InnoDB 缓存
本文主要聊InnoDB内存结构, 先来看下官网Mysql 8.0 InnoDB架构图
MySQL :: MySQL 8.0 Reference Manual :: 17.4 InnoDB Architecture

如上图所示,InnoDB内存主要包含Buffer Pool, Change Buffer, Log Buffer, Adaptive Hash Index
Buffer Pool
其实 buffer pool 就是内存中的一块缓冲池,用来缓存表和索引的数据。默认80%的物理内存分配给缓冲池。
我们都知道 mysql 的数据最终是存储在磁盘上的,但是如果读存数据都直接跟磁盘打交道的话,这速度就有点慢了。所以 innodb 自己维护了一个 buffer pool,在读取数据的时候,会把数据加载到缓冲池中,这样下次再获取就不需要从磁盘读了,直接访问内存中的 buffer pool 即可。包括修改也是一样,直接修改内存中的数据,然后到一定时机才会将这些脏数据刷到磁盘上。
其实缓冲池维护的是页数据,也就是说,即使你只想从磁盘中获取一条数据,但是 innodb 也会加载一页的数据到缓冲池中,一页默认是 16k。
Buffer Pool 管理
Buffer Pool 中的页有三种状态:
-
空闲页:通过空闲页链表(Free List)管理。
-
正常页:通过LRU链表(LRU List)管理。
-
脏页:通过LRU链表和脏页链表(Flush List)管理。(缓冲池中被修改过的页,与磁盘上的数据页不一致)
Free链表
初始化完的buffer pool时所有的页都是空闲页,所有空闲的缓冲页对应的控制块信息作为一个节点放到Free链表中。

要注意Free链表是一个个控制块,而控制块的信息中有缓存页的地址信息。
在有了free链表之后,当需要加载磁盘中的页到buffer pool中时,就去free链表中取一个空闲页所对应的控制块信息,根据控制块信息中的表空间号、页号找到buffer pool里对应的缓冲页,再将数据加载到该缓冲页中,随后删掉free链表该控制块信息对应的节点。
Flush链表
修改了buffer pool中缓冲页的数据,那么该页和磁盘就不一致了,这样的页就称为【脏页】,它不是立马刷入到磁盘中,而是由后台线程将脏页写入到磁盘。
Flush链表就是为了能知道哪些是脏页而设计的,它跟Free链表结构图相似,区别在于控制块指向的是脏页地址。
LRU链表
对于频繁访问的数据和很少访问的数据我们对与它的期望是不一样的,很少访问的数据希望在某个时机淘汰掉,避免占用buffer pool的空间,因为缓冲空间大小是有限的。
MySQL设计了根据LRU算法设计了LRU链表来维护和淘汰缓冲页。
LRU 算法简单来说,如果用链表来实现,将最近命中(加载)的数据页移在头部,未使用的向后偏移,直至移除链表。这样的淘汰算法就叫做 LRU 算法,但是简单的LRU算法会带来两个问题:预读失效、Buffer Pool污染
预读: 当数据页从磁盘加载到 Buffer Pool 中时,会把相邻的数据页也提前加载到 Buffer Pool 中,这样做的好处就是减少未来可能的磁盘IO。
改进LRU 算法
Buffer Pool的LRU算法中InnoDB 将LRU链表按照5:3的比例分成了young区域和old区域。链表头部的5/8是young区(被高频访问数据),链表尾部的3/8区域是old区域(低频访问数据),箭头朝下的是未被访问的数据,朝上的是被访问的数据。

这样做的目的是,在预读的时候或访问不存在的缓冲页时,先加入到 old 区域的头部,等 1s后(大部分场景扫描数据之后同一个请求会马上访问这部分数据,之后可能就不访问了),如果该页面再次被访问才会被移动到新生代。
Buffer Pool刷盘
(1)有一个后台线程,会认为数据库空闲时;
(2)数据库缓冲池不够用时;(执行sql时刚好碰到缓冲池不够用导致的刷盘时, sql执行得等缓存池刷盘完成)
(3)数据库正常关闭时;
(4)redo log写满时(下文详解);
Change Buffer
在MySQL5.5之前,叫插入缓冲(insert buffer),只针对insert做了优化;现在对delete和update也有效,叫做写缓冲(change buffer)。
它是一种应用在非唯一普通索引页(non-unique secondary index page)不在缓冲池中,对页进行了写操作,并不会立刻将磁盘页加载到缓冲池,而仅仅记录缓冲变更(buffer changes),等未来数据被读取时,再将数据合并(merge)恢复到缓冲池中的技术。写缓冲的目的是降低写操作的磁盘IO,提升数据库性能。
写入流程

执行两条Insert语句,其中左侧的要更新的数据页 Page1 不在Buffer Pool,而右侧需要更新的数据页Page2在Buffer Pool缓存中。
- 数据页Page1: 不在Buffer Pool中的话, 将修改写入Change Buffer,最终写入表空间
- 数据页Page2: 在缓存中,直接更新, 最终写入数据文件
两次内存:一次是修改Buffer Pool的数据页、另一次是Change buffer中记录这个写入操作。
三次磁盘: 一次redo log(合并批量), 一次change buffer落盘, 一次脏页落盘. 三次落盘都是等到落盘条件之后触发。
Merge流程
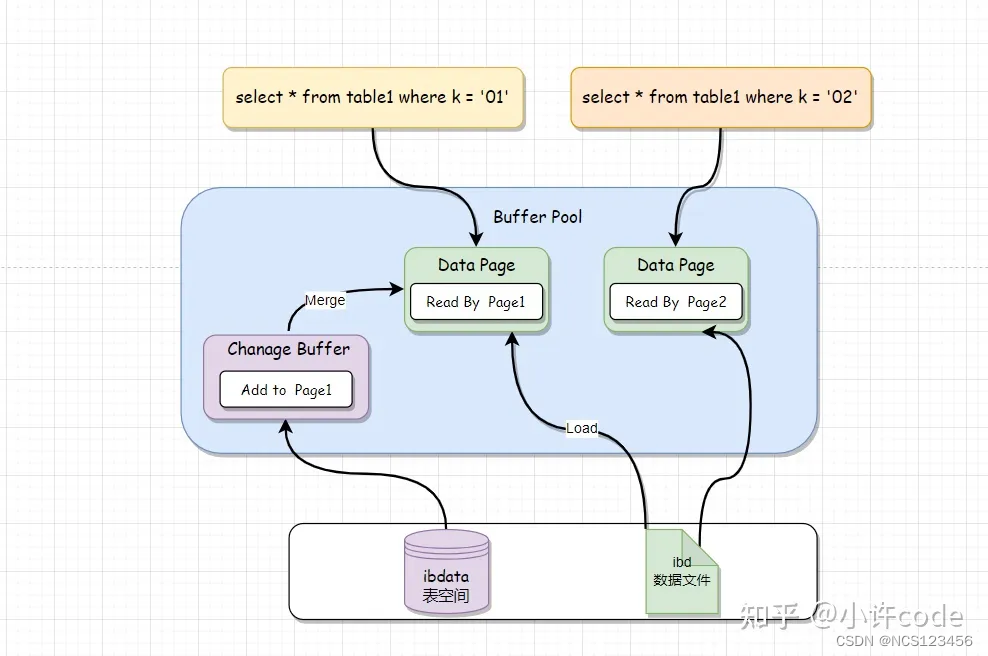
读Page2的时候很好理解,直接从Buffer Pool 中返回,
但是读Page1时,需把Page1从磁盘读入内存,然后将Change Buffer里面的操作日志,Merge生成一个正确版本并返回结果。
适用场景: 数据库大部分是非唯一索引, 并且写多读少。
Log Buffer
Log Buffer是给 redo log 做缓冲用的。redo log 我们都知道是重做日志,用来保证崩溃恢复数据的正确性,innodb 写数据时是先写日志,再写磁盘数据,即 WAL (Write-Ahead Logging),把数据的随机写入转换成日志的顺序写。
即使是顺序写 log ,每次都调用 write 或者 fsync 也是有开销的,毕竟也是系统调用,涉及上下文切换。于是乎,搞了个 Log Buffer(默认16M) 来缓存 redo log 的写入。
刷盘配置
innodb 其实给了个配置,即 innodb_flush_log_at_trx_commit 来控制 redo log 写盘时机。
-
当值为 0,提交事务不会刷盘到 redo log,需要等每隔一秒的后台线程,将 log buffer 写到操作系统的 cache,并调用 fsync落盘,性能最好,但是可能会丢 1s 数据。
-
当值为 1,提交事务会将 log buffer 写到操作系统的 cache,并调用 fsync 落盘,保证数据正确,性能最差,这也是默认配置。
-
当值为 2,提交事务会将 log buffer 写到操作系统的 cache,但不调用 fsync,而是等每隔 1s 调用 fsync 落盘,性能折中,如果数据库挂了没事,如果服务器宕机了,会丢 1s 数据。
redo log
每个 InnoDB 存储引擎至少有 1 个重做日志文件组( redo log group),每个文件组下至少有 2 个重做日志文件(redo log file),默认的话是一个 redo log group,其中包含 2 个 redo log file:ib_logfile0 和 ib_logfile1 。在日志组中每个 redo log file 的大小一致,并以循环写入的方式运行。
如下图举例:
一组 4 个文件,每个文件的大小是 1GB,那么总共就有 4GB 的 redo log file 空间。write pos 是当前 redo log 记录的位置,随着不断地写入磁盘,write pos 也不断地往后移,写到 file 3 末尾后就回到 file 0 开头。CheckPoint 是当前要擦除的位置(将 Checkpoint 之后的页刷新回磁盘),write pos 和 CheckPoint 之间的就是 redo log file 上还空着的部分,可以用来记录新的操作。如果 write pos 追上 CheckPoint,就表示 redo log file 满了,这时候不能再执行新的更新,得停下来先把buffer pool中脏页都flush到磁盘,把 CheckPoint 推进一下。

crash-safe
上面change buffer提到二级索引更新操作,如果 buffer pool中没有更新数据,不会从磁盘拉取数据,而是直接把变更记录在change buffer。假如数据库挂了,更改不是丢了吗?
mysql通过redo log 和 binlog来防止机器宕机之后数据丢失问题。
场景一:redo log 没有commit,binlog没有fsync,数据丢失。
场景二:redo log 没有commit,binlog已经fsync,重启之后会对比binlog中的trx_id和redo log中的trx_id, 进行commit redo log。
场景三:redo log 已经commit,binlog已经fsync,从redo log恢复数据。
Adaptive Hash Index
在MySQL运行的过程中,如果InnoDB发现,有很多寻路很长(比如B+树层数太多、回表次数多等情况)的SQL,并且有很多SQL会命中相同的页面(Page)的话,InnoDB会在自己的内存缓冲区(Buffer Pool)里,开辟一块区域,建立自适应哈希索引(Adaptive Hash Index,AHI),以加速查询。
MySQL 5.5 版本开始提供AHI特性,并在后续版本持续改进。在最新的8.0.33版本中依然将该特性默认开启。

首先,我们来看一下上图中两个InnoDB内部的B树结构,左边的primary key主键索引,右边是secondary key二级索引。当我们需要找到主键值为5的记录时,就需要从主键索引B数的根节点开始,一直搜索到叶子,找到最下面的左边第二页,然后定位到记录(5…)。而当我们想要查找二级索引键值为35的那条记录的时候,就会先搜索左边的二级索引B树,然后定位到(35,5)这条二级索引记录,再通过对应的主键5到左边的主键索引中找到(5…)这条完整的数据记录。
而如下图所示,AHI通过建立主键5到数据所在数据页的hash索引,可以直接定位到记录(5…)所在的数据页,也就是左边数第二个数据页。如此,在查找记录的时候就省略了从根节点到叶子节点的搜索过程。

如下图所示,AHI的主要数据结构是多个哈希表,可以看做它是B+树索引的hash索引

优势场景:读多写少,并且是叶节点定位占比多的场景 。
Doublewrite Buffer
Doublewrite Buffer,翻译成中文:双写缓冲区,缩写:DWB。Doublewrite 是保障 InnoDB 存储引擎操作数据页的可靠性。
我们都知道 innodb 默认一页是 16K,而操作系统 Linux 内存页是 4K,那么一个 innodb 页对应 4 个系统页。所以 innodb 的一页数据要刷盘等于需要写四个系统页。
如下图所示:Buffer Pool中的Page1 对应,系统页中的Page1,Page2,Page3,Page4,在写Page4的时候出现了断电了,则会出现:重启后,MySQL内Page 1的页,物理上对应磁盘上的Page 1、Page 2、Page 3三个页,数据完整性被破坏。(Redo Log无法修复这类“页数据损坏”的异常,修复的前提是“页数据正确”并且Redo日志正常)

针对上面出现的情况,如何解决这类“页数据损坏”的问题呢?很容易想到的方法是,能有一个“副本”,对原来的页进行还原,这个存储“副本”的地方,就是Doublewrite Buffer。
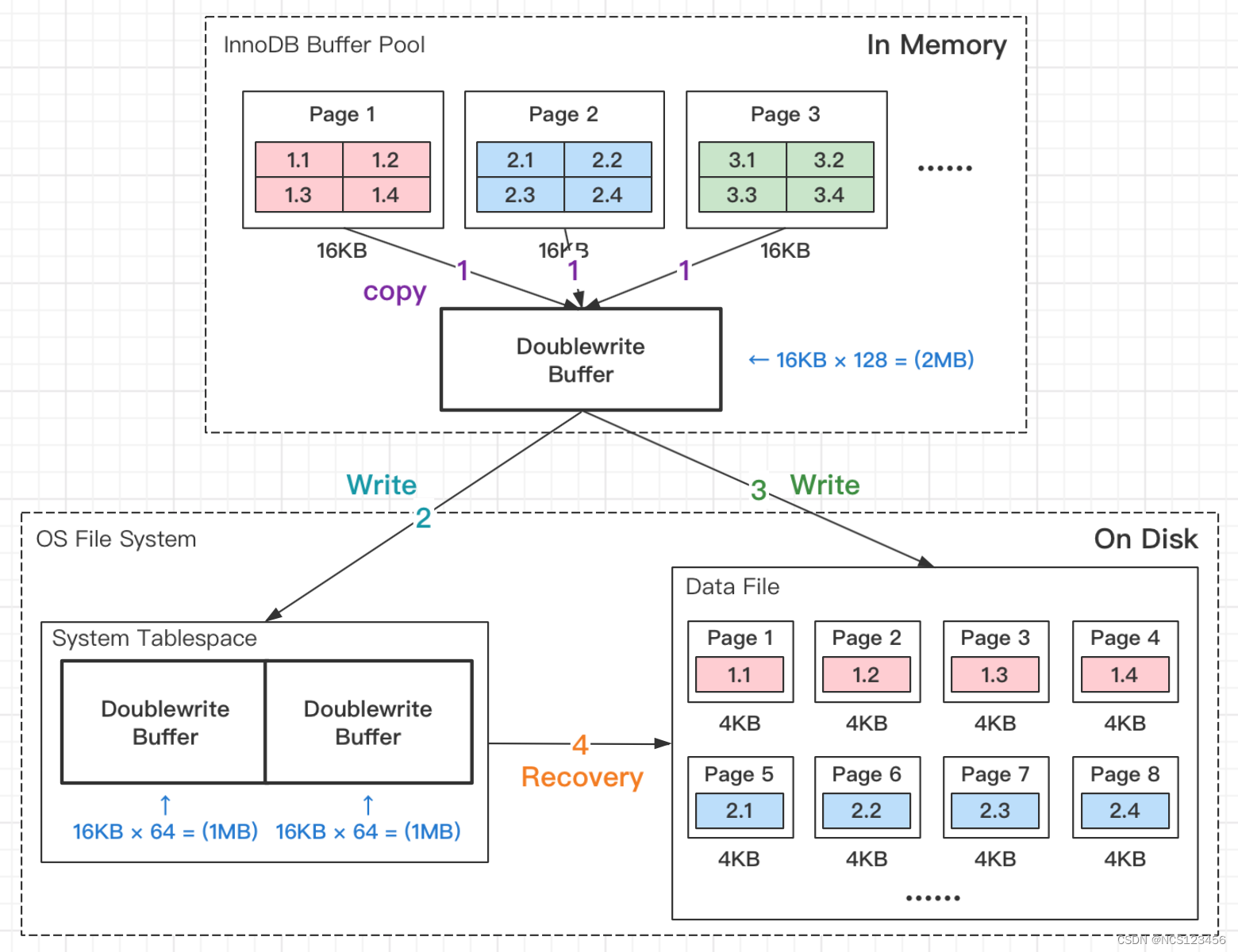
如上图所示,当有页数据要刷盘时:
第1步:页数据先memcopy到DWB的内存里;
第2步:DWB的内存里的数据页,会先刷到DWB的磁盘上;
第3步:DWB的内存里的数据页,再刷到数据磁盘存储.ibd文件上;
第4步:如果出现如上断电场景,从DWB FILE中恢复数据盘;
备注:DWB内存结构由128个页(Page)构成,所以容量只有:16KB × 128 = 2MB。
相关文章:
InnoDB 缓存
本文主要聊InnoDB内存结构, 先来看下官网Mysql 8.0 InnoDB架构图 MySQL :: MySQL 8.0 Reference Manual :: 17.4 InnoDB Architecture 如上图所示,InnoDB内存主要包含Buffer Pool, Change Buffer, Log Buffer, Adaptive Hash Index Buffer Pool 其实 buffer pool 就是内存中的…...
目标检测——PP-YOLOE-R算法解读
PP-YOLO系列,均是基于百度自研PaddlePaddle深度学习框架发布的算法,2020年基于YOLOv3改进发布PP-YOLO,2021年发布PP-YOLOv2和移动端检测算法PP-PicoDet,2022年发布PP-YOLOE和PP-YOLOE-R。由于均是一个系列,所以放一起解…...

轻松解锁微博视频:基于Perl的下载解决方案
引言 随着微博成为中国最受欢迎的社交平台之一,其内容已经变得丰富多彩,特别是视频内容吸引了大量用户的关注。然而,尽管用户对微博上的视频内容感兴趣,但却面临着无法直接下载这些视频的难题。本文旨在介绍一个基于Perl的解决方…...
asp.net mvc 重新引导视图路径,改变视图路径
asp.net mvc 重新引导视图路径,改变视图路径 使用指定的控制器上下文和母版视图名称来查找指定的视图 通过本文学习,你可以根据该技法,去实现,站点自定义皮肤,手机站和电脑站,其他设备站点,在不…...
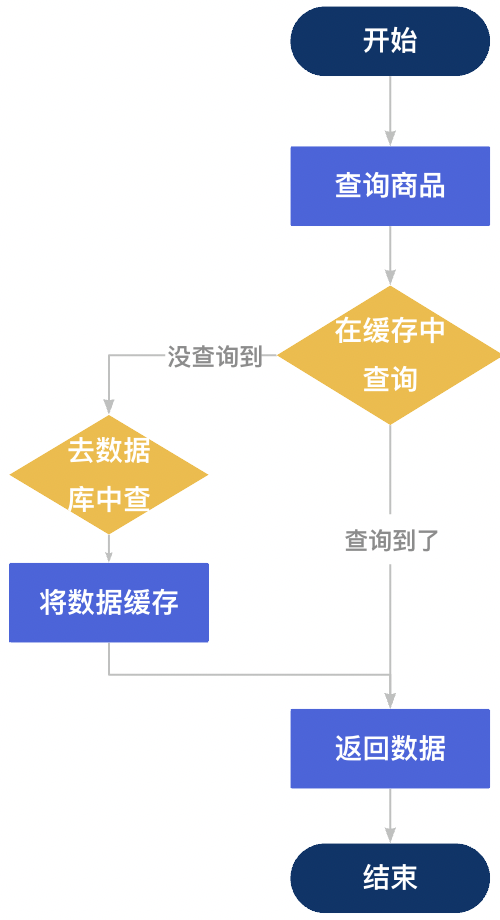
《优化接口设计的思路》系列:第九篇—用好缓存,让你的接口速度飞起来
一、前言 大家好!我是sum墨,一个一线的底层码农,平时喜欢研究和思考一些技术相关的问题并整理成文,限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。 作为一名从业已达六年的老码农,…...

专业130+总分410+西南交通大学924信号与系统考研经验西南交大电子信息通信工程,真题,大纲,参考书。
初试分数出来,专业课924信号与系统130,总分410,整体上发挥正常,但是还有遗憾,其实自己可以做的更好,总结一下经验,希望对大家有所帮助。专业课:(130) 西南交…...

MySQL数据库 - 存储引擎
一. mysql 存储引擎的相关知识 1.1 存储引擎的概念 MySQL中的数据用各种不下同的技术存储在文件中,每一种技术都使用不同的存储机制、索引技巧、锁定水平并最终提供不同的功能和能力,这些不同的技术以及配套的功能在MySQL中称为存储引擎。存储引擎是My…...
时序预测 | Matlab基于BiTCN-LSTM双向时间卷积长短期记忆神经网络时间序列预测
时序预测 | Matlab基于BiTCN-LSTM双向时间卷积长短期记忆神经网络时间序列预测 目录 时序预测 | Matlab基于BiTCN-LSTM双向时间卷积长短期记忆神经网络时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab基于BiTCN-LSTM双向时间卷积长短期记忆神经网络时…...
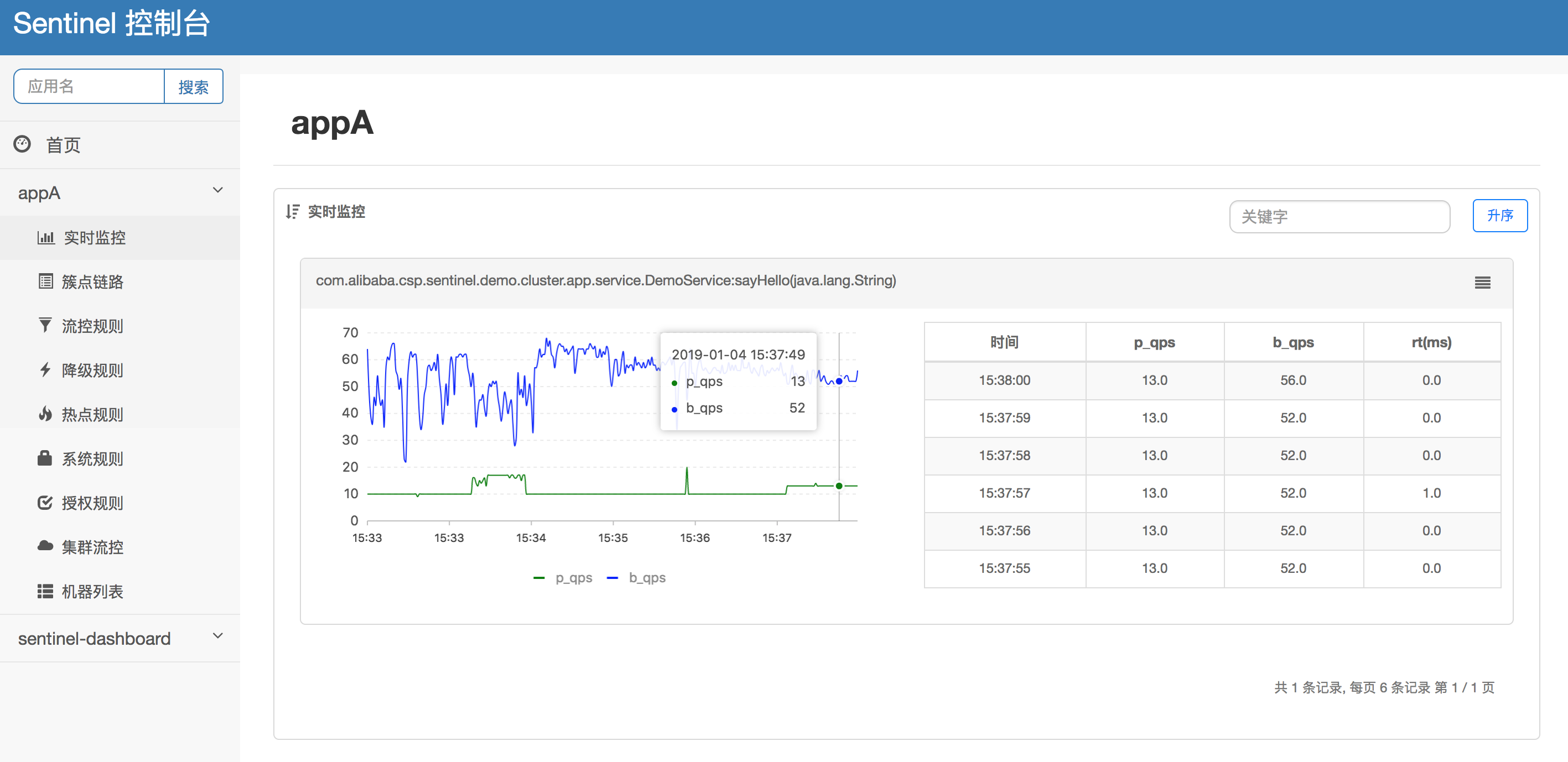
Spring Cloud Alibaba Sentinel 使用详解
一、Sentinel 介绍 随着微服务的流行,服务和服务之间的稳定性变得越来越重要。 Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。 Sentinel 具有以下特征: 丰富的应用场景: Sentinel 承接了阿里巴…...

android gdb 调试
gdbgdbserver远程调试技术(一)——调试环境搭建_gdbserver 远程调试-CSDN博客 GDB/gdbserver 7.4.1 for Android with NEON support (gnutoolchains.com) sudo apt-get install texinfo$ tar zxvf gdb-7.12.tar.gz $ cd gdb-7.12/$ mkdir build$ cd bu…...
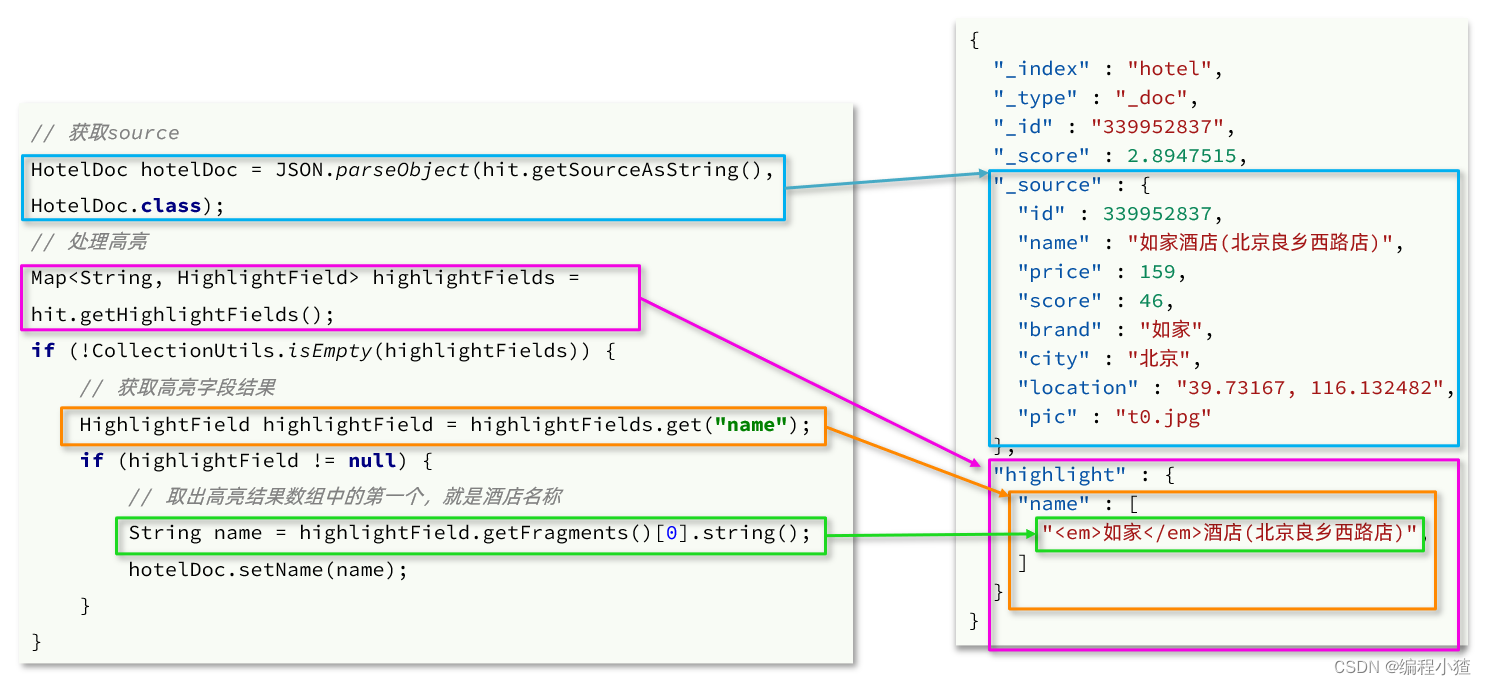
分布式搜索引擎elasticsearch专栏二
上一篇的传送门: 分布式搜索引擎elasticsearch专栏一-CSDN博客 这一篇博文主要讲解elasticsearch的数据搜索功能。下面会分别使用DSL和RestClient实现搜索。 1.DSL查询文档 elasticsearch的查询依然是基于JSON风格的DSL来实现的。 1.1.DSL查询分类 Elasticsea…...
)
LeetCode第一天(495.提莫攻击)
题目: 在《英雄联盟》的世界中,有一个叫 “提莫” 的英雄。他的攻击可以让敌方英雄艾希(编者注:寒冰射手)进入中毒状态。 当提莫攻击艾希,艾希的中毒状态正好持续 duration 秒。 正式地讲,提…...

SQL运维_Unix下MySQL-8.0.18配置文件示例
SQL运维_Unix下MySQL-8.0.18配置文件示例 MySQL 是一个关系型数据库管理系统, 由瑞典 MySQL AB 公司开发, 属于 Oracle 旗下产品。 MySQL 是最流行的关系型数据库管理系统之一, 在 WEB 应用方面, MySQL 是最好的 RDBMS (Relational Database Management System, 关系数据库管…...
python_BeautifulSoup爬取汽车评论数据
爬取的网站: 完整代码在文章末尾 https://koubei.16888.com/57233/0-0-0-2 使用方法: from bs4 import BeautifulSoup 拿到html后使用find_all()拿到文本数据,下图可见,数据标签为: content_text soup.find_all…...

24.2 SpringCloud电商进阶开发
24.2 SpringCloud电商进阶开发 1. 定时任务1.1 使用场景1.2 CRON表达式1.3 代码实战2. 线程池和ThreadLocal应用2.1 线程池1. 配置2. 应用3. Zuul安全性增强(重要)3.1 屏蔽接口转发3.2 异常统一处理4. SpringCloud Gateway网关4.1 Gateway创建基本架构1. 依赖</...

ES6—Module 的语法
export命令 ES6 模块的设计思想是尽量的静态化,使得编译时就能确定模块的依赖关系,以及输入和输出的变量。 模块功能主要由两个命令构成:export和import。export命令用于规定模块的对外接口,import命令用于输入其他模块提供的功…...
GitHub gpg体验
文档 实践 生成新 GPG 密钥 gpg --full-generate-key查看本地GPG列表 gpg --list-keys关联GPG公钥与Github账户 gpg --armor --export {key_id}GPG私钥对Git commit进行签名 git config --local user.signingkey {key_id} # git config --global user.signingkey {key_id} git…...

鸿蒙一次开发,多端部署(十一)交互归一
对于不同类型的智能设备,用户可能有不同的交互方式,如通过触摸屏、鼠标、触控板等。如果针对不同的交互方式单独做适配,会增加开发工作量同时产生大量重复代码。为解决这一问题,我们统一了各种交互方式的API,即实现了交…...

基于python+vue文学名著分享系统的设计与实现flask-django-nodejs-php
随着世界经济信息化、全球化的到来和互联网的飞速发展,推动了各行业的改革。若想达到安全,快捷的目的,就需要拥有信息化的组织和管理模式,建立一套合理、动态的、交互友好的、高效的文学名著分享系统。当前的信息管理存在工作效率…...
[音视频学习笔记]七、自制音视频播放器Part2 - VS + Qt +FFmpeg 写一个简单的视频播放器
前言 话不多说,重走霄骅登神路 前一篇文章 [音视频学习笔记]六、自制音视频播放器Part1 -新版本ffmpeg,Qt VS2022,都什么年代了还在写传统播放器? 本文相关代码仓库: MediaPlay-FFmpeg - Public 转载雷神的两个流程…...
开源大模型研报工具:Pixel Epic与Llama-Research在专业度上的横向评测
开源大模型研报工具:Pixel Epic与Llama-Research在专业度上的横向评测 1. 评测背景与工具介绍 在金融分析、市场研究和学术写作领域,高质量的研究报告生成工具正变得越来越重要。本次评测将对比两款基于开源大模型的研报生成工具:Pixel Epi…...

Android Studio项目集成AI:Phi-4-mini-reasoning 3.8B移动端调用方案
Android Studio项目集成AI:Phi-4-mini-reasoning 3.8B移动端调用方案 1. 移动端AI集成的新机遇 最近在移动开发圈里,AI集成成了热门话题。作为一名长期关注移动端AI落地的开发者,我发现Phi-4-mini-reasoning 3.8B这个轻量级模型特别适合移动…...

string的特性及使用
string这个词很容易让我们联想到str,也就是字符串,实际上string和字符串的关联性还是很强的。 很多字符串的题目都是string类的形式出现的,日常工作中为了方便使用都是用的string类, 标准string类 使用string类时,必须…...

JavaScript中BigInt与Number类型混用的报错机制
JavaScript中BigInt与Number不能直接混合运算,会立即抛出TypeError;所有涉及两者混合的算术和关系操作(如1n1、10n<5)均报错,仅和不报错但返回false。JavaScript中BigInt与Number不能直接混合运算,会立即…...

【微软MVP认证方案】:EF Core 10向量搜索成本压缩三板斧——量化指标、自动缩容阈值、混合检索降权模型
第一章:【微软MVP认证方案】:EF Core 10向量搜索成本压缩三板斧——量化指标、自动缩容阈值、混合检索降权模型在 EF Core 10 集成向量搜索(如 Azure AI Search 或 Qdrant 插件)的生产场景中,向量相似度计算极易引发 C…...

mini Thread:ESP32上轻量确定性并发框架
1. 项目概述“mini Thread”是一个面向 ESP32 平台的轻量级物联网固件框架,其设计目标并非替代 FreeRTOS,而是在 FreeRTOS 基础之上构建一层精简、确定、可预测的并发抽象层。项目摘要中“for useful things”(为实用之事而生)这一…...

Phi-3-mini-4k-instruct-gguf快速上手:VS Code远程开发+Jupyter Notebook联调
Phi-3-mini-4k-instruct-gguf快速上手:VS Code远程开发Jupyter Notebook联调 1. 环境准备与快速部署 Phi-3-mini-4k-instruct-gguf是微软推出的轻量级文本生成模型,特别适合问答、文本改写、摘要整理等场景。本文将带你快速搭建开发环境,实…...
✅)
计算机毕业设计:Python水网数据可视化与水位预测系统 Flask框架 数据分析 可视化 大数据 AI 线性回归 河流数据 水位预测(建议收藏)✅
博主介绍:✌全网粉丝50W,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,…...

基于Matlab Simulink的储能系统变换模型与钒液流电池仿真研究:功能实现及效果展示
基于Matlab/Simulink实现了以下功能,搭建了储能系统变换模型以及钒液流电池模型,仿真效果较好,系统充放电正常。 下图为系统模型图,电池输出电压电流以及SOC波形。 1.钒液流电池本体建模 2.储能变换器建模 3.双向DC变换 4.恒定功率…...

深度解析TFTP与FTP:核心区别、工作原理与应用场景
深度解析TFTP与FTP:核心区别、工作原理与应用场景摘要一、基础定义1.1 FTP 协议1.2 TFTP 协议二、TFTP 和 FTP 核心区别(表格对比)三、工作原理简要说明FTP 原理TFTP 原理四、TFTP 应用场景(最典型)1. **网络设备配置备…...