知识积累(五):Transformer 家族的学习笔记
文章目录
- 1. RNN
- 1.1 缺点
- 2. Transformer
- 2.1 组成
- 2.2 Encoder
- 2.2.1 Input Embedding(嵌入层)
- 2.2.2 位置编码
- 2.2.3 多头注意力
- 2.2.4 Add & Norm
- 2.3 Decoder
- 2.3.1 概览
- 2.3.2 Masked multi-head attention
- 2.4 Transformer 模型的训练和推理
- 2.4.1 训练
- 2.4.2 推理
- 2.4.3 与 RNN 相比的优势
- 3. 复习
- 3.1 Language model
- 3.1.1 训练
- 3.1.2 推理
- 3.2 Transformer 架构(Encoder)
- 3.2.1 嵌入向量
- 3.2.2 位置编码
- 3.2.3 自注意力和 causal mask
- 4 BERT
- 4.1 左右 context 的重要性
- 4.2 BERT 预训练
- 4.2.1 Masked Language Model task
- 4.2.2 Next Sentence Prediction task
- 4.3 BERT 微调
- 4.3.1 文本分类任务
- 4.3.2 问答任务
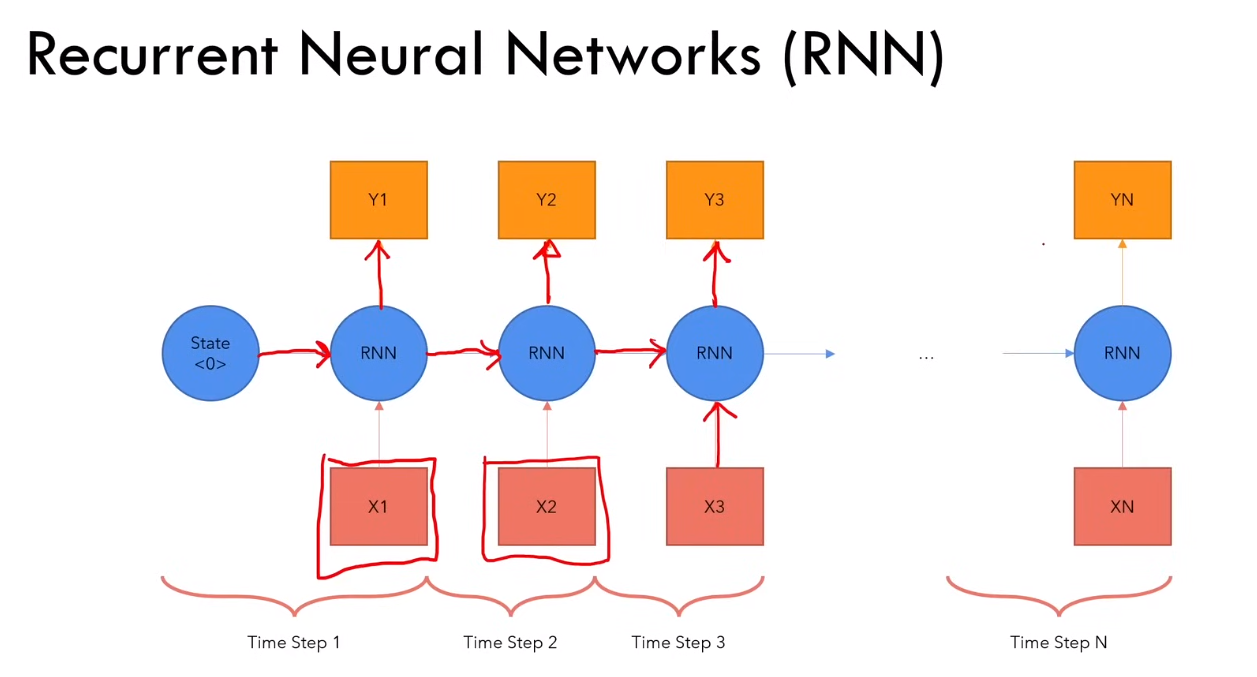
1. RNN
1.1 缺点
1)对于长序列,计算速度慢
2)梯度消失或梯度爆炸(由于链式法则来更新参数,随着计算长度的增加,越小的越小,梯度消失;越大的越大,梯度爆炸)
3)难以获得很长时间之前的信息
2. Transformer
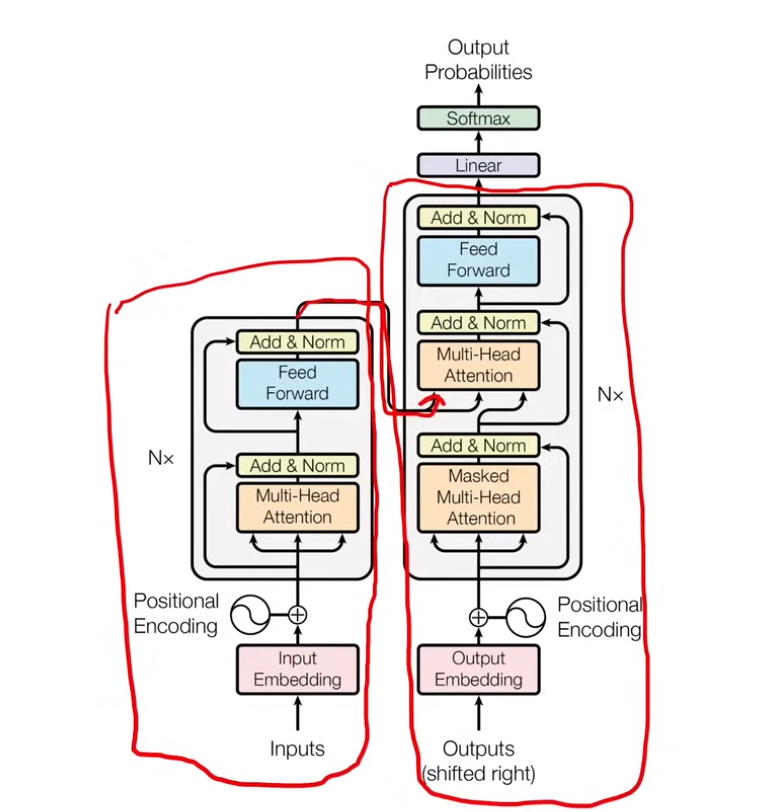
2.1 组成
三部分:encoder + decoder + decoder上面的 linear 层
2.2 Encoder
2.2.1 Input Embedding(嵌入层)
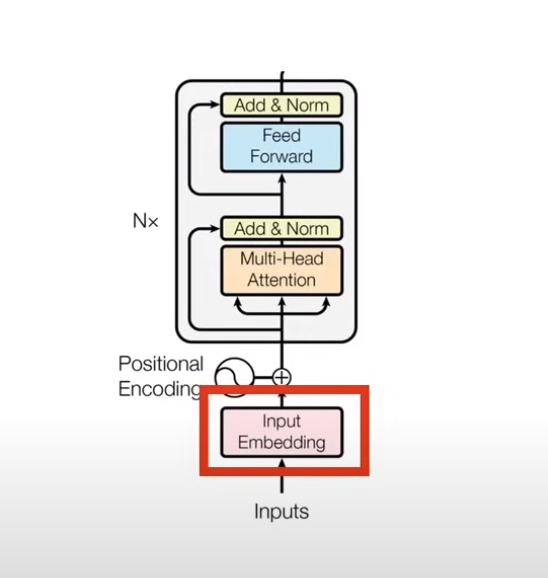

1)嵌入流程
a)将输入进行 tokenizer ,
b)每个 token 映射到单词表中的 token-id
c)每个 id 对应的 embedding(vector size模型有关,传统 Transformer 是512,Bert 是 768)
Ps:token-id 是固定的。但是 Embedding 中的数字是不固定的,值随模型训练而改变
2.2.2 位置编码
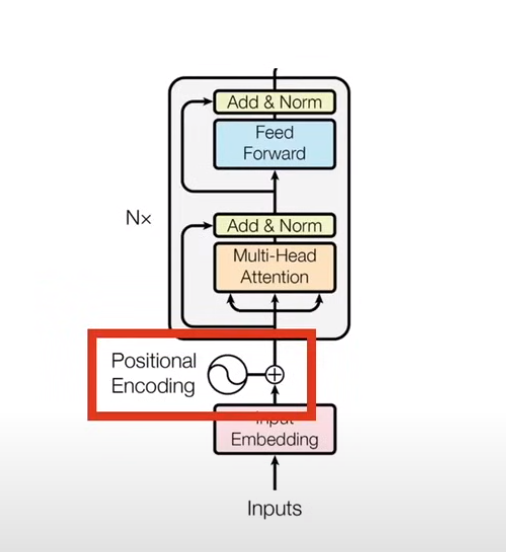
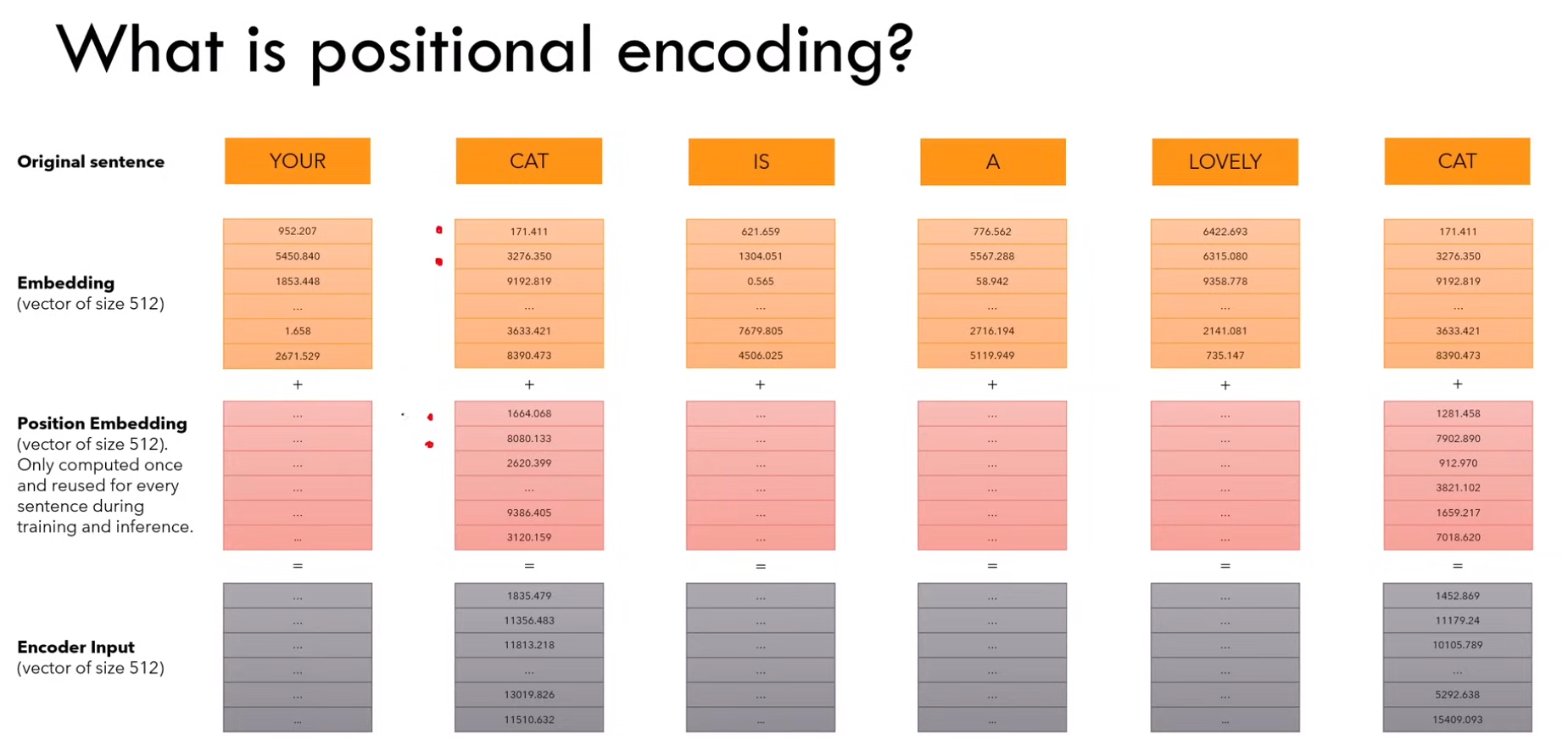
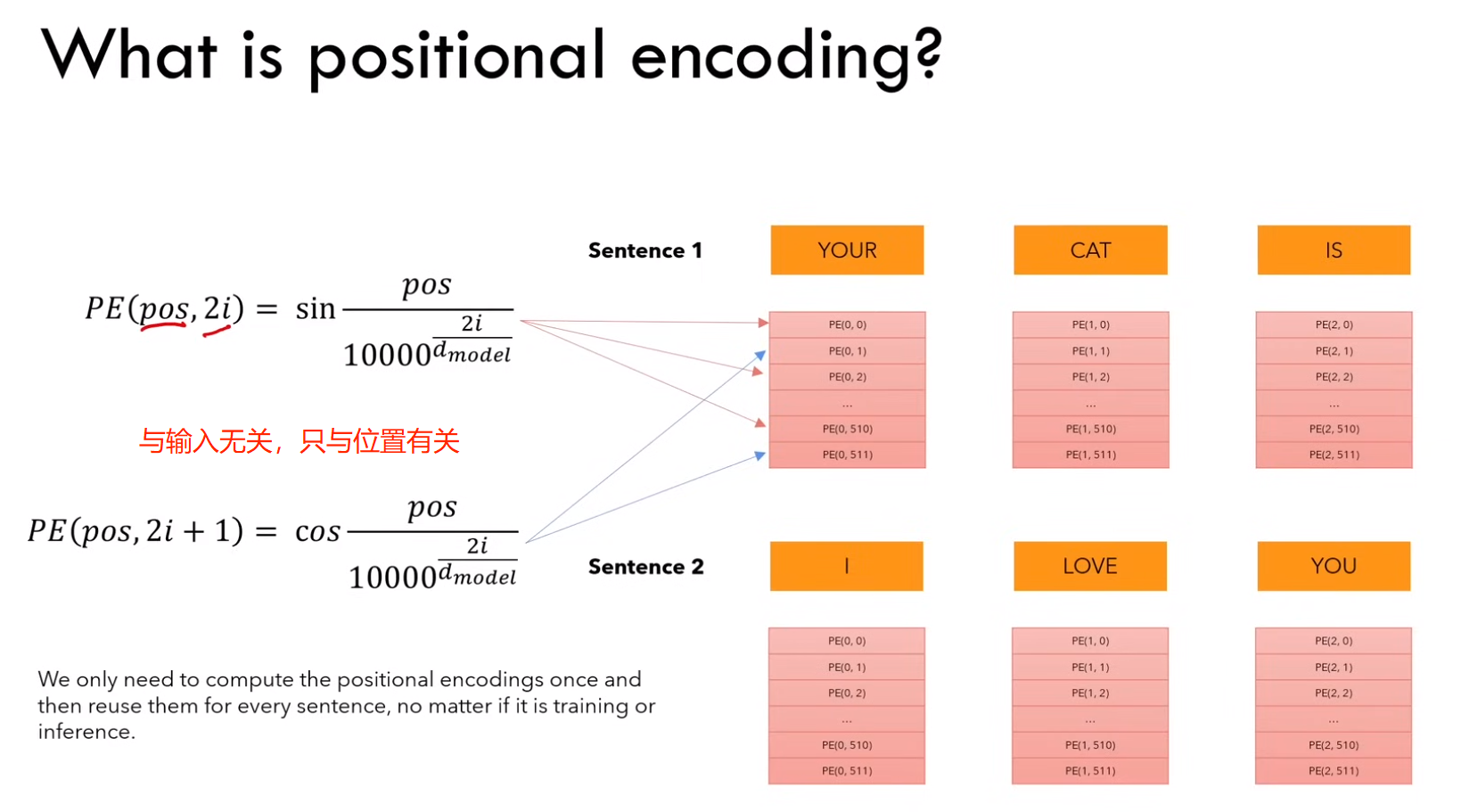
1)什么是位置编码?
a)我们想要 word 带有一些它在句子中的位置信息
b)我们想要模型区分对待离得近的单词,和离得远的单词(因为离得近可能语义上更接近等等原因)
c)希望模型能够学到位置编码带来的 pattern
2)位置编码的特点
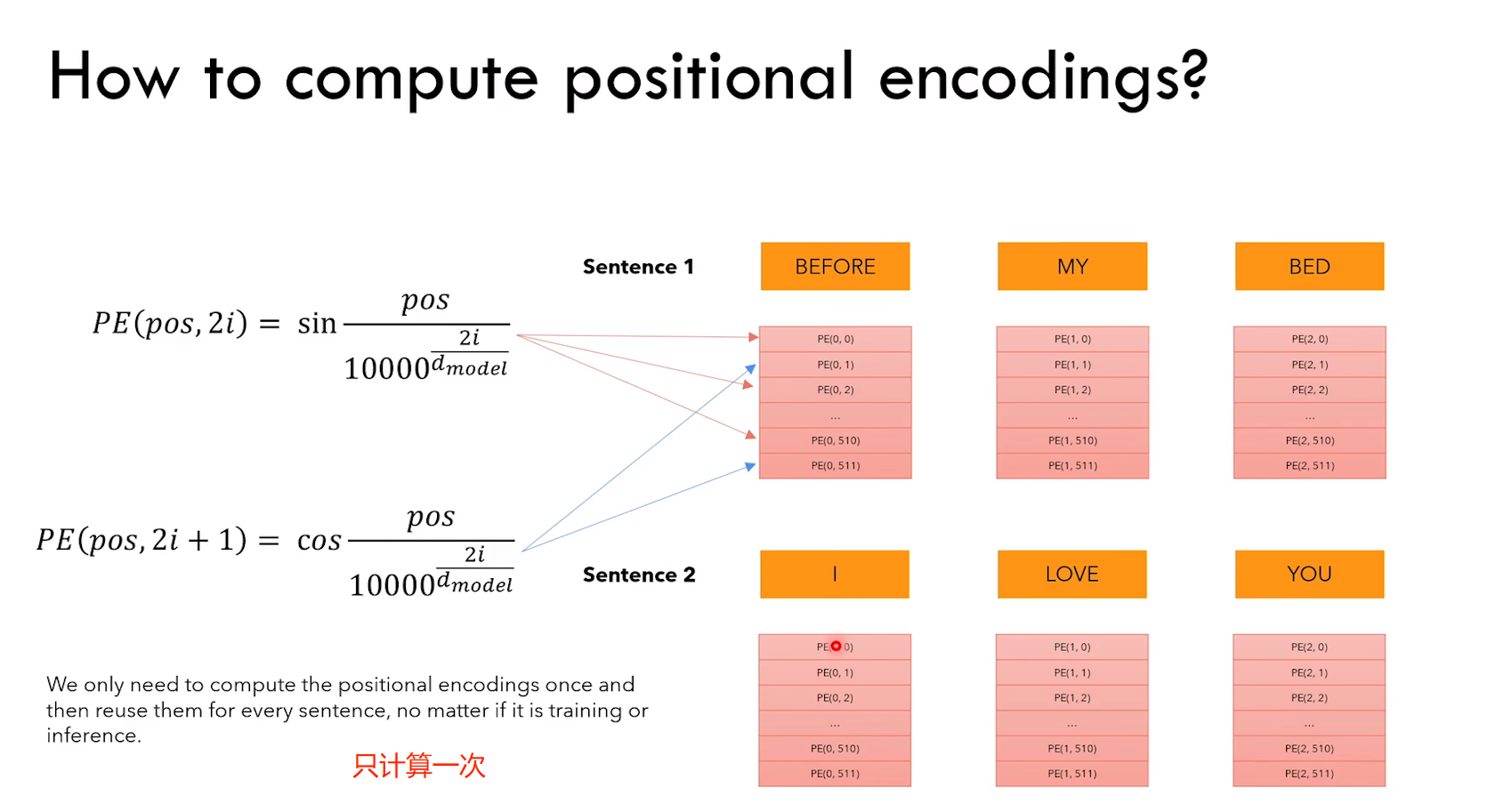
a)embedding + position embedding = encoder input
b)position embedding 只计算一次,然后在训练和测试期间使用
2.2.3 多头注意力
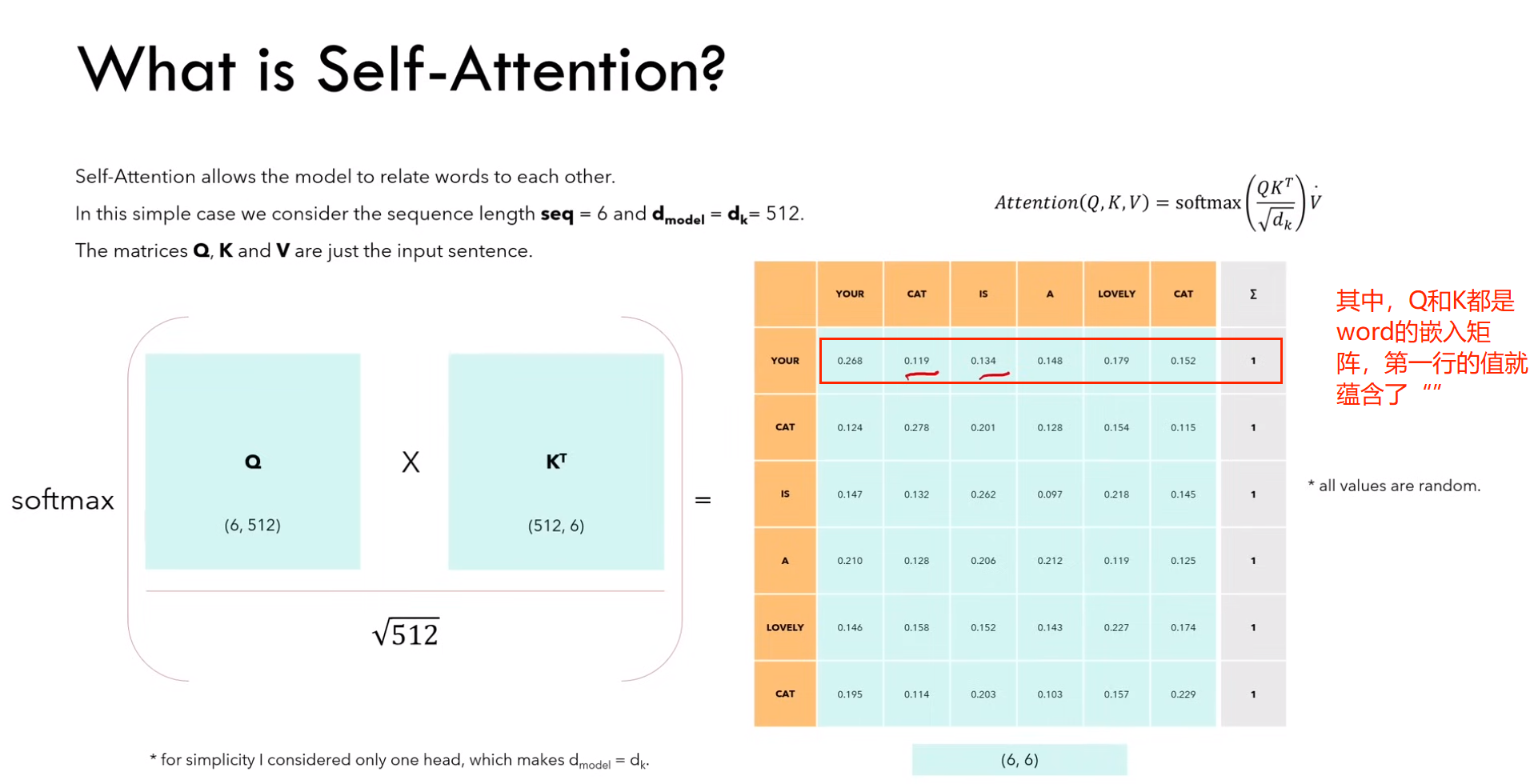
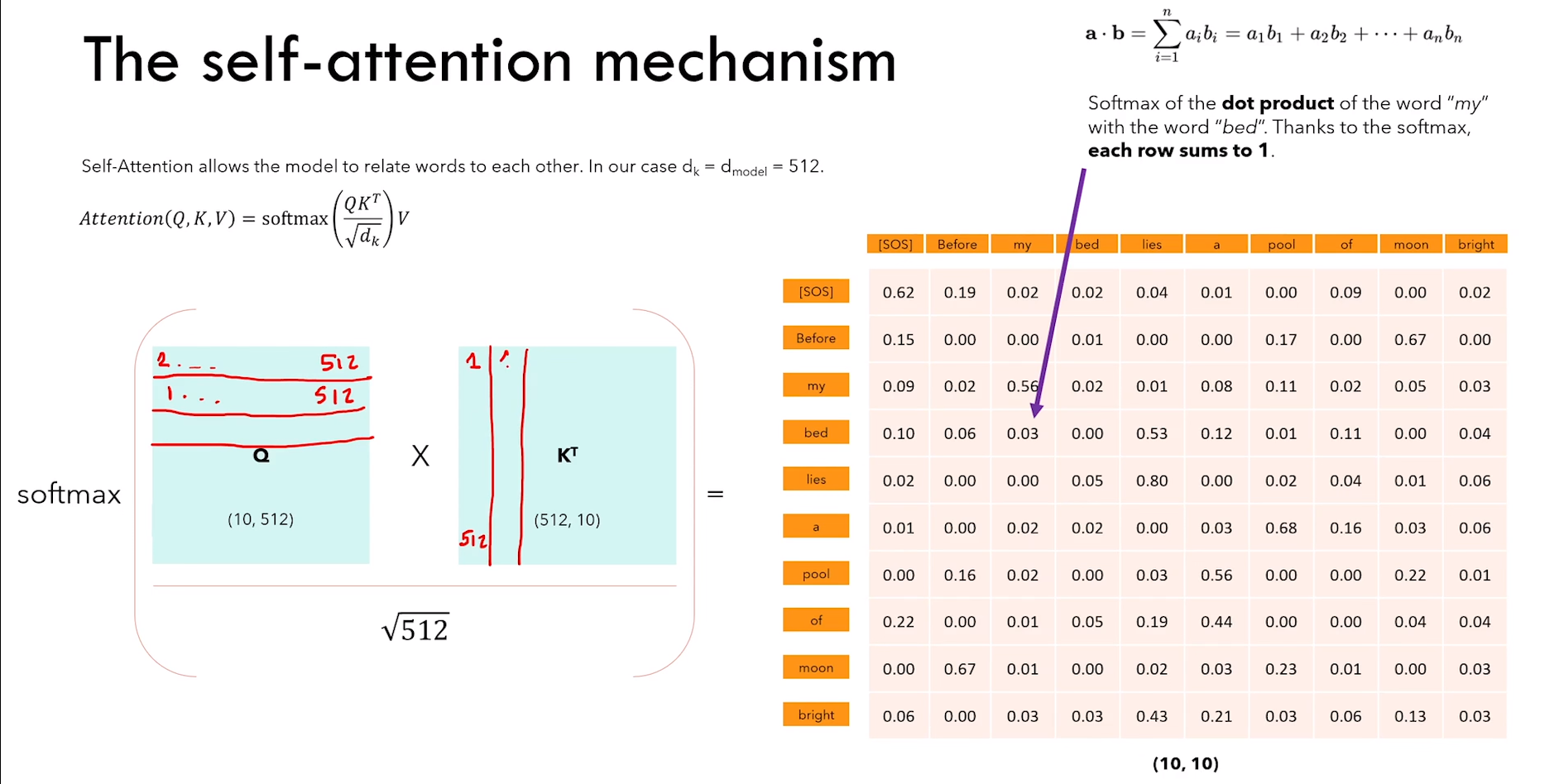
1)什么是 self-attention?(单头)
a)self-attention 允许模型将单词关联起来
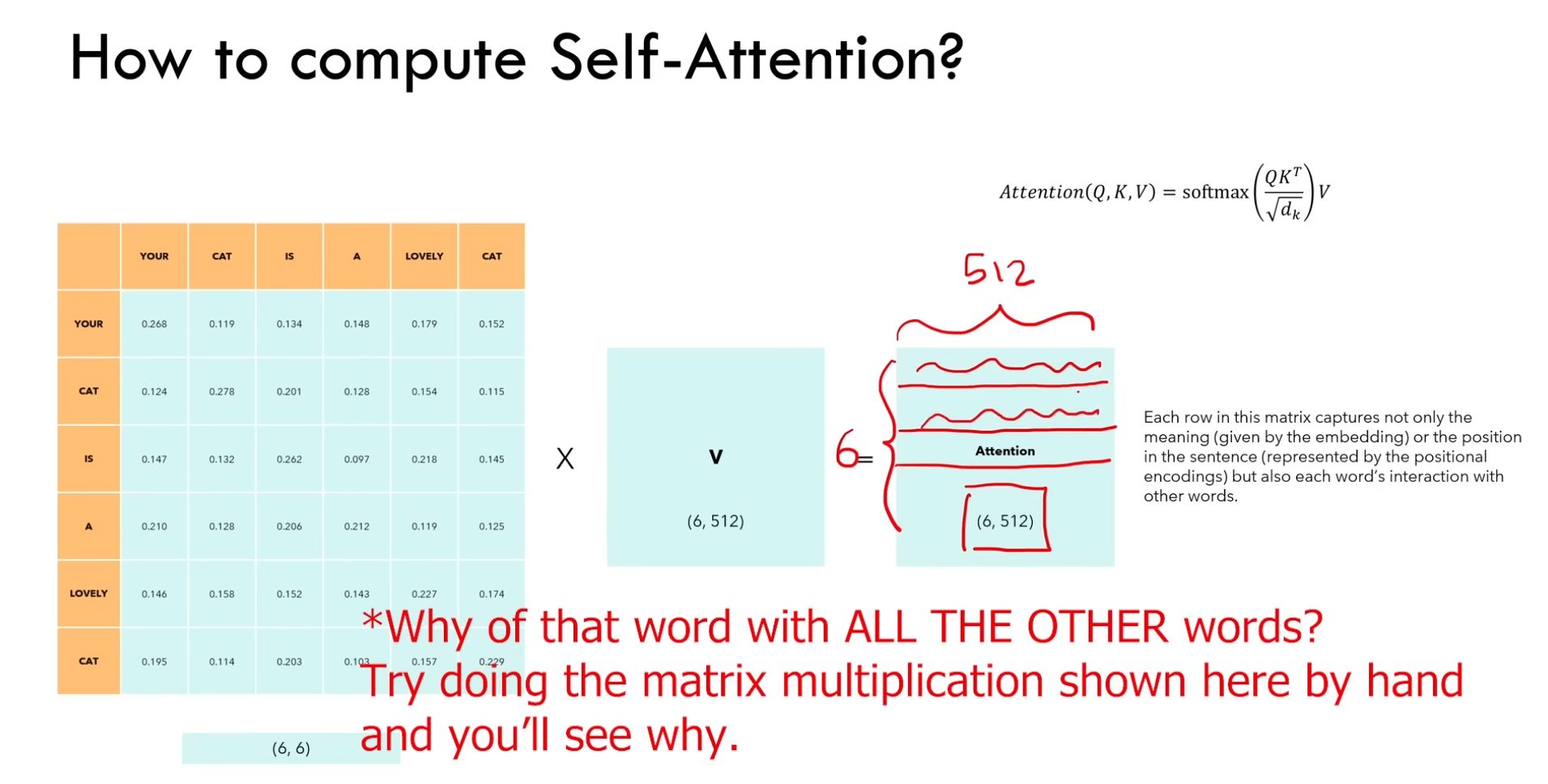
如上图 Q * KT 所示,Q 和 K 维度和单词的嵌入矩阵相同(也就是前面 embedding + position embedding)。
Ps:注意只是维度相同,Q K V 矩阵里面的参数应该是随机初始化的。
所以图中红色框的矩阵第一行中每个元素的含义可以看作单词 “your” 与其他单词之间的关系强弱。
b)再乘以 V 之后得到的矩阵,每个向量嵌入里面包含:语义嵌入、位置信息、与其他单词的交互(下图)
2)self-attention 的一些细节
a)具有排列不变性
eg:输入序列 ABCD 或者序列 ACBD。
其中 BC 的位置交换了,但是最终得到的 B 和 C 的嵌入向量也对应位置交换,向量值是不变的。
b)前面举例的 self-attention 不需要参数。截止到现在的笔记,单词之间的交互只由他们的 embedding 和 position embedding 驱动,后面的笔记会发生改变。
c)Q 和 K 相乘得到的矩阵对角线的值应该是最大的
d)如果我们不想让某些位置交互,可以在使用 softmax 之前,将他们两者对应的值设为 -∞,那么经过 softmax 之后那里的值就变成了0。decoder 中可以使用(eg:想取消“your” 和 “cat” 的交互,就将第一行第二列设置为 0)
3)多头注意力

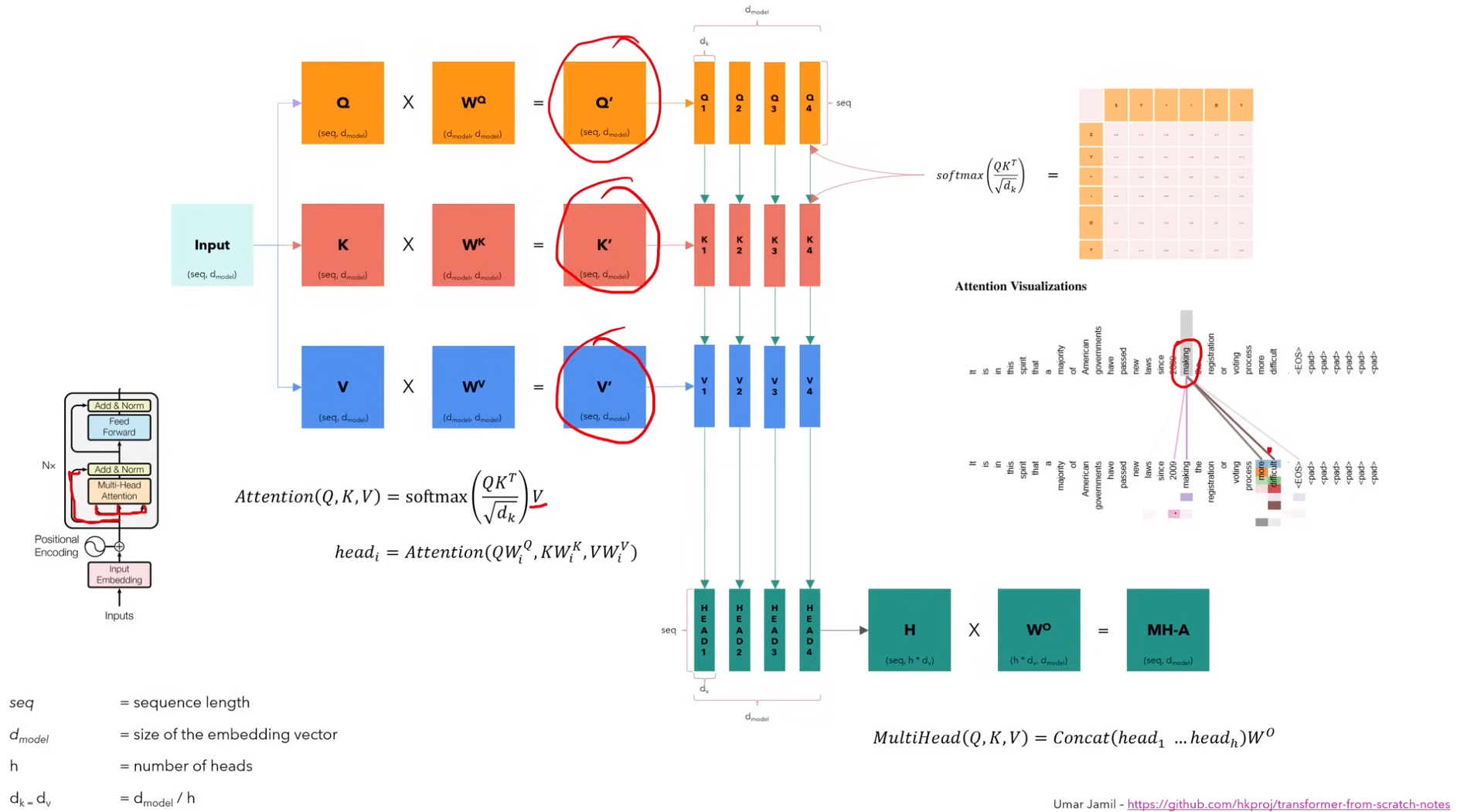
1)如下图所示,最初的 Q、K、V 就是经过positional encoding 的输入,也就是图中蓝色 input 的 copy。分别乘以不同的参数矩阵后,才变成不同的东西
2)其中,注意力头的个数是 h。每个注意力头对应的矩阵(seq,dv),这里dv = dmodel / h。(其中dmodel就是模型vector size)
3)不同头对应的现实含义即,不同的头可能会捕获某个单词的不同含义,不如图中单词图中,某个单词指向了很多的词,那该单词会有多种词义,这些不同的词义就是由不同的注意力头来捕获的
为什么这三个矩阵被称作 Q、K、V?
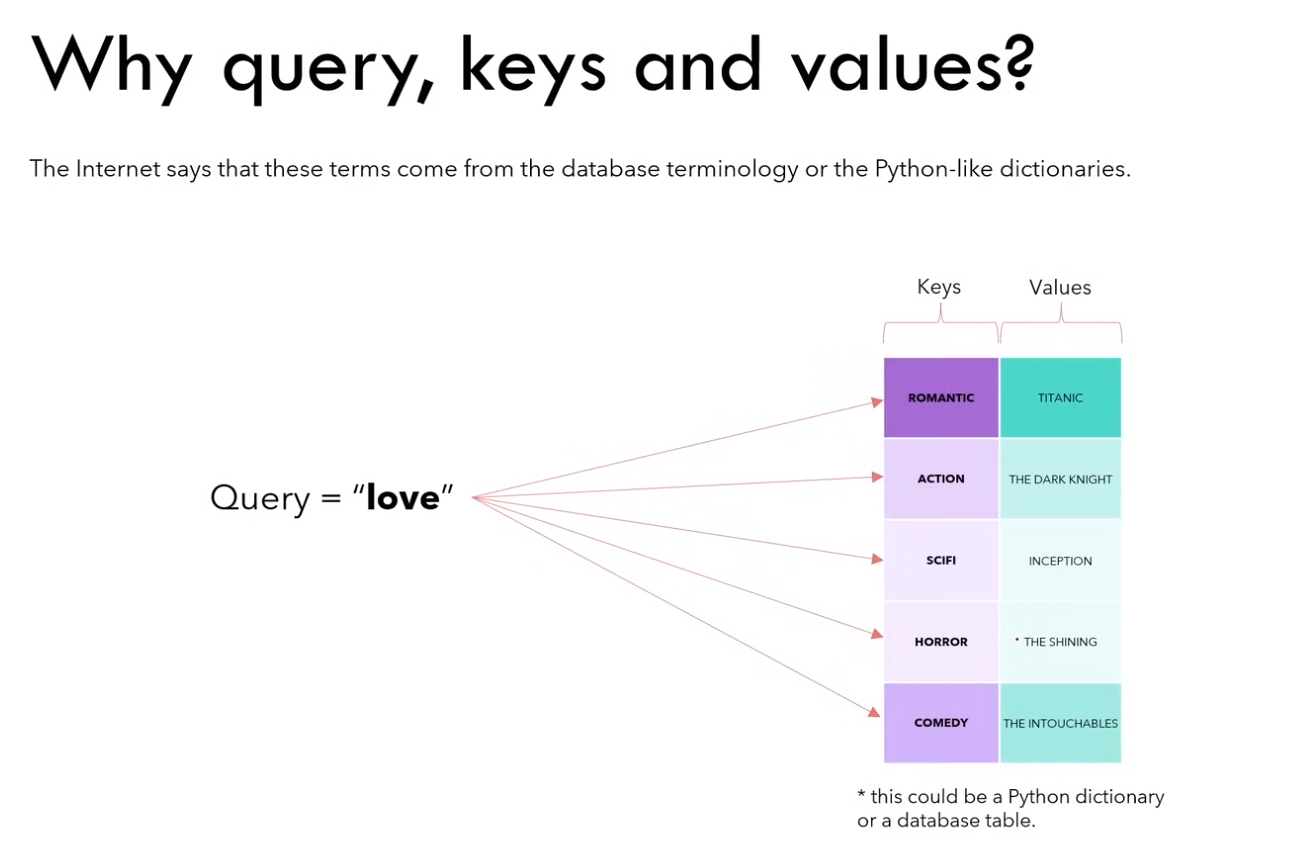
eg:以 python 字典的视角来看,图中的 query、keys 和 values 都是被表示成向量。通过 q 与 k 的运算,实际上是找与 “love” 这种类型的电影最相似的电影,最终 “romantic” 可能是最相似的。
2.2.4 Add & Norm
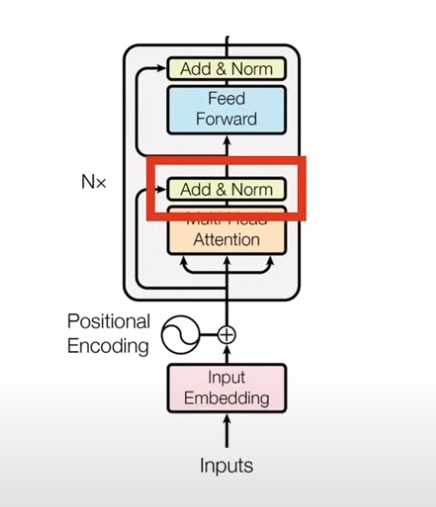

1)什么是 layer normalization?
对于一个batch中的所有item进行独立的归一化,利用均值和方差公式
2.3 Decoder
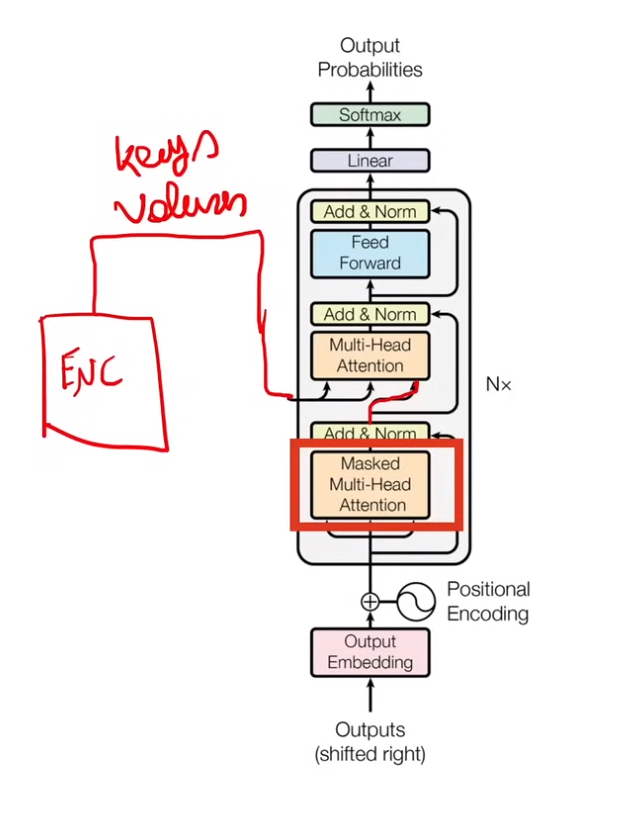
2.3.1 概览
1)首先 output embedding 和 positional encoding,与输入的时候类似
2)经过 masked multi-head attention (这里是decoder的self-attention)得到的是下一次multi-head attention的query
3)encoder 输出以 keys 和 values 的方式传入multi-head attention,querys是decoder。(这里是encoder 和 decoder 的cross-attention)
2.3.2 Masked multi-head attention
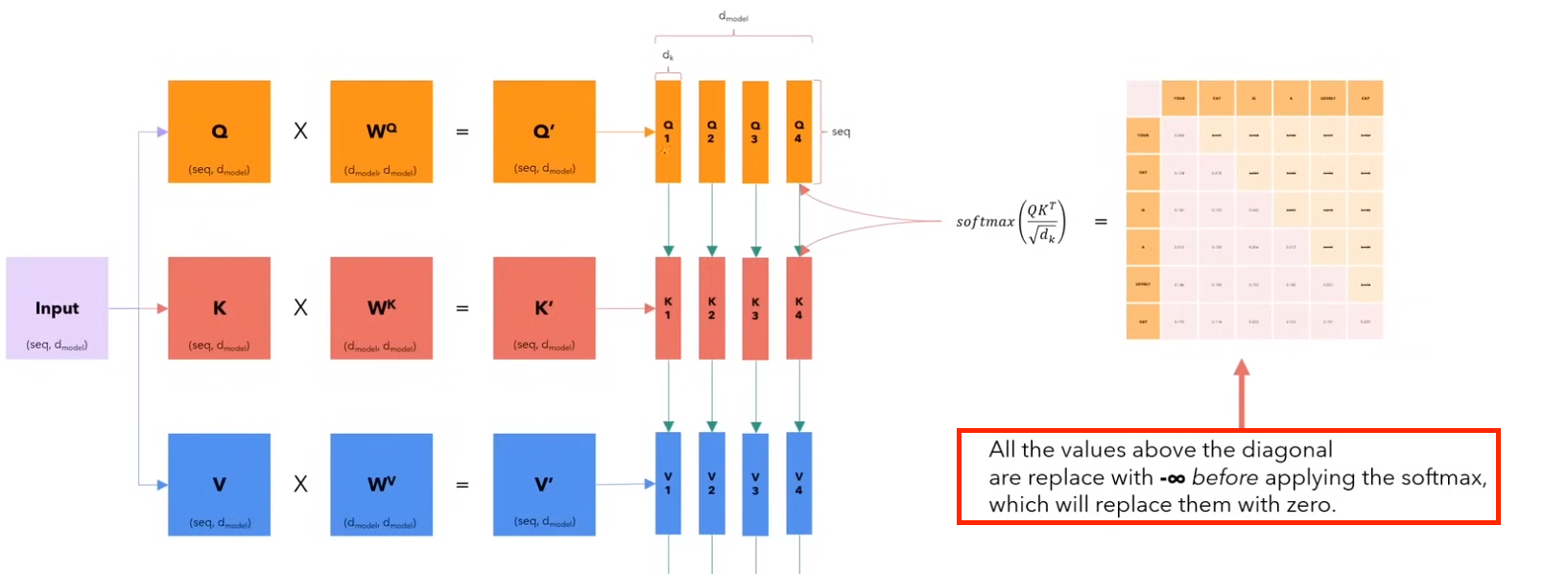

1)使用 masked 的意思是说,在输出的时候,一个词只能根据前面的词输出,而不能看到后面的词
2)也就是图中对角线上方的元素在softmax之前全为-无穷
3)而获取这个矩阵是Q 和 K 的运算来得到的
4)所以只能使用 decoder 的 query 矩阵,而用 encoder 的 key 矩阵
2.4 Transformer 模型的训练和推理
以翻译任务为例
2.4.1 训练
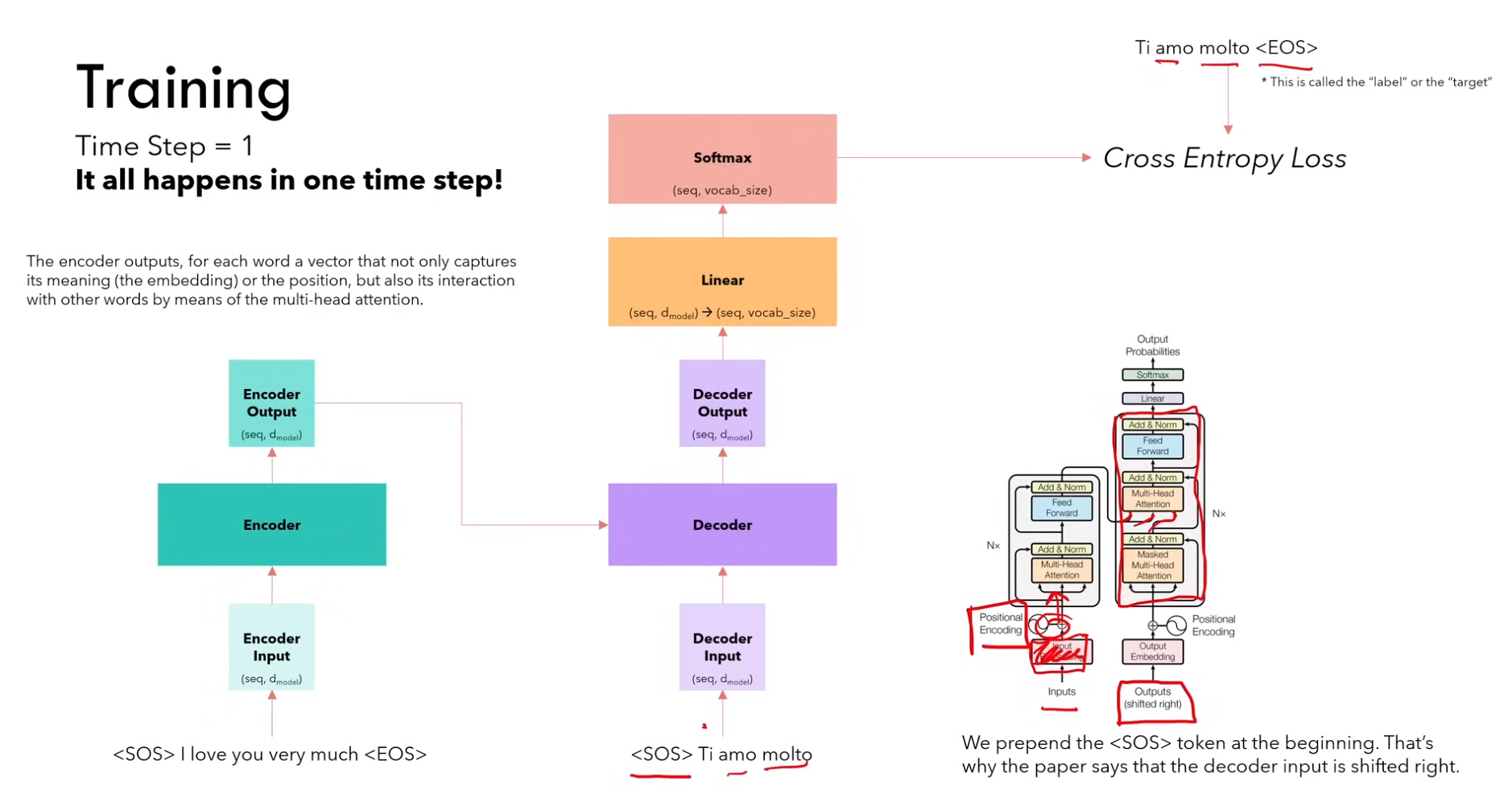
1)encoder输入:<sos> i love you very much <eos>
2)decoder输入:<sos> ti amo molto
decoder输出:ti amo molto <eos>
Ps:由于这种 masked 机制,所以可以一次性输入,输出的 ti 是根据\<sos>获得,输出的 amo 是根据\<sos> ti 获得,以此类推
PPs:当然,除了上面的单词输入,decoder 需要补全 token 来补充其模型需要的输入长度
2.4.2 推理
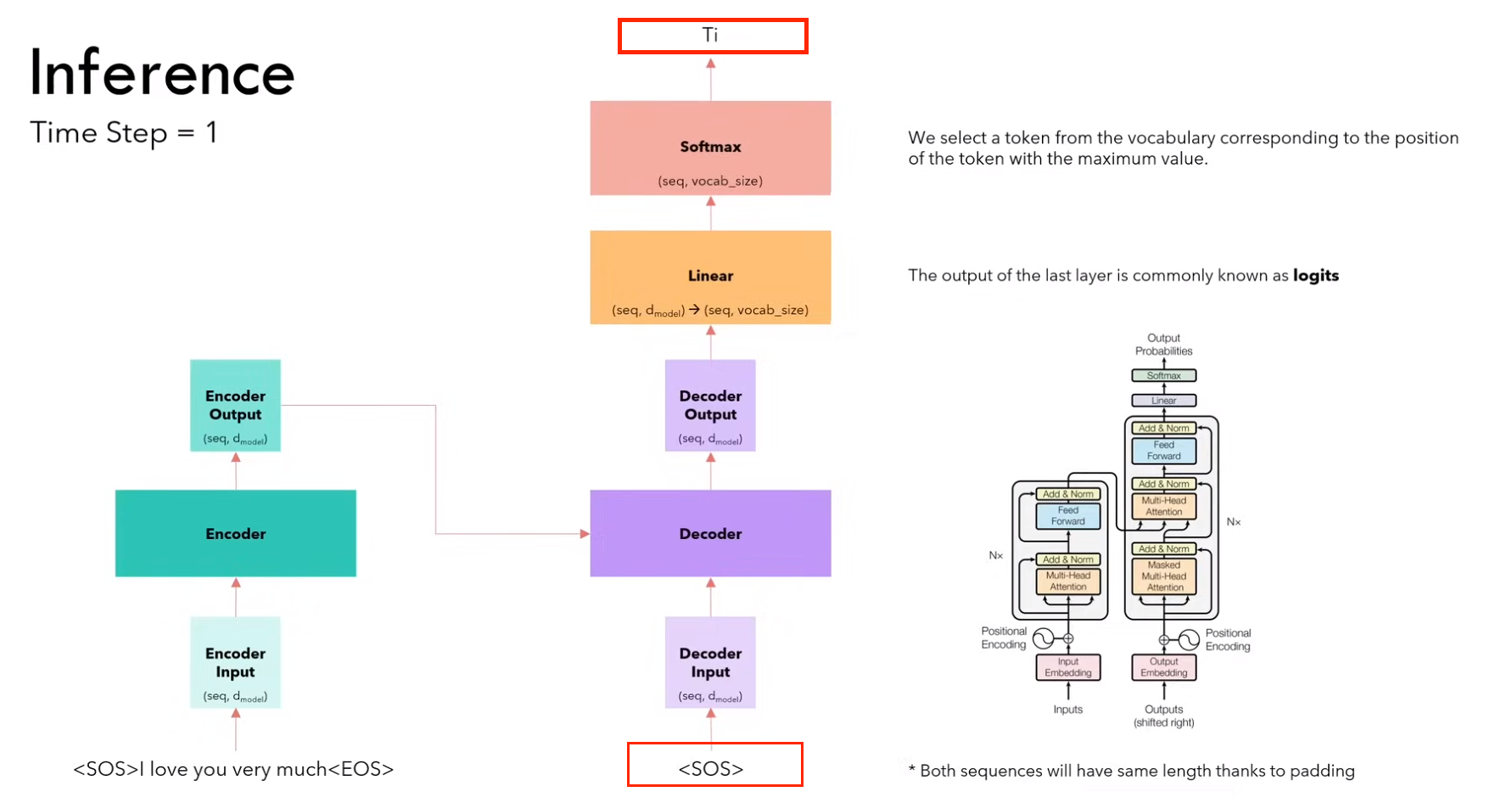
1)第一步:输入 <sos>,输出 ti
(需要进行 encoder 和 decoder 的计算)
2)第二步:输入<sos> it,输出 amo
(因为encoder不变,所以不用计算encoder,只计算decoder)
3)第三步:输入<sos> it amo ,输出 molto
(因为encoder不变,所以不用计算encoder,只计算decoder)
4)第四步:输入<sos> it amo molto,输出 <eos>
(因为encoder不变,所以不用计算encoder,只计算decoder)
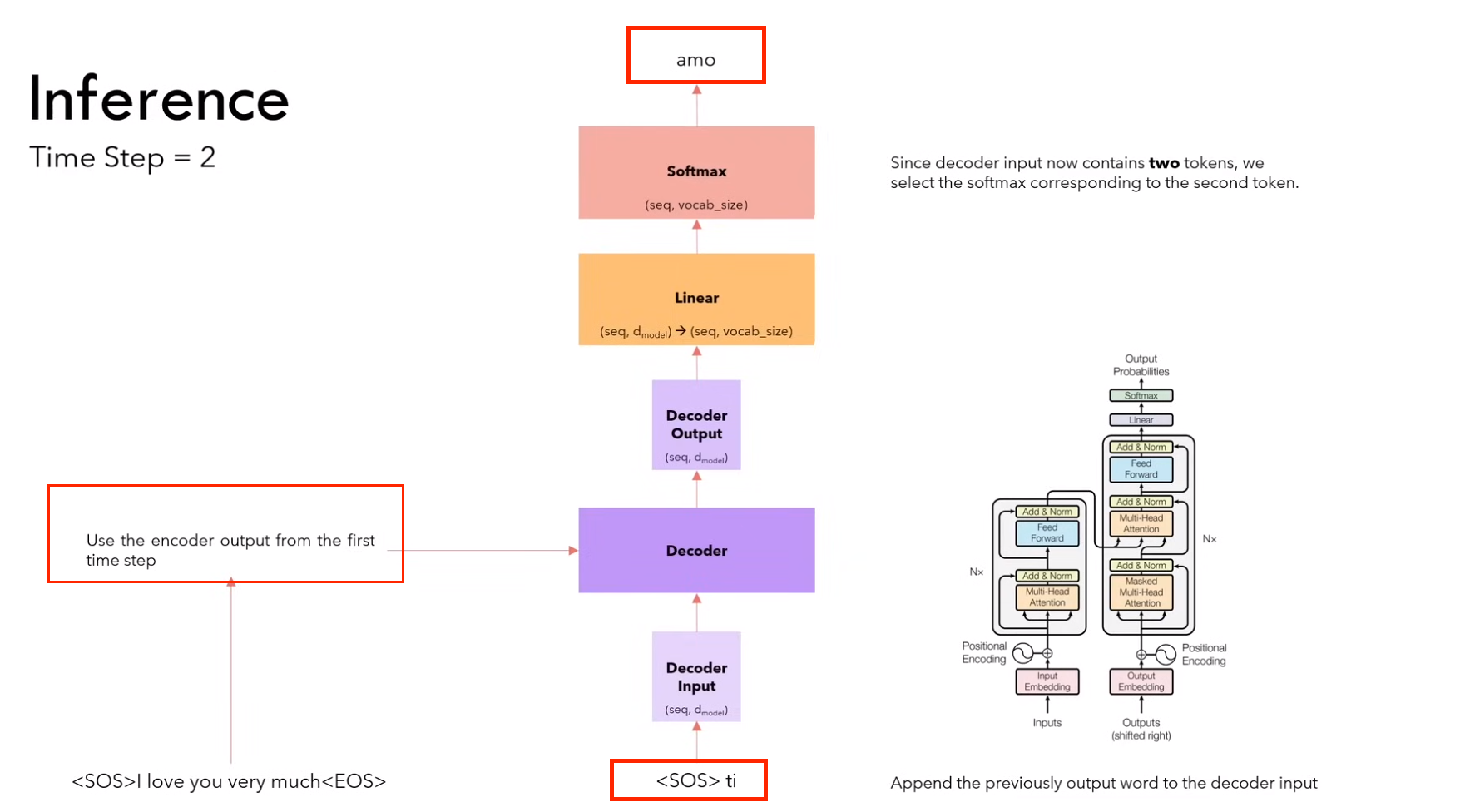
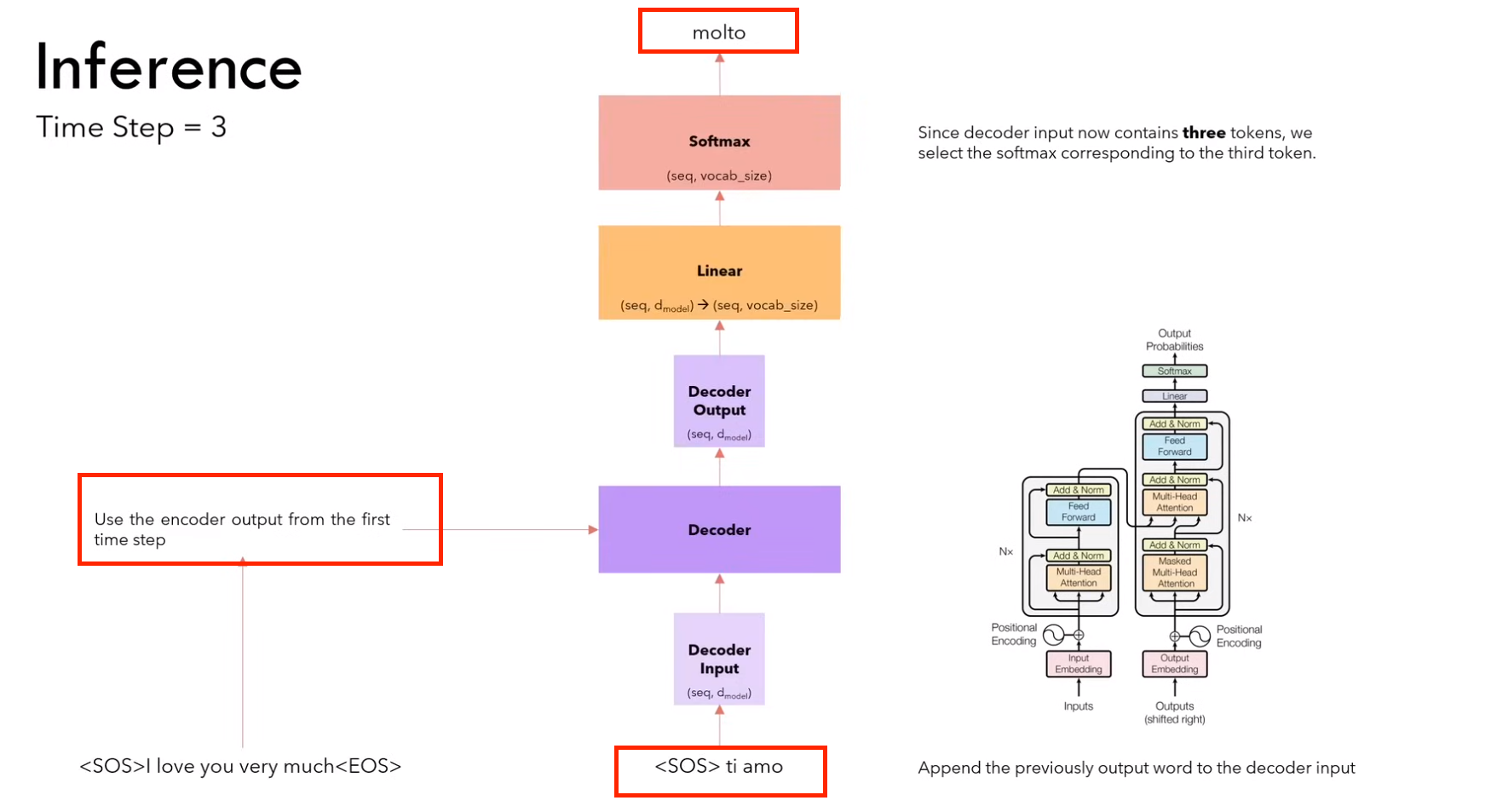
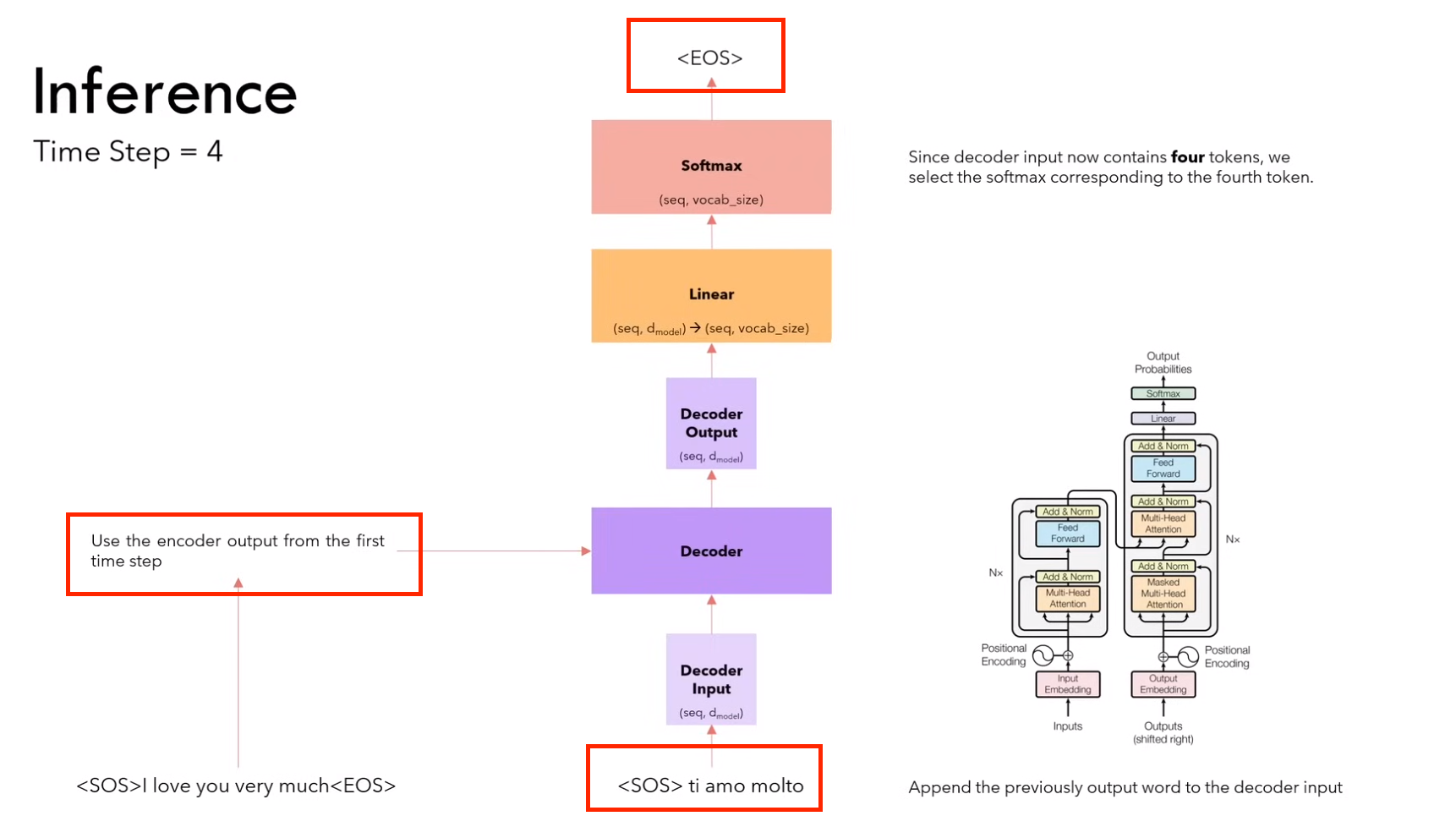
推理策略
通常使用 beam search,而不是贪婪搜索

2.4.3 与 RNN 相比的优势
RNN对于长序列时间长,而 Transformer 的所有的输入都是在同一时间输入完成的,使得训练长序列变得简单和快速。
3. 复习
3.1 Language model

什么是语言模型 language model ?
语言模型是一个概率模型,预测一个 word 出现的概率。
eg:china 这个 word 出现在 shanghai is a city in 后面的概率。
3.1.1 训练
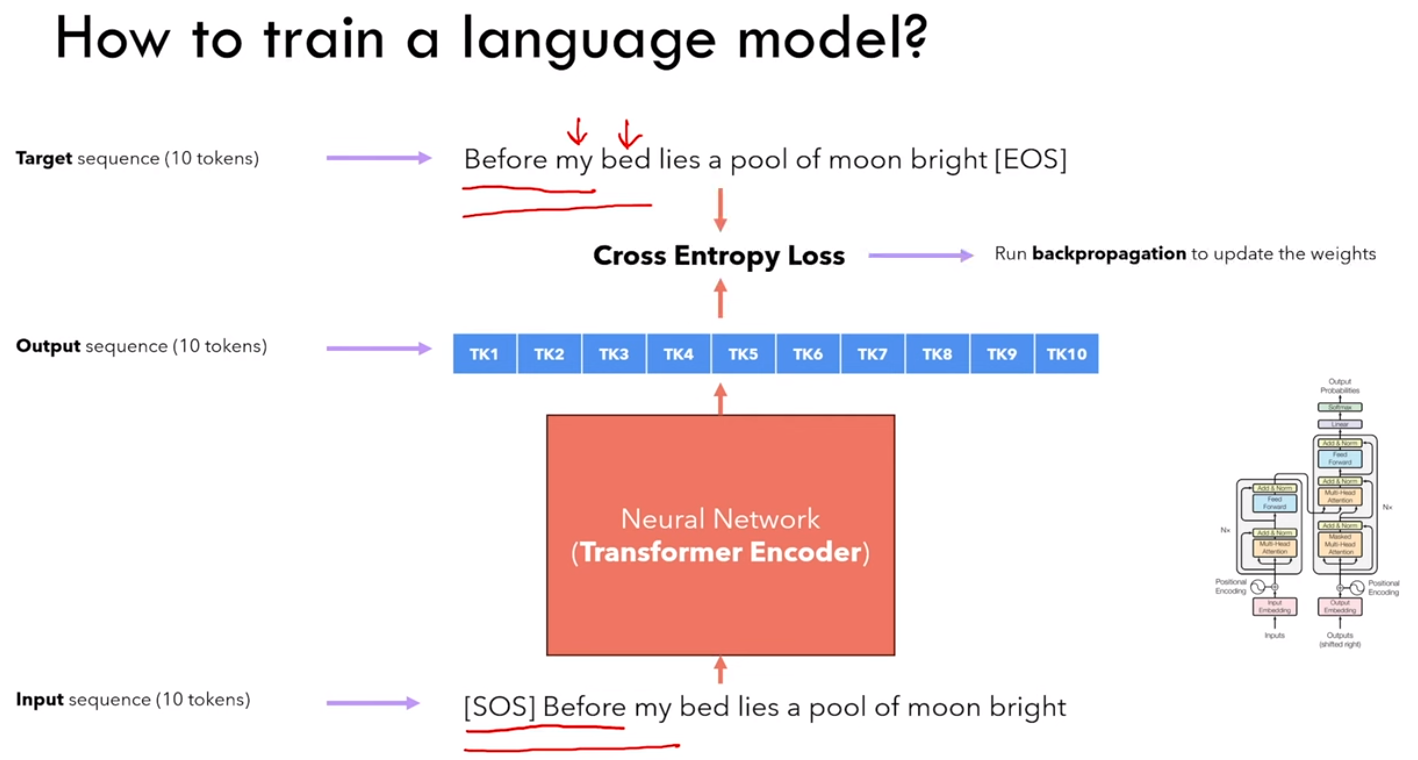
3.1.2 推理

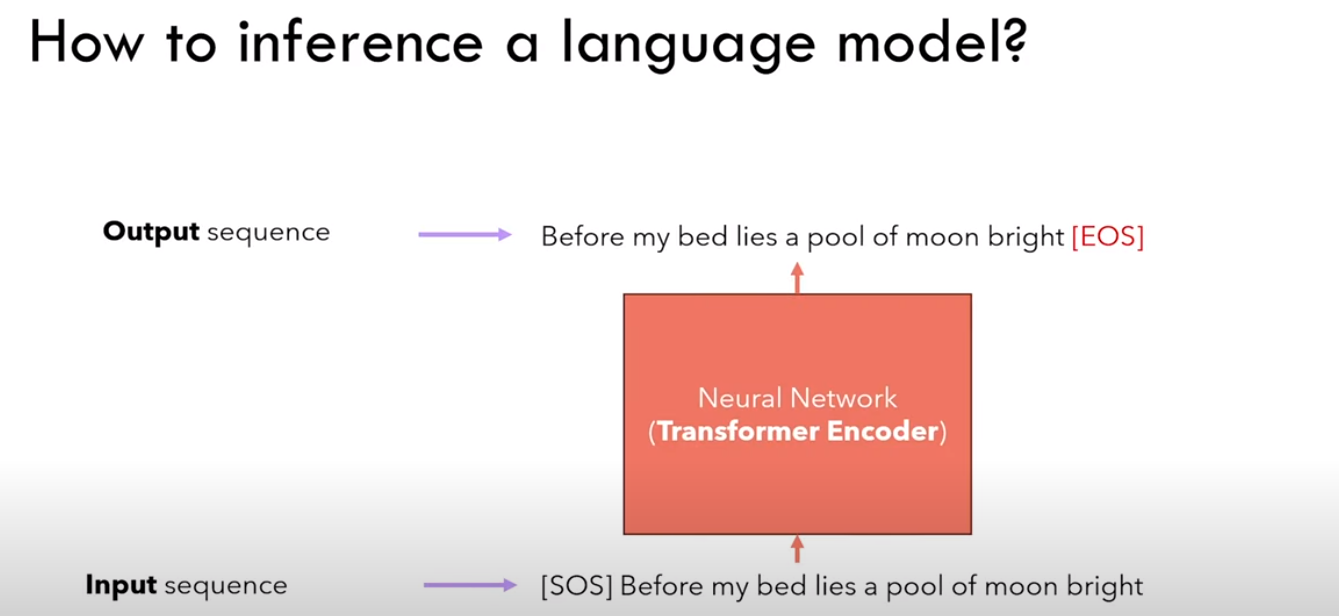
Ps:感觉应该是生成式模型
输入[SOS],输出 Before
接着输入 Before ,输出 my
······,以此类推
最后输入 bright,输出 [EOS]
3.2 Transformer 架构(Encoder)
3.2.1 嵌入向量

为什么使用向量来表示 word ?
1)希望具有相近含义的 word 在向量空间中更接近
2)这里的接近使用余弦相似度来衡量,或者是点积(dot product)
(不同模型用到的 tokenizer:
LLama 使用 Byte-Pair Encoding tokenization
Bert 使用 WordPiece tokenization)
3.2.2 位置编码

3.2.3 自注意力和 causal mask
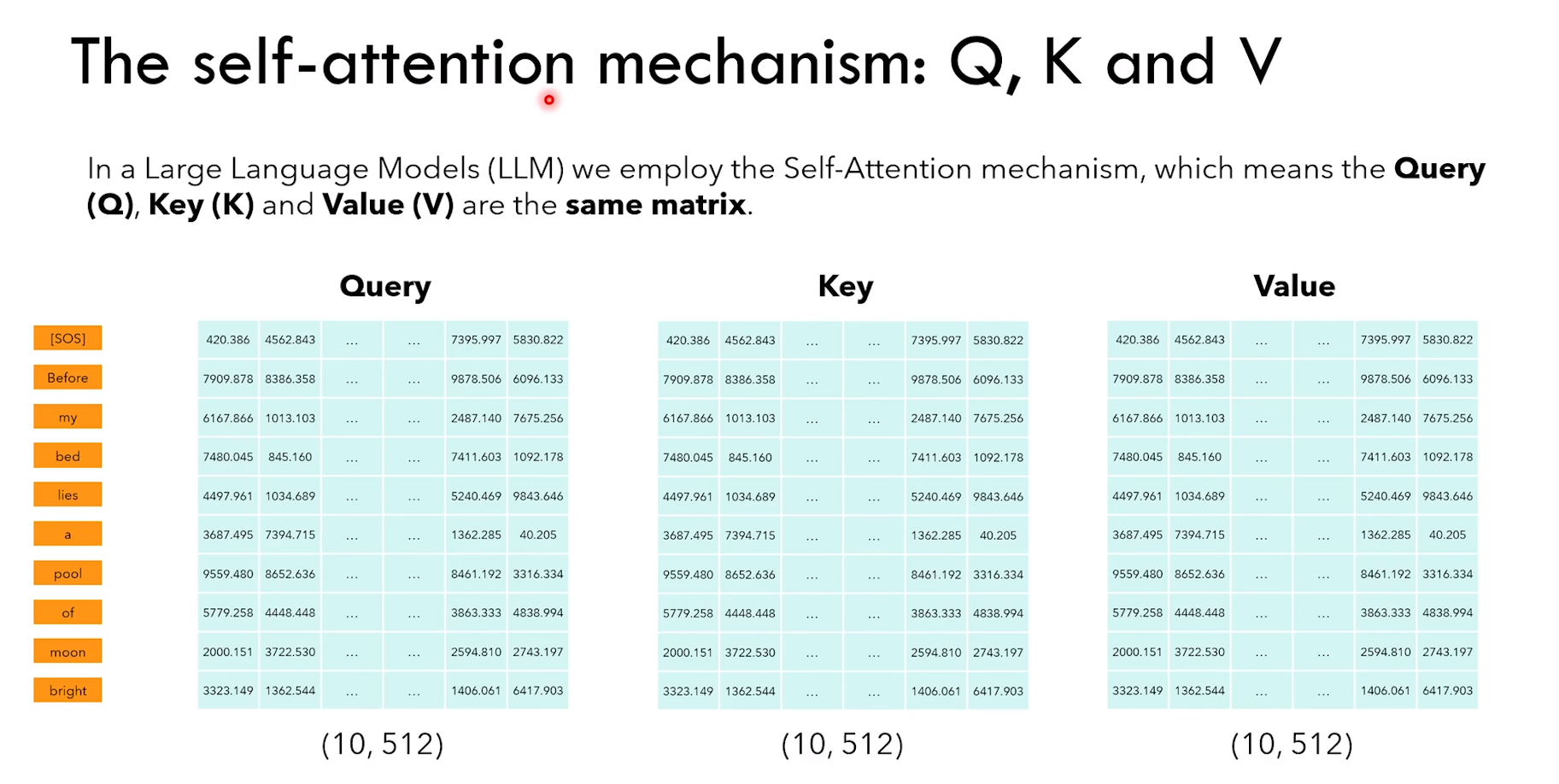

Self-attention(自注意力)
1)所以这里的 query、key、value,都是 encoder 输入矩阵的 copy 版本
Ps:翻译任务中会用到 cross-attention
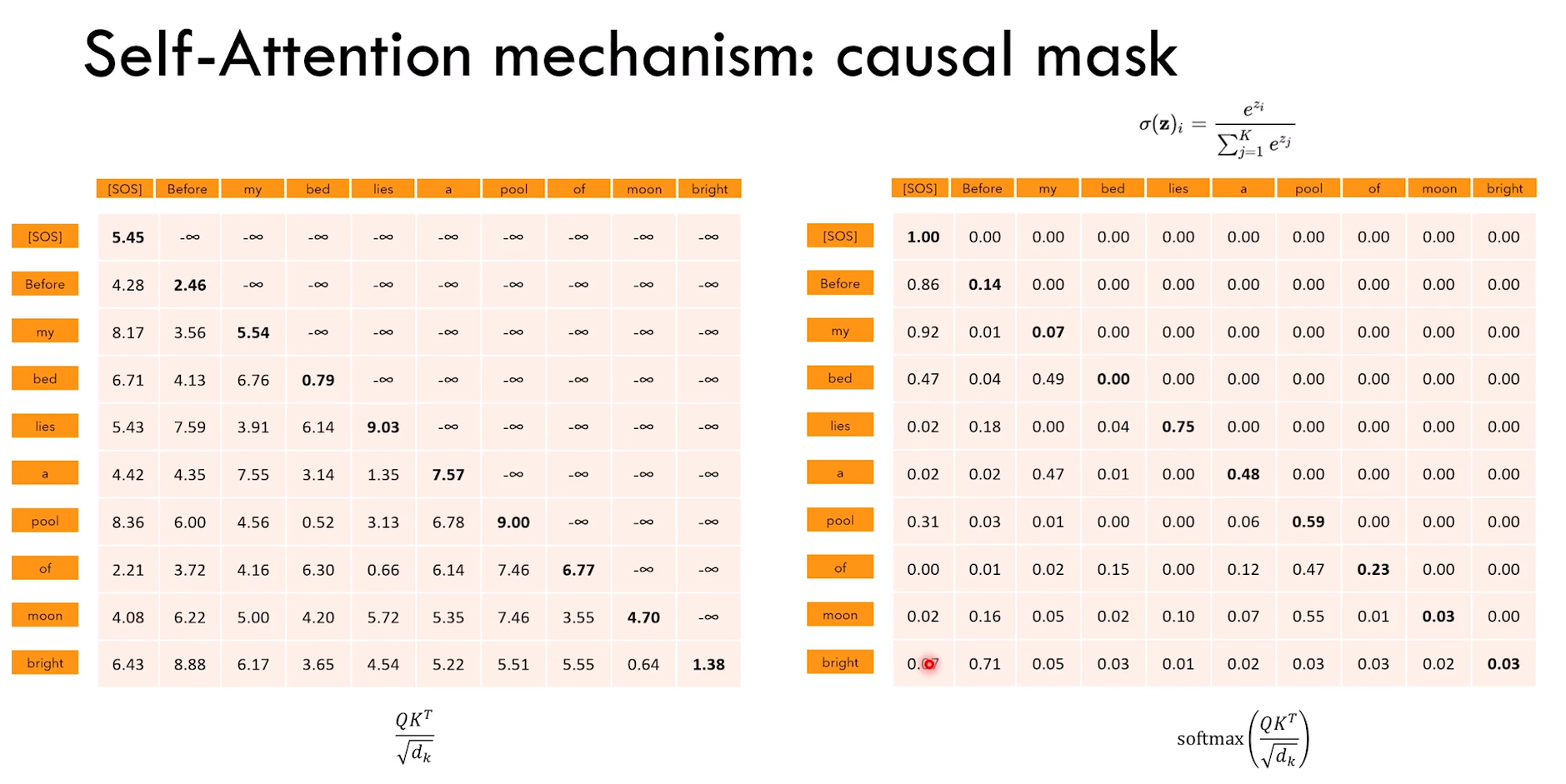
2)causal mask 使得 word 只能 “看到” 出现在它之前的 word
3)而 Bert 能够看到前后的 context
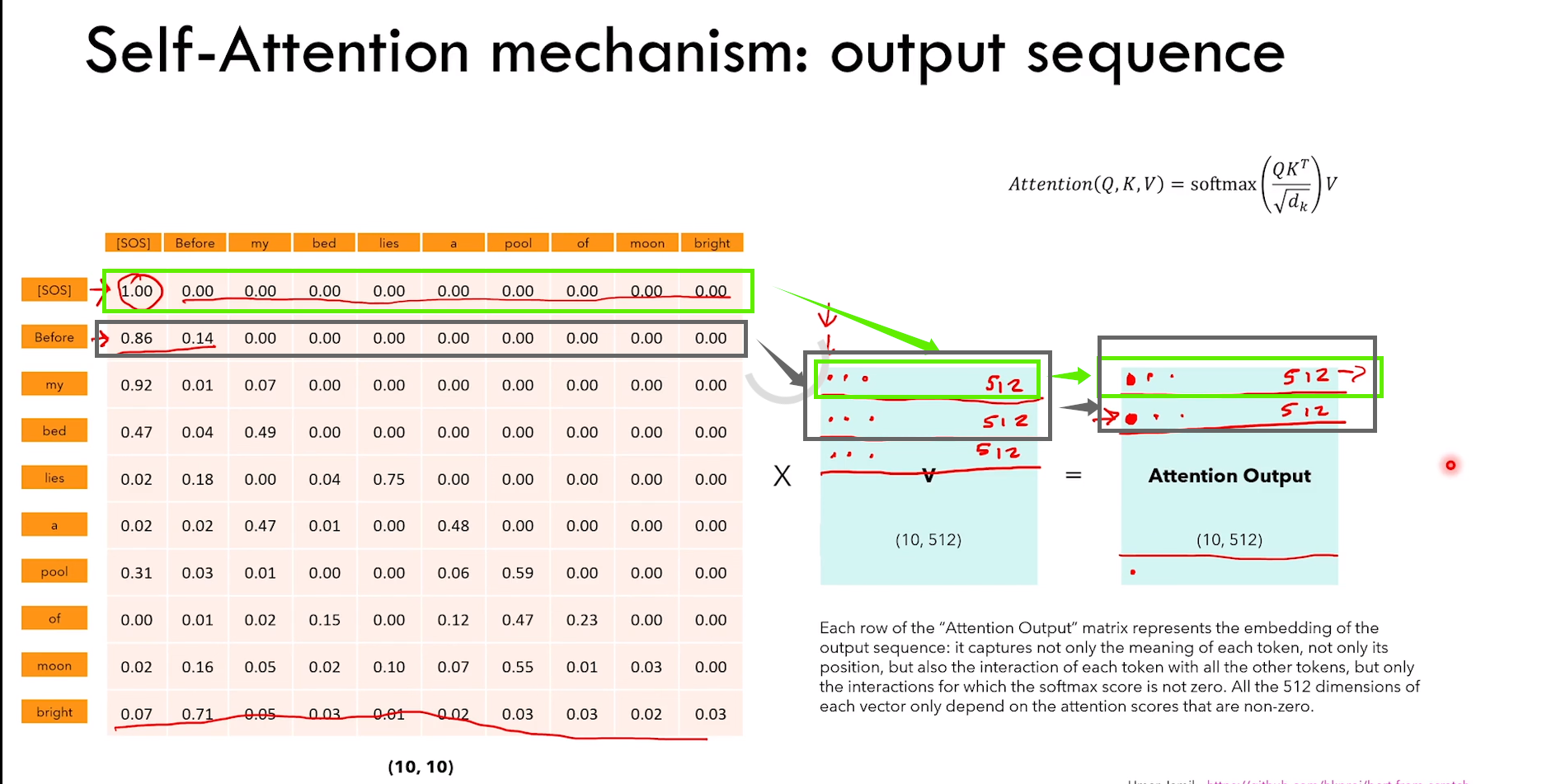
因为 token 只能看到它之前的 token
所以 QK转置 * V 的时候,第一个 token [SOS] 只能与 V 矩阵的第一行相乘(因为后面的元素全是0)
也就是 [SOS] 只有与自己 interaction
后面以此类推,Before 只能与 [SOS] 和 Before interaction
4 BERT
1)允许的最大 input token 数量是 512,但是 token 的嵌入维度(base768,large1024)
2)positional embedding 是训练期间习得的


1)bert 不能处理带有 prompt 的任务
2)bert 使用 left 和 right context 进行训练
3)bert 不能文本生成
4)bert 没有经过 next token预测(生成任务),但是经过了 masked language model 和 next sentence prediction
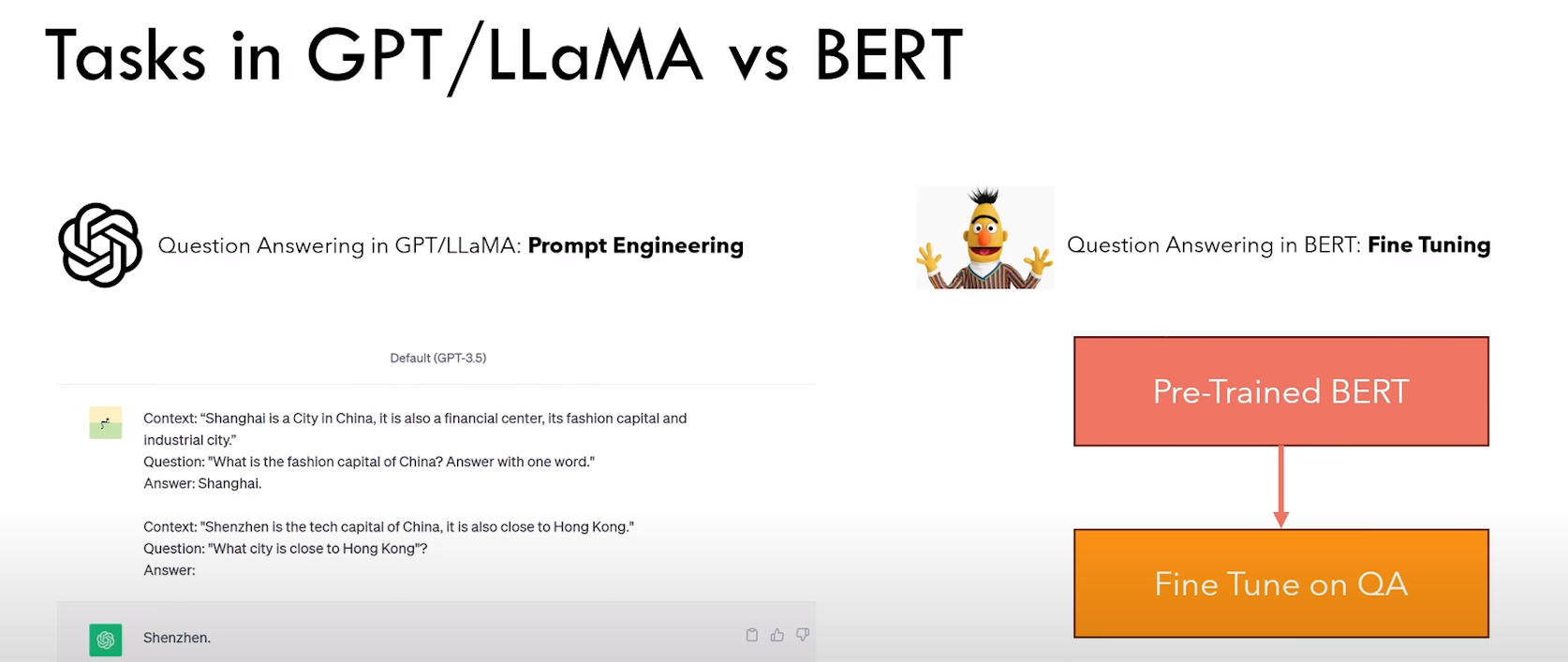
Bert 和 生成模型 使用方式的不同:
1)生成模型通过“上下文” + 提示工程
2)Bert 通过预训练 + 具体任务fine tune
4.1 左右 context 的重要性

4.2 BERT 预训练
4.2.1 Masked Language Model task

MLM 任务细节: 1)随机挑选一个 token,80% 概率用 [MASK] 替换,10% 概率用随机 token 替换,10% 概率不变
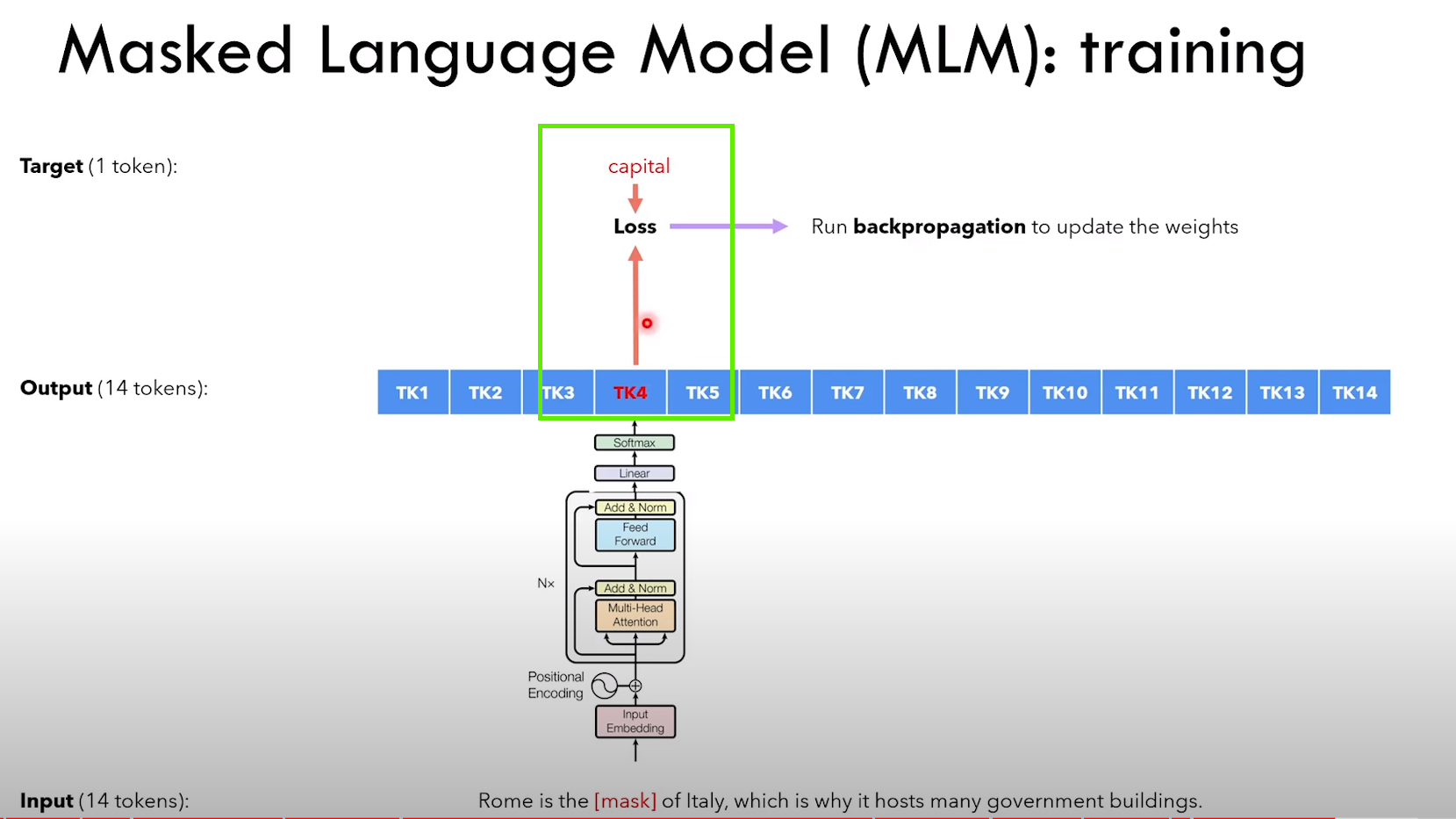
4.2.2 Next Sentence Prediction task
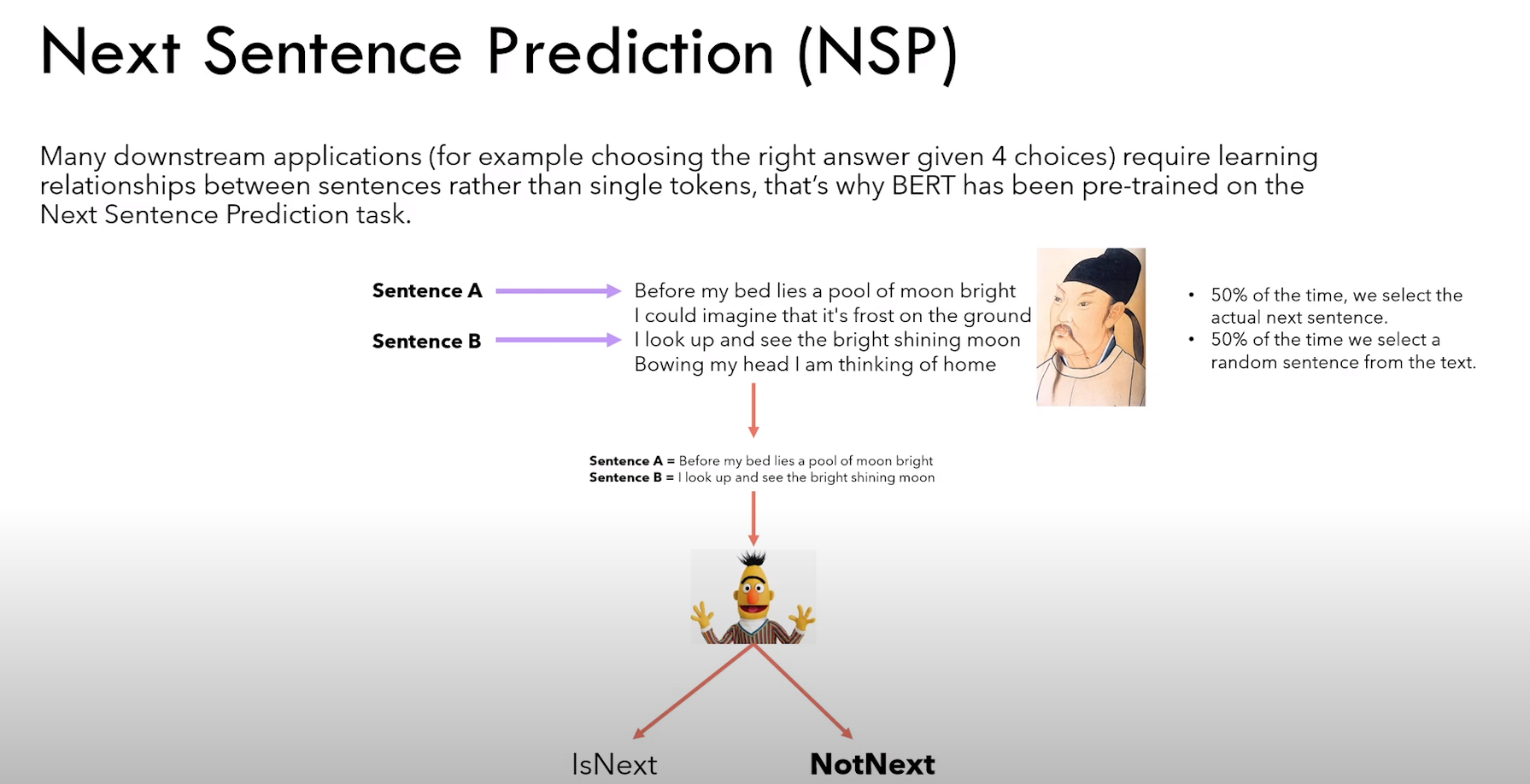
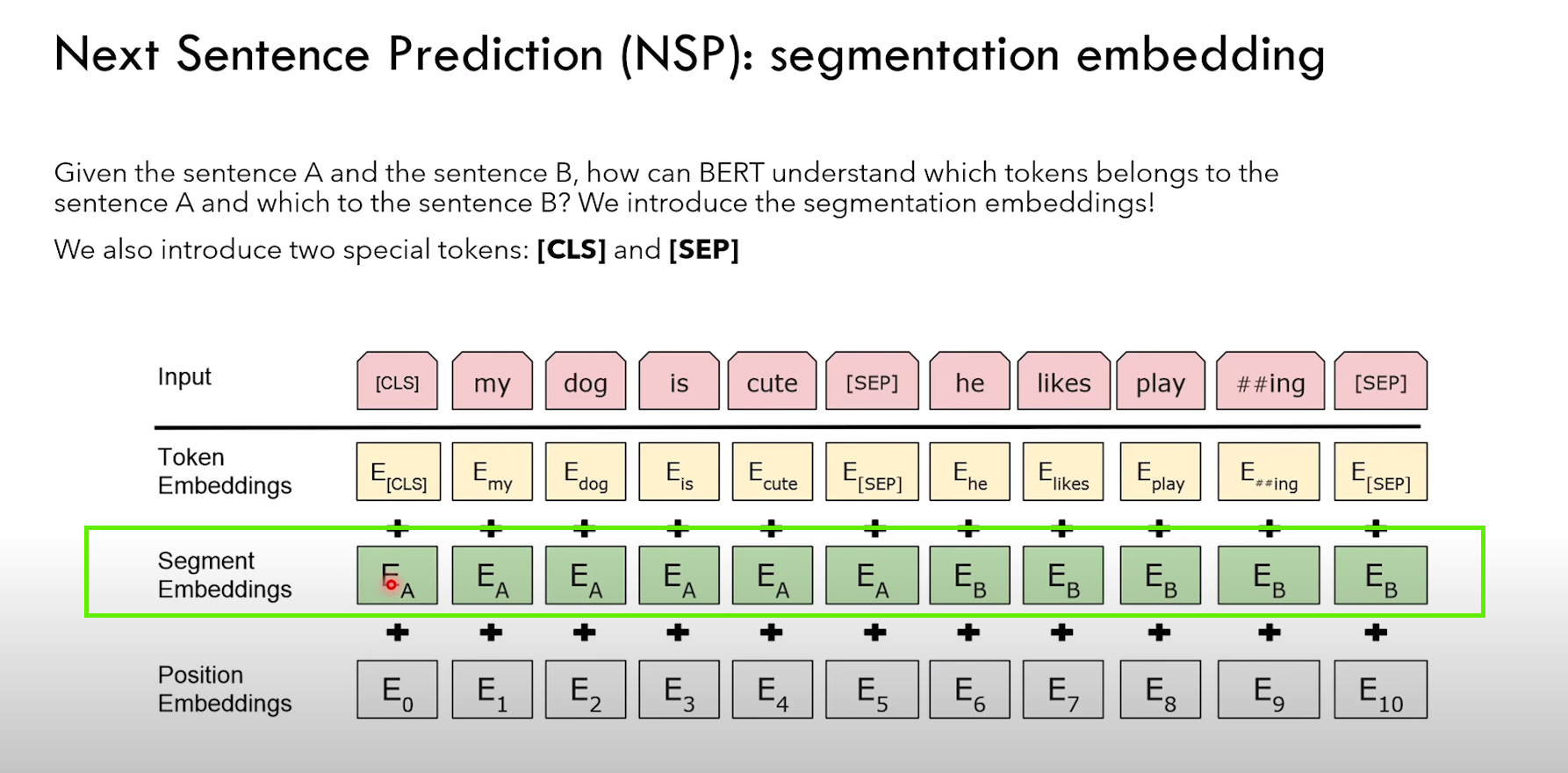
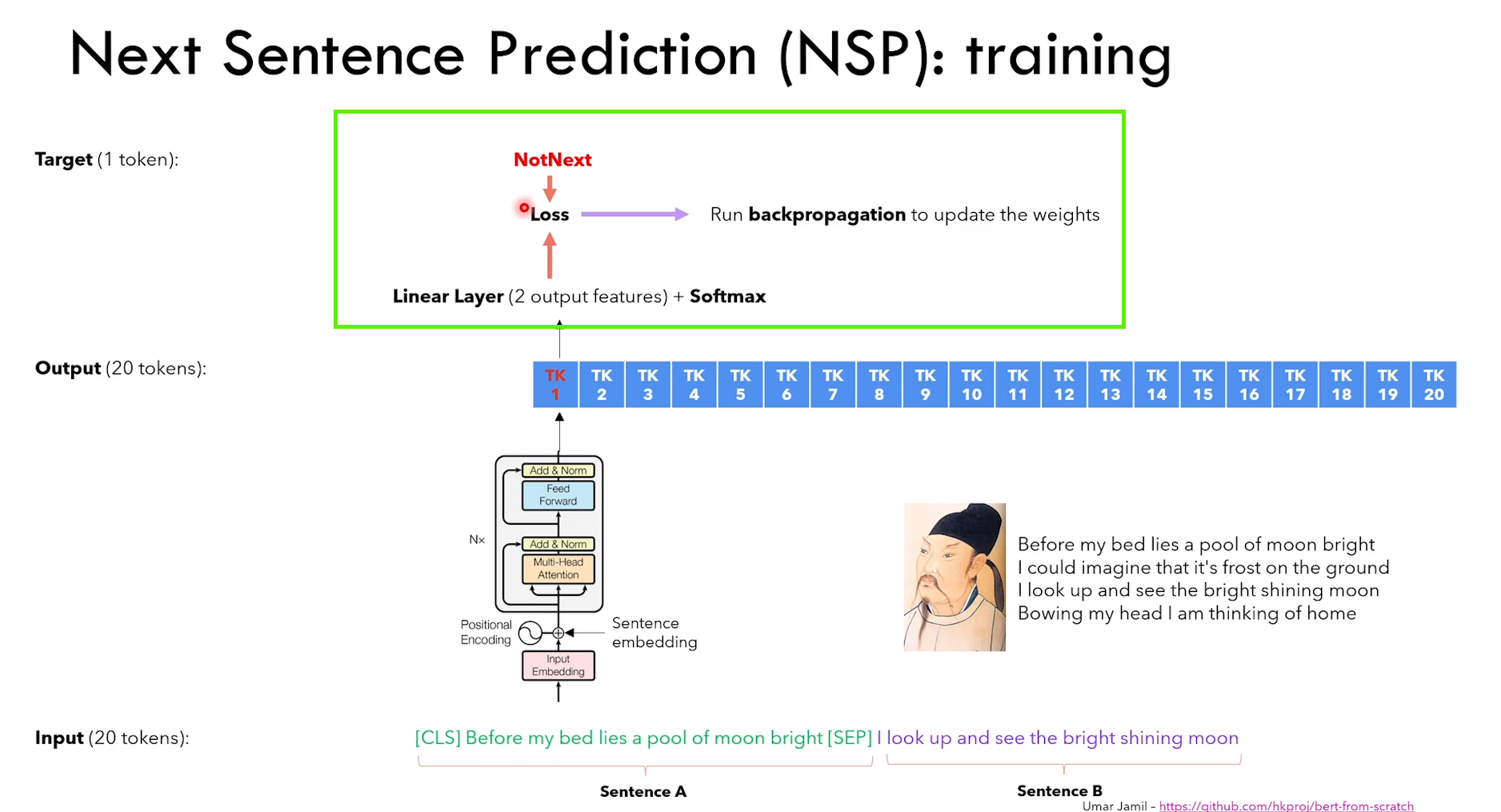
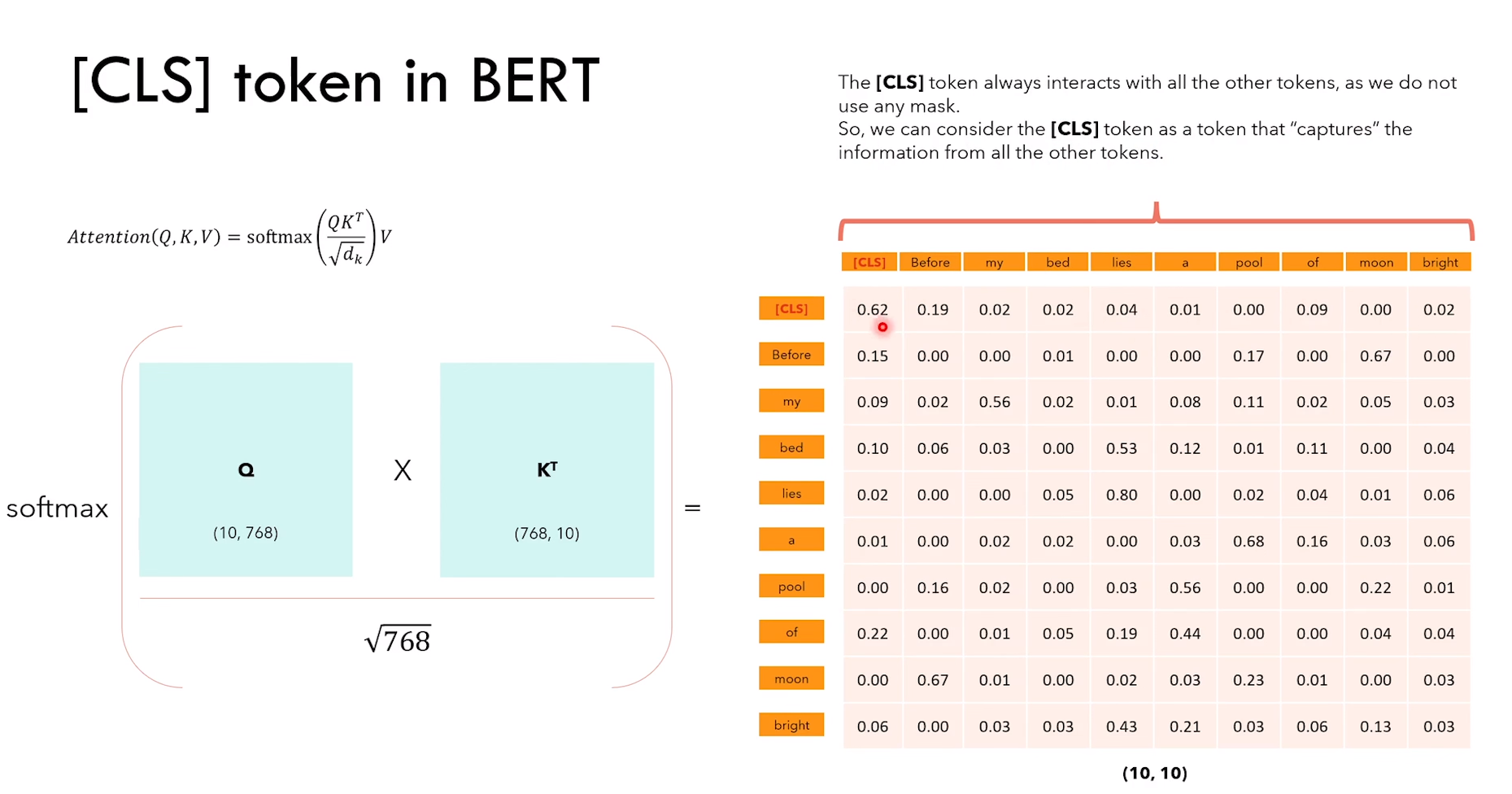

NSP 任务细节:
1)给定句子 A 和 B,判断 B 是不是 A 的下一句话
2)除了传统的 token embedding + positional embedding,还有 segment embedding(表征 token 属于哪个句子)
3)NSP 是一个分类任务,CLS 的输出进行二分类 IsNext or NotNext
4)CLS token 通过Q*K转置,可以看作捕获了所有 token 的信息
4.3 BERT 微调
4.3.1 文本分类任务
和上面的 NSP 任务类似,就是分类
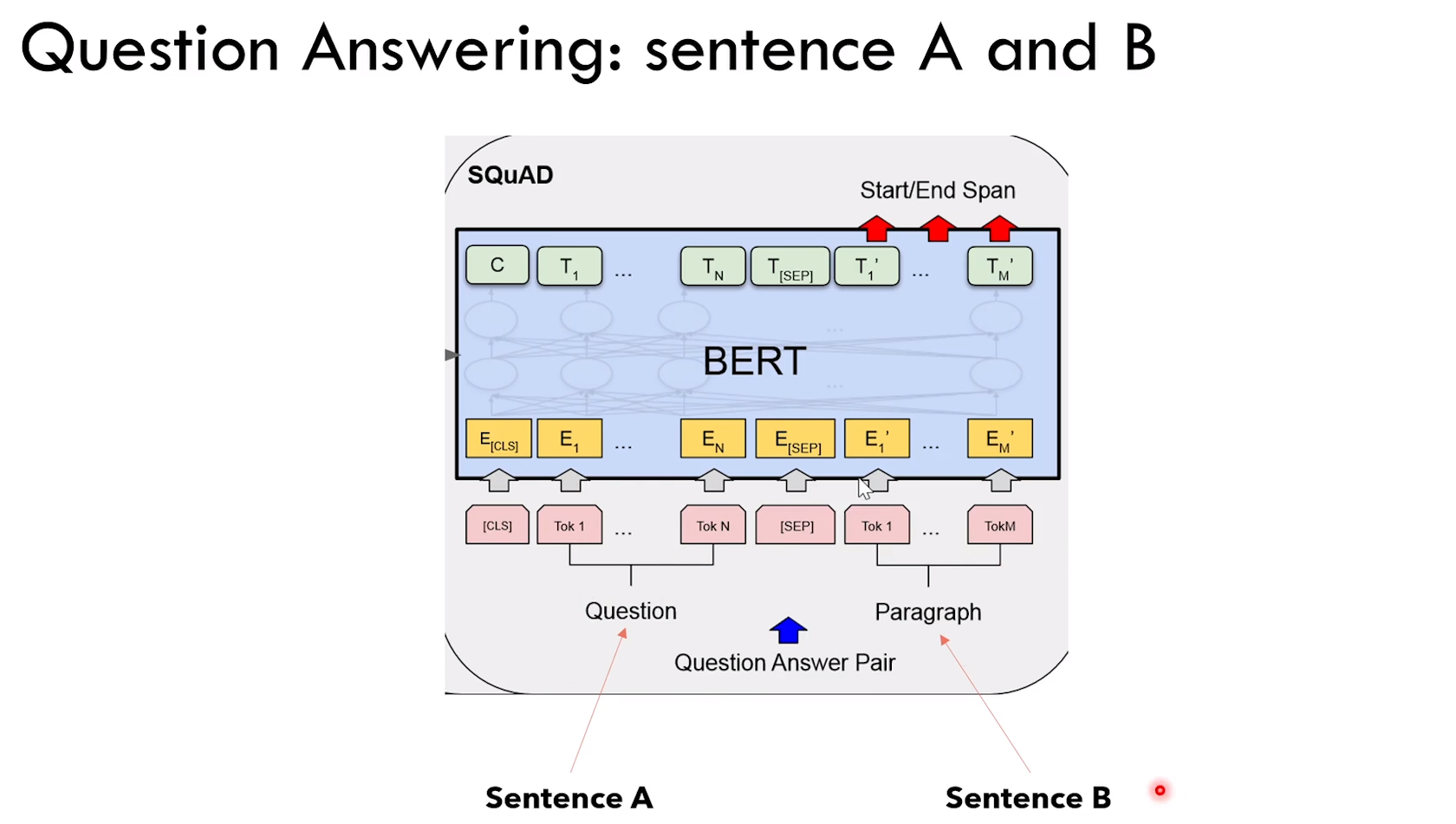
4.3.2 问答任务
任务设定:给定 context + question,输出 answer
1)Bert 需要知道输入里面哪一部分是 context,哪一部分是 question
2)Bert 需要给出 answer 的开始和结束 token:线性层输出两个(起始token和结束token),然后计算损失
解决办法,分别看下面两图

相关文章:
知识积累(五):Transformer 家族的学习笔记
文章目录 1. RNN1.1 缺点 2. Transformer2.1 组成2.2 Encoder2.2.1 Input Embedding(嵌入层)2.2.2 位置编码2.2.3 多头注意力2.2.4 Add & Norm 2.3 Decoder2.3.1 概览2.3.2 Masked multi-head attention 2.4 Transformer 模型的训练和推理2.4.1 训练…...

[Java、Android面试]_13_map、set和list的区别
本人今年参加了很多面试,也有幸拿到了一些大厂的offer,整理了众多面试资料,后续还会分享众多面试资料。 整理成了面试系列,由于时间有限,每天整理一点,后续会陆续分享出来,感兴趣的朋友可关注收…...

Linux进程管理:(六)SMP负载均衡
文章说明: Linux内核版本:5.0 架构:ARM64 参考资料及图片来源:《奔跑吧Linux内核》 Linux 5.0内核源码注释仓库地址: zhangzihengya/LinuxSourceCode_v5.0_study (github.com) 1. 前置知识 1.1 CPU管理位图 内核…...

计算机专业学生的成长之路:超越课堂的自我提升策略
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...
财报解读:“高端化”告一段落,华住开始“全球化”?
2023年旅游业快速复苏,全球酒店业直接受益,总体运营指标大放异彩,多数酒店企业都实现了营收上的明显增长,身为国内龙头的华住也不例外。 3月20日晚,华住集团发布2023年四季度及全年财报。整体实现扭亏为盈,…...

Wifi环境下Unity开发iOS应用启动后HTTPS请求未弹出是否允许无线数据使用数据的弹窗
情况说明 笔者项目在首次启动,登录界面点击登录按钮会先HTTPS请求创建帐号,但是在WIFI网络下,请求后一直提示网络连接失败。但是切换到流量包后,则会弹出"无线数据"使用数据的弹窗,选择允许后则可顺利进入。…...
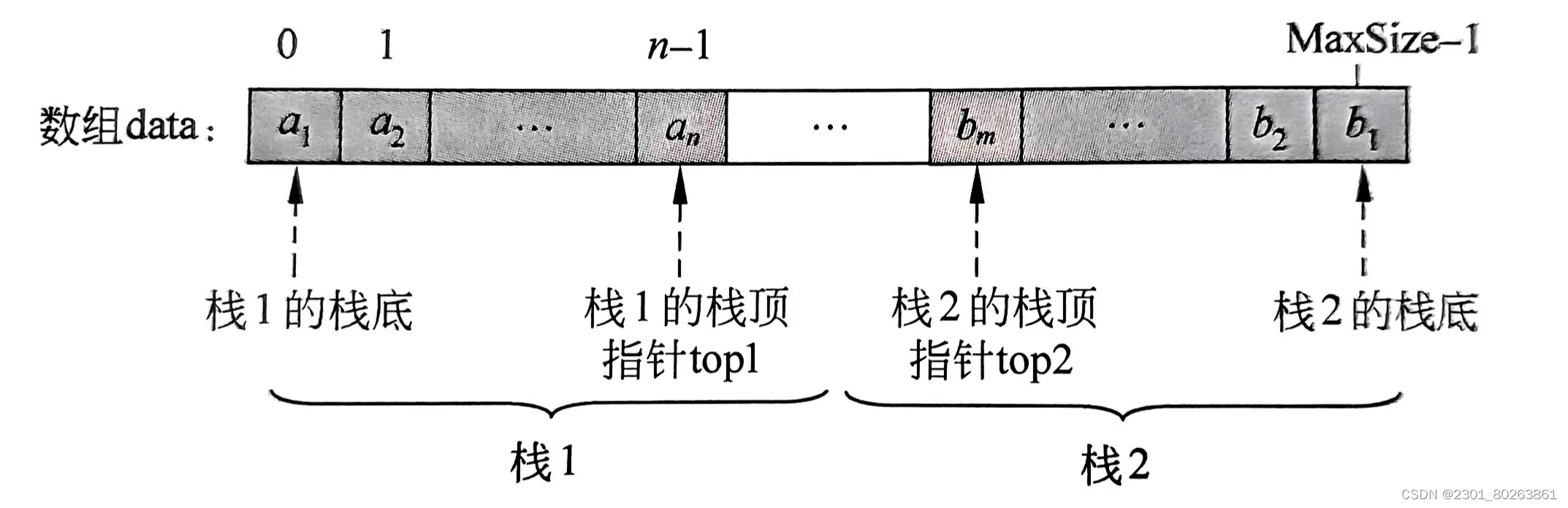
数据结构的概念大合集03(栈)
概念大合集03 1、栈1.1 栈的定义和特点1.2 栈的基础操作1.3 栈的顺序存储1.3.1 顺序栈1.3.2 栈空,栈满,进栈,出栈的基本思想1.3.3 共享栈1.3.3.1 共享栈的4要素 1.4 栈的链式存储1.4.1 链栈的实现1.4.2 链栈的4个要素 1、栈 1.1 栈的定义和特…...
C++ 哈希表
目录 两数之和 面试题 01.02. 判定是否互为字符重排 存在重复元素 存在重复元素 II 字母异位词分组 两数之和 1. 两数之和 思路1:两层for循环 思路2:逐步添加哈希表 思路3:一次填完哈希表 如果一次填完,那么相同元素的值&…...
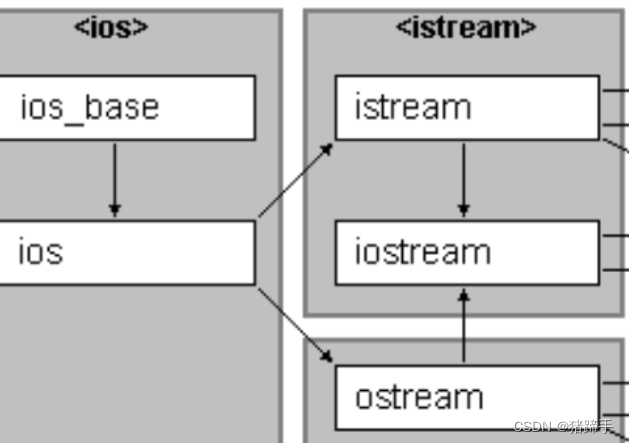
C++之继承详解
一.继承基础知识 继承定义: 继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保 持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称派生类。继承呈现了面向对象 程序设…...

C#装箱和拆箱
一,装箱 装箱是指将值类型转化为引用类型。 代码如下: 装箱的内部过程 当值类型需要被装箱为引用类型时,CLR(Common Language Runtime)会为值类型分配内存,在堆上创建一个新的对象。值类型的数据会被复…...
企业用大模型如何更具「效价比」?百度智能云发布5款大模型新品
服务8万企业用户,累计帮助用户精调1.3万个大模型,帮助用户开发出16万个大模型应用,自2023年12月以来百度智能云千帆大模型平台API日调用量环比增长97%...从一年前国内大模型平台的“开路先锋”到如今的大模型“超级工厂”,百度智能…...
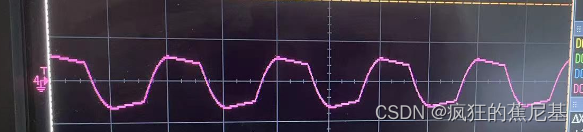
linux 外部GPIO Watchdog驱动适配
前言 文章描述, 利用外部gpio看门狗芯片驱动芯片的复位功能。 芯片:RK3568 平台: Linux ubuntu.lan 4.19.232 #27 SMP Sat Sep 23 13:43:49 CST 2023 aarch64 aarch64 aarch64 GNU/Linux 硬件接线图示 看门狗芯片采用GPIO喂狗,W…...

活动回顾 | 走进华为向深问路,交流数智办公新体验
3月20日下午,“企业数智办公之走进华为”交流活动在华为上海研究所成功举办。此次活动由上海恒驰信息系统有限公司主办,华为云计算技术有限公司和上海利唐信息科技有限公司协办,旨在通过对企业数字差旅和HR数智化解决方案的交流,探…...
【Java】Oracle发布Java22最新版本
甲骨文(ORACLE)已经于2023年3月19日正式发布了最新版本的JDK,版本号:22 根据官方声明,Java 22 (Oracle JDK 22) 在性能、稳定性和安全性方面进行了数千种改进,包括对Java 语言、其API 和性能,以…...

Vue reactive函数的使用
let searchForm reactive({}); let data reactive({ isAdmin: true, isshowAccount: true }); reactive 是什么? reactive 是 Vue 3 Composition API 中的一个函数,用于创建一个包含响应式数据的对象。在 Vue 2.x 中,我们通常使用 data 选项…...

unity自动引用生成
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Text; using UnityEditor; using UnityEngine; using UnityEngine.UI;/// <summary> /// 模板脚本生成 /// </summary> public class ScriptCreater : EditorW…...

【Linux系统】线程互斥与同步
目录 一.几个概念 二.线程互斥 1.定义并初始化锁 2.加锁 3.解锁 4.销毁锁 三.互斥锁的本质 1.xchg的原子性 2.加锁的过程 3.解锁的过程 四.可重入VS线程安全 五.死锁 1.死锁的概念 2.具体实例 3.死锁产生的四个必要条件 4.解决或避免死锁 六.线程同步 七.…...

武汉星起航引领跨境电商新潮流,深耕亚马逊打造全方位合作新模式
在全球化的浪潮下,跨境电商已成为连接各国市场的重要桥梁,为无数企业带来了前所未有的发展机遇。在这一领域,武汉星起航电子商务有限公司以其独特的战略眼光和实战经验,成为引领行业发展的佼佼者。公司自2017年起便深耕亚马逊平台…...
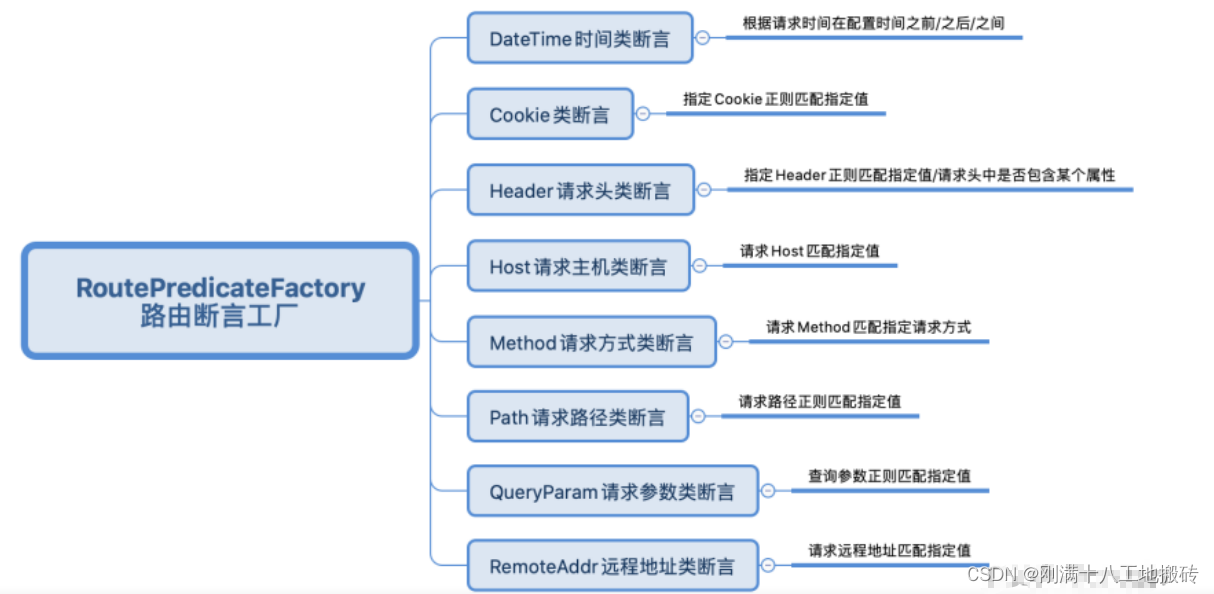
GateWay路由规则
Spring Cloud GateWay 帮我们内置了很多 Predicates功能,实现了各种路由匹配规 则(通过 Header、请求参数等作为条件)匹配到对应的路由 1 时间点后匹配 server:port: 8888 spring:application:name: gateway-servicecloud:nacos:discovery:…...

shell脚本基础改造
一、基础的shell脚本格式 #!/bin/bash 2 #3 #********************************************************************4 #Author: LJH5 #QQ: 2…...
)
从一次生产事故复盘:我们如何优雅地处理用户上传的‘异常’Excel文件(附Apache POI配置详解)
从生产事故到防御体系:构建Excel文件处理的工程化解决方案那天凌晨2点,我被一阵急促的告警声惊醒。监控系统显示,核心文件处理服务的错误率在10分钟内飙升到35%,大量用户上传的Excel文件无法正常解析。更糟糕的是,部分…...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

基于ATtiny84的智能冰箱监控器:低功耗温度与门状态监测方案
1. 项目概述:一个装在树莓派盒子里的智能冰箱管家如果你家里有台老冰箱,或者对食物储存温度特别在意,总担心冰箱门没关严或者突然断电导致内部升温,那么这个自己动手做的“冰箱看门狗”项目就太适合你了。它本质上是一个高度定制化…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...

基于Cynthion逆向USB协议,为DP100电源开发Linux控制软件
1. 项目概述:用Cynthion嗅探USB,为DP100电源打造Linux软件作为一名长期在Linux环境下折腾硬件和嵌入式开发的爱好者,我经常遇到一个头疼的问题:很多不错的桌面小设备,比如电源、示波器、逻辑分析仪,它们的官…...

学了几天 Web 安全,终于搞懂什么是 XSS 了
xss的详细介绍最近开始正式学习 Web 安全。前面陆续学了:HTTPCookieSessionJWT RBAC然后发现很多地方都会提到一个东西:XSS以前一直感觉这个漏洞很抽象。网上很多文章一上来就是:<script>alert(1)</script>然后说:“弹…...

Python-for-Android 完整指南:5分钟将Python应用打包为Android APK
Python-for-Android 完整指南:5分钟将Python应用打包为Android APK 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android࿰…...