走进jvm之垃圾回收器篇
这里我想首先说明一下,虽然我们经常会拿垃圾回收器来做比较,虽然想挑选一个最好的收集器出来,但是目前也没有说哪一款收集器是完美的,更不存在万能的收集器,我们也只是对收集器选择最适合场景的一个收集器。
那么作者将在接下来和大家探讨一些垃圾回收器的发展历程和优缺点,相信读完这篇的你也绝对不是白花时间,不过理解的过程有点枯燥,也希望大家有耐心看完,或者进行完善。
Serial收集器
这款收集器可谓是最原始的垃圾收集器了,这个收集器在回收的时候只会使用一个处理器或者一条收集线程,直到收集结束。也就是说用户的线程是可以并行的,但是在新生代和老年代的收集都是单线程GC,新生代采用复制,老年代采用标记整理,也就是说只要收集垃圾就会stop the world并且不可控还不可知,这对于用户来说简直是灾难。
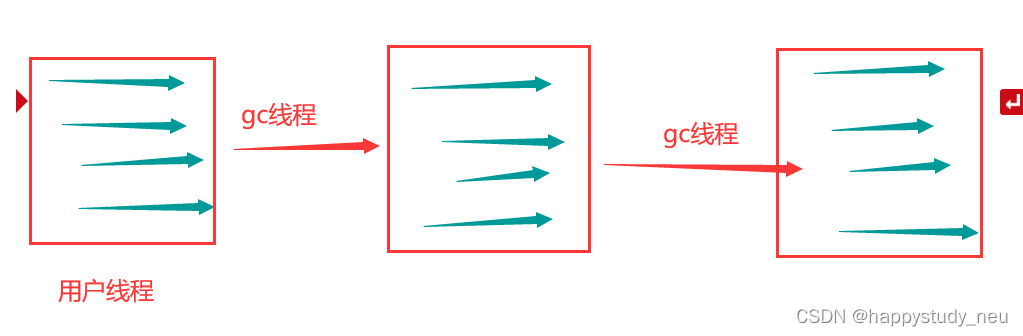
那大师们首先想到的思路就是,既然用户线程都可以进行多线程了,那么垃圾回收的时候如果也进行多线程,会不会更快呢?因此ParNew收集器就来了。
ParNew收集器
这里笔者也就不画图了,它和serial的区别就是在gc线程的时候,在新生代采用复制算法,并且用多线程并行收集。但是在老年代依然是采用标记整理算法的单线程。但是不得不说,在jdk7之前,除了serial收集器只有它能和cms收集器配合工作。
在jdk5发布的时候,hotsopt也推出了一个cms收集器,这个可以说是具有划时代的意义了。但遗憾的是,cms作为老年代收集器,却没有办法与jdk4中存在的新生代Parallel Scavenge配合工作。所以在jdk5中使用cms来收集老年代,新生代只能选择ParNew或者Serial收集器中的一个。parNew也算是抱上了cms的大腿。以后的出场它俩也是搭配出场。但遗憾的是什么,就是在g1回收器出来之后,就不需要其他新生代收集器配合了,因为g1是面向全堆的。
通过堆parnew的了解,也知道,parnew在单核情况下其实是和serial差不多的。
Parallel Scavenge收集器
Parallel Scavenge是一款新生代的收集器,是采用标记-复制算法实现的,同样从名字看出来它也是可以实现并行收集的回收器。但是我们要探究一下他和parnew的区别在哪里。
Parallel Scavenge的特点就是关注点和其他的不同,cms关注的是延迟也就是说尽可能缩短垃圾回收时候用户所暂停的时间,而Parallel Scavenge面向的是一个希望达到一个可控的吞吐量。吞吐量也就是处理器用于运行用户代码的时间和处理器总耗时的比值。当然是希望用户运行代码的时间越长越好。因此这款收集器也常常被称为吞吐量优先的垃圾处理器。
这里呢也可以提出一个参数,如果我们自己把我不好新生代伊甸园和幸存区的比例,新生代大小或者晋升老年大对象的大小,就激活参数-XX:+UseAdaptiveSizePolicy就可以了这个开关打开之后虚拟机会根据当前系统的运行情况去动态设置的。
Serial Old收集器
serial old收集器是serial收集器的老年代版本,同样的他也是一个单线程收集器,使用标记整理算法。这个垃圾收集器的意义就是供客户端模式下的虚拟机用。在服务端的话,jdk之前可以配合 Parallel Scavenge,另外一种就是作为cms收集器失败之后发生fullGc等等的后备方案。
Parallel Old收集器
这个收集器看名字就直到是Parallel Scavenge的老年代版本,采用标记整理算法,这个是支持多线程并行收集的,直到jdk6才有。不然的话往前看Parallel Scavenge其实很尴尬啊,如果新生代选择了这个那么老年代除了serial old(PS MarkSweep)意外就没得选啦,cms就不好使啊。如果但是用Parallel Scavenge作为新生代的话,由于serial old太垃圾的话也没有办法充分利用服务端的多处理器并行能力,直到这个Parallel Old出来了,吞吐量优先才算是脑子和脖子接上了,表示我自己还没有适应这具躯体哈哈哈。
注意第一个是新生代Parallel,是采用的复制算法。后面的才是老年代gc的标记整理。
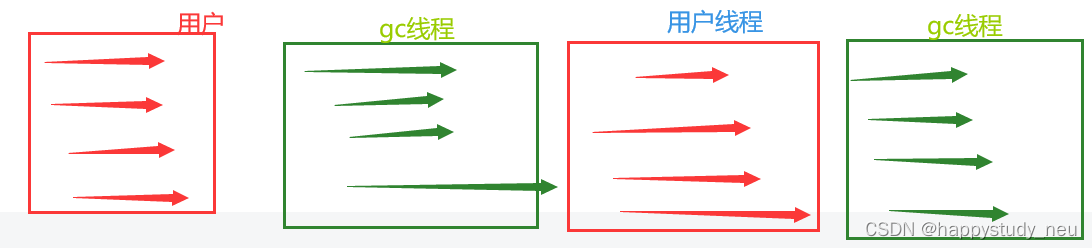
CMS收集器
接下来我们终于介绍到了小时代1.0的cms收集器了。在之前提到的垃圾回收器的时候,优化点在于把单线程的垃圾回收工作转为多线程?那么有没有更好的优化方式呢?随着科技的进步答案显而易见,就是我们可不可以让垃圾回收的过程和用户线程一起并发呢?这就是需要很大的挑战了,下面我们来看看cms是怎么做的。
concurrent mark sweep可以看出,这个是基于标记清除的垃圾处理器,因此下意思的反应就是它是否会产生内存碎片呢?答案是肯定的。
cms的回收工作可以拆分成四个过程,初始标记,并发标记,重新标记,并发清除。除了带并发两个字的,其他的都是需要stop world的。
但是初始标记过程只是标记一下GC Roots能关联到的对象,这个速度是很快的,而并发标记就是从GcRoot直接关联的对象开始遍历整个对象图的过程。这个过程耗时较长但是不需要停顿用户线程。而重新标记阶段则是要修正并发标记期间,因为用户线程可以与垃圾回收器一起工作和产生变动的那一部分对象,这个是需要重新标记的,这个阶段的停顿时间比初始标记稍长但也远比并发标记的时间要短。最后就是并发清除阶段,用于清除已经标记为死亡的对象,这个阶段也是可以与用户线程进行并发的。
这里面耗时最长的就是并发标记和并发回收了。总体上来说,cms内存回收阶段是和用户线程一起进行的。

缺点
但是我们也不得不提到几个问题
1.cms处理器既然不回导致用户停顿,肯定是因为占用一部分线程或者说是处理器,那么应用程序就会变慢,因为资源是有限的不可避免吞吐量会降低。也就是说处理器的核心数非常重要,太少了就别来擦边了。那么为了缓解这种情况,虚拟机也提供了一种增量式并发收集器,主打在并发标记和清理的时候让收集器线程和用户线程交替执行,就是要干活就只有一个干活,别一起上。这样只管速度感受就好一些,但这个已经不建议使用了。
2.由于用户线程和并发标记和并发清理阶段线程是并行的,所以不可避免地就会造成有一部分对象是无法进行回收,只能留着下一次回收,这种垃圾就是浮动垃圾。因此cms收集器不能像其他处理器一样等老年代几乎填满了再进行收集,而是必须预留一部分空间供并发收集时地程序使用。如果cms运行期间预留地空间无法分配对象了,那么不好意思只能并发失败冻结用户线程,临时用serial old去重新收集老年代,这样用户停顿时间就会很长,几乎game over了。
3.在开头我们就已经提到了标记删除不可避免地会带来空间碎片,空间不连续的问题,这个也会造成我们之前提到地full gc的问题。
Garbage First收集器
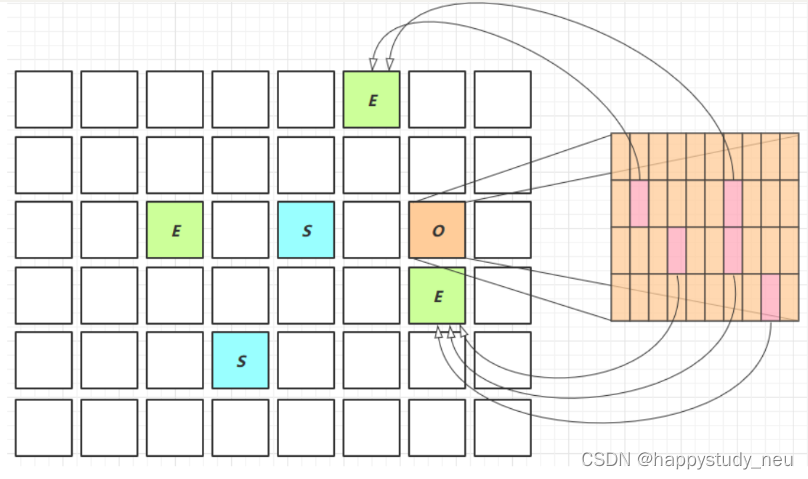
G1收集器又是一个划时代的垃圾回收器。简称小时代2.0版本吧。他有一个很大的思想转变就是把内存的区域化整为零,采用面向局部收集,基于region的内存布局形式。g1是主要面向服务端的垃圾回收器。
它的阶段可以分为,初始标记,并发标记,最终标记,筛选回收。采用复制整理算法。这里可以知道这个是没有内存碎片的。
jdk9发布时直接取代了PS+PS Old了。成为默认垃圾回收器。这里主要讲解它的闪光点和它的缺点。
一款可预测暂停时间的停顿预测模型。这里只指定一个长度为m毫秒的时间片段内,消耗在垃圾收集上的时间打开率不超过n毫秒这样的目标。
g1跳出了回收面向的对象要么是老年代要么是新生代的局限,它可以面向堆内存的任何一部分来组成回收集,衡量标准不再是哪个代而是那块内存中垃圾数量最多,回收效益最大就回收哪部分。


region的每一块是想等大小的,每一个region都可以根据需要来扮演新生代的eden空间,survior空间或者老年代空间。收集器能够根据某一块的角色不同区采用不同的策略。
region还有一类特殊的就是humongous区域,专门用来存储大对象的。当对象空间大于一region容量一般的时候就可以判定为大对象。而g1对humongous当作老年代来看,如果大小超过了一个的话,他也会用连续的内存空间进行存储。
G1之所以能建立可预测的停顿模型,是因为它将region作为单词回收的最小单元,即每次收集到的内存空间都是region大小的整数倍,这样可以有计划地避免在整个java堆中进行全区域地垃圾收集。更具体地处理就是让G1跟踪各个region地垃圾堆积地价值大小,然后在后台维护一个优先级表,每次再结合用户允许地收集停顿时间去回收价值收益最大的那些region。
但是往往将一个整体细化成各个细碎的东西,虽然更灵活,反之带来的代价就是它的维护更麻烦。这个概念就跟单体项目和微服务项目一样。
问题
1.难维护,耗内存
将堆分为region中,跨代引用如何解决?我们可以使用记忆集来避免全堆作为GCRoot扫描,但g1收集器毫无疑问会更加的复杂。g1的记忆集本质上是一个哈希表,key是region的起始位置,value是一个集合,存储元素是卡表的索引号。这种双向卡既知道我指向谁,又知道谁指向我。并且由于region的庞大数量,索引g1至少要花费相当于java堆内容10%-20%的内存来维持收集器工作。
2. 如何在并发标记阶段保收集线程与用户线程互不干扰的运行?这里首先要解决的就是用户线程改变对象引用关系的问题,需要保证不能打乱原来的图结构导致结果错误。cms通过增量更新解决,而g1则是通过satb快照进行解决,有点类似与mvcc里的readview参数的快照,这个应该是类似于可重复读级别的快照。而用户线程在运行的时候肯定又会产生新对象,这部分对象region每一个region设计了两个名为tams的指针,把region的一部分空间分出来用来给这部分新对象进行分配。但是如回收速度赶不上对象创建的速度,就又会导致fullGC,与cms类似,冻结用户线程,产生长时间的stop the world。
3.如何建立起可靠的停顿预测模型呢?
这里最好是更新region的统计状态,这个状态越新肯定效果最好。当然停顿时间不是越短越好,如果垃圾太多却来不及收集,空间没了依然会发生fullGc的。
4.执行负载高
为了实现原始快照satb,还需要使用写前屏障来跟踪并发时的指针变化,相比增量更新,虽然能减少并发标记和重新标记的损耗,但在用户程序运行过程中会产生由跟踪引用变化带来的额外负担。
由于g1的写屏障比cms的复杂很多,所以g1不像cms是同步的,而是采取类似消息队列的结构去异步处理。
最后来看,在小内存的应用上,还是cms比较好,但随着g1的不断优化,这是谁也都说不好的事情。
低延迟垃圾收集器
这里不得不说一下前面垃圾回收器的思想的转变,我的理解是,由单线程到多线程。由只能暂停用户线程到可以部分和用户线程一起进行,再到对管理的对象化整为零,从整个堆内存变成分region的堆内存。
Shenandoah
G1已经那么牛逼了。但是我们是不是还有优化空间呢?随着计算机的发展,硬件提升,这个内存量是越来越能容忍大内存了。但是作文衡量垃圾回收器的指标,内存占用,延迟和吞吐量来说,大内存带来的反而是低延迟,因为回收小区和楼道的垃圾的时间是不一样的。那么在和用户并行的阶段,不可避免地问题就是新对象的不断创建和旧对象的地址引用修改。
Shen的优化思路,能否能让 回收的整个过程都是并发的呢?
因此shen只有在初始标记和最终标记有短暂的停顿,而这个停顿时间基本都是固定的,与GC ROOt对象有关,和堆大小,对象数量没有正比例关系。
shen和G1有着相似的堆内存布局,思想上几乎是一致,那么我们来说说他们的不同了吧。
1.G1的回收阶段不可以与用户并发,但是shen可以。
2.shen没有实现分代,但并不代表着分代不重要。这个只不过权衡利弊后的结果,不用花费大内存去维护记忆集,而是利用连接矩阵来记录region的跨region引用问题,这也降低了伪共享的概率。
它的细碎阶段分为:初始标记,并发标记,最终标记,并发清理,并发回收,初始引用更新,并发引用更新和并发清理阶段。
其实最重要的阶段可以分为三个:并发标记,并发回收,并发引用更新。
说精华:并发标记是遍历处GcRoot全部可达的对象。时间长短取决于堆中对象存活对象的数量以及对象图结构的复杂度。
并发回收:把存活的对象复制到其他未被使用的region里,这点有点类似与copy on write了。但是旧的引用时很难改变到新的引用的,这里用到了读屏障和转发指针来解决。时间长短取决于会收集的大小。
并发引用更新:与用户线程并发,时间长短取决于内存中涉及的引用数量的多少。并发引用更新和并发标记不同。它不再沿着对象图搜索吗,而是按照内存物理地址顺序,线性搜索索引引用类型,把旧值更改为新的值旧可以了。最后一次停顿,只与GCroot数量有关。
最后的并发清理,此后没有任何存活对象了。
问题
这里要注意转发指针改变地址过程中,更新某个对象的字段的问题。这个有点和指令交错的问题有点像,所以这里采用了cas来保证成功实现。但是转发指针每一次使用都会产生一次额外的引用开销。
2.读屏障的过度使用
读屏障由于过于频繁,所以会堆积大量的操作,这里也是不希望有任何重量级的操作,所以后期优化过程中,将内存屏障模型改为引用访问屏障,只拦截对象中数据类型为引用类型的读写操作,而不会去管原生数据类型等其他非引用字段的读写。
成果
最大停顿时间没有实现10ms以内,但是却也远远优于G1,CMS,PS了。因此是低延迟的垃圾回收器。但是吞吐量却下降了。
ZGC
ZGC的目标是希望在对吞吐量影响不大的目标下,还能进一步优化低延迟的回收。
这里说一下它的不同点。堆内存布局,这回不仅仅是面向region了,还从灵活到具体,为region分配了不同大小,例如2MB的,32MB的,小型中型region,还有大小不定的大region。
那么它的核心问题:并发算法是如何实现的呢。这里与Shenandoah的转发指针不同且牛逼的是,它采用了染色指针的技术。如果在对象头中存储信息,例如哈希码,锁记录等这样的,但是如果对象存在被移动的可能性,又如何能够访问成功呢。而ZGC的染色指针直接最存粹,最直接,直接把标记信息放到了引用对象的指针上了。
linux下,尽管64位指针的高18位不能用来寻址,但剩余的46位指针所能支持的依然可以满足大部分服务器的需要。所以ZGC把高四位提取出来存储4个标志信息。通过标志位虚拟机就能看到其引用对象的三色标记状态。
染色指针
染色指针可以使得一旦某个region存活的对象被移走之后,这个region就能够被立刻释放掉和重用掉,而不必等待整个堆中所有指向该region的对象被修正后才能清理,这里可以与shen做一个横向对比。
染色指针可以大幅减少在垃圾回收过程中内存屏障使用数量。这些信息直接维护在指针中,而且目前为止ZGc并未使用过写屏障,只是用读屏障。一部分是因为使用了染色指针技术,一部分是因为还没实现分代收集。
但是要顺利应用染色指针还需要解决一个问题。java虚拟机只是一个进程,随意定义内存中指针的某几位数字,操作系统大哥是否支持呢,处理器大哥是否支持呢。这个问题在Solaris/SpARC平台就比较容易解决,因为他是支持虚拟地址掩码的,设置之后就可以直接忽略染色指针的标志位,有点类似于子网掩码了。但是在X86-64平台上却没有这样的能力,因此ZGC采用了虚拟内存映射技术。ZGC在Linux/x86-64上使用了多重地址映射将多个不同的虚拟内存地址映射到同一个物理内存地址上。这意味着ZGC在虚拟内存中看到的地址空间要比实际的堆内存容量更大。只需要将染色指针的标志位看成是分段符,将这些不同的地址段都映射到同一个物理内存空间就好了,这样多重映射后就可以用染色指针正常寻址了。
运行
它的阶段可以分为,并发标记,并发预备重分配,并发重分配,并发重映射。
并发标记阶段与G1,Shen不同的是,zgc的标记是在指针上而不是对象上,更新染色指针的mark0和marked1标志位。
并发预备重分配:这里并不会像G1做收益优先回收,反而是用范围更大的扫描成本去换取省去G1中记忆集的维护成本。因此ZGC重分配只决定了里面的存活对象会被复制到其他的region中,复制过后原本的region会释放。这个标记过程针对全堆。
并发重分配:核心。这个也是完成对旧对象到新对象得引用转换上。访问操作会被内存屏障截获,从region得转发表上转发到新复制得对象并且修正新引用得值。直接指向新对象。与shen相比,只有第一次访问会陷入转发,其他就不会影响了,因为它会自愈。
并发重映射:这个也不是迫切需要做得工作,因为染色指针有自愈能力,它可以慢慢得改变旧的引用定位到新的引用上面去。这样旧的转发表就可以释放掉了。
缺点
zgc能接收的对象分配速率实际上不是很高,因为zgc要准备对一个非常大的堆做垃圾回收并发收集,因为他是并行的,所以不回给用户感觉上的停顿,创造的大量对象由于来不及进入当此标记的收集范围,因此只能当作全部存活来看,这就是大量的浮动垃圾,如果告诉分配持续的话,一次完整的并发收集周期会很长,除了增大堆内存容量外,更根本的方法是希望引入分带收集。
成果
zgc目前虽然还在实验状态,但它的成果是非常显著的,在吞吐量方面,已经无线接近于PS,直接超越G1,在停顿时间延迟上面,直接控制在10ms以内,秒杀其他所有。相信它商业化之后会非常的牛逼。
好啦,如果大家喜欢的化,就点个赞吧,分享整理笔记不易,欢迎沟通交流
相关文章:
走进jvm之垃圾回收器篇
这里我想首先说明一下,虽然我们经常会拿垃圾回收器来做比较,虽然想挑选一个最好的收集器出来,但是目前也没有说哪一款收集器是完美的,更不存在万能的收集器,我们也只是对收集器选择最适合场景的一个收集器。 那么作者将…...

rtt自动初始化机制学习
通过以下两篇文章基本能搞懂rtt的自动初始化机制,从此你也可以借鉴写自己的自动初始化段(section)。 1点这里 https://blog.csdn.net/qq_38824401/article/details/119717389 2点这里 https://club.rt-thread.org/ask/article/d686458bbba864f4.html section背景…...
基于SpringBoot和Vue的大学生租房系统的设计与实现
今天要和大家聊的是一款今天要和大家聊的是一款基于SpringBoot和Vue的大学生租房系统的设计与实现。 !!! 有需要的小伙伴可以通过文章末尾名片咨询我哦!!! 💕💕作者:李同…...
ai制图常用的软件有哪些?这5款ai生图工具值得推荐!
过去提起制图,它是一项具备高度专业化的创作活动,需要由熟练掌握制图技能的人完成,且制图通常包含的步骤繁多,很容易劝退想学习或者入门制图的新手,但随着 ai 人工智能技术在各个领域的落地,我们有机会用上…...

一分钟了解JAVA语言
Java语言诞生于1995年,由Sun Microsystems(后被Oracle收购)的工程师James Gosling等人开发。最初被设计用于家用电器控制系统,但很快就在互联网应用开发中得到广泛应用。Java之父詹姆斯高斯林希望开发一种可以适应不同计算机架构的…...
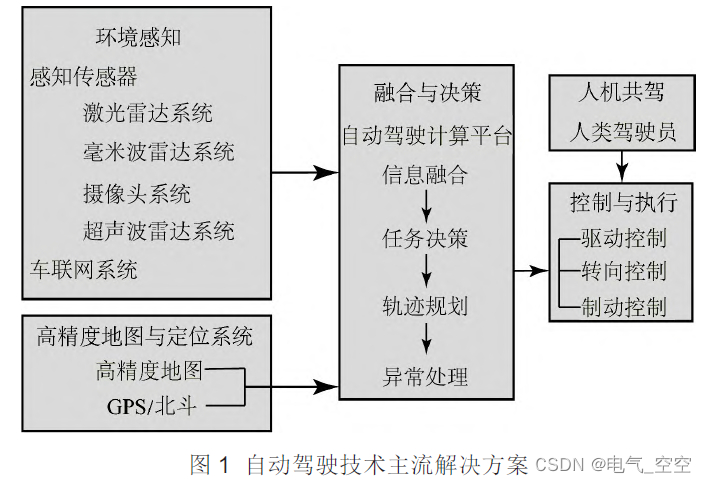
L4 级自动驾驶汽车发展综述
摘要:为了减小交通事故概率、降低运营成本、提高运营效率,实现安全、环保的出行,自动驾驶 技术的发展已成为大势所趋,而搭配有L4 级自动驾驶系统的车辆是将车辆驾驶全部交给系统。据此,介绍了自动驾驶汽车的主流技术解决方案;分析了国内外L4 级自动驾驶汽车的已发布车型、…...

HTML + CSS 核心知识点- 定位
简述: 补充固定定位也会脱离文档流、不会占据原先位置 1、什么是文档流 文档流是指HTML文档中元素排列的规律和顺序。在网页中,元素按照其在HTML文档中出现的顺序依次排列,这种排列方式被称为文档流。文档流决定了元素在页面上的位置和互相之…...
Spring MVC(二)-过滤器与拦截器
过滤器和拦截器在职责和使用场景上存在一些差异。 过滤器 拦截器 作用 对请求进行预处理和后处理。例如过滤请求参数、设置字符编码。 拦截用户请求并进行相应处理。例如权限验证、用户登陆检查等。 工作级别 Servlet容器级别,是Tomcat服务器创建的对象。可以…...

python vtk读取vtk文件
参考: https://cloud.tencent.com/developer/ask/sof/101993637 方法一:使用pyvtk 要使用Python读取VTK文件,可以使用pyvtk库。首先,确保已经安装了pyvtk。如果没有安装,可以通过pip安装: csharp pip ins…...

LeetCode 2671.频率跟踪器:俩计数哈希表
【LetMeFly】2671.频率跟踪器:俩计数哈希表 力扣题目链接:https://leetcode.cn/problems/frequency-tracker/ 请你设计并实现一个能够对其中的值进行跟踪的数据结构,并支持对频率相关查询进行应答。 实现 FrequencyTracker 类:…...

NAT笔记
NAT 用于实现内网和外网之间的互访。 静态NAT 静态NAT实现内网地址和外网地址的一对一转换。 有2种配置方法: 全局模式下设置静态NAT [R1]nat static global 172.10.10.10 inside 192.168.10.10 [R1]int g0/0/1 #外网接口 [R1-GigabitEthernet0/0/1]nat static…...

MySQL 数据库的备份和还原
1.命令行 备份语法 mysqldump -u用户名 -p密码 数据库名称 > 保存的路径还原语法 1.登陆数据库 2.创建数据库 3.使用数据库 4.执行文件 source 文件路径2.图形化(太简单了不写了) 点击返回 MySQL 快速学习目录...

初识CSS样式 与 文本背景样式
目录 前言: 1.什么是CSS: 2.关于css的主要特性: 2.1层叠性: 2.2继承性: 2.3优先级: 2.4.CSS的组成结构: 3.css样式的三种写法: 3.1内联样式: 3.1.2存在的优点和缺点: 3.2内部样式表: 3.2.2存在的优点和缺点:…...

JSR380验证框架
依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-validation</artifactId> </dependency>demo Size(min10,max200 ,message"描述需要控制在10到200字符") Min(valu…...
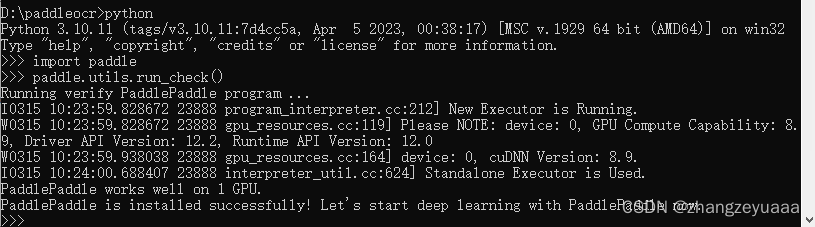
百度paddleocr GPU版部署
显卡:NVIDIA GeForce RTX 4070,Nvidia驱动程序版本:537.13 Nvidia驱动程序能支持的最高cuda版本:12.2.138 Python:python3.10.11。试过python3.12,安装paddleocr失败,找不到相关模块。 飞桨版本…...

node.js 常用命令
Node.js的常用命令包括多种类型,从运行JavaScript文件到管理Node.js的模块和包。以下是一些主要的Node.js常用命令: 运行JavaScript文件: node filename.js 这个命令会调用Node.js程序来运行指定的JavaScript文件。 查看文件和目录…...
)
Easypoi实现导出Excel(简单高效)
今天做报表导出,网上找了很多导出的方法,最后总结发现以下方法是最简便,更易维护的导出方法,下面来分享给大家。 1、首先引入相关依赖 <!--EasyPoi 报表--><dependency><groupId>cn.afterturn</groupId>…...

python之pathlib库使用介绍
pathlib 是 Python 标准库中用于处理文件路径的模块。它提供了一种面向对象的方式来操作文件和目录路径,简化了路径操作的编码和跨平台的兼容性。下面是 pathlib 库的基本介绍和使用方法: 1.导入 pathlib 模块 from pathlib import Path 2.创建路径对…...
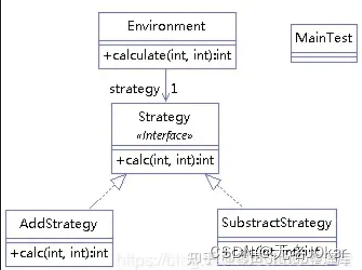
Java:设计模式
文章目录 参考简介工厂模式简单工厂模式工厂方法模式抽象工厂模式总结 单例模式预加载懒加载线程安全问题 策略模式 参考 知乎 简介 总体来说设计模式分为三类共23种。 创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模…...
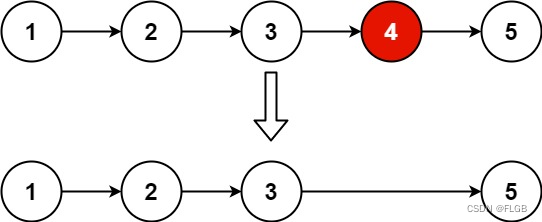
【链表】Leetcode 19. 删除链表的倒数第 N 个结点【中等】
删除链表的倒数第 N 个结点 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5] 解题思路 1、使用快慢指针找到要删除节点的前一个节点。2、删…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...

Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度
Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对抗中经历过这样的挫败:同时按下左右方向键时角色卡…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...
:3类高危使用场景+2个监管红线预警)
Claude SWOT分析(内部风控文档流出版):3类高危使用场景+2个监管红线预警
更多请点击: https://intelliparadigm.com 第一章:Claude SWOT分析(内部风控文档流出版):3类高危使用场景2个监管红线预警 高危使用场景识别 在企业级AI应用中,Claude模型若未经严格风控适配,…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...

3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍
3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在为网易云音乐功能单一而烦恼吗?想要解锁更多个…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...

猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧
猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到心仪的视频无法…...
)
用ESP32-C3的PWM做个RGB呼吸灯吧:从配置结构体到色彩渐变(乐鑫ESP-IDF实战)
ESP32-C3 RGB呼吸灯实战:从PWM配置到色彩渐变算法 当智能家居的灯光不再只是简单的开关控制,而是能像呼吸般自然渐变时,整个空间的氛围立刻变得生动起来。ESP32-C3凭借其出色的LED PWM控制器(LEDC)外设,为开…...

机器学习赋能矩方法:破解稀薄气体强非平衡流动模拟难题
1. 项目概述:当矩方法遇见机器学习在计算流体力学领域,模拟稀薄气体动力学和强非平衡流动,一直是个让工程师和科学家们头疼的“硬骨头”。想象一下,你正在设计一架高超音速飞行器,当它以数倍音速在大气层边缘飞行时&am…...