C++入门(下)
文章目录
- 1:引用
- 1.1:引用概念
- 1.2:引用的特性.
- 1.2.1:引用在定义时必须初始化
- 1.2.2:一个变量可以有多个引用
- 1.2.3:引用一旦引用一个实体,再不能引用其他实体.
- 1.3:应用场景
- 1.3.1:做参数
- 1.3.2:做返回值
- 1.3.2.1:传值返回
- 1.3.2.2:传引用返回(错误示范)
- 1.3.2.3:传引用返回(正确示范)
- 1.4:常引用
- 1.4.1:代码1
- 1.4.2:代码2
- 1.4.3:代码3
- 1.4.4:代码4
- 1.4.5:代码5
- 总结
- 1.5:引用与指针的区别
- 底层角度
- 语法角度
- 2:内联函数
- 2.1:概念
- 代码1(无inline修饰)
- 修改步骤
- 第一步
- 第二步
- 代码2
- 2.2:inline的特性
- 3:auto关键字(C++11)
- 3.1:auto介绍
- 代码1
- 代码2
- 代码3
- 3.2:auto的使用细则
- 3.2.1:auto必须初始化.
- 3.2.2:auto与指针和引用相结合
- 代码1
- 代码2
- 3.2.3:在同一行声明多个变量.
- 3.3:auto不能推导的场景
- 3.3.1:auto不能作形式参数(C++20以前)
- 3.3.2:auto不能声明数组
- 4:基于范围的for循环(C++11)
- 4.1:范围for的语法
- 代码1
- 代码2
- 4.2:范围for的使用条件
- 5:指针空值nullptr
嘿嘿,家人们,今天我们继续就C++入门往下学习,好啦,废话不多讲,开干!
1:引用
1.1:引用概念
引用不是新定义一个变量,而是给已经存在的一个变量取一个别名,编译器不会为引用变开辟新的空间,它与它所引用的变量共同占用同一块空间.
例如水浒传中的李逵,在家称自己为"铁牛",江湖上人称黑旋风.了解了引用的概念后,我们来看下面这段代码.
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int main()
{int a = 25;int& ra = a;cout <<"&a = " << &a << endl;cout <<"&ra = " << &ra << endl;return 0;
}
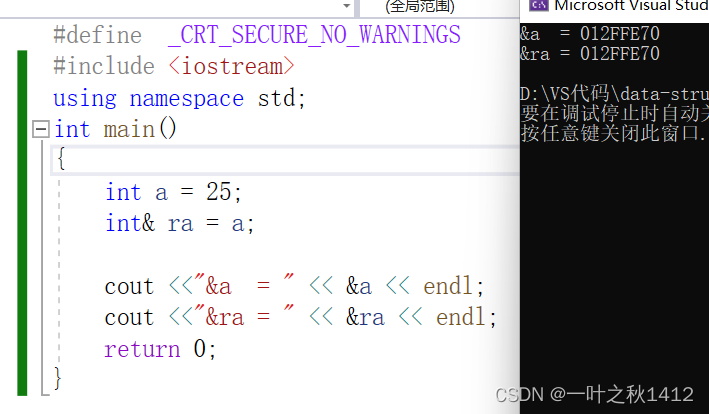
上面这段代码中,ra就是变量a的别名,我们可以清晰地看到,ra与变量a的地址一样的,因此这两个变量所共用同一块内存空间.
PS:引用的类型必须和引用的实体是相同类型的,这句话是什么意思呢?我们来看下面这段代码.
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int main()
{int a = 25;double& ra = a;return 0;
}
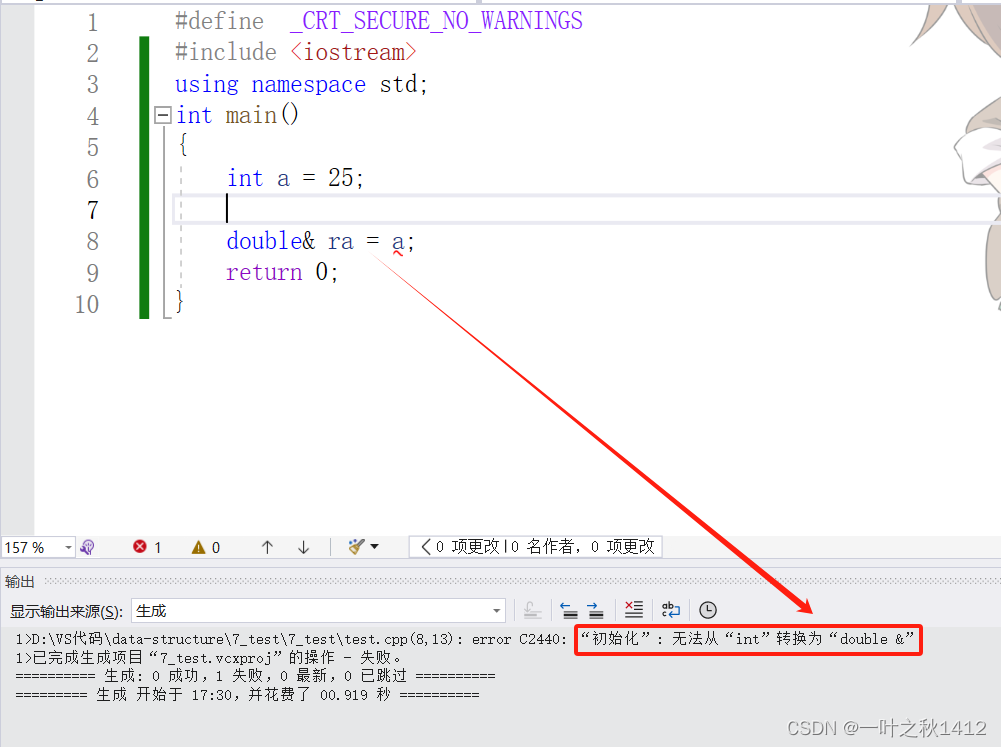
当对变量a使用与之不同的数据类型来引用时,此时我们可以清晰地发现,是无法通过编译的,因此引用的数据类型要与引用的实体是相同的数据类型.
1.2:引用的特性.
了解了引用的基本概念之后,接下来我们来学习引用的特性.
1.2.1:引用在定义时必须初始化
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int main()
{int a = 25;int& ra;return 0;
}
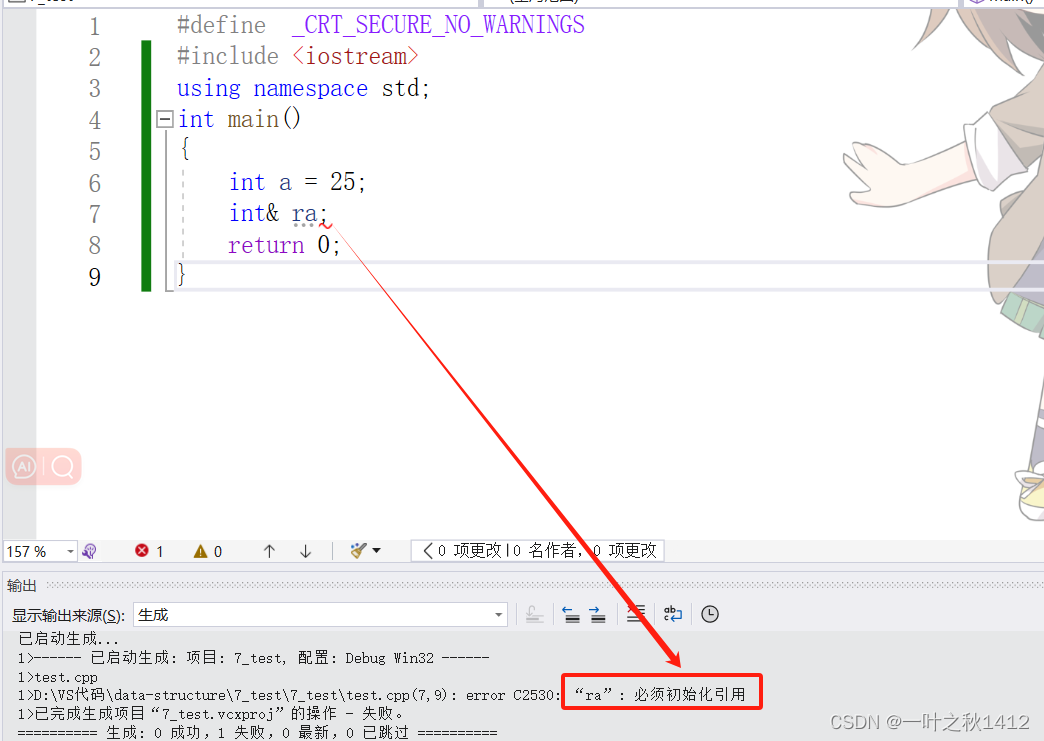
通过观察上面这段代码,我们可以清晰地发现,引用在使用时必须进行初始化即指明实体.
1.2.2:一个变量可以有多个引用
一个变量有多个引用,这句话应该很好理解,这就好比,一个人可以有多个外号,例如,李逵有黑旋风的外号,也有铁牛的外号,但它们最终所指向的对象还是李逵.
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int main()
{int a = 25;int& ra1 = a;int& ra2 = a;ra1++;ra2++;cout << "a = " << a << endl;cout << "ra1 = " << ra1 << endl;cout << "ra2 = " << ra2 << endl;return 0;
}
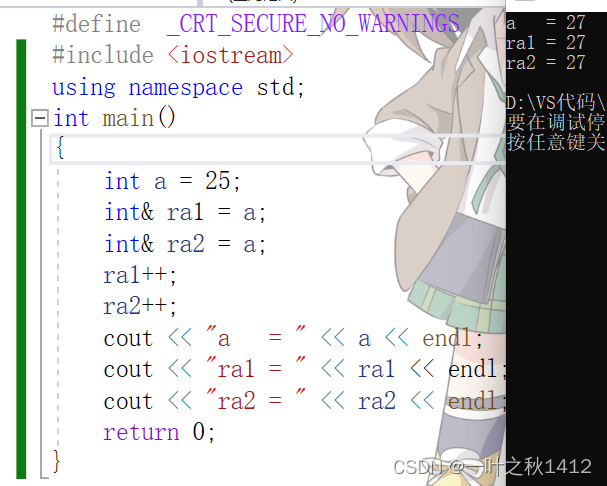
通过观察上面的代码我们可以清晰地发现,对ra1与ra2分别进行了++以后,由于ra1和ra2都是变量a的别名,因此此时变量a也相应地进行了++.
1.2.3:引用一旦引用一个实体,再不能引用其他实体.
这句话是什么意思呢,我们来看下面这段代码.
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int main()
{int a = 25;int b = 30;int& ra = a;//这里ra不是b的引用,而是对其进行赋值.ra = b;cout <<"a = " << a << endl;cout <<"ra = " << ra << endl;cout <<"b = " << b << endl;return 0;
}
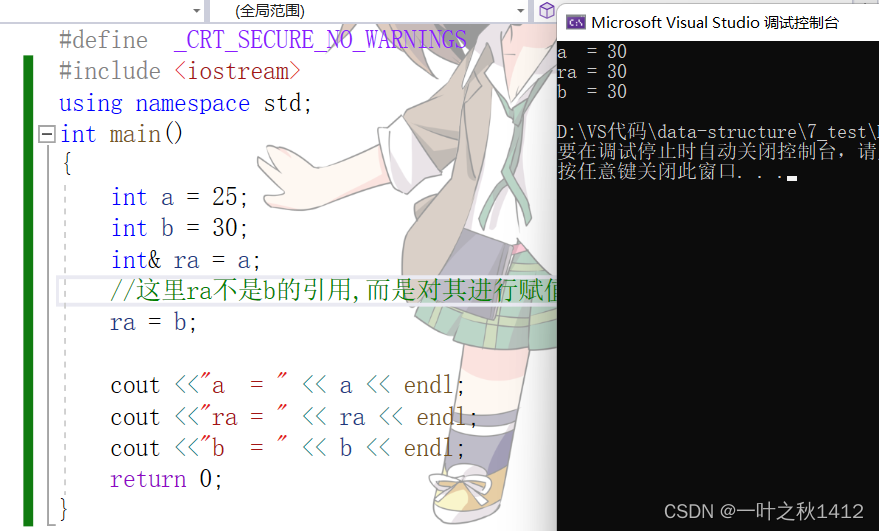
这里的ra为变量a的别名,然后ra = b这一行代码运行了以后并不是说ra就是变量b的别名了,因为引用的特性规定了,引用一旦引用了一个实体以后,就不能再引用其他实体,因此这里ra = b并不是改变引用的指向,而是对其进行赋值,我们通过运行这段代码可以清晰地发现,此时变量a的值发生了变化.
1.3:应用场景
1.3.1:做参数
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
void Swap(int * e1,int * e2)
{int tmp = *e1;*e1 = *e2;*e2 = tmp;
}
int main()
{int value1 = 25;int value2 = 30;cout << "交换前:> value1 = " << value1 <<" value2 = " << value2 << endl;Swap(&value1, &value2);cout << "交换前:> value1 = " << value1 << " value2 = " << value2 << endl;return 0;
}
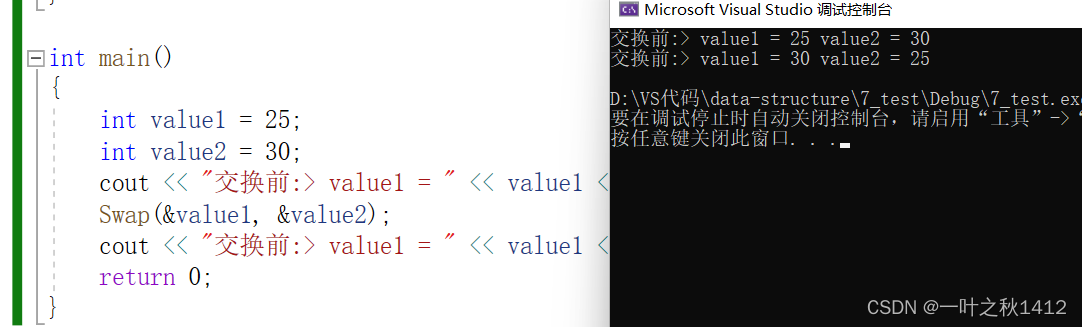
在C语言阶段,实现两数交换这个函数方法时,我们是通过传变量的地址然后形参使用指针接收,接着对其进行解引用从而实现两数交换,而到了C++这一阶段,我们则可以不需要使用指针,而是使用引用.
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
void Swap(int & e1,int & e2)
{int tmp = e1;e1 = e2;e2 = tmp;
}int main()
{int value1 = 25;int value2 = 30;cout << "交换前:> value1 = " << value1 <<" value2 = " << value2 << endl;Swap(value1, value2);cout << "交换前:> value1 = " << value1 << " value2 = " << value2 << endl;return 0;
}
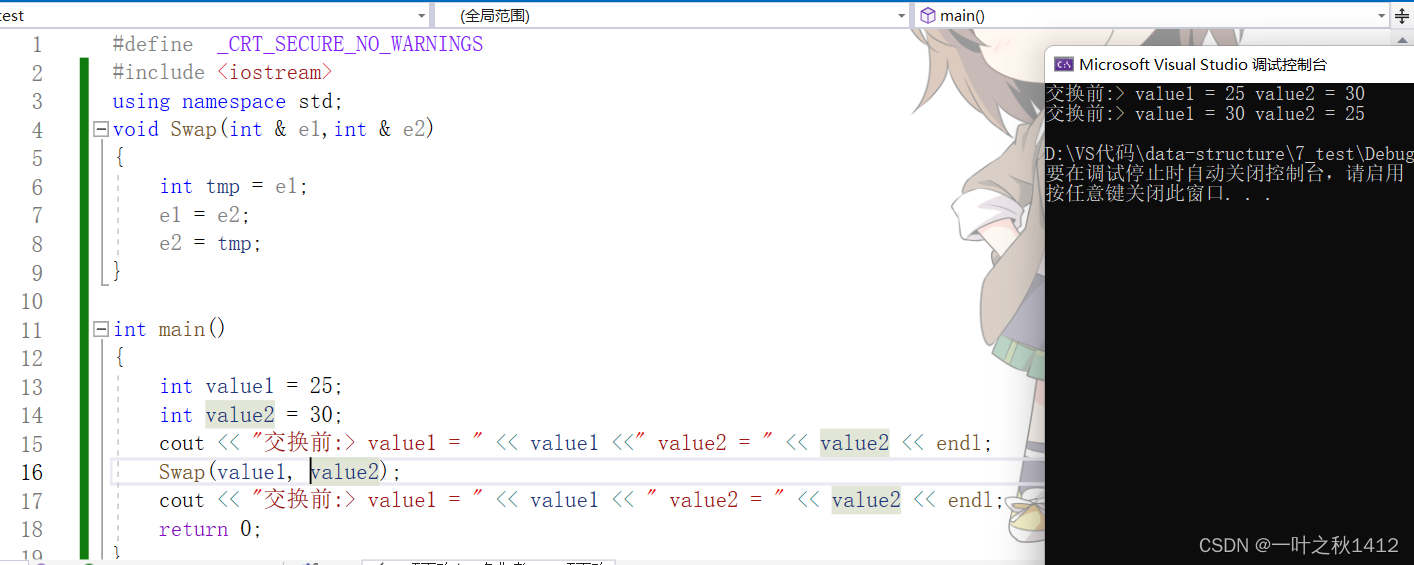
上述代码中则是通过使用引用来实现的两数交换,我们知道引用是变量的别名,既然已经拿到了变量的别名,那么就可以直接对其进行操作,这相较于指针来讲的话更加便捷.
1.3.2:做返回值
引用除了做参数外,还能做返回值,但是是在特定场景下引用才能做返回值,我们首先来看下面这段代码
1.3.2.1:传值返回
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
//值返回
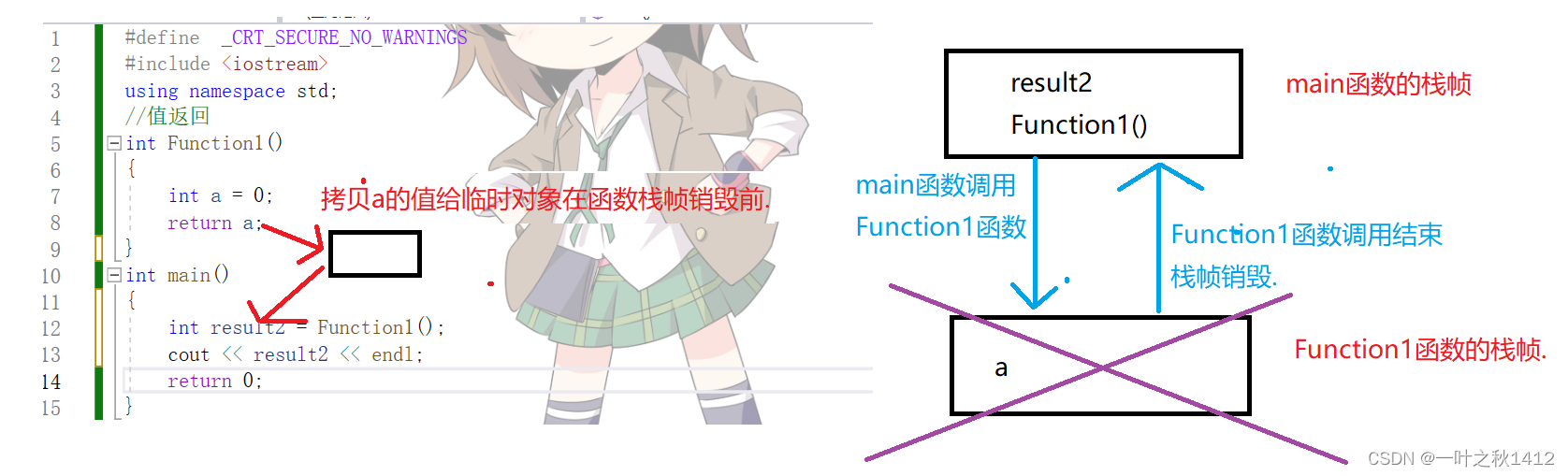
int Function1()
{int a = 0;return a;
}
int main()
{int result = Function1();cout << result << endl;return 0;
}
在C语言阶段,我们学习过,函数调用是会建立栈帧的,每次函数调用完以后会销毁栈帧,上述代码中,返回的并不是变量a,而返回的是变量a的拷贝,也就是说,在Function1函数销毁以前,将变量a的值拷贝给一个临时对象,然后将其带出去,最后再赋值给result,当Function1函数调用完以后,此时函数栈帧销毁,那块空间还给了操作系统.
1.3.2.2:传引用返回(错误示范)
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
//值返回
int& Function2()
{int a = 0;return a;
}
int main()
{int& result2 = Function2();cout << result2 << endl;return 0;
}在上述代码中则是传引用返回,可是,当Function2函数调用完了以后,此时函数栈帧销毁,由于是传引用返回,那么此时就再次对销毁的那块函数栈帧空间进行访问,此时就会出现问题了,那么此时所带回来的值具体是多少,我们是不知道的,这个时候就要取决于编译器是否对那块销毁的函数栈帧空间进行了清理,因此result的结果要取决于在什么样的平台下,不同的平台有不同的结果
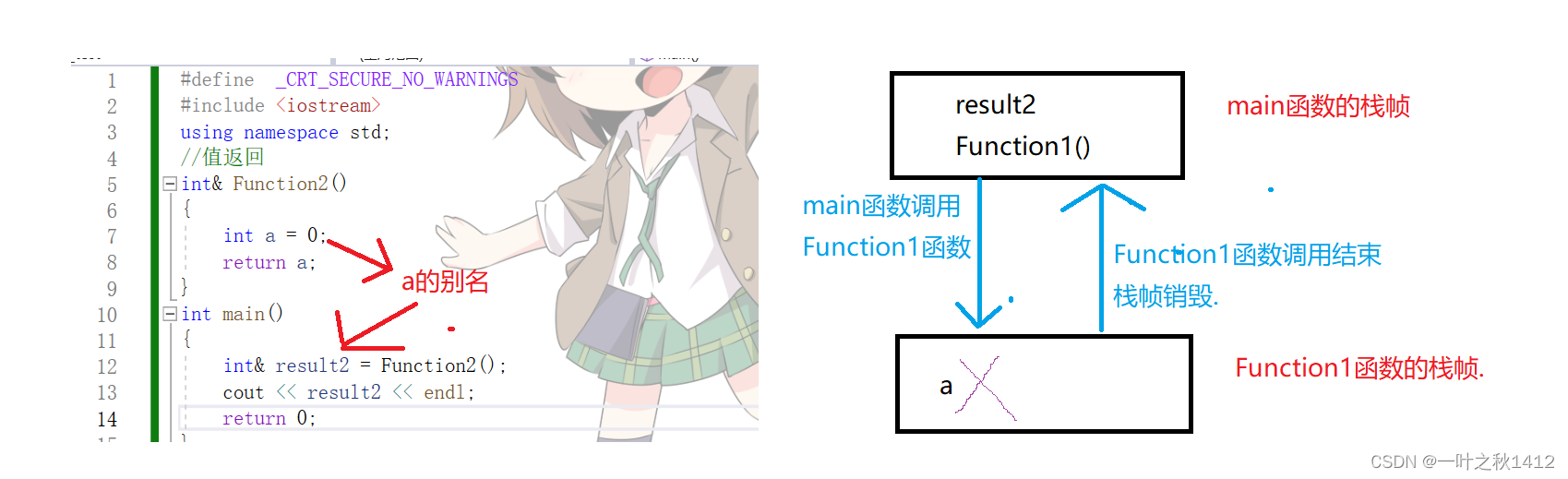
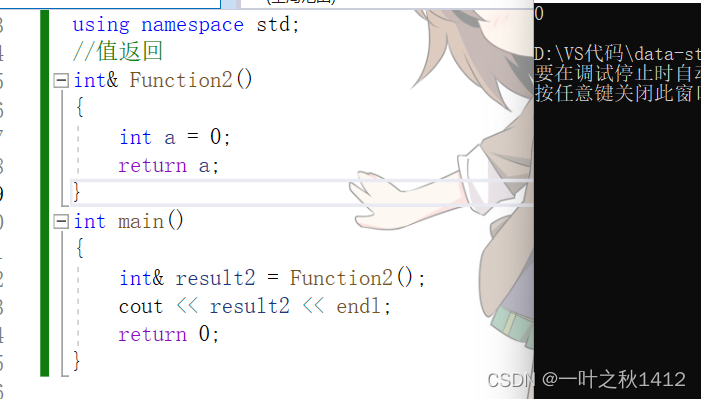
博主使用的vs2022是没有在函数栈帧销毁之后进行清理的,因此这里result2的值为0.但是我们来看下面这个场景.
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
//值返回
int& Function2()
{int a = 0;return a;
}
int& Function3()
{int b = 1;return b;
}
int main()
{int& result2 = Function2();cout << result2 << endl;Function3();cout << result2 << endl;return 0;
}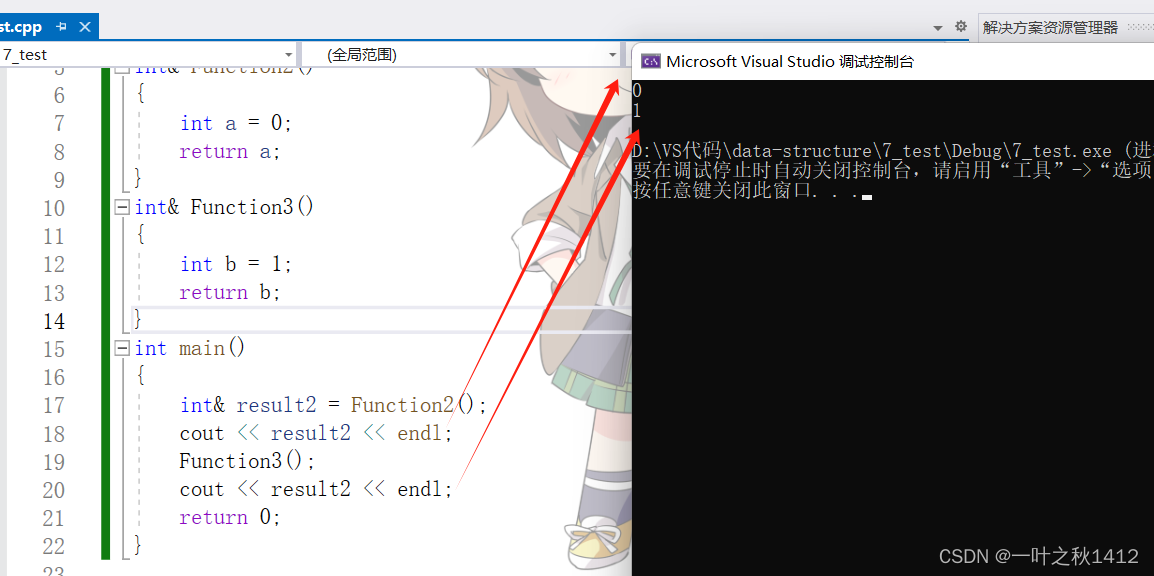
当在打印一次result2之后,我调用一次Function3函数,此时再一次打印result2的结果,我们可以清晰地发现,此时result2的结果与变量b的值相同,我们知道,时间是不能重复利用的,但是空间是可以重复利用的,当Funtcion2函数栈帧销毁后,此时调用Function3,因此Function3的函数栈帧建立,在调用完以后并销毁,由于空间能够重复利用,因此Function3的函数栈帧复用了Function2的函数栈帧,由于博主使用的vs2022编译器没有在函数栈帧销毁之后对那块空间进行清理,因此此时reuslt的值为1
因此,如果函数调用结束时,出了函数作用域,若对象还在,则可以使用引用返回,如果已经还给了系统,则必须使用传值返回.那么到底哪些情况下可以使用传引用返回呢?我们来看下面这段代码.
1.3.2.3:传引用返回(正确示范)
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;//全局变量/静态变量/堆区上的变量等就可以用引用返回
int& Count()
{static int n = 25;n++;return n;
}
int main()
{int& result = Count();cout << result << endl;return 0;
}
上述代码中,使用static关键字来修饰局部变量,在C语言阶段,我们学习过,原本普通的局部变量是放在栈区的,但**被static关键字修饰以后,放在了内存的静态区,为静态变量,静态区的变量的生命周期和全局变量的生命周期一样,程序结束时才会结束.**因此static修饰的局部变量用引用返回,除此之外,以下两种变量可以使用引用做返回值
(1):全局变量.
(2):堆区上的变量.
1.4:常引用
在C语言阶段我们学习到使用const修饰的变量称为常变量,那么在引用这块同样也有常引用,我们首先来看下面这段代码.
1.4.1:代码1
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;int main()
{int a = 0;int& b = a;b++;return 0;
}
上述代码中,对变量a取别名为b,那么为什么可以直接这样子做呢?因为权限是可以平移或者缩小的,原本可以直接对变量a进行修改,即变量a是可读可写的,这里引用b为a的别名,同样也是可读可写的,相当于发生了权限的平移.
1.4.2:代码2
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;int main()
{int a = 0;const int& c = a;c++;return 0;
}
上述代码则发生了权限的缩小,C语言阶段我们学习过使用const 修饰的变量称为常变量,此时该变量是只读的,不能直接被修改,而这里原本变量a是可读可写的,然后通过const来修饰引用c,使用const修饰的引用变量称为常引用,此时引用c是只读的,由原本的可读可写到引用c变成了只读的,这就是权限的缩小.那么我们不能通过引用c来间接地修改变量a.
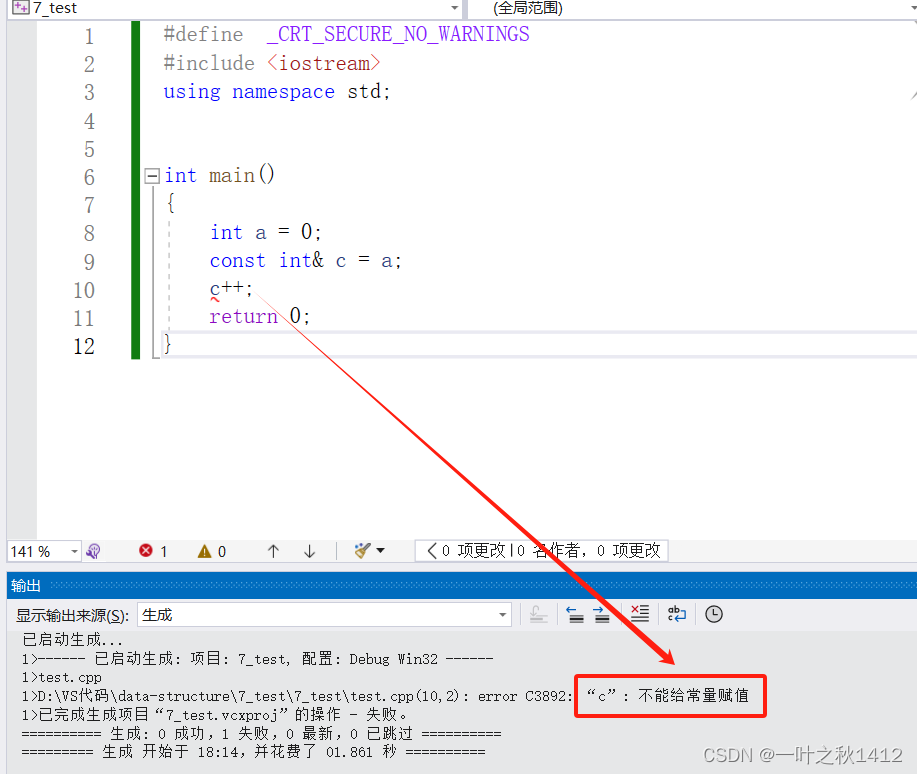
1.4.3:代码3
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;int main()
{const int a = 0;int& c = a;return 0;
}
上述代码中则发生了权限的放大,是不可以的;使用const修饰变量a,那么此时变量a为常变量即是只读的,而当正常使用引用去接收变量a时,此时引用c是可读可写的;也就是说从原本的只读变化到了可读可写,这就是权限的放大.
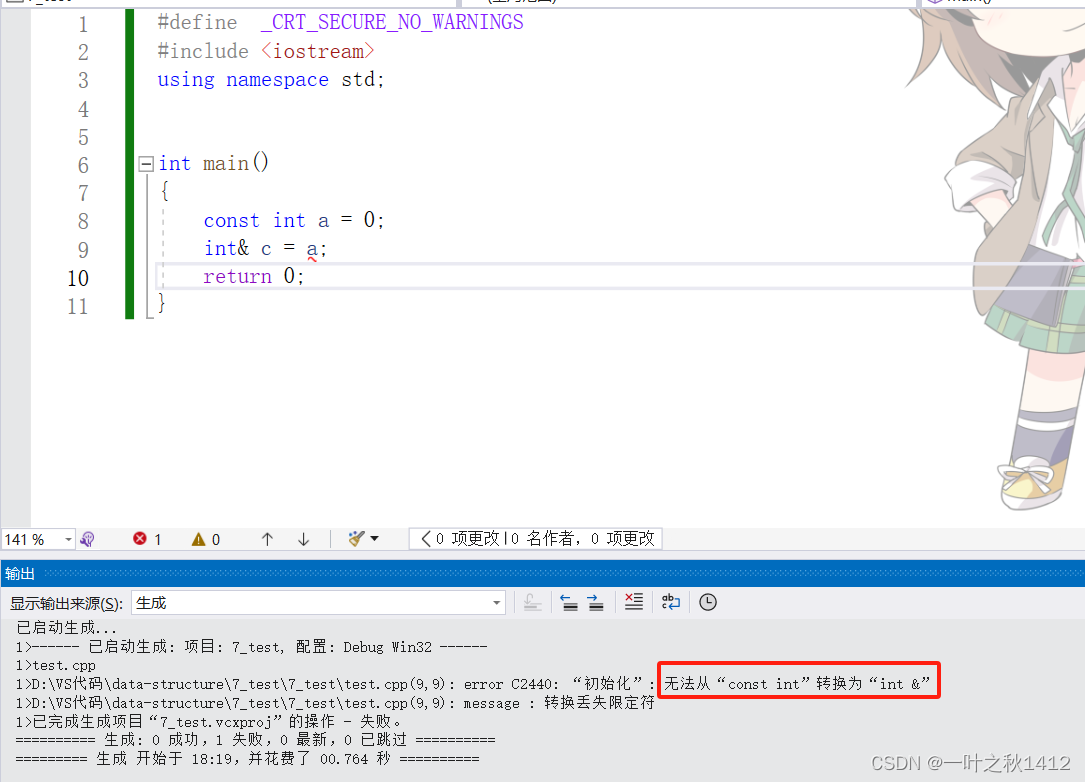
1.4.4:代码4
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;int main()
{int a = 0;int b = 1;int & c = (a + b);const int & d = (a + b);return 0;
}
上述代码可不可以呢?答案是NO.有些uu们会有些疑惑,这里的变量a和b都没有用const关键字来修饰呐,那么为什么不能使用引用c来接收呢?是这样子的,a + b这个表达式发生完以后是一个临时变量,临时变量是具有常性的,那么既然有常性,则当正常使用引用c去接收时则会发生权限的放大.如果想正常接收的话,则需要使用常引用.
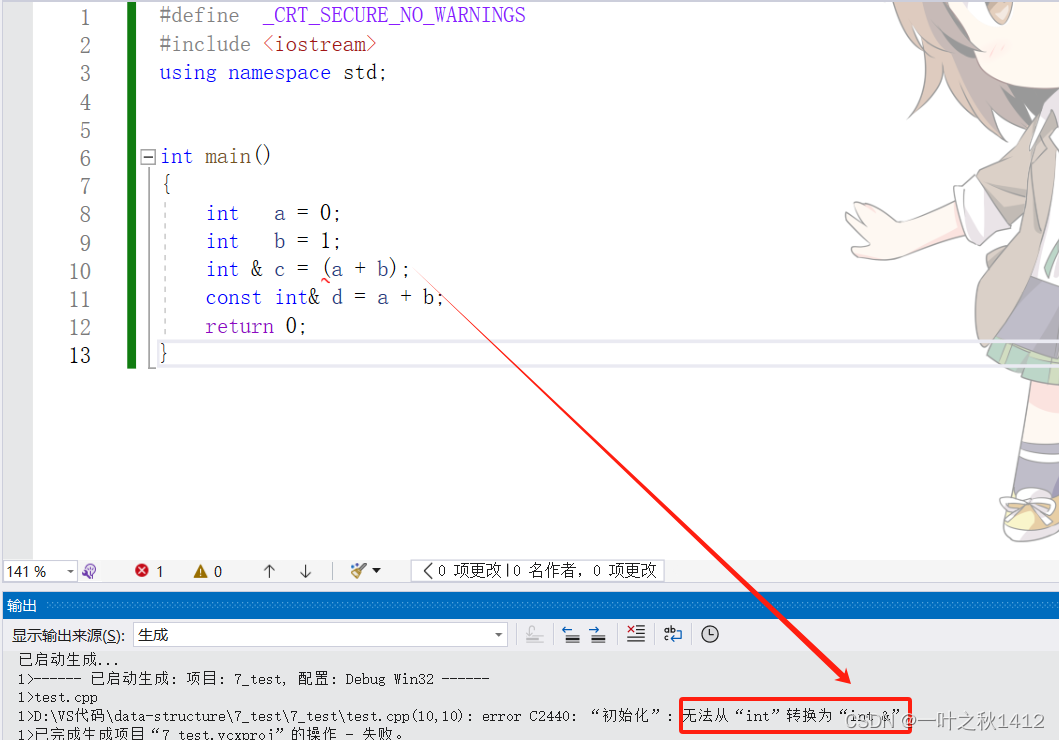
1.4.5:代码5
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;int main()
{const int i = 0;int& r = i;int j = i;return 0;
}
在上述代码中,引用r肯定是不能引用变量i的,因为发生了权限的放大.那么有的uu估计就会类比,变量j也同样不能够接收变量i,因为也同样发生了权限的放大,如果这么想的话,那就是错误滴.这里变量j是可以接收i的,原因在于:这里的int j = i是将i的值拷贝给变量j,那么j的改变不会影响到i,也就不存在所谓的权限放大,而引用r的改变会影响到变量i,因此才会产生权限的改变.
总结
- 权限能够平移,缩小,但权限不能够放大.
- 权限放大---->指针和引用赋值才存在权限的放大.
- 表达式的结果是个临时变量,临时变量具有常性.
1.5:引用与指针的区别
有的uu就会在想,C++中有引用,那么这和C语言中的指针有什么区别呢?博主将带着uu从下面这两个角度来看.
底层角度
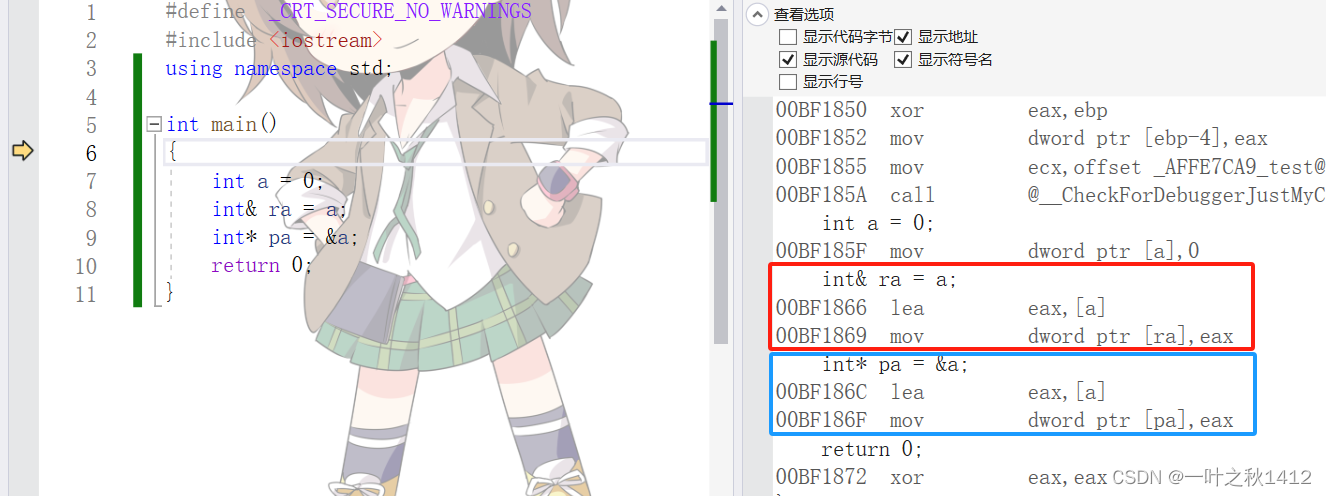
通过观察反汇编我们可以清晰地发现,在汇编层面上,没有引用,都是指针,引用在编译器经过编译后也转换为指针了,因此从底层的角度上,引用是会开空间的.
语法角度
- 引用必须初始化,指针可以不初始化.
- 引用是变量的别名,不开空间,而指针存储的是变量的地址,因此要开空间.
- 引用不能改变指向,指针可以改变指向.
- 引用自增即引用的实体增加1,指针自加即指针向后偏移一个类型的大小.
- 在sizeof中的含义不同:sizeof(引用)结果为引用的数据类型的大小.但指针始终是地址空间所占的字节数,在32位平台下为4个字节,在64位平台下为8个字节.
- 引用相对于指针来讲更加安全,没有空引用,但是有空指针,而且容易出现野指针,但是不容易出现野引用.
- 有多级指针,但是没有多级引用.
2:内联函数
在C语言阶段,我们学习过,函数每次调用都会开辟栈帧,但是当函数调用次数过多时,譬如假设我要调用100万次函数,那么就要开辟100w个函数栈帧,这样子的话,消耗是很大的,C语言阶段,我们是可以通过定义宏函数来解决这个问题的,我们看下面这段代码
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
#define Add(value1,value2)((value1) + (value2))int ADd(int value1,int value2)
{return value1 + value2;
}
int main()
{int result1 = Add(1, 2);int result2 = ADd(2, 3);cout << result1 << endl;cout << result2 << endl;return 0;
}
上述代码呢则是通过宏函数来实现两数相加,假设我要调用100w次这个ADd函数,那么就会开辟100w个函数栈帧,这样子会降低程序的运行速度,C语言是通过定义宏函数来解决这个问题的,但是呢宏有以下几个缺点:
> (1):宏的语法相对来讲比较复杂,坑比较多,譬如可能会带来运算符优先级的问题,不容易控制.
(2):宏是不能够调试的.
(3):宏没有类型安全的检查,不够严谨.
2.1:概念
针对宏的缺点,C++则提出了内联函数的概念,通过使用inline关键字来修饰函数,在编译时C++编译器会在调用内联函数的地方将其展开,从而代替建立函数栈帧的开销,这样子能够提升程序运行的效率.
代码1(无inline修饰)
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int Add(int value1,int value2)
{return value1 + value2;
}int main()
{int result = Add(1, 2);cout << result << endl;return 0;
}
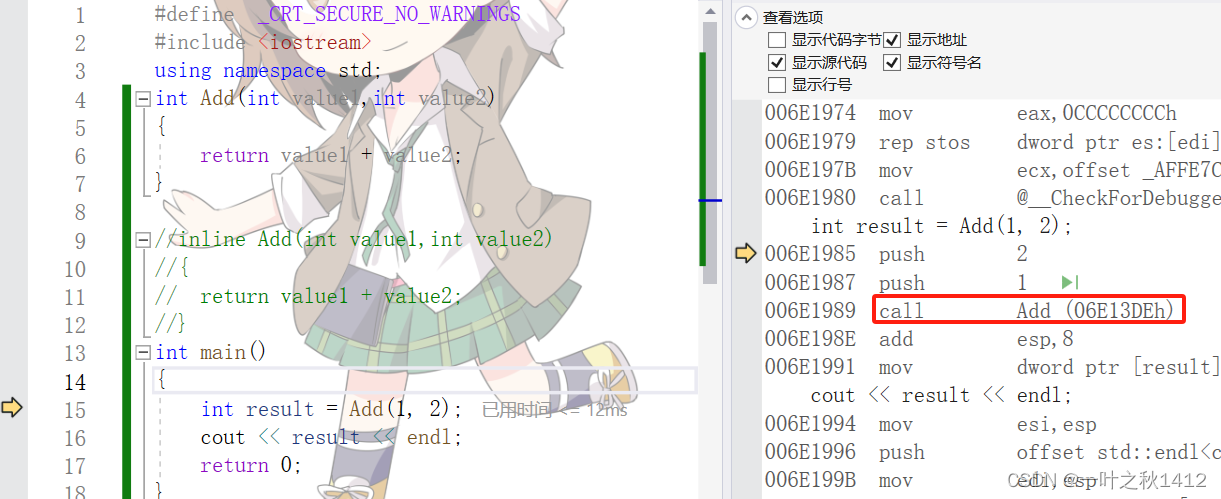
我们通过反汇编可以观察到,当没有inline关键字修饰时,此时通过call这条指令来调用Add函数,此时就会建立函数栈帧.那我们来看通过inline关键字修饰的Add函数.
PS:在此之前,我们需要做一些设置,因为博主是在Debug模式下去观察inline函数的,如果不做此设置的话,此时去观察反汇编还是会看到call指令的.如果是release模式的话,就直接对比是否有call指令就好了.
修改步骤
第一步
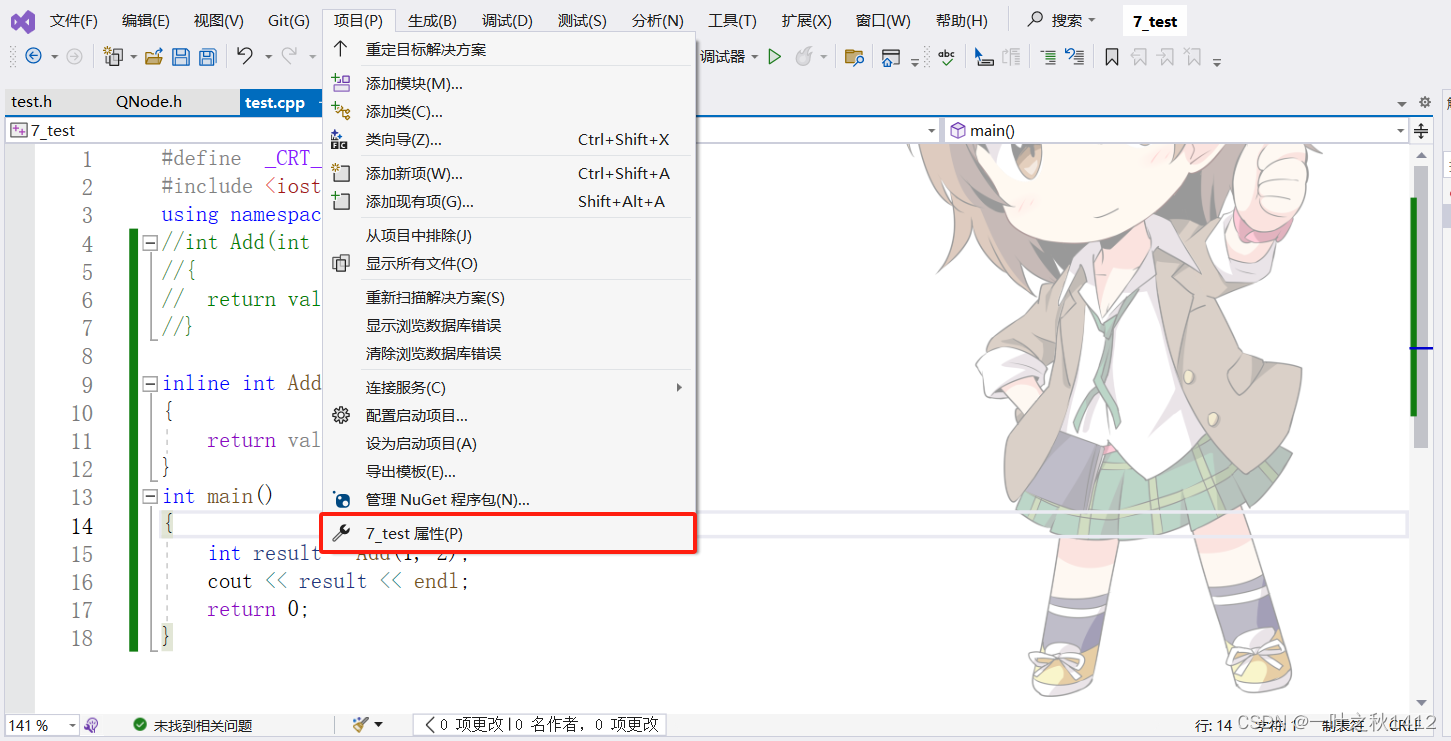
点击上方项目,然后点击最下方的属性.
第二步
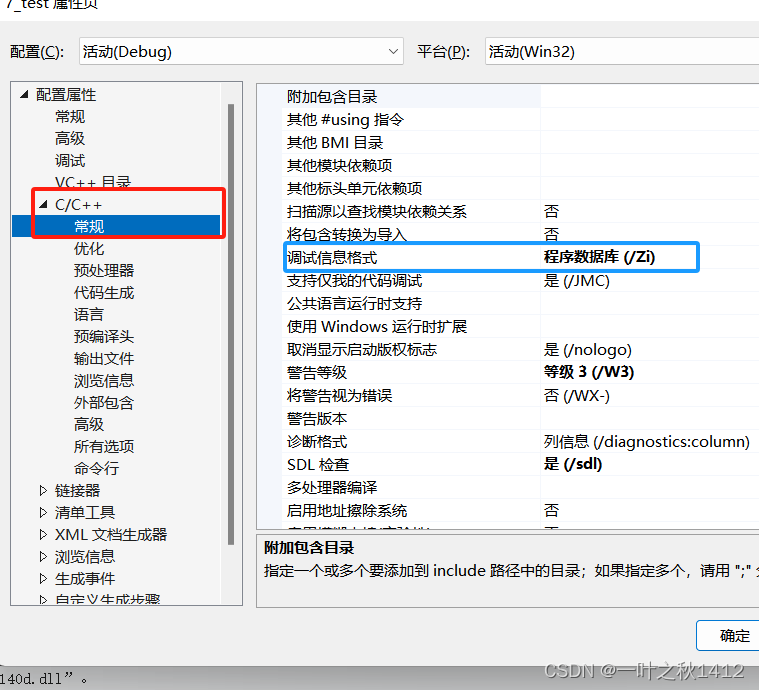
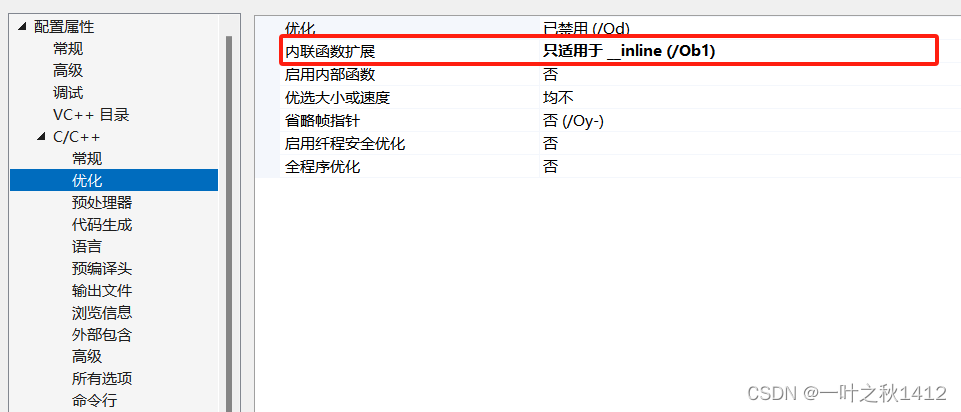
将下面的C/C++展开,然后先点击常规,将调试信息格式修改为程序数据库然后点击优化,将**内联函数扩展修改为只适用于_inline(/Ob1)**即可.做好这些操作后,我们就能在Debug模式下观察下面的代码的反汇编情况了
代码2
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
inline int Add(int value1,int value2)
{return value1 + value2;
}
int main()
{int result = Add(1, 2);cout << result << endl;return 0;
}
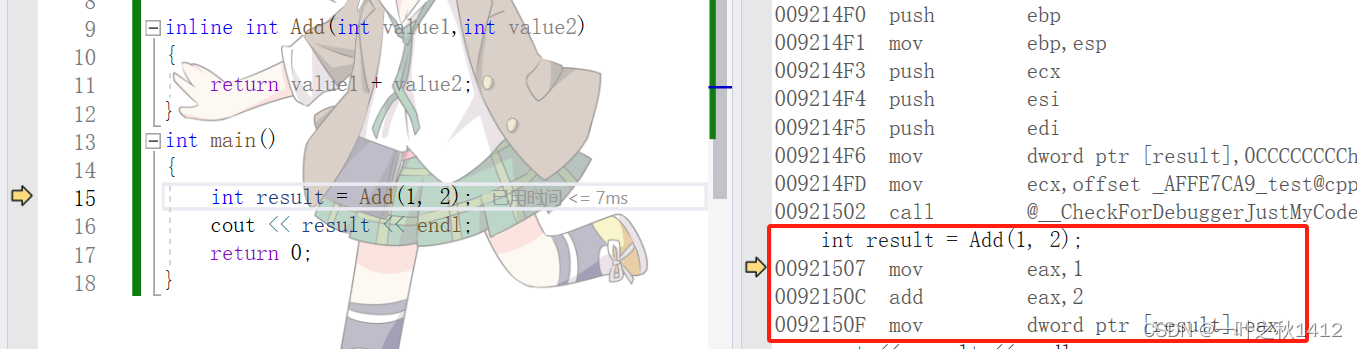
当我们使用inline关键字去修饰函数时,此时我们通过观察反汇编可以清晰地看到没有了call指令,而是将这个函数进行了展开.
2.2:inline的特性
- inline是一种以空间换时间的做法,如果编译器将函数当成内联函数去处理的话,在编译阶段,会把函数当成函数体去使用.这样子的话,就会减少调用函数建立函数栈帧的开销,提高程序的运行效率.但是inline也是有缺陷的
可能会导致目标文件变大.举例简单的例子,譬如有个函数里面封装了100行代码
(1):使用inline修饰时:此时调用100w次,这样子的话就要展开100w次,就会有100 * 100w的代码,这样子的话可能会导致一种叫代码膨胀的现象出现.
(2):使用非inline修饰时,此时调用100w次,这个时候的代码量是100 + 100w左右,因为此时是通过建立函数栈帧来减少代码量的,我只要知道那个栈帧的起始地址就好啦.
- 因此,inline对于编译器只是一个建议,不同的编译器对于inline的实现机制可能不同,一般建议:将函数规模较小,不是递归、且频繁调用的函数可以使用inline修饰
- 使用inline修饰的函数,不建议声明与定义分离,分离的话会导致链接错误.因为使用inline修饰的函数此时会被展开,这样子的话就没有了函数地址,链接的时候就会找不到.
3:auto关键字(C++11)
3.1:auto介绍
随着程序越来越复杂,程序中用到的类型也越来越复杂,经常体现在:
1:类型难于拼写
2:含义不明确导致容易出错.
那么C++中则提出了auto关键字.
在早期的C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量然后再C++11中,标准委员会重新赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型提示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得.
了解了auto关键字后,我们来看下面这几段代码.
代码1
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
void Test()
{cout << "hello world" << endl;
}int main()
{int a = 0;char b = 'c';void (*pf)() = Test;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(pf).name() << endl;return 0;
}
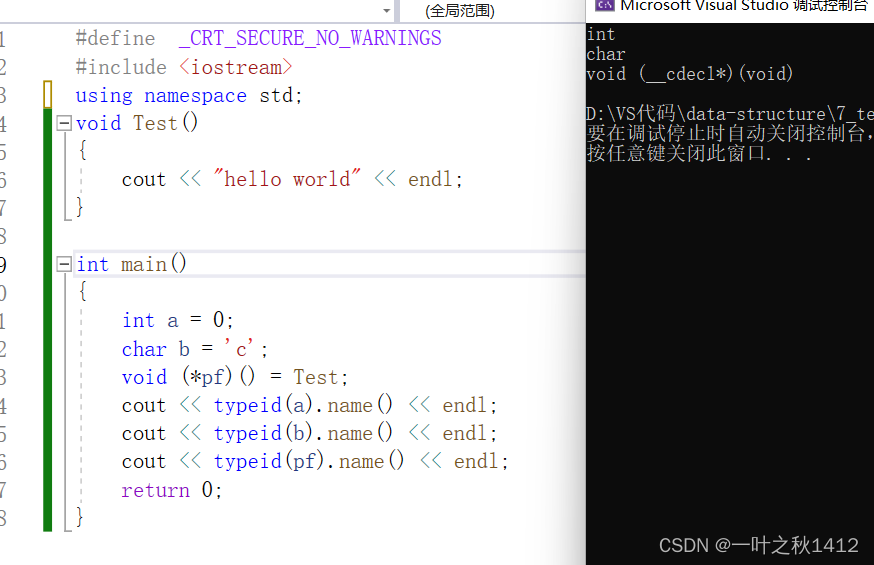
在C++中,我们可以使用typeid().name()这个函数来查看变量的数据类型.通过观察我们可以发现,变量a是一个整型,变量b是字符类型,pf是一个函数指针,指向Test函数.我们可以发现定义一个函数指针变量是不是比较麻烦,那么有什么简便的方法呢?有的uu就会想,这很简单,使用typedef关键字重定义一下,那我们来看下面这段代码.
代码2
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
typedef void (*PF)(void);
void Test()
{cout << "hello world" << endl;
}int main()
{int a = 0;char b = 'c';PF pf = Test;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(pf).name() << endl;return 0;
}
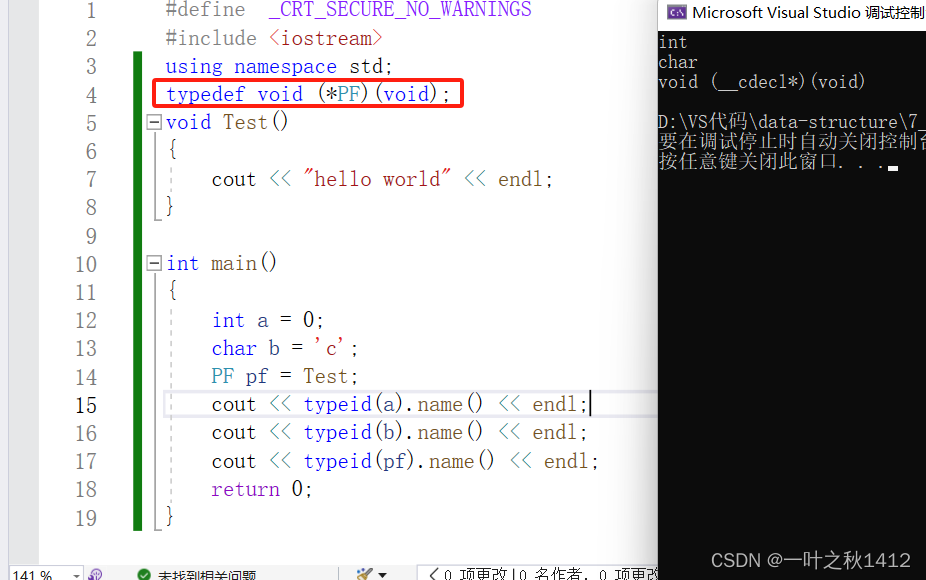
通过typedef重定义类型,我们可以发现确实会比较简便些,但是跟auto相比的话,还是差一些滴,我们来看下面这段代码.
代码3
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
void Test()
{cout << "hello world" << endl;
}int main()
{auto a = 0;auto b = 'c';auto pf = Test;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(pf).name() << endl;return 0;
}
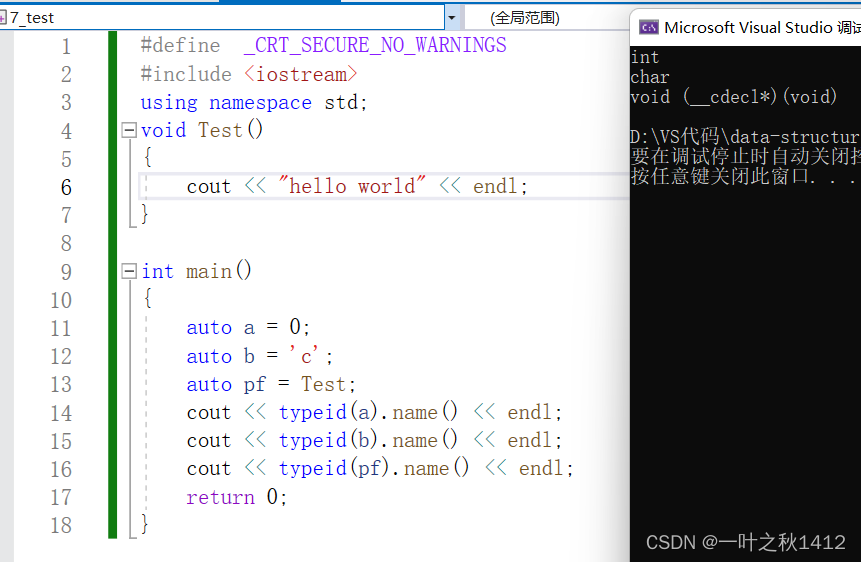
而当使用auto关键字后,此时推导类型的工作就不再是交给我们了,而是交给了编译器来处理,使用auto声明的变量编译器会在编译时期进行推导.
3.2:auto的使用细则
了解了auto的基本概念后,接下来我们来学习其使用细则.
3.2.1:auto必须初始化.
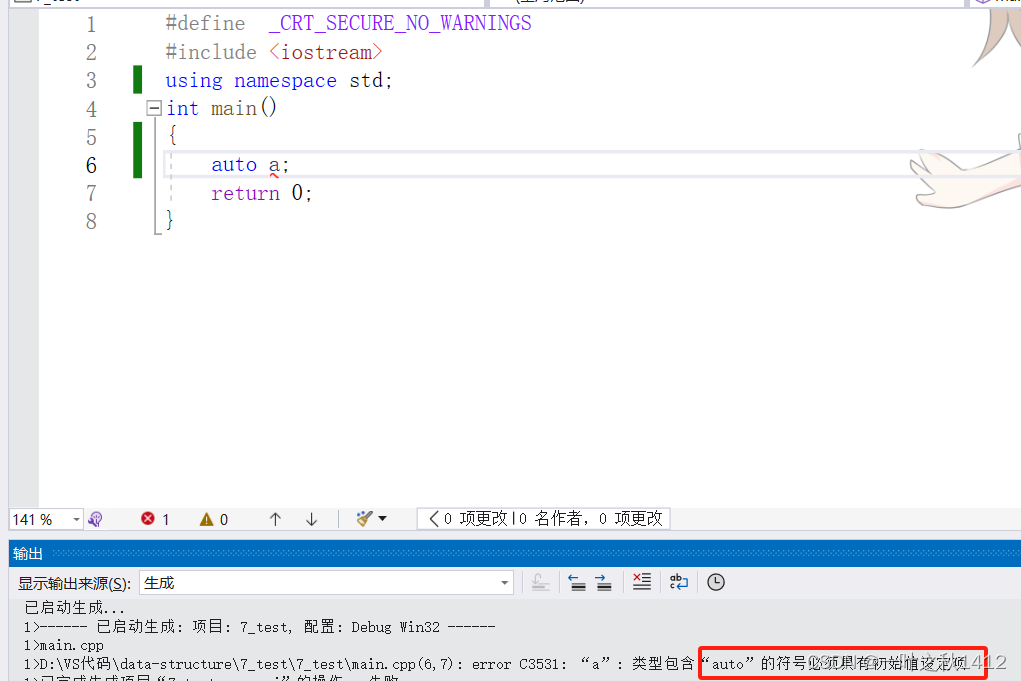
使用auto定义变量时必须对其进行初始化,在编译时,编译器需要根据其初始化的表达式来推导auto的数据类型.
3.2.2:auto与指针和引用相结合
代码1
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int main()
{int a = 0;auto pa1 = &a;auto* pa2 = &a;cout <<"pa1的数据类型:>" << typeid(pa1).name() << endl;cout <<"pa2的数据类型:>" << typeid(pa2).name() << endl;return 0;
}

*当auto声明指针类型时,此时用auto或者auto 没有任何区别.
代码2
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int main()
{int a = 0;auto ra1 = a;auto& ra2 = a;cout <<"a = " << a << endl;ra1 = 40;ra2 = 30;cout <<"a = " << a << endl;cout <<"ra1 = " << ra1 << endl;cout <<"ra2 = " << ra2 << endl;return 0;
}
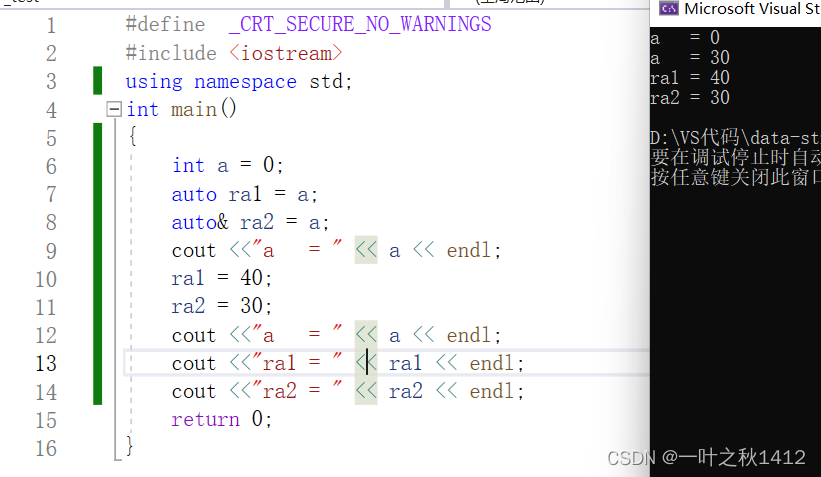
之前我们学习到引用是变量的别名,那么当使用auto声明引用时是需要带上&符号的,不然编译器区分,上述代码中ra1则是单独的一个新变量,ra2才是变量a的别名,因此改变ra1是影响不到变量a的.
3.2.3:在同一行声明多个变量.
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int main()
{auto value1 = 30, value2 = 20;auto value3 = 30, value4 = 25.5;return 0;
}
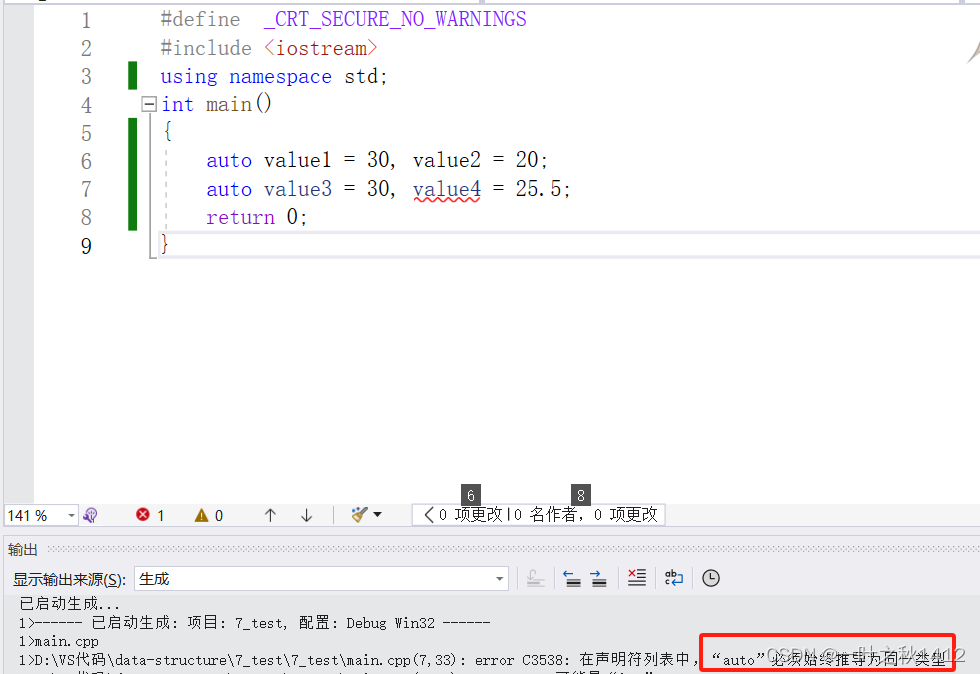
当使用auto声明多个变量时,这些变量必须得是相同的类型,否则会编译器会发生报错,因为编译器首先对第一个变量的数据类型进行推导,然后根据推导出来的数据类型再去定义其他的变量.
3.3:auto不能推导的场景
3.3.1:auto不能作形式参数(C++20以前)
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int Add(auto value1,auto value2)
{return value1 + value2;
}int main()
{int result = Add(12, 33);return 0;
}
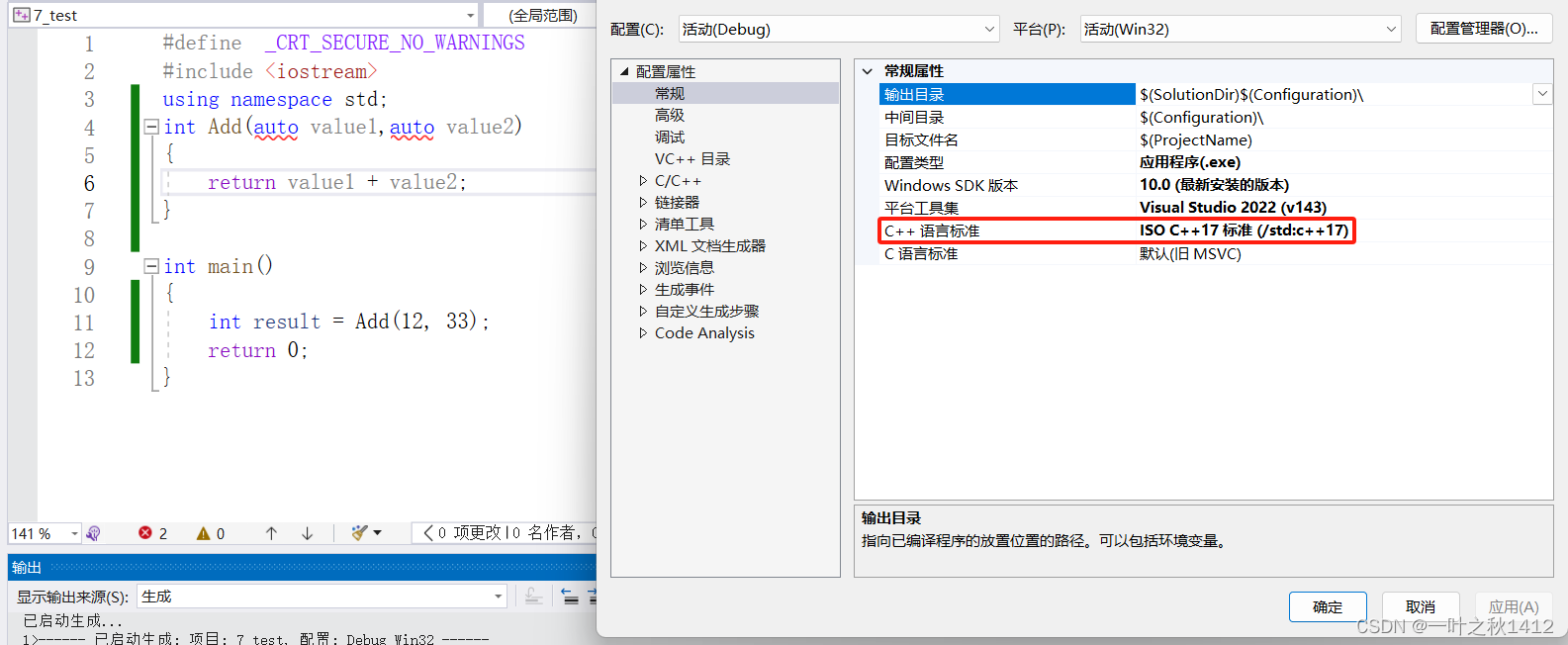
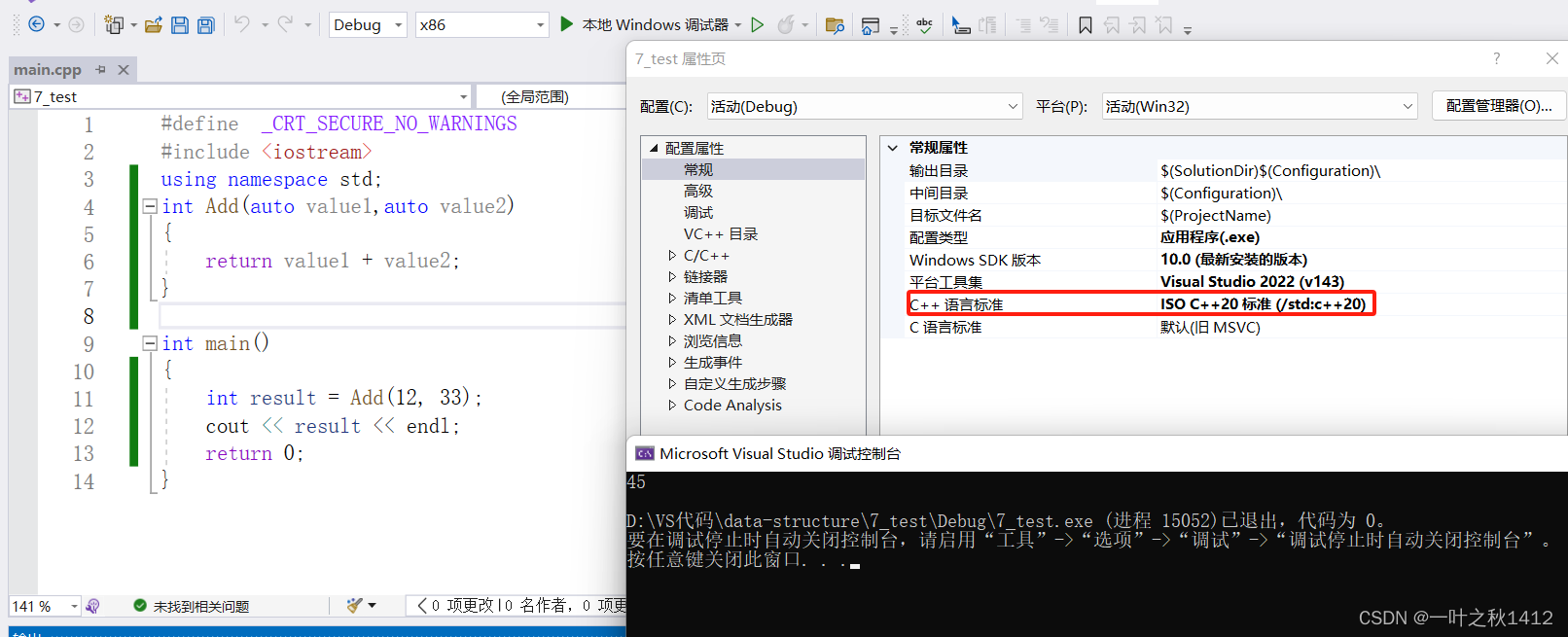
在C++17(包括C++17)以前,auto是不能当作函数的形参的,因为编译器无法对其进行推导,而到了C++20乃至以后,就开始支持auto做形式参数了,因此这里要看是在什么样的C++标准下.
3.3.2:auto不能声明数组
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;int main()
{auto arr[5] = { 1,2,3,4,5 };return 0;
}
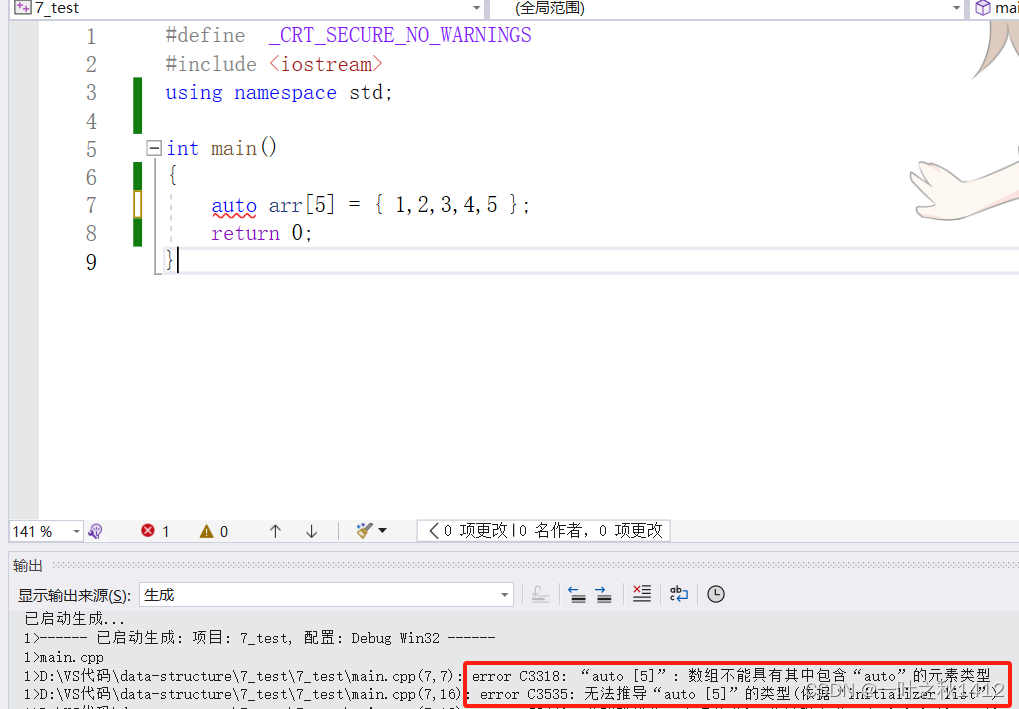
4:基于范围的for循环(C++11)
4.1:范围for的语法
在C语言阶段,我们学习过for循环语句,并且我们在写程序时也会经常用到for循环,但是呢,在一个有范围的集合内,在使用for循环时,我们要经常说明循环的判断范围,这样子的话有些小多余,而且还比较容易犯错,因此C++11中引入了基于范围的for循环.for循环后的括号由冒号":"分割成两个部分:**第一部分是范围内用于迭代的变量,第二部分是被迭代的范围.**我们来看下面这几段代码.
代码1
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int main()
{int array[] = { 1,2,3,4,5 };for (int i = 0; i < sizeof(array) / sizeof(array); i++){cout << array[i] << " ";}cout << endl;for (auto ch : array){cout << ch << " ";}return 0;
}
在上述代码,我们使用了曾经的for循环与范围for循环来遍历数组array,两者相比,范围for循环更加便捷些,不需要写循环的判断部分与调整部分,这个操作交给了编译器来进行处理.
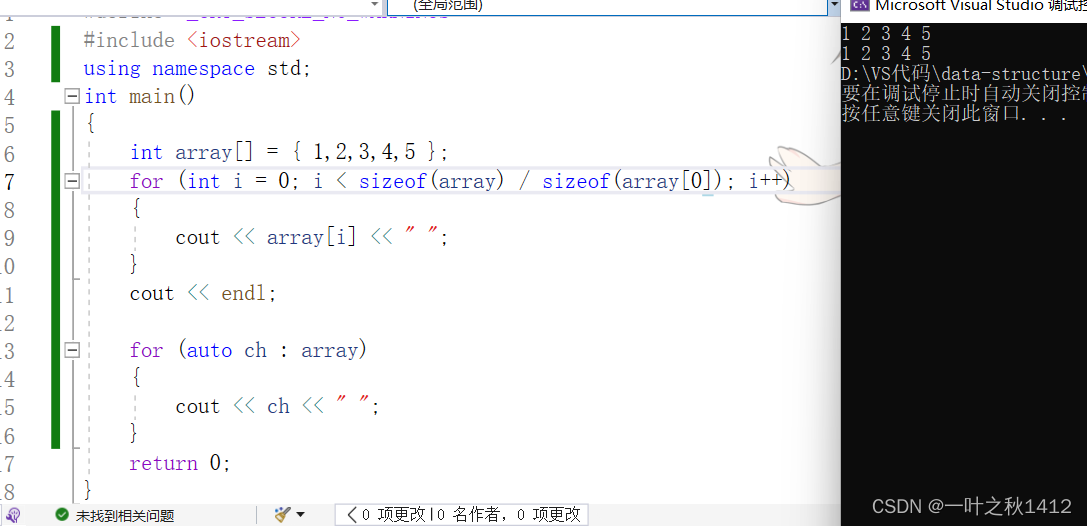
使用范围for循环的同时,我们同样可以带上引用来改变数组中的元素值.
代码2
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int main()
{int array[] = { 1,2,3,4,5 };for (auto& ch : array){cout << ch << " ";}cout << endl;for (auto& ch : array){ch = 1;}for (auto& ch : array){cout << ch << " ";}return 0;
}
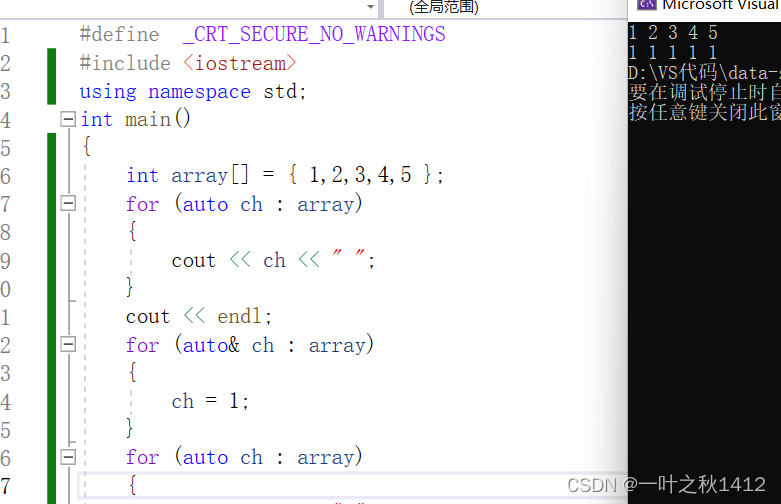
PS:与普通循环类似,范围for同样也能使用continue和break来跳出循环.
4.2:范围for的使用条件
- for循环迭代的范围必须是确定的
- 例如对于数组而言,我们就必须知道第一个元素和最后一个元素的范围.
5:指针空值nullptr
在C语言阶段,我们学习过,定义一个变量如果没有对其进行初始化的话,这个变量的值将会是随机值,可能会发生一些不可避免的错误,因此为了防止这种情况的发生,我们通过在定义变量时要对其给上一个合适的初始值.譬如:在指针阶段,我们学习过,指针如果不对其进行初始化的话,那么就会是个野指针,因此我们通常在初始化指针的时候会对其置NULL
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
int main()
{int* p = NULL;return 0;
}
但是呢,NULL实际上是一个宏,在传统的C头文件中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0#else#define NULL ((void *)0)#endif#endif
可以清晰看到,*NULL被定义为字面常量0,或者被定义为无类型指针(void )的常量,我们知道C++是兼容C的,C++提出了函数重载的概念,那么因此针对NULL这种情况,就会发生一些不可避免的情况,我们来看如下代码.
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;void Function(int val)
{cout << "void Function(int val)" << endl;
}void Function(int* val)
{cout << "void Function(int* val)" << endl;
}
int main()
{Function(0);Function(NULL);Function((int*)NULL);return 0;
}
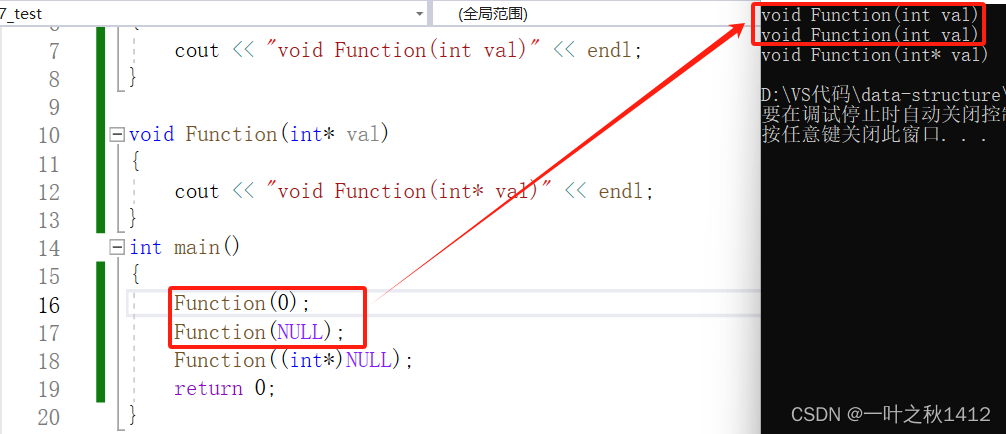
在上述代码中,Function函数构成了函数重载,因为其参数类型不同,但是当实参传入NULL以后,却没有调用原本的Function(int *val)函数,而是调用了Function(int val)这个函数,这就和原本的程序背道而驰了,当对NULL指针进行强制类型转换时,才调用了Function(int *)这个函数在C++98中字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下将其看成是一个整形常量,若要将其当成指针来看待,则要进行强转,因此在C++11中则提出使用nullptr来表示指针空值.
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;void Function(int val)
{cout << "void Function(int val)" << endl;
}void Function(int* val)
{cout << "void Function(int* val)" << endl;
}
int main()
{Function(0);Function(NULL);Function((int*)NULL);Function(nullptr);return 0;
}
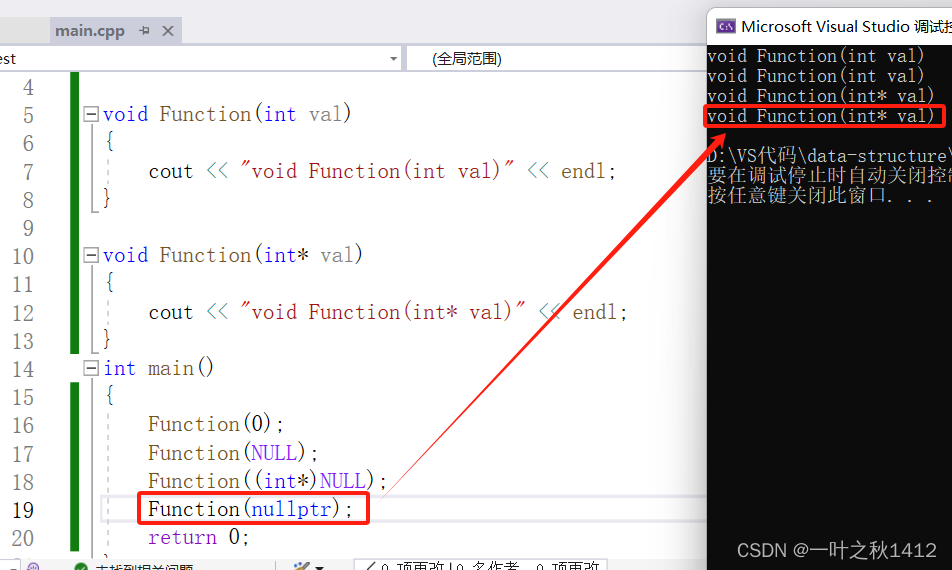
PS:1:在使用nullptr表示指针空值时,不需要包含头文件. 2:为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr.
好啦,uu们,关于C++入门(下)这部分滴详细内容博主就讲到这里啦,如果uu们觉得博主讲的不错的话,请动动你们滴小手给博主点点赞,你们滴鼓励将成为博主源源不断滴动力.
相关文章:
C++入门(下)
文章目录 1:引用1.1:引用概念1.2:引用的特性.1.2.1:引用在定义时必须初始化1.2.2:一个变量可以有多个引用1.2.3:引用一旦引用一个实体,再不能引用其他实体. 1.3:应用场景1.3.1:做参数1.3.2:做返回值1.3.2.1:传值返回1.3.2.2:传引用返回(错误示范)1.3.2.3:传引用返回(正确示范) …...

2024-03-20 作业
作业要求: 1> 创建一个工人信息库,包含工号(主键)、姓名、年龄、薪资。 2> 添加三条工人信息(可以完整信息,也可以非完整信息) 3> 修改某一个工人的薪资(确定的一个&#x…...

【机器学习】深入解析线性回归模型
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步! 【机器学习】深入解析线性回归模型 引入一 初步了解1.1 概念1.2 类比二 基本要素2.1 数据2.2 模型…...

新一代云原生数据库OLAP
2023 OLAP峰会(公开)PPT汇总(25份).zip 新一代云原生数据库的OLAP(联机分析处理)能力是其重要的特性之一,这种能力使得数据库能够支持复杂的数据分析查询,从而满足企业对大数据的深…...
JavaEE--小Demo
目录 下载包 配置 修改文件 pom.xml application.properties 创建文件 HelloApi.java GreetingController.java Greeting.java DemoApplication.java 运行包 运行命令 mvn package cd target dir java -jar demo-0.0.1-SNAPSHOT.jar 浏览器测试结果 下载包 …...

一代大神跌落神坛——Java炸了!
曾经它是只手遮天的一大计算机语言.......可现如今,腹背受敌、大势已去,一代神话跌落神坛! Java薪水20k降至15k难掩颓势,事业编3k升至3500尽显嫡道风范!嫡嫡道道、嫡嫡道道~ 没错,就是它!Java…...

面试算法-64-零钱兑换
题目 给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。 计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。 你可以认为每种硬币的数量是无限的…...

Java复习06 Spring 代码概念
Java复习06 Spring 代码概念 1.基本代码 Component public class CommunityApplicationTests implements ApplicationContextAware {private ApplicationContext applicationContext;Overridepublic void setApplicationContext(ApplicationContext applicationContext) thr…...
【研究僧总结】回顾第1095个创作日
目录 前言一. 机缘二. 日常三. 展望 前言 感觉刚过1024不久,现在又来个1095创作日 一. 机缘 研究僧一直在找平台做笔记,方便之后的回顾总结,也让各位网友见证你我的成长,相互学习 止不住的写文止不住的成长,大家共同…...
QT(6.5) cmake构建C++编程,调用python
一、注意事项 explicit c中,一个参数的构造函数(或者除了第一个参数外其余参数都有默认值的多参构造函数),承担了两个角色,构造器、类型转换操作符, c提供关键字explicit,阻止转换构造函数进行的隐式转换的发生&#…...

Java开发从入门到精通(九):Java的面向对象OOP:成员变量、成员方法、类变量、类方法、代码块、单例设计模式
Java大数据开发和安全开发 (一)Java的变量和方法1.1 成员变量1.2 成员方法1.3 static关键字1.3.1 static修饰成员变量1.3.1 static修饰成员变量的应用场景1.3.1 static修饰成员方法1.3.1 static修饰成员方法的应用场景1.3.1 static的注意事项1.3.1 static的应用知识…...
通过 Socket 手动实现 HTTP 协议
你好,我是 shengjk1,多年大厂经验,努力构建 通俗易懂的、好玩的编程语言教程。 欢迎关注!你会有如下收益: 了解大厂经验拥有和大厂相匹配的技术等 希望看什么,评论或者私信告诉我! 文章目录 一…...
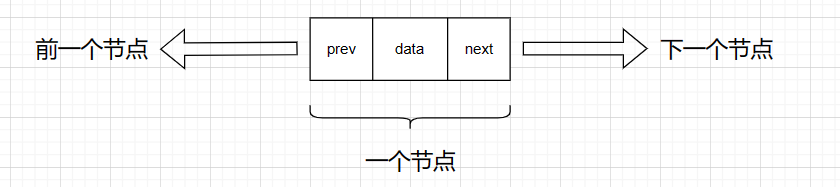
探索数据结构:双向链表的灵活优势
✨✨ 欢迎大家来到贝蒂大讲堂✨✨ 🎈🎈养成好习惯,先赞后看哦~🎈🎈 所属专栏:数据结构与算法 贝蒂的主页:Betty’s blog 1. 前言 前面我们学习了单链表,它解决了顺序表中插入删除需…...
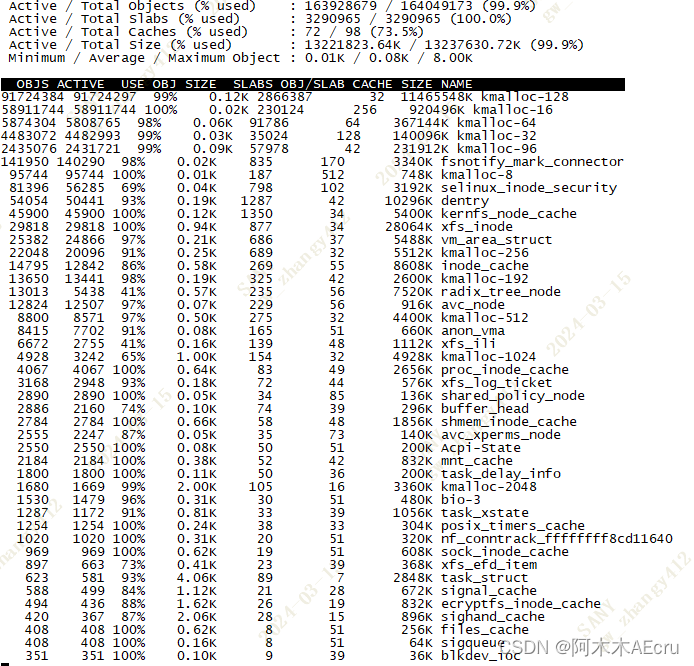
记录一次服务器内存使用率过高达到90%告警问题排查。
目录 一、前言二、问题排查处理三、 结尾 👩🏽💻个人主页:阿木木AEcru 🔥 系列专栏:Docker容器化部署系列 💹每一次技术突破,都是对自我能力的挑战和超越。 一、前言 一大早就有一…...

基于react native的自定义轮播图
基于react native的自定义轮播图 效果示例图示例代码 效果示例图 示例代码 import React, {useEffect, useRef, useState} from react; import {Animated,PanResponder,StyleSheet,Text,View,Dimensions, } from react-native; import {pxToPd} from ../../common/js/device;c…...

Jetson入坑记实
关于虚拟环境python与系统自带python目录下dist-packages与site-packages dist-packages:系统自带的python site-packages:自己安装的python 详细:dist-packages与site-packages_dist-packages和site-packages-CSDN博客 rtsp获取视频流(没…...

算法系列--递归
一.如何理解递归 递归对于初学者来说是一个非常抽象的概念,笔者在第一次学习时也是迷迷糊糊的(二叉树遍历),递归的代码看起来非常的简洁,优美,但是如何想出来递归的思路或者为什么能用递归这是初学者很难分析出来的 笔者在学习的过程中通过刷题,也总结出自己的一些经验,总结来…...

【JS】替换文本为emjio表情
最终效果展示 T1 T2 T3 T4 需求 把评论你好帅啊啊啊[开心][开心],[开心] 替换为图片 思路 正则match提取[开心]到一个数组数组去重创建img标签img标签转文本. 。例:(el.outerHTML),将el元素转文本字符串replaceAll…...

Solr完结版
Solr是基于Apache Lucene构建的用于搜索和分析的开源解决方案。提供可拓展索引、搜索功能、高亮显示和文字解析功能。本质是一个java web项目,内嵌Jetty服务器,安装方便。 请求Solr中的控制器,处理完数据后把结果相应给客户端 正向索引&#…...
外包干了5天,技术退步明显。。。。
说一下自己的情况,本科生,19年通过校招进入广州某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测试&a…...

Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 [特殊字符]
Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 🚀 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一个基于HTML5的雪碧图生成器,它采…...

新手也能懂的SSRF漏洞实战:用iwebsec靶场复现文件读取与内网探测
从零开始掌握SSRF漏洞:iwebsec靶场实战指南1. 认识SSRF漏洞的本质想象一下,你正在一家高档餐厅点餐,服务员承诺可以帮你从任何地方获取食材——包括隔壁竞争对手的厨房。SSRF(Server-Side Request Forgery)漏洞就像这个…...

收藏必看|2026 版大厂 AI 岗位薪资曝光!普通程序员转型大模型最全指南
深夜收到大厂 HR 好友发来的内部资料,再三叮嘱切勿对外泄露。如今网络信息传播速度极快,这份 2026 年企业 AI 岗真实薪资内幕,也值得给广大程序员、零基础入行小白参考借鉴。 翻看完整薪资台账后,真切感受到当下大模型赛道的薪资差…...

微信小程序3D开发框架技术对比:XR-Frame与threejs-miniprogram
随着微信小程序逐步支持3D渲染与AR能力,开发者面临两个主要官方方案:自研的XR-Frame和适配Three.js的threejs-miniprogram。本文将从架构设计、渲染机制、功能集成、开发模式及适用场景等维度进行技术分析,为技术选型提供参考。一、XR-Frame&…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...

如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南
如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download 在数字时代,百度网盘已成为我们存储和分享大型文件的默认…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...

机器学习力场攻克Peierls相变动力学:从对称性描述符到畴生长标度律
1. 项目概述:当机器学习遇见Peierls相变在凝聚态物理和材料科学的前沿,我们常常被一个核心问题所困扰:如何精确地模拟那些由电子和晶格(原子)强烈耦合所驱动的复杂动力学过程?这类系统,比如电荷…...