最简单的线性回归模型-标量
首先考虑yyy为标量,www为标量的情况,那么我们的线性函数为y=wx+by=wx+by=wx+b。每批输入的量batch size 为111,每批输入的xxx为一个标量,设为x∗x^*x∗,标签yyy同样为一个标量,设为y∗y^*y∗。因此每批训练的损失函数LLL可以表示为:
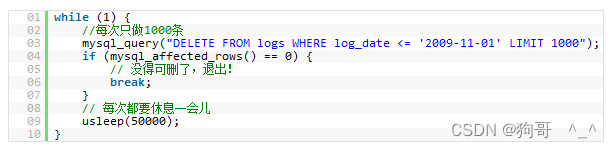
L=(y−y∗)2=(wx∗+b−y∗)2\begin{aligned} L&=\left(y-y^*\right)^2\\ &=\left(wx^*+b-y^*\right)^2\\ \end{aligned} L=(y−y∗)2=(wx∗+b−y∗)2
每次训练完需要更新参数www和bbb,我们采用梯度下降方法对这两个参数进行更新的话,需要求出两个参数的梯度,也就是需要求出∂L∂w\frac{\partial{L}}{\partial{w}}∂w∂L和∂L∂b\frac{\partial{L}}{\partial{b}}∂b∂L,结果如下:
∂L∂w=2(wx∗+b−y∗)x∗\frac{\partial{L}}{\partial{w}}=2(wx^*+b-y^*)x^* ∂w∂L=2(wx∗+b−y∗)x∗
∂L∂b=2(wx∗+b−y∗)\frac{\partial{L}}{\partial{b}}=2(wx^*+b-y^*) ∂b∂L=2(wx∗+b−y∗)
训练之前需要对www和bbb初始化赋值,设定步长stepstepstep。这样每轮www和bbb的更新方法为:
wnew=w−step∗2(wx∗+b−y∗)x∗w_{new}=w-step*2(wx^*+b-y^*)x^*wnew=w−step∗2(wx∗+b−y∗)x∗
bnew=b−step∗2(wx∗+b−y∗)b_{new}=b-step*2(wx^*+b-y^*)bnew=b−step∗2(wx∗+b−y∗)
首先考虑yyy为标量,www为标量的情况,那么我们的线性函数为y=wx+by=wx+by=wx+b。每批输入的量batch size 为NNN,每批输入的xxx为一个向量,设为x∗\boldsymbol{x}^*x∗,标签yyy同样为一个向量,设为y∗\boldsymbol{y}^*y∗。因此损失函数可以表示为:
L=∑n=1N(y−y∗)2=∑n=1N(y−y∗)2\begin{aligned} L&=\sum_{n=1}^{N}\left(y-y^*\right)^2\\ &=\sum_{n=1}^{N}\left(y-y^*\right)^2\\ \end{aligned} L=n=1∑N(y−y∗)2=n=1∑N(y−y∗)2
下面我们对这种最简单的线性回归模型使用python实现一下:
x = np.array([0.1,1.2,2.1,3.8,4.1,5.4,6.2,7.1,8.2,9.3,10.4,11.2,12.3,13.8,14.9,15.5,16.2,17.1,18.5,19.2])
y = np.array([5.7,8.8,10.8,11.4,13.1,16.6,17.3,19.4,21.8,23.1,25.1,29.2,29.9,31.8,32.3,36.5,39.1,38.4,44.2,43.4])
print(x,y)
plt.scatter(x,y)
plt.show()

回归过程如下:
# 设定步长
step=0.001
# 存储每轮损失的loss数组
loss_list=[]
# 定义epoch
epoch=30
# 定义参数w和b并初始化
w=0.0
b=0.0
#梯度下降回归
for i in range(epoch) :#计算当前输入x和标签y的索引,由于x和y数组长度一致,因此通过i整除x的长度即可获得当前索引index = i % len(x)# 当前轮次的x值为:cx=x[index]# 当前轮次的y值为:cy=y[index]# 计算当前lossloss_list.append((w*cx+b-cy)**2)# 计算参数w和b的梯度grad_w = 2*(w*cx+b-cy)*cxgrad_b = 2*(w*cx+b-cy)# 更新w和b的值w -= step*grad_wb -= step*grad_b
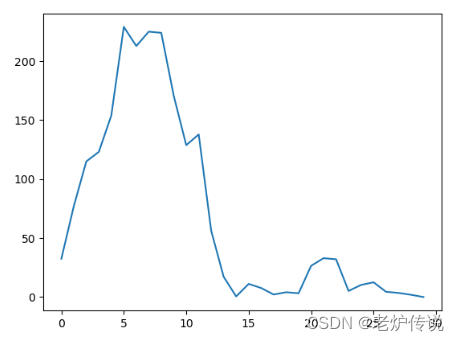
输出loss如下:
plt.plot(loss_list)
plt.show()
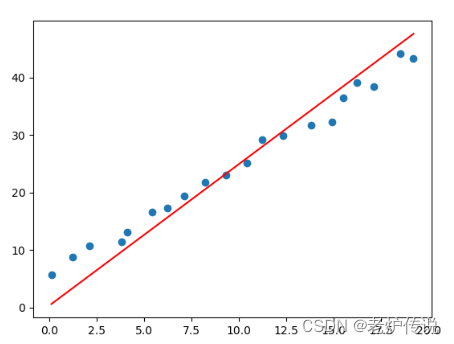
输出拟合函数的结果:
print("y=%.2fx+%.2f" %(w,b))
y=2.46x+0.39
拟合的函数图像与训练数据中的点关系图如下:
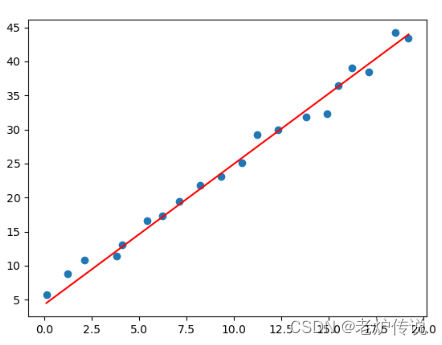
可以看到迭代30次后的函数图像,现在迭代次数增加到3000,拟合结果如下:
loss如下:
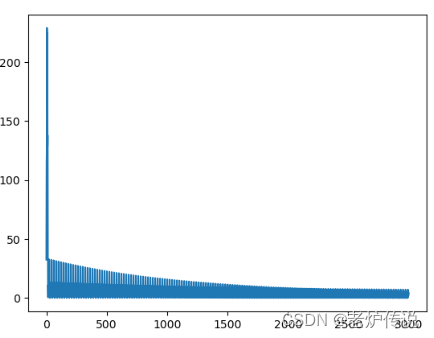
在batchsize为1的时候,loss波动很大。因此有必要增大batchsize,下一篇我们在此基础上增加batchsize看看线性回归的结果。
相关文章:
最简单的线性回归模型-标量
首先考虑yyy为标量,www为标量的情况,那么我们的线性函数为ywxbywxbywxb。每批输入的量batch size 为111,每批输入的xxx为一个标量,设为x∗x^*x∗,标签yyy同样为一个标量,设为y∗y^*y∗。因此每批训练的损失…...

k8s-Kubernetes集群升级
文章目录前言一、集群升级1.部署cri-docker (所有集群节点)2.升级master节点3.升级worker节点前言 一、集群升级 https://v1-24.docs.kubernetes.io/zh-cn/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/ 1.部署cri-docker (所有…...
Linux25 -- 监听队列链接上限测试、命令uname、ulimit
一、监听队列链接上限测试 1、res listen(sockfd,5); //创建监听队列res listen(sockfd,5);不懂版本有不同的限制,2.6早期版本有限制为128,超过默认为128,可使用uname -a 查看版本 2、测试将链接数到达上限, 方法࿱…...

idea:地址被占用
问题启动idea报:java.net.BindException: Address already in use: bind,具体截图如下:解决步骤1、首先想到的是改idea端口,但按网上方法试下了几个4位数和5位数的端口,没啥作用2、根据idea抛异常的弹出框提示…...
)
JavaScript常用小技巧(js优化)
JavaScript常用小技巧(js优化)常见JS操作1、解构交换两数2、短路赋值3、if 判断优化4、 switch 判断优化6、动态正则匹配Number1、幂运算2、安全计算String1、反转字符串、判断是否回文数2、数组求和3、初始化二维数组Object1、对象遍历2、冻结对象3、解…...

【项目实战】MySQL 5.7中的关键字与保留字详解
一、什么是关键字和保留字 关键字是指在SQL中有意义的字。 某些关键字(例如SELECT,DELETE或BIGINT)是保留的,需要特殊处理才能用作表和列名称等标识符。 这一点对于内置函数的名称也适用。 二、如何使用关键字和保留字 非保留关…...

Git图解-常用命令操作
目录 一、前言 二、初始化仓库 三、添加文件 四、Git 流程全景图 五、Git工作流程 六、工作区和暂存区 七、查看文件状态 八、查看提交日志 九、查看差异 十、版本回退 十一、管理修改 十二、修改撤销 十三、删除文件 十四、分支管理 十五、项目分支操作 十六、…...
LeetCode096不同的二叉搜索树(相关话题:卡特兰数)
目录 题目描述 解题思路 代码实现 进出栈序列理解卡特兰数分析策略 相关知识 参考文章 题目描述 给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。 示例 1: …...
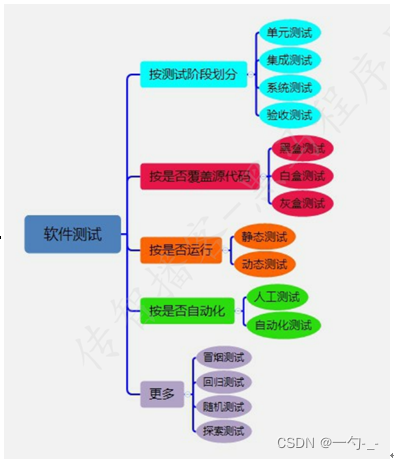
软件测试7
一 CS和BS软件架构 CS:客户端-服务器端,BS:浏览器端-服务器端 区别总结: 1.效率:c/s效率高,某些内容已经安装在系统中了,b/s每次都要加载最新的数据 2.升级:b/s无缝升级,…...
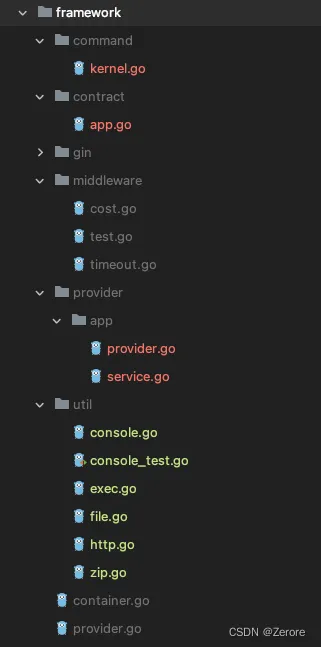
12 结构:如何系统设计框架的整体目录?
到现在,我们已经将 Gin 集成到框架 hade 中,同时又引入了服务容器和服务提供者,明确框架的核心思想是面向服务编程,一切皆服务,所有服务都是基于协议。后续也会以服务的形式,封装一个个的服务,让…...
假如你知道这样的MySQL性能优化
1. 为查询缓存优化你的查询 大多数的 MySQL 服务器都开启了查询缓存。这是提高性最有效的方法之 一,而且这是被 MySQL 的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同…...
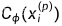
79、ClimateNeRF: Physically-based Neural Rendering for Extreme Climate Synthesis
简介主页物理模拟可以很好地预测天气影响。神经辐射场产生SOTA场景模型。ClimateNeRF 允许我们渲染真实的天气效果,包括雾霾、雪和洪水 ,结果可以通过有物理意义的变量来控制,比如水位 ,这允许人们可视化气候变化的结果将对他们产…...
)
前端面试题(一)
目录 前言 一、css3实现布局的方式有哪些? 1.flex布局 2.grid布局 二、jquery的扩展机制? 三、jquery动画和css实现动画的本质区别? 四、不使用css的动画,如何实现盒子从左到右移动? 五、使用过的框架…...

Java基础常见面试题(七)
序列化和反序列化 Java序列化与反序列化是什么? Java序列化是指把Java对象转换为字节序列的过程,而Java反序列化是指把字节序列恢复为Java对象的过程。 序列化: 序列化是把对象转换成有序字节流,以便在网络上传输或者保存在本地…...

【springmvc】报文信息转换器
HttpMessageConverter HttpMessageConverter,报文信息转换器,将请求报文转换为Java对象,或将Java对象转换为响应报文 HttpMessageConverter提供了两个注解和两个类型: RequestBody, ResponseBody, Reques…...

3.5知识点复习
extern:表示声明。 没有内存空间。 不能提升。const:限定一个变量为只读变量。volatile:防止编译器优化代码。volatile int flg 0; register:定义一个寄存器变量。没有内存地址。register int a 10;字符串:C语言中&a…...

湖南中创教育PMP分享项目经理有哪些优势?
项目经理拥有超强的计划能力;具备大局意识;沟通能力特别强;具备更大的灵活性和反应能力以及总结汇报能力 1、超强的计划能力 项目经理几乎无时无刻都在做计划,因此也就更擅长做计划。 项目管理要抓重点,有主次地处理…...

LeetCode:27. 移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。 元素的顺序可以改变。你不需要考虑数组中超出新长度后面…...
麻雀算法SSA优化LSTM长短期记忆网络实现分类算法
1、摘要 本文主要讲解:麻雀算法SSA优化LSTM长短期记忆网络实现分类算法 主要思路: 准备一份分类数据,数据介绍在第二章准备好麻雀算法SSA,要用随机数据跑起来用lstm把分类数据跑起来将lstm的超参数交给SSA去优化优化完的最优参数…...

哈希表题目:数组中的 k-diff 数对
文章目录题目标题和出处难度题目描述要求示例数据范围解法思路和算法代码复杂度分析题目 标题和出处 标题:数组中的 k-diff 数对 出处:532. 数组中的 k-diff 数对 难度 4 级 题目描述 要求 给定一个整数数组 nums\texttt{nums}nums 和一个整数 k…...

无国界技术创业:构建全球化产品支持与远程协作体系
1. 从“车库”到“云端”:无国界创业的底层逻辑变迁 十年前,如果你在硅谷创立一家芯片设计工具(EDA)或嵌入式软件公司,头两年的客户拜访路线图大概就是101号公路沿线。工程师可以早上开车去圣何塞的客户办公室…...
)
面试记录 (2026/5/12)
问题一:java并发包下的AQS,了解多少? 这个真是没看过源码,就不班门弄斧了 直接学习下 大佬的经验 https://blog.csdn.net/qq_45772447/article/details/149126295?fromshareblogdetail&sharetypeblogdetail&sharerId149126295&…...

基于Helm Chart在Kubernetes中部署docker-mailserver邮件服务器
1. 项目概述与核心价值最近在折腾自建邮件服务器,发现了一个宝藏项目:docker-mailserver。它把邮件服务里那些复杂的组件,比如 Postfix、Dovecot、SpamAssassin、ClamAV 这些,全都打包进了一个 Docker 镜像里,开箱即用…...

CVPR2019 Oral论文DVC复现指南:用TensorFlow搭建你的第一个端到端深度学习视频压缩模型
CVPR2019 Oral论文DVC复现实战:从零构建端到端视频压缩模型 视频压缩技术正经历从传统编码标准向深度学习范式的革命性转变。2019年CVPR Oral论文《DVC: An End-to-end Deep Video Compression Framework》首次提出了完整的端到端深度学习视频压缩框架,其…...

别再为本科毕业论文熬大夜!Paperxie 智能写作,一键搞定终稿的正确姿势
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ai/dissertationhttps://www.paperxie.cn/ai/dissertation 又到了本科毕业论文冲刺的季节,多少同学还在对着空白文档发呆?选题纠结半天定不下来&…...

农文旅融合实践:六亩半如何以草莓采摘+植物染色激活乌鲁木齐亲子游市场
一、行业背景随着文旅产业复苏和乡村振兴战略深入推进,乌鲁木齐及周边地区的农文旅融合项目迎来新的发展机遇。根据相关行业观察,融合农业采摘与非遗文化体验的"农文旅"模式正成为新趋势,为城市居民提供了差异化的周末游选择。五月…...

Agnix:为AI智能体打造安全可控的操作系统级执行环境
1. 项目概述:从“智能体”到“操作系统”的范式跃迁最近在开源社区里,一个名为agent-sh/agnix的项目引起了我的注意。乍一看这个名字,agent和agnix的组合,很容易让人联想到这是又一个基于大语言模型的智能体(Agent&…...

Python 爬虫数据处理:重复页面数据智能合并去重
前言 在规模化 Python 爬虫采集项目中,重复页面数据是高频出现的核心问题,源于站点分页逻辑错乱、镜像页面分发、动态接口返回冗余数据、多入口同源页面采集等多重因素。重复数据若不做处理,不仅会造成数据库存储冗余、占用服务器资源&#…...

LLM RAG还值得做吗?今天一下就顿悟了
在企业级AI应用领域,RAG(检索增强生成)不仅值得深耕,更是当前唯一能站稳脚跟的核心护城河。曾有人断言长上下文窗口(Long Context)会取代RAG,但这一说法早在2024年就被彻底证伪,进入…...

基于Helm与Kubernetes的以太坊节点自动化部署与运维实战
1. 项目概述:当以太坊遇见Kubernetes如果你和我一样,在区块链基础设施领域摸爬滚打多年,从早期手动编译客户端、配置systemd服务,到后来用Docker Compose编排节点,每一步都伴随着大量的重复劳动和运维痛点。当节点数量…...