利用Scala与Apache HttpClient实现网络音频流的抓取

概述
在当今数字化时代,网络数据的抓取和处理已成为许多应用程序和服务的重要组成部分。本文将介绍如何利用Scala编程语言结合Apache HttpClient工具库实现网络音频流的抓取。通过本文,读者将学习如何利用强大的Scala语言和Apache HttpClient库来抓取网络上的音频数据,以及如何运用这些技术实现数据获取和分析。
Scala和Apache HttpClient相关介绍
Scala简介
Scala是一种多范式编程语言,结合了面向对象和函数式编程的特点。它运行在Java虚拟机上,具有强大的表达能力和优秀的可扩展性。Scala适用于大数据处理、并发编程以及Web应用程序开发等领域。
Apache HttpClient简介
Apache HttpClient是一个强大的开源HTTP客户端库,提供了丰富的API,便于进行HTTP请求和处理响应。它支持各种HTTP协议和方法,是网络数据抓取和处理的理想工具。
爬取网易云音乐案例
我们以爬取网易云音乐中热门歌曲列表的音频数据为例,展示如何通过编程实现网络音频流的抓取。通过这个案例,您将了解如何利用技术手段从网络中获取所需的音频数据,为您未来的数据抓取工作提供实用的参考和指导。
爬取思路分析
构建爬虫框架
要开始进行网络数据抓取,首先需要构建一个灵活、可扩展的爬虫框架。这个框架将是整个抓取流程的基础,其中包括发送网页请求、解析HTML等核心功能。通过建立这样一个框架,我们可以更好地组织和管理整个抓取过程,提高效率和灵活性。
请求网页
在网络数据抓取的过程中,我们使用Apache HttpClient发送GET请求来加载网页,获取页面的HTML内容。在我们的案例中,我们将请求网易云音乐中热门歌曲列表的网页,以便后续解析页面内容并提取音频数据。通过网络请求,我们能够获取包含所需音频数据的相关信息。
解析HTML
利用Scala中强大的HTML解析工具,比如jsoup库,我们可以解析网页的HTML内容。通过解析HTML,我们可以精确地识别出包含音频流的标签信息,并提取出我们所需的音频数据。这一步骤至关重要,它决定了我们能否准确地抓取到目标音频数据。
完整爬取代码
将请求网页和解析HTML等步骤整合在一起,编写完整的Scala代码来实现网络音频流数据的抓取功能。通过整合不同环节的功能,我们可以建立一个完整的音频数据抓取流程,以确保数据的完整性和精准性。
在接下来的内容中,我将具体展示每个步骤的实现方法,并提供实际的代码示例,让读者更好地理解如何利用Scala和Apache HttpClient实现网络音频流的抓取。
请求网页
为了实现对网易云音乐热门歌曲列表的音频数据抓取,我们首先要发送GET请求来加载网页并获取网页的HTML内容。这一步是整个抓取过程的起点,也是获取所需数据的第一步。
import org.apache.http.client.methods.HttpGet
import org.apache.http.impl.client.{CloseableHttpClient, HttpClients}
import org.apache.http.util.EntityUtils
import org.apache.http.HttpHost
import org.apache.http.auth.{AuthScope, UsernamePasswordCredentials}
import org.apache.http.impl.client.BasicCredentialsProviderobject WebPageLoader {val proxyHost = "www.16yun.cn"val proxyPort = 5445val proxyUser = "16QMSOML"val proxyPass = "280651"def loadWebPage(url: String): String = {val proxy = new HttpHost(proxyHost, proxyPort, "http")val credsProvider = new BasicCredentialsProvidercredsProvider.setCredentials(new AuthScope(proxy),new UsernamePasswordCredentials(proxyUser, proxyPass))val httpClient: CloseableHttpClient = HttpClients.custom().setDefaultCredentialsProvider(credsProvider).setProxy(proxy).build()val httpGet = new HttpGet(url)val response = httpClient.execute(httpGet)val entity = response.getEntityval content = EntityUtils.toString(entity)httpClient.close()content}
}val url = "https://music.163.com/discover/toplist"
val webPageContent = WebPageLoader.loadWebPage(url)
通过以上代码,我们成功加载了网易云音乐热门歌曲列表页面的HTML内容,并将其保存在webPageContent变量中,以供后续的HTML解析步骤使用。这个步骤确保我们成功获取到目标网页的内容,为接下来的数据提取工作奠定了基础。
接下来,我们将使用Scala中的HTML解析工具来提取出音频数据所在的标签信息。
解析HTML
利用Scala中的HTML解析工具,如jsoup库,我们可以解析网页的HTML内容,精确地定位包含音频链接的标签信息,并提取出我们需要的音频数据。下面是一个示例代码,展示了如何使用jsoup库解析HTML内容并提取音频链接信息。
import org.jsoup.Jsoup
import org.jsoup.nodes.Documentobject HtmlParser {def parseHtml(content: String): List[String] = {val doc: Document = Jsoup.parse(content)val songs = doc.select("div.song-list > ul > li")var audioLinks = List[String]()for (song <- songs) {val audioLink = song.select("a.audio-link").attr("href")audioLinks = audioLink :: audioLinks}audioLinks.reverse}
}// 解析网页内容
val audioLinks = HtmlParser.parseHtml(webPageContent)
在上述代码中,我们定义了一个HtmlParser对象,并编写了一个用于解析HTML内容的方法parseHtml。该方法利用jsoup库解析网页内容,根据特定的CSS选择器定位到包含音频链接的标签,并提取出音频链接信息。
完整爬取代码
最后,我们将请求网页和解析HTML等步骤整合在一起,编写完整的Scala代码来实现网络音频流数据的抓取功能。整合后的代码如下:
object AudioCrawler {def main(args: Array[String]): Unit = {val url = "https://music.163.com/discover/toplist"// 加载网页val webPageContent = WebPageLoader.loadWebPage(url)// 解析HTML内容val audioLinks = HtmlParser.parseHtml(webPageContent)// 输出音频链接audioLinks.foreach(println)}
}
相关文章:
利用Scala与Apache HttpClient实现网络音频流的抓取
概述 在当今数字化时代,网络数据的抓取和处理已成为许多应用程序和服务的重要组成部分。本文将介绍如何利用Scala编程语言结合Apache HttpClient工具库实现网络音频流的抓取。通过本文,读者将学习如何利用强大的Scala语言和Apache HttpClient库来抓取网…...

Linux(openEuler)部署SpringBoot前后端分离项目(Nginx负载均衡)
假如数据库在本地,没有放在Linux中 1.先把数据库中root的主机改成% 2.项目中的数据库链接配置换成本机ip 3.打包 4.把打包好的jar包放到Linux中 一般把jar包放到opt下 5.把前端部分拷贝到Linux的nginx中 5.1在package.json中修改build的值为图中这样 5.2同时由于在…...
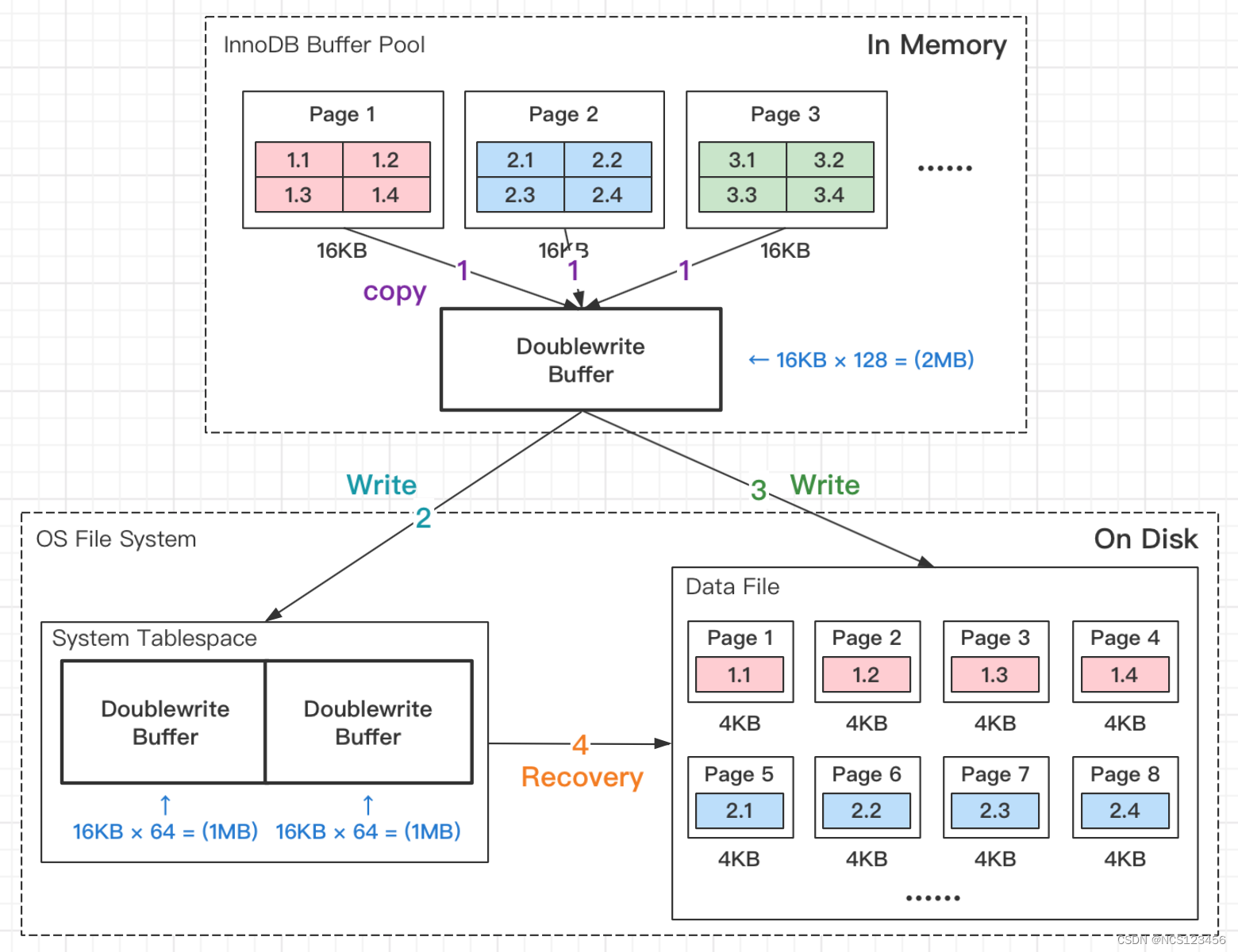
InnoDB 缓存
本文主要聊InnoDB内存结构, 先来看下官网Mysql 8.0 InnoDB架构图 MySQL :: MySQL 8.0 Reference Manual :: 17.4 InnoDB Architecture 如上图所示,InnoDB内存主要包含Buffer Pool, Change Buffer, Log Buffer, Adaptive Hash Index Buffer Pool 其实 buffer pool 就是内存中的…...
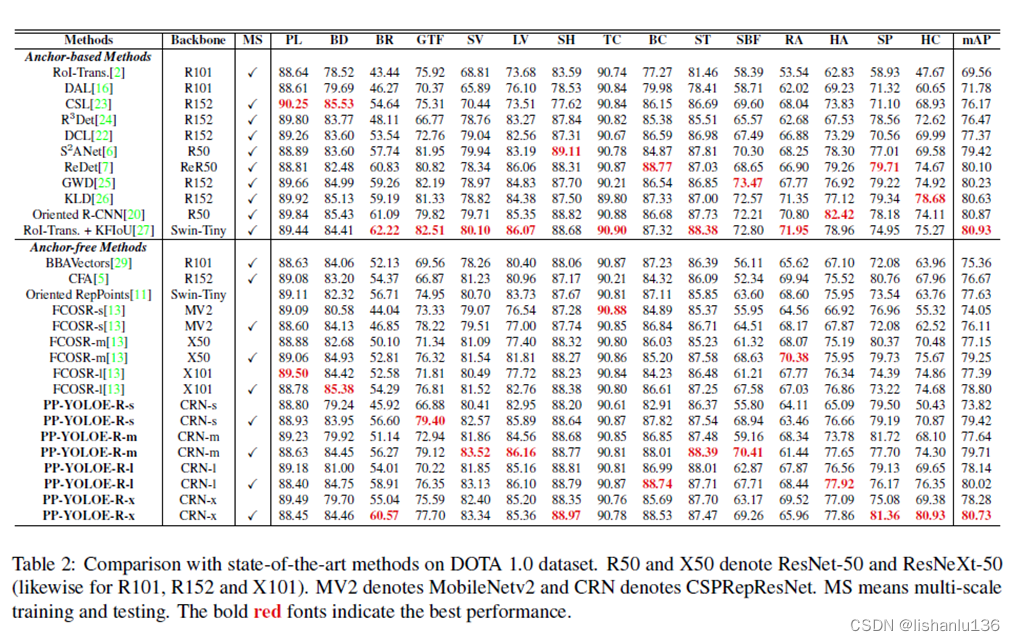
目标检测——PP-YOLOE-R算法解读
PP-YOLO系列,均是基于百度自研PaddlePaddle深度学习框架发布的算法,2020年基于YOLOv3改进发布PP-YOLO,2021年发布PP-YOLOv2和移动端检测算法PP-PicoDet,2022年发布PP-YOLOE和PP-YOLOE-R。由于均是一个系列,所以放一起解…...

轻松解锁微博视频:基于Perl的下载解决方案
引言 随着微博成为中国最受欢迎的社交平台之一,其内容已经变得丰富多彩,特别是视频内容吸引了大量用户的关注。然而,尽管用户对微博上的视频内容感兴趣,但却面临着无法直接下载这些视频的难题。本文旨在介绍一个基于Perl的解决方…...
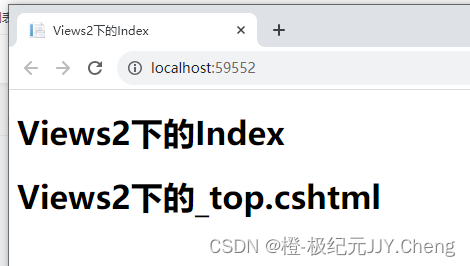
asp.net mvc 重新引导视图路径,改变视图路径
asp.net mvc 重新引导视图路径,改变视图路径 使用指定的控制器上下文和母版视图名称来查找指定的视图 通过本文学习,你可以根据该技法,去实现,站点自定义皮肤,手机站和电脑站,其他设备站点,在不…...
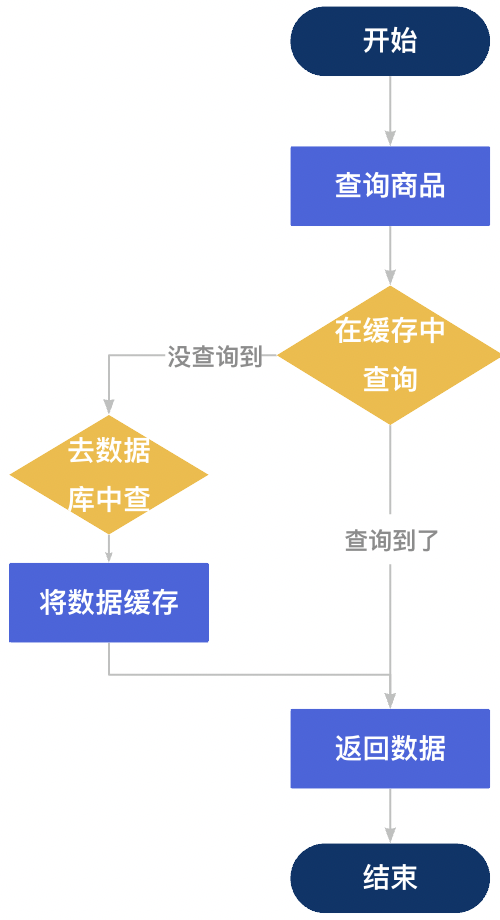
《优化接口设计的思路》系列:第九篇—用好缓存,让你的接口速度飞起来
一、前言 大家好!我是sum墨,一个一线的底层码农,平时喜欢研究和思考一些技术相关的问题并整理成文,限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。 作为一名从业已达六年的老码农,…...

专业130+总分410+西南交通大学924信号与系统考研经验西南交大电子信息通信工程,真题,大纲,参考书。
初试分数出来,专业课924信号与系统130,总分410,整体上发挥正常,但是还有遗憾,其实自己可以做的更好,总结一下经验,希望对大家有所帮助。专业课:(130) 西南交…...

MySQL数据库 - 存储引擎
一. mysql 存储引擎的相关知识 1.1 存储引擎的概念 MySQL中的数据用各种不下同的技术存储在文件中,每一种技术都使用不同的存储机制、索引技巧、锁定水平并最终提供不同的功能和能力,这些不同的技术以及配套的功能在MySQL中称为存储引擎。存储引擎是My…...
时序预测 | Matlab基于BiTCN-LSTM双向时间卷积长短期记忆神经网络时间序列预测
时序预测 | Matlab基于BiTCN-LSTM双向时间卷积长短期记忆神经网络时间序列预测 目录 时序预测 | Matlab基于BiTCN-LSTM双向时间卷积长短期记忆神经网络时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab基于BiTCN-LSTM双向时间卷积长短期记忆神经网络时…...
Spring Cloud Alibaba Sentinel 使用详解
一、Sentinel 介绍 随着微服务的流行,服务和服务之间的稳定性变得越来越重要。 Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。 Sentinel 具有以下特征: 丰富的应用场景: Sentinel 承接了阿里巴…...

android gdb 调试
gdbgdbserver远程调试技术(一)——调试环境搭建_gdbserver 远程调试-CSDN博客 GDB/gdbserver 7.4.1 for Android with NEON support (gnutoolchains.com) sudo apt-get install texinfo$ tar zxvf gdb-7.12.tar.gz $ cd gdb-7.12/$ mkdir build$ cd bu…...
分布式搜索引擎elasticsearch专栏二
上一篇的传送门: 分布式搜索引擎elasticsearch专栏一-CSDN博客 这一篇博文主要讲解elasticsearch的数据搜索功能。下面会分别使用DSL和RestClient实现搜索。 1.DSL查询文档 elasticsearch的查询依然是基于JSON风格的DSL来实现的。 1.1.DSL查询分类 Elasticsea…...
)
LeetCode第一天(495.提莫攻击)
题目: 在《英雄联盟》的世界中,有一个叫 “提莫” 的英雄。他的攻击可以让敌方英雄艾希(编者注:寒冰射手)进入中毒状态。 当提莫攻击艾希,艾希的中毒状态正好持续 duration 秒。 正式地讲,提…...

SQL运维_Unix下MySQL-8.0.18配置文件示例
SQL运维_Unix下MySQL-8.0.18配置文件示例 MySQL 是一个关系型数据库管理系统, 由瑞典 MySQL AB 公司开发, 属于 Oracle 旗下产品。 MySQL 是最流行的关系型数据库管理系统之一, 在 WEB 应用方面, MySQL 是最好的 RDBMS (Relational Database Management System, 关系数据库管…...
python_BeautifulSoup爬取汽车评论数据
爬取的网站: 完整代码在文章末尾 https://koubei.16888.com/57233/0-0-0-2 使用方法: from bs4 import BeautifulSoup 拿到html后使用find_all()拿到文本数据,下图可见,数据标签为: content_text soup.find_all…...

24.2 SpringCloud电商进阶开发
24.2 SpringCloud电商进阶开发 1. 定时任务1.1 使用场景1.2 CRON表达式1.3 代码实战2. 线程池和ThreadLocal应用2.1 线程池1. 配置2. 应用3. Zuul安全性增强(重要)3.1 屏蔽接口转发3.2 异常统一处理4. SpringCloud Gateway网关4.1 Gateway创建基本架构1. 依赖</...

ES6—Module 的语法
export命令 ES6 模块的设计思想是尽量的静态化,使得编译时就能确定模块的依赖关系,以及输入和输出的变量。 模块功能主要由两个命令构成:export和import。export命令用于规定模块的对外接口,import命令用于输入其他模块提供的功…...
GitHub gpg体验
文档 实践 生成新 GPG 密钥 gpg --full-generate-key查看本地GPG列表 gpg --list-keys关联GPG公钥与Github账户 gpg --armor --export {key_id}GPG私钥对Git commit进行签名 git config --local user.signingkey {key_id} # git config --global user.signingkey {key_id} git…...

鸿蒙一次开发,多端部署(十一)交互归一
对于不同类型的智能设备,用户可能有不同的交互方式,如通过触摸屏、鼠标、触控板等。如果针对不同的交互方式单独做适配,会增加开发工作量同时产生大量重复代码。为解决这一问题,我们统一了各种交互方式的API,即实现了交…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

物联网与云技术赋能咖啡后处理:CeriTech 的实时监控系统实践
1. 项目概述:用物联网与云技术重塑咖啡后处理在印尼的咖啡农场里,传统的发酵与干燥过程很大程度上依赖“感觉”和“经验”。一位有经验的农人可能会用手触摸、用鼻子闻,或者根据天气和日照时间来估算发酵是否完成、干燥是否均匀。这种方法固然…...

2026年,揭秘那些真正安全的原生态食材厂家你不可不知的秘密
随着人们生活水平的提升以及对健康的日益重视,选择真正安全的原生态食材已经成为许多人购买食物的标准。但市场的繁杂使得甄别真正安全的食材厂家变得愈加困难。今天,我将通过几个关键角度,为大家揭秘那些真正安全的原生态食材厂家的秘密&…...

Taotoken如何帮助教育科技产品实现个性化学习辅导
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助教育科技产品实现个性化学习辅导 1. 场景与挑战 教育科技公司在开发个性化学习助手时,常常面临一个核…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...

从零构建FOC轮腿机器人:开源平衡机器人完整指南
从零构建FOC轮腿机器人:开源平衡机器人完整指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software development. | 一个…...
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作发愁吗&am…...

终极崩坏星穹铁道自动化指南:3分钟掌握解放双手的智能游戏伴侣
终极崩坏星穹铁道自动化指南:3分钟掌握解放双手的智能游戏伴侣 【免费下载链接】StarRailAssistant 崩坏:星穹铁道自动化 | 崩坏:星穹铁道自动锄大地 | 崩坏:星穹铁道锄大地 | 自动锄大地 | 基于模拟按键 项目地址: https://git…...

自动加字幕软件推荐:口播视频如何批量加字幕过
口播视频加字幕,为什么越做越累?一位知识类博主连续两周日更3条口播视频,每条12–18分钟,需手动校对字幕、拆分金句切片、补气口停顿、匹配背景音乐——最后一条视频发布时,字幕错漏率达17%,平台审核未过。…...

Meteor-Files新手教程:从安装到实现第一个文件上传功能的完整步骤
Meteor-Files新手教程:从安装到实现第一个文件上传功能的完整步骤 【免费下载链接】Meteor-Files 🚀 Upload files via DDP or HTTP to ☄️ Meteor server FS, AWS, GridFS, DropBox or Google Drive. Fast, secure and robust. 项目地址: https://gi…...