【原创】三十分钟实时数据可视化网站前后端教程 Scrapy + Django + React 保姆级教程向
这个本来是想做视频的,所以是以讲稿的形式写的。最后没做视频,但是觉得这篇文还是值得记录一下。真的要多记录,不然一些不常用的东西即使做过几个月又有点陌生了。
文章目录
- 爬虫 SCRAPY
- xpath
- 后端 DJANGO
- 前端 REACT
Hello大家好这里是小鱼,最近我做了一个前后端分离的实时数据大屏,因为是自己做全栈开发,所以从零开始学了不少新的知识,想在这里分享或者说记录一下,这个教程会尽量短,但是从数据获取,到后端项目和前端项目,包括项目部署到云服务器都会讲到,那我们开始吧。
爬虫 SCRAPY
首先我们要考虑数据大屏的数据从哪来,数据大屏的重要优势,一个是多端显示(比如做好了之后无论在手机/电脑还是电视这种更大的显示器都可以看),再一个就是实时性,一般数据大屏不同于那种一次性生成的数据可视化图,数据大屏的数据是实时更新的。
给公司做项目的话可能会有现成的实时数据给到你,那我们做自己项目就要考虑实时数据从哪来,有一些网站会向外提供免费开放的数据api接口,直接调用就可以拿到数据,这是一个方法。但是我今天想做的是全头到尾不依赖其他第三方,独立的写一个完整的项目。
我这边想到的获取数据的方法就是爬虫,先叠个甲,咋们这个视频只是用于交流学习,不涉及商业行为,如有侵权联系我删除。
我选的框架是scrapy,当然你也可以用你熟悉的框架,那我们就直接开始。
首先安装scrapy,安装过程大家根据自己的操作系统搜索一下,到命令行输入scrapy有如下显示则安装成功。
使用scrapy的命令创建项目
scrapy startproject douban
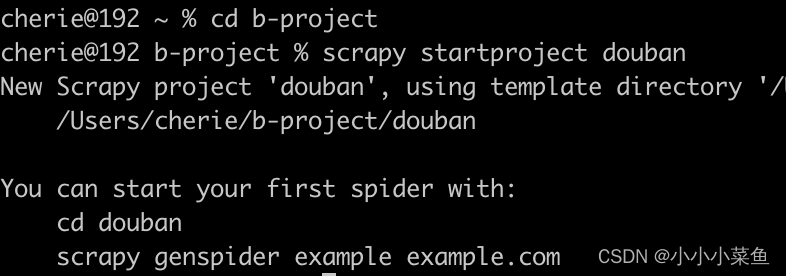
这时候可以用编辑器打开这个项目,能看到目录结构是这样的:
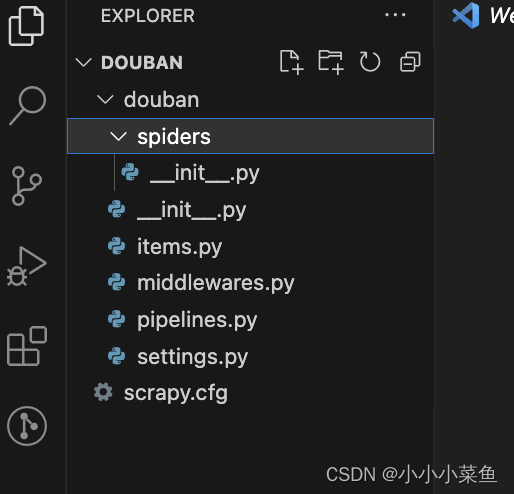
里面有一个 spiders 目录,我们后面爬虫代码的主要逻辑就写在这个目录里。
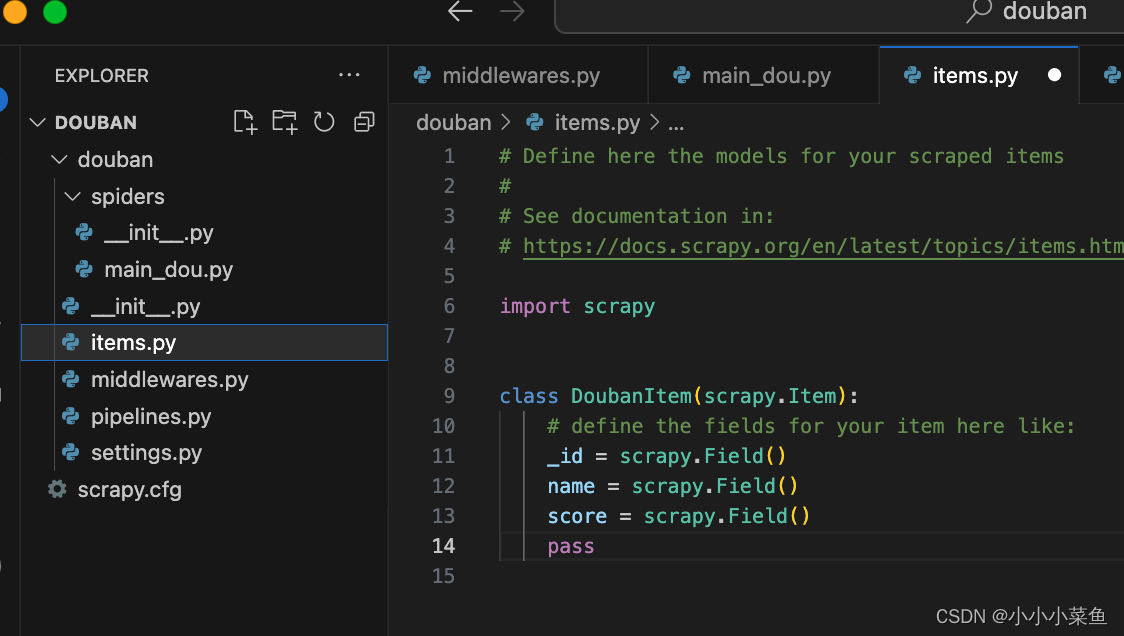
Items 文件用来定义我们爬取到的数据字段和类型。
pipelines 文件用来执行保存数据的操作,后面我们会在其中写和数据库连接相关的代码。
middlewares 文件是中间件,我们这次用不上可以先忽略。
settings 文件顾名思义是设置文件,里面可以配置的东西很多,后面再详细。
好,看完目录现在来写主要的代码,我想要爬取的是豆瓣现在正在上映电影的评价,我们知道豆瓣的评分相对来说还是比较能代表口碑的,它又是一个会实时变化的值,那我们对数据爬取之后存入自己的数据库,就可以在前端展示当前线上电影评价排行还有单个电影的评价趋势等数据图表,方便自己挑选电影。
我们使用这个命令创建一个爬虫主文件,scrapy genspider main_dou 'https://movie.douban.com/cinema/nowplaying/yichang/'命令。
这时会看到spiders目录下有一个main_dou.py文件,里面已经给出了大致的架构,
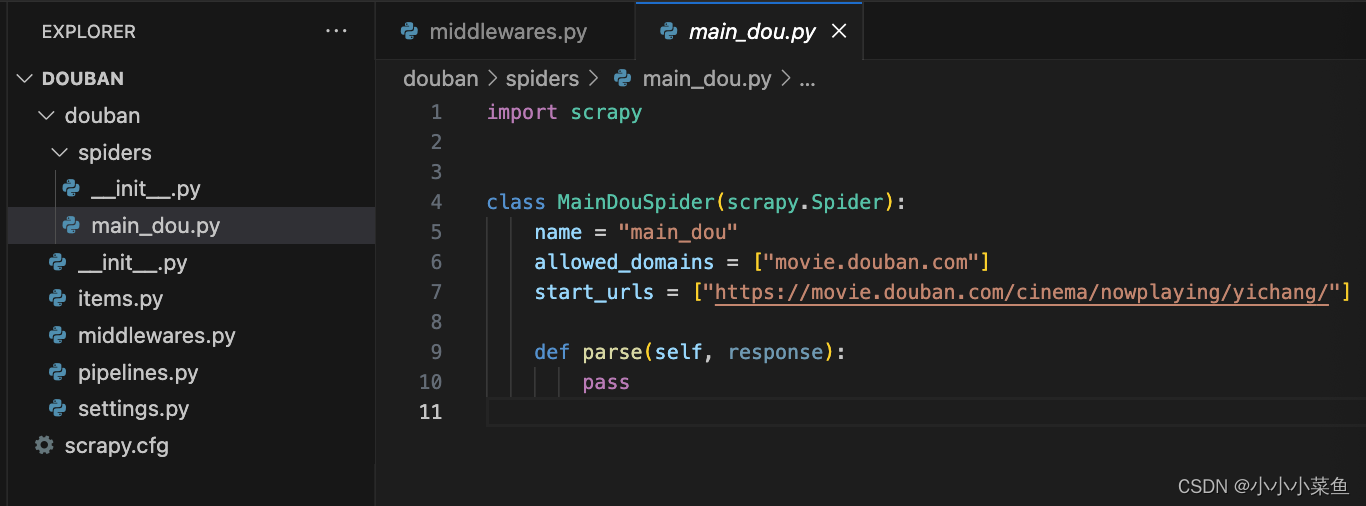
里面有一个用scrapy.Spider类创建的子类,并有三个属性和一个方法。
name 是唯一名称
allow_domains 是搜索的域名范围,规定只爬取这个域名下的网页
从 start_urls 开始抓取数据
parse(self, response) :每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,负责解析返回的网页数据(response.body),提取结构化数据(生成item)
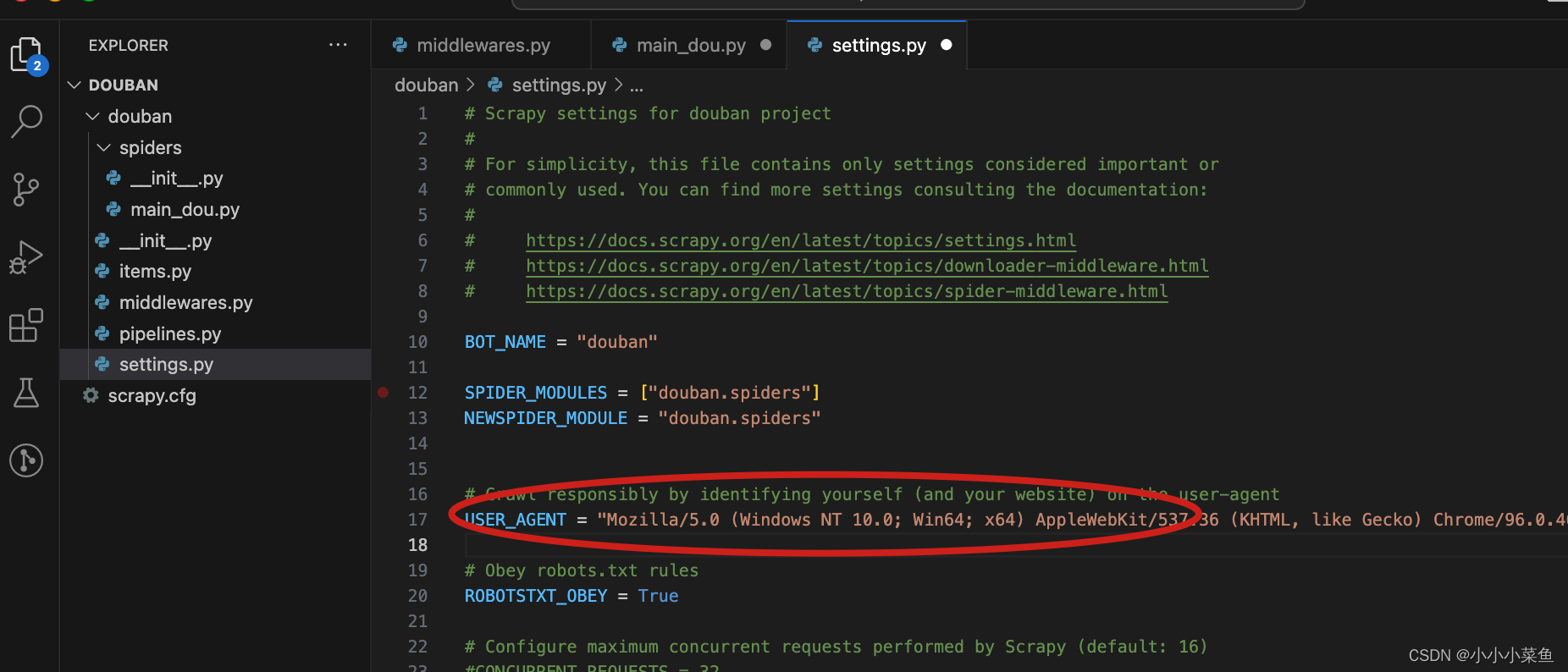
首先在settings中我们将user agent换一下
然后我们输入命令跑一下看能不能成功。
抓出来是乱码,是header的问题。
xpath
只需要懂三个符号
/ 直接子集(根元素)
// 可以跳级(不考虑位置)
@ 属性访问
我们直接在浏览器F12,在dom里可以按xpath语法搜索,
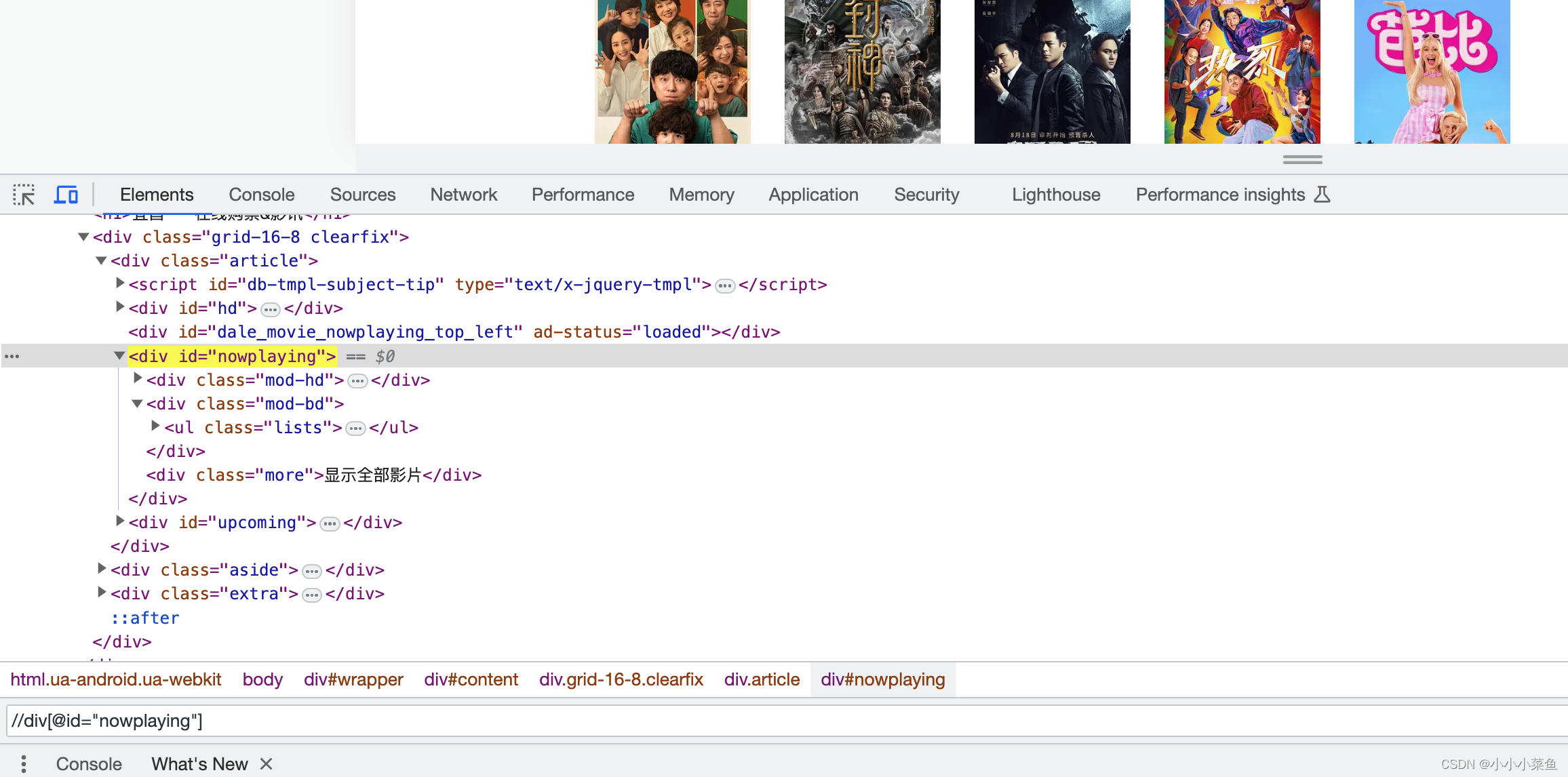
这里输入的意思就是找属性里id为nowplaying的div,是不是很简单。
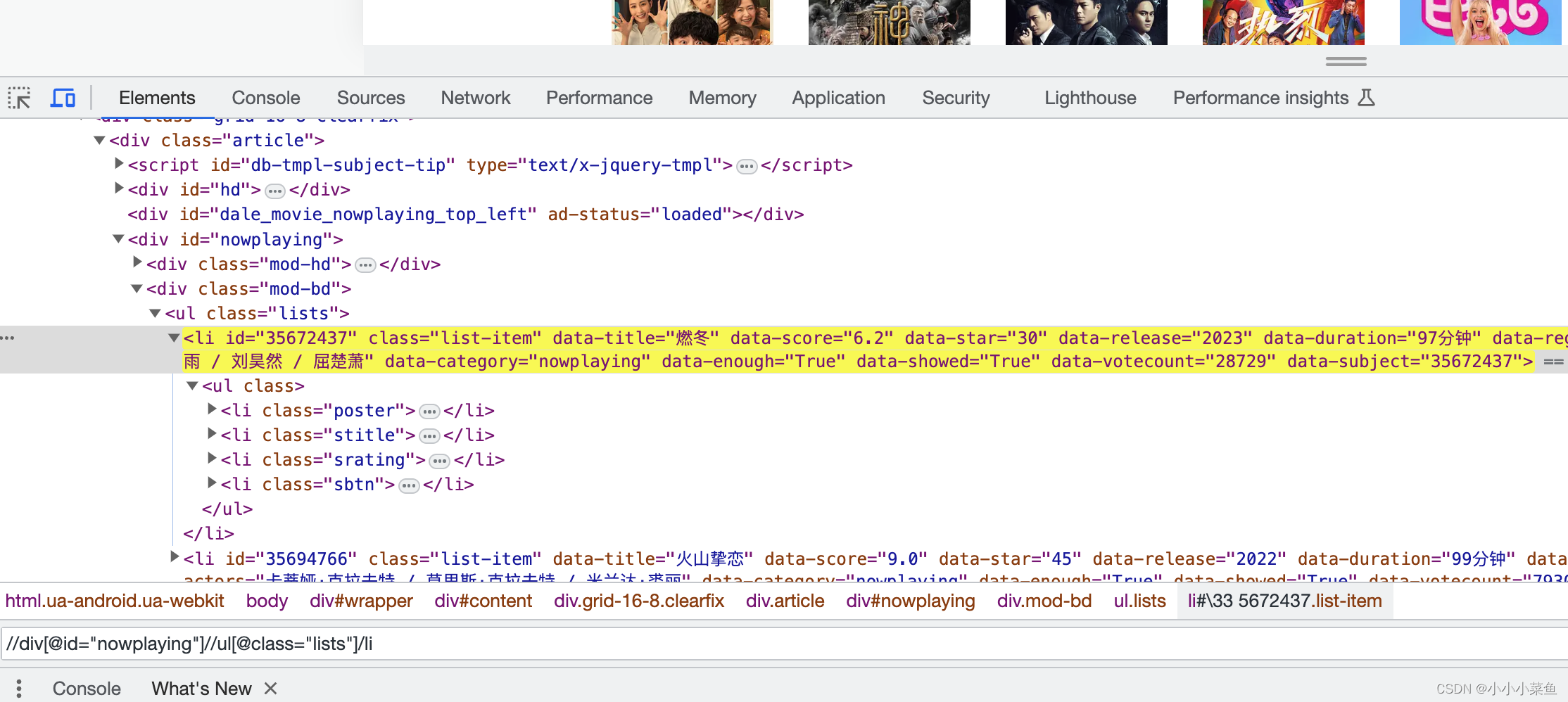
这样就找到了所有有上映影片信息的li标签,可以看到标签里有影片信息,我们提取对应属性就行。
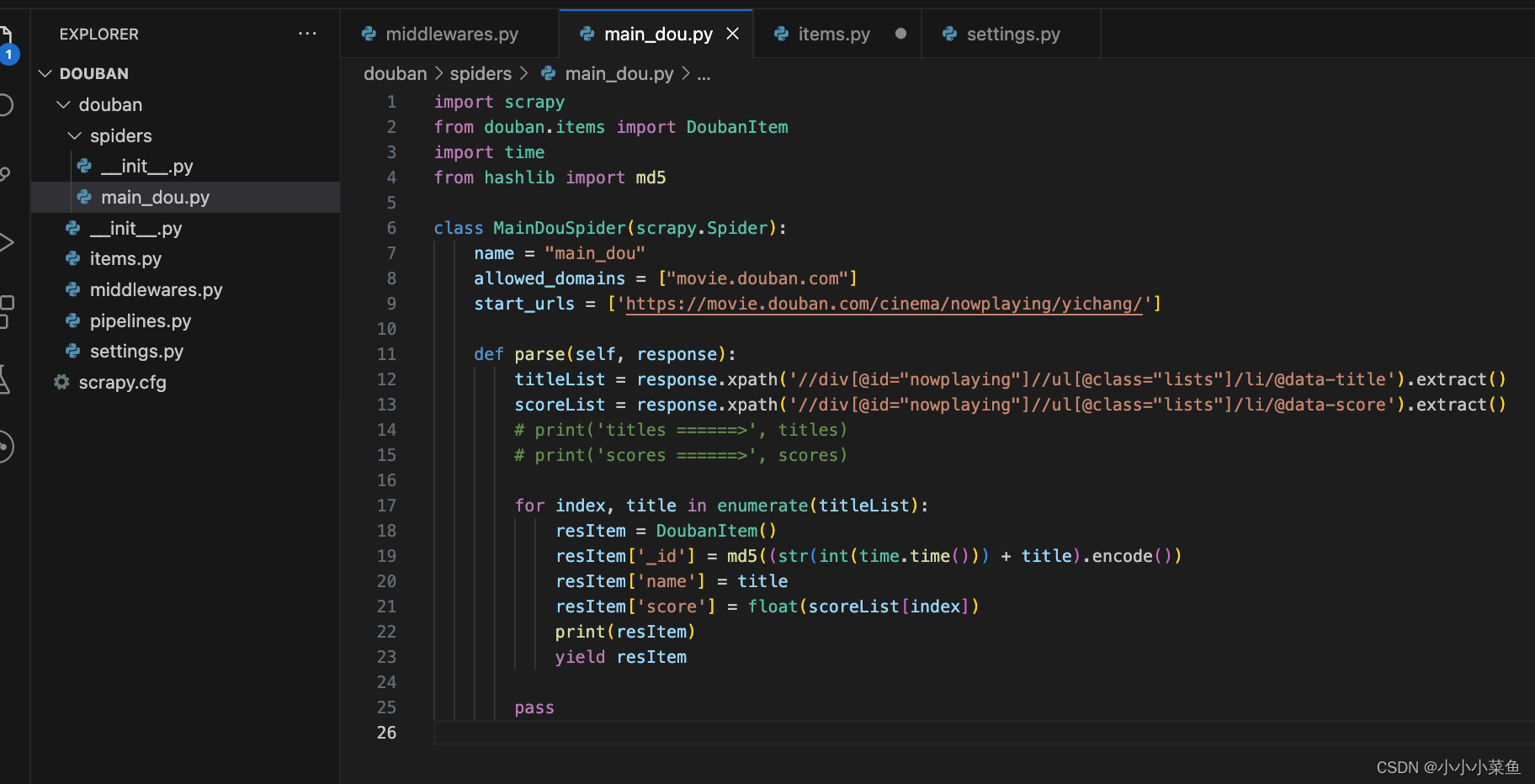
最后的代码是这样,extract()方法用于从XPath结果中提取文本值,这样就爬到了所有影片名字和打分。
接下来我们要将数据存到数据库中,实现持久化。
我们在items文件里定义好数据字段,然后在主程里拼好每一组数据
接下来我们要连接数据库,我这里用的mongodb,你们也可以使用自己熟悉的数据库比如mysql等。
在settings里写好数据库的地址,库名表名,账号密码等信息,在pipelines文件里进行注入。如果你也是用的mongodb,可以和我一样配置,不过其实别的数据库也差不多的。
再跑一下项目,发现数据库里已经成功写入数据了,我们这一步就完成了。
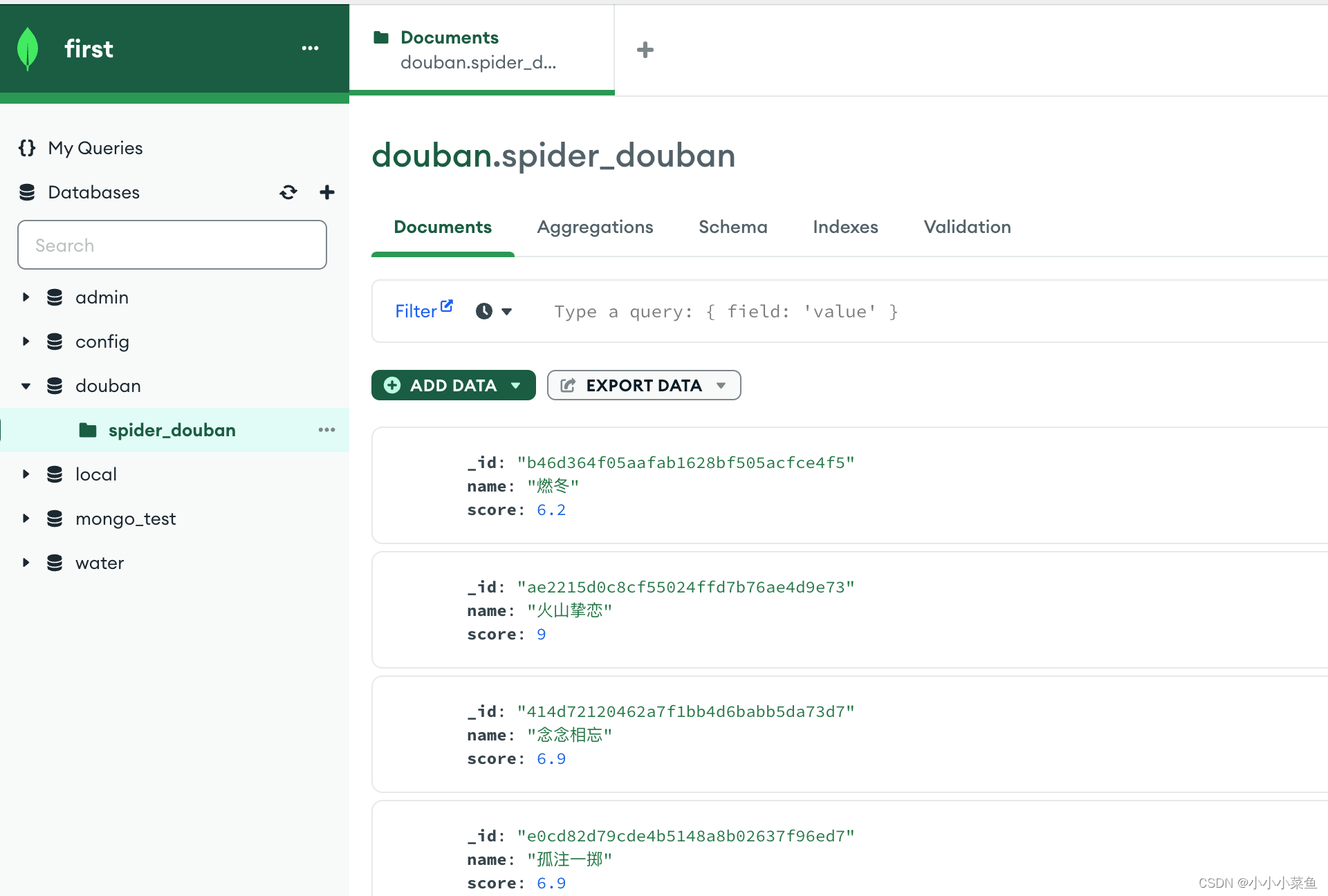
再只需要让这个scrapy项目按时自动执行我们数据库就有实时数据了,这个我们后面部署的部分再讲。
后端 DJANGO
我们已经有了数据,现在需要开发一个后端项目,对数据库的数据进行操作,并暴露api給前端。
因为我平时用python比较多,后端框架选型的时候就选了Django,当然也可以选你熟悉的框架。Django其实是一款前后端不分离的框架,将前端代码写在django的templates文件夹里。前后端冗杂在一块会比较难维护,针对前后端分离的情况,Django退出了DRF(Django Rest Framework)。那我们一步步来做。
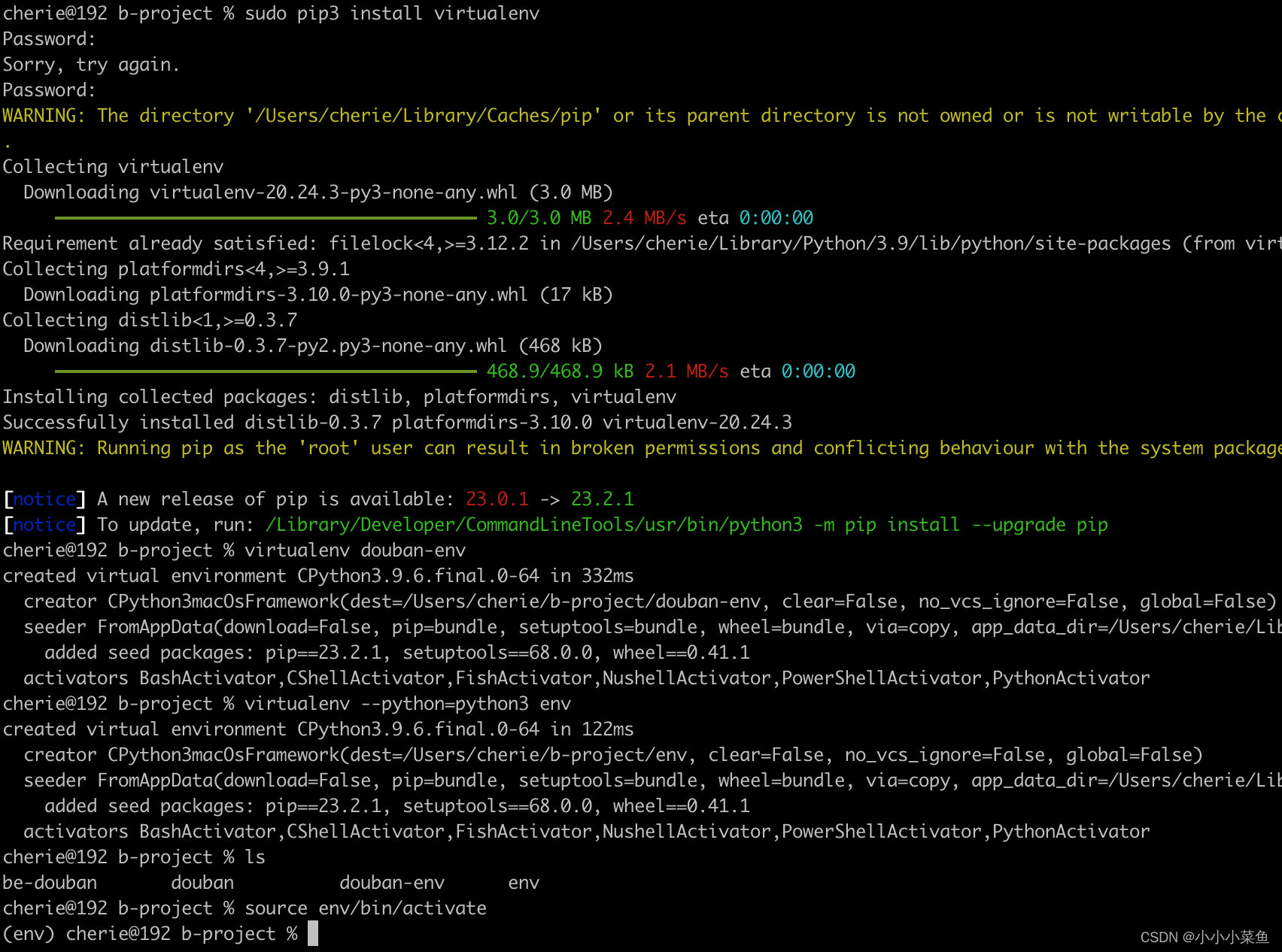
首先在开发后端项目之前可以整一个虚拟环境,因为后端项目依赖的库会比较多,而各个后端项目之间如果库的版本各不相同就会比较麻烦,所以开启一个虚拟环境保证这个项目的依赖都是独立的。
sudo pip3 install virtualenv
virtualenv douban-env
source env/bin/activate
安装django
pip3 install django==3.2.1
pip3 install djangorestframework==3.12.4
django-admin.py startproject be_douban
cd be_douban
python3 manage.py startapp douban
此时的目录结构是这样的
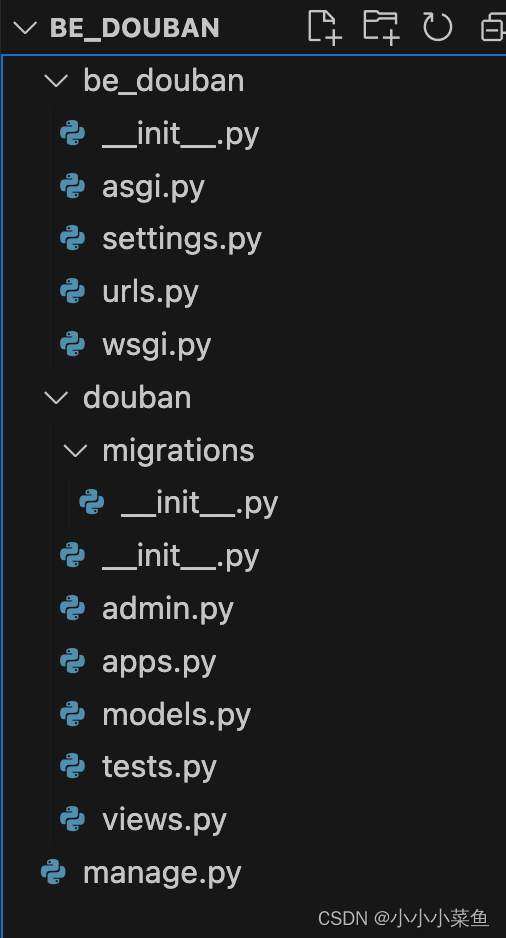
douban那个文件夹是我们创建出来的app,我们先到settings中注册这个app。
为了操作mongodb,我们需要安装djongo
我们来看一下DRF这个架构(这里借用一下大佬的图,图源见水印)
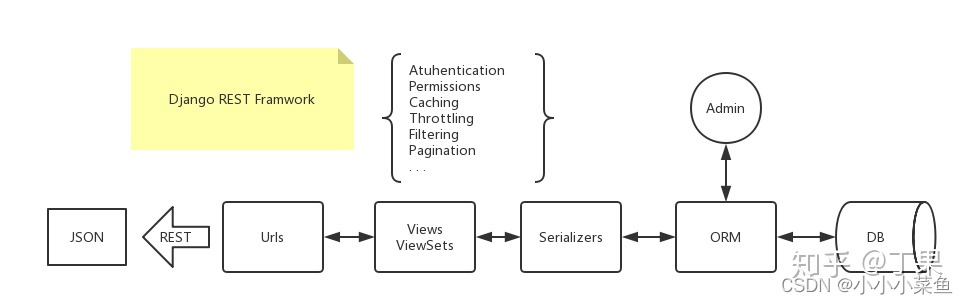
DRF是将数据库的东西通过ORM的映射取出来,通过view和serializers文件绑定REST接口,当前端请求时,返回序列化好的json。
我们从Modal开始修改:Model文件里定义了数据的结构和关系,类似于数据库表的描述。我们把之前爬虫存在数据库里的字段再这边再声明一下。
from djongo import models# Create your models here.class Douban(models.Model):_id = models.CharField(max_length=128, primary_key=True)name = models.CharField(max_length=128)score = models.FloatField()time = models.IntegerField()class Meta:db_table = 'spider_douban'
然后是序列化器,新建一个serializer.py文件,因为我们直接需要所有字段,这边fields直接__all__就行,如果不需要所有的,可以自己用数组定义 例如 fields = [‘_id’, ‘station’, ‘time’]
from douban.models import Douban
from rest_framework.serializers import ModelSerializerclass DoubanSerializer(ModelSerializer):class Meta:model = Doubanfields = '__all__'
最后是视图view文件,定义了API的行为,我们主要对数据处理的逻辑写在这,我们是需要一个接口拿到最新的所有电影的分数,然后在前端进行排行,那么就这么写。
from rest_framework.decorators import api_view
from rest_framework.response import Response
from douban.models import Douban
from douban.serializers import DoubanSerializer
from django.db.models import Max@api_view(['GET'])
def movie_lasttime_list(request):if request.method == 'GET':# 使用Djongo查询获取最后一次时间的时间戳last_time = Douban.objects.aggregate(Max('time'))['time__max']# 使用过滤器获取最后一次时间的所有数据movies = Douban.objects.filter(time=last_time)# 将查询到的数据序列化并返回serializer = DoubanSerializer(movies, many=True)return Response(serializer.data)
之后定义一下url,就是api的路径,我们在douban app下创建一个url文件
from django.urls import include, path
from douban import viewsurlpatterns = [path('api/current', views.movie_lasttime_list),
]
之后在主url文件中引入这个app的url文件
from django.contrib import admin
from django.urls import path, includeurlpatterns = [path('admin/', admin.site.urls),path('', include('douban.urls')),
]
现在就做完了,可以跑项目了,第一次要执行一下迁移命令
python3 manage.py makemigrations
python3 manage.py migrate
python3 manage.py runserver
这时候看到

证明已经跑起来了
浏览器输入对应url可以看到
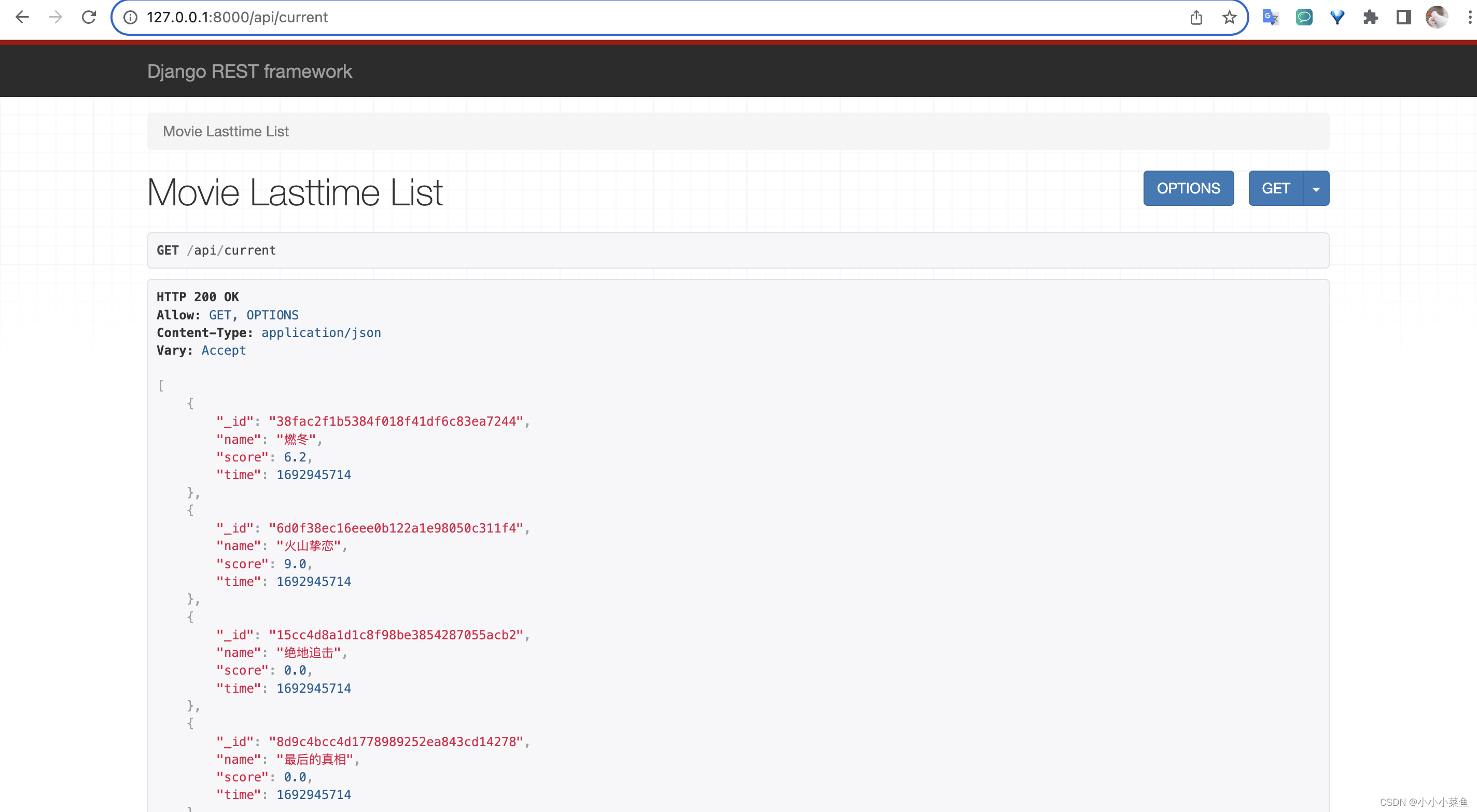
我们的接口就写好了。
除了最新数据,我们还需要一个趋势数据,就不一步步讲解了,和上面的一样,展示一下view文件的逻辑:
@api_view(['GET'])
def movie_scores_by_name(request):if request.method == 'GET':movies = Douban.objects.all() # 获取所有电影数据movie_scores = {} # 创建一个字典来存储电影名称和对应的时间和分数列表for movie in movies:if movie.name in movie_scores:movie_scores[movie.name].append({"time": movie.time, "score": movie.score})else:movie_scores[movie.name] = [{"time": movie.time, "score": movie.score}]return Response(movie_scores)前端 REACT
接下来看前端部分。
一般经常写前端的人都有自己熟悉的脚手架,我也有一套 react + ts + less + webpack 的脚手架。但是为了简单,毕竟这个教程不是一个前端各种技术栈的介绍,我们就是用最简单的官方的脚手架实现一下,它内部封装了webpack。
npm install -g create-react-app
create-react-app fe_douban
我们 npm start 看到下面这个页面就是项目跑起来了:

这是原始的目录,我们稍微调整一下结构。把src下的文件删掉只保留index.js和index.css,再创建一个container和component文件夹分别放容器和组件。
引入echarts,在命令行输入npm install echarts,可以看到package.json文件里已经有Echarts的依赖了
而echarts怎么用呢,我们在component目录下创建一个bar-chart文件夹,新建index.ts文件。用函数组件的写法吧,在useEddect里面对echart实例进行操作,简单来说就是先init初始化,然后定义Option,我们图表的所有配置都在option里面,这部分就不详述了,可以去Echarts官网看例子,还有手册,每个配置项都很详细,我就直接展示了。
import React, { useEffect, useRef } from 'react';
import * as echarts from 'echarts';import './index.css';const mockData = [{"_id": "8c7c957e237ff7ec2f848908fbea9817","name": "奥本海默","score": 8.7,"time": 1693390018}, {"_id": "21d53373fa67f1866993492cfb782d17","name": "燃冬","score": 6.2,"time": 1693390018}
]const BarChart = (props) => {const chartRef = useRef();let data = props.data || mockData;data.sort((a, b) => a.score - b.score);console.log(data)useEffect(() => {const chart = echarts.init(chartRef.current); //echart初始化容器let option = {title: {text: props.title ? props.title : '',textStyle: {color: '#aad8f8',fontWeight: 300,fontStyle: 'italic'}},color: ['#faeea0'],grid: {left: '15%'},tooltip: {trigger: 'axis'},xAxis: {type: 'value',axisLabel: {color: '#ffffff'}},yAxis: {type: 'category',data: data.map((item) => item.name)},series: [{data: data.map((item) => item.score),label: {show: true,position: 'inside',color: '#ffffff'},type: 'bar'}]};chart.setOption(option);const echartsResize = () => {echarts.init(chartRef.current).resize();};window.addEventListener('resize', echartsResize);return () => window.removeEventListener('resize', echartsResize);}, [props]);return <div className='bar-chart-container' ref={chartRef}></div>;
};export default BarChart;写好BarChart组件后在container创建一个homePage=,在其中引用之前写好的组件,并传入数据。数据是通过fetch方法在我们后端接口取得,具体代码如下:
import React from "react";import './index.css'
import BarChart from "../../component/bar-chart";class HomePage extends React.Component {state = {barData: null}componentDidMount() {fetch("http://127.0.0.1:8000/api/current").then(res => res.json()).then(data => {this.setState({barData: data});}, (e) => console.log(e))}render() {return (<div className="home-page">{/* <LineChart /> */}<BarChart title={"今日在映电影评分排名"} data={this.state.barData} /></div>)}
}export default HomePage;
现在打开页面,已经可以看到排名后的电影和评分了。这样整个流程就走通了。
最后将爬虫项目,前后端都部署到云服务器,将爬虫设置为定时任务,前端可以用 nginx,后端用 uwsgi + nginx。就可以了。
相关文章:
【原创】三十分钟实时数据可视化网站前后端教程 Scrapy + Django + React 保姆级教程向
这个本来是想做视频的,所以是以讲稿的形式写的。最后没做视频,但是觉得这篇文还是值得记录一下。真的要多记录,不然一些不常用的东西即使做过几个月又有点陌生了。 文章目录 爬虫 SCRAPYxpath 后端 DJANGO前端 REACT Hello大家好这里是小鱼&a…...

MySQL的备份
为什么要备份: 1.保证重要的数据不丢失 2.数据转移 MySQL数据库备份的方式: 1.直接拷贝物理文件 2.在可视化工具中手动导出 (1)在想要导出的表或者数据库中,右键,选择备份或导出 使用命令行导出 MyS…...
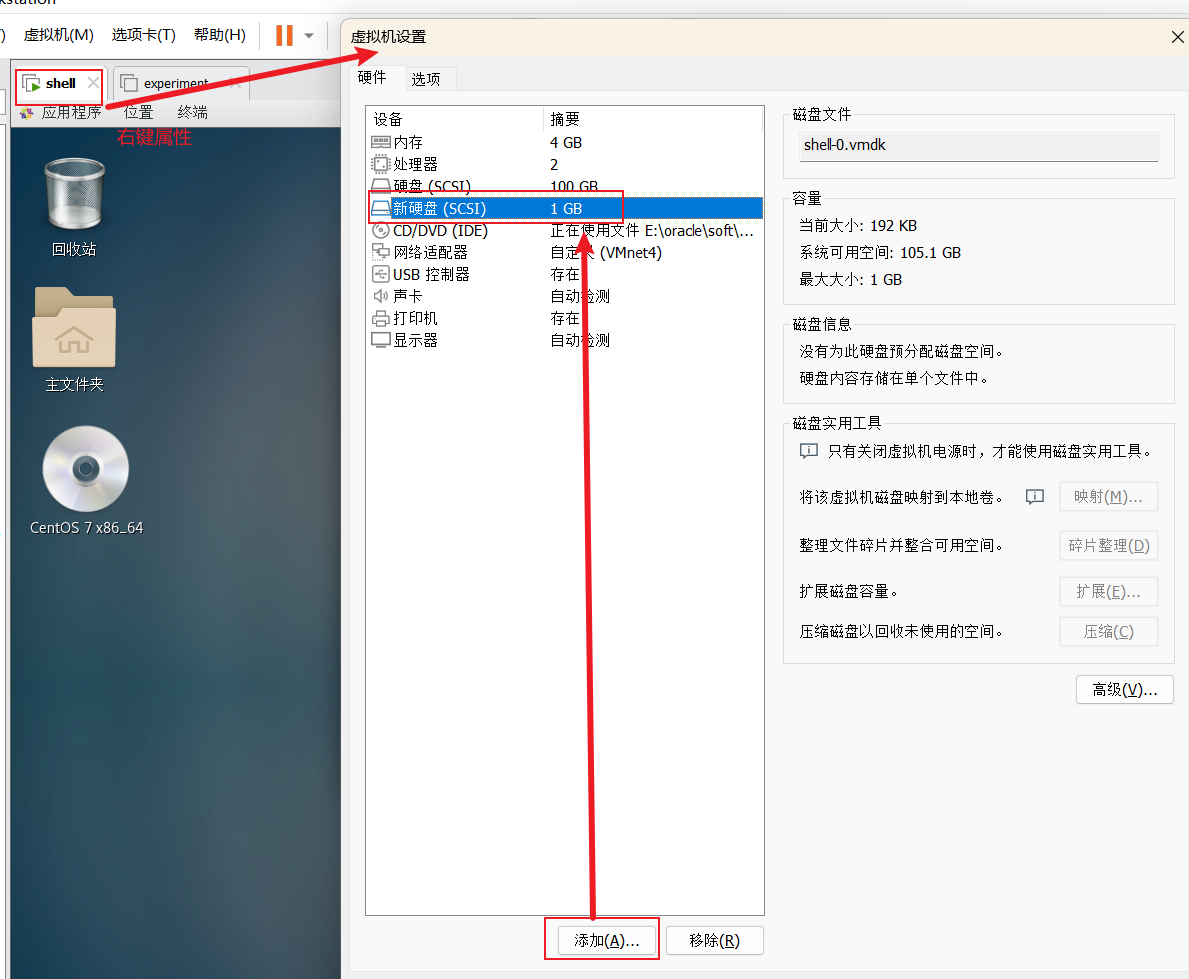
Linux 磁盘的一生
注意:实验环境都是使用VMware模拟 磁盘接口类型这里vm中是SCSI,扩展sata,ide(有时间可以看看或者磁盘的历史) 总结:磁盘从有到无—类似于建房子到可以住 ————————————————————————————————————…...

C#配置连接数据库字段
在Web.config文件中 添加如下配置 <!--连接数据库字段--><connectionStrings><add name"sql" connectionString"server.;uidsa;pwd8888;databaseArticleWebSite" /></connectionStrings>...

QCOM和其他常见芯片平台术语缩写
1 QCOM 1.1 General Qualcomm: Quality Communications ALSA DCP:ALSA由DAI、Codec、Platform三部分组成 ALSA TLV:Type-Length-Value Alternative Mode: 替代模式 ANC:Automatic Noise Canceller ASM: Anntena Switch Module AT:…...

css页面布局
CSS属性书写顺序(重点) 建议遵循以下顺序: 布局定位属性:display / position/ float / clear / visibility / overflow(建议display第一个写,毕竟关系到模式) 自身属性:width / height / margin / padding / border / background…...
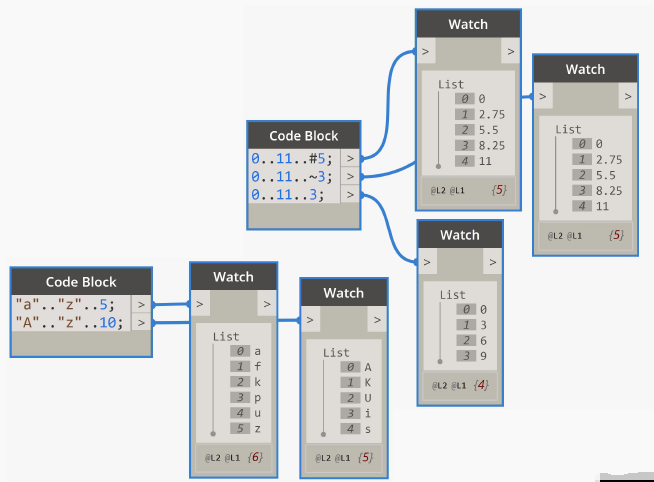
6、Design Script之列表
Range 在DesignScript中,Range是从起点到终点的一系列数字,使用指定的步距(间距类型),并有以下的初始化方法: start..end..step; start..end..#amount; start..end..~approximate; Range可以是数字的,也可以是字母的。 字母范围因大小写而异。 开始,结束. .#数量范围(…...

Mysql数据库的多实例部署
mysql多实例部署 先进行软件下载 上传二进制格式的mysql软件包 [rootcjy ~]# ls anaconda-ks.cfg mysql-8.0.35-linux-glibc2.28-x86_64.tar.xz配置用户和组并解压二进制程序至/usr/local下 创建用户和组 [rootcjy ~]# useradd -r -s /sbin/nologin -M mysql解压软件至/usr…...
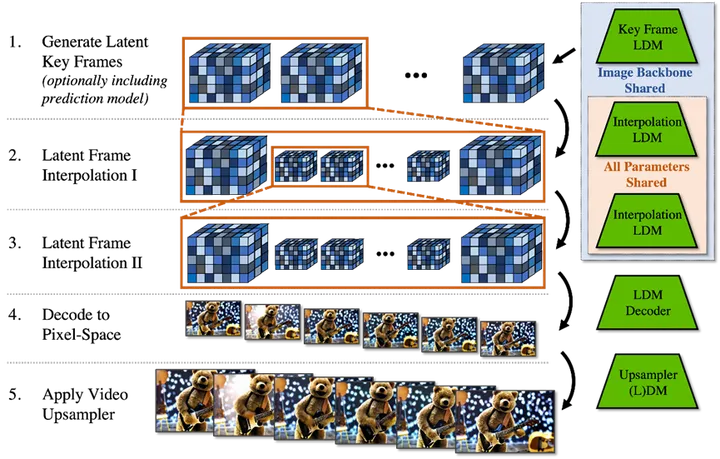
陈巍:Sora大模型技术精要万字详解(上)——原理、关键技术、模型架构详解与应用
目录 收起 1 Sora的技术特点与原理 1.1 技术特点概述 1.2 时间长度与时序一致性 1.3 真实世界物理状态模拟 1.4 Sora原理 1.4.1扩散模型与单帧图像的生成 1.4.2 Transformer模型与连续视频语义的生成 1.4.3 从文本输入到视频生成 2 Sora的关键技术 2.1 传统文生图技…...
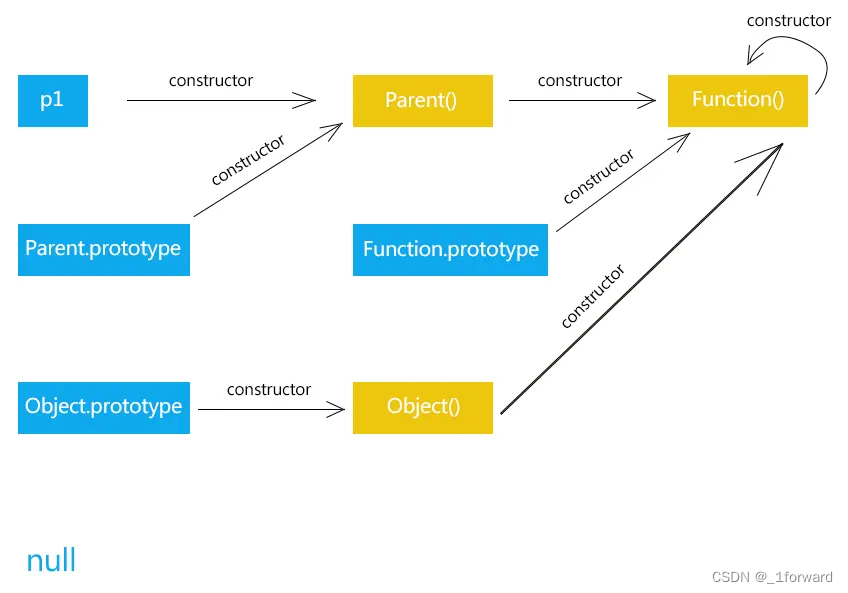
JS原型和原型链的理解
原型链图,图中Parent是构造函数,p1是通过Parent实例化出来的一个对象 前置知识 js中对象和函数的关系,函数其实是对象的一种 函数、构造函数的区别,任何函数都可以作为构造函数,但是并不能将任意函数叫做构造函数&…...

力扣题单(小白友好)
力扣题单 算法小白自用题单,目前对于一些简单的数据结构感觉掌握的还可以,但是力扣很多题还是需要看题解,不够熟练;故整理了一份题单,用于巩固练习; 网上确实有很多对于算法分类讲解的网站,but:有一丢丢选择困难症,每天不知道该刷什么题,再加上网站对于一类题一般就有十几道题目…...

王道c语言ch11-单链表的新建、插入、删除例题
王道c语言ch11-单链表的新建、插入、删除例题 #include <stdio.h> #include <stdlib.h> #define END 33typedef int ElemType;typedef struct LNote {ElemType data;struct LNote *next; } LNote, *LinkList;//头插法 void list_head_insert(LinkList &L) {El…...

蓝桥杯刷题--python-23
2.危险系数 - 蓝桥云课 (lanqiao.cn) n, m map(int, input().split()) map_ [[] for i in range(n 1)] used [0 for i in range(n 1)] used_ [0 for i in range(n 1)] cnt 0 res [] for _ in range(m):u, v map(int, input().split())map_[u].append(v)map_[v].appen…...

蓝桥杯刷题--python-24
0地图 - 蓝桥云课 (lanqiao.cn) from math import * import sys from functools import lru_cache # sys.setrecursionlimit(100000) n, m, k map(int, input().split()) a [input() for i in range(n)] dr [(0, 1), (1, 0)] cnt 0 lru_cache(maxsizeNone) def dfs(x, y, …...
面向对象(C# )
面向对象(C# ) 文章目录 面向对象(C# )ref 和 out传值调用和引用调用ref 和 out 的使用ref 和 out 的区别 结构体垃圾回收GC封装成员属性索引器静态成员静态类静态构造函数拓展方法运算符重载内部类和分布类 继承里氏替换继承中的…...

Lombok:@Cleanup资源释放利器
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 一、Cleanup介绍 二、使用示例 三、价值阐述 总结 提示:以下是本篇文章正文内容,下面案例可供参考 一、Cleanup介绍 Cleanup可以自动管理输…...

IoT 物联网场景中 LoRa + 蓝牙Bluetooth 室内场馆高精定位技术全面解析
基于LoRa蓝牙的室内场景定位技术,蓝牙主要负责位置服务,LoRa主要负责数据传输。 01 LoRa和蓝牙技术 LoRa全称 “Long Rang”,是一种成熟的基于扩频技术的低功耗、超长距离的LPWAN无线通信技术。LoRa主要采用的是窄带扩频技术,抗干…...
SpringCloudAlibaba系列之Seata实战
目录 环境准备 1.下载seata安装包 2.修改配置文件 3.准备seata所需配置文件 4.初始化seata所需数据库 5.运行seata 服务准备 分布式事务测试 环境准备 1.下载seata安装包 Seata-Server下载 | Apache Seata 本地环境我们选择稳定版的二进制下载。 下载之后解压到指定目录…...

蓝桥杯day5刷题日记-分巧克力-天干地支-求和
P8647 [蓝桥杯 2017 省 AB] 分巧克力 思路:二分查找 #include <iostream> using namespace std; int n,k; int h[100010],w[100010];bool check(int x) {int sum0;for(int i0;i<n;i){sum(h[i]/x)*(w[i]/x);if(sum>k) return true;}return false; }int…...

C++ ostringstream用法详解
std::ostringstream 是 C 标准库中的一个输出字符串流类,它可以用于将各种数据类型转换为字符串,并且支持格式控制和字符串拼接操作。 目录 1. 头文件 2. 基本用法 3. 将各种数据类型转换为字符串 4. 格式控制 5. 清空和重置 6. 拼接字符串 1. 头…...

vscode-drawio企业级离线部署:架构设计与安全内网集成方案
vscode-drawio企业级离线部署:架构设计与安全内网集成方案 【免费下载链接】vscode-drawio This unofficial extension integrates Draw.io (also known as diagrams.net) into VS Code. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-drawio vscode-…...

深度技术解析:douyin-downloader架构设计与高性能实现
深度技术解析:douyin-downloader架构设计与高性能实现 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppo…...

高效网站本地化:WebSite-Downloader完整实战指南
高效网站本地化:WebSite-Downloader完整实战指南 【免费下载链接】WebSite-Downloader 项目地址: https://gitcode.com/gh_mirrors/web/WebSite-Downloader 想要永久保存重要的网站内容吗?WebSite-Downloader网站下载器让你轻松实现网站离线浏览…...

中兴光猫配置解密工具:突破运营商限制的终极网络管理指南
中兴光猫配置解密工具:突破运营商限制的终极网络管理指南 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 你是否曾因无法修改光猫的WiFi密码而烦恼?…...

Android字体样式fontFamily属性详解:从sans-serif到casual,一篇搞定所有内置字体的用法与坑
Android字体样式fontFamily属性深度解析:从基础到避坑实战 在Android开发中,字体样式的处理看似简单,实则暗藏玄机。你是否遇到过这样的场景:明明在布局文件中设置了sans-serif-light,但文本看起来并没有变细…...

2025届毕业生推荐的六大降AI率工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在学术写作跟内容创作这个领域当中,文字重复率过于高是较为常见的问题。专业降重…...

WindowsCleaner终极指南:3步解决C盘爆红,让系统重获新生
WindowsCleaner终极指南:3步解决C盘爆红,让系统重获新生 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘空间不足的警告…...

Sunshine游戏串流终极指南:从零配置到专家级调优的完整解决方案
Sunshine游戏串流终极指南:从零配置到专家级调优的完整解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要打造完美的游戏串流体验,却总是被各种技…...

百度网盘下载加速终极指南:如何用PDown免费突破限速限制
百度网盘下载加速终极指南:如何用PDown免费突破限速限制 【免费下载链接】pdown 百度网盘下载器,2020百度网盘高速下载 项目地址: https://gitcode.com/gh_mirrors/pd/pdown 你是否曾经为百度网盘的下载速度而烦恼?当你急需下载一个重…...

终极M3U8视频下载指南:告别命令行,用图形界面轻松下载在线视频
终极M3U8视频下载指南:告别命令行,用图形界面轻松下载在线视频 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 还在为复杂的命令行操作而烦恼吗࿱…...