Python爬虫之Scrapy框架系列(24)——分布式爬虫scrapy_redis完整实战【XXTop250完整爬取】
目录:
- 每篇前言:
- 1.使用分布式爬取豆瓣电影信息
- (1)settings.py文件中的配置:
- (2)spider文件的更改:
- (3)items.py文件(两个项目一致!):
- (4)pipelines.py文件:
- 分布式实现效果:
- ①直接运行项目,发现在等待:
- ②再开一个终端,做如下操作:
- 总结:
- 效果:
- 2.解决一些小问题:
- 2.1 解决爬空问题:(在两个项目中都进行以下操作!)
- ①使用拓展程序(这个文件就是为了解决爬空而生的):
- ②在settings.py文件中设置这个拓展程序:
- 3. 关于分布式(Scrapy_redis)的总结:
每篇前言:
🏆🏆作者介绍:【孤寒者】—CSDN全栈领域优质创作者、HDZ核心组成员、华为云享专家Python全栈领域博主、CSDN原力计划作者
- 🔥🔥本文已收录于Scrapy框架从入门到实战专栏:《Scrapy框架从入门到实战》
- 🔥🔥热门专栏推荐:《Python全栈系列教程》、《爬虫从入门到精通系列教程》、《爬虫进阶+实战系列教程》、《Scrapy框架从入门到实战》、《Flask框架从入门到实战》、《Django框架从入门到实战》、《Tornado框架从入门到实战》、《前端系列教程》。
- 📝📝本专栏面向广大程序猿,为的是大家都做到Python全栈技术从入门到精通,穿插有很多实战优化点。
- 🎉🎉订阅专栏后可私聊进一千多人Python全栈交流群(手把手教学,问题解答); 进群可领取Python全栈教程视频 + 多得数不过来的计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
1.使用分布式爬取豆瓣电影信息
- (此处做了限制,只爬取四页电影数据共计100条,可去除限制爬取全部10页250条数据!)
**项目源码:
链接:https://pan.baidu.com/s/13akXDxNbtBeRTUzUB_2SNQ
提取码:bcuy
**
目标:在本机上使用两个完全一模一样的豆瓣项目,去使用分布式下载豆瓣电影top250电影信息!

其实,我们要进行修改的就只有settings.py文件以及爬虫文件,别的文件都不需要进行改动。
(1)settings.py文件中的配置:
- (两个项目都做此配置)
#设置scrapy-redis
#1.启用调度将请求存储进redis
from scrapy_redis.scheduler import Scheduler
SCHEDULER="scrapy_redis.scheduler.Scheduler"#2.确保所有spider通过redis共享相同的重复过滤
from scrapy_redis.dupefilter import RFPDupeFilter
DUPEFILTER_CLASS="scrapy_redis.dupefilter.RFPDupeFilter"#3.指定连接到Redis时要使用的主机和端口 目的是连接上redis数据库
REDIS_HOST="localhost"
REDIS_PORT=6379# 不清理redis队列,允许暂停/恢复抓取 (可选) 允许暂停,redis数据不丢失 可以实现断点续爬!!!
SCHEDULER_PERSIST = True# 第二步:开启将数据存储进redis公共区域的管道!
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 100, # 开启数据交给redis公共区域的管道'douban.pipelines.DoubanPipeline': 200, # 存储本地txt文件的管道
}
(2)spider文件的更改:
- (两个项目略有不同!)
总共四步:
-
导入RedisSpider类:(既然要使用它,肯定首先要导入!)
from scrapy_redis.spiders import RedisSpider -
继承使用RedisSpider类:(既然要使用它,就要继承去使用这个类)
class DbSpider(RedisSpider): -
既然将请求都放进了Redis里,那爬虫文件中就不再需要start_urls这个初始请求了:
#start_urls = ['https://movie.douban.com/top250'] -
设置一个键,寻找起始的url:(这个键就会在redis中寻找初始的url,所以后面我们只需往redis里放请求即可!)
redis_key="db:start_urls"
完整版爬虫文件:
第一个项目下的爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
import refrom ..items import DoubanItemfrom scrapy_redis.spiders import RedisSpider # 1.导出RedisSpider类class DbSpider(RedisSpider): # 2.使用RedisSpider类name = 'db'allowed_domains = ['movie.douban.com']# start_urls = ['https://movie.douban.com/top250'] # 3.将请求放进redis里redis_key = "db:start_urls" # 4.设置一个键,寻找起始的urlpage_num = 0 # 类变量def parse(self, response): # 解析和提取数据print('第一个项目:', response.url)print('第一个项目:', response.url)print('第一个项目:', response.url)# 获取电影信息数据# films_name=response.xpath('//div[@class="info"]/div/a/span[1]/text()').extract()node_list = response.xpath('//div[@class="info"]') # 25个if node_list: # 此判断的作用:在爬取到10页之后,就获取不到了!判断每次是否获取到数据,如果没有则返回空(即停止了)for node in node_list:# 电影名字film_name = node.xpath('./div/a/span[1]/text()').extract()[0]# 主演 拿标签内容,再正则表达式匹配con_star_name = node.xpath('./div/p[1]/text()').extract()[0]if "主" in con_star_name:star_name = re.findall("主演?:? ?(.*)", con_star_name)[0]else:star_name = "空"# 评分score = node_list.xpath('./div/div/span[@property="v:average"]/text()').extract()[0]# 使用字段名 收集数据item = DoubanItem()item["film_name"] = film_nameitem["star_name"] = star_nameitem["score"] = score# 形式:{"film_name":"肖申克的救赎","star_name":"蒂姆","score":"9.7"}detail_url = node.xpath('./div/a/@href').extract()[0]yield scrapy.Request(detail_url,callback=self.get_detail,meta={"info":item})# 此处几行的代码配合yield里传的参数meta={"num":self.page_num},共同作用实现:# 两个项目的共享变量page_num能正确变化,不导致冲突!!!if response.meta.get("num"):self.page_num = response.meta["num"]self.page_num += 1if self.page_num == 4:returnprint("page_num:", self.page_num)page_url = "https://movie.douban.com/top250?start={}&filter=".format(self.page_num * 25)yield scrapy.Request(page_url, callback=self.parse, meta={"num": self.page_num})# 注意:各个模块的请求都会交给引擎,然后经过引擎的一系列操作;但是,切记:引擎最后要把得到的数据再来给到# spider爬虫文件让它解析并获取到真正想要的数据(callback=self.parse)这样就可以再给到自身。else:returndef get_detail(self, response):item = DoubanItem()# 获取电影简介信息# 1.meta会跟随response一块返回 2.可以通过response.meta接收 3.通过updata可以添加到新的item对象info = response.meta["info"] # 接收电影的基本信息item.update(info) # 把电影基本信息的字段加进去# 将电影简介信息加入相应的字段里description = response.xpath('//div[@id="link-report-intra"]//span[@property="v:summary"]/text()').extract()[0]\.strip()item['description'] = descriptionyield item
第二个项目下的爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
import refrom ..items import DoubanItemfrom scrapy_redis.spiders import RedisSpider # 1.导出RedisSpider类class DbSpider(RedisSpider): # 2.使用RedisSpider类name = 'db'allowed_domains = ['movie.douban.com']# start_urls = ['https://movie.douban.com/top250'] # 3.将请求放进redis里redis_key = "db:start_urls" # 4.设置一个键,寻找起始的urlpage_num = 0 # 类变量def parse(self, response): # 解析和提取数据print('第二个项目:', response.url)print('第二个项目:', response.url)print('第二个项目:', response.url)# 获取电影信息数据# films_name=response.xpath('//div[@class="info"]/div/a/span[1]/text()').extract()node_list = response.xpath('//div[@class="info"]') # 25个if node_list: # 此判断的作用:在爬取到10页之后,就获取不到了!判断每次是否获取到数据,如果没有则返回空(即停止了)for node in node_list:# 电影名字film_name = node.xpath('./div/a/span[1]/text()').extract()[0]# 主演 拿标签内容,再正则表达式匹配con_star_name = node.xpath('./div/p[1]/text()').extract()[0]if "主" in con_star_name:star_name = re.findall("主演?:? ?(.*)", con_star_name)[0]else:star_name = "空"# 评分score = node_list.xpath('./div/div/span[@property="v:average"]/text()').extract()[0]# 使用字段名 收集数据item = DoubanItem()item["film_name"] = film_nameitem["star_name"] = star_nameitem["score"] = score# 形式:{"film_name":"肖申克的救赎","star_name":"蒂姆","score":"9.7"}detail_url = node.xpath('./div/a/@href').extract()[0]yield scrapy.Request(detail_url,callback=self.get_detail,meta={"info":item})# 此处几行的代码配合57行yield里传的参数meta={"num":self.page_num},共同作用实现:# 两个项目的共享变量page_num能正确变化,不导致冲突!!!if response.meta.get("num"):self.page_num = response.meta["num"]self.page_num += 1if self.page_num == 4:returnprint("page_num:", self.page_num)page_url = "https://movie.douban.com/top250?start={}&filter=".format(self.page_num * 25)yield scrapy.Request(page_url, callback=self.parse, meta={"num": self.page_num})# 注意:各个模块的请求都会交给引擎,然后经过引擎的一系列操作;但是,切记:引擎最后要把得到的数据再来给到# spider爬虫文件让它解析并获取到真正想要的数据(callback=self.parse)这样就可以再给到自身。else:returndef get_detail(self, response):item = DoubanItem()# 获取电影简介信息# 1.meta会跟随response一块返回 2.可以通过response.meta接收 3.通过updata可以添加到新的item对象info = response.meta["info"] # 接收电影的基本信息item.update(info) # 把电影基本信息的字段加进去# 将电影简介信息加入相应的字段里description = response.xpath('//div[@id="link-report-intra"]//span[@property="v:summary"]/text()').extract()[0]\.strip()item['description'] = descriptionyield item
(3)items.py文件(两个项目一致!):
# -*- coding: utf-8 -*-# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass DoubanItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()#需要定义字段名 就像数据库那样,有字段名,才能插入数据(即存储数据)# films_name=scrapy.Field() #定义字段名film_name=scrapy.Field()star_name=scrapy.Field()score=scrapy.Field()description = scrapy.Field()
(4)pipelines.py文件:
- (两个项目存储本地txt文件名可改为不一样的,便于观察!)
# -*- coding: utf-8 -*-# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlimport json
import pymysqlclass DoubanPipeline(object):def open_spider(self,spider): #爬虫文件开启,此方法就开启self.f=open("films.txt","w",encoding="utf-8") #打开文件def process_item(self, item, spider): #会来25次,就会调用25次这个方法 如果按常规来写,文件就会被操作25次打开关闭#为了能写进text json.dumps将dic数据转换为strjson_str=json.dumps(dict(item),ensure_ascii=False)+"\n"self.f.write(json_str) #爬虫文件开启时,文件就已经打开,在此直接写入数据即可!return itemdef close_spider(self,spider): #爬虫文件关闭,此方法就开启self.f.close() #爬虫文件关闭时,引擎已经将全部数据交给管道,关闭文件
分布式实现效果:
①直接运行项目,发现在等待:
分别在两个终端中开启两个scrapy项目:(注意:之前要开启redis数据库)

会发现,这俩项目都在等待,不会继续执行。这是因为没有给redis这个公共区域一个初始的请求,这俩项目都在周而复始的向redis要初始url,结果一直要不到!
在两个项目的settings.py文件中设置两个的日志不显示在控制台,而是存储到.log文件中。为了便于观察:
LOG_FILE="db.log"
LOG_ENABLED=False
②再开一个终端,做如下操作:
lpush db:start_urls https://movie.douban.com/top250

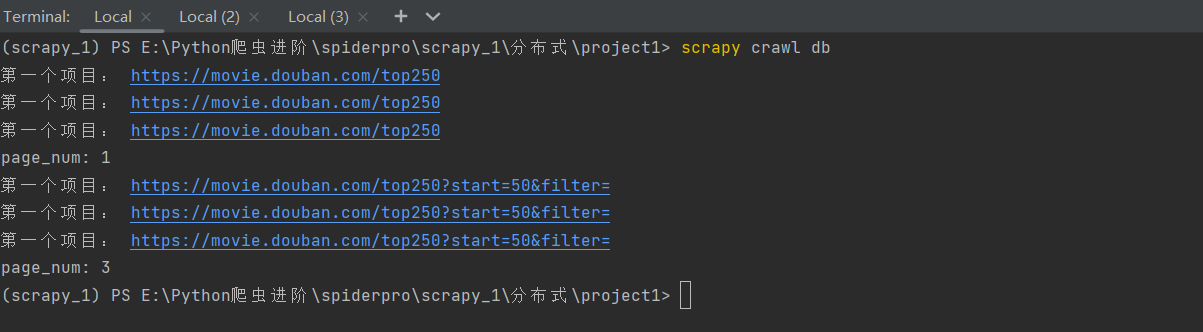
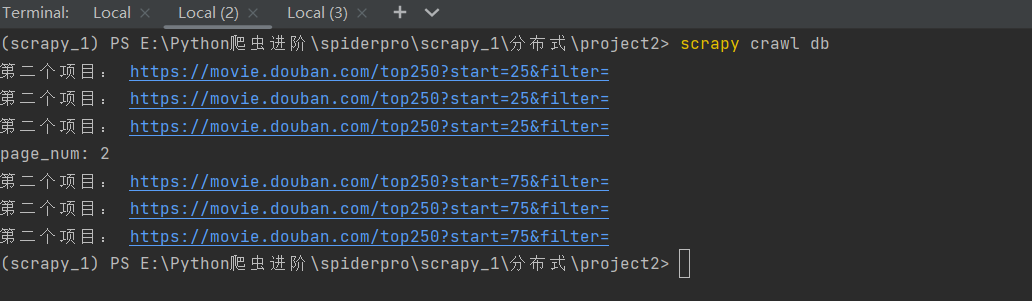
会发现我们的两个项目都会成功的跑起来:(而且总共获取数据刚好是四页的电影信息,共计100条)
总结:
会发现,第一个项目运行会显示使用了parse函数,这也就说明在redis这个公共区域的start_urls请求被第一个项目抢到了,然后就会运行这个项目,
但是,在这个项目的爬虫文件代码执行的过程中会在25次循环中给引擎发送共25次url请求,引擎得到这25个request请求后会将它们都交给scheduler调度器,再通过调度器交给redis数据库这个公共区域。
然后,两个项目的scheduler调度器就会一起抢这公共区域里的请求,并在各自的爬虫程序运行过程中提交给redis别的请求,两个项目继续抢,直到爬空。这就实现了咱爬虫的分布式爬取数据!!!

效果:
- (因为没有解决爬空,所以项目运行完并不会自己关闭,而且,哪怕项目运行完了,也会一直无限的爬空,就导致两个项目爬取的保存本地的数据不够100条,所以,在两个项目运行完在爬空的时候,强制关闭两个项目,就会发现数据是完整的了!!!)
两个项目下的获取存储到本地的txt文本内的电影信息共计刚好我们所要爬取的所有目标数据:四页共100部电影的信息。
2.解决一些小问题:
2.1 解决爬空问题:(在两个项目中都进行以下操作!)
①使用拓展程序(这个文件就是为了解决爬空而生的):
两个项目进行防爬空设置后,如果数据爬取完成,在指定时间内就会自动停止爬虫!!!
(文件名:extensions.py,放到settings.py同级目录里)
加入此拓展之后完整的项目代码:
链接:https://pan.baidu.com/s/1Naie1HsWCxS-1ntorT3_RQ
提取码:e30p
# -*- coding: utf-8 -*-# Define here the models for your scraped Extensions
import loggingfrom scrapy import signals
from scrapy.exceptions import NotConfiguredlogging = logging.getLogger(__name__)class RedisSpiderSmartIdleClosedExensions(object):def __init__(self, idle_number, crawler):self.crawler = crawlerself.idle_number = idle_numberself.idle_list = []self.idle_count = 0@classmethoddef from_crawler(cls, crawler):# first check if the extension should be enabled and raise# NotConfigured otherwiseif not crawler.settings.getbool('MYEXT_ENABLED'):raise NotConfiguredif not 'redis_key' in crawler.spidercls.__dict__.keys():raise NotConfigured('Only supports RedisSpider')# get the number of items from settingsidle_number = crawler.settings.getint('IDLE_NUMBER', 360)# instantiate the extension objectext = cls(idle_number, crawler)# connect the extension object to signalscrawler.signals.connect(ext.spider_opened, signal=signals.spider_opened)crawler.signals.connect(ext.spider_closed, signal=signals.spider_closed)crawler.signals.connect(ext.spider_idle, signal=signals.spider_idle)return extdef spider_opened(self, spider):spider.logger.info("opened spider {}, Allow waiting time:{} second".format(spider.name, self.idle_number * 5))def spider_closed(self, spider):spider.logger.info("closed spider {}, Waiting time exceeded {} second".format(spider.name, self.idle_number * 5))def spider_idle(self, spider):# 程序启动的时候会调用这个方法一次,之后每隔5秒再请求一次# 当持续半个小时都没有spider.redis_key,就关闭爬虫# 判断是否存在 redis_keyif not spider.server.exists(spider.redis_key):self.idle_count += 1else:self.idle_count = 0if self.idle_count > self.idle_number:# 执行关闭爬虫操作self.crawler.engine.close_spider(spider, 'Waiting time exceeded')
②在settings.py文件中设置这个拓展程序:
# Enable or disable extensions #扩展程序
# See https://docs.scrapy.org/en/latest/topics/extensions.html
EXTENSIONS = {# 'scrapy.extensions.telnet.TelnetConsole': None,'film.extensions.RedisSpiderSmartIdleClosedExensions':500, #开启extensions.py这个拓展程序
}
MYEXT_ENABLED = True # 开启扩展
IDLE_NUMBER = 3 # 配置空闲持续时间单位为 3个 ,一个时间单位为5s
注意:redis中存储的数据:
- spidername:items
list类型,保存爬虫获取到的数据item内容是json字符串。 - spidername:dupefilter
set类型,用于爬虫访问的URL去重内容是40个字符的url的hash字符串 - spidername:start_urls
list类型,用于接收redisspider启动时的第一个url - spidername:requests
zset类型,用于存放requests等待调度。内容是requests对象的序列化字符串。
3. 关于分布式(Scrapy_redis)的总结:
(一)分布式爬虫
一.settings里的配置
# 启用调度将请求存储进redis
# 1.必须
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#2. 必须
# 确保所有spider通过redis共享相同的重复过滤。
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"# 3.必须
# 指定连接到Redis时要使用的主机和端口。
REDIS_HOST = 'localhost'
REDIS_PORT = 6379二.spider文件更改from scrapy_redis.spiders import RedisSpider #1 导出 RedisSpiderclass DbSpider(RedisSpider): #2使用RedisSpider类# start_urls = ['https://movie.douban.com/top250/'] #3将要请求放在 公共区域 redis里面redis_key = "db:start_urls"#4 设置一个键 寻找起始url三.redis数据库中 写入 start_urls
lpush db:start_urls https://movie.douban.com/top250/四.解决爬空的问题
1.解决爬空的文件 extensions.py 主要是RedisSpiderSmartIdleClosedExensions
2.设置
MYEXT_ENABLED = True # 开启扩展
IDLE_NUMBER = 3 # 配置空闲持续时间单位为 3个 ,一个时间单位为5s
相关文章:
Python爬虫之Scrapy框架系列(24)——分布式爬虫scrapy_redis完整实战【XXTop250完整爬取】
目录: 每篇前言:1.使用分布式爬取豆瓣电影信息(1)settings.py文件中的配置:(2)spider文件的更改:(3)items.py文件(两个项目一致!&…...
提升效率,稳定可靠:亚信安慧AntDB的企业价值
亚信安慧AntDB分布式数据库凭借平滑扩展、高可用性和低成本三大核心优势,在业界获得了极高的评价和认可。这些优点不仅为AntDB提供了巨大的市场发展潜力,也使其成为众多企业在数据管理上的首选解决方案。 AntDB的平滑扩展特性极大地提升了企业的灵活性和…...

洛谷入门——P1567 统计天数
统计天数 题目描述 炎热的夏日,KC 非常的不爽。他宁可忍受北极的寒冷,也不愿忍受厦门的夏天。最近,他开始研究天气的变化。他希望用研究的结果预测未来的天气。 经历千辛万苦,他收集了连续 N ( 1 ≤ N ≤ 1 0 6 ) N(1 \leq N …...
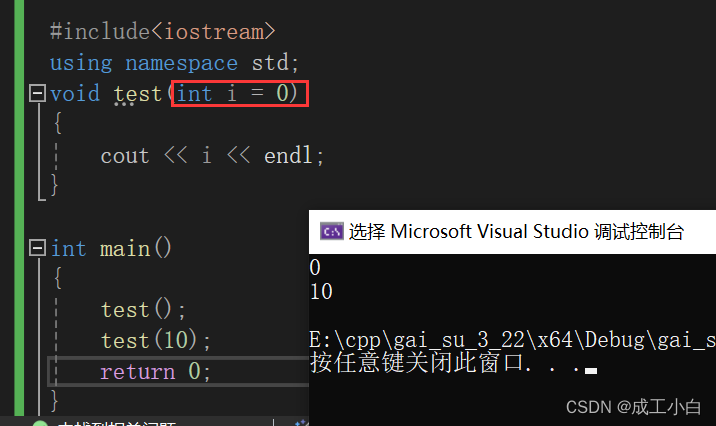
C++概述
目录 一、C关键字(63个) 二、C几个关键点: 三、C语言缺陷一:命名冲突 四、C新概念:命名空间(namespace) 五、命名空间的嵌套: 六、展开命名空间:(using …...

Linux学习笔记16 - 系统命令
1. Linux 常见系统管理命令 命令含义格式su切换用户su [选项] [用户名]ps显示系统由该用户运行的进程列表ps [选项]top动态显示系统中运行的程序(一般为每隔 5s)topkill输出特定的信号给指定 PID(进程号)的进程,并根据…...

读书笔记--阅读华为数据治理之旅有感
通过阅读华为的数据治理之旅,了解到华为公司作为高科技企业的引领者,在数据治理工作、数字化智能化转型方面的确有许许多多值得大家学习的地方,华为公司的业务范围广泛,市场竞争压力大,迫切需要用一些高效的手段来减轻员工的工作量,让员工各司其职,在各自承担的主营业务…...
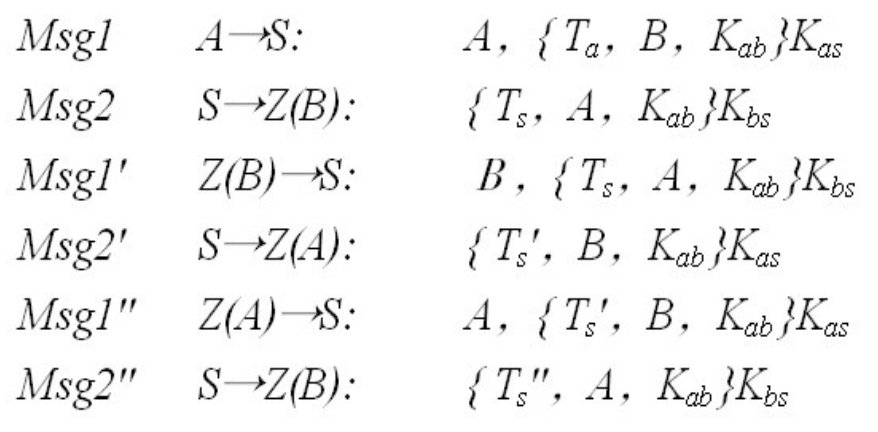
网络安全协议基本问题
Http和Https协议的端口号: Http:80 Https:443 网络监听: 网络监听是一种监视网络状态、数据流程以及网络上信息传输的工具,它可以将网络界面设定成监听模式,并且可以截获网络上所传输的信息。但是网络监…...
)
面试(一)
一. 说一下进程和线程的区别? (1)进程是资源分配的最小单位,线程是CPU调度的最小单位。 (2)线程是进程的一部分,一个线程只能属于一个进程,一个进程可以有多个线程,但至少有一个线程。 (3)进程有自己独立地址空间&a…...
libVLC windows开发环境搭建
1.简介 LibVLC是一个强大的开源库,它构成了VLC媒体播放器的核心部分。 LibVLC提供了一系列的功能接口,使得VLC能够处理流媒体的接入、音频和视频输出、插件管理以及线程系统等核心任务。 跨平台性:VLC作为一个跨平台的多媒体播放器&#x…...

【Netty】Netty的使用和常用组件详解
目录 一、简述 1.1 什么是Netty 1.2 Netty 的优势 1.3 为什么不用 Netty5? 1.4 为什么 Netty 使用 NIO 而不是 AIO? 1.5 为什么不用 Mina? 二、第一个 Netty 程序 2.1 Bootstrap、EventLoop(Group) 、Channel 2.1.1 Bootstrap 2.1.…...

Legacy|电脑Windows系统如何迁移到新安装的硬盘?系统迁移详细教程!
前言 前面讲了很多很多关于安装系统、重装系统的教程。但唯独没有讲到电脑换了新的硬盘之后,怎么把旧系统迁移到新的硬盘上。 今天小白就来跟各位小伙伴详细唠唠: 开始之前需要把系统迁移的条件准备好,意思就是在WinPE系统下,可…...

Windows 11 安装 Scoop
[Windows 11 安装 Scoop](Windows 11 安装 Scoop) 0. 引言 Scoop 从命令行安装您熟悉和喜爱的程序,差异最小。 它的主要功能如下: 消除权限弹出窗口 隐藏 GUI 向导样式的安装程序 防止PATH污染安装大量程序 避免安装和卸载程序的意外副作用 自动查…...

新能源汽车小三电系统
小三电系统 新能源电动汽车的"小三电"系统,一般指车载充电机(OBC)、车载 DC/DC 变换器,和高压直流配电盒(PDU)。一辆纯电动汽车一般配备一台OBC 和一台车载 DC/DC 变换器。OBC将外部输入的交流电转化为直流电输出给电池,DC/DC衔接…...

面试问答示范
文章目录 请做个自我介绍您的学历是统招吗?可以在学信网查询吗是全日制吗是双证吗?请介绍一下你上家公司的情况。介绍一下你们公司的服务器架构(网络架构)。说说你在工作中处理过的最棘手的技术问题讲一讲上家公司做过的项目为什么…...
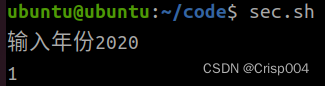
嵌入式3-22
4.输入一个秒数,输出几时几分几秒 eg:输入3670 1小时1分钟10秒 5,输入一个数,使用条件运算符实现,如果是水仙花则赋值1否则赋值0 6.终端输入一个年份,使用条件运算符实现,如果是润年则赋值1否则赋值0 …...
)
JAVA Synchronized对象锁和类锁区别(牛逼)
一个类就像一个四合院,四合院的大门叫做构造方法,盖房子必须经过大门,每new一个对象,就表示在四合院里再盖一间新房子,大门上面的锁,叫做构造锁,里面每一间房子就是一个实例,每间房子…...

力扣算法题之好数对的数目
c语言中的小小白-CSDN博客c语言中的小小白关注算法,c,c语言,贪心算法,链表,mysql,动态规划,后端,线性回归,数据结构,排序算法领域.https://blog.csdn.net/bhbcdxb123?spm1001.2014.3001.5343 给大家分享一句我很喜欢我话: 知不足而奋进,望远山而前行&am…...

C++ vector 删除
erase函数原型 iteratorerase(iterator position);//a.erase(p),删除迭代器p所指向的元素,a为容器对象 iteratorerase(iterator first, iterator last);//a.erase(b,c),删除迭代器b,c区间内的元素,a为容器对象 //返回值都是一个迭代器,该迭代…...

ASP.NET-WebFoms常见前后端交互方式
在 ASP.NET Web Forms 中,实现前后端交互是开发 Web 应用程序的重要部分。通过合适的数据传递方式,前端页面能够与后端进行有效的通信,并实现数据的传递、处理和展示。本文介绍了ASP.NET Web Forms开发中常见的前后端交互方式,包括…...

LWC 学习资源
Lightning Web Components 開発者ガイドlibraryblogs Lightning Web Component (LWC)のご紹介 LWCからデータベースにアクセスする方法 - QiitaLightning Web Component 間の通信の基礎 - Qiita Sodech Developer Blog LWCとApexを連携させてREST コールアウトを実行する Taig…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

Blender渲染通道完全指南:如何像电影后期一样,分离出深度、阴影与反射图
Blender渲染通道完全指南:影视级后期制作的深度解析在数字内容创作领域,Blender已经从一个简单的3D建模工具成长为能够处理复杂视觉特效的全流程解决方案。对于追求影视级质量的中高级用户而言,掌握渲染通道技术是提升作品专业度的关键一步。…...

小米MIMO最新邀请码
欢迎使用,各得10元体验金...
)
第二周(第12周)
1.单电源供电的二阶低通滤波器2.功率放大电路...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...

Office RibbonX Editor:简单三步打造你的专属Office界面
Office RibbonX Editor:简单三步打造你的专属Office界面 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-edit…...

League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理?
League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理? 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit Leag…...

集成Taotoken为OpenClaw工作流提供持久化模型支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 集成Taotoken为OpenClaw工作流提供持久化模型支持 在构建基于OpenClaw的自动化Agent工作流时,一个稳定且可灵活切换的模…...

正视孩童情绪波动,耐心陪伴平稳疏导
孩子的情绪就像夏天的天气,前一秒还晴空万里,后一秒可能就乌云密布。面对突如其来的哭闹、发脾气或者闷闷不乐,很多家长会急着“灭火”——要么讲道理,要么直接制止。但其实,情绪波动本身不是问题,它是孩子…...