Elasticsearch:让你的 Elasticsearch 索引与 Python 和 Google Cloud Platform 功能保持同步
作者:来自 Elastic Garson
Elasticsearch 内的索引 (index) 是你可以将数据存储在文档中的位置。 在使用索引时,如果你使用的是动态数据集,数据可能会很快变旧。 为了避免此问题,你可以创建一个 Python 脚本来更新索引,并使用 Google Cloud Platform (GCP) 的 Cloud Functions 和 Cloud Scheduler 进行部署,以便自动保持索引最新。
为了使索引保持最新,你可以首先设置一个 Jupyter Notebook 在本地进行测试,并创建一个脚本框架,该脚本框架将在出现新信息时更新你的索引。 你可以调整脚本以使其更具可重用性并将其作为云函数(Cloud function)运行。 使用 Cloud Scheduler,你可以将 Cloud Function 中的代码设置为使用 cron 类型格式按计划运行。
先决条件
- 本示例使用 Elasticsearch 版本 8.12; 如果你是新手,请查看我们的 Elasticsearch 快速入门。
- 如果你的计算机上尚未安装 Python,请下载最新版本。 此示例使用 Python 3.12.1。
- NASA API 的 API 密钥。
- 你将使用 Requests 包连接到 NASA API,使用 Pandas 操作数据,使用 Elasticsearch Python 客户端将数据加载到索引中并使其保持最新,并使用 Jupyter Notebooks 在测试时以交互方式处理数据。 你可以运行以下行来安装这些必需的软件包:
pip3 install requests pandas elasticsearch notebook加载和更新你的数据集
在 GCP 内运行更新脚本之前,你需要上传数据并测试用于保持脚本更新的流程。 你将首先从 API 连接到数据,将其保存为 Pandas DataFrame,连接到 Elasticsearch,将 DataFrame 上传到索引中,检查索引上次更新的时间,并在有新数据可用时更新索引。 你可以在此搜索实验室笔记本中找到本节的完整代码。
加载你的数据
让我们开始使用 Jupyter Notebook 进行本地测试,以交互方式处理你的数据。 为此,你可以在终端中运行以下命令。
jupyter notebook在右上角,你可以选择 “New” 来创建新的 Jupyter Notebook。
首先,你需要导入将要使用的包。 你将导入之前安装的所有软件包,以及用于处理 API 密钥等机密的 getpass 和用于处理日期对象的 datetime。
import requests
from getpass import getpass
import pandas as pd
from datetime import datetime, timedelta
from elasticsearch import Elasticsearch, helpers你将使用的数据集是近地天体 Web 服务 (NeoWs),这是一种提供近地小行星信息的 RESTful Web 服务。 该数据集可让你根据小行星最接近地球的日期搜索小行星、查找特定小行星并浏览整个数据集。
通过以下函数,你可以连接到 NASA 的 NeoWs API,获取过去一周的数据,并将响应转换为 JSON 对象。
def connect_to_nasa():url = "https://api.nasa.gov/neo/rest/v1/feed"nasa_api_key = getpass("NASA API Key: ")today = datetime.now()params = {"api_key": nasa_api_key,"start_date": today - timedelta(days=7),"end_date": datetime.now(),}return requests.get(url, params).json()现在,你可以将 API 调用的结果保存到名为 “response” 的变量中。
要将 JSON 对象转换为 pandas DataFrame,你必须将嵌套对象规范化为一个 DataFrame,并删除包含嵌套 JSON 的列。
def create_df(response):all_objects = []for date, objects in response["near_earth_objects"].items():for obj in objects:obj["close_approach_date"] = dateall_objects.append(obj)df = pd.json_normalize(all_objects)return df.drop("close_approach_data", axis=1)
要调用此函数并查看数据集的前五行,你可以运行以下命令:
df = create_df(response)
df.head()连接到 Elasticsearch
你可以通过提供 Elastic Cloud ID 和 API 密钥进行身份验证,从 Python 客户端访问 Elasticsearch。
def connect_to_elastic():elastic_cloud_id = getpass("Elastic Cloud ID: ")elastic_api_key = getpass("Elastic API Key: ")return Elasticsearch(cloud_id=elastic_cloud_id, api_key=elastic_api_key)现在,你可以将连接函数的结果保存到名为 es 的变量中。
es = connect_to_elastic()Elasticsearch 中的索引是数据的主要容器。 你可以将索引命名为 asteroid_data_set。
index_name = "asteroid_data_set"
es.indices.create(index=index_name)你返回的结果将如下所示:
ObjectApiResponse({'acknowledged': True, 'shards_acknowledged': True, 'index': 'asteroids_data'})现在,你可以创建一个辅助函数,该函数允许你将 DataFrame 转换为正确的格式以上传到索引中。
def doc_generator(df, index_name):for index, document in df.iterrows():yield {"_index": index_name,"_id": f"{document['id']}","_source": document.to_dict(),}接下来,你可以将 DataFrame 的内容批量上传到 Elastic,调用您刚刚创建的辅助函数。
helpers.bulk(es, doc_generator(df, index_name))你应该得到类似于以下内容的结果,它告诉你已上传的行数:
(146, [])你最后一次更新数据是什么时候?
将数据上传到 Elasticsearch 后,你可以检查上次更新索引的时间并设置日期格式,以便它可以与 NASA API 配合使用。
def updated_last(es, index_name):query = {"size": 0,"aggs": {"last_date": {"max": {"field": "close_approach_date"}}},}response = es.search(index=index_name, body=query)last_updated_date_string = response["aggregations"]["last_date"]["value_as_string"]datetime_obj = datetime.strptime(last_updated_date_string, "%Y-%m-%dT%H:%M:%S.%fZ")return datetime_obj.strftime("%Y-%m-%d")你可以将索引上次更新的日期保存到变量中并打印出该日期。
last_update_date = updated_last(es, index_name)
print(last_update_date)更新你的数据
现在,你可以创建一个函数来检查自上次更新索引和当前日期以来是否有任何新数据。 如果对象有效并且数据不为空,它将更新索引并让你知道是否没有新数据要更新,或者 DataFrame 是否返回 None 类型,表明可能存在问题。
def update_new_data(df, es, last_update_date, index_name):if isinstance(last_update_date, str):last_update_date = datetime.strptime(last_update_date, "%Y-%m-%d")last_update_date = pd.Timestamp(last_update_date).normalize()if not df.empty and "close_approach_date" in df.columns:df["close_approach_date"] = pd.to_datetime(df["close_approach_date"])today = pd.Timestamp(datetime.now().date()).normalize()if df is not None and not df.empty:update_range = df.loc[(df["close_approach_date"] > last_update_date)& (df["close_approach_date"] < today)]if not update_range.empty:helpers.bulk(es, doc_generator(update_range, index_name))else:print("No new data to update.")else:print("The DataFrame is None.")如果 DataFrame 是有效对象,它将调用你编写的函数并更新索引(如果适用)。 它还会打印出索引上次更新的日期,以帮助你在需要时进行调试。 如果没有,它会告诉你可能有问题。
try:if df is None:raise ValueError("DataFrame is None. There may be a problem.")update_new_data(df, es, last_update_date, index_name)print(updated_last(es, index_name))
except Exception as e:print(f"An error occurred: {e}")保持索引最新
现在你已经创建了用于本地测试的框架,你可以设置一个环境,你可以每天运行脚本来检查是否有任何新数据可用并相应地更新索引。
创建云函数
你现在已准备好部署云功能。 为此,你需要选择环境作为第二代函数,命名你的函数,然后选择云区域。 你还可以将其绑定到 Cloud Pub/Sub 触发器,并选择创建新主题(如果你尚未创建)。 你可以在 GitHub 上查看本节的完整代码。
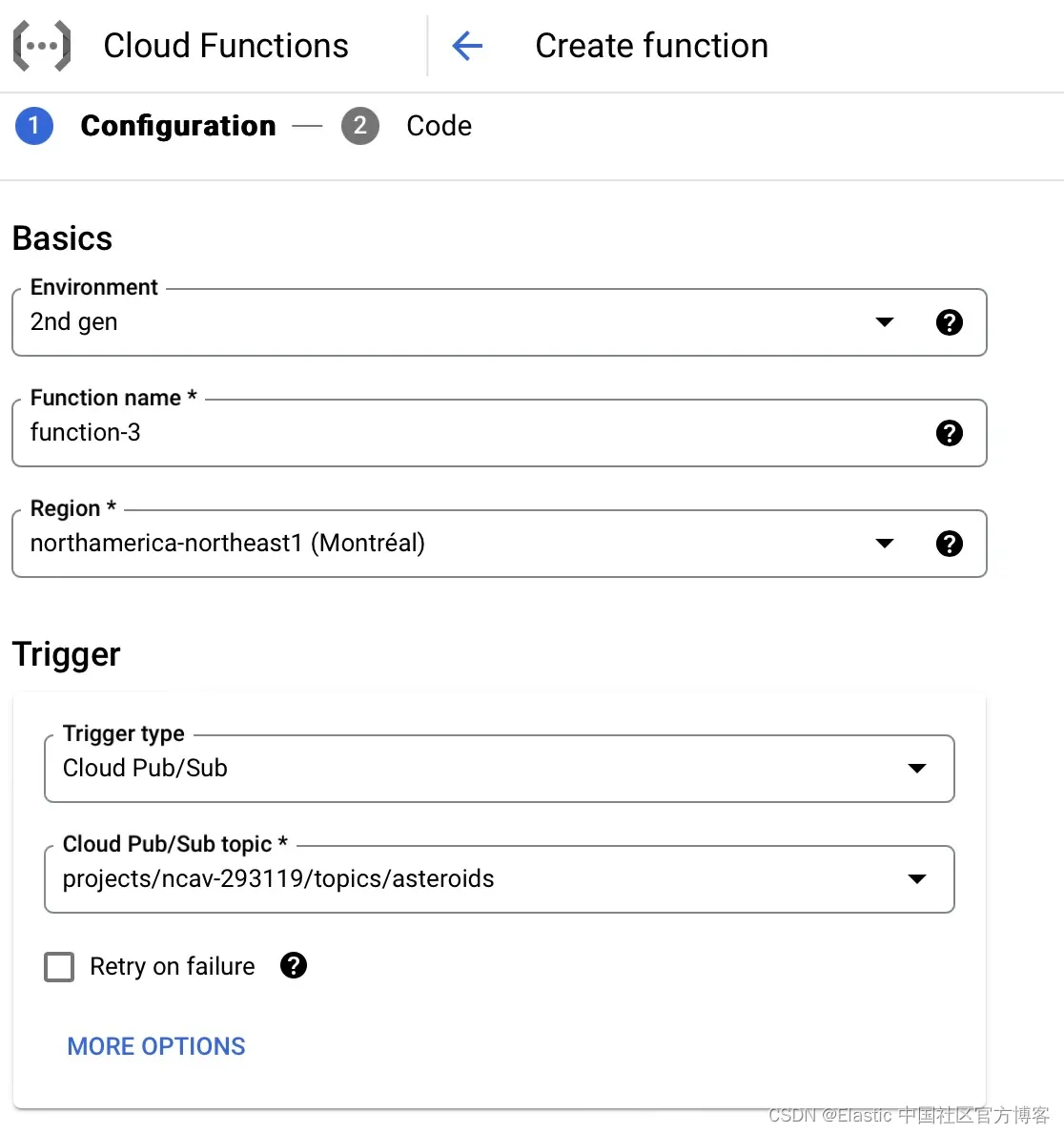
创建 Pub/Sub 主题
创建新主题时,你可以命名主题 ID 并选择使用 Google 管理的加密密钥进行加密。

设置 Cloud Function 的环境变量
在 “Runtime environment variables” 下方,你可以添加 NASA_API_KEY、ELASTIC_CLOUD_ID 和 ELASTIC_API_KEY 的环境变量。 你需要将它们保存为原始值,并且不带单引号。 因此,如果你之前在终端中输入了 “xxxlsdgzxxxxx” 值,你会希望它是 xxxlsdgzxxxxx。
调整你的代码并将其添加到你的云函数
输入环境变量后,你可以按 “下一步(next)” 按钮,这将带你进入代码编辑器。 你需要选择 Python 3.12.1 的运行时或匹配你正在使用的 Python 版本。 之后,将入口点更新为 update_index。 入口点的作用与 Python 中的 main 函数类似。
你将希望使用 os 来执行更自动化的过程,而不是使用 getpass 来获得环境变量(账号信息)。 示例如下所示:
elastic_cloud_id = os.getenv("ELASTIC_CLOUD_ID")
elastic_api_key = os.getenv("ELASTIC_API_KEY")你需要调整脚本的顺序,以使函数首先连接到 Elasticsearch。 之后,你将想知道索引上次更新的时间,连接到你正在使用的 NASA API,将其保存到 DataFrame,并加载可能可用的任何新数据。
你可能会注意到底部有一个名为 update_index 的新函数,它将你的代码联系在一起。 在此函数中,你定义索引的名称,连接到 Elasticsearch,计算出索引的最后更新日期,连接到 NASA API,将结果保存到数据框中,并在需要时更新索引。 要指示入口点函数是云事件,你可以使用装饰器 @functions_framework.cloud_event 来表示它。
@functions_framework.cloud_event
def update_index(cloud_event):index_name = "asteroid_data_set"es = connect_to_elastic()last_update_date = updated_last(es, index_name)print(last_update_date)response = connect_to_nasa(last_update_date)df = create_df(response)if df is not None:update_new_data(df, es, last_update_date, index_name)print(updated_last(es, index_name)) else:print("No new data was retrieved.")这是完整更新的代码示例:
import functions_framework
import requests
import os
import pandas as pd
from datetime import datetime
from elasticsearch import Elasticsearch, helpersdef connect_to_elastic():elastic_cloud_id = os.getenv("ELASTIC_CLOUD_ID")elastic_api_key = os.getenv("ELASTIC_API_KEY")return Elasticsearch(cloud_id=elastic_cloud_id, api_key=elastic_api_key)def connect_to_nasa(last_update_date):url = "https://api.nasa.gov/neo/rest/v1/feed"nasa_api_key = os.getenv("NASA_API_KEY")params = {"api_key": nasa_api_key,"start_date": last_update_date,"end_date": datetime.now(),}return requests.get(url, params).json()def create_df(response):all_objects = []for date, objects in response["near_earth_objects"].items():for obj in objects:obj["close_approach_date"] = dateall_objects.append(obj)df = pd.json_normalize(all_objects)return df.drop("close_approach_data", axis=1)def doc_generator(df, index_name):for index, document in df.iterrows():yield {"_index": index_name,"_id": f"{document['close_approach_date']}","_source": document.to_dict(),}def updated_last(es, index_name):query = {"size": 0,"aggs": {"last_date": {"max": {"field": "close_approach_date"}}},}response = es.search(index=index_name, body=query)last_updated_date_string = response["aggregations"]["last_date"]["value_as_string"]datetime_obj = datetime.strptime(last_updated_date_string, "%Y-%m-%dT%H:%M:%S.%fZ")return datetime_obj.strftime("%Y-%m-%d")def update_new_data(df, es, last_update_date, index_name):if isinstance(last_update_date, str):last_update_date = datetime.strptime(last_update_date, "%Y-%m-%d")last_update_date = pd.Timestamp(last_update_date).normalize()if not df.empty and "close_approach_date" in df.columns:df["close_approach_date"] = pd.to_datetime(df["close_approach_date"])today = pd.Timestamp(datetime.now().date()).normalize()if df is not None and not df.empty:update_range = df.loc[(df["close_approach_date"] > last_update_date)& (df["close_approach_date"] < today)]print(update_range)if not update_range.empty:helpers.bulk(es, doc_generator(update_range, index_name))else:print("No new data to update.")else:print("The DataFrame is empty or None.")# Triggered from a message on a Cloud Pub/Sub topic.
@functions_framework.cloud_event
def hello_pubsub(cloud_event):index_name = "asteroid_data_set"es = connect_to_elastic()last_update_date = updated_last(es, index_name)print(last_update_date)response = connect_to_nasa(last_update_date)df = create_df(response)try:if df is None:raise ValueError("DataFrame is None. There may be a problem.")update_new_data(df, es, last_update_date, index_name)print(updated_last(es, index_name))except Exception as e:print(f"An error occurred: {e}")添加 requirements.txt 文件
你还需要定义一个requirements.txt 文件,其中包含运行代码所需的所有指定包。
functions-framework==3.*
requests==2.31.0
elasticsearch==8.12.0
pandas==2.1.4调度你的云函数
在 Cloud Scheduler 中,你可以将函数设置为使用 unix cron 格式定期运行。 我将代码设置为每天早上 8 点在我的时区运行。

你还需要配置执行以连接到你之前创建的 Pub/Sub 主题。 我目前将消息正文设置为 “hello”。

现在你已经设置了 Pub/Sub 主题和 Cloud Function 并将该 Cloud Function 设置为按计划运行,只要出现新数据,你的索引就会自动更新。
结论
使用 Python、Google Cloud Platform Functions 和 Google Cloud Scheduler,你应该能够确保定期更新索引。 你可以在此处找到完整的代码以及用于本地测试的搜索实验室笔记本。 我们还与 Google Cloud 一起举办了一场点播网络研讨会,如果你想构建搜索应用程序,这可能是一个不错的下一步。 如果你基于此博客构建了任何内容,或者如果你对我们的讨论论坛和社区 Slack 频道有疑问,请告诉我们。
相关文章:
Elasticsearch:让你的 Elasticsearch 索引与 Python 和 Google Cloud Platform 功能保持同步
作者:来自 Elastic Garson Elasticsearch 内的索引 (index) 是你可以将数据存储在文档中的位置。 在使用索引时,如果你使用的是动态数据集,数据可能会很快变旧。 为了避免此问题,你可以创建一个 Python 脚本来更新索引࿰…...

如何定位web前后台的BUG
一、对系统整体的了解 Server端:jspServletjson 数据库:sql、MySQL、oracle等 前台: 涉及到 jstl,jsp,js,css,htm等方面 后台:servlet,jms,ejb࿰…...

谈谈 IOC 和 AOP
我之前面试的时候,真的会有面试官问这个。我感觉确实这个比较高频,因为 Spring 框架最核心的就是这两个东西嘛,掌握了这两个就相当于掌握了 Spring 的半壁江山了。 不过一般面试官不会一上来就问你什么是 AOP 和 IOC,一般都是叫你…...
C/C++之内存旋律:星辰大海的指挥家
个人主页:日刷百题 系列专栏:〖C/C小游戏〗〖Linux〗〖数据结构〗 〖C语言〗 🌎欢迎各位→点赞👍收藏⭐️留言📝 一、C/C内存分布 我们先来了解一下C/C内存分配的几个区域,以下面的代码为例来看…...

Linux下进程的调度与切换
🌎进程的调度与切换 文章目录: 进程的调度与切换 进程切换 进程调度 活动状态进程队列 位图判断 过期队列 总结 前言: 在Linux操作系统中,进程的调度与切换是操作系统核心功能之一ÿ…...
Linux相关命令(2)
1、W :主要是查看当前登录的用户 在上面这个截图里面呢, 第一列 user ,代表登录的用户, 第二列, tty 代表用户登录的终端号,因为在 linux 中并不是只有一个终端的, pts/2 代表是图形界面的第…...
React中 类组件 与 函数组件 的区别
类组件 与 函数组件 的区别 1. 类组件2. 函数组件HookuseStateuseEffectuseCallbackuseMemouseContextuseRef 3. 函数组件与类组件的区别3.1 表面差异3.2 最大不同原因 1. 类组件 在React中,类组件就是基于ES6语法,通过继承 React.component 得到的组件…...

GPT实战系列-智谱GLM-4的模型调用
GPT实战系列-智谱GLM-4的模型调用 GPT专栏文章: GPT实战系列-实战Qwen通义千问在Cuda 1224G部署方案_通义千问 ptuning-CSDN博客 GPT实战系列-ChatGLM3本地部署CUDA111080Ti显卡24G实战方案 GPT实战系列-Baichuan2本地化部署实战方案 GPT实战系列-让CodeGeeX2帮…...

AndroidStudio开发 相关依赖
1、com.google.zxing 用于二维码扫描 2、butterknife 用于简化findView 和 onClick操作 3、pub.devrel:easypermissions 简化权限请求的库 4、 网络请求框架(一):android-async-http 网络请求框架(二):xUtils 网络请求框架(三):Volley Volley…...
)
Zookeeper详解(zk)
文章目录 Zookeeper 概念ZooKeeper的应用场景使用场景zk的原理ZooKeeper、Nacos、Eureka 和 Consul区别Zookeeper的数据结构zk集群脑裂如何解决ZAB 协议假如注册中心挂了,消费者还能调⽤服务吗,用什么调用的dubbo注册中心为什么选择 Zookeeper关于zookee…...

BSD-3-Clause是一种开源软件许可协议
BSD-3-Clause是一种开源软件许可协议,也称为BSD三条款许可证。它是BSD许可证家族中的一种,是一种宽松的许可证,允许软件自由使用、修改和重新分发,同时也保留了一些版权和责任方面的规定。 BSD-3-Clause许可证的主要特点包括以下…...

持续集成平台 02 jenkins plugin 插件
拓展阅读 Devops-01-devops 是什么? Devops-02-Jpom 简而轻的低侵入式在线构建、自动部署、日常运维、项目监控软件 代码质量管理 SonarQube-01-入门介绍 项目管理平台-01-jira 入门介绍 缺陷跟踪管理系统,为针对缺陷管理、任务追踪和项目管理的商业…...

LoadBalancerCacheManager not available, returning delegate without caching
警告:LoadBalancerCacheManager not available, returning delegate without caching 背景:更换了redis集群 解决方案: 重启gateway网关服务 也就是重启引用下面这个包的服务 <dependency><groupId>org.springframework.cloud…...

机器学习金融应用技术指南
1 范围 本文件提供了金融业开展机器学习应用涉及的体系框架、计算资源、数据资源、机器学习引擎、机 器学习服务、安全管理、内控管理等方面的建议。 本文件适用于开展机器学习金融应用的金融机构、技术服务商、第三方安全评估机构等。 2 规范性引用文件 下列文件中的内容通过…...
)
ES6生成器(Generator)
一、function* 概念简介:function* - JavaScript | MDN (mozilla.org) function* 声明创建一个绑定到给定名称的新生成器函数。生成器函数可以退出,并在稍后重新进入,其上下文(变量绑定)会在重新进入时保存。 1.1 y…...
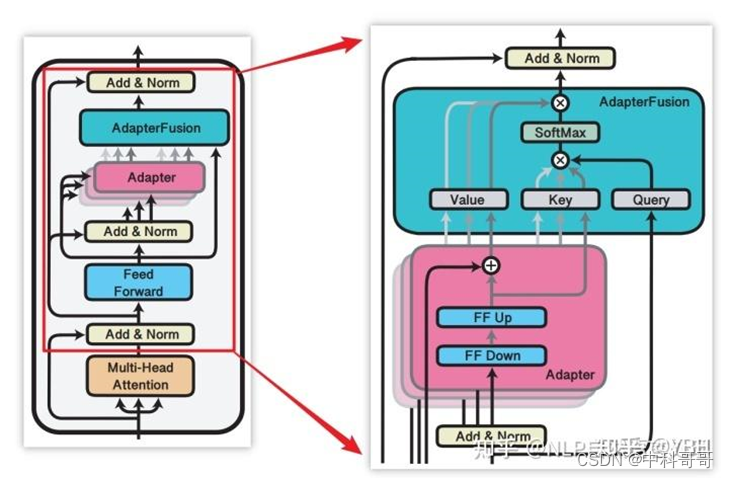
大模型主流微调训练方法总结 LoRA、Adapter、Prefix-tuning、P-tuning、Prompt-tuning 并训练自己的数据集
大模型主流微调训练方法总结 LoRA、Adapter、Prefix-tuning、P-tuning、Prompt-tuning 概述 大模型微调(finetuning)以适应特定任务是一个复杂且计算密集型的过程。本文训练测试主要是基于主流的的微调方法:LoRA、Adapter、Prefix-tuning、P-tuning和Prompt-tuning,并对…...
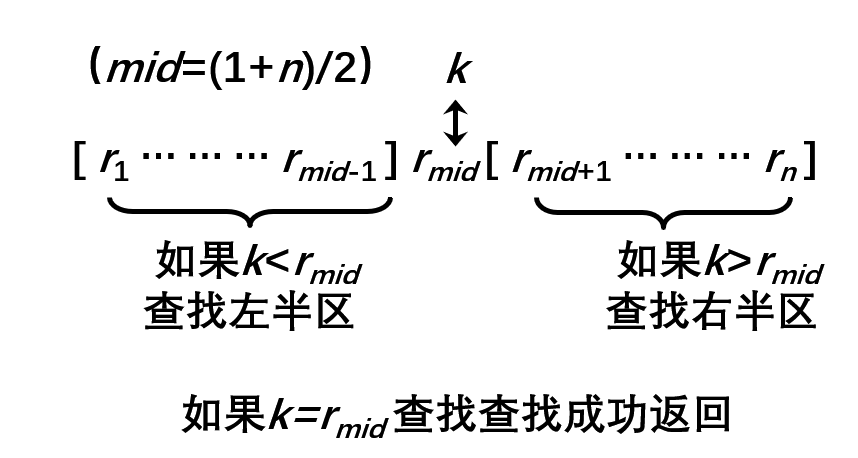
【No.13】蓝桥杯二分查找|整数二分|实数二分|跳石头|M次方根|分巧克力(C++)
二分查找算法 知识点 二分查找原理讲解在单调递增序列 a 中查找 x 或 x 的后继在单调递增序列 a 中查找 x 或 x 的前驱 二分查找算法讲解 枚举查找即顺序查找, 实现原理是逐个比较数组 a[0:n-1] 中的元素,直到找到元素 x 或搜索整个数组后确定 x 不在…...
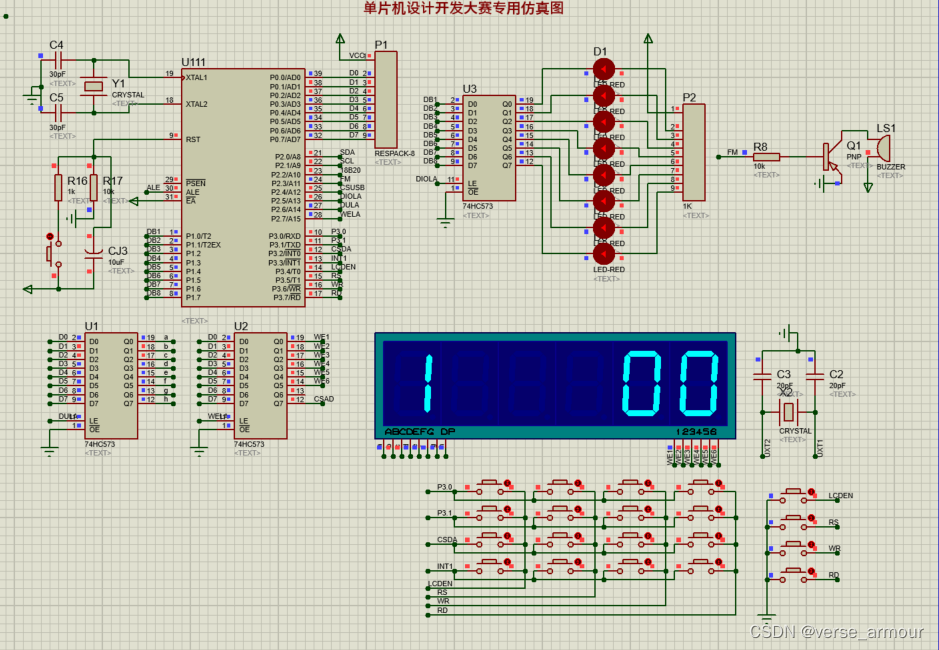
【蓝桥杯-单片机】基于定时器的倒计时程序设计
基于定时器的倒计时程序 题目如下所示: 实现过程中遇到的一些问题 01 如何改变Seg_Buf数组的值数码管总是一致地显示0 1 2 3 4 5 首先这个问题不是在main.c中关于数码管显示部分的逻辑错误,就是发生在数码管的底层错误。 检查了逻辑部分ÿ…...
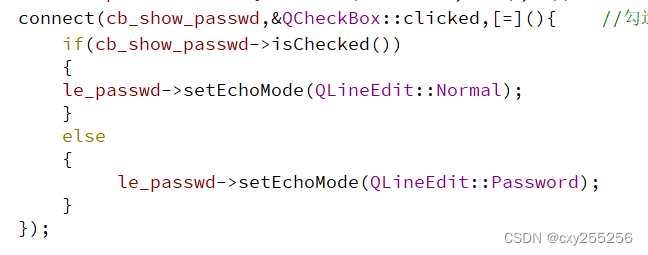
QT:三大特性
QT的三大特性: 1、信号与槽 2、内存管理 3、事件处理 1、信号与槽 当信号产生时,就会自动调用绑定的槽函数。 自定义信号: 类中需要添加O_OBJECT宏 声明: signals标签之下进行声明 定义: 信号不需要定义 …...

无服务器推理在大语言模型中的未来
服务器无服务器推理的未来:大型语言模型 摘要 随着大型语言模型(LLM)如GPT-4和PaLM的进步,自然语言任务的能力得到了显著提升。LLM被广泛应用于聊天机器人、搜索引擎和编程助手等场景。然而,由于LLM对GPU和内存的巨大需求,其在规…...

Unity安卓构建实战指南:解决APK真机安装闪退与构建失败
1. 这不是一本“从零开始”的书,而是一份你真正上手Unity安卓游戏开发前必须撕开的说明书我带过三届Unity实习工程师,也帮二十多个独立开发者把Demo打包进Google Play。每次看到新人在“安卓构建失败”报错里反复挣扎,或者对着“IL2CPP编译卡…...

从多路复用到三维光阵:Arduino驱动8x8x8 LED立方体全解析
1. 项目概述:用Arduino点亮一个三维世界几年前,我第一次在创客展上看到一个8x8x8的LED立方体,那种由数百个光点构成的、在三维空间中流动的动画效果,瞬间就把我吸引住了。它不像普通的平面LED屏,而是真正有“深度”的光…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

量子软件测试的挑战与优化策略
1. 量子软件测试的挑战与机遇量子计算正在从实验室走向实际应用,随之而来的是对可靠量子软件的需求激增。与传统软件不同,量子程序面临三大独特挑战:首先,量子态的叠加性和纠缠性使得测试变得异常复杂。一个n量子比特系统可以同时…...

WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案
WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专…...

LaTeX公式一键转Word:3步告别数学公式编辑烦恼
LaTeX公式一键转Word:3步告别数学公式编辑烦恼 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为Word文档中的数学公式编辑而抓狂…...

OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案
OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 在惠…...

利用FTDI芯片MPSSE模式构建Arduino兼容开发环境
1. 项目概述:当FTDI芯片遇上Arduino生态如果你手头有一些闲置的FTDI USB转串口模块,比如常见的FT232R、FT2232H,或者像我一样,从某个旧设备上拆下来一块FT2232C的老古董,除了用来给单片机烧录程序或者做串口调试&#…...

2026论文顶级降AI率工具大曝光:一键把AIGC率降至安全线!
步入2026年,学术圈的规则已经彻底变了味。过去那种只盯着查重率的“降重焦虑”早就被更可怕的“降AI焦虑”取代了。AI检测算法越来越聪明,高校审核标准也越来越严苛,光是把重复率压下去已经完全不够用了。现在摆在学生和科研人员面前的难题是…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...