自然语言处理-基于预训练模型的方法-chapter3基础工具集与常用数据集
文章目录
- 3.1NLTK工具集
- 3.1.1常用语料库和词典资源
- 3.1.2常见自然语言处理工具集
- 3.2LTP工具集
- 3.3pytorch基础
- 3.3.1张量基本概念
- 3.3.2张量基本运算
- 3.3.3自动微分
- 3.3.4调整张量形状
- 3.3.5广播机制
- 3.3.6索引与切片
- 3.3.7降维与升维
- 3.4大规模预训练模型
3.1NLTK工具集
3.1.1常用语料库和词典资源
- 下载语料库
import nltk
nltk.download()
- 停用词
from nltk.corpus import stopwordsprint(stopwords.words('english'))['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves',
- 常用词典
(1)wordNet
from nltk.corpus import wordnet
syns = wordnet.synsets("bank")
print(syns[0].name())
print(syns[0].definition())
print(syns[0].examples())
print(syns[0].hypernyms())bank.n.01
sloping land (especially the slope beside a body of water)
['they pulled the canoe up on the bank', 'he sat on the bank of the river and watched the currents']
[Synset('slope.n.01')]
3.1.2常见自然语言处理工具集
- 分句
将一个长文档分成若干句子。
from nltk.corpus import gutenberg
from nltk.tokenize import sent_tokenize
text = gutenberg.raw("austen-emma.txt")
sentences = sent_tokenize(text)
print(sentences[0])
3.2LTP工具集
from ltp import LTP
ltp = LTP()segment, hidden = ltp.seg(["南京市长江大桥。"])
print(segment)AttributeError: 'LTP' object has no attribute 'seg'
出现一些问题...
3.3pytorch基础
PyTorch是一个基于张量(Tensor)的数学运算工具包,提供了两个高级功能
- 具有强大的GPU(图形处理单元,也叫显卡)加速的张量计算功能
- 能够自动进行微分计算,从而可以使用基于梯度的方法对模型参数进行优化。
3.3.1张量基本概念
import torchprint(torch.empty(2, 3))
print(torch.rand(2, 3)) # 0-1均匀
print(torch.randn(2, 3)) # 标准正态生成
print(torch.zeros(2, 3, dtype=torch.long)) # 设置数据类型
print(torch.zeros(2, 3, dtype=torch.double))
print(torch.tensor([[1.0, 2.0, 3.0],[4.0, 5.0, 6.0]
])) # 自定义
print(torch.arange(10)) # 排序tensor([[-8.5596e-30, 8.4358e-43, -8.5596e-30],[ 8.4358e-43, -1.1837e-29, 8.4358e-43]])
tensor([[0.7292, 0.9681, 0.8636],[0.3833, 0.8089, 0.5729]])
tensor([[-1.7307, 1.2082, 1.9423],[ 0.2461, 2.3273, 0.1628]])
tensor([[0, 0, 0],[0, 0, 0]])
tensor([[0., 0., 0.],[0., 0., 0.]], dtype=torch.float64)
tensor([[1., 2., 3.],[4., 5., 6.]])
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])Process finished with exit code 0使用gpu
print(torch.rand(2, 3).cuda())
print(torch.rand(2, 3).to("cuda"))
print(torch.rand(2, 3), device="cuda")
3.3.2张量基本运算
pytorch的运算说白了就是将数据保存在向量中进行运算。
±*/
x = torch.tensor([1, 2, 3], dtype=torch.double)
y = torch.tensor([4, 5, 6], dtype=torch.double)
print(x + y)
print(x - y)
print(x * y)
print(x / y)
print(x.dot(y))
print(x.sin())
print(x.exp())tensor([5., 7., 9.], dtype=torch.float64)
tensor([-3., -3., -3.], dtype=torch.float64)
tensor([ 4., 10., 18.], dtype=torch.float64)
tensor([0.2500, 0.4000, 0.5000], dtype=torch.float64)
tensor(32., dtype=torch.float64)
tensor([0.8415, 0.9093, 0.1411], dtype=torch.float64)
tensor([ 2.7183, 7.3891, 20.0855], dtype=torch.float64)
x = torch.tensor([[1.0, 2.0, 3.0],[4.0, 5.0, 6.0]
]) # 自定义
print(x.mean(dim=0)) # 每列取均值
print(x.mean(dim=0, keepdim=True)) # 每列取均值
print(x.mean(dim=1)) # 每行取均值
print(x.mean(dim=1, keepdim=True)) # 每行取均值
y = torch.tensor([[7.0, 8.0, 9.0],[10.0, 11.0, 12.0]
])
print(torch.cat((x, y), dim=0))
print(torch.cat((x, y), dim=1))tensor([2.5000, 3.5000, 4.5000])
tensor([[2.5000, 3.5000, 4.5000]])
tensor([2., 5.])
tensor([[2.],[5.]])
tensor([[ 1., 2., 3.],[ 4., 5., 6.],[ 7., 8., 9.],[10., 11., 12.]])
tensor([[ 1., 2., 3., 7., 8., 9.],[ 4., 5., 6., 10., 11., 12.]])Process finished with exit code 03.3.3自动微分
可自动计算一个函数关于一个变量在某一取值下的导数。
x = torch.tensor([2.], requires_grad=True)
y = torch.tensor([3.], requires_grad=True)
z = (x+y) * (y-2)
print(z)
z.backward() # 自动调用反向传播算法计算梯度
print(x.grad, y.grad)tensor([5.], grad_fn=<MulBackward0>)
tensor([1.]) tensor([6.])Process finished with exit code 0
3.3.4调整张量形状
x = torch.tensor([2.], requires_grad=True)
y = torch.tensor([3.], requires_grad=True)
z = (x+y) * (y-2)
print(z)
z.backward() # 自动调用反向传播算法计算梯度
print(x.grad, y.grad)x = torch.tensor([[1.0, 2.0, 3.0],[4.0, 5.0, 6.0]
]) # 自定义
print(x, x.shape)
print(x.view(2, 3))
print(x.view(3, 2))
print(x.view(-1, 3)) # -1就是针对非-1的自动调整
y = torch.tensor([[7.0, 8.0, 9.0],[10.0, 11.0, 12.0]
])
print(y.transpose(0, 1))tensor([5.], grad_fn=<MulBackward0>)
tensor([1.]) tensor([6.])
tensor([[1., 2., 3.],[4., 5., 6.]]) torch.Size([2, 3])
tensor([[1., 2., 3.],[4., 5., 6.]])
tensor([[1., 2.],[3., 4.],[5., 6.]])
tensor([[1., 2., 3.],[4., 5., 6.]])Process finished with exit code 03.3.5广播机制
3.3.6索引与切片
3.3.7降维与升维
x = torch.tensor([1.0, 2.0, 3.0, 4.0]
)
print(x.shape)
y = torch.unsqueeze(x, dim=0)
print(y, y.shape)
y = x.unsqueeze(dim=0)
print(y, y.shape)
z = y.squeeze()
print(z, z.shape)torch.Size([4])
tensor([[1., 2., 3., 4.]]) torch.Size([1, 4])
tensor([[1., 2., 3., 4.]]) torch.Size([1, 4])
tensor([1., 2., 3., 4.]) torch.Size([4])
3.4大规模预训练模型
相关文章:
自然语言处理-基于预训练模型的方法-chapter3基础工具集与常用数据集
文章目录3.1NLTK工具集3.1.1常用语料库和词典资源3.1.2常见自然语言处理工具集3.2LTP工具集3.3pytorch基础3.3.1张量基本概念3.3.2张量基本运算3.3.3自动微分3.3.4调整张量形状3.3.5广播机制3.3.6索引与切片3.3.7降维与升维3.4大规模预训练模型3.1NLTK工具集 3.1.1常用语料库和…...

【SpringMVC】@RequestMapping
RequestMapping注解 1、RequestMapping注解的功能 从注解名称上我们可以看到,RequestMapping注解的作用就是将请求和处理请求的控制器方法关联起来,建立映射关系。 SpringMVC 接收到指定的请求,就会来找到在映射关系中对应的控制器方法来处…...
【深度学习】BERT变体—SpanBERT
SpanBERT出自Facebook,就是在BERT的基础上,针对预测spans of text的任务,在预训练阶段做了特定的优化,它可以用于span-based pretraining。这里的Span翻译为“片段”,表示一片连续的单词。SpanBERT最常用于需要预测文本…...
)
根据身高体重计算某个人的BMI值--课后程序(Python程序开发案例教程-黑马程序员编著-第3章-课后作业)
实例3:根据身高体重计算某个人的BMI值 BMI又称为身体质量指数,它是国际上常用的衡量人体胖瘦程度以及是否健康的一个标准。我国制定的BMI的分类标准如表1所示。 表1 BMI的分类 BMI 分类 <18.5 过轻 18.5 < BMI < 23.9 正常 24 < BM…...

高并发编程JUC之进程与线程高并发编程JUC之进程与线程
1.准备 pom.xml 依赖如下: <properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target&g…...
css基础
1-css引入方式内嵌式style(学习)<style>p {height: 200;}</style>外联式link(实际开发)<link rel"stylesheet" href"./2-my.css">2-选择器2.1标签选择器(标签名相同的都生效&am…...
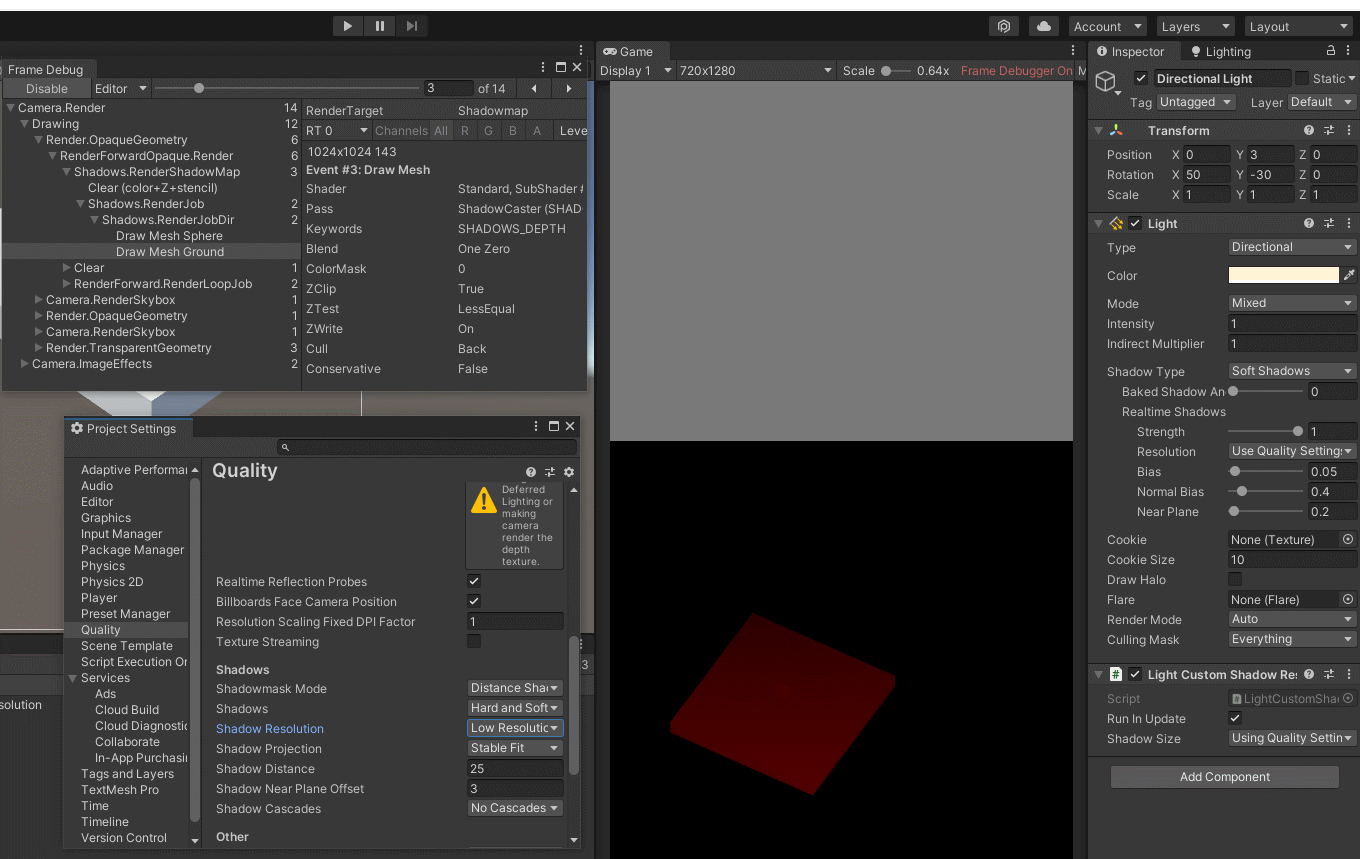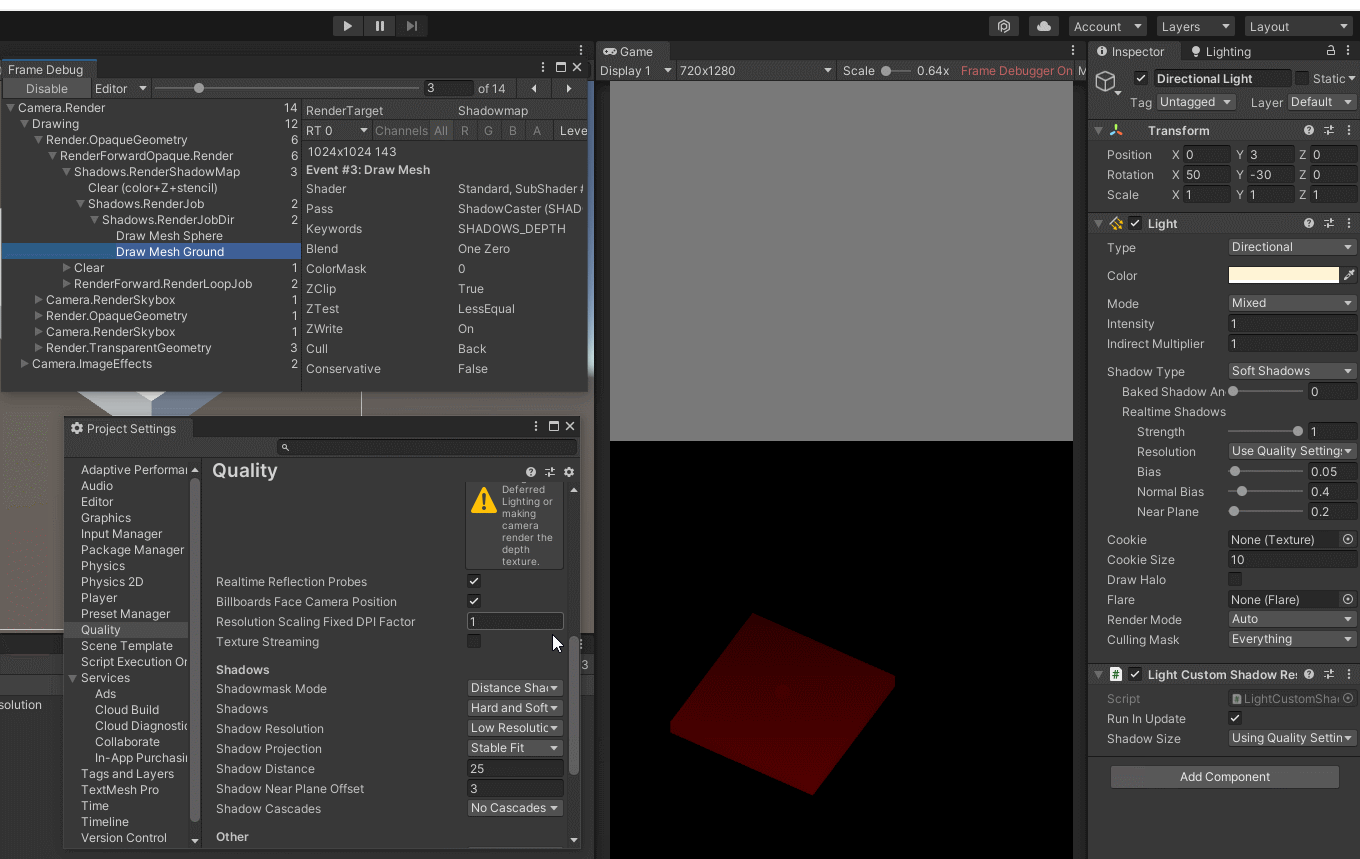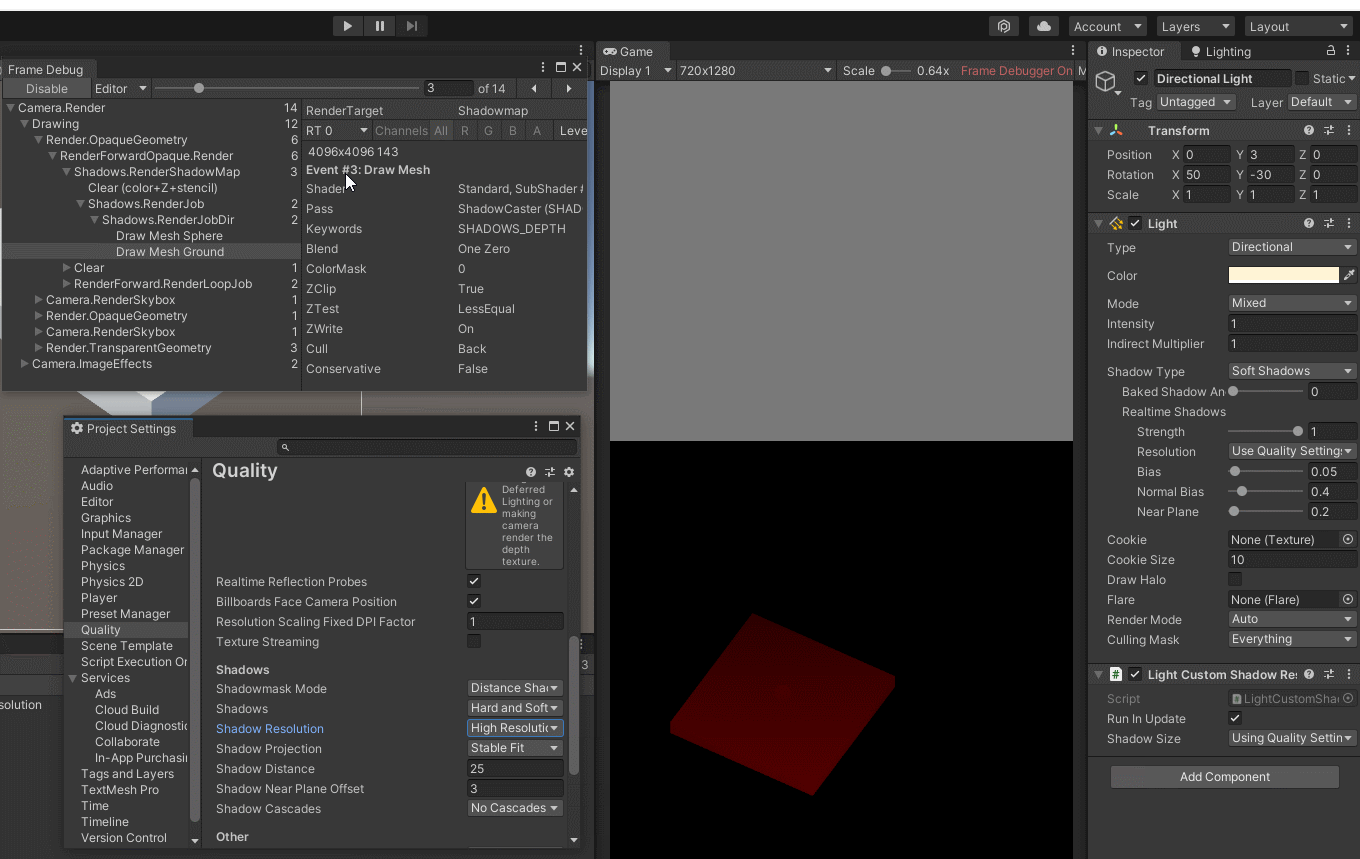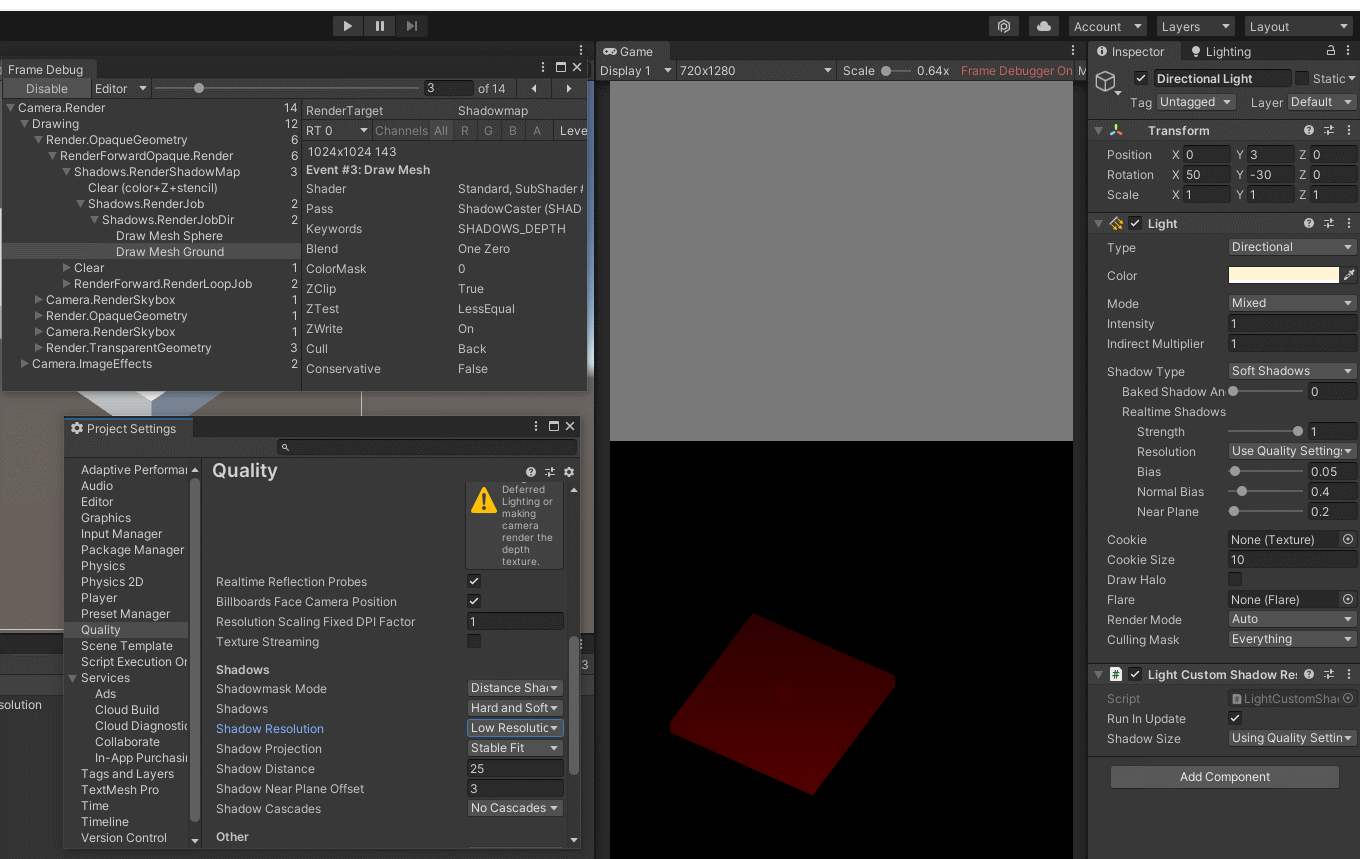
Unity - 搬砖日志 - BRP 管线下的自定义阴影尺寸(脱离ProjectSettings/Quality/ShadowResolution设置)
文章目录环境原因解决CSharp 脚本效果预览 - Light.shadowCustomResolution效果预览 - Using Quality Settings应用ControlLightShadowResolution.cs ComponentTools Batching add the Component to all LightReferences环境 Unity : 2020.3.37f1 Pipeline : BRP 原因 (好久没…...

如何在SSMS中生成和保存估计或实际执行计划
在引擎数据库执行查询时执行的过程的步骤由称为查询计划的一组指令描述。查询计划在SQL Server中也称为SQL Server执行计划,我们可以通过以下步骤来生成和保存估计或实际执行计划。 估计执行计划和实际执行计划是两种执行计划: 实际执行计划:当执行查询时,实际执行计划出…...
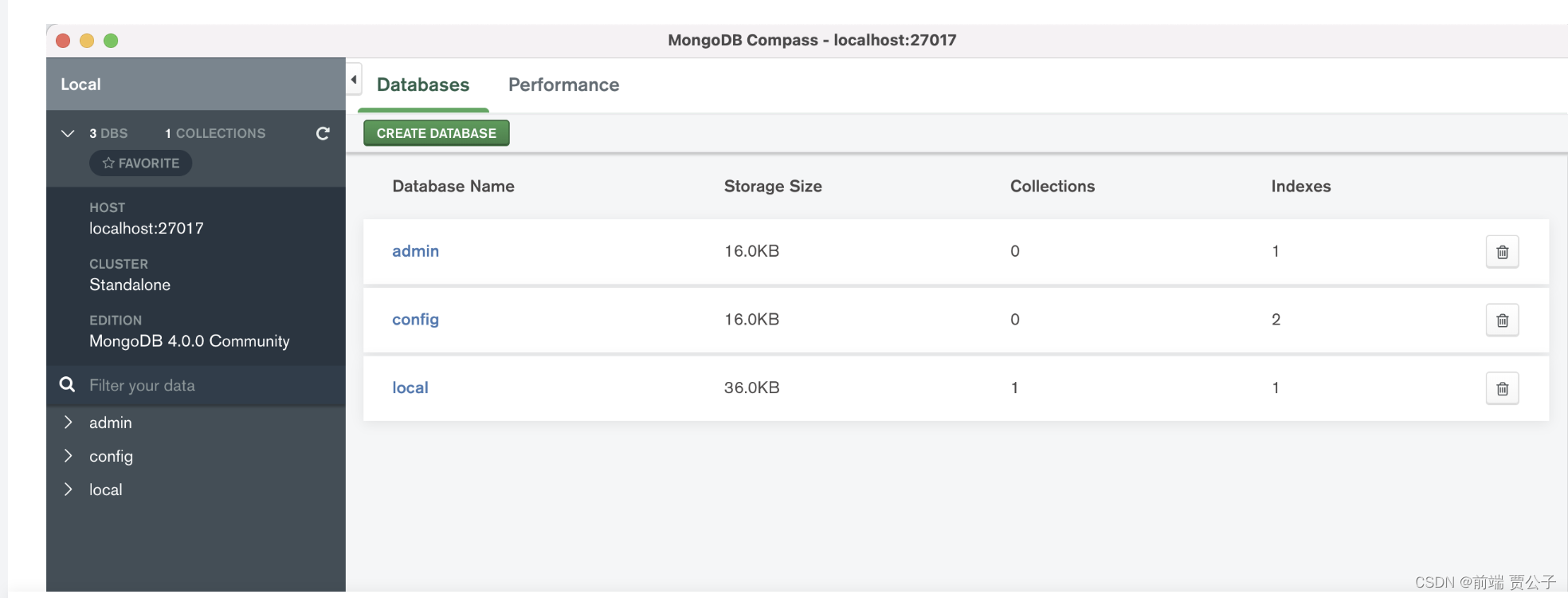
mac 环境下安装MongoDB
目录 一、下载MongoDB数据库并进行安装 二. 解压放在/usr/local目录下 三. 配置环境变量 “无法验证开发者”的解决方法 mongodb可视化工具的安装与使用 一、下载MongoDB数据库并进行安装 下载地址:https://www.mongodb.com/try/download/community 二. 解压…...
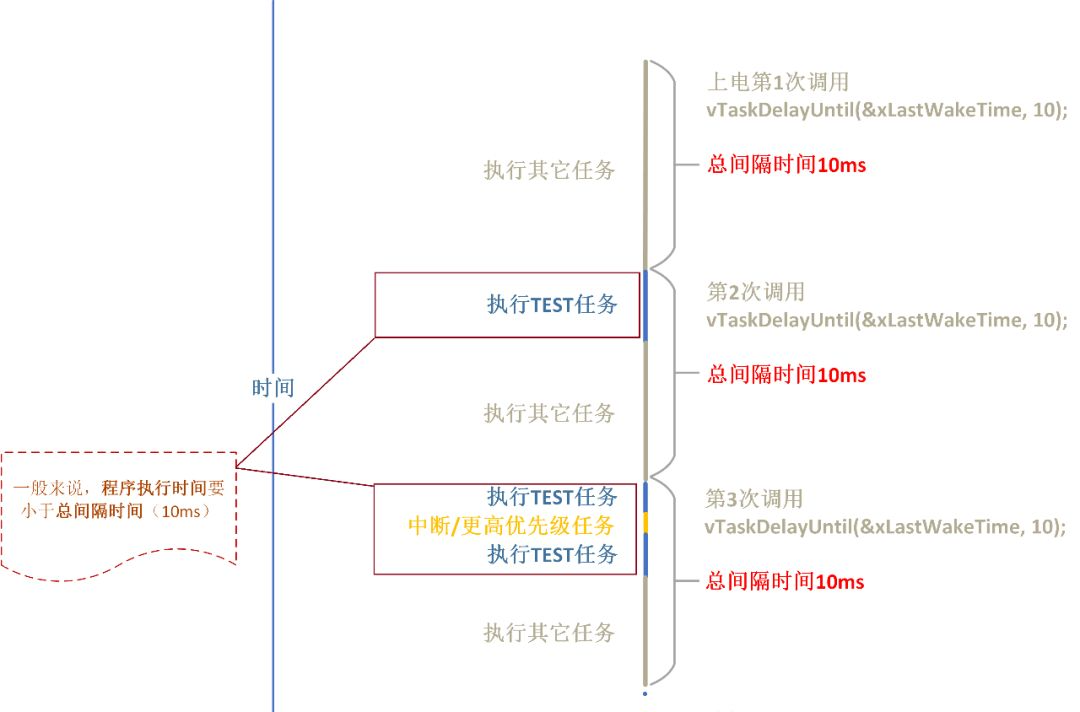
RTOS中相对延时和绝对延时的区别
相信许多朋友都有过这么一个需求:固定一个时间(周期)去处理某一件事情。 比如:固定间隔10ms去采集传感器的数据,然后通过一种算法计算出一个结果,最后通过指令发送出去。 你会通过什么方式解决呢…...

Solon2 项目整合 Nacos 配置中心
网上关于 Nacos 的使用介绍已经很多了,尤其是与 SpringBoot 的整合使用。怎么安装也跳过了,主要就讲 Nacos 在 Solon 里的使用,这个网上几乎是没有的。 1、认识 Solon Solon 一个高效的应用开发框架:更快、更小、更简单…...

Linux 路由表说明
写在前面: 本文章旨在总结备份、方便以后查询,由于是个人总结,如有不对,欢迎指正;另外,内容大部分来自网络、书籍、和各类手册,如若侵权请告知,马上删帖致歉。 目录route 命令字段分…...
MIPI协议
MIPI调试指南Rev.0.1 June 18, 2019 © 2018 Horizon Robotics. All rights reserved.Revision HistoryThissection tracks the significant documentation changes that occur fromrelease-to-release. The following table lists the technical content changes foreach …...

第十届CCF大数据与计算智能大赛总决赛暨颁奖典礼在苏州吴江顺利举办
2月24日-25日,中国计算机学会(CCF)主办、苏州市吴江区人民政府支持,苏州市吴江区工信局、吴江区东太湖度假区管理办公室、苏州市吴江区科技局、CCF大数据专家委员会、CCF自然语言处理专业委员会、CCF高性能计算专业委员会、CCF计算…...
PMP高分上岸人士的备考心得,分享考试中你还不知道的小秘密
上岸其实也不是什么特别难的事情,考试一共就180道选择题,题目只要答对60.57%就可以通过考试,高分通过没在怕的,加油备考呀朋友们! 这里也提一嘴,大家备考的时候比较顾虑的一个问题就是考试究竟要不要报班…...

ubuntu下编译libpq和libpqxx库
ubuntu下编译libpq和libpqxx库,用于链接人大金仓 上篇文章验证了libpqxx可以链接人大金仓数据库,这篇文章尝试自己编译libpq和libpqxx库。 文章目录ubuntu下编译libpq和libpqxx库,用于链接人大金仓libpq下载libpq库看看有没有libpq库编译lib…...

ESP-C2系列模组开发板简介
C2是一个芯片采用4毫米x 4毫米封装,与272 kB内存。它运行框架,例如ESP-Jumpstart和ESP造雨者,同时它也运行ESP-IDF。ESP-IDF是Espressif面向嵌入式物联网设备的开源实时操作系统,受到了全球用户的信赖。它由支持Espressif以及所有…...
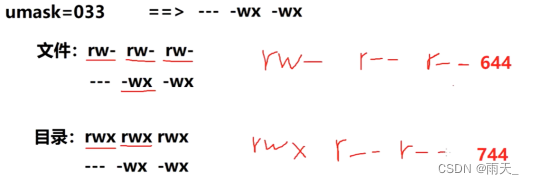
linux权限管理
权限管理 文件的权限针对三类对象进行定义: owner属主,缩写ugroup属组,缩写gother其他,缩写o 1、文件的一般权限 (1)r,w,x的作用及含义: 权限对文件影响对目录影响r(read…...

提高生活质量,增加学生对校园服务的需求,你知道有哪些?
随着电子商务平台利用移动互联网的趋势提高服务质量,越来越多的传统企业开始关注年轻大学生消费者的校园市场。 提高生活质量,增加学生对校园服务的需求 大学生越来越沉迷于用手机解决生活中的“吃、喝、玩、乐”等服务,如“吃、喝”——可…...
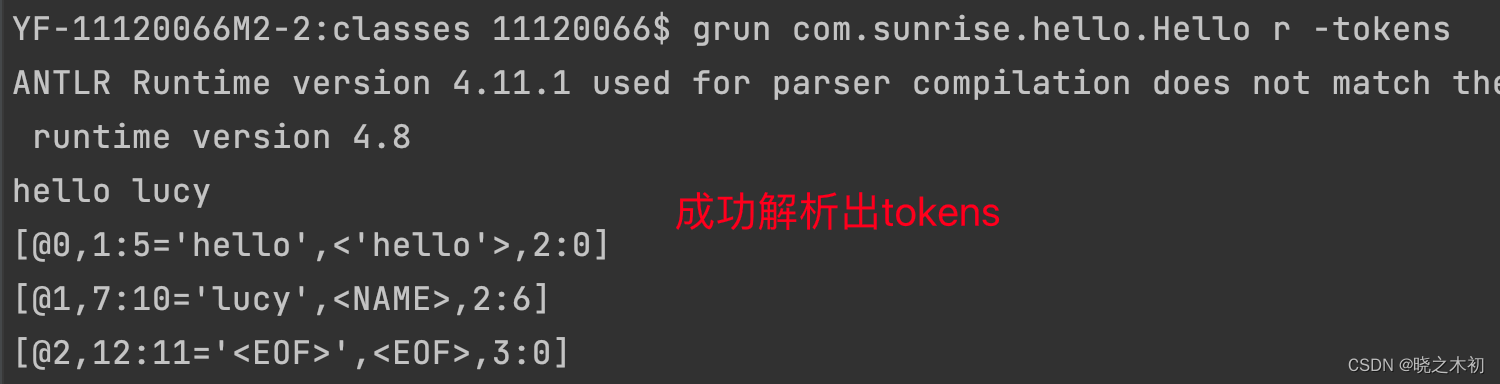
Antlr4:使用grun命令,触发NoClassDefFoundError
1. 意外的发现 在学习使用grun命令时,从未遇到过错误 最近使用grun命令,却遇到了NoClassDefFoundError的错误,使得grun测试工具无法成功启动 错误复现: 使用antlr4命令编译Hello.g4文件,并为指定package(…...

对比按需调用与Token Plan套餐的实际支出感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按需调用与Token Plan套餐的实际支出感受 对于个人开发者或小型团队而言,在大模型API的日常使用中,成本…...

通达信缠论分析插件:如何用开源工具实现智能技术分析
通达信缠论分析插件:如何用开源工具实现智能技术分析 【免费下载链接】Indicator 通达信缠论可视化分析插件 项目地址: https://gitcode.com/gh_mirrors/ind/Indicator 缠论作为技术分析的重要理论体系,其复杂的线段划分和中枢识别让许多交易者望…...
)
Azure VM SSH被锁死?别慌,用Serial Console这招救活你的服务器(亲测有效)
Azure VM SSH被锁死?Serial Console终极救援指南 当你在Azure VM上误操作sshd_config导致SSH被完全锁死时,那种绝望感就像被困在数字孤岛。常规的RDP、Bastion甚至重建VM都无济于事——直到发现Serial Console这个隐藏的救命通道。作为经历过同样噩梦的运…...

带拉杆雨篷的拉杆和耳板的设置原则
带拉杆雨篷的拉杆和耳板的设置原则 同纯悬挑雨篷一样,带拉杆雨篷也常常被设计为静定体系,传力路径中某一环节发生问题,即可导致整体结构体系的破坏,结构容错能力较差。无法形成超静定结构体系所有的多道设防机制,对于设计或者施工缺陷过于敏感,这是带拉杆雨篷事故发生的…...

3分钟掌握Get-cookies.txt-LOCALLY:浏览器Cookie本地导出的终极隐私保护方案
3分钟掌握Get-cookies.txt-LOCALLY:浏览器Cookie本地导出的终极隐私保护方案 【免费下载链接】Get-cookies.txt-LOCALLY Get cookies.txt, NEVER send information outside. 项目地址: https://gitcode.com/gh_mirrors/ge/Get-cookies.txt-LOCALLY 在数字身份…...

DeepSeek总结的DwarfStar 4:专为 DeepSeek V4 Flash 设计的小型原生推理引擎
来源:https://github.com/antirez/ds4 DwarfStar 4 DwarfStar 4 是一个为 DeepSeek V4 Flash 设计的小型原生推理引擎。它是有意限定了范围的:不是通用的 GGUF 运行器,不是其他运行时的封装器,也不是一个框架。其主要路径是一个…...

3步解锁网易云音乐NCM加密文件:ncmdumpGUI图形化工具完全指南
3步解锁网易云音乐NCM加密文件:ncmdumpGUI图形化工具完全指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了喜欢的歌曲…...

幸福依赖于抽象的 能力的庖丁解牛
它的本质是:**将幸福的源头从 具体实现类 (Concrete Implementations)(如特定的伴侣、具体的工作、固定的房产)转移到 抽象接口 (Abstract Interfaces)(如爱的能力、创造价值的技能、感知美好的心智)。具体实现是不可控…...

用Python自动化Photoshop:解锁高效图像处理的终极指南
用Python自动化Photoshop:解锁高效图像处理的终极指南 【免费下载链接】photoshop-python-api Python API for Photoshop. 项目地址: https://gitcode.com/gh_mirrors/ph/photoshop-python-api Photoshop Python API 是一款强大的工具包,让开发者…...

从MATLAB到FPGA:高效生成三种波形COE文件的实战指南
1. COE文件格式解析与FPGA应用场景 COE文件是Xilinx FPGA设计中用于初始化Block RAM(BRAM)的标准文件格式。我第一次接触这种文件时,发现它其实就是一个带有特定格式要求的文本文件,但正是这种简单的结构,让它成为MATL…...