容器中的大模型(三)| 利用大语言模型:容器化高效地部署 PDF 解析器实践...

作者:宋文欣,智领云科技联合创始人兼CTO
01 简介
大语言模型(LLMs)正逐渐成为人工智能领域的一颗璀璨明星,它们的强大之处在于能够理解和生成自然语言,为各种应用提供了无限可能。为了让这些模型更好地服务于实际业务场景,我们引入了检索增强生成(RAG)技术。RAG 技术将各种文档类型转换成 LLMs 易于解读的格式,通过结合检索和生成的方式,极大地提升了模型处理复杂任务的能力,尤其是在处理需要广泛知识和理解的长文本时表现得尤为出色。
PDF 文档作为信息传递的重要载体,其内容的抽取和理解对于实现高质量的 RAG 输出至关重要。要充分发挥RAG技术的潜力,我们需要解决一个关键问题:如何高效地解析和提取PDF文档中的信息。PDF 的文档格式使用广泛,结构复杂且多样,给自动化解析带来了不小的挑战。随着技术的进步,我们有了多种工具来应对这一挑战。本文将带你了解如何在 Docker 容器中运行三个业界领先的PDF解析器:LLMSherpa、Unstructured和LlamaParse。
本文将演示如何在容器化环境中快速部署和使用,完成从环境搭建到PDF解析器选择的全过程:
LLMSherpa[1]
Unstructured[2]
LlamaParse[3]
本文还对关键的技术要点和实践经验进行总结,通过本文的阅读,将对 RAG 技术在 LLMs 中的应用有一个全面的认识,无论是 LLMSherpa 的高效性,Unstructured 的灵活性,还是 LlamaParse 的稳定性,我们都将为您提供全面的比较和深入的分析,帮助选择最适合需求的 PDF 解析器。
02 技术背景
LLMSherpa
LLMSherpa 提供了一个免费的 API 服务器,用于解析各种类型的 PDF文件,同时还支持在私有服务器上托管,确保数据的安全性和隐私性。LayoutPDFReader(基于规则的解析器),作为 LLMSherpa 的核心组件之一,使用来自修改版的 Tika 的文本坐标(边界框)、图形和字体数据,以极高的精度解析 PDF 文件中的文本和布局。
在本次演示中,我们将展示如何在 Docker 容器中运行一个自托管的 LLMSherpa API 服务器,在自己的环境中轻松处理 PDF 文件。
Unstructured
Unstructured 是 unstructured.io 提供的开源库,用于摄取和预处理包括 PDF、HTML、Word 文档等格式在内的图像和文本文档,极大地简化了从文档中提取有价值信息的过程。Unstructured 还提供了一个免费的 API 服务,允许用户免费处理高达 1000 页的文档。
本文演示中,我们将重点关注如何独立使用 Unstructured 的开源库进行文档处理,而不依赖其 API 服务。用户可以在自己的服务器上部署和使用这个强大的库,享受数据处理的灵活性和自主性。
LlamaParse
LlamaParse 是由 LlamaIndex 推出的 API,旨在高效解析和呈现文件内容,进而配合LlamaIndex 框架实现快速检索和上下文增强。截至 2024年2月26日,这项服务目前处于免费预览阶段,且只专注于支持 PDF 格式文件的处理。
03 成果展示
RAG 技术使得模型能够通过解析不同领域的 PDF 文档,适应各种领域的查询,增加了模型的应用范围和灵活性。通过直接从 PDF 文档中检索信息,可以减轻对 LLMs 进行大规模、跨领域训练的需求,降低训练成本。在提高回答的准确性和信息的丰富度的同时,为特定用户群体提供更加个性化和深度的信息服务。
本示例演示步骤如下:
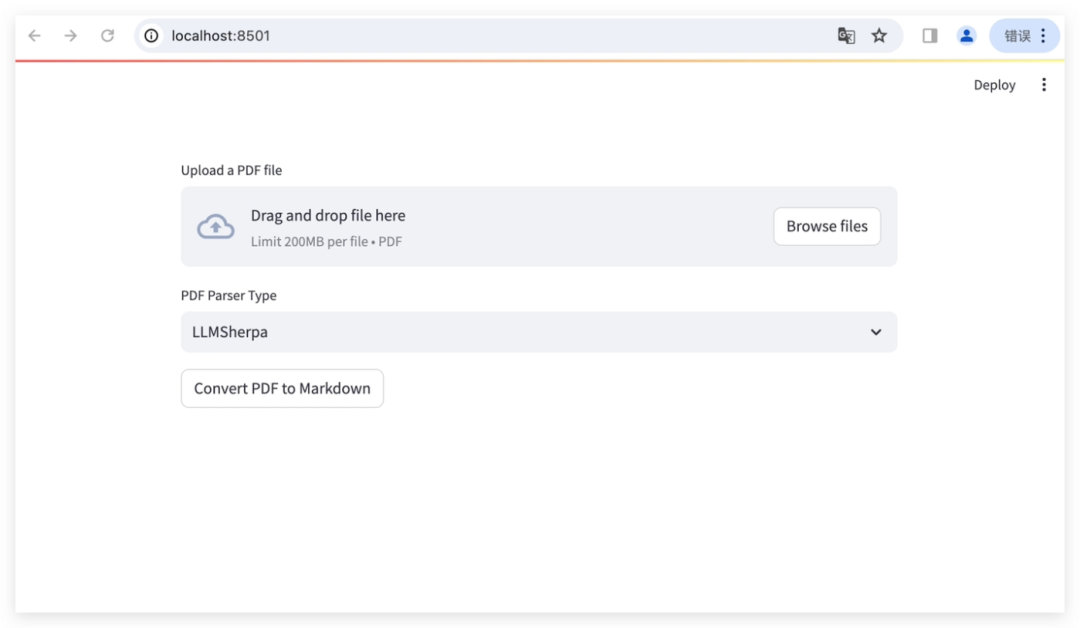
(1) PDF 文件上传
用户通过界面,上传需要解析的 PDF 文件
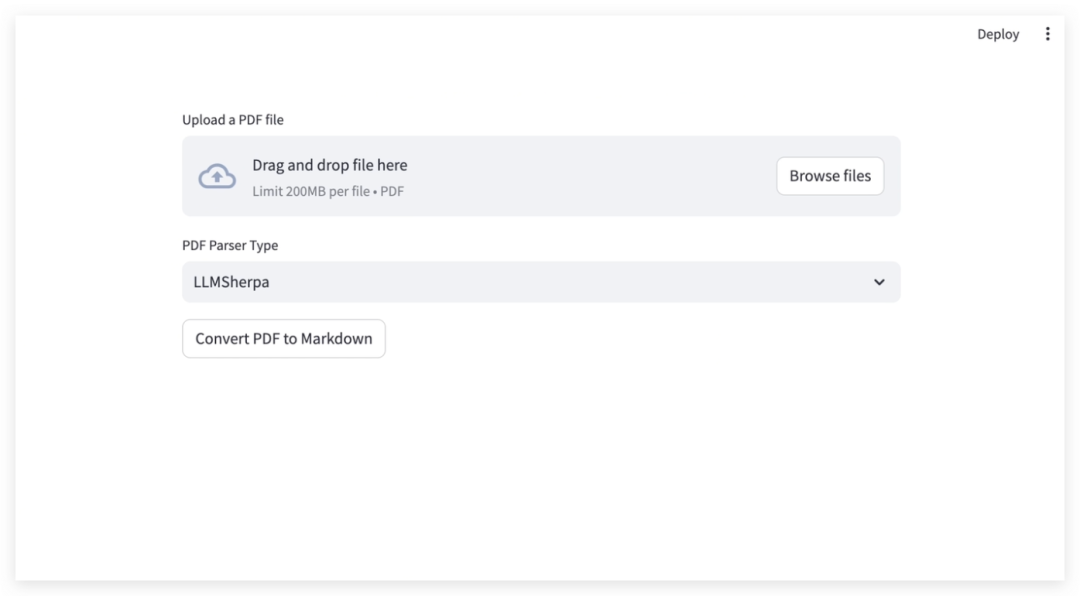
(2) 选择解析类型
本实例运行了三个业界领先的PDF解析器:LLMSherpa、Unstructured 和 LlamaParse,可供用户选择,本文以 LLMSherpa 为例:
LLMSherpa:适用于需要精确文本定位和布局分析的高级文档处理任务,如文本的具体位置、字体大小和样式等。
Unstructured:支持多种文档类型的解析,适合需要统一处理多种格式文档的应用场景,如文档管理系统、内容抽取和索引建立等。
LlamaParse:适合在需要进行大规模文档检索和分析的场景,如需要从大量PDF文档中检索信息并进行上下文增强的应用场景等。
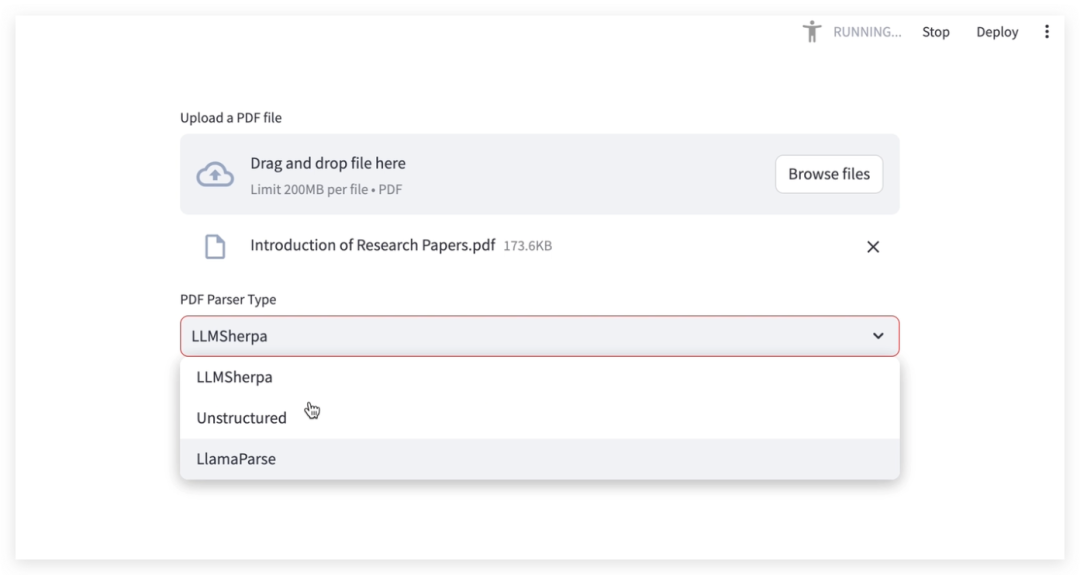
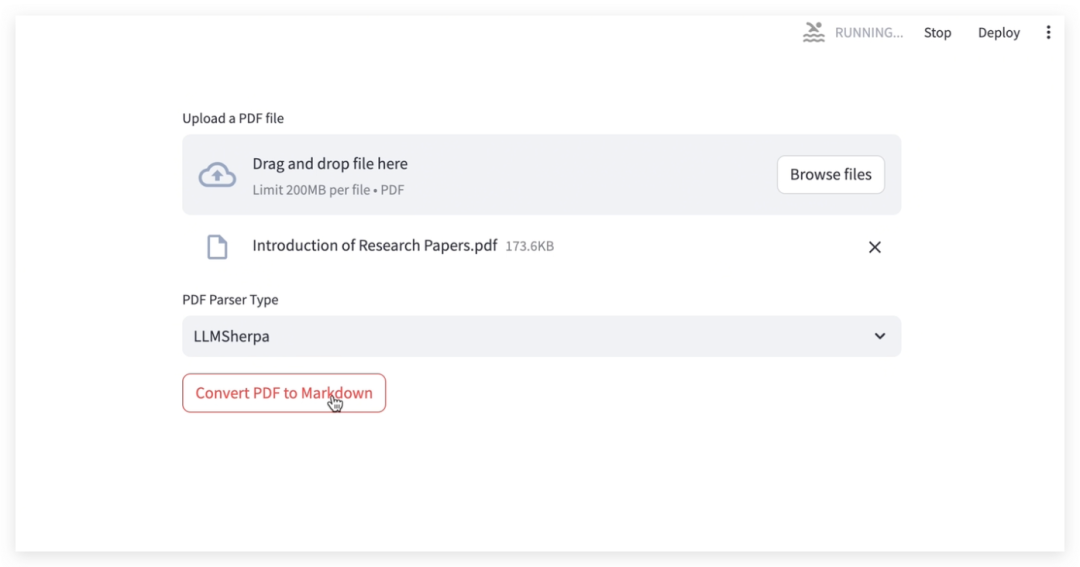
(3) PDF 文本解析
向 LLMSherpa 的 API 发送解析请求,包括要解析的 PDF 文档。
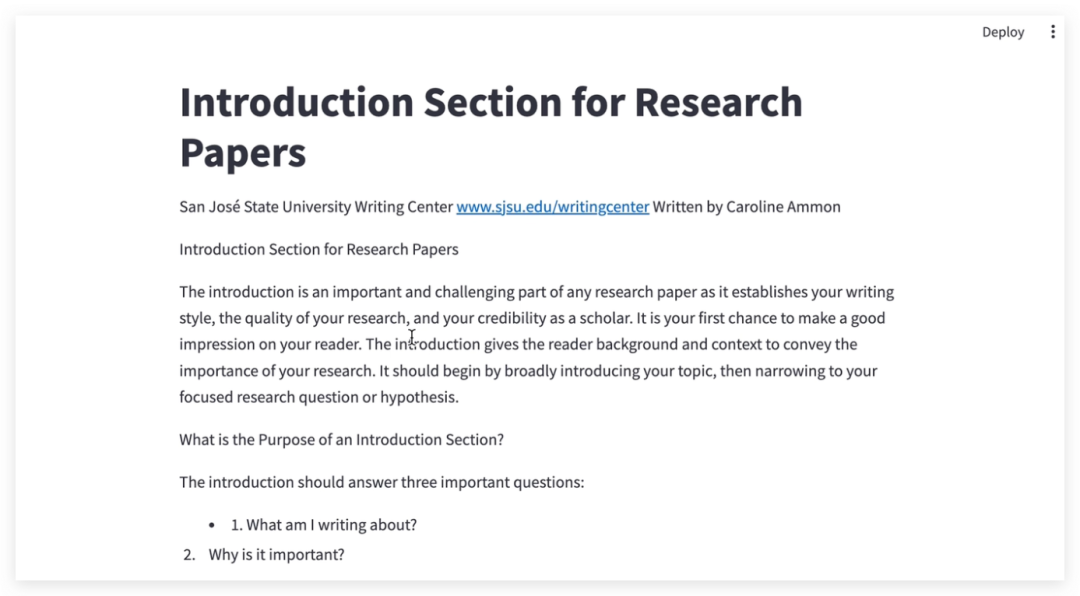
(4) 结果展示
LLMSherpa 处理完毕,会返回响应,其中包含解析结果。根据 LLMSherpa 的设计,其响应可包含文本内容、边界框(文本的位置信息)、图形和字体数据等。本示例中为文本内容:
(5) 后续处理
得到解析结果后,可以根据项目需求对这些数据进行进一步的处理。如将文本内容输入到大型语言模型中进行语义分析,或者使用边界框信息来重构文档的视觉布局等。
04 操作步骤
前置条件
1. 操作系统:应与大多数 Linux 发行版兼容,并已在 Ubuntu 22.04 上进行了测试。
2. Docker:系统上必须安装有 docker。具体来说,我们已经在 Ubuntu 22.04 上使用 Docker Engine 社区版 25.0.1 测试了这个演示。
3. OpenAI API 密钥(可选):如果希望在此演示中使用 ChatGPT 功能,需要 OpenAI API 密钥。请注意,此 API 的使用受 OpenAI 的定价和使用政策的约束。我们使用 OpenAI 文本生成模型来优化解析某些特殊组件(如标题或表格等)。没有这个 API 密钥,仍然可以尝试所有三种方法。
4. LlamaParse API 密钥:如果希望尝试新推出的 LlamaParse API 服务,需要从 其网页门户获取 API 密钥。没有这个 API 密钥,将无法尝试 LlamaParse。
本机电脑(Mac,非GPU配置,已安装 Docker)
以下是在 本机电脑(Mac,非GPU配置,已安装 Docker) 上启动演示的操作指南:
1. 选择合适路径,右键 Open in Terminal,输入如下命令克隆仓库:
git clone https://github.com/LinkTime-Corp/llm-in-containers.git
cd llm-in-containers/pdf2md2.若需要使用 OpenAI 的模型进行推理,将您的OpenAI API 密钥设置到conf/config.json的“OPENAI_API_KEY”中,包括:替换API 密钥 ‘{your-openai-api-key}’ 和 ‘{your-llamaparse-api-key}’ ,使用以下的命令:
export OPENAI_API_KEY={your-openai-api-key}
export LLAMAPARSE_API_KEY={your-llamaparse-api-key}如果用户的OpenAI 未进行订阅,这里则需要修改model为:"OPENAI_API_MODEL": "gpt-3.5-turbo",
3.打开 Docker Desktop
4.启动演示:
bash run.sh5.访问 http://localhost:8501/ 上的用户界面
在用户界面上,您可以选择“LLMSherpa”,“Unstructured”或“LlamaParse”来解析上传的PDF文件
6.关闭演示
bash shutdown.sh在阿里云/AWS服务器运行
过程类似,详情可参见完整博客内容:https://blog.gopenai.com/running-pdf-parsers-in-docker-containers-5e7a7ed829c8
05 要点笔记
PDF解析器选择
在选择PDF解析器时,不仅要考虑敏感信息的处理、成本因素,还需要评估各种工具的准确性和兼容性等。通过在实际文件上进行测试和评估,结合对不同场景的理解,选择或组合最适合您需求的解析器。
敏感信息处理:如果 PDF 文件包含敏感信息,并且对数据的安全性和隐私性有较高要求,在私有服务器上使用开源解决方案可能是最佳选择。LLMSherpa 和 Unstructured 都可在私人服务器上部署的开源 PDF 解析器,可以为处理敏感文档提供更高的安全保障。
成本考虑:如果对成本较为敏感,且 PDF 文件不包含敏感信息,那么可以考虑使用LlamaParse 或 ChatDoc。LlamaParse 目前提供免费的预览模式,而ChatDoc 虽然需要申请获得使用权限,但可能在未来推出收费的高级服务。
准确性和兼容性:目前没有任何工具或服务能够保证 100% 准确无误地解析所有 PDF 文件。PDF 格式的复杂性意味着解析器在处理不同结构或布局的文档时可能遇到挑战。因此,可以在特定的文件上测试不同的解析器,以确定哪个工具在准确性和功能性方面最能满足需求。
混合使用方案:可以在处理非敏感信息时使用LlamaParse 或 ChatDoc,而对于需要更高安全性的敏感文档,则转而使用 LLMSherpa 或Unstructured。
LLMSherpa:解析PDF文件以及层次布局信息
LLMSherpa 的 LayoutPDFReader 提供了一种高效的方法来解析 PDF 文件及其层次布局信息,利用其“智能分块”技术,能够识别文档中的不同部分和小节以及它们的嵌套结构,将文本行合并成连贯的段落并建立部分之间的联系。
尽管在大多数情况下 LayoutPDFReader 的性能表现出色,但也存在一些限制,如某些部分可能不会被正确地分类。对于需要 PDF 文件中信息的上下文感知分块,同时能够接受偶尔出现的分类不准确情况的 LLM 应用,LLMSherpa 的 LayoutPDFReader 成为了一个值得尝试的选项。
Unstructured:使用正确的模型来检测PDF文档中的元素
在处理PDF文档时,正确选择用于检测文档中元素的模型,将直接影响到文档解析的效率和准确性。Unstructured Python 库提供了几种不同的模型选项,以适应不同的需求和应用场景:
detectron2_onnx:是基于Facebook AI的计算机视觉模型,使用ONNX Runtime,提供了快速的对象检测和分割能力。如果主要关注点是速度,并且需要高效的对象检测功能,detectron2_onnx 可以是最佳选择。
yolox:是基于YOLOv3并且进行了优化的单阶段实时对象检测器,使用了DarkNet53作为主干网络。适用于需要实时对象检测同时关注模型准确度的场景。
yolox_quantized:它的运行速度比 YoloX 快,其速度更接近Detectron2。如果寻找一个既快速又相对准确的解决方案,yolox_quantized 是一个不错的选择。
chipper (beta version):chipper 是 Unstructured 内置的图像到文本模型,基于Transformer 架构的视觉文档理解(VDU)模型。适用于需要从图像中提取文本并进行深度理解的复杂应用场景。由于它还处于beta版本,可能需要进一步的测试和调整以满足特定的需求。
您还可以参考此文档https://unstructured-io.github.io/unstructured/best_practices/models.html#bring-your-own-models,将定制模型引入到这个库。
06 链接
本文Github 链接:
https://github.com/LinkTime-Corp/llm-in-containers/tree/main/pdf2md
博客原文:
https://blog.gopenai.com/running-pdf-parsers-in-docker-containers-5e7a7ed829c8
[1] LLMSherpa
https://github.com/nlmatics/llmsherpa
[2] Unstructured
https://github.com/Unstructured-IO/unstructured
[3] LlamaParse
https://github.com/run-llama/llama_parse
作者:宋文欣,智领云科技联合创始人兼CTO
武汉大学计算机系本科及硕士,美国纽约州立大学石溪分校计算机专业博士。曾先后就职于Ask.com和EA(电子艺界)。在Ask.com期间,担任大数据部门技术负责人及工程经理,使用Hadoop集群处理实时搜索数据,形成全球规模领先的Search Ads Arbitrage用户;在EA期间,担任数字平台部门高级研发经理,从无到有组建EA数据平台团队,建设公司大数据平台,为EA全球工作室提供数据能力支持。
2016年回国联合创立智领云科技有限公司,组建智领云技术团队,开发了BDOS大数据平台操作系统。
- Fin -

更多精彩推荐
容器中的大模型(二) | 利用大模型,使用自然语言查询SQL数据库
容器中的⼤模型(一)| 三行命令,大模型让Excel直接回答问题
开篇语 | 容器中的⼤模型 (LLM in Containers)
👇点击阅读原文,访问中文博客原文
相关文章:
容器中的大模型(三)| 利用大语言模型:容器化高效地部署 PDF 解析器实践...
作者:宋文欣,智领云科技联合创始人兼CTO 01 简介 大语言模型(LLMs)正逐渐成为人工智能领域的一颗璀璨明星,它们的强大之处在于能够理解和生成自然语言,为各种应用提供了无限可能。为了让这些模型更好地服务…...

java采集小程序联合航空官方
本文仅限学习研究讨论,切忌做非法乱纪之事 中国联合航空有限公司(以下简称“中国联合航空”)总部位于北京,现为中国东方航空股份有限公司(以下简称“东航”)旗下的全资子公司。中国联合航空成立于1986年12月26日&#…...
)
【力扣每日一题】lc1793. 好子数组的最大分数(单调栈)
LC1793. 好子数组的最大分数 题目描述 给你一个整数数组 nums (下标从 0 开始)和一个整数 k 。 一个子数组 (i, j) 的 分数 定义为 min(nums[i], nums[i1], ..., nums[j]) * (j - i 1) 。 一个 好 子数组的两个端点下标需要满足 i < k < j 。 请…...

ES的集群节点发现故障排除指南(1)
本文是ES官方文档关于集群节点发现与互联互通的问题排查指南内容。 英文原文(官网) 集群节点发现是首要任务 集群互连,重中之重! 在大多数情况下,发现和选举过程会迅速完成,并且主节点会长时间保持当选状…...

使用html+css制作一个发光立方体特效
使用htmlcss制作一个发光立方体特效 <!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><title>Documen…...

贵州省二级分类土地利用数据(矢量)
贵州省,地处中国西南腹地,地貌属于中国西南部高原山地,境内地势西高东低,自中部向北、东、南三面倾斜,平均海拔在1100米左右。贵州高原山地居多,素有“八山一水一分田”之说。全省地貌可概括分为࿱…...
通过nginx+xray服务搭建及本地配置
一、xray服务配置 下载:https://github.com/XTLS/Xray-core 进入下载界面 这里我选择的是Xray-linux-64.zip 将文件解压到 /usr/local/xray 编辑配置文件/usr/local/xray/config.json uuid可以在v2ray客服端自动生成,也可以在UUID v4 生成器 - KKT…...
第一节 Axure RP产品经理原型进阶学习
第一天 1、认识RP9 Axure RP 9,Axure RP 9是美国 Axure Software Solution公司的旗舰产品, 是一个快速的原型工具,常用于各项网络设计,包括了原型图、线框图等等。 要进行原型设计,将文字性文档转变为互动性的可视画…...
 文件压缩)
Linux实战笔记(三) 文件压缩
大家好,我是半虹,这篇文章来讲 Linux 系统中常用的文件压缩方式 0、序言 在 Linux 系统中,存在许多打包或压缩文件的工具 这篇文章会对一些常用的工具进行分类整理和介绍 如果只是需要知道怎么对不同格式的文件做解压缩,可以直…...

树形递归模板
详情参考CSDN链接: https://www.cnblogs.com/lidar/p/12972792.html public class Menu {// 菜单idprivate String id;// 菜单名称private String name;// 父菜单idprivate String parentId;// 菜单urlprivate String url;// 菜单图标private String icon;// 菜单顺序private …...

Python实战:Pandas数据合并与重塑
本文将深入探讨Pandas库在数据合并与重塑方面的强大功能。我们将涵盖多种数据合并方法,如merge、join、concat等,以及数据重塑的技巧,如pivot_table、merge_asof等。 一、引言 Pandas是一个强大的Python数据分析库,它提供了丰富…...
如何理解 Linux 命令行参数与环境变量7
一、命令行参数 1.1参数介绍 在写C语言程序时,main函数是否可以带参数呢?------ 是可以的 int argc: 命令行参数的个数char *argv[ ]: 字符指针数组(指向各个命令行参数的字符指针所构成的数组) 我们写一段代码来打印一下看这…...

奥特曼回应GPT5
欢迎再次与大家会面!在积累了大量的信息和趋势后,今天我们将深入了解 Sora、OpenAI 董事会、以及近期与其有关的所有声讨。我们将直接跳入与 OpenAI 首席执行官 Sam Altman 的深度访谈,探讨从 AGI 到 GPT-5 的未来,以及 Sam 对人工…...
QT----给程序添加上任务栏托盘图标和退出
让我们的程序拥有任务栏托盘图标,实现程序后台运行,退出等功能 1、关闭程序保持后台 重写关闭事件,忽略点击窗口关闭 void MainWindow::closeEvent(QCloseEvent *event) {// 隐藏窗口,而不是真正关闭setVisible(false);// 忽略关闭事件&am…...

arm地址对齐的总结
static void axi_azx_writeb(u8 value, u8 __iomem *addr) { u32 data; u32 offset; offset (u64)addr & 0x03; // 编译器不允许地址做& 操作时要强转为数据 addr (u8 __iomem *)((u64)addr & 0xFFFFFFFFFFFFFFFC); // __iomem是个64位的地址 u8表示从这个地址…...
就业班 2401--3.13 走进网络
走进网络 长风破浪会有时,直挂云帆济沧海。 1.认识计算机 1.计算机网络是由计算机和通讯构成的,网络研究的是“通信”。 ------1946 世界上第一台计算机 2.终端:只有输入和输出功能,没有计算和处理功能。 3.数据:一串…...
)
SWIFT介绍和学习(简单入门级别)
SWIFT介绍和学习 SWIFT功能介绍SWIFT快速使用LLM及LLM最佳实践(LLM系列文章)部署指南 vllm非官方介绍资料 项目地址:https://github.com/modelscope/swift 任何有疑惑的地方,参考项目首页readme寻求答案 SWIFT功能介绍 SWIFT&…...

智慧城市:提升城市治理能力的关键
目录 一、智慧城市的概念及特点 二、智慧城市在提升城市治理能力中的应用实践 1、智慧交通:提高交通治理效率 2、智慧政务:提升政府服务水平 3、智慧环保:加强环境监测与治理 4、智慧安防:提高城市安全水平 三、智慧城市在…...
golang 对接第三方接口 RSA 做签(加密) 验签(解密)
一、过程 1.调用第三方接口前,一般需要按规则将参数按key1value1&key2value2 阿斯克码排序,sign参数不参与加密 2.将排序并连接好的参数字符串通过我方的私钥证书(.pem)进行加密得到加密串,当然加密得到的是 []byte 字节流&…...

Spring Data访问Elasticsearch----Elasticsearch存储库Repositories
Spring Data访问Elasticsearch----Elasticsearch存储库Repositories 一、自动创建具有相应映射的索引二、存储库方法的注解2.1 Highlight2.2 SourceFilters 三、基于注解的配置四、Spring命名空间Namespace 本文包括Elasticsearch存储库实现的细节。 例1:示例Book实…...

机器学习模型评估中的构念效度:超越基准测试分数的科学推断
1. 项目概述与核心问题在机器学习的日常研究和工程实践中,我们每天都在和各种各样的基准测试(Benchmark)打交道。无论是为了比较新提出的ResNet变体在ImageNet上的Top-1准确率,还是评估一个大型语言模型在MMLU上的常识推理能力&am…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...

ARM架构CONSTRAINED UNPREDICTABLE行为解析与应对
1. ARM架构中的CONSTRAINED UNPREDICTABLE行为解析在处理器架构设计中,UNPREDICTABLE行为通常指架构规范未明确定义的执行结果,可能导致不可预期的系统状态。ARM架构通过引入CONSTRAINED UNPREDICTABLE机制,将这类行为限制在特定范围内&#…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

从CTF题看RSA安全:为什么你的密钥不能‘共享素数’?
从CTF实战看RSA密钥安全:那些年我们踩过的坑 在网络安全竞赛和实际渗透测试中,RSA算法的错误实现方式往往成为突破的关键点。本文将通过典型CTF赛题案例,揭示五种常见RSA实现漏洞背后的数学原理和安全启示,帮助开发者在实际项目中…...

如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南
如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 索尼相机逆向工程工具Sony-PMCA-RE是一款专业的开源工具&…...

掌握Umi-OCR:5分钟上手开源免费离线文字识别工具
掌握Umi-OCR:5分钟上手开源免费离线文字识别工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。…...

NPU跑LLM实战指南:KV Cache动态性如何突破硬件限制
NPU跑LLM实战指南:KV Cache动态性如何突破硬件限制 副标题: 从预分配+Attention Mask到三层软件栈,完整解析NPU推理架构 痛点:为什么NPU跑LLM这么难? LLM的生成机制和NPU的硬件特性存在根本冲突: LLM特性 NPU特性 冲突点 逐token生成 固定shape执行 KV Cache动态增长 动…...
CI/CD流水线中的幽灵依赖——DeepSeek项目92%存在未声明的transitive risk,你中招了吗?
更多请点击: https://intelliparadigm.com 第一章:CI/CD流水线中的幽灵依赖——DeepSeek项目92%存在未声明的transitive risk,你中招了吗? 在现代CI/CD实践中,开发者常误以为 package.json 或 requirements.txt 中显式…...