Elasticsearch:使用 OpenAI、LangChain 和 Streamlit 的基于 LLM 的 PDF 摘要器和 Q/A 应用程序
嘿! 您是否曾经感觉自己被淹没在信息的海洋中? 有这么多的书要读,而时间却这么少,很容易就会超负荷,对吧? 但猜猜怎么了? 你可以使用大型语言模型创建自定义聊天机器人,该模型可以帮助您总结 pdf 并根据你上传的 pdf 回答你的问题。 拥有 PDF 摘要生成器就像拥有一个超级聪明的伙伴,他可以阅读那些又长又无聊的文档,并为你提供所需的内容。 不再需要翻阅研究论文或任何报告。 有大量工具可以帮助你总结文档,有些需要付费,有些是免费的。 但是为什么不尝试创建你的 PDF 摘要应用程序并尝试一下最适合你的呢?
在这篇博文中,我将向您展示如何使用 Open AI、Lang chain 和 Stream lit 构建端到端应用程序。 那么,让我们开始吧!
它是如何工作的?

在这个项目中,我们将使用以下内容:
Open AI
Open AI 是一个人工智能研究组织,专注于开发先进的人工智能技术,造福人类。 它的成立是为了负责任地、有益地推进人工智能。 OpenAI 在人工智能的各个领域进行研究,包括自然语言处理、强化学习、机器人技术等。 其主要目标之一是开发能够以类人智能执行各种任务的人工智能系统。 OpenAI 的著名项目和成就之一是语言模型。 OpenAI 开发了大规模语言模型,例如 GPT(生成式预训练转换器)系列,它可以根据提供给它们的输入生成类似人类的文本。 这些模型在自然语言理解、文本生成翻译等领域都有应用。
创建 OpenAI 密钥
要生成 OpenAI API 密钥,请访问网站 https://openai.com/,登录,然后从标记为 “API Keys” 的部分生成一个对每个人来说都是唯一的 API 密钥。 一旦你的 API 密钥生成,它将显示在屏幕上。 复制 API 密钥并安全存储。 将您的 API 密钥视为密码,并避免公开共享。 你现在可以使用 OpenAI API 密钥访问 OpenAI API 并将其集成到你的应用程序、项目或研究中。

LangChain
LangChain 是一个用于构建由语言模型支持的上下文感知推理应用程序的框架。 它使应用程序能够根据上下文理解并做出响应,从而增强决策能力。 LangChain 提供工具、库和预构建组件,用于创建复杂的基于文本的应用程序,包括聊天机器人、数据分析和检索增强生成任务。 其主要目的是使开发人员能够在其应用程序中有效地利用语言模型,使他们能够推理、响应以及与用户或数据进行智能交互。
Streamlit
Streamlit 是一个开源 Python 库,用于为机器学习和数据科学项目构建 Web 应用程序。 它允许开发人员直接直观地编写代码,从而简化了创建交互式 Web 应用程序的过程。 借助 Streamlit,开发人员可以直接从 Python 脚本创建交互式 Web 应用程序,而无需编写 HTML、CSS 或 Javascript 代码。 它提供了易于使用的组件,用于创建交互式小部件、可视化和数据显示。 在此项目中,我们使用 Streamlit 来实现简单的用户界面,你可以在本博客末尾看到。
运行 streamlit 应用可以使用命令:streamlit run app.py
前提条件
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请选择 Elastic Stack 8.x 进行安装。在安装的时候,我们可以看到如下的安装信息:

为了方便大家学习,我在本次的演示中使用 Elastic Stack 8.12 来进行展示。
安装 Python 依赖包
pip3 install langchain OpenAI PyPDF2 python-dotenv streamlit elasticsearch streamlit-extras tiktoken langchain-community你可以使用 pip install 简单地安装所有这些库。
- Langchain:语言链库,可帮助你完成总结文本、回答问题和生成新句子等操作。
- OpenAI:这有助于与 OpenAI 提供的语言模型进行交互
- PyPDF2:处理 PDF 文件。 启用读取和操作 PDF 文档等任务。
- Python-dotenv:你可以将 API 密钥或数据库凭据等敏感信息存储在名为 .env 的特殊文件中,而不是将它们硬编码到代码中。 这有助于确保敏感信息的安全,并使管理不同环境(如开发、测试和生产)变得更加容易,而无需更改代码。
- Streamlit:用于创建交互式 Web 应用程序的框架。
- elasticsearch:- 用于密集向量的相似性搜索和聚类的高效库。
- Streamlit-extras:一个扩展包,为 Streamlit 添加额外的功能,并提供额外的工具、小部件和功能来增强 Streamlit 应用程序的功能。
拷贝 Elasticsearch 证书到当前的目录中
$ pwd
/Users/liuxg/python/PDF-Summarizer-End-to-End-Project
$ cp ~/elastic/elasticsearch-8.12.0/config/certs/http_ca.crt .
$ ls http_ca.crt
http_ca.crt创建环境变量文件
我们在自己的项目根目录下创建如下的 .env 文件:
.env
ES_USER="elastic"
ES_PASSWORD="q2rqAIphl-fx9ndQ36CO"
ES_ENDPOINT="localhost"
OPENAI_API_KEY="YourOpenAIkey"请记得根据自己的 Elasticsearch 配置及 OpenAI key 进行相应的修改。
创建应用
我们在当前的目录下创建一个叫做 app.py 的文件。
导入依赖项
from dotenv import load_dotenv
import streamlit as st
from PyPDF2 import PdfReader
from streamlit_extras.add_vertical_space import add_vertical_space
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from elasticsearch import Elasticsearch, helpers
from langchain_community.vectorstores import ElasticsearchStore
from langchain.chains.question_answering import load_qa_chain
from langchain_community.llms import OpenAI
from langchain_community.callbacks import get_openai_callback
import os创建 SideBar
# Sidebar contents
with st.sidebar:st.title('💬PDF Summarizer and Q/A App')st.markdown('''## About this applicationYou can built your own customized LLM-powered chatbot using:- [Streamlit](https://streamlit.io/)- [LangChain](https://python.langchain.com/)- [OpenAI](https://platform.openai.com/docs/models) LLM model''')add_vertical_space(2)st.write(' Why drown in papers when your chat buddy can give you the highlights and summary? Happy Reading. ')add_vertical_space(2) 上传 PDF 文件
为了方便大家学习,我把一些示例的 PDF 文件进行上传。你可以在地址下载。
我们使用如下的代码来上传 PDF 文件:
pdf = st.file_uploader("Upload your PDF File and Ask Questions", type="pdf")Streamlit 中的 st.file_uploader 功能允许用户上传 PDF 文件,使他们能够交互式地选择和上传 PDF 文档,以便在 Streamlit Web 应用程序中进行进一步处理或分析。
我们使用如下的命令来运行代码:
app.py
from dotenv import load_dotenv
import streamlit as st
from PyPDF2 import PdfReader
from streamlit_extras.add_vertical_space import add_vertical_space
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from elasticsearch import Elasticsearch, helpers
from langchain_community.vectorstores import ElasticsearchStore
from langchain.chains.question_answering import load_qa_chain
from langchain_community.llms import OpenAI
from langchain_community.callbacks import get_openai_callback
import os# Sidebar contents
with st.sidebar:st.title('💬PDF Summarizer and Q/A App')st.markdown('''## About this applicationYou can built your own customized LLM-powered chatbot using:- [Streamlit](https://streamlit.io/)- [LangChain](https://python.langchain.com/)- [OpenAI](https://platform.openai.com/docs/models) LLM model''')add_vertical_space(2)st.write(' Why drown in papers when your chat buddy can give you the highlights and summary? Happy Reading. ')add_vertical_space(2) def main():load_dotenv()OPENAI_API_KEY= os.getenv("OPENAI_API_KEY")ES_USER = os.getenv("ES_USER")ES_PASSWORD = os.getenv("ES_PASSWORD")ES_ENDPOINT = os.getenv("ES_ENDPOINT")elastic_index_name='pdf_docs'#Main Contentst.header("Ask About Your PDF 🤷♀️💬")# upload filepdf = st.file_uploader("Upload your PDF File and Ask Questions", type="pdf")if __name__ == '__main__':main()streamlit run app.py
提前文本并写入到 Elasticsearch
app.py
from dotenv import load_dotenv
import streamlit as st
from PyPDF2 import PdfReader
from streamlit_extras.add_vertical_space import add_vertical_space
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from elasticsearch import Elasticsearch, helpers
from langchain_community.vectorstores import ElasticsearchStore
from langchain.chains.question_answering import load_qa_chain
from langchain_community.llms import OpenAI
from langchain_community.callbacks import get_openai_callback
import os# Sidebar contents
with st.sidebar:st.title('💬PDF Summarizer and Q/A App')st.markdown('''## About this applicationYou can built your own customized LLM-powered chatbot using:- [Streamlit](https://streamlit.io/)- [LangChain](https://python.langchain.com/)- [OpenAI](https://platform.openai.com/docs/models) LLM model''')add_vertical_space(2)st.write(' Why drown in papers when your chat buddy can give you the highlights and summary? Happy Reading. ')add_vertical_space(2) def main():load_dotenv()OPENAI_API_KEY= os.getenv("OPENAI_API_KEY")ES_USER = os.getenv("ES_USER")ES_PASSWORD = os.getenv("ES_PASSWORD")ES_ENDPOINT = os.getenv("ES_ENDPOINT")elastic_index_name='pdf_docs'#Main Contentst.header("Ask About Your PDF 🤷♀️💬")# upload filepdf = st.file_uploader("Upload your PDF File and Ask Questions", type="pdf")# extract the textif pdf is not None:pdf_reader = PdfReader(pdf)text = ""for page in pdf_reader.pages:text += page.extract_text()# split into chunkstext_splitter = CharacterTextSplitter(separator="\n",chunk_size=1000,chunk_overlap=200,length_function=len)chunks = text_splitter.split_text(text)# Make a connection to Elasticsearchurl = f"https://{ES_USER}:{ES_PASSWORD}@{ES_ENDPOINT}:9200"connection = Elasticsearch(hosts=[url], ca_certs = "./http_ca.crt", verify_certs = True)print(connection.info())# create embeddingsembeddings = OpenAIEmbeddings()if not connection.indices.exists(index=elastic_index_name):print("The index does not exist, going to generate embeddings") docsearch = ElasticsearchStore.from_texts( chunks,embedding = embeddings, es_url = url, es_connection = connection,index_name = elastic_index_name, es_user = ES_USER,es_password = ES_PASSWORD)else: print("The index already existed")docsearch = ElasticsearchStore(es_connection=connection,embedding=embeddings,es_url = url, index_name = elastic_index_name, es_user = ES_USER,es_password = ES_PASSWORD ) if __name__ == '__main__':main()我们使用如下的部分来提取 pdf 文件:
if pdf is not None:pdf_reader = PdfReader(pdf)text = ""for page in pdf_reader.pages:text += page.extract_text()它首先检查 PDF 文件是否已上传(即变量 pdf 是否不是 None)。 如果确实上传了 PDF 文件,则会创建一个 PdfReader 对象来读取 PDF 文件的内容。 然后,它迭代 PDF 文档的每个页面,使用 extract_text() 方法从每个页面中提取文本,并将所有页面中的文本连接到一个名为 text 的字符串变量中。
我们使用如下的代码把文档分成 chunk:
# split into chunkstext_splitter = CharacterTextSplitter(separator="\n",chunk_size=1000,chunk_overlap=200,length_function=len)chunks = text_splitter.split_text(text)
“chunks”变量表示从 PDF 文件中提取的文本的分段部分。 将文本拆分为块至关重要,因为它有助于更有效地处理大型文档,因为一次处理整个文本可能会消耗过多的内存和处理资源。 通过将文本分成更小的片段,应用程序可以更有效地管理和分析数据。 对文本进行分段可以更好地组织并有助于有针对性地分析或处理文档的特定部分。
我们使用如下的代码来生成嵌入:
ElasticsearchStore.from_texts( chunks,embedding = embeddings, es_url = url, es_connection = connection,index_name = elastic_index_name, es_user = ES_USER,es_password = ES_PASSWORD)嵌入是对象的数字表示,通常用于捕获它们在数学空间中的语义或上下文。 词嵌入是高维空间中单词、短语或文档的向量表示,其中相似的单词彼此更接近。 在此代码片段中,嵌入是使用 OpenAIEmbeddings() 函数创建的,该函数可能为从 PDF 文件中提取的文本数据生成嵌入(向量表示)。 这些嵌入捕获有关文本的语义信息,使应用程序能够更有效地理解和处理内容。
随后,使用 ElasticsearchStore.from_texts() 函数构建知识库,该函数根据之前分段的文本块创建可搜索索引或结构。 该知识库使用 Elasticsearch 库实现,可根据文本片段的嵌入进行高效的相似性搜索和检索。
成功运行上面的脚本后,我们可以到 Elasticsearch 中进行查看:

连接 LLM OpenAI
llm = OpenAI()chain = load_qa_chain(llm, chain_type="stuff")with get_openai_callback() as cb:response = chain.run(input_documents=docs, question=user_question)print(cb)st.write(response)此代码初始化并利用 OpenAI 语言模型 (LLM) 创建问答 (Q&A) 系统。 它使用 LLM 加载预训练或自定义问答模型,设置回调管理以处理问答过程中的事件,对输入文档和用户问题执行模型,并使用 Streamlit 显示生成的响应以进行用户交互。
最终的完整 app.py 如下:
app.py
from dotenv import load_dotenv
import streamlit as st
from PyPDF2 import PdfReader
from streamlit_extras.add_vertical_space import add_vertical_space
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from elasticsearch import Elasticsearch, helpers
from langchain_community.vectorstores import ElasticsearchStore
from langchain.chains.question_answering import load_qa_chain
from langchain_community.llms import OpenAI
from langchain_community.callbacks import get_openai_callback
import os# Sidebar contents
with st.sidebar:st.title('💬PDF Summarizer and Q/A App')st.markdown('''## About this applicationYou can built your own customized LLM-powered chatbot using:- [Streamlit](https://streamlit.io/)- [LangChain](https://python.langchain.com/)- [OpenAI](https://platform.openai.com/docs/models) LLM model''')add_vertical_space(2)st.write(' Why drown in papers when your chat buddy can give you the highlights and summary? Happy Reading. ')add_vertical_space(2) def main():load_dotenv()OPENAI_API_KEY= os.getenv("OPENAI_API_KEY")ES_USER = os.getenv("ES_USER")ES_PASSWORD = os.getenv("ES_PASSWORD")ES_ENDPOINT = os.getenv("ES_ENDPOINT")elastic_index_name='pdf_docs'#Main Contentst.header("Ask About Your PDF 🤷♀️💬")# upload filepdf = st.file_uploader("Upload your PDF File and Ask Questions", type="pdf")# extract the textif pdf is not None:pdf_reader = PdfReader(pdf)text = ""for page in pdf_reader.pages:text += page.extract_text()# split into chunkstext_splitter = CharacterTextSplitter(separator="\n",chunk_size=1000,chunk_overlap=200,length_function=len)chunks = text_splitter.split_text(text)# Make a connection to Elasticsearchurl = f"https://{ES_USER}:{ES_PASSWORD}@{ES_ENDPOINT}:9200"connection = Elasticsearch(hosts=[url], ca_certs = "./http_ca.crt", verify_certs = True)print(connection.info())# create embeddingsembeddings = OpenAIEmbeddings()if not connection.indices.exists(index=elastic_index_name):print("The index does not exist, going to generate embeddings") docsearch = ElasticsearchStore.from_texts( chunks,embedding = embeddings, es_url = url, es_connection = connection,index_name = elastic_index_name, es_user = ES_USER,es_password = ES_PASSWORD)else: print("The index already existed")docsearch = ElasticsearchStore(es_connection=connection,embedding=embeddings,es_url = url, index_name = elastic_index_name, es_user = ES_USER,es_password = ES_PASSWORD )# show user inputwith st.chat_message("user"):st.write("Hello World 👋")user_question = st.text_input("Please ask a question about your PDF here:")if user_question:docs = docsearch.similarity_search(user_question)llm = OpenAI()chain = load_qa_chain(llm, chain_type="stuff")with get_openai_callback() as cb:response = chain.run(input_documents=docs, question=user_question)print(cb)st.write(response)if __name__ == '__main__':main()我们可以针对文章进行总结:

我们也可以针对文章进行搜索:
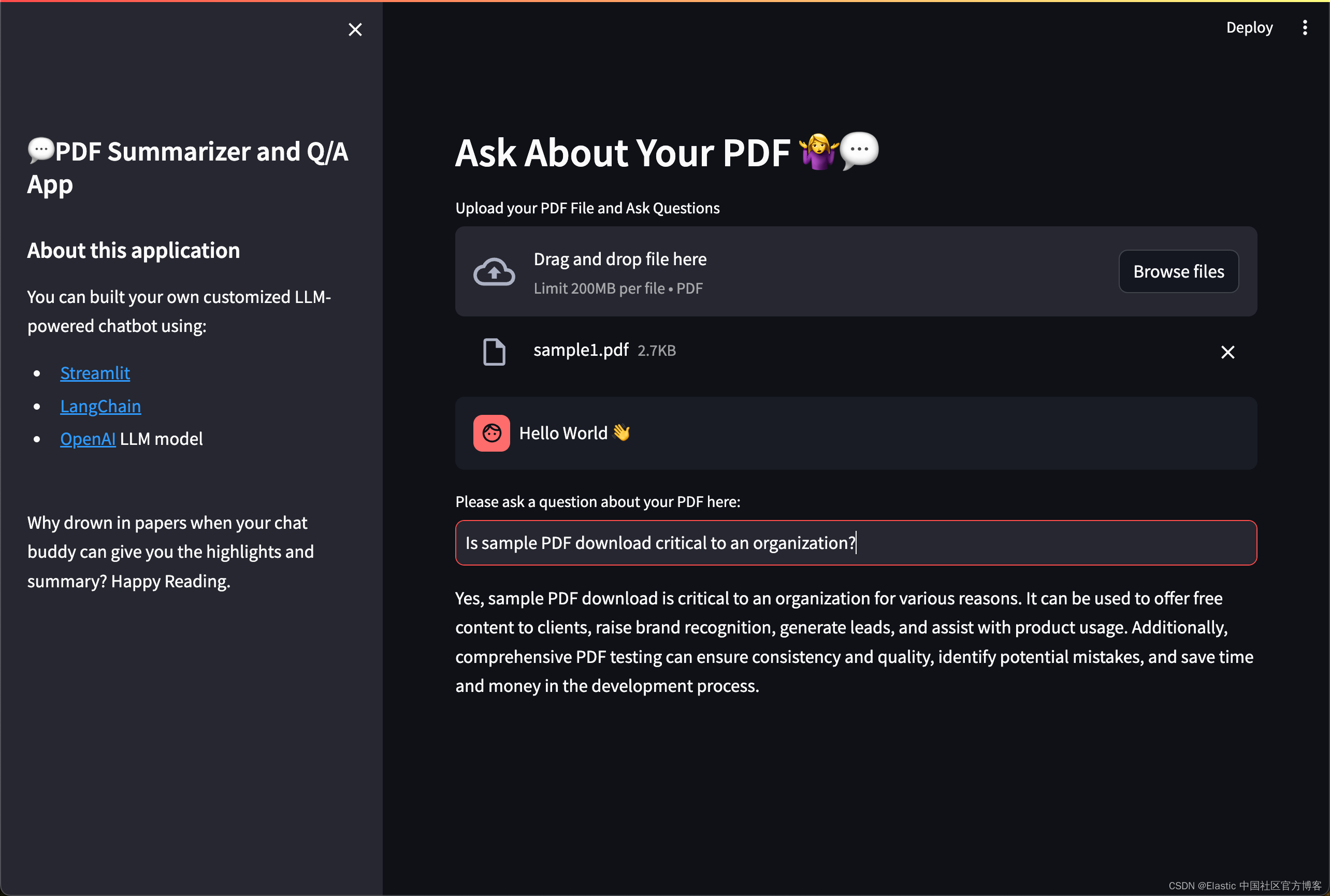
整个项目的源码可以在地址 GitHub - liu-xiao-guo/PDF-Summarizer-End-to-End-Project 进行下载。
相关文章:
Elasticsearch:使用 OpenAI、LangChain 和 Streamlit 的基于 LLM 的 PDF 摘要器和 Q/A 应用程序
嘿! 您是否曾经感觉自己被淹没在信息的海洋中? 有这么多的书要读,而时间却这么少,很容易就会超负荷,对吧? 但猜猜怎么了? 你可以使用大型语言模型创建自定义聊天机器人,该模型可以帮…...

Linux课程____进程管理
记录工作日志 script 240319.log CTRLd 退出 cat 240319.log //查看 一、查看进程 1.静态 ps -aux 显示所有包含其他使用者的行程 ps -elf 2.动态 top 3.pgrep 查看特定条件的进程 pgrep -l “log” 搜索特定的程序 pgrep -l "ssh" pgrep -l -U…...
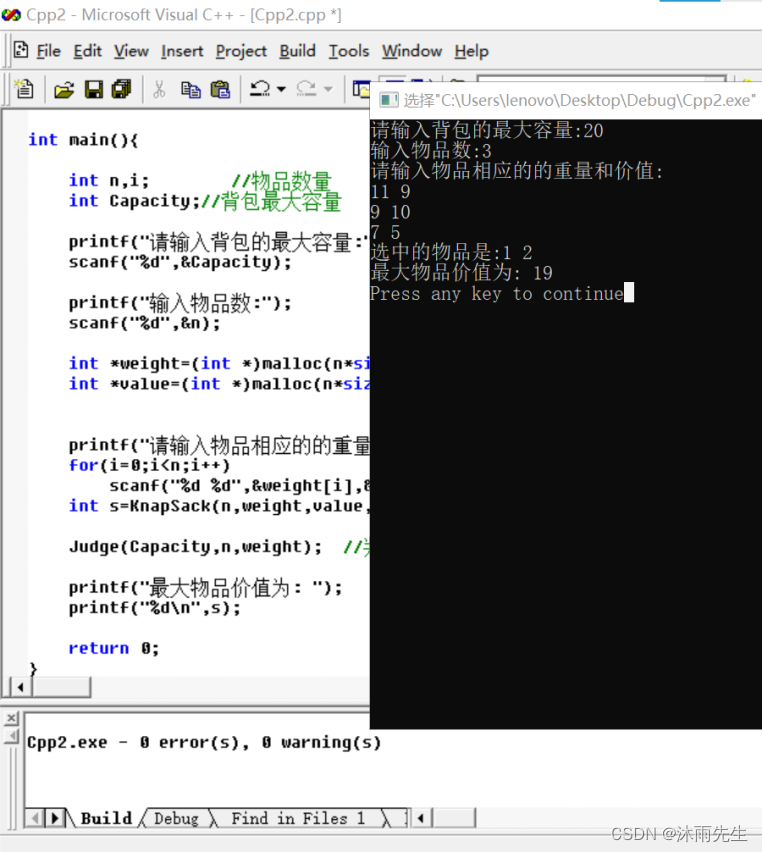
算法设计与分析-动态规划算法的应用——沐雨先生
一、实验目的 1. 掌握动态规划算法的基本思想,包括最优子结构性质和基于表格的最优值计算方法。 2.熟练掌握分阶段的和递推的最优子结构分析方法。 3. 学会利用动态规划算法解决实际问题 。 二、实验内容 1. 问题描述 &#…...

Flutter-仿淘宝京东录音识别图标效果
效果 需求 弹起键盘,录制按钮紧挨着输入框收起键盘,录制按钮回到初始位置 实现 第一步:监听键盘弹起并获取键盘高度第二步:根据键盘高度,录制按钮高度计算偏移高度,并动画移动第三步:键盘收起…...

雷池 WAF 社区版:下一代 Web 应用防火墙的革新
黑客的挑战 智能语义分析算法: 黑客们常利用复杂技术进行攻击,但雷池社区版的智能语义分析算法能深入解析攻击本质,即使是最复杂的攻击手法也难以逃脱。 0day攻击防御: 传统防火墙难以防御未知攻击,但雷池社区版能有效…...

音视频实战---音视频解码
该方法只能解码裸流。 1、使用avcodec_find_decoder查找解码器 根据使用解码器类型,决定是解码音频还是解码视频。 2、 使用av_parser_init获取裸流解析器和方法 3、使用avcodec_alloc_context3分配编解码器上下文 4、使用avcodec_open2将解码器和解码器上下文…...
MyBatisPlus 之四:MP 的乐观锁和逻辑删除、分组、排序、链式的实现步骤
乐观锁 乐观锁是相对悲观锁而言的,乐观锁假设数据一般情况不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果冲突,则返回给用户异常信息,让用户决定如何去做。 乐观锁适用…...
node.js常用的命令
Node.js 是一个用于执行 JavaScript 代码的运行时环境。以下命令是 Node.js 开发中常用的命令,可以帮助你进行包管理、项目配置和代码执行等操作。 node -v:检查 Node.js 的版本。npm -v:检查 npm(Node.js 包管理器)的…...

Python从入门到精通秘籍十
一、Python之了解异常 当在Python中执行代码时,如果发生错误,就会抛出异常(Exception)。处理异常是编写健壮的代码的重要部分。Python提供了try-except语句来捕获和处理异常。 下面是使用Python代码详细讲解异常处理的例子&…...
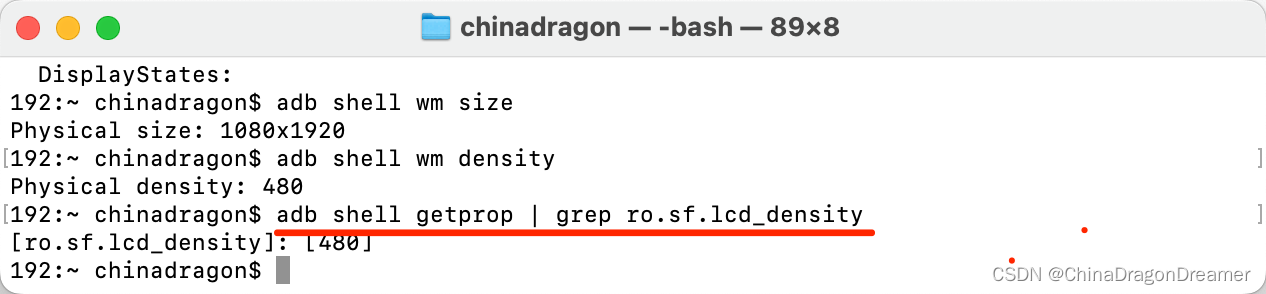
Android:adb命令
执行adb命令的窗口如下 Mac或Linux系统里的终端窗口; window系统运行输入cmd打开的指令窗口; Android Studio 里控制下面的Terminal窗口 1. 查看已链接的设备和模拟器 adb devices -l 2. 查看Android内核版本号 adb shell getprop ro.build.version.re…...

Github基本功能和使用技巧
基础功能 创建仓库(Repository):在GitHub上创建一个新的仓库,可以通过点击页面右上角的“New”按钮开始。选择仓库的名称、描述和许可证等信息,并选择是否将仓库设置为公开或私有。 克隆仓库(Clone&#x…...

mac上系统偏好里无法停止mysql
使用强制杀死进程: sudo kill -9 pid原文:https://www.cnblogs.com/yalong/p/14136997.html 命令行也没有关闭成功:https://blog.51cto.com/u_5018054/5101645...

launchctl及其配置、使用、示例
文章目录 launchctl 是什么Unix / Linux类似的工具有什么哪个更常用配置使用常用子命令示例加载一个 launch agent:卸载一个 launch daemon:列出所有已加载的服务:启动一个服务:停止一个服务:禁用一个服务:启用一个服务: 附com.example.myagent.plist内容有趣的例子参考 launch…...
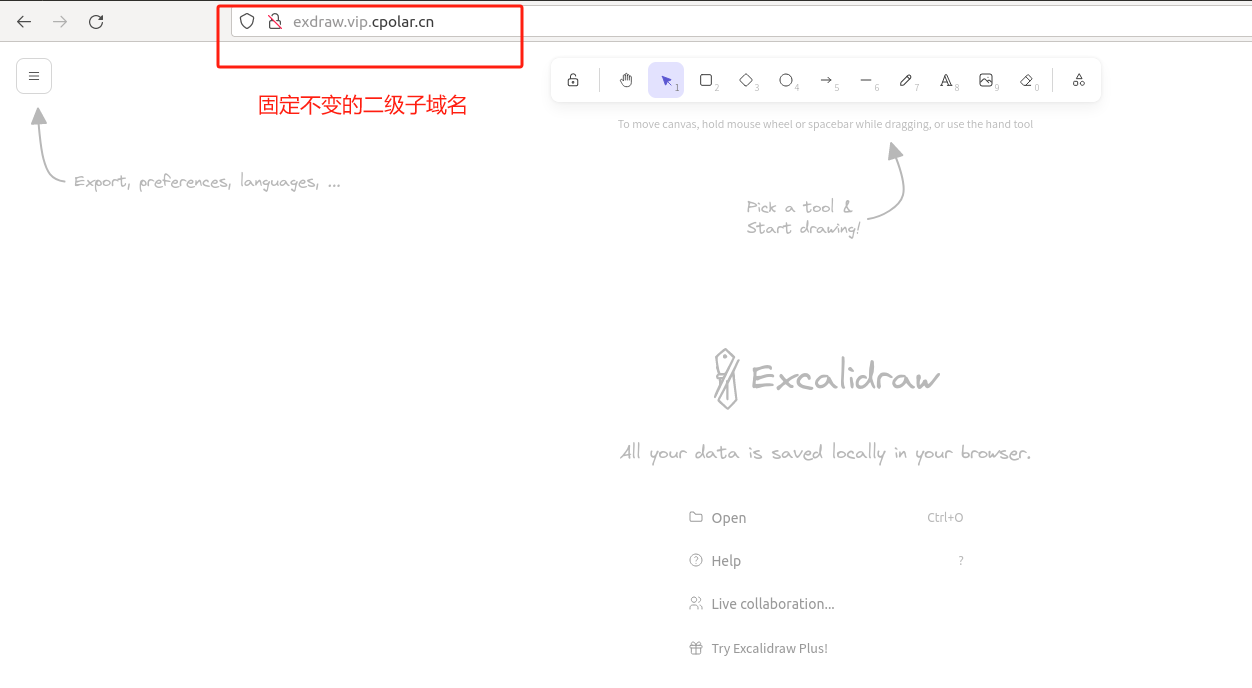
如何在Ubuntu系统搭建Excalidraw容器并实现公网访问本地绘制流程图
文章目录 1. 安装Docker2. 使用Docker拉取Excalidraw镜像3. 创建并启动Excalidraw容器4. 本地连接测试5. 公网远程访问本地Excalidraw5.1 内网穿透工具安装5.2 创建远程连接公网地址5.3 使用固定公网地址远程访问 本文主要介绍如何在Ubuntu系统使用Docker部署开源白板工具Excal…...

PostgreSQL和MySQL的异同
0.前言 MySQL是一个关系数据库管理系统(DBMS),通过该系统,您可以将数据存储为包含行和列的二维表格。它是一个常用系统,支持许多 Web 应用程序、动态网站和嵌入式系统。PostgreSQL 是一个对象关系数据库管理系统&…...

有ai写文案的工具吗?分享5款好用的工具!
在数字化时代,人工智能(AI)已渗透到我们生活的方方面面,包括内容创作领域。AI写文案的软件以其高效、便捷的特点,正逐渐受到广大内容创作者、营销人员、甚至普通用户的青睐。本文将为您盘点几款热门的AI写文案软件&…...

docker+k8s相关面试题
dockerk8s k8s详细介绍docker的工作原理docker的组成docker与传统虚拟机的区别docker技术的三大核心概念centos镜像几个G,但是docker centos镜像才几百兆镜像的分层结构以及为什么要使用镜像的分层结构容器的copy-on-write特性,修改容器里面的内容会修改…...
力扣爆刷第101天之hot100五连刷91-95
力扣爆刷第101天之hot100五连刷91-95 文章目录 力扣爆刷第101天之hot100五连刷91-95一、62. 不同路径二、64. 最小路径和三、5. 最长回文子串四、1143. 最长公共子序列五、72. 编辑距离 一、62. 不同路径 题目链接:https://leetcode.cn/problems/unique-paths/desc…...
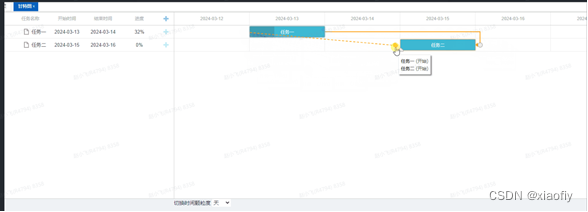
前端vue实现甘特图
1 什么是甘特图 甘特图(Gantt chart)又称为横道图、条状图(Bar chart)。以提出者亨利L甘特先生的名字命名,是项目管理、生产排程、节点管理中非常常见的一个功能。 甘特图内在思想简单,即以图示的方式通过活动列表和时间刻度形象地表示出任何特定项目的…...

SQLiteC/C++接口详细介绍之sqlite3类(十五)
返回目录:SQLite—免费开源数据库系列文章目录 上一篇:SQLiteC/C接口详细介绍之sqlite3类(十四) 下一篇:SQLiteC/C接口详细介绍之sqlite3类(十六) 47.sqlite3_set_authorizer 用法ÿ…...
)
从STM32迁移到普冉PY32F003:UART代码移植保姆级教程(附HAL库对比)
从STM32到普冉PY32F003的UART代码迁移实战指南 1. 国产MCU替代浪潮下的技术选择 近年来,半导体行业的供应链波动促使更多工程师将目光投向国产MCU解决方案。普冉PY32F003系列作为Cortex-M0内核的代表产品,以48MHz主频、64KB Flash和8KB RAM的配置&#x…...

别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务
别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务当你的机器人正在执行一个长达10分钟的导航任务时,突然发现目标点设置错误,这时候如果只能干等着任务完成或者…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析
如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 当建筑师需要在Blender中渲染Rhino设计的建筑模…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

AI IDE 革命:程序员正在被重新定义
很多开发者第一次使用 Cursor 的 CtrlK 或 Composer(高级多文件编辑模式)时,都会有一种强烈的、甚至让人有些脊背发凉的冲击感。 因为: 它已经不再是那个我们熟悉的、只能在原地等待光标落下的: “代码自动补全插件&am…...

零基础怎么学Agent?这个工程师考试内容拆给你看
站在 AI Agent(智能体)爆发的十字路口,很多既没有深厚算法背景、也没有丰富写代码经验的“小白”常常感到迷茫:动辄谈及的大模型交互、复杂的业务编排,零基础真的能学会吗? 事实上,智能体开发早…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...

收藏干货|2026 版双非零基础入局大模型开发,RAG 与 Agent 就业上岸全攻略
日常总能收到不少初学伙伴的私信,大家普遍都有同一个疑惑:二本及普通院校学历,零基础入门 RAG、Agent 大模型应用开发,究竟能不能顺利入职?行业后续发展前景又如何? 本篇 2026 年全新内容,不空谈…...