[数据结构初阶]二叉树
各位读者老爷好,鼠鼠我现在浅浅介绍一些关于二叉树的知识点,在各位老爷茶余饭后的闲暇时光不妨看看,鼠鼠很希望得到各位老爷的指正捏!
开始介绍之前,给各位老爷看一张风景照,有读者老爷知道在哪里吗?
第一个在评论区答出正确答案的老爷鼠鼠会联系你,有惊喜捏!

目录
1.树
1.1.树的概念
1.2.树的相关概念
2.二叉树
2.1.二叉树的概念
2.2.特殊的二叉树
2.3.二叉树的存储结构
3.堆
3.1.堆的概念及分类
3.2.堆的顺序存储的实现(二叉树的顺序存储的实现)
3.2.1.堆(大堆)总览
3.2.2. 定义堆
3.2.3.堆的初始化
3.2.4.堆的插入
3.2.5.堆的删除
3.2.6.获取堆顶的数据
3.2.7.堆的数据个数
3.2.8.堆的判空
3.2.9.堆的销毁
4.运行结构分析
好的,我们在介绍二叉树之前需要了解树的概念!
1.树
1.1.树的概念
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
画个图给各位老爷看看:

我们可以看到:
1.有一个特殊的结点(A节点),称为根结点,根节点没有前驱结点。
2.除根节点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、……、Tm,其中每一个集合Ti(1<= i<= m)又是一棵结构与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继。
3.因此,树是递归定义的。
注意:树形结构中,子树之间不能有交集,否则就不是树形结构。
树形结构除了根节点外,每个节点有且只有一个父节点。如图就不是一个树形结构。
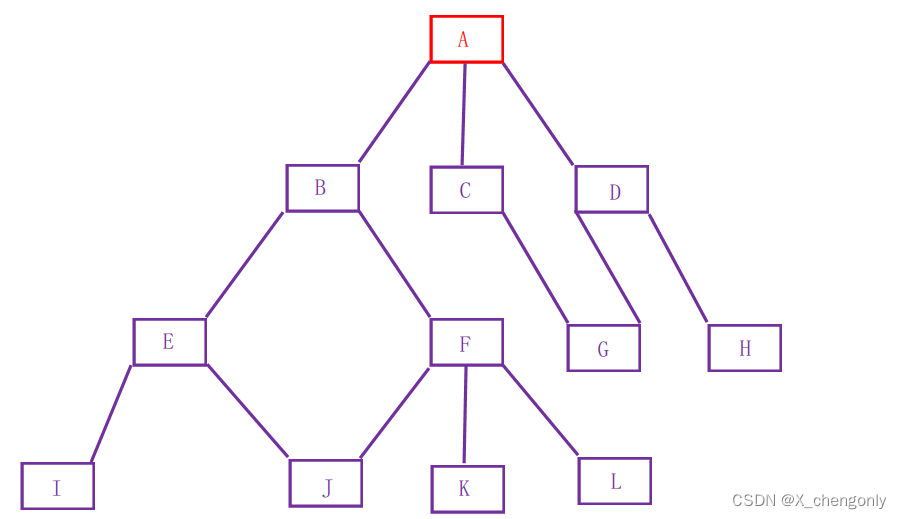
1.2.树的相关概念
介绍下面相关概念鼠鼠以下面树形结构举例:
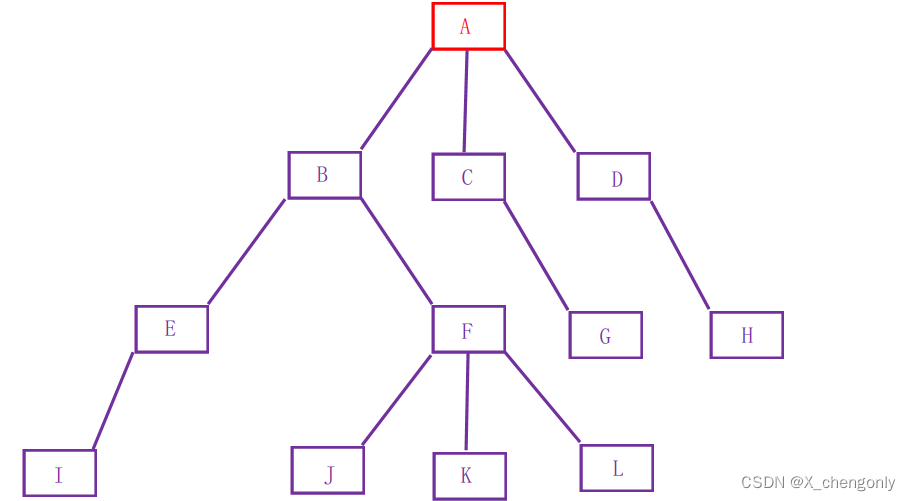
1.节点的度:一个节点含有的子树的个数称为该节点的度; 如上图:A节点的度为3,B节点的度为2。
2.叶节点或终端节点:度为0的节点称为叶节点; 如上图:G、H、I、J、K和L节点为叶节点。
3.非终端节点或分支节点:度不为0的节点; 如上图:B、C、D、E和F节点为分支节点。
4.双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点,也是C的父节点,也是D的父节点。
5.孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B、C和D都是A的孩子节点。
6.兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:J、K和L互为兄弟节点。
7.树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为3。
8.节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推。
9.树的高度或深度:树中节点的最大层次; 如上图:树的高度为4。
10.堂兄弟节点:双亲节点在同一层的节点互为堂兄弟节点;如上图:F和G互为堂兄弟节点。
11.节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先。
12.子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙。
13.森林:由m(m>0)棵互不相交的树的集合称为森林。
有了以上铺垫,我们来了解二叉树的概念!
2.二叉树
2.1.二叉树的概念
一棵二叉树是结点的一个有限集合,该集合:
1. 或者为空。
2. 由一个根节点加上两棵别称为左子树和右子树的二叉树组成。
说简单点呢,二叉树是一颗特殊的树,这颗树的度最大为2,就像是对这颗树的节点进行了计划生育,最多只能生两个节点宝宝。
从图可以看出:
1. 二叉树不存在度大于2的结点。
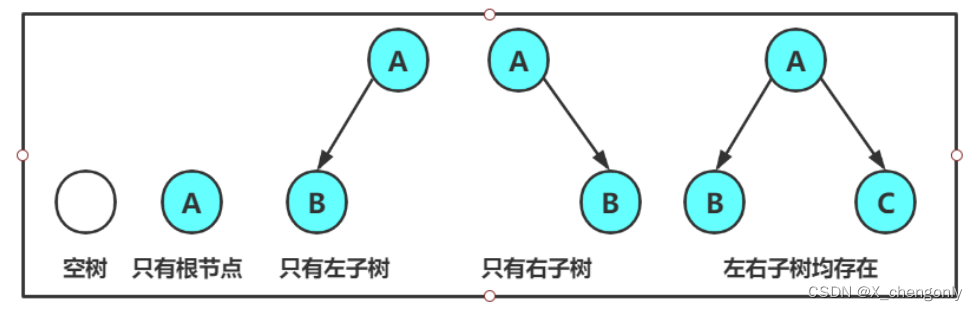
2. 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树。3.二叉树的子树也都是二叉树,既然是二叉树就可以为空树。

注意:对于任意的二叉树都是由以下几种情况复合而成的:
2.2.特殊的二叉树
1. 满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。

很容易知道,满二叉树各层的节点个数构成一个以1为首项,以2为公比的等比数列。如果一个二叉树的层数为K,用等比数列的求和公式或者错位相减法就能得到满二叉树节点的和为2^K-1。
那么反过来,如果知道了满二叉树的节点个数为X,那么它的层数就为log2(X+1),约等log2(X)。
2.完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。 要注意的是满二叉树是一种特殊的完全二叉树。
说简单易懂的话呢,就是说完全二叉树如果有K层,那么前K-1层的节点数都达到最大值,第K层的节点数不一定达到最大值,但是最后一层的节点从左到右必须连续。
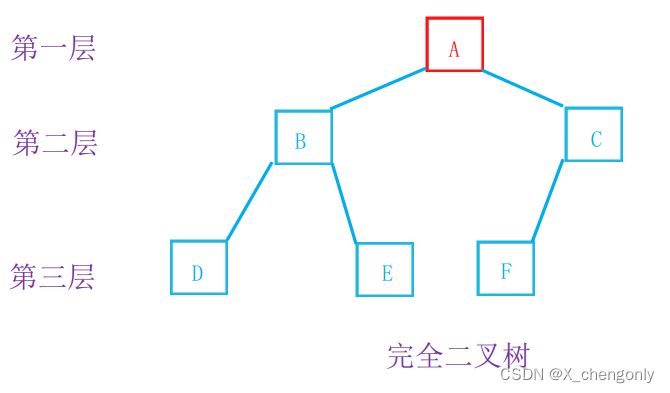
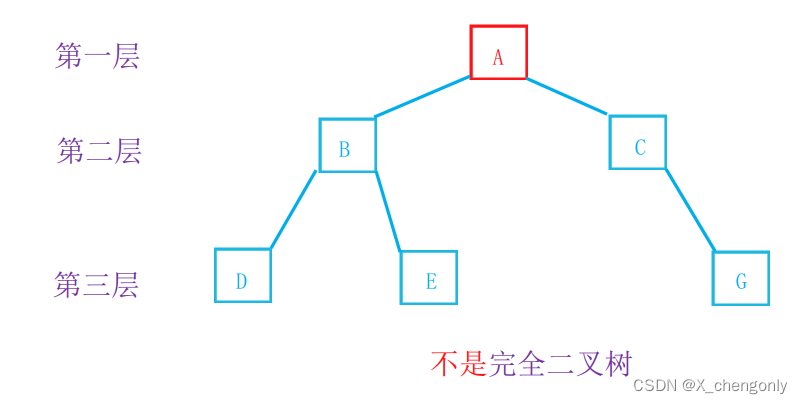
跟上面分析的一样,我们知道完全二叉树的前K-1层的节点数总和为2^(K-1)-1 。最后一层(第K层)的节点个数最少为1个,最多为2^(K-1)个。那么完全二叉树的节点总数范围就是2^(K-1)到2^K-1。
相同的,我们如果知道完全二叉树的节点个数为X,那么它的层数也大概是log2(X)。
2.3.二叉树的存储结构
二叉树一般可以使用两种结构存储,一种顺序结构,一种链式结构。
1. 顺序存储
顺序结构存储就是使用数组来存储,一般使用数组只适合表示完全二叉树,因为不是完全二叉树会有空间的浪费。而现实中使用中只有堆才会使用数组来存储,至于堆是什么鼠鼠下面会讲的捏!二叉树顺序存储在物理上是一个数组,在逻辑上是一颗二叉树。
也许各位老爷不明白为啥可以将二叉树存储到一个数组中呢?

其实我们将二叉树在逻辑上想象成一颗二叉树,在逻辑上我们将二叉树的节点一层一层按顺序存储到数组中。我们通过以下规律可以控制二叉树捏:
1.左孩子节点下标=父节点下标*2+1;
2.右孩子节点下标=父节点下标*2+1;
3.父节点下标=(左孩子节点下标-1)/2=(右孩子节点下标-1)/2;
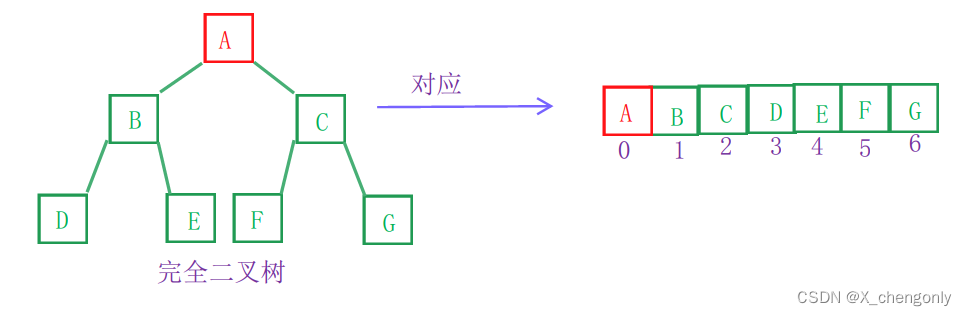
那么为什么只有完全二叉树适合用顺序存储捏?
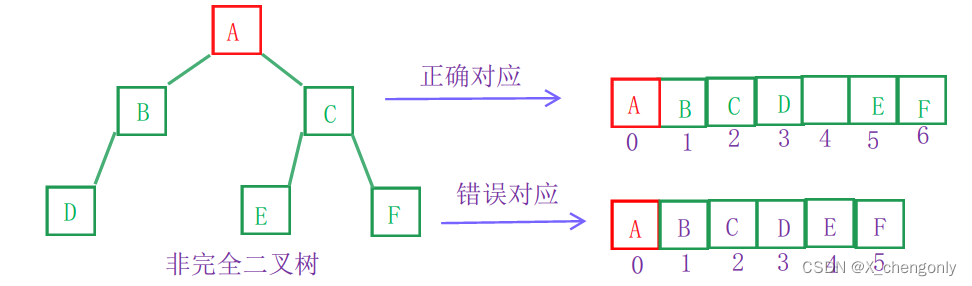
因为用顺序存储(就是用数组存储)的话我们要保证父节点下标和孩子节点下标满足上面三条规律才能控制好二叉树。而非完全二叉树要想满足上面三条规律的话,我们会有空间浪费,如下图:
如果根据错误对应来存储二叉树节点的话,就不符合上面的三条规律了! 所以顺序存储适合完全二叉树,非完全二叉树也可以存储但不适合!
2. 链式存储
二叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法(二叉链)是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址 。
本篇博客不细讲二叉树的链式存储,我们主要搞定顺序存储,链式存储后面博客再介绍!
既然介绍二叉树的顺序存储,而现实中使用中只有堆才会使用数组来存储,鼠鼠就要介绍堆这个概念并实现堆(也就是实现二叉树的顺序存储)捏 !
3.堆
堆就是一颗二叉树,堆一般是将数组数据看做一颗完全二叉树。现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆是两回事,本篇博客讲的堆一个是数据结构,另外一个是操作系统中管理内存的一块区域分段。
3.1.堆的概念及分类
简单讲,堆就是一颗二叉树,不过这颗二叉树对数据摆放有要求:
大堆:任意一个父节点数据要大于或等于它的任意孩子节点数据;
小堆:任意一个父节点数据要小于或等于它的任意孩子节点数据;
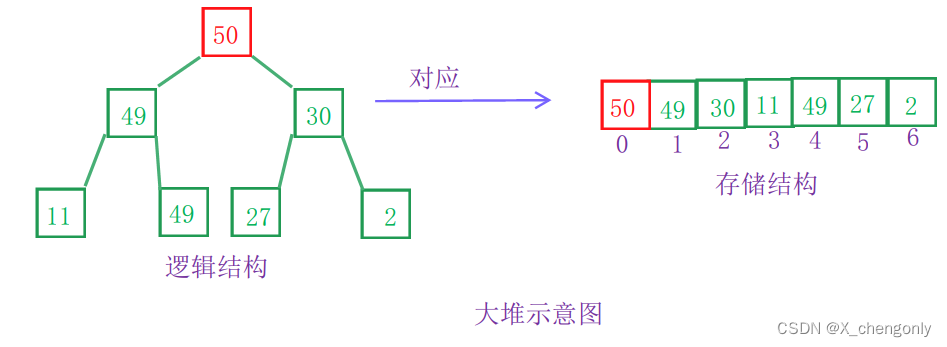
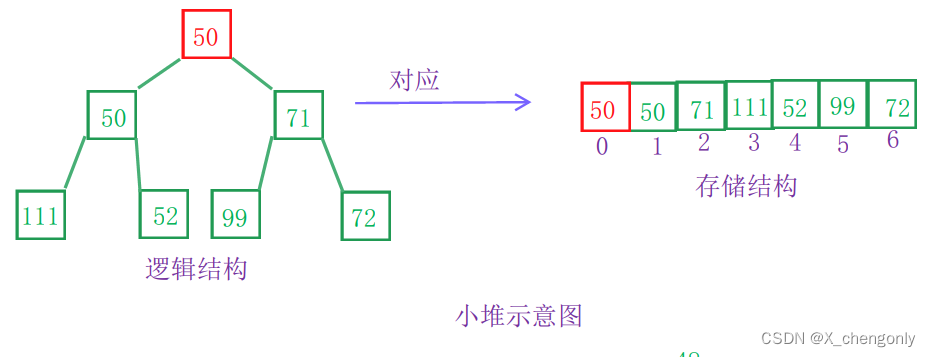
堆只有大堆和小堆之分,没有中堆这个说法!我们来看一道题,方便理解:
1.下列关键字序列为堆的是:()
A 100,60,70,50,32,65
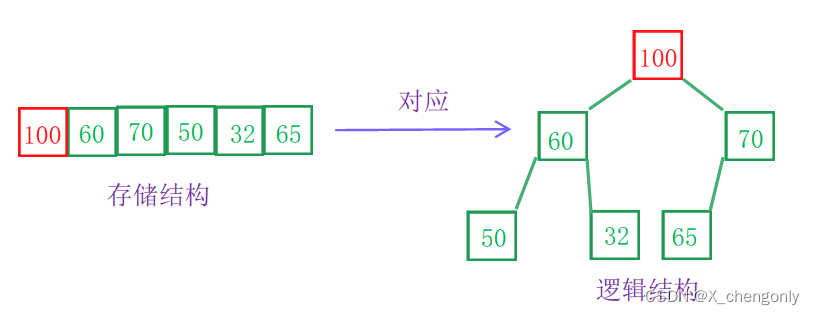
B 60,70,65,50,32,100
C 65,100,70,32,50,60
D 70,65,100,32,50,60
E 32,50,100,70,65,60
F 50,100,70,65,60,32
答案选A,为什么A是堆,其他不是捏?我们来看:
A选项:
还原成逻辑结构的完全二叉树的话,很明显是一个大堆!
B选项:
还原成逻辑结构的完全二叉树的话,很明显不是大堆也不是小堆,比如说60<65,符合小堆要求;但是70>32,又符合大堆要求;所以不是堆!
其他选项分析相同,鼠鼠就不解释了!
3.2.堆的顺序存储的实现(二叉树的顺序存储的实现)
也许有读者老爷不明白为啥用堆的顺序存储的实现代表二叉树的顺序存储的实现?因为堆的顺序存储的实现是有意义的,它能很好的管理数据而并非单纯的存储数据。如果单纯存储数据我们大可不必用二叉树来存储!至于堆能实现什么功能,再下面的讲解中鼠鼠会浅谈。
因为堆有大堆和小堆之分,鼠鼠我实现大堆的顺序存储为例!
3.2.1.堆(大堆)总览
我们先总体看堆的顺序存储实现完的三个文件,有兴趣的老爷可以放到一个工程下面玩玩:
1.heap.h
#pragma once
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<stdbool.h>//大堆typedef int HeapDataType;typedef struct Heap
{HeapDataType* a;int size;int capacity;
}Heap;//堆的初始化
void HeapInit(Heap* HP);//堆的插入
void HeapPush(Heap* HP, HeapDataType x);//堆的删除
void HeapPop(Heap* Hp);//取堆顶的数据
HeapDataType HeapTop(Heap* HP);//堆的数据个数
int HeapSize(Heap* hp);// 堆的判空
bool HeapEmpty(Heap* hp);//堆的销毁
void HeapDestroy(Heap* HP);2.heap.c
#define _CRT_SECURE_NO_WARNINGS
#include"heap.h"void HeapInit(Heap* HP)
{assert(HP);HP->a = NULL;HP->capacity = HP->size = 0;
}void swap(HeapDataType* parent, HeapDataType* child)
{HeapDataType tmp = *parent;*parent = *child;*child = tmp;
}void AdjustUp(HeapDataType* a, int childcoordinate)
{int parentcoordinate = (childcoordinate - 1) / 2;while (childcoordinate > 0){if (a[parentcoordinate] < a[childcoordinate]){swap(&a[parentcoordinate], &a[childcoordinate]);childcoordinate = parentcoordinate;parentcoordinate = (parentcoordinate - 1) / 2;}else{break;}}
}void HeapPush(Heap* HP, HeapDataType x)
{assert(HP);//扩容if (HP->capacity == HP->size){int newcapacity = HP->capacity == 0 ? 4 : HP->capacity * 2;HeapDataType* tmp = (HeapDataType*)realloc(HP->a, sizeof(HeapDataType) * newcapacity);if (tmp == NULL){perror("realloc fail");exit(-1);}HP->a = tmp;HP->capacity = newcapacity;}HP->a[HP->size++] = x;//向上调整AdjustUp(HP->a, HP->size - 1);
}void AdjustDown(HeapDataType* a, int size, int parentcoordinate)
{int childcoordinate = parentcoordinate * 2 + 1;while (childcoordinate < size){if (a[childcoordinate] < a[childcoordinate + 1]&&childcoordinate+1<size){childcoordinate++;}if (a[childcoordinate] > a[parentcoordinate]){swap(&a[childcoordinate], &a[parentcoordinate]);parentcoordinate = childcoordinate;childcoordinate = childcoordinate * 2 + 1;}else{break;}}
}void HeapPop(Heap* HP)
{assert(HP);assert(HP->size > 0);swap(&HP->a[0], &HP->a[HP->size - 1]);HP->size--;//向下调整AdjustDown(HP->a, HP->size,0);
}HeapDataType HeapTop(Heap* HP)
{assert(HP->size > 0);return HP->a[0];
}int HeapSize(Heap* HP)
{return HP->size;
}bool HeapEmpty(Heap* HP)
{return HP->size == 0;
}void HeapDestroy(Heap* HP)
{free(HP->a);HP->a = NULL;HP->capacity = HP->size = 0;
}
3.test.c
#define _CRT_SECURE_NO_WARNINGS
#include"heap.h"int main()
{int a[] = { 100,90,80,110,75,3 };Heap p;HeapInit(&p);for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++){HeapPush(&p, a[i]);}for(int i=0;i<p.size;i++){printf("%d ", p.a[i]);}printf("\n");while (!HeapEmpty(&p)){printf("%d ", HeapTop(&p));HeapPop(&p);}return 0;
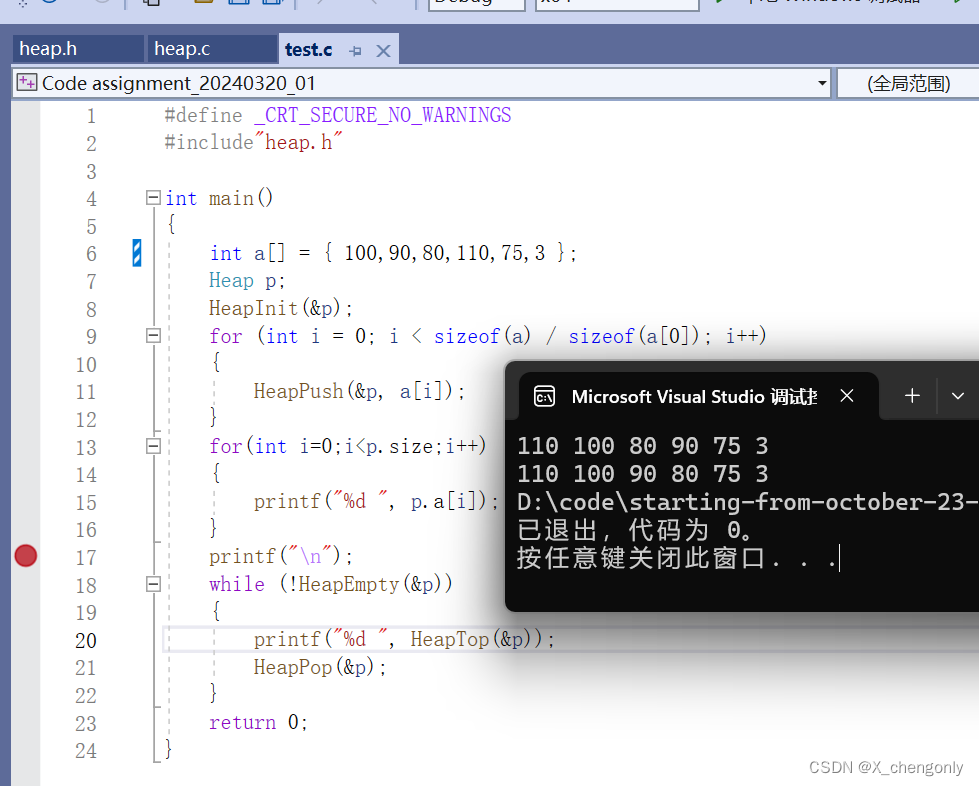
}4.运行结果
运行结果为啥是这样的,我们一会分析!
3.2.2. 定义堆
typedef int HeapDataType;typedef struct Heap
{HeapDataType* a;int size;int capacity;
}Heap;这里重命名int为HeapDataType,大大方便后续代码的维护!用a指向后来动态开辟的连续内存,该连续内存用来存储堆的数据,size用来记录堆的数据个数或者指向堆最后一个数据的下一个,capacity用来记录连续内存可放入数据的容量。
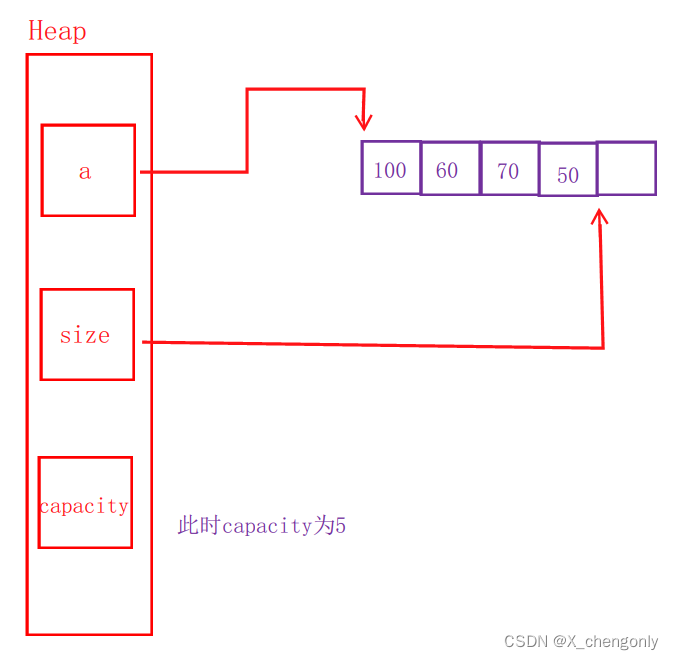
这里用一个结构体来定义堆如代码所示,定义的跟顺序表一样,但是我们这里表示的堆对数据的摆放要求是大堆或者小堆,而顺序表就没有这个要求!
3.2.3.堆的初始化
void HeapInit(Heap* HP)
{assert(HP);HP->a = NULL;HP->capacity = HP->size = 0;
}断言防止传入结构体变量地址为空(下面这点不在赘述。) 不妨将a置空,将capacity和size置0。
3.2.4.堆的插入
void swap(HeapDataType* parent, HeapDataType* child)
{HeapDataType tmp = *parent;*parent = *child;*child = tmp;
}void AdjustUp(HeapDataType* a, int childcoordinate)
{int parentcoordinate = (childcoordinate - 1) / 2;while (childcoordinate > 0){if (a[parentcoordinate] < a[childcoordinate]){swap(&a[parentcoordinate], &a[childcoordinate]);childcoordinate = parentcoordinate;parentcoordinate = (parentcoordinate - 1) / 2;}else{break;}}
}void HeapPush(Heap* HP, HeapDataType x)
{assert(HP);//扩容if (HP->capacity == HP->size){int newcapacity = HP->capacity == 0 ? 4 : HP->capacity * 2;HeapDataType* tmp = (HeapDataType*)realloc(HP->a, sizeof(HeapDataType) * newcapacity);if (tmp == NULL){perror("realloc fail");exit(-1);}HP->a = tmp;HP->capacity = newcapacity;}HP->a[HP->size++] = x;//向上调整AdjustUp(HP->a, HP->size - 1);
}
堆的插入我们表面上是在数组中(动态开辟的空间)尾插,但我们逻辑上要想象成数据插入在树的底层,并调整数据使其符合大堆要求。 这里的精髓是调整数据,也就是代码中的向上调整函数。关于向上调整函数,鼠鼠画一个图方便理解吧:
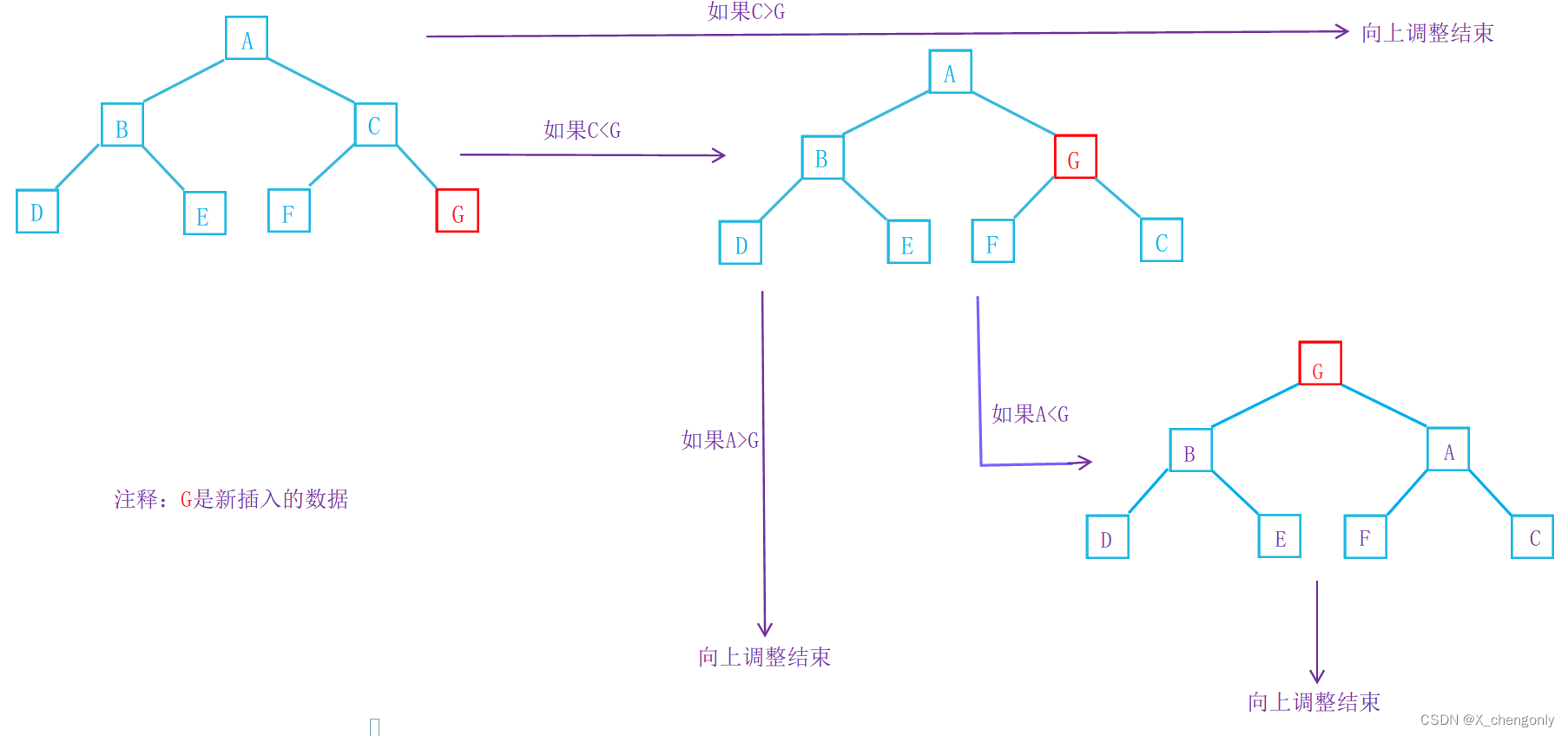
3.2.5.堆的删除
void swap(HeapDataType* parent, HeapDataType* child)
{HeapDataType tmp = *parent;*parent = *child;*child = tmp;
}void AdjustDown(HeapDataType* a, int size, int parentcoordinate)
{int childcoordinate = parentcoordinate * 2 + 1;while (childcoordinate < size){if (a[childcoordinate] < a[childcoordinate + 1]&&childcoordinate+1<size){childcoordinate++;}if (a[childcoordinate] > a[parentcoordinate]){swap(&a[childcoordinate], &a[parentcoordinate]);parentcoordinate = childcoordinate;childcoordinate = childcoordinate * 2 + 1;}else{break;}}
}void HeapPop(Heap* HP)
{assert(HP);assert(HP->size > 0);swap(&HP->a[0], &HP->a[HP->size - 1]);HP->size--;//向下调整AdjustDown(HP->a, HP->size,0);
}对于堆的删除来说,数据结构规定删除的是堆顶的数据(根节点数据),当然删除完堆顶数据后,我们必须将剩余数据再构成大堆。
为啥删除的是堆顶的数据捏?因为堆顶的数据是堆中所有数据中最大的,删除完堆顶数据后新的堆顶就是“次大的”,这样的话我们可以做到选数的功能,后面可以更好体会。
完成堆的删除,我们采取将堆顶的数据根最后一个数据一换,然后删除数组最后一个数据,再进行向下调整算法。堆的删除过程画图理解如下:
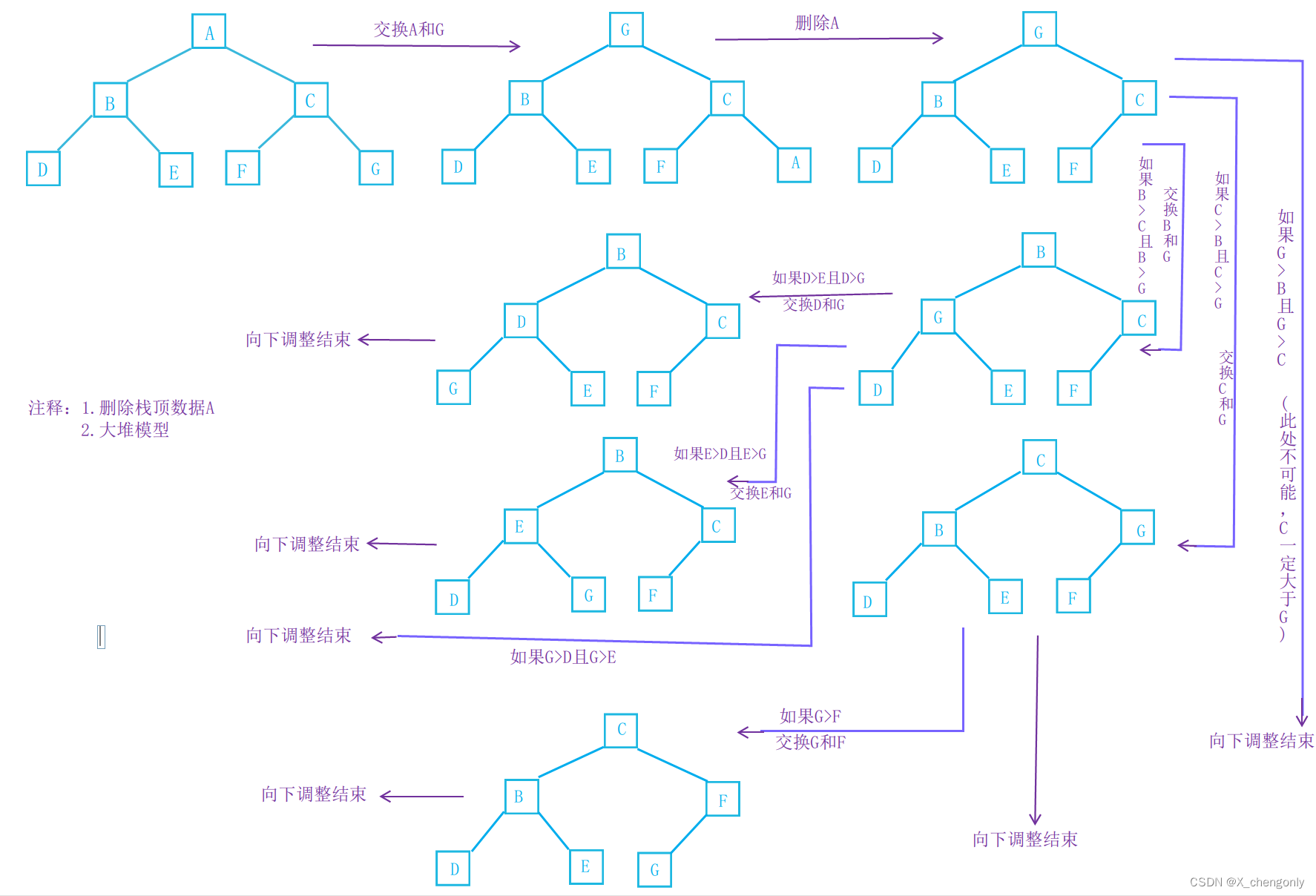
3.2.6.获取堆顶的数据
HeapDataType HeapTop(Heap* HP)
{assert(HP->size > 0);return HP->a[0];
}简单,返回a[0]即可。
3.2.7.堆的数据个数
int HeapSize(Heap* HP)
{return HP->size;
}根据设定,返回size即可。
3.2.8.堆的判空
bool HeapEmpty(Heap* HP)
{return HP->size == 0;
}当堆为空返回真,堆不为空返回假,所以容知上面代码逻辑可以实现逻辑自恰 。
3.2.9.堆的销毁
void HeapDestroy(Heap* HP)
{free(HP->a);HP->a = NULL;HP->capacity = HP->size = 0;
}销毁动态开辟的空间并将a置成NULL,将capacity和size置成0即可。
4.运行结构分析
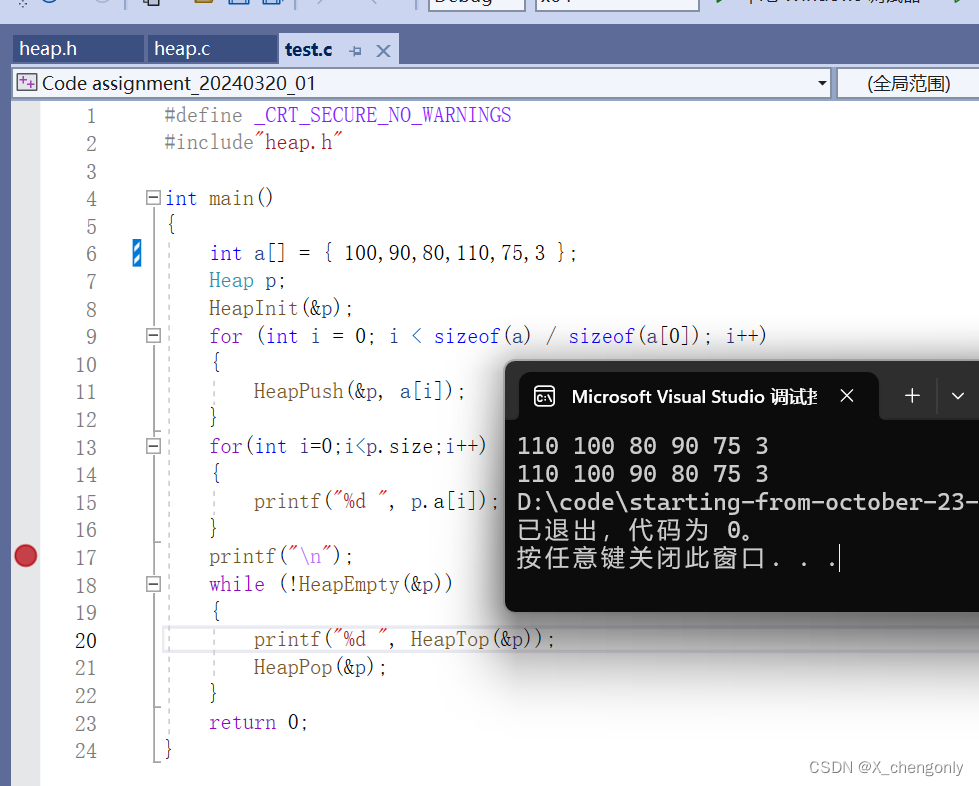
各位老爷先看结果如下:
第一条语句:定义一组数组a,成员为100、90、80、110、75和3。
第二条语句:定义一个结构体变量p。
第三条语句:调用HeapInit函数初始化p。
接下来for循环语句:取数组a成员依次入堆。由HeapPush函数可知,执行完这个for循环语句后,a成员构成大堆!
接下来for循环语句:打印大堆,得出110 100 80 90 75 3。可以看出这样存储确实是大堆。
接下来while循环:当堆不为空时,打印堆顶数据并删除堆顶数据!得出结果为110 100 90 80 75 3,是递减的。
从这里我们可以看出堆(大堆)的管理数据的能力:删除堆顶数据就是删除了(大)堆中最大的数据并将剩下的数据成(大)堆,这样新的(大)堆的新的堆顶数据就是“次大的”,再删除堆顶数据再成(大)堆…………这样出来的数据就是有序的。
我们再看删除堆顶数据的时间复杂度:在PeadPop函数中时间消耗最多的是向下调整函数AdjustDown,而我们知道向下调整函数中最多调整堆的层数-1次,前面我们算过完全二叉树的层数约为log2(X)。再结合时间复杂度的知识,我们就可以说删除堆数据的时间复杂度为O(logN))。
那么我们每删除一次栈顶数据就可以选一次“最大”的数,时间复杂度是O(logN)。如果有1百万个数据让我们选出最大的数,用堆来选的话我们最多选20一定可以选出来;但如果用常规遍历的方法,我们也许要遍历1百万遍。
感谢阅读,如有不足,恳请指正,谢谢!
相关文章:
[数据结构初阶]二叉树
各位读者老爷好,鼠鼠我现在浅浅介绍一些关于二叉树的知识点,在各位老爷茶余饭后的闲暇时光不妨看看,鼠鼠很希望得到各位老爷的指正捏! 开始介绍之前,给各位老爷看一张风景照,有读者老爷知道在哪里吗&#x…...
matlab和stm32的安装环境。能要求与时俱进吗,en.stm32cubeprg-win64_v2-6-0.zip下载太慢了
STM32CubeMX 6.4.0 Download STM32CubeProgrammer 2.6.0 Download 版本都更新到6.10了,matlab还需要6.4,除了st.com其他地方都没有下载的,com.cn也没有。曹 还需要那么多固件安装。matlab要求制定固件位置,然后从cubemx中也指定…...

Opencv面试题
1、OpenCV中cv::Mat的深拷贝和浅拷贝问题? 深拷贝:分配新内存的同时拷贝数据,当被赋值的容器被修改时,原始容器数据不会改变。浅拷贝:仅拷贝数据,当被赋值容器修改时,原始容器数据也会做同样改变。 深拷贝…...

Python连接MariaDB数据库
2024软件测试面试刷题,这个小程序(永久刷题),靠它快速找到工作了!(刷题APP的天花板)【持续更新最新版】-CSDN博客 Python连接MariaDB数据库 一、安装mariadb库 pip install mariadb 二、连接…...

基于python+vue的ITS 信息平台的设计与实现flask-django-nodejs-php
伴随着我国社会的发展,人民生活质量日益提高。于是对系统进行规范而严格是十分有必要的,所以许许多多的信息管理系统应运而生。此时单靠人力应对这些事务就显得有些力不从心了。所以本论文将设计一套信息平台,帮助交通局进行信息共享、交通信…...

MediatR 框架使用FluentValidation对Comand/Query进行自动拦截验证
简介 目录 简介 1. MediatR项目框架 2. 实现步骤 步骤 1:编写管道行为 1. query 查询的管道 2. command命令的管道 步骤 2:注册验证器和管道行为 步骤 3:定义命令类 步骤 4:定义处理程序 步骤 5:编写命令验证器…...
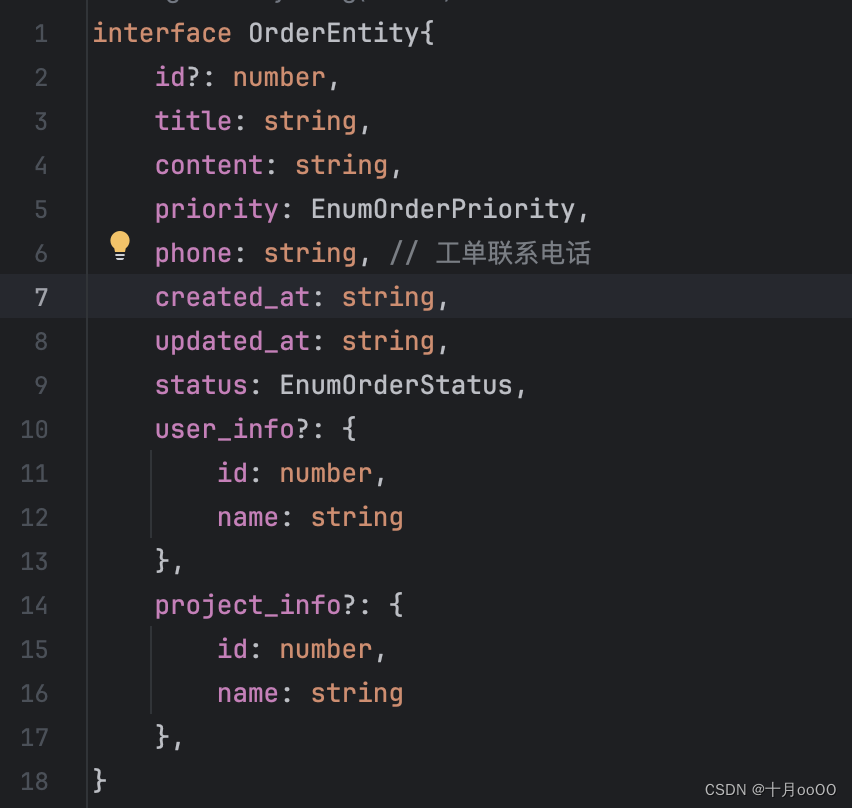
TS + Vue3 elementUI 表格列表中如何方便的标识不同类型的内容,颜色区分 enum
TS Vue3 elementUI 表格列表中如何方便的标识不同类型的内容,颜色区分 enum 本文内容为 TypeScript 一、基础知识 在展示列表的时候,列表中的某个数据可能是一个类别,比如: enum EnumOrderStatus{"未受理" 1,"…...
)
从零开始一步一步掌握大语言模型---(2-什么是Token?)
了解自然语言处理或者听说过大语言模型的同学都听过,token。一般来说,它代表的是语言中不可再分的最小单元。我们人类的语言不仅有文字,还有语音。针对文字、语音来说,它们都各自有不同的划分token的方法。本节将尽可能详细的介绍…...
使用专属浏览器在国内直连GPT教程
Wildcard官方推特发文说他们最近推出了一款专门为访问OpenAI设计的浏览器。 根据官方消息,这是一款专门为访问OpenAI优选网络设计的浏览器,它通过为用户提供专用的家庭网络出口,确保了快速、稳定的连接。 用这个浏览器的最大好处就是直接用浏…...
Wireshark 抓包工具与长ping工具pinginfoview使用,安装包
一、Wireshark使用 打开软件,选择以太网 1、时间设置时间显示格式 这个时间戳不易直观,我们修改 2、抓包使用的命令 1)IP地址过滤 ip.addr192.168.1.114 //筛选出源IP或者目的IP地址是192.168.1.114的全部数据包。 ip.sr…...

分享Pandas 数据分析实战课程
分享Pandas 数据分析实战课程,3 小时掌握数据分析核心技能。 链接:https://pan.baidu.com/s/1Ikk3I1dfoFO0id3EBZJdGg?pwd4y83 提取码:4y83 链接:https://pan.quark.cn/s/fa2acd7513f4 提取码:yWu7...
)
26. 删除有序数组中的重复项 (Swift版本)
题目描述 给你一个 非严格递增排列 的数组 nums ,请你删除重复出现的元素,使每个元素只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。 考虑 nums 的唯一元素的数量为 k ࿰…...
python学生作业管理系统flask-django-nodejs-php
课题主要分为三大模块:即管理员模块和学生、教师模块,主要功能包括:学生、教师、作业信息、学习模块、教学评价、学习情况等; 关键词:学生作业管理系统;作业信息 目录 摘 要 I Abstrac II 目录 III 1绪论 1…...

蓝桥杯第二天刷真题
public class Main {public static void main(String [] args) { //存大数方法String s"202320232023"; // 定义一个字符串,它将被转换为结束循环的数值long end Long.parseLong(s);long sum 0;long primarynumber 1;for(int i 1; i<end; i) {long …...

RK3568 安装jupyter和jupyterlab
首先需要RK3568运行Ubuntu,之前的文章有关于如何安装Ubuntu以及遇到的问题 其次需要安装Miniconda3,详细安装教程:RK3568 安装Miniconda3-CSDN博客 准备好这两步之后就可以开始: 1、更新软件源和软件 sudo apt update sudo apt upgrade sudo apt-get dist-upgrade 2、…...
简易指南:国内ip切换手机软件怎么弄
在网络访问受到地域限制的情况下,使用国内IP切换手机软件可以帮助用户轻松访问被屏蔽的内容,扩展网络体验。以下是虎观代理小二分享的使用国内IP切换手机软件的简易指南。并提供一些注意事项。 如何在手机上使用国内IP切换软件 步骤一:选择I…...

Git学习笔记之Git 别名
Git 并不会在你输入部分命令时自动推断出你想要的命令。 如果不想每次都输入完整的 Git 命令,可以通过 git config 文件来轻松地为每一个命令设置一个别名。命令: git config --global alias.别名 命令例如 git config --global alias.co checkout git …...
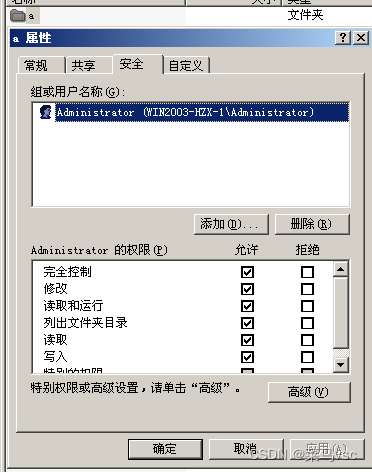
网络安全笔记-day6,NTFS安全权限
文章目录 NTFS安全权限常用文件系统文件安全权限打开文件安全属性修改文件安全权限1.取消父项继承权限2.添加用户访问权限3.修改用户权限4.验证文件权限5.总结权限 强制继承父项权限文件复制移动权限影响跨分区同分区 总结1.权限累加2.管理员最高权限2.管理员最高权限 NTFS安全…...
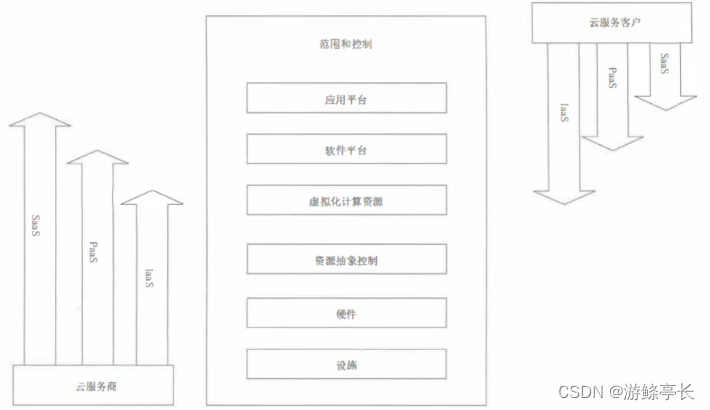
云计算系统等保测评对象和指标选取
1、云计算服务模式与控制范围关系 参考GBT22239-2019《基本要求》附录D 云计算应用场景说明。简要理解下图,主要是云计算系统安全保护责任分担原则和云服务模式适用性原则,指导后续的测评对象和指标选取。 2、测评对象选择 测评对象 IaaS模式 PaaS模式…...

Vue 3项目中结合Element Plus的<el-menu>和CSS3创建锚点,以实现点击菜单项时平滑滚动到对应的锚点目标
安装Element Plus: 确保已经安装了Element Plus库。可以使用npm或者yarn进行安装,具体步骤与上文提到的相同。 引入Element Plus: 在你的Vue 3项目中引入所需的Element Plus组件和样式。 创建el-menu: 在Vue组件中使用<el-me…...
)
Veo 2提示词效能跃迁实战(工业级Prompt链构建全图谱)
更多请点击: https://codechina.net 第一章:Veo 2提示词编写的核心范式演进 Veo 2作为新一代视频生成模型,其提示词(prompt)工程已从早期的“关键词堆叠”转向结构化、语义分层与意图对齐的复合范式。这一演进并非简…...

D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳
D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破坏…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

解决Claude Code Token不足问题并享受Taotoken活动价
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code Token不足问题并享受Taotoken活动价 应用场景类,聚焦于使用Claude Code时遇到Token配额紧张的开发者&…...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

<背包问题>
背包问题是一类组合优化问题,其基本形式是给定一组物品,每个物品都有一个重量和一个价值,以及一个有限的背包容量,目标是在不超过背包容量的前提下,选择物品使得背包中的物品价值最大化。动态规划是解决背包问题的常用…...

Hindsight API参考:REST接口完整文档
Hindsight API参考:REST接口完整文档 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight是一个强大的Agent Memory系统,提供了全面的REST API接口&…...

Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南
Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南 【免费下载链接】Graphin 🌌 A React toolkit for graph visualization based on G6. 项目地址: https://gitcode.com/gh_mirrors/gr/Graphin 在当今数据驱动的时代,图可视化…...