牛客笔试|美团2024春招第一场【测试方向】
第一题:小美的数组询问
小美拿到了一个由正整数组成的数组,但其中有一些元素是未知的(用 0 来表示)。
现在小美想知道,如果那些未知的元素在区间 [l, r] 范围内随机取值的话,数组所有元素之和的最小值和最大值分别是多少?共有 q次 询
输入描述:
第一行输入两个正整数 n, q ,代表数组大小和询问次数。 第二行输入 n 个整数。 接下来的 q 行,每行输入两个正整数 l, r,代表一次询问。输出描述:
输出 q 行,每行输出两个正整数,代表所有元素之和的最小值和最大值。
示例:
输入例子:
3 2 1 0 3 1 2 4 4输出例子:
5 6 8 8例子说明:
只有第二个元素是未知的。 第一次询问,数组最小的和是 1+1+3=5,最大的和是 1+2+3=6。 第二次询问,显然数组的元素和必然为 8。
思路:给从一个范围取值,并给出最大和最小值,必然是取此范围中的两个最值。因此我们可以分别使用范围中的两个最值来填充数组中的 0 并求和。
先对已知元素求和 sum_known
接着计数未知元素 count_unknown
与最值相乘 count_unknown * max (min)
最后与已知元素和相加 sum_known + count_unknown * max (min)
n, q = map(int, input().split())
arr = map(int, input().split())sum_known = 0
count_unknown = 0for num in arr:if num == 0:count_unknown += 1else:sum_known += numfor _ in range(q):l, r = map(int, input().split())min_sum = sum_known + count_unknown * lmax_sum = sum_known + count_unknown * rprint(min_sum, max_sum)第二题:验证工号
假设美团的工号是由18位数字组成的,由以下规则组成:
- 前面6位代表是哪个部门
- 7-14位代表是出生日期,范围是1900.01.01-2023.12.31
- 15-17位代表是哪个组,不能是完全一样的3位数字
- 18位是一位的校验和,假设是 x ,则需要满足 (x+a1+a2+a3+a4+...+a17) mod 8=1 ,a1−a17 代表了前面的17位数字
现在需要写一份代码,判断输入的工号是否符合对应的规则。
提示:出生日期这里需要判断闰年。闰年判断的条件是能被 4 整除, 但不能被 100 整除;或能被 400 整除。
输入描述:
第一行输入一个整数 n 接下来 n 行,每行输入一个字符串,表示一个合法的部门。如果工号不属于合法部门的话,则认为这个工号不符合规则 接下来输入一个整数 m 接下来 m 行,每行输入一个字符串,表示需要验证的工号。输出描述:
如果不满足上述任一个规则,输出 "error" ,都满足的话输出 "ok"
示例1
输入例子:
2 123456 123457 1 123456202312120636输出例子:
ok
示例2
输入例子:
1 123455 1 123456202312120633输出例子:
error例子说明:
部门号不对
示例3
输入例子:
1 123456 2 123456202313120633 123456202302290633输出例子:
error error例子说明:
出生日期不对 2023不是闰年,没有29号
示例4
输入例子:
1 123456 1 123456202312120635输出例子:
error例子说明:
校验码不对
思路:一道模拟题,不涉及算法,具体见代码
def is_valid_date(year, month, day):if year < 1900 or year > 2023:return Falseif month < 1 or month > 12:return Falsedays_in_month = [31, 29 if (year % 4 == 0 and year % 100 != 0) or (year % 400 == 0) else 28, 31, 30, 31, 30, 31, 31 , 30, 31, 30, 31]if day < 1 or day > days_in_month[month - 1]:return Falsereturn Truedef check_work_number(number, valid_departments):if len(number) != 18:return 'error'department = number[:6]if department not in valid_departments:return 'error'year, month, day = int(number[6: 10]), int(number[10: 12]), int(number[12: 14])if not is_valid_date(year, month, day):return 'error'group = number[14: 17]if group[0] == group[1] == group[2]:return 'error'checksum = sum(int(digit) for digit in number)if checksum % 8 != 1:return 'error'return 'ok'n = int(input())
valid_departments = []
for _ in range(n):valid_departments.append(input())m = int(input())
work_numbers = []
for _ in range(m):work_numbers.append(input())for work_number in work_numbers:print(check_work_number(work_number, valid_departments))第三题:小美的平衡矩阵
小美拿到了一个 n ∗ n 的矩阵,其中每个元素是 0 或者 1。
小美认为一个矩形区域是完美的,当且仅当该区域内 0 的数量恰好等于 1 的数量。
现在,小美希望你回答有多少个 i ∗ i 的完美矩形区域。你需要回答 1 ≤ i ≤ n 的所有答案。
输入描述:
第一行输入一个正整数 n,代表矩阵大小。 接下来的 n 行,每行输入一个长度为 n 的 01 串,用来表示矩阵输出描述:
输出 n 行,第 i 行输出 i * i 的完美矩形区域的数量。
示例1
输入例子:
4 1010 0101 1100 0011输出例子:
0 7 0 1
思路:要解决这个问题,我们可以遍历所有可能的矩形区域,并检查每个区域内0和1的数量是否相等。一种方法是使用前缀和。具体来说,我们可以分别维护0和1的前缀和矩阵,这样就可以在O(1)时间内得到任意矩形区域内0和1的数量。
下面是具体的步骤:
构建前缀和矩阵:分别计算并存储0和1的前缀和。对于矩阵中的每个点
(i, j),prefix_0[i][j]表示左上角(0, 0)到(i, j)形成的矩形区域内0的数量,prefix_1[i][j]同理。遍历所有可能的i*i矩形区域:对于每个可能的边长i(从1到n),遍历矩阵中所有可能的 i * i 的矩形区域。
检查矩形区域是否完美:对于每个矩形区域,使用前缀和快速计算区域内0和1的数量,检查它们是否相等。
计数并输出结果:对于每个边长 i,计算满足条件的 i * i 的完美矩形区域数量。
注意:此方法在牛客网上显示大部分用例超时。
n = int(input()) # 矩阵大小
matrix = [list(map(int, input())) for _ in range(n)] # 读取矩阵# 初始化前缀和矩阵
prefix_0 = [[0] * (n + 1) for _ in range(n + 1)]
prefix_1 = [[0] * (n + 1) for _ in range(n + 1)]
# 计算前缀和
for i in range(1, n+1):for j in range(1, n+1):prefix_0[i][j] = prefix_0[i-1][j] + prefix_0[i][j-1] - prefix_0[i-1][j-1] + (matrix[i-1][j-1] == 0)prefix_1[i][j] = prefix_1[i-1][j] + prefix_1[i][j-1] - prefix_1[i-1][j-1] + (matrix[i-1][j-1] == 1)
# 计算完美矩阵数量
for i in range(1, n+1):count = 0for x in range(i, n+1):for y in range(i, n+1):zeros = prefix_0[x][y] - prefix_0[x-i][y] - prefix_0[x][y-i] + prefix_0[x-i][y-i]ones = prefix_1[x][y] - prefix_1[x-i][y] - prefix_1[x][y-i] + prefix_1[x-i][y-i]if zeros == ones:count += 1print(count)选择题
1. 在计算机网络中,端口号的作用是什么?
- A. 区分主机内不同进程
- B. 加密数据传输
- C. 确保数据完整性
- D. 控制数据流量
端口号的主要作用是 A. 区分主机内不同进程。
在计算机网络中,一个主机可能同时运行多个网络服务,比如Web服务器、电子邮件服务器和FTP服务器等。端口号用来标识主机上的特定进程或网络服务,使得数据包能够被正确地发送到目的地进程。每个网络服务监听在特定的端口上,当数据到达时,根据端口号就能知道该数据是为哪个服务或进程而来。
2. HTTPS协议通过使用哪些机制来确保通信的安全性()
- A. 加密和身份验证
- B. 压缩和缓存
- C. 路由和负载均衡
- D. 访问控制和权限管理
HTTPS协议通过使用 A. 加密和身份验证 机制来确保通信的安全性。
HTTPS(超文本传输安全协议)是HTTP的安全版,它通过SSL/TLS协议提供数据加密、数据完整性和身份验证的功能,从而保护用户数据免遭窃听和篡改,并验证通信双方的身份。
3. ETag用于标识资源的唯一标识符,它可以用于()
- A. 验证资源是否发生变化
- B. 控制缓存的过期时间
- C. 指定缓存的最大大小
- D. 加密缓存中的数据
ETag用于标识资源的唯一标识符,它可以用于 A. 验证资源是否发生变化。
ETag(实体标签)是一个HTTP响应头,用于Web浏览器缓存验证。它可以帮助浏览器了解服务器上的资源是否已被修改,从而决定是否需要重新下载资源或可以使用缓存的版本,这有助于优化网页加载时间并减少服务器负载。
4. 在一个单道系统中,有4个作业P、Q、R和S,执行时间分别为2小时、4小时、6小时和8小时,P和Q同时在0时到达,R和S在2小时到达,采用短作业优先算法时,平均周转时间为()。
- A. 15小时
- B. 12小时
- C. 6小时
- D. 9小时
短作业优先(SJF)算法优先执行预计执行时间最短的作业。作业的到达和执行时间如下:
- 0时刻:P(2小时),Q(4小时)到达
- 2时刻:R(6小时),S(8小时)到达
执行顺序如下:
- 在0时刻,P和Q到达,P的执行时间最短(2小时),所以首先执行P。
- P执行完毕后是2时刻,此时Q、R和S都已到达。在这些中,Q的执行时间最短(4小时),接下来执行Q。
- Q执行完毕后是6时刻,此时R和S待执行,R的执行时间最短(6小时),接下来执行R。
- R执行完毕后是12时刻,最后执行S(8小时)。
- S执行完毕后是20时刻。
周转时间是指从作业提交到作业完成所需的总时间。根据执行顺序,各作业的周转时间如下:
- P:2小时(从0到2)
- Q:6小时(从0到6)
- R:10小时(从2到12)
- S:18小时(从2到20)
平均周转时间 = (2 + 6 + 10 + 18) / 4 = 36 / 4 = 9小时。
5. 系统中现有一个任务进程在11:30到达系统,如果在14:30开始运行这个任务进程,其运行时间为3小时,现求这个任务进程的响应比为()。
- A. 0.5
- B. 2
- C. 1
- D. 1.5
响应比是指作业的周转时间与服务时间(运行时间)的比值。公式可以表示为:
响应比 = 周转时间 / 服务时间
周转时间是指从作业提交到作业完成的总时间,包括作业在系统中等待的时间加上作业的执行时间。
根据题目,任务进程在11:30到达系统,14:30开始运行,运行时间为3小时。所以:
- 等待时间 = 14:30 - 11:30 = 3小时
- 运行时间 = 3小时
- 周转时间 = 等待时间 + 运行时间 = 3小时 + 3小时 = 6小时
因此,响应比为:
响应比 = 6小时 / 3小时 = 2。
6. 在一个物流管理系统中,需要一个功能来处理不同类型的货物运输请求,如陆运、空运或海运。该系统应能够根据运输类型的不同选择不同的处理策略。哪种设计模式最合适()
- A. 工厂方法模式
- B. 桥接模式
- C. 策略模式
- D. 适配器模式
这个场景最适合使用 C. 策略模式。
策略模式允许在运行时选择算法或行为的具体实现。在给定的问题中,根据不同的运输类型(陆运、空运、海运)选择不同的处理策略正是策略模式的典型应用场景。使用策略模式,可以定义一系列的算法(即不同的运输策略),并将每一个算法封装起来,使它们可以相互替换,这样算法的变化不会影响到使用算法的客户端。
- 工厂方法模式主要用于创建对象,特别是在创建对象时需要考虑到系统的扩展性时,而不是用于选择行为或算法。
- 桥接模式主要用于将抽象部分与实现部分分离,以便两者可以独立地变化,更多关注于不同维度的组合,而不是行为的选择。
- 适配器模式主要用于使原本因接口不兼容而不能一起工作的类可以一起工作,关注的是接口的兼容性,而非行为的选择。
7. 对关键码序列{9, 27, 18, 36, 45, 54, 63}进行堆排序,输出2个最大关键码后的剩余堆是()。
- A. {9, 18, 27, 36, 45}
- B. {9, 18, 45, 27, 36}
- C. {45, 9, 18, 27, 36}
- D. {45, 36, 18, 9, 27}
剩余堆是 D. {45, 36, 18, 9, 27}。
首先,我们需要构建一个最大堆,然后交换堆顶元素(最大值)与堆的最后一个元素的位置,这样最大值就被放到了数组的最末端。之后,将剩余的元素再次调整为最大堆,继续上述操作,直至堆中剩余元素足够少,无法继续进行交换为止。
8. 以下哪个设计模式主要用于在不改变原始类的情况下扩展其功能()
- A. 装饰器模式
- B. 适配器模式
- C. 工厂模式
- D. 建造者模式
A. 装饰器模式 主要用于在不改变原始类的情况下扩展其功能。
装饰器模式通过创建一个包装对象,也称为装饰器,来给原始对象动态地添加额外的功能或责任。这种模式非常有用,因为它允许在遵守开闭原则的前提下,即对扩展开放、对修改封闭,来增加对象的功能。
9. 设哈希表长m=10,有一堆数据元素,关键字分别为{14, 25, 36, 47, 58, 69, 80},按照哈希函数为H(key)=key%10,如用线性探测法处理冲突,求关键字90填装的哈希表位置的序号是()。
- A. 3
- B. 4
- C. 1
- D. 6
线性探测法处理哈希冲突时,如果发现预期的哈希位置已被占用,它会检查下一个位置,依此类推,直到找到一个空闲的位置。给定哈希函数
H(key) = key % 10,我们首先计算每个关键字的哈希位置,然后按顺序填入哈希表,处理冲突时采用线性探测法。关键字及其哈希位置如下:
- 14 % 10 = 4
- 25 % 10 = 5
- 36 % 10 = 6
- 47 % 10 = 7
- 58 % 10 = 8
- 69 % 10 = 9
- 80 % 10 = 0
按照这些关键字填表,哈希表的填装情况为:
- 位置0:80
- 位置4:14
- 位置5:25
- 位置6:36
- 位置7:47
- 位置8:58
- 位置9:69
当关键字90被插入时,
90 % 10 = 0,但位置0已经被关键字80占据,因此需要采用线性探测法向后查找空闲位置。位置1是表中下一个空闲的位置,所以关键字90将被放置在位置1。因此,关键字90填装的哈希表位置的序号是 C. 1。
10. 在一颗深度为8的完全二叉树中,最少可以有多少个结点,最多可以有多少个结点?
- A. 128和255
- B. 256和512
- C. 511和1022
- D. 512和1024
在一棵深度为8的完全二叉树中:
最少结点数发生在除了最后一层外,所有层都完全填满,而最后一层只有1个节点的情况下。这种情况下,完全二叉树变成了一个满二叉树,加上最后一层的一个节点。满二叉树的节点总数为
2^深度 - 1,所以深度为7的满二叉树的节点数为2^7 - 1 = 127,加上最后一层的一个节点,总数为128。因此,最少结点数是 128。最多结点数发生在所有层都完全填满的情况下。完全二叉树在所有层都完全填满时,其节点总数为
2^深度 - 1。因此,深度为8的完全二叉树的节点数为2^8 - 1 = 255。所以,最多结点数是 255。综上所述,正确答案是 A. 128和255。
11. 在编译器的目标代码生成阶段,以下哪个不是优化的主要目标是()
- A. 降低程序的功耗
- B. 减小目标代码的体积
- C. 提高目标代码的执行效率
- D. 减少程序的编译时间
在编译器的目标代码生成阶段,优化旨在改进最终生成的代码,使其在执行时更高效。然而,D. 减少程序的编译时间不是目标代码生成阶段优化的主要目标。编译时间的优化关注的是编译器的性能,而不是生成的目标代码的性能。编译时间优化旨在改进编译过程本身,使编译器能够更快地完成工作,但这通常是编译器设计者需要考虑的问题,而不是目标代码优化的直接目标。
12. 若入栈序列为1, 3, 5, 2, 4, 6,且进栈和出栈可以穿插进行,则不可能的输出序列为()。
- A. 1, 3, 5, 2, 4, 6
- B. 1, 3, 6, 2, 5, 4
- C. 1, 3, 5, 4, 2, 6
- D. 1, 3, 5, 4, 6, 2
B. 1, 3, 6, 2, 5, 4 不可能,手动模拟一下即可。
13. 在用KMP算法进行模式匹配时,若是指向模式串"mnopmn"的指针在指到第5个字符"m"时发生失配,则指针回溯的位置为()。
注:字符串中字符从字符数据1号位开始存储,也即从1开始编号。
- A. 1
- B. 2
- C. 3
- D. 4
KMP算法中的关键是next数组(也被称为部分匹配表),该数组用于在发生失配时决定模式串中指针应该回溯到的位置。对于模式串"mnopmn",我们首先需要计算其next数组。
模式串:"mnopmn"
- m (1号位): next[1] = 0,因为m之前没有更短的相同前缀和后缀。
- n (2号位): next[2] = 0,因为n之前没有更短的相同前缀和后缀。
- o (3号位): next[3] = 0,因为o之前没有更短的相同前缀和后缀。
- p (4号位): next[4] = 0,因为p之前没有更短的相同前缀和后缀。
- m (5号位): next[5] = 1,因为在m之前,有一个字符m可以作为相同的前缀和后缀。
- n (6号位): next[6] = 2,因为在n之前,有"mn"可以作为相同的前缀和后缀。
根据这个分析,当指向模式串的指针在指到第5个字符"m"时发生失配,根据next数组,指针应该回溯到next[5] = 1的位置。
因此,正确答案是 A. 1。
14. 代码需要经过一系列步骤编译成机器指令,根据完成任务不同,可以将编译器的组成部分划分为前端与后端。下列选项是编译器前端在编译源程序时编译的顺序,正确的是()
- A. 词法分析器->语法分析器->中间代码生成器
- B. 语法分析器->词法分析器->中间代码生成器
- C. 词法分析器->中间代码生成器->语法分析器
- D. 语法分析器->中间代码生成器->词法分析器
编译器前端的工作主要包括词法分析、语法分析和中间代码生成等步骤。正确的编译顺序是:
词法分析器:将源代码的字符序列转换成一系列的记号(Token)。这个过程涉及到识别变量名、关键字、操作符等。
语法分析器:根据词法分析器输出的记号序列和语言的语法规则,构建出一棵抽象语法树(AST)。这一步骤检查代码的语法结构是否正确。
中间代码生成器:将抽象语法树转换成一种中间表示(IR)形式的代码。这种中间代码是一种独立于具体机器语言的高级表示,用于进一步的优化和转换。
因此,正确的选项是 A. 词法分析器->语法分析器->中间代码生成器。
15. 不同的数据存放区存放的数据和对应的管理方法是不同的。对于某些数据,如果在编译期间就可以确定数据对象的大小和数据对象的数目,在编译期间为数据对象分配存储空间,这些数据对应的存储分配策略是()
- A. 栈式存储分配
- B. 堆式存储分配
- C. 动态存储分配
- D. 静态存储分配
存储分配策略是 D. 静态存储分配。
静态存储分配是指编译时就确定了每个数据对象的存储空间大小和生命周期的存储方式。这些数据在程序的整个运行期间都存在,不会被创建和销毁。常见的静态存储包括全局变量和静态变量。
16.
某硬盘有240个磁道(最外侧磁道号为0),磁道访问请求序列为30, 60, 90, 120, 190, 150, 220,当前磁头位于第180号磁道并从外侧向内侧移动。按照SCAN调度(电梯调度)方法处理完上述请求后,磁头移过的磁道数是()。
- A. 280
- B. 200
- C. 230
- D. 250
在SCAN调度(电梯调度)方法中,磁头移动的方式类似于电梯运行:当它移动到一个方向的最边缘时,如果没有更远的请求,就会改变方向。根据题目,当前磁头位于第180号磁道并从外侧向内侧移动。
给定的磁道访问请求序列是
30, 60, 90, 120, 190, 150, 220,我们首先将这些请求按照磁道号排序,并根据当前的磁头位置和移动方向处理请求。排序后的请求序列为
30, 60, 90, 120, 150, 190, 220。从180号磁道开始,向内侧移动,磁头首先访问
190和220。到达220后,由于已经是内侧最远的请求,磁头将改变方向,向外侧移动,并按顺序访问150, 120, 90, 60, 30。计算磁头移过的磁道数:
- 从180到220 = 40磁道
- 从220回到30 = 220 - 30 = 190磁道
所以,磁头移过的磁道总数是
40 + 190 = 230。因此,正确答案是 C. 230。
17. 下列选项中只要其中一个表中存在匹配,则返回行的SQL JOIN的 类型是()。
- A. INNER JOIN
- B. LEFT JOIN
- C. RIGHT JOIN
- D. FULL JOIN
当你想从两个表中返回匹配的行,并且当其中一个表中存在匹配时也返回行,即使另一个表中没有匹配,你应该使用 D. FULL JOIN。
FULL JOIN返回左表和右表中的所有记录。当左表(table1)和右表(table2)中的行在 JOIN 条件上匹配时,它将返回这些匹配的行。如果在一个表中没有匹配的行,则结果集中相关表的部分将包含 NULL 值。这意味着它会返回左表的所有记录(与 LEFT JOIN 相同)和右表的所有记录(与 RIGHT JOIN 相同),以及这两个表的交集(与 INNER JOIN 相同)。
相关文章:

牛客笔试|美团2024春招第一场【测试方向】
第一题:小美的数组询问 小美拿到了一个由正整数组成的数组,但其中有一些元素是未知的(用 0 来表示)。 现在小美想知道,如果那些未知的元素在区间 [l, r] 范围内随机取值的话,数组所有元素之和的最小值和最大…...
:前言)
Docker搭建LNMP环境实战(一):前言
缘起:不久前学习了Docker相关知识,并在Docker环境下学习了LNMP环境的搭建。由于网上的文章大多没有翔实、可行的案例,很多文章都是断章取义,所以,期间踩了太多太多的坑,初学者想要真正顺利地搭建一套环境起…...

SCI一区 | Matlab实现PSO-TCN-BiGRU-Attention粒子群算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测
SCI一区 | Matlab实现PSO-TCN-BiGRU-Attention粒子群算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测 目录 SCI一区 | Matlab实现PSO-TCN-BiGRU-Attention粒子群算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测预测效果基本介绍模型描述…...
界面控件DevExpress ASP.NET Ribbon组件 - 完美复刻Office 365体验!
无论用户是喜欢传统工具栏菜单外观、样式,还是想在下一个项目中复制Office 365 web UI,DevExpress ASP.NET都提供了所需要的工具,帮助用户打造更好的应用程序界面。 P.S:DevExpress ASP.NET Web Forms Controls拥有针对Web表单&a…...

vue2【详解】mixins —— 抽离公共逻辑
mixins 用于在 Vue 中便捷复用变量、方法、组件引用、生命周期等 使用方法 创建文件myMixin.js export const myMixin {data() {return {webName: 朝阳的博客}},created() {alert(欢迎来到${this.webName})},methods: {hi() {alert(欢迎来到${this.webName})}} }vue文件中引入…...

ArrayList的常用方法
ArrayList是Java中常用的动态数组类,它提供了一系列用于操作和管理数组的方法。下面是一些ArrayList常用方法的介绍: add()方法:向ArrayList中添加元素,可以指定位置添加元素或者在末尾添加元素。 ArrayList<String> list …...

ES-Hadoop:将Elasticsearch与Hadoop无缝集成的开源工具
hadoop 大数据技术之Hive(3)PyHive pyhdfs ES,Elasticsearch https://zhuanlan.zhihu.com/p/595505475?utm_id0 Hadoop hdfs 、hive、spark https://blog.51cto.com/u_16099278/6901638 ES-Hadoop:将Elasticsearch与Hadoop无缝集成的开源工…...

质量模型、软件测试流程和测试用例
质量模型 衡量一个优秀软件的维度 可以从功能性、性能、兼容性、易用性、安全、可靠性、可维护性、可移植性这几个方面去做软件测试,但咱们在正常测试中一般是选取前五项进行测试 测试流程 1、需求评审:确保各部门对需求的理解一致 2、测试计划编写&a…...
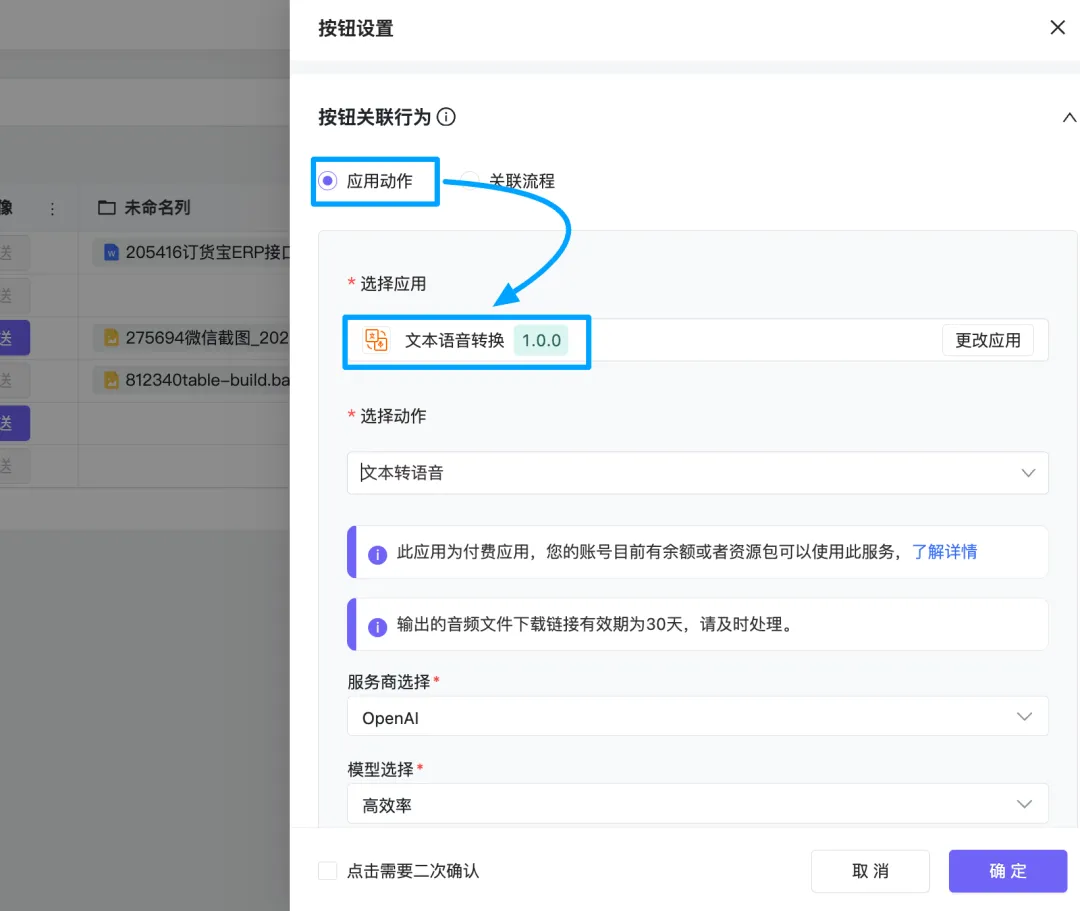
集简云新增“文本语音转换”功能,实现智能语音交互
为丰富人工智能领域的应用集成,为用户提供更便捷和智能化的信息获取和视觉创作方式,本周集简云上线了内置应用—文本语音转换。目前支持OpenAI TTS和TTS HD模型,实现文本语音高效智能转换,也可根据你的产品或品牌创建独特的神经网…...

图像处理领域专业术语
图像处理中的一些常见术语,涵盖了从基础概念到高级处理技术的各个方面。 以下是一些图像处理领域常用的专业术语及其解释: 像素(Pixel): 图像的最基本单元,每个像素都有一个或多个与其关联的数值࿰…...
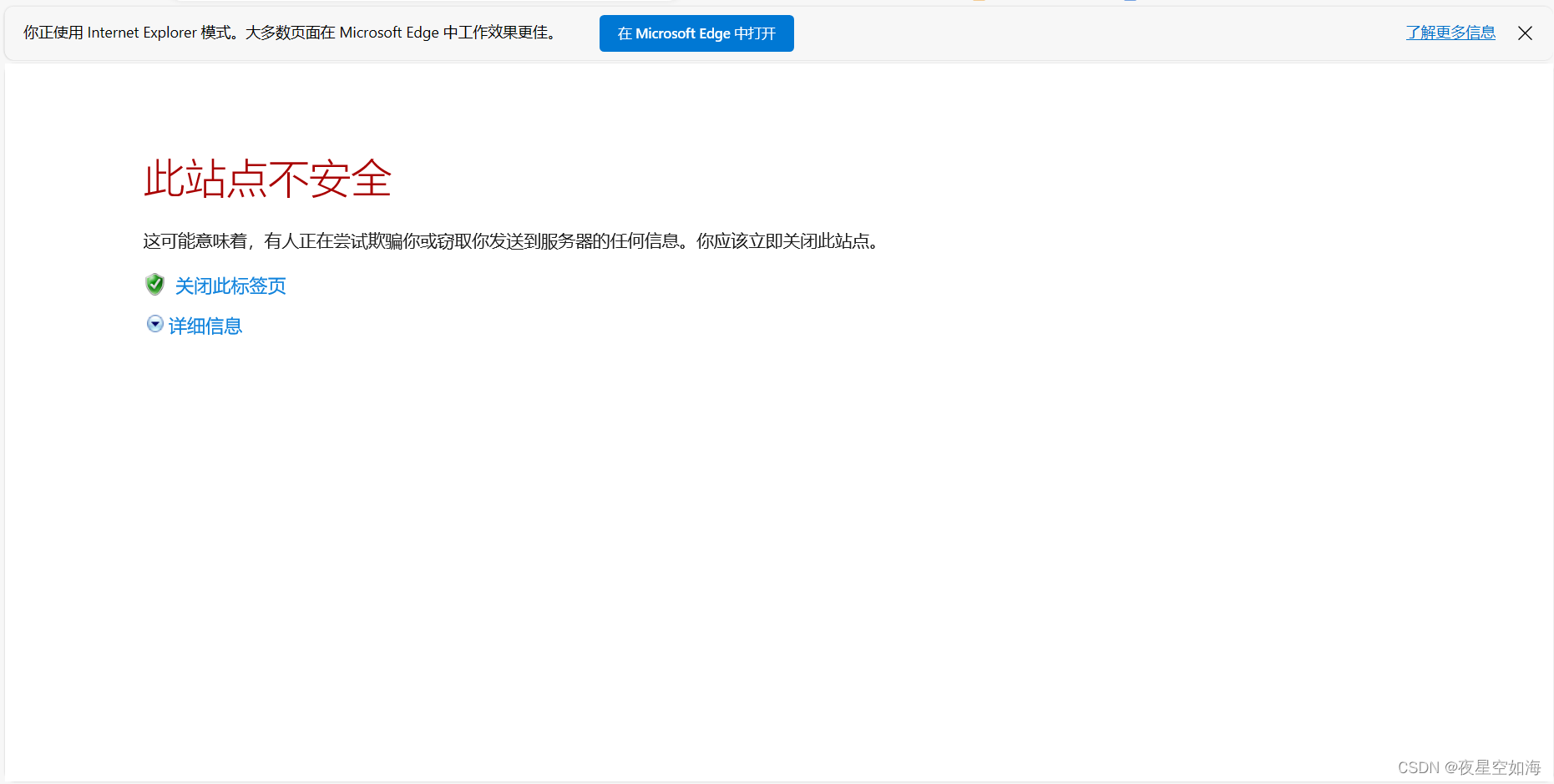
Microsoft Edge 中的 Internet Explorer 模式解决ie禁止跳转到edge问题
作为网工,网络中存在很老的设备只能用ie浏览器访问打开,但是win10后打开Internet Explorer 会强制跳转到Edge 浏览器,且有人反馈不会关,为此找到了微软官方的Microsoft Edge 中的 Internet Explorer 模式,可以直接在Mi…...
理清大数据技术与架构
大数据并不是一个系统软件,更不是一个单一的软件,它实际上是一种技术体系、一种数据处理方法,甚至可以说是一个服务平台。在这个技术体系中,涵盖了许多不同的部件,比如Hadoop服务平台。这一服务平台可以根据具体情况自…...

小白DB补全计划Day2-LeetCode:SQL基本操作selectJOIN
链接:1683. 无效的推文 - 力扣(LeetCode)1378. 使用唯一标识码替换员工ID - 力扣(LeetCode)1068. 产品销售分析 I - 力扣(LeetCode) 来源:LeetCode 1683 # Write your MySQL quer…...
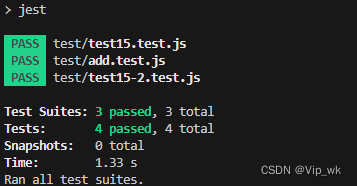
【Node.js从基础到高级运用】十五、单元测试与集成测试
引言 在Node.js开发过程中,测试是确保代码质量和功能正确性的关键步骤。单元测试和集成测试是最常见的测试类型。下面我们将使用Jest框架来进行测试。 单元测试 单元测试是指对软件中的最小可测试单元进行检查和验证。在Node.js中,这通常指的是函数或者…...

哈工大sse C语言 困难
Q565.(10分数, 语言: C)程序中函数 fun()的功能: 将一个由八进制数字字符组成的字符串转换为与其值相等的十进制整数。规定输入的字符串最多只能包含5位八进制数字字符。 **输入格式要求:gets 提示信息:"输入一个八进制字符串(5位&…...
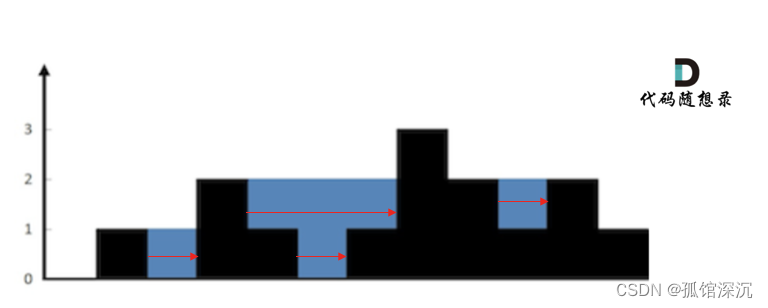
力扣● 503.下一个更大元素II ● 42. 接雨水
503.下一个更大元素II 与496.下一个更大元素 I的不同是要循环地搜索元素的下一个更大的数。那么主要是对于遍历结束后,单调栈里面剩下的那些元素。 如果直接把两个数组拼接在一起,然后使用单调栈求下一个最大值就可以。 代码实现的话,不用直…...

Java中的包装类
Java中的包装类 一、包装类是什么?二、对应关系:三、举例说明:Integer构造器:包装类特有的机制:自动装箱 自动拆箱常用方法 总结 一、包装类是什么? 以前定义变量,经常使用基本数据类型&#x…...

实时数仓的另一种构建方法starRocks的物化视图
一、 StarRocks是什么 StarRocks是一个分布式的、高性能的OLAP(联机分析处理)数据库,物化视图在StarRocks中具有重要作用。 二、 StarRocks物化视图能干啥 物化视图(Materialized Views)是数据库中的预先计算结果的存储。它们是由一个或多个基础表的聚合数据组成的,这…...

【PHP】通过PHP实时监控Apache、MySQL服务运行状态
一、前言 有些时候我们需要监控一些服务的运行状态,比如说Apach或MySQL的运行状态,最近工作中也开发了这方面的功能,记录下来怎样使用PHP语言来实时监控Apache、MySQL服务的运行状态。 如果想一键开启Apache或MySQL等其他服务可以看这篇文章…...
ETL的全量和增量模式
在当今信息爆炸的时代,数据管理已经成为各行各业必不可少的一环。而在数据管理中,全量与增量模式作为两种主要的策略,各自具有独特的优势和适用场景,巧妙地灵活运用二者不仅能提升数据处理效率,更能保障数据的准确性。…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤
从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤在当今数据驱动的时代,对象存储已成为现代应用架构中不可或缺的一部分。MinIO作为高性能、兼容S3协议的开源对象存储解决方案,凭借其轻量级和易用性赢得了众多…...

2026年,本地精准营销高性价比服务商来袭,你还不了解一下?
在本地商业竞争日益激烈的2026年,实体店面临着诸多挑战,引流难、成本高、复购率低等问题困扰着众多商家。而中粤(广州)信息科技有限公司作为本地精准营销的高性价比服务商,正以其独特的优势和卓越的服务,为…...
)
Mysql:事务管理(中)
在前面的章节中,我们提到了 MVCC(多版本并发控制),它巧妙地通过“版本快照”解决了“读-写”冲突,实现了非阻塞读。但如果两个事务同时执行 UPDATE 操作修改同一行数据,即 写-写(Write-Write&am…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

浏览器指纹识别机制深度剖析与反识别技术实现
一、浏览器指纹技术基础认知1.1 浏览器指纹的核心定义在数字化时代,每一台接入互联网的设备都会留下独特的数字标识,浏览器指纹便是其中最关键的识别凭证之一。浏览器指纹是网站通过 JavaScript 脚本、HTTP 请求头、硬件接口调用等多种技术手段ÿ…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

MaxEnt建模总失败?别急着换数据,先检查ArcGIS裁剪栅格这1个像素的坑
MaxEnt建模失败?ArcGIS栅格裁剪的1像素陷阱与精准修复指南当你花费数小时整理好WorldClim气候数据、本地DEM高程和物种分布数据,满心期待地点击MaxEnt的运行按钮时,屏幕上突然跳出"Error projecting, two layers have different geograp…...