cls_id)+" " + " ".join([str(a) for a in bb]) + "\n")return filenameFormat
# 获取当前工作目录
wd = getcwd()
# 遍历每个数据集(train、val、test)
for image_set in sets:# 如果labels目录不存在,就创建它if not os.path.exists(dir + "labels/"):os.makedirs(dir + "labels/")# 从数据集文件中获取图像id列表image_ids = open(dir + "ImageSets/Main/%s.txt" % (image_set)).read().strip().split()# 打开要写入的文件,写入图像文件路径和格式list_file = open(dir + "ImageSets/Main/%s.txt" % (image_set), 'w')for image_id in image_ids:filenameFormat = convert_annotations(image_id)list_file.write(abs_path + '/Y2-fruit_data/images/%s.%s\n' % (image_id,filenameFormat))list_file.close()
执行后得到结果:

四、创建 fruit.yaml 文件
新建fruit.yaml 文件:
train: D:/jupyter notebook/365-DL/YOLO/Y2/yolov5-master/Y2-fruit_data/ImageSets/Main/train.txt
val: D:/jupyter notebook/365-DL/YOLO/Y2/yolov5-master/Y2-fruit_data/ImageSets/Main/val.txt# number of classes
nc: 4# class names
names: ["banana", "snake fruit", "dragon fruit", "pineapple"]
五、开始用自己的数据集训练模型
(1) 输入训练指令
由于本机没有GPU,所以执行:python .\train.py --img 900 --batch 2 --epoch 100 --data .\fruit.yaml --cfg .\models\yolov5s.yaml --weights .\yolov5s.pt --device cpu

如果有GPU,则执行:
python .\train.py --img 900 --batch 2 --epoch 100 --data .\fruit.yaml --cfg .\models\yolov5s.yaml --weights .\yolov5s.pt --device '0'
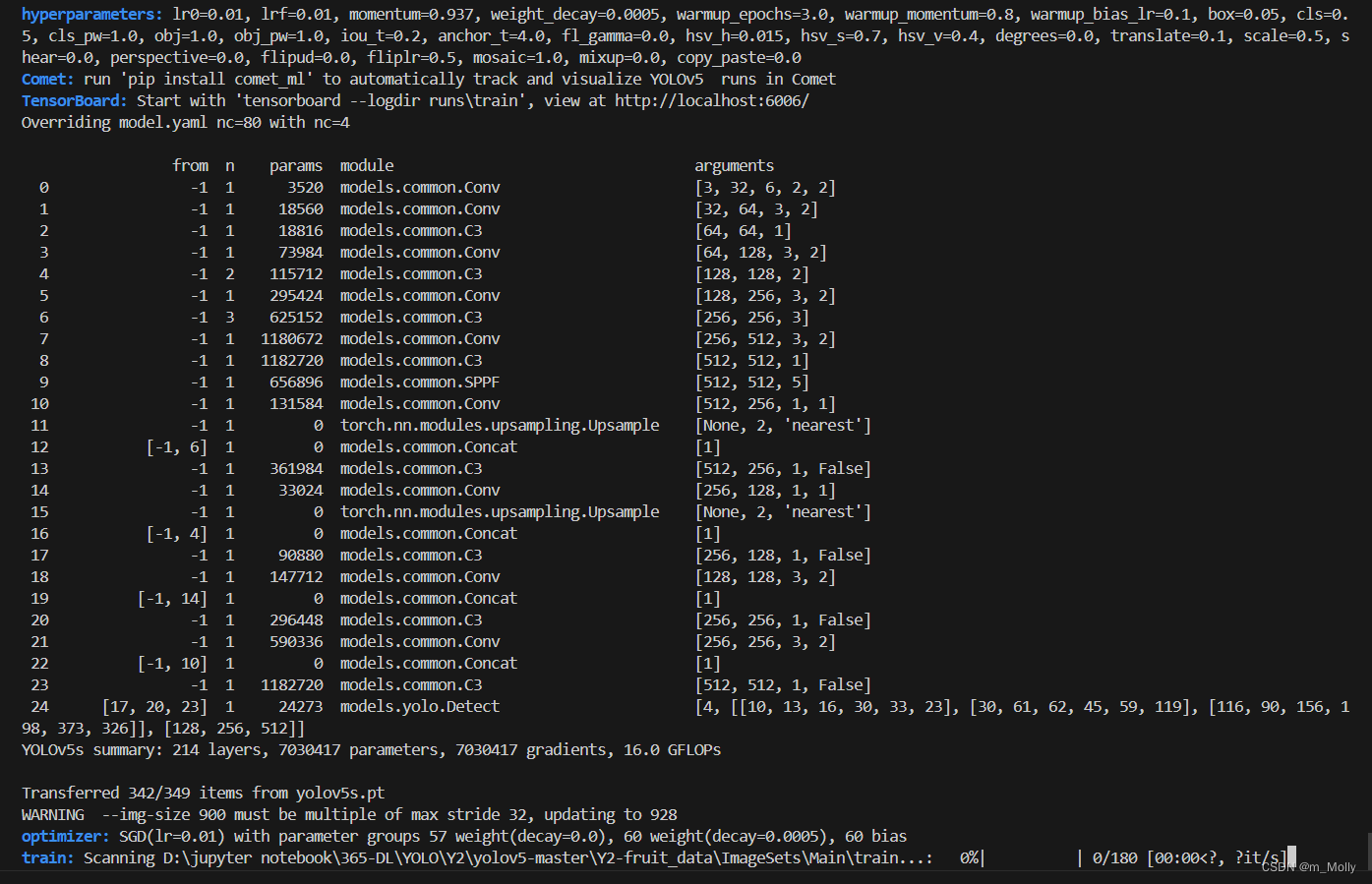
执行命令后,出现如下提示,表明训练进行中,等待训练完成,查看训练结果。

(2)查看训练结果
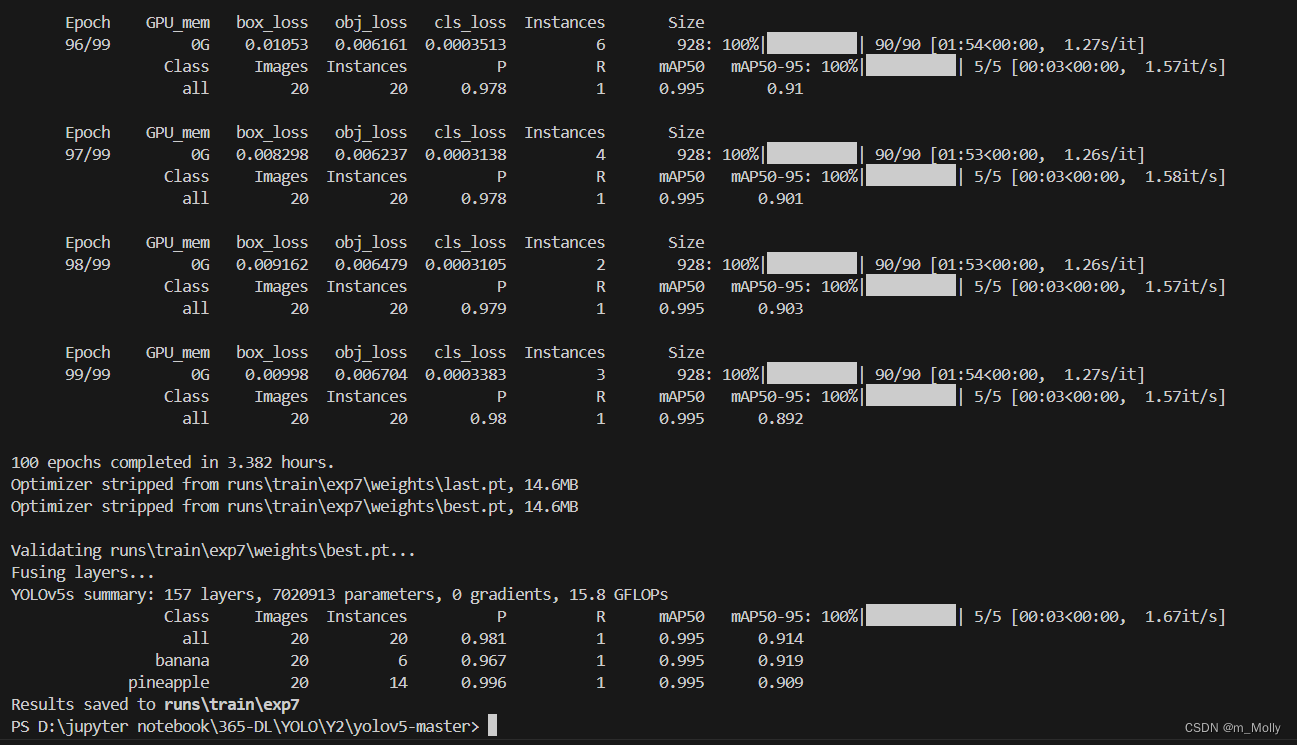
如图中所示,使用YOLO-v5s训练本文的数据集:
- a. 100个epoch需要的时间是3.382小时
- b. YOLOv5s 网络结构: 157 层, 参数量是7020913 , 梯度是0 , GFLOPs是15.8
- c. 还显示了类别的训练结果,包括P-R值、mAP50的值
- d. 训练结果保存在
runs\train\exp7,在该路径下生成了许多文件: 
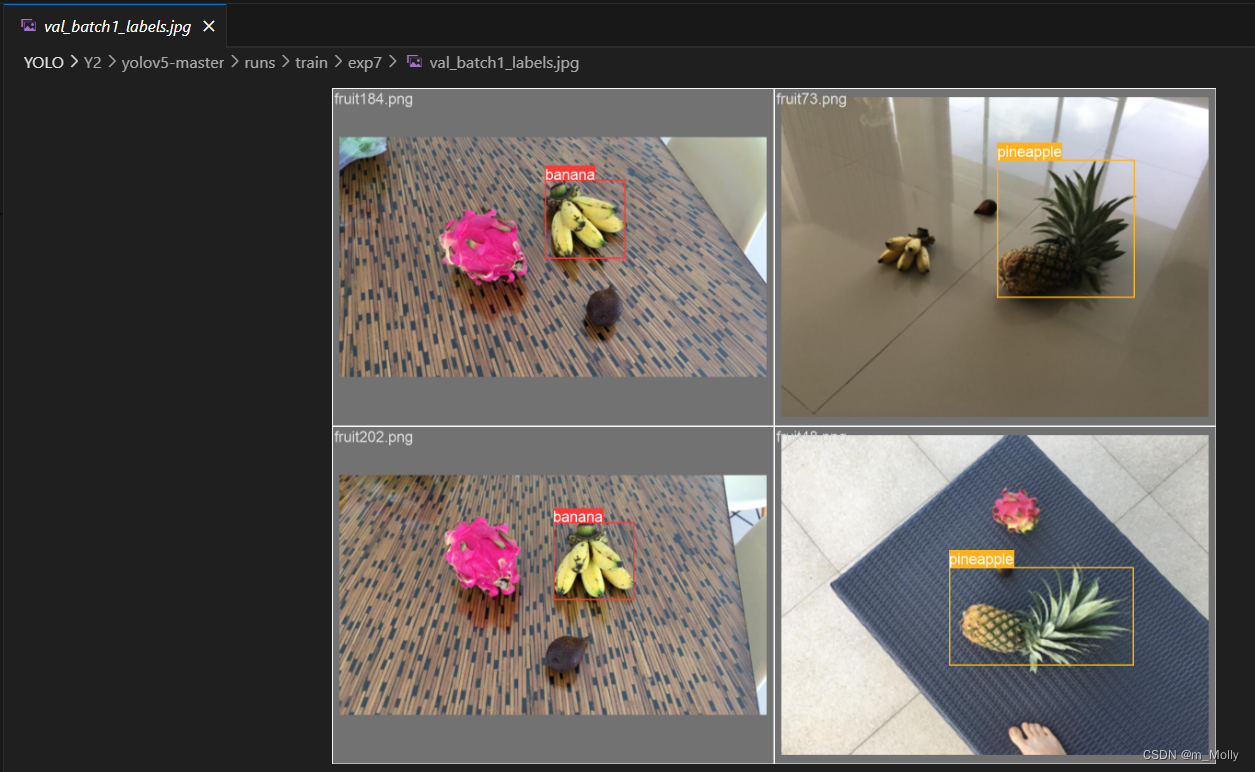
打开其中一张图片,如val_batch1_labels.jpg,如下图,显示了各水果的标签:
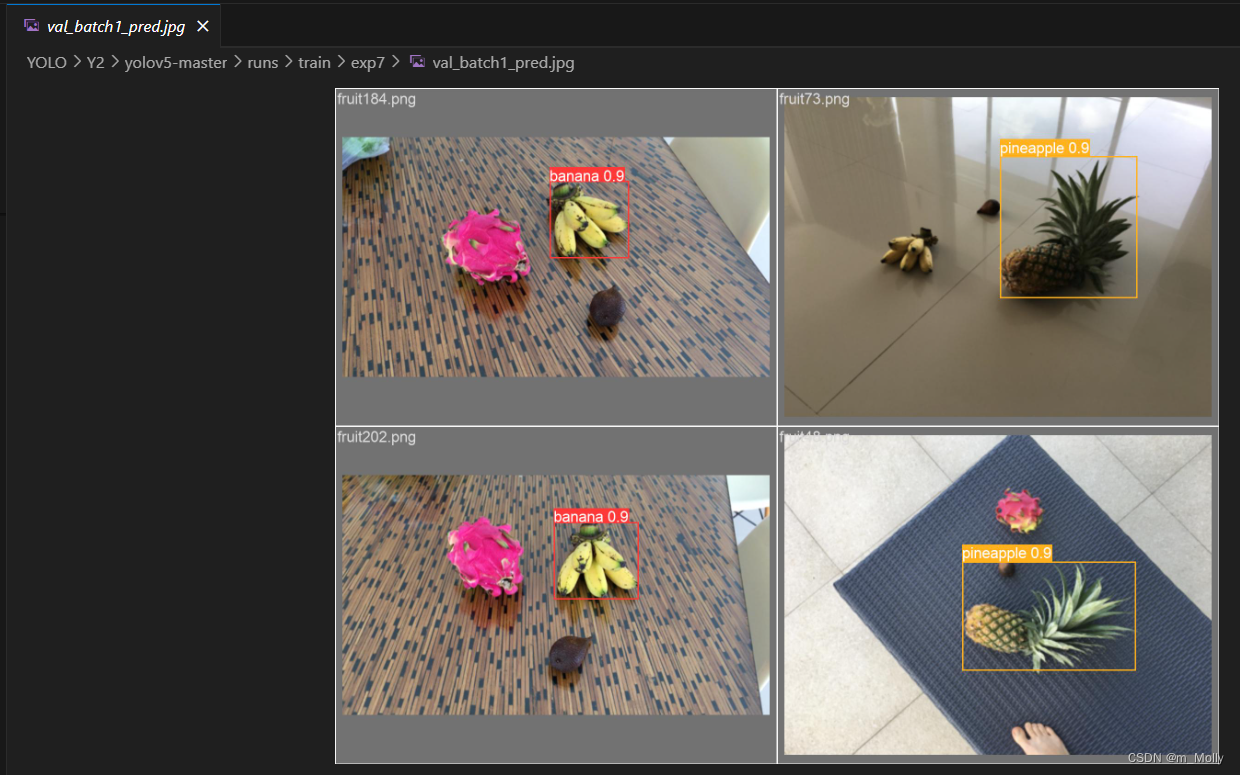
打开val_batch1_labels.jpg,则显示了带预测值的标签:
相关文章:
【Week Y2】使用自己的数据集训练YOLO-v5s
Y2-使用自己的数据集训练YOLO-v5s 零、遇到的问题汇总(1)遇到git的import error(2)Error:Dataset not found(3)Error:删除中文后,训练图片路径不存在 一、.xml文件里保存…...

蓝桥杯--基础(哈夫曼)
import java.util.ArrayList; import java.util.Collections; import java.util.List; import java.util.Scanner;public class BASIC28 {//哈夫曼书public static void main(String[] args) {Scanner Scannernew Scanner(System.in);int nScanner.nextInt();List<Integer&…...

【Redis内存数据库】NoSQL的特点和应用场景
前言 Redis作为当今最流行的内存数据库,已经成为服务端加速的必备工具之一。 NoSQL数据库采用了非关系型的数据存储模型,能够更好地处理海量数据和高并发访问。 内存数据库具有更快的读写速度和响应时间,因为内存访问速度比磁盘访问速度快…...

JavaScript基础知识2
求数组的最大值案例 let arr[2,6,1,7,400,55,88,100]let maxarr[0]let minarr[0]for(let i1;i<arr.length;i){max<arr[i]?maxarr[i]:maxmin>arr[i]?minarr[i]:min}console.log(最大值是:${max})console.log(最小值是:${min}) 操作数组 修改…...

Linux之线程同步
目录 一、问题引入 二、实现线程同步的方案——条件变量 1、常用接口: 2、使用示例 一、问题引入 我们再次看看上次讲到的多线程抢票的代码:这次我们让一个线程抢完票之后不去做任何事。 #include <iostream> #include <unistd.h> #inc…...

03 龙芯平台openstack部署搭建-keystone部署
#!/bin/bash #创建keystone数据库并授权,可通过mysql -ukeystone -ploongson验证授权登录 mysql -uroot -e “set password for rootlocalhost password(‘loongson’);” mysql -uroot -ploongson -e ‘CREATE DATABASE keystone;’ #本地登录 mysql -uroot -ploo…...

定义了服务器的端口号和Servlet的上下文路径
server: port: 1224 servlet: context-path: /applet 这个配置定义了服务器的端口号和Servlet的上下文路径。 下面是配置的解释: server.port: 1224:这表示服务器应该监听在1224端口上。server.servlet.context-path: /applet:这表…...

AI论文速读 | UniST:提示赋能通用模型用于城市时空预测
本文是时空领域的统一模型——UniST,无独有偶,时序有个统一模型新工作——UniTS,感兴趣的读者也可以阅读今天发布的另外一条。 论文标题:UniST: A Prompt-Empowered Universal Model for Urban Spatio-Temporal Prediction 作者&…...
rabbitmq-spring-boot-start配置使用手册
rabbitmq-spring-boot-start配置使用手册 文章目录 1.yaml配置如下2.引入pom依赖如下2.1 引入项目resources下libs中的jar包依赖如下2.2引入maven私服依赖如下 3.启动类配置如下4.项目中测试发送消息如下5.项目中消费消息代码示例6.mq管理后台交换机队列创建及路由绑定关系如下…...
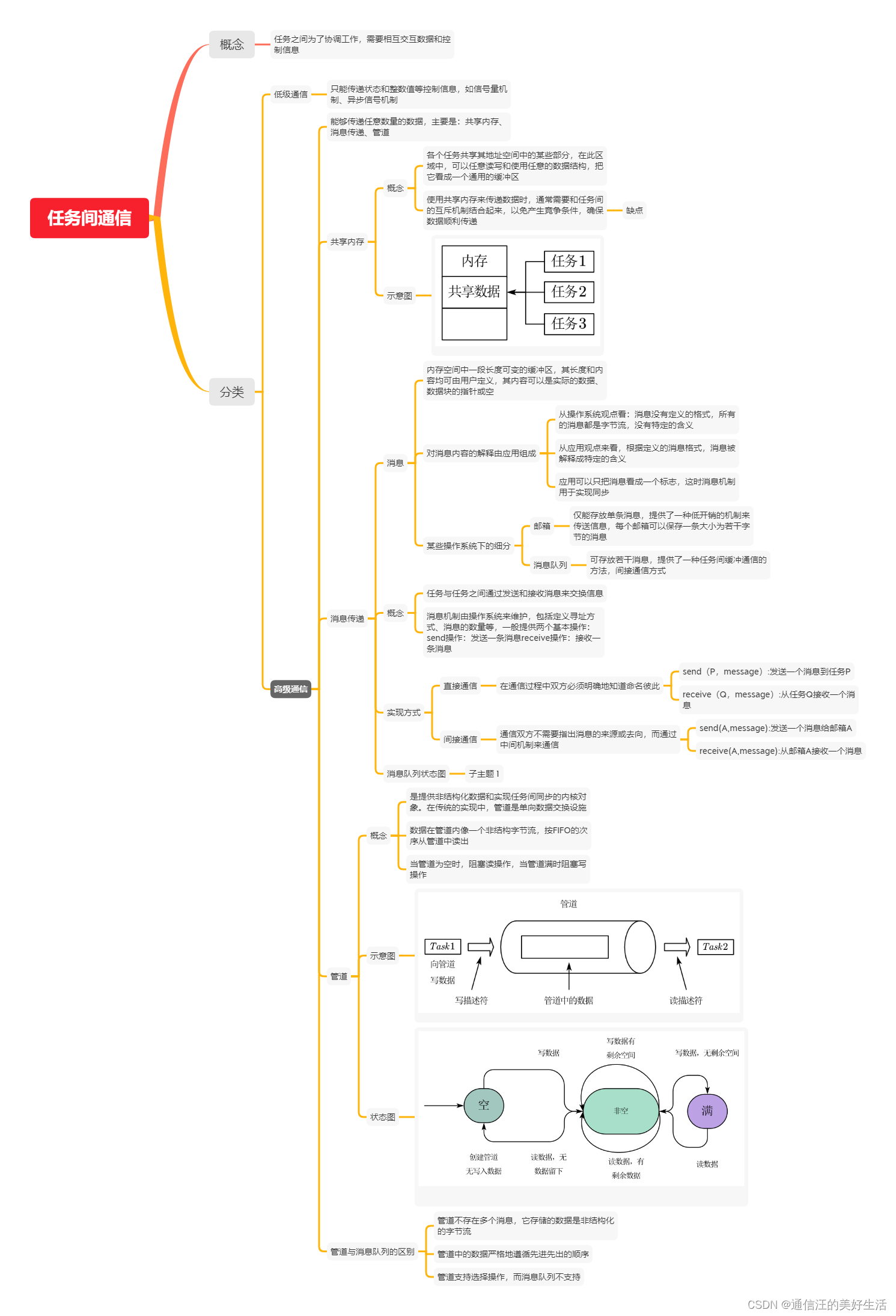
操作系统知识-操作系统作用+进程管理-嵌入式系统设计师备考笔记
0、前言 本专栏为个人备考软考嵌入式系统设计师的复习笔记,未经本人许可,请勿转载,如发现本笔记内容的错误还望各位不吝赐教(笔记内容可能有误怕产生错误引导)。 本章的主要内容见下图: 1、操作系统的作用…...
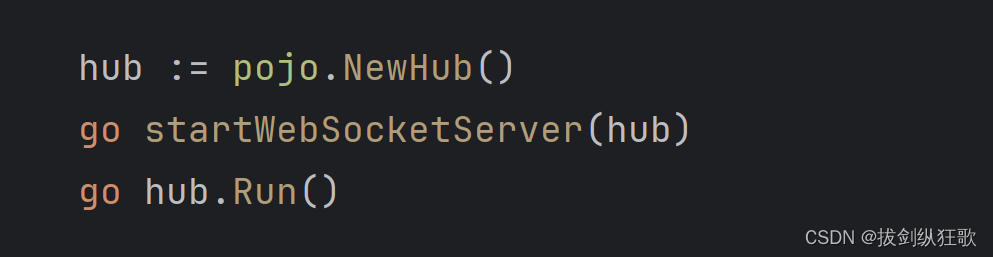
Go语言中的锁与管道的运用
目录 1.前言 2.锁解决方案 3.管道解决方案 4.总结 1.前言 在写H5小游戏的时候,由于需要对多个WebSocket连接进行增、删、查的管理和对已经建立连接的WebSocket通过服务端进行游戏数据交换的需求。于是定义了一个全局的map集合进行连接的管理,让所有…...
前端 - 基础 表单标签 -- 表单元素( input - type属性) 文本框和密码框
表单元素 : 在表单域中可以定义各种表单元素,这些表单元素就是允许用户在表单中输入或选择 的内容控件。 表单元素的外观也各不一样,有小圆圈,有正方形,也有方框,乱七八糟的,各种各样…...

关于MySQL模糊搜索不区分大小写
在我们日常使用ORM框架进行模糊查询时,会发现,搜索的结果是不区分关键字的英文大小写的,那这是为什么呢? 原因是MySQL的like本就不区分大小写;如果在建表的时候,没有设置好字段区分大小 //包含j和J的都会被…...

论文阅读——MoCo
Momentum Contrast for Unsupervised Visual Representation Learning 动量在数学上理解为加权移动平均: yt-1是上一时刻输出,xt是当前时刻输入,m是动量,不想让当前时刻输出只依赖于当前时刻的输入,m很大时࿰…...
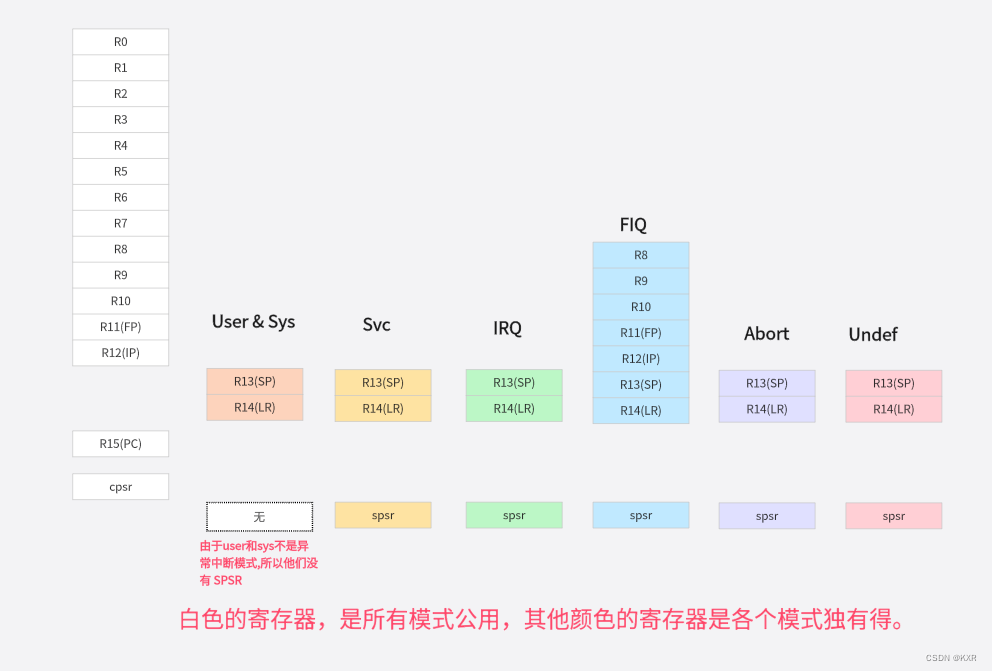
ARM 寄存器学习:(一)arm多种模式下得寄存器
一.ARM7种状态以及每种状态的寄存器: ARM 处理器共有 7 种不同的处理器模式,在每一种处理器模式中可见的寄存器包括 15 个通用寄存器( R0~R14)、一个或两个(User和Sys不是异常模式,没有spsr寄存器)状态寄存器(cpsr和spsr&…...

【nfs报错】rpc mount export: RPC: Unable to receive; errno = No route to host
NFS错误 问题现象解决方法 写在前面 这两天搭建几台服务器,需要使用nfs服务,于是六台选其一做服务端,其余做客户端,搭建过程写在centos7离线搭建NFS共享文件,但是访问共享时出现报错:rpc mount export: RPC…...

备战蓝桥杯---牛客寒假训练营2VP
题挺好的,收获了许多 1.暴力枚举(许多巧妙地处理细节方法) n是1--9,于是我们可以直接暴力,对于1注意特判开头0但N!1,对于情报4,我们可以把a,b,c,d的所有取值枚举一遍,那么如何判断有…...
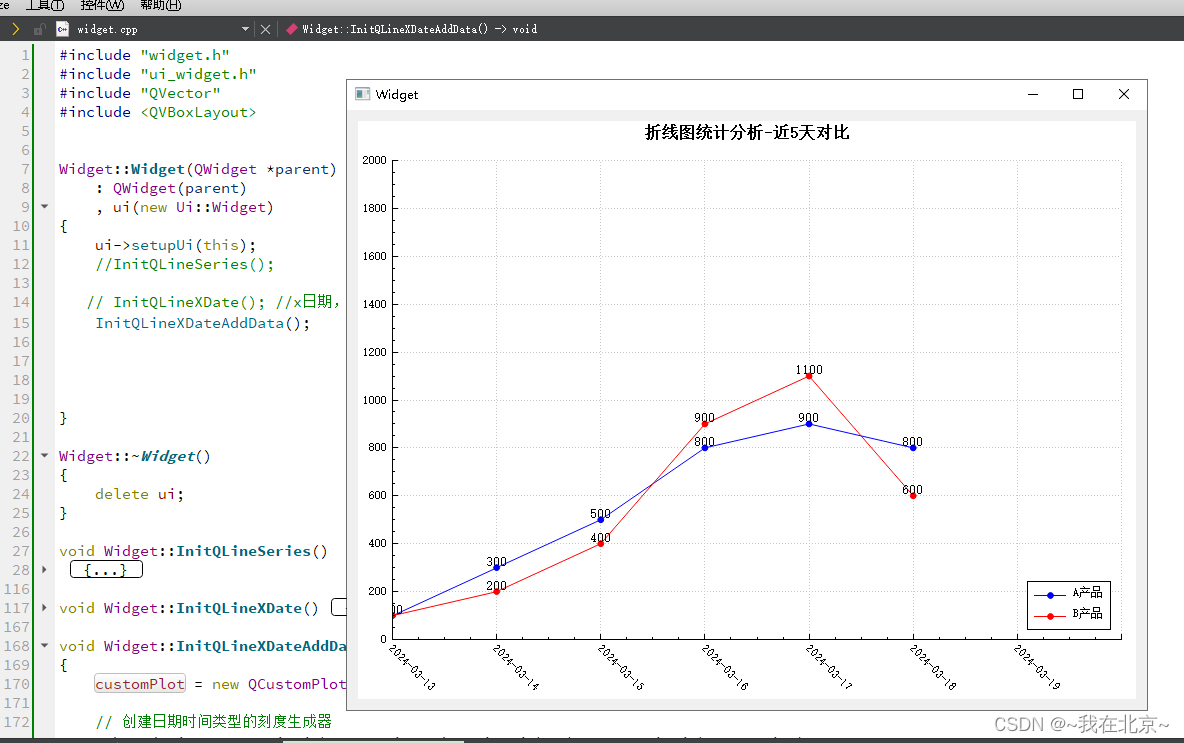
QCustomPlot-绘制X轴为日期的折线图
主要代码如下: void Widget::InitQLineXDateAddData() {customPlot new QCustomPlot(this);// 创建日期时间类型的刻度生成器QSharedPointer<QCPAxisTickerDateTime> dateTimeTicker(new QCPAxisTickerDateTime);dateTimeTicker->setDateTimeFormat(&quo…...
腾讯春招后端一面(算法篇)
前言: 哈喽大家好,前段时间在小红书和牛客上发了面试的经验贴,很多同学留言问算法的具体解法,今天就详细写个帖子回复大家。 因为csdn是写的比较详细,所以更新比较慢,大家见谅~~ 就题目而言,…...

Filebeat rpm方式安装及配置
一、使用服务器root用户、filebeat8.11.1版本,rpm安装方式进行安装 curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.11.1-x86_64.rpm sudo rpm -vi filebeat-8.11.1-x86_64.rpm 二、配置核心的采集文件、使用inputs热更方式、配置filebeat本身…...
)
从白炽灯到LED:聊聊那些“不听话”的非线性元件(附特性曲线解读)
从白炽灯到LED:聊聊那些“不听话”的非线性元件(附特性曲线解读) 记得我第一次用电阻给LED限流时,那颗蓝色LED在我眼前发出"啪"的一声轻响就永远熄灭了。那时我才明白,电路世界里不是所有元件都像电阻那样&q…...

从手机双摄到自动驾驶:对极几何与基础矩阵在现实场景中的三种典型应用分析
从手机双摄到自动驾驶:对极几何与基础矩阵在现实场景中的三种典型应用分析 当你在手机上使用人像模式拍照时,背景虚化的效果是如何实现的?无人机如何在飞行过程中实时估算自身位置?自动驾驶汽车又是怎样通过多摄像头系统感知周围环…...

手机检测落地标准化:实时手机检测-通用模型企业级部署Checklist
手机检测落地标准化:实时手机检测-通用模型企业级部署Checklist 1. 引言:为什么企业需要标准化的手机检测方案? 想象一下,你是一家大型电子产品质检工厂的负责人。每天,成千上万的手机从流水线上经过,需要…...

OpenCV多线程编程:从单线程到多线程的视频处理
一、最简单的摄像头显示程序让我们从最基础的版本开始:一个单线程程序,直接从摄像头读取并显示画面。基础版本代码#include <iostream> #include <opencv2/opencv.hpp> using namespace std;int main() {// 打开摄像头(默认摄像头…...

Go反射reflect包高级用法
Go语言反射机制探秘:深入reflect包高级用法 Go语言的反射机制通过reflect包为开发者提供了强大的运行时类型检查与操作能力。尽管反射会带来一定的性能开销,但在需要动态处理类型、实现泛型逻辑或构建框架时,它往往是不可替代的工具。本文将…...

SQL检查开发提效:sql-lint让数据库操作更可靠
SQL检查开发提效:sql-lint让数据库操作更可靠 【免费下载链接】sql-lint An SQL linter 项目地址: https://gitcode.com/gh_mirrors/sq/sql-lint 当你在深夜排查线上SQL错误时,当团队因SQL风格不统一争论时,当执行DELETE语句忘记WHERE…...

工业五官:04 电感、电容、光电、超声波:谁才是工厂最强“探测四兄弟”?
04 电感、电容、光电、超声波:谁才是工厂最强“探测四兄弟”? 今天聊位置和接近传感器——就是专门干“有没有东西”“靠没靠近”“到了没”这仨活儿的。工厂里,传送带上零件一过,机械手一抓,门一开一关,全靠这四兄弟瞪大眼睛盯着。它们不吹牛,不睡觉,比你家看门狗靠谱…...

游戏开发实战:Unity中合并带材质的.obj模型文件全攻略
Unity游戏开发实战:高效合并带材质的.obj模型文件全流程解析 在游戏开发中,资源优化始终是提升性能的关键环节。当项目涉及大量.obj格式的3D模型时,合并这些文件不仅能减少Draw Call,还能显著简化资源管理流程。本文将深入探讨如何…...
零基础入门指南)
OFA视觉语义蕴含(iic/ofa_visual-entailment_snli-ve_large_en)零基础入门指南
OFA视觉语义蕴含(iic/ofa_visual-entailment_snli-ve_large_en)零基础入门指南 1. 镜像简介 本镜像已经完整配置好了 OFA 图像语义蕴含模型 运行所需的一切环境,基于 Linux 系统 Miniconda 虚拟环境构建。你不需要手动安装任何依赖、配置环…...
你确定拿对了吗?)
逆向阿里系227滑块,除了n值,这几个固定参数(a/t/p/x5secdata)你确定拿对了吗?
逆向阿里系227滑块:那些被低估的固定参数陷阱 在逆向工程的世界里,我们常常被那些复杂的算法和动态生成的值所吸引,却忽略了那些看似简单却同样关键的固定参数。就像建造一座高楼,大家总是关注最显眼的钢结构,却很少有…...