麻雀算法SSA优化LSTM长短期记忆网络实现分类算法
1、摘要
本文主要讲解:麻雀算法SSA优化LSTM长短期记忆网络实现分类算法
主要思路:
- 准备一份分类数据,数据介绍在第二章
- 准备好麻雀算法SSA,要用随机数据跑起来
- 用lstm把分类数据跑起来
- 将lstm的超参数交给SSA去优化
- 优化完的最优参数给lstm去做最后一次训练
2、数据介绍
Cll:出料量
Lsp:量水平
Djzsp:电解质水平
Djwd:工作温度
Fzb:分子比
Fe:铁含量
Si:硅含量
Ludiyajiang:压降
Ddlsp:打点量水平
Avv:平均电压
wv:工作电压
avaev:平均故障发生时的电压
ae:故障发生标签(0:未发生,1:发生)
除分子比、压降、打点量水平外其余数据均是一天一采集,数据异常时发生故障,故障电压高于工作电压。
数据下载链接
3、相关技术
麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种新型的群智能优化算法,在2020年提出,主要是受麻雀的觅食行为和反捕食行为的启发 ,以下是一些图片,可加深你的理解:

4、完整代码和步骤
此代码的依赖环境如下:
tensorflow==2.5.0
numpy==1.19.5
keras==2.6.0
matplotlib==3.5.2
麻雀算法用随机数据跑起来的代码:
# -*- coding: utf-8 -*-
import numpy as np
import random
import matplotlib.pyplot as pltdef fun(x):a = np.sum(x ** 2)return adef Bounds(x, lb, ub):temp = x.reshape(-1, 2)I = temp < lbtemp[I] = lb[I]J = temp > ubtemp[J] = ub[J]return tempdef SSA(M, pop, dim, P_percent, c, d):# M 迭代次数 SSA(1000, 20, 2, 0.2, -10, 10)# pop 麻雀种群数量# dim 寻优维度# P_percent 麻雀在生产者的比例# c d分别是寻优范围的最小值与最大值pNum = round(pop * P_percent) # pNum是生产者lb = c * np.ones((1, dim)) # 下边界ub = d * np.ones((1, dim)) # 上边界x = np.zeros((pop, dim))fit = np.zeros((pop, 1))# 种群初始化for i in range(pop):x[i, :] = lb + (ub - lb) * np.random.rand(1, dim)fit[i] = fun(x[i, :])pFit = fit.copy()pX = x.copy()fMin = np.min(fit)bestI = np.argmin(fit)bestX = x[bestI, :].copy()Convergence_curve = np.zeros((M,))trace = np.zeros((M, dim))for t in range(M):sortIndex = np.argsort(pFit.reshape(-1, )).reshape(-1, )fmax = np.max(pFit)B = np.argmax(pFit)worse = x[B, :].copy()r2 = np.random.rand()## 这一部分为发现者(探索者)的位置更新if r2 < 0.8: # %预警值较小,说明没有捕食者出现for i in range(pNum): # r2小于0.8时发现者改变位置r1 = np.random.rand()x[sortIndex[i], :] = pX[sortIndex[i], :] * np.exp(-i / (r1 * M))x[sortIndex[i], :] = Bounds(x[sortIndex[i], :], lb, ub)temp = fun(x[sortIndex[i], :])fit[sortIndex[i]] = temp # 计算新的适应度值else: # 预警值较大,说明有捕食者出现威胁到了种群的安全,需要去其它地方觅食for i in range(pNum): # r2大于0.8时发现者改变位置r1 = np.random.rand()x[sortIndex[i], :] = pX[sortIndex[i], :] + np.random.normal() * np.ones((1, dim))x[sortIndex[i], :] = Bounds(x[sortIndex[i], :], lb, ub)fit[sortIndex[i]] = fun(x[sortIndex[i], :]) # 计算新的适应度值bestII = np.argmin(fit)bestXX = x[bestII, :].copy()##这一部分为加入者(追随者)的位置更新for i in range(pNum + 1, pop): # 剩下的个体变化A = np.floor(np.random.rand(1, dim) * 2) * 2 - 1if i > pop / 2: # 这个代表这部分麻雀处于十分饥饿的状态(因为它们的能量很低,也是是适应度值很差),需要到其它地方觅食x[sortIndex[i], :] = np.random.normal() * np.exp((worse - pX[sortIndex[i], :]) / (i ** 2))else: # 这一部分追随者是围绕最好的发现者周围进行觅食,其间也有可能发生食物的争夺,使其自己变成生产者x[sortIndex[i], :] = bestXX + np.abs(pX[sortIndex[i], :] - bestXX).dot(A.T * (A * A.T) ** (-1)) * np.ones((1, dim))x[sortIndex[i], :] = Bounds(x[sortIndex[i], :], lb, ub) # 判断边界是否超出fit[sortIndex[i]] = fun(x[sortIndex[i], :]) # 计算适应度值# 这一部分为意识到危险(注意这里只是意识到了危险,不代表出现了真正的捕食者)的麻雀的位置更新c = random.sample(range(sortIndex.shape[0]),sortIndex.shape[0]) # 这个的作用是在种群中随机产生其位置(也就是这部分的麻雀位置一开始是随机的,意识到危险了要进行位置移动,b = sortIndex[np.array(c)[0:round(pop * 0.2)]].reshape(-1, )for j in range(b.shape[0]):if pFit[sortIndex[b[j]]] > fMin: # 处于种群外围的麻雀的位置改变x[sortIndex[b[j]], :] = bestX + np.random.normal(1, dim) * (np.abs(pX[sortIndex[b[j]], :] - bestX))else: # 处于种群中心的麻雀的位置改变x[sortIndex[b[j]], :] = pX[sortIndex[b[j]], :] + (2 * np.random.rand() - 1) * (np.abs(pX[sortIndex[b[j]], :] - worse)) / (pFit[sortIndex[b[j]]] - fmax + 1e-50)x[sortIndex[b[j]], :] = Bounds(x[sortIndex[b[j]], :], lb, ub)fit[sortIndex[b[j]]] = fun(x[sortIndex[b[j]], :]) # 计算适应度值# 这部分是最终的最优解更新for i in range(pop):if fit[i] < pFit[i]:pFit[i] = fit[i].copy()pX[i, :] = x[i, :].copy()if pFit[i] < fMin:fMin = pFit[i, 0].copy()bestX = pX[i, :].copy()trace[t, :] = bestXConvergence_curve[t] = fMinreturn bestX, fMin, Convergence_curve, trace# In[]
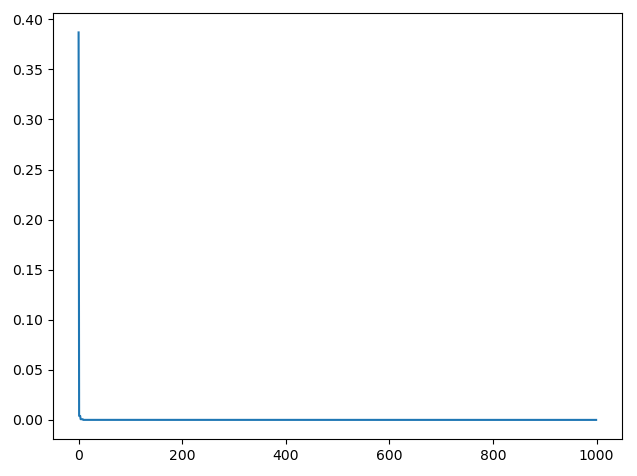
bestX, fMin, Convergence_curve, trace = SSA(1000, 20, 2, 0.2, -10, 10)
plt.figure()
plt.plot(Convergence_curve)
plt.show()代码输出如下:
lstm分类算法实现:
import osimport matplotlib.pyplot as plt
import pandas as pd
from tensorflow.python.keras import Sequential
from tensorflow.python.keras.layers import Dense, CuDNNLSTM
from tensorflow.python.keras.layers import Dropout
from tensorflow.python.keras.models import Sequential
from numpy.random import seedseed(7)os.chdir(r'C:\Projects\old\判断异常是否发生')
train_path = 'data.csv'
# train_path = '15.xlsx'
usecols = [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
df = pd.read_csv(train_path, usecols=usecols)
df['ae'] = df['ae'].map(lambda x: 1 if x >= 1 else 0)
df.fillna(0, inplace=True)
train_size = int(len(df) * 0.9)
train = df.iloc[:train_size, :]
test = df.iloc[train_size:, :]X_train = train.loc[:, train.columns != 'ae'].values # converts the df to a numpy array
y_train = train['ae'].values
X_train = X_train.astype(float)X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
print(X_train.shape, y_train.shape)X_test = test.loc[:, test.columns != 'ae'].values # converts the df to a numpy arrayy_test = test['ae'].values
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], 1))
X_test = X_test.astype(float)
print(X_test.shape, X_test.shape)def create_model(input_length):model = Sequential()model.add(CuDNNLSTM(units=50, return_sequences=True, input_shape=(input_length, 1)))model.add(Dropout(0.2))model.add(CuDNNLSTM(units=50, return_sequences=False))model.add(Dropout(0.2))model.add(Dense(1, activation='sigmoid'))model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])model.summary()return modelmodel = create_model(len(X_train[0]))
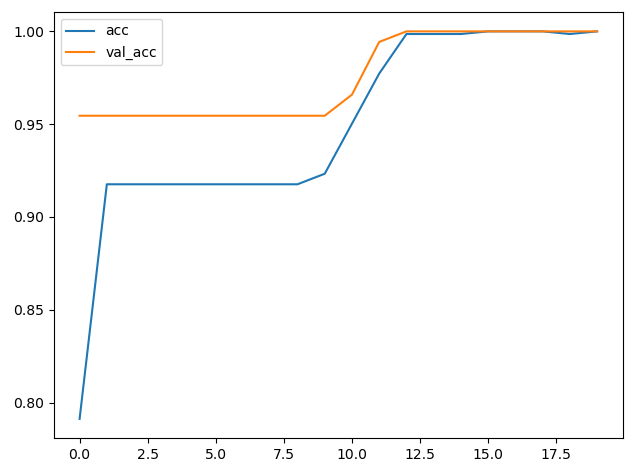
hist = model.fit(X_train, y_train, batch_size=64, validation_split=0.2, epochs=2, shuffle=False, verbose=1)plt.plot(hist.history['accuracy'], label='acc')
plt.plot(hist.history['val_accuracy'], label='val_acc')
plt.legend()
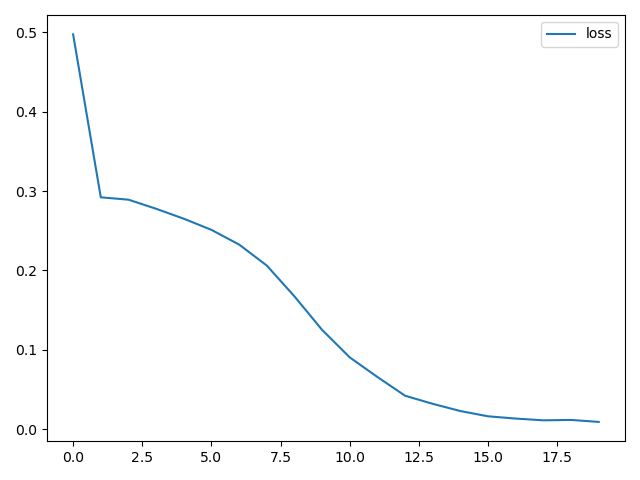
plt.show()plt.plot(hist.history['loss'], label='loss')
plt.legend()
plt.show()分类算法效果如下:
损失图如下:
合并麻雀算法和lstm算法,用麻雀算法SSA优化LSTM长短期记忆网络实现分类算法
from random import seedimport matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.metrics import precision_score, recall_score, classification_report
from tensorflow.python.framework.random_seed import set_random_seed
from tensorflow.python.keras.layers import CuDNNLSTM
from tensorflow.python.keras.layers import Dense, Dropout
from tensorflow.python.keras.models import Sequential# 这两行代码解决 plt 中文显示的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 用黑体显示中文
set_random_seed(11)
seed(7)def pdReadCsv(file, sep):try:data = pd.read_csv(file, sep=sep, encoding='utf-8', error_bad_lines=False, engine='python')return dataexcept:data = pd.read_csv(file, sep=sep, encoding='gbk', error_bad_lines=False, engine='python')return dataclass SSA():def __init__(self, func, n_dim=None, pop_size=20, max_iter=50, lb=-512, ub=512, verbose=False):self.func = funcself.n_dim = n_dim # dimension of particles, which is the number of variables of funcself.pop = pop_size # number of particlesP_percent = 0.2 # # 生产者的人口规模占总人口规模的20%D_percent = 0.1 # 预警者的人口规模占总人口规模的10%self.pNum = round(self.pop * P_percent) # 生产者的人口规模占总人口规模的20%self.warn = round(self.pop * D_percent) # 预警者的人口规模占总人口规模的10%self.max_iter = max_iter # max iterself.verbose = verbose # print the result of each iter or notself.lb, self.ub = np.array(lb) * np.ones(self.n_dim), np.array(ub) * np.ones(self.n_dim)assert self.n_dim == len(self.lb) == len(self.ub), 'dim == len(lb) == len(ub) is not True'assert np.all(self.ub > self.lb), 'upper-bound must be greater than lower-bound'self.X = np.random.uniform(low=self.lb, high=self.ub, size=(self.pop, self.n_dim))self.Y = [self.func(self.X[i]) for i in range(len(self.X))] # y = f(x) for all particlesself.pbest_x = self.X.copy() # personal best location of every particle in historyself.pbest_y = [np.inf for i in range(self.pop)] # best image of every particle in historyself.gbest_x = self.pbest_x.mean(axis=0).reshape(1, -1) # global best location for all particlesself.gbest_y = np.inf # global best y for all particlesself.gbest_y_hist = [] # gbest_y of every iterationself.update_pbest()self.update_gbest()## record verbose valuesself.record_mode = Falseself.record_value = {'X': [], 'V': [], 'Y': []}self.best_x, self.best_y = self.gbest_x, self.gbest_y # history reasons, will be deprecatedself.idx_max = 0self.x_max = self.X[self.idx_max, :]self.y_max = self.Y[self.idx_max]def cal_y(self, start, end):# calculate y for every x in Xfor i in range(start, end):self.Y[i] = self.func(self.X[i])# return self.Ydef update_pbest(self):'''personal best'''for i in range(len(self.Y)):if self.pbest_y[i] > self.Y[i]:self.pbest_x[i] = self.X[i]self.pbest_y[i] = self.Y[i]def update_gbest(self):idx_min = self.pbest_y.index(min(self.pbest_y))if self.gbest_y > self.pbest_y[idx_min]:self.gbest_x = self.X[idx_min, :].copy()self.gbest_y = self.pbest_y[idx_min]def find_worst(self):self.idx_max = self.Y.index(max(self.Y))self.x_max = self.X[self.idx_max, :]self.y_max = self.Y[self.idx_max]def update_finder(self):self.idx = sorted(enumerate(self.Y), key=lambda x: x[1])self.idx = [self.idx[i][0] for i in range(len(self.idx))]# 这一部位为发现者(探索者)的位置更新if r2 < 0.8: # 预警值较小,说明没有捕食者出现for i in range(self.pNum):r1 = np.random.rand(1)self.X[self.idx[i], :] = self.X[self.idx[i], :] * np.exp(-(i) / (r1 * self.max_iter)) # 对自变量做一个随机变换self.X = np.clip(self.X, self.lb, self.ub) # 对超过边界的变量进行去除# X[idx[i], :] = Bounds(X[idx[i], :], lb, ub) # 对超过边界的变量进行去除# fit[sortIndex[0, i], 0] = func(X[sortIndex[0, i], :]) # 算新的适应度值elif r2 >= 0.8: # 预警值较大,说明有捕食者出现威胁到了种群的安全,需要去其它地方觅食for i in range(self.pNum):Q = np.random.rand(1) # 也可以替换成 np.random.normal(loc=0, scale=1.0, size=1)self.X[self.idx[i], :] = self.X[self.idx[i], :] + Q * np.ones((1, self.n_dim)) # Q是服从正态分布的随机数。L表示一个1×d的矩阵self.cal_y(0, self.pNum)def update_follower(self):# 这一部位为加入者(追随者)的位置更新for ii in range(self.pop - self.pNum):i = ii + self.pNumA = np.floor(np.random.rand(1, self.n_dim) * 2) * 2 - 1best_idx = self.Y[0:self.pNum].index(min(self.Y[0:self.pNum]))bestXX = self.X[best_idx, :]if i > self.pop / 2:Q = np.random.rand(1)self.X[self.idx[i], :] = Q * np.exp((self.x_max - self.X[self.idx[i], :]) / np.square(i))else:self.X[self.idx[i], :] = bestXX + np.dot(np.abs(self.X[self.idx[i], :] - bestXX),1 / (A.T * np.dot(A, A.T))) * np.ones((1, self.n_dim))self.X = np.clip(self.X, self.lb, self.ub) # 对超过边界的变量进行去除# X[self.idx[i],:] = Bounds(X[self.idx[i],lb,ub)# fit[self.idx[i],0] = func(X[self.idx[i], :])self.cal_y(self.pNum, self.pop)def detect(self):arrc = np.arange(self.pop)c = np.random.permutation(arrc) # 随机排列序列b = [self.idx[i] for i in c[0: self.warn]]e = 10e-10for j in range(len(b)):if self.Y[b[j]] > self.gbest_y:self.X[b[j], :] = self.gbest_y + np.random.rand(1, self.n_dim) * np.abs(self.X[b[j], :] - self.gbest_y)self.X = np.clip(self.X, self.lb, self.ub) # 对超过边界的变量进行去除self.Y[b[j]] = self.func(self.X[b[j]])def run(self, max_iter=None):self.max_iter = max_iter or self.max_iterfor iter_num in range(self.max_iter):self.update_finder() # 更新发现者位置self.find_worst() # 取出最大的适应度值和最差适应度的Xself.update_follower() # 更新跟随着位置self.update_pbest()self.update_gbest()self.detect()self.update_pbest()self.update_gbest()self.gbest_y_hist.append(self.gbest_y)return self.best_x, self.best_yimport osos.chdir(r'C:\Projects\old\判断异常是否发生')
train_path = 'data.csv'
# train_path = '15.xlsx'
usecols = [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
df = pd.read_csv(train_path, usecols=usecols)
df['ae'] = df['ae'].map(lambda x: 1 if x >= 1 else 0)
df.fillna(0, inplace=True)
train_size = int(len(df) * 0.9)
train = df.iloc[:train_size, :]
test = df.iloc[train_size:, :]X_train = train.loc[:, train.columns != 'ae'].values # converts the df to a numpy array
y_train = train['ae'].values
X_train = X_train.astype(float)
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
print(X_train.shape, y_train.shape)X_test = test.loc[:, test.columns != 'ae'].values # converts the df to a numpy array
y_test = test['ae'].values
X_test = X_test.astype(float)
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], 1))
print(X_test.shape, X_test.shape)precisions = []
recalls = []
accuracys = []def create_model(units, dropout):model = Sequential()model.add(CuDNNLSTM(units=units, return_sequences=True, input_shape=(len(X_train[0]), 1)))model.add(Dropout(dropout))model.add(CuDNNLSTM(units=units, return_sequences=False))model.add(Dropout(dropout))model.add(Dense(1, activation='sigmoid'))model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])return modeldef f13(x):epochs = int(x[0])units = int(x[1])dropout = x[2]batch_size = int(x[3])model = create_model(units, dropout)model.fit(X_train, y_train, batch_size=batch_size, validation_split=0.2, epochs=epochs, shuffle=False, verbose=1)y_pred = model.predict(X_test)y_pred_int = np.argmax(y_pred, axis=1)precision = precision_score(y_test, y_pred_int, average='macro')recall = recall_score(y_test, y_pred_int, average='macro')print('recall')print(recall)recalls.append(recall)print('precision')print(precision)t = classification_report(y_test, y_pred_int, target_names=['0', '1'], output_dict=True)accuracy = t['accuracy']print('accuracy')print(accuracy)accuracys.append(accuracy)precisions.append(precision)return 1 - precision'''根据WIFI数据和成绩数据使用麻雀算法加lgb做一个挂科预测pr曲线,roc曲线和auc值
'''if __name__ == '__main__':# 用于优化的四个参数范围 epochs units dropout batch_sizeup_params = [8, 55, 0.55, 55]low_params = [1, 5, 0.05, 5]# 开始优化ssa = SSA(f13, n_dim=4, pop_size=10, max_iter=2, lb=low_params, ub=up_params)ssa.run()print('best_params is ', ssa.gbest_x)print('best_precision is', 1 - ssa.gbest_y)print('best_accuracy is', max(accuracys))print('best_recall is', max(recalls))epochs = int(ssa.gbest_x[0])units = int(ssa.gbest_x[1])dropout = ssa.gbest_x[2]batch_size = int(ssa.gbest_x[3])model = create_model(units, dropout)model.fit(X_train, y_train, batch_size=batch_size, validation_split=0.2, epochs=epochs, shuffle=False, verbose=1)y_pred = model.predict(X_test)y_pred_int = np.argmax(y_pred, axis=1)precision = precision_score(y_test, y_pred_int, average='macro')recall = recall_score(y_test, y_pred_int, average='macro')print('recall')print(recall)recalls.append(recall)print('precision')print(precision)t = classification_report(y_test, y_pred_int, target_names=['0', '1'], output_dict=True)accuracy = t['accuracy']print('accuracy')print(accuracy)
输出如下
D:\Program\CONDA\python.exe D:/Program/JacksonProject/SSA/SSA_LSTM_CLASS.py
2023-03-06 22:51:51.834759: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cudart64_110.dll
2023-03-06 22:51:53.071157: I tensorflow/compiler/jit/xla_cpu_device.cc:41] Not creating XLA devices, tf_xla_enable_xla_devices not set
2023-03-06 22:51:53.071890: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library nvcuda.dll
(880, 12, 1) (880,)
(98, 12, 1) (98, 12, 1)
2023-03-06 22:51:53.091260: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: NVIDIA GeForce RTX 3070 computeCapability: 8.6
coreClock: 1.755GHz coreCount: 46 deviceMemorySize: 8.00GiB deviceMemoryBandwidth: 417.29GiB/s
2023-03-06 22:51:53.091462: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cudart64_110.dll
2023-03-06 22:51:53.097473: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cublas64_11.dll
2023-03-06 22:51:53.097585: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cublasLt64_11.dll
2023-03-06 22:51:53.100620: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cufft64_10.dll
2023-03-06 22:51:53.101778: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library curand64_10.dll
2023-03-06 22:51:53.109522: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cusolver64_10.dll
2023-03-06 22:51:53.112297: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cusparse64_11.dll
2023-03-06 22:51:53.112870: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cudnn64_8.dll
2023-03-06 22:51:53.112999: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0
2023-03-06 22:51:53.113308: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-03-06 22:51:53.114119: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: NVIDIA GeForce RTX 3070 computeCapability: 8.6
coreClock: 1.755GHz coreCount: 46 deviceMemorySize: 8.00GiB deviceMemoryBandwidth: 417.29GiB/s
2023-03-06 22:51:53.114374: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cudart64_110.dll
2023-03-06 22:51:53.114483: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cublas64_11.dll
2023-03-06 22:51:53.114591: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cublasLt64_11.dll
2023-03-06 22:51:53.114692: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cufft64_10.dll
2023-03-06 22:51:53.114785: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library curand64_10.dll
2023-03-06 22:51:53.114881: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cusolver64_10.dll
2023-03-06 22:51:53.114980: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cusparse64_11.dll
2023-03-06 22:51:53.115076: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cudnn64_8.dll
2023-03-06 22:51:53.115187: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0
2023-03-06 22:51:53.585208: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1261] Device interconnect StreamExecutor with strength 1 edge matrix:
2023-03-06 22:51:53.585330: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1267] 0
2023-03-06 22:51:53.585394: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1280] 0: N
2023-03-06 22:51:53.585616: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 6573 MB memory) -> physical GPU (device: 0, name: NVIDIA GeForce RTX 3070, pci bus id: 0000:01:00.0, compute capability: 8.6)
2023-03-06 22:51:53.586592: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set
2023-03-06 22:51:53.917241: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2)
Epoch 1/7
2023-03-06 22:51:54.744603: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cublas64_11.dll
2023-03-06 22:51:55.357995: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cublasLt64_11.dll
2023-03-06 22:51:55.362788: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cudnn64_8.dll1/40 [..............................] - ETA: 1:33 - loss: 0.7500 - accuracy: 0.33332023-03-06 22:51:56.317708: I tensorflow/stream_executor/cuda/cuda_blas.cc:1838] TensorFloat-32 will be used for the matrix multiplication. This will only be logged once.
40/40 [==============================] - 3s 16ms/step - loss: 0.4230 - accuracy: 0.8329 - val_loss: 0.1822 - val_accuracy: 0.9545
Epoch 2/7
40/40 [==============================] - 0s 7ms/step - loss: 0.3202 - accuracy: 0.9040 - val_loss: 0.1702 - val_accuracy: 0.9545
Epoch 3/7
40/40 [==============================] - 0s 7ms/step - loss: 0.2662 - accuracy: 0.9040 - val_loss: 0.1241 - val_accuracy: 0.9545
Epoch 4/7
40/40 [==============================] - 0s 7ms/step - loss: 0.1704 - accuracy: 0.9089 - val_loss: 0.0482 - val_accuracy: 1.0000
Epoch 5/7
40/40 [==============================] - 0s 7ms/step - loss: 0.0522 - accuracy: 0.9981 - val_loss: 0.0148 - val_accuracy: 1.0000
Epoch 6/7
40/40 [==============================] - 0s 7ms/step - loss: 0.0212 - accuracy: 1.0000 - val_loss: 0.0079 - val_accuracy: 1.0000
Epoch 7/7
40/40 [==============================] - 0s 7ms/step - loss: 0.0123 - accuracy: 1.0000 - val_loss: 0.0048 - val_accuracy: 1.0000
D:\Program\CONDA\lib\site-packages\sklearn\metrics\_classification.py:1268: UndefinedMetricWarning: Precision is ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior._warn_prf(average, modifier, msg_start, len(result))
D:\Program\CONDA\lib\site-packages\sklearn\metrics\_classification.py:1268: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior._warn_prf(average, modifier, msg_start, len(result))
recall
0.5
precision
0.47959183673469385
accuracy
0.9591836734693877
Epoch 1/6
20/20 [==============================] - 1s 18ms/step - loss: 0.4540 - accuracy: 0.8943 - val_loss: 0.2004 - val_accuracy: 0.9545
Epoch 2/6
20/20 [==============================] - 0s 10ms/step - loss: 0.3300 - accuracy: 0.9040 - val_loss: 0.1801 - val_accuracy: 0.9545
Epoch 3/6
20/20 [==============================] - 0s 10ms/step - loss: 0.2932 - accuracy: 0.9040 - val_loss: 0.1763 - val_accuracy: 0.9545
Epoch 4/6
20/20 [==============================] - 0s 9ms/step - loss: 0.2894 - accuracy: 0.9040 - val_loss: 0.1689 - val_accuracy: 0.9545
Epoch 5/6
20/20 [==============================] - 0s 9ms/step - loss: 0.2875 - accuracy: 0.9040 - val_loss: 0.1584 - val_accuracy: 0.9545
Epoch 6/6
20/20 [==============================] - 0s 10ms/step - loss: 0.2486 - accuracy: 0.9040 - val_loss: 0.1403 - val_accuracy: 0.9545
recall
0.5
precision
0.47959183673469385
accuracy
0.9591836734693877
Epoch 1/6
18/18 [==============================] - 1s 22ms/step - loss: 0.4610 - accuracy: 0.8135 - val_loss: 0.1842 - val_accuracy: 0.9545
Epoch 2/6
18/18 [==============================] - 0s 10ms/step - loss: 0.3438 - accuracy: 0.9025 - val_loss: 0.1815 - val_accuracy: 0.9545
Epoch 3/6
18/18 [==============================] - 0s 10ms/step - loss: 0.3157 - accuracy: 0.9025 - val_loss: 0.1755 - val_accuracy: 0.9545
Epoch 4/6
18/18 [==============================] - 0s 8ms/step - loss: 0.3025 - accuracy: 0.9025 - val_loss: 0.1599 - val_accuracy: 0.9545
Epoch 5/6
18/18 [==============================] - 0s 8ms/step - loss: 0.2707 - accuracy: 0.9025 - val_loss: 0.1373 - val_accuracy: 0.9545
Epoch 6/6
18/18 [==============================] - 0s 9ms/step - loss: 0.2300 - accuracy: 0.9025 - val_loss: 0.1047 - val_accuracy: 0.9545
recall
0.5
precision
0.47959183673469385
accuracy
0.9591836734693877
Epoch 1/5完整代码和数据链接
相关文章:
麻雀算法SSA优化LSTM长短期记忆网络实现分类算法
1、摘要 本文主要讲解:麻雀算法SSA优化LSTM长短期记忆网络实现分类算法 主要思路: 准备一份分类数据,数据介绍在第二章准备好麻雀算法SSA,要用随机数据跑起来用lstm把分类数据跑起来将lstm的超参数交给SSA去优化优化完的最优参数…...

哈希表题目:数组中的 k-diff 数对
文章目录题目标题和出处难度题目描述要求示例数据范围解法思路和算法代码复杂度分析题目 标题和出处 标题:数组中的 k-diff 数对 出处:532. 数组中的 k-diff 数对 难度 4 级 题目描述 要求 给定一个整数数组 nums\texttt{nums}nums 和一个整数 k…...
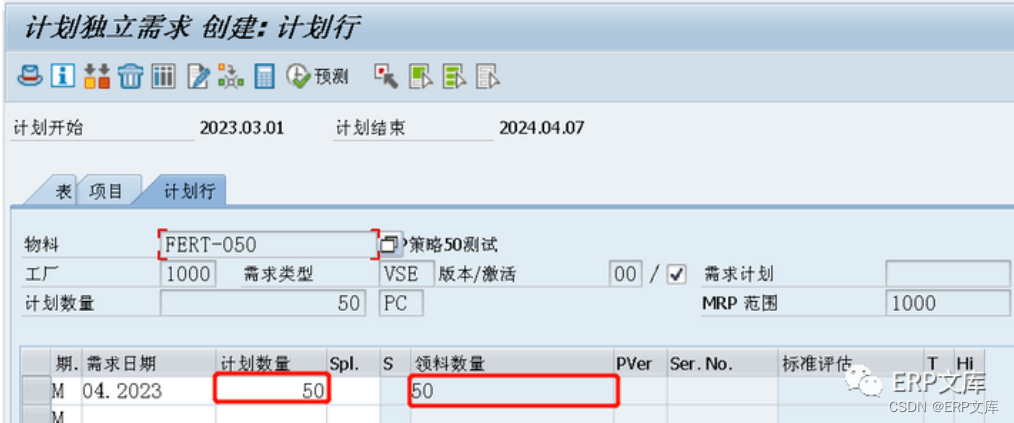
SAP ERP系统PP模块计划策略2050详解
SAP/ERP系统中面向订单生产的计划策略主要有20和50两个策略,这两个策略都是面向订单生产的计划策略,也是离散制造行业应用比较广泛的策略。它们之间最大差异就是在于20策略完全是由订单驱动,而50策略是预测加订单驱动,本文主要介绍…...

TIA博途中将硬件目录更改为中文的具体方法演示
TIA博途中将硬件目录更改为中文的具体方法演示 基本步骤可参考如下: 第一步: 第二步: 具体的操作演示: 如下图所示,在所示的目录中找到zh-chs文件夹,删除或修改文件夹的名称均可,这里建议大家修改文件夹的名称,防止以后需要恢复成英文目录, 如下...

【多线程操作】线程池模拟实现
目录 一.线程池的作用 二.线程池的模拟实现 1.线程模块(Thread.hpp): 2.线程锁模块(LockGuard.hpp): 3.任务模块(Task.hpp) 4.线程池核心(ThreadPool.hppÿ…...
HBase---Hbase安装(单机版)
Hbase安装单机版 文章目录Hbase安装单机版Master/Slave架构安装步骤配置Hbase1.上传压缩包解压更名修改hbase-env.sh修改hbase-site.xml配置HBase环境变量配置Zookeeper复制配置文件修改zoo.cfg配置文件修改myid配置Zookeeper环境变量刷信息配置文件启动hbase步骤hbase shellMa…...
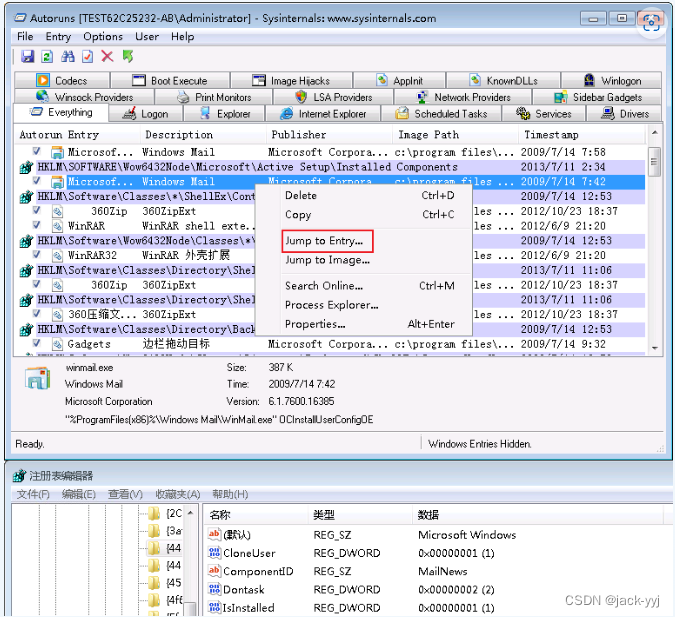
启动项管理工具Autoruns使用实验(20)
实验目的 (1)了解注册表的相关知识; (2)了解程序在开机过程中的自启动; (3)掌握Autoruns在注册表和启动项方面的功能;预备知识 注册表是windows操作系统中的一个核心数据…...

BFD单臂回声实验详解
13.1.1BFD概念 BFD提供了一个通用的、标准化的、介质无关的、协议无关的快速故障检测机制,有以下两大优点: 对相邻转发引擎之间的通道提供轻负荷、快速故障检测。 用单一的机制对任何介质、任何协议层进行实时检测。 BFD是一个简单的“Hello”协议。两个系统之间建立BFD会…...
详解JAVA类加载器
目录 1.概述 2.双亲委派 3.ServiceClassLoader 4.URLClassLoader 5.加载冲突 1.概述 概念: 类加载器(Class Loader)是Java虚拟机(JVM)的一个重要组件,负责加载Java类到内存中并使其可以被JVM执行。类…...
)
记录一些常用C标准库函数,以及Linux系统调用函数的作用(不断更新)
C标准库函数 perror() 函数 作用:perror函数是C标准库中的一种函数,用于在STDERR(标准错误输出流)中输出给定的错误信息字符串。它不属于Linux系统调用函数。 具体使用方法:perror("调用的函数名") 所需…...
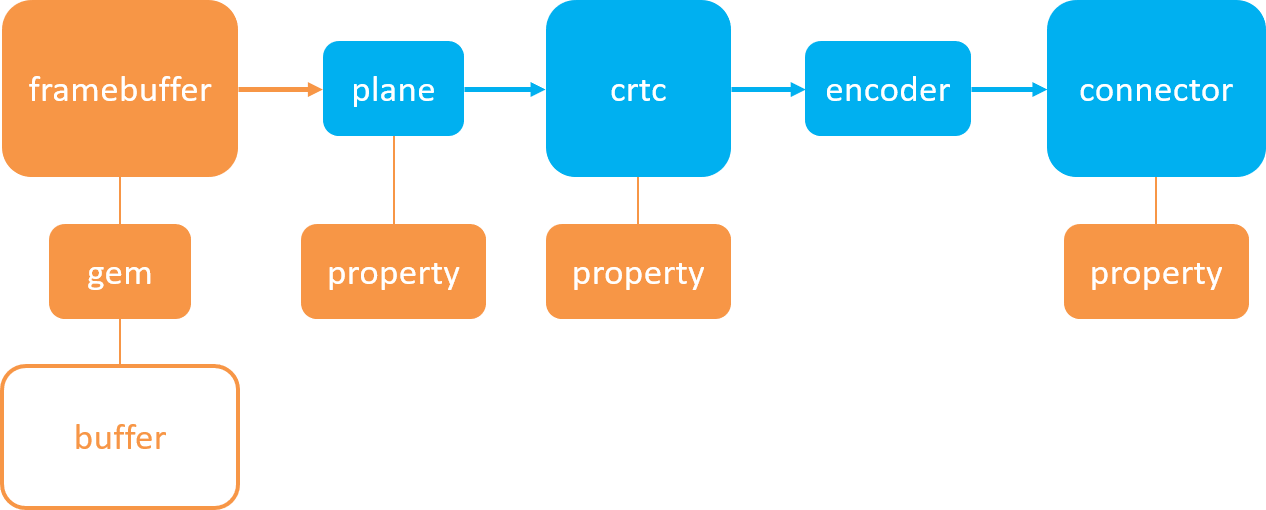
RK3568平台开发系列讲解(显示篇)DRM的atomic接口
🚀返回专栏总目录 文章目录 一、Property二、Standard Properties三、代码案例沉淀、分享、成长,让自己和他人都能有所收获!😄 📢目前DRM主要推荐使用的是 Atomic(原子的) 接口。 一、Property Property(属性)—– Atomic操作必须依赖的基本元素 Property把前面的…...

2022年MathorCup数学建模C题自动泊车问题解题全过程文档加程序
2022年第十二届MathorCup高校数学建模 C题 自动泊车问题 原题再现 自动泊车是自动驾驶技术中落地最多的场景之一,自动泊车指在停车场内实现汽车的自动泊车入位过程,在停车空间有限的大城市,是一个比较实用的功能,减少了驾驶员将…...

【需求响应】基于数据驱动的需求响应优化及预测研究(Matlab代码实现)
👨🎓个人主页:研学社的博客💥💥💞💞欢迎来到本博客❤️❤️💥💥🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密…...
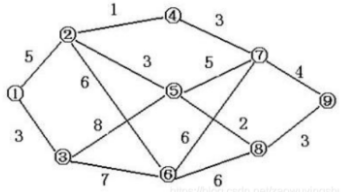
Bellman-ford和SPFA算法
目录 一、前言 二、Bellman-ford算法 1、算法思想 2、算法复杂度 3、判断负圈 4、出差(2022第十三届国赛,lanqiaoOJ题号2194) 三、SPFA算法:改进的Bellman-Ford 1、随机数据下的最短路问题(lanqiaoOJ题号1366&…...

假如你知道这样的MySQL
数据库三范式是什么? 第一范式(1NF):字段具有原子性,不可再分。(所有关系型数据库系 统都满足第一范式数据库表中的字段都是单一属性的,不可再分)第二范式(2NF)是在第一范式(1NF)的…...
SpringBoot笔记(一)入门使用
一、为什么用SpringBootSpringBoot优点创建独立Spring应用内嵌web服务器自动starter依赖,简化构建配置自动配置Spring以及第三方功能提供生产级别的监控、健康检查及外部化配置无代码生成、无需编写XMLSpringBoot缺点人称版本帝,迭代快,需要时…...
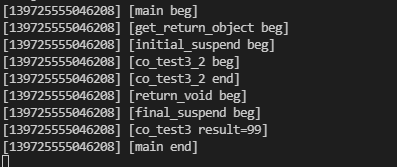
C++20 协程体验
1 介绍协程是比线程更加轻量级并发编程方式,CPU资源在用户态进行切换,CPU切换信息在用户态保存。协程完成异步的调用流程,并对用户展示出同步的使用方式。协程的调度由应用层决定,所以不同的实现会有不同的调度方式,调度策略比较灵…...

这三个小事你做HIGG FEM时要知道
【这三个小事你做HIGG FEM时要知道】1.为什么做了Higg FEM 自评后要做验证?「自评 验证」Higg FEM 是一个持续改善的框架方法,来帮助工厂实现持续的环保改善,是一个最基本的要求,如果工厂期望得到一个更加客观的评价,…...

.net6 wpf程序一个内存不断增长问题的解决方法
一个.net6的应用程序,底层不断采集数据。使用wpf制作了一个简单的界面显示数据接收的情况。程序中引用了 Material Design UI框架。当程序长时间运行时发现内存在不断增长。一个星期后工作集占用内存达到1GB。使用dotnet-dump工具收集内存使用情况,并且分…...
NICEGUI---ROS开发之中常用的GUI工具
0. 简介 对于ROS来说,如果不具备一定知识的人员来使用这些我们写的算法,如果说没有交互,这会让用户使用困难,所以我们需要使用GUI来完成友善的数据交互,传统的GUI方法一般有PYQT这类GUI方法,但是这类GUI工…...

数字遗产:我们写的代码,在死后将归于何处?
一行注释里的永恒追问测试工程师的日常,往往是从一行日志或一个断言开始的。但你是否注意过,在那些被反复修改的代码文件最顶端,常常躺着一行注释:“Author: [某位早已离职的同事]”。这行注释像一座小小的墓碑,标记着…...

【Midjourney Tempera风格终极指南】:20年AI绘画专家亲授3大参数黄金配比与5类易踩翻车点
更多请点击: https://intelliparadigm.com 第一章:Tempera风格的本质解构与历史溯源 Tempera(蛋彩画)作为一种古老而精密的绘画媒介,其技术逻辑与现代前端渲染范式存在深层隐喻关联——尤其在“分层合成”“介质绑定”…...

零基础避坑指南什么工具可以录音转待办
还在手动把面试录音扒成文字再摘待办?做HR的谁没踩过这个坑:整理一小时,漏了候选人关键信息,还把待办记错,今天直接讲能直接上手的方法,零基础也不会踩坑。我做HR那几年,光整理录音待办就熬了无…...

OpenClaw智能体引导基准测试:本地LLM多步骤任务执行能力评估
1. 项目概述:一个专为LLM智能体设计的“开箱即用”能力基准测试 如果你最近在关注本地大语言模型(LLM)和智能体(Agent)的进展,可能会发现一个现象:很多模型在标准问答或代码生成任务上表现不错…...

交完Essay才发现Turnitin更新了AI检测?我是这么应对的
上学期我的一个朋友被约谈了。 教授发邮件说:"你的Essay和AI生成文本相似度过高,请来办公室解释。" 他确实用了AI——谁没用呢——但他也认真改写了好几遍。问题是,Turnitin在2025年更新了AI检测模型,现在它不只看词汇…...

别再手动点选了!用C#写个SolidWorks插件,一键智能识别并拉伸草图里的特定轮廓
用C#开发SolidWorks智能插件:一键识别并拉伸特定草图轮廓的工程实践 在机械设计领域,SolidWorks作为主流三维CAD软件,其草图绘制与特征创建是产品开发的基础环节。工程师们经常遇到这样的场景:复杂草图中包含多个相交轮廓…...

量子网络远程纠缠生成技术及其应用
1. 量子网络中的远程纠缠生成技术解析量子纠缠作为量子计算与量子通信的核心资源,其非局域特性为分布式系统提供了经典方法无法实现的协调能力。在金融高频交易、智能电网调度等对延迟极度敏感的领域,量子纠缠带来的协调优势尤为显著。基于腔量子电动力学…...

Bootstrap 标签页
Bootstrap 标签页 Bootstrap 标签页(Tab)是 Bootstrap 框架中的一种交互组件,允许用户在多个页面元素或内容区域之间进行切换。本文将详细介绍 Bootstrap 标签页的使用方法、特点以及如何将其应用于实际项目中。 一、Bootstrap 标签页的使用方…...

superpowers skill 3.1: using-git-worktrees
智能体工作流 安装 $ npx skills add https://github.com/obra/superpowers --skill using-git-worktrees摘要 具有智能目录选择和安全验证的隔离 Git 工作树。 通过检查现有目录、CLAUDE.md 偏好设置或询问用户来自动检测工作树目录位置;支持项目本地ÿ…...

终极NDS游戏资源编辑器Tinke:免费开源工具轻松提取和修改任天堂DS游戏文件
终极NDS游戏资源编辑器Tinke:免费开源工具轻松提取和修改任天堂DS游戏文件 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke 你是否曾经好奇任天堂DS游戏内部包含了哪些精美的图像、动听…...