探索数据结构:双向链表的灵活优势
✨✨ 欢迎大家来到贝蒂大讲堂✨✨🎈🎈养成好习惯,先赞后看哦~🎈🎈
所属专栏:数据结构与算法
贝蒂的主页:Betty’s blog

1. 前言
前面我们学习了单链表,它解决了顺序表中插入删除需要挪动大量数据的缺点。但同时也有仍需改进的地方,比如说:我们有时候需要寻找某个节点的前一个节点,对于单链表而言只能遍历,这样就可能造成大量时间的浪费。为了解决这个问题,我们就要学习今天的主角——带头双向循环链表。

2. 双向链表的功能
- 初始化顺序表中的数据。
- 对顺序表进行尾插(末尾插入数据)。
- 对顺序表进行头插(开头插入数据)。
- 对顺序表进行头删(开头删除数据)。
- 对顺序表进行尾删(末尾删除数据)。
- 对顺序表就像查找数据。
- 对顺序表数据进行修改。
- 任意位置的删除和插入数据。
- 打印顺序表中的数据。
- 销毁顺序表。
3. 双向链表的定义
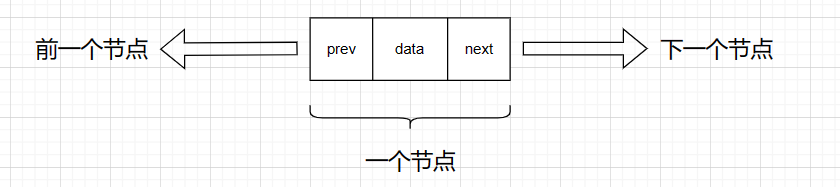
双向链表的定义结构体需要包含三个成员,一个成员存储数值,一个成员存储前一个节点的地址,最后一个成员存储下一个节点的地址。
typedef int LTDataType;
typedef struct DoubleList
{struct DoubleList* prev;//指向前一个节点LTDataType data;struct DoubleList* next;//指向下一个节点
}DListNode;
4. 双向链表的功能
4.1 初始化双向链表
在初始化双向链表时,我们需要创建一个头节点,也就是我们常说的哨兵位头节点。
(1) 创建头结点
DListNode* DLNodeCreat(LTDataType x)
{DListNode* newnode = (DListNode*)malloc(sizeof(DListNode));if (newnode == NULL){perror("malloc fail:");return NULL;}newnode->prev = NULL;newnode->next = NULL;newnode->data = x;return newnode;
}
(2) 初始化
初始化将头节点的前后指针都指向自己,并将数值至为-1。
DListNode* InitDList()
{DListNode* phead = DLNodeCreat(-1);phead->prev = phead;phead->next = phead;return phead;
}
(3) 复杂度分析
- 时间复杂度:没有其他额外的时间消耗,时间复杂度为O(1)。
- 空间复杂度:固定创造一个节点,空间复杂度为O(1)。
4.2 双向链表尾插
因为我们实现的双向链表存在头节点,所以我们不需要像实现单链表一样先判断链表是否为空。
(1) 代码实现
void DListPushBack(DListNode* ptr, LTDataType x)
{assert(ptr);DListNode* tail = ptr->prev;DListNode* newnode = DLNodeCreat(x);tail->next = newnode;newnode->prev = tail;ptr->prev = newnode;newnode->next = ptr;
}
(2) 复杂度分析
- 时间复杂度:没有其他额外的时间消耗,时间复杂度为O(1)。
- 空间复杂度:固定创造一个节点,空间复杂度为O(1)。
4.3 双向链表头插
因为带头双向循环链表的特性,即使只有头节点进行头插,代码实现也是相同的。
(1) 代码实现
void DListPushFront(DListNode* ptr, LTDataType x)
{assert(ptr);DListNode* next = ptr->next;DListNode* newnode = DLNodeCreat(x);ptr->next = newnode;newnode->prev =ptr;newnode->next = next;next->prev = newnode;
}
(2) 复杂度分析
- 时间复杂度:没有其他额外的时间消耗,时间复杂度为O(1)。
- 空间复杂度:固定创造一个节点,空间复杂度为O(1)。
4.4 双向链表尾删
有了循环找尾节点也十分容易,双向链表尾删自然并不困难。但是需要防止删除头节点。
(1) 代码实现
void DListPopBack(DListNode* ptr)
{assert(ptr);assert(ptr->next != ptr);//放置删除头节点DListNode* tail = ptr->prev;DListNode* tailprev = tail->prev;free(tail);tail == NULL;tailprev->next = ptr;ptr->prev = tailprev;
}
(2) 复杂度分析
- 时间复杂度:没有其他额外的时间消耗,时间复杂度为O(1)。
- 空间复杂度:没有额外的空间消耗,空间复杂度为O(1)。
4.5 双向链表头删
头删与尾删一样,都需要防止删除头节点。
(1) 代码实现
void DListPopFront(DListNode* ptr)
{assert(ptr);assert(ptr->next != ptr);DListNode* phead = ptr->next;DListNode* pheadnext = phead->next;free(phead);ptr->next = pheadnext;pheadnext->prev = ptr;
}
(2) 复杂度分析
- 时间复杂度:没有其他额外的时间消耗,时间复杂度为O(1)。
- 空间复杂度:没有额外的空间消耗,空间复杂度为O(1)。
4.6 双向链表查找
和单链表一样,我们也可以对双向链表进行查找。如果找到就返回该节点的地址,否则返回NULL。
(1) 代码实现
DListNode* DListFind(DListNode* ptr, LTDataType x)
{assert(ptr);DListNode* cur = ptr->next;while (cur != ptr){if (cur->data == x){return cur;}cur = cur->next;}return NULL;
}
(2) 复杂度分析
- 时间复杂度:可能需要遍历整个链表,时间复杂度为O(N)。
- 空间复杂度:没有额外的空间消耗,空间复杂度为O(1)。
4.7 修改双向链表
我们可以结合双向链表的查找,对双向链表进行修改。
(1) 代码实现
void DListModify(DListNode* ptr, DListNode* pos, LTDataType x)
{assert(ptr);assert(ptr != pos);//防止对头节点操作DListNode* cur = ptr->next;while (cur != ptr){if (cur == pos){cur->data = x;}cur = cur->next;}
}
(2) 复杂度分析
- 时间复杂度:可能需要遍历整个链表,时间复杂度为O(N)。
- 空间复杂度:没有额外的空间消耗,空间复杂度为O(1)。
4.8 双向链表指定插入数据
随机插入数据可以分为:向前插入与向后插入。
(1) 向前插入
void DListInsertF(DListNode* ptr, DListNode* pos, LTDataType x)
{assert(ptr);DListNode* newnode = DLNodeCreat(x);DListNode* prev = pos->prev;newnode->prev = prev;newnode->next = pos;prev->next = newnode;pos->prev = newnode;
}
(2) 向后插入
void DListInsertB(DListNode* ptr, DListNode* pos, LTDataType x)
{assert(ptr);DListNode* newnode = DLNodeCreat(x);DListNode* next = pos->next;newnode->prev = pos;newnode->next = next;next->prev = newnode;pos->next = newnode;
}
(3) 复杂度分析
- 时间复杂度:没有其他额外的时间消耗,时间复杂度为O(1)。
- 空间复杂度:没有额外的空间消耗,空间复杂度为O(1)。
4.9 指定位置删除数据
任意删除也需要放置删除头节点,并且因为其特点只需要一个参数就能完成该操作。
(1) 代码实现
void DListErase(DListNode* pos)
{assert(pos);assert(pos != pos->next);pos->prev->next = pos -> next;pos->next->prev = pos->prev;free(pos);pos = NULL;
}
(2) 复杂度分析
- 时间复杂度:没有其他额外的时间消耗,时间复杂度为O(1)。
- 空间复杂度:没有额外的空间消耗,空间复杂度为O(1)。
4.10 打印双向链表
打印双向链表只需将循环之前的数据全部打印即可。
(1) 代码实现
void DLTPrint(DListNode* ptr)
{assert(ptr);printf("guard");DListNode* cur = ptr->next;while (cur != ptr){printf("<==>%d", cur->data);cur = cur->next;}printf("\n");
}
(2) 复杂度分析
- 时间复杂度:没有其他额外的时间消耗,时间复杂度为O(1)。
- 空间复杂度:没有额外的空间消耗,空间复杂度为O(1)。
4.11 销毁双向链表
(1) 代码实现
void DListDestroy(DListNode* ptr)
{assert(ptr);DListNode* cur = ptr->next;while (cur != ptr){DListNode* next = cur->next;free(cur);cur = next;}free(ptr);
}
(2) 复杂度分析
- 时间复杂度:没有其他额外的时间消耗,时间复杂度为O(1)。
- 空间复杂度:没有额外的空间消耗,空间复杂度为O(1)。
5. 完整代码
5.1 DList.h
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int LTDataType;
typedef struct DoubleList
{struct DoubleList* prev;//指向前一个节点LTDataType data;struct DoubleList* next;//指向下一个节点
}DListNode;
DListNode* InitDList();//初始化
void DListPushBack(DListNode* ptr, LTDataType x);//尾插
void DLTPrint(DListNode* ptr);//打印
void DListPushFront(DListNode* ptr, LTDataType x);//头插
void DListPopBack(DListNode* ptr);//尾删
void DListPopFront(DListNode* ptr);//头删
DListNode*DListFind(DListNode* ptr, LTDataType x);//查找
void DListModify(DListNode* ptr, DListNode* pos);//修改
void DListInsertF(DListNode* ptr, DListNode* pos, LTDataType x);//任意位置之前插入
void DListInsertB(DListNode* ptr, DListNode* pos, LTDataType x);//任意位置之后插入
void DListErase(DListNode* pos);//任意位置删除
void DListDestroy(DListNode* ptr);//销毁双向链表
5.2 DList.c
#include"DoubleList.h"
DListNode* DLNodeCreat(LTDataType x)
{DListNode* newnode = (DListNode*)malloc(sizeof(DListNode));if (newnode == NULL){perror("malloc fail:");return NULL;}newnode->prev = NULL;newnode->next = NULL;newnode->data = x;return newnode;
}
DListNode* InitDList()
{DListNode* phead = DLNodeCreat(-1);phead->prev = phead;phead->next = phead;return phead;
}
void DListPushBack(DListNode* ptr, LTDataType x)
{assert(ptr);DListNode* tail = ptr->prev;DListNode* newnode = DLNodeCreat(x);tail->next = newnode;newnode->prev = tail;ptr->prev = newnode;newnode->next = ptr;
}
void DListPushFront(DListNode* ptr, LTDataType x)
{assert(ptr);DListNode* next = ptr->next;DListNode* newnode = DLNodeCreat(x);ptr->next = newnode;newnode->prev =ptr;newnode->next = next;next->prev = newnode;
}
void DListPopBack(DListNode* ptr)
{assert(ptr);assert(ptr->next != ptr);//放置删除头节点DListNode* tail = ptr->prev;DListNode* tailprev = tail->prev;free(tail);tail == NULL;tailprev->next = ptr;ptr->prev = tailprev;
}
void DListPopFront(DListNode* ptr)
{assert(ptr);assert(ptr->next != ptr);DListNode* phead = ptr->next;DListNode* pheadnext = phead->next;free(phead);ptr->next = pheadnext;pheadnext->prev = ptr;
}
DListNode* DListFind(DListNode* ptr, LTDataType x)
{assert(ptr);DListNode* cur = ptr->next;while (cur != ptr){if (cur->data == x){return cur;}cur = cur->next;}return NULL;
}
void DListModify(DListNode* ptr, DListNode* pos, LTDataType x)
{assert(ptr);assert(ptr != pos);//防止对头节点操作DListNode* cur = ptr->next;while (cur != ptr){if (cur == pos){cur->data = x;}cur = cur->next;}
}
void DListInsertF(DListNode* ptr, DListNode* pos, LTDataType x)
{assert(ptr);DListNode* newnode = DLNodeCreat(x);DListNode* prev = pos->prev;newnode->prev = prev;newnode->next = pos;prev->next = newnode;pos->prev = newnode;
}
void DListInsertB(DListNode* ptr, DListNode* pos, LTDataType x)
{assert(ptr);DListNode* newnode = DLNodeCreat(x);DListNode* next = pos->next;newnode->prev = pos;newnode->next = next;next->prev = newnode;pos->next = newnode;
}
void DListErase(DListNode* pos)
{assert(pos);assert(pos != pos->next);pos->prev->next = pos -> next;pos->next->prev = pos->prev;free(pos);pos = NULL;
}
void DLTPrint(DListNode* ptr)
{assert(ptr);printf("guard");DListNode* cur = ptr->next;while (cur != ptr){printf("<==>%d", cur->data);cur = cur->next;}printf("\n");
}
void DListDestroy(DListNode* ptr)
{assert(ptr);DListNode* cur = ptr->next;while (cur != ptr){DListNode* next = cur->next;free(cur);cur = next;}free(ptr);
}
相关文章:
探索数据结构:双向链表的灵活优势
✨✨ 欢迎大家来到贝蒂大讲堂✨✨ 🎈🎈养成好习惯,先赞后看哦~🎈🎈 所属专栏:数据结构与算法 贝蒂的主页:Betty’s blog 1. 前言 前面我们学习了单链表,它解决了顺序表中插入删除需…...
记录一次服务器内存使用率过高达到90%告警问题排查。
目录 一、前言二、问题排查处理三、 结尾 👩🏽💻个人主页:阿木木AEcru 🔥 系列专栏:Docker容器化部署系列 💹每一次技术突破,都是对自我能力的挑战和超越。 一、前言 一大早就有一…...

基于react native的自定义轮播图
基于react native的自定义轮播图 效果示例图示例代码 效果示例图 示例代码 import React, {useEffect, useRef, useState} from react; import {Animated,PanResponder,StyleSheet,Text,View,Dimensions, } from react-native; import {pxToPd} from ../../common/js/device;c…...

Jetson入坑记实
关于虚拟环境python与系统自带python目录下dist-packages与site-packages dist-packages:系统自带的python site-packages:自己安装的python 详细:dist-packages与site-packages_dist-packages和site-packages-CSDN博客 rtsp获取视频流(没…...

算法系列--递归
一.如何理解递归 递归对于初学者来说是一个非常抽象的概念,笔者在第一次学习时也是迷迷糊糊的(二叉树遍历),递归的代码看起来非常的简洁,优美,但是如何想出来递归的思路或者为什么能用递归这是初学者很难分析出来的 笔者在学习的过程中通过刷题,也总结出自己的一些经验,总结来…...

【JS】替换文本为emjio表情
最终效果展示 T1 T2 T3 T4 需求 把评论你好帅啊啊啊[开心][开心],[开心] 替换为图片 思路 正则match提取[开心]到一个数组数组去重创建img标签img标签转文本. 。例:(el.outerHTML),将el元素转文本字符串replaceAll…...

Solr完结版
Solr是基于Apache Lucene构建的用于搜索和分析的开源解决方案。提供可拓展索引、搜索功能、高亮显示和文字解析功能。本质是一个java web项目,内嵌Jetty服务器,安装方便。 请求Solr中的控制器,处理完数据后把结果相应给客户端 正向索引&#…...
外包干了5天,技术退步明显。。。。
说一下自己的情况,本科生,19年通过校招进入广州某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测试&a…...

Cronos zkEVM 基于 Covalent Network(CQT)数据可用性 API,推动其 Layer2 DeFi 生态更好地发展
在一项旨在显著改善 DeFi 生态的战略举措中,Cronos 与 Covalent Network(CQT)携手合作,以期待 Cronos zkEVM 的推出。这一整合,预计将进一步降低以太坊生态系统的交易成本、提升交易速度,并带来更好的交易体…...

基于SpringBoot的高校办公室行政事务管理系统
采用技术 基于SpringBoot的高校办公室行政事务管理系统的设计与实现~ 开发语言:Java 数据库:MySQL 技术:SpringBootMyBatis 工具:IDEA/Ecilpse、Navicat、Maven 页面展示效果 功能清单 教师信息管理 办公室管理 办公物资管…...
)
Linux系统及操作 (04)
Linux系统及操作 (03) RPM 软件包 网络下载对应软件包光盘镜像文件,具备软件包 Windows 系统软件包的管理 可以指定安装位置安装是集中安装到一个目录Linux 系统 与 Windows 系统相反。 常见的软件包(生态)类型 电脑入侵99%都是通过软件…...
粒子群算法 - 目标函数最优解计算
粒子群算法概念 粒子群算法 (particle swarm optimization,PSO) 由 Kennedy 和 Eberhart 在 1995 年提出,该算法模拟鸟群觅食的方法进行寻找最优解。基本思想:人们发现,鸟群觅食的方向由两个因素决定。第一个是自己当初飞过离食物…...

关于MySQL数据库的学习3
目录 前言: 1.DQL(数据查询语言): 1..1基本查询: 1.2条件查询: 1.3排序查询: 1.3.1使用ORDER BY子句对查询结果进行排序。 1.3.2可以按一个或多个列进行排序,并指定排序方向(升序ASC或降序DESC&#…...

笔试题——得物春招实习
开幕式排练 题目描述 导演在组织进行大运会开幕式的排练,其中一个环节是需要参演人员围成一个环形。演出人员站成了一圈,出于美观度的考虑,导演不希望某一个演员身边的其他人比他低太多或者高太多。 现在给出n个参演人员的身高,问…...

动手做简易版俄罗斯方块
导读:让我们了解如何处理形状的旋转、行的消除以及游戏结束条件等控制因素。 目录 准备工作 游戏设计概述 构建游戏窗口 游戏方块设计 游戏板面设计 游戏控制与逻辑 行消除和计分 判断游戏结束 界面美化和增强体验 看看游戏效果 准备工作 在开始编码之前…...

【极简无废话】open3d可视化torch、numpy点云
建议直接看文档,很多都代码老了,注意把代码版本调整到你使用的open3d的版本: https://www.open3d.org/docs/release/tutorial/visualization/visualization.html 请注意open3d应该已经不支持centos了! 从其他格式转换成open3d…...
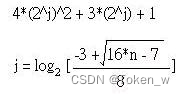
C语言经典算法-6
文章目录 其他经典例题跳转链接31.数字拆解32.得分排行33.选择、插入、气泡排序34.Shell 排序法 - 改良的插入排序35.Shaker 排序法 - 改良的气泡排序 其他经典例题跳转链接 C语言经典算法-1 1.汉若塔 2. 费式数列 3. 巴斯卡三角形 4. 三色棋 5. 老鼠走迷官(一&…...
【计算机考研】杭电 vs 浙工大 怎么选?
想求稳上岸的话,其他几所学校也可以考虑,以留在本地工作的角度考虑,这几所学校都能满足你的需求。 如果之后想谋求一份好工作,肯定优先杭电是比较稳的,当然复习的时候也得加把劲。 这个也可以酌情考虑,报…...
激活函数
优秀的激活函数: 非线性:激活函数非线性时,多层神经网络可逼近所有函数 可微性:梯度下降更新参数 单调性:当激活函数是单调的,能保证单层网络的损失函数是凸函数 近似恒等性:当参数初始化为…...

使用Jackson进行 JSON 序列化和反序列化
在Spring应用程序中,您可以通过Maven添加Jackson依赖,并创建一个工具类来封装对象的序列化和反序列化方法。以下是详细步骤: 1. 引入 Jackson 依赖 如果使用 Maven,您可以在 pom.xml 文件中添加以下依赖: <depend…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

亚马逊卖家公开信息数据提取:反爬攻防战与 Python 批量采集实战
摘要: 批量获取亚马逊(Amazon)第三方卖家的商业名称、信用代码和注册地址等信息,对于跨境 B2B 拓客和供应链分析具有重要意义。然而,亚马逊的 Cloudflare 盾和 Robot 验证码构成了极高的反爬门槛。本文将深度解析亚马逊…...

除了排错,你可能不知道OPC Expert v8.1还能做这些:数据归档、计算与冗余实战
解锁OPC Expert v8.1的隐藏潜力:数据归档、实时计算与冗余架构实战指南在工业自动化领域,OPC Expert常被视为故障排查的"急救箱",但它的能力远不止于此。当大多数工程师还在用它解决DCOM配置问题时,少数先行者已经用它重…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...
)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)第一次戴上Meta Quest 3时,那种虚拟与现实交织的震撼感至今难忘。但作为开发者,更让我着迷的是如何让虚拟物体在真实空间中"记住"…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

OpenRASP原理与实战:Java应用层实时防护技术详解
1. 为什么我宁愿花三天部署OpenRASP,也不愿再写第五个自定义WAF过滤器去年冬天,我在给一家做在线教育SaaS平台做安全加固时,连续踩了三个坑:第一次用NginxLua写了套SQL注入规则,结果学生提交的“SELECT * FROM courses…...