Spark Join
Spark Join
- 关联形式
- 内关联
- 外关联
- 左外关联
- 右外关联
- 全外关联
- 左半/逆关联
- 关联机制
- NLJ
- SMJ
- HJ
- 分发模式
- Join 选择
- 等值 Join
- 不等值 Join
Join 按照关联形式(Join Types)划分 : 内关联、外关联、左关联、右关联
- Join 按实现机制划分 : NLJ (Nested Loop Join) 、SMJ (Sort Merge Join) 、HJ(Hash Join)
- Join 按分发模式划分 : Shuffle Join、Broadcast Join
关联形式
Spark SQL支持的关联形式 :
| 关联形式 | Join Type | 效果 |
|---|---|---|
| 内关联 | inner | 结果集中只包含满足关联条件的数据 |
| 左外关联 | left/leftouter/left_outer | 内关联结果集+左表中不满足关联条件的剩余数据 |
| 右外关联 | right/rightouter/right_outer | 内关联结果集 + 右表中不满足关联条件的剩余数据 |
| 全外关联 | outer/full/fullouter/full_outer | 内关联结果集 + 左、右表中不满足关联条件的剩余数据 |
| 左半关联 | leftsemi/left_semi | 内关联结果集,但只保留左表部分的数据 |
| 左逆关联 | leftanti /left_anti | 左表中不满足关联条件的数据 |
内关联
内关联的效果 : 仅保留左右表中满足关联条件的那些数据记录
- 在员工表与薪资表中,只有 1、2、3 这三个值同时存在它们各自的 id 中。所以结果集中就只有 1、2、3 的这三条数据
// 左表
salaries.show
/** 结果打印
+---+------+
| id|salary|
+---+------+
| 1| 26000|
| 2| 30000|
| 4| 25000|
| 3| 20000|
+---+------+
*/// 右表
employees.show
/** 结果打印
+---+-------+---+------+
| id| name|age|gender|
+---+-------+---+------+
| 1| Mike| 28| Male|
| 2| Lily| 30|Female|
| 3|Raymond| 26| Male|
| 5| Dave| 36| Male|
+---+-------+---+------+
*/// 内关联
val jointDF: DataFrame = salaries.join(employees, salaries("id") === employees("id"), "inner")jointDF.show
/** 结果打印
+---+------+---+-------+---+------+
| id|salary| id| name|age|gender|
+---+------+---+-------+---+------+
| 1| 26000| 1| Mike| 28| Male|
| 2| 30000| 2| Lily| 30|Female|
| 3| 20000| 3|Raymond| 26| Male|
+---+------+---+-------+---+------+
*/
外关联
外关联能细分 3 种形式:左外关联、右外关联、全外关联
左外关联
左外关联,用 left/ leftouter/ left_outer
- 左外关联的结果集 : 内关联结果集 + 左表的不满足关联条件的剩余数据
- 不存在的记录,在结果集中的所有字段值均为空值 null
val jointDF: DataFrame = salaries.join(employees, salaries("id") === employees("id"), "left")jointDF.show
/** 结果打印
+---+------+----+-------+----+------+
| id|salary| id| name| age|gender|
+---+------+----+-------+----+------+
| 1| 26000| 1| Mike| 28| Male|
| 2| 30000| 2| Lily| 30|Female|
| 4| 25000|null| null|null| null|
| 3| 20000| 3|Raymond| 26| Male|
+---+------+----+-------+----+------+
*/
右外关联
右外关联,用 right/ rightouter/ right_outer
- 右外关联的结果集:内关联的结果集 + 右表的剩余数据
- 不存在的记录,在结果集中的所有字段值均为空值 null
val jointDF: DataFrame = salaries.join(employees, salaries("id") === employees("id"), "right")jointDF.show
/** 结果打印
+----+------+---+-------+---+------+
| id|salary| id| name|age|gender|
+----+------+---+-------+---+------+
| 1| 26000| 1| Mike| 28| Male|
| 2| 30000| 2| Lily| 30|Female|
| 3| 20000| 3|Raymond| 26| Male|
|null| null| 5| Dave| 36| Male|
+----+------+---+-------+---+------+
*/
全外关联
全外关联,用 full/ outer/ ullouter/ full_outer
- 全外关联的结果集:内关联的结果 + 那些不满足关联条件的左右表剩余数据
val jointDF: DataFrame = salaries.join(employees, salaries("id") === employees("id"), "full")jointDF.show
/** 结果打印
+----+------+----+-------+----+------+
| id|salary| id| name| age|gender|
+----+------+----+-------+----+------+
| 1| 26000| 1| Mike| 28| Male|
| 3| 20000| 3|Raymond| 26| Male|
|null| null| 5| Dave| 36| Male|
| 4| 25000|null| null|null| null|
| 2| 30000| 2| Lily| 30|Female|
+----+------+----+-------+----+------+
*/
左半/逆关联
左半关联,用 leftsemi/left_semi
- 左半关联的结果集 : 内关联结果集的子集,但仅保留左表数据
// 左半关联
val jointDF: DataFrame = salaries.join(employees, salaries("id") === employees("id"), "left_semi")jointDF.show
/** 结果打印
+---+------+
| id|salary|
+---+------+
| 1| 26000|
| 2| 30000|
| 3| 20000|
+---+------+
*/
左逆关联,用 leftanti/left_anti
- 左逆关联的结果集 : 不满足条件结果集的子集,但仅保留左表数据
// 左逆关联
val jointDF: DataFrame = salaries.join(employees, salaries("id") === employees("id"), "left_anti")jointDF.show
/** 结果打印
+---+------+
| id|salary|
+---+------+
| 4| 25000|
+---+------+
*/
关联机制
Join 有 3 种实现机制 :
- NLJ(Nested Loop Join): 嵌套循环连接
- SMJ(Sort Merge Join): 排序归并连接
- HJ(Hash Join): 哈希连接
俗定 : 左表 = 驱动表,右表 = 基表
- 驱动表较大,主动扫描数据的一边
- 基表较小,被动参与数据扫描的一方
| Join实现机制 | 范围 | 效率 | 工作原理 |
|---|---|---|---|
| Nested Loop Join | 全部关联 | 最差 | 用嵌套循环来实现关联,效率最低,算法复杂度为 O(M * N) |
| Sort Merge Join | 等值关联 | 次优 | 先将两表排序,再用游标滑动实现关联,算法复杂度为 O(M + N) |
| Hash Join | 等值关联 | 最优 | 关联过程分两阶段:Build:用哈希算法对基表建立哈希表。Probe:遍历驱动表每条数据,动态计算哈希值,再找哈希表来实现关联计算。复杂度为 O(M) |
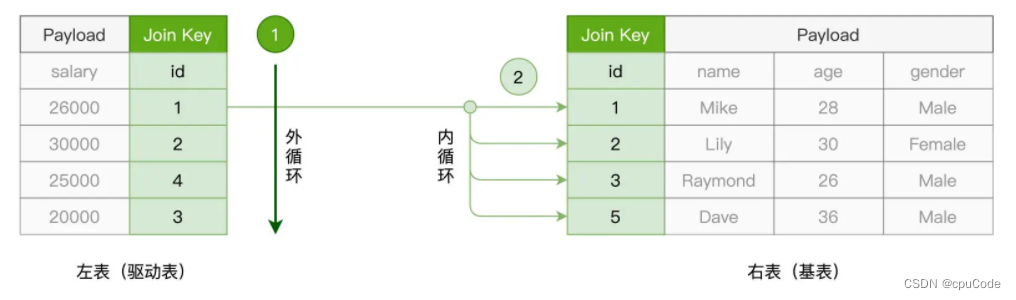
NLJ
NLJ (Nested Loop Join ) 的实现机制:用外、内两个嵌套的 for 循环,来依次扫描驱动表与基表中的数据记录
- 外层的 for 循环遍历驱动表的每一条数据
- 驱动表中的每条数据,内层 for 逐条扫描基表的所有记录,依次判断记录的 id 字段值是否满足关联条件
- 驱动表有 M 行,基表有 N 行,NLJ 计算复杂度是
O(M * N)
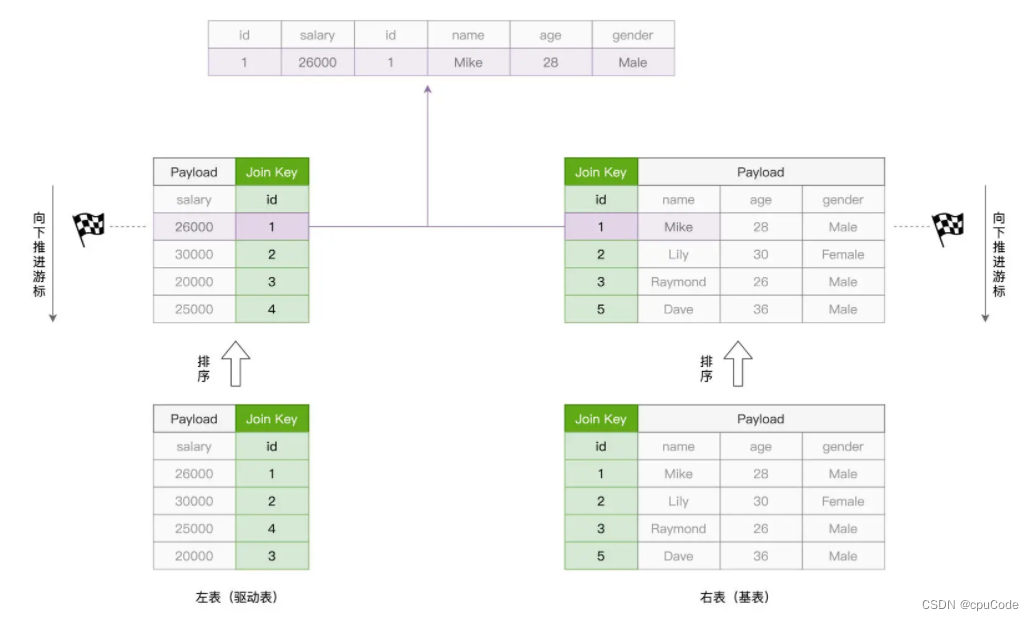
SMJ
SMJ (Sort Merge Join) 的实现思路 : 先排序、再归并
- 对关联的两张表,SMJ 先各自排序,然后再使用独立的游标,对排好序的两张表做归并关联
- SMJ 算法的计算复杂度为
O(M + N)
游标对比的 3 种情况:
- 满足关联条件:两边的 id 相等,把两边的数据记录拼接并输出,然后驱动表的游标下滑
- 不满足关联条件:驱动表 id 值 < 基表的 id 值,驱动表的游标下滑
- 不满足关联条件 : 驱动表 id 值 > 基表的 id 值,基表的游标下滑
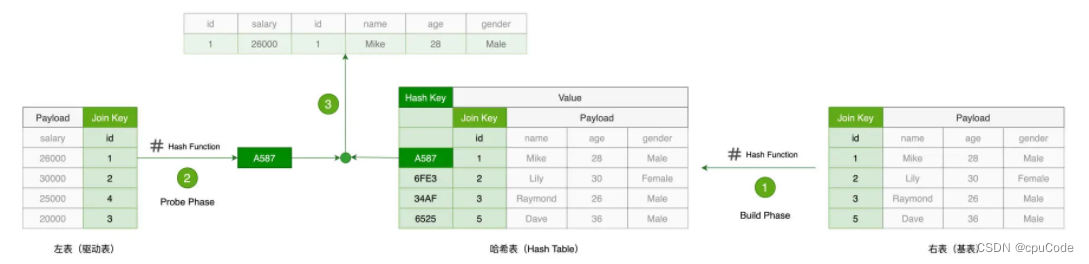
HJ
HJ (Hash Join) 的设计初衷 : 以空间换时间,将基表的计算复杂度降到 O(1)
HJ 的计算的两个阶段:Build 阶段和 Probe 阶段
- Build 阶段:在基表上,用自定的哈希构建哈希表。哈希表的 Key 是 id 哈希后的哈希值,哈希表的 Value 是基表数据
- Probe 阶段:依次遍历驱动表的每条数据。先用同样的哈希,得到哈希值。然后用哈希值去查询刚 Build 好的哈希表。当查询失败,就跳过;当查询成功,就对比两边的 Join Key。如果 Join Key 一致,就拼接并输出
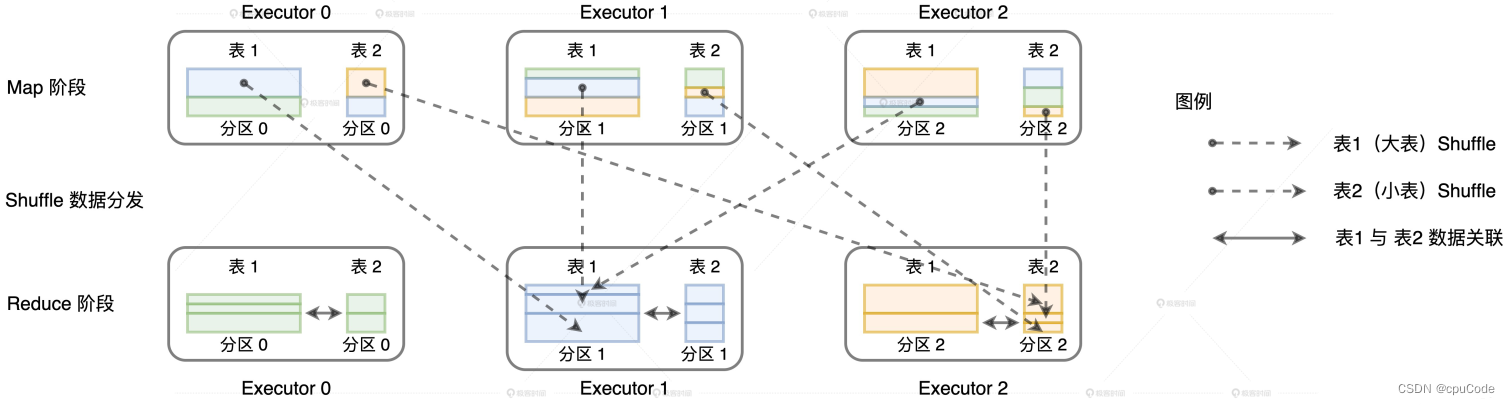
分发模式
Join 按照分发模式划分 : Shuffle Join、Broadcast Join
- Shuffle Join :任何情况,都能完成数据关联的计算
- Broadcast Join : 广播数据表的全量数据到 Driver 的内存、以及各个 Executors 的内存
| Join策略 | 前提条件 | 优势 | 劣势 |
|---|---|---|---|
| Shuffle Join | 无 | 适用范围广,不受数据体量、内存大小 | 会有 l/O开销,容易性能瓶颈 |
| Broadcast Join | 基表 < Executors 内存 | 只需广播基表,消除驱动表的 Shuffle 过程,执行效率高 | 无 |
用 Shuffle 完成数据关联 :
用广播机制完成数据关联 :
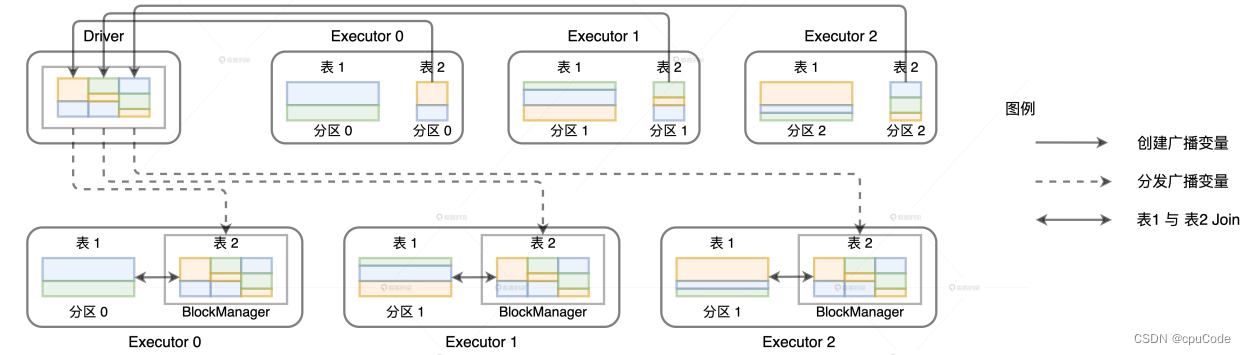
6 种分布式 Join :
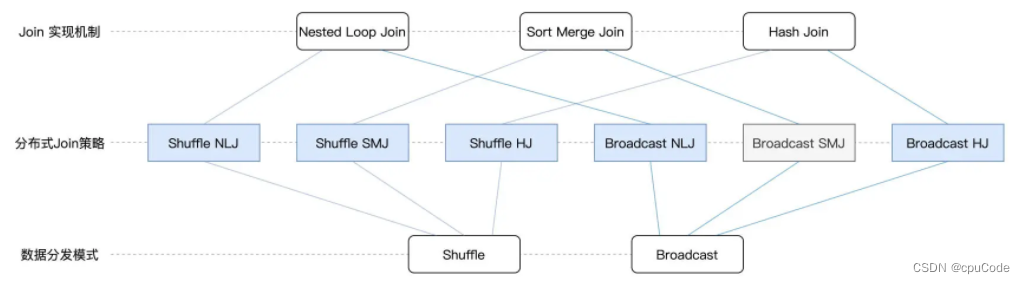
Spark SQL 的5 种 Join :

Join 选择
| 关联条件 | Join 策略排序 |
|---|---|
| 等值关联 | Broadcast HJ > Shuffle SMJ > Shuffle HJ |
| 不等值关联 | Broadcast NLJ > Shuffle NLJ |
等值 Join
等值数据关联时,Spark 会按照 BHJ > SMJ > SHJ 的顺序选择 Join 策略
BHJ 效率最高,前提条件:
- 连接类型不能是全连接(Full Outer Join)
- 基表要足够小,能放到广播变量
SHJ 前提条件:
- 外表大小大于内表的 3 倍上
- 内表数据分片的平均大小 < 广播变量阈值
spark.sql.join.preferSortMergeJoin为 False 时,Spark SQL 才会先尝试 SHJ
不等值 Join
不等值 Join 只能用 BNLJ和 CPJ
- Spark SQL 会按照 BNLJ > CPJ 的顺序尝试
- BNLJ 前提条件:内表小能放进广播变量
相关文章:
Spark Join
Spark Join关联形式内关联外关联左外关联右外关联全外关联左半/逆关联关联机制NLJSMJHJ分发模式Join 选择等值 Join不等值 JoinJoin 按照关联形式(Join Types)划分 : 内关联、外关联、左关联、右关联 Join 按实现机制划分 : NLJ (Nested Loop Join) 、S…...

数字的转化规则?
数字的转化规则?js将字符串转换为数字的方式有哪些?1. 使用 parseInt()2. 使用 Number()3. 使用一元运算符 ()4.使用parseFloat()5. 使用 Math.floor()和Math.ceil()6.乘以数字7. 双波浪号 (~~) 运算符其它值到数字的转化规则1.Undefined 类型2.Null 类型…...

MySQL面试题-锁相关
目录 1.MySQL 锁的类型有哪些呢? 2.如何使用全局锁 3.如果要全库只读,为什么不使用set global readonlytrue的方式? 4.表级锁和行级锁有什么区别? 5.行级锁的使用有什么注意事项? 6.InnoDB 有哪几类行锁ÿ…...

Windows 终端编译 C代码
E:\My_SoftWare\Window gcc\windowbianji\mingw64\bin 此电脑--》属性--》系统--》高级系统设置--》环境变量--》Path--》新建--》粘贴路径 E:\My_SoftWare\Window gcc\windowbianji\mingw64\bin 打开命令终端 E: 回车 dir 显示所有文件 cd E:\My_SoftWare\Window gcc\C_co…...
SpringCloud:Feign的使用及配置
目录 Feign的使用及配置 1、Feign替代RestTemplate 2、使用Fegin步骤 3、自定义配置 4、Feign使用优化 5、Feign的最佳实践方式 Feign的使用及配置 1、Feign替代RestTemplate RestTemplate方式远程调用的问题 问题: 1、代码可读性差,编程体验不同…...

Parquet学习与使用之BloomFilter的应用
写在前面 最近在自己做自定义的OLAP系统,文件格式上用的是Parquet,但是发现Parquet各个API的示例代码很少。所以就打算把这个系列的文章写一下。 1. Parquet的Filter Parquet的过滤支持两大类,一类是基于Footer中的元数据进行RowGroup级别…...

95%置信区间计算-理解
机器学习中做多次试验后,需要计算指标的95%置信区间。 假设做了10次试验,计算得出的某指标分别为{x1,…,x10} 其均值为μ(x1...x10)/10\mu(x1 ... x10)/10μ(x1...x10)/10 方差σ∑(xi−μ)2/10\sigma\sum(x_i -\mu)^2/10σ∑(xi−μ)2/10 95%置信…...
深度学习pytorch实战三:VGG16图像分类篇自建数据集图像分类三类
1.自建数据集与划分训练集与测试集 2.模型相关知识 3.model.py——定义AlexNet网络模型 4.train.py——加载数据集并训练,训练集计算损失值loss,测试集计算accuracy,保存训练好的网络参数 5.predict.py——利用训练好的网络参数后,…...

2023年3月软考高项(信息系统项目管理师)报名走起!!!
信息系统项目管理师是全国计算机技术与软件专业技术资格(水平)考试(简称软考)项目之一,是由国家人力资源和社会保障部、工业和信息化部共同组织的国家级考试,既属于国家职业资格考试,又是职称资…...
模电学习11 运算放大器学习入门
一、基本概念 运算放大器简称运放,是一种模拟电路实现的集成电路,可以对信号进行很高倍数的放大。一般有正相输入端、反相输入端、输出端口、正电源、负电源等接口。 运放可工作在饱和区、放大区,其中放大区极其陡峭,因为运放的放…...

spring学习3.5
Bean是什么 Spring里面的Bean就类似是定义的一个组件,而这个组件的作用就是实现某个功能的,这里所定义的Bean就相当于给了你一个更为简便的方法来调用这个组件去实现你要完成的功能。 IoC是什么 谁控制谁,控制什么? 传统Java SE程…...

名创优品:国内“触礁”,海外“提速”
在互联网经济十分发达、实体经济不太景气的时代背景下,自有品牌零售商代表名创优品却逆势而上,开始向着全球品牌类生活用品零售市场发起冲击,并凭借着“极致性价比大规模跑量”的独特优势在该领域取得了十分可观的成绩。 随着“Z时代”人群逐…...
Java学习笔记 --- Tomcat
一、JavaWeb 的概念 JavaWeb 是指,所有通过 Java 语言编写可以通过浏览器访问的程序的总称,叫 JavaWeb。 JavaWeb是基于请求和响应来开发的。请求是指客户端给服务器发送数据,叫请求 Request。 响应是指服务器给客户端回传数据,叫…...

面向对象设计模式:行为型模式之状态模式
文章目录一、引入二、状态模式2.1 Intent 意图2.2 Applicability 适用性2.3 类图2.4 Collaborations 合作2.5 Implementation 实现2.5 状态模式与策略模式的对比2.5 状态模式实例:糖果机2.6 状态模式实例:自行车升降档一、引入 State Diagram 状态图&am…...

【Python入门第二十五天】Python 作用域
变量仅在创建区域内可用。这称为作用域。 局部作用域 在函数内部创建的变量属于该函数的局部作用域,并且只能在该函数内部使用。 实例 在函数内部创建的变量在该函数内部可用: def myfunc():x 100print(x)myfunc()运行实例 100函数内部的函数 如…...
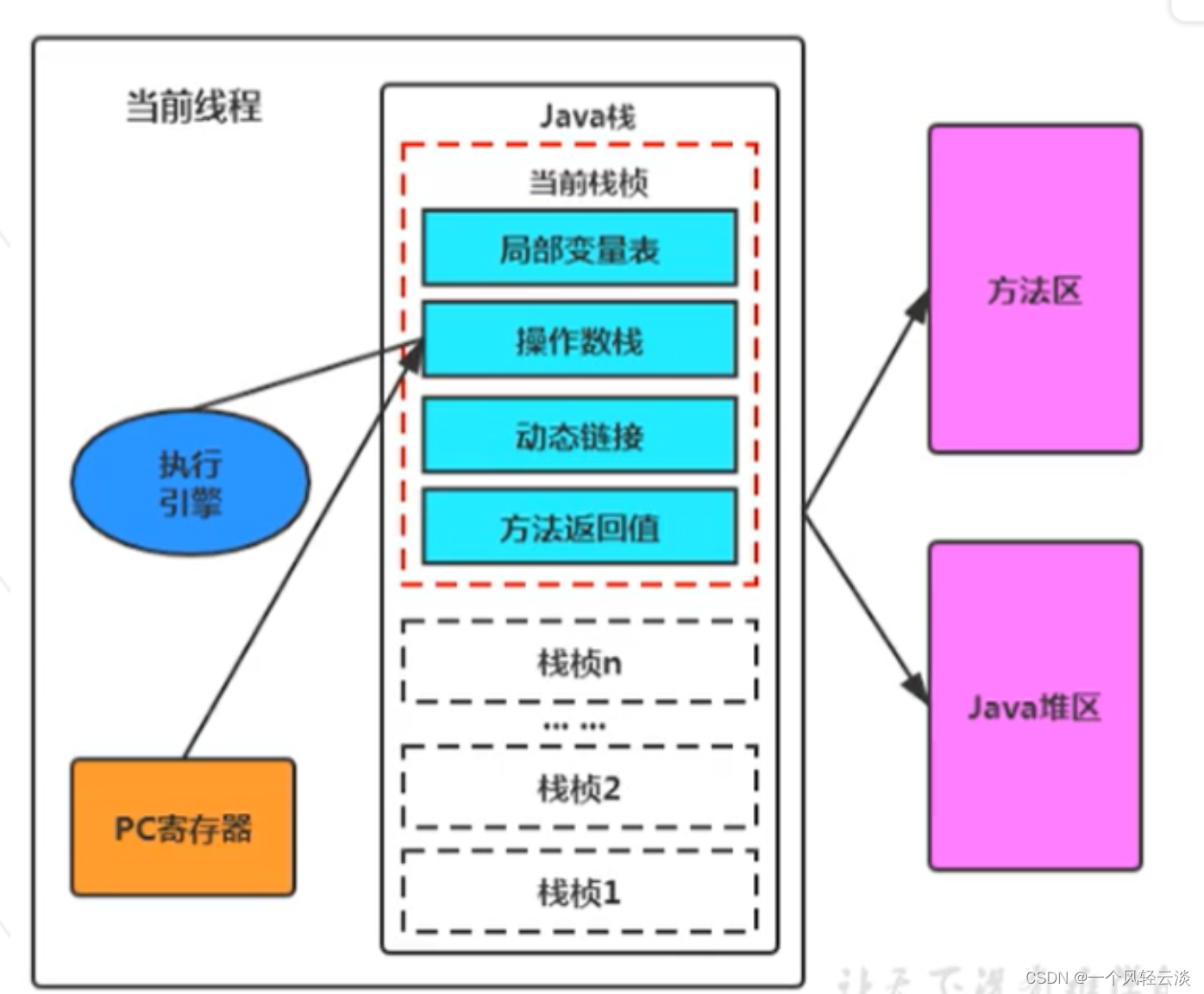
运行时数据区及程序计数器
运行时数据区 概述 运行时数据区,也就是下图这部分,它是在类加载完成后的阶段 当我们通过前面的:类的加载-> 验证 -> 准备 -> 解析 -> 初始化 这几个阶段完成后,就会用到执行引擎对我们的类进行使用,同时…...
手写操作系统+文件系统开源啦
哈喽,我是子牙,一个很卷的硬核男人。喜欢研究底层,聚焦做那些大家想学没地方学的课程:手写操作系统、手写虚拟机、手写模拟器、手写编程语言… 今年是我创业的第二年,已经做了两个课程:手写JVM、手写操作系…...
小众但意外觉得蛮好用的剪辑软件!纯良心分享
爱剪辑 有开屏广告,一共3个界面:首页、剪同款、我的。 剪辑、配乐、字幕、滤镜、加速、贴纸、配音等主流功能都有。 特色功能有剪裁视频、倒放视频、视频旋转、视频转换GIF、转场、提取音频、画中画等。 还可以拼接视频,不过不支持FLV等小众文…...
)
一文带你入门angular(下)
一、angular get数据请求 angular5.x之后get,post和服务器交互使用的是HttpClientModule模块。 1.首先要在app.module.ts中引入HttpClientModule并注入 import {HttpClientModule} from "angular/common/http" 注入: import:[ …...

2023-3-6刷题情况
分巧克力 题目描述 儿童节那天有 KKK 位小朋友到小明家做客。小明拿出了珍藏的巧克力招待小朋友们。 小明一共有 NNN 块巧克力,其中第 iii 块是 HiWiH_i \times W_iHiWi 的方格组成的长方形。 为了公平起见,小明需要从这 NNN 块巧克力中切出 KKK…...

Smoothieware 分支固件编译与配置项深度解析
1. Smoothieware分支固件编译全流程实战 第一次接触Smoothieware_best-for-pnp这个分支时,我完全没想到一个开源3D打印机固件能有这么多隐藏玩法。这个由社区开发者维护的分支,在保留官方核心功能的同时,针对OpenPNP应用场景做了大量优化。最…...

从白噪声到ARMA谱:平稳随机信号功率谱的实战解析
1. 平稳随机信号功率谱密度的工程意义 第一次接触功率谱密度这个概念时,我也被那一堆数学公式搞得头晕。直到有次在调试通信设备时,发现接收端总是有奇怪的干扰,导师让我做个频谱分析,这才真正明白功率谱密度到底有什么用。简单来…...

如何3步永久保存QQ空间十年回忆:GetQzonehistory数据备份实战指南
如何3步永久保存QQ空间十年回忆:GetQzonehistory数据备份实战指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字记忆时代,QQ空间承载了无数人的青春印记…...

DroidCam OBS插件终极指南:3分钟将手机变身高清直播摄像头
DroidCam OBS插件终极指南:3分钟将手机变身高清直播摄像头 【免费下载链接】droidcam-obs-plugin DroidCam OBS Source 项目地址: https://gitcode.com/gh_mirrors/dr/droidcam-obs-plugin DroidCam OBS插件是一款免费开源工具,它能让你的智能手机…...

HarmonyOS 6 CalendarPickerDialog 日历选择弹窗使用文档
文章目录完整代码功能概述代码结构说明核心参数详解1. 基础参数2. DateRange 结构说明3. 示例禁用区间配置说明总结完整代码 Entry Component struct CalendarPickerDialogExample {private selectedDate: Date new Date(2025-08-05);private disabledDateRange: DateRange[]…...

OpenClaw 用户迁移至 Taotoken 平台享受更优 Token 价格
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw 用户迁移至 Taotoken 平台享受更优 Token 价格 对于正在使用 OpenClaw 这类兼容 OpenAI 协议客户端的开发者或团队而言&a…...
)
别再乱用`define了!SV宏定义实战避坑指南(从`ifdef到字符串拼接)
别再乱用define了!SV宏定义实战避坑指南(从ifdef到字符串拼接) 在SystemVerilog开发中,宏定义(define)是提高代码复用性和灵活性的利器,但同时也是隐藏最深的"代码地雷"之一。许多开发…...

AbMole丨CL 316243:β3-肾上腺素受体激动剂,在代谢调控与能量消耗研究中的应用
CL 316243是一种高选择性的β3-肾上腺素受体(β3-AR)激动剂,其对β3-AR的选择性远高于β1-AR和β2-AR[1]。CL 316243(CAS No.:138908-40-4)通过激活β3-AR,刺激腺苷酸环化酶(AC&…...

精准测试:未来已来,只是尚未流行
一、从“全量覆盖”到“精准打击”:测试范式的必然转向 在软件测试领域,有一个根深蒂固的信仰:测试得越全面,质量就越高。这种思维催生了庞大的测试用例库、漫长的回归周期和不断膨胀的测试资源投入。然而,随着系统复…...

基于BMapGL与MapVGL,实战城市人流热力图可视化
1. 从零开始搭建热力图开发环境 第一次接触百度地图GL版开发时,我也被各种配置搞得晕头转向。现在把完整的环境搭建流程梳理出来,帮你避开我踩过的那些坑。BMapGL作为百度地图的WebGL版本,相比传统API渲染效率提升明显,特别适合数…...