【深度学习】BERT变体—RoBERTa
RoBERTa是的BERT的常用变体,出自Facebook的RoBERTa: A Robustly Optimized BERT Pretraining Approach。来自Facebook的作者根据BERT训练不足的缺点提出了更有效的预训练方法,并发布了具有更强鲁棒性的BERT:RoBERTa。
RoBERTa通过以下四个方面改变来改善BERT的预训练:在MLM任务中使用动态掩码而不是静态掩码;移除NSP任务,仅使用MLM任务;通过更大的批数据进行训练;使用BBPE作为分词器。
1 动态掩码
RoBERTa使用动态掩码。BERT中,对于每一个样本序列进行mask之后,mask的tokens都固定下来了,也就是静态mask的方式。RoBERTa的训练过程中使用了动态mask的方式:对于每一个输入样本序列,都会复制10条,然后复制的每一个都会重新随机mask,其中每个句子被mask的token不同:即拥有不同的masked tokens。
![]()
MASK结果如下所示:
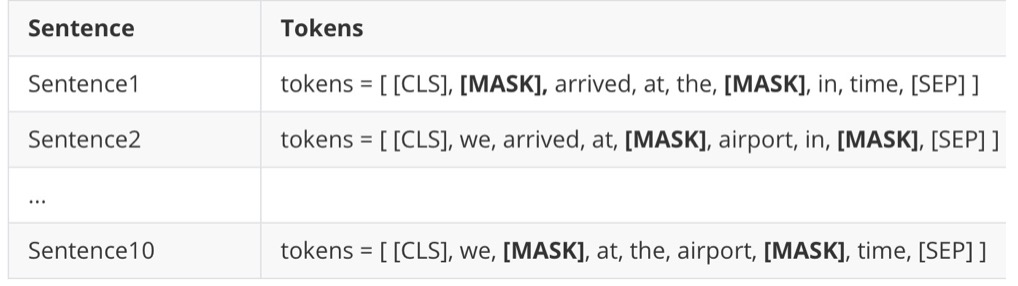
在模型训练时,对于每个epoch,使用不同标记被[MASK]的句子喂给模型。这样模型只会在训练10个epoch之后看到具有同样掩码标记的句子。比如,句子1会被epoch1,epoch11,epoch21和epoch31看到。这样,我们使用动态掩码而不是静态掩码去训练RoBERTa模型。
2 移除NSP任务
为了证明可以移除NSP任务,论文进行了以下对比实验:
1.SEGMENT-PAIR+NSP: NSP任务保留。每个输入是段落(segment),每个片段由多个自然句子组成,最大长度为512;
2.SENTENCE-PAIR+NSP:NSP任务保留。每个输入是一对自然句子,每个自然句子可是一个文本的连续部分,也可以是不同文本。因为这些输入显然少于512,因此增加了批大小,让一个批次总的单词数和SEGMENT-PAIR+NSP差不多。同时保留NSP loss;
3.FULL-SENTENCES: 每个输入都包含从一个或多个文档中连续采样的完整句子,因此总长度差不多512个单词。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加文档边界标记。移除NSP loss;
4.DOC-SENTENCES: 每个输入都包含从一个连续采样的完整句子,输入格式和FULL-SENTENCES类似,除了它们不会跨域文档边界。在文档末尾附近采样的输入可能短于 512 个单词,所以动态增加了批大小让单词总数和FULL-SENTENCES类似。移除NSP loss;
实验结果如下图所示:

从实验结果看,BERT在FULL-SENTENCES和DOC-SENTENCES设定中表现的更好,这两者都剔除了NSP任务。对比FULL-SENTENCES和DOC-SENTENCES,DOC-SENTENCES只从一篇文档中采样,此种设定的表现比FULL-SENTENCES在多篇文档中采样要好。但在RoBERTa中,作者使用了FULL-SENTENCES,因为DOC-SENTENCES导致批大小变化很大。
3 更大规模训练数据
3-3-1 训练语料
BERT的预训练语料是 BOOKCORPUS+English WIKIPEDIA的16GB语料。RoBERT除了在Toronto BookCorpus和英文维基百科上进行训练,还在CC-News(Common Crawl-News)数据集、Open WebText和Stories(Common Crawl的子集)上进行训练。RoBERT模型在5个数据集上进行预训练,这5个数据集总大小为160G。
3-3-2 batch size
BERT预训练的batch size为256,训练了1M步。而RoBERTa则使用了更大的batch size,训练RoBERTa时采样了更大的批大小,达到了8000,训练了300000步。在同样的批大小上,也训练了一个更长训练步的版本,有500000步。训练一个更大的批大小可以增加训练速度同时也可以优化模型的表现。
4 BBPE作为分词器
BERT使用WordPiece分词器。WordPicce分词器类似于BPE分词器,它基于符号对的概率还不是频率来合并符号对。
而RoBERTa使用BBPE作为分词器。BBPE基于字节级序列,先将文本转换为字节级序列,然后应用BPE算法根据字节级符号对构建词表,BERT使用30000大小的词表,RoBERTa使用大约50000大小的词表。
5 Roberta使用
#导入模块
from transformers import RobertaConfig, RobertaModel, RobertaTokenizer
#加载模型
Robert_model = model = RobertaModel.from_pretrained('roberta-base')
#加载分词器
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
RobertaConfig {"_name_or_path": "roberta-base","architectures": ["RobertaForMaskedLM"],"attention_probs_dropout_prob": 0.1,"bos_token_id": 0,"classifier_dropout": null,"eos_token_id": 2,"gradient_checkpointing": false,"hidden_act": "gelu","hidden_dropout_prob": 0.1,"hidden_size": 768,"initializer_range": 0.02,"intermediate_size": 3072,"layer_norm_eps": 1e-05,"max_position_embeddings": 514,"model_type": "roberta","num_attention_heads": 12,"num_hidden_layers": 12,"pad_token_id": 1,"position_embedding_type": "absolute","transformers_version": "4.10.3","type_vocab_size": 1,"use_cache": true,"vocab_size": 50265
}Reference:
https://helloai.blog.csdn.net/article/details/120499194?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&utm_relevant_index=2https://helloai.blog.csdn.net/article/details/120499194?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&utm_relevant_index=2
相关文章:
【深度学习】BERT变体—RoBERTa
RoBERTa是的BERT的常用变体,出自Facebook的RoBERTa: A Robustly Optimized BERT Pretraining Approach。来自Facebook的作者根据BERT训练不足的缺点提出了更有效的预训练方法,并发布了具有更强鲁棒性的BERT:RoBERTa。 RoBERTa通过以下四个方面…...

java面试准备1
JVM、JRE和JDK的关系 JVM:Java Virtual Machine是java虚拟机,Java程序需要运行在虚拟机上,不同的平台有自己的虚拟机,因此java可以实现跨平台使用。 JRE:Java Runtion Envirement包括Java虚拟机和Java程序所需要的核心类库等。 J…...
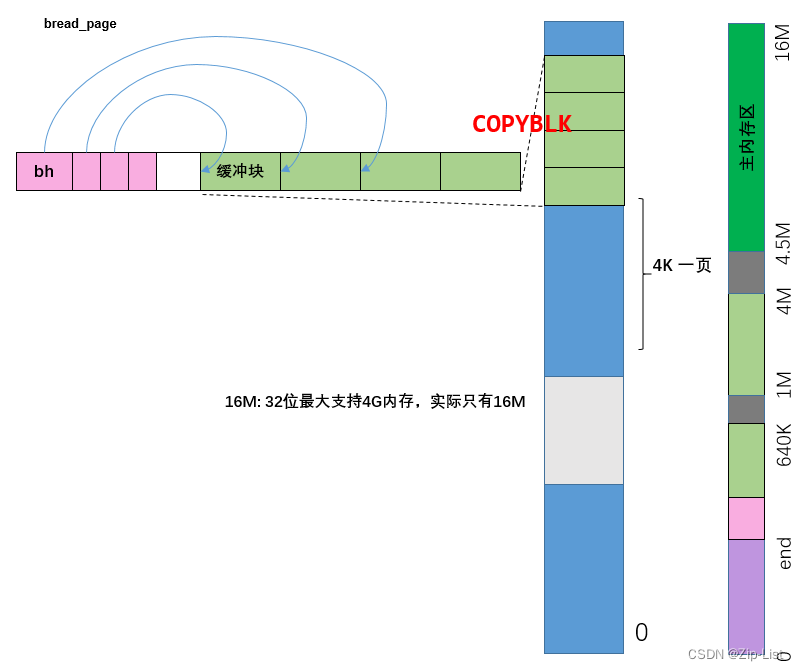
buffer它到底做了个啥,源码级分析linux内核的文件系统的缓冲区
最近一直在学习linux内核源码,总结一下 https://github.com/xiaozhang8tuo/linux-kernel-0.11 自己整理过的带注释的源码。 为什么要有buffer 高速缓冲区是文件系统访问块设备中数据的必经要道(PS:如果所有程序结果都不落盘,只是int a, a直接在主存…...

【蓝桥杯刷题】盗版Huybery系列之手抓饼赛马
【蓝桥杯刷题】—— 盗版Huybery系列之手抓饼赛马😎😎😎 目录 💡前言🌞: 💛盗版Huybery系列之手抓饼赛马题目💛 💪 解题思路的分享💪 😊题…...

【微信小程序-原生开发】实用教程16 - 查看详情(含页面跳转的传参方法--简单传参 vs 复杂传参)
需在实现列表的基础上开发 【微信小程序-原生开发】实用教程15 - 列表的排序、搜索(含云数据库常用查询条件的使用方法,t-search 组件的使用)_朝阳39的博客-CSDN博客 https://sunshinehu.blog.csdn.net/article/details/129356909 效果预览 …...

论文精读:Ansor: Generating High-Performance Tensor Programs for Deep Learning
文章目录1. Abstract2. Introduction3. Background4. Design Overview5. Program Sampling5.1 Sketch Generation5.2 Random Annotation6. Performance Fine-tuning6.1 Evolutionary Search6.2 Learned Cost Model7. Task Scheduler7.1 Problem Formulation7.2 Optimizing with…...
SpringBoot With IoC,DI, AOP,自动配置
文章目录1 IoC(Inverse Of Controller)2 DI(Dependency Injection)3 AOP(面向切面编程)3.1 什么是AOP?3.2 AOP的作用?3.3 AOP的核心概念3.4 AOP常见通知类型3.5 切入点表达式4 自动配…...
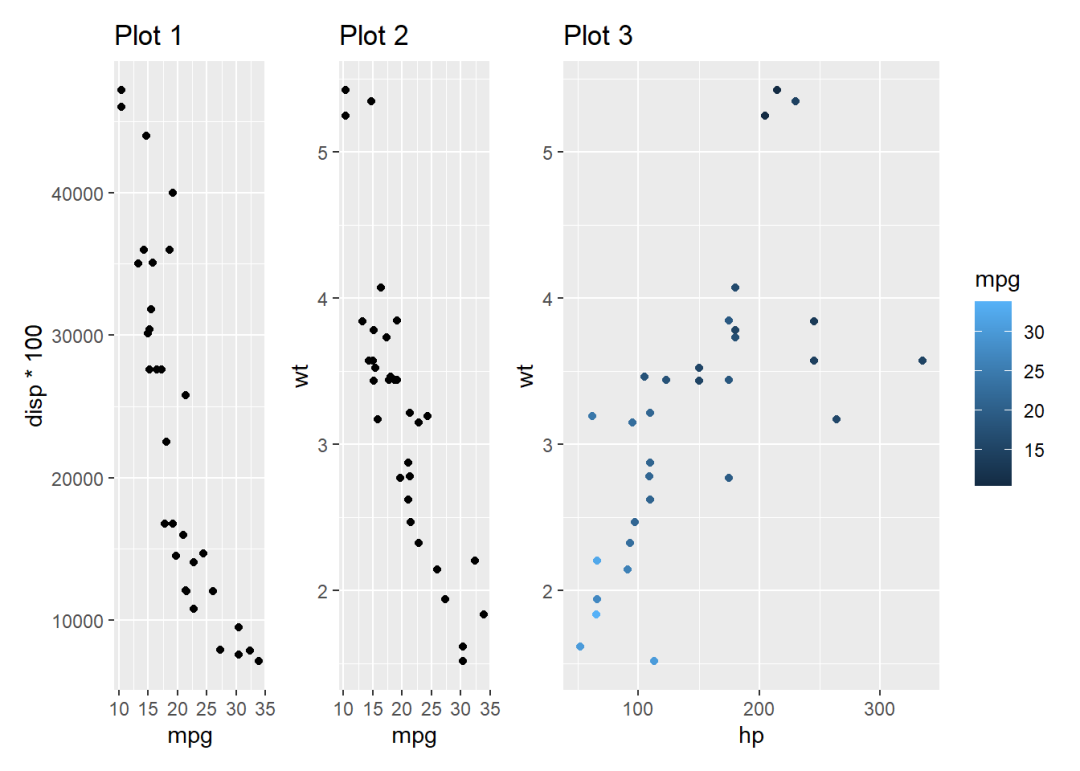
ggplot2的组图拓展包(1):patchwork(上篇)
专注系列化、高质量的R语言教程推文索引 | 联系小编 | 付费合集patchwork是ggplot绘图系统的拓展包,主要功能是将多个ggplot格式的图形组合成一幅大图,即组图。patchwork工具包十分好用,它主要利用几个类似四则运算符号的操作符进行组图&…...
)
Python 异步: 异步迭代器(15)
动动发财的小手,点个赞吧! 迭代是 Python 中的基本操作。我们可以迭代列表、字符串和所有其他结构。 Asyncio 允许我们开发异步迭代器。我们可以通过定义一个实现 aiter() 和 anext() 方法的对象来在 asyncio 程序中创建和使用异步迭代器。 1. 什么是异步…...
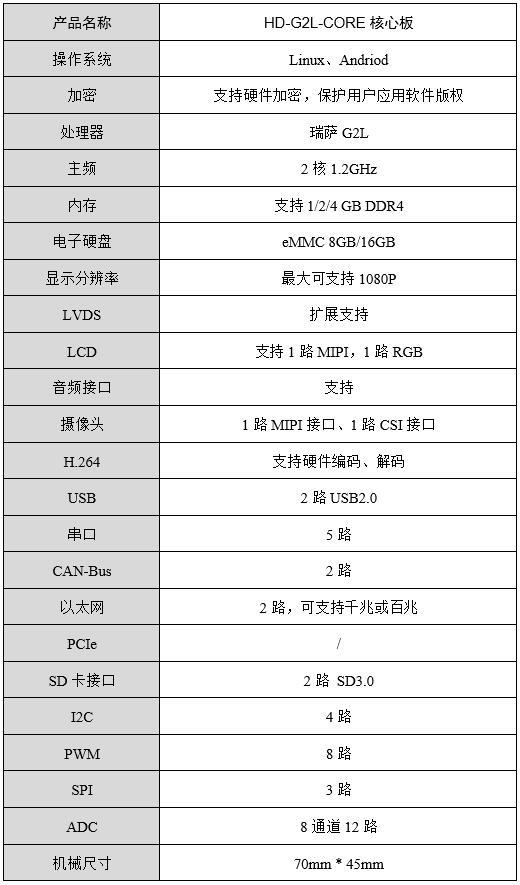
HD-G2L-IOT V2.0核心板MPU压力测试
1. 测试对象HD-G2L-IOT基于HD-G2L-CORE V2.0工业级核心板设计,双路千兆网口、双路CAN-bus、2路RS-232、2路RS-485、DSI、LCD、4G/5G、WiFi、CSI摄像头接口等,接口丰富,适用于工业现场应用需求,亦方便用户评估核心板及CPU的性能。H…...

scikit-image:遥感图像geotiff格式转mat格式
scikit-imagescikit-image 是一个专门用于图像处理的 Python 库,它可以与 Scipy 库和其他可能有助于计算的 Python 库一起使用。Github地址:https://github.com/scikit-image/scikit-image Star有5.3k首先pip安装scikit-image包,或者直接使用…...

吉利银河L7、长城哈弗B07、比亚迪宋Plus DM-i,自主品牌决战混动
2月23日,吉利推出全新的中高端新能源产品序列——吉利银河。当日,吉利推出了首款智能电混SUV「银河L7」,新车将在二季度交付。本月10日,长城汽车也计划举办智能新能源干货大会,其「颠覆技术」等宣传直面新一代的新能源…...

附录3:说一说 Ambari 视图编译相关
一、Ambari View Ambari 视图,即 Ambari Views 。其实 Ambari 视图并不是很好用,所以大部分人很自然地就把 Ambari 视图给忽略了,心里会冒出一句:“还有这东西?”。然而作为 Ambari 的一部分,今天还是要讲一下,万一有人追求 Ambari 完整性,要编译并安装汉化他们呢? …...

Arduino双色LED实验记录
接线图片:双色LED实物和布线有区别:代码:int RED_LED 11; //设置红色为11 int GREEN_LED 10; //设置绿色为10 int val 0;//全局变量val void setup() {// put your setup code here, to run once:pinMode(RED_LED,OUTPUT);//引脚配置pinMo…...

flex布局
十分简单灵活,区区几行代码都可以实现各种页面的布局,曾经学习页面布局时候,深受float、display、position这些属性的困扰,但是学习flex布局,只需要学习几个CSS属性,就可以写出简介优雅复杂的页面布局。 F…...
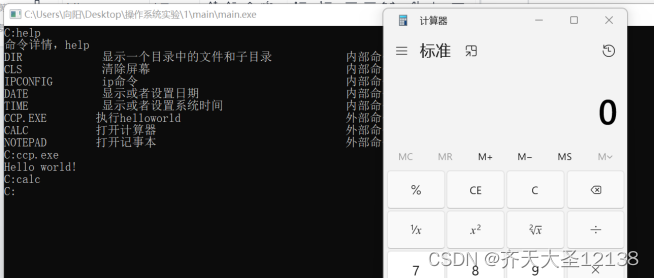
【操作系统原理实验】命令解释器模拟实现
选择一种高级语言如C/C等,编写一类似于DOS、UNIX中的命令行解释程序。 1)设计系统命名行提示符; 2)自定义命令集(8-10个); 3)用户输入help命令以查找命令的帮助; 4)列出命令的功能,区分内部命令…...
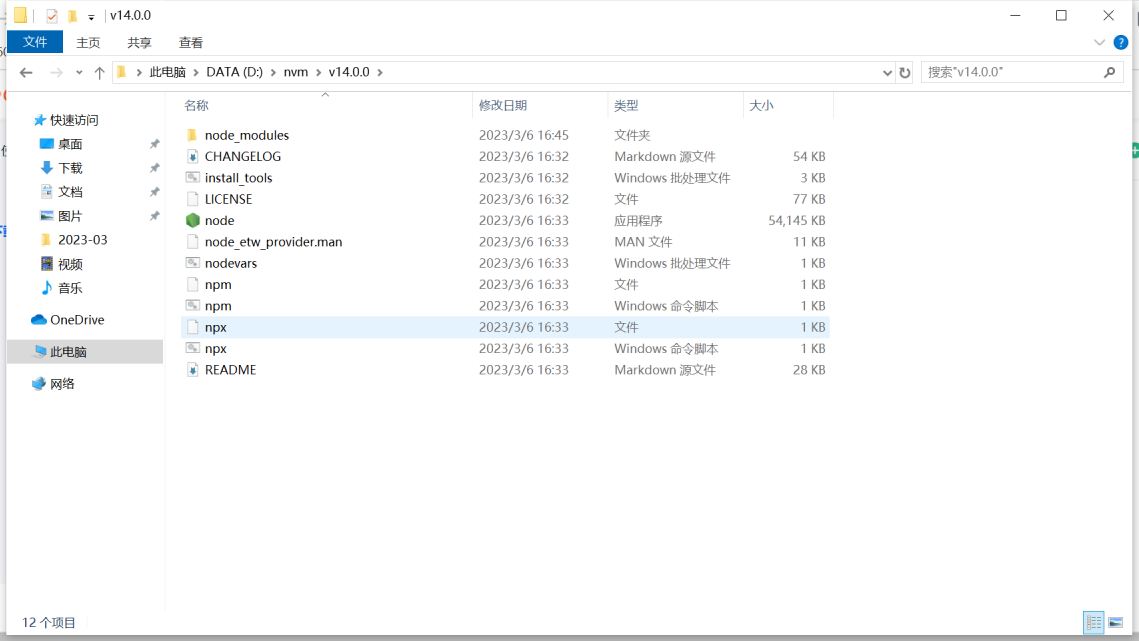
使用nvm管理node版本
下载nvm版本参考文章:https://blog.csdn.net/langmanboy/article/details/126357952下载安装选择nvm的目录为d:\nvm,nodejs的目录为d:\nodejs:v14.0.0:执行nvm install 14生成的目录v16.0.0:执行nvm install 16生成的目…...

jQuery BootStrap
1、jQuery的使用方式 1、下载jQuery库文件 网址 2、将下载好的js文件放到项目中,并引入到需要的HTML文件中 3、使用jQuery 注意:jQuery库文件的导入必须在自己写的代码之前。就绪函数在页面上可以写n个。 <!DOCTYPE html> <html lang"en…...

Vue2.0开发之——购物车案例-Footer组件封装(50)
一 概述 导入Footer子组件定义fullState计算属性把全选状态传递给Footer子组件实现全选功能 二 导入Footer子组件 2.1 App.vue中导入Footer组件 import Footer from "/components/Footer/Footer.vue";2.2 App.vue中注册Footer子组件 components: {Header,Goods,F…...

HTML基本概述
文章目录网站和网页浏览器的作用HTML标签元素注释乱码问题web系统是以网站形式呈现的,而前端是以网页形式呈现的。 网站和网页 网站(web site):互联网上用于展示特定内容的相关网页的集合。也就是说,一个网站包含多个…...

如何通过Python快速接入Taotoken并调用多模型API完成文本生成任务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何通过Python快速接入Taotoken并调用多模型API完成文本生成任务 1. 准备工作:获取API Key与模型ID 在开始编写代码之…...

R3nzSkin英雄联盟皮肤修改器完整教程:免费体验全皮肤的终极指南
R3nzSkin英雄联盟皮肤修改器完整教程:免费体验全皮肤的终极指南 【免费下载链接】R3nzSkin Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3n/R3nzSkin R3nzSkin是一款专为《英雄联盟》玩家设计的开源皮肤修改工具&a…...

HDLbits实战解析:从异步复位到同步复位,掌握三段式FSM的核心差异与设计要点
1. 异步复位与同步复位的本质区别 在数字电路设计中,复位信号就像电脑的重启按钮,它能将电路恢复到初始状态。但很多初学者第一次在HDLbits上做FSM练习题时,会被"asynchronous reset"和"synchronous reset"这两个概念搞…...

Docker部署RabbitMQ后,你的admin账号真的能连上吗?一个权限配置的深度踩坑实录
Docker部署RabbitMQ后admin账号连接失败的深度排查指南 当你用Docker快速部署了RabbitMQ,创建了admin用户,甚至能通过Web界面登录,却在代码中遭遇ACCESS_REFUSED错误时,那种挫败感我深有体会。这不是简单的密码错误问题࿰…...

Vivado里FIFO IP核的Standard和FWFT模式到底怎么选?一个波形对比就懂了
Vivado中FIFO IP核模式选择:Standard与FWFT的深度解析与实战指南 在FPGA开发中,数据缓冲是几乎所有高速数据处理系统不可或缺的一环。作为Xilinx工具链中的核心IP之一,FIFO Generator提供了灵活的数据缓冲解决方案。但当面对Standard FIFO和F…...

LT8650S双通道同步降压稳压器设计与汽车电子应用
1. LT8650S双通道同步降压稳压器设计解析在汽车电子和工业设备领域,电源管理系统的设计往往面临严苛挑战。LT8650S作为一款42V输入、双通道4A输出的同步降压稳压器,其Silent Switcher 2架构和6.2μA超低静态电流特性,为工程师提供了高性价比的…...

Android MediaProjection实战:从权限适配到异常处理,构建Android Q+的稳定截屏录屏功能
1. 理解MediaProjection的核心机制 在Android Q及以上版本中,MediaProjection API是系统级截屏和录屏功能的唯一官方入口。与早期版本直接调用adb screencap或反射获取Surface不同,这套机制通过用户显式授权的方式实现隐私保护。我曾在多个项目中遇到过因…...

Flink:Keyed State vs Operator State 原理与实践
一、引言在 Flink 实时计算的世界里,流处理的本质可以概括为公式:实时流处理 业务逻辑 状态(State)。无论是窗口聚合、双流 Join 还是复杂的 CEP 模式匹配,都离不开状态管理。Flink 提供了两种基本的状态类型&#x…...

不止于水:用MS动力学模拟和RDF分析,探究任意离子/分子在溶液中的溶剂化结构
从水到多元溶液:MS动力学模拟与RDF分析的高级应用指南 当我们需要理解溶液中离子或分子的行为时,径向分布函数(RDF)分析提供了一个强有力的工具。传统的纯水体系研究固然重要,但现实中的溶液系统往往更为复杂——电解液中的锂离子、蛋白质溶液…...

从零构建开发者效率工具:CLI脚手架与自动化工作流实践
1. 项目概述与核心价值最近在开源社区里,一个名为smouj/smouj的项目引起了我的注意。乍一看这个标题,可能会让人有些摸不着头脑,它不像常见的vue/vue或tensorflow/tensorflow那样直白地揭示了其技术栈。但恰恰是这种看似“神秘”的命名&#…...