【论文阅读】MSGNet:学习多变量时间序列预测中的多尺度间序列相关性
MSGNet:学习多变量时间序列预测中的多尺度间序列相关性
- 文献介绍
- 摘要
- 总体介绍
- 背景及当前面临的问题
- 现有解决方案及其局限性
- 本文的解决方案及其贡献
- 背景知识的相关工作
- 背景知识
- 问题表述:
- Method论文主要工作
- 1.输入嵌入和剩余连接 (Input Embedding and Residual Connection)
- 扩展:embedding
- 2.尺度识别(Scale Identification)
- 3.多尺度自适应图卷积(Multi-scale Adaptive Graph Convolution)
- 4.多头注意力和尺度聚合(Multi-head Attention and Scale Aggregation)
- 5.输出层(Output Layer)
- 实验/评估/结果
- 实验设置
- 结果分析
- 实验1:对比实验
- 实验1:对比实验——Flight 数据集
- 实验2:学习序列间相关性的可视化
- 实验3:消融实验
- 实验4:泛化能力
- 实验5:较长输入序列下的性能
文献介绍
论文标题:MSGNet: Learning Multi-Scale Inter-Series Correlations for Multivariate Time Series Forecastin
论文链接: https://doi.org/10.48550/arXiv.2401.00423
代码链接: https://github.com/YoZhibo/MSGNet
发表年份: 2024
发表平台: AAAI
平台等级:CCF A
作者信息: Wanlin Cai 1 ^1 1, Yuxuan Liang 2 ^2 2, Xianggen Liu 1 ^1 1, Jianshuai Feng 3 ^3 3, Yuankai Wu 1 ^1 1
- Sichuan University
- The Hong Kong University of Science and Technology (Guangzhou)
- Beijing Institute of Technology
摘要
在多变量时间序列预测的领域中,时间序列数据通常表现出不同的序列内和序列间相关性,导致错综复杂和相互交织的依赖关系,精确理解和利用不同时间尺度上的多变量时间序列间的动态相关性是一个关键的挑战。为了应对这一挑战,本文提出了MSGNet模型, 该模型通过结合频率域分析与自适应图卷积技术,旨在高效捕捉跨不同时间尺度的多变量时间序列之间的相互依赖关系。MSGNet通过快速傅里叶变换(FFT)提取时间序列的周期性模式,并映射至关键时间尺度相关的空间,然后结合自注意力机制(self-attention mechanism)来捕获序列内依赖性,同时引入自适应混合跳图卷积层(adaptive mixhop graph convolution layer),以自主学习每时间尺度内的序列间相关性。
通过在数据集(Flight Weather ETTm1 ETTm2 ETTh1 ETTh2 Electricity Exchange )上进行的长时序预测实验(96 192 336 720),与TimesNet DLinear NLinear MTGnn Autoformer Informer相比,MSGNet的平均MSE和MAE达到sota。并且,MSGNet具有自动学习可解释的多尺度序列间相关性的能力, 即使在应用于分布外样本时也表现出强大的泛化能力,即该模型还表现出良好的对抗外部干扰(如COVID-19疫情)的能力,证明了其在面对未见过的数据分布时仍能保持较高性能的稳健性。(Flight数据集在疫情期间出现骤降,作者将骤降前作为训练集,骤降后作为测试集,因此样本分布不一样,但效果依旧sota)。
总体介绍
背景及当前面临的问题
时间序列预测在许多领域中都非常关键,它依赖于过去数据的模式来预测未来或隐藏的结果,核心挑战在于准确分析数据,识别数据之间的相互依赖性和时间趋势。研究主要集中在两个方向:一是内部序列相关性建模,它依据特定时间序列内的模式来预测未来值;二是序列间相关性建模,该方法研究多个时间序列之间的相互关系和依赖。
然而,现有的深度学习模型在捕捉多个时间序列在不同时间尺度上的序列间相关性变化方面存在显著不足。例如,在金融领域,不同资产价格之间的相关性,包括股票、债券和商品,在市场不稳定时期可能会因为避险现象而增加。相反,在经济增长期间,由于投资者分散投资组合以寻求不同的机会,资产间的相关性可能会减少。类似地,在生态系统中,控制物种种群数量和环境变量的动态动态表现出在不同时间尺度上的复杂时间相关性。不同时间尺度上序列间的相关性可能因市场或环境的变化而显著不同,现有模型未能有效捕捉这种在不同周期中序列间的复杂动态相关性,这构成了当前面临的一个主要问题。
以下图为例,我们在一个较长时间尺度上(scale1)可能观察到两个时间序列表现出正相关性,而在一个较短的时间尺度上(scale2),这两个序列可能展现出负相关性。这种情况下,如果我们采用基于图的分析方法,就能够构建出反映这两种不同时间尺度相关性的独特图结构。

在较长的时间尺度 1中,绿色和红色时间序列呈正相关,而在较短的时间尺度 2 中,它们呈现负相关。
现有解决方案及其局限性
虽然近年来深度学习模型,特别是循环神经网络(RNNs)、时间卷积网络(TCNs)和Transformers,在捕捉单个时间序列的内部动态方面取得了显著进展。同时,将多变量时间序列理解为图信号的新视角也逐渐浮现。在这类模型中,时间序列中的每个变量都可以视作图中的一个节点,它们通过隐藏的依赖关系相互连接。因此图神经网络(GNNs)便成了挖掘多时间序列间错综复杂依赖关系的有力工具。但这些模型在分析多变量时间序列作为图信号时,通常采用固定的图结构,难以适应序列间动态变化的相关性。尽管一些研究尝试通过动态和随时间变化的图结构来改进这一点,但这些方法往往忽视了相关性与具有显著稳定性的时间尺度之间的关键联系。
本文的解决方案及其贡献
为了克服上述局限,本文提出了一种新型深度学习模型——MSGNet(Multi-Scale Graph Network,它包含三个核心组件:尺度学习与转换层、多图卷积模块和时态多头注意力模块。MSGNet通过快速傅里叶变换(FFT)提取时间序列的周期性模式,并映射至关键时间尺度相关的空间,从而有效捕捉在不同尺度中的相关性。该模型还包含一个具有可学习邻接矩阵的多自适应图卷积模块,对于每个时间尺度,动态学习一个专用的邻接矩阵,使得模型能够捕捉与尺度相关的序列间相关性。另外还融合了一个多头自注意力机制,以同步捕捉序列内相关性。我们的贡献主要有三方面:
-
我们观察到序列间相关性与不同的时间尺度紧密相关。为此,我们提出了一个名为 MSGNet
的新型结构,它能够高效地发现并捕捉这些多尺度序列间相关性。 -
为了同时捕捉序列内和序列间的相关性,我们引入了多头注意力和自适应图卷积模块的组合。
-
通过在真实世界的数据集上进行广泛的实验,我们提供了实验证据,证明 MSGNet在时间序列预测任务中一致性地超越现有的深度学习模型。此外,MSGNet 展现出了更好的泛化能力。
背景知识的相关工作
背景知识
时间序列预测技术随时间不断进化,传统方法如VAR和Prophet基于序列变化遵循预设模式的假设,但面对现实世界中的复杂变化时,这些方法显得力不从心。为了应对这些挑战,被设计用于时间序列分析的深度学习模型,包括MLPs、TCNs、RNNs和基于Transformer的模型,相继被提出。此外,虽然某些研究如DEPTS和TimesNet尝试通过周期性分析来增强预测能力,但它们未能充分考虑在不同时间尺度上存在的序列间多样化相关性。另一方面,图神经网络(GNNs)近年来在捕获序列间相关性方面展现出潜力而受到关注,,但大多数GNN模型设计针对具有预定义图结构的情况,使得在没有明确图结构的多变量预测任务中,基于先前知识定义一个通用图结构的模型存在挑战。虽然已经有尝试探索可学习的图结构,但这些方法往往局限于考虑有限的图结构,并且在连接不同时间尺度的图结构方面存在不足,因此无法完全捕获序列间的复杂动态相关性。
问题表述:
在多变量时间序列预测的背景下,假设变量的数量为 N N N。给定输入数据 X t − L : t ∈ R N × L X_{t-L:t} \in \mathbb{R}^{N \times L} Xt−L:t∈RN×L,它代表了一个回顾窗口的观察值,包含从 t − L t-L t−L 到 t − 1 t-1 t−1 范围内每个变量 i i i 在 τ \tau τ 时刻的 X i τ X^\tau_i Xiτ 值。这里, L L L 表示回顾窗口的大小, t t t 表示预测窗口的起始位置。时间序列预测任务的目标是预测未来 T T T 时间步内的 N N N 个变量的未来值。预测的值由 X ^ t : t + T ∈ R N × T \hat{X}_{t:t+T} \in \mathbb{R}^{N \times T} X^t:t+T∈RN×T 表示,它包括了从 t t t 到 t + T − 1 t+T-1 t+T−1 每个时间点 τ \tau τ 对所有变量的 X i τ X^\tau_i Xiτ 值。
我们假设能够识别出 N N N 个时间序列在不同时间尺度上的不同序列间相关性,这些相关性可以通过图表示。例如,给定一个时间尺度 s i < L s_i < L si<L,我们可以从时间序列 X p − s i : p X_{p-s_i:p} Xp−si:p 中识别出一个图结构 G i = { V i , E i } G_i = \{V_i, E_i\} Gi={Vi,Ei}。这里, V i V_i Vi 表示节点集合, ∣ V i ∣ = N |V_i| = N ∣Vi∣=N, E i ⊆ V i × V i E_i \subseteq V_i \times V_i Ei⊆Vi×Vi 表示加权边, p p p 表示任意时间点。
考虑到 k k k 个时间尺度,表示为 { s 1 , ⋯ , s k } \{s_1, \cdots, s_k\} {s1,⋯,sk},我们可以识别 k k k 个邻接矩阵,表示为 { A 1 , ⋯ , A k } \{\mathbf{A}^1, \cdots, \mathbf{A}^k\} {A1,⋯,Ak},其中每个 A k ∈ R N × N \mathbf{A}^k \in \mathbb{R}^{N \times N} Ak∈RN×N。这些邻接矩阵捕捉了不同时间尺度上的不同序列间相关性。
Method论文主要工作
MSGNet旨在捕捉不同时间尺度上的不同序列间相关性。整个模型架构如图所示。模型由多个ScaleGraph块组成,每个模块包含三个关键模块:用于多尺度数据识别的 FFT 模块、用于时间尺度内系列间相关性学习的自适应图卷积模块以及用于系列内相关性学习的多头注意模块。即每个ScaleGraph块包含四个步骤:
- 确定输入时间序列的尺度;
- 使用自适应图卷积块揭示尺度相关的序列间相关性;
- 通过多头注意力捕捉序列内相关性;
- 使用SoftMax函数自适应地聚合不同尺度的表示。

1.输入嵌入和剩余连接 (Input Embedding and Residual Connection)
概述:这部分主要参考的是Informer等工作,输入主要是对原始输入序列做1维卷积,并加上position embedding和时间embedding。
我们将同一时间步的 N N N个变量嵌入到一个大小为 d model d_{\text{model}} dmodel的向量中: X t − L : t → X emb \mathbf{X}_{t-L: t} \rightarrow \mathbf{X}_{\text{emb}} Xt−L:t→Xemb,其中 X emb ∈ R d model × L \mathbf{X}_{\text{emb}} \in \mathbb{R}^{d_{\text{model}} \times L} Xemb∈Rdmodel×L。我们采用了Informer提出的统一输入表示法来生成嵌入。具体来说, X emb \mathbf{X}_{\text{emb}} Xemb是使用以下公式计算的:
X emb = α Conv1D ( X ^ t − L : t ) + P E + ∑ p = 1 P S E p . \mathbf{X}_{\text{emb}} = \alpha \text{Conv1D}\left(\hat{\mathbf{X}}_{t-L: t}\right) + \mathbf{PE} + \sum_{p=1}^{P} \mathbf{SE}_p. Xemb=αConv1D(X^t−L:t)+PE+p=1∑PSEp.
这里,我们首先对输入 X t − L : t \mathbf{X}_{t-L: t} Xt−L:t进行归一化,得到 X ^ t − L : t \hat{\mathbf{X}}_{t-L: t} X^t−L:t,因为归一化策略已被证明能有效地提高数据的平稳性。然后我们使用一维卷积滤波器(核宽度=3,步长=1)将 X ^ t − L : t \hat{\mathbf{X}}_{t-L: t} X^t−L:t投影到一个 d model d_{\text{model}} dmodel维的矩阵中。参数 α \alpha α作为一个平衡因子,调整标量投影与局部/全局嵌入之间的幅度。 P E ∈ R d model × L \mathbf{PE} \in \mathbb{R}^{d_{\text{model}} \times L} PE∈Rdmodel×L表示输入 X \mathbf{X} X的位置嵌入, S E p ∈ R d model × L \mathbf{SE}_p \in \mathbb{R}^{d_{\text{model}} \times L} SEp∈Rdmodel×L是一个可学习的全局时间戳嵌入,具有限定的词汇量大小(以分钟为最细粒度时为60)。
我们以残差方式实现MSGNet。在最开始,我们设置 X 0 = X emb \mathbf{X}^0 = \mathbf{X}_{\text{emb}} X0=Xemb,其中 X emb \mathbf{X}_{\text{emb}} Xemb代表通过嵌入层将原始输入投影到深层特征中。在MSGNet的第 l l l层,输入为 X l − 1 ∈ R d model × L \mathbf{X}^{l-1} \in \mathbb{R}^{d_{\text{model}} \times L} Xl−1∈Rdmodel×L,过程可以正式表达为:
X l = ScaleGraphBlock ( X l − 1 ) + X l − 1 , \mathbf{X}^l = \text{ScaleGraphBlock}\left(\mathbf{X}^{l-1}\right) + \mathbf{X}^{l-1}, Xl=ScaleGraphBlock(Xl−1)+Xl−1,
这里,ScaleGraphBlock表示构成MSGNet层核心功能的操作和计算。
扩展:embedding

这张图描绘了时间序列数据在输入到模型前的处理过程,尤其是在进行时间序列预测时如何将不同类型的时间信息嵌入(embedding)到模型中。这里有三层不同的嵌入:
- 标量投影(Scalar Projection):原始时间序列数据通常会被投影成一定长度的向量。在这个图示中, u 0 , u 1 , … , u 7 u_0, u_1, \ldots, u_7 u0,u1,…,u7 代表连续时间步的标量投影。
- 局部时间戳(Local Time Stamp):时间序列数据中的每一个时间点都会被分配一个位置嵌入(Position Embeddings),用来保持时间序列中的顺序信息。 P P P 代表位置编码, E 0 , E 1 , … , E 7 E_0, E_1, \ldots, E_7 E0,E1,…,E7 代表不同时间步的位置嵌入。
- 全局时间戳(Global Time Stamp):除了局部的时间顺序信息,全局时间戳嵌入提供了额外的时间信息,如所在的周、月、甚至假日信息。例如,周嵌入(Week Embeddings)能够让模型理解每个数据点是周中的哪一天;月嵌入(Month Embeddings)和假日嵌入(Holiday Embeddings)分别让模型知道每个时间点属于一年中的哪个月份和是否是特殊的日期或假日。
通过embedding能考虑局部时序信息以及层次时序信息,如星期、月和年等,以及突发时间戳信息(事件或某些节假日等),更全面地理解和捕捉时间序列数据中的时间动态和周期性模式。
2.尺度识别(Scale Identification)
作者将周期性作为尺度来源的选择,受 TimesNet的启发,采用快速傅立叶变换 (FFT) 检测突出的周期性作为时间尺度:
F = Avg ( Amp ( F F T ( X emb ) ) ) , f 1 , ⋯ , f k = argTopk f ∗ ∈ { 1 , ⋯ , L 2 } ( F ) , s i = L f i . \mathbf{F}=\operatorname{Avg}\left(\operatorname{Amp}\left(\mathbf{FFT}\left(\mathbf{X}_{\text{emb}}\right)\right)\right), f_1, \cdots, f_k=\operatorname{argTopk}_{f_* \in \left\{1, \cdots, \frac{L}{2}\right\}}(\mathbf{F}), s_i=\frac{L}{f_i}. F=Avg(Amp(FFT(Xemb))),f1,⋯,fk=argTopkf∗∈{1,⋯,2L}(F),si=fiL.
这里, F F T ( ⋅ ) \mathbf{FFT}(\cdot) FFT(⋅)表示对输入数据进行FFT,以将时间序列从时域转换到频域。在频域中,数据的周期性模式可以表现为不同频率的振幅。 Amp ( ⋅ ) \operatorname{Amp}(\cdot) Amp(⋅)用于计算FFT后各频率点的振幅值。振幅越大,表示该频率的周期性成分在时间序列中越显著,向量 F ∈ R L \mathbf{F} \in \mathbb{R}^L F∈RL包含了所有频率的平均振幅值,这个振幅在 d model d_{\text{model}} dmodel维度上通过函数 Avg ( ⋅ ) \operatorname{Avg}(\cdot) Avg(⋅)进行平均。
FFT检测显著周期性(TimesNet):

基于选定的时间尺度 { s 1 , … , s k } \left\{s_1, \ldots, s_k\right\} {s1,…,sk},我们可以通过使用以下方程将输入重塑为3D张量,得到对应不同时间尺度的多个表示:
X i = Reshape s i , f i ( Padding ( X in ) ) , i ∈ { 1 , … , k } , {X}^i=\operatorname{Reshape}_{s_i, f_i}\left(\operatorname{Padding}\left(\mathbf{X}_{\text{in}}\right)\right), \quad i \in \left\{1, \ldots, k\right\}, Xi=Reshapesi,fi(Padding(Xin)),i∈{1,…,k},
其中, Padding ( ⋅ ) \operatorname{Padding}(\cdot) Padding(⋅)用于在时间维度上通过添加零来扩展时间序列,使其适合 Reshape s i , f i ( ⋅ ) \operatorname{Reshape}_{s_i,f_i}(\cdot) Reshapesi,fi(⋅)操作。注意, X i ∈ R d model × s i × f i {X}^i \in \mathbb{R}^{d_{\text{model}} \times s_i \times f_i} Xi∈Rdmodel×si×fi表示基于时间尺度 i i i的第 i i i个重塑后的时间序列。我们使用 X in \mathbf{X}_{\text{in}} Xin来表示ScaleGraph块的输入矩阵。
3.多尺度自适应图卷积(Multi-scale Adaptive Graph Convolution)
作者提出了一种新颖的多尺度图卷积方法,用以捕捉特定和全面的序列间依赖关系。通过该方法,模型能够在不同的时间尺度上学习和表征时间序列之间复杂的关系,这对于提高时间序列预测的准确性非常关键。具体方法如下:
首先将对应于第 i i i个尺度的张量通过线性变换投射回含有 N N N个变量的张量,这里 N N N代表时间序列的数量。这个投射通过以下定义的线性变换来执行:
H i = W i X i . H^i = \mathbf{W}^i X^i . Hi=WiXi.
这里, H i ∈ R N × s i × f i H^i \in \mathbb{R}^{N \times s_i \times f_i} Hi∈RN×si×fi, W i ∈ R N × d model \mathbf{W}^i \in \mathbb{R}^{N \times d_{\text{model}}} Wi∈RN×dmodel是一个可学习的权重矩阵,专门为第 i i i个尺度的张量定制。
在该的方法中,图学习过程涉及生成两个可训练参数, E 1 i \mathbf{E}_1^i E1i 和 E 2 i ∈ R N × h \mathbf{E}_2^i \in \mathbb{R}^{N \times h} E2i∈RN×h。随后,通过乘以这两个参数矩阵后,根据以下公式得到一个自适应邻接矩阵(此处使用SoftMax函数来规范化不同节点间的权重,确保序列间关系的表示是均衡且有意义的。):
A i = SoftMax ( ReLU ( E 1 i ( E 2 i ) T ) ) . \mathbf{A}^i = \operatorname{SoftMax}(\operatorname{ReLU}(\mathbf{E}_1^i (\mathbf{E}_2^i)^T)) . Ai=SoftMax(ReLU(E1i(E2i)T)).
获得第 i i i个尺度的邻接矩阵 A i \mathbf{A}^i Ai 后,我们使用Mixhop图卷积方法来捕捉序列间的相关性,其已被证明具有代表其他模型可能无法捕捉的特征的能力。图卷积定义如下:
H out i = σ ( ∥ j ∈ P ( A i ) j H i ) , H_{\text{out}}^i = \sigma(\|_{j \in {P}} (\mathbf{A}^i)^j H^i), Houti=σ(∥j∈P(Ai)jHi),
其中, H out i H_{\text{out}}^i Houti 表示在尺度 i i i融合后的输出, σ ( ) \sigma() σ() 是激活函数,超参数 P \mathrm{P} P 是一组整数邻接幂次, ( A i ) j (\mathbf{A}^i)^j (Ai)j 表示学习到的邻接矩阵 A i \mathbf{A}^i Ai 自乘 j j j次, ∥ \| ∥ 表示列级连接,连接在每次迭代过程中生成的中间变量。然后,我们继续使用多层感知器(MLP)将 H out i H_{\text{out}}^i Houti 投射回一个3D张量 X ^ i ∈ R d model × s i × f i \hat{X}^i \in \mathbb{R}^{d_{\text{model}} \times s_i \times f_i} X^i∈Rdmodel×si×fi。

4.多头注意力和尺度聚合(Multi-head Attention and Scale Aggregation)
在每个时间尺度上,我们使用多头注意力(MHA)机制来捕捉序列内的相关性。具体地,对于每个时间尺度的张量 X ^ i \hat{\mathcal{X}}^i X^i,我们在该张量的时间尺度维度上应用自注意力的多头注意力机制:
X ^ out i = MHA s ( X ^ i ) . \hat{X}_{\text {out }}^i=\operatorname{MHA}_s\left(\hat{X}^i\right) . X^out i=MHAs(X^i).
这里, MHA s ( ⋅ ) \operatorname{MHA}_s(\cdot) MHAs(⋅)指的是Vaswani等人(2017年)提出的,在尺度维度上的多头注意力函数。在实现上,这涉及到将输入张量的大小从 B × d model × s i × f i B \times d_{\text {model }} \times s_i \times f_i B×dmodel ×si×fi重塑为 B f i × d model × s i B f_i \times d_{\text {model }} \times s_i Bfi×dmodel ×si的张量,其中 B B B是批量大小。尽管一些研究对于多头注意力在捕捉时间序列长期时间相关性的有效性提出了担心(Zeng等人,2023年),但我们通过采用尺度转换将长时间跨度转换为周期长度,成功地解决了这一限制。我们的结果显示,即使输入时间增长,MSGNet的性能也能保持一致(见附录)。
最后,为了进入下一层,我们需要整合 k k k个不同尺度的张量 X ^ out 1 , ⋯ , X ^ out k \hat{X}_{\text {out }}^1, \cdots, \hat{X}_{\text {out }}^k X^out 1,⋯,X^out k。我们首先将每个尺度的张量重塑回一个二维矩阵 X ^ out i ∈ R d model × L \hat{\mathbf{X}}_{\text {out }}^i \in \mathbb{R}^{d_{\text {model }} \times L} X^out i∈Rdmodel ×L。然后,我们根据它们的振幅来聚合不同的尺度:
a ^ 1 , ⋯ , a ^ k = SoftMax ( F f 1 , ⋯ , F f k ) , X ^ out = ∑ i = 1 k a ^ i X ^ out i . \begin{aligned} \hat{a}_1, \cdots, \hat{a}_k & =\operatorname{SoftMax}\left(\mathbf{F}_{f_1}, \cdots, \mathbf{F}_{f_k}\right), \\ \hat{\mathbf{X}}_{\text {out }} & =\sum_{i=1}^k \hat{a}_i \hat{\mathbf{X}}_{\text {out }}^i . \end{aligned} a^1,⋯,a^kX^out =SoftMax(Ff1,⋯,Ffk),=i=1∑ka^iX^out i.
在这个过程中, F f 1 , ⋯ , F f k \mathbf{F}_{f_1}, \cdots, \mathbf{F}_{f_k} Ff1,⋯,Ffk是每个尺度对应的振幅,使用FFT计算得到。然后应用SoftMax函数来计算振幅 a ^ 1 , ⋯ , a ^ k \hat{a}_1, \cdots, \hat{a}_k a^1,⋯,a^k。这种专家混合(MoE)策略使模型能够根据各自的振幅强调来自不同尺度的信息,有助于将多尺度特征有效地融合到下一层(见附录)。
5.输出层(Output Layer)
为了进行预测,我们的模型在时间维度和变量维度都使用线性投影,将 X ^ out ∈ R d model × L \hat{\mathbf{X}}_{\text {out }} \in \mathbb{R}^{d_{\text {model }} \times L} X^out ∈Rdmodel ×L 转换为 X ^ t : t + T ∈ R N × T \hat{\mathbf{X}}_{t: t+T} \in \mathbb{R}^{N \times T} X^t:t+T∈RN×T。这个转换可以表示为:
X ^ t : t + T = W s X ^ out W t + b . \hat{\mathbf{X}}_{t: t+T}=\mathbf{W}_{\mathbf{s}} \hat{\mathbf{X}}_{\text {out }} \mathbf{W}_{\mathbf{t}}+\mathbf{b} . X^t:t+T=WsX^out Wt+b.
这里, W s ∈ R N × d model , W t ∈ R L × T \mathbf{W}_{\mathbf{s}} \in \mathbb{R}^{N \times d_{\text {model }}}, \mathbf{W}_{\mathbf{t}} \in \mathbb{R}^{L \times T} Ws∈RN×dmodel ,Wt∈RL×T,和 b ∈ R T \mathbf{b} \in \mathbb{R}^T b∈RT 是可学习的参数。矩阵 W s \mathbf{W}_{\mathbf{s}} Ws 沿着变量维度执行线性投影,而 W t \mathbf{W}_{\mathbf{t}} Wt 则沿着时间维度执行同样的操作。结果 X ^ t : t + T \hat{\mathbf{X}}_{t: t+T} X^t:t+T 是预测的数据,其中 N N N 表示变量的数量, L L L 表示输入序列的长度,而 T T T 表示预测范围。
简单来说,这个过程首先通过 W s \mathbf{W}_{\mathbf{s}} Ws 将模型输出的特征映射到与原始变量数量相同的维度上,然后通过 W t \mathbf{W}_{\mathbf{t}} Wt 将这些特征映射到预测时间范围 T T T 上。这样,模型能够从多尺度特征提取的综合信息中,生成对未来时间步长 t t t 到 t + T t+T t+T 之间各变量的预测值。这种方法允许模型利用在整个训练过程中学习到的深层时间和变量间的关系,进行有效的时间序列预测。
实验/评估/结果
实验设置
实验环境:NVIDIA GeForce RTX 3090 24GB GPU
loss function:平均平方误差(MSE)
回顾窗口大小设置为L = 96
预测长度T = {96, 192, 336, 720}
初始学习率为LR = 0.0001
批量大小为Batch = 32
训练周期数为Epochs = 10,并在适用的情况下使用了早停策略
数据的划分比例为训练集、验证集和测试集分别占(0.7, 0.1, 0.2)
结果分析
实验1:对比实验
具有 96 个回顾窗口和预测长度 {96, 192, 336, 720} 的预测结果。最佳结果以粗体表示,次等的下划线。

如图表所示,MSGNet在5个数据集上取得了最佳性能,在2个数据集上取得了第二佳性能。在面对与COVID-19大流行相关的Flight数据集时,MSGNet超越了当前最佳方法TimesNet,平均MSE和MAE分别降低了21.5%和13.7%。虽然TimesNet使用了多尺度信息,但它采用了纯计算机视觉模型来捕捉序列间和序列内的相关性,这对于时间序列数据并不非常有效。Autoformer在Flight数据集上展现了出色的性能,这可能归因于其建立的自相关机制。MTGnn由于缺乏对不同尺度的关注,它的性能明显弱于MSGNet。通过评估模型在所有数据集上的平均排名,MSGNet显示出优异的泛化能力,平均排名超过了其他模型。这些结果证明了MSGNet在处理复杂时间序列预测任务时的优势,尤其是在对抗分布外样本时的鲁棒性方面。
实验1:对比实验——Flight 数据集
Flight预测结果的可视化:黑色真实值的线,预测值的橙色线,以及蓝色标记表示明显偏差

图为Flight预测结果的可视化图,MSGNet紧密地反映了真实情况,而其他模型在特定时间段内出现了明显的性能下降。图中的峰值和谷值与关键的飞行数据事件、趋势或周期性动态相一致。其他模型无法准确跟随这些变化,可能是由于其架构约束限制了它们捕捉多尺度模式、突然变化或复杂的序列间和序列内相关性的能力。
实验2:学习序列间相关性的可视化
图所示是MSGNet模型为不同的时间尺度(24小时、6小时和4小时)学习到了不同的自适应邻接矩阵,有效地捕捉了航班数据集中机场之间的交互作用。在机场6与机场0、1和3的距离较远,但在较长的时间尺度(24小时)上,它对这三个机场有着显著的影响。然而,随着时间尺度缩短(6小时和4小时),其对这些机场的影响显著减弱。另一方面,距离较近的机场0、3和5在较短的时间尺度上表现出更强的相互影响。这些观察结果反映了现实生活中的情况,表明在某些时间尺度上,由于物理接近性,航班之间可能存在更强的空间相关性。

Flight 数据集的学习邻接矩阵(第一层的 24h、6h 和 4h)和机场地图。
实验3:消融实验

考虑了5种消融方法,并在3个数据集上对它们进行了评估。以下将解释其实现的变体:
- w/o-AdapG:从模型中移除了自适应图卷积层(图学习)。
- w/o-MG:移除了多尺度图卷积,只使用了共享的图卷积层来学习整体的序列间依赖。
- w/o-A:移除了多头自注意力机制,消除了序列内相关性学习。
- w/o-Mix:用传统的卷积方法替换了混合跳跃卷积方法。
通过这些实验,发现移除图学习层会导致性能大幅下降,强调了学习序列间相关性的必要性;多尺度图学习的采用显著提升了模型性能,揭示了不同尺度间相关性的多样性;多头自注意力机制虽然只提供了边际性能提升,但其改进依然证明了其价值;最后,混合跳跃卷积的应用进一步提高了性能,尽管其缺失导致的性能降低有限,但仍突显了其对捕获复杂时间序列依赖关系的贡献。这些发现综合表明,MSGNet通过其独特的设计有效地捕捉了时间序列数据的复杂动态,证实了其先进性和有效性。
实验4:泛化能力
COVID-19 影响下的泛化测试:Decrease显示分区修改后性能下降的百分比。
在COVID-19大流行期间,欧洲主要机场的每日航班量急剧下降,类似于急剧下降,后来逐渐恢复
为了验证疫情对航班预测的影响以及MSGNet抵抗外部影响的性能,将Flight数据集的分区修改为4:4:2。将训练集限制为疫情爆发前的数据,并使用后续数据作为验证集和测试集。具体结果如图所示。通过捕获多尺度的系列间相关性,MSGNet不仅在两个不同的数据分区下实现了最佳性能,而且表现出最小的性能下降和最强的对外部影响的抵抗力。结果表明 MSGNet 对分布外(OOD)样本具有强大的泛化能力。我们假设这种优势归因于 MSGNet 捕获多个序列间相关性的能力,其中一些相关性即使在多元时间序列的 OOD 样本下仍然有效。
实验5:较长输入序列下的性能
MSGNet12:使用不同回顾窗口进行336个时间步的Flight数据集预测。我们用另外四个模型进行比较。
MSGNet13:MSGNet在ETT数据集上,针对不同回顾窗口大小进行336个时间步的预测性能
如图MSGNet12,在Flight数据集上的实验显示,MSGNet利用不同大小的回顾窗口来预测随后的336个时间步的值,能够有效提取时间序列的长期依赖关系。通过融合自注意力机制,MSGNet在捕获时间信息方面的表现超越了早期可能受到时间噪声过拟合影响的模型。即便在长回顾窗口的设置下,MSGNet相较于传统线性模型和其他模型,展现了更为稳健和显著的性能提升,这归功于其在内部采用的尺度转换技术(将长序列缩短为较短的序列),有效解决了捕捉长期时间序列相关性的挑战。此外,在图MSGNet13,通过在ETT数据集使用不同回顾窗口的性能进行了更深入的分析,我们进一步验证了MSGNet在处理扩展回顾窗口时的高效性,证明了尺度转换策略在优化模型处理广泛时间范围数据时的关键作用。
相关文章:
【论文阅读】MSGNet:学习多变量时间序列预测中的多尺度间序列相关性
MSGNet:学习多变量时间序列预测中的多尺度间序列相关性 文献介绍摘要总体介绍背景及当前面临的问题现有解决方案及其局限性本文的解决方案及其贡献 背景知识的相关工作背景知识问题表述: Method论文主要工作1.输入嵌入和剩余连接 (Input Embedding and R…...

智慧城市与数字孪生:共创未来城市的智慧生活
目录 一、智慧城市与数字孪生的概念与特点 二、智慧城市与数字孪生共创智慧生活的路径 1、城市规划与建设的智能化 2、城市管理与服务的智慧化 3、城市安全与应急管理的智能化 三、智慧城市与数字孪生面临的挑战与对策 四、智慧城市与数字孪生的发展趋势与展望 1、技术…...
【Ubuntu】FTP站点搭建
配置顺序 前提条件:确保软件仓库可以正常使用,确保已正常配置IP地址 1.安装FTP服务 2.编辑FTP配置文件 3.设置开机自启 4.创建用户 5.配置用户限制名单 6.重启服务 7.查看运行状态 8.测试在同一局域网下的Windows查看文件 1.安装FTP服务 sudo apt insta…...

RK3228H is the same SoC as rk3328.
RK3228H is the same SoC as rk3328....

Golang 开发实战day04 - Standard Library
Golang 开发实战day04 - Standard Library 接下来开始我们第四天学习,Go语言标准库提供了丰富的功能,可以帮助开发者快速完成各种任务。 golang就像其他语言一样,附带了一些非常轻量级的函数和特性,都是开箱即用的,这里…...

程序员排查BUG指南
程序员排查BUG(错误)是软件开发过程中的重要一环, 以下是一份程序员排查BUG的指南,帮助你更有效地识别、定位和修复问题: 1、重现BUG:确保能够准确地重现BUG,这是解决问题的第一步。尽量记录重现BUG的步骤。…...

【Vue】elementUI-MessageBox组件相关
官方代码: <template><el-button type"text" click"open">点击打开 Message Box</el-button> </template><script>export default {methods: {open() {this.$confirm(此操作将永久删除该文件, 是否继续?, 提示…...

数据库运行状况和性能监控工具
数据库监控是跟踪组织中数据库的可用性、安全性和性能的过程,它涉及通过跟踪各种关键指标来分析数据库的性能,确保数据库的正常运行并具有深入的可见性,并在出现潜在问题时触发即时警报,以采取主动措施来确保数据库的高可用性。 …...
CTF-辨别细菌
题目描述:try your best to find the flag. 进入靶场后发现是一个游戏,需要全部答对才可以得到最后的flag 查看了一下源码,发现有一个答案模板的模块 尝试解释一下代码 <!-- 答案模版 --> <script id"template_game_pi…...
RuoYi-Vue开源项目2-前端登录验证码生成过程分析
前端登录验证码实现过程 生成过程分析 生成过程分析 验证码的生成过程简单概括为:前端登录页面加载时,向后端发送一个请求,返回验证码图片给前端页面展示 前端页面加载触发代码: import { getCodeImg } from "/api/login&q…...

error: C preprocessor fails sanity check
问题 ./configure --prefix/opt/mips_lib/libev --hostmipsel-openwrt-linux CCmipsel-openwrt-linux-gcc运行后提示 checking how to run the C preprocessor... mipsel-openwrt-linux-gcc --sysroot/opt/mt7628/toolchain-mipsel_24kc_gcc-8.4.0_musl -I/opt/mt7628/toolch…...
-安装containerd)
Kubernetes实战(三十一)-安装containerd
1 资源 containerd项目官方地址 GitHub - containerd/containerd: An open and reliable container runtime containerd的发布版本地址: Releases containerd/containerd GitHub 2 安装containerd 2.1 解压安装 2.1.1 下载压缩包 curl -LO https://github…...

使用docker搭建faiss向量数据库
为了不污染服务器环境,保证程序运行时有更好的隔离性,领导要求基于容器运行程序。 一、准备工作 1、创建文件夹faiss 该文件夹有用于存放faiss相关的文件及脚本 mkdir ~/faiss 2、创建data文件夹 cd ~/faiss mkdir data 这个文件夹用于volume…...

安卓面试题多线程 121-125
121. 简述当一个线程进入某个对象的一个 synchronized 的实例方 法后,其它线程是否可进入此对象的其它方法 ?如果其他方法没有 synchronized 的话,其他线程是可以进入的。 所以要开放一个线程安全的对象时,得保证每个方法都是线程安全的122. 简述乐观锁和悲观锁的理解及如何…...
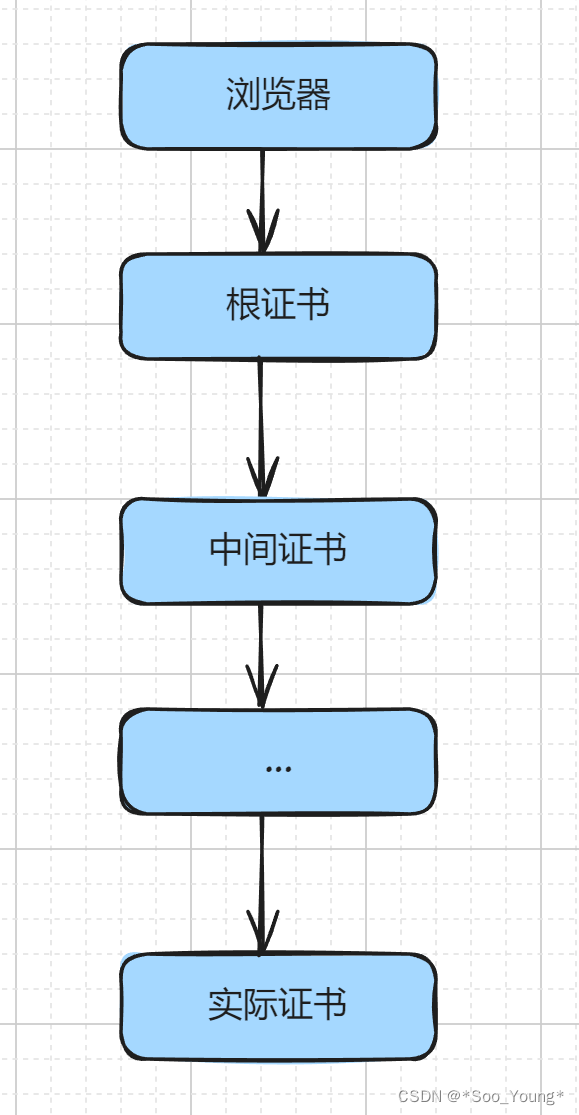
什么是 HTTPS?它是如何解决安全性问题的?
什么是 HTTPS? HTTPS(HyperText Transfer Protocol Secure)是一种安全的通信协议,用于在计算机网络上安全地传输超文本(如网页、图像、视频等)和其他数据。它是 HTTP 协议的安全版本,通过使用加…...
C++入门(下)
文章目录 1:引用1.1:引用概念1.2:引用的特性.1.2.1:引用在定义时必须初始化1.2.2:一个变量可以有多个引用1.2.3:引用一旦引用一个实体,再不能引用其他实体. 1.3:应用场景1.3.1:做参数1.3.2:做返回值1.3.2.1:传值返回1.3.2.2:传引用返回(错误示范)1.3.2.3:传引用返回(正确示范) …...

2024-03-20 作业
作业要求: 1> 创建一个工人信息库,包含工号(主键)、姓名、年龄、薪资。 2> 添加三条工人信息(可以完整信息,也可以非完整信息) 3> 修改某一个工人的薪资(确定的一个&#x…...

【机器学习】深入解析线性回归模型
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步! 【机器学习】深入解析线性回归模型 引入一 初步了解1.1 概念1.2 类比二 基本要素2.1 数据2.2 模型…...

新一代云原生数据库OLAP
2023 OLAP峰会(公开)PPT汇总(25份).zip 新一代云原生数据库的OLAP(联机分析处理)能力是其重要的特性之一,这种能力使得数据库能够支持复杂的数据分析查询,从而满足企业对大数据的深…...
JavaEE--小Demo
目录 下载包 配置 修改文件 pom.xml application.properties 创建文件 HelloApi.java GreetingController.java Greeting.java DemoApplication.java 运行包 运行命令 mvn package cd target dir java -jar demo-0.0.1-SNAPSHOT.jar 浏览器测试结果 下载包 …...

Android 11开发避坑:为什么你的App获取的Wifi MAC地址总是变?手把手教你配置固定MAC
Android 11开发实战:彻底解决Wifi MAC地址随机化问题最近在开发一个设备管理系统时,遇到了一个棘手的问题:我们的App在Android 11设备上获取的Wifi MAC地址每次都不一样,导致基于MAC地址的设备识别功能完全失效。经过一周的深入研…...

零基础轻松拿捏!魔珐星云青少年健康运动教学数字人搭建全流程指南
大家好!本次给大家分享一款面向青少年体育教育的AI创意实践项目——青少年健康运动教学智能数字交互系统。本项目聚焦青少年体质健康痛点,围绕体育教学智能化升级需求,打造集健康知识教学、运动动作陪练、健康知识考核、运动能力评测于一体的…...

组态王通用扫码枪配置
使用组态王扫码枪驱动,是绑定变量,扫码后直接就可以显示扫码内容。解决每次扫码输入数据时必须先用鼠标点进输入框内的问题。驱动安装先添加驱动,亚控网站的文件为 barcodescanner,这个文件是组态王通用扫码枪的驱动,但…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...

基于TESS光变曲线与深度学习的O型星物理参数预测研究
1. 项目概述与核心挑战在恒星天体物理研究中,大质量O型星扮演着至关重要的角色。它们不仅是宇宙中光度最高的天体之一,其强烈的辐射、恒星风和最终的超新星爆发,更是驱动星系化学演化和能量注入星际介质的关键引擎。然而,深入理解…...

NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台
NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft世界文件…...

5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南
5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 在Windows 10系统中使用PL2303 USB转串口设…...

软件测试行业的未来趋势:这3类测试将成为主流
随着数字化转型的深入推进,软件已经成为驱动各行业变革的核心生产力,从自动驾驶汽车到企业级云原生平台,从智慧医疗设备到工业互联网系统,软件的复杂度、规模和对安全性的要求都在呈指数级增长。作为软件质量保障的核心环节&#…...

修复 PowerShell 7 下 conda activate 报错的指南
修复 PowerShell 7 下 conda activate 报错的指南 适用场景:升级到 PowerShell 7.x 后,conda activate 突然报错,但 Windows PowerShell 5.1 正常。 发布日期:2026-05-24 适用版本:conda 23.x PowerShell 7.x 一、问题…...