Spark Rebalance hint的倾斜的处理(OptimizeSkewInRebalancePartitions)
背景
本文基于Spark 3.5.0
目前公司在做小文件合并的时候用到了 Spark Rebalance 这个算子,这个算子的主要作用是在AQE阶段的最后写文件的阶段进行小文件的合并,使得最后落盘的文件不会太大也不会太小,从而达到小文件合并的作用,这其中的主要原理是在于三个规则:OptimizeSkewInRebalancePartitions,CoalesceShufflePartitions,OptimizeShuffleWithLocalRead,这里主要说一下OptimizeSkewInRebalancePartitions规则,CoalesceShufflePartitions的作用主要是进行文件的合并,是得文件不会太小,OptimizeShuffleWithLocalRead的作用是加速shuffle fetch的速度。
结论
OptimizeSkewInRebalancePartitions的作用是对小文件进行拆分,使得罗盘的文件不会太大,这个会有个问题,如果我们在使用Rebalance(col)这种情况的时候,如果col的值是固定的,比如说值永远是20240320,那么这里就得注意一下,关于OptimizeSkewInRebalancePartitions涉及到的参数spark.sql.adaptive.optimizeSkewsInRebalancePartitions.enabled,spark.sql.adaptive.advisoryPartitionSizeInBytes,spark.sql.adaptive.rebalancePartitionsSmallPartitionFactor 这些值配置,如果这些配置调整的不合适,就会导致写文件的时候有可能只有一个Task在运行,那么最终就只有一个文件。而且大大加长了整个任务的运行时间。
分析
直接到OptimizeSkewInRebalancePartitions中的代码中来:
override def apply(plan: SparkPlan): SparkPlan = {if (!conf.getConf(SQLConf.ADAPTIVE_OPTIMIZE_SKEWS_IN_REBALANCE_PARTITIONS_ENABLED)) {return plan}plan transformUp {case stage: ShuffleQueryStageExec if isSupported(stage.shuffle) =>tryOptimizeSkewedPartitions(stage)}}
如果我们禁用掉对rebalance的倾斜处理,也就是spark.sql.adaptive.optimizeSkewsInRebalancePartitions.enabled为false(默认是true),那么就不会应用此规则,那么如果Col为固定值的情况下,就只会有一个Task进行文件的写入操作,也就只有一个文件,因为一个Task会拉取所有的Map的数据(因为此时每个maptask上的hash(Col)都是一样的,此时只有一个reduce task去拉取数据),如图:
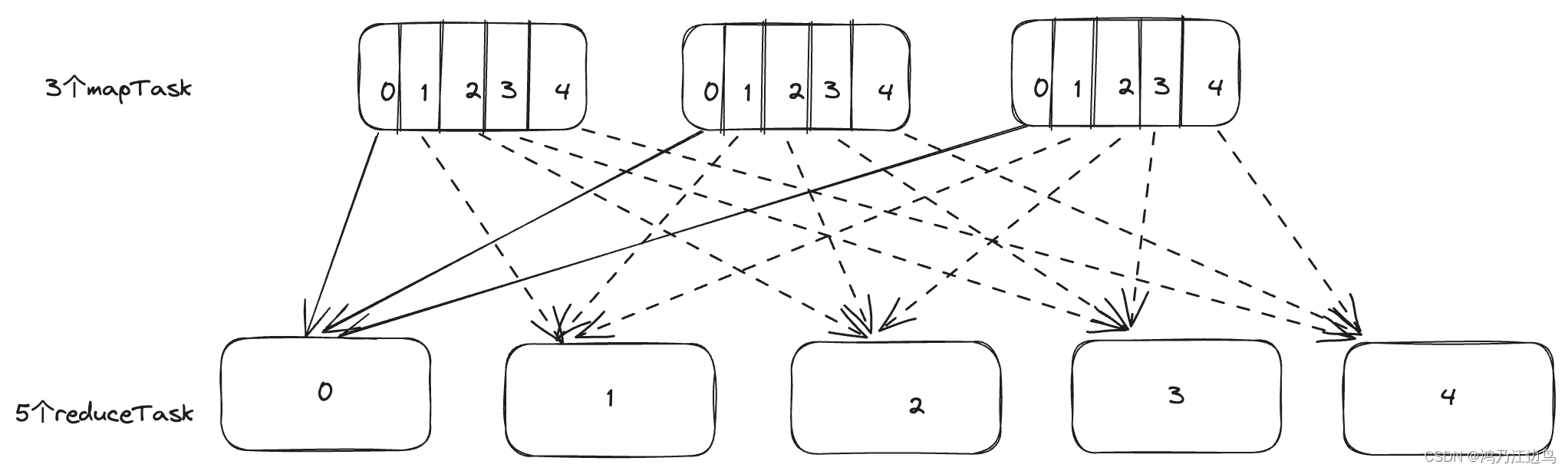
假如说hash(col)为0,那实际上只有reduceTask0有数据,其他的ReduceTask1等等都是没有数据的,所以最终只有ReduceTask0写文件,并且只有一个文件。
在看合并的计算公式,该数据流如下:
tryOptimizeSkewedPartitions||\/optimizeSkewedPartitions||\/ShufflePartitionsUtil.createSkewPartitionSpecs||\/ShufflePartitionsUtil.splitSizeListByTargetSize
splitSizeListByTargetSize方法中涉及到的参数解释如下 :
- 参数 sizes: Array[Long] 表示属于同一个reduce任务的maptask任务的大小数组,举例 sizes = [100,200,300,400]
表明该任务有4个maptask,0表示maptask为0的所属reduce的大小,1表示maptask为1的所属reduce的大小,依次类推,图解如下:
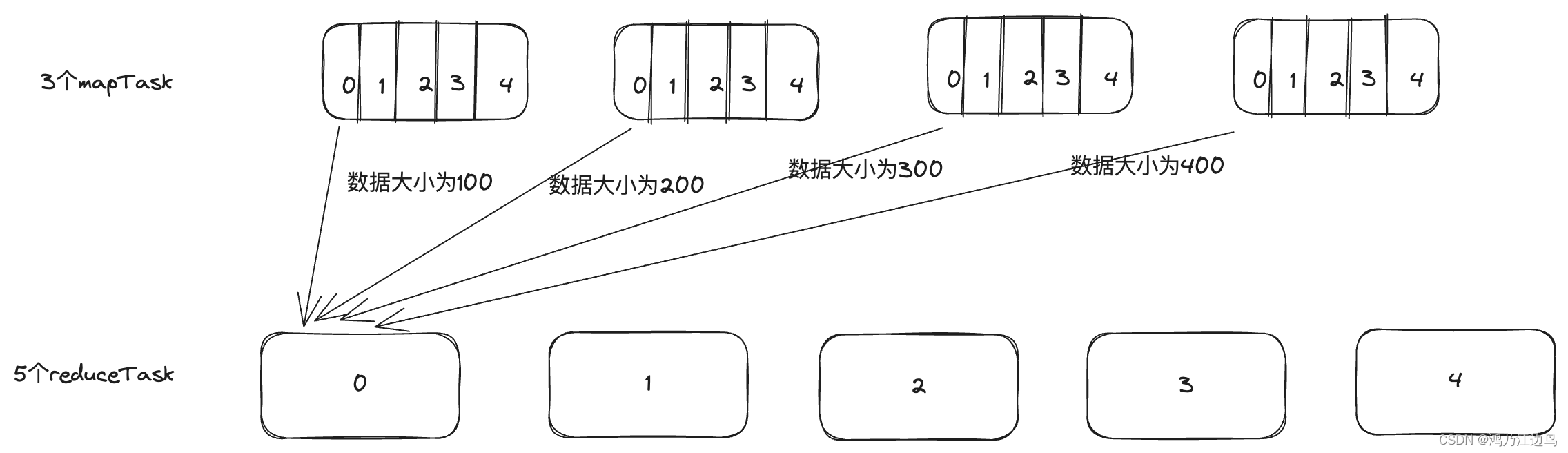
比如说reduceTask0的从Maptask拉取的数据的大小分别是100,200,300,400.
- 参数targetSize 为
spark.sql.adaptive.advisoryPartitionSizeInBytes的值,假如说是256MB - 参数smallPartitionFactor为
spark.sql.adaptive.rebalancePartitionsSmallPartitionFactor的值,默认是0.2
这里有个计算公式:
def tryMergePartitions() = {// When we are going to start a new partition, it's possible that the current partition or// the previous partition is very small and it's better to merge the current partition into// the previous partition.val shouldMergePartitions = lastPartitionSize > -1 &&((currentPartitionSize + lastPartitionSize) < targetSize * MERGED_PARTITION_FACTOR ||(currentPartitionSize < targetSize * smallPartitionFactor ||lastPartitionSize < targetSize * smallPartitionFactor))if (shouldMergePartitions) {// We decide to merge the current partition into the previous one, so the start index of// the current partition should be removed.partitionStartIndices.remove(partitionStartIndices.length - 1)lastPartitionSize += currentPartitionSize} else {lastPartitionSize = currentPartitionSize}}。。。while (i < sizes.length) {// If including the next size in the current partition exceeds the target size, package the// current partition and start a new partition.if (i > 0 && currentPartitionSize + sizes(i) > targetSize) {tryMergePartitions()partitionStartIndices += icurrentPartitionSize = sizes(i)} else {currentPartitionSize += sizes(i)}i += 1}tryMergePartitions()partitionStartIndices.toArray
这里的计算公式大致就是:从每个maptask中的获取到属于同一个reduce的数值,依次累加,如果大于targetSize就尝试合并,直至到最后一个maptask,
可以看到tryMergePartitions有个计算公式:currentPartitionSize < targetSize * smallPartitionFactor,也就是说如果当前maptask的对应的reduce分区数据 小于 256MB*0.2 = 51.2MB 的话,也还是会合并到前一个分区中去,如果smallPartitionFactor设置过大,可能会导致所有的分区都会合并到一个分区中去,最终会导致一个文件会有几十GB(也就是targetSize * smallPartitionFactor`*shuffleNum),
比如说以下的测试案例:
val targetSize = 100val smallPartitionFactor2 = 0.5// merge last two partition if their size is not bigger than smallPartitionFactor * targetval sizeList5 = Array[Long](50, 50, 40, 5)assert(ShufflePartitionsUtil.splitSizeListByTargetSize(sizeList5, targetSize, smallPartitionFactor2).toSeq ==Seq(0))val sizeList6 = Array[Long](40, 5, 50, 45)assert(ShufflePartitionsUtil.splitSizeListByTargetSize(sizeList6, targetSize, smallPartitionFactor2).toSeq ==Seq(0))
这种情况下,就会只有一个reduce任务运行。
相关文章:
Spark Rebalance hint的倾斜的处理(OptimizeSkewInRebalancePartitions)
背景 本文基于Spark 3.5.0 目前公司在做小文件合并的时候用到了 Spark Rebalance 这个算子,这个算子的主要作用是在AQE阶段的最后写文件的阶段进行小文件的合并,使得最后落盘的文件不会太大也不会太小,从而达到小文件合并的作用,…...
Vue 3中实现基于角色的权限认证实现思路
一、基于角色的权限认证主要步骤 在Vue 3中实现基于角色的权限认证通常涉及以下几个主要步骤: 定义角色和权限:首先需要在后端服务定义不同的角色和它们对应的权限。权限可以是对特定资源的访问权限,比如读取、写入、修改等。用户认证&#…...

Visual Studio 2022进行文件差异比较
前言 Visual Studio 2022在版本17.7.4中发布在解决方案资源管理器中比较文件的功能,通过使用此功能,可以轻松地查看两个文件之间的差异,包括添加、删除和修改的代码行。可以逐行查看差异,并根据需要手动调整和编辑文件内容以进行…...
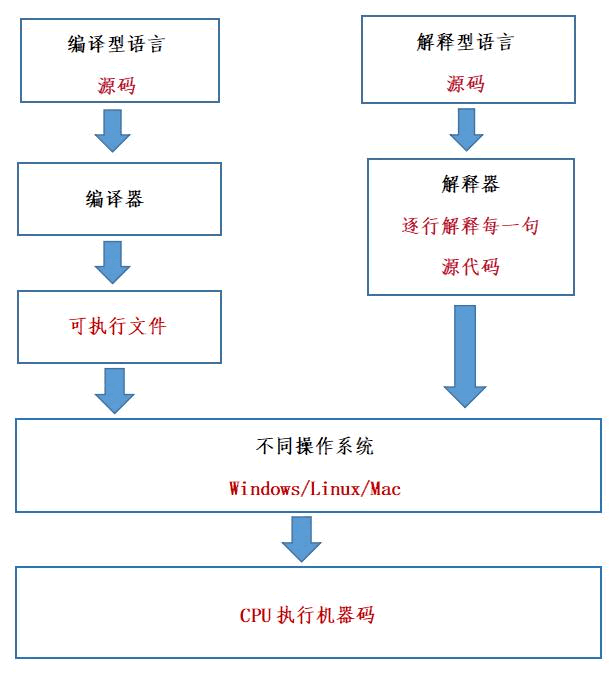
1.2 编译型语言和解释型语言的区别
编译型语言和解释型语言的区别 通过高级语言编写的源码,我们能够轻松理解,但对于计算机来说,它只认识二进制指令,源码就是天书,根本无法识别。源码要想执行,必须先转换成二进制指令。 所谓二进制指令&…...

C语言-常量
什么是常量? 答:常量是在程序执行过程中,其值不发生改变的量,常量分为直接常量和符号常量两种。 其中直接常量又可以分为整型常量、实型常量、字符型常量、字符串常量。 直接常量 1.整型常量 整型常量即整数,包括正整数,负整数和0。c语言中常量可以用八进制,十进制和十六…...

开源的OCR工具基本使用:PaddleOCR/Tesseract/CnOCR
前言 因项目需要,调研了一下目前市面上一些开源的OCR工具,支持本地部署,非调用API,主要有PaddleOCR/CnOCR/chinese_lite OCR/EasyOCR/Tesseract/chineseocr/mmocr这几款产品。 本文主要尝试了EasyOCR/CnOCR/Tesseract/PaddleOCR这…...
vue3实现输入框短信验证码功能---全网始祖
组件功能分析 1.按键删除,清空当前input,并跳转prevInput & 获取焦点,按键delete,清空当前input,并跳转nextInput & 获取焦点。按键Home/End键,焦点跳转first/最后一个input输入框。ArrowLeft/ArrowRight键点击…...
[C#]winformYOLO区域检测任意形状区域绘制射线算法实现
【简单介绍】 Winform OpenCVSharp YOLO区域检测与任意形状区域射线绘制算法实现 在现代安全监控系统中,区域检测是一项至关重要的功能。通过使用Winform结合OpenCVSharp库,并结合YOLO(You Only Look Once)算法,我们…...

个人网站制作 Part 14 添加网站分析工具 | Web开发项目
文章目录 👩💻 基础Web开发练手项目系列:个人网站制作🚀 添加网站分析工具🔨使用Google Analytics🔧步骤 1: 注册Google Analytics账户🔧步骤 2: 获取跟踪代码 🔨使用Vue.js&#…...
划分的方法)
数据按设定单位(分辨率)划分的方法
1. 问题描述 需要将使用公式计算后的float数值换算到固定间隔数轴的对应位置上的数据,比如2.186这个数据,将该数据换算到以0.25为间隔的数轴上,换算后是2.0,还是2.25呢?该方法就是解决这个问题。 2. 方法 输入&…...
Ubuntu 搭建gitlab服务器,及使用repo管理
一、GitLab安装与配置 GitLab 是一个用于仓库管理系统的开源项目,使用Git作为代码管理工具,并在此基础上搭建起来的Web服务。 1、安装Ubuntu系统(这个教程很多,就不展开了)。 2、安装gitlab社区版本,有需…...
-QNetworkRequest)
QT(19)-QNetworkRequest
attribute(QNetworkRequest::Attribute code, const QVariant &defaultValue QVariant()) const 获取指定的请求属性。如果该属性未设置,则返回默认值。 hasRawHeader(const QByteArray &headerName) const 检查是否存在指定名称的原始请求头。 header(Q…...
基于Vue的社区旧衣回收利用系统的设计与实现
经济的高速发展使得每一个家庭的收入都获得了大幅增长,随之而来的就是各种梦想的逐步实现,首当其冲的就是各类衣服的更新换代而导致了大量旧衣物在家中的积存。为了帮助人们解决旧衣物处理的问题而以当前主流的互联网技术构建一个可于社区中实现旧衣回收…...
【网站项目】291校园疫情防控系统
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...

win git filter-repo教程
git filter-repo 是一个用于过滤和清理 Git 仓库历史的工具,它可以高效地批量修改提交历史中的文件内容、删除文件、重命名文件以及进行其他历史重构操作。相较于 git filter-branch,它通常更快且更易于使用。 以下是一个基本示例,说明如何使…...
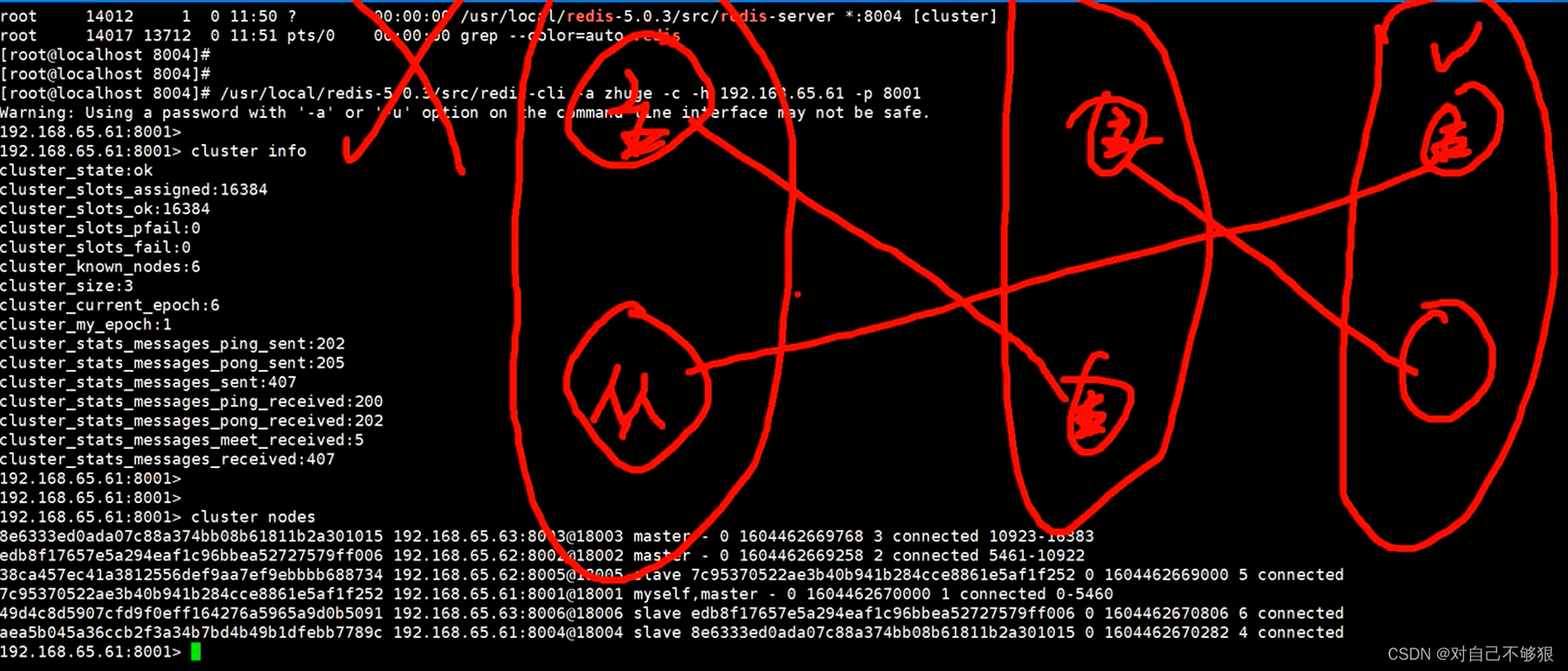
Redis相关操作高阶篇--集群搭建
Redis相关操作大全一篇全搞定-CSDN博客 Redis集群 是一个由多个主从节点群组成的分布式服务器群,它具有复制、高可用和分片特性。Redis集群不需要seninel哨兵也能完成节点移除和故障转移的功能。需要将每个节点 设置成集群模式,这种集群模式没有中心节…...
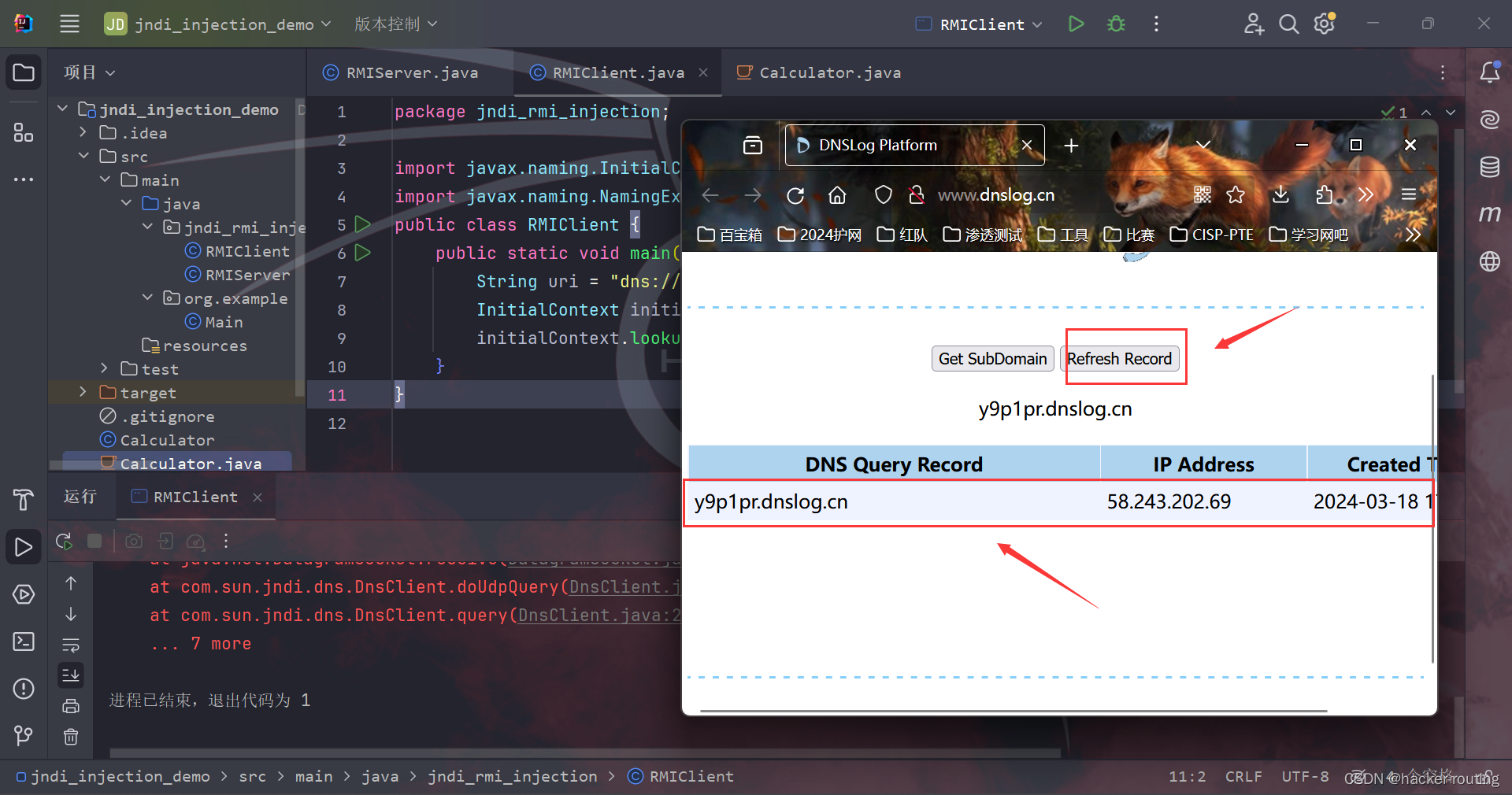
JNDI注入原理及利用IDEA漏洞复现
🍬 博主介绍👨🎓 博主介绍:大家好,我是 hacker-routing ,很高兴认识大家~ ✨主攻领域:【渗透领域】【应急响应】 【Java、PHP】 【VulnHub靶场复现】【面试分析】 🎉点赞➕评论➕收…...

大数据,或称巨量资料
大数据,或称巨量资料,指的是在传统数据处理应用软件不足以处理的大或复杂的数据集。大数据也可以定义为来自各种来源的大量非结构化或结构化数据。从学术角度而言,大数据的出现促成广泛主题的新颖研究,这也导致各种大数据统计方法…...
windows上打开redis服务闪退问题处理
方法1:在windows上面打开redis服务时,弹窗闪退可能是6379端口占用,可以用以下命令查看: netstat -aon | findstr 6379 如果端口被占用可以用这个命令解决: taskkill /f /pid 进程号 方法2: 可以使用…...

分布式锁简单实现
分布式锁 Redis分布式锁最简单的实现 想要实现分布式锁,必须要求 Redis 有「互斥」的能力,我们可以使用 SETNX 命令,这个命令表示SET if Not Exists,即如果 key 不存在,才会设置它的值,否则什么也不做。 …...
上午题回忆与解析(非标答版))
2026上半年数据库系统工程师(软考)上午题回忆与解析(非标答版)
本文为考后回忆整理,非官方标准答案,旨在为考后对答案及下半年备考的同学提供参考。题目顺序和表述可能与原卷有出入,欢迎在评论区指正、补充。📊 整体考情分析 刚结束的2026年上半年数据库系统工程师考试,上午题的风格…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...
)
CentOS服务器上VNC连接失败?手把手教你排查并修复个人端口问题(附重启命令)
CentOS服务器VNC连接故障深度排查指南:从原理到实战当你在深夜赶项目时,突然发现VNC连接不上服务器,那种焦虑感我深有体会。去年参与半导体器件仿真项目时,我也曾被这个问题困扰整整两天。本文将分享一套经过实战检验的排查方法论…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...

基于ESP32与MQTT的家庭环境监测系统:从传感器选型到数据可视化实战
1. 项目概述与核心价值最近几年,我身边越来越多的朋友开始关注家里的空气质量、温湿度这些看不见摸不着,但又实实在在影响生活舒适度和健康的环境指标。从新装修的房子担心甲醛,到有老人小孩的家庭在意PM2.5和二氧化碳浓度,再到南…...

人类防伪指南:为什么你越写错字,HR越信你是真人?
前言各位码农、算法侠、CtrlC/V十级学者请注意:你有没有过这样的经历?辛辛苦苦肝了一晚上文档,逻辑严密、语法丝滑、连Markdown都对齐得像军训方阵,结果老板幽幽来一句:“这真是你自己写的?”那一刻&#x…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...

RevSSH反向SSH隧道:无公网IP设备的安全远程运维方案
1. 这不是又一个SSH封装工具——RevSSH解决的是“根本性连接悖论”你有没有遇到过这样的场景:一台部署在客户内网的嵌入式设备,没有公网IP,NAT穿透失败,防火墙策略死死锁住所有入向端口,连ICMP都被禁了;或者…...

如何快速解锁艾尔登法环帧率限制:终极性能优化指南
如何快速解锁艾尔登法环帧率限制:终极性能优化指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenR…...
)
微信聊天图片丢了别慌!保姆级教程:找回并解密DAT文件(支持新旧版微信路径)
微信DAT图片恢复实战:从文件定位到批量解密的完整指南 微信聊天记录中的图片突然消失?别急着放弃!那些看似无法打开的DAT文件里,可能藏着您的重要回忆或工作资料。本文将带您深入微信存储机制,手把手完成从文件定位到…...