MapReduce全排序和二次排序
- 排序是MapReduce框架中最重要的操作之一。
- MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
- 默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。
(1)部分排序
MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部有序。
(2)全排序
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
(3)二次排序
在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
(4)辅助排序:(GroupingComparator分组)
在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
输入:

输出:

compareTo()方法 二次排序(全排序就把二次比较删掉)
@Overridepublic int compareTo(FlowBean o) {// 按照总流量倒序,上行流量正序if(this.sumFlow>o.sumFlow){return -1;} else if (this.sumFlow<o.sumFlow) {return 1;}else {if (this.upFLow > o.upFLow) {return 1;}else if(this.upFLow<o.upFLow){return -1;}else {return 0;}}}mapper
package com.mingyu.mapreduce.writableCompareTo;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class FlowMapper extends Mapper<LongWritable, Text,FlowBean,Text> {private Text outV = new Text();private FlowBean outK = new FlowBean();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 1、获取一行String line = value.toString();// 2、行内切割String[] split = line.split("\t");// 3、获取数据String phone = split[0];String upFlow = split[1];String downFlow = split[2];// 4、设置数据outV.set(phone);outK.setUpFLow(Long.parseLong(upFlow));outK.setDownFlow(Long.parseLong(downFlow));outK.setSumFlow();//5、封装context.write(outK,outV);}
}
Reducer
package com.mingyu.mapreduce.writableCompareTo;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class FlowReducer extends Reducer<FlowBean,Text,Text, FlowBean> {@Overrideprotected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {for (Text value : values) {context.write(value,key);}}
}
Driver
package com.mingyu.mapreduce.writableCompareTo;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class FlowDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 1、获取jobConfiguration conf = new Configuration();Job job = Job.getInstance(conf);// 2、设置jarjob.setJarByClass(FlowBean.class);// 3、关联mapper、reducerjob.setMapperClass(FlowMapper.class);job.setReducerClass(FlowReducer.class);// 4、设置mapper输出的key和value类型job.setMapOutputKeyClass(FlowBean.class);job.setMapOutputValueClass(Text.class);// 5、设置最终输出的key和value类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(FlowBean.class);// 6、设置数据的输入和输出路径FileInputFormat.setInputPaths(job, new Path("D:\\QQ_file\\bigdatda\\note_info\\hadoop3.3\\output\\output_phone2"));FileOutputFormat.setOutputPath(job, new Path("D:\\QQ_file\\bigdatda\\note_info\\hadoop3.3\\output\\output_phone4"));// 7、提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
相关文章:
MapReduce全排序和二次排序
排序是MapReduce框架中最重要的操作之一。MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。对于MapTask…...

【Vue3】封装数字框组件
数量选择组件-基本结构 (1)准备基本结构 <script lang"ts" setup name"Numbox"> // </script> <template><div class"numbox"><div class"label">数量</div><div cla…...

C++-简述strcpy、sprintf 和 memcpy 的区别
回答如下: strcpy 函数:用于将一个字符串(以 NULL 结尾)从源地址复制到目标地址。函数原型为 char* strcpy(char* destination, const char* source)。需要注意的是,该函数会复制整个字符串,包括 NULL 终止…...

用CPU大法忽悠ChatGPT写前端,油猴子工具库+1
文章目录用CPU大法忽悠ChatGPT写前端,油猴子工具库1源起对话1. 作为一名天才js程序员,开发一个油猴子脚本,实现所有浏览器网页的自动下滑功能,每一个步骤都加上中文注释2. 加一个按钮,只有我点击了按钮才会开始自动下滑…...
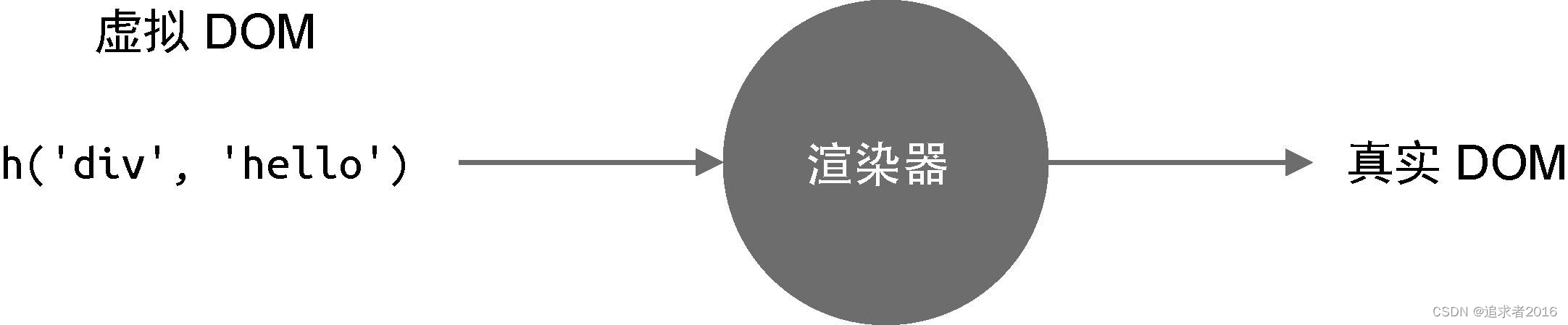
初识虚拟DOM渲染器
初识虚拟DOM渲染器什么是虚拟DOM什么是渲染器渲染器的实现组件是什么什么是虚拟DOM 首先简单说一下什么是虚拟DOM,虚拟DOM就是一个描述真实DOM的JS对象 例如: 真实的DOM元素 <div onClick"alert(click me)">click me</div>可以…...
工作日志day03
同时构建静态和动态库 //如果用这种方式,只会构建一个动态库,虽然静态库的后缀是.a ADD_LIBRARY(hello SHARED ${LIBHELLO_SRC}) ADD_LIBRARY(hello STATIC ${LIBHELLO_SRC}) //修改静态库的名字,这样是可以的,但是我们往往希望他…...

【数据挖掘与商务智能分析】第三章 线性回归模型
一元线性回归 一元线性回归的代码实现 1. 绘制散点图 import matplotlib.pyplot as plt X = [[1], [2], [4], [5]] Y...
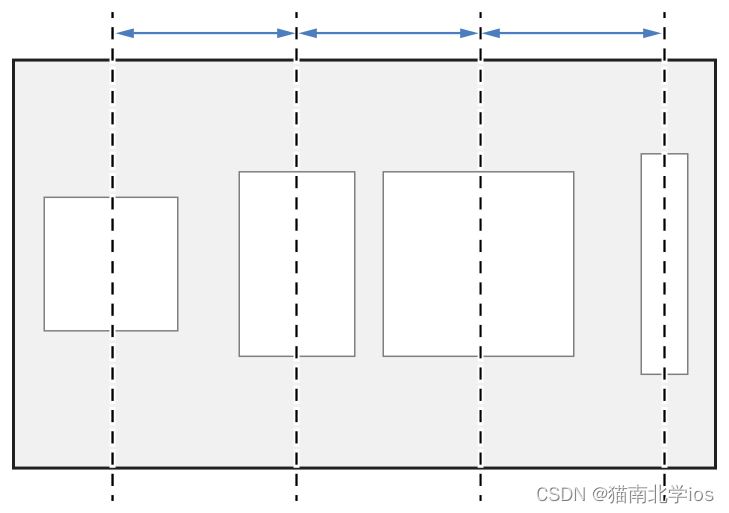
iOS开发之UIStackView基本运用
UIStackView UIStackView是基于自动布局AutoLayout,创建可以动态适应设备方向、屏幕尺寸和可用空间的任何变化的用户界面。UIStackView管理其ArrangedSubview属性中所有视图的布局。这些视图根据它们在数组中的顺序沿堆栈视图的轴排列。由axis, distribution, align…...

【java】为什么 main 方法是 public static void ?
main 方法是我们学习Java编程语言时知道的第一个方法,你是否曾经想过为什么 main 方法是 public、static、void 的。当然,很多人首先学的是C和C,但是在Java中main方法与前者有些细微的不同,它不会返回任何值,为什么 ma…...
最简单的线性回归模型-标量
首先考虑yyy为标量,www为标量的情况,那么我们的线性函数为ywxbywxbywxb。每批输入的量batch size 为111,每批输入的xxx为一个标量,设为x∗x^*x∗,标签yyy同样为一个标量,设为y∗y^*y∗。因此每批训练的损失…...

k8s-Kubernetes集群升级
文章目录前言一、集群升级1.部署cri-docker (所有集群节点)2.升级master节点3.升级worker节点前言 一、集群升级 https://v1-24.docs.kubernetes.io/zh-cn/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/ 1.部署cri-docker (所有…...
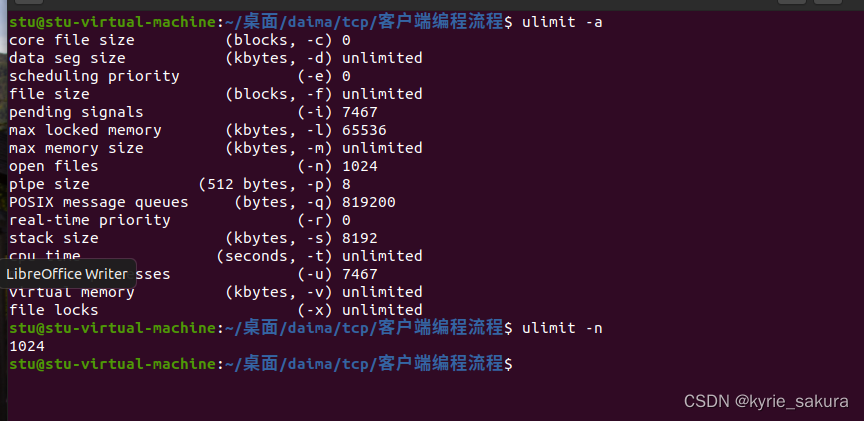
Linux25 -- 监听队列链接上限测试、命令uname、ulimit
一、监听队列链接上限测试 1、res listen(sockfd,5); //创建监听队列res listen(sockfd,5);不懂版本有不同的限制,2.6早期版本有限制为128,超过默认为128,可使用uname -a 查看版本 2、测试将链接数到达上限, 方法࿱…...

idea:地址被占用
问题启动idea报:java.net.BindException: Address already in use: bind,具体截图如下:解决步骤1、首先想到的是改idea端口,但按网上方法试下了几个4位数和5位数的端口,没啥作用2、根据idea抛异常的弹出框提示…...
)
JavaScript常用小技巧(js优化)
JavaScript常用小技巧(js优化)常见JS操作1、解构交换两数2、短路赋值3、if 判断优化4、 switch 判断优化6、动态正则匹配Number1、幂运算2、安全计算String1、反转字符串、判断是否回文数2、数组求和3、初始化二维数组Object1、对象遍历2、冻结对象3、解…...

【项目实战】MySQL 5.7中的关键字与保留字详解
一、什么是关键字和保留字 关键字是指在SQL中有意义的字。 某些关键字(例如SELECT,DELETE或BIGINT)是保留的,需要特殊处理才能用作表和列名称等标识符。 这一点对于内置函数的名称也适用。 二、如何使用关键字和保留字 非保留关…...

Git图解-常用命令操作
目录 一、前言 二、初始化仓库 三、添加文件 四、Git 流程全景图 五、Git工作流程 六、工作区和暂存区 七、查看文件状态 八、查看提交日志 九、查看差异 十、版本回退 十一、管理修改 十二、修改撤销 十三、删除文件 十四、分支管理 十五、项目分支操作 十六、…...
LeetCode096不同的二叉搜索树(相关话题:卡特兰数)
目录 题目描述 解题思路 代码实现 进出栈序列理解卡特兰数分析策略 相关知识 参考文章 题目描述 给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。 示例 1: …...
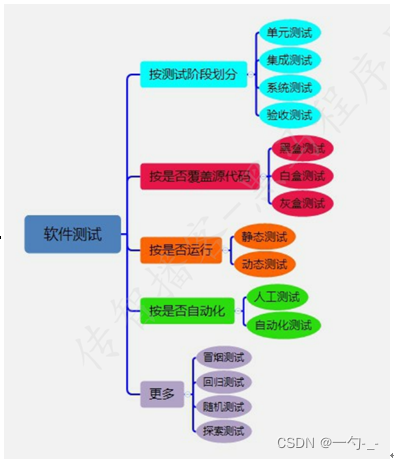
软件测试7
一 CS和BS软件架构 CS:客户端-服务器端,BS:浏览器端-服务器端 区别总结: 1.效率:c/s效率高,某些内容已经安装在系统中了,b/s每次都要加载最新的数据 2.升级:b/s无缝升级,…...
12 结构:如何系统设计框架的整体目录?
到现在,我们已经将 Gin 集成到框架 hade 中,同时又引入了服务容器和服务提供者,明确框架的核心思想是面向服务编程,一切皆服务,所有服务都是基于协议。后续也会以服务的形式,封装一个个的服务,让…...
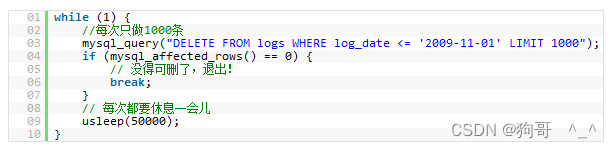
假如你知道这样的MySQL性能优化
1. 为查询缓存优化你的查询 大多数的 MySQL 服务器都开启了查询缓存。这是提高性最有效的方法之 一,而且这是被 MySQL 的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同…...

如何用3分钟搞定视频字幕提取?揭秘这款本地化硬字幕提取神器
如何用3分钟搞定视频字幕提取?揭秘这款本地化硬字幕提取神器 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测、字…...

【灶台导航】 RAG系统的容错设计:从向量搜索到关键词降级,一个都不能少
当三个外部依赖都可能随时挂掉时,如何保证用户永远有响应?问题:完美主义害死人 做RAG系统时,我们很容易陷入一种思维定势:向量检索要准、LLM要强、整个链路要丝滑。但现实是——任何一个外部服务挂了,用户就…...

多模式MRI数据融合显示帕金森病患者抑郁的结构、功能和神经化学相关
论文总结1、研究问题:帕金森病中抑郁症非常常见,但机制复杂,既涉及脑结构异常,也涉及脑功能异常,还可能涉及多种神经递质系统。且现有研究大多是基于单模态,只看结构或者只看功能,很少研究“结构…...

NExT-GPT:从多模态对齐到任意模态生成的架构与实战
1. 项目概述:从“多模态”到“任意模态”的进化 如果你在过去一年里关注过AI领域,一定对“多模态大模型”这个词不陌生。从GPT-4V到Gemini,主流模型都在努力让AI能同时理解文本和图像。但不知道你有没有想过一个问题:为什么我们和…...

边缘部署模式:在边缘位置部署应用
边缘部署模式:在边缘位置部署应用 一、边缘部署概述 1.1 边缘部署的定义 边缘部署是指将应用或服务部署在靠近用户或数据源的边缘位置,以减少延迟、提高性能、降低带宽消耗并增强数据隐私保护。 1.2 边缘部署的价值 低延迟:减少数据传输延迟高…...
技术解析与AI硬件加速实践)
计算内存(CIM)技术解析与AI硬件加速实践
1. 计算内存(CIM)技术解析:突破传统架构的能效瓶颈 在AI硬件加速领域,计算内存(Compute-in-Memory, CIM)正引发一场架构革命。传统冯诺依曼架构中"内存墙"问题已成为制约AI计算效率的主要瓶颈——…...

DelphiOpenAI:原生集成OpenAI API,赋能Delphi开发者构建智能应用
1. 项目概述:DelphiOpenAI,一个为Delphi开发者打造的AI桥梁如果你是一名Delphi开发者,看着Python、JavaScript社区热火朝天地集成各种AI能力,自己却苦于没有成熟、好用的原生库,只能望“AI”兴叹,那么今天介…...

【临床研究者必藏】Perplexity+Lancet联合检索SOP:从预印本争议到正式发表的全周期追踪方案
更多请点击: https://intelliparadigm.com 第一章:PerplexityLancet联合检索SOP的临床价值与范式变革 在循证医学实践加速数字化的当下,Perplexity(基于语义理解与推理增强的检索引擎)与《The Lancet》开放文献元数据…...

Avalonia AI助手插件:为.NET跨平台UI开发注入专家级智能
1. 项目概述:一个为Avalonia开发者量身定制的AI助手插件如果你正在使用Avalonia这个跨平台的.NET UI框架,并且同时也在探索如何利用像Claude、ChatGPT、GitHub Copilot这样的AI助手来提升开发效率,那么你很可能遇到过这样的困境:当…...

基于MCP协议与FFmpeg构建AI视频处理服务器:原理、部署与实战
1. 项目概述:一个面向视频处理的MCP服务器 最近在折腾一些AI应用,发现很多工具在处理视频内容时,总感觉差了那么一口气。要么是功能太单一,只能做简单的剪辑或转码;要么就是流程太复杂,需要把视频下载、处…...