【深度学习】四种天气分类 模版函数 从0到1手敲版本
引入该引入的库
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torch.nn.functional as F
import torchvision
import torch.optim as optim
%matplotlib inline
import os
import shutil
import glob
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
注意:os.environ[“KMP_DUPLICATE_LIB_OK”]=“TRUE” 必须要引入否则用plt出错
数据集整理
img_dir = r"F:\播放器\1、pytorch全套入门与实战项目\课程资料\参考代码和部分数据集\参考代码\参考代码\29-42节参考代码和数据集\四种天气图片数据集\dataset2"
base_dir = r"./dataset/4weather"img_list = glob.glob(img_dir+"/*.*")
test_dir = "test"
train_dir = "train"
species = ["cloudy","rain","shine","sunrise"]
for idx,img_path in enumerate(img_list):_,img_name = os.path.split(img_path)if idx%5==0:for specie in species:if img_path.find(specie) > -1:dst_dir = os.path.join(test_dir,specie)os.makedirs(dst_dir,exist_ok=True)dst_path = os.path.join(dst_dir,img_name)else:for specie in species:if img_path.find(specie) > -1:dst_dir = os.path.join(train_dir,specie)os.makedirs(dst_dir,exist_ok=True)dst_path = os.path.join(dst_dir,img_name)shutil.copy(img_path,dst_path)
生成测试和训练的文件夹,
目录结构如下:
rain 下面就是图片了
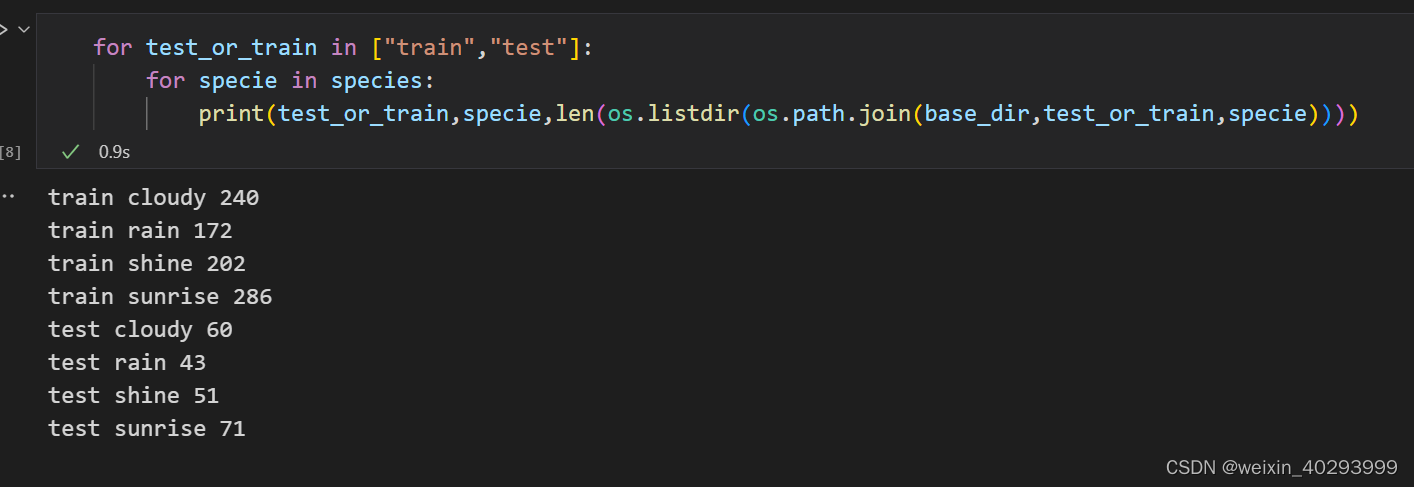
构建ds和dl
from torchvision import transforms
transform = transforms.Compose([transforms.Resize((96,96)),transforms.ToTensor(),transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])])
train_ds=torchvision.datasets.ImageFolder(train_dir,transform)
test_ds = torchvision.datasets.ImageFolder(train_dir,transform)
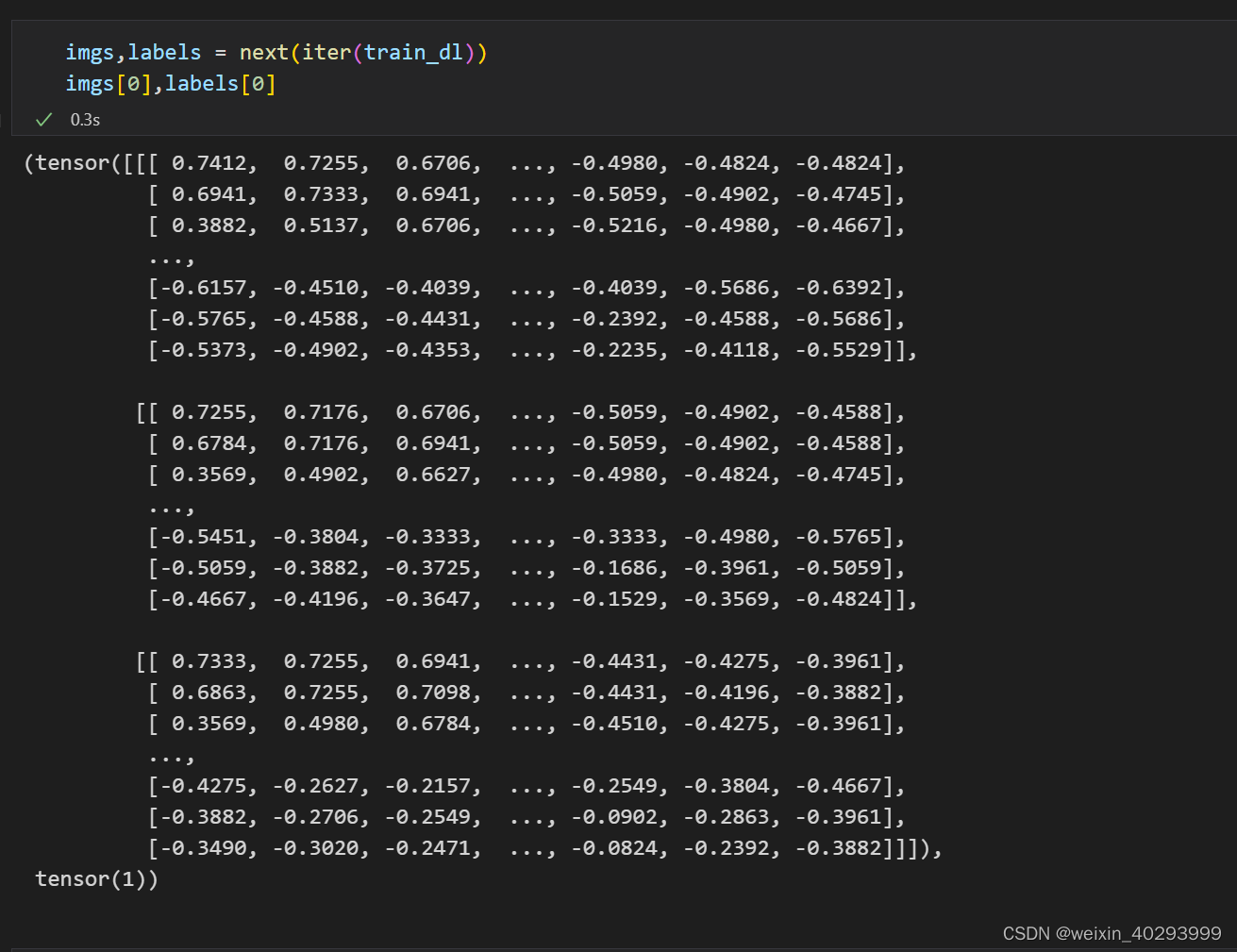
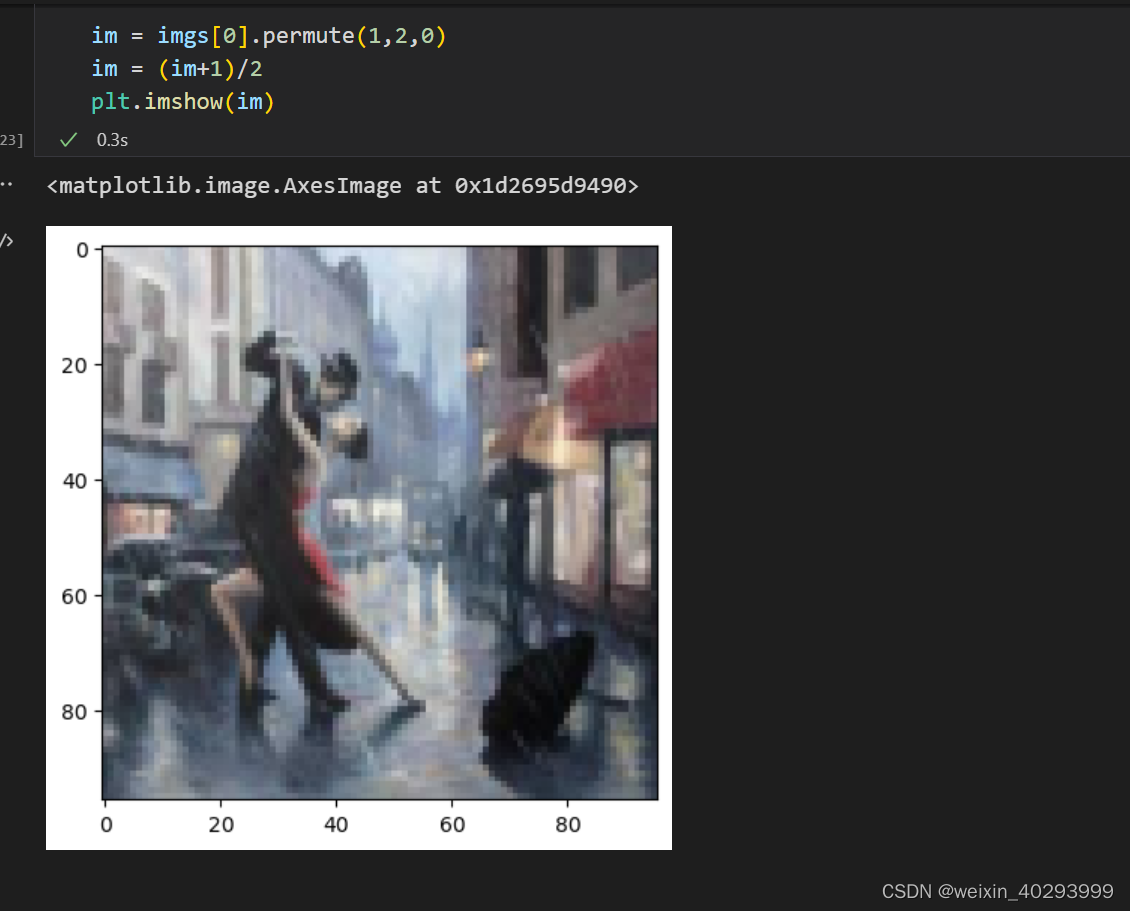
一张图片效果,这是rain图片 这里需要转换维度,把channel放到最后。同时把数据拉到0-1之间,原本std 和mean 【0.5,0,5】数据在-0.5~0.5之间
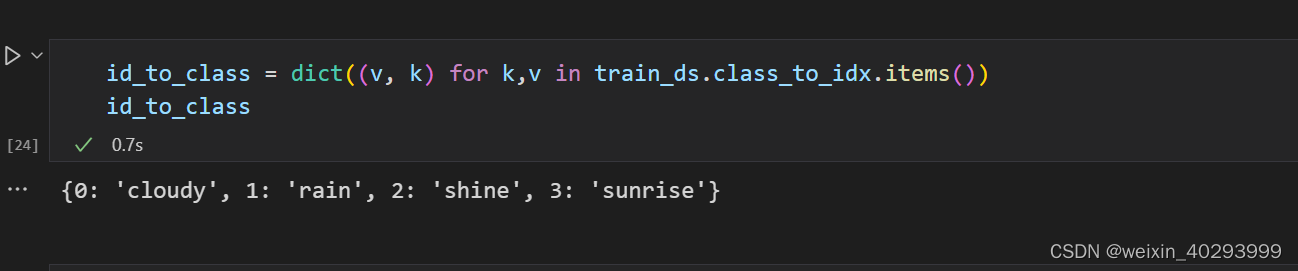
类的映射
plt.figure(figsize=(12, 8))
for i, (img, label) in enumerate(zip(imgs[:6], labels[:6])):img = (img.permute(1, 2, 0).numpy() + 1)/2plt.subplot(2, 3, i+1)plt.title(id_to_class.get(label.item()))plt.imshow(img)
这个方法要学会

定义网络
class Net(nn.Module):def __init__(self) -> None:super().__init__()self.conv1 = nn.Conv2d(3,16,3)self.conv2 = nn.Conv2d(16,32,3)self.conv3 = nn.Conv2d(32,64,3)self.pool = nn.MaxPool2d(2,2)self.dropout = nn.Dropout(0.3)self.fc1 = nn.Linear(64*10*10,1024)self.fc2 = nn.Linear(1024,4)def forward(self,x):x = F.relu(self.conv1(x))x = self.pool(x)x = F.relu(self.conv2(x))x = self.pool(x)x = F.relu(self.conv3(x))x = self.pool(x)x = self.dropout(x)# print(x.size()) 这里是可以计算出来的,需要掌握计算方法x = x.view(-1,64*10*10)x = F.relu(self.fc1(x))x = self.dropout(x)return self.fc2(x)
model = Net()
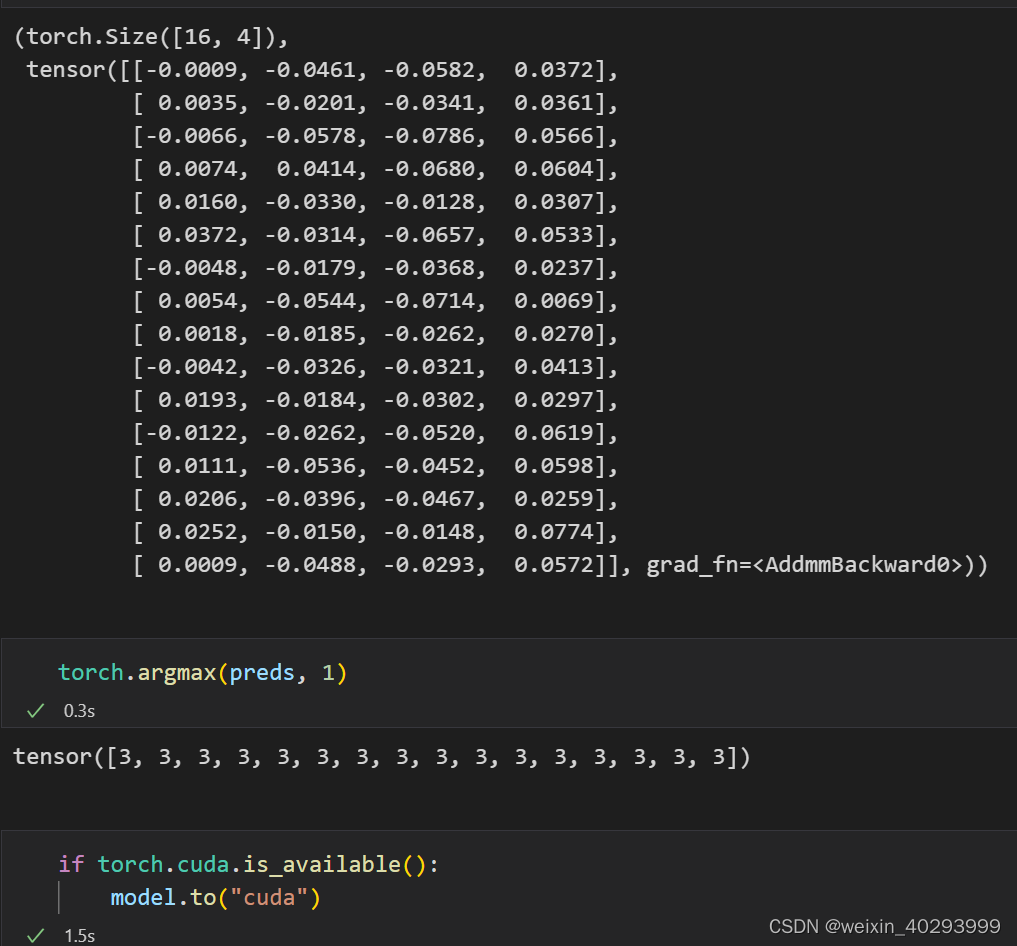
preds = model(imgs)
preds.shape, preds
定义损失函数和优化函数:
loss_fn = nn.CrossEntropyLoss()
optim = torch.optim.Adam(model.parameters(),lr=0.001)
定义网络
def fit(epoch, model, trainloader, testloader):correct = 0total = 0running_loss = 0for x, y in trainloader:if torch.cuda.is_available():x, y = x.to('cuda'), y.to('cuda')y_pred = model(x)loss = loss_fn(y_pred, y)optim.zero_grad()loss.backward()optim.step()with torch.no_grad():y_pred = torch.argmax(y_pred, dim=1)correct += (y_pred == y).sum().item()total += y.size(0)running_loss += loss.item()epoch_loss = running_loss / len(trainloader.dataset)epoch_acc = correct / totaltest_correct = 0test_total = 0test_running_loss = 0 with torch.no_grad():for x, y in testloader:if torch.cuda.is_available():x, y = x.to('cuda'), y.to('cuda')y_pred = model(x)loss = loss_fn(y_pred, y)y_pred = torch.argmax(y_pred, dim=1)test_correct += (y_pred == y).sum().item()test_total += y.size(0)test_running_loss += loss.item()epoch_test_loss = test_running_loss / len(testloader.dataset)epoch_test_acc = test_correct / test_totalprint('epoch: ', epoch, 'loss: ', round(epoch_loss, 3),'accuracy:', round(epoch_acc, 3),'test_loss: ', round(epoch_test_loss, 3),'test_accuracy:', round(epoch_test_acc, 3))return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
训练:
epochs = 30
train_loss = []
train_acc = []
test_loss = []
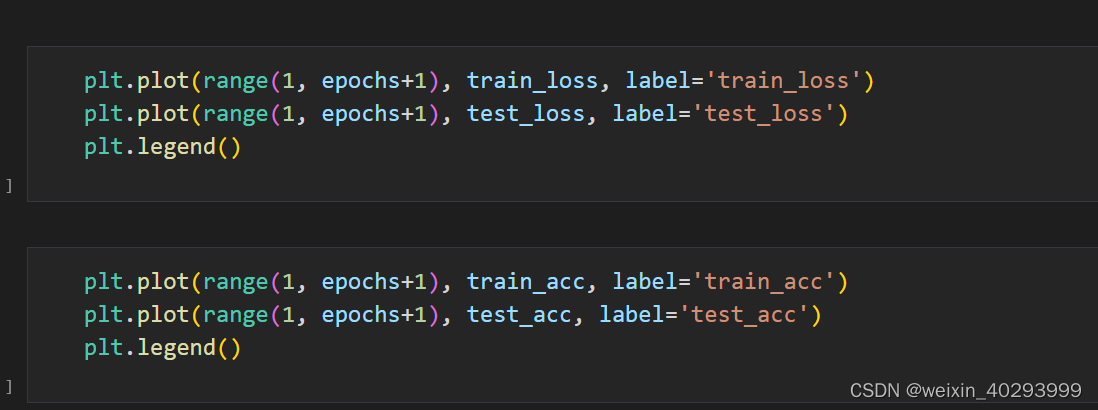
test_acc = []for epoch in range(epochs):epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch,model,train_dl,test_dl)train_loss.append(epoch_loss)train_acc.append(epoch_acc)test_loss.append(epoch_test_loss)test_acc.append(epoch_test_acc)
epoch: 0 loss: 0.043 accuracy: 0.714 test_loss: 0.029 test_accuracy: 0.809
epoch: 1 loss: 0.03 accuracy: 0.807 test_loss: 0.023 test_accuracy: 0.867
epoch: 2 loss: 0.024 accuracy: 0.857 test_loss: 0.018 test_accuracy: 0.888
epoch: 3 loss: 0.021 accuracy: 0.869 test_loss: 0.017 test_accuracy: 0.894
epoch: 4 loss: 0.018 accuracy: 0.886 test_loss: 0.014 test_accuracy: 0.921
epoch: 5 loss: 0.017 accuracy: 0.897 test_loss: 0.022 test_accuracy: 0.869
epoch: 6 loss: 0.013 accuracy: 0.923 test_loss: 0.008 test_accuracy: 0.944
epoch: 7 loss: 0.009 accuracy: 0.947 test_loss: 0.011 test_accuracy: 0.924
epoch: 8 loss: 0.006 accuracy: 0.966 test_loss: 0.004 test_accuracy: 0.988
epoch: 9 loss: 0.004 accuracy: 0.979 test_loss: 0.002 test_accuracy: 0.998
epoch: 10 loss: 0.004 accuracy: 0.979 test_loss: 0.005 test_accuracy: 0.966
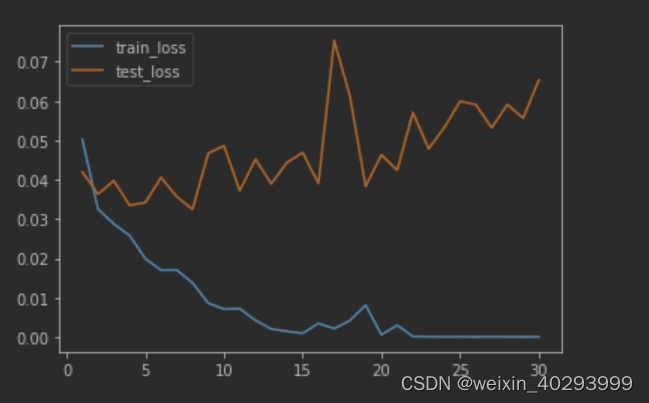
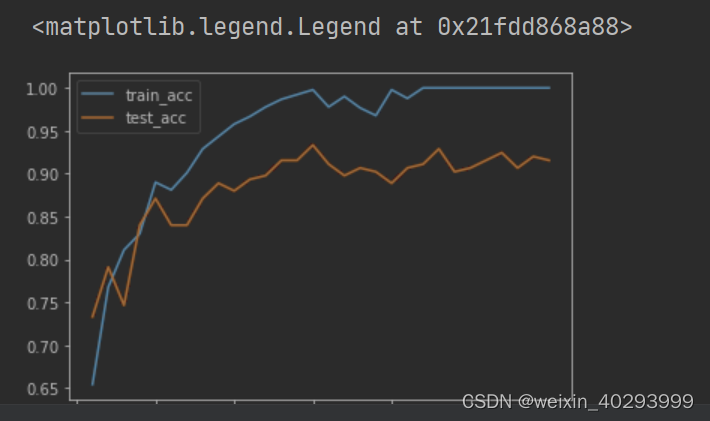
比较重要的点,
1.分类的数据集布局要记住
2.图片经过conv2 多次后的值要会算 todo
3.图片展示的方法要会
相关文章:
【深度学习】四种天气分类 模版函数 从0到1手敲版本
引入该引入的库 import torch import torch.nn as nn import matplotlib.pyplot as plt import torch.nn.functional as F import torchvision import torch.optim as optim %matplotlib inline import os import shutil import glob os.environ["KMP_DUPLICATE_LIB_OK&q…...
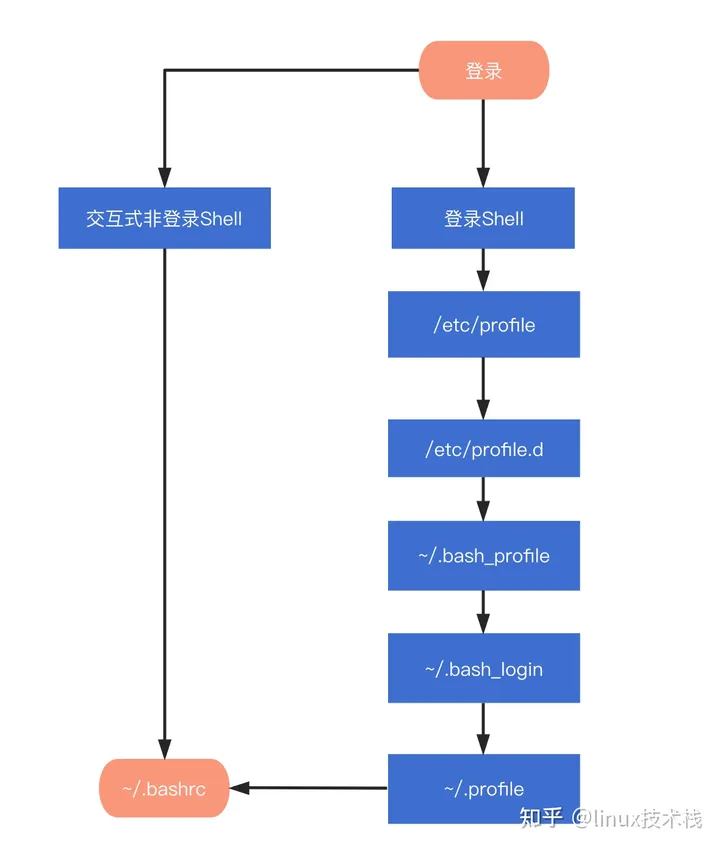
Linux文件 profile、bashrc、bash_profile区别
Linux系统中,有三种文件 出现的非常频繁,那就是 profile、bash_profile、bashrc 文件。 1、profile 作用 profile,路径:/etc/profile,用于设置系统级的环境变量和启动程序,在这个文件下配置会对所有用户…...

blender记一下法线烘焙
这里主要记一下使用cage的方式 原理 看起来是从cage发射射线,打中高模了就把对应uv那个地方的rgb改成打中的点的normal的rgb 正事 那么首先需要一个高模 主要是几何要丰富 无所谓UV 然后一个低模,既然上面提到UV,那低模就要展UV, 展完之后…...
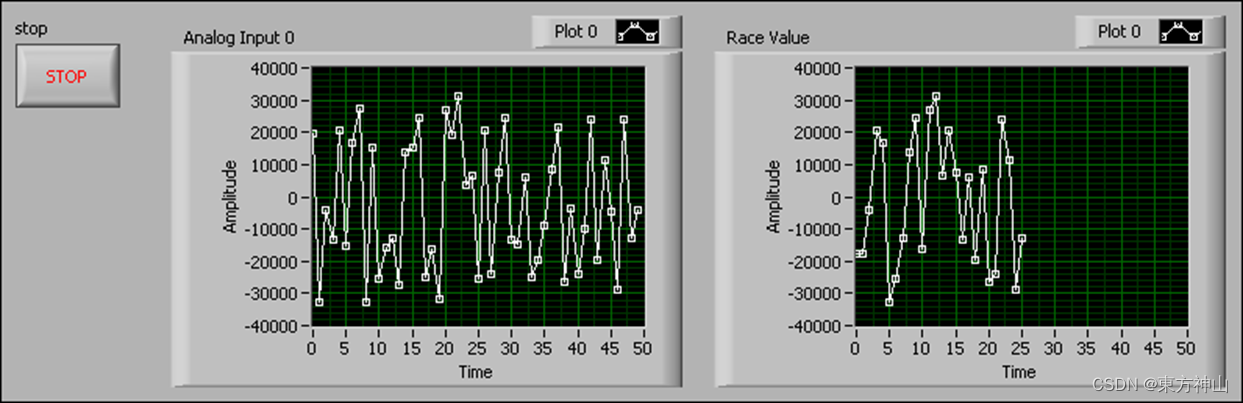
【LabVIEW FPGA入门】FPGA 存储器(Memory)
可以使用内存项将数据存储在FPGA块内存中。内存项以2kb为倍数引用FPGA目标上的块内存。每个内存项引用一个单独的地址或地址块,您可以使用内存项访问FPGA上的所有可用内存。如果需要随机访问存储的数据,请使用内存项。 内存项不消耗FPGA上的逻辑资源&…...
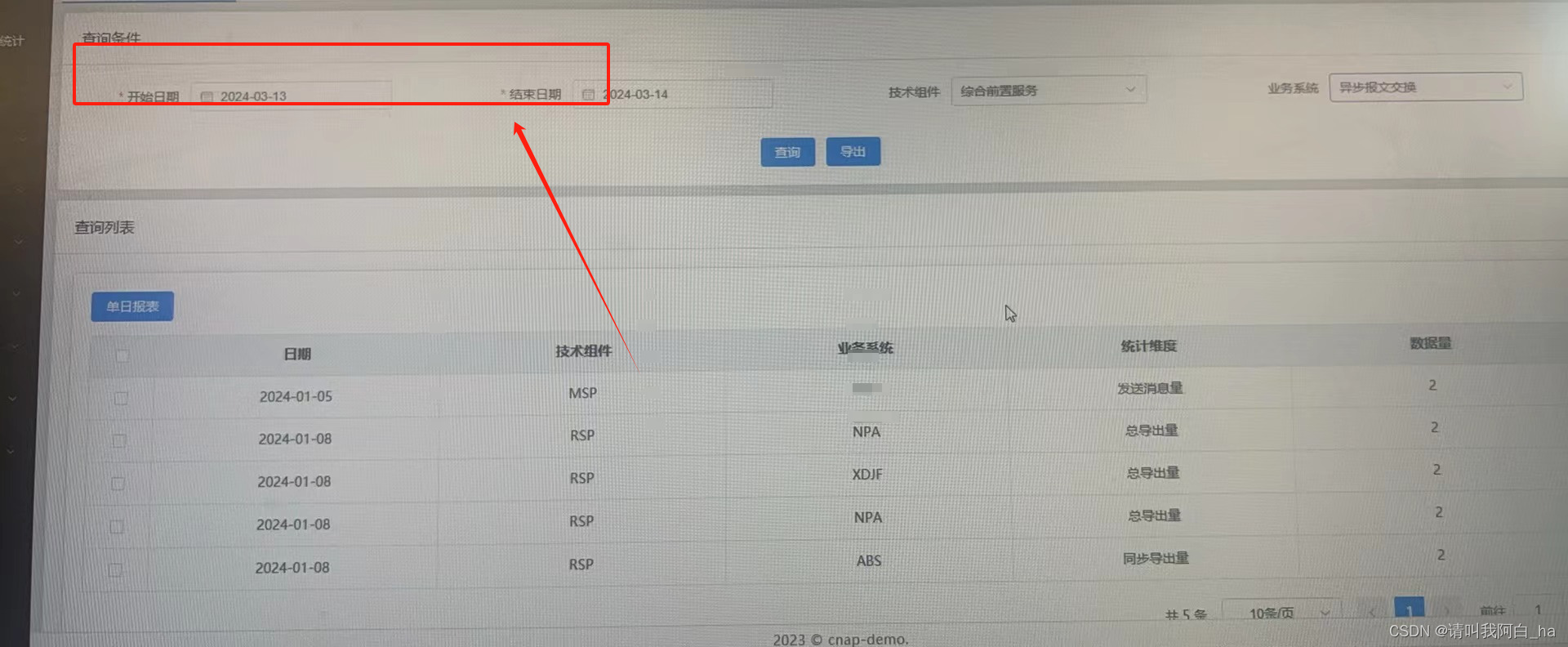
vue3+element Plus form 作为子组件,从父组件如何赋值?
刚开始接触vue3时,碰到一个很low的问题,将form作为子组件,在页面中给form表单项输入内容,输入框不显示值,知道问题出在哪,但因为vue3组合式api不熟悉,不知从哪下手... 效果图: 父组…...

Kafka系列之:Exactly-once support
Kafka系列之:Exactly-once support 一、Sink connectors二、Source connectors三、Worker configuration四、ACL requirementsKafka Connect 能够为接收器连接器(从版本 0.11.0 开始)和源连接器(从版本 3.3.0 开始)提供一次性语义。请注意,对一次语义的支持高度依赖于您运…...

Spring Boot2
SpringBoot 配置文件 properties配置文件 application.properties 以配置端口和访问路径为例 server.port8080 yaml配置文件 application.yml / application.yaml server:port: 81 在实际开发中,更常用的是yaml配置文件 yaml层级表示更加明显 yml配置信息书…...
)
【idea做lua编辑器】IDEA下lua插件报错编辑器打不开(同时安装EmmyLua和Luanalysis这2个插件就报错,保留EmmyLua插件即可)
C:\Users\Administrator\AppData\Roaming\JetBrains\IntelliJIdea2021.1\plugins 同时安装EmmyLua和Luanalysis就报错,删除Luanalysis这个文件夹只使用EmmyLua这个插件即可! 为啥不用vscode呢? 我个人不太喜欢vscode,更喜欢idea&…...
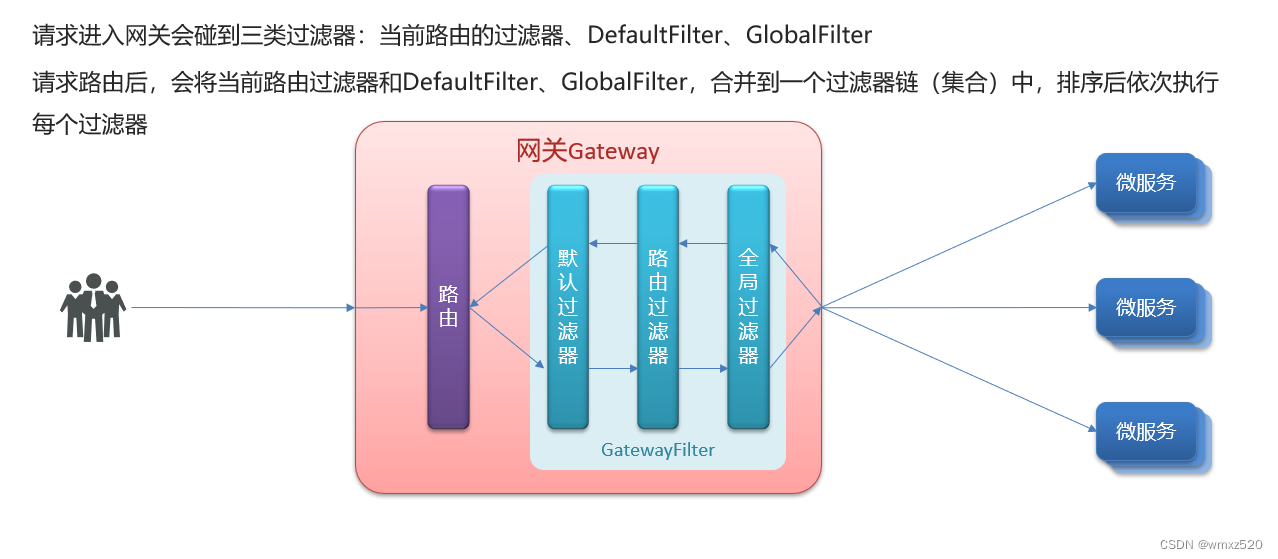
SpringCloud之网关组件Gateway学习
SpringCloud之网关组件Gateway学习 GateWay简介 Spring Cloud Gateway是Spring Cloud的⼀个全新项目,目标是取代Netflix Zuul,它基于Spring5.0SpringBoot2.0WebFlux(基于高性能的Reactor模式响应式通信框架Netty,异步⾮阻塞模型…...

全球大型语言模型(LLMS)现状与比较
我用上个博文的工具将一篇ppt转换成了图片,现分享给各位看官。 第一部分:国外大语言模型介绍 1,openai的Chatgpt 免费使用方法1:choose-carhttps://share.freegpts.org/list 免费使用方法2:Shared Chathttps://share…...
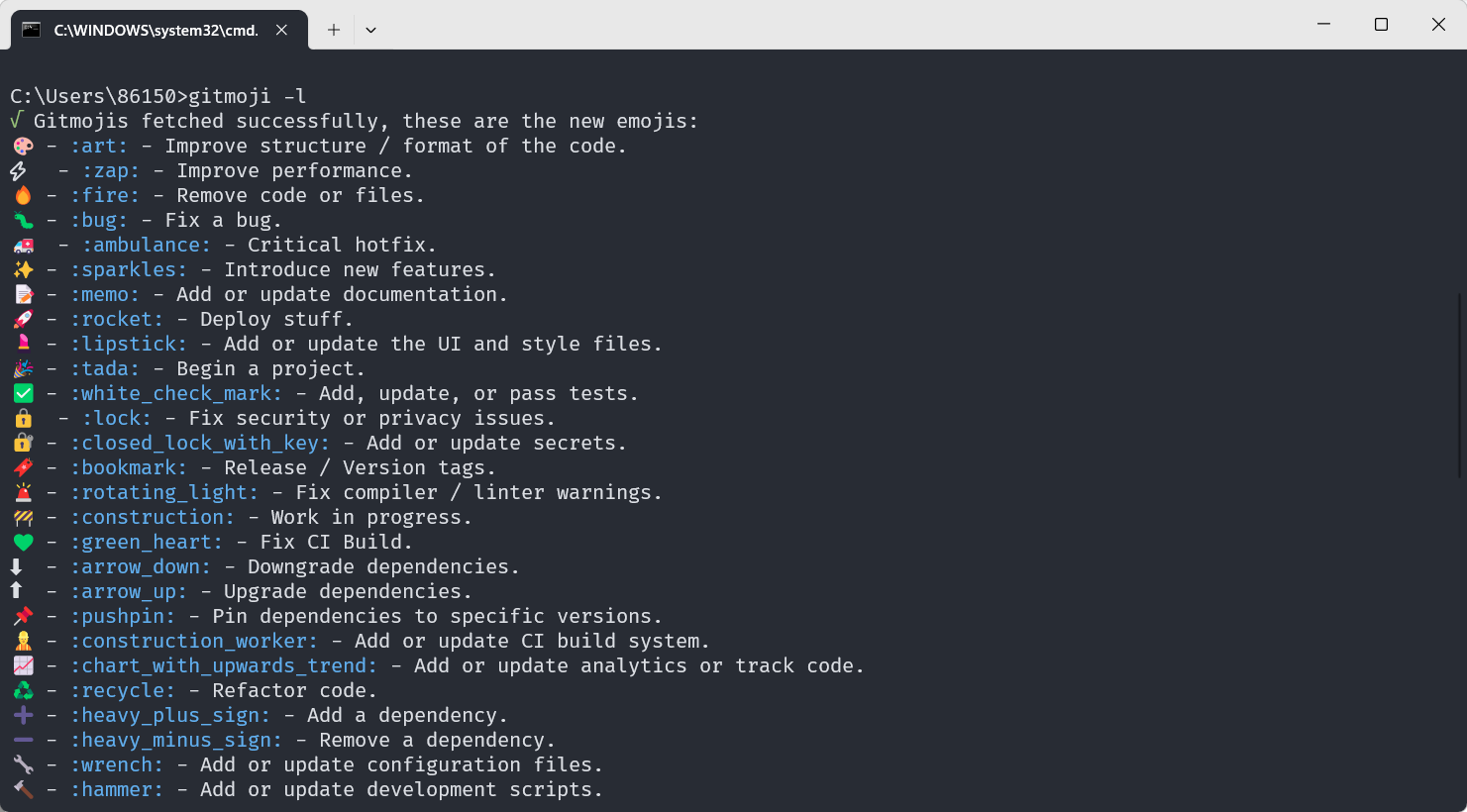
Git Commit 提交规范,变更日志、版本发布自动化和 Emoji 提交标准
前言 Git Commit 是开发的日常操作, 一个优秀的 Commit Message 不仅有助于他人 Review, 还可以有效的输出 CHANGELOG, 对项目的管理实际至关重要, 但是实际工作中却常常被大家忽略,希望通过本文,能够帮助大家规范 Git Commit,并且展示相关 …...

Spark与flink计算引擎工作原理
Spark是大批量分布式计算引擎框架,scale语言开发的,核心技术是弹性分布式数据集(RDD)可以快速在内存中对数据集进行多次迭代,支持复杂的数据挖掘算法及图形计算算法,spark与Hadoop区别主要是spark多个作业之…...
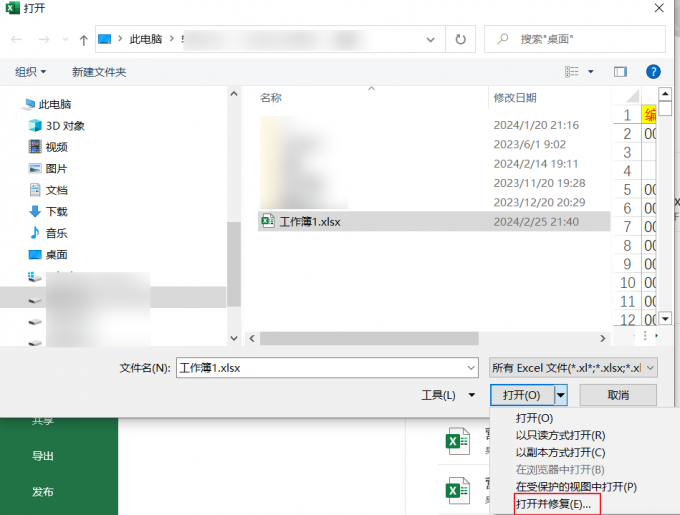
Excel数字乱码怎么回事 Excel数字乱码怎么调回来
在日常工作中,Excel是我们最常使用的数据处理软件之一,它强大的功能使得数据处理变得既简单又高效。然而,用户在使用Excel时偶尔会遇到数字显示为乱码的问题,这不仅影响了数据的阅读,也大大降低了工作效率。那么&#…...
实例:NX二次开发使用链表进行拉伸功能(链表相关功能练习)
一、概述 在进行批量操作时经常会利用链表进行存放相应特征的TAG值,以便后续操作,最常见的就是拉伸功能。这里我们以拉伸功能为例子进行说明。 二、常用链表相关函数 UF_MODL_create_list 创建一个链表,并返回链表的头指针。…...

【VSTO开发】遍历 Ribbon 中的所有控件或按钮
在 VSTO(Visual Studio Tools for Office)中,可以通过代码来遍历 Ribbon 中的所有控件或按钮。可以使用 C# 或 VB.NET 等编程语言来实现这个功能。 下面是一个简单的示例代码,演示如何遍历 Ribbon 中的所有控件或按钮:…...
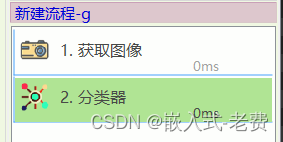
上位机图像处理和嵌入式模块部署(qmacvisual图像识别)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 所谓图像识别,就是对图像进行分类处理,比如说判断图像上面的物体是飞机、还是蝴蝶。在深度学习和卷积神经网络CNN不像现在这…...
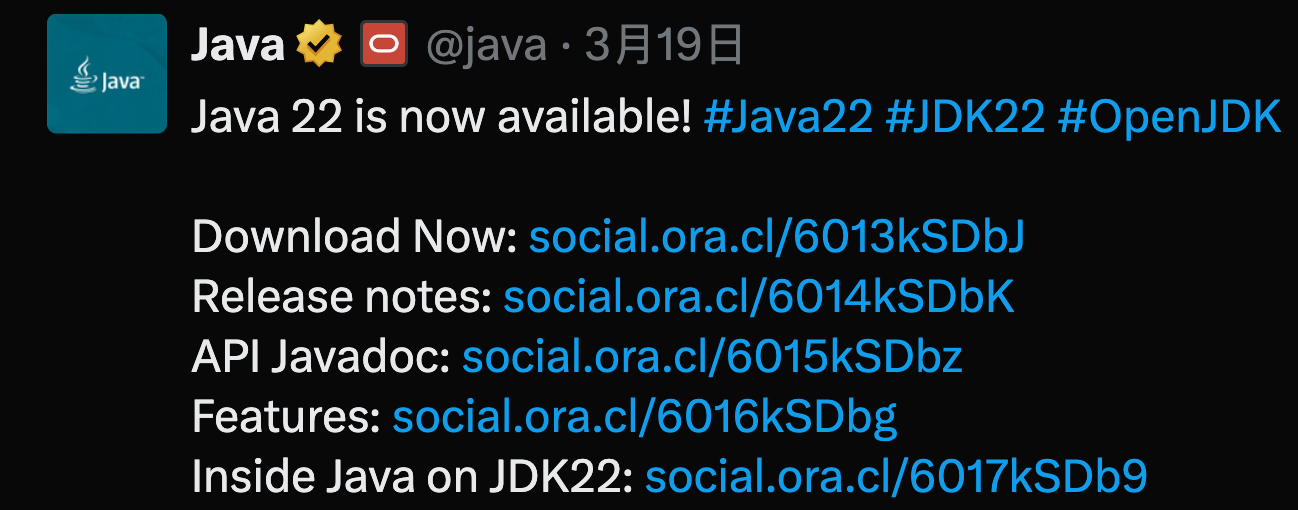
当Java 22遇到 SpringBoot 3.3.0!
工程 | JOSH LONG | 0条评论 Java 22发布快乐! Java 22 是一个重大的进步,是一个值得升级版本。有一些重大的最终发布功能,如 Project Panama及一系列更优秀的预览功能。我不可能覆盖它们全部,但我确实想谈谈我最喜爱的一些。我们…...
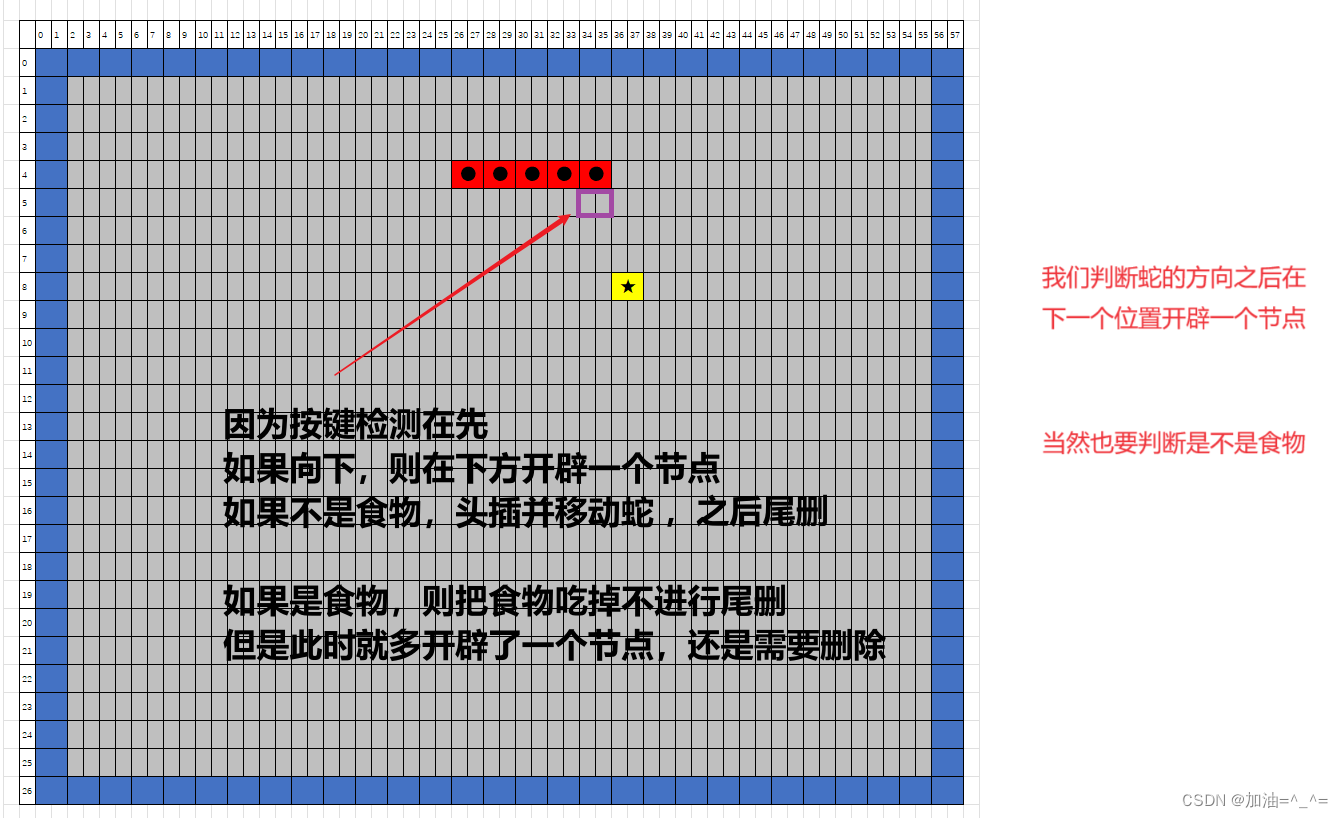
贪吃蛇(C语言超详细版)
目录 前言: 总览: API: 控制台程序(Console): 设置坐标: COORD: GetStdHandle: STD_OUTPUT_HANDLE参数: SetConsoleCursorPosition: …...
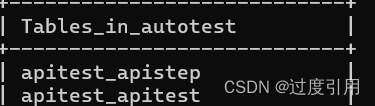
python(django)之流程接口管理后台开发
1、在models.py中加入流程接口表和单一接口表 代码如下: from django.db import models from product.models import Product# Create your models here.class Apitest(models.Model):apitestname models.CharField(流程接口名称, max_length64)apitester model…...
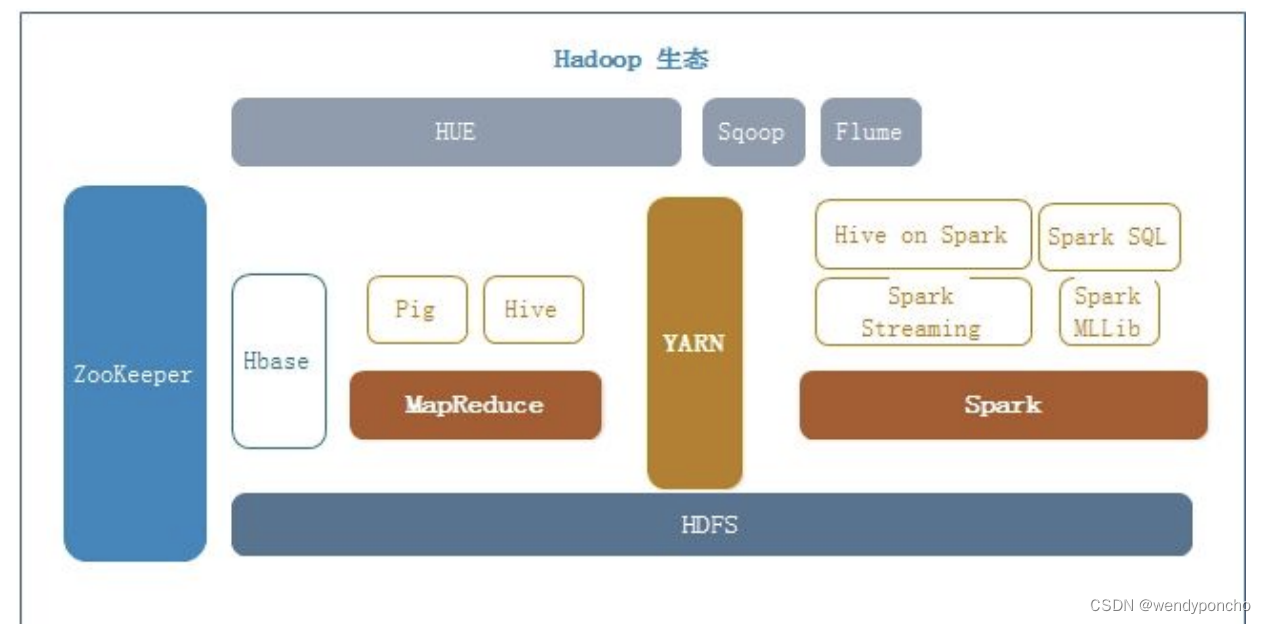
Hive入门
什么是hive? - Hive是Facebook开发并贡献给Hadoop开源社区的。它是建立在 Hadoop体系架构上的一层 SQL抽象,使得数据相关人 员使用他们最为熟悉的SQL语言就可以进行海量数据的处理、 分析和统计工作 - Hive将数据存储于HDFS的数据文件映射为一张数据库…...

如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。
如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。 Word中脚注线不会删?这里有妙招!,教育,职业教育,好看视频...

从多路复用到三维光阵:Arduino驱动8x8x8 LED立方体全解析
1. 项目概述:用Arduino点亮一个三维世界几年前,我第一次在创客展上看到一个8x8x8的LED立方体,那种由数百个光点构成的、在三维空间中流动的动画效果,瞬间就把我吸引住了。它不像普通的平面LED屏,而是真正有“深度”的光…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...

3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流
3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools …...

警惕!AI正在悄悄重构全球攻防格局
警惕!AI 正在悄悄重构全球攻防格局 热点聚焦 AI重构网络安全:全球巨头加速布局 2026年5月,全球网络安全领域迎来重大变革,AI技术正在重塑攻防格局。OpenAI发布专为网络安全防御打造的集成化AI平台Daybreak,将安全防…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷?
更多请点击: https://intelliparadigm.com 第一章:上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷? 在软件交付生命周期末期,传统人工代码审计与通用SAST工具常因误报率高、上下文理解弱而漏检高危漏…...

神经网络与深度学习 第3周课程总结
深度学习视觉应用课程总结 一、常用计算机视觉数据集数据集名称发布方/年份规模图像规格类别数主要用途核心特点MNIST美国国家标准与技术研究院60k训练10k测试2828灰度图10类(0-9手写数字)入门级图像分类最经典的手写数字识别基准数据集Fashion-MNISTZalando(2017)60k训练10k测…...
P2P聊天程序)
基于C#实现(WinForm)P2P聊天程序
♻️ 资源 大小: 29.8MB ➡️ 资源下载:https://download.csdn.net/download/s1t16/87430269 p2p聊天程序 一、功能介绍 1.1 登录 用户凭用户名和密码登录系统,可以更换服务器 IP 和端口,以防网络不畅通,连接服务…...