深度学习pytorch实战三:VGG16图像分类篇自建数据集图像分类三类
1.自建数据集与划分训练集与测试集
2.模型相关知识
3.model.py——定义AlexNet网络模型
4.train.py——加载数据集并训练,训练集计算损失值loss,测试集计算accuracy,保存训练好的网络参数
5.predict.py——利用训练好的网络参数后,用自己找的图像进行分类测试
一、自建数据集与划分训练集与测试集
1.自建数据文件夹
首先我们确定这次分类种类,采用爬虫、官网数据集和自己拍照的照片获取三类,准备个文件夹,里面包含三个文件夹,文件夹名字随便取,最好是所属种类英文,每个文件夹照片数量最好一样多,五百多张以上。如我选了蒲公英,玫瑰,郁金香三类,如data_set包含flowers_data,它包含flowers_photos,它包含三个文件夹,分别是三个类文件夹。
2.划分训练集与测试集
这里需要使用通用的划分数据代码,这次是与flowers_data同一目录下运行。
import os
from shutil import copy
import randomdef mkfile(file):if not os.path.exists(file):os.makedirs(file)# 获取 photos 文件夹下除 .txt 文件以外所有文件夹名(即3种分类的类名)
file_path = 'flower_data/flower_photos'
flower_class = [cla for cla in os.listdir(file_path) if ".txt" not in cla]# 创建 训练集train 文件夹,并由3种类名在其目录下创建3个子目录
mkfile('flower_data/train')
for cla in flower_class:mkfile('flower_data/train/' + cla)# 创建 验证集val 文件夹,并由3种类名在其目录下创建3个子目录
mkfile('flower_data/val')
for cla in flower_class:mkfile('flower_data/val/' + cla)# 划分比例,训练集 : 验证集 = 9 : 1
split_rate = 0.1# 遍历3种花的全部图像并按比例分成训练集和验证集
for cla in flower_class:cla_path = file_path + '/' + cla + '/' # 某一类别动作的子目录images = os.listdir(cla_path) # iamges 列表存储了该目录下所有图像的名称num = len(images)eval_index = random.sample(images, k=int(num * split_rate)) # 从images列表中随机抽取 k 个图像名称for index, image in enumerate(images):# eval_index 中保存验证集val的图像名称if image in eval_index:image_path = cla_path + imagenew_path = 'flower_data/val/' + clacopy(image_path, new_path) # 将选中的图像复制到新路径# 其余的图像保存在训练集train中else:image_path = cla_path + imagenew_path = 'flower_data/train/' + clacopy(image_path, new_path)print("\r[{}] processing [{}/{}]".format(cla, index + 1, num), end="") # processing barprint()print("processing done!")最后运行,在flowers_data会多两个文件,是train和val(训练集和测试集)
二、模型相关知识
之前有文章介绍模型,如果不清楚可以点下链接转过去学习
深度学习卷积神经网络CNN之 VGGNet模型主vgg16和vgg19网络模型详解说明(理论篇)
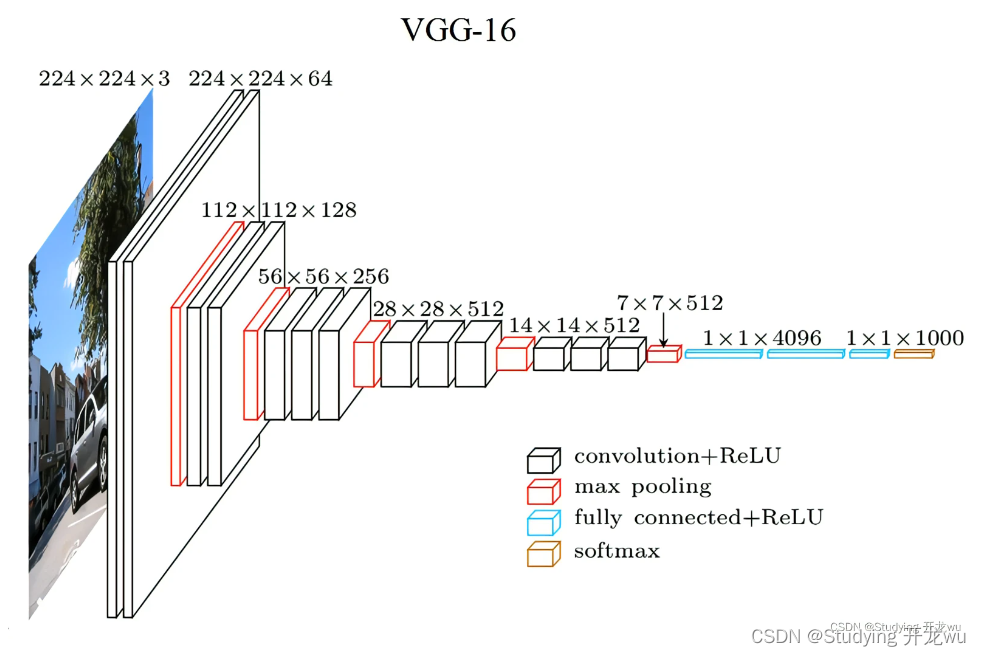
三、model.py——定义AlexNet网络模型
这里还是直接复制给出原模型,不用改参数。
import torch.nn as nn
import torch# official pretrain weights
model_urls = {'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth','vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth','vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth','vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}class VGG(nn.Module):def __init__(self, features, num_classes=1000, init_weights=False):super(VGG, self).__init__()self.features = featuresself.classifier = nn.Sequential(nn.Linear(512*7*7, 4096),nn.ReLU(True),nn.Dropout(p=0.5),nn.Linear(4096, 4096),nn.ReLU(True),nn.Dropout(p=0.5),nn.Linear(4096, num_classes))if init_weights:self._initialize_weights()def forward(self, x):# N x 3 x 224 x 224x = self.features(x)# N x 512 x 7 x 7x = torch.flatten(x, start_dim=1)# N x 512*7*7x = self.classifier(x)return xdef _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')nn.init.xavier_uniform_(m.weight)if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.xavier_uniform_(m.weight)# nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)def make_features(cfg: list):layers = []in_channels = 3for v in cfg:if v == "M":layers += [nn.MaxPool2d(kernel_size=2, stride=2)]else:conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)layers += [conv2d, nn.ReLU(True)]in_channels = vreturn nn.Sequential(*layers)cfgs = {'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}def vgg(model_name="vgg16", **kwargs):assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)cfg = cfgs[model_name]model = VGG(make_features(cfg), **kwargs)return model四、train.py——模型训练,加载数据集并训练,训练集计算损失值loss,测试集计算accuracy,保存训练好的网络参数
在63行修改为3,因为只有三类
net = vgg(model_name=model_name, num_classes=3, init_weights=True)
import os
import sys
import jsonimport torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdmfrom model import vggdef main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val": transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root pathimage_path = os.path.join(data_root, "data_set1", "flower_data1") # flower data set pathassert os.path.exists(image_path), "{} path does not exist.".format(image_path)train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),transform=data_transform["train"])train_num = len(train_dataset)# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}flower_list = train_dataset.class_to_idxcla_dict = dict((val, key) for key, val in flower_list.items())# write dict into json filejson_str = json.dumps(cla_dict, indent=4)with open('class_indices.json', 'w') as json_file:json_file.write(json_str)batch_size = 64nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using {} dataloader workers every process'.format(nw))train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size, shuffle=True,num_workers=nw)validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),transform=data_transform["val"])val_num = len(validate_dataset)validate_loader = torch.utils.data.DataLoader(validate_dataset,batch_size=batch_size, shuffle=False,num_workers=nw)print("using {} images for training, {} images for validation.".format(train_num,val_num))# test_data_iter = iter(validate_loader)# test_image, test_label = test_data_iter.next()model_name = "vgg16"net = vgg(model_name=model_name, num_classes=3, init_weights=True)%%%%%%%%这一行net.to(device)loss_function = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=0.0001)epochs = 10best_acc = 0.0save_path = './{}Net.pth'.format(model_name)train_steps = len(train_loader)for epoch in range(epochs):# trainnet.train()running_loss = 0.0train_bar = tqdm(train_loader, file=sys.stdout)for step, data in enumerate(train_bar):images, labels = dataoptimizer.zero_grad()outputs = net(images.to(device))loss = loss_function(outputs, labels.to(device))loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)# validatenet.eval()acc = 0.0 # accumulate accurate number / epochwith torch.no_grad():val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar:val_images, val_labels = val_dataoutputs = net(val_images.to(device))predict_y = torch.max(outputs, dim=1)[1]acc += torch.eq(predict_y, val_labels.to(device)).sum().item()val_accurate = acc / val_numprint('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, val_accurate))if val_accurate > best_acc:best_acc = val_accuratetorch.save(net.state_dict(), save_path)print('Finished Training')if __name__ == '__main__':main()训练结果截图如下
五、predict.py——利用训练好的网络参数后,用自己找的图像进行分类测试
import os
import jsonimport torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as pltfrom model import vggdef main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")data_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# load imageimg_path = "1.jpg"assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)img = Image.open(img_path)plt.imshow(img)# [N, C, H, W]img = data_transform(img)# expand batch dimensionimg = torch.unsqueeze(img, dim=0)# read class_indictjson_path = './class_indices.json'assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)with open(json_path, "r") as f:class_indict = json.load(f)# create modelmodel = vgg(model_name="vgg16", num_classes=5).to(device)# load model weightsweights_path = "./vgg16Net.pth"assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)model.load_state_dict(torch.load(weights_path))model.eval()with torch.no_grad():# predict classoutput = torch.squeeze(model(img.to(device))).cpu()predict = torch.softmax(output, dim=0)predict_cla = torch.argmax(predict).numpy()print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],predict[predict_cla].numpy())plt.title(print_res)for i in range(len(predict)):print("class: {:10} prob: {:.3}".format(class_indict[str(i)],predict[i].numpy()))plt.show()if __name__ == '__main__':main()在网上下载了一郁金香的图片,使用VGG16网络查看是否可以将图片种类正确识别。
相关文章:
深度学习pytorch实战三:VGG16图像分类篇自建数据集图像分类三类
1.自建数据集与划分训练集与测试集 2.模型相关知识 3.model.py——定义AlexNet网络模型 4.train.py——加载数据集并训练,训练集计算损失值loss,测试集计算accuracy,保存训练好的网络参数 5.predict.py——利用训练好的网络参数后,…...

2023年3月软考高项(信息系统项目管理师)报名走起!!!
信息系统项目管理师是全国计算机技术与软件专业技术资格(水平)考试(简称软考)项目之一,是由国家人力资源和社会保障部、工业和信息化部共同组织的国家级考试,既属于国家职业资格考试,又是职称资…...
模电学习11 运算放大器学习入门
一、基本概念 运算放大器简称运放,是一种模拟电路实现的集成电路,可以对信号进行很高倍数的放大。一般有正相输入端、反相输入端、输出端口、正电源、负电源等接口。 运放可工作在饱和区、放大区,其中放大区极其陡峭,因为运放的放…...

spring学习3.5
Bean是什么 Spring里面的Bean就类似是定义的一个组件,而这个组件的作用就是实现某个功能的,这里所定义的Bean就相当于给了你一个更为简便的方法来调用这个组件去实现你要完成的功能。 IoC是什么 谁控制谁,控制什么? 传统Java SE程…...

名创优品:国内“触礁”,海外“提速”
在互联网经济十分发达、实体经济不太景气的时代背景下,自有品牌零售商代表名创优品却逆势而上,开始向着全球品牌类生活用品零售市场发起冲击,并凭借着“极致性价比大规模跑量”的独特优势在该领域取得了十分可观的成绩。 随着“Z时代”人群逐…...
Java学习笔记 --- Tomcat
一、JavaWeb 的概念 JavaWeb 是指,所有通过 Java 语言编写可以通过浏览器访问的程序的总称,叫 JavaWeb。 JavaWeb是基于请求和响应来开发的。请求是指客户端给服务器发送数据,叫请求 Request。 响应是指服务器给客户端回传数据,叫…...

面向对象设计模式:行为型模式之状态模式
文章目录一、引入二、状态模式2.1 Intent 意图2.2 Applicability 适用性2.3 类图2.4 Collaborations 合作2.5 Implementation 实现2.5 状态模式与策略模式的对比2.5 状态模式实例:糖果机2.6 状态模式实例:自行车升降档一、引入 State Diagram 状态图&am…...

【Python入门第二十五天】Python 作用域
变量仅在创建区域内可用。这称为作用域。 局部作用域 在函数内部创建的变量属于该函数的局部作用域,并且只能在该函数内部使用。 实例 在函数内部创建的变量在该函数内部可用: def myfunc():x 100print(x)myfunc()运行实例 100函数内部的函数 如…...
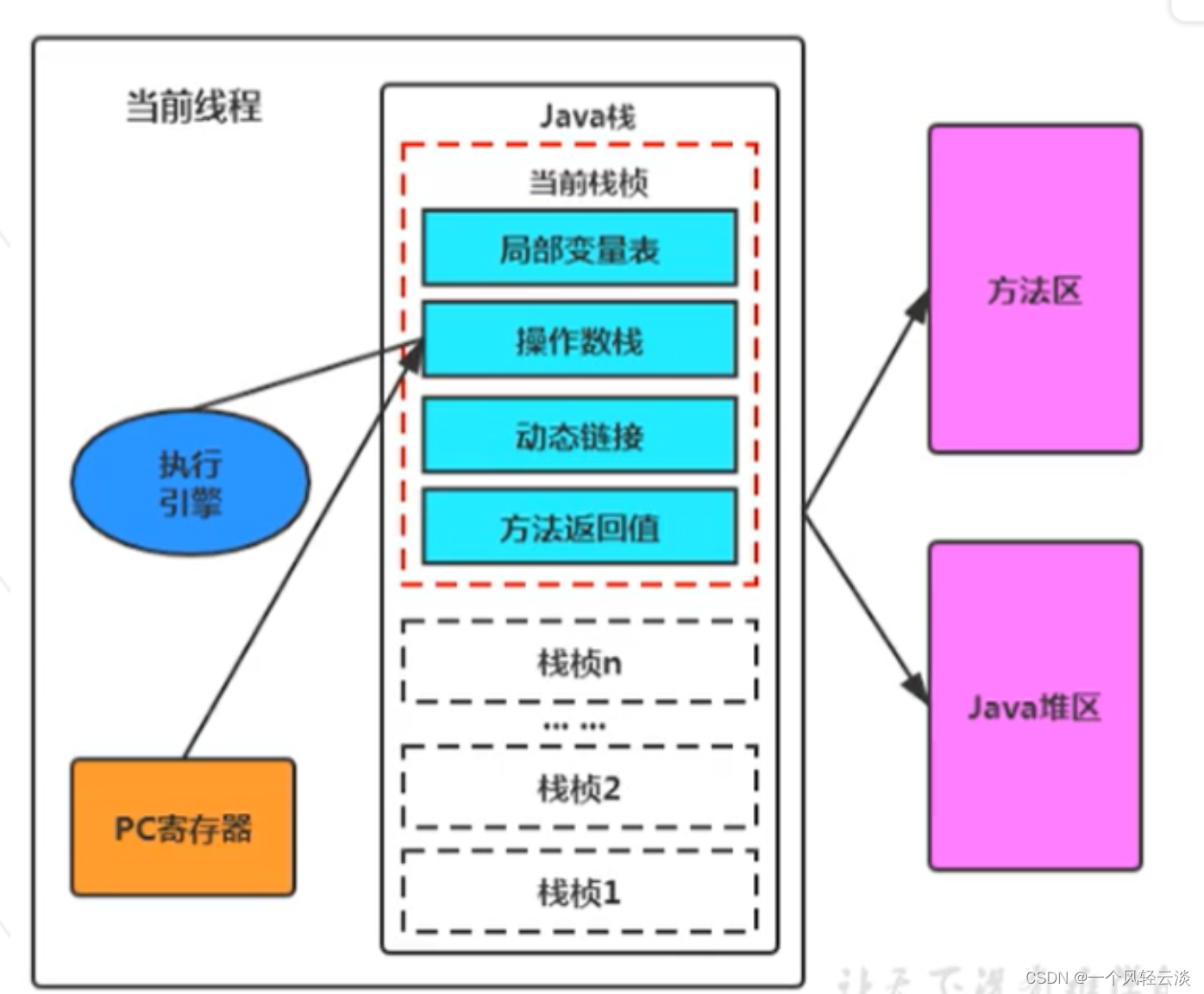
运行时数据区及程序计数器
运行时数据区 概述 运行时数据区,也就是下图这部分,它是在类加载完成后的阶段 当我们通过前面的:类的加载-> 验证 -> 准备 -> 解析 -> 初始化 这几个阶段完成后,就会用到执行引擎对我们的类进行使用,同时…...
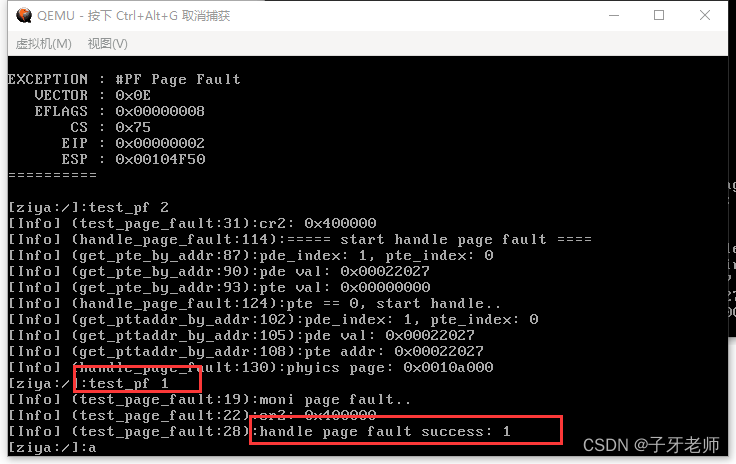
手写操作系统+文件系统开源啦
哈喽,我是子牙,一个很卷的硬核男人。喜欢研究底层,聚焦做那些大家想学没地方学的课程:手写操作系统、手写虚拟机、手写模拟器、手写编程语言… 今年是我创业的第二年,已经做了两个课程:手写JVM、手写操作系…...
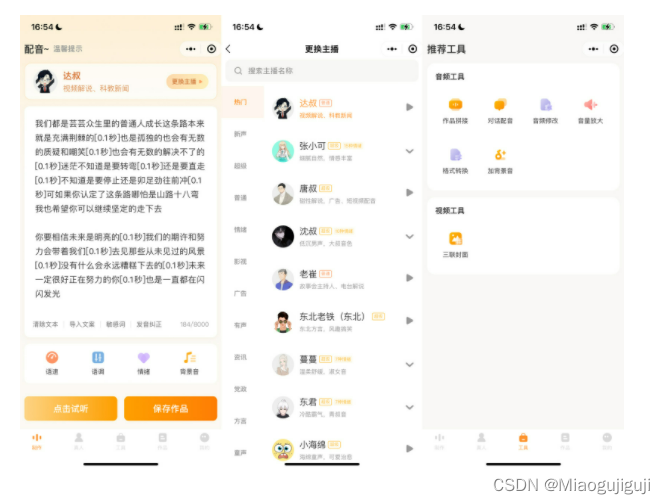
小众但意外觉得蛮好用的剪辑软件!纯良心分享
爱剪辑 有开屏广告,一共3个界面:首页、剪同款、我的。 剪辑、配乐、字幕、滤镜、加速、贴纸、配音等主流功能都有。 特色功能有剪裁视频、倒放视频、视频旋转、视频转换GIF、转场、提取音频、画中画等。 还可以拼接视频,不过不支持FLV等小众文…...
)
一文带你入门angular(下)
一、angular get数据请求 angular5.x之后get,post和服务器交互使用的是HttpClientModule模块。 1.首先要在app.module.ts中引入HttpClientModule并注入 import {HttpClientModule} from "angular/common/http" 注入: import:[ …...

2023-3-6刷题情况
分巧克力 题目描述 儿童节那天有 KKK 位小朋友到小明家做客。小明拿出了珍藏的巧克力招待小朋友们。 小明一共有 NNN 块巧克力,其中第 iii 块是 HiWiH_i \times W_iHiWi 的方格组成的长方形。 为了公平起见,小明需要从这 NNN 块巧克力中切出 KKK…...

一篇教你解决如何在不加锁的情况下解决多线程问题!
怎样在不加锁的情况下解决线程安全问题,你需要了解lock free和wait free这两个概念,在此之前我们先从最简单的有锁编程开始。 我们知道,多线程同时修改共享变量时会出现数据不一致的问题,比如多个线程同时对一个变量加1ÿ…...

OPT(奥普特)一键测量传感器SmartFlash高精度的四重保证
OPT(奥普特)一键测量传感器SmartFlash集成了机器视觉的边缘提取、自动匹配、自动对焦、自动学习及图像合成等人工智能技术,采用双远心光路及多角度照明系统设计,搭载高精度运动平台,并通过亚像素边缘提取算法处理图像&…...
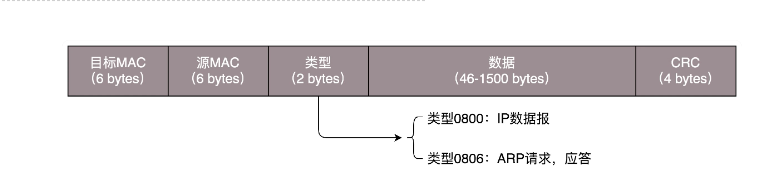
网络协议丨从物理层到MAC层
我们都知道TCP/IP协议其中一层,就是物理层。物理层其实很好理解,就是物理攻击的物理。我们使用电脑上网时的端口、网线这些都属于物理层,没有端口没有路由你没有办法上网。网线的头我们叫水晶头,也是物理层的一份子。如果你的面前…...
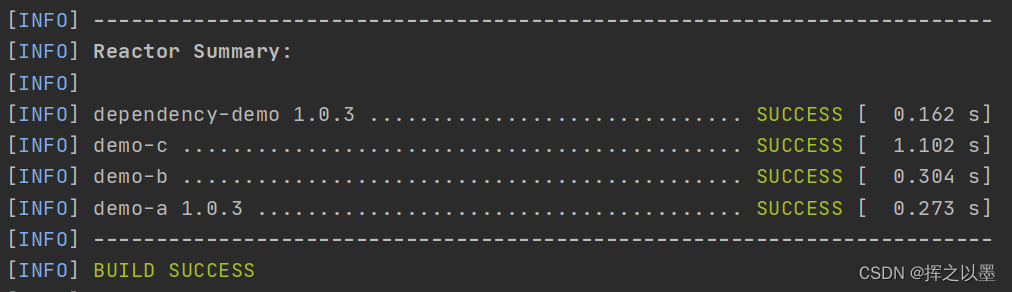
【Maven】(五)Maven模块的继承与聚合 多模块项目组织构建
文章目录1.前言2.模块的继承2.1.可继承的标签2.2.超级POM2.3.手动引入自定义父POM3.模块的聚合3.1.聚合的注意事项3.2.反应堆(reactor)4.依赖管理及属性配置4.1.依赖管理4.2.属性配置5.总结1.前言 本系列文章记录了 Maven 从0开始到实战的过程,Maven 系列历史文章清…...
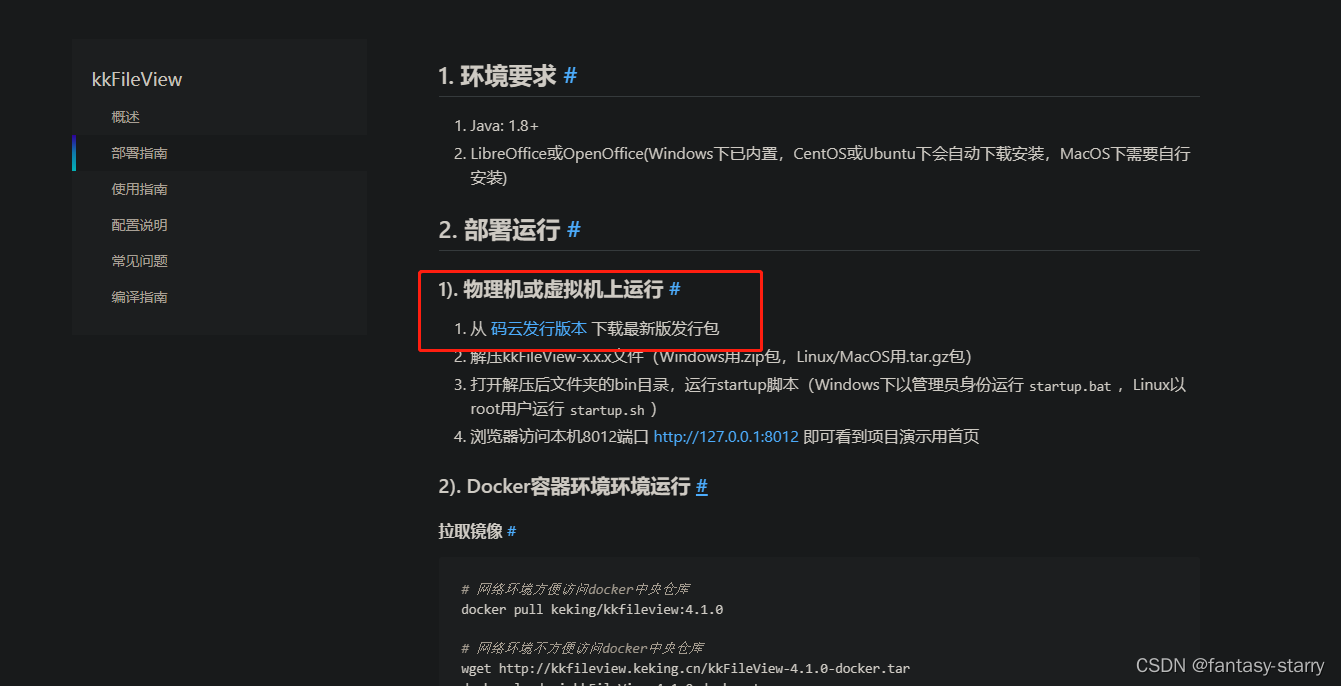
Linux 常用软件安装(jdk,redis,mysql,minio,kkFileView)
1.jdk安装 查询所有跟Java相关的安装的rpm包 rpm -qa | grep java卸载所有跟openjdk相关的包: 执行命令。删除以上除了noarch 结尾的所有文件 rpm -e --nodeps java-1.8.0-openjdk-1.8.0.252.b09-2.el8_1.x86_64 rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0…...

单链表及其相关函数
实现功能BuySListNode ————————————申请一个新节点并赋值SListLength —————————————计算链表的长度SListPushBack————————————尾插SListPushFront————————————头插SListPopBack—————————————尾删SListPopFront—…...

Linux段错误调试
1、设置ulimit ulimit -a 查看 ulimit -c 2048 设置core大小 2、设置core文件信息 下面两个设置需要在root下设置,否则权限不通过 echo 1>/proc/sys/kernel/core_uses_pid echo "/tmp/corefile-%e-%p-%t" >/proc/sys/kernel/core_pattern 3、编译…...

告别窄带!用ADS仿真带你搞懂Doherty放大器带宽瓶颈与三种宽带方案
突破Doherty放大器带宽限制:ADS仿真实战与三大宽带方案解析 在射频功率放大器设计中,Doherty结构因其高效率特性成为5G基站和现代通信系统的核心组件。然而传统设计面临严峻的带宽挑战——当信号频率偏离中心频点时,效率可能骤降30%以上。本文…...

R语言clusterProfiler包KEGG富集分析报错?别慌,这份2024最新避坑指南帮你搞定
R语言clusterProfiler包KEGG富集分析2024避坑实战指南 当你在深夜的实验室里盯着RStudio不断弹出的红色报错信息,第十次尝试调整enrichKEGG参数却依然看到"replacement has length zero"这个令人绝望的提示时,可能已经忍不住要摔键盘了。这份…...

PYTHON基础入门----商品库存管理系统
如果商品信息只保存在程序运行过程中,那么程序关闭后,所有数据都会丢失。因此,我们需要将商品数据保存到文件中,下次运行程序时还能继续读取和使用。本题要求你编写一个简单的商品库存管理系统,实现商品的添加、查看、…...

为什么92%的团队把DeepSeek CQRS配错了?资深SRE曝光3个被文档刻意弱化的配置陷阱
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队把DeepSeek CQRS配错了?资深SRE曝光3个被文档刻意弱化的配置陷阱 陷阱一:事件序列号(Sequence ID)与数据库事务隔离级别的隐式冲突 Deep…...

如何用RPG Maker多层级视差地图插件创建专业级游戏场景?
如何用RPG Maker多层级视差地图插件创建专业级游戏场景? 【免费下载链接】RPGMakerMV RPGツクールMV、MZで動作するプラグインです。 项目地址: https://gitcode.com/gh_mirrors/rp/RPGMakerMV RPG Maker多层级视差地图插件是一个功能强大的开源工具…...

别再只刷Demo了!手把手教你用CCS给AWR1843毫米波雷达写自己的‘大脑’
从Demo玩家到雷达开发者:AWR1843毫米波雷达CCS深度开发实战 毫米波雷达技术正在智能驾驶、工业检测等领域掀起革命浪潮。作为TI明星产品,AWR1843凭借其高性价比和丰富功能成为众多开发者的首选。但大多数用户止步于运行官方Demo,未能真正释放…...

告别裸机轮询:在STM32F103上为AHT20温湿度采集加入FreeRTOS实时任务管理
从裸机轮询到RTOS任务管理:STM32F103与AHT20温湿度传感器的架构升级实战 在嵌入式开发领域,如何从简单的功能实现进阶到健壮的软件架构设计,是每个开发者必须面对的挑战。本文将带你完成一次典型的架构升级——将基于STM32F103的AHT20温湿度传…...
——GPIO输入实验)
STM32单片机学习(11)——GPIO输入实验
文章目录实验一:按住按键LED点亮实验题目要求接线与程序框架程序实现存在的问题 —— 按键抖动优化后的程序代码实验二:光敏电阻传感器控制LED实验光敏电阻光敏电阻传感器各部分元器件介绍比较器正极输入电压分析比较器负极输入电压分析最终结论临界状态…...

Midscene.js视觉驱动自动化测试终极教程:跨平台AI测试实战深度解析
Midscene.js视觉驱动自动化测试终极教程:跨平台AI测试实战深度解析 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 还在为多设备、多平台测试的碎片化…...

Laravel-admin图表组件终极指南:从零实现ECharts与Chart.js数据可视化
Laravel-admin图表组件终极指南:从零实现ECharts与Chart.js数据可视化 【免费下载链接】laravel-admin Build a full-featured administrative interface in ten minutes 项目地址: https://gitcode.com/gh_mirrors/la/laravel-admin Laravel-admin作为一款高…...