使用Redis做缓存的小案例
如果不了解Redis,可以查看本人博客:Redis入门
Redis基于内存,因此查询速度快,常常可以用来作为缓存使用,缓存就是我们在内存中开辟一段区域来存储我们查询比较频繁的数据,这样,我们在下一次查询的时候,会直接去内存中查询,如果命中(查询到),就直接返回,否则就去数据库等在磁盘位置存储的数据进行查询,去磁盘硬盘等位置查询数据就比较慢了。因此,用好缓存对于我们的用户体验也是很重要的。
本文基于springboot+mybatisplus+Redis进行实现。
首先创建一个springboot项目:
不勾选依赖:
导入依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.2</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>配置application.yaml
spring:redis:host: localhostport: 6379password: 123456datasource:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverusername: rootpassword: rooturl: jdbc:mysql://localhost:3306/hongyan_sso?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowMultiQueries=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true&allowPublicKeyRetrieval=true编写实体类:
package com.qcby.springbootdata.pojo;import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;@TableName("t_user")
@Data
public class User {private Long id;private String userName;private String password;private String nickName;
}
编写mapper:
package com.qcby.springbootdata.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.qcby.springbootdata.pojo.User;
import org.apache.ibatis.annotations.Mapper;
import org.apache.tomcat.websocket.BackgroundProcess;@Mapper
public interface UserMapper extends BaseMapper<User> {
}
编写controller:
package com.qcby.springbootdata.controller;import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.qcby.springbootdata.mapper.UserMapper;
import com.qcby.springbootdata.pojo.User;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.util.Arrays;
import java.util.List;@RestController
@Slf4j
public class UserController {@Resourceprivate UserMapper userMapper;@Resourceprivate RedisTemplate<String,String> redisTemplate;@GetMapping("/get-user-by-nick")public String getUserByNick(Long id){String key = buildKey(String.valueOf(id));if(Boolean.TRUE.equals(redisTemplate.hasKey(key))){log.info("命中缓存,id:{}",id);return redisTemplate.boundValueOps(key).get();}User userPO = userMapper.selectById(id);if(userPO == null){redisTemplate.boundValueOps(key).set("暂无此人");return "暂无此人";}redisTemplate.boundValueOps(key).set(userPO.toString());return userPO.toString();}/*** 更新用户* 一般情况下,修改后删除就行了* 但是并发比较高,而且对数据比较敏感,比如说金钱,需要双删** @param userId 用户id* @param nickName 尼克名字* @return {@link String}* @throws InterruptedException 中断异常*/@GetMapping("/update-user-by-nick")public String updateUser(Long userId,String nickName) throws InterruptedException {User userPO = new User();userPO.setId(userId);userPO.setNickName(nickName);//这一步删除是为了保证,当sql指令发送给mysql以后,查询出来的值还是旧的redisTemplate.delete(buildKey(userId.toString()));userMapper.updateById(userPO);//这一步是为保证在sql指定发送给mysql的时候,来了查询,如果说这个时候的查寻还是修改之前的,导致缓存不更新redisTemplate.delete(buildKey(userId.toString()));return "22";}/*** 缓存预热*/@PostConstructpublic void initCache(){log.info("=========进行缓存预热=======================");List<Long> id = Arrays.asList(101110L,101112L,101116L,101118L);List<User> userPOS = userMapper.selectList(new LambdaQueryWrapper<User>().in(User::getId, id));userPOS.stream().forEach(item->{redisTemplate.boundValueOps(buildKey(item.getId().toString())).set(item.toString());});}private String buildKey(String Id){return "user:Id_"+Id;}
}
我们看一下controller中的思路:
①.@GetMapping("/get-user-by-nick")
public String getUserByNick(Long id)
这个方法首先根据给出的查询参数构造Redis的key,我们查询Redis或者存Redis数据通常会构造一个key,按照这个key来存储值。
首先从Redis数据库中查询,是否存在该查询结果的数据,如果存有,就直接拿取返回即可,否则走下一步。
然后从数据库中查询需要的数据,首先判断这个数据是否存在,如果存在就存入Redis该数据值,否则说明不存在,直接存储“无此数据”即可。
这个函数的大体思路就是,有数据就拿,没数据就存一个下次方便拿。
②.@GetMapping("/update-user-by-nick")
public String updateUser(Long userId,String nickName)
这个函数就是用来更新数据库数据,并且做到数据库与缓存之间保持同步。主要是考虑并发情况下,保证缓存数据和数据库数据的最终一致性。更新前删除缓存中的数据,保证尽可能的让其他进程或线程感知到数据库变化,进而在缓存中没有命中,进数据库中查询数据,此时,数据可能已经被更新了,或者还没有更新。
第二次删除就是为了保证数据更新以后,删除缓存中数据,让其他进程或线程在缓存中无命中,进而进入数据库读取最新的数据,保证了最终一致性。
③.@PostConstruct
public void initCache()
这个方法主要是做缓存预热,在查询数据之前,预先将访问频繁的数据存入缓存,进而提高缓存命中,提高查询效率。
相关文章:
使用Redis做缓存的小案例
如果不了解Redis,可以查看本人博客:Redis入门 Redis基于内存,因此查询速度快,常常可以用来作为缓存使用,缓存就是我们在内存中开辟一段区域来存储我们查询比较频繁的数据,这样,我们在下一次查询…...

剧本杀小程序功能介绍
剧本杀功能介绍 剧本杀,一种融合了角色扮演与推理解谜的社交游戏,近年来在年轻人中越来越受欢迎。它不仅可以锻炼参与者的逻辑推理能力,还能增进朋友间的感情,提升团队协作能力。下面,我们将详细介绍剧本杀的核心功能…...
)
C#基础语法学习笔记(传智播客学习)
最近在学习C#开发知识,跟着传智播客的视频学习了一下,感觉还不错,整理一下学习笔记。 C#基础语法学习笔记 1.背景知识2.Visual Studio使用3.基础知识4.变量5.运算符与表达式6.程序调试7.判断结构8.循环结构9.常量、枚举类型10.结构体类型11.数…...
)
图论01-DFS和BFS(深搜和广搜邻接矩阵和邻接表/Java)
1.深度优先理论基础(dfs) dfs的两个关键操作 搜索方向,是认准一个方向搜,直到碰壁之后再换方向 换方向是撤销原路径,改为节点链接的下一个路径,回溯的过程。dfs解题模板 void dfs(参数) {if (终止条件) {存放结果;return;}for …...
【Python】Miniconda+Vscode+Jupyter 环境搭建
1.安装 Miniconda Conda 是一个开源的包管理和环境管理系统,可在 Windows、macOS 和 Linux 上运行,它可以快速安装、运行和更新软件包及其依赖项。使用 Conda,我们可以轻松在本地计算机上创建、保存、加载和切换不同的环境 Conda 分为 Anaco…...
Redis消息队列与thinkphp/queue操作
业务场景 场景一 用户完成注册后需要发送欢迎注册的问候邮件、同时后台要发送实时消息给用户对应的业务员有新的客户注册、最后将用户的注册数据通过接口推送到一个营销用的第三方平台。 遇到两个问题: 由于代码是串行方式,流程大致为:开…...

【Ubuntu】常用命令
一般操作 pwd(present working directory) 显示当前的工作目录/路径。 cd (change directory) 改变目录,用于输入需要前往的路径/目录。 有一些特殊命令也很常用 : 解释 前往同一级的另一个目录 cd ../directory name cd .. 表示进入上…...
稀碎从零算法笔记Day22-LeetCode:
题型:链表 链接:2. 两数相加 - 力扣(LeetCode) 来源:Leet 题目描述 给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 …...

Nacos下载和安装
(1)下载地址和版本 下载地址:Releases alibaba/nacos GitHub 解压在没有中文及空格的文件夹 (2)启动nacos服务 在bin目录下,打开命令行,输入 启动命令:sh startup.sh -m standalone - Linux/Unix/Mac …...
)
pandas简介(python)
pandas是什么 Pandas 是一个开源的第三方 Python 库,从 Numpy 和 Matplotlib 的基础上构建而来,享有数据分析“三剑客之一”的盛名(NumPy、Matplotlib、Pandas)。Pandas 已经成为 Python 数据分析的必备高级工具,它的…...

个人网站制作 Part 13 添加搜索功能[Elasticsearch] | Web开发项目
文章目录 👩💻 基础Web开发练手项目系列:个人网站制作🚀 添加搜索功能🔨使用Elasticsearch🔧步骤 1: 安装Elasticsearch🔧步骤 2: 配置Elasticsearch🔧步骤 3: 创建索引 …...

Springboot+vue的仓库管理系统(有报告)。Javaee项目,springboot vue前后端分离项目。
演示视频: Springbootvue的仓库管理系统(有报告)。Javaee项目,springboot vue前后端分离项目。 项目介绍: 采用M(model)V(view)C(controller)三层…...
vue3 + vite 实现一个动态路由加载功能
假设后端返回的格式是这样子 {"menu": [{"path": "/admin","name": "adminLayout","redirect": "/admin/index","componentPath": "/layout/admin/index.vue","children&quo…...

【征稿进行时|见刊、检索快速稳定】2024年区块链、物联网与复合材料与国际学术会议 (ICBITC 2024)
【征稿进行时|见刊、检索快速稳定】2024年区块链、物联网与复合材料与国际学术会议 (ICBITC 2024) 大会主题: (主题包括但不限于, 更多主题请咨询会务组苏老师) 区块链: 区块链技术和系统 分布式一致性算法和协议 块链性能 信息储存系统 区块链可扩展性 区块…...

若依jar包运行脚本,从零到一:用Bash脚本实现JAR应用的启动、停止与监控
脚本使用说明: 启动应用:sh app.sh start停止应用:sh app.sh stop检查应用状态:sh app.sh status重启应用:sh app.sh restart 注意事项: 请确保你的系统上安装了 Java 环境,并且 ruoyi-admin…...
)
Unix运维_FreeBSD-13.1临时环境变量设置(bin和include以及lib)
Unix运维_FreeBSD-13.1临时环境变量设置(bin和include以及lib) 在 FreeBSD 系统上设置用户环境变量可以通过编辑用户的 Shell配置文件 来实现。 cshrc 与 csh_profile 的区别: cshrc: 每个脚本执行前都执行一遍这个脚本。 csh_profile: 根据不同使用者用户名, 会先去其 home…...
Apache Dolphinscheduler - 无需重启 Master-Server 停止疯狂刷日志解决方案
记录的是一个 3.0 比较难搞的问题,相信不少使用过 3.0 的用户都遇到过 Master 服务中存在一些工作流或者任务流一直不停的死循环的问题,导致疯狂刷日志。不过本人到现在也没找到最关键的触发原因,只是看到一些连锁反应带来的结果…… 影响因素…...

竞争优势:大型语言模型 (LLM) 如何重新定义业务策略
人工智能在内容创作中的突破 在当今快节奏的商业环境中,像 GPT-4 这样的大型语言模型 (LLM) 不再只是一种技术新颖性; 它们已成为重新定义跨行业业务战略的基石。 从增强客户服务到推动创新,法学硕士提供了企业不容忽视的竞争优势。 1. 加强…...

Spring AOP和AspectJ AOP区别
Spring AOP(Aspect-Oriented Programming)和 AspectJ AOP 是两种不同的 AOP 实现方式,它们在实现上有一些区别。下面是它们之间的主要区别: 基于代理 vs 字节码增强: Spring AOP: Spring AOP 是基于代理的…...
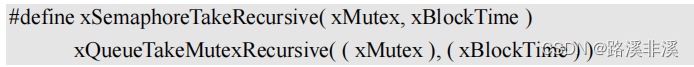
FREERTOS信号量详解
信号量是操作系统中重要的一部分,信号量一般用来进行资源管理和任务同步,资源管理其实就是用变量来标记现有资源的数量,任务同步其实就是用标志位来控制任务的先后执行顺序,这些概念在操作系统中以及裸机开发中都有所涉及。 FreeR…...

使用Python进行文件读写的API或方法及其注意事项
本文总结了Python文件读写的核心API及注意事项。主要内容包括:1)文件打开与关闭方法,推荐使用with语句自动管理资源;2)文件读取方法,如read()、readline()等,注意大文件应使用迭代器方式&#x…...
)
告别在线API:在嵌入式Linux上用Ekho TTS实现离线语音播报(避坑实录)
嵌入式Linux离线语音方案:Ekho TTS深度集成指南 在智能硬件开发领域,语音交互已成为提升用户体验的关键要素。然而,当项目部署在无网络环境的嵌入式设备时,传统在线TTS服务立刻暴露出致命缺陷——网络依赖性。我曾在一个工业级智能…...
)
SAP月结实操:手把手教你配置FAGL_FC_VAL外币评估(含OB59/OBA1避坑指南)
SAP月结实操:从零到精通的FAGL_FC_VAL外币评估全流程指南 第一次接触SAP月结外币评估时,我盯着屏幕上跳出的报错信息手足无措。作为刚入行的财务顾问,OB59里密密麻麻的配置项和OBA1中复杂的记账规则让我差点崩溃。直到后来在项目上踩过无数坑…...

别再从头训练了!DeepFaceLab模型复用实战:用旧项目快速打造新视频
DeepFaceLab模型复用实战:用旧项目加速新视频创作 看着屏幕上那个已经训练了整整两周的模型,我突然意识到一个严重问题——如果每次换新人物都要从头开始,这样的效率根本无法满足客户需求。去年接手商业项目时,我曾固执地认为每个…...

5分钟彻底掌握Balena Etcher:最安全的系统镜像烧录工具完全指南
5分钟彻底掌握Balena Etcher:最安全的系统镜像烧录工具完全指南 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher 你是否曾经因为制作系统启动盘而烦恼…...

晶体管负反馈原理与放大器设计实践
1. 晶体管反馈原理基础解析在电子放大器设计中,反馈是决定电路性能的核心机制。简单来说,反馈就是将放大器输出信号的一部分重新送回到输入端的过程。这种看似简单的操作却能彻底改变放大器的行为特性。1.1 反馈的基本分类反馈根据相位关系主要分为两种类…...

flutter-unity-view-widget AR 增强现实开发完全指南:ARKit 和 ARCore 集成
flutter-unity-view-widget AR 增强现实开发完全指南:ARKit 和 ARCore 集成 【免费下载链接】flutter-unity-view-widget Embeddable unity game engine view for Flutter. Advance demo here https://github.com/juicycleff/flutter-unity-arkit-demo 项目地址: …...

原神60FPS限制终极解锁指南:突破性能瓶颈的完整解决方案
原神60FPS限制终极解锁指南:突破性能瓶颈的完整解决方案 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 你是否曾经在原神游戏中感受到60FPS的限制?即使你的硬件配…...

从地震预测到社交网络:Hawkes过程如何成为‘连锁反应’建模的瑞士军刀?
Hawkes过程:从地震余震到社交传播的连锁反应建模利器 想象一下,当你看到社交平台上某条内容突然爆红时,背后是否存在某种规律?或者当电商平台某个商品销量激增时,是否受到前期购买行为的影响?这些看似无关…...

终极PDF视觉对比解决方案:diff-pdf深度解析与实践指南
终极PDF视觉对比解决方案:diff-pdf深度解析与实践指南 【免费下载链接】diff-pdf A simple tool for visually comparing two PDF files 项目地址: https://gitcode.com/gh_mirrors/di/diff-pdf 在数字化文档协作、技术文档版本控制和法律合同审核等场景中&a…...